即梦ai怎么ai俩人抽象
这破天的富贵也是轮到抽象圈了,喜人也是好起来了,直接进化到和 ai 一 起抽象的新阶段了!看的我是一愣又一愣,本来还不理解这么有未来感的前后转头是在干什么,随承想呢?下一秒,张成的脸直接出现在整条街的大屏上,记得买年货的雷子看见这一幕,大海 你不是说就是个小商务吗?下一秒直接飞到月球,结果月球也全是应援骑,真是又怕兄弟哭,又怕兄弟开路虎!就当我以为这已经抽象到顶时, 没想到前一秒还在被各种亲切唠叨的李豆豆,下一秒直接骑马破窗而出!就这个大馋鱼,爽,看得我是一整个大震惊啊! 好好好,这完全就是梦到哪出演哪出啊!重点是,我敢说在雷子坐火箭李豆豆骑马之前,没人看出这是急梦做出来的视频,这人物表情,尤其是雷子破房大喊的表情,和实拍有什么区别?这 ai 造梦机,我直接梦住梦境级抓马,想哪出就演哪出!今年春节必须给我自己安排上数字分身皮肤!

粉丝316.9万获赞3179.4万
相关视频
 14:30查看AI文稿AI文稿
14:30查看AI文稿AI文稿这些这些这些 都是我用极梦 synx 二点零生成的效果。嗨,我是 ai 先生,我也算是一个干了整整十年的影视编导了哈,所以我花了整整两天时间,光充值就充了一千多,把极梦所有的功能案例以及网上各种神奇的用法 全部都测试了一遍,就只为了帮大家搞清楚一件事情, sims 二点零是不是 ai 界的 deepsea? 它真的有网上吹的那么强吗?以及它有哪些神奇的用法,并对咱们普通人有何影响?这应该是全网最完整的吉梦 sims 二点零评测解析视频, 视频有点长啊,但全都是干货,并且我把以下全部的测试的使用技巧,案例、提日词素材全部都整理到了线上文档,这么干的视频要个三连不过分吧? ok, 家人们坐好准备发车, 想要看懂 sims 二点零对于 ai 视频是否有颠覆意义,是不是 ai 界的 deepsea, 咱们要先搞清楚整个 ai 视频行业的发展脉络,那咱们就先花点时间来梳理一下啊。其实早在二零二二年菜的 gpd 刚刚震撼全球的时候啊, 就已经有了 ai 视频的概念了,但还没有一个完整的产品。甚至当时我们为了跟风啊,还把实拍的视频调个色,加个风格化, 伪装成 ai 视频。视频行业的朋友应该知道我在说什么哈。直到二零二四年, oppo ai 的 ai 视频模型 sorry 一 点零上线,这才一下子拉开了 ai 视频的大幕,尤其是这几个 ai 画面,不知道大家还有没有印象啊,当时确实把我给震撼到了。之后呢,国内的厂商也快速跟进, 快手的可灵、抖音的极梦也逐渐成为了咱们国内使用频次最高的两个 ai 模型,毕竟国外的 sora 和双威啊, 封门槛太高了,论性价比啊,还得是咱们国内的软件更懂咱们国内的市场。但即便是发展了两年,各种 ai 视频软件的顶配还是有几个核心的痛点, ai 视频一直没办法解决。第一个,人物不真实,虽然在质感上已经有了非常大的突破,但是很多人物的动作或者表情还 还是不太符合现实的物理规律。而第二个呢,人物缺乏一致性,生成剧情和故事的时候往往需要多个镜头画面,但这个时候主要人物就很难保持长的一样。第三,生成的结果不可控,就是每次生成都需要开盲盒,俗称抽卡,又花钱又浪费时间。那么这个极梦的 sims 二点零解决这个问题了吗? 其实啊,目前几个顶级的 ai 软件,他们的攻克方向各有不同,就比如说骚扰二,在技术上其实领先了很多,它采用的是 trance 八八的架构和隐士物理引擎,尽可能的还原物理规律,让画面的人物更真实。而可灵呢,则是采取了小步快跑的策略,迭代了很多 的版本。现在的三点零版本呢,是主打的人物动作的精细化。我不知道大家有没有印象,可灵之前有一个画笔的功能,轻轻一画人物这一块确实也沉淀了很多年了。当, 当然,这也和他背靠快手庞大的短视频美资库有关系。快手上什么最多呢?还不就是跳舞直播的小哥哥小姐姐比较多吗?那抖音呢?刚好相反,抖音这几年主打的是短剧或者是精选视频, 所以极梦主攻的方向就是在镜头的故事性和人物的一致性上。哎,那可能有朋友要问了,这个极梦和这个 sims 到底有什么关系?其实啊,这俩还真的不太一样, 因为极梦 ai 呢,它是属于字节推出的 ai 视频创作平台,它其实是归属在剪映的开发团队,也就是深圳的脸萌。而这个 c 震四呢,其实是字节实验室里自研的底层视频生成模型。 其实这俩并不能完全等同于一个东西,但两个产品呢,实际上是深度绑定的。这个 c 震四呢,不对外开放任何接口,也不允许第三方调用。 如果大家想要使用的话,只能在极梦平台豆包 app 和小云雀 app 以及火山引擎的这个 app 上来进行 使用。而 synx 二零二五年初上线之后呢,一共也就更新了两个半版本,到最近的二点零版本,能有这么夸张的成绩,进步速度啊,也算是相当快了。咱们在用之前呢,先来重点介绍一下这个 synx 二点零的核心的技术优势是什么? 它是采用了双分支扩散变换器的模式,视觉分支啊,是基于三 d 卷积加川字发嘛架构处理时空信息,生成帧序列。而音频分支呢,则是基于波形扩散加川字发嘛架构来处理声音,频谱生成顿化和音效。 说白了呢,就是相比于传统的 ai 视频,先拍画面再配音,我这个画面和音频呢,同时生成,就像有一个剧组一样,导演在这里想镜头,而音效是同时配声音,所以这个镜头的效果呢,就大大提升了。哎,那 这样的话,未来是不是还有可能是三分之或者四分之?编剧来想剧情,导演想画面,摄影师来想镜头,而演员来想表演, 甚至音效师再来想声音。哇,但这样想想, ai 电影还不马上就要来了, ok, 说了这么多啊,相信大家对于整个 ai 行业的发展脉络和痛点,以及吉梦森纳斯二点零的优势都了解的七七八八了哈,吹,都吹了这么多了,我也没收什么钱,那究竟好不好用?是骡子是马,咱们必须拉出来遛一遛。 ok, 我 现在就给大家实际演示一下这个极梦怎么使用哈。目前呢,这个 cns 呢,是只支持字节旗下的平台可以使用,主流的呢,就是这个极梦 ai 和小云雀, 这俩呢,都有 app 和网站,如果简单一点呢,就可以用 app, 那 复杂一点呢,我建议大家还是用网站好一点。那这两个软件有什么区别呢?就这个极梦呢,它是主站,它的功能会非常的全,但是呢,因为用的人也很多,所以生成一次呢,要等很长时间。那个小云雀啊,我自己实测,我就发现它生成的快很多, 当然它的功能不是很全,如果你想上传参考视频,它就不行。对,所以可能按你自己的需求来使用哈。 但是用过的朋友应该都知道啊,这两个软件有一个最致命的缺点,就是这个积分太贵了,每天一几百个积分也就只能用两三次。那今天大家算是来着了啊,我给大家分享一个我的秘密基地,随便升,不收费, 就是这个字节旗下的内侧中心火山方舟,大家可以看一下,你看这就是 sims 二点零,并且所有的功能都可以免费使用。但是既然是测试啊,人家肯定也有一个问题,就是他只能支持首尾帧,目前的参考视频目前还不支持测试。 ok, 我 们接下来就用极梦官网给大家来演示啊。 进来之后呢,大家可以先点击左上方的这个灵感,打开这个输入框,在下面呢,大家可以先点击左上方的这个灵感,打开这个输入框,在下面呢,大家可以先点击左上方的二点零。 当然可能有同学要问了,哎,我的这个打开怎么没有这个 c c 的 二点零,最高只有到一点五,那实际上可能你是一个新号, 你可以选择左下方的这个一元会员,先白嫖个七天啊,然后就可以使用这个 c c 的 二点零了。那接下来呢,我们还可以选择它的功能,比如说全能参考或者手尾针,这两个用的比较多啊, 然后也可以选择画幅以及选择时间,那有一个点大家要注意这个,每一次你的生成需求,他都会评估你的积分,这个积分大概是三十多分,所以有些新人朋友啊,就是一开始还没想好怎么升,就胡乱的提交,导致这个积分都快用完了,还没有生成想要的片子, 所以大家一定要小心。大家其实也不用担心啊,我会把我接下来所有测试的这个素材提制词,包括成片全部都放到我的教程里,大家可以模仿着来使用,让大家少走弯路啊,把这个积分用在刀刃上 哦,我自己其实也摸索出了一些白嫖积分的野路子,等一下我再给大家讲。 ok, 我 们接下来就围绕 c n s 二点零的核心功能,从不同的使用场景有简入深的来带大家测试一下。 第一层呢,我们先来测试一下这个 c n s 主打的这个人物移植性和运镜效果,为了这个保证这个真实性呢,我还同时邀请了两位对比选手, 一个呢是这个全球遥遥领先的这个骚扰二,另一个呢是极梦的一生之敌可灵。三,第一题呢,我们就简单一点,我找了一张图片, 这个大家应该都不陌生啊,这个是全游里面雪诺对阵千军万马的画面,大家都知道后面的剧情啊,我们让 ai 来续写一个不同的剧情,怎么样?我先上传了一张图片,提示词呢是镜头跟随着男的的男子,然后一群骑士冲过来,他转身要跑, 然后镜头侧拍,后边的马冲过来把他顶翻。最后一个镜头呢,是镜头自上而下的俯拍,他被顶上了天空。 ok, 我 把这个提示词发给了吉梦以及包括可灵。大家看看啊,我们选的是三点零版本,以及发给了这个三二二, 因为为了公平起价,我们每个平台只给一次升成机会,来看一下他们的能力。 ok, 我 们先来看一下吉梦的效果, 这个镜头跟随运动还是非常不错的,被顶翻的感觉也很真实,真的有点像拳游里的画面啊。 ok, 我 们再来看一下,可怜可怜,这个人物被撞的怎么这么窝囊呀! ok, 我 们看一下。 sorry, 哇, sorry, 这个人物的质感明显要好很多,但是最后怎么飞起来了,有点离谱哎,大家发现一个问题没有,我给到三个平台的都是一个人物的背身,可玲和 sorry 其实都没有认出来,只有吉梦认出来这是全友里面的女男主角雪诺。 哇,这可能就是 tim 担心的那个问题,大数据快速解锁就可以知道这个人到底长什么样子。 ok, 吉梦,可灵、 sorry 分 别是一二三,大家觉得哪个好一点,可以打个分。接下来呢,我们再用它的首尾针来测试生成一下画面,这也是可灵的拿手好戏了,我们看一下吉梦能不能反超我的手针呢是一个小米汽车的图片,尾针呢是一个变形金刚, 奇石呢是汽车飞快的驶过,然后冲出悬崖,在空中变成了机器人。然后镜头呢是环绕拍摄,最后机器人落在地上,整个的风格呢是这个末日沙丘风。来,我们同时看一下,两个视频的效果 还是挺明显的,积木这个镜头环绕就非常有感觉,可怜的就在死满。 ok, 左和右大家觉得哪个好一点呢?第二层咱们再来测试一下他的仿拍视频的能力,这个就复杂很多了啊,需要调用到图片、视频以及音频,我就不让另外两个小手参与了, 我先找了一个抖音的热门音乐。这个银龙鱼大家应该也不陌生啊,我又找了五个动物来替换掉视频中的五个舞蹈演员, 来我们看一下生成的效果,还是挺真的。哇,这两个老哥怎么没有去掉啊,还有那个狮子在旁边摸鱼哎,不过大家看到没有,他整个的镜头运动和原视频非常接近,并且甚至是黑夜的噪点他都还原出来了, 真的不错啊,我今天这个功能真的急么?可以再深更一下,感觉以后的抖音热榜全部都是 ai 生成的视频了。哎,那如果想要仿照更专业的 t v c 广告呢? 那这个时候我们的人物啊,就要更精细一些了。我先让娜娜补,娜娜帮我生成了一个模特的三式图,然后再找了一个苹果的经典广告题,日词呢,就是把视频中的女主角换成男主,把手机换成板砖,然后完全模仿原视频的画面意境和人物动作。来我们看一下效果, 板砖有点突兀,但这个质感还不错,哎,最后怎么又切成手机了?这个女生还出现了有点小 bug, 不 过几分钟就能生成一个这样质感的广告,已经很牛了,想要入局广告行业的同学们可真的要三思了。 ok, 前面呢还都是小顺牛刀。第三层,咱们直接让他来拍个电影怎么样?要玩就玩最大的 黑之王悟空。不是前两天刚发了那个钟馗的 cg 短片吗?让我有点好奇呢,就是他最后被蒙面的那个人到底是谁?结束的时候不是戛然而止了吗?没关系,我们让 ai 帮忙去续拍一下。这个准备的环节就比较复杂了,我给大家简单描述一下。就是我先让拆的 gpd 帮我构建了一下接下来的剧情以及分镜头脚本, 然后再让那那不单的生成每一帧的画面,最后把这些图片全部都上传到节目的这里。其实词呢,也相对说复杂一点,就是零到八秒呢,我先描述在昏暗的客栈里,有一个人们套着头套,然后八到十秒,孙悟空和钟馗打起来了, 十一到十五秒,孙悟空直接冲上了钟馗的眼睛,大概这样的一个剧情。哇,我这条真的等了好久,来我们看一下效果,还原度还是挺高的, 帅啊,大家觉得怎么样?这个镜头质感是不是已经可以在黑神话悟空里以假乱真了? 不过就是时间有点赶啊,中间有点小 bug, 大家见谅啊。哦,如果大家在生成的时候积分不够用的话,我给大家推荐几种我常用的方法。第一个呢,就是多注册几个手机号,新号啊,可以白嫖,吃点低保,又或者是开个一元会员都可以用。 那又或者呢,是参加一下集梦的这种拉新活动,或者去海鲜市场淘一淘?但这个呢,就不好明说了,我把我过去踩过的坑或者觉得比较有用的都放到文档上了,大家可以按需来使用。 不过呢,大家注意到没有,我整个的测试呢,从单个的运动镜头到访拍视频,再到组合起来讲电影故事,一整套流程下来,其实就是一个完整的电影制作流程。 所以啊,你看似这个 cds 二点零只是对运动镜头的一个阶段性的升级,但它实际上呢,是突破了整个 ai 生成视频的瓶颈,让 ai 彻底颠覆影视行业更近了一步,这也是让 tim 都如此惊讶的真正原因。能看到这里的朋友呢,相信对于 ai 视频都非常的感兴趣,也有一定的见解了哈。 我呢也想说几句我自己的真心话,如果一定要评价或者总结的话,说实话,这个 c c 四二点零的升级啊,其实并没有让我那么觉得惊艳,我也不想无脑的吹它,它确实在人物一致性和运动镜头上有了非常大的改变,但如果以一个电影画面的标准来看的话,它差的还很 远。但其实我也看到了希望。你想啊, ai 视频从二零二四年问世到现在也就两年时间,已经能做到这种效果了,如果再给它两年呢?再给它五年, 咱们等得起,他又能给我们多少惊喜呢?也许到未来的某一天,我们就不需要再等待了,那些易难平的大作,全运的游戏,三体魔界, 咱们都可以用 ai 来实现,各位会期待哪一步呢?好了,这就是本期视频的全部内容了,感谢点赞,这会让视频推荐给更多的人。如果需要上述的所有的案例、提示词以及教程,欢迎留言,我免费送到。在这里呢,祝大家二零二六年新年快乐!
842AI先生李豪 01:39查看AI文稿AI文稿
01:39查看AI文稿AI文稿今天我们又来说极梦 ai 制作,朋友只有这么一张二十多岁的照片,想做一个恋爱主题的视频,没问题,我们在图片生成四点一中去还原他们的青春近景。半身男子身穿蓝色中山装,内衬白领 女子红色花裙子。二人在九十年代影院前侧面镜头相对站立凝视,表情温柔。墙上张贴的电影海报中有二人的明星造型,柔光电影质感。随后在图声视频中写女子轻抚男子胸前,然后二人看向海报。 这样循环的创作,我们就得到他们一个个青春的画面和镜头。来我们看效果吧!
