csdn都spring从入门到精通
粉丝339获赞2347
相关视频
 01:59查看AI文稿AI文稿
01:59查看AI文稿AI文稿你以前用过扑克员吗?时间十分钟,写扑克不写,看后来用过哪些类似的这种技术网站。没用过的就是看笔记本。 嗯,自己的小笔记本都是。哈哈哈哈,一点都没有那种互联网精神,一点都不爱分享。哈哈哈,哪有时间分享啊,你整那玩意一写一个文章你还得从头捋一遍,然后整着。我花一天整一个文章。 哈哈哈哈哈哈我以前我以前试过,但是这玩意太难受了,除非说我随手整随手记,但是这边边整着那边边记着,哎呀,一会思路没了。确实确实, 我以前就是一直坚持不下去,我觉得是那个网站的问题,先后就换过,比如说一开始博客源,后来 c s d n, 再后来掘金网,然后还写过公众号,就是这拉一坨那拉一坨的,感觉就就没有体系化, 也坚持不下来。我以前反正写的有道云笔记,现在还有用没有?我我基本上都。嗯, 那你们查一些东西,基本上经常逛的技术博客啊,网站有哪些?百度?哈哈哈,我以为你会说什么 get up 啊,什么 stand over floor 啊,那些 就查技术问题,技术问题也百度也百度啊,是出来哪算哪啊?哈哈哈,出来个广告, 要不然有的时候你去那个 style 你 找不着呢。啊,我一百度出来的全是四 s 店,一点进去就要我充钱,不充钱就一个大半屏的广告 就。哎,那现在开始要变现了吗?哈哈哈哈。
32宇宙落单乘客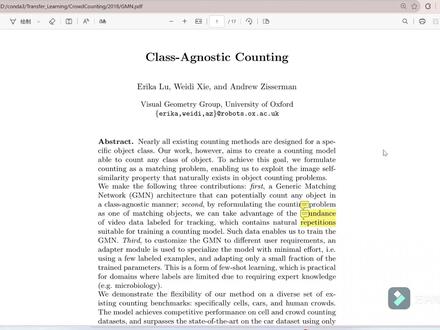 13:29查看AI文稿AI文稿
13:29查看AI文稿AI文稿hello, 各位小伙伴们大家好,今天要讲的是类比五官的目标统计算法,前面我们已经讲过了有关 their short 零二百目标统计算法 那几篇, their short 算法在方法上面是比较经典的做法,也希望大家可以先把前面的 their short 相关算法看一下。 而我们今天要讲的是类别无关的目标统计算法,虽然是幺八零的,但是这个算法也算是很多思想的基础和基础,因此还是值得去了解的。 我们今天要讲的算法 g m n 通用匹配网络模型并不算是要求的目标统计, 因为论文的这个方法在面对新的领域时还是需要进行 speech adapter 的 一个微调的,即使你可以把它归类为 future 的 领域。 forecaster 的 相关算法我们之前设计的稍微少一点。它这种算法在推理阶段还是依赖于要统计的目标,也就是必须让它稍微认识一下当前的标的类别模型才能进行目标统计。 论文要提出来的,呃,进入时,论文主要提出了进入呃进入模块提取特征,还有匹配模块、四倍镜模块,实现少量版的微调。 这些模块细节后面我们会进行一个细讲,我们先大致了解一下文本的方法流程。这个算法,嗯,首先在大量视频数据集上训练了一个通用的匹配网络模型 g m n 嗯,然后通过训练一个极小的适配器,嗯,这个模块 adapter 来快速适应新的技术类别里或者领域 而冻结主干网络的大部分参数。这种方法不仅解决了传统方法的类别依赖性问题,还大幅度降低了在新领域应用时所需要的数据量和集中成本,为实际应用提供了极大的便利性。 嗯, 其实论文的概要部分描述的很清楚呢,我们来看一下论文的图一部分 可以看到根据要统计的目标类别 patch 以及对应的云图网络可以根据目标类别 patch。 呃,是呃嗯,统计相关的目标的一个数量。 然后我们来看一下本问提出的大致网络结构图,包含了一个七六模块,特征匹嗯,特征匹配网络模块以及设备器模块。 首先,原图和要统计的类别 patch 分 别输到网络模型,网络模型中,提取到相应的原图以及啊 patch 特征之后进行特征的一个融合, 最后经过密度图预测模块得到最终的密度图, 对列表图求和即可得到对应的目标的数量。而适配器模块是我们要应用到新的领域进行统计时使用的。好了,我们来看一下论文的笔记部分。 在这次讲解呃算法之前,我们先来看一下之前已经存在算法的一个矩形心。 第一,传统的方法只针只针对特定的类别进行目标数量的统计,比如我们的车辆、行人等模型缺乏一个发话能力,遇到新的类别时需要去重新训练模型。 第二,依赖大量的标注数据。如果我们要训练一个目标检测模型来检测目标的一个数量,或者训练一个基于密度图的一个检测模型,这些算法都需要依赖大量的训练数据,导致难以实际应用。 第三,面对复杂的场景来进行准确的统计。第四是传统的方法没有很好的利用嗯,途中相同目标的一个重复信息,这些重复信息对于准确的统计当前指定目标是非常重要的。 好了,我们来看一下本问提出的具体方法实现,这里将提出的方法稍微进行了一定有序总结,大家看一下就好。 接下来我们具体看一下金融城模块、特征匹配模块以及思维器的一个具体实现。 首先我们来看一下金融城模块,金融城模块其实它是由嗯 resident 五零作为基础来实现的。 