git如何清理未跟踪文件

粉丝4.3万获赞10.3万
相关视频
 12:08查看AI文稿AI文稿
12:08查看AI文稿AI文稿大家好,今天给大家介绍下如何在 c n b 中使用 gitlives 实现大文件存储, 也就是模型持久化存储的问题。整个内容按照仓库的复刻,模型的下载和 gitlives 的 使用这几个方面展开。首先复刻仓库 哦,复刻完毕,我们现在启动开发环境 哦。开发环境进入以后, 我们先确认一下,现在的数据存储目录中没有任何模型存在。我们使用势力的下载文件, 下载 ge 一 枚值的这几个模型,把这个 主模型文本 v e 现在开始下载模型文件。 第一个是主模型正在下载, 我们耐心的等待一下模型下载完成, 下载完毕,现在是检验模型的完整性。模型下载完毕, 文本编码器下载完毕。好,三个模型全部下载完毕,一共用时是两分钟二十 gb。 我 们现在看一下模型的存储目录。 主模型文本编码器 v e 下面开始进入到 getlives 的 设置。 首先第一步是确认系统是否支持 delete 的 大文件存储 输入命令,我们在 doc file 当中已经安装了 delete。 下一步是执行 delete 的 出使化, 因为在原始的这个仓库当中已经执行过 gitleafs 的 初步化,所以这里会提示你原始仓库已经执行过 gitleafs 的 初步化。 初步化完成后,下一步是创建一个文件,文件名是 get attribute。 回车打开这个文件,输入需要跟踪的大文件的相关信息,大家可以根据自己的需要, 一般如果只使用这个 cptencil 格式的话,就可以只选择它,其他可以省略好。编辑完毕后,我们需要 提交这个新建的文件给 get 仓库,然后添加提交 显示已经提交,然后复制。 这个操作完成以后,下面是需要检查 delete 的 规则是否生效,我们可以输入跟踪命令检查一下, 没有任何问题,对这四个文件,四种类型的文件进行跟踪。 好,下一步就到了最关键的步骤了,我们看一下远端的仓库,远端的仓库现在 my data 目录下是没有模型目录的,现在我们在 my data 目录下的默带儿目录下已经下载了三个文件,下面需要把这三个文件提交到远端仓库。 首先复制文件的路径,然后输入命令地址 add, 这里需要加一个撇 f, 表示强制性的添加,因为我们已经在我们的 get 里边省略掉了这些大模型,省略掉了这个 model 思路 被撤,因为模型比较大,所以这这个提交会需要一定时间,我们耐心的等待, 现在添加已经完成, 此时需要确认的是添加状态是否成功。输入命令 下面已经看到了 l f, 看到了这个标识,必须要有 l f o s 标识才能确认已经被正确的添加到了大文件的系统, 这是第一个文件,然后我们现在添加第二个文件, 添加 好第二个文件,添加完成,添加第三个文件, 添加完成之后一定要运行 状态查询的这个命令,看一下是否使用的是 lives 系统。 我们看到三个文件都已经是下面的这个是我们刚才修改了这个 file list 的, 这个可以大家不要管它。 确认好三个文件的 left 标识之后,我们可以统一进行提交, 我们看到已经提交, 可以再次运行一下,这里已经显示提交完成,等待部署好最后一步部署, 这时候我们可以确认一下,在远端的模型目录下是没有这三个模型文件的好部署, 我们布置成功,我们看到这里面有一个标识显示的是上传了 大文件存储对象,一共有三个,总共二十一 gb 完成,这就证明我们的文件已经上传成功,我们可以看一下远端的仓库,更新一下, 现在已经出现了这三个文件文本编码 v e, 就是 说现在这三个大文件已经被提交到了远端仓库。好,我们确认好之后 关闭系统重启,你们可以看到已经 最新的这个 c c 已经关闭,下面我们重新打开,或者是直接在代码仓库当中 启动。 因为上传了三个二十 g 的 文件,所以在每次启动的过程当中会耗费一定的时间去 远端拉取这个文件,不会像平时开机的时候速度那么快, 这是需要,这是持久化存储必须承受的一个小小的缺点,在启动的过程当中可能会拖慢一下速度 哦。下面这个容器已经启动成功,我们看一下目录文件已经要去完成, 这就是可以直接使用不需要再下载的文件, 这就是在 cnb 当中通过 gitlives 实现 大模型的持续化存储的一个简单的介绍,大家有什么问题可以留言随时交流,今天就到这里,谢谢大家。
 02:06查看AI文稿AI文稿
02:06查看AI文稿AI文稿我来看一个在 get 里面一个非常常见的问题啊,这个问题你要不小心的话,到时候调能调死你。比如说目前一个工程啊,它已经被 get 所跟踪了,现在呢,有一天啊,你不知道抽什么风,你把这个文件的大小写呢给我改了,比如那个 arata, 你 把这个首字母呢变成小写了,然后这个文件牙呢,你把首字母变成小写了, 改了之后呢,你会发现一个神奇的现象啊,但很多同学其实是没有注意到的,就这个 get 呢,没有对这个改动进行跟踪,你看,没有任何跟踪哎,但是如果说你去改这个文件的话,那没问题啊,把文 键也跟着变成小写,是吧?把路径也跟着变成小写啊,这个玩意呢,肯定是能被跟踪的,你看这里呢,是不是被跟踪了,对吧?这里呢,也得到跟踪了。好,于是呢,你把这个玩意推送到 get 仓库了,那就要出问题了,为啥呢?为啥前边没有跟踪,后边跟踪了呢?前边没有跟踪是因为 get 呢?默认情况下,它是忽略掉文件或者是什么文件夹路径的大小写的,它忽略了,它认为没有变化, 但是个文件内容变化肯定不行,是吧?它肯定要被跟踪,那于是就会出现一个什么情况呢?你本地是一个什么大写的文件名? 远程仓库呢,也是一个大写的文件名,对吧?推送过去了嘛?现在呢,你把本地的文件仓库的文件名呢变成小写了,但这个小写呢,没有被 diss 所跟踪。于是呢,你再推送到远程仓库的时候,远程仓库那边文件的名字是没有变化的,它还是大写,但是你这个玩意是能推送的,是吧? 这些路径变成小写了,是能推送的,那么推送上去了过后呢,就是远程仓库,他文件是大写,但是路径是小写,你说出不出问题,这个直观的问题就是你本地开发啥问题没有?但是一旦推送到远程仓库,那么服务器呢,再从远程仓库去拿取,那也就是生产环境,它的运行呢,它就要出问题,到时候调能调死你, 因为这个玩意很不好调,你很难定位,到底是什么原因导致的?你要掉很多头发,你才能知道是这里的原因,所以这种问题呢,最好是在最开始的时候就给它规避掉。怎么规避呢?就是你在创建的工程的时候啊,你就输入一行命令, 这个命令呢就是 git config call ignore case, 给它做一个配置,把这个忽略大小写呢,给它禁用了就完事了。忽略大小写一旦禁用,你看一下这些对文件名的大小写改动,就全部被跟踪了, 那么到这里推送到服务器的时候,那么服务器那边也有对应的小写的文件名呐,对吧?这样呢,才不会导致出问题啊,这是一件小事啊,但是这件事特别重要,朋友们以后建工程的时候呢,把这句话运想一遍啊。
677渡一前端提薪课 06:44查看AI文稿AI文稿
