halcon的mlp做分类
各位同学大家好,欢迎来到由心动智能科技出品的机器视觉入门课程,我是主讲刘嘉兴。首先带大家了解一个完整的机器视觉项目总体流程,同时这也是我们学习模块的划分。 首先,在一个视觉项目开发前,我们根据项目的需求选择合适的工业相机镜头光源,就像我们在开始学习时,要打开灯光,戴上合适的眼镜,我们才可以正常的工作学习一样。 所以说工业相机镜头光源是决定我们这个项目能否完成的选题。其次,我们相机镜头光源一切都准备就绪的情况下,我们开始要对图像采集, 将现实空间的影像捕捉到我们的计算机中,这个过程需要对相机的开发,从而获取到我们所需要的图像。第三,在相机捕获到图像后,我们需要对采集到的图像进行识别处理, 比如有些情况下,我们需要去掉黑色的部分,或者需要保留像中圆形的物体,或者筛选出一个红色的物体。因此为了这些结果,我们需要对图像进行识别处理,写出相应的处理程序。 最后,在获取到图像处理结果后,需要对结果做出反应。在自动化设备中,就是控制系统对视觉结果做出不同的动作,如同我们眼睛看到不同的人,会识别出来这个人到底是谁,通过嘴巴喊出不同人的名字一样。 在我们整个机器视觉入门班中,第一个学的不是相机镜头光源的选型,也不是对相机的开发,而是第三个我们整个机器视觉的灵魂,也就是图像的处理,图像处理我们会需要用到一个叫做好看的软件, 那我们为什么要使用薅啃图像处理软件呢?那是因为薅啃的开发周期短,编程难度相较低一点,可湿化程度高。薅啃调整的过程中非常方便,不需要用户有比较好的变声基础,并且图像可以实时的观测并调整。 号口算子可以被 c、 j 加 abc 井等高级开发语言调用。这个是我们 hoken 手把手实战教学的课程目录,我们整个课程分为十四 解,好肯的安装好肯软件功能介绍,图像中的玉质分割以及玉质分割的一些案例。形态学处理形态学的一些案例。相机的标定与测量, 以颜色识别模板匹配手眼标定及好肯与可视化界面的一个联合。

粉丝3020获赞4574
相关视频
 03:09查看AI文稿AI文稿
03:09查看AI文稿AI文稿今天花三分钟教大家怎么用黑奥看实现条形码的机器视觉的读码,先打开这个软件,然后打开案例, 这个是他自带的案例,然后选择一维码识别,选择嗯,条形码的识别,然后选择第四个巴克的, 呃,然后把我们就是相机拍到的这张牛奶的照片,比如说保存在这个位置,然后命名为一 n 二零二二,这个是案例的位置,然后将名称 原来案例中幺三零五的名称改成二零二二,好,然后就能运行了,这些都是他的算子, 反正这个就是应该是读取图片的算子,这个是读取尺寸的算子。呃,还有一些么?就是读取二维码呀,还有以及旋旋转图片角度的算子,其他的什么都不用改,只要改一下图片名称就行了。 然后点击运行,按 f 六,啊,竟然出现了,我们现在拍到的这张牛奶的照片, 可以放大或者缩小, 然后再按 f 六继续下一步往下一步,这他都是一步一步, 之前我也没有学过,只是最近突然就看懂了。 这片下面这一条指令是把它框了出来, 主要 使用的这条指令翻的拔扣的,这条指令运行之后就会自动读取这个二维码, 然后这边的变量窗口就会读取到哦,条维码的值就是我们的六九零七九九二五零七零九五, 非常简单,读条微码什么都不用改,只需要改一个图片名称。
949叶强讲电气PLC编程调试 16:39
16:39 05:35查看AI文稿AI文稿
05:35查看AI文稿AI文稿好,下一步的话就是模型推理,推理的话就是用咱们的咱们的额外的图片进行一个推理,就是咱们的测试,测试图片进行推理,咱们不是用那个训练训练图片进进行进行推理的, 评估的时候是用训练图像里面的一部分图像进行评估的,然后再翻下来,翻下来这还是那个图像目录不变啊,用的就是这个 sigma 的地方的, 用的是 这个里面的 segment, 这个是用的这一个,它是就在这个下面,就是下这个目录下面,嗯,还有这么一个 hdr ct 的一个文件。嗯,然后完了之后, 下面下面就是用他的,用他的一个最后的模型,最后的模型进行一个啊, 进行一个推理的,就是这样的话,你就是看最后的模型好了,还是最终的模型好了,这个看自己,然后完了之后就可以用行,你把这几个设置一下,就可以用行 运行,就是可以看到他走到走到这个区域, 这我们之前的裂纹那块就是裂了,是一块缺陷,但是没有边缘,没有缺失,这种它能算出来它的下数值面积大小, 在圆的 这个也走出来了, at 这也走出来了,这也走出来了, 这 ok 的。好,那咱们的这个 how can 深度学习就这四步, 这是四步,做完之后咱们的就是可以用这个最后的模型或者是最终的模型来作为自己最终的一个训练的训练的模型。哎,不是进行一个 什么推理的模型,嗯,他一下子把词忘推理的模型,就是后面的话可以抖成 c 加加程序什么的。哎,我去,点错了, c 加加程序 就是把这个推力模型抖成 c 加加,然后把咱们的库,嗯挂上去,你看这可以抖,抖成 c 加加,嗯, c 加加, 然后抖出来,抖出来之后就是一个 ctr, 一个程序,嗯,然后修改一下,可以转成库文件什么的,然后咱们就可以直接设备上可以调用了 啊。深度学习方面,咱们除了这个 health 的深度学习,还有一个,还有一个那个,嗯, 拍照是有了 v 八的一个深度学习的一个风格,哎,现在之前的话, v 五的, v 五做那个目标检测比较好一点,但是风格的话感觉效果不太好, 一直就是哈肯这方面能力比较强一点,但是 y 八出来之后,今年 y 八出来之后啊,这 y 八的风 效果也比较强,做出来是这种东西也是也是非常非常不错,你看他也能完整的分割下来,效果也比较好。咱们下节的话,咱们就讲这 y 八的一个分割 啊, y 八的一个风格啊,咱们看一下这个 y 八怎么进行分割的啊?分割的效果啊,然后拍摄,拍摄的一个,首先拍摄的一个,嗯,安装, 安装,安装教程,咱们可以先进行安装一下,就是拍套词很难很很难看的,这这个可以安装一下,安装完之后呢,咱们就 就讲后面的深度学习的一个缺陷检测,嗯,基于这个 v 八的, ulo v 八的, 嗯,现在的话,今天的话,这个 harken 这个深度学习就在这里,嗯,如果下面的话,嗯,如果你你们想要训练 自己的模型啊,有自己的图图像训练自己模型啊,也可以根据我这个方法进行一个训练,然后导出,好,谢谢大家。
45图像处理大学堂 26:37查看AI文稿AI文稿
