svm分类器python实现
之前我们讲过, svm 的终极目标就是要寻找一个线性分类超平面,将所有的样本划分开,但是这又有一个问题,我们真的需要将所有的样本必须正确无误的划分开吗?好,这就是我们本节将要引出的两个问题,也就是支持下相机的硬间格与软间格的问题。 我们先来看硬件格,当我们的支持下相机要求必须都将所有的样本正确划分的时候呢,这种情况呢是非常理想的,我们也叫做硬件格好,英文叫做哈士马嘴,那我们来看下面这幅图,好, 那么假如说对于我们所有的红色样本,我们把它的标签好都记为一,那么对于下面的所有蓝色的样本呢?把它的标签都记为负一,那么穿过红色样本的支持项链这根线呢?好,或者叫这个超平面呢?我们叫做 wx 加 b 等于一。穿过蓝色样本的支持项链的这根线呢,叫做 wx 加 b 等于负一,那么中间的这根线或者中间的这个超平面呢,我们叫做 wx 加 b 等于零。 好,那么现在也就说对于所有的样本,他到中间抄平面的距离必须要大于等于支持项链到抄平面的距离。转换成我们的数学公式来说,就是说,好,对于所有的红色样本,就是 y i 等于一的情况, w x 加 b 必须大于等于一。对于所有的蓝色样本,也就是对于所有的 y 等于负一的这些样本呢,我们的 wx 加 b 要小于等于负一,对吧?好,这是我们非常简单的啊,这个点到线之间的距离这个公式转化来的。那么上面这两种情况呢,大家看,我们就可以合成一个公式,就是 y w x 加 b 大于等于一, 那么这种呃转化的公式呢?啊,这个在我们记忆学习的呃过程中呢,非常常见,也就是说经常会把多个式子转化成一个式子,因为这样更简便了,好,那么这个式子翻译成我们的人话,也就说对于所有的样本,他到中间抄平面的距离都必须大于等于支持销量到中间抄平面的距离, 好,这就是我们的哈尔马铁,那么好,我们再把刚才的狮子啊进一步的推爆。那么如果说对于所有的样本到中间超平面的距离啊, 必须都要大于等于现我们的支持销量到超平面的距离,那么转换中的数学公式,也就说咱们是不是必须要最大化这个啊,我们的支持销量到超平面的距离,好,那么而支持销量到超平面的距离是不是都等于一啊,对吧?好,所以说呢,我们是不是所谓的要转化要最大化这个式子相当于就要最大化一除以大规模。 好,那么一出 w 要最大化是不是要相当于最小化我们的大规模,为什么呢?因为字母是大规模呀。好,那么一般在积极学习中呢,我们在求导的过程中呢,我们再进行一个转化,最小化大规模就相当于最小化二分之一的 w 模的平方,好,那么这个就是我们的硬间格所最终要达成的目标,好,也就是再说一遍,要做什么事情呢?在这个 ywxi 加 b 发于等于一的条件下,最小化二分之一 w 一 w 的平方。好, 那么下来呢,我们再看一下软间格,但是呢,咱们刚才说过,硬间格是非常理想化的,但是在现实情况中呢,往往呢,我们很难确定合适的合法术来使得我们的样本啊限定可分,即使你找到了,你怎么能确定这不是由于在宣传样本上的过敏合所造成的呢?所以呢,缓解该问题的一个办法就是允许我们 sum 在一些样本上划分错误啊,也就是我们的软间格 soft 玩具。 那么大家请看,在这幅图中我们圈起来的这个样本呢,他就是划分错位样本。好,那么我们软间格只是像样的这个数学表达呢啊,其实跟硬间格呢,只是有一点点区别,什么区别呢?就是他允许了犯错的情况,就是划分错误的情况。那么大家看,我们还是这个条件啊, y m x 加 b 等于一,但是后面 一个条件剪一个啊,折台啊,这个折台呢,就相当于是一个松弛变样啊,也就说引入了一个,可以引入一个错误。记者,那么在这个条件下,我们最小化上面这个式子,不,上面这个是也有一个正在拉射啊,这是 l 一正则,当然 l 正则呢,跟 l 一正则的目的是一样的,只不过 l 正则在优化过程中,咱们正则是则它挨的平方好,那么换颜值呢?