3585卢某人(不回评就是限评了) 49:59查看AI文稿AI文稿
49:59查看AI文稿AI文稿欢迎收看二零二五全新极梦 ai 视频系统教程。明明用的同一个极梦,为什么别人做的视频就能一发入魂,符合预期效果,而你的视频却像脱缰的野马一样浪费积分不说,结果还得全靠运气。今天这期全是技巧,手把手教你从零到一,搞定完整 ai 视频, 不论你是新手小白,还是有一定经验的老手,学完都会有所收获。另外,视频里提到的所有工具、工作流框架和 操作要点,我都整理成了一份懒人文档,需要这份文档的小伙伴直接在评论区扣六六六就行,我会一一安排。话不多说,咱们直接开整。在上一期视频中,我们讲解了极梦 ai 的 纹身图功能, 同时也讲解了提示词的书写框架。那么有了图片之后,我们会时常对图片进行后续的修改,以此使得图片更加符合我们的需求。所以今天这节课就来学习一下关于极梦 ai 的 首页点, 点击左侧的生成选项可以看到这里我已经生成了一个桌子上放着香蕉的图片,是水彩风格的。我们将鼠标悬置在这张图片的上方,可以看到在下面这个位置就弹出了一个二级菜单,可以对当前的图片进行后续的各种操作, 或者点击这张图片来查看大图,在右下方有相应的操作选项。首先来讲解超清和智能超清, 顾名思义就是让图片变得更加清晰。例如我们现在点击智能超清选项,此时会弹出一个窗口,左下方是选择图片类型的, 通常选择自动就可以,大家也可以根据实际的图片类型来选择是场景还是人像,在这个位置有参考程度 机,打开之后会有两个选项,分别是原图保持程度和细节生成程度,都是字面意思,原图保持程度越高,那生成的结果和原图就越接近。而细节生成程度越高,在生成时就会给画面赋予更多的细节。当然这两个值都并非是越高或者越低越好, 太多的细节反而会使得画面失真,而太高的原图保持程度可能会导致增加的细节不够,所以这里建议大家保持默认即可。在右下方有放大的倍率,此时我们的这张图片已经是二 k 了,所以要放大的话也是选择四 k。 在 参数设置好之后, 点击右下方的生成,一段时间后,我们就获得了一张进行了四 k 智能超清放大的图片了。在点击查看大图之后,中间会有一条分割线,可以用鼠标点击拖拽的方式来查看放大之前和放大之后效果具体有什么差异。可以看到当前所示的画面是放大之后的效果, 我们将这条线向右拖动,此时所看到的就是放大之前的效果。如果仔细观察画面的话,应该可以发现这样的效果差异前后对比起来还是比较明显的,确实给画面增添了很多细节,也将一些原本模糊的部分进行了高清化处理,我们下面再来讲解。第二个功能就是局部重绘, 现在回到极梦 ai 这里,我提前生成了一个红色眼睛的动漫二次元少女。局部重绘功能通常是用来修改画面当中的局部的,在很多情况下,我们生成的图片可能摆 分之八十,百分之九十都是满意的,唯独剩余一小部分不够满意。这个时候就可以使用局部重绘功能。在点击查看大图之后,选择右下方的局部重绘选项,这时同样会弹出一个新的窗口,我们将鼠标悬置在这个窗口当中。图片的上方可以看到此时的光标已经变成了一个选区。笔 用来选择需要重绘的区域,例如现在我们就选择人物的眼睛部分,在选择好之后,可以看到下方还有其他的选项,例如橡皮擦工具,这个橡皮擦不是用来擦除画面的原本内容的,而是用来擦除我们所选择的区域的。在点击之后,和选曲笔工具一样,这里有一个滑块,可以选择橡皮擦工具的大小。 在这里还有一个移动工具,在点击之后,光标会变成一个手的图标,这个工具主要是用来移动画面的仕图内容的。 有时想要对边边角角的部分进行选中或者解除选中,但受限于当前这个窗口的大小不太好选中的话,就可以将画面通过移动工具将试图移动到中间位置,以此对边边角角的位置进行处理。 此外就是撤销和重做,点击这个箭头就会解除之前我们所操作的内容。在进行了选区工作之后,需要在最下方来描述我们要重绘成什么样子。 当前选择的是眼睛的部分,所以这里我们就描述将眼睛修改为绿色,然后点击右下方的生成一段时间后,我们就获得了以刚刚生成的第一个人物为基础进行了局部重绘的绿色眼睛的人物了,不过当前所生成的绿色还是比较炸眼的,大家在描述时也不妨 描述的更加确切一些,比如低饱和度的绿色,偏蓝一些的绿色,以此来使得重绘的结果更加自然。我们下面再来看扩图功能,这项功能也非常实用,同样的点击查看大图,在右下方有一个扩图选项,在点击之后会弹出一个新的窗口,在这个窗口当中 会显示两部分的内容,一部分是原图,而另一部分是扩充之后的区域。我们可以用鼠标来拖拽这个选框的大小,以此来决定将图片扩充到何种程度。也可以用鼠标去拖拽选框中间原本的图片,让其位置更加靠上或者靠下,以此来调整图片在扩充之后 所吸引产生的区域。而在下方可以选择扩图的比例,比如当前的比例是按照原图的宽高比进行扩图的,也可以选择一比一、三比四、九比十六、四比三、十六比九等这些常用的固定宽高比。在最下方可以描述扩图的内容, 如果不描述的话,会基于画面当中原有的内容来生成近似的元素进行扩充。在确定好参数之后,就直接点击右下方的开始生成, 一段时间后,扩充好的图片就生成好了,可以看到它基于原图的内容生成了人物的全身像。其实在极梦 ai 当中, 有些时候我们想要生成全身像是一个比较困难的事情,哪怕选择了宽高比较为合适的生成比例,在提示词中也描述了要生成人物全身,但在某些特定情况下也无法生成令人满意的效果 时,不妨尝试一下使用扩图功能,将人物的半身像扩展为全身像,这样的成功概率是很高的。我们下面再来看第四个功能,就是消除画面内容的功能。 现在的很多 ai 手机其实也具备这样的功能,在拍照时如果旁边多占了个人的话,可以用这项功能进行消除。再次点击查看大图,在右下方选择消除笔这个选项,此时就会弹出消除笔相关的窗口,我们需要做的事情就是调节左下方的滑块,来改变消除笔所选的范围大小, 然后用鼠标拖拽的方式在原画面当中选择需要消除的内容。比如现在我们通过拖拽的方式选中人物,同时选中左上方的水印,在选择完成之后,直接点击右下方的生成选项,可以看到此时我们就成功的消除了画面当中的人物和水印。 不过需要注意的是,虽然上一张内容的水印成功消除了,但本身极梦 ai 生成的图片依然保留有一个水印,所以大家想要消除水印的话,不妨尝试使用其他平台的专门用来消除图片水印的工具。我们最后再来看细节修复功能。在目前极梦 ai 的 版本下,其实并不是很推荐大家使用这项功能, 因为在很多时候他往往会起到负面效果。我们依然是以这个香蕉为例,点击查看香蕉的大图,然后选择右下方的细节修复。这项功能是不需要我们设置参数或者填写提示词的,在点击之后直接就开始进行了,一段时间后进行了细节修复的效果就生成好了。现在点击查看一下, 可以发现最终修复好之后的效果和我们之前所看到的原图其实并没有十分明显的差异,不是说反而弱化了很多画面当中原有的 桌子上的纹理等。这些细节。之所以会产生这样的效果,是因为这项功能原本是针对于极梦 ai 平台上所生成的一 k 分 辨率图片进行优化的,而现在我们在极梦 ai 上所生成的图片最低是二 k 的 分辨率,所以这项功能没有及时的更新就会导致如今这样的效果。 在将来如果想要使用这项功能的话,要么不如选择智能超清选项,要么不妨尝试一下,如果它效果确实变得更好,届时对细节修复的模型进行了更新,也可以使用这项功能。那么以上就是关于在极梦 ai 当中图像处理功能的知识,大家在使用这些 ai 工具时也可以多尝试一些不同的平台, 每家平台的功能不同,特性不同,擅长修改图像,生成图像的方向也不同,可能有时单一的平台是无法满足我们的生成或者修改需求的。如果觉得本期视频的内容对你有帮助,也不妨点赞关注、支持一下,我们就下期视频再见。大家好,我们这期视频来讲解极梦 ai 的 参考图生图功能, 共有这七项,我们下面逐一进行演示。来到极梦 ai 的 首页,点击左侧的生成选项,将模式修改为图片生成模式。既然是参考图生图,我们首先要上传一张参考图,通过点击这里的加号或者鼠标拖拽的方式,将参考图上传上来,我们此次生成就以这张图片为例, 来看参考图生图的第一项演示功能,修改颜色。这里我们直接在提示词里面描述,将人物的头发修改为暗红色,其他部分保持不变。回车发送可以看到一段时间后图片就生成好了,整体的修改效果还是非常不错的, 十分稳定的将人物的头发颜色修改为了红色,同时和原图相比,人物在造型和背景上都保持了高度的一致,如果我们想要修改其他部分的颜色,就直接在提示词中描述修改某个部位的颜色即可。我们下面来看第二项功能就是修改环境, 此次生成就以这个站在草地上的人物为例,回到吉梦 ai 的 生成页面,我们将这张参考图上传到预备窗口当中,而提示词方面就直接描述给人物的背景更 更换为健身房,只改变背景不改变人物。现在点击发送可以看到此时我们生成的结果,就在原图的基础上,将人物所处的草坪背景更换为了健身房背景。而相较于原图,我们可以看到人物在造型设计、长相特征上,甚至连打光上都是没有发生改变的,而是让背景的光影和环境 主动去适配人物,一次性会生成四个结果,我们可以从中找一个与人物融合程度更好的。下面再来看第三项功能,就是修改姿势和角度,我们再次更换一张新的参考图,以 这张图片为例,回到极梦 ai 的 生成页面,将参考图上传到预备窗口当中,而提示词方面,我们就直接描述想要人物做的事情 及想要人物所处的环境。例如这里我们就直接描述生成人物在咖啡厅喝咖啡的画面,点击发送可以看到一段时间后图像就生成好了, 现在点击查看大图,可以看到我们新生成的图像在人物的长相特征和穿着上,是不是和原图保持了高度的一致性呢? 同时在人物改变姿势和所处环境的时候,我们也能感受到人物身上的光影也随着环境发生了改变,并不会产生单纯的抠图 p 图后的违和感,这就是如何修改姿势和视角。下面再来看第四项功能,如何固定造型修改环。 此次生成我们以这张图片为例,因为这项功能经常会应用在一些电商产品宣传图更换背景上,我们依然回到极梦 ai 的 生成页面,将参考图上传到预备窗口当中,在上传好之后,提示词就描述固定产品的造型,给 产品更换一个沙漠的背景,背景中有金字塔和河流。此外,在生成之前,为了能够更好的固定产品的造型,我们可以点击上传产品参考图的位置,再点击之后会弹出一个叫做智能参考的窗口,在窗口中点击左下方这个人像图标, 此时就会识别画面当中的主体内容,在识别好之后,会以淡蓝色的形式覆盖在主体上面,以此来标记选中的区域。 看到这里,我们就成功的选中了产品的主体部分,现在点击右下方的保存,这样一来我们在生成时就能够更好的固定产品的造型设计。下面点击生成,可以看到一段时间后效果就生成好了,成功的生成了我们在提示词中所描述的沙漠、金字塔 和河流的背景,且产品和环境之间在光影上十分统一协调。这里我们同样放置一张原图来对比一下,可以看到产品原本的受光以及造型是没有任何改变的,而背景的受光已经 地面上的影子则主动迎合了原本的产品进行了生成。所以和上一个演示不同,这种锁定主体的生成方式是不会改变主体本身原有的受光的。我们下面来看第五个功能,就是参考风格,我们此次生成就以这张图片为例。回到生成页面,将 张图片作为参考图上传到预备窗口当中,在上传好之后,提示词这样书写参考图片的风格。生成配色、姿势设计不同的图片,现在点击发送,可以看到一段时间后符合要求的四张图片就生成好了, 在设计、配色和人物姿势上都产生了不同的效果。我们继续来讲解第六项参考图生图功能,那就是 control night。 如果大家使用过 stable fusion 的 话,相信对这项功能并不陌生,或者多少听说过这样的功能,其实在极梦 ai 上同样有这样的功。 回到极梦 ai, 我 们将下方的图片模型由四点零更换为三点零,在更换好之后,点击图片预备窗口中的图片,此时弹出的窗口在选项上和四点零模型会有很大的差异, 看到下方提供了更多的图片参考选项,有智能参考、角色特征、人像写真、主体识别、风格参考、边缘轮廓、紧身和人物姿势。其中后三项就是和 control night 相关的功能,例如我们现在选择这里的边缘轮廓,可以看到右侧就会输出对应的检测图,将 将人物的线稿轮廓进行锁定,点击右下方的保存,此时再生成新的结果,就会生成在轮廓和设计上与参考图非常近似的结果。比如现在我们输入将图片的色调改为黑金色调,现在点击 发送可以看到由于锁定了人物的线稿轮廓,所以最终生成的效果。人物在造型设计上就和我们上传的参考图保持了高度的一致,但同时也不难发现最终生成的结果在环境的表现上并不是很好,同时也并没有很好的理解我们的意图。我们要的是黑金色调相关的设计, 而并非将人物变成金属质感带有黑色装图的人物。这也是三点零模型和四点零模型之间的差距,对于语言的理解能力,四点零模型会更胜一筹。而其他的三点零模型当中,和 controntight 相关的参考图升图功能亦是如此。 现在我们来看下一项功能就是景深检测,这项功能通常用来修改一个风景图的四季,例如现在我们上传一张风景图,然后将检测类型改为景深,在修改好之后,可以看到右侧的检测图就成功的检测出了 我们所上传这张风景图片的深度,点击保存。而提示词方面,我们就书写将季节改为冬季,回车发送一段时间后,修改了季节的图片就也生成好了,现在点击大图看一看效果如何吧! 看到最终生成的结果并不是十分理想,虽说整体的画面深度和原参考图相比,确实在深度构图上保持了高度的一致,但也不难发现 整体的美术风格发生了巨大的变化。所以需要大家知道的是,这项功能同样是一个比较过时的功能,大家想要改变图片的季节的话,还是建议将图片生成模型修改回四点零模型。虽说四点零模型并没有专用的 control night 相关功能, 我们在修改时只需要在提示词中强调其他部分保持不变,然后点击发送可以看到,通常来说就能获得比使用了深度检测更好的转换季节的效果,在美术风格上与原图保持了高度的一致。 我们下面再来看第三项 control night 功能,那就是人物的姿势检测, open pose。 现在上传一个人物的图像,我们依然是以这张图片为例,在上传好之后,将图片的生成模型修改为三点零模型,然后点击图片预备窗口中的图, 将参考方式选择为最右下方的人物姿势,记得在选择好之后要修改一下生图的比例,改为适配当前参考图 的比例,这里我们就选择九比十六。可以看到,此时的检测图就非常完整的检测出了人物的骨骼轮廓,这就代表着待会生成的新的图片在姿势上也会与这张图片的姿势保持高度的统一,而具体的设计 内容和风格就取决于提示词的描述了。在选择任意的参考方式时,包括在使用四点零生成模型参考时,在左下方都会有一个参考强度的选项,这个选项通常保持默认即可, 当然具体要看生成的结果来决定。