26:37查看AI文稿AI文稿how can? how can? how can? how can? how can? 零基础入门课堂同学们大家好,欢迎大家来到 halt can 零基础入门课堂,我是主讲李源。这是我们的 qq 群,大家有什么问题可以加群, 今天我们来学习 ocl 自负识别。 ocl 自负识别就是指光学自负识别,是用电子设备,比如说是扫描仪或相机打检查打印的自负,通过检测按量的模式来确定其形状,然后用自负识别的方法将其翻译成 计算器文字的过程。自服识别在日常生活中和工业生产中的应用非常的多,比如我们常见的车牌识别,食品、日用品以及药品的包装上的文字识别,还有各种工业零件容器表面的喷涂 文字都需要进行识别。今天我们用 holk 来识别工业零件上的字符,我们打开 holkan, 首先关闭窗口, 然后读取我们的图片, 得到图片的框高, 然后打开窗口, 这里我们选择这个算子,这个算子就是让我们的窗口来自适应图片大小,显示 限时图片。 我们运行一下,这里我们看到我们的图片是一个三筒的图片,然后我们为了后续的一个处理,我们将其转化成回读图片。 然后接下来我们在自服识别之前,需要对我们的自服区域进行一个定位,这里为了快速定位,我们选择手动框选的方式, 点击这个绘制 l y 去选择绘制着平行句型, 点击右键, 然后插入我们的代码, 这里就是我们插入进来的带。这个是得到我们一个轴频型句型,这是他的左上角的坐标,这是右下角的坐标, 这个就是将我们的两个区域给他整合成一个区域,然后这里我们刚才框选了三个 r y 区域,所以这里使用了两次合并区域的算子,然后我们运行一下, 接下来我们用 radiostome 来裁剪图片, 这个是我们要裁剪的图片,这是我们刚才框选的三个 ry, 去,这个就是输出的一个被裁剪后的图片。 接下来我们就需要提取我们的字符, 我们点开灰度直方图,然后点击预值,滑动我们的最大值来进行筛选。 可以看到由于我们弓箭表面铁锈等因素的一个影响, 我们直接使用全局预支的方法来分割图片,效果不好,所以我们这里考虑考虑用局部预支来分割图片。 我们调用好啃的局部一只蒜子, 我们点击右键打开帮助文档,在这里可以查看这个算子的一些详细解释,我们把它放到 ppt 上来进行一个查看。 这个算子的功能就是使用局部预值分割图片,然后这个参数是我们的原始图像,这是处理后的图像,一般我们指的是用均值率播中值 绿波的绿波处理后的图像。然后这个就是我们的输出参数,他是分割以后的区域, offset 是我们的一个回度值,偏移量一般在五到四十是最好的。然后最后一个参数是我们要提取区域的类型, 他总共分为四个类型,就是暗区、亮区、相似和不相似区, 然后我们的字符可以看到是 是比较暗的,然后我们这里就选择按去, 然后我们的灰度偏移一亮就设置为三十。 so, 在局部预值之前,我们首先要用小,首先要对图像进行一个绿波处理,我们这里用均值绿波来对图像进行处理。 同样我们也在 ppt 里看一下这个算子的一个解释, 他的功能就是对图像进行均值绿波处理,这是输入图像,这是我们绿波后的输出参数, 然后这个是我们平滑模板的一个宽度和高度均值绿波就是对目标像素以及周边像素求平均之后再填充目标像素来实现绿波目的的方法。比如我们下面这幅图,左边是我们要进行绿波的图片,中间这个是我们的三成 三的平滑模板,然后最右边这个就是我们绿波后输出的一个图像。我们首先将我们的平滑模板放在图片上,然后求这个覆盖区域所有像素的一个平均值,然后把这个值付给我们的中心像素, 然后继续继续向用滑动,滑动到这个区域以后,然后计算这个区域所有像素的一个平均值,然后将这个值付给我们的中心像素,这个值算下来大概是六十九, 然后坚持绿波,他就是通过这种方法来实现对图像的一个绿波处理。 一般我们平滑模板的尺寸越大,他所提取的区域就越大,然后根据经验,我们模板尺寸的大小一般设置为要提取目标直径的两倍,这里我们可以看一下我们一个字符的宽度大概是多少, 这一个字符的宽度大概是七十四、七十五,所以我们这里设置为一百五。 我们运行一下, 我们把经过军职绿播后的图像给我们第二个参数,往这里运行一下, 这个就是我们提取的字符,可以看到除了我们字符区域以外,还有许多我们不需要的区, 接下来我们就要去除这些区域。 首先断开取, 然后我们用形态学中的开运算来去除掉一些面积较小以及粘连在我们字符上的一些部分。 这里我们使用圆形结构的开运, 圆的半径我们设置为二点五, 可以看到他去除掉了一些面积较小的区域,以及将我们粘连在支付上的部分也断开了,但是我们注意到他这个虽然断开,但是他们仍然属于一个区域, 这不便于我们后续进行一个处理,所以我们再调用一次。 然后我们打开特征脂肪图, 将一些面积较小的部分给筛选掉, 换一下颜色, 可以看到他把我们的字符也给筛选掉了,所以我们需要选择一个合适的纸 插入袋子 清除一下窗口,这里看到还有一个区域没有被筛选 出来,然后我们通过观察他的特征,发现他是列坐标最大的,我们可以根据这个特征来去除掉他特征,这里换为列坐标滑动这个最大值 用插入代码。 经过上面的处理,我们得到了我们要进行识别的字母区域,但是我们注意到这个二被分成了两个区域, 这不便于后续的进行一个正负识别,所以我们需要将这个区域给他变成一个一个区域。 这里首先想到的就是用形态学中的膨胀和避孕算来进行连接,在连接在连接这个区域之前,我们需要我们首先需要把这个整个区域给它整合为一个整体, 这个算子和我们上面的这个算是不一样的,这个是把所有区域整合为一个整体,而这个算子是只针对两个区域, 然后我们用圆形结构的膨胀 圆的半径设置为五,然后断开区域, 将我们断开后的区域和和整合整合为一个整体的区域进行求交集, 这里我们就使每一个字符都是一个单独的区域, 然后我们需要把这个横杠给他筛除掉,我们只需要识别出字母和数字就可以了,这个横杠我们可以通过高度这个特征来进行筛选, 下来我们就可以识别字母了。然后在识别之前,我们首先要对我们的区域进行一个排序,因为如果不排序的话,我们最后识别的结果将会按照这个顺序来进行排列, 就会就会复查中断,然后不利于我们进行一个查看, 所以我们要对对这个区域进行一个排序,我们希望我们的区域按照我们的阅读习惯从左到右,从上到下的进行排序。我们调一个好看的 selter raise 算了, 查看一下他的解释,这个算词的功能就是对区域进行排序,这是我们要 进行排序的一个区域,是排序后的区域,这是他的一个排序模式,排序模式总共有以下几种,然后这个就是我们按照第一个点排序,他就指的是我们一个区域 他第一行最前面的这个点,而我们最后一个点就是一个区域最后一行最后一列的那个点, 像这个就是外接矩形的左上角,这个是外接矩形右上角,这个是我们外接矩形左下角和右下角。然后我们想要从左到右,从上到下的顺序排列,可以使用 carico 来解决。 这里我们将排序模式 变成我们这个, 然后这个就是我们按顺序递增或者是按顺序递减,串就是按顺序递增,把锁就是按顺序递减, 最后一个算最后一个参数就是,呃,就是指的是我们先按行排列还是按列排列,这里设置为行的话,他就是先排行,然后再排列, 然后我们看一下他是否按照我们的要求进行拍摄, 可以看到他的顺序是正确的。