千问语音克隆效果
阿里刚刚开用了一个国内最强的声音克隆模型千问三 tts, 只需要三秒的素材就能实现声音克隆,还能做各地方言,直接给你们看实测效果。 今个俺教恁几个河南方言啊,中不中?今在商场看到帅哥走不动道而来,这咋整啊你那算啥子,有个事情多盯了我两眼,我就一坨子,打不开卵米子,就过了两年, 老子数到三,你撒不撒手?你不撒手我弄你嘞。比声音克隆更厉害的是,他这回还开放了九个音色,可以写一些复杂的情绪提示词,让他来呈现对应的情绪效果。哈哈哈,快点放假吧。哈哈哈,快去快 讲吧。如果你需要 ai 帮你做一些比较丰富的情绪解说视频,这个目前来看真的很合适,有兴趣的赶紧去试试。

粉丝1.0万获赞5.7万
相关视频
 04:25查看AI文稿AI文稿
04:25查看AI文稿AI文稿说到声音克隆,很多人都会想到 index tts, 如今千问也出了一款声音编辑模型,千问三 tts, 它不仅可以克隆声音,甚至可以模仿多国语言。可以看到这次一共发布了五款模型, 一点七 b 大 小的有三款,分别是自定义音色,预设音色,还有克隆音色。零点六 b 大 小的有两款,自定义音色和克隆音色。当然一点七 b 的 模型显卡显存八 g b 的是可以跑通的, 所以零点六 b 的 就不参与测试了。我们看到下面这个自定义音色分别有着不同的语种和音色, 我也会把这个截图放进工作流里面,好让大家能分清。这里为了更好的让大家体验,我把所有的工作流都放在一起了,并且上传到了云端,需要的留言分享。可以看到这里有四种模式, 分别有预设音频、自定义音色、克隆音色,还有多人对话模式,如果大家想使用其中一个功能的话,在这里把其他三个关闭就行, 这里为了演示效果就把全部打开了。先看第一个预设音频,首先这里加载的是一点七 b 的 custom voice 模型,这边输入需要说的话, 下面这个预设说话人对应的就是这张图片里的角色与种和音色,这里选择的是 eric, 对应的是这个四川方言。我们来听一下,你知道吗? ai 净化的速度比你想象的还要快,昨天我们还在惊叹他能画出,今天他就能完美复刻你的声音了, 别眨眼,接下来的十几秒我要带你见证奇迹,我是极简 ai, 让我们开始这场探索之旅吧!可以听到真的很对味,大家可以根据自己的需求来选择对应的人物,下面也可以调整他的语速。 再来看第二个自定义音色,下载的是一点七 b 的 voice design 模型,上面输入我们想要说的话, 下面用提示词输入需要设置什么样的音色来听一下。停华总你就亏大了,这绝对是你今年见过最离谱的黑科技,不需要昂贵的设备,也不需要专业的团队,只需要点一下鼠标就能搞定一切。 还在等什么?赶紧上车,手慢无啊兄弟们可以看到音色很符合下面提示词的描述,我这个其实写的有点短, 大家可以用智能体来帮忙参照填写。继续来看这个声音克隆,我这里上传一段小岳岳的声音,有个小孩叫小明,小明上学,上学的时候,同学这边加载一点七 b 的 face 模型, 然后添加了相对应的去除背景声音的节点,接着输入提示词来听一下效果。 那天午后,阳光透过树叶的缝隙洒在地上,形成斑驳的光影,他抬起头,眯着眼睛看着天空,仿佛在等待一场久违的重逢。 风轻轻吹过,带来了夏天的味道,也吹乱了他的头发,跟原声还是非常相似的。最后再来看多人对话,我这里设置了自定义音色与声音克隆结合起来的,让大家有多项选择。这里自定义音色我选的比较全,然后再来看一下,这里 最多能设置八个角色,我这里以角色 abc 来填写来听一下。 哎,这康复 ui 也太难了吧,全是节点连线,连的我头都晕了,根本跑不起来啊, 慌什么,那是因为你没用对方法,来试试我这个极简 ai 整合包,不用连线,点一下就能出图。真的假的?这么神奇? 骗你干嘛,赶紧上车带你飞。可以感觉到声音跟音色设置有很大关系, 小岳岳角色 c 的 声音也很自然。首先给大家讲一个笑话,如果大家想全部用声音克隆来进行多人对话的话, 可以直接先把下面这个声音克隆复制一份下来,然后把上面的自定义音频删除,再把线连接一下,重新上传音频就可以了。本期视频就到这里,我们下期再见,拜拜。
90极简AI 02:50查看AI文稿AI文稿
02:50查看AI文稿AI文稿当我强行用 ai 器克隆我老婆的声音, 先录好她的说话声音, 然后整合在一起。你知道这凤凰蛋有多重要吗?红帽的听力还没有完全恢复,大家先练习一次 导出。导出完成, 现在打开千万准备克隆声音。 克隆完成, 现在准备提问听一下效果。 见证奇迹的时刻就要到了!这张照片拍得很有生活气息,构图稳定,色彩还原真实,是一张不错的街拍作品。 画面主体是一辆敏运的客运大巴,车身颜色为深紫红色与亮粉色,搭配 车头正对镜头,视觉冲击力强。车头挡风玻璃上清晰可见由西到三明的路线标识。 车门敞开,似乎正在上下课或停靠。车牌号为闽 g 杠 y 三五八三,属于福建省三明市由西县的营运车 辆。车身侧面印有福建闽通长运股份有限公司的字样,说明这是正规客运公司的车辆。 好奇怪,听起来有点别扭,有点像,但又有点不像,在座的各位觉得如何呢?
