redis为什么不能做主数据库

粉丝3023获赞8323
相关视频
 15:12查看AI文稿AI文稿
15:12查看AI文稿AI文稿release 的缓存怎么跟数据库的数据保持一致性?那怎么回答这道面试题呢?我们先来说一下什么情况会出现数据的不一致。那在项目当中,我们去使用 release 读取数据的一个场景呢?通常会这么来用,当客户端发起一个查询数据的接口,我们首先呢会去 release 当中去看一下有没有数据,有的话直接返回,那没有的话呢,会去查询数据库,再把数据库的数据呢给他保存在 release 当中,然后设置一个过期时间,这是过期时间的作用呢,是为了保证一些冷数据没有人用呢 啊,过期自动淘汰,不至于一直存储在瑞斯当中,占用瑞斯的空间,对吧?那保存完之后呢,返回到客户端,那么这个呢,就是我们使用瑞斯最常用的一个读取数据的场景,对不对?但是呢,如果我们只读的话,他肯定不会出现这个数据的不一致,对吧?也就是瑞斯跟数据库,如果你只是 查询的话,他肯定不会出现数据的不一致,对不对?只有读跟写并发一起,才会出现这个数据的不一致。那我们再来说一下这个写的场景啊,那写的场景这个情况就比较多了,总结起来呢,无非就是到底是更新缓存还是删除缓存, 或者呢,是先操作数据库还是先操作缓存,无非就是这两点区别,好吧,什么意思呢?可能很多同学听到这里有点懵逼,对不对?比如说,当我们去修改一个数据,你到底是修直接修改 redis 还是直接删除掉 redis 的数据呢?同学们想一下,你会用哪一种? 其实更推荐大家用直接删除缓存的方式,也就是你修改一条数据的情况,直接把 redis 数据给他删除掉,为什么呢?因为你删除掉逻辑非常简单对不对?你只需要等待下一个县城去查询这个 redis, 然后没有呢,再去查询数据库,把数据 数据呢放回到 redis 就行了,对不对?但是如果你是修改 redis 数据呢?我们通常修改 redis 数据会经过一系列复杂的业务逻辑计算,对不对?完了之后呢,再给他 去保存修改,所以说整个过程修改,其实他所需要付出的成本呢,其实是更高的,所以推荐大家直接把这个缓存直接给他删除掉,我们更推荐大家用直接删除缓存的方式。 然后呢,我一个修改数据的一个场景,首先呢,我们到底是先把 redis 的数据修改了,还是先把数据库的数据修改了呢? 这是先操作数据库跟先操作 reds 区别,那么这两种到底用哪一个?好吧,我们分别来讲一下,怎么在矮个子里面挑高个子,也就是先操作缓存更好还是先操作数据库更好呢? 那我们分别都来说一下,以及他们出现数据不一致的情况,又应该如何分别的去处理呢?我们先来说一下先操作缓存啊,那先操作缓存再这个修改数据也就是写的场景啊,那假如先乘一, 他先把 red 的数据删掉,对吧?然后呢再去修改数据库,这是先操作缓存的这样的一个场景。那如果是读跟写并发,是如何出现数据的不一致呢?我们来说一下, 首先线程一发起了一个修改数据的这样的一个请求,对不对?首先第一步呢,先把 read 的数据给他删除掉, 然后呢再去修改数据库,那么此时呢,在这里出现了网络的卡顿。线程二,由于他是并发进来,他执行的是一个查询的请求,他会去 redis 当中呢查询数据,那么 能查到吗?由于县城一把数据删掉了,对不对?他查不到,那么此时呢,他就会去数据库里面查,但查他查到的数据呢,其实是一个老的数据,对不对?因为新的数据呢,在县城一这里还没修改进来。 那么线程二,他查到老数据之后呢,会把这个老数据呢,存在 red 三中,对不对?完了,线程一,此时反应过来呢,会把新数据 给他更新在数据库当中,那么此时呢,就会出现 regis 当中存的是老数据,数据库当中存的是新数据,下次比如说现成更多的现成进来查询到的数据呢,就一直是这个老数据,必须要等到这个老数据呢,过期时间到了, 才能查到新数据,对不对?所以这个过程呢,一直都会是数据不一致,那这个情况怎么解决呢?那其实解决起来非常 简单,我们再来重演一下刚刚那个过程。首先呢,线程一执行修改操作,他删除掉这款团,然后呢去执行修改数据库操作,出现了网络延迟。线程二执行查询的这个操作,他查到类似三中,没有去查询数据库,查到老数据,把它放在 red 三中。