postgresql 18.2 发布时间
我们来看一下 p e 的时间日期类型啊,总共有下面六种啊,前面两种的话都是表示这个时间错啊,这个的话是不带失去的一个时间错,这个是带失去的一个时间错啊,他们都是八个字结,后面这个 n 是代表这个进度啊,比如说我们经常使用的这个函数是 laptop la 啊, 你看实际说的话,他是表示前面的这个是日期,后面这个是时间,对吧?后面这个是精度吗?咱们说了啊,这是一二三四五六,默认的话就是六位啊,这个的话是咱们的这个东八区啊啊,比如说我们再来进行一个查看 啊,然后是二零二三年一月一号。好,我们来进行一下 time step, 是不是啊?把这个日期给显示出来了时, 时间的话他没有的话是就从这个零啊,零时零分零秒开始的啊啊?如果说我们后面这样再加一些时间,比如说现在,是啊,十七幺幺 二二三,好,是不是也是把这个给写出来的啊?如果说我们后面的话要这个精度,一二三四五六,是不是啊?咱们可以来 这个定一下他这个进度,比如说两位啊,你看是不是这里只有两位了啊?这个是这个的话他是会四舍五入的,比如说我们这里给他加大一些,这里设置成五,是不是这里变成幺三了啊? 呃,但是下我们说了这个的话,它是不带死去的啊,如果说我们后面要加这个 with times 中 看,是不是啊变成了这个东巴区了啊?啊?然后这个的话是时期,呃,这个日期类型呢?它是占了四个字节的,比如说我们来 select, 二零二三年一月一号, 对头,是不是啊?这个是日期类型啊?这个比较简单,然后下面这个的话是时间类型呢?表示其实就是这个,把后前面这一段,把这个日期给它去掉,就变成这个时间类型了啊。这个的话是不带时区的,这个是带时区的,这个是占了八个字节,这个是十二个字节 啊,比如说我们还是以 select club, 哎, 好,然后我们来 time, 是不是啊?然后咱们还可以制定它这个精度,对不对? 呃,比如说两位是不是变成两位了啊?当然现在他是没有带四驱的,咱们可以来位置太阳目中。好,现在就带了这个四驱了啊,这个是时间类型的啊,后面这个是时间间隔类型的啊,他是占了八个字节的啊。 呃,然后的话我们可以来看一下,比如说 select 啊,咱们可以以 second 一秒钟, 是不是这里是一秒钟,然后一分钟的话是这样的啊, minute 是不是这里就变成了一 分钟了啊?也可以是这个一个小时啊,他这个很灵活的 o u r 一个小时,看见没?这个表示一个小时啊。然后的话也可以是这个一天啊, one day 一天,或者说是一个一个月, 是不是一个月,或者说是一年啊?都是可以的 啊,总共时间类型的话就是这么几个啊,其实都是比较简单的,都是。

粉丝7518获赞1.7万
相关视频
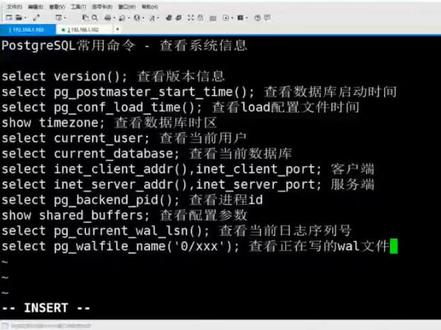 05:35查看AI文稿AI文稿
05:35查看AI文稿AI文稿我们来看一下 p g 里面查看系统信息的常用命令啊。首先第一个的话是查看版本的信息啊,我们这里直接来啊, select 不任性 啊,可以看到我们这里是十四点六这个版本的啊。然后第二个,呃,命令的话是查看数据库的一个启动时间啊,用到这个 post master star time 啊。然后我们来试一下 pg post master star time 啊,这就是它的一个启动时间啊。然后第三个的话是加载这个配置文件的时间啊,如果说你这个数据库没有 low 得过它,其实就是它的一个启动时间,咱们可以来看一下啊, p g comfort low 的太 啊,这里是已经加载过了,和这个不太一样。然后我们重新来加载一下啊,你看 reload 看哦,我们来加载一下,然后再来查询一下,你看是不是就变了啊,变成我刚刚的这个时间了啊 啊。然后这个的话是查看我们数据库的一个时区啊,然后我们来秀 temp 中 啊,这个的话是上海,这个是亚洲,上海这个市区,其实就是我们的这个东巴区,我们可以来查看一下这个时间, 你看是不是后面这个是东八区啊,加零八就是代表东八区的意思。然后这个的话是查看当前的一个用户啊, select current user 啊,是 percept 过一次。其实看这里也可以看到 啊,这个前面的这个前缀就是当前的一个用户,或者说你看这里这个 user press 啊,也可以这么来查看啊。然后这个的话是查看当前的这个啊,数据库,我们连接的这个数据库 啊, database 是不是 please grace 还是这里也可以看到啊, database pressed grace 啊啊,然后这个的话是查看客户端的一个 address 地址和它的一个端口啊,我们来看一下 啊,然后是 clander a dress 啊,然后是 client 的一个 port 啊,这里什么都没有,是因为我们是用这个啊, socket 来进行连接的啊,你可以看到我们是用用 socket 来进行连接的,我们现在不用 socket 来进行连接。