06:44查看AI文稿AI文稿同学们大家好,我是金城智能马工,今天我们来学习一下 get def 这个命令,它可以用来查看文件在工作区、暂存区以及版本库之间的差异,它还可以查看文件在两个特定版本之间的差异,或者文件在两个分支之间的差异。我们平时开发过程当中 更多的使用的是一些图形化工具,但是了解一下 git diff 这个命令还是很有必要的,因为有的时候我们需要在一些没有图形化工具的服务器上使用 git git diff 命令后面如果什么都不加的话,会默认比较工作区和暂存区之间的内容,它会显示发生更改的文件 以及更改的详细信息。下面我们来演示一下还是使用上一节课创建的仓库,这个仓库目前有三个文件,而且有三次提交, 每一次提交都是新增了一个文件,比如说 file 一 点 test, 里边是幺幺幺,然后第二次提交增加了 file 二点 test, 第三次提交 file 三点 test。 get diff 这个命令非常的简单,我们先来修改一下 file 三这个文件, 这里我们把内容改成 hello world, 保存退出一下。我们现在使用 get def 这个命令查看一下它默认比较的是工作区和暂存区之间的差异,可以看出刚才的差异已经显示出来了, 这里输出的第一行表示发生更改的文件,第二行我们稍微解释一下。 get 会将文件的内容使用哈希算法生成一个四十位的哈希值,这里只显示了哈希值的前七位, 后面的幺零零六四四,它代表的是文件的权限。再往下就是修改的内容了,红色文字表示删除的内容, 绿色文字代表刚刚添加的内容。我们现在比较的是工作区和暂存区之间的差异,因为我们修改的内容还没有添加到暂存区,现在我们来添加一下,然后再看一下输出结果, 可以看出刚刚比较的差异性现在已经不存在了。除了比较工作区和暂存区之间,我们还可以比较工作区和版本库之间的差异,在命令后边直接加上 hit 就 可以了, 比如我们现在还没有将添加的内容提交到仓库里边,而这个差异的内容又出现了,这是因为我们刚刚还没有进行提交操作,所以说工作区和版本库之间的内容是不相同的。我们还可以比较一下暂存区和版本库之间的差异, 在 get diff 命令后边加上 catch 就 可以了, 可以看到输出的内容是相同的,那我们现在来提交一下, 然后我们再使用 get diff 来比较一下, 可以看出暂存区和版本固之间的差异已经不存在了。 get diff 命令除了可以比较工作区、暂存区、版本固之间的差异以外,还可以比较两个特定版本之间的差异,用法就是在后边加上两个版本的提交 id。 我 们先来看一下当前仓库的提交记录, 我们比较一下最新两次提交的版本, 可以看出最新两次提交版本也已经显现出来了。 除了使用提交 id 之外,我们还可以使用 head 来表示当前分支的最新提交。 head 是 get 当中一个非常重要的概念,它指向分支的最新提交节点,在后面的学习当中我们也会经常用到,我们可以使用某一个版本的提交 id 和 head 进行比较, 这里我们可以改一下, 可以看出和刚才的输出结果是一样的。当然如果我们每次比较都要查看 id 的 话,确实有些麻烦。 我们经常用到的就是比较当前版本和上一个版本之间的差异,这里 get 也给我们提供了一个更加简变的方式,就是我们使用 head 加上波浪线来表示上一个版本,那么刚刚的比较就可以改一下, 可以看出和刚才的输出内容还是一样的。当然这里的波浪符号也可以改成尖角号,也是表示上一个版本。我们还可以在波浪线前面加上具体的数字,它表示当前版本的前几个版本。 head 波浪线二,它代表当前版本的前两个版本和当前版本的一个比较, 我们可以看一下波浪线三,这里我们查一下提交日期 前面的这个 head 波浪号三,它代表的其实就是第一次提交,而第一次提交和当前提交有哪些区别?就是新增了两个文件 file 二和 file 三,这里也体现出来了多了一个 file 二文件和一个 file 三文件。 get def 后面加上文件名也可以查看这个文件的差异,当然如果这样比较的话,就只会显示当前文件的一个差异,其他的差异就不再显示了,这里我们来比较一下, 我们比较一下 there 三点 test, 可以 看出它只显示了一个 hello world, 刚刚显示的这里的 第二个文件 feel, 二点 test 已经没有显示了。 get diff 还可以比较两个分支之间的差异,加上两个分支的名字就可以了。这个等到我们后面学习完分支的内容再来讲解。好,今天的内容就到这里,我们下节课再见,谢谢大家。
12金橙嵌入式 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿昨天有个粉丝问,提到代码的时候如果有冲突怎么解决?可以看一下这一个图,它一般是报这样子的错误, 然后我们用 get status 可以 看一下它的状态,它会告诉我们 boost modifier, 就是 说两个用户同时修改了这一个文件,那这种情况下我们要怎么去解决? 这有个使用技巧,就是我们先从源头上解决,避免经常遇到冲突。第一个是每次你修改代码的时候,你就先拉一下远端的最新的代码,修改后呢你要立刻去提交,你不要攒着攒很久再提交。 第二点是作为测试工程师,一般是分模块测试的,每个模块你最好是用不同的文件,每一个模块有不同的负责人,所以就是不同的负责人,你去负责对应的测试文件,那你每次 只改自己的文件,只提交自己的文件的话,那遇到冲突的可能性是比较小的。但是如果还是遇到的冲突,你要做的就是首先你要确定留哪一部分,比如说刚才这个报错的冲突是这样子的,上面这一片是我自己的代码,下面这个是远端的代码, 然后这两个代码这个同一个位置,它不一样,要手动的去改这一部分,怎么样?手动修改,重新确定保留哪一部分,或者是合并两边的逻辑也是可以的。修改代码之后,删掉所有的不是代码的这一部分,然后重新去提交就可以了。 另外如果你想放弃本地的改动,直接用远端,那你也可以用这两个命令强制去拉取远端的代码,但是这个一定要小心一点,因为你本地的所有的改动都会被覆盖。 另外如果命令不太熟的话,你也可以直接用 get 的 可缩化工具,比如说 sos tree 这种工具。
60Yoyo慢 09:13查看AI文稿AI文稿