又说我们在软间格的过程中呢, 不光要考虑咱们之前讲过的 fm 的目标,也就是要使这个马尔警对大话,而且现在还要考虑我们允许某一些样本划分错误,因为我们在训练样本集中某些样本,也许他就是异常样本,划分错误也无所谓对不对。好,所以呢,这就是我们的软件团的最终的目标。 好,那么我们啊,必须要注意一点啊,比如说我们在软件格的这个正合像前面的 c, 比如说这个 c 啊,他呢越大呢,也就说明我们相等容错空间越小。为什么呢?因为我们现在软件格是不是目标有两两个啊?一个是是我们的 man 最大化,一个是 如果 c 越大,那是不是说明我们的容错空间啊,在优化过程中就应该越小呀?为什么呢?因为我们现在目标是要最小化这个两两部分,那你 c 越大,是不是相当于后面的权重越大?也就是说我们在最小化的过程中,把更多的精力集中在我们的容错空间更小的情况下。好,那么如, 如果说 c 非常大,已经起到正无穷了,那也就是逼迫着我们的每一个泽卡,也就是松弛变量都必须得为赢,那这个时候呢, c 如果真的为最大的话,那我们泽卡都为赢了,那是不是就成了硬间隔了?也就说此时的软间隔就变成了硬间隔。 好,那么本节呢?啊,我们就讲到了这个硬间格和软间格,那么最终总结一句话,硬间格非常严格,非常理想,超平面将所有的样本都能正确划分,那么软间格呢,就考虑到了现实情况,我们允许一些样本划分错误。好,那么本节我们就到这里,大家加油。

粉丝760获赞7535
相关视频
 04:57
04:57 08:50查看AI文稿AI文稿
08:50查看AI文稿AI文稿欢迎来到本期视频,今天我们要解决两个问题,一是为什么 sum 的 超参数如此关键,二是粒子群算法又是如何在参数空间中帮我们找到自由解的?跟着这个视频,你将彻底搞懂 pso 优化 sum 参数的一个完整逻辑。 我们从一个最经典的场景说起,假设有一批数据,红色是一类,蓝色是一类,我们的任务是找一条分界线,把它们给分开。 我们最直觉的想法是画一条直线,但你会发现,不管怎么画,总有几个点跑到错误的那一侧,我们图中的叉号显示的这样, 这不是因为画的不好,而是因为这种数据本来就是现行不可分的。也就是说,现行是分割,是无法处理复杂边界。那么既然现行方法失效,我们就需要更强大的一个工具。 这就轮到 svm 支持摄像机出场了,他的核心思想不只是找一条能够分开数据的线,而是要找那条离两边距离最远的线,这个距离叫做间隔。 两条平行的虚线夹住中间的决策边界。离这两条虚线最近的那几个点就叫做支撑向量,而它们是整个模型的关键支撑点。我们 svf 的 目标就是最大化这个间隔宽度。下面这个公式是在上面公式的一个约束, 但在实际数据中往往会有噪声。如果数据中有几个捣乱的异常点,我们到底要不要允许分错?这又引出了第一个常数 c。 我 们来做一个对比实验,左边 c 设的非常小模型对错误非常宽容,间隔很宽,但分错了很多点。而右边 c 设的极大 模型强迫自己分对每一个点,边界开始扭曲,这就是过你核,我们再看中间它的 c 适中,间隔合理,分裂效果最好。而这就是我们想要的 第二个超弹肉是伽玛,它控制核弹肉的影响宽度,伽玛越小,每个点能影响的范围越大,边界越平滑。而伽玛越大,每个点只能影响周围自己很小的一部分, 边界就开始逐渐包裹每个训练点,我们看右边这一列边界,几乎把每个训练点都包住了。这就是严重的一个过你核, 如果遇到新数据的话,他就会失败,也就是说伽马太小,会产生欠你核,伽马太大,他记住了这个训练程序,却忘了如何放话。 问题来了, c 和伽玛必须同时调好模型,才会变得优秀。这是一个二维的参数搜索搜索问题。针对这种问题,最朴素的方法就是网格搜索法,就是把所有的 c 和伽玛的组合都试一遍, 但每设一格,就要完整训练一次 svm, 如果每个参数有十个获选值的话,我们就要训练十乘以十一百次。参数范围一旦扩大,这个代价就会急剧增长,变得不可接受。 那有没有更聪明的方法呢?