《eCognition遥感图像处理教程》

粉丝396获赞5291
相关视频
 12:53查看AI文稿AI文稿
12:53查看AI文稿AI文稿我们来学习四点二节辐射矫正。本节主要包括下面三部分内容,一、辐射矫正的概念二、辐射定标三、大气矫正 首先介绍一下俯视矫正的基本概念,在理想情况下,遥感图像的低 n 值能够直接反映低于自身的光谱差异。 那么什么是理想情况呢?传感器没有误差,没有大气的影响,光照条件是恒定不变的,但是显然这样的理想情况在现实中是不存在的。 由于诸多因素的影响,遥感传感器记录的数值和低物实际的辐射值并不一致,导致了辐射误差,或者说辐射积变, 图像不能全部真实的反应丢特征,因此要消除遥感丞相过程中的辐射误差,这就是辐射矫正。 辐射误差产生的原因主要是两个方面的,一方面是内在因素, 也就是传感器段的因素,传感器把接收的入桶处的辐射能量转化为灰度值,在此过程中,由于透镜光电转换误差等影响,记录的数值 存在一定的误差。另一方面是外部因素,电磁波在大气中的传输过程中受到大气散射、吸收等影响, 地形的起伏以及太阳位置的变化也会导致向源的光照条件发生变化,这些都会带来辐射误差。 如何进行辐射矫正呢?第一步是辐射定标,标就是标准的意思,相当于刻度 辐射顶标,把没有物理意义的遥感图像的灰度值转换为入桶处的辐射亮度,通过这个步骤消除传感器本身产生的误差,并且得到具有物 意义的辐射信息。没有辐射定标,就无法对观测对象进行定量监测,辐射定标是遥感数据定量化研究和应用的重要前提。 那么如何进行辐射定标呢?辐射定标的思路是通过灰度值和辐射亮度之间的定量关系来完成的。 遥感卫星的运营方通常会给出官方的辐射定标方程和方程中的定标系数, 那么最常见的定标方程就是这样的形式,把遥感图像的 dn 值乘以 gain 争议值,再加上 buyers 偏移值,得到辐射亮度。 比如兰德赛的数据、资源三号零三数据等等,都采用了这样的定标方程的形式。 这张表格给出了资源三号零三数据所有不断的给引值和 boss 值,这些系数值都是可以在中国资源卫星应用中心的网站下载的。 可以看到指定标并不难,就是一个简单的运算而已。但是有同学可能会好奇,这个定标方程和定标系数又是怎么获取的呢? 有三种途径获取定标系数、实验室定标、心上定标和场地定标。实验室定标 是在传感器发射之前,通过系风球和可控的人造光源对摇杆器成像,获取系风球所测量的辐射值和对应的摇杆向源值,建立两者之间的经验方程,得到定标系数。 当传感器发射运行之后,仪器的性能可能会衰变,需要调整定标系数。 当然,这个时候已经无法重新进行实验室定标了,不可能把卫星摘下来做个定标再放上去。 这种情况下呢,要开展新上定标或者场地定标。新上定标利用卫星自带的定标设备对传感器 进行定标,他的思路方法和实验室定标差不多。可见光和镜红外波段通常采用太阳或者标定的乌斯灯作为较整圆,而热红外波段通常利用黑体做定标。 场地定标呢,是在卫星过境的时候,在定标场地开展同步观测,测量地标反射率、太阳辐射、大气参数等等。 通过大气辐射传输模型,计算出卫星摇杆传感器的入桶处的辐射亮度和摇杆影像值,建立定量关系,得到定标系数。在辐射定标的基础 属上,可以计算表关反射率。表关反射率又称为大气顶层反射率,它是把地表和大气看作一个整体,计算的反射率是大气顶层的反射辐射和大气顶层入射辐射的笔直。 大气顶层的反射辐射就是辐射定标所得到的辐射亮度值。大气顶层的太阳入射辐射亮度可以根据这个波段大气顶层的太阳浮照度 乘以太阳天顶角的余弦,除以日地距离的平方,再除以 pai, 值得到两者的笔直,就是方程最后的这个形式。这也是常见的表观反射率 计算公式。表观反射率能够在一定程度上表征地物反射特征,但是它包含了大气的影响,和地表的真实特征还存在一定的差别, 因此还需要消除大气散射、吸收等影响。把辐射定标得到的表观辐射亮度或者表关反射率转换为地表真实反射率,这个过程称为大气矫正。 大气矫正的方法比较多,有暗象圆法、线性回归法和大气辐射传输模型法等等。暗象圆法的基础是认为 遥感图像中存在暗象源。什么叫暗象源呢?这种象源在特定波段的反射率可以看作近似为零,比如说农历植被在近红外波段,水体在短波红外波段等等。 由于大气散射的影响,由俺图像中暗象源的反射率不为零,而这个值就是大气沉浮射所导致的。 假定整幅图像大气的散射是均一的话,那么每个向源的呈辐射的值都是一样的。把每个向源的值减去这个不断的暗向源的值就是去除了呈辐射的影响。这种方法简单方便,但是他只考虑 呈辐射的影响不够准确。线性回归法,通过回归方法建立地面的实测样点反射率和对应遥杆向原直之间的线性经验方程, 把方程应用于整个图像,得到所有象源的地表反射率。这种方法需要采集地面光谱, 对采样点的数量和代表性要求都比较高,并且不同地物的经验关系未必一致,因此他的应用相对比较少。 大气辐射传输模型法,利用大气辐射传输模型模拟电磁波在大气中的辐射传输过程, 对腰杆图像进行大气矫正。为了进行辅助传输模拟,需要太阳角度传感器角度、大气模式、气溶胶光学厚度传感器的光谱特性、 地表高度传感器高度、地表反射特征等一系列的参数。 把这些参数输入辐射传输模型,得到大气矫正系数的竖直减,计算出地表反射率。这种方法虽然相对复杂一些,但是精度高,是目前主流的大气矫正方法。 常见的辅助团中模型有六 s 啊,猫群啊、弗莱逊啊等等,其中六 s 模型和猫群模型都是有着很长历史的经典的大气复仇传中模型。而腐烂熊模型呢,是恩威软件的大气矫正扩展模块,他是在猫群基础之上所开发的具有图形界面的大气矫正工具。 我们通过这几张图来回顾和总结一下辐射矫正过程。 这张图给出了某个植被向源的灰度值光谱曲线啊。旁边这张图呢, 则是经过辐射定标的辐射亮度光谱曲线。和灰度值相比,我们可以看到辐射亮度曲线有一定的差别。一方面呢,是数字的差异,几个波段的 灰度值主要在三十到一百、二十之间,而辐射亮度主要在零到一百之间。另一方面啊,光扑取形的形状也有差别,因为不同波段的定标系数,尤其是争议值是不一样的。 定标后的辐射亮度在短波红外波段非常低,因为太阳辐射冷量主要集中在可见光镜红外区间, 入社的短波红外辐射比较低,那么反射后进入传感器的短波红外辐射也低。这张图给出的是表关反射率曲线,它的数值主要在零点零五到零点三五之间。 表光反射率是各个不断入同辐射和大气顶层入射太阳辐射的笔直,它消除了不同不断太阳辐射差异带来的影响,相比辐射亮度 更能够表真地无特征。最后这张图呢,给出的是大气矫正后的地表反射率曲线,和表观反射率相比, 消除了大气的影响。在兰博段矫正后的地表反射率明显比表患反射率要低, 因为蓝不断受大气散射影响最大。另外在近红外不断,表关反射率在零点六左右,明显要比表关反射率高。相比于表关反 反射率,经过大气矫正的地标反射率能够更好的反映植被的反射特征。
43吉人天象 04:29查看AI文稿AI文稿