那么此时想一下,线程一,他把数据库修改成新的之后,我能不能再执行一遍删除 redis 数据的这样的一个操作, 删完之后,我后面再有现成请求进来, res 当中是不是没有数据了?没有的话是不是会查到这个新的数据,然后再放回到 res 当中,那么此时是不是就保证了数据的一致性,对吧?但是呢, 县城二查到的这一次,他其实是老的数据,对不对?所以只会出现数据的一次不一致,那有同学可能会说,老师能不能把这一次也能保证,那,那你就得引入这个强一致性的概念了。强一致性, 我们的 release 跟数据库数据是强一致的话,必须要保证他们的操作是原子性的, 那么我们的 redis 跟数据库他可能存储在不同的服务器,他是需要两步操作的,对不对?那你要保证他们的原则性呢?你就得保证他们在操作的时候呢,去上一把锁,对不对?那你加了锁之后, 是不是会影响我们整个系统的一个吞吐量啊?对不对?你想一下,我们用 read some 目的是什么?是不是就是为了提高系统的一个性能? 那么此时你用为了保证强一致性又去加锁,是不是就得不偿失了,对吧?所以说一致性跟性能我们只能保证一种好吧? ap 跟 cp 呢,我们只能保证一种,所以说在 ap 的这个基础上,我们可以用刚刚所说 的这个双删,也就是再删一次的方式呢,保证数据的这个一致性。虽然线程二他会出现一次数据的不一致,但是你的 reaches 跟数据库呢,是保证了最终的数据一致的,对不对?他们最终的数据都是新的, 所以我们要保证数据一致性呢?我们通常会采用这种最终一致性,而不会采用刚刚所说的这个强一致性,因为强一致性他会影响我们系统的吞度量。 ok, 所以说我们通常呢会采用这种最终抑制性。然后呢,我们还得注意一点,也就是在这里再一次删除,我们称之为双删,好吧,因为你前面删了一遍嘛,后面又删一遍,所以称之为双删。那么第二次删除的时候啊,要使用延迟,延迟删除,比如说延迟几百毫秒之后再删除, 为什么要这样做呢?来,我们再来重演一下。首先建成一,他去执行修改操作,对吧?删除 res, 然后呢,此时他去更新数据库,出现了黄颜值,那现场二,执行查询没有查到,去查询输入,他查到了老数据,那么此时呢,建成一进来,他把出去更新,是吧?更新出去,然后呢,你,你如果不延迟啊,是不是会立马执行删除啊? 对吧?那么你删完之后呢?此时县城二才把老数据呢,给他放回到瑞斯三中,此时你这一步如果没有延迟,是不是删了跟没商一样的,伤了个寂寞,对不对?所以说县城二他又把老数据呢放回到了瑞斯三中,又出现了数据不一致, 所以说你必须要延迟,那么这个就是我们所谓的延迟双杀,比如说我们延迟五百毫秒,五百毫秒之内啊,这个 reece 当中,它存的一直都是老数据,对不对?所以这在这个五百毫秒之内呢,它就一直是脏数据, 但这个没有办法,对吧?我们只能保证最终的意志性。 ok, 那这个五百毫秒也不一定啊,你得结合你自己的这个项目的这个业务,好吧,自己评估他的一个耗时时间, ok, 也就是评估一下现成二,他去查询数据库,然后呢放到 release 的这个时间删除,那么就延迟多久,好吧,那这就是所谓的通过延迟双删的来保证数据的最终一致性, ok? 然后我们刚刚说的是什么先操作缓存的情况?我们再来说一下,先操作数据库,什么情况会出现数据不一致?那先操作数据库的话, 同样的执行一个修改请求,先把数据库的数据呢先修改掉,然后呢再去把 redis 的数据删掉,那么这种情况如果是在病发的情况下,读跟写一起,会不会出现数据不一致呢?我们在 再来重演一下这个过程。线程一,他执行一个修改操作,由于先执行数据库操作对不对?那么把数据修改成新的, 那么此时你在修改的过程当中啊,线程二,他进来了,他执行一个查询的这个请求,他查到的数据是什么?老数据对不对?然后就直接返回了, 然后呢线程一,它最终会把 redis 给它删掉,对吧?那么下一个线程进来查到 redis 当中,没有,会把这个新新数据再放回到 redis 当中,所以在这个过程当中,其实我们先操作数据库,再去删 redis, 是不是 能保证最终的一致性啊?对不对?