当然是有的,这是我们提到的粒子群优化算法 pso, 他的灵感来自自然界的一个群体行为,比如这个鸟群觅食,想象一群鸟在寻找食物最多的地方,他们就会记住自己找到过最好的位置,也会向大家发现的最好位置靠拢。 在这个 p s o 中,每只鸟就是一个例子,食物最多的地方就是参数最优的位置, 每个粒子的运动由这条公式来决定。第一项,惯性项,它是保持自己原来的运动方向,防止搜索太快,陷入了局部最优。 第二项是个体记忆,拉向自己历史上找到过的最好位置。第三项,社会学习,拉向整个群体中迄今找到的最好位置。在这三种力的一个合力下,会决定粒子下一步往哪走。 我们可以看到,最开始粒子是四散分布的,也就是随机分布,它的精度只有百分之六十二。随着每次迭代,粒子们开始互相跟风向更好的区域靠拢,精度会从百分之六十七跳到百分之七十八,跳到百分之八十九。 可以看到,整个群体会越来越密集地集中在热力图最亮的那块区域,在不到十五次迭代,精度就会稳定在百分之九十六点三。一群随机戳手化的粒子自发地找到了最后解, 也就是说,我们这个 omega 控制的探索范围。 c 要相信自己,而 c 二是要相信群体,这三者相互平衡能够决定这个收敛质量。 那么 p、 s、 o 和 svm 是 怎么连接起来的呢?它的关键在于适应度函数的设计。 每个粒子的位置就是一个二维坐标,横坐标是 c, 纵坐标是伽玛。每次粒子移动到一个新的位置,我们就用这组 c 和伽玛训练一次 svm, 然后去做交叉验证,把验证精度作为这个粒子的适应度, 精度越高说明这个位置越好,然后我们的 p、 s、 o 就 会像粒子朝这个方向靠拢。 适应度函数是整个算法的核心枢纽,常用的有五折交叉验证精度。如果样本的类别不均衡的话,也可以用 f e 分 数。我们这里有一点要特别注意,每次评估适应度都要完整训练一次, s o m 计算成本很高, 正是因为这个代价,我们才需要 p s o。 用尽量少的屏幕次数找到最优 好。现在我们把所有的模块给拼起来看完整的算法运行。左边是参数搜索空间,粒子们正在 c 伽马平面上四处探索,右边对应的 svm 分 列效果会随着参数的变化,边界会实时更新。 他第一次耕带,第一次迭代,精度百分之六十八,外界还很粗糙,边界还很粗糙,分错了很多点。注意观察左右两侧的联动,粒子每移动一部分类,边界就随之更新。 随着迭代这个推进,粒子们开始相互吸引,向这个高度集中的区域集中,而右侧的分裂边界会越来越合理,净度会七十二、七十二、八十四,迭代到第五次可以达到百分之八十九点七。 接下来算法快速迭代,粒子会越来越密集,精度也会越来越高。最终在这个二十次迭代的时候,精度为零,在九十六点六不再有明显变化,这就是完整的一个收敛。 左边的粒子安静下来,停在日历图最亮的位置,而右边的分列边界会清晰的将两类数据完美分开, 可以得到自由参数精度和提升效果。好,最后我们来做一个横向对比,左边是默认参数, c 等于一,伽玛等于一,分类精度只有百分之七十四,边界明显不可合理。 然后中间是网格搜索找到的最优精度九十三点八,效果还不错,但花了一百二十次评估。我们右边是 pso 优化的效果,精度有百分之九十六点六,而且只用了二十次评估,节省了百分之八十三的一个效果。 pso 杠 sm 的 一个核心优势,第一是效率,用远少于网格搜索的评估次数来找到更好的参数。 第二个是效果,全区搜索不容易陷入局部增优。第三个是自动化,我们无需人工反复去调参,算法能自己搞定 好。我们来快速回顾一下今天学到的内容,第一, sm 的 分类效果高度依赖 c 和伽马两个超参数。第二, p s o 通过粒子群协助在参数空间中进行全聚搜索。第三,深度函数是交叉验证精度,把 p s o 和 svm 连接起来的桥梁。第四,修脸后的参数显著优于人工调参和暴力搜索。 如果你想深入,可以去继续探索,比如说多目标 p s o, 自适应权重以及混合策略。 好,今天的内容就到这里,如果这个视频对你有帮助,欢迎点赞收藏,我们下期再见!