然后我们来看一下, 呃,幺九二点幺六八点幺点幺零二啊,没有这个调目,我们来看幺二七点零点零点幺。好,登进去了,然后我们再来试一下, 哎,是不是啊?这是咱们客户的一个地址,是因为我是本机上链接的嘛,所以说是这个回馈地址,然后他用的这个端口是四二五零四啊, 然后下面这个的话就是服务端的一个地址啊,然后我们来看一下 server, 我注意是,然后是 server 的一个 port 好,可以看到这里也是幺二七点零点零幺啊,然后这个是默认的一个端口,不是三二 啊,然后这个的话是查看,查咱们这个进程的一个 id 啊,当前会获得一个进程 id 啊, p g bank end 啊,是 p i d。 好,可以看到是幺七三五啊,咱们这里可以再来开一个 幺七三五,咱们看一下有没有他可以看到这个绘画,是不是这个幺七三五的这个进程啊?幺七三五。 呃,然后后面这个的话是查看这个配置参数了啊,这个的话就是挺简单的,你直接绣就把它绣出来,就就像咱们之前查看这个时区一样啊,你说需要的 buffers 啊,这个是咱们配置的这个共享内存啊,用了二百五十六兆啊,然后这个的话是查看当前的这个日志训练号啊,我们来看一下啊。 pg current 或 l s n 当前这个日字训练号是这个啊,啊,然后这个的话是查看咱们正在写的这个万日字啊,他,他给的这个参数就是把这个当前的这个日字训练号给进去,咱们可以来看一下。 呃,我自己考吧, one name。 好,然后我们把这个这个函数给他写进去。好,这个的话就是咱们当前正在写的这个 word 字。好,我们可以到 进里面来看一下。 pg data。 啊,是哪个?就是这个啊,咱们当前正在写的这个,嗯,常用的这个查看系统的姓命令的话就只有这么只有这些啊,并不太多这个。
22DBA叶巍 03:10查看AI文稿AI文稿
03:10查看AI文稿AI文稿如果想在 linux 环境下快速体验 p g 数据库的功能,往往会遇到一些小麻烦。 一、使用各个 linux 发行版本中自带的 p g 软件包,通常版本比较旧,无法体验最新功能。二、安装 p g 官方的最新软件包,不同的 linux 发行版本的安装方法都不一样,整个过程稍显麻烦。 三、红帽 linux 的 e l 八下编辑好的 p g 软件包只能在 e l 八下运行,无法直接拷贝到 e l 七下使用,也不能拷贝到 debm 或 open 下使用。 四、最后最重要的一点是,当 linux 大 版本升级之后,主机上的 p g 数据库通常会出现锁影损坏的情况,必须重建锁影才可以正常使用,具体请见链接。 那么是否存在一套拷贝到任意 linux 机器都可以直接使用的通用软件包呢?答案是肯定的,中启陈树科技发行的 p g 绿色便携软件包就可以满足这个需求,而且此软件包是完全免费的。 中启陈树科技是一家专注数据库技术的公司,所出产品必属珍品。此 p g 绿色软件包 可以拷贝到任意 linux 下直接使用。经过测试,在红帽 linux 的 red hat 七、 red hat 八、 red hat 九以及基于红帽的三重 s blocky linux、 alma linux、 oracle linux 都可以直接运行, gabion、 obunto 等等常见的 linux 发行版也不在话下。用此绿色包搭建的数据库,实力在操作系统大版本升级之后,无需考虑锁影损坏的问题,还可以搭建跨 linux 操作系统大版本的流复制机型, 数据库的物理备份和恢复也无需考虑 linux 操作系统的版本兼容问题。 p g 十八点一已经发布,带来了诸多性能优化与功能升级,大家赶紧用我们重磅推出个绿色 p g 软件包,实际体验 p g 数据库的强大吧。 运行绿色版本的 p g 与官方的 p g 版本基本没有其他区别,除了需要设置一个环境变量, 下面我们以一个实际的例子来说明此绿色便携版本的使用方法。 注意,如果要下载 im 六四 cpu 架构的版本,需要替换 x 八六六四为二尺六四,需要 p g 十六点一一或者 p g 十七点七的版本替换下十八点一为对应的版本号。安装 p g 绿色便携版 bash 执行脚本, 并文件里面实际上是一个 tar 压缩文件,执行命令时会将其解压到 u s r 下面,这里数据库软件就安装好了。创建操作系统,用户 p g 登录用户设置下环境变量,能够快速搭建数据库。想了解详情请见链接,欢迎大家使用。
 14:17查看AI文稿AI文稿