09:13查看AI文稿AI文稿嘿,欢迎回来,咱们已经学到第四章了,你看啊,我们之前不是一直在做提交吗?这就好像在为我们的项目写一本厚厚的历史书。但问题来了,万一写错了怎么办? 别担心,今天咱们就来学习怎么当一个时间旅行者,我教你怎么看懂这段历史,还会给你三颗 get 的 后悔药,让你能随心所欲地在代码时间线上来回穿梭,不管什么错误都能轻松搞定。 你来想象一下这个场景啊,你不再是个普通的程序员了,你现在是代码世界的钟表匠,你不只是在咔哒咔哒的记录时间,你甚至有能力让时钟倒着走回到过去,把那个不小心写错的地方给他修正过来。 没错,这个超能力就是我们今天要掌握的核心技能,完完全全的掌握代码的时间线。 好,那咱们这就出发吧!作为一个合格的时间旅行者,第一步是什么?当然是得学会看地图啊,你在哪,要去哪,都得清楚。在 get 的 世界里,这张历史地图就是要用 get log 这个命令来展开的。 你看,如果你直接在终端里敲一个 git log, 回车就会看到这么一大堆东西,是不是有点眼花缭乱?这感觉就像是一本水流势障,信息倒是挺全的,但又长又乱,想一眼看出整个项目是怎么一步步发展过来的,太难了。 但是如果我们稍微变通一下呢?你看这个,我们只要加上几个小参数,比如杠 one、 line、 杠 graph, 还有杠 o。 哇,瞬间就不一样了, 那本乱糟糟的流水账,一下子就变成了一张超级清晰的拓谱地图,你看所有分支怎么分叉的,又在哪里合并的,都一目了然。我跟你说,这玩意你一定要设个别名,比如 git l g。 相信我,这绝对会是你每天用得最爽、效率最高的拿倒工具。 ok? 如果说 log 是 给我们看宏观的地图,那 diff 命令就是我们手里的显微镜,专门用来观察微观的细节。不过用这个显微镜有个诀窍,你必须非常清楚,你到底在比较哪两个东西。 比如说光秃秃一个 get diff, 它看的是你手头正在改的文件和赞存区之间的差别, 加上杠 stage 的 呢,他看的就是赞存区和上一次提交的版本库有啥不一样?甚至你还可以像 get diff head 杠杠二这样直接穿越时空,比较现在和两个版本之前的代码差异是不是很强大? 好,到现在我们已经学会看地图,也会用显微镜了。但你有没有想过一个根本问题, git 他 是怎么知道我们现在到底在哪儿的?他怎么知道当前是哪个时间点? 嗯,这就要讲到 git 时间机器的核心了。一个叫 head 的 东西,它是个指针,你可以把它想象成老式唱片机上面那个唱针,唱针指到哪里,唱片机就播放哪里的音乐。在 git 里, head 指到哪里,你的工作区就显示哪个版本的代码。 我发现啊,很多人一听到 had 就 觉得,哇,好神秘,好复杂,其实一点儿也不,它的原理特别简单,你就记住它是个指向,指真的指。 这么说可能有点绕,我换个说法, had 它很懒,它不直接去指某一次,具体的提交它干嘛呢?它指向你当前所在的分支,比如说 master, 这个分支指征才是真正指向最新那次提交的。 所以每次你一提交 master 指征就往前走一步, had 呢?就好像骑在 master 上面一样,也就跟着往前走了。明白了吗? 注意!注意!前方高能预警,这儿有一个锯坑,新手特别容易掉进去。就是什么呢?就是当你用 checkout 直接跳到一个过去的 commit hash 值上时,这时候你的 had 就 好像脱轨了一样,不再指向任何分支了。 这就叫分离头指真状态,或者叫游离状态。在这个状态下写代码做提交是极度危险的。 为什么?因为你这些新的提交,它不属于任何一个分支。等你一切换回别的分支,这些提交就成了没人要的孤魂野鬼,过不了多久就会被 get 的 垃圾回收机制给彻底清理掉,那就真的找不回来了。 ok, 既然我们搞懂了 had 是 怎么回事,那接下来就好办了,我们就可以开始学习怎么去操控它,真正地去改变历史了。 get 官方给我们准备了三颗效果不同的后悔药,它们的名字分别叫 reset, revert, 还有 restore。 记住啊,这三颗药药效和副作用那可是天差地别。 咱们先说药效最猛的这坎儿, yet reset, 它就是个名副其实的时光机,它有三种模式。第一种, dash soft 模式,这是轻度后悔药, 它只会把 head 指针挪回去,但你改的东西都好端端地待在暂存区里。这就好比你刚把信装进信封,又后悔了,于是你小心翼翼地把信封拆开,信纸还在,啥都没丢。 第二种, dash mixed, 这是默认模式,药效中等。它不仅移动 head, 还会把暂存区清空,把你改的东西退回到工作去。这就像你把信纸拿出来,还把它揉成一团,但至少信纸还在,你可以重新把它抚平。 最后一种 dash heart 模式啊,这是强力后悔药,也是最危险的。它会把 head、 暂存区、工作区里的所有相关修改通通给你销毁的一干二净。这就像你一怒之下把信和信封一起扔进了碎纸机,咔嚓一下全没了。所以用这个一定要小心! 好!说到这儿,我们必须强调一条在团队协助里的绝对红线,听好了 reset 这个命令,因为它会粗暴地修改甚至抹掉历史,所以它只能也只应该用在你自己的还没跟别人分享的私有分支上。 一旦你的代码被推送到大家都能看到的公共分支,比如 main 或者 develop, 你 就绝对绝对不能再用 reset 了。那怎么办? 这时候就该用 revert, revert 不 会删除历史,它很文明,它会创建一个全新的提交,这个提交的内容刚好是把之前那个错误的提交给反向操作一遍。你看,这才是对队友负责任的做法,因为它保留了完整的历史记录。 那么问题又来了,如果我没犯那么大的错,我只是不小心把某一个文件给改乱了,我也不想去动什么提交历史,就想把这一个文件恢复原样。怎么办? 很简单,这时候咱们的第三颗药 get restore 就 该登场了,你可以把它想象成一把手术刀,非常精准。它能帮你把某个文件嗖第一下恢复到上一个版本的状态,或者把它从暂存区里给撤销出来。整个过程非常干净利落,不会影响到任何历史记录。 讲到这里,我猜你心里可能会有一个最大的恐惧在悄悄冒头。就是万一我真的手滑了,真的犯了个灾难性的错误。比如不小心用了一下那个最可怕的 reset hard, 那 是不是一切都完蛋了?代码是不是就灰飞烟灭了? 对,就是这个问题,想想都后怕对吧?你辛辛苦苦写了一整天的代码,结果脑子一抽,一个 reset hard 敲下去,回车瞬间工作区干净了,历史记录也没了。 那种感觉是不是天都塌下来了?你的心血真的就这么永远消失了吗?别慌,先别急着辞职。 get 的 涉及者早就想到了这一点,他给我们留了一个终极保险,一个最后的救命稻草。 它的名字叫 relog, 你 可以把它想象成是飞机的黑瞎子,它默默地记录了你的 head 指真每一次的移动轨迹。所以,只要你的代码曾经被提交过,哪怕后来被 reset 无情地删掉了,你都可以在 relog 里找到它的遗骸。 然后你只需要一个简单的命令,就能让它起死回生,是不是瞬间安心了?所以你看,咱们现在可以把这些工具总结成一个非常清晰的决策指南了,来,跟我一起记。只是把某个文件改乱了,用手术刀 restore 在 自己的私有分支上,想退倒重来,用时光机 reset, 不小心把错误推送到公共分置了。快用安全气囊 revert, 万一感觉自己把整个仓库都给毁了,天塌下来了,别怕,咱们还有黑匣子 reflog! 你 把这张图记在脑子里,以后不管遇到什么需要后悔的场景,都能从容应对了。 那么到今天为止呢,你已经完全掌握了在一条单一的时间线上来回穿梭修改历史的超能力了。但这也引出了一个更有意思也更脑洞大开的问题,如果时间并不只是一条直线呢?如果它能分叉,能创造出无数个平行宇宙呢? 没错,下一章我们就将一起探索, get 最核心、最强大的功能分支与合并,咱们下回见!
