cuisor怎么运行Java

粉丝135获赞1042
相关视频
 04:12查看AI文稿AI文稿
04:12查看AI文稿AI文稿本期教程将带你搭建热门整合包远梦之官二点零的服务器,我们使用云服务器来部署,这样服务端在云端运行不会占用你的电脑性能,还能二十四小时稳定在线,朋友们随时都能进服,而且延迟最低也仅有个位数。 那么话不多说,马上开始安装吧。首先下载远梦之观二点零的客户端和服务端资源,打开网页后点击所有整合包,找到远梦之观二点零这篇文章, 往下滑到部署准备点击下载按钮,跳转到 curl forge 官网,进入 curl forge 后,点击 files 菜单,选择需要下载的游戏版本,点击 download 开始下载。这是客户端文件,等待五秒后会自动开始下载。下载完成后,回到刚才的页面, 找到 additional files, 这是服务端文件,按照相同方式下载,我们稍后会用它来部署服务器,耐心等待下载完成就可以了。下载完成后,接下来我们安装客户端, 把下载好的客户端文件拖入我的世界启动器内,就开始自动下载安装了。本视频演示的是 p c l 二启动器,其他启动器也是类似操作,下载完成后就可以启动游戏开始游玩了。整合包是国产整合包,所以不需要繁琐的汉化操作, 如果你只想单人游戏到这一步就可以了。如果想和小伙伴联机就继续往下看。我们需要购买一个云服务器,可以在浏览器里进行搜索,也可以点击视频简介下方的链接进行跳转, 点击立即前往远梦之观二点零整合包对性能要求较高,这里推荐元光云的五九五零 x 四和十六 g 或七九五零 x 四和十六 g, 其他默认即可。如果同时在线人数多,建议按需增加内存,若发现任务管理器中宽带资源占用较高, 也可以适当提升贷款 up 主现在也给大家争取到福利了,给大家准备了大量的八折券,可以直接访问视频下方的链接,来到这个页面后,绑定 up 主为代理商,完成后私聊 up 主,就可以把优惠券送给大家了。接下来我们打开元光云的控制台, 点击端口映设,如果选择的是 windows 系统,则点击三三八九远程端口,点击确认后再添加一个 minecraft 的 二五五六五端口,添加完成后,点击上方的 r d p 远程连接,下载 m s t s c 配置文件 账号默认是 administrator, 密码就是购买云服务器时设置的密码。接下来我们部署服务端, 把下载好的服务端压缩包从自己电脑复制,再在远程桌面粘贴,就可以进行文件传输。传输完成后先解压一下服务端文件夹,解压的时候可以先下载一个 java 环境,可以打开桌面上的远光云技术云盘, 这个链接我也会放简介里的,跟着我的步骤打开存放 java 的 路径。我们需要安装 java 时期, up 主是在自己电脑上安装的,就不演示安装流程了,一直默认下一步就可以了。安装完成后,我们打开服务端文件夹,双击打开这个文件,修改一下内存设置,将前面的警号删除,把这里的四 g 修改成服务器最大内存减三 g, 根据自己的服务器内存进行修改,比如你服务器最大内存为十六 g, 那 么这里设置成一三 g 就 可以了。修改完成后保存并退出,双击打开启动脚本,稍微等待一会儿。 这是让我们同意优拉协议,先关闭正在运行的服务端脚本,找到优拉,点 txt 这个文件,将 files 改成处。 修改完成后保存并退出,重新打开启动脚本,耐心等待一会儿。这一次启动较慢,需要补全服务端文件,等它跑马不动后,我们输入 list, 出现在线人数,就说明开服成功了。开服成功后,回到远光云控制台,点击防火墙内网 ip, 二五五六五端口对应的公网连接 ip 就是 给小伙伴的进服 ip。 那本期视频到这里已经结束了,如果本期视频对你有帮助,记得一键三连关注 up 主,那么我们下期再见!
