kafkatools用法

粉丝4.3万获赞10.5万
相关视频
 01:44查看AI文稿AI文稿
01:44查看AI文稿AI文稿什么是 cafka? 它是用于解决什么问题的? cafka 是由 linkedin 开发的一种高性能、分布式、可扩展的消息对列系统。它是一个开源项目,目前由 apache 软件基金会维护。 cafka 的设计目标是为了解决大规模实时数据流处理和消息传递的问题。 主要特点包括,一、高吞吐量, kafka 能够处理非常高的消息吞吐量,每秒数百万条消息。二、持久性 kafka 将消息持久化存储在磁盘上,因此数据不会丢失。三、分布式, kafka 是一个分布式系统,可以通过横向扩展来增加容量和吞吐量。 四、多副本复制 cafka 支持多副本复制,确保数据的高可用性和容错性。五、实时流处理 cafka 的设计使其非常适合实时数据流处理场景,如日志收集、 事件处理、指标监控等。 kafka 主要用于以下情况,一、日志收集与聚合 kafka 可以作为中心化的日志收集和聚合平台,收集来自各个应用程序的日志,并将其发送到中央存储 和处理系统。二、消息对列 kafka 可以用作消息对列,用于一部通信骄傲生产者和消费者,以及处理大量消息。三、事件流处理 kafka 可以用于处理事件流数据,例如实时监控、实时分析和实时决策。 四、流式处理 kafka 可以与流处理框架,如 apache frank、 apache spark 结合使用,支持实时流处理应用程序。 总的来说, cafk 是一个功能强大的消息传递系统,可用于构建实时数据管道,处理大规模的事件流和日制数据,并支持高可用性和可扩展性,他在处理大规模数据和构建实时数据处理系统方面发挥着重要作用。
111大数据老司机 13:05查看AI文稿AI文稿
13:05查看AI文稿AI文稿减速卡副卡的瑞班冷是机制,那么这道面试题呢,其实更加的偏向这个实战啊,因为我们在 使用卡不卡的过程中,不知道大家呢有没有去观察过这个卡不卡的这个日志啊,这个日志里面,我们从这个卡富卡的这个如果当出现这种日志量啊,就是我们的这个卡富卡的这个消息量啊,比较大的情况下,这种高并发的情况下, 当我这个瑞巴伦子呢,可能会出现的比较的频繁啊,我们会在日子中经常看到这种这种问题,就是卡夫卡瑞巴伦子中,那么这个瑞巴伦子呢,是卡夫卡中的一种很重要的一种机制啊,这种机制呢,他,他会影响这个卡夫卡的这个读写性能啊, 如果说卡不卡,他在进行这个 red 的时候,那么这个芭提犬呢,他是不能够进行读写的,这个读写会进入主色,我们这个 red 以及 red 会进入主色,直至这个 red ex 完成。所以说我们如果明白了这个 red 是 一种机制啊,那么我们要尽量的避免这个卡布卡的瑞贝尔,也就是让这个瑞贝尔发生的几率呢降低啊,那么此时呢,就是其实也是卡布卡的一个调优的一个方向,那么我们首先要明白卡布卡中的这个瑞贝尔的机制到底是什么。当然这道面试题呢,可能在呃,针对一般的这种,嗯, 程序员可能不会去问啊,但是呢,如果说你工作经验有点长的话,那么这道题呢,其实也是啊,面向这个卡夫卡底层的一种这种啊实现机制吧,呃,算是一道相对来说啊,比较啊有难度的一道面试题,好了,我们接下来了啊,卡夫老师给大家简单的分析一下这卡夫卡中的这个瑞贝尔是到底是是怎么回事啊? 那么这个瑞贝呢?是其实实际上是指的是什么呢?指的是我们这个坑是 q 马哥入库啊,这个概念呢?我们在前面的这个卡不卡的这个面试题中多次提到这个消费者主,对不对?那 这个消费者主,比如说他下面啊有有多个消费者啊,那么这个多个消费者呢,会被分配到这个托比克啊,我们这个主呢?这个消费者主啊,在我们这个卡夫卡中啊,他是一个逻辑概念,其实是一个啊,就一个, 哪怕你是有多个消费者,他在逻辑上都是一个啊,逻辑上都是一个概念,那么呢,比如说我们脱皮,脱皮狗不是可以进行分区吗?对吧?