哪个api token好用
openclaw 跑 ai agent 太勺 token 用这个接口直接省一半 mini engine 一 键接入 mini max m 二点五, deepseek v 三点二,全是 openclaw 榜单顶流模型,速度快,推理强,权本低,兼容 openai 协议,不用改代码,稳定高,并发不崩,长期跑项目划算。

粉丝1获赞25
相关视频
 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿家人们养龙虾是不是特别耗费? tokyo? 现在机智下呢? open call, 呃,它是真实的去做浏览器自动化和本地的文件驱动,所以说 tokyo 耗费特别大 啊。我这边整理了几个,呃每天可以免费使用上千万 tokyo 的 api k 的 模型。第一个是 open note, 呃,它是一个海外的 a p i 的 聚合网站。 那我们最近呢,每天呃跑了一千万的 tokyo, 然后几百次调用都是完全免费的。 那它现在在那个龙虾的正榜上排行也特别高。对,大家基本上是一个可以看到现在是前四对第四位的视频。然后现在已经呃有七百二十三 building token 的 消耗了。对, 然后下个网站呢,是火山。嗯,火山引擎呢,其实就是自结旗下豆包的一个母平台,它上面支持自结自己的豆包的模型,然后还有集成的 jimmy 以及智普的 gm 系列。 然后呢,那个火山有一个写作奖励计划,大概每天呃你可以花费两百万投屏,然后次再返返回你两百投屏相一直免费。我建议呢,就是用 gatsby v 三零二版本去在龙虾里面进行使用。然后我之前是呃使用一些多包的,包括一点八,一点六等等,目前它的写作奖励计划只知道多包一点八,二点零还不支持。 然后第三个呢,其实是讯飞星辰。对,呃,它其实是一个模型的聚合商,它上面的呃 mini max 两点五加 m 五以及 kimi 的 k 二零五,其实目前都是免费的,不过马上免费期要结束到三月五号。目前的话呢,就是呃千万三点五,它其实目前也是免费的,可以看到。 嗯,目前它没有反馈具体的生效时间,我们可以先用起来,然后这个地方是英伟达的开发商网站。嗯,它提供每分钟四十四的一线模型的调用,比如说智普的 g m。 嗯,毕竟达子赚我们这么多显卡钱,它提供一些面向开发者的免费模型能力,其实我觉得蛮好的,希望对大家养龙虾有所帮助。
434AI产品君坤梼 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿今天给大家分享一个比较便宜的普通小白都能用的一个大模型。我们知道我们在学习 ai 或者使用 ai 的 过程中,就会发现 它是一个巨大的氪金的东西,因为会消耗大量的 token, 很多大模型靠这个 token 的 消耗令来盈利来赚钱。今天分享的这个呢,就是阿里云的一个最新的叫扣丁普兰的 这个头,跟他这个主题呢,说是量大环保,支持阿里云的千万的三点五,还有 mini max, 还有 嗯 g m m 等等各种模型,他是按照消耗的次数调用的,次数就每月呢大概有一万八千次的这个调用额度,每月的这个套餐费用是四十块钱,现在打折啊,现在二十块钱 对于普通小白是完全够用的,因为很多人反映这个 投币量很少,而且比较慢,如果你只是说我掌握一下 ai 的 基本应用,跑一下简单的流程,知道这个 ai 是 干嘛的, 我觉得是完全够用,它还支持这个龙虾,还有支持可乐扣的。