原图和目标类别 patch 对 应的基础网络架构都是差不多的 啊,原图输入大小是 h 乘 w 乘三,而 patch 输入大小为六十三乘六十三乘三。只不过 patch 呃经过基于网络提取特征之后,经过一个平均词化呃,将其特征向量转化为一乘一 乘以五幺二的选项,再进行成规划操作。经过成规划的呃原图特征向量和帕奇对应的特征向量进行一个拼接, 然而输入到特征匹配网络当中,其实特征匹配网络是一个由三乘三的卷积和一个三乘三的反卷积组成的,最后通过一个一乘一的卷积输入通道为一的卷积得到预测的一个密度图, 最后对密度图球和几何得到最终要统计的一个目标数量。 在训练流程部分,作者也给出了整个网络模型架构的一个实现。这个通用匹配网络嗯,框架首先是在一个视频数据集上进行一个训练的,并通过高斯平法函数得到真实标签对应的密度图 其实了解过我之前讲过的人群记录算法方面的小伙伴都知道这个密度图是怎么样以及怎么生成,是什么样以及怎么样生成的。经过前面通用匹配网络特模型训练之后,我们来看一下要统计的目标的一个情况。 从图上可以看到文本通用匹配网络模型检测效果还是差不多的,还是不错的。 该模型已经学会了对简单级别的一个匹配实力的一个统计,哪怕部分的嗯,被遮挡,外观颜色都能很好的被检测出来。 通用匹配网络架构已经训练完成,如果真的新的领域目标该怎么办呢?难道是重新训练模型吗?那这样的话岂不是又回到了最初的样子?为了解决这个问题,本问提出一个简单的适配器 adapter 模型, 嗯,这个适配器模型 adapter 使用现有的三层三权,即实现 在新的领域训练识别器过程中。之前的通用匹配网络模型参数需要进行一个冻结,只需要训练这个识别器网络即可。让整个网络模型只有呃六 m 的 一个参数量,整个训练过程需要更新的参数只有一百七十八 k, 只有总的参数量的百分之三,因此这样可以快速的让模型适应新的领域,并进行一个目标统计。 可以看到相比于之前的 future 的 方法来讲的话,确实要方便一些,主要统计的准确率也得到了提升。 好了,关于论文的核心部分算法啊,我们就讲到这里,我们大致来看一下模型的代码实现部分吧,它这里给出的代码是使用 carrots 框架来搭建的,好了,我们来看一下代码, 嗯,代码部分的话,因为它是使用 chaos 框架啊层次 flow 来实现的,我们就不对其训练过程来进行一个讲解,因为它主要是集中在它的一个网络模型架构方面。我们来简单看一下模型架构, 呃,这是它的一个整个模型架构的一个流程。从这里开始,首先是针对我们输入的一个 patch, 这个 patch 对 应我们要统计目标类别以及我们的原图, 然后这里是一个我们的 patch 提取特征的一个网络模型架构。我们来看一下它其实是一个基于的网络模型架构来组成的,这个基于的网络模型架构你可以把它看成是 resident 五零的一部分, 然后针对我们的一个原图的话,它的一个基础网络模型其实和刚才我们所说的一个 patch 对 应的基础模型是差不多的。 然后我们现在对我们的一个嗯,派起来提取它所对应的一个特征,然后经过我们的平均取货之后,然后得到一个一乘一乘一的乘五幺二的一个特征限量, 然后对我们的一个呃原图进行一个特征的提取, 然后再对我们的一个呃,呃, patch 对 应的一个特征项链以及原图对那个提取的特征项链进行一个成规划, 然后后面呃再进行一个维度的变换,最后进行一个特征项链的拼接,然后输入到我们的这个匹配网络模型里面,它是由呃,一个三乘三卷机,一个啊反卷机,三乘三的反卷机组成。 提取之后,再经过我们的一个通道输入通道为一的一个全景网络架构,然后得到最终的一个预测的一个列表图, 可以看到它这里会判断我们是否采用一个适配器,这是我们上面已经搭建的网络模型,然后我们现在对网络模型进行一个啊筛选,我们要判断我们是否使用适配器,因为我们当前训练的过程它分为两种, 一种是进行模型的一个预训练,就是对我们的通用匹配网络进行一个训练,另外一种是对我们的一个适配剂进行一个训练, 那这就好理解了,我们如果是直接,首先我们是训练我们的通用匹配网络模型, 等到通用匹配网络模型之后,我们可以对简单的目标利弊进行一个统计,如果你要适用到新的领域的话,那么我们就对我们的一个四倍器网络架构进行更新。那这个四倍器是来自哪里呢?其实他在搭建网络结构的时候, 嗯,比如在这这里面,他在搭建这个呃 resync 的 这个 block 的 时候,他就已经加入我们的设备企业模块, 以及这里也加入了识别器模块。因此它在整个过程中,它是根据我们的一个训练的一个方法去获得对应的一个层,然后对其进行一个更新。这个代码实验部分我们主要讲网络的一个部分,就讲到这里, 嗯,关于这个核心算法,我们已经部分,我们已经讲的差不多了。 好了,今天的视频就讲到这里,感谢大家观看,谢谢。
 01:49查看AI文稿AI文稿