 06:15查看AI文稿AI文稿
06:15查看AI文稿AI文稿有段时间,公司需要统计每个人的 commit 改了多少行代码,于是我一个不小心把一个七夕学习模型 git commit 了好几万行。我的 git 目录一下变成了几百页。 结果就是同事要克隆我这个仓库,得等十几分钟。于是我赶紧删掉模型,再次 commit, 但 git 并没有变更小。然后我试了各种办法, git ignore 等等等等都没有用。那一刻,我突然意识到,我其实根本不懂 git 是 怎么工作的,我只是记住了各种命令。 这个视频将用五分钟向你解释 git 是 怎么工作的。我保证,看完这期视频,你会是周围人中最懂 git 的 那个。简单来说, git 其实是依靠三种对象的引用来工作的。 三个对象分别叫做 commit tree 和 blob。 commit 就是 我们每次改动代码后的提交,它会指向一个 tree 对 象, tree 对 象表示这次 commit 发生时的目录,然后 tree 对 象再指向 blob 对 象。 blob 对 象就存储了文件的具体样子, 这些对象都存储在 get 目录中的 object 里。举个例子,这是我一个全新的项目,它还没有任何 commit。 我 刚刚新增了一个文件 text 一, 里面只有一行文本,然后我要提交一个 commit, 叫 commit one, 然后提交。 提交之后我们就可以看到这里有了我们刚刚的提交,它的哈希值是 e, d, d, f。 如果你不太了解哈希值,可以查看我之前的一个视频。简单来说,它是根据这个 commit 内容产生的唯一标识。 我们来看一下这个 commit 具体里面是什么样子的。我们需要使用一个 get 命令, get hit file, 然后参数 p 后面接。这次 commit 哈希值只需要写前几位就可以了。 于是我们就可以看到了这个 commit 里面的东西。我们可以看到它引用了一个去对象,这个去对象的哈希值是 c, a, a, e 以及这个 commit 的 作者是谁,这个 commit 的 提交者是谁,以及这个 commit messaging。 我 们继续看一下这个去对象里面是什么。 同样只用这个命令,然后使用去对象的哈希值, 就会看到这个 tree 对 象引用了一个 blob 对 象。 blob 对 象的哈希值是七三七 c 以及这个 blob 对 象所对应的文件的名称。我们再看一看这个 blob 对 象里面是什么。 改成 blob 的 哈希值就会看到它存储了文件原本的内容。通过这个例子,我们看到了 commit tree 和 blob 之间的引用。这样做的好处在于节省空间, 因为每个 commit 它都需要记录完整的结构信息,但如果将所有的文件都存储一遍,那这样耗费的空间就太大了。所以通过引用的方式,对于没有变化的文件,新的 commit 依然引用原本的 blob。 对 于变化或者新增的文件才引用新的 blob。 比如说我现在要新增一个文件,叫做 text 二,然后对于这个新增的 text 二,我提交一个 commit, 这 commit 就 叫 commit 二。简单点,那我们回到我们的提交历史,可以看到 commit 二,它的哈希值是九五七 c, 我 们再来看这个九五七 c 里面是什么样的。 可以看到同样有 tree or the commit 和 message 四个蓝位,但多出了一个刚刚我们没有见过的蓝位,叫做 parent。 parent 是 e、 d, d, f, 刚好和我们的 commit 一 的哈希值是一样的,所以这个阈尾它表示的是这一次 commit, 它是从哪个 commit 衍生而来。那我们再看看这个 commit 二所引用的 tree 对 象是什么样的。使用这个 tree 对 象的哈希值看一下啊, 可以看到它引用了两个 blob 对 象,一个依然是我们刚刚用的七三七 c, 就 像这里用的是七三七 c。 另一个是新增的一个 block 对 象一六九 d, 它对应的是我们新增的 text 二。 这样 text 一 的 blob 对 象就被再次利用了,不需要再存储一遍,节省了一些空间。但是 blob 对 象一旦被创建, 就不会再被修改或者删除。也就是说,即使我修改或者删除了 text 二,这个一六九 d 的 blob 对 象都将永远存在。比如我现在删除这个 text 二,然后再提交一个 commit, 可以 看我现在提交了第三个 commit, 删除了 text 二文件。那么看一看我们的 git object, 下面 我们还是可以找到这个一六九 d。 这个文件就是我们的 blob 对 象,它的命名方式是文件夹的名称加上文件的名称,就是全部的哈希值。到这里 你应该就能明白视频开头我的 get 步入那么大的原因了,因为表示我模型的 blob 对 象一旦生成了就不会消失。 但解决方案你可能也想到了,我可以先删除提交模型的这次 commit, 让模型的 blob 对 象成为没有被引用的悬空对象,再删除掉没有被引用的对象。 总之, commit tree、 blob 这三种对象就是 get 工作的本质。你可能会疑惑,哎,我们熟悉的 branch 去哪了? branch 不是 一个对象, 只是对某个 commit 的 引用。我们每次 check 到一个分支上,其实也只是跳到某个 commit 而已。我们随时可以指定任何 commit 作为任何 branch。 我 们还可以删除 branch, 但不会影响 commit。 你 可以在 git 目录下的 revs 下面找到各个 branch, 它存储在 head 下面。 像我的这个仓库,目前就只有 main 分 支。打开看看,你可以看到它的文件内容是九八 e a, 刚好和我的 commit 三的哈希值是一样的。以上就是本次视频的全部内容,现在的你应该完全理解了 git 是 怎么工作的,并且应该再也没有任何 git 问题会难住你了。感谢你的观看,我们下次再见。
3.4万Hucci写代码 02:57查看AI文稿AI文稿
