spss27显示个案摘要在哪

粉丝4596获赞2.5万
相关视频
 02:58查看AI文稿AI文稿
02:58查看AI文稿AI文稿我们看一下个案的排序。为什么需要个案的排序啊?为什么需要个案的排序?有些时候呢,我们录入进去的原始数据,它可能是顺序比较乱的, 比如说,呃,一般来说都是以一个课题组来进行的数据录入啊,比如说 a 同学我录这个部分, b 同学你录那个部分, c 同学又录另外一个部分,好,我们各自录好之后,我是不是得把它合并到一起啊? 啊?当我合并到一起之后,我发现我这一整个数,我这一个数据库当中呢,有两千个个案,这两千个个案就很乱了,既有一年级的数据,又有二年级的数据啊,既有这个父亲的数据,又有母亲的数据,既有这个,呃,这个高年级的数据,又有中年级的数据, 而且每一个班的顺序全部都是乱的,这个时候我第一个我看着不舒服,第二个 啊不方便我统计,所以我,所以呢我需要进行个案的排序。怎么进行个案的排序呢?它的功能呢?也是一样的,在数据这个功能下面有一个叫个案排序的一个键啊。呃,我们可以选择升序或者是降序 啊,在这里我们可以选择升序就可以了啊。呃,然后这里呢有一个排序依据,所谓的排序依据就是, 呃,你想要以哪一个变量来进行排序?比如我想要以 id 来进行排序,我就把 id 这个变量我直接选进去,如果我想要以性别来进行排序,我就选性别进去。如果我想要以这个父母受教育水平从低到高进行排序, 我选它,然后再点击确定就可以了啊,很简单,我们来演示一下,在这里数据有一个各按排序 点,点击它,打开一个弹窗,现在我想要按照比如说学习时间啊,从低到高来排序,选它,然后排列顺序,这里默认就是顺序啊,当然你也可以选择降序,降序就是从高到低嘛,顺序就是从小到大嘛,好,点击确定。 然后我们现在来看一下,现在它就重新排过了,我们发现原本呢,我的 id 这一列,它是从一号一直到四十号,但是现在你看 经过我重新排序之后,我们发现我是按照学习时间来排序的,所以学习时间这一列变量它就是从小到大了啊,从啊,最少的。是啊,这个七个小时的啊,它是第二十七个个案 啊,然后是七点五个小时的,他是第十一号个案啊,我现在就是按学习时间来排序的,这就是所谓的个案排序。至于变量排序,我们 一般不需要变量排序啊,我输入进去的变量是什么就是什么呗,我不需要去改变它吧?好,这个就是变量。呃,个案排序啊,异常。
 04:12查看AI文稿AI文稿
04:12查看AI文稿AI文稿我们继续学习如何在 space 中处理重复的数据。重复数据是指在数据集中出现的相同的观测值或者记录就是样本重复了, 那这种产生的原因可能是录入的错误。数据合并操作的时候,我们可能有些误操作,数据提取等等,这种操作不当,或者本身我们获得的数据里面就是有重复的记录,那重复数据会影响到我们数据分析或者统计分析的准确性和可信, 然后一直影响到我们假设检验啊,自行区间回归分析等等的结果。那在十八式中处理重复数据的方法有很多,第一个我们可以删除重复的个案,直接进行删除,但是如果我们数据量特别大的情况下这种方法,那么效率就很低。 第二种可以合并一些重复的个案。第三个我们标记重复的个案,在我们处理的时候,我们就不处理这些有标记重复的个案。 第四,我们可能要检查一些原始数据录入的情况,比如说我们做的是一个问卷调查,可能要检查一下到底是原始数据录入的时候是不是有问题。我们来看一下这个案例, 数据集员工信息,这是包含的重复值的这么一个数据集中查找出重复的个案。 现在我们打开数据集,我们从数据这里进入,这里有个识别重复个案, 打开了一个对话窗口。首先我们要定一个匹配个案的依据,就是我们用什么来判断他是不是重复的呢?你不能说用男女这个单是不行的,因为太多的都是男和女,那么唯一的代码我们在这里就是员工的代码, 他是只能是唯一的排序的,这个依据我们可以任意选一个都可以,比如说按性别啊,或者其他的也都可以。在下面的话要创建的变量就说他会创建新的变量。第一个选择默认的他是 主个案指示符,一他是唯一的零,是代表重复,也就是员工代码,到时候他会标志出来一他是唯一的零,说明我们员工代码他是重复了员工的, 那每一组最后一个他是主个案,到时候软件里面他会给我们标识出来,我们也可以把这个同时选了。