01:49查看AI文稿AI文稿通过这个视频你可以了解到一个普通的 spring boot 项目是怎样变成一个微服务项目的。首先创建一个普通的 spring boot 项目,它的目录长这样的 创建完成之后,把 s、 r、 c 目录下面的东西全部给删掉,接着他就变成这样子,让他作为一个副工程,然后在这个工程下面创建具体的模块,然后在每一个模块下面创建对应的 form 点 xml。 这一步做完之后,接下来要做的就是在每一个模块下面创建具体的包名,然后每一个模块都创建一个启动类。接下来要做的就是把一些公共的依赖放到副工程的 pdf 文件里面, 对于一些像模块特有的一些依赖,那么直接放到具体的模块里面就可以,比如这个网关依赖。最后给大家推荐一下我的这几份实战手册,手册的价值在于,一,提高学习效率,通常来说你跟着手册操作十五分钟就能完成一个实战视力。 二是学习有个兜底的地方,如果你在遇到问题的时候,我会及时帮你解决,并且把具体的原因告诉你,就避免的话,你去到处查资料,浪费了大量的时间。 至于项目是一个从零开始搭建的微服务项目,这个项目你除了能学习微服务的搭建,还能全面了解一个项目的整体开发流程。 我这个项目从需求整理、原型图绘制、设计图正常的开发到项目的部署以及基础的运维监控都设计,并且项目中的代码都有对应的注示。 在学习手册和项目的过程中,如果大家遇到问题,推荐直接打语音,这样的话解决起来效率高。
103编程实战派 02:00查看AI文稿AI文稿
02:00查看AI文稿AI文稿各位编程新手们,你们知道吗?学习拍丧就像盖房子,基础语法就是最重要的地基。今天咱们就来聊聊拍丧编程中最基础也最重要的几个概念。首先说说变量和数据类型。变量就像一个个小盒子,用来存放数据。在拍丧里, 我们不需要提前告诉电脑盒子里要放什么类型的东西,它会自动识别,比如写 h 等于二十五,电脑就知道这是个整数,写 name 等于小红,它就知道这是字母串。 不过给变量起名字可是有讲究的,不能随便乱取,要符合命名规则,最好能让人一眼就看出这个变量是干什么用的。 开像中最常用的数据类型有三种,数字,字母串和布尔值。数字又分整数和带小数点的浮点。数 字符串就是文字信息,可以用单引号、双引号或者三引号包裹。布尔值就更简单了,只有 true 和 false 两个值,专门用来做判断的。 有时候我们需要把用户输入的数字字母串转成真正的数字,这时候就要用到 int、 float、 str 这些转换函数了。接下来是运算符,它们能让数据动起来算数,运算符负责加减乘除比较。运算符用来比较大小逻辑,运算符可以把多个条件组合起来判断。特别提醒一下, python 里的等于是用两个等号, 一个等号等于是赋值的意思。最后要说说代码注是这个好习惯。写注是就像给代码做笔记,用开头的单行注是,或者用三引号包裹的多行注是,都能让代码更容易理解。 记住,好的程序员不仅要会写代码,更要会写注,是大家觉得 python 的 基础语法里,哪个概念最容易搞混呢?是变量命名规则还是数据类型转换?欢迎在评论区分享你的学习心得。
18阿宇~ 09:10查看AI文稿AI文稿
09:10查看AI文稿AI文稿作者写文章的时候是免费的,但是用户看文章的时候就变成了收费的了,这简直是离谱啊。昨天啊,看了一下我的 c s d n。 的 账号,没想到已经马玲十三年了, 回想最初写博课的时候啊,其实就是在 c s d n。 上写的,那个时候呢,我还在研究安卓开发,每天呢,就用着安卓 studio 啊,在那瞎琢磨。 可惜的是啊,当年因为各种各样的原因,我删掉了不少的老文章,现在呢,能翻到的最早印记啊,也只能追溯到二零一五年了。 看着那些青涩的技术的记录,其实心里挺不是滋味的,因为当年的 csd 啊,那可是国内技术圈实打实的老大哥,当时呢,也涌现出了不少的技术大神啊,不过 时过境迁啊,很多当年的大神现在也都不再更新文章了。而 c s d n 呢,如今大家再提起来这四个四,大家的感觉也不再是一个技术平台,而变成了吃相难看。 大家好,我是 sandy。 今天啊,我就想站在一个十三年的老用户的视角,来聊一聊 c s d n 是 如何从当年的 type one 的 巅峰一步一步走下坡路,变成现在这个样子的。 回想当年啊,在那个移动互联网还没有完全统治我们的生活,并且更没有什么所谓的 ai 的 时候,我们去解决技术问题的方式其实非常的纯粹啊,就是靠搜索引擎。如果你是那个年代过来的开发者,那么你一定记得,无论你 搜索什么奇形怪状的技术问题啊,那么搜索引擎,尤其是百度,它的前三个结果里面,必定会有至少一个 c s d n 的 不可链接。 c s d n 当年的火爆啊,本质上其实就是在 seo 上的一个巨大程度, 那个时候呢,涌现出来了很多的大神啊,很多现在活跃在各大厂里面的架构师啊,特别是老架构师啊, 当年呢,可能都是 c s d n。 的 博客专家,大家呢,只是单纯地去分享代码,那么讨论区里面其实也是比较和谐的一个技术讨论的声音。 