比如说分成 p 一 b 二 p 三啊, p 一 p 二是 p 三,那么此时呢,我三个消费者可能呢就会去对应到这个三个 party 选区进行消费,哎,那么此时我这个 cos kimi 如果是挂掉了,挂掉了的话,那么就意味着这个 party 选就没人来消费了,此时呢 就会去进行这个瑞班能使机制啊,或者说我如果是一 c 二 c 三,比如说我只是又增加了 c 四, c 五, c 六啊,增加了几个啊?客户端进来了,那么此时呢?哎,我可能呢又要进行这个,那么我这个 party 选 啊,怎么来分,对不对?此时可能比如说我想 c 一跟 c 四,我想两个呃两个,这个呃客户端来消费一个 party 选,从而呢提高我的这个消费速度,对不对?因为我 c 一跟 c 四来消费这个 party 选的话,那么一条消息呢,只会发往 c 一或者是发往 c 四,只会发往其中一个,对不对?那 通过两个两个消费者来消费一个扒鸡犬,也是可以提高这个消费的一个速度的啊。那么我把这个 c 四加进来了,怎么样?让这个 c 四去消 为这个 a p e 了,对不对?那么此时呢,也是通过这个 rebans 这种机制来达到的啊,也就说我新加了节点都是需要把这个分居数跟我的这个消费者的这个数量进行重新的一个匹配,这个就叫做 rebans 啊, 那么什么时候,什么情况下会产生这个锐半的时呢?有这么四点,首先第一个是这个啊,个入口中的这个成员个数发生变化,也就是说这个个入口中的这个 消费者的这个数量变了,那么你跟这个啊,他 t 选的这个对应关系肯定也会相应的会发生变化啊,那么此时就会发生这个 rebax。 第二个呢,就是这个消费端消费超时, 比如说我消费端消费这条消息超时了,然后呢,呃,就一直没有提交这个,没有提交这个 oppos i 的,那么此时呢,也会产生这个锐办的事啊。 那么第三个是这个割肉婆订阅的这个脱皮狗个数发生变化,那么这个的话就是这个 party 选这一边了,对吧?如果我这个割肉脯订阅一个脱皮狗,突然变成了订阅两个脱皮狗, 那么此时啊,这个新进来的这个脱皮狗,对吧?他这个 party 选也要进行这个瑞班男子,对不对?也要进行这个匹配啊,然后第三个就是订阅的这个脱皮狗的分区数量,也就是说这个 party 选的数量啊,脱皮狗,你比如说你之前可能只只进三个 party 选啊,如果说你这个消息越来越 多,你可能想让让他的这个消息的这个呃堆积能力更强,对吧?那么此时呢,就可以把这个啊头皮革的这个分居数进行增加啊,那么这个 party 选数量变化了,那么跟我们组消费组组中的这个消费者数量啊,也是需要进行重新匹配的,那么也就是在在在这四种情况下面会产生这个锐败的事, 所以我们如果想降低这个瑞贝尔的一个频率,那么有几种方式对不对?那么你消费超时了,是可以设置预值的啊,消费超时可以设置预值,那么比如说啊这个成员个数的,当然这个成员个数变化了,其他的几种方式的可能可能没有太多的这个啊控制的一个办法啊, 但是呢我们来了可以控制这个脱皮狗个数变化,就是我们人人工来增加脱皮狗或者是增加趴体选,那么此时我们可以了,就是考虑一下这个 rebans, 那么在这个业务 低峰期的时候去做这个操作啊,好,那么这个是锐半的时候,什么时候会产生锐半的时,那么这个锐半的时候到底是什么呢?那么首先我们要来明白一个概念,叫做啊抠钉的一头,那么这个呢,其实这个单词就是协调者吗?就协调者啊,那么这个协调者是个什么呢?其实这个协调者啊,在我们这个 卡不卡中,其实他就是啊,一般来说就是这个 party 选的这个力的节点所在的这个,包括我们知道这个 party 选的话,他是有这个主重复制的这种,有这个主重的这种加购吗?对吧?那么我一个 party 选是有很多副本的,这就是卡不卡中这种副本机制,对不对?副本, 那么这个副本呢,就存在一个利的跟 flow 的这种区分啊,那么这个利的跟 flow 啊,这个利的所在的这个不柔和节点,一般来说他就是一个协调者,作为一个协调者,那么这个协调者负责干什么呢?