46鹤川川川川 02:27查看AI文稿AI文稿
02:27查看AI文稿AI文稿本集学习 gitlab runner, 部署 java 服务,通过 docker compose 运行,打开 gitlab, 在 之前的基础上修改 gitlab c i emo, 前面是直接打 java 包,然后发送到服务器,通过 shell 运行服务, 现在稍作修改,分为三个阶段, 第一个阶段和之前一样打乍耳包,第二个阶段是制作镜像,将第一个阶段打好的乍耳包通过 kanikou 制作镜像,并上传到私有镜像仓库,最后再远程登录服务器执行 docker compose 运行服务, 提交修改的某文件 流水线正在运行中, 此处过程较长, 先来看下镜像仓库,这里面是之前打的镜像, 等待一段时间可以看到第二阶段镜像制作成功。再到 harbor 中刷新,可以看到制作好的镜像已经上传成功了, 在等片刻,第三阶段也已经完成。此时回到远程服务器,可以看到当前目录中已经有 docker compose 那 某文件了。 查看服务已经成功运行了 访问接口, 可以看到接口正常响应了,部署成功。最后附上部署文档。
64码了个码 05:09查看AI文稿AI文稿
05:09查看AI文稿AI文稿前面介绍了 gitlabranner 部署 java 服务,通过 docker compose 运行。本集介绍通过 k 八 s 运行,打开 qbird 面板,创建工作负债, 选择负债类型为部署,选择微服务层,输入工作负债名称, 添加工作容器,输入名称,填写镜像,镜像可以使用以前上传好的 选择仓库密码,没有就创建选择拉取策略, 添加服务和路由, 添加端口, 添加应用路由。注意这里面的自定义虚拟域名需要配置 hold 保存配置应用后就可以启动服务。 服务启动成功后,访问接口可以看到报错, 通过日制可以看到是正常的,但是访问显示五零三,此时想到这个域名应该是被使用了,并且服务关闭了, 现在去更改域名, 同理这个域名也要配置 host。 再次访问 可以看到接口,访问成功了。接下来到 gitlab 中修改下接口, 取消流水线,再去修改 gitlab c i in 某文件,保留前两个阶段已有的制作叉二包核镜像并上传至私有镜像仓库 harbor, 只需要修改。最后部署阶段触发 k 八 s c i c d 脚本, 回到 cuber 面板获取 c i c d 脚本, 粘贴进 gitlab c i 一 某,注意缩进 并修改为动态镜像, 保存文件后运行流水线。 部署过程较长,稍等片刻,镜像制作成功,在 harbor 中查看已经上传成功了, 在等待最后阶段触发 k 八 s 脚本,此事看到报错了。查看日期 可以看到域名解析,不鸟,需要添加到 host 中, 修改 gitlab c i 列表文件, 在调用接口前添加域名和 ip 到 host 中再次保存运行流水线, 等待流水线运行完成, 查看日制,可以看到调用 k 八 s 脚本成功了。再到 cuber 面板, 可以看到 pad 正在启动中。 啪!启动成功后查看镜像,镜像更新为最新了。 接下来刷新接口,可以看到接口变更了,部署成功了。最后附上 gitlab c i e mail 文件。
69码了个码 02:26查看AI文稿AI文稿
02:26查看AI文稿AI文稿哈喽,大家好,我是隔壁小马,很高兴跟大家一起学习 jdk 的 安装与环境变量的配置。 首先我们需要下载 jdk, 我 们找到 oracle 官网,进入官网以后一直往下滑,找到 java 八,选择对应的操作系统和版本,点击链接即可下载。 需要注意的是, oracle 官网下载需要登录 oracle 账号,如果没有账号的同学可以点击下方的创建账户注册一个新的账号。 等待 jdk 下载好以后,找到下载好的文件,双击打开,根据提示点击下一步,此处可以选择安装目录,可以根据自己的需要安装合适的目录, 在安装时会弹出新的安装窗口。我们确认一下这个安装的是 j r e, 是 java 的 运行环境,我们已经安装了 j d k, 就 不需要再安装 j r e 了,直接点击关闭就可以 看到这个提示, jdk 就 安装成功了。那我们接下来配置一下环境变量,用快捷键 win 加 e, 打开文件管理器,找到此电脑,右击选择属性,在此处找到高级系统设置。选择环境变量,点击新建 变量名,输入 java home 变量值,输入 jdk 的 安装目录。也可以点击浏览目录来选择 jdk 的 安装目录,点击确定。再从环境变量中找到 path, 双击或点击编辑,点击新建,输入百分号 java home 百分号斜杠 bin, 点击确定。再配置 classpath 变量,同样点击新建变量名,输入 classpath 变量值,输入屏幕上的这一串,注意开头是点分号,不要把点丢了。到此我们的环境变量就配置好了。我们按快捷键 win 加二,输入 c m d, 或者在开始栏输入 c m d, 打开命令行, 输入 java 回车,再输入 java, c 回车都有内容输出,就说明环境变量配置成功了。