这个意思说每个祖宗匹配个案连续的技术,比如出现了一次,出现了两次,出现了三次,我们点确定, 确定完了之后,大家看他同时输出了一个标记重复数据,重复个案的这么一个输出的结果,我们看这里, 这里有效的这个个案是四百七十五,那这里面呢?有重复的是四个,有四个个案就四个样本重复,那实际上是主个案,就是没有重复的,应该是四百七十一。那这里的是什么意思呢?就是出现这个数字三,一会我们回到数据集去看, 出现三的有一个个案,出现二的有三个个案,出现一的有三个个案,标标示为零的是四百六十八个个案。回到编辑器的窗口,编辑窗口大家看他这里的话,他出现了三个变量,第一个是匹配的顺 序,匹配就是按照员工代码匹配的顺序,首先看这里是重复个案,他已经显示了这个是主个案,是应该要保留的,那出现了一个重复个案,这里第 二百零九和一百零三他都是有一个重复的个案,这个个案这个样本就是说他的员工代码是三百五十一号的,这个他有出现了两个重复的个案, 所以一共呢出现的重复个案,一共有四个重复的个案,刚刚还有个表格就是出现了三,有一次出现了二,他有三次出现了一的这个代码,他有一次经过我们这个对重复个案做了一个标识之后,你就可以对他进一步进行处理。比如说我们可以把这 重复的给它删除掉,或者我们直接做一个标识,那我们在进行数据处理的时候,我们可以直接把这些重复个案给它删除了,你也可以在这里做个排序, 比如我们做个声序,声序完了以后我们直接把这几个给它删除了就可以了,直接给它删除掉,删除完了员工代码,你这里还可以再重新做一个排序,这样我们就删除掉了重复重复的个案,最后就是四百七十四个。那么处理重复数据我们就学习到这里。
10何晓琦老师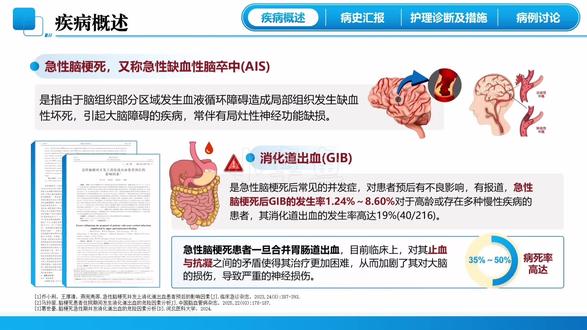 00:31查看AI文稿AI文稿
00:31查看AI文稿AI文稿快看,如此清晰的导航栏用在 ppt 里真的太绝了!于是聪明的你点开了插入形状,一不小心选择了圆角矩形,手滑画出了一个长条矩形,又不小心复制了一份,手抖将它缩小了,还改成了白色。放到上面突然飘来四个文字目录,你一激动就 复制了三页出来,还把每一页的内容都填上了。于是你点开第二页,把白色矩形移动到第二个目录,结果手一抖,点到了切换选项卡里的平滑效果。恭喜你已经学会了这个导航栏!
522小章鱼护理PPT 11:10查看AI文稿AI文稿
11:10查看AI文稿AI文稿大家好,欢迎来到 spas 课堂,接下来我跟大家分享的呢是 摘要独立样本体检验,他呢主要是针对我们在数据分析过程中,原始数据未知,我们已知两组样板量均值标准差已知的情况下进行的两组的独立样本体检验。 呃,这个摘要独立样板体检验呢,在一些 s p s s 某些版本里面呢,可能会安装上这个插件,但是呢,经过我在 多个版本上测试之后呢,就是说安装这个摘药独立样本体检线这个插件呢非常困难,所以呢, 我就是根据他的一个原理制作了这么一个 aser 程序,然后呢我们就可以根据我们已知的样本量均值 还有标准差的情况来计算他的。呃,独立样本体检验的一个批值和批值,他是怎么做的呢?首先我们来了解一下。呃,这独立样本体检验呢,他主要还是 检验来自两个总体的样板这一段两个总体均值是否存在差异,他的前提呢跟我们前面介绍的是一样的, 还是这三个前提独立就是两组数据呢相互独立,这个呢是基本都满足的正态呢,就是因为我们这里呢是没有原始数据, 我们就是没有原始数据的情况下,怎么来判断他是否满足正带径呢? 这里呢就是有一个不成文的规定呢,他呢就是说基本上呢就是标准差小于 他的样本均值的三分之一,我们基本上就认为他是满足正态分布的,如果呢就是标准差大于均值的三分之一,或者接近呃 呃,均值的一半啊之上,这样呢,我们一般就认为他是不满足正态颁布的,我们就需要用原始数据去核核对他的数据正态性。第三个呢,就是方差其性,方差其性呢,我们就是没有原始数据的情况下,怎么样来判 判断他两组数据是否满足方扎奇性?好,接下来呢,我们主要是针对方扎奇性这一块做一个说明。