他负责监控这个啊,就是消费者祖宗 这个消费者的存活啊,这个协调者其实就是我们的这个力的啊,就是这个力的,那么呢这个消费者呢,他会维持到这个协调者的一个心跳,也就是说定时的去上报心跳判断呢,这个康斯科尔的消费的一个超时啊,就说我这个康斯科尔消费是否超时也是由他来判断的啊。 好,那么我们,呃,先首先明白这个协调者到底干了一些什么事情啊?接下来再详细看一下,他做这些事情到底怎么来做的啊? 我一直心跳很简单,对吧?就是我们这个消费者呢,要定期的给这个协调者这个力的啊,去上报你的这个心跳,如果说你要是断掉了,就,那么那么这个协调者可能就认为了你这个消费者已经挂掉了,那么此时肯定要进行这个 red 的事,对不对啊?或者说你要是消费超时了,那么此时我可能也需要进行这个 red 的事啊。 好,接下来看一下,那么这个协调者呢,他是通过心跳返回了去通知这个同时给我们进行锐办的事,比如说 此时啊,我,我可能,比如说有 c 一, c 二, c 三啊,这三个消费者在一个组中,比如说此时这个 c 一挂掉了,那么我这个协调者就应该要开始进行这个锐半的时,对不对?那么进行锐半的时的话,其实在锐半的时钟,所有的消费者都所有的这些啊,这些 啊节点呢,都是不可以进行读写操作的,对不对?那么此时呢,他就要通知这些 c 一、 c 二,通知这些啊,消费者 是不能够进行消费啊,又我要开始进行这个 redelans 了,那么怎么样通知到你们的呢?他们呢?因为你们不是跟我维持维持了一个,跟跟这个协调者维持了一个心跳吗?对不对?那么你们给我发包的时候,我是可以给你们返回的吗?对吧?通过这个返回机制告诉你们啊,就是现在要开始进行 readys 了啊,好, 那么所有的这个,呃,消费者就进入这个瑞班的时的一种状态,那么进入瑞班的时会做什么呢?这个消费者呢?他会马上重新去请求这个协 表者,请求他加入组啊,因为只是进行为办的是我的歌入谱还是没变,对不对?歌入谱没变啊,那么我还是会根据我配置中的这个歌入谱,然后呢重新去请求这个协调者,哎,我要加入这个组,那么这个协调者此时他就会知道,哎,有哪些,这个 有哪些消费者,对吧?就是请求了我请求了要加入这个组,那么此时我就知道啊,这个购入中目前来说还有哪些消费者是存活的啊?或者说新加进来了哪些消费者,那 那么此时的这个协调者呢?他就会进行一个选举,就会进行选举产生一个 v 的科目,也就是我们的这个,呃, 当然这只是一个简单的角色啊,丽的跟我,这个丽的跟跟我了,跟我们普通的消费者他也是一样的,他也是要消费消息的,并没有什么,他并不是真正的主从啊,只不过说是一个领导者角色,这个不是我们常规意义上理解的这个主从啊, 那么比如说这个,比如说把 c 一选为这个利的,那么 c 二 c 三呢?也是要去进行消费的啊,那么这个利的的这个更是跟我,他这个角色主要干什么用的?他呢?会从这个这个利的跟是跟我的,他主要是从这个协调者去获取。当前呢有哪些跟? 就是因为你这个协调者,你不是知道啊,就是谁请求了你加入组吗?对不对?那么你就知道当前这个组下面有哪些公司,根本包括新加进来的,以及了哪些踢掉了他都是知道的,对不对?那么这个力的从这里面去获取所有的这个消费者,然后呢 就进行分配啊,把这个消费者跟这个趴地犬去进行分配,分配完了之后将这个分配结果分装成一个性格入谱的一个东西啊,分装成一个性格入谱的一个对象,然后把这个东西呢发送给到这个可定了的就是,呃,发送给到这个协调者,那么这个协调者拿到这个包之后,他会把这个包呢,通过这个心跳机制下 发给所有的消费者,那么此时这个消费者啊,拿到了这个心格肉普,拿到这个东西之后,他就知道他该去消费哪一个 party 选的,那么此时这个瑞贝勒斯这个过程就完成了, 当然这个是肯定的,他这个协调者就是能够监控到这个更是给我们挂掉,对吧?或者是超时啊,那么这是啊,坑定了他,他主动发起了这种锐办的事。但是还有一种情况是什么呢? 