另外一个呢,就是我们在调用这个 api 的 时候,一定要记得是扣丁普兰的 api, 不是 那个百炼的 api, 因为百炼的那个 api 呢,它是后付费的,你消耗多少投币就扣多少钱。 我上个月签约的时候,当时结果 api 填的是那个百炼的,他一天就给我花费了一百块钱,当时把我吓坏了。我觉得阿里云他这个售后比较好,因为是今天那个售后小哥给我打电话, 我把这个事情给他说了,他说你是调用错了 api 了,今天就把那个 api 给改过来了,我觉得这个是比较划算,因为一个月就二十块钱,大家可以试试。
5079年老登宁叔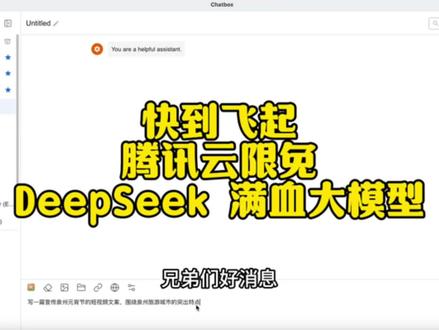 03:12查看AI文稿AI文稿
03:12查看AI文稿AI文稿兄弟们好消息,今天我调取的这个地方是一个二万,这个速度你们看是不是快到飞起,直接发出去秒回复啊,免费的,哪个平台的?腾讯云赞助的?我给大家已经整理好一个完整的教程了, 在那个公共群里面,我给他录一个完整的操作视频,随便打开个浏览器,你搜索腾讯云,点开腾讯云, 然后在右上角先登录,用你的绿泡泡去扫码登录,这个大家肯定都懂,对吧?登录完以后,右上角这里会有你的 id, 然后我们接下来选择菜单栏这个产品,往下拉,人工智能与机器学习,往右边找腾讯运营 pi 平台,点击 到了这个页面,这个页面以后点击立即使用,立即使用,会进入一个大模型广场,在大模型广场里面有 seek, 有会员,那我们今天就是第一个 seek, 直接点击,点击完第一个 seek, 上面这些都不用管,你要现场体验你就体验一下,如果不体验直接往下拉,这里有个 api 调用指引,打开用心创口,查看 这些域名地址名称都是要用的,等一下,这些名称就是我们调的模型 id, 域名请求地址都有,然后往下看,重要消息在这里免费,然后到北京时间二零二五年二月二十五日啊,二十四点之前,总之就是二月二十六日开始收费,你没有在里面存钱,你不 不用担心他扣你钱,你就大胆的用,到时间不能用了,你再决定,然后他就算收费以后价格也是跟官方是一样的,那既然官方是一样的,我们就看哪个反应更快,你说对吧?然后再往下走,我们要申请个 apa, 这里面有一个 基础地址,然后这里面有个 api 管理,点击往下拉,往下拉,因为我们刚才已经登录过了,所以直接拉到,你可以在立即接入这里点击,或者在 apik 管理这里面点击 啊,总共就能设置两个 apa, 我刚刚已经设置完了,所以不能再创建了,然后你直接查看和复制就好了。好,这 apa 申请就到这里,接下来我们来看怎么设置。你去下载一个 checkbox, 这个软件我用的还是比较简单,相对傻瓜坏一点。然后在缺 box 的左下角设置,然后 点击右左上角这里,这里有个添加自定义提供方,点击添加自定义,输入什么呢?输入,我刚给你们看一下,我输入做好的那个页面,输入第一个名称,你自己命根,你记得住的,我就叫做 腾讯第二十二万啊,二月二十六日。对,第二个 api 域名就是这一个,你把它复制过去,粘贴到这里。第三 api 路径,不用管它。第四 apik 就是刚才最后的这个 apik, 查看复制,然后粘贴到这里面。 最后一个就是你要调用的模型,有两个模型可以调用,阿万就是那个推理模型,现在别的地方很卡,但腾讯员真的是很顺畅,然后你把它保存就完事了, 就可以使用了。还不清楚的话,你直接去群里面呃,去看一下那个链接的详细教程,或者私信我,我给你再次发一个链接好吗?