如果你觉得生成的结果,可以再参考多一些,原图就可以将这里的参考强度调整的高一些,反之则调整的低一些,现在点击保存。而提示词方面,我们就先描述一个人物的形象,例如这里我们描述一个穿着 jk 的 高中少女, 点击发送可以看到一段时间后图片就生成好了。不难发现,生成这四张图片在人物的姿势上都与参考图保持了高度的一致,是一个正面双臂自然下垂的站姿。我们最后来看多图参考功能,这项功能很好理解,就是字面意思,可以将多张参考图 同时进行参考,融合在一张图上。例如这里我们首先将图片生成模型修改为四点零来获取更好的融合效果,然后分别将一件衣服的图片以及一个人物的图片上传到参考图的预备窗口当中。在实际操作时,大家也不仅可以上传两张图片,想要上传第三张、 第四张也是可以的。不过上传的图片越多,在融合的时候可能融合的效果就会越差。在大多数情况下,我们也不需要用到那么多参考图, 现在就在提示词中描述,让图二的人物穿上图一的衣服。这里图二指的就是我们上传的第二张图片, 图一指的是我们上传的第一张图片,以此类推,现在点击生成,需要注意的是,在生成的时候,在宽高比上一定要选择合适的宽高比,例如当前的两张图片都是九比十六的,我们就选择九比十六,或者调节为最左侧的智能选项,让 ai 自行判定什么样的比例是最合适的。 段时间后图片就生成好了,我们点击查看大图看一看效果如何吧。可以看到,生成的结果就成功的让人物穿上了在参考图当中,我们所提供的碎花长裙,且人物的长相特征、姿势都是保持不变的,与周围环境的光影也融合的非常恰如其分。 当然,如果有对应的鞋子或者帽子或者像眼镜这些内容想要穿在人物的身上的话,我们可以一并将这些内容相关的参考图上传到预备窗口中,并在提示词里面描述对应的要求。 相信大家都具备举一反三的能力,所以这里就不再做庸俗的演示。那么以上就是关于本期极梦 ai 参考图升图功能的全部讲解,如果觉得本期视频的内容对你有帮助,也不妨点赞、关注、支持一下, 我们就下节课再见!大家好,我们这节课来讲解极梦 ai 的 视频生成功能。首先来看文生视频,要想使用文生视频功能,我们就需要特别注意,在提示词的书写上要尽可能全面。在先前的课程中,我们讲解了提示词的书写公式,这样的公式在文生视频时同样适用, 我们下面来简单演示一下。来到极梦 ai 的 首页,点击左侧的生成选项,将下方的下拉菜单更改为视频生成,下面来输入提示词。 首先是主体元素,例如这里我们描述一个戴着眼镜的猫头鹰,穿着西装,戴着帽子,然后是背景环境,这里我们就描述在办公室中,我们让他看报纸。下面来描述视觉风格,这里描述三 d 高精度建模风格 这一项色调、文字构成和氛围用语,大家需要的话可以做详细的描述,如果不需要的话就直接生成。但是在生成之前,我们需要注意和生成一张图片有所区别的是,在纹身视频时 了描述图片本身的内容。我们还需要额外描述两个内容,一个是镜头的运镜,例如固定镜头、镜头推进镜头拉远等等。 而另一个是画面当中事物的运动状态,例如这里我们书写办公桌上放着一杯冒着热气的咖啡,这样一来就构成了生成一条纹身视频的完整提 现。在点击发送,在等待生成的时间,我们来简单介绍一下生成视频时的参数设置。首先是视频生成模型,和图片生成模型一样,版本标号越高的模型生成效果就越好。然后右侧是视频生成的模式,有首尾帧、智能多帧和主体参考, 接下来都会讲到。然后是视频生成的比例以及视频生成的分辨率,在图生视频时,默认生成的比例和图片是一致的。再往右侧是视频生成的秒数,有五秒和十秒可选,在大多数情况下,选择五秒就足够成为一个分镜头片段了。不是很建议大家生成十秒钟时长的视频, 因为时间越久,画面出现问题的可能性越高,非必要的话还是尽可能选择五秒钟的时长。最后是一些官方所给出的运镜,这里我们用提示词描述或者选择官方给出的镜头都可以可以看到,现在视频已经生成好了,整体的效果表现还是不 错的,像办公室办公桌冒着热气的咖啡,还有看报纸穿西装的猫头鹰。可以说生成的视频完全符合了提示词的描述。但这里我们必须要强调一下,那就是在百分之九十九点九的情况下,都不建议大家使用纹身视频的方式来生成视频片段,因为这样生成的画面存在很大的不可控性, 怕文字描述的再细致,可能在设计、美术、风格、色调等等方面总会有我们不满意的部分。而相较于修改一张图片,对视频进行后期修改所要花费的时间成本会非常的巨大,且生成一条视频本身就需要消耗很多的点数,不像生成图片,在极梦 ai 上会员是免费的,几乎是零成本。 所以大家最好还是先生成图片,将画面的内容、色调、风格等方面都确认好之后,再生成视频 一个更加稳妥的方法,成本也会更低。所以我们下面就来讲解关于徒生视频相关的操作。想要使用徒生视频,自然是要上传一张图片作为手帧图。 和徒生图中上传参考图一样,我们将作为手帧图的图片通过拖拽的方式上传到预备窗口中。这里简单解释一下手帧图的意思,它的意思就是将来在生成的视频中,这张图片会作为视频的开头来进行后续的生成, 而伪真图的意思想必大家也清楚了,会作为视频的结尾来生成视频。我们先来尝试手真图生视频,提示词方面,我们就描述镜头的运镜以及画面当中事物的变化,比如这里我们就描述固定镜头, 人物戴上墨镜。可以发现我们这次生成时就不需要描述那么多的提示词内容了,因为图片已经给出了充足的内容信息,所以就只需要描述画面当中镜头的运镜和事物的变化。现在点击生成一段时间后,视频就生成好了。可以看到整体的视频表现还是非常不错的, 人物动作流畅,并且十分稳定的听从了提示词的要求,给人物戴上了墨镜。不过通过手真图升视频的方式,我们是无法决定最终在视频结尾时所呈现的画面效果的。例如我们现在想要人物戴上固定款式的墨镜,通过手真图升视频的方式就无法实现, 此时就要使用首尾真升视频功能了。例如这里我提前使用参考图升图的功能,给人物戴上了一个紫色镜片的墨镜,而其他的部分是保持不变的。现在将这张戴上紫 墨镜的图片作为伪真图上传到预备窗口当中,在上传好之后,提示词方面就保持不变,依然让人物戴上墨镜,现在点击发送一段时间后,视频就生成好了。可以看到此时人物所佩戴的墨镜款式就是我们在伪真图当中指定的有紫色镜片的款式了,不 过每次生成都会伴随着一些随机性,如果没有生成好的话,可以点击下方的再次生成选项,尝试多生成几次。了解了什么是首尾真生视频。 到生成页面,我们将首尾针生视频的下拉菜单展开更换为智能多针。可以看到此时在这个位置会出现一个新的图片上传窗口,用来上传第三针图片。 此时我们刚刚所上传的第二针图片就变成了一个中间针,而第三张图片才是画面的尾针。这个时候如果我们想要人物连贯的做出很多不同的行为,比如先戴上墨镜,然后拿出汉堡吃汉堡,我们就可以使用智能多针功能,一次性生成人物做出多个行为的视频。 例如现在我们将这张图片作为第三针进行上传,而这张图片作为第四针进行上传。在上传好之后,可以看到图片与图片之间会有一个添加提示词描述的部分,点击这个部分会弹出一个提示词输入窗口, 用来描述两张图片之间是如何进行转换的。例如在戴墨镜和戴墨镜拿出汉堡之间,我们就描述人物拿出汉堡,在拿出汉堡和吃汉堡之间,我们就描述人物吃汉堡点 确认。需要注意的是,添加的生成图片越多,在生成时所消耗的点数就越多,同时也有更高的概率会使得生成的画面出现不好的情况,所以非必要的话,大家也不要一次性生成太长的视频。 现在点击发送,看一看效果如何吧。最终生成的效果还是非常不错的。可以看到在画面中,人物先拿出了墨镜,然后戴上墨镜之后又掏出了汉堡,把汉堡对着镜头进行了展示,然后就是吃汉堡的画面, 整个画面非常的连贯流畅自然。不过这样的生成同样也存在随机性,特别是当图片与图片之间在美术风格、人物姿势、场景环境跨度较大时, 很多时候可能就无法达成有逻辑的转换了。所以大家在使用智能多帧功能时,尽量使用固定镜头,同时人物在造型和角度上也 不要有过大的转换。我们最后来看参考图生视频功能,回到极梦 ai 的 生成界面,将下方的智能多帧下拉菜单更改为主体参考。这项功能和参考图生图功能非常类似, 只不过生成的结果由图片换成了视频。例如现在我们依然以这个人物和这个裙子为例,分别将人物的图片和裙子的图片上传到预备窗口当中。 而提示词方面,我们就书写图一的人物穿着图二的裙子在公园散步。镜头跟随在生成之前,可以看到在右下方有一个艾特符号,我们点击这个符号,上方会弹出主体内容,选定这个内容, 此时可以对图片当中的主体进行引用,相比于单纯的描述图一当中的人物或者图二当中的裙子,这样的引用指向性会更加明确,所以我们现在来修改一下书写格式,就修改为镜头跟随图一的人物穿图二的裙子, 持图一和图二为引用的状态,然后加上在公园散步,在书写好提示词之后,就点击右下方的生成,可以看到最终我们就成功的生成了人物穿着裙子在公园当中散步的画面。不过不得不说这项功能整体的表现并不是很好,人物的造型和 服装的款式在生成之后都发生了一定的变化,且动作也不是十分流畅自然,而环境方面也更倾向于原图的环境,而并非是我们所描述的公园, 这项功能目前还不推荐使用。以上就是极梦 ai 的 视频生成功能讲解,我这里也整理了一份视频生成的提示词技巧相关攻略,如果大家需要的话,可以查看评论区的置顶,如果觉得本节课的内容对你有帮助,也不妨点赞关注支持一下,我们就下期视频再见。 大家好,我们这节课讲解动漫与电影一次性生成多分镜视频片段,一共分为三个部分, ai 生成手帧图、生成运镜提示词以及生成视频。 我们首先来看 ai 生成手帧图,来到豆包 ai 当中,我们首先来获取生成图片的提示词,这里我们这样填写,你是一个提示词书写大师,给我三个可以生成新海城电影风格的中文提示词,要求包括主体、背景 风格、色调、氛围的描述。现在点击发送一段时间后,我们就获取了非常详细的提示词描述,现在将任意一段提示词复制下来,然后来到极梦 ai 的 生成页面,将生成模式更改为图片生成,将提示词复制粘贴过来。这里的生成参数方面竟然是要生成电影相关的分镜头, 比例自然是选择十六比九,然后直接点击生成,可以看到一段时间后我们就获得了新海城风格十足的电影分镜头画面, 可以看到生成的这几张结果效果都是不错的,不仅人物的长相和穿着特征十分符合新海城电影当中的风格,像人物所处的环境以及画面当中光照的设定也和新海城电影的风格十分契合。现在我们从中挑选一张自己较为满意的结果,将其下载到电脑本地, 在下载好之后,回到豆包 ai 中,将刚刚下载好的本地图片上传到豆包 ai, 我 们下面来进行第二步生成运镜提示词, 提示词方面我们可以这样书写,请以这张图片作为起始镜头,打造一个多机位视频,呈现出壮观的氛围。需要四个连贯分镜,分镜头脚本包含景别视角、运镜画面等内容,每个分镜用不同的运镜方式, 要求用词简洁,字数不超过四百字,下面点击发送。当然这里大家也可以更改连贯分镜头的数量,通常来说五秒钟的视频两三个分镜头就已经比较多了,一段时间后我们需要的分镜头多机位描述就生成好了,直接将这些描述复制下来, 然后回到极梦 ai, 将生成模式修改为视频生成,然后将刚刚我们下载好的参考图上传到手抷图的位置。而提示词方面就直接将豆包 ai 中 生成好的不同分镜头画面提示词内容粘贴过来,这里可以根据我们的需求来修改生成的时间。像四个分镜头画面的话,其实十秒钟的时间也是可以的,不过此次演示我们就暂且选择五秒,然后直接点击发送, 一段时间后视频就生成好了,来看一看效果如何吧。可以看到整体的画面表现还是非常连贯流畅的,且画面和画面之间也存在逻辑和风格上的关联。用相同的方式,我们想要制作怎样的电影多分镜头片段,也可以使用类似的方法。 重新向豆包 ai 提问。给我三个可以生成阿凡达电影风格的中文提示词,要求包含主体、背景、风格、色调、氛围的描述。现在点击发送一段时间后,提示词就生成好了,我们将提示词复制下来,一共有三个,大家都可以尝试生成一下,从中挑选一个自己最满意的。 在复制好之后,回到吉梦 ai 的 生成页面,将提示词粘贴到输入框中,尺寸方面依然保持十六比九的比例,现在点击发送 可以看到一段时间后,我们所需要的阿凡达电影风格对应的分镜头图片就也生成好了。这样的生成效果是不是和电影当中的截图非常相近呢?再来看第二张,同样有着非常好的生成效果。再来看第三张,还有第四张,我们就从中挑选一张效果不错的,将其下载到本地, 在下载完成之后,重复刚刚的方法,将参考图上传到豆包 ai 当中,而提示词方面我们就稍加修改,之后使用 具体的内容填写。请以这张图片作为起始镜头,打造一个多机位视频,呈现出星球环境的壮观和飞行的场面。需要设计四个连贯分镜,包括景别、视角、 运镜、画面等内容,每个分镜用不同的运镜方式,要求用词简洁,字数不超过四百字。现在点击发送片刻之后提示词就生成好了,我们将这些提示词直接复制下来,回到极梦 ai 当中,将生成模式修改为视频生成, 上传我们刚刚下载好的手真图,而提示词就使用豆包 ai 帮我们生成的,然后直接点击生成, 一段时间后,包含了多个分镜头的阿凡达视频片段就生成好了,来看一看效果如何吧。可以看到整体的效果还是非常连贯的,并且从多个角度展现了人物和场景,不过这样的生成通常会伴随一些随机性, 如果觉得效果不好的话,可以点击再次生成来挑选一个更加满意的结果。以上就是本期视频的全部内容,其实不仅仅是我们今天所说的新海城风格或者是阿凡达风格,像很多知名电影的风格,大家都可以尝试用今天所学的知识举一反三来生成类似的多角度的分镜头视频。 这里也给大家准备好了一些一次性生成多分镜头视频片段的相关提示词素材,需要的话可以查看评论区的置顶。如果觉得本期视频的内容对你有帮助,也不妨点赞关注支持一下,我们就下期视频再见。 大家好,我们这期视频来讲解像刚刚那样的水墨风格的短视频该如何用极梦 ai 制作。来到极梦 ai 的 首页,我们这次生成依然使用的是 agent 模式。在提示词方面,我们就书写生成十六张水墨风格的故事图, 要求前后连贯有逻辑。故事讲述的是中国古代故事,彩色水墨风格,中式美学,人物造型简洁生动可爱比例十六比九。和上节课的流程类似,一段时间后,我们就获得了由 a 镜的模式所生成的十六张前后连贯且具有逻辑的中国古代故事风格是 彩色水墨风格,带有中式美学。可以看到整体生成的带有前后逻辑的图。 如果说不做额外的要求,通常 agent 模式是不会给我们回值具体的故事内容是什么的。我们可以通过生成的图片所使用的提示词来分析出当前的故事讲述的是什么内容。 看到像第一张图片是一个年轻的女画家正在专心的作画,而第二张图片是画家在取水的时候,有一条鲤鱼闪闪发光,紧接着鲤鱼化做人形,并且指导这个小画家如何进行作画。所以这一系列图片大致讲述的就是一个小画家的奇遇。