14:17查看AI文稿AI文稿记录一下我微信时安装秘密和数据库的过程,包括秘密克斯瑞和秘密克 four。 首先安装这个软件可以默认他的一个安装地址,但是我因为 c 盘第三对,因为安装这个数据两个数据库的话至少要一百多个 g, 所以我还是想换一下安装地址 放在我的地盘吧,咪咪口 正常安装就行了,这个要一样的默认就行,然后密码的话一二三四,一二三四,随便是 举手就行,然后这个都是默认,然后给他安装 next, 这边允许所有程序操作这个报错。没关系啊,警告,没关系,直接点确定, 然后完成,完成以后,首先第一步要右击计算结果此电脑,然后管理服务服务,把这个数据铺这个服务开启, 首先属性登录改成本地账户应用确定,然后再启动 啊,启动好了,启动完以后,然后我们就正式安装我们的绿科数据库了, 点击刚才我们安装的这个软件里面有一个这个 sql, 然后回车回车回车回车。然后这边立马就是我们刚刚安装程序的时候输入的一二三四, ok, 然后进入到这个界面就证明安装成功了。 那么接下来就是间接数据库了,我们首先安装 amy 和 siri 吧, 根据我这个啊,首先复制这个 drop dead base exist, 妹妹靠 strike, 就是如果存在,因为客 sui 就会,就先把它给删除掉,然后这边不存在就不管它了,然后这个创建一个妹妹和手指铺用户名这个, 然后连接数据库存, 嗯,半夜人吧,然后 连接数据库,连接成功以后,然后就创建我的这个 bo, 然后设置 mix three 的路径,设置成功,然后就是我们这个,这个就是安装数据库,数据库的话 我是放在地盘里面的这个 mimic three, mimic three 首先要把这几个文件,一个 note data 七 z i p, 然后 crate table, 然后增加这个缩影的文件,然后 check 的文件,然后这个数据库的这个电子表格文件,然后另外还有一个这个 concepts, 这个后面会讲到,那么首先就是把这个路径复制过来,就是一个斜杠 i, 然后它的一个路径,这个就是创建表格的问题, 创建表格表格创建好以后呢,设置一个,就是如果出错就是记录一下, 然后设置我们那个数据文件的数据库,这个数据文件的表格文件的地址,也就是我们这个因为克斯瑞克尼尼克 dtbs 一点四,然后点回去了。 设置好以后,然后就是设置我们的中文密码,然后就是导入我们的这是 note, 这个七 z, 首先,嗯,在这个之前你应该就系统安装我们的这个 ccp 的一个这个解压锁包文件,呃,软件我之前安装过了,所以这边就直接直接复制,也是斜杠 i, 然后这个文件所在地址,然后回车, 嗯,然后这个就是正在安装我们的这个秘密口数据库,这个第三个文件,嗯,非常大,是零,可能要花费好几个小时,所以这边我们就先等待吧。 那这个十一点半到三点半,四个小时,四个小时才装完,咱们看一下啊,看一下装在这个秘密壳里面的,看一下多大啊?四四十六点几 几个 g 啊?因为这个底盘是固态的,那个机械硬盘最近装的比较慢,如果中间 c 盘是固态的,肯定会快一点啊, 那么接下来就是装这个,呃,这个缩影文件复制,然后一样的就是找到这个 index, 这个文件所在的地址,写到 i, 然后回车, 然后也是一样等待这个,所以我就装好之后就可以用。然后最后一步就是检查这个啊,然后一样的,这个也要花蛮长时间的,现在是三点半啊,你看不到, 当然了,我们再等等吧,那这个结束了啊,嗯,三点半到四点半,大概一个多小时,一个小时多一点点吧,那么这个就,嗯,所以严重完成了,所以 完成一会,然后我们再这个就 check 一下,看看有没有安装成功啊。直接也是一样的啊, check 文件在这,然后前面切开 i, 输入他的一个地址,稍微等一下。 明明和 sorry 数据库一共有二十六个表格,那么如果安装成功的话,这边会显示二十六个这个 past 的表格啊, 那,嗯,这个回收完以后,他就会显示有二十六行记录,然后所有的的二十六行啊,然后这个就安装成功了,我们可以直接查掉,然后我们打开这个软件啊, pig 这个小大象的软件 一次启动有点慢, 然后这个就是我们安装时候输的密码一二三四,然后同样的这个也是一二三四, 你可以看到数据库里面有一个 mimic three, 然后里面的话架构里面有个 mimic three, 有个比如像表,那比如 mimic curve 这个 order automation, 那么我们查询一下工具,查询工具,然后比如说我们这个 就差一百条记录吧,啊,那么就查到一百条记录,一秒死死三三号秒一百条记录,那么这个米米克狮子库就装完了,装完了以后呢?那我们另外还有一个米米斯瑞,还有一个可可石化的一个师图, 嗯,怎么做呢?就是首先要把我们这个 coss 文静放在这个里面,这个在官网都可以吓到的,然后我们仍然是运行这个 这个,然后链接到数据库,首先要登录还是一样回车,回车,回车,四个回车以后,然后按一二 三四,然后链接数据后设置数据后,然后这个选择我们这个文件夹的地址, cd 到这个地方,然后写到 i, 选择里面 concept 里面的这个 make a concept 点 sql 这个文件,然后开始也是一样的,这个巫师话也要一段过程 一段时间啊,四点五十三,那可是话就装好了啊,一共是人这么多。 