1469波波师兄 01:02查看AI文稿AI文稿
01:02查看AI文稿AI文稿最近 oppo ai 推出了 gbt 五点四,来看一下在全网比价的结果是怎样哈,然后这里不单单是有 gbt 五点四,还有它对比出了 gbt 五点四 pro 的 一个价格啊,是官网的一个模型价格哈, 然后下面呢,它也有其他的聚合平台的一个 gbt 的 价格,但是呢,现在聚合平台收入到的是没有 gbt 五点四啊,只有五点三。 然后呢,乡下也给你做了一些分析,比如说啊,五点四比五点二哈,虽然说价格上涨了,但是呢,对于功能的一个 token 的 消耗是降低了百分之四十七啊,给大家做好了一些分析。然后呢这些网址也给大家 啊,已经备好了,大家可以通过这个笔架的报告去进行自己的选择哈,如果说你想要了解其他的一些模型呢,也可以在这里去搜索啊,得到一个全网的笔架,如果想了解这个小程序的话,可以私信我一下。
 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿说这个 open curl 烧 tokyo 的 问题,咱们找到了非常具有性价比的方案,结果视频发出去之后,好多人在评论区里说这个方案很贵, 有两个说我还没有在意啊,结果说的人有好多,我就认真的看了一下啊,结果发现问题在哪呢?我们工作人员把这个单位啊设置成了倒了符号,其实它只是一个计量单位啊,并不是倒了。所以说 这么多优质的大模型,在你预期价位的基础上,你觉得还差不多的情况下,我还能再除以七,这就叫性价比。
796点力中国 01:39查看AI文稿AI文稿
01:39查看AI文稿AI文稿open 可乐的烧投屏速度可能多数人养不起,我的 open 可乐安装完成之后呢,我给他了几个简单的小任务,比如说浏览网页,然后解托发送给我,简单的几轮对话就花掉了几美元,而且我用的还是性价比非常高的 mini max m 二点五模型。 我一位朋友,他用的是公司免费的 app 无限投屏吗?那每天的账单都在大几百美元,这个数字还是非常具体的。 那 open 壳为什么这么烧 token 呢?我想核心有两点原因,第一是屏不理解 open 壳,它本身无法理解屏幕上的像素,那么当你做一些具体的指令,比如说去发小红书,它只能去对小红书网页进行截图,然后发送给大模型和问询大模型这个发布的按钮在哪里? 大拇指识别之后呢,会返回对应的坐标,然后 open color 再执行对应的点击操作,所以这个过程是极其高频,而且极其消耗透杆的。那第二点原因,我们知道 open color 有 非常完整的上下文系统,它能够记住你说的每一句话,记住自己做过的每件事, 那么这是一个优势,也是一个劣势。那么在他进行新的对话的过程中,他会把尽可能把完整的上下文都塞给大模型,那这就导致了大模型的 input token 数量是非常恐怖的。我去 open core open router 的 后台看我每一轮对话的一个记录,发现基本上每一轮的 input token 都在几万甚至十几万的这么一个量级,这基本相当于一本书的大小了啊,所以这个消耗的透光的速度也是非常快的。
 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿什么内三点一 pro 二月二十号发布了,那今天给大家介绍一个什么内三点一 pro 的 一个快速便宜的一个使用平台 while api 点 a, 而一站式的 a 模型聚合平台,就这个,我们看一下首页 a 接口聚合管理平台,一站式接入各种 a 服务,你注册呢,还送零点二每刀的 a p a 免费额度,我们来看一下它的价格,三点一今天刚上线的三点一 pro, 这个价格,那限时特价这个价格呢? 一百万的 tokin 只需要一点二元,这是输入的,那输出的一百万的 tokin, 这么的三点一 pro 的 价格只要七块二,用这个限时特价这个分组官方网站 中转的这个它的价格是多少呢?是十二,输入呢?是十二,输出呢?是七十二,贵了很多很多了。那么想降本增效的,想使用便宜的,不管你是 ai 编程呢,还是大龙虾上来使用,都可以来看看。
146陆通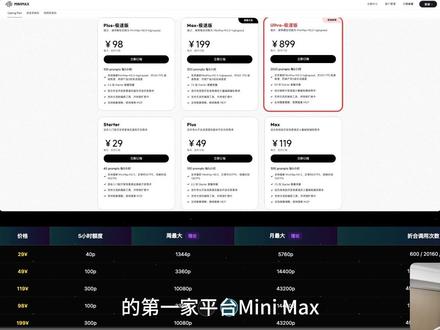 08:01查看AI文稿AI文稿