接受了来自于湖中 神仙的指导,变得更加擅长绘画。那么了解了大致的故事梗概,我们可以从生成的这十六个结果当中挑选一些我们认为比较好的结果,特别是像这种场景当中带有人物的,我们最好能够保持人物的一致性,所以在人物的造型方面要有所筛选。有时可能会需要重新生成分镜头图片。 再将这些分镜头图片生成好之后,我们下面要做的事情就是将它们下载到本地电脑,根据出场的前后顺序以及我们对故事的了解,从小到大,从前到后进行标号。在标号完成之后,我们下面要做的事情就是回到极梦 ai 当中,使用智能多帧功能来生成一条连贯的视频 图片与图片之间使用不同的运镜和画面描述。比如第一张和第二张图片,我们使用的是推镜头,但和上节课的运镜描述会有所区别。这样的区别主要源自于画风的差异, 我们当前生成的是有大量流白的水墨风格,且除了这样的风格外,故事本身也伴随着一些神话色彩,会出现一些超越常识的画面表现。所以我们这里来举几个例子。首先将生成模式切换为首尾帧生成 来看第一个分镜头画面,我们生成的是推镜头,镜头推进来到窗外,自然过渡到下一张图片,此时的第一张图片是这个样子的,而第二张图片是这个样子的。 可以看到在景别上,两张图片基本是一致的,近景画面镜头的高低也基本一致,所以我们要做的事情就是在同一高度下对镜头进行运镜,这里就使用了推镜头。而像第一张图片,画面当中是有窗户的,通常像这样的画面,根据我们观看一些影视剧的经验,通 常导演会安排一个镜头向窗外推进的运镜,所以这里我们就使用了同样的运镜,让镜头推向窗外来展示下一个画面。现在点击生成一段时间后,视频就生成好了,可以看到整体的效果还是不错的。镜头逐渐向窗外推进, 展示到第二张图片的画面,同时得益于水墨风格的加持,像画面当中一些事物的消失和出现也显得非常的自然。 我们刚刚讲过,此次生成的故事会带有一些神话色彩,所以可以看到像第二张到第三张所展现的故事其实会相对抽象一些。第二张展现的是现实世界中年轻的小画家遇到锦鲤时的画面,而第三张则展示的是锦鲤化做人形,将神笔 赐予小画家的画面。这样的画面也许是梦境,也许是锦鲤化成的仙女,将小画家拖入了异空间。因此,对于这样的画面,我们就需要根据画面原有的内容 来发挥我们的想象力,来设计一个巧妙的转场效果。例如这里的提示词,我们就填写降镜头,镜头从水面进入水中,自然过渡到下一个 图片。我们以镜头逐渐入水的方式,营造出一个在水下的异空间,让第一张图到第二张图的过渡变得合理。现在点击生成看一看效果如何?一段时间后视频就生成好了,可以看到这样的转场效果也是比较自然的。镜头不断下降,进入到水底, 在水底展示出第二张图片所显示的画面。当然,每次生成都会伴随着一定的随机性,如果对当前的视频片段生成结果不满意,可以点击下方的再次生 成。越是一些极具创意的转场效果生成起来,生成好的概率越低一些。在实际制作中,如果大家同样是制作一些带有神话色彩的故事,其实类似的情形还有很多,届时大家要具体问题具体分 分析。至于像其他的分镜头画面,在转场效果上和我们之前所学习的就基本一致了。例如像平移镜头或者平移后旋转镜头, 可以看到之后的图片,在镜头的景别上都是基本一致的,所以我们使用的无非是推镜头、拉镜头或者是旋转镜头。无论使用何种镜头,关键在于让转场的效果更加巧妙,更加自然。我们最后再来说一下剪辑 成片的相关技巧。在剪辑这样的短视频时,由于镜头与镜头之间的转场衔接都是以十分丝滑自然的方式进行的, 所以通常不需要添加转场效果,所以更多的时候我们进行的是配音和配乐。在配乐方面就根据画面的风格和内容,在左上方的音频分选项中搜索对应的题材,比如我们当前搜索的是国风,当然如果你的视频需要商用的话,也 可以通过 ai 来生成一个国风音乐。此外就是音效的部分,在不同的场景下,我们要根据生活经验的常识来判断哪些部分该加入什么音效。比如像当前的画面是一个倒水的镜头,我们所添加的音效就是一个倒水的音效。还有像这一段里 鱼从水面跃入水底,我们所添加的就是一个物体掉入水中的音效。还有像这里神女赐予神笔的画面,我们所添加的就是一个魔法发光的音效,好像山顶上有风的音效,鸟鸣的音效,以及有孩童的画面,孩童欢声笑语的音效,大家在实际制作时,根据当前画面可能 出现的声音以及可能出现的位置来添加相应的音效即可。那么以上就是本期视频的全部内容,在制作这个短视频时,我所使用的素材以及提示词都整理成一个文档放到评论区的置顶了,大家需要的话可以自取, 也希望大家通过这两节课的学习,能够掌握这种首尾真生成时,不同的警别之间该如何转场的要领。如果觉得本期视频的内容对你有帮助,也不妨点赞关注、支持一下,我们就下期视频再见。 大家好,我们这期视频来讲解像刚刚那样的非常连贯流畅的写意山水 ai 视频该如何制作。我们首先来简单了解一下写意国画的特点, 通常有四项,第一项是神似,悠闲,不拘形似。第二项是笔墨简练,洒脱自由。第三项是意境留白,虚实相生。而第四项是诗书画印融合共生。其中的第一项和第三项其实就非常适合在 生成好图片之后,将图片生成为视频,便让场景自然转换,因为神似优先,不拘形似,就意味着在画面当中的事物出现变形时,变形的过程会显得十分自然。而意境留白,虚实相生同样意味着在经过运镜进行转场效果时,大量的留白有助于 ai 以十分自然的形式让新的场景出现。在了解了写意国画的特点之后,我们回到极梦 ai, 此次生成同 同样使用 agent 模式。提示词方面,我们就这样书写生成十六张写意水墨山水风格的故事图片,要求具备大量的写意画留白,前后连贯,有逻辑,有一定故事性比例十六比九, 确认无误后直接点击发送。当然,如果对生成的画面有特别的要求,比如需要画面当中出现竹子,或者需要画面当中出现山出现水,也可以提前在这里提 出要求,毕竟协议化的类型是有很多的,在提出了要求之后,可以看到这里就一共生成了十六张画面效果非常完整的协议画作品。而我们要做的事情就是从这十六张当中挑选出较为适合生成视频且能够表达完整故事的作品, 将其进行保存。这次生成的协议化故事大致讲述的就是山中的一位老者从出门到回家的整个经历,因此我们将这些需要的图片在下载好之后,整合到一个文件夹当中, 根据画面本身所展现的内容对其进行排序,来一次展现山中风景的空镜头。老者的家,老者在家中弹琴,再到出门,再到途中经历各种各样的风景,以及最后到了夜晚老者归家的画面。想要生成自然连贯且转场效果十分丝滑的 ai 视频, 我们使用的方法依然是吉梦 ai 的 智能多帧功能,将刚刚已经进行了标号的每一个图片都上传到智能多帧上,同时在每一帧之间进行合适的提示词描述。所以这里我们就再挑选几张图片,以首尾帧升视频的方式给大家讲解几个运镜技巧。 通常像这样的写意山水画面当中的山峦是很多的,所以使用推镜头或者拉镜头,让镜头越过山峰, 一个既巧妙同时又符合画面内容的转场手法。所以可以看到我们第一个镜头描述的是推镜头,镜头推进越过山峰,拍摄桥梁自然过渡到下一张图片,现在点击生成一段时间后,视频就生成好了,可以看到整体的转场效果还是非常自然的, 镜头越过山峰,最终抵达了桥梁的位置。此外,当我们遇到画面当中有瀑布的镜头时,这样的镜头就非常适合使用生镜头的方式 生成相应的转场效果。留下一个镜头是人物在山顶,而这个镜头更像是人物在山腰处的瀑布,所以通过升镜头,让镜头从山腰处的瀑布逐渐上升,最终到达山顶, 同样是一个十分自然且巧妙的转场效果。所以这里我们回到吉梦 ai, 首帧图就上传瀑布的图片,而伪帧图则上传山顶的图片。 在提示词方面,我们就书写镜头上移,自然过渡到下一张图片。现在点击生成片刻之后,视频就生成好了,可以看到整体的视频效果还是非常自然的。从半山腰的瀑布缓慢上移,再到拍摄山顶。至于像最后一个画面, 我们同样可以使用一个较为巧妙的转场效果。可以看到第一张图片是人物在日落时分盘坐在山顶观看日落。 第二张画面则是到了夜晚,人物在抬头看月亮。像这两张图片,镜头所处的位置在景别上基本是一致的。如果我们想要表现这样带有时间流逝的画面,通常提示词可以这样书写, 斗转星移,延时摄影,月落日升。现在点击生成一段时间后,视频片段就生成好了,可以看到这样的转场效果是不是也十分自然呢? 老者起身下山,慢慢的月亮出现,再到第二张图片的效果。在获取了每一个分镜头片段后,我们最后要做的事情就是来到剪辑软件当中,对生成好的视频片段添加音乐音效剪 辑成片了,不过由于使用的是智能多帧功能生成的,所以通常来说,如果片段当中是不需要后期以首尾帧生成的方式 优化某些段落的,我们通常是不需要添加转场效果的,因为每一个转场都是以自然平滑过渡的方式来添加。而配乐方面就点击左上方的音频选项,选择音乐库内容就搜索和当前题材相关的内容。这里我搜索的是写意山水, 总的来说,由于写意国画当中本身就具备神似悠闲、不拘形似,且意境留白、虚实相生的特点,所以在生成视频时想要获得连贯 流畅的转场效果,通常并没有特殊的技巧,像山峰的层峦叠嶂,山体本身的高低起伏都非常适合在运镜时使用前推后拉,上升或者下降这样的运镜。我们最后再来完整的看一下最终的成片效果吧。生成这条视频使用的素材我也整理成了文档 放在评论区的置顶了,大家需要的话可以自取,我们就下期视频再见。 相信大家在学生时代都经历过一些用课本内容制作 ppt 参加比赛的经历,而在 ai 时代,有了 ai 生成视频这么好 用的创作工具,我们自然也可以让课本当中的插画配图按照我们的需要动起来作为这样的参赛素材,或者让课本配图当中的人物与我们指定的人物照片进行互动。所以我们今天就来讲解如何制作这样的视频。 首先要做的事情就是获取课本当中的插图,采用直接拍照的方式,所获取的内容都是不太清晰的,所以这里我们可以使用任意的搜索引擎 搜索 andy 老师的 blog, 在 搜索结果中找到这个选项,在点击进入后,可以看到左侧有很多分选项,这里标注了不同年级每一个语文课本中每一篇文章的配图内容,我们可以从中选择我们想要的内容。在点击展开之后,这里就可以下载相应的配图, 可以直接右键这张图片,然后复制或者另存为将其保存到本地。我们此次生成就以这张孔子见两小儿便日的课文插画作为素材给大家进行演示。来到极梦 ai 的 首页,点击左侧的生成选项,然后将下方的生成模式修改为视频生成模式。 在修改好之后,此次生成使用的是首尾帧生视频,将刚刚下载好的图片分别上传到首帧以及尾帧的位置。哎,到了这里,大家可能会想到了我们生成的是一个首尾帧循环的视频, 上一来在课间讲解的过程中就能够有效避免重复播放,前后衔接不连贯的问题。当然如果大家有需要的话,也可以仅采用手阵图声视频,让整个视频的内容更加具有故事性。而提示词方面,我们就根据课文的内容来描述每个人物的动作。既然是孔子 见两小儿便日,那么提示词我们就这样书写。固定镜头,画面中左侧的人物抬头看太阳,再看两个孩童, 两个孩童互相交谈。而生成的时间方面,因为此次生成使用的是首尾帧循环的方式,通常来说五秒钟的时长会使得画面当中人物的动作为了迎合首尾帧的循环而在幅度上大幅减弱,所以这里建议大家在使用首尾帧相同的图片来生成循环视频时,将生成的秒数从五秒修改为十, 这样画面当中人物的动作幅度会相对更大一些,现在点击生成。当然,如果想要获取更长的动作幅度,也可以使用智能多帧的方式,将智能多帧当中每一张图片同样上传为相同的 图片。相信大家对这项功能已经很熟悉了,所以这里就不再做庸俗的演示。一段时间后,视频就生成好了,来看一看效果如何吧。可以看到整体的效果还是不错的, 孔子先抬头看太阳,再低头看两个正在辩论的孩童。在做好了这些操作之后,下面要做的事情就是将视频下载下来,然后来到 ppt 当中,将视频以 拖拽的方式添加到 ppt 的 编辑窗口,同时调整合适的大小,进行合适的排版。如果觉得有必要的话,也可以插入一些相应的文字, 例如这里我们就插入两小儿便日同时在上方的选项中,如果希望视频循环播放,我们就勾选这里的循环播放,直到停止这个选项。在需要使用这一页 ppt 时,我们就直接双击左侧的 ppt 预览窗口将其展开,然后单机当前的画面进行播放,同时进行相应的讲解即可。可以看到这样的效果是不是 非常方便呢?我们接下来再来讲解如何生成让课本当中的人物与我们指定的人物做交互的画面。首先回到极梦 ai 选 择图片生成功能,在生成的比例方面,我们就保持当前的九比十六来生成一个竖版的在课文当中出现的人物, 例如这里我们就直接要求生成语文课文两小儿变日中的孔子形象水墨插画风格。现在点击生成,可以看到此时生成的效果还是非常不错的。我们挑选一张作为满意的对其进行保存, 然后将其添加到 ppt 页面当中,同时我们再上传一张指定的人物照片,也将其拖拽到 ppt 当中。在调整好位置和大小之后,我们选中这张图, 可以看到在右上方有一个 ai 抠图的选项,点击这个选项,然后选择抠人像这个功能,片刻之后图片就抠好了,点击下方的完成。当然如果你使用 ppt 的 抠图功能是需要会员的,也可以直接在 ps 当中将图片上传上来,点击选择,点击主体,此时也能完整的选择人物主体的 部分,在选中好之后,按 ctrl 加 x 进行剪切, ctrl 加 shift 加 v 进行原位置粘贴,然后按下 f 七,打开图层面板,可以看到此时主体 和背景之间是分层的状态,我们将最下方的图层取消锁定,然后按住 ctrl 键不要松开,将其与背景图层一起选中,按下键盘的 delete 键进行删除,这样一来一个抠好图的人物就也制作完成了。下面点击左上方的文件,下拉菜单,选择 导出,这里一定要选择导出为 png, 那 么此时我们导入到 ppt 当中的素材就是一个抠好图的工具,还有很多,像极梦 ai 同样具备抠图的功能, 相信大家都能找到合适的方法,所以这里就不再做荣誉的演示,而我们最后要做的事情就是对当前 ppt 的 全部画面进行截图,在截取好之后,回到极梦 ai 的 生成页面,选择视频生成选项,然后使用手抷图生视频的方式。提示词我们就书写,让左侧人物和 和右侧的老先生进行互动,内容是两侧人物互相靠近,左侧的小学生向右侧人物行礼,当然具体想要做其他的动作,大家也可以描述其他的内容,现在点击生成一段时间后,视频就生成好了,可以看到整体的效果还是不错的,两侧人物相互靠近, 互相行礼。而我们现在要做的事情就是将视频下载下来,同样的拖拽到 ppt 上调整大小和位置,在调整好之后,双击左侧的预览选项,然后单机当前的画面,就可以播放当前生成好的视频了。 以上就是本期视频的全部内容,制作这些内容时使用的素材和需要用到的网址我已经整理好放在评论区的置顶了,大家需要的话可以直接在评论区自取。如果觉得本期视频的内容对你有帮助,也不妨点赞、关注、支持一下,我们就下期视频再见!