04:29查看AI文稿AI文稿大家好,欢迎来到遥感大白的频道,俄乌战争目前是国际上的热点事件,我们就以俄乌前线亚素钢铁场威力来看看如何从遥感图像中解决实地情况。 真彩色图像就是将多光谱图像中的红、绿、蓝波段的灰度图像分别做红、绿、蓝变换,然后通过 rgb 彩色合成得到的彩色图像。真彩色图像中地雾呈现出的色彩与我们人眼所见到的地雾色彩是一致的, 因此在一般情况下,人们可以基于常识在真彩色图像上进行地物的判别。从亚素钢铁厂的真彩色遥感图像上可以清晰的观察到不同地物呈现出不同的色彩,正是因为这些色彩的差异,才形成了我们人眼可见的地物轮廓、边界、纹理、阴影等特征。 我们依据这些特征就可以判读出不同的地物。亚素钢铁厂附近区域还可以清晰的分辨出耕地、建设用地、林地、水池、罗地等土地利用类型。那么是什么特点能够帮助我们在遥感图像上快速识别这些土地利用类型呢? 首先来讲耕地,耕地大致可分为水田和旱田,水田形状规则,引纹特征细腻,因其含水量较大,色调多为深绿色或者墨绿色,且附近常伴有河流等充足的水源。旱地同样形状规则且影纹细腻,因种植农作物的品种不同, 常常显示出不同色调的条带状纹理,色调为绿色或浅绿色,与水田相比颜色较浅。再来看林地,林地的种类较多,影像判毒时可将其大致分为有林地、 灌木林和其他林。第三类,树木较为密集的有林地,在影像上呈片状或带状分布,色调多成绿色,颗粒感强烈,纹理特征清晰且较为密集。灌木林较为低矮,眼纹粗糙,影像上呈深绿色。 然后是建设用地,这类地物比较容易分辨,例如卫星影像上排列整齐、色调杂乱的房屋区域一般为城镇、村庄。而交通运输用地在影像上主要呈交错有质的现状或带状分布。其中水凝质的道路在影像上呈现亮灰、灰白色调, 柏油路呈现出深灰灰色色调等,土路、渣路则呈现土黄黄色色调等。最后是水体,以常见的河流和湖泊为例,河流多成界线明显自然弯曲,宽窄不一的带状色调, 深浅差距较大。浑浊且水位较浅的河流在影像上呈现浅色调,清澈或水位较深的河水,其色调也相对较深。对于湖泊,奇湖岸在影像上呈自然弯曲的闭合曲线,轮廓较为明显。 清澈且平静的湖泊在遥感影像上通常呈均匀的深色调,而人工水体多具有较为规则的边界,例如亚素钢铁厂附近的水池成规则的矩形,因水体较浅,较易结冰,呈灰白色。 从这张真彩色遥感影像上我们可以看到,亚素高铁厂涂区东北部建筑物保留较为完整, 建筑物未浸泡火轰炸成明显的砖红色形态,排列均非常规整。而图区的西南部遭受了严重的轰炸,建筑物受损严重。图像上颜色发暗且结构较为混乱。二者中 间的水泥道路呈现亮灰之灰白色调,宽度大致相同,延伸较远,成条带状展布,草地站比较少呈现标志性的绿色, 而在真正的遥感解逸工作中,解逸者还需要考虑地物的遥感判毒标志在不同的地理环境和时空条件下也会存在差异,且不同的彩色合成方式对地物解异标志的影响也较大。 解意时就会根据具体情况制定不同地物的判堵标志,从而确保解意结果的准确与严谨。 地质工作中的遥感解意同样如此,例如对图中的北巴岩、喀拉山地区的严性进行解意,地质工作者首先要进行野外考察,建立区内各种目标地物的判毒标志。经过在室内对全区解意后,还需进行野外验证,检验专题解意中图班的内容是否正确。 另外,室内简易工作还会结合多元数据、多种类型遥感数据、区域地质调查信息等进行分析,这样在面对情况复杂的目标地误时,才能实现高精度遥感简易工作目标。以上就是这个视频的所有内容啦,希望对你有所帮助,感谢您的观看!
371遥感大白 15:08查看AI文稿AI文稿
15:08查看AI文稿AI文稿我们来学习四点一节,数字图像基础。 本节主要包括下面三部分内容,一、数字图像二、数字图像存储格式。三、数字图像特征。 首先介绍一下数字图像的基本概念,什么叫数字图像?与数字图像相区别的是模拟图像。 模拟图像又称连续图像,是在二维坐标系中连续变化的图像,比如现实中的纸质照片啊,图画呀等等,都属于模拟图像。而数字图像则是能够被计算机存储、处理和使用 用的。用数字表示的图像,由于他是以数字来表达的,那么必然是离散的。 自然界中连续变化的信息是如何转换为计算机中离散的以数字表示的图像呢?这个过程就是图像的数字化。数字化过程包括两个步骤,采样和量化。 采样是空间坐标或者说是空间位置的离散化处理。 他按照一定的间隔把模拟图像划分为若干个离散的小区域,形成了二为举证。离散的小区域,构成了数字图像的基本单元,称之为象源。由于非均匀采样 会导致问题复杂化,大部分情况下采用的是等间格采样,也就是说像源的大小是一样的。 彩样决定了图像的空间细节。彩样间隔越大,数字化得到的相源数就越少,空间分辨率越低,图像的质量也越差。而反过来呢,彩样的间隔越小,图像的质量越好,但是数据量也越大。 经过了彩样之后,模拟图像被分割为空间上离散的向源,但是每个向源的灰度或者说亮度还是连续的, 要将连续的亮度转换为离散的数值,这个过程称之为量化。量化之后 的整数灰度值又称为 dn 值、低低头 number。 量化级数越多,图像层次越丰富,第五,辨析能力越强。这就是前面所讲的辐射分辨率。 常见的遥感图像,亮化级数有二百五十六级、一千零二十四级等等。 左边这张图像是一个连续的模拟图像,他在空间上和灰度上都是连续的。 经过数字化以后,他在空间上被分割为若干个离散的向源,在灰度集上也被量化为若干个不连续的灰度值,他就从模拟图像转变成了离散的数字图像。数字图像有两种, 单波段图像和多波段图像。单波段图像的本质是一个二维素,主 不断直就是向源直。而多不断图像呢,本质是一个三维数组,有几个不断向源,就有几个对应的灰度值。 那么,数字图像在计算机里是什么样子的呢?这张图像给出了一个单波段数字图像的例子。 在计算机里,他是一个十行十列的二维数组,每一个项元都是数组中的一个元素,灰度值就是这个元素的数值。如果灰度值是自觉型的,每个项元值 在一个字节,在计算机里总共就是一百个字节。第一个字节是第一行第一列的像原值,第二个字节是第一行第二列的像原值, 而第十一个字节则是第二行第一列的像原值。以此类推, 相比于单波段图像,多波段图像的存储要复杂一些,涉及到不同的存储顺序。 多拨断图像的存储顺序有三种, bsqbil 和 bipbsq, 按照拨断顺序存储多拨断图像,首先存储第一个拨断的所有相原值,然后存储第二个拨断 所有相缘值,再然后是第三个不断的所有相缘值,以此类推。 bip 按照相缘顺序存储,首先存储第一个相缘的所有不断值, 然后存储第二个项元的所有不断值,再然后是第三个项元的所有不断值,以此类推。 b、 i、 l 呢,是按照行顺序存储,首先存储第一行的所有不断值,然后存储第二行的所有不断值,再然后存储第三行的所有不断值,以此类推。 这样直接讲大家可能会缺乏直观的理解,下面我们结合实力来分别讲一下这 三种存储顺序。那我们这边有一个例子,是一个六行六列三个波段的多波段图像,那么如果灰度值是字节型的话,每个波段有三十六个灰度值, 占三十六个字节三个不断,一共有一百零八个字节。这一百零八个字节在计算机中是怎么样存储的呢? 我们看一下这张图,这张图给出的是 bsq 的存储顺序,前面三十六个字结存储的是第一个不断的所有一项原值, 就跟单不断图像一样,首先是第一行六个像原直,然后是第二行六个像原直,再然后是第三行,然后接着的这三十六个字结, 存储的是第二个不断的所有相原值,最后三十六个字结存储的是第三个不断的所有相原值。这样的存储方式可以方便读取一整个不断的数据和是用来做空间为的信息处理。 同样的图像,如果采用 vip 存储顺序的话是什么样的呢? bip 按照相源顺序存储, 前三个字结存储的是第一个相缘的三个不断之,接着的三个字结存储的是第二个相缘的三个不断之,再然后三个字结存储的是第三个相缘的三个不断之。这样 的存储方式可以方便的读取一个向源的所有拨断值,合适用来做光谱为和时间为的信息处理,但是他打破了向源空间位置的连续性,不合适空间为的信息处理。 b、 i、 l 以行顺序进行存储,前六个字结是第一行的第一个不断值,然后是第一行的第二个不断值,然后是第一行的第三个不断值。 这前十八个字节存储了第一行的所有象源值,再然后的十八个字节存储的是第二行的所有象源值,再然后是第三行。 这种纯属顺序是 bsq 和 bip 顺序的折中综合平衡的,两者优点和缺点都是比较中庸。 刚刚讲的是图像的存储顺序,那图像是以哪种文件格式存储在计算机中的呢? 遥感数字图像的纯属格式有很多种,比如二进制格式、九 t 服格式、 hdf 格式等等。二进制格式 把图像数据以普通的二定制方式直接存储,另外还需要附带一个头文件,说明数据的类型、行列数、波段数、存储顺序等等。 比如 nv 的文件格式就是一种典型的二禁止文件格式。九、替付文件是传统替付文件格式的扩展,在替付文件格式基础上增加了地理信息的标签,使得图像具有地理空间定位信息, 比如 landsat 系列数据主要采用交替副格式。 