我们这里说一下这个先按行再按列排序是怎样排序,先按行的话,他这个就是我们的第一行,然后这里面有许多的区域, 这时候他就会继继续按照列进行排序,这就是第一个、第二个、第三个这样的,然后这个是我们第二行,他只有一个区域, 这个是我们第三行。两个区域,他这会的时候就会按照我们按照我们的列列坐标进行一个排序。如果你这里设置为设置为列的话,他就是先拍我们的列,然后再拍我们的行, 就是这个是我们第一列,然后这是我们第二列、第三列、第四列,然后到第五列的时候,他有两个区域,这个时候他就会按照行,就是先拍这个,再拍这个, 这第五列也是同样的,他就是按照这样的一个顺序进行排序的。接下来我们就对字符进行一个识别,字符识别会用到两个算字, 一个就是我们读取 ocr 分类器的算子,另一个就是使用 ocr 分类器对多个字符进行识别的算子。我们首先看一下这个读取 ocr 分类器的这个算子, 这个就是我们的文件名或者是我们的文件路径,你可以自己训练这个 ocr 分类器,也可以使用 好很训练好的分类器,这个就是我们后面输出的一个分类器的一个句柄。 在读取了 ocr 分裂器以后,我们就可以对字符进行识别了,这个是我们要识别的字符,这是我们要识别字符的回读图像, 这个就是我们刚才那个 ocr 分类器的句柄,这个就是我们输出的一个识别结果,这个是识别结果的一个精度, 因为我们选择 holk 肯训练好的工业字符分类器, 因为我们这里又有数字又有字母,所以我们选择零到九, a 到 z 的这样一个来气, 这里是我们的回族图像, 运行一下,然后点击我们的控制变量,看他识别的结果是否正确, 我们可以看到识别结果是正确的,并且我们的识别精度也比较高。 接下来我们就要将我们识别的结果进行一个显示,我们设置颜色为红色, 设置边缘显示, 然后显示我们的回购图片, 显示我们排序以后的区域, 你学一下, 接下来就显示我们识别的结果。首先设置一下显示字体的格式, 这个是我们窗口的区别,这是字体的字号,这是字体的名称,这个是加粗,这个是倾斜。然后我们调用 hopen 的显示算字, 这个是我们窗口距离,这是要显示的识别结果,这个是我们显示在 窗口坐标系还是图像坐标系,这个是是我们显示的一个位置行列坐标, 这个参数是我们字体的一个颜色,我们这里将颜色设置为绿色,然后做标系设置,为我们的图像做标系。 boss, 我们这里选择不需要这个 boss, 我们的坐标设置为 七百五和五百, 这就可以看到他把我们的识别结果显示在了图像上,然后我们 不想让他这么显示,想让他显示在我们字符的下方。我们可以使用 holk 的球最小外界巨型的算子 来得到我们每个字符他的一个最小外界举行的左上角和右下角的坐标,然后知道这两个坐标以后,我们就可以知道他左下角的坐标。根据这个坐标我们就可以将我们的识别结果显示在字符下方, 然后运行一下, 这就是我们最终的一个显示结果。到这里我们就完成了一个字符的识别, 我们下节课讲尺寸测量。
152西安西动智能科技有限公司 07:21查看AI文稿AI文稿
07:21查看AI文稿AI文稿首先我们打开一个 cock job, 然后在 image souls 里面添加我们将要测试的图像, 这里我们加载了一张汽车的尾牌图像,打开工具箱,找到 call a blob too, jammage sauce 和 call a blob too 连接起来,这样我们就可以在 call a blob too 里面来处理这个图像。 我们使用抑郁症的方法 将这里的几个车牌字符给提取出来。通过观察图像,我们可以发现这几个英语值的灰度值大概会落在哪个范围内, 我们大概检查一下灰度值不大于 90。 检查完图像,我们将模式设为应预值,将预值设定为 90, 运行一下,在 last run 里面输出图像,里面可以找到 blob 处理后的一个图像。 为了便于后面的分析,把默认的不需要的筛选项给删掉,这里我们留下一个 重心的 x 坐标指作为后面的字符排序使用。 添加 bonding 的一个宽度和 bonding 的一个高度, 我们来对字符数字区域进行提取,这里我们观察一下他的字幅宽度大概在什么范围, 比如说第一个 g, 我们从左移到右,还有 a 也是从左移到右,我们可以根据像素只坐标的信息,然后得出大概一个宽度,我们把宽度 设置在 50 到 80 之间,发现只提出一个 a 字符,然后把这个范围在设置大 1, 30 到 80 这几个字符就全部提出来了,还有其他的几个干扰。这个时候我们再通过 王丁 hide 的高度范围,把符合我们要求的高度范围也圈选进来。同样的,我们在图像呢 的观察框里面观察一下高度坐标信息,取得大概的一个高度范围值, 运行一下,我们就可以得到我们想要的自扶的 blob 区域。输出的时候进行一下排序,按照中心 x 坐标方向排序,这里我们做一下升序,排序 好了第 0 个就是 g, 然后依次往下是几个字符, 就这样我们就完成了 vegan pro 第一个 blob 分析。 好,接下来是 hacking 实现 blob 分析的一个过程。首先我们读取同样的一个汽车尾牌的图片, 这里呢我们获取显示窗口聚柄优于后面的一些处理。然后我们打开灰度的直放图, 畸形玉植上的一个测试,我们可以挪动这个玉植的上线和下线,就是红色和绿色的这两个标线,然后我们在挪动过程中可以发现我们的 图像上是有变化的,就是在符合预值范围内的,他就会把这个 有区域把它显示出来,可以看到我们刚才加了一个 connection 的一个动作,这个也是为了让我们直接输出 联通之后的一个结果, 我们把颜色设置多一点,这样看起来车牌都会更明显一些。 现在这几个字符都已经通过一个灰度律博把它给提取出来了,然后我们把这一段代码插到我们的程序川口 这里呢,就可以得到几个字符的一个分割的联通之后的区域。 同样的我们这里打开一个特征脂肪图,通过类似钢材 vision pro 里面的操作一样进行一些特征的筛选,这里我们同样的 输入宽度,宽度的话我们同样拉取一下这个上下线的标线,就可以把宽度限定在一定的范围内,然后为了方便我们这观察显示的一个效果, 我们在程序框里面把他的区域显示的方式改为一个 margin, 就是边缘显示的一个功能,这个叫 dev set draw, 我们把它改成一个 margin 的一个方式, 默认的是 feel 填充的方式,现在我们改为 margin。 改为 margin 之后就可以看到联通区域的边缘轮廓线,然后我们通过调节轮廓线宽度, 以特殊的颜色和线宽选十选取区域。我们在移动上下标线的时候,就可以看到被选出来的区域当前是哪一些是有效区域。宽度之后我们把高度也添加进来, 为了防止干扰,我们把宽度给取消掉,仅看高度方向的 好了,高度方向上也可以达到一个令人满意的一个效果了,可以看到一些杂象在宽度上没有滤掉,现在通过高度都滤除掉了。我们把高度和宽度的特征同时做一个筛选, 这样我们就可以提取出车牌的字符了。 你喜欢哪种方式呢?评论里留言告诉我吧。