1.3万AI视频制作教程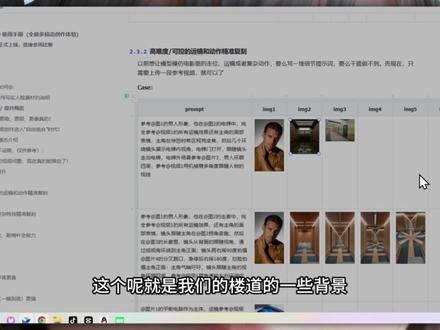 15:15查看AI文稿AI文稿
15:15查看AI文稿AI文稿寂梦的 sedance 二点零直接杀死比赛,即将迎来全民 ai 创作时代,人人都能当导演,只要一个想法就能用 ai 实现。 这次升级和以往不同的是,直接有全能参考,不需要再一个个纹身图,涂上视频,费劲脑子想提示词了,这个视频用十五分钟教会你用好。寂梦 sedance 二点零, 有需要文档的可以一键三连回复,六七八领取。这次升级了,非常大的亮点就是第一个是参考图像,可以精准的还原图像的一些构图细节,角色细节。 第二个它能参考视频,支持镜头语言复杂,动作节奏,创意的特效复刻。第三个就是它可以平滑的延长,还有衔接,可以按照用户提示来生成连续的镜头 啊,不仅能生成,还能直接拍。第四个他可以去编辑的视频,你可以根据视频来进行角色的更替,删减、替换。那这里的话是我用极梦来生成的几个视频,我们来看一下效果, 这是我自己的一个肖像,祝大家马年快乐,非常的真实, 哎,在这这个视频, 这是完全用提示词做出来的效果,很遗憾告诉大家一个事,今年的春晚我不打算上了,大家也不用再等我的节目了,不过好消息, 这个完全是我用 ai 用提示词直接生成的, 不需要去角色定义什么什么主体,也不需要各种复杂的技术。那这里的话我们来看一下怎么去做呢?首先呢,看一下参数,参数我们可以上传哪些参数可以上传我们图片,图片的话支持这些格式啊,图片它是可以上传 最多九张图片的一些参考,那还可以上传视频来输入参考,他可以上传最多三个视频,而且呢 我们还可以去输入音频,这里的话我们可以来要记住啊,如果参考视频的话会贵一点啊,但是呢我们这个效果是非常好的。再就是我们文本输入,就是我说直接用自然语言,那这里的话我们可以去搭建一个呃智能体来给我们相对应的一些 ai 的 提示词,那生成的时长的话,我们可以从四秒到十五秒自由的选择,而且呢是自带音频,自带配乐来去输出的。 那我们来看一下交互的方式,这里的话我们可以去打开我们的极梦的首页啊,这里的话我们打开极梦首页 就可以看到这里有个视频之城,有 simmons 二点零,如果说你没有更新的话,就是如果没更新的话,可以看一下有没有权限,如果有那种开通 就是一块钱开通一次会员的,可以开通一下之后他也会出现,不过这两天应该是全部都全面的开放了,他可以去选择一个是全能参考,一个是我们首尾帧啊,全能参考的话就是我们可以去上传对应的一些图片或者视频来去自由的组合啊生成, 然后我们这里可以去用艾特,就是我们只需要输入艾特 就能去我们把上传的一些图片,比如说我上传了一个音频,直接把这个音频艾特一下,然后提取这个音音色在哪里啊?然后我们可以去删,还可以去什么 参考对应的图片,参考对应的我们的一些视频,这个非常简单啊,不需要复杂的一些提示词, 那这里是我们的一些就是参考多,就是全能参考的这个模式,那接下来我们还可以让,因为现在平台呢有可贵的要求啊,暂时他不允许不支持上传真人,就是写着脸真人脸部的一些素材,之前数二二也是一样的, 就是不不能上传真人,但是你可以就是如果说你想要生成这样的视频啊,生成这样的效果,你可以在 app 上面去使极梦的 app 上面去使用,直接上传自己的一个人脸啊,然后呢你可以用自己的人脸生成这样的一些效果, 那这里我们看到了,因为有写实的一些素材,那我们怎么可以去解决这个办,这个就是真人脸部的一些素材呢?怎么办呢?这个呢啊,等后面的开发了之后,我们会给大家再讲一课, 那这里的话我们看一下,呃,基础的能力显著的增强,更稳,更顺,更像真的。这里呢我们可以看到之前做视频能看出来很大的 ai 的 味道,那现在的话,我们只要一个简单的一个题词,可以看到我们上面的图片,是这一张图片, 那是什么?女孩在优雅的晒衣服,晒完接着在桶里拿出另外一件,用力抖一抖衣服,那我们来看一下深层的效果,看一下 是不是更贴近我们真实的一个世界的一个效果 啊,那我们再看一下这些效果就是,呃,这是我们的参考图,然后呢他是一个可口可乐的啊,可口可乐的一个广告,一样的 啊,就是我们参考一口可乐啊,这里为了规避一下平台的风险,一口可乐,然后我们这里看,这是参考图片,然后这个视频啊, 是不是和名画来交互,是不是更具有创意性?就是你想做广告啊,对不对?用这个模型直接一键生成,完全不需要技术。那这里的这些题词呢,其实也非常简单。那再人啊,这个上传的一张图片 啊,这是我们摄像视频,跟着这个视频啊,也是非常简单的一些词,摄像效果非常平滑。 那这里呢,我们还可以,就比如说你想去模仿谁的视频,想复刻谁的视频,都是非常简单,所以呢,视频创作进入了自由组合的时代。 那这里的话,我们啊, simdams 二点零的多模态,它是支持上传文本,上传图片,上传视频、上传音频,这些素材都可以去当做一个使用对象或者参考对象,你可以任意的去参考里面内容的动作、特效、形式、运镜、人物、场景、声音。 只要你的题词写的清楚,但啊,这个题词不是说你写的越多越好,而是写的够 清晰明了啊,所以呢,我们这里明确是参考对应的一些素材。那我们还有一些,有的时候呢,我们想去做一些首尾针的,那这里呢 凸起作为手针,然后参考什么什么的视频的打斗动作,那这里呢,我们就可以去做出模仿很多的一些啊,影视的一些打斗动作来去啊,把自己融合在里面去。 那还有呢,我们可以看一下啊,我们可以去上传很多的图片,上传很多图片,然后他可以去做出的一些效果,比如这里啊,我上传的图片是呢,这是我的图一, 这是我的图一,我直接艾特图片一,然后这里啊,对应下班后疲惫的走在走廊上,脚步变缓,最后停在家门口,脸部特写,那这里我们看一下,我们只参考图片。 参考图片它生成的效果是怎么样的?我们看一下,我只参考它的脸部啊, 爸爸,这个效果是非常炸裂的啊,以前我们需要怎么办呢?需要把对应的人物主体 啊,去对应的人物主体去确定,然后呢,还需要去确定对应的背景,还需要对应的场景,就是我们还需确定人物一致性,场景一致性,但现在一张图片就能搞定。那这里呢,我们啊,第二个就是案例呢,我们是通过一个视频来我们看一下我们参考的视频, 这是我上传的一个参考视频, 那这里我想要的一个想法是什么?我想把对应的女主啊,女生换成一个戏曲的花旦,然后呢,场景换成在一个精美的舞台, 参考视频的运镜和转场的效果,利用镜头的匹配,人物的动作,来去极致的展示舞台的一个美感,增强视觉的冲击力。那我们来看下成品啊,这个呢,看一下这效果。 所以呢,现在的 ai 需要你去学习吗?不需要了,只要你有想法,你有很多的 idea, 你 就能把它变成实实在在的一个美感,具有美感的一些视频。 那在我们来看下这个案例啊,这个案例呢,我们是参考了视频一,就是我上传的这个视频,他的一个转场已经一, 还有运镜,一镜到底。然后呢,我们现在把它变一下啊,变成这样的啊,就是这里,这里啊,我们把它看一下啊,看一下,这是我们的一个参考视频,它的运镜, 好,这是它的运镜。然后呢我们来看一下实际的效果啊, 它是自己带声音的,看这个是如何变的。 再就是我们这里的贴纸呢,我们还可以怎么写了?嗯,就是你如果想做这种快切的, 就是快速去闪切的这种,呃,炫酷的一些视频,那比如说有的变装的视频呢,你就可以去采用这吗零到多少秒啊?几第几秒到第几秒的画面是怎么样的?然后呢你就可以去用这样的贴纸,纯的就是完全用一个 一个纹身视频那个方式就能生成。那这里我还可以给他参考参考的一些图片,这是我参考图片。那这里呢你看一下, 马上,那这个的话我们是不是可以去做一些啊?比如说电商带货的一些视频,或者是做一些炫酷的一些变装的视频,都可以采用这种方式啊,就是你第几秒到第几秒的画面是怎么样的? 用文字描述啊?那在这里的话啊,过多的一些展示呢,你们可以看一下文档。那在 第二个就是我们高难度的一些啊,运镜和动作的一些精准复刻。那这里的话,我们比如说这是我们参考,这是我们的一些主体,这是我们的主体啊,是这样的一个男人,这是我们的背景啊,这是我们的背景, 这个呢就是我们的楼道的一些背景,你看参考图一的一些形象,在图二的电梯中完全参考视频一,这是视频一, 这是视频一啊,来,这是参考视频一的,我们可以去参考视频,然后呈现的效果来看一下, 这个效果非常惊艳,对不对?那紧接着的话,这里的一些你们可以看一下啊,这里面的一些效果,但是暂时的话,我们现在是不允许,不可以上传我们真人的一些呃,照片了啊,因为规避一下这个风险 啊,后续的话应该是慢慢的会开放一些啊,公共的一些角色,角色库的。 那这里的话和前面的这个 sorry 是 差不多的。那后续的话我们还可以干嘛呢?可以去打斗气的。那这里的话参考图一,这是我上传的一些打斗的一些动作啊,这是图片眉针是怎么样的?我就参考这些啊。呃,图片,然后呢,我这里是我参考的一些 啊视频,这个视频的话是我比如说做的一个动画的一个模拟的视频,对不对?那这里我们 ai 就 能直接能生成这样的效果, 看一下非常的高深。所以呢,这一次更新了之后呢,我一直在想一个问题,就是我们需不需要去学习 ai 啊? 啊?需要学习来了,不需要学习了啊,我们只需要把很多的创意,很多想法,你去学习该学习的,是吧?学习一些基本功啊,就学习美感,学习怎么去有更好的创意。然后呢,让 ai 来做 复刻啊,让 ai 来给你做这些视频,把它做出来,你只需要一个好的想法,所以呢,有什么比如说你在梦里梦到的内容,它都可以去给你复刻出来。那这里的话你看还可以去参考对应的一些模板 啊。这里的我这里的话我们还可以什么?比如说还可以做什么音乐卡点的啊?做一些音乐卡点的,这是我的一些,你看海报中的女生在不停的换装换的一些。嗯, 这个你看换的这个衣服都换着衣服,然后我们参考的视频,这是我参考的视频。 嗯,视视频节奏的话,这是视频节奏啊,来听一下,它有鼓点。那我们试听的效果来看一下,它只是参考了这个鼓点呢,这个视这个参考视频是没有任何的一些画面来看一下,效果 就是这么强大啊, 那这里的话更多的一些啊,我都把整理好了,这个文档我已经整理好了,大家有需要的话可以一键三连。到时候呢?我可以,我还有这里已经整理好的一些通用视频的生成提示词的模板全部都整理到这里了, 有需要的可以一键三连。然后呢?啊,可以找我领取一下。
228Ai冉冉 02:17查看AI文稿AI文稿
02:17查看AI文稿AI文稿我说我花了几块钱请李小龙和成龙在云港石窟前拍了一场打戏,你相信吗?效果如何,大家自己看。 这就是用吉梦刚推出的 cnn 四二点零视频模型做出来的效果。你只需要几张照片,写一句这样的提示词,它就会自动分镜,自动添加声音和音效,做出这样的效果。 有人说人人做大片的时代,它来了,真的是这样吗?让我们来看一看吉梦 cnn 四二点零还可以做些什么,你自己感受一下。 幺妹儿,霸王别姬有得没得?没得,美式要不要?得嘛?美式,我有事得嘛?孙儿,我来买个奶茶,就叫个啥子霸王别姬嘛。 看到这里,你是不是已经近乎这样的效果?他也可以做出来吗?是的,他可以。这就是吉梦提出来的概念,万物皆可参考,万物皆可修改。 传统视频行业的制作流程正在被 ai 重塑。如果你是相关的从业者,要么学习,要么改变,要么被淘汰,这不是危言耸听。
3097黄戌的AI世界 07:19查看AI文稿AI文稿
07:19查看AI文稿AI文稿千万别等到别人用 ai 赚到第一桶金了,你还在研究怎么剪辑 cds 二点零,彻底杀疯了,全网博主都在测,为什么?因为它真正实现了言出法随,不用拍摄配音、分镜,动动嘴 ai 就 能通通搞定。现在很多博主都藏着掖着不敢教,今天我把这套三大基础 家十大进阶玩法,还有这几十个爆款 cds 二点零提示词模板全盘脱出,目的只有一个,让你抓住这波红利,现在学,现在做,现在赚,干货都在这了!屏幕前的吴彦祖们给个免费的三连支持下,我们直接开始喂饭教学。 本期视频我会以文档的形式把制作 ai 视频用到的工具、工作流和操作步骤全部记录下来,有需要的小伙伴可以在评论区给我留言。话不多说,我们直接开始吧!今天我们要做的是一个骏马除年兽的打斗短片,用的是最新的 cds 二点零模型。 关于这个模型相信大家也看了不少相关的介绍和模型讲解了,但完整的教程案例可能还不是很多, 所以今天我就会从角色设定、剧本大纲、分镜、脚本、视频生成、剪辑配乐这几个部分,一步步教会大家如何用 c dance 二点零模型制作出一个完整的打斗短片。那我们现在就正式开始吧! 首先我们可以去花瓣这个网站找一些角色设定的参考图,例如我这个视频的两个主要角色是骏马和年兽,那我就要找跟这两个角色设定高度相关的参考图,这里是我下载的一些参考图,大家可以看一下。 找好参考图后,我们就可以打开豆包,上传参考图,输入这样一段提示词,豆包就会帮我们生成一个文生图的提示词。复制这段提示词,打开寂寞的网站,在这里选择图片生成模型,这里我选择的是四点五 尺寸,选二比三或九比十六都可以,然后把提示词粘贴到这里,点击生成就可以了。如果生成出来的效果不太满意,可以再自己调整一下提示词,重新生成一下。场景的设定也是用同样的方法生成就 ok 了。 到这一步,我们的设定图就做好了,那设定图做完了之后呢,就要开始出剧本大纲了,我们可以先打开豆包,上传好我们做的设定图,发送这样一段提示词给他。 提示词的格式就是身份加主题加剧本数量加视频长度加风格加画面内容。把这段内容发送给豆包之后呢,他就会帮我们生成想要的剧本大纲了。 大家可以选择一个比较满意的剧本,继续让他帮我们生成详细的分镜表。因为有的时候豆包不会给我们生成可编辑的文档, 这里我们就要给他这样一段提示词,把以上的剧本生成一个可编辑的文档,把每一个剧本拆分成三个十五秒的段落,每一个十五秒段落设置一个分镜表,分镜表要包含镜号、景别运镜、画面、音效。 因为现在季梦最新的 cds 二点零模型可以支持十五秒的长视频了,而且可以上传分镜表格图,直接生成视频,就不用像之前那样先生成图片再去生成视频了。所以这里我们可以在一段十五秒的视频里设置多个分镜,这样就能节省很多时间和算力了。 生成好分镜表后,我们还是要检查一下每个分镜的内容,看看每个分镜之间的衔接是否顺畅,不顺畅的话还是要自己去修改一下的,如果觉得分镜数量不够的话,可以让他帮我们再多拆几个分镜。 处理好分镜表后,就可以开始生成视频了,我们可以先截取出三段十五秒视频的分镜表,然后回到寂寞的网站,在这里点击视频生成模型,选择最新的 cds 二点零,这里选择全能参考 尺寸还是十六比九,视频长度现在可以支持四至十五秒了,大家可以根据实际情况去选择。 这里给大家展示一下怎么用分镜表和设定图生成十五秒的视频片段。首先上传好截取下来的分镜表图片,角色设定图和场景图,然后输入这样一段提示词, 参考图片一分镜头脚本里的分镜景别运镜画面音效。参考图片二的年兽设定。参考图片三的骏马设定。参考图片四的场景生成一个年兽和骏马激烈打造的场面。 参考后面的这个图片一呢,要点击这里的引用参考选择对应的图片才可以。写好提示词之后点击生成就可以了。 虽然季梦这个最新的 cds 二点零模型已经非常强大了,但生成出来的十五秒视频还是会有一些问题的。 例如这个镜头片段前面年兽顶飞骏马的效果还不错,但顶飞之后的切径出了问题,我想要的是骏马被顶飞后撞碎门倒地的效果,但他给我生成的是撞碎门后马就直接溜走了,我们就可以只用前面的部分,有问题的部分裁掉就好了。 有的镜头效果不太好的话,可能还要再单独重新生成一下,例如这里的变身效果,整个片段其实都挺好的,就是这里的变身感觉不太自然,我们就可以重新生成一下这个变身片段。这个片段我是用首尾针来生成的, 需要先生成一张骏马站在原地的手真图片,再从变身后的片段里截取一张伪真图,就可以去生成变身片段了。这里我写的提示词是展现骏马全身汇聚火焰能量,随后将全部火焰能量炸开,变身成人形的过程,镜头慢慢推进。 当然这个片段我也是优化了几次提示词,生成了好几次才出来的效果。那之后的片段呢?只要按照同样的方法去生成就可以了。 好,那这个就是视频生成的部分。所有视频片段生成完之后,我们就可以开始去剪辑了。首先打开剪映,把我们生成好的所有视频片段素材导入进去,把每个素材的顺序放置好,按照之前说的保留好的片段,裁掉有问题的片段,再调整一下各个片段的速度就可以了。 背景音乐的话,我们可以直接在音频音乐库里去搜索,比如我输入古风战斗,那它就会给我展示很多和古风战斗相关的背景音乐。 如果想根据不同的场景做出一些音乐变化的话,也可以插入多段背景音乐,做更细致的音乐处理。但要注意两段音乐之间的衔接一定要自然流畅,可以用弹入弹出的方法去处理音乐衔接的部分,最后导出就可以啦。以上就是我们整个 ai 打造短片的制作流程啦 啊啊啊啊。
3005AI-七七 03:38查看AI文稿AI文稿
03:38查看AI文稿AI文稿观众朋友们大家好,今天我们来玩憋笑挑战偷笑 ai 法。注意这不是 ai 这不是 ai! 我 们是精神不会间所有的素材都是极梦 ai 制作的啊,这不是 ai 啊。错房了,而且这次笑了的惩罚也更严重。好,我们现在开 新包装底均匀肤色,重点遮盖面部棱角加额头抬头纹,做到面部无细纹,平整服帖修容重点收窄鼻翼,弱化大鼻子的男性化特征,拉长女性放大细纹眉妆容美妆可以明显显气色号叠涂增加面部柔美感最后佩戴造型假发成龙顶。 这是你吗?我没笑啊。我是看你笑了我才笑的。刚才没完事我听着这旁边有人 再来抽抽抽抽抽第一个呢。你来吧。大嘴大嘴大嘴。就是证明你嘴很大嘛。一人十瓣蒜啊白死你。哈哈哈哈五块啊好好好一啊 三四五啊哈哈哈。哎呦我这味啊。杀几段哈哈哈。下一个刘氏家宴食材招标现在开启。 这头猪的后半生我包了。按我腹肌切八块,谢谢。三小时内后花园改香菜基地。听好了,整个市场我妈看三眼的,以后就是本村指定年货老公,现在咱们上商场也这么打呢不是。 哎呦我我以为我以为是切那头猪的时候巴尔老会煮了。哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈 哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈我我我我我我我我我我我我我 还有个毛哎高跟鞋。哎呀真牛啊。这你自己做的啊。不是,这急忙应该弄的。只要把你们形象录入进去然后描述一下画面就可以生成老简单。你想整啥我教你啊。你别嘚瑟了赶紧看下一个。我没笑。我也是。我俩来。你俩指的是你和谁?你没笑吗。 他也笑了。哈哈哈。你也笑了都笑了。那我来吧。大脸是什么。大脸就是咱们一会换上短袖短裤大喊南方 就是暖和好简单。哎呀你干啥呀我可以大喊半个小时哈哈哈来三二一拿张去暖了。哎呦我寻思哎太丢人了 哈哈哈南方不冷哈哈哈。众爱妃平身,今日朕要考考你们。陛下,臣妾今日新学了一支舞,不知陛下可有兴趣观赏哦,那爱妃就跳来看看,若是跳的不好,朕可要罚你抄一百遍女界。陛下臣妾做不到啊。平 身,今日朕要考考你。哎呦我都没跳太吓人。我我感觉他跳出来我就要吐了。我想问一下子为什么不跳哈哈哈我的我的后裔 娘娘这水有问题。哎呦妈呀哎呦我瞎了。东宫和三十七本宫可算得救了。你有病啊。不好意思全是我的女装,你不能天天拿个玩意搁家生成自己看吧。哈哈哈这里面啊有一个是没事没事没事好不对哈哈哈 我看你那啥玩意啊哎你你哈哈哈哈大脚大脚啊大脚大脚一台大脚让外面去哈哈哈一脚牙子啊 哈哈哈。我靠啊我为啥他妈天天在这走。你这会搞的这个挑战很没意思,这个惩罚我媳妇要手办。
3.1万锅包白眼狼 04:32查看AI文稿AI文稿
04:32查看AI文稿AI文稿大家好,我是准哥,今天给大家实操一下 cden 四二点零傻瓜式操作,后续还有成品展示。首先在浏览器搜索极梦,点开第一个就是官网 对话框的第一个选项里,选择视频生成模型,选择 cden 四二点零。 如果没有这个模型,那么就点击左边的会员开一个新用户,有一个一块钱的会员可以充 a b, 这里已经充过了,充完之后记得点击刷新按钮,刷新一下网页,然后就能正常选择生成十二点零模型了。选好模型后,第三个选项我们选择全能参考。 接下来我们要上传参考内容,比如你想生成赛文奥特曼大战赛罗奥特曼,那么你就上传这两个奥特曼的图片给 ai 做参考, 对话框里就写你想要生成的内容,比如恶补组想看他们两个打架,就在对话框里,且生成图一角色和图二角色战斗的画面,风格迂迂,参考日本特色。 这时候肯定有人要问了,我们为什么不告诉 ai 它们是奥特曼呢?答,因为奥特曼是有版权的字节,可不想被告所有,其他有版权的人物也一样。你可以上传人物的参考图片来让 ai 生成,但不要直接在输入框输入角色名字, 否则就会因为违规导致生成失败。最后的比例和秒数自己选就行。好了,接下来让我们看成品 ten two three 啊,咦呀咦呀,没有没有,还有还有! yeah ah ah ah love you have she need to go to the end of the world while you love love me i can't do it i can't do it i can't do it i can't do it i can't do it i can't do it 呀呀呀!