hdf 文件是一种面向对象的数据文件格式,采用分层数据管理结构,具有自描述的特点, 并且能够在同一个文件中包含不同类型的数据,比如图像啊、文本啊、史亮啊等等。像猫迪斯数据主要采用 hdf 格式,摇杆 图像文件格式还有很多,此处就不一一细讲了。 数字图像具有空间位置信息和灰度信息,因此他在空间为和灰度为上都具有一些特征,可以进行统计、分析和处理。 那么空间分布特征包括位置、形状和大小等等。 位置最直观的体现是象源的行业号,比如第二点、第三行。与数字图像相比, 遥感数字图像还具有地理空间定位信息,除了以行列号表达之外,还可以以经纬度或者大地坐标 来表达。空间位置形状主要坑为点、线和面。这三类在图像中体现出不同的组合特征,比如椒盐噪声通常体现为点状,信息 道路体现为现状,而湖泊则体现为面状等等。大小体现了地物的尺寸或者说面积,比如乡镇和村庄都是居民区,但是他们的尺寸存在明显的差异。 这些空间特征无论是在目视解义中还是在计算机识别中,都能够起到非常重要的作用。除了空间信息之外, 数字图像灰度值也有一些统计特征,包括平均值、方差值、方图等等。 平均值反映了某个波段的整体亮度情况,那比如在直背覆盖区域,近红外波段整体平均值要明显高于红波段方叉呢?表增了地物的区分度,也就是信息量。 直方图则是描述了图像的灰度分布,它是一个非常重要的图像特征, 我们就直方图来详细讲一下。直方图表增了图像中不同灰度极的向圆数目或者说频率,以灰度极为 横轴,每一个灰度集所对应的向元数或者说频率为重轴绘制的图形能够直观的表达灰度分布,这也是直方图最常见的形式。我们看一下这个例子, 这是一个八行八列的灰度图像,在图像中灰度值最小值为一,最大值为十五,我们分别统计灰度值为一、二、三,直到十五的向圆数目就得到了下面的直方图。 那么直方图在摇杆中有哪些作用呢?我们说两个比较常见的作用,一是反映图像质量,二是确定分割预值。 这里给出了三张图像和他们对应的直方图,第一张图灰度值分布均匀,直方图呈静思正态分布,图像层次丰富,质量比较高。 第二张图灰度值主要集中在高值区值,方图呈偏太分布,图像偏亮,并且层次不分明。 第三张图则是反过来,灰度值主要集中在地址区,图像偏暗,层次同样不分明。所以 指方图可以在一定程度上反映图像质量,这也是我们后面做对比度增强处理的基础。这是一张 改进规划水体指数 n n d w i 图像,图像中高指表示水体信息比较强,低指表示水体信息比较弱。我们看一下这张图像的指方图,可以看到它呈现出非常明显的双峰特征, 高直区的窄波峰对应水体向源,那低直区的比较宽的波峰呢?对应非水体向源,我们取双峰之间的谷底对应的灰度值零点二三作为谕直,进行二直化分割,就可以提取出水体。
24吉人天象 04:46查看AI文稿AI文稿
04:46查看AI文稿AI文稿高分一数据解压号之后,里面有两部分内容,一部分内容是 nss 传感器,传感器中多光谱这部分的数据,下面这部分内容是 pen 全色的数据,一共两部分。 首先最上面第一是 mss 多光谱的一个 gpg 文件, 那这个 gpg 文件就是一个快视图,可以双击打开,通过这个系统里面在图片查看器就可以进行查看,这个是一个快视图, 快视图就是方便我们快速查看这份影像的一个成像质量,可以看出这个是标准假彩色的一幅图像,可以查看影像的有云,无云和云 量多少,大概怎么样这个影像,这就是一个快视图。那些第二个文件呢?就是一个点 rpb 的一个后缀,这个是有利于多样式系数,这个文件用于政设校证的。 那接着还有一个 tiff 的一个主文件,炸格文件,主文件, 这个就是高分一号图像,这个主文件接着是一个 xml 的一个原文件,一个文本文件, 我们可以双击打开这个原文件,大家可以通过这个记事本写字板打开,或者是写字程序等等都可以进行一个打开。在这里面你可以看到 整个的一个数据原文件,包括这个传感器名称,高分一号,还有这个传感器 id, pms 传感器,然后是这个影像的一个接收时间以及这个轨道号, orbit id 轨道号,然后是这个传感器的这个类型数据类型标准, 接下来是 cid 还有 productid 产品号, cid 是不唯一的,假如说你高分一号有一个,唉,高分一号地星或者说 b 星都有一个相同的一个井号,那下 下面是 product id, 就是产品号,你可以在数据检索网站上面输入这个唯一的产品号,来检索这唯一的这景影像,这是井号和产品号的一个区别,还有这个用户级别和产品级别 一二三四四个波段,还有这个 start time, 还有 under time, 这个是传感器的这个快门的开始和关闭时间,还有 center time 就是中央时间,也是传感器的拍摄时间, 这里是一四年七月份获取这个影像,然后 image gsd 就是影像的地面采用距离, ground assembling distance, 实际上就是地面采 用距离,这个像原代表影像的地面的真实距离就是八米,实际上就是影像的空间分辨率八米。然后下面还有一些卫星的天顶角和方位角,传感器的天顶角、方位角等等,这些信息就不多看了, 这个就是他的这个原文件, xml 原文件都在这个文件家里进行了一些描述。 然后接下来下面这个就是自带的 dm 高层数据,那这里面就是可能是早期的这个高分一号数据,就会带这个 dm 高层数据,现在可能没有了。然后还有一个 some gpg, 这个是一个拇指图,也就是一个小的一个快视图, 这个就是多光谱这部分数据。下面这部分是全色的内容,跟这个多光谱的 nss 基本一致,也是有块式图,有 zmo 原文件以及这个拇指图等等,那这部分就不多介绍了, 主要就是这个原文件原数据信息都在这个原文件里面,可以进行一个查看,那这是高分一号数据的一个介绍。
163S图像美学 13:11查看AI文稿AI文稿
13:11查看AI文稿AI文稿我们来学习四点三节摇杆图将几何矫正。 本节主要包括下面三部分内容,一、遥感图像几何机变的原因。二、几何矫正的方法。三、几何经矫正。 首先了解一下腰杆图像几何疾病的原因。几何疾病的原因 可以归纳为内部因素和外部因素,内部因素包括传感器和平台的影响, 比如平台的姿势的变化、转感器扫描速度不均匀等等。外部因素包括地球自传、地球曲律、地形起伏 和大气折射等影响。这些因素综合在一起,使遥感图像相对真实位置发生了偏移、扭曲、挤压等等,导致了遥感图像的几何疾变。 几何机变给遥感图箱的处理和应用带来了很大的误差和不确定性,所以要对遥感图箱的几何机变进行矫正,这就是几何矫正。 遥感几何矫正分为几何初矫正、几何经矫正和正社矫正。几何初矫正根据卫星运行和丞相过程中引起疾病的原因,也就是之前讲过的内部因素 和外部因素,利用传感器的较准数据、卫星姿态数据、地形数据等,通过理论公式进行矫正,又称为几何系统矫正。 这个工作通常是由卫星运营方来开展的。用户获取的遥感图像一般都是做过了几何出缴证的,也因此我们对遥感图像几何疾病的原因没有展开来细讲。 由于遥感器的位置、姿态等测量值的误差,经过几何出矫正之后的遥感图像定位精度还存在一定的误差,需要进行几何经矫正。几何经较正,不考虑产生几何机变 的原因,回避了丞相的空间几何过程,直接通过地面控制点建立向源坐标和真实坐标之间的对应关系。矫正几何疾变 震慑较真了,它的目的是消除地形起伏造成的几何激变,把摇杆图像从中心投影转换为震慑投影。 通常需要遥感图像的有理多项式的系数、数字、高成模型、 dm 或者地面控制点等信息,矫正之后的图像称之为正摄影像。 我们来详细的学习一下几何经教症。几何经教症 主要有三个步骤,一、选取地面控制点。二、进行坐标转换。三、灰度值的空间重采样, 在基准数据和代矫正图像上选取相同的目标地物点,对,就是控制点。选取控制点是几何经矫正最关键的步骤, 如果控制点的选择有错误,那么无论后面怎么做都得不到正确的矫正结果。 