就是这个托比格的数量,或者是说趴体选的数量发生的变化,那么他是不知道的,对不对?你因为因为他呀,他是一个,他是一个这个 procon 结点,对不对?那么这个趴体选数量发生的变化,或者是托比格数量发生的变化,他肯定不关心,对不对?那么此 有时是由这个丽的康斯 q 码来监控,因为我是一个消费者,对不对?我是个消费者,那么我是知道这个透皮革发生了变化的啊,因为你要我这个康斯 q 码,我要去监控了 哪些脱皮狗,那么我可是根本肯定要知道,对不对?我要都不知道我要消费哪些脱皮狗,那怎么可能呢?对不对?我要消费的脱皮狗肯定自己是知道的,那么只是如果我要消费的脱皮狗发生了变化,或者说我正在监控这个我正在消费这个脱皮狗上的 party 选,然后这个 party 选的数量发生的变化,他也是需要去监控到的, 那么监控到了之后就去通知这个协调者触发锐半零四。那么怎么触发了这个锐半零四之后啊,下面的流程就是一样的了啊,好, 那么这个是这个瑞贝尔的触发,以及呢?他进行了这么一个流程啊,那么明白了这个瑞贝尔的这种流程以及他的触发的话, 那么接着呢,我们还要明白这里边呢,还有一个概念啊,就是有一个问题,存在什么问题呢?如果说,比如说啊,这个 c 一这个消费者啊,他消息超时了,对吧?触发了这个 vbox, 那么在这个 vbox 之后,那么呢这个趴地选择进行重新分配,对不对?重新分配, 那么重新分配之后,这一条消息,因为你还是你消费超时,你并没有提交这个 office 的,对吧?并没有提交 office 的,那么 此时这条消息就极有可能会被发到其他的消费者上面去,对吧?比如说此时可能发到了 c 二这上面去了,然后 c 二也拿着去消费了,当然呢,这个时候我们可以去进行这个驱虫啊,可以进行驱虫,但是从卡佛卡本身的机制上面来说,那么是有可能存在这条消息又被发到了 c 二,但是你 c 一 前面超时了,那么此时如果发到了 c 二, c 二也在处理这条消息,还没有提交欧赛的了,那么 c 一呢?只是呢超时完成了,对吧?处理完成的,那么去提交这个欧服赛的,那么你这个欧服赛的一提交上去,极有可能就导致这个数据就错误了, 对吧?因为你这个欧布赛的一提交上去的话,就意味着这条消息已经消费完了,那么十一号再去提交了,相当于提提交了这个同一条消息,提交了两次欧赛了,对不对?好,那么这个瑞半的时机制怎么样来解决 这个问题了?因为这是由瑞贝尔导致的,对不对?是瑞贝尔导致的这种错误,导致了这种重新消费,那么重复消费啊,那么怎么样来解决这个问题啊?那么这个协调者,他每次进行这个瑞贝尔斯的时候,都会了 加一个标记,叫做尖的锐笋,这个尖的锐笋呢,其实我们就可以理解为他是零一二三四这种数字啊,其实就可以理解为,就像我们这一黑中的这种选举的这个周期一样, 我每次进行一个 wifi, 那么呢我都记一个数字在这里,这个数字呢,我会发给,发给这个消费者,把这个数字发给消费者,然后消费者你在提交这个 officel 的时候,你要把这个 officel 跟这个尖端锐选全部提交上来 啊,就是把欧夫赛的跟这个尖头锐选都提交上来,提交上来了之后,这个可定了头了,这个协调者他会去判断,判断这个判断这个尖头锐险是不是对的,如果是对的啊, 那么我就能够让你提交,如果不是对的,就不让你提交,就拒绝提交啊。因此呢,我每次进行锐办的时候,我都会将这个阶段微信进行加一,然后呢发给这个消费者,直接就可以避免上面的这种问题了。 那么如果你这个 c 一你超时完成了,你再去提交这个欧夫赛的,明显你的这个阶段锐选是一个老的阶段锐选,对不对?那么此时呢, 你的提交是会被拒绝的啊,会被拒绝。那么以上呢,就是这个卡夫卡中的这个 rebans 机制啊,以及他的一个简单的一个流程的一个分析啊,以及呢?这个 rebans 在合同情况下呢会去触发。
 03:47查看AI文稿AI文稿