252视觉机器人 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿大家好,非常高兴与大家分享 how can 二十点一新特性,希望能和大家在这里共同学习,共同进步。 下面我们来看新特性之一,深度学习边缘提取,下面进行实操演示。 首先打开 open 二十点一,可通过快捷键 ctrl 加 e 打开浏览 hdyl 实力程序,在方法一栏中找到深度学习与分割。然后打开 segment address deep learning 这个程序。 这个程序使用预先训练好的网络,在低对比度、高噪声等复杂的环境下,利用深度学习网络模型提取边缘。下面是效果展示。 我们可以看出,与其他网络训练模型相比,深度学习与训练的边缘检测模, 适用于复杂且具有挑战性的场景,如在低对比度、边缘模糊、纹理清晰、存在线扫噪声等的情况下,深度学习边缘检测能力具有良好的鲁棒性。 上述视力使用了已经训练好的网络进行边缘提取,如果对网络进行再训练,深度学习边缘提取效果会更好。 我们可以在浏览 h develop 实力程序方法一栏中找到深度学习语意分割,然后打开 segment address diplomatory, 说明这个程序,查看网络在训练的过程,与其进行对比。 以上就是 hog 二十点一一新特性之一深度学习边缘提取介绍,谢谢大家的关注。
59大恒图像 10:38查看AI文稿AI文稿
10:38查看AI文稿AI文稿大家好,欢迎收看本期视频, 本次视频我将为大家分享一下如何实现 plc 对海肯极其视觉程序的控制。 我们知道机器视觉一般应用于工业现场,与 plc 等一些控制模块进行配合使用,其基本上充当了传感器的角色,具体他怎么实现与 plc 的联合控制, 从而达到最终的目的呢?这里我们就为大家分享一下实现与 ps 通行,以 ps 对其控制的一些基本方法。这 我为大家做一个简单的演示。首先我们新建一个哈肯的积极视觉程序, 我们以打开一个图片,并把图片由 rgb 图形转化成 灰度图为例讲解。首先我们从电脑的文件管理器打开一个图片, 这个算子是从文件管理器打开一个图形文件, 然后我们将打开的这个图形文件读取出来, 这里我们可以看到打开的图形文件是存储在这个这个 变量里边的,所以说我们需要把对应的图形文件的变量进行调整,调整到选择的图形文件, 然后图形打开后,我们通过算子 把 rgb 图形转化成坡度图。好,这里我们已经完成了程序的编写, 然后我们运行一下,看一下现象,然后这里打开一个图形,选择电脑上已经存储好的图形, 选择名字简单一点,然后现在已经选择了一个图形,然后我们再点单 显示出这个图形,然后再点单步,然后把 rgb 图形转化成绘度图, 然后这个简单的查看程序就完成了,我们可以把它导出为其他语言的一个程序, 我们选择导出,然后这里我们主要用到了 c 煞普语言啊,对这个功能进行实现,我们这里选择 c 刹普哈坑点 nice, 好,现在我们已经导出了,已经导出到桌面了,然后这里注意的是我们要关闭这个程序,要不然可能在 c 差不多运行中可能会出错。 接下来我们对 plc 的控制部分的程序进行编写。 首先我们现场没有真实的 plc, 我们需要 plc 的仿真软件,建立一个虚拟的 plc, 这里我们用到了 plcsm 的 ktv 软件, 我们先打开它,我们这节可以 s 七杠一千五百的 plc 为例进行讲解。 首先我们新建一个 pfc, 好,我们直接用先前已经建立好的 pfc 快一点。这里如果说不知道怎么建立 psc 的话,可以上 百度搜索一下,有对应的具体的方法。建立好 plc, 并且打开以后我们就要建立相应的 plc 的控制程序, 下面我们打开国图建立相应的程序。这里我们如果 没有安装 ps 五 adv 的软件的话,用 plcsm v 十五的软件也是可以的, 正常版本的也是可以的。创建一个新的程序, 然后新建一个 plc, 我们任意一个小事为例, 这里因为我们用到了虚拟的 ps, 所以说相关的设置是必须的, 要不然可能会出现无法通信的情况, 这一个选项答对哈。 然后注意检查一下 plc 的 ip 地址是否与虚拟 plc 的 ip 地址一致,现在是零点一,我们看一下虚拟 plc ip 地址 也是零点一样的,所以说这里就对了。还有连接机制里边的允许来自远程对象的通行访问也需要答对, 因为我们这里是简化演示的,所以说就不建立相应的程序了, 我们直接以一个 m 区的变量控制他的通段来进行讲解。 我们以 m 四的耳音为例, 增加一个新的监控表,通过监控表对 m 十点零的通段进行控制来显示 哈算程序的状况。好,程序建立完成以后,我们下载到 plc 中。 好,程序下载完成以后,我们 plc 控制部分的程序就编写完成了。好,前边我们已经完成了哈肯积极视觉程序的编写以及 plc 控制程序的编写。 接下来我们就要实现他们两个之间的通信,然后接下来我们需要完成 cstop 程序的编写。
165耳落兀霖 12:35查看AI文稿AI文稿
12:35查看AI文稿AI文稿各位同学大家好,欢迎来到由心动智能科技出品的豪肯入门课堂,我是主讲柳嘉欣。上节课我们简单的了解了下威风可视化洁面,相信同学们对威风编程有了一定的了解, 本节课就带大家学一下如何在微风中显示好看的图片。在课程正式开始前,我们依旧加下我们的 qq 群,关于我们的课程有些什么样的问题,大家可以在 qq 群中进行反馈讨论。 首先带大家看一下本节课学习完成后的成果, 我们可以看到界面有四个按钮和一个图片显示区域组成, 点击图片一可以看到 plus box 显示出第一张图片,点击图片二可以看到显示第二张图片,图片三图片四,接下来我就带大家去实现这个功能。 首先还是新建一个威风程序, 接下来添加饮用, 将好看的电压文件添加进来 饮用。 接下来正式开始程序。 首先定义一个窗口, 定义完成后打开一个窗口,我们可以看到每一个薅啃的算子之前都要添加这样一个薅啃的类名。 打开窗口变量参数可以看到大小聚丙等。首先设置窗口大小,在设置之前在界面中添加一个配置 box 空间, 添加完成后,我们将窗口的大小设置为和配置 box 一尺寸大小一样。 将配置 box 一的锯柄设置为窗口,锯柄 显示格式为默认。 最后输出设定好的窗口变亮, 完成后,再将窗口变亮添加到显示对列中即可。 瀑布的设定已经完成,接下来开始添加按钮,只限按钮功能。 我们先添加图片一的按钮功能,首先是读取一张图片, 其中的参数和薅啃中的参数一样, 找到一个图片路径 粘贴进来,注意薅啃中的图片路径和 c 下部程序中的路径斜杠是相反的。 再添加一个显示算子, 现在我们运行一下程序, 看一下显示效果。 我们可以看到窗口中只显示了图片的一部分,我们打开原图看一下, 显示的图片是左上角的 h 部分, 这是因为窗口的尺寸大小只有这么大。接下来实现窗口显示尺寸的大小设置。首先使用 gettem maxs 算子获取图片的大小, 再使用塞托帕的算子将窗口显示大小设置为和图片尺寸一样大。 接下来我们再运行一下程序,看 图片完整的显示在配车 box 空间中了。 将这段程序复制进其他四个按钮中, 更改图片名称。 再次运行程序, 我们可以看到现在已经实现了最开始的那个功能了。