然后我们看一下可说话的结果, 密码一二三四, micro three 加勾 mix three, 护花使徒都有了,嗯,比如我这边有一个 first day hit i see you the tears, 采取一下看看 i see you tears 还是一百多吧。嗯, isio, 好,这样就 ok 了。手机给我转完了, 那么接下来同样的方法去装 mimicafer 一样的 mimicafare, 然后仍然是打开这个 一二三四,输入密码一二三四,然后首先如果存在密密 oppo 数据库,就把它删除掉,不存在,那它就新建一个, 然后新建一个密密克夫儿,然后链接密密克夫儿水库。哦,要稍微等一下,这个 机械硬盘可能真的是运行速度比较慢,苹果版的这个 mig four 安装的话好像就二十几分钟就好了,不知道这个 windows 机械硬盘装要多长时间啊?互联硬盘装其实也很快, 我们看一下啊,我们看一下目前它的一个内存是多大?一米克斯瑞是包括它的一个刻式化仕途,一共是五十一个 g, 这个是链接 vip fro 数据库,链接成功以后,然后是创建,然后设置路径, 然后是雪刚爱,我是 crazy 表格, crazy 就是 mimic board 里面的这个 crazy 点 s q air, 然后就要会车一样的啊。装好了以后,然后就是我们讲的这个是设置,如果出错,把它记录一下, 坚持一,然后这个就是设置他的一个数据库的数据。呃,末路,我是在 micfor 里面这个 micfor 一点零回撤, 然后设置他的一个阿斯柯玛,中文阿斯柯玛,然后,嗯, load, load, 这 七 z, 这个点 sq f 问题,然后这个就跟那个二十六个表格一样,因为克罗斯瑞的二十六个表格一样,他装载他的一个这个,嗯,同样也是要一段时间啊,现在是六点 十三,六点十三,嗯,等会再看, 呃,九点零七吧。这个装好了,美女看 four 数据库不需要 check, 那我们来运行一下啊, 看一下 mini curls, three minute four 装完以后这个有多大 一层啊?哇,一百二十八 g 啊,两个数据会一百多 g 啊。然后 那么这个 mimica, three mimic four 的出现呢?然后同样的是架构里面有,比如说 icu, minicle, icu, 它里面有表格,比如说 icus dis。 同样呢,我们也去看一下它的一个, 你看一下一百条记录,查询一下 一百条吧,还是差一百条记录啊。一百条 ok, now mimics, three mimic four 都装好了,两个手提裤,一百二十八个 g, 完美。
38無名之辈 04:25查看AI文稿AI文稿
04:25查看AI文稿AI文稿数据量明明没变,磁盘却直接爆满了。别下山数据了,没用的来,今天咱们聊聊 post graduate 里最坑爹但也是也是大场面试必问的表膨胀。兄弟们, 你们有没有遇到过这种情况?核心订单表维持在一千万行,每天就是改改状态,结果呢?行数没变, 词盘占用却像坐火箭一样往上涨。本视频完整笔记,我都整理进了两百万字的 java 加 ai 面试提库里了,里面包含了主流技术栈与几十个项目场景题,还有各个工作年限的简历模板,以及 java 和 ai 大 模型的学习路线, 查询也越来越慢。这时候很多转行做 p g 的 同学第一反应就是删历史数据啊。我告诉你,在 p g 里,你越删,空间可能越不释放。为什么会这样,这得从根儿上说起。 如果你是卖 circle 玩家,你习惯的是原地更新,改了就是改了,但在 posgrid circle 里,机制完全不一样, p g 没有 android log, 它搞的是追加更新。 什么意思呢?在 p g 里, update 等于 delete 加 insert。 你 改一条数据, p g 是 先把旧的那行标记为死源组 dead top, 也就是尸体,然后在旁边新插一行。这就吓人了。 你想想,如果你每秒有几千个 update, 那 就等于每秒产生了这就几千具尸体。 如果清理不及时,你的表就像这张图一样,看着是满的,其实全是无法附用的,费空间,这就是表膨胀。 那怎么知道我的表种没种?别猜,直接上代码。大家截个图,用这个 circle 查 p g status tables, 重点看 ndt2。 如果膨胀率 blood ratio 超过百分之二十,你就得报警了。有人会问了,老师, p g 不是 有 auto-turbo? 超过百分之二十你就得报警了?有人会问了,老师, pg 不是 有 auto-turbo 自动清理进程吗?它在摸鱼吗? 他倒是想干活,但有时候干不了。看这张图,只要你的数据库里有一个连接,处于 idol in transaction 事务空闲状态。比如有个开发连着生产库跑,长事务没提交 auto vacuum 就 完全不敢动, 因为 m v c c 机制要求它保留旧数据给那个长事物看。结论就是,只要有一个长事物卡着,你的膨胀速度就会远超清理速度。那现在磁盘快满了,怎么就千万别手滑去敲 welcome 那 会所表业务直接挂掉, 老板会杀人的。