02:57查看AI文稿AI文稿兄弟们大家好,今天我给大家分享一下关于我平时 get 的 使用。首先第一个就是 get clone, 是 比如说平时我们要拉拉一些开源的项目,或者拉我们自己呃工作当中要拉的系统的话, 嗯,那原码的话,其实我们要通过 get clone 把项目拉下来。其次就是 get add, 比如说我们在项目当中改动了一个需求,那其实 get states 是 去看这个需求的变更, get add 是 相当于是把啊这个需求提交了,而 get commit 其实就相当于一个 commit 的 命令。之后一般我们 get commit 的 时候会比如说添加一些备注,比如说文档, 文档内容的优点,而 get pushed 就是 相当于我们本地的提交和远程的提交,我平常那个,呃,其次还有 get remote, 就是 就是 remote, remote 就是 比如说我们拉到一个本地的一个项目之后,要和远程的项目建立一个连接,通过 get remote。 其次还有一个平时不不怎么用的,就是我们平时可能项目当中其实会遇到一些什么问题呢?就是我们要回滚一个版本,回滚一个版本的话,那其实,嗯 嗯,那其实我们其实要回滚到某个版本,相当于我们可能会跨越版本之后把那个版本回滚了。那首先我们要 get log 先找到那个版本,比如说我现在要回滚的版本是回滚到变更标题的这个版本,也就说前面的版本我现在不要了, 那我们其实通过 git log, 呃呃,那个 git logs 先找到,先找到我们,呃要跳的那个版本,也就是变更标题这个版本,对吧?我们把它的 版本拉过来,拉过来之后 git 这个版本号 啊,那我们看一下是不是这个相当于这个版本就已经提交过来了。那如果说我们,嗯,当然啊,这个我们在通过 getstate 状态,其实发现我们已经跳过两个版本了。嗯,如果说我们不需要, 呃,跳过这个版本,我们也可以,比如说,呃通过 git pull 的 话还原,如果我们就是需要提交的话,正常的 git push 是 提交不了的,要 git push 杠 f 之后提交到远程的 master, 远程的 master origin master 才行。今天就分享这一点点吧。嗯,感谢大家。
 06:08查看AI文稿AI文稿
06:08查看AI文稿AI文稿大家好,我是加购数据局,如果你刷到我的视频,请先给我点击一个免费的关注,然后我们开始今天的内容。 你有没有经历过代码写着写着就报错了,回想到昨天能运行的状态,却发现根本回不去了,或者想试试新功能,又怕把原来的代码改坏,复制了好多备份文件夹,最后哪个是哪个都搞不清楚了。 大多数新手会用复制文件夹的方式备份,比如说项目 v 一、 项目 v 二、项目最终版、项目最终版 v 二。这种方式呢,不仅浪费空间,而且无法快速找到哪个版本特有的功能。 get 的 诞生正是为了解决这个问题的。 那么 get 到底是什么呢?其实你需要的只是 get。 get 是 一个版本控制系统,就像给代码装上时光机,让你随时存档,随时读档。想象一下,你在玩游戏时可以随时存档读取 get 对 你的代码就是一样的功能,就比如说我们玩 呃竞速逃亡,你可以给每一个很难跳上去的地方存档,然后你在前面再往前走,摔倒之后你可以存档到回到你之前的 位置。那 get 呢?是由 linux 支付 linux 叉 word 在 二零零五年创建的,当时 只是因为 linux 社区使用的版本控制工具 backslash 收费了, linux 只用了两周,就写出了 get 的 初试版本。 get 这个名字在英国俚语中是饭桶的意思,是 linux 的 自嘲。 接下来是 get 的 核心概念。 get 的 工作原理其实很简单,就三个区域,工作区、暂存区、仓库。你的代码在工作区里编辑,用 get id 命令放到暂存区,再用 get commit 命令保送到仓库。 为什么需要暂存区?因为你可以分批提交,比如说只提交其中两个文件,而不是全部。这就好比购物,先挑商品,加入购物车暂存区,最后再一起结账,这就是提交到仓库。 仓库里的每一个提交都有唯一的一个哈希值,比如说八 a, 二 b, 三 c, 这是根据提交内容自动生成的,即使文件内容完全相同,只要时间不同,哈希值也是不同的。 接下来我们来讲出售化仓库,我们可以开始实战了。第一步,打开终端,输入 getint, 这条命令会在你的项目里创建一个点 get 隐藏文件夹, get 会把所有的版本信息都存在这里, 点 get 文件夹默认是隐藏的,在 windows 上需要开启显示隐藏文件夹才能看到。这个文件夹包含了所有的版本历史,删除它就等于删除了所有的 get 记录。一个项目只需要触触划一次之后就可以一直用。如果你想把一个已经存在的项目变成 get 仓库,直接在项目根目录运行 get in 就 行。 那接下来是保存和修改。第二步,保存你的修改,先输入 get add, 注意这个点表示当前目录下的所有文件,然后输入 get commit gm 描述, 把赞助区的文内容提交到仓库。 get ad 后面的点表示当前目录,你也可以指定具体文档,比如说 get ad app 点 gs index html。 如果说第一次提交, get 会提示你配置用户信息。 get config conglomerate user name, 你 的名字,还有 对于你邮箱信息的提交,提交描述一定要写清楚。好的描述,例子是添加用户功能,登录 登录功能,还有说是修复首页导航 bug, 不好描述就是 update fix 完成这些描述。你一周之后,可能你明天你都不知道你改了些什么,那接下来是 查看状态,有时候你会忘记自己改了什么,这时候输入 get status, 这是 get 里最常用的秘密,会告诉你哪些文件被修改,哪些是新增的,哪些已经准备好了。 get 会用 不同颜色标识文件状态,红色表示未暂存,绿色表示已暂存。你会看到三种状态, modified 文件被修改了,但还没有加入缓存区。 rtricky 的 新文件 get 还没开始跟踪, manager 已加入缓存区,等待提交。 get status 还会提示你下一步该做什么,非常友好,建议养成习惯。每次提交前都用行一下 get status, 确认你要提交的文件, 然后就是查看历史,想看看自己的提交历史。输入 get log, 你 会看到所有的提交记录,每一个提交都有一个唯一的哈希值,还有提交时间和描述。 get a log 默认会打开一个分页查看器,按空格翻译,按 q 退出。每个提交的开头就是哈希值,比如说八幺二 b 三 c, 通常值显示前七位,这个哈希值是全居为一的,即使不同的项目也不会重复哦。 常用参数呢?有 get log online 简洁显示,每个提交只占一行。 get log 三查看最近的三条提交。 get log group 图形化显示分支截框 q 等可以退出 get log 的 查看界面。 最厉害的来了,假如你的代码改坏了,想回到之前的版本,只需要 get checkout 加上那个版本的哈希值,啪的一下,代码就恢复到那个版本了。 回退时记得先提交当前修改,否则会丢失。 checkout 有 几个常用写法, get checkout 八幺二 b 三 c 回收到指定版本 to checkout hide one 回收到上一个版本,波浪一表示呢是退一步。 如果回退后发现不对,可以用 get checkout 回到刚才的版本。注意,这个命令在 get 二点二三版本后被 get switch 和 get risk 取代了,但 checkout 还能用。好了,今天的 getty 讲解就到此结束了。