首先方扎奇性呢,他是没有原始数据的情况下呢,我们是用的他,这里还不简念 他呢,主要是统计量呢,这 f 呢是呃最大对应的样本,最大的样本方差比上了最小的一个样本方差,这自由度呢,就是样本量不等的时候呢,就是对应 最大组的值样板减一。这样呢,我们就通过这个 a heartly f 检验呢,判断两组样板方叉是否相等。判断完方叉相等之后呢,我们就可以 进行选择相应的统计量了。若方差相等呢,我们是选择 t, 检验呢,是服从 n 一加 n 二减二左右度的液体分布, 这样呢,我们就通过可以通过这一系列公式呢,首先呢,就算 s c 方,然后呃 s 呢是 呃样板一的均值减样板二的均值的一个标准差,然后带入这个梯值里面来,就是说呢,他呢梯值呢,我们就可以计算出来了,然后对应 p 值表呢,查找 n 一加 n 二减二的自由度的液体分布,这样呢,我们就可以得到一个概率 p 值。 好,如果,如果方叉不讲等的时候呢,我们对它的一个自由度 做了一个纠正,这是他的自由度的一个修正公式。然后同样呢,这个期值呢,是根据这个公式来得到。呃,这样就通过纠正 和自由度呢,我们可以计算出他方差不等的时候对应的梯值,这样呢,我们两种情况下对应的梯值和梯值就都有了,这样呢,我们就是可以进行一个概要的一个独立样板体检验了。 好,我们针对这个呃摘药独立样本体检验呢,写了一个 aj 二程序,它呢主要是特点呢,主要有这三个方面。一个呢就是我们不再需要每个样本的数据,就是 可以进行两组样本的独立样本体检验。第二个呢,在写的程序文件里面呢,我们可以进行方叉轻音检验,输出结果呢,不再是对他的方叉轻音检验结果进行展示,直 只输出的是对应判断好的批值和批值。第三个呢就是我们在眼线里面操作,就是呃,非常简便操作,呃,而且方便我们进行复制啊,以及呃一些表格的编辑处理工作。 好,我们分别来看一下。呃,这两个例子。第一个例子呢是我们是用一个他的一个原始数据来检验这两组样本是否具有差异, 就是用到的是独立样板气垫。好,我们先来看这 s a v 软件, 这呢就是我们用到的一个 suv, 就是文件判断呢,不同境别下乘机是否有差异。我们呢来做一下独立样板体检验正态性呢,我们这里先不管,先看一下结果, 性别呢,一格二乘机选进来。 好,这是我们的一个独立样本纪念片,你的结果我们可以看到呢,你看,这就是刚才我们输出的一个结果,特均值标准叉两组的样板量 n t 和 p 值,这里呢是满足方杀器性,所以 t 值呢对应负的一点五二 g, p 值呢是零点一四一, 就是我们这个表格里面截图部分了。然后呢,我们这里的摘药样本体检验呢, 主要是针对我们没有原始数据的情况下,只有这个样板量均值标准差,我们来做这个批值和批值。好,我们再通过这个摘药独立样本检验。这个程序文件呢,我们来做一下。 呃,这是我做的一个 a l 程序文件,因为里面有很多程序呢都保护起来了,所以呢,这里面我们做的时候呢,只需要把这个 a 组 b 组要买辆均值标准渣,这里我们对应复制过来就行了。呃,这里呢我已经录入好了,直接复制过来。 好,复制过来,你看我们这里 p 值和 p 值呢都对应改,改好了,我们可以看到了, 这个 t 值呢是负的一点五二九,然后 p 呢是对应零点一四一, p 值呢是完全相等, t 值呢是我们这里呢是稍有误差的,因为这里呢 我们小数点后的数值是没有他这个精确的,所以说呢,这期值呢,呃和批值呢在一些计算情况下呢会稍有差异,但是呢对他的结果是没有影响的。这这个 有效程序文件呢,你看我们在做的时候呢,就是很方便的输入样板量均值标准差两组的分别输入,然后这个 t 值和 p 值呢,我们是不需要动的,这里呢我保护起来了也动不了, 因为这是保护后的一个程序,所以说呢,我们在做的时候呢,只需要输入这一部分的内容就可以了。 好,我们回到。呃再进行第二个详情,就是说我们在有些分期的时候, 呃需要对长模进行比较,长模就是文献里面一些做量表的时候呢做的一些数值的结果,这里呢我们是肯定没有男士数据的,然后我们有的呢只是我们通过调查之后得到的一些数据,这里面呢就是 在一篇论文里面故事情节卷在长摩与准的标准研究,这一篇论文里面呢就是研究数据呢跟长摩数据做一做了一个比较, 做了一个比较呢,我们就看他是怎么得出来的。