生产环境首选 pj repack, 在 线重组业务几乎无感,但是这里有个大坑, pj repack 也是要建新表的,它需要大概一点一倍的剩余空间。 如果你的磁盘已经红了,用了百分之九十五,这时候你是跑不起来的,所以运为红线百分之八十,报警时必须介入,别等到百分之一百再哭。只选只能救急, 怎么才能根治呢?这就要请出 pg 的 杀手锏, hot heap only top 机制。它的原理是更新时新数据直接塞在旧数据那个页面里, 完全不改缩影,这样开销最小。但是号的生效有两个死命令,缺一不可,第一,数据页里得有空地儿 free space。 第二,你的 update 语句不能修改任何缩影列。 所以实战中最大的坑是什么?看这里,很多人习惯给 update time 加,所以你每次更新数据都会变时间,一变时间,所以就得改 hold 直接失效, 所以严禁在频繁修改的字段上建,所以这就是锁瘾洁癖。那怎么保证页面有空地儿呢?调参数,把 fill fact 填充因子设为百分之八十, 意思就是每页我只填百分之八十,预留百分之二十给未来的更新,用以空间换时间,强制触发 hot。 好 了,最后咱们总结一下 p g 表膨胀治理的三板斧 tier 一, 紧急排查,先杀尝试五,再用 p g repack, 注意此盘水位。 tier 二,架构调优, 去掉没用的高频,所以把 feel factor 设为百分之八十 t 二三参数调优,让 auto vacuum 跑得更勤快点学会了吗?我是 fox, 关注我技术面试不迷路。
133FOX说技术 17:59查看AI文稿AI文稿
17:59查看AI文稿AI文稿我们进入下一阶段性能,性能其实大家非常关心的一个点,那么我认为以前 mysql 之所以在中国或者互联网崛起的时代占据一个先机,那么就是在那段时间 pg 并没有专门的去扣性能,而 micco 扣了,所以那时候我承认 micco 在过去的性能确实比 pg 要好, 但是从最近十年来看, p g 的性能已经不输,甚至超过 mexico。 那么我这里引用了 my s q r。 官网的三个,引用的三个报告就是 my s q 在四十八核机器下的一个 suspense 测试, 那么我自己也在 a w s 二使用 c o d matter, 使用这个 c sponge 去同样的规格去压测,那么黄条是 my s q, 蓝条是 p g c 口,可以说两者的性能基本相同啊。在点查上 pg 比 myscale 要好一些,那么在 update 上 myscale 比 pg 要稍好一些。两者在性能上的差距我认为已经在现在这个时代啊,当然特别要强调是 oltp 简单查询的性能表现已经是伯仲之间,各有所长。 而说起比较复杂的分析类查询的话,那么 my s k l 仍然被 post gracile 吊吊吊打,因为 post gracile 的优化器仍然是公认的更好一些。 举个例子,那么在 h tab 的一些场景中呢?如果我们用 t b c h 来看的话, p g 在这个领域还是 可以在比如说五十仓一百仓的 t p c h 下跑出一个相当不错的成绩。那么 my s k l 呢?在分析领域则可以说基本上是我们说原生的 my s k l 基本上是不能打,如果能打的话,也李浩老师也不会专门来为 my s k r 做一个分析引擎了, 所以回到我们的结论就是,我们认为 post grass kill 和 my s kill 在当下的性能在伯仲之间, p p 性能各有所长, a p 性能 y s k l 则被 post grass 要吊打,那么这是我们的一个结论。 李浩老师您有什么看法呢?从 a p 这个来说吧,这个首先要承认这个 p g 的查询优化,呃,它里面的实现的完成度, 对于这个这个优化相当于早期的这个买 sigo 来说,这个是比较优的,尤其是对于这些此查询啊,包括这种这种复杂查询的处理。但是在八点零后,嗯,呃,我从我的角度来看,就是买 sigo 的优化器已经 长足的进步,就是对于对你所说的这个这个这块的 a p 可能说,比如说当前这个版本来说,可能还是还是有一定的差距。这个 这个,呃,但是说在未来的后续的这个版本里,我,我认为这个差距,呃不足以说大到有特别大量级的这个差距。因为呃,从 t g 的这个叉云计划机的代码,包括这个买 cog 的代码,就是, 呃,最近反正我两边都在买,我都,我都在这看。然后我认为这个买 circle 这方面的这个这个进步已经 赶上了 pg 对开,就是你说的那个在 ip 里面的一些这方面的一些差距,已经已经追上了这个在未来后续的这个这个几个版本之内,我,我认为他不是 一个一个特别大的一个一个相对 pg 来说的一个一个优势了,这是我的一个从我的个人的角度来个人的这个这个感官来看,因为呃 就从 pg 这几年的对于这个查询优化来说,他做的一些优化,你比如说对于这种并行查询的优化啊,这些支持来说啊,包括后面一些 呃 p g 里面的一些那个,呃整体的那个常元化的代码,呃在应该在后前几个版本,比如说 十三、十五这几个好像也做过一定的这个,这个相当于类似于大概一个重构这样。