选取控制点的基准数据或者说参考数据主要有三种来源,第一种是具有准确的地理信息的遥感图像,这也是最常用的 几何矫正参考数据。第二种是地形图,包括纸质的地形图和数字地形图等等。第三种是利用 gnss 等定位仪器实测得到的控制点。 选取控制点要注意几个原则,一、在图像上选取容易分辨的有明显特征的位置,比如十字路口、桥梁、河流、风岔口、机场的跑道、水库的大坝等等。 二、在特征变化大而且精度要求高的地区,要适当的多选择一些控制点,而在特征变化不明显的区域可以少选一些, 比如沙漠地区。三、尽可能满足选举控制点,因为结合经矫正的实质是基于经验统计方法做的矫正,那么样本也就是控制点, 他是否能很好的代表总体,对于矫正结果有很大的影响。 四、尽量不选择容易随着时间变化的点。比如草原上的河流、拐弯处、高山雪线等等, 在不同的时期,他们的位置很可能会发生变化,所以不合适作为控制点。除了这几个原则之外,还要注意在选取控制点 的过程中,去掉误差明显偏高的控制点。通常情况下,要保证控制点的总体误差在一个项元以内。 选取了足够多的控制点以后,就可以根据控制点数据进行坐标转换, 也就是找到一种数学模型,建立变换前的图像坐标和变换后图像坐标的对应关系。 坐标转换有两种方法,直接法和间接法。直接法通过原始图像计算出每个向源在输出图像中的坐标值。这种方法输出的向源值不变,但是向 向源坐标位置发生了变化,输出图像的向源分布不均匀,无法用规则举证表示,所以很少使用。而间接反了 是从输出的图像出发,计算其中的每个向源在原图像中的位置,然后根据原图像周围向源的值计算出这个位置新的向源值。他所得到的输出图像 是规则举证,便于处理,是常用的方法。间接法中计算的输出向源在原图像中的位置很可能不是整数,那么它的向源值要根据周围的向源值进行空间 从采样来计算。从采样的方法有三种,最零进法、双线性插直和立方卷机 最灵镜法,直接把距离目标位置最近的向远直作为输出向远的回度值。我们看一下这张示意图, x 一撇 y 一撇这个向源距离 x y 这个点最近,所以直接取 x y 点的向源值作为重采样的结果值。 这种方法简单方便,处理速度快,还能保持原相原直,但是 结果图像不够平滑,相邻相圆值差异比较大的地方可能会出现明显的锯齿状的这样的特点。 双线性插直把距离目标位置最近的四个向源进行双线性插直插直结果作为输出图像向源的灰度直。线性插直呢, 大家之前应该都学过,知道是什么意思,那么双线性插直的双字是什么意思呢?是二维的意思, 就是说在 x 方向和 y 方向都做线性差值。我们看一下这 张示意图来通过双线性插直计算 x 一撇 y 一撇这个相源值。 可以首先在 x 方向根据 x y 和 x 加一 y 这两个点 进行插值计算,计算出 x 一撇 y 这个点的值。根据 x y 加一和 x 加一 y 加一这两个点进行线性差值,计算出 x 一撇 y 加一这个点的值。 然后根据 x e 撇 y 和 x e 撇 y 加一这两个点,在 y 方向再做一次 线性差值,计算,得到 x 一撇 y 一撇的值。当然也可以先在 y 方向分别做两次线性差值,得到 x y 一撇 和 x 加一 y 一撇这两个点的直。再在 x 方向做一次线性差值,得到 x 一撇 y 一撇的直。结果是一样的, 和最零净化相比,双线性插直结果图像比较平滑,计算速度 又比立方卷机要快,实际工作中用的比较多。立方卷机以距离目标位置最近的十六个 值进行加权计算,作为输出图像象源的会度值。这种方法利用三次多项式来逼近理论上的最佳差之函数。新课函数 在 x 方向分别运用三次多项式进行四次插直运算,得到 x v 减一、 x v、 x v 加一和 x v 加二这四个点的值,然后在外方向 再一次的运用三次多项式进行差值运算,得到 xy 这个点的值。同样也可以先在 y 方向进行四次 插直,然后再在 x 方向进行插直,结果是一样的。和前两种重采样方法相比,立方卷机结果图像的平滑程度最高,计算量也最大。 最灵净法双线性插直,立方卷机依次能够产生更加平滑的图像,计算量也逐渐增加。 这三张图分别给出了三种重采样方法的结果,直观的揭示了不同的平滑程度。 当然平滑是优点,但是在某些情况下也是缺点。比如当遥感图像中有缺失值或 或者眼膜背景直的时候,在缺直向源或者背景向源临近的向源进行双线性插直,或者立方卷机就会把缺失直或者背景直带入插直计算, 给结果图像带来误差。这种情况下应该采用最邻净法。
25吉人天象 07:41查看AI文稿AI文稿
07:41查看AI文稿AI文稿大家好,本课程为大家详细介绍在 nv 下边进行土色正式校正的操作方法。首先我们来介绍一些背景知识,比如说为什么要进行正式校正, 因为在卫星飞行和拍摄过程中会存在一些几何误差,而这些误差主要是由以下原因引起的,比如说比利时变化传感器的姿态方位, 以及说传感器的一个系统误差,而正式校正可以消除这些误差。第一个原因就是比例尺的变化,是在所有的一个深影像中都会发生的, 像我们现在图中两个房屋的一个大小,他们的宽度都是一样的,都是八米,但是我们人眼的这个位置去看就是不一样的,但因为距离的不同,导致了比例尺的一个变化,比如说比例尺分 分别是一比四百和一比一百三十三,这就是一个非常常见的现象,而且在所有的摄影图像里都会发生,这是不可避免的,而且各个点的比例尺都是不一样的。另外因为遥感图像都是从上方往下方拍摄的,在图像的千指方向 也会有同样的一个情况,比如说同样的房屋宽度是八米呃,但是由于距离的不同,因为这个房屋在山顶,这个房屋在山脚下,也会导致比例尺的一个不同。另外一种呢, 是传感器的姿态和方位导致的误差,在这里呢,我们有三个示意图,首先一二三这三个圆锥,他表示的就是传感器的姿态或方位一号,他是拍摄是千指方向拍摄的,就是我们所谓的这个下面的这个中间的这个楼层是位于新下点,而他拍摄 效果是左上角是个一图,可以看一下它的效果。二号可以看到有一些偏差,而且是倾斜拍摄,三号 的拍摄效果单号的倾斜角度更大,这些都是传感器的姿态和方位引起的误差,那么这些误差就需要我们提供传感器的姿态和方位,把它的位置和方位这些内方位引元素进行构建来消除误差。第三个 就是传感器它本身的系统误差,比如说我们推扫式的扫描中心,它沿着一条线进行扫描,但是,但是虽然线上的点它是位于星下点,它的分辨率也是最高的, 位于扫描线两侧,与扫描线越距离越来越远,他的分辨率也就越来越低。而多项式的纠正只能针对分辨率较低的,比如说二十米或者更低一点的。而对于我们高 分辨率影像,我们一般是要用到严格的物理模型,比如说要用到 d m 原数进或者 r p c, 就是游历函数多项式进行图像的正式纠正,下面介绍一下它的使用条件。我们刚才也提到了,对于不同的分辨率需要用到不同的算法, 而对于分辨率较高,比如说小于或者高于十五米或者更高分辨率的图像呢,而且具有 r p c 文件或者参数的话呢,可以用正设校正进行几何校正,这样可以达到更高的一个精度要求。但是对于中等分辨率,比如说二十米的, 如果影像覆盖山区,而且地形起步比较大,我们可以用震慑纠正。但是对于中低分辨率的,比如说三十米或者更低分辨率的,我们一般不进行震慑纠正,除非他的地形起步非常大。下面介绍一些常见的传感器卫星的一些震慑 矫正参数,比如说我们常用常见的快鸟 wordwill 这些他们都是用的 rpc 的文件,然后 sport 系列的包括葡萄牙的数据,他们都是这种 putchbroom sensor, 还提供心力参数文件,这个 d i m 文件,然后国产数据包括资源一号,资源三号 和高分一号,这些也都是采用的 r p c 文件,而且 n v 对于国产卫星的支持,或者是他 r p c 文件信息的识别是非常好,我们可以去参考。好,下面我们来进行一个练习,那么练习用到的数据 是我们快鸟的一个多光谱的数据,它覆盖的位置呢是位于美国亚利桑那州菲尼克斯,也叫凤凰城,这个也是 nv 原厂商他公司的一个总部的位置。