20顶呱呱程序 02:49查看AI文稿AI文稿
02:49查看AI文稿AI文稿你以为 ai 在 做分类的时候,靠的是复杂的神经网络,其实很多时候,它只是在找一条线。没错,一条线就能把世界分开,这就是支持向量机。 svm 听起来很简单,对吧? 但他干的事情其实很狠。在一堆数据里,找到一条最有分寸感的分界线。什么叫最有分寸感?不是随便画一条线,把两类分开就行,而是要让这条线离两边的数据都尽可能远,中间留出一条安全带。 这背后的核心可以理解为 max margin, 也就是让分类边界尽可能远离风险。听起来抽象, 我给你换一个工业场景,你在做质量检测,有一批产品有的合格,有的不合格。你拿到了很多特征,尺寸、重量、震动参数、温度曲线。问题来了,怎么判断一个新产品是好还是坏?你可以画一条线, 把好产品和坏产品分开,但问题是,如果这条线贴的太近,一点点波动就可能误判。 而 svm 做的事情是把这条线往中间推,尽量远离两边的数据。这样一来,新来的产品只要稍微有点偏离,就能被稳稳识别出来。这就是它在工业里特别好用的原因。 抗干扰能力强,对小样本也有效。分类边界非常稳,但真正厉害的还不止这一点。 现实世界大多数数据根本不是现象可分的。怎么办? svm 有 一个非常聪明但不直觉的操作,它把数据拎到更高维,空间在二维里分不开,那就丢到三维、四维, 甚至更高维,在那里,也许就能用一条线或者一个面轻松分开。这个操作有个很酷的名字和函数,你可以理解为换一个维度看清世界, 所以你会发现 svm 不是 在硬分数据,而是在找一个更容易分的世界。这也是它在很多工业场景里的典型应用, 比如缺陷识别、 okn、 设备状态分类正常、异常工艺窗口判断稳定失控。很多时候数据不多,边界复杂,噪声还大, svm 反而比复杂模型更靠谱。 所以回到一句话总结, svm 不是 在画一条线,而是在用一条线把不确定性隔离在外,这才是工业 ai 真正需要的能力。有很多粉丝说 人工智能算法的基础学起来好难,可以参考一下人工智能算法基础这本书,方便更全面地了解人工智能算法。
27工业软件老宋 02:35查看AI文稿AI文稿
02:35查看AI文稿AI文稿大家好,给大家介绍一个股票数据分析及预测系统,它以登录界面为入口,含盖多维度数据分析与股价预测功能,数据可对不同股市的成交量、成交额、股价换手率等指标进行直观化展示。股价预测模块支持对上证、深证 a 股股票的未来股价进行预测并输出结果,同时提供个人信息管理功能, 整体实现了股票数据的可化分析与股价预测辅助,为用户提供全面的股票分析服务。 你的脸。
 01:55查看AI文稿AI文稿
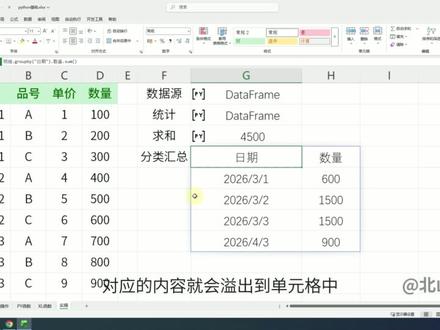
01:55查看AI文稿AI文稿在 excel 中使用 python 可以 实现分类汇总,比如要按照日期对数量进行分类汇总。输入 py 函数,然后输入上面定义的变量明细,再输入一个点,然后再输入 groupby 函数, 在这个函数的参数中输入日期,注意日期要用单引号或者双引号包裹起来。继续输入一个点以及数量,再输入一个点,然后输入 sum 函数, 最后按 ctrl 加 enter 键执行 python 代码,得到一个名字为 series 的 python 对 象,点击这里,再点击 excel 值,对应的内容就会溢出到单元格中,可以看到数量会按照日期进行汇总。如果要按照月份进行分类汇总,咱们可以修改一下代码。 为了方便修改代码,咱们可以点击公式选项卡,然后再点击编辑器,就会打开 python 编辑器的任务窗格, 在任务窗格中会显示当前工作簿中所有已经开启了 python 模式的单元格。咱们点击这里,再点击当前工作表, 找到要修改的 python 单元格,然后点击右上角展开 python 编辑器,然后就可以修改代码了。输入字母 p d, 这里的 p d 是 pandas 的 缩写, pandas 是 python 中的一个数据分析库。继续输入一个点,然后输入 group 和左括号。 group 是 pandas 中的一个类,用来定义分类汇总规则。输入 key 等于日期,表示依照日期进行分类。再输入逗号 freeq 等于 m, 表示按照月度进行汇总,接着补全右括号,最后按 ctrl 加 enter 键执行 python 代码,可以看到数量会按照月份进行分类汇总。在 excel 中使用数据透视表也可以实现上述类似效果,但是使用 python 更简单高效, 比如将 m 修改为 w, 就 会按照周进行分类汇总。另外,当我们修改数据源中的数据后,对应的结果也会自动同步更新。