那回到这个 myseco 这个来说, myseco 的八点零相对于五点七之前的那个优化器来说,可以说是天壤之别。就从我的这个角度来说,呃 呃 pg 这块的这个所谓的这个 a a p 这块相当于复杂查询的这块优势很快就会被被赶上了, 这块是不不是成为一个一个一个主要的东西?还有一个就是说像 p g 跟买 c 口所谓的这个两者之间竖起步的,在业务上的一个定位来说,呃早期的买 c 口定位可能就是更多的是 在这个 t p 领域。因此说呃从早期的一个出发点来说,对于这块的这个这块的这个工作,我认为呃是由于这个当时的一个一个业务场景来决定,并不能决定。比如说后续的这块 这个这个后续的这个这个所谓的这个啊 ap 方面的一些走势吧。这是这是我的一些一些看法,就是就是总结一句话来说说你说的那些所谓的这些复杂 发现这些优化,呃在后面来说并不是一个特别特别大的一个优势了。让我们期待 misco 在未来 ap 领域的表现,相信十元子数据库肯定是专门做这方面的,肯定会引起一个好奖。也也也不是说是那个吧?因为呃我们这块做的跟 跟那个还是不一样,因为我们这个是 a p 的专用的,是属于一个裂损的。相对来说你像呃 p g 包括买 co 里面它 这块基于行存的这个 a p 的这个这块的更多的是呃基于这个查询优化器的一些能力,你比如说一些复杂查询的一些呃一些的处理等等这一块的一些能力,包括一些一些就是说呃索引啊,包括之类的一些这个统计信息,类似于这样一个基于此类这样一个一个 能力来来做的这个航存跟列存在 a p 这块其实还并不是一个,就是从技术路线来说,还不是一,还不是一个技术路线。李老师,就是比如说您对 p g 有什么样的 challenge 嘛?就是您觉得 p g 在您看来有什么, 或者说在正确性也好,性能也好,在各个方面有什么您觉得值得一提的显著问题吗? 呃,其实这个问题的话,其实就是呃我觉得更多的是主要是在于他,呃底层存储以及这些实现的一些方式。 呃这一块来说,你比说 p g 它是一个黑布表的一个方式,你比说它对于这个,呃这个这个所谓的这个老版本的一些管理的问题带来的一系列的这样一个一个东西,比如说主页缩影二, 所以那些更新的一些效率的问题等等等等这些问题。那么这些问题带来的在实际生产过程中,呃,尤其是在生产库上,我觉得呃还是一个比较大的一个,一个 一个一个考虑吧。就说可能假如说我作为一个一个用户或者一个企业来说,假如说在于,比如说负载特别重的一个环境下,比如说呃会涉及到经常一些更新的一种 呃,尤其是对于这种像,比如说像电商这种场景的话,呃,我可能对于 pg 的使用来说,我可能是 抱有一定的一定的谨慎的一个态度来,尤其是那种呃经常会会发生一种更新操作,那么刚才也说了,就是带来的一个问题,就是说他的一个呃空间的一个暴涨的问题,是吧?还有更新效率的一个问题,那么当然说你这个 呃 pg 对于这种,比如说呃呃某些场景下他有一些这个这个 hot 这种机制,来来来来这个优化这个,但是这种这种场景下使用的这种 呃场景还是还是比较苛刻的,大概我是这样的一个观点吧。当然说还有早期的一个就是说所谓我,我知道你不用放这个这个表, 这个是一个比较是共识的这样一个东西。还有一个就是说早期的或者说是最近 pg 才支持的一个所谓的一个复制的一个能力吧。那么这个带来的一个问题,就是说 你这部分的功能或者能力的这个提供,或者说是 ready 的这个状态来说,会导致我当时我现在这个解决方案,或者说我这个项目的一些周边系统,或者说周边那些工具的一些支持等等这些,这都是假如说 我作为一个企业选择的话,那么这是我所需要考虑的一个点吧。其实像李老师说的正是 myscale 或者其他数据库用户对于 postcarcle 最为诟病的一个点,因此在这里我也借这个机会呢,其实想解释阐述一下, 应该来说 pg 没什么黑点,在以前可能最大的黑点是不流行,招不到人,现在这个问题解决了,那么唯一剩下的我认为是算半个缺陷的点就是这个 mvcc 表膨胀语是我 id 回卷, 但是考虑到其实 p g 的 m v c c 实现带来了一系列的好处,比如说 d m l 不阻塞查询,毒和血互相补锁,然后无需昂度,那么对于大事物的支持也相对买这个来说更好一些。比如说你 不会担心撑爆回滚回滚断的问题,你不用担心回滚,一个大事务非常长的问题,你不用担心提交一个长事务,提交一个大事务产生巨大的主从延迟的问题,那么相比于这些收益来说,磁盘空间和内存空间的一个浪费对于现代情况下 已经并不是一个非常重要的考虑了。呃,这些都属于啊,他其实并不是简单的一个空间的问题,他带来的一个问题还有一个就是 sid, 对,还有一个是 x i d 的问题。