03:47查看AI文稿AI文稿卡不卡消息积压产生的场景以及解决方案。第一种啊,就是生产消息的速度大于消费消息的发送方,发出消息的速度比消费方处理消息的速度更快,他会导致游客积压大量的消息。 那我们来看这张图,在这张图中他就是一个消息的整个流转过程,我们的生产者把消息推送到博客,然后我们的消费者啊去博客中把这个消息给拉,拉到自己本地,然后进行一个业务逻辑的处理,那业务逻辑处理完毕之后来进行一个 offsit 这样的一个提交。 那如果说,哎,我们生产消息的速度,比如说,哎,他每秒产生三十条消息,但是你消费者啊,处理业务逻辑啊的能力,哎,只能每秒只能处理十条消息,那这样的话 pro 客肯定会积累大 大量的消息。那我们来看这样一个问题,如果说我们的线上系统已经堆积了百万条消息,我们该如何处理? 那这种情况呢?一般我们的处理方案就是说我们对消费者这边进行一个改造, 那之前,哎,我们消费端这边是拉取消息之后直接进行业务处理,那现在就是说我们进行一个消息的一个中转,我们消息消费者这边拉取到消息之后,哎,我们不做任何的一个业务逻辑的处理,我们会创建一个新的 topic, 然后把这个消息直接推送到新的 topic 里面。同时,哎,我们在创建这个新的 topic 的时候,我们要创建更多的这个分区。那比如说,哎,我们 生产者他每秒能产生三十条消息,那我们消费者啊,一台消费者实力的机器,他能够消费每秒消费十条啊,十条消息,那如果说通过这个新建了一个 topic, 我们来创建三个这个分区, 然后,哎,我们对这个消费者,哎创建啊三个实力,那我们每一个实力呢?都对, 都对应一个分区,那这样的话对不对?那我们一个实力能每秒处理十条消息,那我们三个实力是不是就可以达到每秒处理三十条消息? 那这样的话,哎,我们消费消息的一个速度和哎我们产生生产消息的一个速度,哎就达到了一个平衡。那第二种情况呢,就是消费端,哎,我们系统异常 会造成消息的一个堆积,那比如说,哎,由于消息数据格式的变动,哎,或者说,哎,我们消费端,哎这个程序有 bug, 他会导致消费者一直消息消费不成功,然后他一直从事嘛,他也会导致不会积累大量的消息。 那我们来看这张图,那比如说生产端,哎,他推送消息,他采用的那个序列法方式是 fast 接生进行一个 啊序列化,然后我们消费端这边在对消息拉到消息进行一个反序列化的时候,它采用的是谷歌的我的八数这样的一个反序列化方式,那这种情况下,哎他就会导致,哎我们的这个 啊,这个消费肯定是不成功的,那是这是这样一种情况,那第二种情况呢,就是我们消费端这边,哎,我们处理啊处理 消息的这个业务业务逻辑他本身是有异常的,所以说他也不能及时的去提交 offset。 那遇到这种情况呢,就是说我们要设置合理的消息从事的次数,当我们达到这个从事次数之后, 哎,我们让这样消息直接进入到死性对列,那后面我们直接对死性对列的数据进行一个分析处理。
107I上编程 03:10查看AI文稿AI文稿
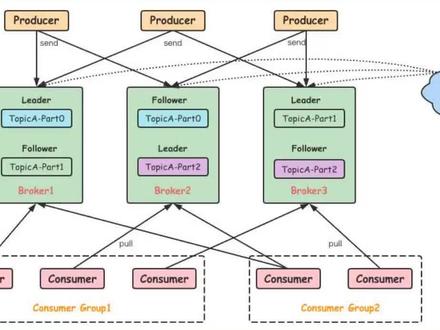
03:10查看AI文稿AI文稿请谈一谈卡副卡的工作流程,这是一个卡副卡常见的面试问题,那我们看一张图, 卡富卡作为消息队列也有三个要素,分别是左侧的生产者,右侧的消费者,以及中间的消息服务器不落。可那我们中间这个呢,是一个卡富卡的集群,那么这里边又有四个概念,分别是托皮壳、爬低性、 offshi 的和副本。 那首先我们看一下脱皮哥,脱皮哥呢,他是一个存储消息的抽象的逻辑的概念,不是真实存在的,可以认为这个里边就是存放消息的一个集合,可以作为消息的分类, 比如说不同的消息也可以用不同的脱皮稿来存放。好,那么爬低性这个概念呢?它是脱皮稿之下的一个概念, 在一个托闭口下边可以有一个或者是多个爬低行,爬低行也叫分区,那么这个概念很重要,爬低行是真正的存放消息的消息队列。哎,我们消息呢,就是存放在爬低行里面的,我们看一张图, 那我们左侧这个是生产者,右侧这是消费者,那么中间这个呢,就是我们的一个托闭口,托闭口的名字我们叫埋托闭口,那么这个托闭口下边就有三个 pad 型,三个分区,我们简称叫 p n、 p 一和 p 二。