38北山Excel 01:43查看AI文稿AI文稿
01:43查看AI文稿AI文稿在 python 自动化框架中,是怎么实现失败重试机制异常分类处理和日制结构化输出的这块的啊,我整体的设计思路呢,是做成可配置可扩展的,而不是写死在代码里的。就先说失败重试啊,我不是所有用力都统一重试次数, 而是做成按用力维度控制的。我在 excel 里面加了一个 rerun 字段,用来标记这条用力最多允许重跑几次,然后在 pytest 里面真正的开始执行之前,我会先拿到所有要跑的用力集合, 根据这个字段动态呢,给他们加上对应的重试策略,这样的核心链路的用力就可以多试几次,非核心的用力呢,就啊,也不会浪费资源。异常分类这块呢,我是通过啊自定义异常体系来做的,就比如说啊,数据库连接异常,配置加载异常啊,接口返回异常, 我都会拆成不同的异常类型,而不是啊全部抛一个 exception 𠮿 我 每个异常里面啊,我都会带上一些啊关键的上下文, 比如说当前的环境啊,请求参数啊,返回内容啊等等这些。这样的话,在日制里面一看啊,就知道是环境问题啊,业务问题还是啊框架问题了, 这样定位起来呢,也会快很多。日制结构化输出这一块呢,我是基于 padata 自带的日制体系统一封装的,我会在配置文件里面啊统一定义日制的输出路径格式啊,时间戳啊,模块名等等这些信息,然后在 代码里面就只用了 logo 啊,就不直接地去 print, 这样产出的日制是结构化的,后面不管是排查问题还是呃接日制系统做分析呢啊,都是会比较方便的。
46李同学聊测试面试 02:01查看AI文稿AI文稿
02:01查看AI文稿AI文稿刚刚我用 codex 把我这个几亿的进销准系统做成通用的进销准系统,他也帮我做了一个商品分类,比如我食品分类,是吧?然后就添加 饮料添加,然后就可以在我的商品信息里我可以做,做我的分类。啊,这里可以做编辑, 把这个改成饮料百事可乐,这里做一下,饮料修改好 也可以新增,比如食品,食品的这种面包块。好,这样我客户信息我也可以添加,比如, 呃,马斯克,好,供应商信息也有,那个就叫奥本海默,好,员工信息也有了。好,这里还有采购信息,比如我采购面包选择供应商 采购一百个,采购数量十个全人入库。好,销售信息我这里,比如销售面包有散客,比如销售给马斯克五个。好, 好,这里弄完以后,销售的这里的信息数据都会实时更新。刚刚是一百克一百个面包,现在销售出去了,系统设置这里都会有业务日制,都会展示。刚刚,呃,做了什么都会显示出来。销售还有库存信息啊,你看 库存信息这里都有,实时展示财务信息,我这里也可以自己做财务信息啊,你看我刚刚做了销售,他直接会销售收入面包多少钱, 还有支出了多少钱,这里也都会展示出来,还是非常智能的。这个系统我今天也就花了两个多小时通过 codex 开发出来的。好的,今天的视频展示就到这里,谢谢大家。
15Leo数据说 02:38查看AI文稿AI文稿
02:38查看AI文稿AI文稿大家好,今天给大家带来的毕业设计是基于拍范的新疆特产推荐系统的设计与实现,专为地方特色产品线上展示与销售打造,前端提供流畅的浏览体验。 包含系统首页、关于我们特产简介、系统简介四大基础模块,让用户快速了解平台特色与产品信息。个人中心支持用户信息修改,订单查询,使用更便捷。后台管理功能全面 覆盖用户管理、类型管理、特产管理、新疆特产管理、系统管理、订单管理,管理员可一键上架特产分类维护、订单处理、用户权限管控、数据实时同步 操作,简单高效。系统采用拍份后端开发,搭配数据库,实现数据稳定存储,整体架构清晰,扩展性强,页面响应快,运行稳定。请大家耐心看文,毕业设计演示视频,欢迎大家后台咨询。