36隔壁小码 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿今天这个视频我要从零开始带你们学习 java。 java 是 一款跨平台、面向对象,带有自动内存管理,语法严谨的编程语言,常用于大型后端开发、大数据计算和企业架构开发,是一款成熟、稳定、高效的语言。那么接下来我们先学习下载 java, 输入这串网址,进入 java 官网 下滑,找到对应自己的系统,然后下载文件,运行安装即可。然后我们下载 id 一, 也就是集成开发环境,搜索我输入的这些内容。这是一个强大的 java id, 我 鼠标指真指的这个网站就是官网了,我们点进去, 然后我们下载安装就行了。我这里已经下载,不再演示。我们打开这个翻译器,新建一个项目,选择 java 项目,随便起名。这里已经有了一个 java 程序势力,让我们运行一下看看效果。 可以看到先输出了 hello and welcome i 等于一,然后 i 每次都加一,然后输出 i 当前值。有一个易错点在开头,不要跟我一样使用 main, 这里需要根据你的文件名进行更改。 学过 c 加加的同学看第二行肯定很简单, main 程序的入口, java 从这里开始执行。第三行的意思是让电脑在控制台输出 hello java, 第四行也是相应的输出,我是加内扣 m c 加 java 牛符,让我们先猜一猜最终会输出什么? 输出了 hello java, 我是 e k o m c java 牛符,为什么没有输出?我是那个没个 java 牛符那?因为这里有多个引号,代表着拼接, 相应的,如果不拼接,直接输入完整内容是一样的。看到这里的同学有福了,我在这里渗透一个 java 二十一有的新特性,字母串模板,平时我们拼接字母串需要写一大堆引号,加号不优雅不美观,还浪费时间, 而运用上这个新特性,只需要这样写就可以拼接,不过这是预览版,需要特殊设置才能开启,想学的扣个一,超过十个,下期详细讲。综合我们刚刚学的内容,我们可以写出这样一个程序,这里是输出三行内容,第二行运用了拼接,其他就是基础的输出,运行之后也是没有问题。 那么今天的作业内容就是新建一个字母串,然后拼接输出出来,我等着你们交作业。今天我们学习了下载环境安装 id 与输出,那么今天的教学就到这里,再见。
55NekoMC 02:28查看AI文稿AI文稿
02:28查看AI文稿AI文稿大家好,我是大树,今天我们讲清楚 java lock 到底是怎么工作的。你写的 lock, unlock 背后不是一句简单语法,而是操作系统 jvm, cpu 指令层层配合的并发控制。听懂这一段,你对并发编程就入门了。 lock 解决什么问题?我们知道 synchronize 的是隐私锁, 而 log 是 显示,所显示的意思就是你能控制什么时候加,什么时候释放,可中断,超时等待。但底层核心只有一个目标,多县城竞争资源时,保证只有一个县城能执行。底层总揽三层世界 log 底层跑在三层里。一、 java 层 lock reentrant, lock 接口与实现。二、 jvm 层 aqs 队列同步器,这是核心骨架。三、操作系统层 newtext 互吃量 catch park on park 系统调用。我们今天从最核心的 aqs 加 catch 加挂起唤醒讲起。第一层, a qs 队列同步器,核心股价 aqs 就是 lock 的 总指挥部,它内部有三样东西,一个 state 变量零无锁。一有锁,一个 exclusive vulnerability 的 记录。当前持有现成,一个 clh 双向队列排队的现成都在这。现成来抢锁先 cas 修改 state, 抢到就持有, 抢不到就排队。第二层, c a s 是 什么?底层原子性 c a s equals, compare and swap 比较并交换,它是 cpu 源语支持的一行指令,完成读比较写 不被中断。三个参数,内存值,预期值、更新值,预期和内存相等,才更新,不等就失败。这就是 log 不 足色, 不停轮循的基础。第三层,抢不到锁怎么办?排队加挂起现成,抢锁失败,不会一直空转,而是一进入 clh 队列排队。二,执行 park 挂起现成进入 waiting 状态。三, 不占 cpu, 不 浪费资源。什么时候唤醒只有锁的线成,执行 unlock, 唤醒队列里的下一个第四层 unlock 做了什么?释放加唤醒 unlock 底层流程,一, state 减一,二,判断是否完全释放锁。三,唤醒对头线成。四, 对头线成再次 c a s 抢锁,抢到就执行。这就是可重入的原因。同一线成,多次 lock state, 多次加一,必须对应次数。 unlock java lock 底层三件套, a q s 框架与排队 c a s 原子修改无所竞争。 park on park 挂起唤醒节省 cpu, 它比 synchronize 的 更灵活。底层原理却是同一套,保证原子可见有序控制并发安全。