但是啊,老话说的好呀,为爱发电啊,它长久不了只做纯技术播客,它是不赚钱的,并且呢,在那个时候,还没有太多的像技术视频啊,然后付费课程,付费小册, 没有直播带货这样一些东西。 c s d n 呢,它作为一个商业公司,运营成本是巨大的,所以说他们必须要找到盈利的模式,于是他们就想到了一个最直接的方式,那就是广告。 其实作为用户啊,我们并不是不能接受广告,最初呢, c s d n 的 广告做得还算克制,通常只是在文章的两侧, 或者呢,在底部的某一个角落那里静静地躺着,虽然偶尔会弹出一些不相关的网页或者说是游戏呢,但是起码他不影响咱的阅读,对吧?大家呢,也就睁一只眼闭一只眼,权当给平台交服务费了。 但是资本的胃口啊,或者说资本家们的胃口啊,总是很难填满的,人的底线,他也是一点点突破的。或许是发现简单的侧边栏广告收益啊, 不高啊,或许是为了要赚更多的钱,那么 c s d n 呢,它的广告变得越发的丧心病狂了,比如说,我记得之前很多文章,当你看到一半的时候,它一定会跳出来一个浮动广告,单纯是这样就罢了啊, 最关键的是,它的文章里面还充斥着大量的标题的,点进去一看啊,全是各种培训机构, 同时呢,他在侧边顶部悬浮啊,底部啊,各种地方弄的全是广告。你看文章就像在一堆广告里面去找代码,弄得以为自己电脑跟中病毒似的。正是这种 竭泽而渔的方式啊,其实就直接伤害了平台最核心,最核心的资产,那就是一些优质的用户和作者。 当一个平台的环境变得非常的嘈杂,或者说是低质的时候,那么真正爱惜羽毛的一些开发者就会开始流失。 这也正是因为在这个阶段啊, c s d n。 呢,忙着去收割流量进行变现,而忽视了对纯净社区氛围的一个维护,这才给了一些后来者的机会。比如说现在大家比较熟知的掘金啊,那么他们的一些崛起,其实某种程度上都要去感谢 c s d n。 的 这波操作, 大家受够了在垃圾堆里面去找金子,于是就会去尝试找更好或者说更加纯粹的平台。 同时呢,如果说单纯的只是广告多啊,单纯的只是标题党,这些操作其实还能忍啊,因为哪怕到现在很多标题党依然存在。但是最离谱的操作来了, c s、 d n。 它开始尝试把原本属于公共知识的内容给变成自己的资产。比如说当作者写文章的时候是免费的对吧?但是用户看文章的时候就变成收费的了, 同时作者自己都不知道自己的文章什么时候变成了收费的了,这简直是离谱啊! 我身边有不少的博主朋友都反映过这样的一个诡异的现象啊,自己做了一些技术总结,明明设置的是公开发布, 然后过了一段时间也不知道咋回事儿,莫名其妙就变成了 vip 专享或者是付费阅读。你像这种平台带你领工资的行为是不是就过分了? 咱们先不提平台是否有权限直接把作者的内容转化为收费的项目,单纯的从技术人的角度来看, 当你很着急急着去解决一个 bug 的 时候,点开链接,映入眼帘的不是解决方案,而是扫码开通会员日均四毛七解锁全文章啊,你说这不是离谱吗?关键是有时候你给他解锁了之后,发现 文章下边变成广告了,这就更离谱了吧?你的内容收费了,那么你的文章质量也提升了,也没问题,但是 c s、 d a 的 内容质量并没有因为收费而提升,反而还是会出现 大量的甚至特别大量的爬虫抓取的内容,搬运的内容,甚至是广告的内容。 这就导致你花了钱买的可能只是去看了一些硬广的广告,也有的是一些本来就在 get up 上面或者别的平台上面早就已经存在的内容。 ok? 那 么看着我这十三年的一个勋章啊,我其实思考了挺久的,那 c、 s、 d、 n 它到底是怎么把这一手好牌打得稀烂的? 我觉得主要有以下三点。首先呢,第一点呢,就是丢掉了对开发者的尊重。开发者其实是一个非常特殊的群体, 他们对效率有着近乎偏执的要求,对广告有着天然的免疫力和反感,但是他们又愿意为真正的价值去进行付费。四 s d n。 错在把开发者当成了可以肆意收割的流量小白,而不是共建生态的合作伙伴。 第二点,就是丢掉了对内容质量的敬畏。曾经的 c s d n 是 有门槛的,现在的 c s d n 里面充满了大量的重复内容、无效内容。 当你为了流量而纵容一些爬虫和广告,为了 kpi 而去纵容很多的营销号存在的时候,那么平台就慢慢地从一个技术的殿堂变成了一个技术的垃圾场了。第三点啊,就是错失了移动端和生态转型的机会。 嗯,像微信公众号掘金,然后知乎他们在技术圈进行发力的时候,四 s d n。 呢,似乎还只是沉迷于 seo 所带来的躺赢的一些流量。等他反应过来,想要去做自己的 app, 想要去做自己的收费小册,想要去做自己的 ai 助手的时候, 口碑啊,早就已经跌倒谷底了。因此,四 s d n 这个事情啊,告诉了我们一个道理,就是无论是什么时候,都要把用户放到第一 位,不管你曾经多么辉煌。如果你不把用户当朋友,而只是当成一个资源的话,那么被抛弃也就只是时间问题了。 we are sunday, 咱们下次见喽!