134准哥AI 02:23查看AI文稿AI文稿
02:23查看AI文稿AI文稿为什么你用 ai 出图做不了这种全景式人物背影,中景有景物、严谨式、一面墙,超大严谨式、月亮的这种紧身感的透视图,百分之九十九的人用 ai 绘画的时候,第一步就做错了。 你是不是看到一张有紧身感的图片,立即把图片丢给 ai, 让他逆推出提示词给你,但出来的结果依旧没有紧身感。有时候明明在提示词里写了超大严谨, 甚至一直跟 ai 讲屠猪人物距离镜头多少米,但出来的结果还是没有透视感。今天三个小技巧,让你随心所欲控制图片中的任何一个物品。我还在视频后面整理了笔记, 请大家点赞、关注、收藏后继续往下看。方法一,当我们看到一张有紧身感的图片的时候,依旧是来到 ai 工具这边逆推提示词必须要有前景、 中景、远景、超大远景。当你拿到这个提示词的时候,就可以生成这种有紧身感的图片来了。因为一张图片里, ai 是 通过背景去理解镜头与眼 镜的,只有通过正确的指令, ai 才能按照你的要求去做,从而做出有层次感的图片出来。方法二,就是构图了,还是看这张图片前景,我只让画面右侧出现一个背影, 然后分别去布局中景。严谨的要素很多,不懂构图的人就会出现,人物的背影直接出在了图中心,把你绞尽脑汁写出来的提示词,想要绘画一张紧身感的图片给弄丢了。正确的方法,你应该用三分构图、九宫格等构图 去构思你的图片,从而让图片每个位置都能向下围棋一样精准落子。方法三,那就是视角了。许多人一上来就是使 平视角,但这一步就错了。在 ai 的 平视角里,它会有主体的眼睛视角作为镜头的基准线,从而导致你哪怕出来的图片感觉好像有紧身感,但一出视频的时候就好像在看这种动态 ppt 了。 正常来讲,我们要用很多特殊视角,然后结合背景构图一起,最终才能做出这种完美的 ai 图片出来。当然, ai 深图还有许多小技巧,我也整理了一份笔记,有需要的可以在评论区留下,无恙。
2632AI自贸港影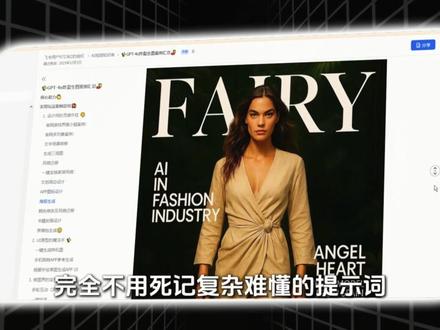 14:52查看AI文稿AI文稿
14:52查看AI文稿AI文稿万万没想到, ai 圈又又又炸了!其梦 c d s 二点零正式登场,漫剧创作迎来全新机会,各大科技博主连夜为他制作视频,创作难度直接大幅降低。这是我仅用一分钟生成的成片, 完全不用死记复杂难懂的提示词,你只要像日常聊天一样说出想法, ai 就 能自动生成流畅运镜,就算是零基础小白也能快速上手。这期全是干货 脚本创作、角色生成、配音配乐,到 ai 漫剧完整制作流程,我会一步步带你从头到尾实操,再加上当下平台对 ai 漫剧内容的支持, 这正是普通人轻松入局的好时机。视频里用到的实用提示词、免费工具包和全套入门教程我都已经整理好了,感兴趣的三三三。话不多说,我们直接开始实操这个视频,给大家分享一下奇梦二点零最好用的几个操作。首先第一个就是广告的拍摄, 以往我们在用 ai 制作广告宣传片的时候,每个镜头都需要自己去逐个生成,其实是我们的物品的一致性,在不同的镜头当中,它其实有一定的难度去保持的。 在简默点零里面,我们是可以直接通过上传产品的一个参考图,不同的一个角度,包括说侧面的角度, 还有正面的角度,包括一些纹理细节的一个图片展示,直接告诉题目二点零根据这一个图片的包包进行一个商业化的摄影展示。包的侧面参考第一张,图片,包包的正面参考第二张,它的材质参考第三张。要求这个视频 展示所有的一个细节,背景音乐给他一个要求,他就可以直接帮我们生成对应的一个效果。这种商业级别的一个视频展示,我们在直播二点零当中可以直接一次性给他生成,这是比较厉害的一个点。 再给大家分享一个操作,也是非常好用的,我们可以选择任何一张角色的一个图片参考,让他去模仿,比如说这样的一个,那我们如果说让二点零去将这个女主换成我们图片的这个角色,他就能生成对应的这样的一个效 果。这也就意味着在节目二点零的时代,我们可以在网上找到任何一个爆款的视频,我们直接去复刻, 这个是没有问题的。包括像汽车的视频,只要我们有一个视频参考,比如说我们有这样的一个视频参考,我们可以直接让二点零参考我们的图一的一个汽车照片, 将这个视频的一个内容,就比如说这个汽车改成我们图仪的汽车,保持它画面切换的一个节奏对不对?包括它的运镜,那么我们最终也能生成这样的一个高。我们在 ai 慢距的时代,还有一个非常牛的操作,我们可以直接上传一个这种漫画, 让 ai 直接根据这个漫画的内容,从左到右,从到上下的顺序进行漫画演绎,然后保持人物说话台词和图片上方的是一致的,可以参考这个视频的一个风格,幺六八路, 我们让 ai 参考这个视频的风格,大家可以看在这个漫画我们直接点击生成之后,就可以得到 这样的一个想法,现在在屠宰场杀猪,我现在靠脑吃饭,是一名数据分析师,我现在是靠脸吃饭,什么玩意发布了,你现在靠脸吃饭,真的吗?还是很不错的,意味着我们每个人,只要你是有想法的, 包括你如果说跟某个漫画达成合作,有版权了,我们是可以直接通过二点零给他生成动漫的一个风格动漫的效果,包括在二点零时代,我们甚至可以直接拿到一个视频片段,然后通过二点零给他改换成 里面的内容,比如说这个视频本身它就是一个比较有氛围的一个感觉。 ok, 我 们可以直接通过这个视频告诉 ai, 我 们每一秒的画面当中,它是怎么样去变化的。比如说零到三秒画面是什么内容,三到六秒画面是什么内容?六到九秒,什么内容? 九到十二秒,十三到十五秒,可以直接改成这种,有点类似于广告那样的感觉有多大?反正你非常牛。 所以在积木二点零的一个时代,我们会发现我们去操控 ai, 去要求 ai 帮我们生成对应的内容,变得更加的便捷了。那么在二点零当中,它有几个点是比较突出的,首先呢就是参考图片,可以精准还原画面的构图、角色的细节。 我会发现在二点零当中生成的一个内容跟我们预期的是更加相符的,包括它是支持多语言的,多镜头的一个语言,复杂的一些动作节奏,还有一些创意特效的复刻,它都是可以很轻松拿捏的。并且其实在二点零当中,视频它是可以 灵活的延长与衔接。以往我们一个视频最长只能升个十秒钟,但是在节目二点零它可以直接生成十五秒的视频,并且这个十五秒的视频你还可以去延长, 比如说在这十五秒的基础上,你再给他额外的延长,比如说三秒、五秒,十秒、十五秒都可以,而且他还可以向前向后延长,不只是说只能往后延,你还可以有一个视频让他往前延长都可以, 并且他的编辑能力也是同步增强的,就包括我们视频当中,你也可以进行角色的更替、删减、增加,这些都是没有问题的。所以在 ai 时代,真的每个同学啊,我们都是可以尝试去使用一下,这个就是我们这一课的分享。 同学们都知道哪些乌鹫兽?轮流回答一下。我知道凤凰舞狮的指法。黑马。下一位同学,到你了啊, 还有一个叫 哈哈哈哈。请问我能不能跟你们一起玩呀? 嘿,玩捉迷藏怎么样?快跑快跑, 小王快走。你妈让我来喊你回家吃饭了。哎,那谁跑哪里去了?谁?哦哦,那谁啊,估计早回了吧。 谁家小孩啊,这不是那谁吗?那谁来了那谁来了。 那谁考那么差肯定要被你妈妈说了。那谁回来了?谁是谁啊?这孩子,哪呢谁慢点。 是是你 根本没人在乎我。 你喜欢我该不是因为我最引人注目吧? 儿子,你看这是什么呀?孩子他爸怎么选了一个没见过的,我只希望儿子能做自己。 知道了,我明白了。嗯,做自己,走,你去闯出自己的一片天吧。 最后那个叫什么?他的名字是? 老师是什么意思?老师是谁? hello, 同学们大家好,欢迎大家继续来到我们的一个 mid jennie 零基础的一个教程视频。 好,我们上一期有给大家讲过如何去生成一张图片对不对?今天给大家讲解一下我们提示词的结构以及 i r 的 一个指令。好,那么我们话不多说,一起来进入今天的一个正题。首先我们一起来讲解一下提示词的一个结构, 如果说是生图,大家要记住以下几点。首先就是图像要位于提示词的前面。 第二个题必须有两个图像或者是一个图像和文本,那么我们的这个 mid jane 才能去工作。第三点是图片必须指向是在线图片的直接链。最最后一点, 在大多数的浏览器中,大家这一点应该也知道,在我们右键单机这个图片的时候,他会有一个复制图像地址,那这样我们就可以获取到他这个链接啦。第二个也就是纹身图,是我们比较常用的一个模式的一个完整的文本提示词应该包括 一个主体,关于主体的一个描述,或者是编料细节,艺术风格,参数等等。最后一个就是参数,参数可以更改图像的生成方式,可以更改图片的一个大小模型,升频器等等。参数位于提示词的末尾, 这个并不是必要的选项啊,这个我们可以通过这里来看出对不对?我们后面这个参数是他自己加上去的,但是我们前面就只输入了这个提示词对不对? 好,那这个就是关于我们提示词的一个结构讲解,我们继续来往下看。好。第二个要跟大家说明,就是这个 ar 的 机制以及说明使用说明, 那它这个是什么意思?它的意思就是更改我们图像的一个纵横笔,也就是咱们图像的一个宽高笔, 我通常将它称之为画布大小,因为以前用 ps 用惯了,我就会称它为画布大小。 好,那通常他用两个冒号分隔开的数字表示啊,比如大家比较常见的一个十六比九以及四比九,对不对?那这里要注意的一点是什么?我们的这个指令 与数字之间需要用空格分开,这个等一下在演示当中会给大家提到使用方法,我们就使用两个杠杠, 然后再输入 ar 或者是这个提示词就可以了。那如果说我们没有输入 ar 去控制它的画布大小,那,那那它的一个默认的画布大小就是一比一。 需要注意的一点就是我们必须要使用整数,例如我们不能使用一点一,二比一,而要使用一百一,十二比一百。大家要记住某些时候我们去使用放大,它会影响到我们的一个纵横比,可能会有变化, 纵横笔它其实是会影响我们图像的一个构图以及形状的,大家可以根据自己的一个画面去调整这一个纵横笔。那么这里也给大家列出了一组官方比较常用的一个比例啊,比如说四比五、二比三、四比七、一比一, 然后五比四、三比二、七比四等等,大家可以去进行一个尝试。好,那讲解完之后,我这里给大家做一个演示。好,那这里我们重新给大家输入一组提示词, 我想一想应该去输入一个什么提示词。借用一下我们的翻译软件,比如说想一个粉色头发, 头发的少女正在吃冰淇淋,好,那这个就是我想要的一个提示词,我们给它复制一遍吧,英文版的复制过来。好,来到我们 major jenny 的 这一个界面,我们先打一个斜杠,然后点击这个 image, 然后在这个提示词框里把我们这个英文的提示词给它输入进去,我们点我们空格输入,杠杠 a r, 还记得刚跟大家说过没有,我们指令与数字之间需要用空格去隔开,对不对?所以我们打上空格,我们首先用十六比九的这一个尺寸来看一下, 然后点击回车发送。好,那这样我们是不是已经设置好了这个十六比九的一个宽高,我们一起来看一下它的 它会是一个什么样的效果。好,大家可以看到,那我们图片已经生成完毕了,它是一个横版的一个构图对不对? 那如果说我们不去设置尺寸,它就是一个一比一的一个尺寸,这里也给大家去演示一下,我们点击 emoji 哦,输入之后我们直接点击发送。好,我们等待一下图片的生成。 好,大家可以看到,那么如果说我们不去设置一个尺寸,它就是一个一比一的一个尺寸啊。好,那相信大家听完这一期视频之后,就知道我们这一个指令的一个用法,以及如何去设置我们一个画面比例对不对? 大家赶紧去进自己进行尝试一下呢。本期视频的以上就是本期视频的所有内容了,大家记得课后去尝试一下,我们下期视频再见啦!