169程序员大树 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿jvm 内存结构是 java 程序运行的核心骨架,也是面试必过的硬核关卡。其核心分为县城私有与县城共享两大区域,边界清晰且各司其职。 县城私有区域随县城升面,包括存储局部变量、方法参数的虚拟基站、记录方法、调用轨迹的程序计数器,以及支撑本地方法执行的本地方法站,三者共同保障单县城的执行链路稳定。 县城共享区域则贯穿程序生命周期。堆是最大的内存区域,负责存储对象实力与数组,也是垃圾回收的核心战场。 方法区、存储类信息常量、静态变量等。 jdk 八后由原空间替代永久带,直接占用本地内存, 掌握各区域的功能边界,一出场景与内存分配机制,既能精准定位内存,一出问题也能为 jvm 调优助牢基础,是 java 开发者进阶的必修课。站管运行,堆管存储战士,现成私有随方法创建销毁。
 06:56查看AI文稿AI文稿
06:56查看AI文稿AI文稿现在越来越多的团队在做同一件事,把 java 换掉。理由就一个,启动太慢。 servulus 架构下,你的服务按需拉起,没有请求就不运行。用户一发请求构语言,五十毫秒就有响应。 python 三百毫秒, java jvm 版本得让用户等将近五秒, 这五秒不是你代码写得烂,是 jvm 每次启动都要重新加载,运行时做类加载跑 jit 预热,几十年了改不掉。于是大家开始换语言。 java 程序员的饭碗正在被这个问题一点点蚕食。 grov m 是 java 的 反击手段,它能把同一个 spring boot 应用的启动时间从六秒压到六十毫秒,内存从两百兆降到五十兆。这不是吊餐优化,这是彻底换掉了 java 程序的运行方式。但这东西的坑比你想象的深得多。 我见过有人签完上线第三天,接口开始莫名报错,追了整整一天才发现根本原因。今天把 ground v m 讲透,为什么能宽这么多,原理是什么,最要命的坑在哪里?以及面试被问到该怎么答才不丢分?先讲第一层, j v m 启动到底慢在哪儿? 你有没有想过 jvm 每次启动要干多少事儿?第一步, jvm 运行时环境初识化,内存模型、垃圾回收器、线程调度器,这些都要从零建立,本身就要消耗几百毫秒。第二步,类加载, 把你的 class 文件一批一批读进来,做字节码验证类链接静态初识化,快执行。 第三步, j i t。 及时翻译, j v m 先用解释模式跑,发现哪些方法被频繁调用,才把它们翻译成机器码。这个阶段叫预热期,预热没完成之前性能很差。第四步, spring 容器初识化,自动扫包,条件注解判断, 闭眼依赖注入 a o p 代理,生成一个中等复杂度的 spring boot 应用。光这一步就能吃掉一到两秒。你的第一行业务代码还没跑, jvm 已经忙活了好几秒,这在长期驻留的服务器上没问题。毕竟 jit 热身完之后, java 的 吞吐量是顶级的, 但 service 场景每次冷启动都要重走一遍,这套机制就成了纯负担。第二层, grovm 凭什么能做到五十八毫秒?嗯,它的解法其实一点都不复杂,就是把 jvm 在 运行时做的活全部挪到翻译期,提前做完,这叫 aot 提前翻译。 普通 java 的 路径是这样的,源码编辑成自解码, jvm 运行时读取自解码, jit 把热点代码编成机器码,然后才真正跑起来,最后内部转机器码是在运行时做的。这就是冷启动慢的根源。 java vm native image 换了一条路,源码编辑成自解码, 然后 graph v m 做全量静态分析,把你程序里所有用到的类方法、代码路径全部分析清楚,直接提前翻译成目标平台的原声二帧制文件。这个二帧制文件里面已经是机器码了,启动的时候不需要 j v m, 不 需要 j i t 热身,直接运行。 打个比方, j i t 就 像现炒现卖,每次要等厨师准备,但能根据当天食材灵活发挥,做出来的东西最香。 a o t 就 像流水线预制的盒饭,取出来加热就能吃,省时间,但灵活性差。 