 12:52查看AI文稿AI文稿
12:52查看AI文稿AI文稿hello, 各位小伙伴们,大家好,前面有几个视频,我们也讲过了关于人群技术的一些相关算法,以及对那些已经实现过的一个代码史。 然后我们这个视频主要讲解的是我自己实现了一个统一的人群技术的一个训练框架。 嗯,当然这个训练框架主要还是基于主流的列表图来进行一个模型的一个训练的,然而这个框架其实对于大部分任务都已经可以使用了,而这个代码呢,我到时候会开源在 getup 上面相关的链接,我最后会在视频下方留言。 那我们来看一下,这里主要给出了两个文档,一个是英文的和中文的, 而这下面给出了一个参考链接,就是我在写代码的时候参考的哪些代码以及相关的一个开源的库,然后这里都是分别给出来的,大家如果有什么问题可以看这些链接。 当然我这里并不会一一给大家讲解每一行代码,而是讲解这个框架其实非常容易,理解也非常清晰。 那我们首先来看一下,在进入人群技术这个训练框架的时候,最主要的一点还是理解它的一个数据集的一个处理。 关于数据集的一个介绍,我们之前有一个视频已经介绍了,我就不过多的一个讲不过,嗯,不过多的一个讲解,大家可以看前面的视频, 然后这个关于灭毒毒的生成还是看之前的视频已经讲过了。然后我们来看一下这个统一处理这个数据局的一个训练的统一处理这个数据集的一个代码, 然后它包括就是数据的一个密度图的一个生成,以及把我们当前的一个就是数据的保存的一个结构给配置好来看一下。 然后我们这里它这里主要是支持几种数据,于是 nio 一 节 graph, 还有上来一节上海币,然后它主要支持的是这几种数据的一个预处理, 并且像我们当前基于主流的地图的一个呃训练框架,其实大部分使用的一个对比数据都是采用了这些。 然后我这里,然后我们关于这个代码我们不会去细讲,大家可以自己去细看一下,因为这个训练框这个预处理的这个数据的这个框架其实是比较容易理解的, 而且如果你看过之前就是密度图的生成之后,你直接来看这个代码就可以了。 然后我们这里,呃,我当前正在处理这个数据,然后我们看一下它处理的数据之后,它会自动给你保存到当前这个文件夹下面, 它会自动根据你当前指定的要处理这个数据的类型,然后在当前这个目的下面生成它的 test 以及 test 这文件 夹,那下面 会把生成的地图保存到这个文件下面对应的一个图像,它会根据你指定的下载的一个数据集指定的一个根目录,然后从下面把对应的一个图像给复制到当前这个目录下面, 其实就是这么意思,然后这个类主要是负责一个数据的一个复制,就是你指定的一个原文件以及目标文件之后他将数据从原文件复制到我们的目标目录下面,就相当于把图片复制到我们当前的这个页面主下面, 而且你只要指定,嗯,你这里首先需要去创建你这个要保存的这个根目录, 其实就是这里我指定了这一个要保存的这个目录。指定之后,那么你下载好你对应的一个数据之后,你直接指定数据的跟目录就可以点一键生成。这当前在你保存的这个目录下面,他的 text 的 一节券都已经给你生成好了。 那么在进行训练的时候,直接进入这个 man 或者 man u c f 这个五十,这个数据机为什么两个分开选呢?主要是这个五十它采用的是 k 轴交叉运正, 但我们来看一下这个 man 就 可以了。其实这个 man 的 结构呃也是参考了前面我刚才已经列出来相关链接里面的一个代码, 其实这里面大部分数据都是,呃代码都是进行了一个参考,然后把它整合 做了一个统一的一个训练框架,这框架大家只需要去一键生成数据,并且 直接指定数据集的一个路径,就可以进行一个模型的训练,然后这里指定了分别对于不同的数据集,它的一个元数据以及目标数据的一个裁剪。为什么这里是什么意思呢?这个元指的是我们在训练的时候对数据一个随机裁剪, 这个 target 就是 我们在进行验证的时候对数据的一个拆解,因为我们验证的时候不可能把一张很大的图像直接输到模型,然后进行一个训练,其实这样会造成一个显存的遗出的 啊,为了克服这个问题,然后就采用滑动窗口的方式对这个验证的图像进行一个一一裁剪之后输入到模型当中,并进行一个预测,然后再对最后预测的结果进行一个地图的一个拼接,得到一个完整的一个预测图像。 嗯,这里也支持一个分布式的一个训练。 然后这个训练框架呢,其实非常清晰,比较容易理解,我们就不过多去讲解,其实在之前讲过代码的时候,我们已经讲过了,然后你读者只需要做的就是更换模型就可以了,你可以根据你自己的需求对模型的一个模改,或者一个更改之后, 那么你就可以直接替换这里面的模型,然后就可以直接进行一个训练。当然我这里也提供了一些主流的 backbone, 然后大家也可以进行一个训练,这些只是一些比较简单的,并没有进行一个太多的修改,然后直接输出他的一个列表图,然后就可以最终 得到一个预设的一个结果。当然这个代码是可以训练的,因为这里已经提供了一些基础的模型进行一个训练,如果你要改的话,只需要更改模型即可。 然后这里也提供了一些常见的一个损失函数,比如像 mse 军方误差损失函数以及 l e boss, 还有一些相关的一些多此的一个损失,还有就像我们那个独立化传播损失。关于这些我已经在这个 啊 redmi 这个文件里面提供的一些参考链接,大家可以去看一下,这就是它的整个代码的一个框架,大家可以看到非常的简洁,而且层次还是非常清晰的, 而且整个训练的代码也是非常清晰的,它并没有太多的容易的性,而且这个代码是偶核性比较低,便于初学者去理解。 你只需要去更换模型的一个架构,然后就可以进行训练,当然你输出的一个结果必须要是输出一个列表图所对应的一个模式模式, 然后当然你也可以采用一个分布式的训练,刚才你讲过这里有这里他的一个配置参数,当然关于配置参数的一个,呃,模式大家可以有多种写法,这里只是写了一种比较常见的,因为大家比较容易理解了,这里只需要指定我们训练的一个 啊,录屏,就是我们的劝录屏已经开始录屏,然后数据的话,呃,就是读取数据的话,其实在我们这个这里 就是我们这里加载数据,这已经写好了,大家可以不用动它,然后直接就可以使用了。 这里的训练的数据的一个加载部分以及测试数据的一个加载部分都不需要去改动,你指你要做的就是直接指定这个训练以及测试的一个路径,就可以进行一个模型的训练。 然后我们这里支持的啊,刚才我们也说过支持的一个 graph 的 一个标签的一个格式就是 npy 格式,当然你这里一键生成的就是 npy 格式,因此大家不用担心, 嗯,这就是整个代码的一个框架,然后大家着重要看的是就是模型这个数据的一个预处理部分,需要着重去看看一下,这是我们之前已经讲过了关于数据介绍那部分, 然后损失部分的话,大家如果感兴趣也可以去看一下,甚至也可以提出自己的新的损失。