37架构狮与橘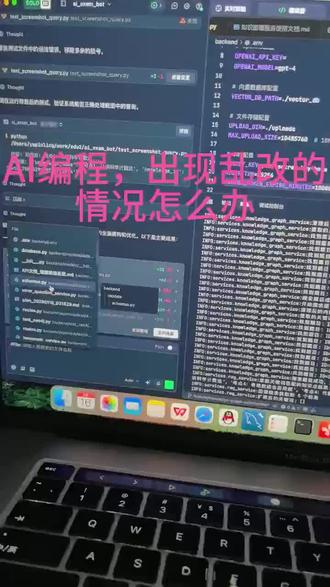 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿a a 编程会出现乱改的情况怎么办?目前来说无法避免。 a a 不 会乱改,所以我们一定要在使用技巧上面去改进。那第一个,呃,如果我们改某个具体的功能的时候,我们最好是指定某个文件, 指定某个文件之后再给他说我改某个功能有加一个删除功能,或者修改一个什么功能,直接给他说他只会在这个文件上面去改这个,避免他乱改。如果这个时候你乱笼统的去讲,他就会全截去改啊,这个一定要注意点。第二个, 如果让他改了某个功能,他改了一大堆文件,你这个时候你要去验证一下,你要去看一下,看他是不是你想要的,还有那功能有没有其他影响,如果发现他乱改了,这个时候这里有个全部撤回的功能, 一撤回他就回到原来版本,这里也有学会使用。第三一个就是,呃, ai 编程工具上面应该现在都会有一个原代码管理工具, 把这个开通掉,开通好了之后,在你每次改好每一个功能的时候,你都有让他去帮你提交,提交如果出错了,他会自己帮你解掉。 好,这个时候你后面再改乱了,你可以回滚到当前提交的一个点上面,所以尽最大的方式避免乱改。
21余品灵说AI 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿作为一名程序员,防止敏感文件进入 git 仓库是必须的。意外提交点 envo 文件可能会泄露生产环境的密钥。隆重介绍 cryptokeyim, 你 的 git 守护者,它采用军事级别的加密技术,在敏感文件进入你的仓库之前自动检测并进行加密。 操作非常简单,但安全却无懈可击。扫描你的项目加密敏感文件,然后就可以自信地提交了, 从此你再也不用担心生产环境的密钥会暴露在 get 中。现在就去保护你的 get 仓库吧!访问 kryptokyim, 构建一个绝对防泄露的开发工作流。
 02:52查看AI文稿AI文稿
02:52查看AI文稿AI文稿第二部分就是 get 的 一个安装啊, get 安装的话,它的安装过程非常简单,因为 get 的 话,它是也是分为一个服务端和客户端的,我们本地去使用的话,我们要装个客户端工具,对吧? 它个安装过程是非常简单,我们只要一直下一步,下一步就行了。安装完成之后的话,我们打开这个 cmd, 输入这个命令,如果出现你的 get 版本,比如我们输一下, 那么就说明你安装成功了,知道吧?安装完之后一定要配置用户名和密和邮箱啊,配置的话就是 get, 配置全级的话,就使用这个命令啊,使用这个命令,然后配置项目级的话,这个的话 这个邮箱正常情况下,如果说你的你的这个 get lab, 就 你的 get 使用那个服务端,它有配置邮箱的话,有有那个专用邮箱的话,你可以写那个邮箱,如果没有的话,你可以写,随便写个邮箱也行啊。 这个名称的话就是标记你后续写代码,你提交代码,他会以这个名称来记录的,知道吧?就是比如说我们在这里,我们比如说在这里看看 这个,这就是你本地配置的这个 get lab, 不是 你本地装这个 get 的 这个客户端,他配置的这个用户名就会在这里显示,知道吧?就你每次提交代码,他就以这个用户名来标识这个代码了, 这是配置全级的,如果你想配置项目级别的话,你就切换到这项目根目录下去执行啊,根目录下去执行,然后他就配置到项目级别的,比如说你某个项目,他特他比较特别,对吧? 或者你的电脑也是公司用的,也是你个人用的,然后你公司用的话,你想配一个公司的那个名称,比如你们公司要求一个,就像阿里呀,他不是也要起一个花名吗?对吧?你们公司需要使用这个花名,然后你自己又想要你的这个项目,比如说你自己也会写一个项目,那你可能 不想把这个全局的都更改掉,那你就可以跟就可以配置这个项目级别的啊。这个用户名和邮箱, 这个的这些命令的话,可不是在 cmd 执行啊,这些命令的话是通过这个给它办起的一个命令窗口啊,我们可以看一下,你可以在任意地方打开啊,都会有这个,你安装完之后的话它就会有这个,我们就可以点这个命令窗口, 这个命令窗口的话它跟这个 linux 命令是通用的,通用的就一些 linux 命令其实也可以在这个窗口里面去使用的, 我们是在这里去执行的,不是在 cmd 窗口,这个要知道,然后查看是否配置成功,你就通过这些命令进行查看就可以了,就可以了。
25拙野lds 17:22查看AI文稿AI文稿
17:22查看AI文稿AI文稿今天讲的是自动化测试,目前是第四小节,话不多说,让我们开启今天的测试之旅。框架的封装好,这里带大家看一下啊,比如说 excel 的 封装,你像这个东西,我觉得啊,也比较简单,大家看老师曾经手写的一个框架,大家随便看一下, 我会把我的一个个的用力,我把它全部写到我的 excel 文件里面。大家看啊,我们真正去做自动化的时候,那无非就是三个流程吗?第一,我要发送我的请求, 那么你每次发送你的请求,你得告诉他你的地址,我这里,我给它放大一下,你的地址是什么?你的路径是什么?哎,我是 get 还是 post 的 方法,请求头参数是什么?好,这些信息我给它封装好了, 那么接下来就是我要去解析请求,解析请求了之后,最后呢,我要去较验我的一个返回的参数。好了,你看这里,我每次我要较验什么?比如说,这里我要较验 message。 第二个,我要较验我的内蒙。第三个,我要较验我的 message。 好, 我预期的结果是什么?你看,在这里我就可以把它写到我的 excel 文件里面来。 最关键的啊,你看我里面用到了一些什么接收表达式啊,接收器啊这些东西。喂,我都,老师讲话卡吗?同学们,卡不卡?还是只有我们某一个同学卡?同学们,你看啊,像这样的一个框架,首先我就,哎,我的文本全部写在这样的文件里面啊,这个就叫数据驱动,我不仅可以写在我的 excel 文件里面,包括写在 word 文档,甚至是写在数据库里面,那都是没有关系的。最关键的就是里面你的一个逻辑是什么? 哦,你看我这里写的一些逻辑,我写了很多的版本,具体的一个逻辑就是,哎,每次这个文件我会去逐行的去读取它, 读取它了之后每一行,对吧?我先把这些请求给他发出去,然后根据你写的这些教验点,我去教验,如果说他通过了,哎,我就把这个通过两个字回写到这里, 没通过,哎,我就回写一个,不通过在这里,那原理就这么简单,哎,通过使用咱们的 pytest 的 框架,也能生成一份自动化的测试报告,这个就是咱们框架的封装呀,同学们, 这个原理搞清楚了之后,来写这样的一个小工具,小框架,那真的跟玩一样啊。老师,你为什么写在这个 excel 里面,是吧?你这种方法你自己随便去封装啊。同学们,你看我这里写的写的一个方法是,我是写的 read excel, 嗯,我看一下啊, api post, 嗯,对 drive 啊,大家看这里,我是 excel read 啊,我就是读取咱们的 excel。 那 你要是想写在 excel 文件里面,没关系啊,你直接就把这里名字你改成 excel 也可以啊,然后相对应的下面的方法你给它改一下。