limit是什么语句在mysql

粉丝3.2万获赞12.3万
相关视频
 03:57查看AI文稿AI文稿
03:57查看AI文稿AI文稿好的,今天呢,我们将用一道 lead code 的中等思考题来学会 if, none, distinct, order by 以及 limit 的使用。 话不多说,我们开始那本期视频呢,也是我们 myseco 系列第二块就常用的一些 seco 语句。好的,我们来看一下题目。那首先我们有个表是 en pro e 表,在这个表里面呢,就两个字段, id 字段和 salary 字段, id 呢是这个表主见。 然后 celery 呢是员工的工资。那这道题目要你求的是什么呢?就让你编写一个思考查询,获取并返回 employ 表中第二高的薪水,如果不存在第二高的薪水呢,则返回个闹。我们来看两个小例子, 那比如说我这个 carry 表中有一百,两百,三百这么三个薪水,那第二高的话就是两百,返回两百,那如果这张表中只有一个,比如说一百,那就只返回跟闹。大家可以暂停一下,看看如果是你 品牌系的话会怎么写。好的,我们继续。首先讲一下这个求解思路,这道题目要我们求的是什么呢?它是让我们求 inpro e 表中第二高的薪水,那如果不存在第二高的薪水呢,就返回格闹。那这个第二高的薪水怎么求呢?我们自然会想到 old by, 去进行一个排序, 然后再用一个 limit 去获取第二高的,那这个第二高什么呢?就是 limit 一杠一。这边需要注意的是,就 limit 这个东西,第一个表示的是我当前的这个下标逗号,后面的这个或者说是 offset, 后面这个表示是我基于前面这个下标往后的偏移量。那如何判断存在不存在呢?就是不存在的时候返回,那这个怎么处理呢? 我们可以考虑用 if not 函数。那我们第二点这考虑全了吗?有没有什么遗漏的情况,这边先留个悬念,我们后面会揭晓啊。好的,我们把刚才的思路呢来串一下。首先我们要求第二高的薪水,那是不是 select server from employee 表 order by server, 然后 limit 一到一,或者说呢是 limit 一 offset 一, ok, 那处以不存在的情况呢?就是用 if no 函数 if no, 然后里面是这个查询,如果不存在就给他付个 no, 就是逗号后面一个 no, 那查询符合条件 series 怎么查呢?就在二基础上前面加个 select, 然后把这个查询出来。结果呢,去取一个别名叫 second heist celery, 这个也是我们题目要求的一个别名。 ok, 那到这里呢,我们基本上得到了一个完整的四口语句了。 ok, 我们试一下。那为了节约时间呢,我这边把试的结果截图放过来了, 我们看到他只通过三个用力,这个是为什么?这个我们看到其实他有两条数据,但他们的那个薪水是一样的,那这种情况其实不存在第二稿的,因为他们都是一样的嘛。那这个就是说我们遇到一样 siri 的时候,他处理不符合预期,那怎么解呢?那其实我们要做的呢,就是对这个 siri 要进行一个驱虫,就说这 siri 呢,只能是唯一的,比如说像上面这种一百 一百,那它 siri 值就只有一个,就是一百,那这种要怎么处理呢?就是用 distinct 的关键字,那这样的话就把我们查询到的所有 siri 去进行一个驱虫,每个 seri 值呢?保证只出现一次。好,我们来试一下,我们试以后发现结果还是不对,那这里又遇到什么问题呢?我们来看一下。 遇到像这种有两个数据,一个是一百,一个是两百的时候,我们返回的是两百,按照预期的话,那第一个大是两百吗?