所以说更推荐大家呢,先操作数据库,再来操作缓存,好吧,只不过呢,你先操作数据库,他其他县城去其他县城,在这个过程当中查到的数据呢,是脏数据,对吧?但是我们 最终呢保证了他的数据一致性是不是?那么这种先操作数据库的情况,他其实呢还是会有问题,也就说你先 把数据库修改成新数据之后呢?三缓存的时候呢?删除失败了,但这种情况下比较极端,但,对吧?但是还是会有,但是如果你删除失败了,是不是下次一直也是查到的是老数据啊?必须要等待这 res 时间过期之后才能查到新的, 对不对?那么针对这种删除失败的情况,那么我们可以采用删除重试的一个机制,我们可以利用一个 m q, 好吧,也就是你在这里删除失败,不管你先操作这个缓存,还是先操作数据库,都可能会出现删除 release 失败的情况,对不对?那么一旦出现了删除 release 失败啊, 我们可以通过易步好吧易步请求的方式发送一个这个易步消息到这个 m q 当中,对吧?然后你的系统呢,去监听 m q, 一旦监听到有某一个这个 race 的 key 删除失败了,那么就怎么样执行重试删除对不对? 那么这样呢,就能够保证出现这种极端情况的删除失败的情况,对不对?所导致的数据不一致,好吧,我们可以采用这个删除重试,但是我们加入了删除重试之后呢,他有什么缺点呢?朋友们可以想一下,是不是这个业务的数据代码, 是不是这个代码的偶合度太高了,对不对?也就是 m q 操作的这一块的偶合代码,我们放在系统当中,是不是代码过于偶合对不对?那如果我们要实现结偶的话,我们可以采用另外一个组件叫做 这个 canno, 好吧,它是一款阿里巴巴的开源组件,通过它呢,可以去监听这个 my circle 的一个啊,冰落和日志,你可以把它理解成什么主从,好吧,也就是说,当我们的这个 my circle 出现了数据变动, canno 它能够立马感知到, 好吧,然后呢,再通知 candle 的客户端,那么 candle 的客户端啊,它可以有很多种,那么我们可以通过 spring 步的应用来充当这个 candle 的客户端。 我给大家举个例子,整个过程是什么样的啊?首先呢,线程一删除,对吧?单执行一个修改操作,整个操作过程是什么样的?我给大家说一下。也就是我们刚刚呢,把这个删除重试的整个过程啊,都放在了这个 candle 客户端去做,也就是一个专门用来监听这个 candle 的一个 spring boot 应用。那么这个过程是什么样的呢?我来给大家说一下。说白了 就是把这个删除 release 的操作呢,给它放在了我们的 cano 客户端,也就是我们的可以是一个 spring boot 的应用。好吧,这个 spring boot 应用呢,它用来接收 cano 的通知,也就是一旦我们的数据库发生了数据的修改, 他会通知 candle, 那么 candle 呢,再去通知我们的 candle 的客户端,也就是 spring 部的应用吧。那么整个过程是什么样的呢?我们再来重演一下。首先呢, 线程一它执行修改操作,对吧?它去删除 release, 当然不管你是先操作缓存还是先操作数据库啊,我们都可以采用这种。 好吧,监听并 log 采用这种 candle 的方式来进行解偶,并且呢啊删除重试,好吧,然后现成一修改在这里呢,出现了网络延迟,对吧?然后呢现成二,去查询数据,没有查到,去查询数据库, 查到老的数据,把这个老师的数据呢存到 red 三中,然后呢现成一醒过来把数据修改成新的,那么 candle 一旦监听到这个数据库发生了变化,他会发送一条对吧消息通知我们的 candle 客户端, 然后再携带这个新的数据啊,好吧,告诉这个 spring 部的我们的 candle 客户端,那么 candle 客户端呢?他再去执行什么?延迟删除 redis, 对不对?那么如果删除失败呢?同样的 再去发送一条消息,好吧,也就是我们的这个天路客户端发送一条消息到 mq, 对吧?那么 mq 呢,再去通知 我们的 mq 的订阅者执行删除重试,对不对?好吧,整个过程呢,就是这样的。那么最后呢,再来给大家总结一下,就是我们 首先在项目当中使用 reese, 当中如果你只是只读的话,肯定不会出现数据不一致,对不对?