 02:06
02:06 02:52查看AI文稿AI文稿
02:52查看AI文稿AI文稿海肯深度学习工具 dlt 零点五稳定版新功能新的拆分页面显示图像在拆分中的单个类的分布。现在可以创建和管理多个不同的数据拆分。在训练模型之前,必须创建拆分,并将其分配给训练。可以重命名、复制和删除拆分。 如果在训练页面或评估页面上选择了训练,则将训练使用的拆分视为活动拆分。也可以在新的拆分页面上设置活动拆分。 图库页面上会显示一个活动分割,用于对图像进行过滤操作,并在创建新训练时用作默认分割。如果从 hdict 文件导入包含拆分信息的数据及则拆分信息现在始终插入到活动拆分中,这可以覆盖受影响图像的分割类型。如果项目中 还没有拆分,则会创建一个新拆分,其名称设置为导入的 hdst 文件的基本名称。在将导入的拆分信息合并到集中之前,训练使用的拆分不会被修改,而是被复制。为了在自动生成拆分时获得可重复的数据。拆分 现在可以设置随机种子的值。在图库页面上,现在可以为每个图像打开上下文菜单,其中包含以下选项,在文件浏览器中查看当前图像,从文件系统中删除当前图像,或将当前图像复制到不同位置。 在图库页面上,现在可以扩展图像上的拆分类型覆盖。此外,分体式的缩写现在只有一个字母。现在可以在第一个 apple 后停止训练,从而将其标记为已完成。现在可以使用选项 fmi fowin sir 导出深度学习模型。训练设置已经扩展,可以配置训练期间使用的类的权重。在重置训练之前,现在会显示一个确认对话框,以避免意外覆盖经过训练的模型。 现在可以复制训练,以便可以使用具有调整设置的新训练,而不会丢失第一次训练。现在可以重命名训练的名称。现在可以评估暂停训练的模型。 现在可以更改暂停训练的 app 数和学习率。策略过滤器栏中的快速图像过滤器现在允许通过使用标签类的任意组合过滤图像。此外,对于分类项目,还有一个快速过滤器, 允许按当前活动分割内的图像分割类型过滤图像。在训练页面上,现在可以使用使用确定性算法选项,如果启用, 则仅在 gpe 上使用确定性算法,以变为在同一硬件上的每次运行启用可重现的结果。 这对应语将系统变亮, c u b i n dpl 门 misstay 设置为出入。感谢您一见三连,支持、点赞收藏,下次还能找到你喜欢的视频哦!感谢关注,咱们下次再见!
15外星眼机器视觉 00:53
00:53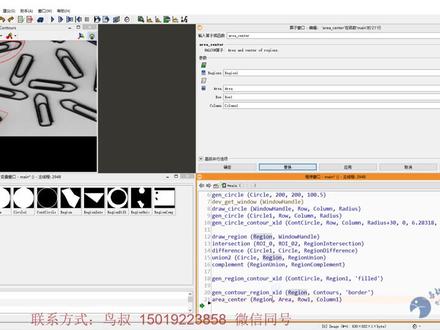 21:46查看AI文稿AI文稿
21:46查看AI文稿AI文稿大家好,我是 amy 老师,很高兴我们又见面了。前面我们学过呢,从文件夹读图,从文件读图,包括呢?从相机彩图, 有了这么多图片我们就可以做处理了,是吗?但是有的时候我们这个图片可能先要存下来一下,那怎么办呢?接下来我们就会来学习保存图片。 保存图片呢,其实我们有两种,第一种就是我们相机拍到的原始图片,这个我们是用 red image 这个扇子来保存原始图片, 那我们都说过了,有了图片之后我们会处理,处理了之后呢,在处理后的图片上可能会显示一些我们处理的 信息,这个时候我们又想保存下来,怎么办呢?这个时候其实就像我们手机嗯,聊天信息想要截屏一样,类似的啊,我们处理的图片也可以截屏,这个时候我们是用 dump window 这个算字。 好,接下来我们一个一个来跟大家讲,我们来看一下保存图片, right image, 就是我们得到了这张图片之后,我们希望把它写到一个本地磁盘的位置,这个是图片需要给他一个路径,这个地方写的是 fire lane, 当然我们要给他一个路径啊,比如说我们希望存到桌面, 那我希望存成什么呢?今天的日期二零二一零四三零,是不是?那你要有一个格式,它这里其实已经有一个格式, 是 t i f f 格式,我们先点保存, ok, 这个他存的是一个 b m p, 是不是?好,我们点确定,我们到桌面上来看一下,我们这张图片存下来了吗? 这就是我刚才刚刚保存的这张图片,是不是叫二零二一零四三零点 bmp 点 t i f 是吧? 其实是不需要这个 trf 的啊,好,我们来看一下格式这一块啊,格式这块其实是有很多格式可以选的,比如说我们选中 bmp, 那如果不要刚才那个怎么办呢?我们在这个位置,我们再来一次啊,二零二一零四三零零幺, ok, 点保存,他还是出来一个 b m p 是不是没关系?我们先点确定来看一下,然后再看我们 存下来这张图,这个就是完整的 bmp 的格式的图片啊,是不是我们已经存好了原始图片?那处理后的图片我们刚才不是说可以处理吗?我们用我们学过的 绘图直方图来处理,看看我把黑的字体选出来,是不是看一下啊?哎,这是我选出来的黑的部分,点插入代码,插入代码之后,然后我们运行就出现这个部分,把这张图片存下来,怎么办呢?我们要使用当 window, ok, 在当 window 的时候,他其实就是把这个图形窗口的显示截图下来,所以你需要告诉他是哪一个图形窗口,那我们第一第一个呢就需要填写窗口句柄,窗口句柄呢?我们是通过 d v get window 算起来获取的窗口据柄传过来。那第二个呢?其实就是选择图片格式,我们选择 bmp 好。第三个就是路径,我们同样还是存在我们的桌面上面,保存二零二一零四三零, 保存好点,确定。然后我们来看一下这个时候有没有呢? 大家发现这就是我们存下来的实时图片。在这个地方要特别提醒大家一下,我的保存原始图片和保存这个窗口截图的话都是写在循环里面的,实际上正常使用时候我们可不可以这样写呢? 肯定不行啊,为什么?因为我采集的第一张我存成了他,第二张也存了他,所以他永远都只存了最后一张。 如果我们要改怎么办?我们需要动态的去改变这个路径才可以的,是吧?这个后期有机会我们再讲。讲完了保存图片之后,我们再跟大家讲一讲 onoi。 什么是 onoi 呢? onoi 呢是 region of interest 的缩写,也就是感兴趣区域。 大家知道我们前面讲数据类型的时候,我们讲过图像,图像呢就代表整张图像, 但是很多时候我们做处理的时候,其实我们不需要处理整张图像,我可能只需要处理图像中的一块,比如说像我这个照片,我只处理顶端的这一块,是不是?所以呢,这一块就是我们的感兴趣区域。 那我们怎么样去定义这个感兴趣区域呢?在 hawken 中间感兴趣区域呢?是包括 region 和 chaod 的, 这个我们大家也都很清楚,因为我们在讲数据类型的时候就讲过了,是吧?