哎,我从 excel 文件里面去啊, 去读取文件,就这种叫数据驱动,关于这种数据驱动,它具体的载体是什么?我觉得这个东西它并不重要,它并不重要,所以我觉得呢,用咱们的这个 excel, 我 觉得是最简单最方便的,你们就用 excel 就 行了。有的同学他喜欢问啊,老师,我搞个 excel, 他 要问你为什么不用 excel? 当老师在这里给你展示样的时候,那肯定有同学问,老师,你为什么不写在数据库里面?我免得大家问我一次性,我告诉你们答案,好像这种框架很好封装呀,啊,等等啊,你看最关键的还有一个数据库的一个教员,同学们, 我们为什么做接口自动化?哎,要去教咱们的数据库啊,要使用数据库呀。第一同学们,我们有时候要去准备一些数据,哎,我们要用到咱们的数据库,你比如说你要去验证一个下订单的接口, 那你肯定得保证,首先你的那个商品是在的吧,它的库存是有的吧,并且它是可购买的一个状态,那么每次你为了确保你的这个用力,它能够运行的通,那么我要先一 set 一个商品的信息 好。第二个,凡是涉及到数据的真删查改的,我就比如说真的而你下了一笔订单,那么你单纯的给我返还一个下订单成功就 ok 了嘛。我肯定要接下来就要去交易库看数据库里面有没有这笔订单呀, 包括这是第二种啊,还有第三种,有时候我们要去啊,我们的一通用力修改了,全部执行完了之后,我们会去做数据的清理,那么这个时候我们就去啊,连接咱们的数据库,去做一些清理的一些操作,这就是我们为什么要用数据库的一个原因 啊,这里面还有很多很多一些框架等等等等啊,这是我们接口智能化要去学习的一个内容。这里呢老师想跟大家分享两个经验啊。 第一,我觉得没有没有涉及业务的接口自动化,他是没有灵魂的,你不要说你业务完全不了解,你上来就对着这种接口文档想当然的去搞一些接口自动化,那是没有任何意义的。 然后第二个没有验证数据库,验证数据的接口自动化我觉得是肤浅的,你只是单纯的去验证什么返回状态码,两百, cs 这种,那太肤浅了。同学们,你这个自动化写的跟没写一样, 一旦他报错了,那是什么问题啊?只有他那只,一旦你写的这种脚本报错了,那说明很多时候都是你们的什么网络有问题的呀,你们的服务挂了呀。好,一旦他每次都成功,然后成功又不能代表什么问题,他检测不出什么问题, 所以说你这样的脚本他就没有任何意义,没有任何意义。好吧,好,这三个东西全部学完了之后,同学们啊, 我们一定要学东西,要学一个一条龙,你不要把你每个经历,你就啊或者低层次,我就钻到编程里面去,我每天就编程,编程,编程,好吧,去学你们的东西,然后你也不要啊,我去学自动化,我就钻在你们的某一个环节里面去了,某个元素我识别不到,我就想尽一切办法去识别它啊,我花了七七四十九天, 我,我建议大家千万不要把自己的精力钻在某一个方面去了,要把自己把它抽理出来,去学一个一条龙的东西,先把这个骨架,先把这整条流程给他跑起来,然后有些东西不会的,你再回过头来再去看。你比如说我们要学个持续基层,那什么叫持续基层啊?好给大家看一下啊, 你,即使你代码写的再好,你看啊,你代码写的再好,你也不是说每次在你本地去运行吧?首先你像这些脚本,你看老师在企业里面啊,我们都是通过咱们的 get 的 工具去进行一个管理,去进行一个管理,你比如说我跟他演示一下,好,这是老师在本地的一个代码,你比如说这里我加一行东西啊, 我 logo 一下咱们,我非得把你这个名字给它打进去。这个同学,我不知道你这两个名字怎么写,我看能不能复制过来啊, 复也复制不过来呀,你这个名字我打不好啊,我比方说我现在加一行代码,加一行代码叫都胜,是吧?啊?都胜, 你这个名字我真的不会打,那我就加一行这个记录啊。好,我在本地,比如说我新增的某一行代码了,那么这个时候呢,我们该怎么做?大家看看我们企业里面自动化测试工程师他是怎么配合的? 只要你的团队啊,有超大于不小于两个人的团队,你都要用到这种 get 的 工具去进行咱们代码的一个管理。你比如说用了数据库,好,这个时候在我本地来看啊,他就提示了,哎,我更改了某一个文件, 然后呢他,我新加了某一行的一个网址,他叫 log, 什么什么啊?好,这个时候我就可以把它上传到我的一个 get 到我的 master 分 支了,比如说这里我提交一个信息,好吧,同,这个名字我是真的不会打,比如说彭佳琪,好吧,好,我立即推送啊,我就推送了, 这个时候呢,我就把我本地最新的代码推送到我的 master 分 支上面去了,当然了,这里我是跟大家检阅了啊,一般我会先拉取一下,因为我要在本地解决一个冲突。好吧,这里 get 那 肯定是一个基本功。那么这个时候啊,给大家看我们的 get 仓库啊,同学们, get get 仓库, 比如说这里的,这就惨了,耶,稍等一下啊,同学们,密码 这个不能给大家看到了,哈哈哈哈,这里我没有把它提前打开,我要给大家看到我们的 get, 好 吧, get 了,我要,我要登录一下,大家等我登一下啊,当然这是我的 get, 然后我的一个密码,密码大家应该没有看到吧,我把它拉到我的分屏上去了,啊哈哈哈,好,闪映 好。登录了之后,大家看,这是我们刚才的那个仓库,我们刚才那个仓库呢,我们点进去,我们看它的 history, history 里面呢,我们就看到刚才老师是不是提交了一个信息,彭佳琪就在这里了啊,就在这里了,是咱们的 master 分 支,这是第一个我们的代码, 通过咱们的这种哎, get 了 get lab 的 这种工具代码仓库来进行一个版本的管理。大家看,每次哎,我们提交的信息都在这里,然后这个时候呢,同学们,我们要用到一个金坑式的平台,金坑式的平台它的一个作用是什么?我先给他登录一下,给他看,就是给他搞成一条龙嘛。 好,你比如说我们去执行执行,比如说我执行一个,随便选个项目,执行到,我点一下标的了,好,我点一下标的了, 好,他就直接去执行了,执行的时候我们看他执行的一个记录啊,好,他说, study, 拜拜,谁拜我嘛,对吧?拜文老师。然后呢,第一行,大家看他这里,他是不是, 他是不是就拉取了咱们 get 仓库里面最新的一个分支了? get 仓库里面最新的分支啊,这里面一些 get 的 信息全部都有。哎呀,我们那个彭佳琪同学呢?怎么没有在这里显示啊?我再看一下啊, 这里直接失败了,啊,不是这个,我看错了,好,这里第一是在我们刚才对应的那个脚本,应该是这个,我再让它辨认到一下啊, 好,马上跟大家讲这个东西的原理。好吧,现在它就已经开始运行了,大家看,我点击一下标得到,它就开始已经运行了,我们看它运行的一个网址啊,首先第一步,同学们,他会从 get 仓库拉取我们最新的代码,何以见得?你看这里面有 get 的 信息, 然后在这里呢,我们顺带着看到了老师的刚才那个提交的信息了吧?彭佳琪,看到了没?彭佳琪同学,是吧?啊?彭佳琪,然后呢,他就噼里啪啦,你们去 pass, pass, pass, 去执行咱们的脚本了,我们具体看啊,看一个任务,它的原理是什么?