08:01查看AI文稿AI文稿随着 open core 的 爆火,调用大模型所花费的掏根数也随之水涨船高,如果你还在用 api king 的 方式,那么离破产可能只差几句话了,因此我做出了一个违背祖宗的决定,给大家带来国内四家平台 cookie plan 月套餐的对比。首先出场的就是我们的 mini max, 然后就是 g m l 智谱, 然后是火山引擎,最后就是我们的阿里百链平台。介绍完了这四家厂商,接下来就来介绍一下我们的规则说明。 我们仅以四家平台的月 coding plan 套餐作为对比,记住是月而不是季度或者是年。然后就推出我们的换算规则,换算规则就是一 p 等于十五次模型调用, p 就是 promote, 一 promote 就 相当于你使用 coding plan 套餐完成了一次完整的调用,而一次完整的调用在模型后台可能被切成了十几个任务, 有读取上下文,提出建议,修改建议,调用工具之类的就会非常的复杂。然后官方为了简化计费计算,就统一把这十几次连续的模型调用打包成了一次 promote。 然后我们再来介绍它的额度限制,它有第一种就是五个小时限制,一次额度就是你每五个小时达到了它的调用上限, 它就会限制你调用,然后直到这五个小时过去,然后它会再刷新额度,然后就可以再次使用,然后一个月就是这样一直重复。接下来就是周总额度限制,就是在五个小时的额度限制之上,你每次花费的 token 在 一周内累计不能超过它一周内的总额度上限。 然后就是月总额度,在周总额度限制的前提下,每家你每周所使用的额度不能超过一个月的总额度上限。如果你超过一个月总额度上限,那么你这个月就不能再用这个套餐了,因为它已经额度用满了。最后我再来提一下,我们的月是按每个月三十天来计算的。好了,接下来就介绍一下我们的第一家平台 mini max。 mini max 我 们看一下它是有六种套餐的,我们先来看最下面三种,从 star 每五个小时掉,我们的 promax 数也是逐渐长高的。 然后再看上面三种,有 plus 极速版到 ultra 极速版,它的价格也是这样递增的,然后它每五个小时可以调用的 oppo 的 次数也是在递增的, 但是它多了一个后缀就是极速版。极速版就是相对于下面三种套餐来说,它们模型的调用速度快了不少。然后我们总结了上面的价格和每五个小时的额度限制,我们就统计出了这样一个表格, 因为 mini max 只限制五小时额度,所以我们就通过一周大概等于三十三点六个五小时,推算出了它的周最大额度上限。然后我们再计算出一个月等于一百四十四五个小时,可以推算出它的月额度最大上限。 因此我们整理出了这张表格,然后就是它支持的模型定有 mini max 二点五、 mini max 二点一和 mini max 二。然后我们再来看第二家智普, g m l g m l 是 有三种套餐呢,只有 leader pro 和 max 版本。智普也是在国内 callenplan 套餐中它是最抢手的,每天早上十点钟刷新,你去看一看,其实很快货就会被抢空了,也不知道为什么,难道是饥饿营销吗?然后我们来继续往下看,相比于 mini max 的 每五个小时只限制一次额度,它增加了一层规则,那就是周额度上限。 既然有了周五的双线,因此我们可以算出每个月大概有个四点三个周,我们可以得出大致的月利润最大双线。然后我们再看它支持的模型,它 leader 套餐不支持 gm 幺五模型,然后其他所有套餐都支持 gm 幺五和 gm 幺四点七及其所有的历史文本模型。 接下来我们再来看第三家,也是我们的火山引擎,也就是豆包,它只有两种套餐, leader 和 pro 套餐。然后它跟前面两家比的话,不一样的就是 它不采用了 promote 来计数,它采用的是模型调用次数,但是在它的文档中也说明了它每一次调用也会花费大概十几二十多个不等的调用次数,所以我们也可以 理论上给它计算回来,这样就得出了每五个小时然后周额度和月额度的 promote 次数。然后可以看到它支持的模型是 豆包二点零, coder, 还有豆包 coder, 还有 g m 幺四点七,然后 d s c v 三点二,还有 kimi 二点五,支持的也是非常多。然后再看最后一个就是阿里一百链平台,它的套餐是和豆包其实一模一样的,然后它的收费标准还有额度上限都和豆包是完全一模一样的, 它两个不愧是相互对标的模型平台,搞的套餐都是一模一样的。