大家要知道啊,这因为后肯有这两个数据类型,所以呢他有很多针对于这个数据类型的处理的算子,那他就变得非常灵活,这也是后肯一个很明显的优势。 ok, 那我们也知道有这个数据类型了,那怎么样来创建这个类型的数据呢?接下来我们就一个一个来讲创建 r o i 呢,我们有最主要的两种方式, 首先就是我们可以通过图像预处理去得到它,通过就是我们的算子去处理图像,比如说预知分割分到我们的回形针区域,这样子去得到它。另外一种呢,我们也可以自己生成,你想要一个什么样形状, 你可以根据参数来生成,你也可以自己画出一个什么样的东西来,根据你画的再来生成。好吧, 那我们首先要跟大家讲一个概念,就是我们在创建 roi 的时候,它是分形状的,比如说我们要分为圆形、 直线还有矩形,矩形又分为齐轴矩形 rectang 一,仿设矩形 rectang 二,还有像椭圆呢等等这些为什么要分形状呢?因为 roi 的参数跟形状相关,这样子他才能够比较准确的去定义啊。 好,接下来我们来看一下到底怎么使用。开始我们读取一张图片,还用我们原来的这张回形针的图片,是吧?原来我们把回形针分 出来,我们是用预值分割这个算子,然后把按的区域分出来,再生成代码就可以了,把这个区域分出来了,这样子我们得到了一个 region 类型的数据,就是区域,如果我们只要处理 尾形针区域,那这只就是我们一个感兴趣的区域了,这就是我们通过图像处理来得到 r y, 是吧?但是呢,这个区域是图像处理出来的,他并没有去严格定义他是什么形状,是不是? 好,现在我们想自己来做一个 r o i, 怎么做呢?比如说我想做一个 r o i 去把我左上角这个回形针 框出来,这样子呢,我就只要处理这一块了,是吧?那我们有一个工具,同样在这里叫创建 roi 工具,我们来看一下啊,刚才我们讲过 roi 是分形状的,那我们可以创建一个 个圆形,椭圆矩形,仿设矩形,还有任意形状等等这些啊,那我们来先画一个任意形状吧,这个比较特别啊,那我们来画一个任意形状。 ok, 大家可以鼠标左键按住不动一直画,也可以停下来再点,他不需要连续,他会自动把前一点和后一点的连起来。 ok, 点右键确认,必须要点右键确认啊,就画出来这个区域。我们说过了,我们有很多工具都可以帮我们插入代码,那我们插入代码来看一下,关掉它, ok, 运行一下,这个时候大家就会看到了,我们有一个 r o i 杠零,它的语意是 region, 所以它也是一个 region 类型的数据,是吧?然后我们拿到这边来看一下,它的算子是通过什么算子来得到的呢?通过 game region runs 这个 算子来得到的是不是?但是呢,这个中间有很多 row 和 column, 就是有很多很多的点。 好,这个呢,任意区域是比较特别的,那我们再来画一个区域看看,这个时候我们来画一个,嗯, 矩形区域,一个反射矩形。好吧,大家会发现反射矩形是这样子的,它可以旋转角度的啊,好,把右上角这个框出来了,点右键确认,同样来生成一下 看看。我们的反射矩形就是 rectangle two, 这个是跟 rectangle two 生成了一个这样的反射矩形,是不是?好,我们也还可以再生成一个矩形,来看看 一个哦,我们要生成一个矩形啊,来看这两个矩形有什么区别?看这是一个矩形,是不是这两个矩形的话,就是一个 可以旋转,一个是不可以旋转,这个叫起轴矩形是不可以旋转的啊,同样点右键确认这里又生成了一个矩形。 齐轴矩形的话是 gan rick tender e, 是不是 rectangle 一,我们来看一下它生成这个矩形啊,这个算子 gain, 我们简称 gain 呢,其实它是 generation 的缩写。 gain rectangle 一的话呢,我们看这个算字,它输出一个 region 类型的数据,当然这个变量我们可以自定义它的名称,比如说你叫 region 零一是不是 好,但是呢,它输入的话需要有 row e, colon 一, ro r, colon 二,那 ro 一和 colon 一呢,其实就是代表一个点 roar colon 二也代表一个点的 x 和 y, 所以我们生成起一轴矩形,其实需要的是这 这个骑轴矩形左上角的一点和右下角的一点,这个我们一定要搞清楚啊,因为当你知道了这个时候,下次你想生成矩形的时候,你就一定会去想办法得到左上角的点和右下角的点,这样子你就可以生成你想要的矩形了。 okay, 这是 rectangle 一,那 rectangle 二呢?我们发现,咦,它跟我们 rectangle 一不一样的,它同样可以输出一个 region 类型的变样,但是它的输入的话,它有五个参数, 咦,它同样有肉和 column, 但是呢,它还有一个 pi, let's see, let's 二,这是为什么呢?它所需要的五个参数就是这个反射矩形的中心点 坐标和它跟 x 轴的夹角,以及它这个长轴的半轴长度和短轴的半轴长度, 这就是我们反射矩形所需要的一个参数。好,那我们还会有圆 game circle 啊,我们自己来生成看一下, circle 是什么呢?它需要的,诶,这是一个圆哈,它需要的参数是 row 和 corner, 还有 ready 是不是就是它的中心和半径? 所以最后发现我们说啊, oi 要跟形状关联,那生成某一个形状的啊, oi 的时候,它的参数其实就跟这个形状的特点关联起来了,是吧?好在这里 game 我们都是利用已有的这些数据来 生成的,是不是?那要不呢?我们就是借助这个 r o i 工具创建,要不呢?我们就是借助这个创建 r o i 工具画出来的,然后再生成的。 但是,嗯,在我们实际应用中间,我们当我们做好了软件之后,有可能我们没有这个 ry 工具,那怎么办呢? 这个时候我们其实我可,但是大家会发现我们也可以让别人来画,那怎么办呢?其实我们还有一个叫猪,比如说我们有一个算子叫, 其实我们还有个算字叫 draw, 当然你要画什么形状,就是 draw 什么形状了啊,比如说我们 draw second okay, 那我们来试一下看啊, 大家发现这个画的算子呢,它其实需要四个参数,但是我们没有传第一个参数给它,它就报错了。第一个参数是什么呢?就是 window handle, 这个我们其实已经很熟了,我们要获取窗口距离 好再传过来,你就,你才能告诉他是在哪个窗口上去画,是不是?比如说我们在这个窗口上画,咦,我们画一个,我们可以来试一下画一个比他大一点的啊。 ok, 好,这样子画完了之后,我们刚才其实是画了一个形状,是吧?画完了之后得到这个形状吗?并没有。画完了之后,我们看这个算子的输出, 他只得到了这个形状的参数,我们需要跟在他后面,再用一个生成这个形状区域的算子,他才会帮我们生成这个形状,是不是?