26鹰厦永安段 04:12查看AI文稿AI文稿
04:12查看AI文稿AI文稿大家好,今天给大家更新一个千问 t t s 多功能语音节点,包含语音克隆、语音设计、预设角色声音生成、多角色对话可保存角色预设到本地,随时调用,并可调用来进行多角色对话。由于功能众多,我们就挑几个重点进行讲解, 现在我们来看看多功能语音节点。这里有三个角色括号,里填角色的声音特点,双引号后面是角色的说话内容,等于二秒和等于三秒是停顿的时间长度, 需要在哪里停顿就填,等于号,后面填时间 s 就是 秒,要实现停顿需要打开启动停顿控制按钮。多角色对话需要选择智能对话,内置模型选择自动。我们来听一下多角色对话的效果。你好, 这是一段测试文本。好的,我现在测试一下,看看你们这是在干什么。现在我们来看看角色预设保存, 可以把语音克隆成随时可以调用的语音预设文件,可以加载预设文件进行语音克隆,可以在多功能语音节点直接进行调用,无需手动加载。这里填简短的文本内容即可, 能生成三秒到十秒左右的语音文件即可,不要小于三秒,不然加载角色预设文件会失效。 这里填角色预设的文件名,方便调用。这里加不加文件后缀名都可以,没有添加后缀名会自动追加后缀名。 角色预设文件默认保存在 config 下的 output 文件夹里的 q w n t t s presets。 新生成的角色预设文件小强点 p t 已经保存到本地目录了。刷新一下网页就可以在角色预设选择节点预设,选择下拉列表,选择角色预设文件了,可以在角色预设语音克隆工作流加载预设文件进行语音克隆, 这其实跟加载音频进行语音克隆效果是一样的,但是这个方便后续调用,做成自动化的工作流多功能节点,可以直接输入对话内容,进行多角色对话语音生成 输入的内容在括号中填角色的音色描述,然后开启批量保存角色预设,方便下次在这个节点进行调用,只需输入角色名,不需要再描述音色了。 这些本地存储调用的功能只能在本地电脑部署的 comfy ui 使用,然后选择智能对话模式,内置模型,选自动选自动角色预设,如果本地没有就重新设计角色音色,本地有的话就可以直接调用。 我们来听一下效果。周末咱们去新开的那家游乐园吧,听说有超大的过山车,过山车会不会太吓人呀,我有点不敢坐。没事,游乐园也有旋转木马、碰碰车这些温和的项目, 咱们可以先玩那些再决定要不要坐过山车,这些参数是需要开启起用高级彩样配置才生效的。最后我们来看一下这两个音色预设描述选择的节点, 这个节点可以选择进行组合,然后底部输入框可以输入自定义的音色描述。输入自定义音色描述后,如果下拉选项也选择了,那么就是合并在一起进行输出的, 这个节点一次只能选择一个,都是内置的声音描述,不能进行组合输出。 感谢大家的观看,如果有 bug 欢迎在评论区进行评论,我们一起把这个节点进行完善。 工作流和节点已放在简介区,可以通过 running hub 在 线体验。 running hub 是 我平时学习工作流的网站,通过简介区的链接注册,可以赠送一千点算力。已注册还未绑定邀请码,也可以绑定邀请码 r h 杠 v 幺幺二七赠送一千点算力。谢谢观看,我们下期见!