只有读跟写并且存在并发的情况呢,才会出现数据的不一致。那数据那在我们这个写的场景啊,我们不推荐大家 用修改缓存的方式,而是呢,推荐大家用删除缓存的方式,对吧?因为他的这个性能,他的这个成本更低。然后呢,是先操作缓存还是先操作数据库?我们更推荐大家采用这种先操作数据库的方式, 对吧?因为它能够尽最大限度的呢,保证我们最终的数据一致性。但是不管你是先操作数据库还是先操作缓存,其实都会出现数据的不一致性,对不对?因为 redis 跟数据库呢,它不是原子性的,你要保证原子性呢?只能 怎么样?上锁对不对?那上锁的话就会影响我们系统的一个吞吐量,所以说我们只能保证最终的数据一致性,对不对?那数据最终一致性呢?我们也不能完全的去保证, 因为假如说我们在删除缓存的时候, reese 出现了失败,那么我们就需要使用重试,对不对?删除重试,利用 mq 来异步的重试删除,当你利用 mq, 假如说这些逻辑代码都放在一个系统当中呢?过于吻合 对不对?那么我们就可以最终呢采用这个 canno 来进行解偶,这样呢,我们就可以把删除 release 的这个操作呢放在这个 canno 客户端去做,对不对?然后呢,如果出现了删除同事呢,也放在 canno 客户端,从而呢 跟我们的业务代码进行解我,对吧?好,这就是我们的这个 redis 跟数据库怎么保持数据的一致性,好吧。
1747Java小叮当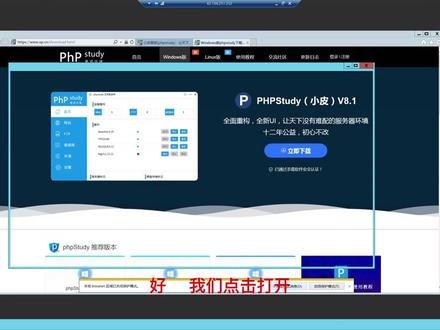 02:21查看AI文稿AI文稿
02:21查看AI文稿AI文稿哈喽,大家好,这一次我们搭建绿地石数据库,我们这一次还是使用这个小皮去搭建,我们在浏览器输入擦皮点,先 我们下载一下个小皮,点击个 windows 版本,点击这个客户端,点击立即下载,我们选择六十四位 啊,打开,为什么说要使用这个小皮呢?因为他是一个脐橙化玩具啊,后期的话比较方便,我们操作跟管理 好,我们点击打开,然后双击这个,点击运行,运行立即安装好,我们等待一下他安装就可以了,好, 这样子比较方便啊,使用这个小皮去管理这些东西。后期我们 fdp 啊, mc 口啊, 我们的网站呢,都比较友好,点击安装完成,好,这时候他都会是这样子的一种状态,我们点击这个软件管理,点击这个绿地石,看见没有啊?我们下载这个版本 啊,这个是这个,这下面是客户端,这是我们控制的好, 然后点了回到这里,然后点击启动好,然后他就启动成功了,然后这是绿历史的一些配置啊,这里是指我们本地 ip 的意思啊,端口, 然后连接,然后这里是可以输入密码的,我这里先不管他,好,我怎么进入呢?我们点击这一个,点击进入好,然后我们直接直接这里添加一个服务器啊,这个服务器直接来一个一吧,然后这是地址 好,这是端口啊,这是密码,因为我之前没有没有做,我们 没有做那个密码,我们直接进去就可以了,停下, ok 啊,然后这时候我们就进来了,这就是他的数据库,这时这就他就完成了,很快很快很方便。
34玖伴一鹏 02:08查看AI文稿AI文稿
02:08查看AI文稿AI文稿什么是 riders? 我们先来看一下 riders 这个词儿的意思啊,它是源于这三个单词的缩写 remote dictionary、 solar 远程字典服务器。 呃,为什么这么叫呢?是这样,就是他是一个独立的数据库的软件啊,所以他可以被独立的安装在一台服务器上,他可以远程操作,所以他是远程的。然后他是用剑直存主的形式啊,剑城存剑直存主是不是就像查字典一样,我们根据一个一个词去查这个词的解释。那我们的见就是根据一个关键字 k 查,他对应的只是歪柳,是不是就是这这个意思啊?所以呢,他叫远程字典服务器啊,他是一个基于内存的啊,当然是开源的数据库,然后通常的用作建筑存储, 然后缓存,或者是消息列队等等等等。然后如果你不知道什么是数据库,你去看我的一万小时计划十一那一期的视频。然后我们 来看一下什么叫做基于内存的数据库呢?是这样,瑞迪斯通常呢,将所有的数据都存在内存中。当然,嗯,不通常的情况下就是你有寻你内存吗?寻你内存本质上不在内存里对吧?但他也是内存, 他逻辑上也是内存啊。