- 15:15查看AI文稿AI文稿
寂梦的 sedance 二点零直接杀死比赛,即将迎来全民 ai 创作时代,人人都能当导演,只要一个想法就能用 ai 实现。 这次升级和以往不同的是,直接有全能参考,不需要再一个个纹身图,涂上视频,费劲脑子想提示词了,这个视频用十五分钟教会你用好寂梦 sedance 二点零, 有需要文档的可以一键三连回复,六七八领取。这次升级了,非常大的亮点就是第一个是参考图像,可以精准的还原图像的一些构图细节,角色细节。 第二个它能参考视频,支持镜头语言复杂,动作节奏,创意的特效复刻。第三个就是它可以平滑的延长,还有衔接,可以按照用户提示来生成连续的镜头 啊,不仅能生成,还能直接拍。第四个他可以去编辑视频,你可以根据视频来进行角色的更替,删减、替换。那这里的话是我用极梦来生成的几个视频,我们来看一下效果, 这是我自己的一个肖像,祝大家马年快乐,非常的真实, 哎,在这这个视频, 这是完全用提示词做出来的效果,很遗憾告诉大家一个事,今年的春晚我不打算上了,大家也不用再等我的节目了,不过好消息, 这个完全是我用 ai 用提示词直接生成的, 不需要去角色定义什么什么主体,也不需要各种复杂的技术。那这里的话我们来看一下怎么去做呢?首先呢看一下参数,参数我们可以上传哪些参数可以上传我们图片,图片的话支持这些格式啊,图片它是可以上传 最多九张图片的一些参考,那还可以上传视频来输入参考,他可以上传最多三个视频,而且呢 我们还可以去输入音频,这里的话我们可以来要记住啊,如果参考视频的话会贵一点啊,但是呢我们这个效果是非常好的。再就是我们文本输入,就是我说直接用自然语言,那这里的话我们可以去搭建一个呃智能体来给我们相对应的一些 ai 的 提示词,那生成的时长的话,我们可以从四秒到十五秒自由的选择,而且呢是自带音频,自带配乐来去输出的。 那我们来看一下交互的方式,这里的话我们可以去打开我们的极梦的首页啊,这里的话我们打开极梦首页 就可以看到这里有个视频之城,有 simmons 二点零,如果说你没有更新的话,就是如果没更新的话,可以看一下有没有权限,如果有那种开通 就是一块钱开通一次会员的,可以开通一下之后他也会出现,不过这两天应该是全部都全面的开放了,他可以去选择一个是全能参考,一个是我们首尾帧啊,全能参考的话就是我们可以去上传对应的一些图片或者视频来去自由的组合啊生成, 然后我们这里可以去用艾特,就是我们只需要输入艾特 就能去我们把上传的一些图片,比如说我上传了一个音频,直接把这个音频艾特一下,然后提取这个音音色在哪里啊?然后我们可以去删,还可以去什么 参考对应的图片,参考对应的我们的一些视频,这个非常简单啊,不需要复杂的一些提示词, 那这里是我们的一些就是参考多,就是全能参考的这个模式,那接下来我们还可以让,因为现在平台呢有可贵的要求啊,暂时他不允许不支持上传真人,就是写着脸,真人脸部的一些素材,之前数二二也是一样的, 就是不不能上传真人,但是你可以,就是如果说你想要生成这样的视频啊,生成这样的效果,你可以在 app 上面去使极梦的 app 上面去使用,直接上传自己的一个人脸啊,然后呢你可以用自己的人脸生成这样的一些效果, 那这里我们看到了,因为有写实的一些素材,那我们怎么可以去解决这个办,这个就是真人脸部的一些素材呢?怎么办呢?这个呢啊,等后面的开发了之后,我们会给大家再讲一课, 那这里的话我们看一下,呃,基础的能力显著的增强,更稳,更顺,更像真的。这里呢,我们可以看到之前做视频能看出来很大的 ai 的 味道,那现在的话,我们只要一个简单的一个题词,可以看到我们上面的图片,是这一张图片, 那是什么?女孩在优雅的晒衣服,晒完接着在桶里拿出另外一件,用力抖一抖衣服,那我们来看一下深层的效果,看一下 是不是更贴近我们真实的一个世界的一个效果 啊,那我们再看一下这些效果,就是,呃,这是我们的参考图,然后呢他是一个可口可乐的啊,可口可乐的一个广告,一样的 啊,就是我们参考一口可乐啊,这里为了规避一下平台的风险,一口可乐,然后我们这里看,这是参考图片,然后这个视频啊, 是不是和名画来交互,是不是更具有创意性?就是你想做广告啊,对不对?用这个模型直接一键生成,完全不需要技术。那这里的这些题词呢,其实也非常简单。那再人啊,这个上传的一张图片 啊,这是我们摄像视频,跟着这个视频啊,也是非常简单的一些词,摄像效果非常平滑。 那这里呢,我们还可以,就比如说你想去模仿谁的视频,想复刻谁的视频,都是非常简单,所以呢,视频创作进入了自由组合的时代。 那这里的话,我们啊, simms 二点零的多模态,它是支持上传文本,上传图片,上传视频,上传音频,这些素材都可以去当做一个使用对象或者参考对象,你可以任意的去参考里面的内容啊的动作,特效,形式,运镜,人物、场景、声音, 只要你的题词写的清楚,但啊这个题词不是说你写的越多越好,而是写的够 清晰明了啊,所以呢,我们这里明确是参考对应的一些素材。那我们还有一些有的时候呢,我们想去做一些首尾针的,那这里呢 凸起作为手针,然后参考什么什么的视频的打斗动作,那这里呢,我们就可以去做出模仿很多的一些啊,影视的一些打斗动作来去啊,把自己融合在里面去。 那还有呢,我们可以看一下啊,我们可以去上传很多的图片,上传很多图片,然后他可以去做出的一些效果,比如这里啊,我上传的图片是呢,这是我的图一, 这是我的图一,我直接艾特图片一,然后这里啊,对应下班后疲惫的走在走廊上,脚步变缓,最后停在家门口,脸部特写,那这里我们看一下,我们只参考图片。 参考图片它生成的效果是怎么样的?我们看一下,我只参考它的脸部啊, 爸爸,这个效果是非常炸裂的啊,以前我们需要怎么办呢?需要把对应的人物主体 啊,去对应的人物主体去确定,然后呢,还需要去确定对应的背景,还需要对应的场景,就是我们还需确定人物一致性,场景一致性,但现在一张图片就能搞定。那这里呢,我们啊,第二个就是案例呢,我们是通过一个视频来我们看一下我们参考的视频, 这是我上传的一个参考视频, 那这里我想要的一个想法是什么?我想把对应的女主啊,女生换成一个戏曲的花旦,然后呢,场景换成在一个精美的舞台, 参考视频的运镜和转场的效果,利用镜头的匹配,人物的动作,来去极致的展示舞台的一个美感,增强视觉的冲击力。那我们来看下成品啊,这个呢,看一下这效果。 所以呢,现在的 ai 需要你去学习吗?不需要了,只要你有想法,你有很多的 idea, 你 就能把它变成实实在在的一个美感,具有美感的一些视频。 那在我们来看下这个案例啊,这个案例呢,我们是参考了视频一,就是我上传的这个视频,他的一个转场已经一, 还有运镜,一镜到底。然后呢,我们现在把它变一下啊,变成这样的啊,就是这里,这里啊,我们把它看一下啊,看一下,这是我们的一个参考视频,它的运镜, 好,这是它的运镜。然后呢我们来看一下实际的效果啊, 它是自己带声音的,看这个是如何变的。 再就是我们这里的贴纸呢,我们还可以怎么写了?嗯,就是你如果想做这种快切的, 就是快速去闪切的这种,呃,炫酷的一些视频,那比如说有的变装的视频呢,你就可以去采用这吗零到多少秒啊?几第几秒到第几秒的画面是怎么样的?然后呢你就可以去用这样的贴纸,纯的就是完全用一个 一个纹身视频那个方式就能生成。那这里我还可以给他参考参考的一些图片,这是我参考图片。那这里呢你看一下, 马上,那这个的话我们是不是可以去做一些啊?比如说电商带货的一些视频,或者是做一些炫酷的一些变装的视频,都可以采用这种方式啊,就是你第几秒到第几秒的画面是怎么样的? 用文字描述啊?那在这里的话啊,过多的一些展示呢,你们可以看一下文档。那在 第二个就是我们高难度的一些啊,运镜和动作的一些精准复刻。那这里的话,我们比如说这是我们参考,这是我们的一些主体,这是我们的主体啊,是这样的一个男人,这是我们的背景啊,这是我们的背景, 这个呢就是我们的楼道的一些背景,你看参考图一的一些形象,在图二的电梯中完全参考视频一,这是视频一, 这是视频一啊,来,这是参考视频一的,我们可以去参考视频,然后呈现的效果来看一下, 这个效果非常惊艳,对不对?那紧接着的话,这里的一些你们可以看一下啊,这里面的一些效果,但是暂时的话,我们现在是不允许,不可以上传我们真人的一些呃,照片了啊,因为规避一下这个风险 啊,后续的话应该是慢慢的会开放一些啊,公共的一些角色,角色库的。 那这里的话和前面的这个 sorry 是 差不多的。那后续的话我们还可以干嘛呢?可以去打斗气的。那这里的话参考图一,这是我上传的一些打斗的一些动作啊,这是图片眉针是怎么样的?我就参考这些啊。呃,图片,然后呢,我这里是我参考的一些 啊视频,这个视频的话是我比如说做的一个动画的一个模拟的视频,对不对?那这里我们 ai 就 能直接能生成这样的效果, 看一下非常的高深。所以呢,这一次更新了之后呢,我一直在想一个问题,就是我们需不需要去学习 ai 啊? 啊?需要学习来了,不需要学习了啊,我们只需要把很多的创意,很多想法,你去学习该学习的,是吧?学习一些基本功啊,就学习美感,学习怎么去有更好的创意。然后呢,让 ai 来做 复刻啊,让 ai 来给你做这些视频,把它做出来,你只需要一个好的想法,所以呢,有什么比如说你在梦里梦到的内容,它都可以去给你复刻出来。那这里的话你看还可以去参考对应的一些模板 啊。这里的我这里的话我们还可以什么?比如说还可以做什么音乐卡点的啊?做一些音乐卡点的,这是我的一些,你看海报中的女生在不停的换装换着一些。嗯, 这个你看换的这个衣服都换着衣服,然后我们参考的视频,这是我参考的视频。 嗯,视视频节奏的话,这是视频节奏啊,来听一下,它有鼓点。那我们试听的效果来看一下,它只是参考了这个鼓点呢,这个视这个参考视频是没有任何的一些画面来看一下,效果 就是这么强大啊, 那这里的话更多的一些啊,我都把整理好了,这个文档我已经整理好了,大家有需要的话可以一键三连。到时候呢?我可以,我还有这里已经整理好的一些通用视频的生成提示词的模板全部都整理到这里了, 有需要的可以一键三连。然后呢?啊,可以找我领取一下。
112Ai冉冉  00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿小梦梦手机端重磅推出全新互动玩法出镜,搭载近期火爆外网的 cds 二点零模型,操作简单,一次分身随时出演, ai 圆梦、 ai 社交。接下来进入实操环节。 第一步,打开小梦梦 app, 先点右下角头像,再点创建分身,接着点立即创建,最后按提示开始录制。第二步,打开分身管理,开启权限。最后一步,玩转出镜,先点出镜,接着选择出镜主角,转写故事,最后按确认即可生成。 小梦梦手机端重磅推出出镜玩法哦!不知道怎么写故事,可以跟做同款,先点推荐页面浏览站内视频,再点视频右下角 做同款。接着修改所有原本昵称为你希望出镜的角色昵称,最后按确认即可生成。看看最终效果吧!现在每人每天都能畅享二十次使用机会,福利超给力!让你天才般的脑洞在小梦梦完美落地,这叫力不从心,哈哈哈!
7蛇栗栗 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿闺蜜,这下我们不出门也能一起拍抽象小视频了!看到网友一个个都用激萌 ai 给自己弄了整活小视频,让不属于自己偶像的朋友认人,哪个是吉米奎莫西?莫西,这个看着挺帅的,是不是他 哦,真棒!对了,就是他,要不就是给自己讨厌的人邦邦两拳,甚至还能让我的老板去给我打工,看着就超级有意思,就连操作都简单到飞起。找到小梦点出镜,然后如果 十秒的视频生成分身,最后再选择场景合拍,就能拉朋友们一起出镜整活了。不管是脑洞二创还是现实吐槽,零成本就能落地我的所有奇思妙想,简直就是我的 ai 嘴 t! 闺蜜,就现在跟我一起来演掉段名场面,就当过年小节目了!
1584鲤娱Der妹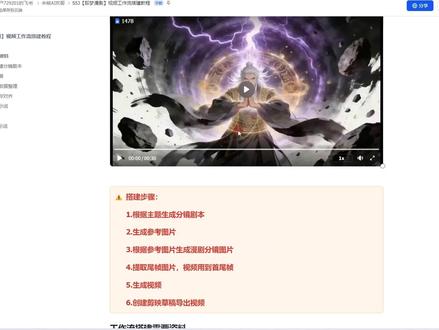 28:30查看AI文稿AI文稿
28:30查看AI文稿AI文稿接下来给大家分享一个很炸裂的工作流啊,流氓生成漫剧。在这里我先给大家看几个工作流生成的视频效果,然后会手把手教大家去搭建这个工作流啊,这些的话都是工作流生成的视频效果 啊,这是一种风格,还有个动漫的风格。 好,下面这个是修仙的风格呀,呵,你终于来了, 好,我们先搭建出工作流以后这些风格的话自己去设定就可以了,在提示词里边去换风格就可以了,包括你的脚码都在这里边去更换就可以了。 那么接下来以后我会手把手教大家搭建这个工作流,把这个工作流搭建他所用到的插件的话是极美的插件,搭建步骤的话也是比较简单,我们先去根据主题,然后去生成风景脚本,然后再去根据风景脚本生成参考图片。这里的话我们先会去生成参考图片,然后把参考图片给到他, 然后这个工作流会根据参考图片去给我们生成相对应的风景的图片,有了这个参考图片以后,我们人物包括场景的一致性,他呢才保持一致性,然后根据参考图片去生成漫剧的风景图片。那么第四步这里的话是非常关键的,如果想让我们这个视频比较丝滑的话,必须拿到这个参考图片的伪真图片 的话,我们生成视频的时候会用到一个首尾帧的图片,那么提取到这个尾帧图片以后,我们会用到首尾帧去生成视频,这样的话生成的视频还是比较丝滑的,然后衔接效果也是比较好, 然后生成视频以后,然后再创建,点击草稿导出就可以了。这个搭建步骤的话是非常简单,也是非常清晰啊。工作流搭建出来以后,你想要改风格的话,自由去改就可以了。好,那么接下来以后开始实操搭建,打开自己的扣子空间,选择资源库, 右边有个资源,这里我们选择工作流,这里是创建新的工作流, 这里需要注意工作流名称,这里不能输入中文,然后工作流描述的话,可以去描述详细一些,要选择确认。 好,这就来到工作流的搭建页面,我们先把搭建步骤复制过来,搭建步骤的话前面讲过了,是比较简单把这个复制一下 啊。工作流这里的话有一个注是把这个搭建步骤放在这,我们再看这个搭建步骤。首先的话,第一步根据主题去生成分镜句吧,那么开始的话我们需要去设置一个参数, input 就是 设置主题的地方,这里选择 b 前, 这里展开以后,我们可以对这个变量进行描述。 好,这个工作流的话,我们是需要根据主题去生成这个麦剧的,所以说呢,这个开始的话是需要设置这个参数就可以了。 那么接下来以后根据主题去生成风景剧本,这里我们需要去添加大模型,好,添加第一个节点,这个大模型给它改个名称。 好,这个大模型的作用是创建封印脚本,我们看一下模型的配置,这个模型这里我们选择 deepsafe v 三点二,这个运行速度是比豆包要快一些,那么变量值这里我们需要拿到开始的 input 就是 主题,它会根据主题去给我们生成封印脚本, 那么系统设置这里的话我已经写好了,先复制过来,它是根据我们输入的主题,然后给我们生成一个修饰的结构,然后三十秒内必须包含这些东西, 如果说你想改的话可以改这个时长就可以,还有它的动作镜头语言,还有一个物理的反馈。 然后在这里的话,我们一共会生成一个六个风景图,一个风景图的话是五秒钟时长,那么用户启动此,我们把上面这个变量引用进来,那么输出的话我们需要输出两项,第一个是风景,把这里给它改个名字, 然后再添加一下,还有输出的一个剧本,好封境的话,我们会用这个封境去生成图片,然后剧本的话会后面根据它去生成一个剧情, 把这个大模型这里的话就设置好了。那么第二步的话我们需要去生成参考图片,这个工作流的话,我们会先去生成参考图片,然后再根据参考图片去生成风景的图片,这里的话我们先去把这个参考图片的题词给它做出来, 好在这里再添加一个大模型, 这个大模型是生成参考图片的数据,同样这个模型这里我们选择 deepsafe v 三点二,那么输入这个变量值,这里我们需要拿到第一个大模型生成的剧本,那么系统其实在这里的话我就写好了, 这里它会根据剧本去给我们生成一个符合国漫美学的绘图的题日词。下面这些是核心的构建原则,输出的话它会输出一个对象数组格式,它里面包含一个名称,还有一个题日词,那么用户题日词,我们把上面变量引用进来。 好,那么输出这里的话,我们需要去参考这个输出的案例,它这里输出的这个变量类型,这里需要改成 array object, 不是他这个对象数据库里面包含两项,第一个是名称,还有一个是图片的提日期,那我们生成图片之前的话,先要把这个图片提日期提取出来,因为他这个对象数据库里面包含以后还有一个名称,我们不需要名称,但要把这个提日期提取出来,根据提日期去生成参考图片的。 好,在这里的话我们需要去添加一个代码, 当然你也可以去添加个大模型,那么代码的话运行速度比较快,而且不容易出错,这里的话我就添加个代码。好,代码给它改个名字。 