呃,这里呢还是我们已知的这个样板量均值标准差, 以这情绪衰竭为例呢,你看这,恩呢两组的样板量都知道了,均值标准差都有了,我们呢就可以通过我们这个这个小程序文件呢来计算他的一个期值和批值。好,我们再来看一下, 这里呢你看这情绪分解呃衰竭的样本量呢是一三二零,然后 呃对应均均值呢是二十三点零二,标准差呢十点二九,就这一组这一组速度过来, 你看我们这里呢 p 值和 p 值呢又自动更新了,所以呢对应的是二点零五九,就会对应他的二点零六,然后 p 值呢就是小于零点零,这样呢我们就可以通过 两组的样板量均值的标准差来计算他的一个 t 值和 p 值了。 好,关于大家如果需要这 a c r 独立样本旗舰店程序文件呢,可以联联系我们,这是我们的联系方式,就是说这个程序文件呢是经过 呃我们呃反复验证之后的呢,大家如果需要呢联系我们,但是呢这个是有偿的,需要。呃,付费。好,关于这个摘药独立样本几点呢?就介绍到这里。好,谢谢。
88数据分析李博士 04:11查看AI文稿AI文稿
04:11查看AI文稿AI文稿我们继续学习处理异常值,那所谓的异常值是指在数据集中与其他的观测值,其也就是其他样本显著不同的一些极端值。异常值可能是由于测量误差,数据录入的错误,还有样本本身有些特殊性 导致的。那么处理异常值的目的是为了确保数据的准确性和可信,以避免异常值对分析结果产生不良影响。我们在统计学中,我们学习到的经验法则已经告诉我们,一般来说 样本如果超过三个标准差,我们可以认为它是异常值。我们来看一下这个案例,对数据及员工信息中的变量当前心经,根据本节学习的方法,对变量的数据进行异常值的分析。 对于员工来讲,比如说经理或者一些资深的高管,他的收入高,他是有理性的,所以不一定就是异常值。在这里我们主要是做一个例子, 书里面使用的两种方法来处理异常值,第一种是使用探索命令来分析异常值,第二种是使用标识异常个案的命令来分析异常值。 我们打开员工信息这个数据集,首先我们进行探索分析,我们从分析这里进入描述统计,这里有个探索命令,我们进入我们要研究的是 当前心经,那我们就把这个当前心经放到这个音变量的列表里面,那这里统计的话,我们可以大家看这里有个离群值,在这里我们可以选择这个离群值,然后图这里的话,他已经有默认的敬业图,我们就不管他了。然后我们点确定, 我们得到了这么一个输出的结果,这个描述性统计分析我们后面再会学,我们看这个极值,这个表,极值这个表他就把当前薪金最低的五个值和最高的五个值都显示出来了,那我们就看一下 有可能出现的这个异常值,就是这十个异常值,那是不是有的员工太低了,有的员工的薪水太高了?第二个我们来看一下这个敬业图, 敬业图我们后面还会学那敬业图,它是一个很简单的而且有效的数据格式的方法,那么这种数据格式化的这个方法,我们可以看到这个 工资他的薪水主要集中在这个区域,那么两头是比较少一点的。那如果有出现这种的极端值,就是异常值会出现在两两端,那下面这个是镶嵌图,我们后面也会学习。那么镶嵌图 可以看到这个异常值和离权点,如果这个数据在这个两条,这个虚就是这两条虚的,超过这个我们一般都认为它是异常值, 那么这个异常值是针对平均值来说的,所以这个图并不能很好的说明我们心经的情况,这个说明什么呢?说明这个这家公司低收入的员工,他的占的比例是比较高的。 接着我们来学习标识异常个案,我们从数据这里进入,这里有一个命令标识异常个案,我们打开对话窗口,我们把当前心经给他选择过来,选择过来的话,个案的标识变量就是员工代码,这个是一个唯一的, 其他的这些输出保存缺失值,这些你用他的默认的就可以了。然后我们点确定,确定之后他生成了三个表,第一个这表格异常个案锁影列表,它是显示数据集中被标识为异常值个案的行的这个锁影 异常个案,所以它列表会列出哪些个案,它认为是异常的,那第二个是异常个案对等 id 的 列表,它显示的是被标识为异常值的个案,在数据集中对应的变量的这个值。 第三个就是异常个案原因的列表,这个它是显示每个异常个案的原因或者标识,它就提供了关于 标示某个个案为异常值的原因,就是为什么他把它标视为异常值呢?这三个表大家有时间可以自己去进行分析,这一节我们就学习到这里。