那第二大应该是一百吗?那至于返回两百是为什么呢?我们看其实返回的这个两百呢,是从小到大的第二个,也就是说是第二低的,比如说我们一二三四五,那第二高的是应该是四吗?但按照我们这个逻辑的话,返回是个二, 也就说不是第二高的,那第二高是什么呢?第二高的话就需要从大到小来进行一个排序,那怎么解?就是在我们原来的 odeby 后面加上一个 d e s e 表示道序排序。那我们来改一下思考,就在 select eve down, 然后 bla bla from employe odeby siri, d i c, 然后 limit 一杠一。改完以后呢,我们再跑一下,哎,发现这回可以了,呃,所有的测试用力呢都通过了,那到这里呢,我们这条四口语句呢,也基本上就写好了。好的,我们最后呢再来总结一下,通过这条四口语句呢,或者说这道题目呢,我们学习哪些呢?我们学习了一个英文档, 就处理不存在的情况,可以按照你的预期给他一个当值或者一个别的值,然后呢用 order by 去进行一个排序,如果你要倒序的话,用一个 dse, 然后去取值,你要取第几个?可以用 limit, 然后前面的这个呢是个基准,后面这个数呢,是基于前面这个基准的一个偏音量,然后你要去重的话,就用 distinct 对结果值进行一个去重。好了,本期的视频呢,就到这里,欢迎大家点赞、关注、收藏、留言,后续不迷路,让我们一起进步。
53程序员一棵树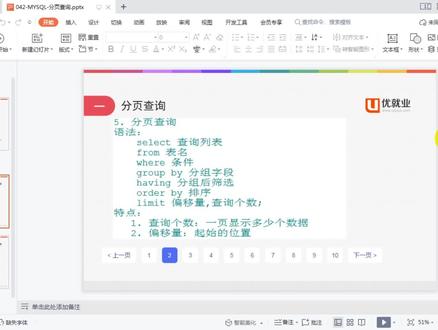 05:51查看AI文稿AI文稿
05:51查看AI文稿AI文稿大家好,本次课我们来介绍一下分页查询,首先呢来看一下分页查询的一个语法,语法的话呢是 select 查询列表 from 表明 where 条件 google by 分组词段 have your 分组后的一个 c 选, 还有什么呢? order by 培训 limit 添一亮逗号查询个数。那么以上的语法的话呢,是我们查询语句的一个完整的一个语法, 那么要实验分验的话呢,其实主要是通过我们的关键字 limit 来进行分验的,那么 limit 后面的话呢,它有两个数据,一个是偏移量,一个是查询个数。那么首先呢,查询个数指的是什么呢?指的是每一页显示的数据 的调速,就比如说我们经常呢会在什么呢项目中呢,用到这样的一个副业工具栏,当我点击第一页的时候呢,他会显示第一页的数据,点击第二页呢,会显示第二页的数据,那么这么每一页什么呢?他显示的数据的调速就是我们厘米头中第二个什么呢? 参数的值,那么厘米的后面呢,还有第一个值,第一个值的话呢叫偏移量,这个偏移量指的是什么呢?指的是起始位置, 指的是起始位置。那么给大家举一个例子,比如说我们当前的话呢,要进行一个分页查询,我要求每一页显示的数据呢是十条, 那么我们在什么呢?查询第一页的数据的时候呢,咱们从数据库里边去获取的时候,应该是从数据库里边的第一条 取到什么呢?第十条。那如果说我现在呢要获取第二页的数据的话呢,同样每页还是十条,那么第二页的数据他应该从数据空中的第十一条开始取,取到什么呢?第二十条, 对吧?那如果说我要获取第三页的数据的话呢,他是应该是从数据库中的第二十一条开始取,然后呢取到第什么呢?第三十条等等的一次什么呢?以此类推。 那么对应的这个偏移量的话呢,他是什么呢?他其实就是指的是你当前这一页数据呢,对应的起始位置,比如说第一页的起始位置呢是一,第二页的起始位置呢是十一,第二,第三页呢是二十一。但是呢有一点需要注意,这个偏压偏移量对应的起始 位置呢,他是什么呢?