 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿我的好奇心被点燃了,快给我占卜一下。你好,我是战斗力只有半只野猪的派蒙, 每个月能吃掉三十万摩拉的伙食费。这款保湿面霜质地清爽不黏腻。小朋友们跟着老师一起读 一二三四五。哈喽,大家好,这期我们来讲一下千问三 t t s 的 音色克隆功能,也就是这个 voice alarm 的 节点。与音色设计不同的是,它需要有一段参考音频来作为音色参考,那么我们就可以拉出一个加载音频的节点音频我们选择用之前音色设计的功能 生成了一段比较偏向于电商方面的女性的声音,那么这一段呢,大家在开头也已经听过了,我就不再放一次了。 接下来我们来看它的克隆节点,与音色设计一样,在最上面的这个文本框是我们需要它讲出来的台词,那么我们这里就随便写一段模型呢,我们可以选择一点七 b, 现在在第二个文本框,我们需要写上我们的参考音频里面的台词,也就是说这个参考音频里面说了什么,我们就要在这里写什么。 我们检查一下我们的 attention, 确定不会在这里进行报错。最后我们要检查的是这个 x v k o n 的 选项,如果我们就必须要在这里写上台词, 不然的话就会报错。如果我们开启的话,这里不写也没有问题,可以正常的生成。但是我个人觉得在打开这个选项之后,连同文本一起写上去效果比较好,所以我还是推荐大家开启这个选项,确认参数设置没问题之后,我们直接运行就可以了。好的,那现在我们可以听到 克隆出来的声音跟原声比较接近了,大家如果觉得不满意也可以再次运行进行抽卡。另外如果我们想复刻某个游戏里面的角色的声音的话,同样也可以进行操作。例如这里选择一个派蒙的语音, 将它的文本替换一下,同样直接点击运行就可以了。要注意一点的就是,我实测下来,其实这款模型并不能百分百的还原它们的音色, 很多角色只能说是相近,但是可以听出是完全不同的两种音色,不要对这个抱有太大的期望。好的,本期的分享就到这里结束,下期我们讲一下关于这个模型的自定义音色的一个节点,我们下期再见。
12李北北的AI 03:14查看AI文稿AI文稿
03:14查看AI文稿AI文稿声音克隆哪家强?老曹替你把坑防!今天要为大家评测的是阿里同意新出品的千问三 tts。 千问三 tts 号称除了可以做基础的声音克隆,还能通过自然语言控制语气和设计音色,并且支持十种语言。 这些功能效果如何?老曹今天就为大家一一测评。首先,在声音克隆上,千问三 t t s 和其他大模型的显著区别就是,除了要上传声音样本,还要提供样本对应的文本,是不是似曾相识?嗯,没错,同为阿里出品的 cosy voice 也是这样要求的。老曹都怀疑千问三 t t s 是 不是套壳的 cosy voice 三。千问三 t t s 克隆效果如何?我们来听听他克隆的甄嬛, 轻轻地我走了,正如我轻轻地来,我挥一挥衣袖,不带走一片云彩。嗯,总体还行,接下来我们加点难度,让他克隆一下校长,我不明白 为什么大家都在谈论着声音克隆,很难,仿佛在 ai 新战场对于我们注定了凶多吉少。 怎么样?之前测试 cosy voice, 他 明显 hold 不 住,校长这种口音看起来千万三 tts 比起 cosy voice 三明显进步了,音色复刻能力可以跟 index ts 二 maggot 拜拜手腕了。 下一个评测的功能点是自然语言控制语气的能力,简单点说就是你想 ai 用怎样的语气去说话,就直接告诉 ai。 老曹随机输入了一些提示词,结果如下,家人们,声音克隆测评炸场来袭!先问三 t t s 到底藏着啥猫腻? 今天老曹直接巴透。总体而言,老曹使用下来的感受就是不精准。之前 index t s 二也推出过同样的功能,但是老曹更多还是用 index t s。 二的语气参数控制,用自然语言控制,非常不精准,调半天也调不出想要的效果。 目前看,千问三 t t s。 也同样有这个问题。下一个主要功能是音色设计,千问团队声称他们的这个音色设计比 min max 更强,我们今天就来对比一下。你好,我要买一瓶可乐你好,我要买一瓶可乐! 你好,我要买一瓶可乐。你好,我要买一瓶可乐。