然 然后内容的话呢就是正式校正啊,因为在 nv 五点一和 nv 克拉斯克这两个里面做正式校正的工具呢,它是有一些偏差,有些区别的,所以我们呢就是这两个都进行一下演示。下面我们启动 nv, 这里先用到的是 nv 五点一,先打开我们的一个 nv 五点一的软件, 然后下面我们第一步呢,先打开我们的数据 file open a, 然后打开这个快鸟,然后点击一下我们的一个素材,点击这个 t i l 文件,将它打开做一下拉伸, 这就是我们代交政的影像,我们可以看一下他的一个数据情况,这里我们可以点击 data manager, 然后看在这里看一下他的一个整体的数据信息,这里面就有 r、 p、 c, 包括他的向源大小,还有他的一个波长的一个范围,支持他识别 pc 的一个信息。另外可以在这里右键 will medita, 就是查看它的一个原数据,这里有一些 mapping for 的一些信息,这里也有一些 rpc for 的这些信息,可以在这里查看到。然后有了 rpc 信息之后,我们现在就可以进行震慑校正了, 我们用的工具就在我们的工具箱里,位于这个文件夹下面,在几何纠正的文件夹下面,然后我们 nv 五点一里,所有和几何纠正有关的都在这个文件夹里,然后这个的话是在这个文件夹里,这里有构建 rpc, 然后 rpc 正式矫正的流程化工具, 然后是拓展模块,然后我们点击第二个,因为现在我们只有一个数据啊,所以它自动选择了我们的快鸟数据,所以我们选择它,然后这里的一个数据呢是我们 nv 自带的一个数据。我们 nv 五点一开始的话呢, nv 里面是自带了很多的一个数据,包括全球的一个 dm 数据,然后这个是二零一零年的全球的一个范围,然后它的空间分辨率比较低,一般情况下不到万不得已我们是不需要用它的,所以我们提供了一个分辨率更高一点的 来打开我们净度比较高的那一个,打开它,我们用这个来进行操作流程化工具的好处呢,就是这样,我们把它选择好之后,就可以进行下一步,如果我们不小心选错了,我们也可以返回再重新选,这个时候我们点击下一步, 然后他就到了这样的一个面板,然后这个面板呢我们输入的参数也是比较多的,选项卡呢,他也有四个选项卡啊,现在我们来一一介绍一下。首先 第一个选项卡就是 gcps 需要输入控制点的信息,比如说我们在实地测的一些控制点,一般控制点是用实地测量或者是从其他的参考数据里面获取,然后这里我们把应眼图打开,查看它的一个大概的位置,比如说在这里我在现场 或者这个点的位置,我们测量了一下他的地理信息或者地理坐标,然后在这里我们选中就是鼠标左键单击就可以添加一个控制点, 然后控制点列表它就有一个 g c p 一,它是这样命名的,再点一个它就是 g c p 二,右边呢它是可以修改的,包括它的一个经纬度信息。假如说我们这边呢, 测量他是一一二零七,然后这里比方说是三三 点四一,我们就可以这样去进行一个输入,当然如果有高层信息可以填进去,如果没有的话呢,他会用到 dm 的一个信息。
 09:22查看AI文稿AI文稿
09:22查看AI文稿AI文稿选择我们的高光库反射率数据,点击 ok 就打开了我们这样的一个界面, 那在这样的一个界面中呢,我们可以去选择三种植被指数参与分析。首先呢是选择我们的绿度指数,优先选择窄度, 优先选择窄带绿度指数,还可以设置我们的一个最小绿度指数,这里我们设置零点二,这里我们设置成零点二,那么低于这个值的区域呢,他就不参与计算,会被研磨掉。下面这个呢就是选择夜色素指数,我们保持默认就好了。 然后下面是要选择灌层水分含量指数或光利用率指数,我们也是保持默认就好了。最后呢就是给他一个输出的文件铃木 健康分期,然后点击他就在分析了,嗯,结果呢是以 nv 分类结果的格式输出的,我们可以将它打开, 可以看到就是这样的一个植被分类的结果,那他根据森林的一个健康程度呢,一共是分了九类,我们可以在这里去勾选不同的一个,去查看不同分级的一个结果, 那么数字越大呢,就代表我们的铃木越健康,你可以看一下就是我们这个红色区 绿的我们把它关掉,这样看着会更明显一点,就是我们红色区域的这部分铃木他是最健康的。好,下面我们来看下一个工具,农作物斜坡,那下面我们来看下一个工具,农作物斜坡,使用农作物斜坡工具呢,就能够创建农作物斜坡的一个空间分布, 因为干旱的农作物呢是不能有效的利用蛋和光能的表现为胁迫,较高,而健康生长的作物表现为较低的胁迫,那我们就能够从胁迫途中去判断适合农作物生长的区域。 这个工具呢是可以用在精确农业分析,那我们农作物协作工具是用绿度、光利用绿灌成氮含量,叶绿素灌成水分含量这几种只被指数来进行分析的。 那接下来呢,我们就实际的操作一下,还是在这个文件夹下。第一个工具就是我们的农作物胁迫工具,我们双击双击打开后选择我们的高光铺发射率数据,点击 ok 就打开了我们这样的一个面板,那在这个面板里呢,是可以选择三种植被指数参与分析的。首先是选择绿度,那我们还合上一个一样,我们优先选择窄带绿度指数,这里也给他设置成零点二。然后第二个呢就是灌成水 和惯成蛋,我们这里呢按照默认就好了。最后一个是光利用率或叶绿素指数,也是默认,然后选择我们的一个输出文件,当然这些所有的一个设置的话呢,你都可以根据你具体需要做的一 分析来进行相应的修改,我们这里呢就都按照默认了,那我们这里就是农作物胁迫,我们打开,然后点击 ok, 他就输出了。 同样的我们这个文件它也是以 n v 分类结果的一个格式输出的,我们这里点击 open, 将我们的这个农作物胁迫的这个文件打开 好,我们就可以看到他也是分了九类,那么数字越高呢,就说明他的斜坡性越高,他的一个植物长势就会越低 啊,我们可以看到这个红色区域的话,就是不太适合植物生长的,我们的黑色区域黑色、 灰色、蓝色、浅蓝色这一片区域的话都是比较适合植被生长的,然后我们这个绿色浅绿色也还好。接下来我们介绍我们的第三个工具,易燃性分不分析工具。 那主要呢就是创建某一区域植被易燃性的一个空间分布图,主要是运用在森林规划,也可以用它来分析成交混合区的一个火灾风险。通常我们这个高易燃区,它都是干燥或者干旱状态下的植被构成的,它的含水含量非常少,那我们就可以通过 绿度、灌成水分含量、干旱或碳衰竭这三个植被指数来判断我们的一个易燃性。我们的工具还是在这个文件夹下选择第二个选择我们的文件,点击, ok, 这里呢我们可 可以看到他还是三类植被指数。首先我们选择绿度,这里选择窄带,绿度指数 最小值零点二,然后这里呢他就是灌成水分含量之数,我们默认这里的话呢是干旱和碳衰竭,我们默认就可以了啊,如果你这里有一个对应的选项,你需要去修改的话,直接修改就可以了。这里我们设置一下我们输出的一个位置,给他命名易燃性分析。 好,我们点击 ok, 他这样就慢慢的输出了,同样的他也是以分类结果的方式输出,我们打开来看一下, 他是分了九类,我们的数字越高,他的一个依然性就越高,这里看一下 就是在这些区域它的一个依然性都是比较高的,那下一个工具呢?就是植被抑制工具,植被抑制工具呢主要是利用影像的红波段和近红外波段,从高光谱和多光谱影像中移除或减少植被光谱信息, 对影像进行植被变换,那我们经过处理后的影像就能更好的或者地质以及城市地物解议的结果,我们可以用植被意志的结果来做定性的分析,他一般呢就是用在地图地质制图上, 那我们打开我们的一个数据,我们这个的话就不用我们现在这个数据了,我们重新打开一个新的数据, 我们重新打开的数据呢是我们软件自带的一个数据,在我们的目录下,在我们的安装那我们会用到我们 nv 自带的一个数据,在我们的安装目录下, 在 n v 五点一,然后 classic data, 然后选择我们的一个数据 打开 好。打开后呢我们来看一下职位移植工具,是在我们的光谱下,是在我们的波普大文件夹下,在我们的这个小文件夹下最后一个,然后双击 进入到这个面板,之后我们选择好我们的数据,点击 ok, 设置我们的一个输出路径即可, 这里我们还是对它进行一个命名, 我点击 ok, 他就进行输出了, 在我们的主面板下呢,我们去给他进行一个两个面板的这样的一个显示, 然后我们两个数据的话呢,分别都用 我们的假彩色去进行一个, 那么就能看到很明显的一个对比,这样我们植被被一直处理后,基本上就没有植被的一个光伏信息了。那么以上呢就是我们植被分析的 工具的一些讲解,那么本节课主要是了解了植被波普的一个特征,学习了指数的一个计算, 就是我们的一个纸杯计算器去进行计算,然后学习了四种纸杯分析工具的一个使用,我们可以根据我们需要达成的一个效果来选择对应的一个纸杯分析工具去进行分析, 整体的话是偏流程化的一个工具,也是比较简单的,大家都可以去学一学。那我们本节课就到这里了,大家再见。