然后模型部分大家也可以尝试去看一下,只需要做出修改替换自己的模型,就可以进行一个啊你自己的一个人群技术模型的一个训练。 嗯,这里还提供了一些,就是像训练还有我们的一个验证它的一个代码,还比如学习力,也就是调度器,并且在学习力调度器我们是支持多种格式的。 嗯,因为我们这里已经给出了不同学习调度呃学习率和调度器它的一个的所对应的一个名称,然后大家只需要去指定就可以使用了,然后在这里 可以指定我们对应的一个学习率的一个呃调度器的一个名称,然后就可以进行一个模型的一个训练。 你指定之后,然后我们去会根据我们指定的一个学习率调度器的一个名称,然后去加载对应的一个学习率的一个更新。 嗯,这一点是我自己集成进去的,大家可以看一下。然后还有这保存模型部分,这里保存模型部分它当然是针对不同的,像我们的分布式的时候,它的一个保存的一个格式都是差不多的,只不过这里需要稍微注意下。 然后这个虚面框架呢,我到时候会开源在 gitlab 上面,然后链接我会给在视频下方。 那欢迎大家去进行一个使用,或者有什么问题也可以在评论区进行一个留言, 然后如果这个框架遇到什么问题,也可以直接联系我,可以和我进行一个讨论。最后我们在训练完成之后,你可以进行一个测试,这里的测试代码也给出来了,也欢迎大家去使用。 然后这里面可能有一些小小的细节,那我也可能我到时候会优化一下。 然后还有这个 channel 就是 我们的一个训练的一个过程, have vest tag get, 这 vest tag get 就是 便于我们的一个,就是我们可收获我们的一个关联措施这个标签。 当然这里还有个 visual demo, 就是 对我们的一个 test 数据机进行一个抽象,就像我们论文里面所看到的一个抽象之后它所对那个 midi 图,以及我们最终的一个预测的一个人群的一个数量。 这是 visual demo, 其实已经有相关作者也提供了相关的案例,那我这里只不过进行了一个修改, 当然这里也可以说是自己写的,嗯,整个代码主要就是这样的,其实会发现整个代码看起来很庞大, 但是其实对于初学者我觉得是还是比较友好的,而且整个代码的偶合性是比较低,大家可以进行一个即插即用。好了,关于今天的视频就讲到这里,感谢大家观看,谢谢。
 13:16查看AI文稿AI文稿
13:16查看AI文稿AI文稿hello, 各位小伙伴们大家好,今天我们要讲解的是 mask g i t 野马生成图像的论文。 前面我们已经讲过部分基于 gam 的 纹身图相关算法,那算法具有比较坚定的思想,但是我们今天要讲的是基于野马的生成图像,也可以认为是图像重建的一部分。 而今天这篇论文提重的是基于双向矩阵 form 和野马预测的高效图像生成的一个方法。 其实通过题目我们就可以看到,并不是根据纹身图图像来的, 而是通过野马视觉 token 建模训练双向的注意力模型,并提出一个迭代解码策略,快速生成图像相比于传统的智慧轨迹的 former 效率更高。 并且在实现整个算法的过程中设计的鱼形野马调度函数和自信度筛选机制,即使是通过鱼形调度函数来决定野马的一个比例, 通过自信度筛选机制得到那些野马最可能的一个预测结果。将预测的结果输入到 vgo gand 的 解码器,得到生成的一个图像。 论文提出的方法只需要八到十二步即可生成高质量的图像,相比于传统的质回归方法加速的六十四倍。好了,我们来看一下论文解读的笔记部分。 这里需要稍微注意下的是,图像外推是根据当前的图像预测图像的外围区域, 相当于根据当前图像进行外围的扩展。 首先我们来看一下之前方法存在的一个局限性。第一点是传统的智慧规矩 former 的 训练生成效率低的问题, 因为传统的方法是从左向右竹行的扫描生成结果,并且之前的方法并没有很好的利用上下文信息。 第二点是干本身模型本身的缺陷,比如训练不稳定和模式崩溃问题,这些问题在干中也在不断进行一个优化。 第三点是两阶段生存框架本身存在的问题。 好了,我们现在来直接看一下方法部分,这里将方法按序进行的一定总结和以及具体方法的总结。方法总结我们刚才已经提到了,那我们直接来看具体方法实现部分。 我们先来看一下传统的智慧规矩 farmer 模型生成图像过程。 从这幅图我们可以看到,传统的智慧官学的 form 模型是图行按像素级来生成,最终的呃结果导致生成的过程较慢。 而论文提出来的方法采采用了野马快速预测的一个方式,效率相比于传统方法快了很多,同时任务也达了,也得到了拓展。 在了解本方法之前,我们首先来看一下 vqve 的 大致过程。 vqve 提出了一种潜在空间分阶段生成图像的方法 v q v e。 作者也认为直接在像素空间最大,自然估计可能存在挑战性。首先,第一阶段是将原图 x 通过一个编码器 e 得到编码之后的一个向量。 其次,根据学习的码本计算及和编码之后的视觉特征向量之间的距离, 对于每一个视觉特征向量,找到和码本中距离最近的那个向量,作为当前视觉特征向量的一个呃代码,并使用锁影进行标记, 将计算得到的锁影标记经过切入成 embedding 得到所对应的一个切入向量, 将计算得到呃,将切入得到的一个向量经过编码器得到最终重建的图像 x hat。 其实像后续的 dali 和 vego gain 等算法都是基于此来进行改进的。好了,我们来正式看版文的方法。 首先是返回方法的训练部分, 基于 viktor gund 的 编码器得到的编码特征向量,得到嗯编码之后的向量,然后进行随机的演码得到 mask 呃 tokens, 也就是这里 将呃去呃野马得到的 mask tokens 向量通过一个双向的一个 transformers 得到最终的 predict tokens。 经过 viktorgan 的 码本得到切入向量, 最终通过 viktorgan 的 解码器得到重建的一个图像。那我们来细看一下这个方法的实现。 那我们按这里的大 y 表示图像经过 vgo 编码之后的结果,其中大 n 表示视觉特征向量的一个场矩阵的长度, 大 m 表示对应的二阶式掩码表示哪些区域需要掩码,其中一表示不对其视觉特征进行掩码。 为了更好的生成图像,作者这里设计了一个鱼形野野马调度函数, 当然作者这也比较了挺多的野马调度函数。 根据最终的相容实验,选择了一个鱼形调度函数。 