呃,然后当然呢,他他为了实实现持久化,他是这样,他是默认情况下是每隔两秒把这个数据也写入到硬盘来实现持久化。但是他写入到硬盘里的数据呢,仅仅仅仅是为了重新打开这个软件的时候把数据给加载回来,加载回内存。 为什么要这么做啊?是因为我们内存的速度是不是要比硬盘快一个数量挤压,这样做我们这个数据库的性能就会非常的 nice。 正因为他性能的非常的 nice, 他在这个 dbnjins 的里的排名,他也是连续好多年是这个兼职存储的第一名啊。最受欢迎最受欢迎的。咱们来看一 ridis 的发展减少一个意大利成全,叫做萨罗巴 toli。 三飞利普他发明了 redisa。 他最早的是用普通的原来的传统的数据库 做了一个实时的外部日制分析仪器啊。然后他对这个传统数据库的性能不是很满意,然后就开发了 redis。 不过要注意的是,二零二零年的六月,呃,他已经辞去了 reds 的这个维护者的身份啊。就就就是这样就没了。你明白了吗? fun channel。
353FangChannel 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿使用 ad 作为缓存数据库的过程中出现的一些问题以及解决方法。问题一缓存穿透制止当用户查询某个数据时, ad 生不存在该数据,也就是缓存没有命中。此时查询请求就会转向十九层数据库。 mac 额查询结果发现, iceo 数据库中也不存在该数据, msu 数据库只能返回一个空对象,代表此次查询失败。如果车内请求非常多,或者用户利用这种请求进行恶意攻击,就会给 msu 数据库造成很大压力,甚至于崩溃。 这种现象就叫缓存穿透。缓存穿透问题有两种解决方案。方案一缓存空对象。就是当买 ceo 数据库返回空对象时, id 想该对象缓存起来, 同时未及设置一个过期事件。当用户再次发起相同请求时,就会从缓存中拿到一个空对象。用户的请求被阻断在了缓存层,从而保护了后端数据库。但是这种做法也存在一些问题,虽然请求进不了 masu 数据库,但是这种策略会占用 ades 缓存空间。方案二不隆过滤器我们 知道布隆过滤器能判定不存在的数据,那么当该数据一定不存在时,利用他的这一特点可以防止缓存穿透。首先,将用户可能会访问的热点数据存储在布隆过滤器中,也称缓存预热,是指系统启动时,提前将相关的数据加载到该地缓存系统中,这样避免了用户请求的时再去加载数据。当有一个用户请求到来时,会先经过布隆过滤器。如果请求的数据 不隆过滤器中不存在,那么该请求将直接被拒绝,否则将继续执行查询。相较于第一种方法,用不隆过滤器方法更为勾销实用。问题二缓存击穿是指用户查询的数据缓存中不存在,但是后端数据库却存在。 这种现象出现原因是一般是由缓存中 p 过期导致的。比如一个热点数据 p, 他无时无刻都在接受大量的并发访问,如果某一时刻这个 p 突然失效了,就致使大量的并发请求进入后端数据库,导致其压力瞬间增大。这种现象被称为缓存击穿。缓存击穿问题有两种解决方案方案一改变缓存中 p 的过 时间,即设置热点数据,对应的 t 可以永不过期。方案二分布式锁采用分布式锁的方法,重新设计缓存的使用方式过程如下一、上锁当我们通过 t 区查询数据时,首先查询缓存,如果没有,就通过分布式锁进行加锁。 第一个获取所的进程进入后端数据库查询,并将查询结果换到该地所。二、解锁当其他进程发现所被某个进程占用时,就进入等待状态。知识解锁后, 其余晋城在依次访问被缓存 bt。 问题三缓存雪崩支持缓存中大批量的 t 同时过期,而此时数据访问量又非常大,从而导致后端数据库压力突然暴增,甚至会挂掉。这种现象被称为缓存雪崩。他和缓存击穿不通。 缓存击穿是在并发量特别大时,某一个热点 t 突然过期,而缓存血崩则是大量的 t 同时过期。因此他们根本不是一个量级的解决方案。与缓存击穿有相似之处,所以也可以采用热点数据永不过期的方法来减少大批量的 t 同时过期。再者就是为 t 设置随机过期时间,避免 t 集中过期。
13网星java直播
















猜你喜欢
- 2569大厂联播
最新视频
- 6031𝑳𝒔𝒆𝒗𝟕