你去盒饭工厂说我要加个菜,工厂说做不到,因为已经打包封装好了。实测数据,一个 spring boot 应用传统 jvm 版本,启动时间六秒,内存占用大约两百兆。切到 native image 之后,启动时间六十毫秒,内存占用五十兆,启动快了一百倍,内存省了百分之七十五。 在 surface 或者高密度容器化部署里,这省出来的资源是实实在在的成本。第三层最大的坑,反射。 native image 的 工作前提叫封闭世界,假设 编一期能看到的代码才会被打进二境制,看不到的运行时一律不存在。问题是反射是运行时动态决定加载哪个类的,静态分析根本看不见 spring 注入 jason 系列化动态代理, 这些背后全是反射。在普通 jvm 上跑得好好的。切到 native image, 轻则启动报找不到类, 重则某个接口一条就崩日之里什么有用的信息都没有,极难排查。解决方式是给 graph vm 提供一份反射白名单,告诉他哪些类要在编辑期保留。手写的话在项目里加一个 reflect configure t n jason 里面用 json 列出类名,需要保留的方法和字段,格式不复杂,但你得自己知道哪些类用了反射,漏一个就可能运行时炸。更省事的做法是用官方的辅助 agent, 让应用在普通 jvm 模式下跑一遍,完整的测试 agent 自动把所有反射调用记录下来,生成配置,省掉大部分手工排查。 spring boot 三点三之后,框架层面已经内置了大量适配,常用的注入,序列化基本不用操心,但你业务代码里自己写的反射还是得自己补。 迁移建议说直接点,想用 grov m 又不想踩太多坑,新项目优先选 corkas 或者 micronote, 这两个都是专门为云原生设计的 java 框架,和 spring boot 一 样是做后端服务的,但它们从架构层面就为 aot 翻译优化过。 native image 支持是一等公民,不是后来打补丁加上去的,踩的坑少很多已有的 spring boot 老项目想签版本至少要升到三点三,做完全量回归测试在上,别直接切生产面试被问到 grov m, 这样答不会丢分,面试官问你 grov m 是 什么,或者为什么用它? 别只说能把 java 翻译成本地程序,这等于没达完整思路。分三层,第一层讲背景, jvm 的 j i t 翻译在长期运行的服务上是优势,热身完之后吞吐量顶级, 但在 serverless、 短生命周期容器这些冷启动敏感的场景是瓶颈,这是 grovm 解决的问题。第二层讲原理, grov m native image 用 a o t 在 编一期做封闭世界静态分析,把所有需要的代码提前编一成原生二进制运行时不需要 j v m, 冷启动从秒级降到毫秒级, 内存占用也因为去掉了 j v m, 运行时大幅下降。第三层讲代价,封闭世界假设决定了它不支持运行时动态行为,反射动态类加载运行时字节码生成都需要额外配置或规避迁移。老项目有真实成本, 而且 native image 的 峰值吞吐量可能低于 j i t 充分预热后的 j v m, 所以 它适合冷启动敏感的场景,不适合对峰值吞吐量要求极高的长期驻留服务。 能把这三层说清楚,面试官基本就满意了。再能说一句, spring boot 三点三之后原声支持好很多,但业务代码里的反射还需要手工配置,说明你真的动过手,不是背的。八谷最后一个问题留给你,你们现在的 java 服务部署在哪儿? servolus 容器还是传统机器?如果是长期驻留的服务,其实根本不需要 graph vm, git 热身完之后反而更快。这个选择本身就是一个很好的架构判断题。评论区聊聊你有没有在项目里用过 graph vm, 踩过哪些坑。
217程序员Mike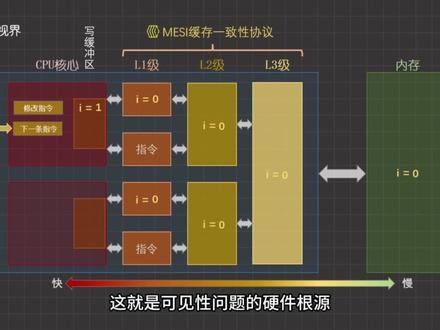 06:27查看AI文稿AI文稿
06:27查看AI文稿AI文稿你有没有遇到过各种诡异的问题?代码写的好好的,可就是不按照预期运行。比如这段代码逻辑很清晰,子线程在循环判断 flag 标识一旦为 false, 子线程会立即退出。 可明明已经在主线程中把 flag 改成 false 了呀,结果子线程就像瞎了一样,还在那傻傻的死循环,根本没有要退出的迹象。百般确认,逻辑确实没有问题, 可跑起来就是不对劲,是不是很邪门?先别慌,作为一个优秀的程序员,咱不信鬼也不信神,遇到事先点根香,啊!不对,是先点根烟压压惊!其实这根本不是啥神秘事件,而是并发编程里的一个非常典型的坑可见性问题。 今天我们就来拆解这个问题,顺便认识一位编程界的大神沃洛特尔,他不仅能解决可见性问题,还能避免指定重排带来的一系列问题。 