所以刚才在我们这个绘制新的 roi 工具中间,我们先画再插入, 实际上在我们这个地方是相当于写了两行代码的,大家一定要注意啊,并且在执行 画的这行代码的时候,同样你画完了之后,一定要点鼠标右键确认他才能退出来,不然他一直在画的那个算字执行当中啊。 ok, 这就是化和生成,同样生成的时候,我们不仅可以生成 region, 也可以生成叉 d, 我们可以来看一下 game cycle count x o d 的时候就是生成了 x o d, 是不是?我们只是用原来举了个例子,如果是矩形或者是反射矩形,同样是 gary tiger e count, x o d 等等。啊,这个我就不仔细讲了, 那我们在生成这个叉 l d 的时候,我们相对来说比他稍微大一点点,这样会比较明显一点,好吧,加三十啊,我们来看一下,那么这个就是一个叉 l d, 放到这里我们也能够 发现它的语意是 charity count, 是吧?所以现在我们已经学会了怎么样去画得到你所画形状的参数,然后再通过生成来得到你想要的 roi。 ok, 在这里有一个比较特别一点的,我给大家讲一下,有一个捉 region, 他比较特别的,就是呢,你画完了之后,他是直接得到你想要的你画的这个区域的,因为我们是捉 region 嘛,所以他直接得到一个 region, 而不是这个 区域的参数啊,这个比较特别,我们稍微注意一下,如果你要任意形状,我们就用做 region。 好,现在我们已经有了 roi, 是吧?感兴趣区域哇,这样子我们就可以把图像的处理的这个数据量变小了很多,其他地方 都不关心呢,只关心我们 r o i 区域。那可是我们这个 r o i 的话,比如说我画了一个,哎,画了另外一个,但是呢,我还想得到这两个相交的部分怎么办呢? 我们的 r o i 呢,是可以做很多运算的,比如说你的 region 是可以做交叉并补,这些运算可以让你得到的 r o i 区域在通过运算之后就变成非常灵活。 刚才我们画了这个 rectangle 一和 rectangle 二,是不是如果我们想要求他的交集怎么办呢?交集的话是 intersection, 求我们 rectangle 一是 r o i 零是吧? rectangle 二的话呢是 r o i 零二。 ok, 我们来看一下它得到的区域, 就是这一小块,是不是哪一小块呢?就是这一小块了啊,这是他们俩的交集。 ok, 差级,我们再来看一下,差级呢,一定要有一个包含和被包含的关系,所以我们来可以求一下这个大圆和小圆的差级,你看这样我们看不见了,是吧?怎么办呢?我们可以用这个轮廓模式来显示看一下。咦,这是大圆和小圆, 记住啊,虽然现在看起来像轮廓,但是他要看羽翼的哦,只是因为我们设置的显示模式为轮廓,但是他的羽翼还是 region。 他们的差级的话是用 difference 是大圆。 okay, 第二个圆大一点啊,减去小圆。 我们来看一下,得到的就是这个环形区域了,是不是我们也可以填充来看一下啊? 就是这是他们的差级区域。嗯,还有并级区域,是不是并级区域是什么样子的呢?比如说我们现在这个任意区域和我这个圆形区域他们两个是分开来的, 没有关系的,是吧?那我们现在把它合到一起去变成一个整体可不可以呢?也可以的啊,我们用的是 union 一 用点二啊。 sorry, 用点一的话,我们需要放到嗯 trooper 中间去让它一起合并才可以的。 ok, 那我们这个时候呢,就是让 circle 和 region 来合并 之后,大家发现了吗?从这个地方我们就可以看出来他们已经是一个整体了,你选中的时候就两个一起被选中是吧?这个就是病急补急。什么是补急呢?补急就是除了这个区域之外,图像中间的其他区域就是补急,也就是说 区域和他的补给区域一起构成整张图,那补给的算子是 confim max。 看啊,我们刚才这个 b 级区域,它的普及就是除了它之外其他的区域,是吧? 这个就是我们区域的交叉并谱运算啊,非常的灵活。好,我们再来讲一个呢,就是我们看到了我们有区域 也有轮廓,是不是?我们来看一下他们有什么区别吗?就算他们都显示成轮廓形状,有没有区别?其实是有区别的,看我们的轮廓,轮廓线是拟合出来比较光滑的,是不是我们的区域他其实是有锯齿形状的啊?他是根据像素点一个一个来拼凑成的啊? ok, 那区域和形状呢?他们其实是可以相互转换的,也就是我们可以通过区域来生成轮廓,也可以通过轮廓来生成区域。怎么做呢? 使用算字呢?就是你想生成什么?比如说我想生成区域,那我就是 gain region, 那通过什么生成呢?通过 counter chao d 生成,那就是 gain region, counter chao d, 是吧?如果我想生成轮廓呢?那我们就是 gain counter。 通过什么生成呢?通过 region 生成, 那就是 gain count region 叉 o d 了,我们先生成一个区域看看。 gain region 通过轮廓来生成是吧? counter 叉 o d, 我们刚才有一个 轮廓的,这个大的就是轮廓啊,来看一下生成出来是什么样子呢?看到了吗?这里有两根,是不是哪一根是轮廓, 哪一根是区域?很显然这是一个区域,是不是如果我们填充模式显示,他立马就可以填充了啊? ok, 这是根据轮廓来生成区域,如果我们要根据区域来生成轮廓呢?我们就是跟生成什么就是产生什么啊?跟 counter region charity。 好,再运行一下。这个时候我们用什么来生成呢?用我们刚才画的那个任意区域来生成看一下。好吧,记得 这里是不是刚才我们是画了一个微卷,是不是?但是他现在生成了区域之后而生成轮廓,你发现当我们把区域生成轮廓的时候,这个轮廓会自动 会平滑吗?也不会,是不是他只是变成一个轮廓罢了啊? ok, 这就是根据区域生成轮廓,根据轮廓生成区域这个变换的算字。当然跟大家说过了,我们的 roi 呢,其实还有非常多的 算字,像这些获取区域内的点组啊,求区域的面积中心啊等等,这些都是非常非常经常的算字啊。后面课程我们再跟大家一个一个详细来讲。 好,我们来看一个最简单的,比如说我们要求取这个区域的中心是不是?那怎么办呢? aerial center 就求取到它的中心坐标啊,这个 ok, 我们用这个 region 来啊, region 求取这个区域的中心坐标,是不是你看我们就能够得到它的中心坐标的 x 和 y, 这个地方输出的是 x 和 y, 包括这个区域的面积,我们也求出来了 area, 是不是?那我们也可以把这个 x y 显示出来,通过 game cross 显示出来啊。跟 cos 的话是生成一个十字叉,这个非常有用,帮我们看一个点在哪个地方是经常用到的,大家看到吗?这就是我刚才求出来的区域中心,并且生成一个十字叉给大家来看 啊。好,这就是我们讲到的图像与 r o i, 谢谢大家。