那么就目前来说呢, p g 社区对于这个问题的解决方案是自动垃圾回收, 我们在一些生产环境中做过一些测试,十三十四版本使用默认的 auto y com 参数级一个固定的规则,那么基本上在跑了一两年也没有需要人工介入的这么一个场景。所以, 所以我认为其实炒作的一个表膨胀问题,或者说 x i d 事物回卷问题,在现代硬件条件下已经是已经是一个运为可解的问题。 呃,我不同意这个观点啊,我我我认为当前的这个就是当前的这种技术条件下, io 还是一个比较宝贵的一个系统资源,而且是一个容易造成一个系统的一个瓶颈所在。 但我不知道像李老师您针对的环境啊,就是是使用什么样的磁盘硬件,是 h d d 还是 s s d 还是 n v m e 的 s s d? 因为我感觉现在这个时间点,那么根据就各种报价来看, s s d 的单位价格马上就要 跌破超过比 h s d 更 h d 力更低了。那么在这种情况,如果大家都有 s s d 的情况下, 我认为这种 vacuum 的速度已经不是一个生产中实践的问题了。 auto vacuum 已经可以很好地利用好现在硬件下的 i o p s。 举个例子, s s d h e d 的 i o p s 这才多少 s s d 的 i o p s。 现在一千几百万的 l p s 都有了, 对于这样性能的硬件来说, nikem 还会是一个问题吗?我认为不是,现在无论是消费级硬件还是些主流数据中心,都已经普及了这样的硬件,那么在这样的硬件基础下,我认为数据库在操心这些问题其实是 其实有点多余了,因为现在我们观察到的真正瓶颈往往是在 cpu 本上 ok, 那么关于可维护性,其实我们就想说这么多, ok, 现在我可以发言了吗? 他说的那个刚才你提到那个就是 cpu 作为一个当前是一个是一个,应该说就是一个比较比较宝贵的一个一个资源吧,是吧?当然说,但是现在这个问题来说,就当前的情况下,呃,从我的角度来说, 呃,还没有一个数据库可以把这个 cpu 去,就是在在在普通的场景下就是能充分的利用账 这个东西来说,就是无论是你比说你像,你像像像 pg, 你比如说你开启了并行还是等等,这种场景下他其实并没有把 cpu 的这个资源 去,就相当于是可以去完整的利用到。从我的这个这个认知来看,其实当前来说,呃, cpu 这块其实还并不是一个, 当然说是一个优化的一个点,比如说利用这个多核能力来提升这个这个计算这块是现在大家都在做的这个这个主要这个点,但是说这块的提升 我觉得还是相对来说收益,或者说是这个需要做的工作。从底层的这个,比如说存储机制来说,能得到这个这个收益还需要去去花更多的时间或者是精力去做这个事情吧?所以没错,我特意强调的是在现现代硬件条件下, 呃,那这样的话就就回到这个,如果现在的硬件条件下,相同的这种这种存储引擎来说,呃,买 sco 的 iot 这种这种所谓的这种这种结构来说应该是更占有一定的优势的。 为什么呢?因为,呃,李浩老师您是精通 pg 和 maysco 内核架构的专家,那么从理论上来说, mayscale 英东 d b 引擎我写了一条记录,我应该要写 redo, 写 on do, 然后写 bellock, 然后呢?我还要在索引组织表里面去把它放到合适的位置。而 postgrad scale 呢?它只需要写一个 vlog, 然后还要放在堆表里面,按照道理来说,那么应该是 postgrad scale 性能更好才对。 但是就是就是,如果是你没有,所以的话,你不需要维护,所以开销的话肯定是堆表这种判的这种方式,是吧?这种你比如说这就是插入一条新的记录,这种方式是来的更快一点。这个是,我是同意的这个观点, 但是就是说假如说你这上面有一些,呃,所以你需要维护的话,他可能去维护的开销来说就相对来说比较比较多一点。这也就是为什么这个,这个,这个安定那边,是吧?写了一篇文章来诟病这个,这个,为什么说这个, 呃,这个这个这个 the word 是吧?这个 mvcc, 哈哈哈,是吧?就是对他说 the word part of postcars。 对,是的,我同意您的观点。这也是为什么在性能比较这里,我特别强调 my skl 在很多缩影的 update 下,相对 postcarcell 还是有一些优势的。 那么其实关于可扩展性也就是这些,就前面讲到性能吗?对吧?讲到 tp 和 ap 吗? 我先说一下 a p a p 的优化器,呃, p g 比买 c 扣强,我承认, 我承认。 but, 谁会用 p g 去做大数据的存储和分析呢?我们不是应该用 clear house 或者是 have 嘛?我要至少在苹果我们是这么做的,至少在我, 我们大厂,在中国的互联网大厂里面,我们用的是大数据的这个平台,对吧?你比买机构强,我承认,但是用的更广的是大数据的这些平台, ok, 这是我的一个观点。第二点是关于 t p 的这样的一个性能。 