虽然说 minx 也没有多好吧,但他好歹知道什么叫八岁,什么叫低沉。千万三 t t s。 也太拉垮了,这是八岁女孩吗?这不六十岁大妈吗? 最后,生成速度和算力消耗方面,在同样本同文本下,千万三 t t s。 的 生成时间大概是 index 二的一点八倍,建议电脑二十 g 显存以下的宝子们去做本地部署,部署起也会很慢。 最后总结一下,前问三 t t s。 声音克隆的能力较 cosy voice 有 明显进步,但新推出的语气控制、音色设计功能当前都无比拉垮,还远达不到实用要求。综合比较下,老曹认为 index t s。 二仍然是当下声音克隆最佳模型。
19声音克隆哪家强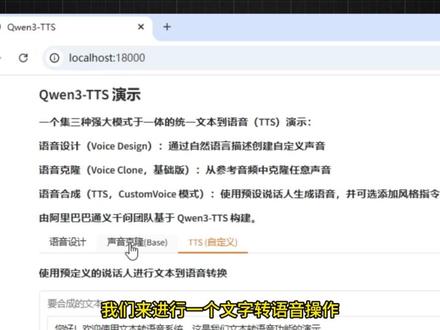 03:27查看AI文稿AI文稿
03:27查看AI文稿AI文稿最近爆火的千万三 tts 模型在这几天也进行了开源,此模型支持稳定有情感且可持续输出,是一个集语音克隆、语音设计、 超高质量拟人生化语音生成三大模型为一体的文本转语音工具,支持中文、日文、韩文、英文等多国语言配音,非常强大。我也给大家提供的完整且免费的离线整合包,接下来就给大家分享和演示一下 千万三 t t s 离线整合包,它的体积一共是二十五点二 g b, 支持在温系统进行运行,需要电脑有六 g b 显存以上。 打开这一个文件夹,里面有一个 run 点 bat 的 文件,双击或者是以管理员身份运行,它就可以在我们的电脑上进行打开。首次运行需要我们等待一下,按一下 n t 键, 等待它进行启动以及加载模型。加载完成以后,在这里面有一个这样的链接地址,我们可以将这一个链接地址复制到浏览器进行打开,同时它自己也会跳转打开到我们的浏览器上。打开后这一款工具整合包,它里面是没有任何广告植入的,一共是集成的三种模型,比如语音设计、 语音克隆以及语音合成。我们可以使用这三个模型对我们来进行一个文字转语音操作,或者是对声音进行克隆。首先以语音设计这一个来给大家进行演示,在这一个文本框内输入我们的需要合成语音的文本, 比如这里面他内置的文本语言,我们可以选择中文、英文、日语等等其他国家不同的语言,我们这里就选择中文语音的话,可以根据我们自己需要的一个语气进行描述,点击使用,查看任务管理器,点击性能,再点击 gpu, 可以 看到我们的 gpu 基本上是跑满的。 生成好以后的语音,在这里面可以直接进行预览和试听。它在最上面的抽屉里等等,抽屉是空的, 不可能,这绝对不可能,我肯定是我放在那里的这个声音,它是流露出了这一种难以置信的语气,同时也有一丝恐慌。这一个语音描述和这一个深沉的语音,它的效果基本上都是匹配的,同时它还支持声音克隆,我们可以选择导入参考音频,或者是点击录制的按钮, 录制我们麦克风的声音,现在我对我自己的声音进行录制,接下来对它进行克隆,点击停止,我们在目标文本框输入我们自己需要生成的目标文本,我们可以选择不同国家的语言,以及选择不同的模型大小模型一点七 b, 它的效果比零点六 b 肯定会好。 点击克隆语音生成好以后的语音,在这里面也可以对它进行预览和试听,同时也可以点击下载的按钮,对它保存到我们的电脑本地。怎么样? 大家好,我给大家分享和他这一个效果生成,相对于 index t t s, 他的克隆声音效果会稍微差一点,但是没有关系,这一款语音工具他还支持语音合成,这一个效果我觉得非常强。在这里面输入我们自己需要合成的文本, 选择不同的发音人,这里面有着非常多的一些不同人物的声音,在这里面还可以输入自己的风格、语气等等,然后点击生成语音,生成好的语音点击试听。您好,欢迎使用文本转语音系统,这是我们文本转语音功能的演示, 可以看到这一个声音非常的清澈,而且这一个声音也不算很虚假。这款工具还是非常不错的,尤其他是一个完全免费的离线整合包工具,就给大家演示到这,谢谢各位收看。
23资源汇社区 02:23查看AI文稿AI文稿