如果你不清楚这两个概念,请不要划走,我们一一说来。这里是源码世界,用动画带你轻松搞定编程知识,专治各种看不懂。 先说说刚才的子线城为啥会眼瞎,以及啥是可见性问题。来打个比方,想象一下,你和同事用 get 维护同一个项目,你这边咔咔改完代码,还没来得及部署到远程仓库,结果你的同事一看,哎,代码怎么还是旧的呢?问题出在哪呢? 很简单,用过 get 的 都知道,你得先将最新提交推送到远程,然后同时再拉取一下,才能看见最新的改动。 像这种协助场景下,一个人的改动,别人无法立即看到的现象,就是可见性问题的雏形。在 java 的 世界里,为了屏蔽不同硬件的底层差异, jvm 搞了一套规范,叫 java 内存模型, 也就是 j m m。 在 这套规范里,所有的共享变量都存在主内存里,并且每一个县城都有自己的工作内存, 里面放着主内存变量的副本。县城要改一个变量,得先修改自己工作内存里的副本,这时候,主内存和其他县城的工作内存里的值都还是旧值。 如果此时另一个县城恰好来读这个变量,它读到的自然是自己工作内存里的旧版本。不过这只是 jvm 层面的解释。其实问题的根源在硬件那儿。 我们知道 cpu 跑的太快了,内存根本跟不上。为了不让 cpu 干等着,工程师们在 cpu 和内存之间加了多层缓存,每个 cpu 核心都有自己的缓存。那问题来了,对于同一个共享变量,不同核心缓存里的数据不一样,怎么办呢?工程师们自然也意识到了这个问题, 于是他们搞了一个叫缓存一致型协议的东西,专门用来让各个核心的缓存数据保持一致。照理说,有了它,数据就应该一致了呀,不应该有可见性问题了吧? 问题没那么简单,工程师们觉得多级缓存虽然读起来快,但同步起来还是太慢了。举个例子, 一个核心要改某个共享变量,他不光要把结果写到自己的缓存里,还要扯着嗓子喊,嘿,兄弟们,我改了啊,你们手里的那个版本已经作废了,不能再用了,收到请回复。然后他就傻等着, 直到所有的核心都回复收到,已作废,这时候才可以继续干下一件事。对于 cpu 来说,这种等待简直就是浪费时间,于是工程师又在每个核心和缓存之间加了一个斜缓冲区。这下爽了,要写数据,直接扔到斜缓冲区里就行,不用再等了, cpu 可以 继续疯狂的执行后面的指令,效率确实提高了。但问题也来了,数据没有从协缓冲区写入缓存时,不同核心看到的数据仍然是不一样的,这就是可见性问题的硬件根源。聊完可见性,再来说一说另一个坑,指令重排问题。 也就是说,代码实际执行的顺序可能和你写的代码顺序不一样。这事发生在两个阶段,编一期和 cpu 执行期。由于代码的执行顺序一定程度上会影响 cpu 的 执行效率, 所以在编一代码时,为了尽可能的充分利用 cpu 的 性能,可能会根据一些规则适当的调整代码的前后顺序。 而 cpu 执行时,还记得前面说的斜缓冲区吗?可能会出现这种情况, a 等于一的数据还在斜缓冲区里等待时, b 等于二可能已经执行完了,并且数据先一步来到了缓存里,此时从别的核心的视角来看,相当于先执行了 b 等于二,就好像发生了指令重排。不过,无论是哪种重排,在单线程下都是能够保证程序的最终结果是正确的。 但在多县城下可能会出大问题。比如这个例子,主县城负责出售化配置数据,然后设置 over 为处,表示配置已就绪,子县城循环等待,一旦配置就绪,就读取配置数据并执行后续逻辑。 但是如果主县城发生了指令重排,先执行了 over, 等于处子。县城一看配置已经就绪了,立即去读取配置数据,但是配置数据可能还没有初步化完,这时候很可能会发生空置针异常。 好了,问题搞清楚了,一个是看不见,一个是乱排序,怎么解决呢?没错,就是开头我们提到的关键字 volatile。 从语义上说,它有两个作用, 第一,保证可见性,被他修饰的变量一有改动,立马强制同步到主内存,同时其他工作内存中的变量副本会立即失效,需要时必须从主内存重新读取, 从而做到县城间的立即可见。第二,禁止指令重排,它在变量读写前后各加了一道内存屏障,这就像在代码里砌了一道墙,告诉编辑器和 cpu, 墙前面的代码不允许跑到墙后面去,墙后面的代码也不允许跑到墙前面去。 在硬件层面,这个所谓的屏障其实就是一条特殊的指令,比如叉八六架构下的 lock 前缀指令,它会以原子操作,强制把斜缓冲区里的数据刷到缓存里,这就保证了可见性。 由于前一条指令的可见性一定在后一条之前,所以从其他核心的视角来看,也就没有指令重排的效果了。对于硬件层面的解释比较粗糙, 并且不同硬件的实现细节也不一样。但作为 java 程序员,我认为能理解到 jvm 规范这一层,就足够能写出健壮的代码了。底层硬件的事就留给爱卷的大神们在评论区讨论吧,如果你喜欢我的视频,别忘了关注我,下期更精彩!