好,这就是我们的 pad 型。 那接下来第三个概念就是我们的欧赛的,欧赛的就是每个 party 型里边的消息有一定的顺序性,我们这里有一个序号,就代表我们消息的顺序,那么这个就是我们消息的欧赛的。好,那么最后一个概念就是副本,副本呢就是 每个 party 型的备份,一个 party 型可以有一个或者多个副本,也就是他可以有一个或者是多个备份,那么这个副本呢?他有主副本和重副本啊,主副本我们叫 lid, 从副本叫 follow, 主副本负责读写,从副本只负责从主副本同步数据。好,那这四个概念我们解释完以后,我们下面可以看一下我们这个图,我们生产者发上一个消息,他会按照一定的策略把消息来发送到脱皮壳下的某个爬地形下, 那么他肯定是发送到这个主的爬地形啊,立德的爬地形,因为虫的爬地形他是只负责同步组的数据,他是不接收读写的。然后我们消费者这边呢,他也是按照一定的策略从这个立德的 这个爬低性这个分区中来获取消息。一个爬跌性下的消息他是有顺序的,这个爬低性下他的消息有顺序,这个爬低性下他的消息也有顺序。但是如果我们跨分区的跨爬跌性的消息,他就是没有顺序的。 如果我们要想实现一个顺序消息,那这个时候把消息发送到同一个 party 形象,那么这个时候他的消息是有顺序的。我们这个立的 party 型,那么他对于有一个重的副本 follow party 型, 我们这个 lid 的爬地形,它也对于有一个虫的啊 follow 的爬地形。那么以上这个呢,就是卡副卡的工作流程。
1003动力节点IT教育 04:54查看AI文稿AI文稿
04:54查看AI文稿AI文稿今天分享的这道面试题呢,是一个工作了两年的小伙伴私信我的,我觉得这个问题呢要简单,本来呢不打算说,但是,哎,作为一个新的二部主呢,满足粉丝基本要求才能获得更多的点赞啊,对不对?好,关于卡不卡如何保证消息不丢失这个问题呢,我们看看普通人和高手是如何回答的。 普通的回答,嗯。呃,卡夫卡如何保证消息不丢失?呃, 我觉得可以从像博客上去做考虑吧,就是我,我要保证博客他是一个高可用的,我可以搭建一个集群嘛,然后生产端的话,我要确保这小姐发送出去嘛, 所以就是我记得生产端有一个从事就通过一个什么参数去配置一个从事就可以 在网络出现问题的时候他可以重发,然后 brok 做集群,应该是可以解决这个问题的。高手的回答, 卡佛卡呢,是一个用来实现异步消息通讯的一个中间键,它的整个架构呢是由 producer, consumer 和 brook 来组成。所以啊,对于卡夫卡如何去保证消息不丢失这个问题呢,我认为啊,可以从三个方面来考虑和实现。首先是 producer 端需要去确保消息能够到达 brook, 并且实现消息的存储, 在这个层面上有可能会出现网络问题,导致消息发送失败。所以呢,针对 pro 手端可以通过两种方式来避免消息丢失。第一个 pro 丢手默认是一步发送消息的,那么这种情况下 需要确保消息是发送成功,那么这里面有两个方法,第一个是把一步发送改成同步发送,那么这样的话呢, podosa 就能够去实 实时的知道消息发送的一个结果。第二种是添加亦不回调的函数来监听消息的发送结果,如果发送失败,可以在回调中去进行从事。第三个啊 producer 本身提供了一个从事参数叫 retras, 如果因为网络问题或者 brook 故障导致发送失败,那么 pro 丢 sir 会自动从事,然后是 pro 可端, pro 可能需要确保 pro 丢色发送过来消息是不会丢失的,也就是说只需要去把这个消息持久划到磁盘就可以了。 但是啊,卡不卡为了提升性能,采用了一步批量刷盘的实现机制,比如说按照一定的消息量和时间间隔去刷盘, 而最终刷新到此番这个动作是由操作系统来调度的,所以如果在刷盘之前系统崩溃了,就会导致数据丢失。卡不卡呢,并没有提供同步刷盘的一个实现机制,所以针对这个问题需要 通过 party 型的副本机制和 ack s 机制来解决。