t p 的性能,你前面说这个数据是引用官方的, 其实我不太清楚这数据在哪里,但是正好今天买秀官方的同学也在线上嘛,也在线上,其实我觉得你们可以去看一下这个数据 这情况是不是对的,如果是对的,那我们就应该好好的去优化他,如果有人在这里是做了这些手脚,那我们就应该拿起我们的这个法律的武器去捍卫自己这个权利,对吧?这个我觉得是我,我想表达一个观点,但是另外一个观点我想 想说的是,如果谈到性能的话,我们不是应该看 t p c c 的这样的一个性能的榜单吗?在这样的一个更符合真实场景的这样的一个呃,榜单之下, 我只知道现在排第一的是基于买 c 口的这个体系的 t d c 口,而并不是 p g。 如果你说 pg 的这个数据库性能很强,那么我觉得至少在前前三里面应该是可以看到 pg 的身影,那么为什么我们看不到呢? pg 的性能真的像你说的这么好吗? 我们真正要用的并不是 suspension, 而是类似 t p c c 这样的一个事物的场景。 好,姜老师表达了 t p c c 是性能的一个衡量标准,我相信这一定是因为腾讯的这个 t d c 扣啊,在 tbcc 上打了个榜一,刚把阿里的这个欧神被子给打下来。但不管是哪一个,我都要说 tbcc 已经是一个三十年前的半尺标准,已经是相当过时的一个标准,而且还可以通过堆积器的方式来累积。我承认,我承认你说的都对,那么为什么 pg 不堆积器啊? 为什么没有厂商去参加这样的跑分?你是因为这我觉得这是一种人傻钱多,给美国评测标标准机构送钱的 sb 行为。所以你觉得腾讯和 ob 和蚂蚁是 ob 的行啊,是 sb 的行为是吧? 我觉得为了你的直播间,你在直播间这样说都是有录屏的好吧。嗯,然后一,你是否定了 d b engines 这样的这个这么多年的这个排行。二,你又否定了 t p c c 这样的一个权威的这个测试,那我觉得这个就是你的这个结论吗?其他我是没有问题了,在我觉得你这个帽子安的有点不对,马西口是是是,是不如 pg 的,但是 应用就是另外一回事情了,对吧?这就是我的观点。好的,那关于这点我没有意义,您可以这么说啊,您可以认为我认为 d b c c 是一个过时的标准。
 02:47查看AI文稿AI文稿
02:47查看AI文稿AI文稿面试官问你, pos sql 的 主键是拒促锁影吗?如果你张嘴就来?是啊,主键存数据锁影是必加数。那恭喜你当场挂科。很多兄弟被 my sql 的 八股文洗脑了, 以为全世界的数据库都是 micro, 但在 p g 里,主键就是个普通的二 g, 所以 为什么会这样?我放在这份两百万次 java 与 ai 大 学习笔记里了,里面包含 jvm ready、 mq 微服务、 ai 大 模型等三十多个技术站与一百多个项目场景实战笔记,还有不同工作年限同学的鉴定模板。大家看这张图, micro 是 i o t 缩影组织表, 数据就住在主键必加数的叶子节点里,井里井井有条。但 p g 是 堆表 hepu table, 它的数据像一堆乱炖的砖头, 随便堆在字牌上,根本没有顺序。所以 p g 的。 所以里存的不是数据,也不是主键 id, 而是一个物理地址,指真叫 ct 的。 那这有什么好处呢?看这里, maccode 查二级,所以得先回表查主键,再查数据。要走两棵树, p g 呢?拿着 c t i d 直接飞到物理地址去拿数据,少走一趟弯路。读性能贼快,但是有得必有失。如果我 update 改了一条数据,导致它的物理位置变了, c t d 变了, mexico 只需要改主键二级,锁影不用动。但在 p g 里, 所有指向这一行的缩影全部都要改一遍,这就叫写放大 write amplification, 写性能压力山大。再来个更坑的。面试官问, p g 里有覆盖缩影吗? 你以为只查缩影列就不用回表了?错, p g 的 缩影里不存事物信息,就算缩影里有数据, p g 也不知道它是不是活的,必须回表去看一眼 visibility check, 除非你勤快地跑。 vacuum 更新了 vm 可见性印刷表, 告诉 p g 这页全是干净的,他才敢走。 index only scan 被虐了这么久, p g 到底强在哪儿?它强在武器库,太丰富了。搞 jason, 别用 my circle 的 虚拟列了 p g 的 j 的 倒排,所以查 jason 比 mongodb 还快。搞互联网持续数据几十亿,行 用 brain, 所以 它不存指标,只存数据快的最大最小值几 tb 的 数据,所以只有几 mb。 最后送大家一个 p 八级的闭坑指南, 千万别在 p g 里用乱序 u u i d 做主键。为什么看这张图 u i d 是 乱序写入的,会把数据页弄得满天飞? p g 的 机制是,只要数据页脏了,第一次修改就要把整个页写入 ll 日制 four page right。 后果就是 l 日制暴涨 l 直接打满数据库卡死。解法是用 t s i d 或者 u u i d v。 七,保证有序性,没有最好的架构,别拿 micro 的 经验硬套 p g。
60程序员FOX