2522猿码视界 02:00查看AI文稿AI文稿
02:00查看AI文稿AI文稿想让 ai agent 越用越强,功能无限扩展,插件系统就是它最核心的方案。 简单来说,把所有能力做成可插拔的模块,想用就装,不用就给它卸了,让系统灵活又好维护。 那怎么设计一个靠谱的插件系统呢?我们要抓住三个核心原则。第一,核心, 标准化的接口,所有插件都遵循着同一套规范,有统一的生命周期,企划执行、销毁, 就好像我们的手机都遵循着系统规则。第二点,互相隔离,插件之间要独立的运行,一个崩了不影响整体资源,错误都能隔离开来,保证系统的稳定。 第三点,可发现,可管理,我们实现一个插件管理器统一,负责插件的注册、加载、卸载、配置,全程可控,一目了然。第二, 插件和 a 键怎么交互呢?呃,这里一般有三种方式,分别为工具调用、事件驱动、钩子机制。 那么安全上又怎么保证呢?一般情况下,我们通过这个全控制沙箱隔离,还有签名验证,哎,去保证我们的安全。
3阿俊AI 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿java 后端还在手写 c r u d? 你 out 了? 实体类 controller service marker 一 套写下来半小时,纯纯体力活。直到我用了这个 ai 神器,只需要输入表明和字段,十秒直接生成全套代码,以前半小时,现在十秒,效率直接翻一百八十倍,代码规范,结构清晰,直接复制运行。 以后谁还手写 c r u t 啊?想要这个 ai 工具,加万能提示词的评论区扣效率我直接发你。
 12:37查看AI文稿AI文稿
12:37查看AI文稿AI文稿hello, 大家好,欢迎大家来到这个加瓦零基础啊,从入门到精通的一个课程系列, 然后上节课的话给大家讲了这个加瓦的一个主要应用场景啊,它适合做哪些系统啊?然后呢,包括它的一个在这个生态圈的一个位置啊,它在各个行业的一个应用。 然后我们来看一下这节课,来看一下怎么去准备这个开发环境啊。首先我们要学习 java, java 它是一门编程语言,它需要相关的环境才能运行,那我们怎么去呃,去准备它的开发环境呢?我们要装哪些东西?之前我们在做 java 简介的时候有讲到啊, java 它主要分为这么个东西,一个是 jdk 啊,我们作为开发者,我们要装的一个东西就是 jdk, jdk 它里面包含了 gre 啊,就是 gre 里面它有一些 java 基础的一些核心内库啊, 啊,它已经有了一些基础的一些代码库,然后呢还有就是 gre 里面又包含了 jvm 啊, jvm 就是 运行这个 java, 运行这个 java 字节码的一个平台, 然后从而达到加一次翻译啊,到处运行啊,就是它可以在各个操作系统上运行啊, 虽然 java 语言它不跨平台,但是呢它这个 gvm 它是跨平台的呀,因为它最终这个代码它交给谁执行的呀?交给 gvm 执行的,那不同的操作系统它有不同版本的那个 gvm 啊,所以说 java 它达到一个跨平台的一个效果。 那我们来看一下怎么去准备这开发环境,那我们要装 jdk 啊,这 jdk 的 话已经给大家放到这里了,这个就 jdk, 然后呢我会根据这个 jdk 八来讲啊, 这是一个经久不衰的一个版本,然后后续的话给大家单独出一张,就是 jdk 到最新 jdk 的 一些区别啊,以及升级的一些点来讲就行了。我们还是去加网吧来讲解,然后加网吧然后怎么去安装它啊?首先 我们我先找到我 c d k 的 一个路径啊,首先你就双击它就可以了,然后点四啊, 然后呢它就会出现一个安装的一个一个过程,然后我们先选一下啊,就选开发工具可以了,然后安装路径的话,你根据的实际情况啊,我是不会装 c 盘的,然后我就装到,呃, d 盘啊,放到我的这个叫八里面, jdk 八里面啊,我看一下 d 盘扣的音 v 有 一个叫我们新建一个目录吧,新建一个目录叫 jdk 八啊, jdk 八, 然后我们再来看一下 jdk 八有了啊,那我们点确定,然后就点下一步啊,然后让让他去安装就可以了, 嗯,到一半了啊, 然后然后出现这个界面的话, 呃,它进度条走完了之后就是这个界面啊,就说明我们 j d k 已经安装完成了。