好,这里边的话它会将这两个给提取出来,一个是名称,还有一个记日词,分别单独提取出来,那么代码的输入这里,我们需要拿到这个参考图片的数据,好选择这个 altfort。 好, 这个变量名的话,我们需要去改一下, 我们看一下代码里边的设置,再把初设代码删掉。代码这里的话我已经写好了, 我们来看一下这里第四个输出的两个数据,第一个是名称,还有一个提示词,这样的话就将这两个数据提取出来了,那么同时输出的话,我们需要把这个两个变量名复制过来。 好,这个变量类型这里我们选择 array string, 哎,里边包含了好多这个名称,还有好多这个格式, 同样的这个是图片提亮词,这变量类型我们选择 orange space。 好, 代码这里的话就设置好了,把这个变量名这里的话一定要和我这个保持一致,不然代码会报错。我们现在把这个参考图片的提亮词提取出来以后,我们去分成参考图片, 好在这里去添加一个批处理,因为参考图片的话也有多张这个并运行数量,这里我们选择三个,如果说数值太大的话,它就会容易失败,并运行数量的意思就是我们同时运行多少组数据,那么输入这里的话,我们需要拿到 刚才这个代码输出的图片记日词,我们再看一下批处理体里面,这里的话我们需要用到一个极梦的图片生成,我在插件里边搜索极梦图片生成 好,选择这个积木的图片生成,这里有两个,一个是根据提示词生成图片,还有一个是无限的结果查询,我们添加第一个就可以了。我这里有个 k, k 的 话这个插件需要算力的,我们再开始设置一下,然后再开始添加一下, 好再来到这个插件这儿,我把开始的 api 给到它,那么提示词的话,我们需要拿到这个批处理,刚才拿到的这个 item, 那 就是提示词这里一个参考图片,我们现在不需要参考图片, 然后这个模型的话,我们选择图片四点五,它生成的质量是比较高的,这是 bm 的 最高的模型, 把这个复制过来,那么比例的话根据自己的需求去选择就行了。这里有先选择十六比九,这是横屏的,这里的话就设置好了,把线给它连起来, 我们看一下 p 处里的输出,输出这里我们需要去输出图片的数据,在 u r i 了,把这个图片的链接输出就可以了。好,整体来测试一下这一些, 然后把线连到结束,结束拉到 p 处里的 image, 好, 点击试用型,然后输入主题,这里我们需要随便去输入个主题就可以了。 好,点击运行好,它,这里会给我们生成六个图线,因为我们有六段视频。 好,这个可以看出它生成的图片质量还是非常不错的啊,这个图片的话是给我们生成的参考图片,我们会用到这个参考图片去做后面的风景图片, 所以说在这里的话是非常关键的,你想要这个质量更高一些,你要去修改这个参考图片的其实词就可以了啊,这个逻辑的话,在这里是没问题,没问题,我们接着往下做,我们来看一下第三步,然后再去根据参考图片生成麦剧的风景图片。 那么在生成之图片之前的话,我们先要去对图片和这个名称进行对齐,因为它每个片段它对应的是一个名称,就是每个图片它对应的是一个名称,在这里的话我们需要去添加一个代码。 好,这个代码的话是参考图片和名称对齐。 首先第一个我们需要拿到名称,那这个代码已经将名称和图片提样式提取出来了。好,现在我们需要拿到它输出的这个名称。 好,选择参考图片数据,整理一遍内容,这就是名称,然后这个变量名给它改一下, 然后再添加一项,就是这个 p 处里输出的参考图片。好,选择这个 altfort, 把这个变量名也给它改一下。 好,我们再看一下代码里边的设置,同样的初识代码先删掉。好,这里的话我已经写好了。 好,这个代码主要的作用是将获取到的两个数据,一个是名称,还有一个图片的链接,它是每个图片的链接对应一个名称,对齐以后,在这里输出了一个这个变量,它复制过来就可以了, 好多余的删掉。把这个变量类型这里我们选择 object。 好, 这个代码这里的话就设置好了。好,现在参考图片和名称对齐以后,我们需要去把这个数据给到下面的大模型,让它去参考这个 l 图片,去帮我们生成图片提日期, 在这里再添加一个大模型。好,这个大模型是给我们生成风景图片的,提日期。 好,同样的这个模型,这里我们选择 type c 为三点二,那么输入需要拿到两个数据,再添加一下啊,第一个需要拿到创建封境剧本的,这个剧本我们有了剧本才去生成图片, 然后再添加一下还是这个创建封境里边的这个封境,把图片的提成词,把这个多的删掉,那么系统提成词这里的话,我已经写好了 啊,这个提示词的话和这个提示词它是有点像,但是里边有一些微小的变化啊,同样的它这个核心逻辑这里是比较重要的, 那么输出的话,同样的它会输出一个对象数字格式,它里边包含名称,还有一个图片的提示词啊,这个图片提示词的话是我们需要用到真正的分镜的图片提示词,那么用户提示词把上面两个变量引用进来就可以了。 好,第一个是剧本,还有一个是风景。好,同样的这个输出,这里我们需要去输出一个对象数字格式,这个 eric object, 它里边包含名称,还有一个图片的提示词,这个输出变量这里我们改个名字。 好,这个大模型这里的话就设置好了。好,那么接下来同样的步骤,我们需要去把这个里边的它的名称和提示词单独给提取出来,这里话需要去添加个代码,而和这个代码的原理是一样的,把这个复制过来就可以了。 好,把线连起来,这个变量值,这里的话我们需要去拿到这个封境的图片提示词,我们现在需要去提取它里边的名称和提示词,把这个换一下,选择封境图片提示词。好,输出的话保持默认就可以了,这两个是一样的。 好,现在提示词提取出来以后,我们需要去根据提示词去生成图片,同样的我们需要去添加一个 p 处理, 把这个 p 处理改个名字吧, 把对应行数量这里我们选择三个,我输入这里我们需要拿到这个代码提取到的。 好,选择这个,下面这个提示词。好,我们再看一下这个 p 处理体里边, 基础立体里边,我们需要去生成图片,同样的会用到这个极梦的图片生成,那么在生成图片之前的话,我们需要去提取到他这个生成的参考图片,这个是我们生成的参考图片,我们这里去添加个大模型,先将参考图片的数据提取过来 好,这个大模型的作用是提取参考图片数据, 好模型,这里选择 deepsafe 为三点二,那么输入这里的话,需要拿到三个数据,首先第一个的话是这个批处理拿到的数据 好,选择这个生成风景图片的提示词,选择 atm, 把这个变量名给它改一下,然后再拿到一项数据好,这里的话我们需要拿到这个代码对齐的这个数据 好,参考图片和名称对齐,然后再添加一下,这里的话我们还需要拿到第一个大冒险生成的剧本 好,选择创建分镜脚本里边的剧本啊,这里话需要拿到这三个数据,那么系统其实在这里的话我已经写好了 啊,这个系统其实在这里的话是比较关键的啊,然后的话这个我会放到文档里边,那么用户其实我们需要把上面三个变量引用进来, 这个是图片的记日词, 这个是参考图片和名称对齐的一个数据,而这个是剧本。而输出这里的话,我们选择 a ring, ring 就是 字母串数字,它里面包含多条图片记日词, 接下来以后我们需要去判断它这个大模型能不能提取到这个参考数据,在这里去添加一个判断器啊,选择一个 if 选择器 啊,这里的话选择条件,这里我们需要拿到提取参考图片的这个数据啊,如果说它这里不为空,不为空的情况下,它就是拿到提取到这个参考图片的数据了,我们直接去生成图片就可以了,在这里添加一个 em 的 图片生成 啊,还是选择这个图片生成,根据提示词生成图片, 这里的话,这个 key 我 们需要拿到开始的 api key, 那 么提示词的话,我们需要拿到这个 p 处里提取到的提示词, 选择生成风景图片的 atm, 这个就是提示词,那这个大模型它提取到的是参考图片的数据,所以说呢,在这里我们需要去定义它。 选择提取参考图片数据的 output 模型的话,我们还是选择图片四点五把这个复制过来就可以,那么比例的话选择十六比九, 那么它是提取到参考图片数据以后,它会走上面这条线,否则的话它是没有提取到参考图片数据,那么同样的我们在这里去添加一个这个插件就可以了,没有提取到以后,它是有提示的,直接让生成也是可以的, 不然的话这个工作流会报错,只是在这里的话他是没有参考数据了,这里的设置的话,我们需要去把这个参考图片这里这个设置给关掉,就是他没有参考图片,同样的也会去生成图片。 好,那么生成图片以后,我们在这里去添加一个变量聚合,把这个线也给到它,就是不管是有参考图片还是没有参考图片,它都会生成图片,那么只要有数据以后都会给到这个变量聚合, 这里的话我们需要拿到第一个图片生成的 u r i 了,还有第二个图片生成的 u r i 了,在这里聚合以后,然后由这个变量聚合进行输出, 把这个 p 处理体里面就设置好了,我再看一下 p 处理的输出,输出,我们需要输出变量聚合的数据, 把这个风景图片的话在这里就做好了。好,现在风景图片做好以后,我们看一下这个搭建步骤。 第四步的话是提取图片的尾帧,我们视频的话会用到一个首尾帧的效果,所以说在这里的话我们需要去添加一个代码, 当然大模型也是可以代替的,代码的话是用行速度比较快,不容易出错。 那么输入这里的话,我们需要拿到这个生成的风景图片,然后让这个代码去提取风景图片的尾帧和手帧,好选择生成图片里边的 image, 那 么这个变量名的话给它改一下 好图层代码,先删掉 好这个新的链接的话,就是提取到的伪真图片的链接,把这个复制过来, 多余的删掉就可以了。这里的话我们选择 a ring stream 代码,这里的话就设置好了。那现在伪真图片提取到以后,我们需要去根据伪真图片去生成视频,那么生成视频之前的话,我们先要去定义它视频的用境效果,就是动态的描述词, 这里先添加个大模型,好大模型给它改个名字, 这个模型这里我们还是选择 dp 为三点二,那么输入这里的话,我们需要拿到两个变量,好选择第一个风景图片提日词里边的这个提日词,然后再添加一项 创建封境脚本里边的剧本还是需要去根据剧本,那么系统提示词这里的话我已经写好了。 同样的这个输出的话是一个对象数字格式,它里边包含包含一个视频的封境一的这个名称,还有一个视频的提示词, 那么用户记歌词,我们需要把上面两个变量引用进来,这个是封禁的记歌词,还有这个是剧本那么输出,这里的话我们选择 array object, 它里边包含一个名称,还有提示词, 那么同样的道理,我们需要去把这两个单独提取出来,和这个代码是一样的,把这个复制一个, 我把线连起来,这个代码给它改个名字, 好,这个输入变量值,这里我们需要拿到这个分镜提示词, 好,选择这个封境。视频的记日词不出的话是不用管的,它两个输出变量是一样的,这里的话就设置好了。好,接下来所有的东西准备好以后,我们需要去生成视频这个大模型,在这里给我们定义的是生成六个封境,也就是会生成六段视频, 这里我们需要去添加一个循环, 好,循环这里的话选择使用数值循环,那么循环数值这个变量,这里我们需要拿到三个数据, 首先第一个的话,我们需要拿到这个尾帧的数据,我们需要去根据首尾帧去生成视频,然后再添加一下,就是提取到的这个视频的记日词, 好选择这个下面这个 promote, 然后再添加一下就这个 p 处里生成的图片, 好,生成风景图片的这个我这里给它改个名字,这个是伪真图片,这个是格式,这个是风景图片,我们再看一下循环体里边的设置。 好,这里的话我们需要去找到一个视频生成的插件,这个是扣子官方的,最近升级了一个一点五 pro, 这是非常好用的,里面自带音效,我这里边有两个,一个是纹身视频,还有一个图,纹身视频我们选择第二个图,纹身视频 分辨率的话自己去选择就可以了,你想视频质量更高,可以选择幺零八零 p。 那 生成模型这里我们选择一点五 pro, 它是里边自带音效,包括一些打动的场面它都会生成出来。 比例的话我们选择十六比九,因为我们前面图片的话是十六比九啊。分辨率的话自己去选择,这里有个是否包含音效,这里我们把这个开关打开。好,这里的话需要用到一个首尾针的图片了,首针图片的话我们需要拿到循环。 好,这个 image 图片的话就是一个补帧图片,那么伪帧图片同样的我们刚才给它进一行。好,这个是伪帧图片,那么输入这里的话,我们需要拿到这个提示词, 好,这个是提示词,那么提示词这里把这个变量引入进来 啊。异常处理,这里的话异常处理方式这里我们选择执行异常流程就可以了,然后把这个线连起来,那么执行异常流程,这个线也要需要连起来好循环的,输出的话我们需要输出视频生成的,选择这个 video。 好,到这一步以后我们这个视频就做好了,我们接下来以后不需要去把视频添加到剪映草稿里面,我们先去创建一个剪映草稿,然后在插件里边搜索剪映小助手。 好,找到这个剪映小助手,依次用的建议收藏一下,收藏完以后后面用起来是比较方便,这里的话我已经收藏过了,然后关掉这里。 好,在收藏的插件里边搜索剪映小助手,再去创建一个剪映草稿。好,选择这个创建草稿。好,给它改个名字。 这个草稿箱的高度和宽度的话,我们和前面的图片要对应起来。好,选择幺零八零等于幺九二零。 好,接下来以后我们需要去获取到视频的时间线,有了时间线以后,我们把视频添加进来就可以了。还是点一小助手,从视频列表中获取时间线列表,找到这个, 这里有个视频链接,我们需要拿到这个循环输出的链接。好,选择这个 output, 它会提示这个变量类型不一致,这是没关系,是可以运行的。好,现在有了时间线以后,我们把这个视频素材制作出来。 好,点击小助手,里边有个 video 跟 force, 根据时间线制作视频数据, 这个时间线的话就是刚才创建的时间线。好选择。视频时间线里边有一个 timeless 和 o timeless, 这两个是,上面这个是分段的时间线,下面这个是总的时间线,因为我们视频有六段,我们需要去选择上面这个分段的时间线, 那么视频列表的话,我们需要拿到循环啊,循环输出的这个视频数据,下面这些保持默认就可以了。好,现在这个视频制作好以后,把它放到剪映草稿里边。 好,剪映小助手里边有一个好选择。这个批量添加视频, 这个是草稿的 id, 我 们选择创建草稿这视频,我们选择视频制作 好,选择这个 enforce, 下面这些保持默认就可以了。好,到这一步以后,整个工作流就搭建完了,然后把结果给到结束, 结束这里的话我们需要拿到创建草稿的 id。 好,接下来我们来试用行一下,如果说有问题的话再去修改,它是这些数据,点击试用行本运行速度是比较慢的,因为它里边有六段视频需要去生成,我先去等待一下 啊,运行的话也是相对来说比较慢一点,用了十分钟时间把这个输出变量下载下来,然后复制这个顶号里边这是个数字,然后打开剪映小助手创建草稿,我这里提示已经下载完成,我们打开剪映看下效果, 我这个黑色的图标的话是刚才下载的,点开看效果 好,这里的话它是生成了六段视频,效果还是非常不错的啊。把这个工作流搭建的资料的话,我放到这个文档里边。
1305欢哥AI智能体 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿给你们看一个超级上头又炸裂的东西,像这种霸道总裁的剧情,其实都是用即梦生成的,不仅可以帮助我们快速起号,还能圆自己的演员梦。你藏了我六年,让我找了六年,现在说走就走。首先打开这个 ai 工具,在个人中心找到管理分身,按照提示录制好自己的模样, 回到首页,点击搜索。比如你要做霸道总裁系列的直接搜索,就有很多爆款视频,点击做同款,把想要出演的角色艾特换成自己的短剧视频。
117南枫Ai 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿平常爱和朋友爆改戏精护眼的有福了,这下 ai 真的 帮你打造零成本片场了!以前看小说看剧后,天天上班上学急的脑子里放空脑补如果自己和朋友当主角,要怎么怎么演。而如今只需要打开小梦,点击管理分身录入后,就能拥有自己的角色形象 在出镜那描述你的梦境。选择出镜主角艾特朋友,立马和朋友开始随地大小演。先来到复古片场,和朋友爆改黑衣神秘人在昏暗的路灯旁秘密接头货带了吗?带了,在那里怎么那么少?最近不太好弄,下次需要再找我。 好好好,你是体验上地下党了!再来到民国片场,和对象上演一场情感线对手戏,你无理取闹,你才无情你才冷酷你才无理取闹!我哪里无情哪里冷酷哪里无理取闹,你哪里不无情哪里不冷酷哪里不无理取闹?如果闹矛盾了,还能直接让对象跟在车后上演追车名场面,你说解不解气吧? 燕子燕子你别走,没有你我怎么活啊!最后来到霸总片场,闺蜜被同事欺负,你直接化身总裁出场,霸气户贵妃当场抱起她就走,谁都不能欺负我!闺蜜这是想怎么演就怎么演,我将拉着朋友们大拍特拍!
5012非传统漫游选手



猜你喜欢
- 1.3万Ai十二