然后再来看它支持的模型是千万三点五 plus kimi 二点五, g m 幺五 和 mini max 二点五,还有千万三, max 还有千万三, codenix 还有千万三, codenix 还建妙四点七,所以从模型的角度上来说,它还是略胜火山引擎一筹的。 我们介绍完了四个平台,我们再看下全平台的性价比对比。我们的性价比对比,采用它每个月理论上能调动的最大蓬勃的次数, 除上它的价格,我可以算出来多少 promote 美元,这样我可以计算出它理论上最大的性价比。然后我们可以看到,在这个排名中, mini max 家族可以说是遥遥领先,垄断了第一的位置,接下来就是我们 g m l 垄断了第二的位置,接下来就是豆包和火山引擎 并列第三名。好吧,这究其原因其实也很简单,因为 mini max 平台它只限制五个小时的调用额度, g m l 平台只限制一周的调用额度, 火山引擎和百联平台限制了一个月总额度,所以从理论上极限来计算,那么必然是限制越少,它理论上调用的次数就越高,所以 mini max 领先于 g m l, g m l 领先于火山引擎和百联平台。然后分析了极致性价比之后,我们再来看模型丰富度对比, mini max 中只有支持它的 mini max 的 三款模型,智普只支持它的 g g m l 家族, 然后火山引擎的话就支持豆包还有 deeptech gm, 它都支持。最牛的就是百炼平台了,它有八款模型,分别是千问系列,还有 kimi gm 幺五, gm 三七。 mini max 二点五,它可以说是把过年以来国产最好的四款模型都集齐了,也就是 我们的千问三点五、 plus kimi 二点五、 gm 幺五、 mini max 二点五,这可以说是过年以来最好的四款模型。 从模型丰富上对比,我们的百例平台有八款模型,我们的火山引擎只有五款,仙妙的话只有三款, 还有迷你 max 的 话也是只有三款。从模型丰富上对比,我们的百例平台遥遥领先。说完了模型丰富度和我们的性价比,接下来我们就推荐一下。推荐那当然是要为不同人群量身定制的,我们第一个就是为小白新入门的小白人群推荐, 每个月预算大概四五十块钱,我们就推荐他火山引擎和百联引擎的 live 套餐,他足够便宜,而且每个月有一万八千次的模型调用,也足够你入门了。 然后他的模型还很丰富,就可以支持你用多种模型,让你感受一下是不是新手小白,肯定都很想感受一下不同模型的效果到底怎么样,这是非常适合新手小白入门使用。接下来就是追求极致性价比的人群了,他每个月预算大概一百到一百五十元,我就推荐 mini max 的 max 套餐, 它的性价比最高,理论上来说是美元,可以调用三百六十三次 promote, 理论上每个月可以调用六十四点八万次大模型,所以它的价格也适中。然后性价比是最高的,就是最适合追求极致性价比的人群。 然后如果你如果是日常开发者,预算在一百五到两百元之内,那么推荐你用 g m l pro 或者火山引擎 pro。 g m l 的 理论上调用次数还有豆包的都是很多的,而且豆包上的模型也比较多,然后 g m l 五的编码能力也是非常强的,这样就推荐我们日常开发者使用。 如果你是,如果你是 vivac 的 重度依赖用户,那么就肯定是提高你的预算四百到九百了,那我们就推荐你用 mini max ultra speed 或者是 g m l max, 那么调用次数是有着最大的保障,同时还兼具着最最快速的响应速度,这样足够重度用户使用,不仅兼顾了量,而且还有速度,而且因为它有足够大的量和足够大的并发症,所以它还可以支持多团队使用,团队可 能买这样一个大套餐就够一个团队使用,但是接下来我们再看,如果你是一个疯狂的模型体验党,然后呢?预算大概在四百到两百元,那么肯定推荐你是百练的 excel 或者是 pro 套餐了,它有八款模型 可以供你选的,同时还有四款是国内最好的大模型,一站式可以体验多种 ai。 最后一种就是追求稳定额度的,他们就推荐火山引擎和百联引擎, 他们的每个月调用次数都有明确的上限,不像其他平台 promote 计算的模模糊糊,然后它还不会产生多余的额外花费,算是可预算可控场景,适合追求稳定额度的人群。这样一份 cookie plan 保姆级入门教程,你喜欢吗?