 02:53查看AI文稿AI文稿
02:53查看AI文稿AI文稿今天我们接下来讲数据类型的衍生知识。数据类型转换首先我们来搞清楚一个核心问题,到底什么是数据类型转换? 简单来说,数据类型转换就是按照 python 的 规则,将一个值的数据类型去转换成另一种数据类型。比如把字母串一,我们去转换成整数数据类型,它就变成了数字一。或者我们将整数零呢去转换成负点数,数据类型就变成了零点。 通过数据类型转换,我们的变量能够适配更多的运算场景,使用起来呢也会更加的灵活。 在开始中,我们数据类型转换,它主要分为两类,自动类型转换和强制类型转换。区分这两类的关键就是看是否需要手写转换标志。首先我们来看自动类型转换, 自动类型转换它是指的在程序运行过程中,我们的拍摄会根据数据的计算逻辑和精度要求,自动地将低精度的数据去转换成高精度的数据,整个过程是完全不需要我们手动操作的。我们来看这个例子, 我们这里定义了一个整数类型 a, 它等于一,然后浮点数类型 b, 它等于一点零。我们用 c 呢去存储 a 加 b 的 结果,最终 c 的 数据类型它会变成浮点数数据类型。为什么会出现这种情况? 这是因为我们的 python, 他 会考虑到整数加福点数,他的计算结果可能会包含小数位,所以我们会自动的把整数数据类型 a 去转换成福点数数据类型,这里也就变成了一点零,再和 b 去进行相加,结果自然就是我们的福点数。 这里我们一定要记住,自动类型转换,它的核心规则精度呢,只能够从低到高进行转换。比如我们这里的布尔数据类型,它可以转换成 int 数据类型,整数数据类型呢,它也可以转换成浮点数数据类型,这个顺序它是绝对不能反过来的。 接下来我们来看最常用的数据类型转换、强制类型转换。 强制类型转换呢,它需要我们手动地去调用 python 的 内置函数,转换成不同的目标数据类型,所使用的函数是不一样的。 比如我们这里将整数数据类型 a 却通过我们的 a 等于 string a 去重新建立复制,那 a 它就变成了字母串数据类型。 不过,使用长字类型转换的时候,我们需要注意,转换它必须符合逻辑。如果字母串它本身不是数字,比如我们这里的 abc 字母串,那它是没有办法去转换成整数或者浮点数的, 强行转换它只会报错。那么关于数字类型的转换,我们就先讲到这里,下节课我们来讲音符的函数。
 02:21查看AI文稿AI文稿
02:21查看AI文稿AI文稿大家好呀,今天想跟大家聊聊, python 在 数据科学领域到底有多厉害。可能有朋友会问,数据科学不就是处理数据吗?为什么偏偏 python 这么火呢?其实啊, python 就 像数据科学家的万能工具箱, 不管你是想整理杂乱的数据,还是想从数据里挖出有用的规律,他都能帮上大忙。先说说最基础的数据处理吧,咱们平时手机里的运动数据、购物记录, 这些原始数据往往又乱又多,就像一堆没整理的积木。这时候, python 的 pandas 库就派上用场了, 它能帮咱们快速筛选清洗数据,把乱糟糟的积木分类整理好,让数据变得整齐又好用。再比如,数据可视化,光有数字可不行,得把数据变成图表,才能一眼看出规律。 pyxon 的 modplatum 和 cbnq 就 像画笔,不管是折线图、柱状图还是热力图,都能轻松画出来。想象一下,老板问你这个季度的销售额变化,你直接甩出一张清晰的趋势图,是不是比念一堆数字直观多了? 最厉害的还是 ai 推荐。预测分析背后其实都有 python 的 影子, 比如用 skikit learn 的 库,你可以轻松实现简单的预测模型,想预测明天的天气,或者分析用户喜欢什么商品。就像教电脑从数据里学习经验,然后自己做判断是不是很神奇。 而且 python 特别友好,代码简洁易懂,就算你不是计算机专业的,也能很快上手。很多大学和企业都把 python 当成数据科学的首选工具,就是因为它功能强大又好用。 所以啊,如果你对数据科学感兴趣,想搞懂那些复杂的数据背后藏着什么秘密? python 绝对是你的不二之选。那么问题来了,你觉得 python 在 数据科学里还有哪些让你惊艳的应用呢?欢迎在评论区分享你的看法哦!