30何晓琦老师 06:17查看AI文稿AI文稿
06:17查看AI文稿AI文稿各位朋友大家好,今天我们开始学习 spas 统计分析实战终极篇,本次我们讲解的内容是 cox 比例风险模型回归, 我们来看一下具体的案例,研究某种新药的抗肿瘤效果。 将肺癌患者随机的分为两组,分别采用新药和常规药物进行治疗,同时要考虑年龄和性别的影响,也就是这里面我把年龄和性别当做邪变量。 在 spa 的数据文件里面呢,总共有五个变量,第一个变量也就是 group, 它表示新药和常规药。第二个变量呢是性变,分别是男女。第三个变量呢是年龄,这里面年龄呢也将它处理成了分类变量。 第四个变量是生存时间,最后的变量呢就是生存结局,那生存结局这里面呢,我们是用一表示死亡,零表示山势。 我们看一下在 spot 的界面里面如何进行分析。首先呢,在 spot 界面里面找到分析,然后再找到生存分析,那这里面呢,有个 cos 回归,我们点击 cos 回归,那这时候呢,就会弹出来 cos 回归的分析界面, 将生存时间拖入到时间,再严格将结 据拖入到状态的严格。然后呢,再将三个变量,性别,年龄,药物风阻拖入到鞋变量里, 那这里面的方法我们就直接使用强制进入法,不考虑逐步回归。 然后点击定义事件,出现新的对话框,在这里面呢,我们输入一,也就是表示结局,这个变量如果取值等于一,他就表示事件已发生,然后点击继续。 之后呢,我们再点击分类,因为我们的三个斜变量他都是分类变量,所以这时候呢,我们要把三个变量拖入到分类斜变量 单元格,那这时候呢,我们要来指定他的参照水平,就以性别为例,性别呢,他是两个水平,男性和女性,你究竟是以男性为参照,女性和他比,还是女性为参照,男性和他比? 你假设男性他的死亡风险是女性的一点五倍,那这时候反过来,女性的死亡风险是不是男性的一除以一点五倍啊?所以呢,你的参照水平不同,他的结果就会有所差异。 这里面通常而言,我们是以他取值最小的这个水平为参照,所以呢,我们就点击第一个,然后点击变化量,让每一个分类型变量后面都出现 force 的,那这时候呢,他们就以他取值最小的那个值 作为参照,然后我们点击继续,然后呢点击选项,在选项这里面呢,我们要勾上 e x p, 只有勾上 e x p, 它才会返回来 h r 的百分之九十五可行区间。 之后呢就是自主抽样,这个呢使用的比较少,我们就不过多讲解, 我们来看一下结果。首先呢,我们的样码量是七十, 发生结局事件的有三十三个,未发生结局事件的有三十七个,然后不存在趋势值, 然后是分类变量编码,比如这里面药物分组零是常规药。 一是星耀,我们当时在设置的时候呢,是以参照水平最小的为参照,所以这里面呢,我们是星耀和常规要进行比较。性别呢,我们是男性和女性进行比较,年龄呢是大于六十岁的与小于等于六十岁的进行比较。 之后呢就是模型的结果。在这个 ppt 里面呢,我们看的是方程中的变量这个表格,在这个表格里面呢,第一列是回归系数, 第二列是回归系数标准物,第三列是对回归系数进行假设检验所得到的瓦尔德卡方值。那第五列呢,就是它的 p 值,最后三列就是 hr 值以及 hr 值的百分之九十 区间。那这里面呢,我们先看一下 p 值,药物风阻,它的 p 值是小于零点零五,也就是说药物风阻是存在统计学意义,它的 o r 值呢,是零点三九零 over 的百分之九十,肯定区间呢是零点一七四到零点八七六。第二个变量性变,第三个变量年龄,它的 p 值呢,都是大于零点零五的,也就是说不存在统计和意义。 这里面药物分组,它是新药和常规药比,也就是说新药 他发生死亡的风险是常规药的零点三九零倍,或者我们可以描述成新药他的死亡风险 比常规药降低了百分之六十一,这个百分之六十一呢,就是一减去零点三九得来的。 感谢大家的观看,我是大鹏统计工作室的大鹏。
 00:27
00:27










猜你喜欢
最新视频
- 35.9万墨九玄