我简单说一下 party 型的副本机制啊,它是针对每个数据分区的高可用策略。每一个 paty 型副本级呢,会包含唯一的一个 leader 和多个 follow lead, 专门去处理事物类型的请求,而否冷呢,去负责同步 lead 的数据。那么在这样一个趋势的基础上呢,卡福卡提供了一个 a c k s 的一个参数, producer 可以去设置 a c k s 参数,去结合 brook 的副本机制来共同保障数据的可靠性。 a c k s 这个参数的值呢,有几个选择,第一个是 a c s 等于零,表示 producer 不需要等待 brook 的响应, 就认为消息就发送成功了,那么这种情况下会存在消息丢失,前面已经讲过了。第二个是 ack s 等于一表示啊, brok 中的 leader perty 选收到消息之后,不等待 其他的 follow protection 的同步,就给 produce 返回了一个确认,这种情况下啊,假设 leader protection 挂了,就会存在数据丢失。第三个是 a c k s 等于负一表示 brook 中的 leader protection 收到消息之后,并且啊等待 rsr 列表中的所有佛罗同步完成,再去给 producer 返回一个确认,那么这样一个配置是可以保证数据的一个可靠性的。最后就是 ctrlmer 必须要能够消费到这个消息。 实际上,我认为啊,只要 producer 和博客的消息可靠性得到了保障,那么消费端是不太可能出现消息无法消费的问题的。除非是 说嘛,没有消费完这个消息就已经提交了这样一个 offset。 但是即便是出现这样一个情况,我们也可以通过重新调整 offset 的值来实现重新消费。以上就是 我对于这个问题的一个理解,从高手的回答中我们可以发现啊,任何的技术问题是可以按照请求的顺序或者调用关系来逐层去推导和回答的。 当然啊,技术的底子要足够厚啊,至少像卡斯卡里面的副本呐,数据同步啊,分区啊,刷盘呐等这些功能,至少要有一个深度的思考和研究。 好的,本期的普通人 vs 高手面试系列视频就到这结束了,喜欢的朋友记得点赞和收藏,另外有任何技术上的问题和职业发展有关的问题都可以私信我,我会在第一时间给大家回复。 我是麦克,一个工作了十四年的家化程序员,咱们下期再见!
2071跟着Mic学架构〈3月突击版〉 05:03查看AI文稿AI文稿
05:03查看AI文稿AI文稿我们上节课给大家介绍了 cafa 的一个机器安装与验证啊,那上节课呢,我们给大家通过 cafa 给我们提供的一个脚本工具啊,嗯,演示了一下 cafa 的一个 top kit 创建,还有一个生产者如消费啊, 那么这节课呢,我们,嗯做一个快速热门,快速热门里面内容是什么呢?就直接只是通过我们的加号代码去集成卡不卡的一个客户端,然后实现咱们的一个生产日消费啊。好,废话不多说,我们直接进入正题啊。 好,我们首先如果要需要切成卡夫卡的一个工具的话,我们需要引入他的一个依赖啊,判断依赖啊,判断依赖的话,我们直接复制这个就行了啊, 然后我们这节课啊是用咱们最基本的加油单码去直接去实践啊,我们接下后面一节课的话,我们会使用会介绍一下卡布卡是如何在斯本布的中的一个使用方式啊。我们首先复制这个依赖啊,然后呢 复制这个依赖之后呢,我用我这里直接这复制好了啊,直接放丢在把,把咱们的依赖可爱呢放在这里就行了啊。然后我们再继续写我们的生产者啊,生产者的话,这个方式啊,其实和那也差不多,对不对啊?我们需要定义几个,嗯,配置啊,定义几个?配置 好,第一个的话,我们定义他一个服务端就是卡不卡的一个,呃,一个服务地址对不对?如果你有多个的话,你可以直接用逗号分割,然后写多个,然后我们再去要定义一个 topic, 因为我们需要生产者是需要 把那个消息发送到纸巾那个 top 课里面的,因为我们上节课啊,已经通过我们这个 creat 命令啊,已经创建了咱们的一个 咱们的这个 topic, 所以呢我这里面直接去,嗯,复用这个 topic 名称就好了。