 10:20查看AI文稿AI文稿
10:20查看AI文稿AI文稿这节我们一起来学习遥感图像计算机分类,我们前面也提到过遥感图像简易呢,主要包括两个途径,一个是人工牧师简易,第二个呢是计算机分类处理, 两种方法呢,各有利弊,但是呢,由于人工目视解疑啊,真的很浪费人的时间和精力, 目前的发展趋势呢,以第二种,也就是既然季节一样为主,虽然呢面临很多困难,但是他在在不断进步。这一节我们一起来学习洋房分类, 这里包括四个部分,一个呢是分类基本原理,第二个是腰杆图像非监督分类,第三个是腰杆图案的监督分类以及 分裂进度评价。首先来学习分裂基本原理和遥感图像非精度分裂这两个部分。 首先我们来了解遥感图像分类的基本概念,什么是遥感图像分类呢?也就是根据遥感图像相缘的光谱信息或者是空间信息特征啊,他们的差异,将图案中所有相缘按照他性质分为若干类别的过程。 那么也就是说呢,它输入的是一幅摇杆图像,输出的是分类结果,专地图摇杆图像中的每个项目呢,都分配一个类别。 接下来我们来学习遥感图像降级分类基本原理。降级分类呢,其实啊,就是遥感数据到地理 信息的过程,降级分类属于第五信息提取的范畴,第五类型信息呢,也属于第五信息的一种。书的图像属于图像空间,将每个波端或者是分类特征作为变量,这样可以构成数学特征空间。 在素有特征空间里面的每个点,以我们图像中的每个相眼呢,是一一对应的 根据物以类聚的特点,相同的地物呢,它的影像特点相似,因此啊,在它的特点空间中也表现为记忆在一起形成点击。 最后,我们通过判别函数将每个点击呢进行分割,并赋予类比属性,并将类比属性啊重新转换。 但是图像空间形成信息空间并获得最终的分类专题图。 不同的地物在多个波段图像上亮度呈现规律也不相同,这也构成了我们在图像上难以区分不同地物的物理依据。 第五点,不同波段图样中亮度的观测量将构成一个多维的随机项链 x, 那么我们称它为光谱特征项链。 光补特征空间的维度与光补特征项量维度是一致的。那么如何将光补特征空间里的据点根据类型的差异进行分割呢?这里面的核心就是判别函数和判别准则。在了解 攀比函数和攀比准则概念之前呐,我们首先要了解相眼相似度,他的这个方法,那么常用的是距离和相关系数来衡量遥感图像相缘的相似度。 如果是采用距离衡量相似度呢,那么距离越小代表相似度越大。如果是采用相关系数来衡量呢,那么相关系数越大,那么他相关程度也就越大,其相似度也就越大。 然后我们再来学习判别函数。判别函数啊,是在各个类别的判别区域确定后某个特点使量属于哪个类别,可以用一些函数来表示和鉴别,这些函数呢,就称为判别函数。 判密准则是确定某项元属于某类所需的判别依据,比如已知 ab 距离啊,大于 aca, 通过什么依据和标准之判别,他属于 b 呢?还是属于 c 类呢? 接下来,我们以距离判别函数判别规则该例判别函数和贝尔斯判别规则为例,进一步进行学习距离判别函数与判别规则,他的基本思想是,设法计算位置使量 x 到有关类比集权之间的距离, 哪类距离最近,这该位置死量就属于哪一类。距离判别规则是按最小距离判别的原则进行的,其判别规则如下,若对于所有的比较类别,这个阶,它属于一到 m 这个 个阶啊,和 a 呢,它是两个不同的类别。那么现在有一个 x, 这个使量分别计算他到 j 和到 a 的距离,那就分别叫做 da 和 dj。 如果低矮这个距离小于低阶,那么 x 呢,就判为低矮类。那么长的距离判别函数呢,有马式距离、欧式距离和继承距离 概率判别函数何必也是判别规则?它的基本思想是,把某特种使量 x 落入某利集群 w i 的条件概率 pw x 当成分类判别函数,把 x 落入某集权的条件概率最大的类为 x 的类别。 这种判别规则就是被也是判别规则。被也是判别规则呢,它是以错分概率或者风险最小为准则的判别规则。错分概率呢,就是类别判别分界两侧作出不正确判别的概率之和。 我们对分类方法啊,如果从人工干预程度的不同,我们可以把它分为监督分类和非监督分类这两大类。 腰杆图像非进度分类呢,它是指啊,在没有心眼类别,那比如叫训练场作为样本的条件下, 也就是说呢,事先不知道类别特征,我们主要根据相言之间相思度的大小进行归类合并。它的分类结果呢,是对不同类别达到了区分,但不能够 确定类比的属性。其类比的属性呢,主要是通过分类结束后不时判读或者实地调查来进一步确定的。非进度分类呢,我们也称它是剧烈分析。 接下来我们来了解一下常见的几种非监督分类方法,主要包括 k 君子方法,还有就是 is 都对的方法,也就找迭代自主的数据分析技术。 首先我们看到 k 君子方法, k 生方法啊,他这个方法的九角八和几个步骤。首先呢,选起 m 个中心, 这个 m 格中心呢,可以是任意的,也可以是呢这个传统里面的前面 k 格相原的灰度值。 第二步,我们按照距离中心的远近,对所有带分向远进行分类。三、根据以上计算结果,重新计算调整后的类别中心。 四、每一类的向远变化数少于选择的向远,一直或已经达到了迭代的最多次数,就结束计算。 现在我们举一个具体的例子啊,来解释一下 k 军事方法的这个算法原理。现在要将十个项元分成两类,即这里的 k 啊等于。二。第一步, 任意从中选择两个种子,即红色的两个点。第二步,分别计算十个带分类的点,通红色种子点的距离,以最小距离整责进行判别,从而得到如有上图的初步分裂结果。第三步, 根据以上初步分离结果,求取美丽的几何中心,即右上图中红点,就是以新的几何中心作为种子,对十个点重新计算距离,同样以最小距离准则进行判别,得到新的判别结果,其结果如右下图所示。 按上述方法,叠带指导分裂结果中相应变化比例小,预定一直会达到最大叠带次数则停止叠带,本地中则没变化。如左下图与右下图分裂结果相同,这颗停止叠带。 这时 nv 软件中啊,可以君子方法操作界面,这个界面里面主要包括三个参数,一个是类别数 k, 第二个是变化预值,第三个呢,是迭代次数。 接下来我们了解一下 isod 的方法,它是在 k 菌子算法的基础上,加入了试探性的步骤冷吸取中间结果的经验。在迭代的过程当中呢,可以进行类别的分离和合并,也就是说呢,具有自主性。 这个是峨眉中的 isod 的方法操作界面,除了可以正常方法中的三个参数外,另外呢,还增加了四个不同的参数,一、美类的最小样本数。二、内类的分散程度参数,比如说类的标准差。 三、内间距离参数。通常呢,我们用最小距离。四、每次允许合并的类的对数。此外呢,由于类别的数啊在动 动态变化,因此内壁素啊是有个给出一个范围,而不是一个定值。
27吉人天象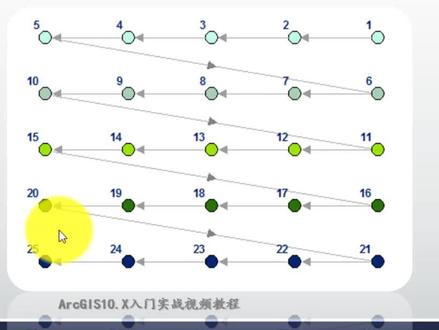 04:46查看AI文稿AI文稿