1763大学牲 05:07查看AI文稿AI文稿
05:07查看AI文稿AI文稿中国 ai 杀疯了! token 掉用量首超美国,全球第一!朋友们,今天咱们必须得聊聊这个惊天大逆转。说实话,作为在这个圈子里摸爬滚打了这么多年的科技博主,我见过了太多的技术迭代、风口变迁,但这几天出的这个消息,我是真真正正被震撼到了,甚至有点头皮发麻的感觉。 一直以来,在 ai 大 模型这个赛道上,咱们心里的默认设置是什么?美国是领头羊, open ai, 谷歌那是高山羊脂,咱们中国企业是在后面苦苦追赶。但就在这短短的一两个月里,天变了!全球最大的 ai 模型 a p i 聚合平台 open router 给大家科普一下,这相当于全球 ai 开发者的批发市场, 全世界的程序员都在这挑模型,用它们的数据显示,就在二月份,中国 ai 模型的 token 掉用量历史性的超过了美国。 咱们来看这组炸裂的数据,二月中旬那周,中国模型掉用量飙到了五点一六万亿, tucker 短短三周暴涨了百分之一百二十七,而同期的美国模型呢?跌到了二点七万亿!这是一条怎样陡峭的增长曲线啊,简直就是旱地拔葱,直接反潮!更绝的是什么? 这不是某一家企业的单打独斗,这是咱们中国 ai 场上的大模型里,中国直接霸占了四个席位, minimax、 月至暗面的 kimi、 智浦 g o m, 还有 deep seek, 这四家加起来拿走了前五名里百分之八十五的份额。这意味着什么?意味着在全球 ai 的 竞技场上,中国战队已经不仅仅是参与者,而是妥妥的主力输出了。 大家可能会问,这数据会不会是咱们自己人在国内刷出来的?还真不是。这个 openroot 平台最有意思的地方就在于,它的平台上将近一半的用户是美国开发者,中国开发者占比才百分之六出头, 这说明了什么?这说明是全世界的程序,包括美国本土的开发者,再用鼠标投票,再用真金白银投票,他们大规模的选择了中国 大模型来开发他们的应用,这不是自嗨,这是实打实的全球市场认可。那么问题来了,中国 ai 凭什么能在这么短的时间里让全球开发者集体倒戈?第一个杀手锏,简单粗暴,就是极致的性价比。咱们中国的企业 真的是把价格屠夫的基因刻在了骨子里。咱们来看看价格对比,同样处理一百万个 token 的 信息输入, mini max 和智普只要零点三美元,而国外对标的一流模型 cloud opus 要多少? 五美元?这差了将近十七倍啊!朋友们!在输出环节差距更大,国外要二十五美元,咱们只要一块多美元。这对于那些需要大量调用 ai 接口的创业公司来说,用中国模型一年能省出一辆法拉利来,这诱惑谁顶得住?但是, 如果你们认为中国 ai 仅仅是靠便宜取胜,那就太小看咱们的技术实力了。能把价格打到地板上,还能保持世界顶尖的性能, 这背后是硬核的技术创新。咱们这次霸榜的模型,普遍采用了一种叫模型的架构,也就是混合专家模型。我打个比方大家就懂了,传统的大模型就像是让全校所有老师一起去解一道数学题,不管你是教语文的还是教体育的,都得上去出力,这得多浪费资源? 而 mo 一 架构呢?就像是精准点调动,遇到数学题就只叫醒数学老师去解,遇到历史题就叫历史老师。这种按需激活,让计算资源的使用效率极大提升,数据显示推理时的显存占用能降低百分之六十, 吞吐量能提升十几倍,这才是降本增效的核心秘密,是实打实的工程能力。而且咱们国内的大厂还在搞垂直整合, 从最底层的 ai 芯片,到中间的云计算,再到上面的模型算法,全部打通,一体化优化,恨不得榨干每一分算力的价值。所以说,中国 ai 的 崛起,不是靠补贴烧钱烧出来的,而是靠聪明的工程师们在架构和工程上一点一点抠出来的竞争力。