好,然后呢,这两个创建好之后啊,我们就需要去构建一个 prop protiss 啊,然后把这些内容放进去。好,关键的,最主要的大家看啊, 这里面有一个序列,一个序列化器啊,序列化啊,序列化的话这个东西一定要填,不然的话你不填的话就有可能会报错,因为这里面要填两个,一个 t 和 v 的这个序列化啊,序列化好,然后我们当我们把这个序列化,这个是,嗯,都穿进好了, 嗯,我们就可以创建我们的生产者对象啊,生产的对象 produce, 对不对? produce。 然后呢,这里面会丢入咱们的一个配置的一个信息,把它丢到这里面去,丢到这里面之后呢,然后我们会构造一个 pro 卡不卡 produce 的这个对象, 这对象之后啊,我们就会可以教用他的一个肾的方法啊,这叫用肾的方法,默认的话,他这他这个是一个一步发松的啊,一步发松的,我们需要调用 get 的方法进行一个同步等待,进行同步等待好,然后这里面割造了一个 realcode record, 这里面其实一个消息封窗底啊,消息封窗底,然后这里面,嗯,构造哪一 信息呢?就有 topic, 还有一个咱们的一个数据啊,好消息好默认的,往哪分去分分呢?我们上节课之前课程也讲过,就是他会根据他的 k 啊进行按照一定的规则进行一个计算。 好,然后我们来看消费者,消费者同样的我们这前面几个参数都是一样的,需要构造,嗯,而且也是进行了做一个 k 的一个反序列化,大家只要搞清楚这里是一个反序列化,不要弄错了啊,反序列化不要搞成也是序列化了,他就会导致我们的消费者起不起来的。嗯,好, 然后配置完之后呢,我们还要需要配这个消费组啊,嗯,因为大家这,嗯,大家现在还不清楚,就是卡不卡的话,他是嗯把所有消息他会往不同的组里面发啊,就是一个组里面他只会发一个,然后呢一个组里面也只会有一个消费者进行一个消费的。好,那么消费组这 里面要有唯一区别的。嗯,地方,这个设备组的话,这个 id 啊可以是是你一个随意的任何任意的一个 id 啊,任意的一个数值就行了啊。然后这个做完之后呢,我们需要各自 ctrl, ctrl, 然后我需要去订阅啊,订阅这个 topic, 我们同样的是我们生产者的一个 topic, 订阅这个 topic 第二套笔之后呢,我们在这里面搞一个死循环,对不对?搞个死循环,然后一直从咱们的这个里面破拉取消息,然后呢这个超时时间是一秒啊,一秒 拿取消息之后,如果是不为空的话,那么我就可以进一个便利这个消息,便利消息之后,然后把它打印出来啊,这就是一个简单的生产日消费。好,那么我们现在把大码跑一下,看一下是什么样的效果啊? 首先啊,我们需要启动咱们的消费者啊,因为不然的话你生产的话就消息就没了啊,就他就不会从那开始了,需要你指定他 offset 啊。好, 我们生产消费者是已经启动起来了,我们接下来我们启动我们的生产厂,我们看下生产者发的内容是什么?嗯,我们这里发一个 demo, 是不是?好,我们点一下,看一下他是什么效果?好,这个已经结束了,是不是结束之后,然后你发会发现这个已经亮了,亮了就说明咱们已经收到这个消息了。好,那我们再发一次,看一下是什么样? 再发一次。好,我们又收到了一个消息,是不是?好,我们再来一次,对不对?再来一次。 ok, 这个已经发完,发完之后这个绿了,绿了之后呢?这就收到消息了, 所以呢,咱们的这个生产使用加法代码继承咱们的客服卡斯 dk 啊,这已经是成功了,实现了咱们的生产和消费啊,这只是一个简单一个 demo 啊,后续的话会讲解更加的一个深入,按照生产的消费者的 接动一下,然后会结合他的一些原理啊,原码进行个讲解。好, ok, 那么今天的内容就到呃,这里啊,下节课我们来讲 smile boot 如中,如何去使用卡普卡。好,谢谢大家。
41乐哥聊编程 03:58
03:58