他是从数据库的这个第零位开始的,比如说他的下标呢,是从零开始的,所以说呢,这个一呢,咱们对应的这个偏移量呢,就写成了什么呢?零。也说如果你要查第一页的数据,偏移量呢就是零, 第二页的数据呢,偏移量呢,他就是十了。第三页的呢,他的偏移量呢就变成了什么呢?他就变成了二十了。 那么最终的话呢,也就是说,如果说我要求第一页的数据,那么咱们这个厘米特这块呢,应该写的是零逗号十。 那么第二页的数据呢,这块就是十逗号时,第三页的话呢,就是二十逗号时,看到了吧,第一页零逗号时,第二页十逗号时,第三页呢是应该就是二十逗号时了。那么第 n 页的话呢,应该怎么着?每一 页的数据呢?肯定都是十吧,对吧?这个呢是固定的,那么重点是第一个数据是怎么来的?那么第一页是零,对吧?第二页是十,第三页的话呢,是什么呢?二十吧, 对应的呢?第 n 页的话呢,他应该什么呢?他应该是 n 减一乘以每一页的条数,就比如说第一页的话呢,他是一减一,乘以什么呢?乘以十,一减一乘以十,是不是应该就是零? 第二页的话呢,这块呢,这个十我们可以怎么计算得来呢?可以拿页码。第二页是二,二减一乘以十,对吧?二减一乘以十的话呢,是不是应该就是 就是十吧,对吧?就是十。那么如果说第三页的话呢,是不是应该是页码是三了,对吧?一码是三的话呢,应该是三减一了, 三减一。然后呢我们让它乘以什么呢?乘以十,那么这个时候呢,它第三页的偏移量呢,就是什么呢?就是二十。所以说呢,第 n 页的话呢,它的偏移量呢,就是 n 减一,对吧?就是页码 n, 对吧?点页页码减一乘以每一页的条数,据说也就是一页的个数哈,也就是每一页的条数, 这个呢就是我们的一个分页查询。那么接下来呢,咱们可以什么呢?给大家来演示一下。首先呢,我们这里边呢,还是对我们的这个职工表的数据呢进行一个什么呢?分页查询, select 信号 from emp。 然后呢接下来呢,分页的话呢,就是用的关键字 limit。 首先如果说我要求第一页的数据的话呢,应该是 秘密的,后面的话呢,对应的偏离量应该是什么呢?从零开始,零,逗号十。我去,是不是应该就是第一页的数据啊?而第二页的数据的话呢,咱们说这个偏移量应该变成什么呢?第二页他应该变成二减一乘以十了,二减一乘以十是不应该就是十了? 回车,这个呢就是我们第二页的数据,大家会发现第二页数据变成五条了,是因为我们数据库里边一共只有十五条数据,所以说呢,第二样呢,其实已经是我们的最后一样了,所以说他这块呢一共是只有什么呢? 五条。那么以上的话呢,就是我们关于什么呢? my circle 分页的相关内容,就先给大家怎么呢介绍到这里。
 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿嗯,你学习买车和数据故事吗?那我考你一个题吧,我这呢有一个学生的成绩表,他只有两个字的姓名和成绩。那怎么查询成绩排名前三的学生他的姓名和对和分数呢?嗯,这听起来挺简单的。这个我会用 limiter, 先按照成绩从大到小排序,再 limiter 三就行了。 嗯,那你这个答案有考虑过第三名和第四名和成绩相同的情况吗?就是说其实他们应该是并列第三才对,最后应该能查出四个记录。那你这个另一的三这块是不是有 bug 呢? 嗯,这个我确实没处理过啊。好了,我也不回答你了啊,这个题呢,他确实是有点难度的,我给你一个参考答案,你回去试试吧。我这个最后一句呢,可以解决排名有相同质的情况。大家有什么好的解决方案呢?也可以一起讨论一下。
521小码哥聊软件测试 03:02
03:02















猜你喜欢
- 12.0万小吓(进群取视频)