鱼弦调的函数主要是用于选择野马的比例,比如现在的视觉特征展平之后的一个视觉特征长度为 n, 那 么计算的野马比例为 r, 那 最终要进行野马数量为 r 乘以答案。将野马处理之后的大 y 使用 y m 来表示, 然后输入到双向的矩阵 form 模型中得到预测的一个呃,得到预测的一个结果, 这个预测的结果是表示每个掩码标记对应的一个概率,然后使用交叉损失函数来计算它的一个损失结果。 这里的讯字 former 由于使用的是双向的,因此模型可以关注到上下文信息。 然后这里的话,我们先来看一下作者对于野马调度函数的设计, 反正根据论文中作者的描述,总结得到以下两条讯字,第一是野马调度函数必须是连续并且是有界的。 第二个性质是野马调度函数必须是单调递减的,因为我们的野马比例是随着训练的进行越来越低的,所以需要单调递减。 最后我们来看一下具体的野马迭代,直至生成最后的图像过程。 因为上面的我们已经讲过,训练的那一个双向的全是 form 模型 以及 vico 杆的一个解码器模型。对于自回归生成图像的过程是按照渲染方式进行,因此这个过程没有办法进行一个并行的呃处理,导致速度很慢。 所以在推理阶段呃生成图像时,采用一张空白的画布来开始生成图像。其实它这里使用的是一个矩阵 y m 零来表示所有的啊位置被严码标记, 现在就是用来迭代式的预测这些野马的位置。迭代式解码过程主要分为四个步骤,第一个步骤是呃使用双向的 transformer 预测得到 p, 这里的维度为 n k 表示一个野马位置预测的一个概率啊,嗯, y m, 嗯,这里的 n 大, n 表示视觉特征向量取整长度, k 表示瓦本的一个大小。 第二个步骤是进行采样,我们因我们已经预测得到了 p 概率, 现在根据预测的这个概率, p, 那 对码本 p i, 呃,对码本,嗯,进行一个呃,所有可能进行采样得到对应的 y i 作为我们的一个自信度分数, 这个自信度分数表示模型。对于当前野马位置确信度,对于那些没有进行野马的位置,自信度分数使用一来表示,而这些未野马的位置可认为是已经被上一次确定的位置。 第三步是基于野马调度函数,嗯,来得到需要野马的一个托肯的数量的一个比例。 关于野马调度函数性质,我们刚才已经讲过。最后一步就是根据计算的野马数量进行一个野马, 然后这里公式的嗯,表达公式,表达式就是含义,就是将那些执行度分数呃低于指定大小的都设置为一,表示这些位置没有进行野马,嗯嗯,没有进行野马, 也就是对这些位置不确定。 从第一步到第四步,整个过程不断的迭代式生成最终的一个图像。 其实讲到这里,核心算法内容我们已经讲完了,大部分的话这里已经讲过还是实践的部分的话这里已经讲过,还是,嗯,这已经给出来了,其实还是比较容易理解的,大家可以去好好去看一下。 代码实现的话,我们后面来进行一个讲解。好了,关于今天的视频就讲到这里,感谢大家观看,谢谢。
 05:55查看AI文稿AI文稿
05:55查看AI文稿AI文稿三、控制程序流程条件与循环掌握变量数据类型和运算符后,能让程序进行简单计算和数据处理。但真正的程序需根据不同条件决策重复执行某些任务,这就要用到控制流程 拍伞中。控制流程主要通过条件语句和循环语句实现,它们是构建复杂逻辑程序的。股价。三点一,条件语句做出判断条件语句能让程序根据一个或多个条件的真假决定执行哪段代码,使程序可根据输入或内部状态做出不同反应。 三点幺点幺 f 语句的基本结构 f 语句是 python 最基本的条件语句,语法是用 f 关键字后跟条件表达式和冒号 下一行开始缩进代码块。若条件表达式为 true, 执行缩进代码块,否则跳过 python。 age 等于十八。 if age 等于十八。 print 你 已成年,可以进入。 print 程序结束此例中 age 等于十八,为 true 之星 print, 你 已成年,可以进入。无论 if 条件是否满足, print 程序结束都会执行,因为它不在 if 缩进代码块内。 在 python 中缩进通常四个空格是语法一部分,用于定义代码块范围,替代其他语言的大括号。同一代码块内与据缩进级别要相同,可提高代码可读性。 三点幺点二, if else 与 if ellifelse 结构单一。 if 语句只能处理条件为 true 的 情况,用 else 语句可处理条件为 false 的 情况。 else 语句要跟在 if 语句后,本身无附加条件,当 if 条件为 false, 执行 else 后面的代码块 python age 等于十六 if age 等于十八。 print name 未成年禁止入内。此例中 age 等于十八,为 false, 执行 else 快 代码有多个条件,需判断时,可用 ellifelse 的 缩写语句。 ellif 语句要跟在 if 之后, else 之前,数量不限。程序从上到下依次检查条件,某个条件为处时执行对应代码快,跳过剩余 ellif 和 else 快。 pi 三、 score 等于八十五。 if score 等于九十, grade 等于优秀。 alif score 等于八十, grade 等于良好。 alif score 等于七十, grade 等于中等。 alif score 等于六十, grade 等于及格。 else grade 等于不及格。 print f, 您的成绩等级是 grade。 此例中 score 为八十五, score 等于九十,为 force, score 等于八十,为 true, 执行 grade 等于良好,跳过剩余部分,最终打印结果。三点二,循环语句重复执行任务循环语句用于满足特定条件时重复执行代码, 处理重复性任务很有用。 python 有 for 循环和 while 循环两种主要循环结构。三点二点幺 for 循环便利序列 for 循环是 python 常用循环类型,用于便利可迭代对象,如列表、圆组、字母、串字典等的每个元素。 基本语法是 for 变量 in 虚列后根缩进代码块,每次迭代虚列下一个元素复制给变量,然后执行代码块。 python fruits 等于苹果香蕉橙子 for fruit in fruits print f 我 喜欢吃 fruit。 此例中, for 循环依次将列表元素复制给 fruit, 并执行打印语句。 for 循环常与 range 函数结合生成整数序列,实现指定次数循环。 range n 生成从零到 n 一 的整数序列。 range start stop step 可接受三个参数, start 七十之默认零。 