 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿machine vision ensures high quality and a smooth production sequence mv tech merlig simplifies building machine vision applications in an unprecedented way focusing on the image you're able to define regions of interest and processing parameters via easy touch to solve your application configure and combine merlex wide range of industry proven tools utilize rule based and the latest ai deep learning technologies without writing a single line of code in addition to its powerful tall library merlicoffers all important components of a machine vision solution such as broad compatibility with various platforms, image acquisition system communication and visualization with the help of drag and drop functions easily create an individual interface for your application all in all merlik is second to none powerful, flexible and user friendly merlik you're easy to use machine vision software。
 07:29查看AI文稿AI文稿
07:29查看AI文稿AI文稿各位同学大家好,欢迎来到由西动智能科技出品的蒿肯入门课程,我是主讲刘嘉欣。 本节课主要学习薅啃中的育植分割,学习内容包括一些简单的图像基础知识,育植的概念,区域的处理方法,区域的一些信息要素获取。 我们可以看到灰度图像,大家经常把它称作为黑白图像,其中的细节色差都是通过颜色的深浅来表示出来的,通常被称为灰度, 如亮黄色和红色,两者在转化为灰度图像后,可以看到颜色的深浅不同。在机器视觉中,彩色相机采集到的图像为彩色图像, 黑白相机采集到的图像为灰度图像。通常在不需要对颜色进行识别的时候采用黑白相机,因为可以采集到更多的细节。 灰度图像中的灰度通常分为二百五十五个,等级为零到二五五,零表示纯黑,二五五表示纯白。 灰度随着数值的变化递增或者递减。预值,一张灰度图像中,我们所设定的某个灰度值被称为预值,如图像的灰度值大于五十的区域,此时五十就是设置的预值。接下来为大家举例进行说明。 大家可以看到图像中灰度值大于五十的部分显示为红色,也就是我们所选中的部分。 大家可以看到预值选择为零到二百四十二,可以帮助我们区分背景,预值选择为七十一到一百,区分一些颜色,预值选择为二百二十三到二百四十一。 在我们完成浴池分割后,我们可以看到在同浴浴池内所有的区域都是被同时选中的,可谓是易溶、聚溶,易损俱损,但是我们只想要某一个浴池下的某一个区域,怎么办呢? 接下来为大家介绍肯耐克乘算子,这个算子被称为断开算子,功能是将所有不直接接触到的区域全部分割开,这样我们就可以根据不同区域的特点筛选出 我们所需要的区域。在进行预知分割时,我们需要有请一位帮手叫做灰度直方图。 灰度直帮图可以帮助我们清晰明了的看到每一个灰度值所代表的面积,灰度值的大小。在选定完灰度值后,我们就可以使用 ctrl 算子将不连续的区域进行断开。 点击运行,我们可以看到所有没有连接的区域都被分割成一块一块的了,用不同的颜色进行表示,再 图像变量中选择被分割后的图像变量,右键选择显示目录。被分割后,每一个区域的属性都可以从对象中查看,里面有我们每 一个区的面积以及中心点的坐标。接下来就有请特征指方图出场,顾名思义,它是根据这些灰度区域的不同特点进行区域的筛选,如大小、位置、 高度、宽度等。这里选中的是面积大小,我们通过移动光标观察区域面积颜色的变化,可以判断区域是否被选中。从图像中我们可以看到有许多相同灰度值的小点, 可能是由于杂物、灰尘以及相似的东西所引起的干扰。 这里我们将其面积范围调至大于等于六百, 点击插入代码执行程序, 我们可以看到在新的图形变量中只保留了面积大于等于六百的区域, 这行代码就是我们刚才通过特征脂肪图所插入的代码,我们也可以改变这行代码最后的两位数字,进行面积范围的调节,现在我将取面积的最小值调至八百,重新执行代码。 我们可以看到同样筛选出了两个小面积的区域,接下来我们通过区域的位置进行区域的筛选,在这里我们先筛选出区域的上下部分,再筛选出区域的左右部分, 打开特征直方图,将特征选择为 roo, 我们可以看到特征直方图中的区域排布发生了变化, 这就是由面积大小排布转化成了纵向位置排布。我们现在开始将取于面积按照上下的方式进行筛选。 选中 rai 特征,将最大指光标,也就是这个红色光标向左平移观察图形窗口,直到将下方三个区域筛选出后即可停止。点击插入代码执行程序, 打开筛选后的图形变亮,我们可以看到已经将下半部分的区域筛选出去了, 现在开始以横向坐标进行筛选。同样打开特征脂肪图,不过这次将 roo 选项改为 clome 选项,将特征脂肪图中的最小值光标,也就是绿色光标向右移动,直到筛选出最右边的两个区域。点击插入代码 执行程序,打开最新筛选出的图形变量,我们可以看到最终筛选出的区域位置范围。那 那么接下来三个离得非常近的区域该怎么办呢?我们可以使用我们区域的宽高来进行筛选。同样打开特征直方图,将我们刚才的克拉姆选项改为为选项 为代表了宽的意思,这里我们同样拖动光标筛选出最窄的一个区域。点击插入代码运行程序, 查看最新筛选出的图像,再次打开特征脂肪图,选择汉特特征,拖动光标筛选出最低的区域。再次执行程序,打开最 筛选出的图形变亮,我们可以看到已经筛选出了一块单独的区域,这就是我们所要筛选区域的大致流程。 在获取到目标局后,就要对目标信息进行提取,如在识别定位时需要找到目标的中心点,这是需要 arr 森特算子。 arr 森特算子可以获取目标区域的面积以及区域的中心坐标。我们在这里输入 arr 森特算子 执行程序,我们可以在变量窗口中看到获取到的区域中心坐标和区域面积。
355西安西动智能科技有限公司