你们要跑到它的配置里面去看啊,配置里面去看。 首先你们看啊,为什么它会从 get 里面拉?因为我们把 get 仓库,你看这里 get, get, 我 们往回退,往回退一步, 这里有一个 clone, 大家看这里是不是有个 clone, 我 们就可以把这里的一个链接,我们给它配置在咱们的 get 仓库里面,来 get 仓啊,配置在咱们的这里来 配置这里的,然后把你的用户名密码给它输进去,然后你这里再设置一下,每次相当于这个任务一启动,我就从我的 master 分 支从这个仓库拉取最新的代码,拉取最新的代码,并且把代码存放在你的一个路径下面,我给大家看啊,路径的话应该在 这里好好,比如说存在这个路径下面,这里是你自定义的啊,然后接下来你看啊,我们这里面有一个构建触发器, 你可以手动的去触发,你也可以在这里设置一个定时器啊,比如说这里就是每天凌晨三点自动的去进行一个触发,然后最关键的啊,同学们,为什么咱们的金根使它能够自动的去执行你的脚本?最关键就是你在里面去配了命令行啊, 就是相当于每次只要你执行了,第一时间哎,他会拉取你最新的脚本,然后第二时间他就会这里挨行挨行的去执行你在这里配置好的脚本。 为什么?咱们的 postman 哎,也可以和金克斯打通咱们的 gmail, 也可以打通任何工具,只要他支持命令行,他就可以实现咱们的持续集成。金克斯是个啥东西?那不就是到了什么点,我去执行什么样的操作命令,我还能够和 get 打通 最关键的他在这最后大家看他还有一个构建后的操作,什么发送邮件啊,发送报告呀,那都是你在这后面给他配置好的这个东西呢,又叫咱们的一个金根石, 金根石呢它里面每一次你操作的记录,它也给你保存在这里,包括我们也可以触发。现在阿文老师啊,我不用什么邮箱,邮箱链接了,大家看, 比如说我每一次谁执行了什么,结果怎么样,我都是像阿文老师,企业里面我是用的企业微信,我会和咱们的企业微信直接打通, 因为企业微信它里面有很多第三方的接口,哎,给我去开发,我开发了之后,每次我这里跑完了之后,我就直接掉接口, 哎,然后以这种方式去通知谁,你像谁,什么时候执行了什么自动化,通过这个平台我觉得就更一目了然,比那个比那个什么,比那个邮件更好,因为老师以前我也用过邮件,你看啊, 就说,哎,哪个项目,什么批次执行,上报成功,哎,总共成功多少个,失败多少个,我觉得这种方式啊,是更友好更友好的啊,同学们,好吧,这个呢,基本上就到了一个自动化测试的第二个层次了。 第二个层次就是,哎,你现在会一些设计的方式了,设计的方法,你比如说老师刚才跟大家讲的各种封装啊, p o 的 设计的模式啊,是吧?然后你得想我如何让我的脚本变得更稳定了啊?然后呢,你现在还甚至学会了一个持续集成, 持续集成了,然后你会自动的啊,把 get 金克斯多克这些工具给它融会贯通了。那么恭喜你啊,同学,这个时候你已经到了哎,老师所说的自动化的第二个层次, 然后老师跟大家说自动化测试的第三个层次,也就是咱们决定你自动化测试水平平台的一个展示。好吧,现在给大家看一下,老师啊,在企业里面开发的一个自动化的测试平台,这是老师一个人啊,完全度你自主研发开发的这么一个平台, 给他打开一下啊。老师喝口水, 这个平台里面模块挺多,我只是挑一个自动化测试平台给大家看啊,就比如说你看啊,虽然说老师你现在用了金链子这种工具,你每天都去跑,你看这是你每一天的结果啊,你在这里面显示就是幺三幺二批次,幺三幺幺批次,但是我想去看你过去运行的一段时间到底执行的怎么样, 对吧?你们整个测试团队啊,你们执行的一个啊,你们的成功率怎么样啊?每天有没有去执行啊?并且你们的这个工具我如何让我们的开发也能够用得到, 你们有没有发现一些 bug 等等等等,你看我就直接啊我们开发出一套平台出来给大家展示一下啊,一个思路, 这里我就给大家展示每一个格子代表着我们过去半年的每一天,然后这里面的颜色就代表着某一天的一个成功率。你比如说今天是三月十四号,他的一个成功率就达到了九十八点七九, 像这种红色的,哎,就只有八十八点八三。通过这么一个图,我就作为一个总监,我就能够一目了然的看到,在过去半年,我们自动化测试团队每天有没有去执行,执行的一个总的成功率怎么样,通过这个平台我能够一目了然, 一目了然。好吧,之前公司今年子是愿为同事维护的,压根实在没接触过,所以我跟大家讲, 现在自动化缺的不是说我把某一个环节啊搞得很很精通,就比如说有的同学我 python 贼六,而我 web 自动化贼六等等,我们缺的不是这样的同学, 我觉得一个自动化测试人员应该具备的一个能力,就是我具有一条龙的一个水平的能力,能够把这些东西全部,我能够意思就是我现在到了一家企业里面,这家企业他没有自动化,我能够成为第一人进去,我能够从零到一的搭建这家 企业的自动化的测试体系,并且到最后,哎,我还能够他落就是切入到整个研发流程当中去,让他起到相应的一些测试的作用。所以说啊,阿文老师的技术再有了一下, 比较深,比较深好吧,就好像那个英雄联盟,有的有的有的人呢,可能说他是英雄池,像阿文老师呢,我可能是英雄海啊,这些东西我全部都接触了,因为我搞这个东西搞的太久了, 一五年搞到现在搞了八年了。同学,这个任何行业只要你在一个行业,你一直待五年,你有啊,第一个你方向选择正确,第二个你足够努力,第三你有兴趣,第四你有天赋,那么你在任何一个行业你都不会混的差,你都不会混的差。好,接下来听阿文老师继续给你讲平台啊,这个你看 这里,我就给到我们的开发去进行使用,你比如说我们某个开发,对吧?他发了版本,他想知道这次我发了版本之后对我们项目有没有影响啊?那么在这个时候他就可以把他最新的代码合并到咱们的自动化的测试环境,然后他点一下自己的手动执行。啊, 这里面有点问题啊,我点这个吧,他点击一下自己的手动执行,然后我们这里面结果就会自动去跑了,跑完了 之后呢,也会给这个人,给他自动发送信息啊,就说什么时候已经执行完了,执行完了之后,你看啊,这个人他这次他在跑过来,他可以看一个与上一次结果的对比, 你比如说上一次是八幺九啊,一个失败的都没有,他发了最新的版本,跑了之后,八二零还是一个失败的没有,那就说明这个人发的这是版本没有问题啊。但相反啊,如果说是另外一种情况,我给大家看一下啊。如果说是另外一种情况,比如说 这里面啊,这里面看不到。如果说之前没有失败的,现在你发了版本之后有了失败的,那就说明你比如说这里是没有失败的,那你这是发了版之后有失败的,那不就说明你这是发的这个版本有可能引发了一些问题了吗?是不是啊?等等啊, 这种东西百度有教程吧,我先进去,然后要搞的时候边学边搞,也能够搞的出来吧?其实上面的一些教程啊,就是即使我现在我把这份课程大纲我发给你们啊, 发给你们,你们后面还是把它学不好,我可以告诉你们,很明确的告诉你们,待会告诉你们原因,你看我们自动化,我刚才跟大家讲的,这是一个平台啊,包括我们也可以。
18不做IT秃头男







猜你喜欢
- 11.6万绾绾书院