stop 结束值不包含 step 不 长,默认一 pi 三,打印零到四 for i in range 五 print i 计算一到一百的和 toto 等于零。 for num in range 一 幺零幺 toto 加等于 num print f 一 到一百的合适 total 三点二点二 while 循环,基于条件的循环 while 循环不是便利系列,而是在给定条件为处时持续执行代码快。基本语法是 while 条件后跟缩进代码快。每次循环开始前检查条件未处执行代码快 为 false, 循环终止。 python count 等于零 while count 五 print f 计数 count count 加等于一 print 循环结束。此例中出示 count 为零,条件为 true 打印技术并增加 count, 直到 count 为五十,循环结束。使用 while 循环要确保循环内有改变条件的语句,避免无限循环。三点二点三,循环控制 break 与 continue 循环执行中可用 break 和 continue 关键字提前退出循环或跳过本次循环。剩余部分 break 语句用于立即终止整个循环。无论循环条件是否为 true, 执行到 break 就 跳出当前循环,继续执行后面代码。 python fruits 等于苹果香蕉橙子梨 for fruit in fruits if fruit 橙子 print 找到橙子了,停止搜索 break print f 当前水果 fruit print 循环已结束。 此例中循环到橙子时执行 break 结束, for 循环梨不会被打印。 continue 语句用于跳过当前循环迭代的剩余代码,立即开始下一次循环迭代。 python fruits 等于苹果香蕉橙子梨 for fruit in fruits if fruit 香蕉 print 跳过香蕉 continue print f 当前水果 fruit。 此例中循环到香蕉时执行 continue, 跳过打印语句,进入下一次循环。 break 和 continue, 可精细控制循环流程,让循环逻辑更灵活高效。
21阿宇~ 04:36查看AI文稿AI文稿
04:36查看AI文稿AI文稿在编程中,我们常需处理成组的数据。 python 提供了几种核心数据结构,下面介绍最常用的四种,四点一列表 list。 有 序的集合列表是 python 最基本常用的数据结构,是有序可变的元素集合 创建于访问用方括号和逗号分隔值创建列表元素可以是任意类型,通过缩阴访问元素 锁影从零开始,也支持副锁影。 python fruits 等于苹果相交橙字梨 print fruits 零输出苹果 print fruits 一 输出梨增删改操作 可通过锁影修改元素,用 ipad 方法在末尾添加元素。 insert 方法,在指定位置插入元素。 pop 方法删除指定锁影元素。 dale 语句根据缩影删除元素。 python fruits 一 等于草莓 fruits append 葡萄 fruits insert 一 蓝莓 fruits remove 草莓 last fruit 等于 fruits pop dale fruits 零 常用方法, land 函数返回元素数量 saw 的 方法,排序 reverse 方法,反转元素缩影 count 方法,统计元素出现次数。 python print land fruits numbers 等于三一四一五 numbers sort fruits reverse print fruits index 橙子 print numbers counts are 四点二元组 tuple 不 可变的有序集合元组与列表相似,也是有序集合, 但不可变,创建后不能修改内容。创建与访问用圆括号和逗号分格元素创建圆组,访问元素方式与列表相同。 python coordinates 等于十二十 french coordinates 零输出十与列表的区别,列表可变 源组不可变源组用于数据固定,不希望被意外修改的场景,性能相对较快,还可作为字典的键。若源组包含可变元素,如列表 可修改该可变元素内容。 python t 等于一二三四 t 二零等于三十四点三、字典 dictionary 键值对的集合字典是无序 可变的。键值对齐和键合值用冒号分隔,键值对用逗号分隔,放在花括号中。创建与访问用花括号创建字典, 通过键访问值,使用 get 方法可避免访问不存在的见时出错。 python person 等于 name ellis h study city new york friend person name friend person get country usa 曾删改操作, 通过键赋值可添加或修改元素 pop 方法删除指定键的键值队。 del 语句根据键删除键值队,可便利键值或键值队。 python person age 等于三十一 person email equals alice at example dot com removed age 等于 person pop age del person city for key value in person dot items print f key value 四点四、集合 sent 无序且不重复的元素集合,是无序可变不重复的元素集合,用于成员关系测试和消除重复。元素创建与操作,用花括号创建集合,也可从列表创建 add 方法添加元素 remove 或 discard 方法删除元素 remove 在 元素不存在时会报错, discard 不 会。 python unique numbers 等于一二三四五 numbers list 等于一二二三三四 unique underscore from underscore list equals set numbers underscore list unique numbers add 六、 unique numbers remove 三、数学运算支持并级交级、 差级对称差级运算。 python a 等于一二三 b 等于三四五 分架必输出一二三四五数据结构选择指南列表需要有序且可变的元素集合时使用原组需要有序但不可变的元素集合 保护数据不被修改时使用字典,通过唯一键快速查找对应指示。使用集合存储不重复元素或进行集合间数学运算时使用。
31阿宇~









猜你喜欢
最新视频
- 1827摸鱼游鉴