02:23查看AI文稿AI文稿三十年了,整整三十年,老夫为了这大梁的江山,素心夜魅不敢有一丝懈怠,可陛下您呢?您听信谗言,自毁长城, 如今敌军兵临城下。 i knew i should have told her to leave i knew it was a setup, but in this town nobody walks away from a payout like that not even a fool like me。 哈喽,大家好,本期我们来讲一讲千万新推出的一个 tts 的 模型,它的功能非常多,包括音色设计、音色克隆、自定义语音以及多人对话。由于功能较多, 所以我们会分成几期来分享,那么本期我们先来讲一讲它的音色设计的功能,也就是这个 voice 三节点,它的构成非常的简单,这里两个文本框,上方是我们需要讲的台词,而下方则是我们需要给它设定的音色,这里就是我们的一个提示词, 我这里可以给大家做一个示意,例如我想生成一段老将军说的话,那么在上方我们就可以输入他要讲的台词,而下方则是他的一个人设以及音色的设定。那么接下来是下方的参数。第一个就是他的模型,他有零点六 b 跟一点七 b 的 模型, 但是一般来说这个模型需要消耗的配置不高,所以我们一般选一点七 b 就 可以了。之后我们可以关注一下它的语言,它这里设定成了自动以及各国的语言,当然我们一般选自动就足够了。最后我们可以看一下它的一个 attention, 这里也是很多人会报错的一个点,如果这里没有下载对应的选项,那么就有可能会报错,如果出现报错,就可以把这里每个选项都试一下,看看有没有哪个是下载了的,接下来我们直接点击生成即可, 那么我们再等待一会之后,这边的音频就已经生成完毕了,我们可以点击这里进行试听,如果对于结果不满意,我们也可以重新抽卡再次运行。另外在音色设计的框内,我们可以直接将一个角色的人物设定丢上去,效果也是不错的。 另外在音色设计的方面,我们可以直接将角色的一个人物背景以及人物设定等直接丢上去,也是有一定效果的。好的,那么本期分享到此结束,我们下一期再见。
13李北北的AI 03:55查看AI文稿AI文稿
03:55查看AI文稿AI文稿千问三 tts 是 通用千问推出的开源语音大模型,以三秒极速克隆自然语言,控声九十七毫秒超低延迟,多语言 方言覆盖,长文本稳定生成与高音质为核心优势,开源免费且支持本地部署,综合能力领先同类开源模型。现在说话的音色就是用这个模型生成的。进入程序界面,上传一段音频,听听声音, 尊师重道。那时候他很希望我可以考上音乐系,然后读大学。系统自动识别出的参考文本可能会有错误,有的需要改一下。目标文本就使用缺省的模型,可选择缺省一点七 b 的, 零点六的生成速度更快一些,但效果差一些。 点击克隆语音,生成时间大概二十秒,显存占用七 g 左右。听听生成的结果。冤滴之水中能够磨损大石,不是因为它气力富强,而是由于昼夜不舍的滴坠。我们再换一个音色, 光动嘴不如亲自做给你看,等我一下听听生成的声音, 捐滴之水终能够磨损大石,不是因为他气力富强,而是由于昼夜不舍的滴坠。 我们点击进入语音设计标签,这个是通过文字描述生成音色语言,这个下拉菜单可以选择十个国家的语言,有兴趣的可以自己测试。语音描述,我们就使用缺省的生成一个,点击生成语音, 他在最上面的抽屉里,等等,抽屉是空的,不可能,这绝对不可能,我肯定是我放在那里的。我们先更换一个要合成的文本,然后在语音描述里写上男生播音腔,充满磁性,点击生成, 用难以置信的语气说话,但语气中要开始流露出一丝恐慌。点击下面灰色的按钮,把定义好的语音送去克隆界面。 用难以置信的语气说话,但语气中要开始流露出一丝恐慌。点击生成语音 捐滴之水中能够磨损大石,不是因为它气力富强,而是由于昼夜不舍的滴坠。点击第三个标签 t t s 这个标签使用预设说话人生成语音可以添加风格指令,这里有很多本地方言,我们可在方言的基础上加上喜怒哀乐等情感,生成我们想要的音色。先听听这个大叔的声音。 您好,欢迎使用文本转语音系统,这是我们文本转语音功能的演示,选择这个北京话。 您好,欢迎使用文本转语音系统,这是我们文本转语音功能的演示,我们加个声音描述,声音低沉。 您好,欢迎使用文本转语音系统,这是我们文本转语音功能的演示,这个声音太低沉了,我们换个欢快的。 您好,欢迎使用文本转语音系统,这是我们文本转语音功能的演示,发送到声音克隆界面。 您好,欢迎使用文本转语音系统,这是我们文本转语音功能的演示。听听克隆厚的声音 捐滴之水终能够磨损大石,不是因为他气力富强,而是由于昼夜不舍的低坠。 这个视频的配音都是用这个整合包完成的,整合包包含全部原代码,便于大家进行研究。我把整合包的获取办法放到简介里了,今天的视频就到这里,我们下期再见。