04:46查看AI文稿AI文稿直接来看一下我们今天要介绍的内容,我们直接来到阿克玛把这个软件界面我们来做个介绍哈,那么这是一个呃,中地图层,中地图层哈,那如果说我们一般要对他进行一个图帮排序,比如说就是这样排啊,从左到右,从上到下这样来排序是吧?哈, 但是一般来说呢,我们是没有排的哈,就说一般的情况就是说,呃,比如说这样的一个数据是吧?那么他呢?是没有排的啊,就是比他这个 fid, 我们可以把这个 fid 给它标注出来啊,来看看,给大家看一下, 我们用 fid 做一个排序啊,你看看他其实没有什么排序一个规律是吧?这边这边什么三十几、二十几的,上面又是都不没有规律是吧?那我们就要从根从上到下来排,然后我们就给大家做一个介绍啊,怎么来操作?那么我们今天介绍的 工具呢?它就是在这个 august toolbox 下面一个数据管理工具,有个常规,然后我们来排序工具哈,把它打开,我们做个介绍哈,那么对于这个工具来说呢,你把数据输进去,它会生成一个新的一个数据哈,好,那么它的工具的一个作用就是根据排序这段中 就根据一个字段或多个字段来进行一个排序啊,就是那么就会生成一个新的一个数据,那么他那个排列呢?就反映在我们刚才的字段 f、 i、 d 当中啊,那么他不一定只对空间排,也可以对字段排啊,比如说我对这个数据来说是吧? 我这边有个面积啊,有个面积,那我现在想要面积重排啊,啊?想让面积重排,就是面积小的排在前面是吧?啊?面积小的排在前面,那怎么来操作呢?那更简单了哈,我只要选中这个面 机制段。好,那我选择保保持这个升序的制段不变啊,保持升序不变,那你当然你可以升为降序啊,是吧? ok, 那么你看看,我选择这个面积段,上面空间排气方法是亮不起来的哈,好了,我现在把它确定一下,我又生成了一个新的一个数据, 是那个新的一个数据。好,我这个时候呢,我们来看一下我的 f i d, 你可以看一下哈,它生成一个新的一个 f i d, 然后你看看我这个面积 是不是,你看它面积最小的排在了第一位,九百多平方啊,最大的往后排,一直往前排啊,就是这样的一个情况哈。好,那我们现在又提出了个需求,就是说我现在要对图邦 从这边从左到右,从上往下排,就是空间的排序方法啊,那么就需要用到了排序工具当中, 我们选择中地,然后我们这个字段要选择这个 shift 段啊,我选择 shift 的时候呢,他就是按空间来排的,那么话我们依然声序不变,那你可以看到我选择 shift 字段的时候呢,他在下面的空间排序方法他就会亮起来,我们这个时候呢,就可以选择下面好多种啊,那么他默认的就是 ur, 就是从这个右上角啊, 他们美国人可能喜欢这边哈,我们现在可能就喜欢从这个左上角开始排。好,那么你就可以选择这个 u l 的方法。 up left up left, 英文缩写哈,从左上角开始排序哈,那么最后一种呢?还有一种叫皮亚诺的曲线排发。皮亚诺曲线啊,那我们这边主要是这种方式哈,你也可以去参考帮助 看它的原理啊,就要进行介绍啊,这个是我们的四种空间排序,就是 u l u r l l, 就从四个角来排,是吧? 那么这个比亚诺曲线的一个原理图这样子拍啊,大家知道一下啊,有兴趣的可以去研究一下这个比亚诺曲线啊。好了,那么我们现在直接对他进行一个确定,直接定一个确定,他就生成一个新的数据啊,我们把这个数据关掉, 这个时候呢,我们重新对我们的 f i d 进行一个标注,我们先来看一下下,你就会看到, 是吧?我是不是一二,因为他是根据他的左上角一个坐标来排,那你这个一刚好是是最上面,所以呢一二好,然后呢?三四五三四是吧?六七八九这样子排,看到没?基本上都是这样的排列, 然后就可以看这样的牌,是不是那幺三二幺三七幺四零这样拍拍拍啊?因为他并不是说完全的玩这样的牌,他那个方法是根据他那个 几何中心,或者说根据他的这这样的一个左上角的一个坐标,根据他最外接举行左上角的一个坐标来进行排的。好,大家注意一下。好,那关于他这个原理呢?可以去去就是这样子的啊,你看看,那就排到最后就是排到这个两百了啊,排到这个两百 啊,来注意一下我们今天介绍的空间排序啊。好,那么关于 gs 技巧一百一,第十二讲空间排序,我们就介绍到这边,欢迎大家学习我们的其他课程啊,我们已经非常推出了非常多的一个实战教程,今天就到这里再会。
136GIS思维 07:51查看AI文稿AI文稿
07:51查看AI文稿AI文稿这个呢,就是关于 models 的一个集合校正的结果,那下面呢,我们来看一下第二个练习阿萨数据的一个集合校正。首先呢,我们把这些数据啊全部清除。 一步,打开数据文件,几乎是同样的步骤,在 vives 里寻找相对应的一个传感器类型 elsa, 然后点击打开, 在我们的数据中找到二阿萨芬芳的一个位置, 选中要打开的文件, 我们就将数据打开。第二步呢,选择校正的模型,在 two box 工具箱中。呃,几何校正,通过传感器,通过传感器进行几何校正。然后我们选择阿萨, 选择我们要矫正的文件,点击 ok, 打开,进入到进行投影设置的一个面板。在这一步呢,我们要设置输出的参数,我们选择这个,然后在底下的这里选择 no, 然后单击 ok, 那么 nv 呢,自动计算了一些参数,在这里呢,我们要进行一下修改,也就是说关于他的这个配准的方法,我们选择重采样的时候选择最高级别的,这样的结果呢,更加的精确。然后 我们选择它的输出路径以及文件名 啊嘶, 然后单击 ok, 他就开始进行集合校正。 嗯,这样呢,我们就得到了几何矫正的一个结果。嗯,那么最后一步呢,我们可以对几何矫正的结果进行查看和验证。我们在 two boss 工具栏中打开 bear spare, google air sprage, 这样呢,可以利用流程化的工具将校准结果叠加到 google air 上进行显示。 嗯,然后因为我们的电脑呢,没有就是可以打开 google airs 的一个工具啊,所以说我们没有办法 去查看,但是如果大家呃有 google airs 的这样的一个软件呢,可以看到我们的一个结果是和 google airs 中的底图呢基本吻合的。 接下来是第三个练习,是基于 g l t 文件的国产卫星的几何教程方法。我们首先第一步 打开数据,在这里呢,我们用的是国产数据 vc 风云三号的一个 vc 影像,然后它的影像的一个后缀呢是 h e 五,我们点击 进入到 hdf 五的数据选择的一个面板,嗯,可以看到这样的一个界面,文件中呢,包含了非常多的一个信息, 我们选择一个有用信息,呃,比如说表格反射率,选中这个信息,然后点击中间的这个按钮,将影像信息下载到右边的这个信息栏中,然后呢单击右下角的这个打开,将影像打开, 然后同样的方法, 然后同样的方法,我们来打开它的几何, 我们来打开它的几何信息机,几何信息和位置信息,我们打开, 那么在数据管理器中呢,我们可以看到同时打开的它,它的文件呢?同时打开的数据集呢,会形成一个多波段的一个数据文件。然后第二步呢, 就是生成 g r t 文件,也就是说生成地理查找表文件,那么在 two box 工具箱中,几何校正,新建 g r t 文件。 build g r t 双击打开,在弹出的对话框中, input x, 我们选择的是 located 信息文件,点击 ok, 而在 input y 这个选项中呢,我们选择的是 plotted 文件, 然后进入到投影系的选择的对话框中,在这里呢,我们都选择这个, 然后选择 ok, 这是建立地理查找表的参数的设置,那么我们的校园大小呢?是默认,但他的一个旋转角度呢?我们设置为零,然后将地理查找表进行保存。 终于有你了, 点击 ok, 好在生成了 g r t 文件之后呢?第三步,我们要利用 g r t。 文件来进行几何校正。在 two box 工具栏里几何校正,然后通过 g r t。 文件进行几何校正。 在弹出的电话框中 input d 查找表的文件,我们刚才我们点击我们刚才设置这个 d d 查找表文件,点击 ok。 在输入影像数据这个里面,我们选择 该矫正的影像,我们同样可以通过右边的具体信息来查看到底是要进行哪个文件,点击 ok, 在这里呢选择输出路径和文件名, 点击 ok。 这样呢就完成了基于 g l t 文件的一个集合矫正。那么最后一步,我们可以同样对集合矫正的结果进行浏览验证,和刚才的操作都是一样的,一样是和 google airs 进行对比。那么我们 这一节课了解了低分辨率微型影像矫正方法,而且学习了 modest, nv set 等中低分辨率数据的几何校正, 学习了基于 g l t 的一个几何校正方法。以上就是本节课的主要内容,谢谢大家。