聊到这,我还想跟大家深挖一层, 这次 token 调用量的井喷,除了中国模型强,还蚀出了一个全球 ai 行业的大趋势。 ai 的 角色变了。以前大家用 ai 可能就是聊聊天,写个周报,把它当个问答工具。 这种用法消耗的 token 其实很有限,但现在不一样了, token 消耗量指数级攀升,是因为 ai 正在进化成生产力工具,成了能深度参与工作流的数字员工。比如程序员,以前是自己写代码, 现在是让 ai 写整个模块,然后 ai 自己跑测试,自己找 bug。 比如金融分析师,以前是自己读财报,现在是扔给 kimi 一 份几百页的文档,让他在一分钟内总结出核心风险点。甚至现在流行 ai agent, 你 给他一个目标,他自己会拆解成几十个步骤,调用几十次模型去执行。 这就好比什么呢?在互联网时代,我们看的是流量,流量越大越好。但在 ai 时代, token 就是 工业时代的燃料和电力, token 消耗量越大,说明 ai 干的活越重,越复杂,创造的实际价值就越高。中国模型 token 调用量全球第一, 这意味着全球最大规模的 ai 生产力浪潮正在中国的地基上奔涌向前。朋友们,从被人卡脖子到如今反客为主,让全球开发者依赖咱们的基础设施, 这一步跨越真的太不容易了。这证明了在最前沿的科技领域,咱们中国人的智慧和工程能力绝对是世界顶级的。当然,我们要清醒,在基础理论研究上,咱们还有路要走。但今天这个里程碑告诉我们,中国 ai 已经站到了世界舞台的中央,未来的好戏才刚刚开始。
372消费增长官 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿哈喽,大家好,最近我们都叫 openclo, 非常火,但是使用它的一个托管花费可不便宜,所以最近也给大家整理了一批高性价比的一个 api 套餐。然后第一个的话是阿里最近推出的一个 codingplay 计划,然后它的价格是七块九每个月, 然后它应该是目前为止性价比最高的一款这个 cody 套餐。然后目前的话它是支持国内呃众多一线大模型厂商的模型,比如说像 呃千万三点五 plus 还有千万三 max 还有千万三 cody 以及 mini max 二点五,还有智普的 glm 模型五,还有 kimi 二点五。 然后第二个是最近呃自己的一个方舟计划,也是 callinplay, 然后它的价格是每个月八点九元,然后模型自由,并且支持接入 openclock。 然后目前的话我订阅的也是这款套餐,然后目前使用下来,目前使用下来感觉它的一个速度跟效率都还可以。 然后第三款的话是呃科大讯飞的星火大模型,这个也是呃科大讯飞最近推出的 openclo, 可以 免费调用, 免费调用它的一个推理模型,但是这个应该是有时间限制,有需要的小伙伴可以自行自取,评论区也有对应的一个订阅链接。
485Cc-g 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿啊,新媒体啊,拍视频啊,图片啊等等啊,那么但是很多这个朋友呢,给我反馈 就是说调 api 太贵了,然后这些老师这边有没有一个办法,有没有一堂课程是能够解决这个问题?其实我们呢在我们的这个这样一个大模型的这样的一个推理工具啊, 然后支持 windows、 linux 和 macos 都支持,那我们做了什么事呢?呃,我们是怎么去这样的一个机制?那么怎么去省省算力呢?其实特别简单,就是我们现在目前, 然后呢降低温度,让我们这个模型回答呢,一段输出的 token 最好是在二零四八左右啊,或者就干脆掉 api, 但是就是非不需要你付高额的这个 api 的 费用。
2生图师