 05:48查看AI文稿AI文稿
05:48查看AI文稿AI文稿凌晨一点打印时还亮着灯,实习生李默在复印资料,门被推开了,还没走啊,苏总监马马上就好,他指尖若有若无,略过他领口, 午夜加班算特殊工时哦。预知后事如何,请听下回分解。哈喽,大家好,我是香酥幻想。今天这期视频给大家带来千问三 tts 合集,到目前为止,我发过的视频里面就差一个文本转语音的工作流,那刚好今天咱们把它补齐。 在这里首先感谢千文的开源,大家可以看一下这个模型支持的语言特别多,中文、英语、日语、韩语等等,而且它的这个模型容量也很小,一点七 b 的 模型它容量就在四点二三 g 这样,所以说这个模型啊,这工作流八 g 显存就可以畅玩了。 其次感谢派派大佬开发的这个节点,大家记得给他点个 star 啊。那我们回到工作流那首先就是语音克隆,这块,语音克隆很简单,在这里上传你的参考音频,经过这个节点在这里出来结果, 那这个节点需要注意的地方就在这这里输入的是你的参考音频转成的文字,写在这里,这里我是用手敲的, 因为我的环境的问题,我装那个语音转文本的那个插件老是报错,所以我就没有装了。然后你这里要是不写的话,你可以把这个开关打开, 就是他单纯的参考你这个声音的音色去生成,但是这样的话效果会差一些,我试过,所以在这大家最好还是输入一下,或者就装那个 whisper 的 插件。 那这个工作流我也部署到 rng 汉堡了, rng 汉堡也是我平时常用的在线云平台,他的模型更新速度非常快,像这个模型刚出来这边就已经能用了,包括这个派派大佬的这个节点,那像在这里就不用手动去输入了,他通过这个节点把你的参考音频转成文字输入到这 就 ok 了啊,这个大家注意一下就行了。那下来就是这个预设角色的文本转语音,他这里面是内置了这么些角色的,大家可以看一下, 在这可以选他每个角色都有说明对应的语种啊之类的,你看这个小东,他是北京话,所以我这边试了一下,大家可以听听。嘿,您猜怎么着?昨个碰见一新北京,跟我掰着半天,什么豆汁必须配胶圈, 这感觉还行吧。那这个节点顾名思义啊,就是用预设的角色去完成这个文本转语音,你在这里选择好了你的角色之后,可以在这写提示词,控制 控制他的一个情绪啊,各方面的东西,然后在这的输出,那下来就是这个声音定制啊,声音定制是先锋 tts 的 一大特点,也是一大亮点, 就是你可以通过写提示词的方式来生成你自己想要的一个音色,那比如说在这里我写的是性感妩媚的御姐音,大家可以听一下这个声音呦, 这位小哥,我看你不像是本地人啊,那这个提示词大家可以自己写,也可以通过大模型来生成,我这里用的是提示词小助手,我试了一下这个智普四点六 跟这个我本地部署的这个前文三都可以,如果用提示词小助手的话,就在这里设置规则管理器,里面提示词优化规则,你这添加一个,那就是这个大家可以看一下, 然后把这一段提示词给它放进去保存,保存完了之后 刷新一下 f 五,刷新一下这个页面,在预设这里就可以选了,那个提示词我也放到这里了,大家到时候根据自己的需求去用就行了,用提示词小助手,或者说前文三,或者用其他的 api 都可以啊。那最后一个就是属于重量级的,大家可以看一下 多人对话文本转语音,那他这里输入的类型,你可以直接上传,你生成好的语音,大家可以看一下,在这上传音频,那跟前面还是一样啊, 这里输入的内容就是你这个音频所说的话,把它输入到这儿,这里选择模型,正常咱们选一点七 b 的, 一般显存都能跑得动, 大家可以跟 rung 这边我部署好的对比一下,你看就这样的也是一样,跟上面的通过这个节点把你的语音转成文字传到这里,那本地这边我是手动输入的,大家也看到了啊, 这边接的三个声音,下面两个是直接上传的,那第一个是定制的,也就是说你可以在这直接定制, 然后在这里输入,你看在这里我写的是二十四岁的男性实习生巴拉巴拉巴拉什么,然后他经过这个大模型的反推,他在这里生成的就这个音色,因为我想要这样的声音,然后在这里可以直接定制这一句,还是一样,就是他说的这句话的内容, 然后经过这边传进去,然后咱们在这里需要注意的就是把这个角色名字写上,对应你后面的这些文字, 你看里末苏线,然后旁白就用这种格式来写,这边对一对应好,然后这边生成了就 ok 了。