 12:37查看AI文稿AI文稿
12:37查看AI文稿AI文稿大家好,欢迎收听本节的内容,图像融合,在这节中呢,将向大家介绍简单的图像融合知识,以及在 nv 中如何进行具体的图像融合操作。 图像融合实际上是图像进行重采样的过程,它是利用遥感的图像处理技术,将低分辨率的多光谱影像和高分辨率的单波段影像进行重采样, 从而生成既具有高分辨率又具有多光谱特征的这样的一个摇杆图像处理的一个过程。图像融合的关键呢,是融合前两幅图像的精确配准以及处理过程中融合方法的选, 也就是说,只有将两副融合图像进行精确的配准,才可能得到满意的结果。而对于融合方法的选择,则要取决于被融合图像的特征以及融合的目的。 在 n v 中呢,也为大家提供了一些主流的融合方法。然后我们 g s 融合法可以满足绝大部分图像的一个融合。在这里推荐使用, 因为它能够保持融合前后图像波普信息的一致性,是一种高保真的 图像融合方法。下面我们介绍两个例子,在 nv 中如何实现图像融合。针对不同传感器的影像图像融合,以及相同传感器器不同分辨率的图像 融合。不同传感器的图像融合我们使用的是 sport 数据和 lamps and t m 数据,而相同传感器图像融合我们使用的是 crack board 全色和多光谱图像。利用工具箱中的图像融合的工具, 我们来进行 cs 图像融合。接下来我们打开 nv, 在 nv 的界面中,我们首先点击 feel open 来打开我们的一个数据。 第一个练习是我们不同传感器的影像的图像融合。这里我们用的是 t m 数据和 sport 数据。我们选中这两幅影像,点击打开, 对影像进行一个拉伸显示。 首先来观察一下这两幅影像的特征, 一个是较低分辨率的多光谱 pm 三十米以下,我们可以选中这个图像。 点击右键 we will make data 来查看它的分辨率。在 map in four 中, 我们可以看到它的分辨率是三十米,而对于单波段的影像,我们同样右键选中 map 音符,我们可以看到它的分辨率是十米,相 对较高。也可以呢通过右上角的这个查看窗口来进行两幅对图像的一个对比。 可以看到融合前的图像为一幅 t m 三十米的较低分辨率的多光谱影像和 support 十米的较高分辨率的单波段影像。 好,关闭这个小窗口。下一步我们进行图像的一个融合。在 two box 工具栏中选择图像融合的这个选项。我们可以看到这里有一些图像融合的方法。 选择 gs 图像融合方法,双击打开,选择融合影像的面板。首先要选择的是 是低分辨率的多光谱影像,我们选中 tm 三十米的图像。在这里呢,我要进行融合的图像已经被打开了,如果没有,我们可以在底下 open feel, 选择我们要进行打开的影像。 好选择我们要进行融合的影像,或者说我们已经将影像打开了,但又在刚刚又关闭了。现在呢,我们需要打开刚才关闭的影像,可以在 open recent 这个选项夹来实现。最左边这个带问号的是我们的一个帮助文件, 我个人认为 nv 中的这个帮助还是非常有用的,如果大家感兴趣的话,可以研究一下 help 里的一个内容。好在第一步中呢,选中 低分辨率多光谱影像之后,我们可以看到底下显示他有六个波段,然后我们点击 ok 进行下一步。下一步呢是要选择高分辨率的单波段影像, 我们选中可以看到他只有一个波段的一个信息,点击 ok, 点击 ok 之后呢,我们就进入了图像融合参数的设置面板。 由于我们进行的是不同传感器的图像进行图像融合,所以在传感器这一栏我们选择 on no 未知。在虫采样这一栏,我们选择最高级的三次选机。虫采样的级别越高呢,它需要进行的计算也就越长,效果也就越好。 在这里我们一般都是选用最高级别的重采样方法 output, 选择输出的文件格式,我们来选择 nv 的标准格式进行输出。最后呢选择输出的路径以及文件名。 在 nv 流程化的操作工具中,他几乎每一步都有一个这样的 herp 来供大家进行参考。在这里呢,我来选择输出文件存放的位置以及他的命名, 最后点击打开。最后呢就可以点击 ok 来完成图像处理的整个流程, 可以看到他处理的一个进度条,在右下角,最终我们得到融合后的一个 摇杆影像,我们也是给他显示拉伸一下,这是融合之后的一个摇杆影像,可以看到他已经具有了多光谱的影像特征。 选中这个影像,单击右键查看它的一个空间分辨率 map in for 可以看到它的空间分辨率已经提高到十米了。 除此之外呢,我们也可以打开右上角的这个小窗口, 将融合之后的影像与之前的 tm 三十米多光屏影像进行一个对比,可以看到融合之后的影像与融合之前的影像相比而言,分辨率大大提 高了。也可以呢,将融合之前的影像和当波段的图像去进行一个对比, 可以看到虽然具有相同的分辨率,但是融合之后也具有了多光谱的一个特性,所以说融合效果还是不错的。那这个小练习呢,是针对不同传感器的影像进行图像融合的一个操作。 那接下来我们学习相同传感器不同分辨率的影像进行图像融合的一个操作。首先我们要关闭我们现在所有的一个数据, 然后打开我们下一个数据。 下一个数据呢,我们使用的是快鸟的一个相同传感器的不同分辨率的两张影像。打开影像文件,我们进行一个拉伸显示, 第一步还是要观察一下这两副影像选择。打开小窗口, 可以看到 这幅单波段的影像具有较高的分辨率,而多光谱的影像 具有较低的分辨率。也可以点击选中图像,点击右键 will meet data 来。在 map map in four 里,我们可以看到这个全侧影像,它是零点七米, 而我们多光谱影像它的分辨率是二点八米。这样我们在 two box 工具箱中选择我们 gs 图像融合的方法, 双击进入这个工作流中。首先是选择图像融合的文件,第一张图片为低低分辨率的多光谱影像, 我们点击 ok 进入下一步,选择高分辨率的全色影像,然后点击 ok 进入到我们图像融合参数的选择,由于这个练习呢,我们是针对相同传感器不同分辨率的影像 进行图像融合,因此在传感器的菜单下面,我们有一个下拉列表,这个下拉列表中罗列了基本上现在主流常用的各种传感器,这里我们使用的数据是 crick board, 所以我们就选择 crick board 传感器, 然后重采样方法,我们选择三次卷机输出文件的格式,也选择我们 nv 的一个默认的标准格式。最后一步,输出融合图像的位置和文件名, 我们来给他起名,点击,打开最后一步,点击 ok, 然后在我们右下角就有这样的一个 进度条, 最终我们得到我们图像融合的一个结果。先关闭这个小窗口,我们来进行一下图像的一个拉伸, 可以看到融合效果还是不错的,首先他的分辨率更高了,然后我们打开我们刚刚的这个小窗口, 将融合的影像和之前的这个全色影像对比,可以看到他有了多光谱的一个特征, 然后我们打在打开之后,可以看到他的一个分辨率明显的是比我们的一个多光谱 像是提升了很多。然后我们点击图片的右键, 我们可以在 mapping four 里看到它的一个分辨率也变成了零点七米。以上就是图像融合在 nv 中的具体操作。 总结一下,我们利用 nv 中图像融合的工具 gs 图像融合的方法进行两个小练习,一个练习呢是针对于不同传感器的图像进行图像融合的方法的练习。一个练习呢,是针对于相同传感器、不同分辨率图像进行图像融合的一个过程。 通过这两个练习呢,我们基本掌握了图像融合的方法和流程,也学习了 gs 融合的一个方法,并且对不同传感器或者相同传感器的图像融合有了基本的一个认识。那我们本节课的内容就到这里,谢谢大家。