所以说我们通过这个节点,那这个模型的可玩性就大大增强了,我们可以去做一些有声书啊之类的,那这个节点这边最多可以支持八个角色 啊。还有一个注意的点就是你不管是你克隆也好,或者说这里要用的也好,比如说你上传的音频是英文的,那你在这就要输入英文的,如果是中文的,你就这输入中文, 那工作流需要注意的东西也就这些,其他的也就没什么了。咱们再看一下网盘吧,同样今天网盘也很简单啊,就是两个文件,大家把这个模型下下来之后,整个文件夹放到你的 model 文件夹里就可以了。好的,那今天的视频就先到这里,我是乡村幻想,咱们下期再见。
34像素幻想Lab 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿比如我们现在做那个,呃,短视频带广告,这个赛道需要克隆人声,我现在就是用的那个千万的一个开源的克隆人声的,非常好用,十秒钟就能克隆自己的声音,然后去去去读这个刚才吉米尼写的那个文案,嗯, 也是用我,我那个电脑配置也不高,四零六零太在现场就能待起来。你就觉得之之前之前用过克隆声音的基本都是这种,有的飞影啊,或者说其他的 就是在线充值的这种。但是我发现近期这种开源的模型它可能装就是占硬盘空间比较大,二三十个 g, 但它真正下台起来用的时候非常好用,对,比以前强太多了。 之前克隆一个声音,我之前用的开源的得至少得三五步甚至十来步,这个只是一两步就能把一个声音就能克隆出来,挺好用,比之前的技术又又迭代了好多。
2圣僧 06:07查看AI文稿AI文稿
06:07查看AI文稿AI文稿除夕夜别人都在放鞭炮,阿里直接放新模型,困三点五三百九十七 b a 十七 b 呢,正式开源了,这次呢,不是参数再大一点的升级,而是架构层面动刀, 它是一款原生多模态模型,就不是那种视觉,一个模型语言一个模型,在推理的时候呢,做一下拼凑, 而是从训练阶段开始啊,图像视频文本就混在一起学,属于从底层就打通了。参数呢是三千九百七十亿,用的是 m o e 的 混合专家架构,每次推理呢,只需要激活一百七十亿参数,简单来说呢,就是三百九十七币的脑子,只花十七币的电费,再加上啊限行注意力, getty dotnet 上下文呢,直接给到了一照支持二百零一种语言,速度呢,比上一代更快了,成本却更低。榜单成绩呢,的确很好看啊,但是呢,我们更关心另外一个问题,就是这些听起来很猛的架构升级,到底能不能够实际落地呢? 他能不能够真正做到看图,搜信息,写代码,读视频,一条龙完成?所以说今天这个视频呢,我们就不看榜单,不念指标,直接上真实任务, ok, 我 们现在开始。 那我们首先呢,丢给他一道之前很多模型都翻车的问题,我会问他啊,我想去洗车,洗车店呢,离我们家五十米,我应该是开车过去还是走过去,那很多模型呢,可能会下意识的回答,走过去更加环保,但忽略了一个关键点,就是我们洗的是车,而不是人。 困三点五呢,直接是抓住了这个问题的核心逻辑啊,车还在家里,最终呢,是必须要把这个车开过去, 他没有被距离很近这种表层信息带偏,而是理解了真正的目标。那这类题目呢,不是很复杂,但是他很考验啊,场景理解的一个能力。 所以说接下来呢,我们就把这个难度再拉高一点,我这里准备了一张电影截图,我会跟他说这部电影呢,我有点印象,但是具体的剧情,主演导演是谁我已经记不清了,你帮我做一个详细介绍的 html 网页, 我们点开看一下他的这个执行过程吧。那首先呢,他会识别图像,从而确定这是哪部电影,然后他就开始获取电影阿甘正传的一个详细信息了, 紧接着他会开始整理信息,并构建结构化的内容。最后呢,生成了这样的一个网站,我们现在呢,把这个网站下载下来,看一下它的效果。整体的这个电影脉络呢,他已经是梳理的非常清楚了, 不过呢,他这边是没有去搭配啊剧照图片,而且整体的这个紫色配色还是有些单调的,对吧?那于是呢,我就去啊,让他再加一点剧照,然后改一下这个电影感的配色。稍等片刻呢,他就开始去搜索相关的一个电影剧照了。然后呢做了这个配色 ui 的 一个调整,我们再次看一下它的这个效果, 那这一版呢,整体内容就更加丰富了,对吧?而且呢,他每一个经典的画面都会有这种匹配的剧照,这个呢,其实就是一次完整的多默契协同任务啊。从图片的这个理解,到互联网搜索,再到最后的这个网站代码的编辑落地,大家觉得他做的怎么样呢?可以在弹幕给他打个分啊, 那接下来的话呢,我们来测试一下它的这个代码能力和任务规划的能力啊,我这边呢使用 open code 来做,来到 open code 的 配置文件,首先呢我们需要去修改这个 base url 和 api key, 那 这些信息呢,大家可以在百联云平台获取。 配置完成之后呢,我们输入斜杠 models 来切换这个 queen 三点五 plus 模型。那这次呢,我们做的不是一个小 demo 小 游戏,而是呢直接让它在一个现有的后台里面做一个完整的电商后台 mvp。 并且呢我对范围做了一下控制啊,只需要做商品管理,订单管理, 库存扣减以及基础的一些状态流转。并且呢我们这边只需要去完成管理端,不需要去做小程序。那我把这个需求调给他之后呢,他没有开始直接写代码,而是先分析需求,拆解模块,规划结构, 这一点呢是很关键的,因为真正的工程能力啊,不是说你速度有多快,而是思路是否清晰,在任务执行的过程当中呢,他会边思考,然后边调用相关的工具。这种连续的任务推进呢,其实就是原生视觉语言模型的一个优势 啊,所有的步骤呢,都在同一个模型当中去完成,而不是拼接式的写作。在数据库部分呢,它设计了这个 product order, order item, 还有 user 这些核心表,库存校验啊,订单状态啊,也都是考虑进去了。 后端层面呢,它也做了这个代码分层,结构是非常的清晰。前端部分呢,它生成了商品列表,页表单页和订单管理前端后端数据库都是在协助推进的,项目也是可以直接启动并运行的。来我们看一下它的这个实际效果,商品列表搜索,新增上架、订单查询这些呢,都是可以去完美跑通的, 从任务规划到最终的代码落地,它没有出现结构混乱或者是推翻前面设计的这种情况,整体的逻辑啊,还是非常的连贯的。同样的任务呢,我之前也用这个 gmail 三 pro 测试过啊,虽然说两者最后都能够把这个项目给做出来,但是昆三点五呢,它这边是开源模型,而且 api 成本是更低的, 那如果说两个模型能力接近,但是其中一个成本更低,步数更自由,这对开发者来说意义就不一样了。如果是我的话呢,我会选择做的到但是更划算的那一个。最后呢,我们来测试一下他的视频理解能力啊,那这里呢,我准备了一个小游戏的测试视频,我们把它上传上去, 我让他呢自己去读懂这个视频,然后复刻这个小游戏。首先呢,他会去分析这个游戏的核心机制,玩法与视觉风格。接下来的话呢,他就开始构建游戏的一个视觉与交互框架。最后呢,他开始用 html 代码编写游戏。 ok, 现在他已经全部写完了,我们下载下来看一下效果。 整体功能界面我觉得还原度还是很高的啊。星空的背景,星空的元素大家可以看到,而且呢,在生命值这个地方,它没有去像呃原来的素材那样继续去使用数字,而是采用 icon 来代替。 并且呢在 level 这里,他也会随着数值越大,游戏难度相应增大,整体可玩性我觉得还是非常不错的。 ok, 那 到这里的话呢,四个 case 就 已经全部测试完毕了啊,从图像到搜索,从文本到代码,从视频到程序,这种端到端的能力呢,正是原生视觉原模型想要去解决的问题。 那这条视频呢,其实只是一个开始啊,后面我们还会继续用更加复杂的业务系统,甚至是多轮智能体写作。 如果说你对上面某 case 印象深刻,或者说想要让我去加大难度,可以在评论区告诉我。那现在呢,这个 quan 三点五相关模型啊,已经是开放使用了,大家可以在掐点 quan, 点 ai 或者是摩达社区使用。 ok, 那 以上呢,就是本期视频的一个全部内容了,感谢大家的收看,我们下个视频,再见, peace!
164程序员御风 07:54
07:54