然后我们来看一下 c m d windows 加 r, 然后输入 c m d, 然后加网干 vs 看一下啊, j d k 八已经安装完成了,加网 c 干 v r s i o 看加网 c, 它说加网 c 不是 命令啊, 不是命令,那说明什么?说明我们还需要配置一个环境变量啊,就是在为什么配置环境变量呢?就是我们可以,我们可以在任何目录啊下使用 java c 和 java 啊,那系统能够找到那个 jdk 的 一个安装位置, 然后我们来看一下这个右键,首先右键点击此电脑点击属性啊, 然后呢进入到这里,然后我们点高级系统设置,然后点环境变量啊,然后我们首先建一个 java java 后的一个目录啊,然后就是 我们把这改一下啊,扣的音 v, 我 们之前我们叫 gdk 八,然后我们就把这个目录放到这里啊,第一步配置好了,然后我们还需要在那个 pass 里面配置一下啊, pass 里面, pass 里面的话就点这里啊,要新建两个,一个是 java 后啊,然后这个 它前后有白封号,然后斜杠并啊,还有一个是 java 后 j r e 斜杠并啊,这两个我之前已经配置好了啊,大家如果说没有的话,你就点新建,把这个复制进去就行了啊,然后这个文档里面也有, 但是,但是你这个一定要注意啊,这个一定要是你那个 jdk 的 一个安装路径啊,加网控 啊,加网控一定要是你 jdk 路径,就比如说你最开始第一步啊,你选的时候哎,你选的是哪个位置啊?比如说我选的 jdk 八这个位置啊,你看就直接复制这个目录就行了啊,不要搞到这里面去啊,你看为什么是 b 呢?因为 b 里面有加网啊,你看 有 java 点 exe, 还有 java c 点 exe 啊,就是说你在任何路径下面啊,这些点 exe 你 是可以用的啊, 这环境变量就是这么一个效果啊,然后一个是用户变量,用户变量的话就是你当前登录是恶意用户啊,那你配在这里面,那你就只能是恶意这个用户去用, 如果你系统变亮的话,你配置性能变亮,相当于是你这个操作系统,不管是哪个用户来登录啊,他都是可以访问你配置的这些环境变量。好,这里的话环境变量我就配完了啊,配完了,然后的话接下来还要配一个。什么配一个这个玩意啊? 配置就这个玩意,这个玩意我已经配过了啊,这个玩意我已经配过了,就是在这个高级系统变量里面,然后环境变量 啊,有一个 class pass 啊, class pass, 这个,这个就是这个啊,记住啊,这个一定这些符号一定要是什么一定要是那个英文状态下的啊,你记住这个一定要是这个状态下的。好, 然后的话我们来验证一下他是不是啊?环境变量已经配置成功了。首先我们记住啊,你刚才打开 cmd, 你 配置完环境变量之后,你要重新打开这个 cmd 啊,他才能他才能正确的执行这些啊。 java 改为 rsln, 好, 第一步 我们出现了这个啊,加瓦干瓦,加瓦尔森,后面跟的是他的一个加瓦的一个版本号, jdk 版本,那这样的话我们就成功了啊,然后我们再来看一下加瓦 c 干 v r s i o n 啊, 那现在是不是加瓦 c 也出现了它对应的一个版本号,那到这里的话,我们这个环境变量已经配置完成了环境变量已经配置完成了,那就什么?那就说明我们现在已经是可以编辑和啊运行加瓦 代码了啊,然后这里的话,哎,为了大家后面方便大家去学习,然后呢,我这里也给大家,呃,把那个安装工具带大家装一下啊, 我们常用的话就是这个叫艾迪尔这个开发工具,然后我这工具的话二零二四版本的啊,然后这个的话也放到这个网盘上面了,大家下载下来直接安装就行了。然后我呢现在去找一下这个,呃,安装,我下载一个滤镜啊,这个滤镜的话 在哪个位置?去找一下,在这个位置啊,这个位置大家解压完,首先解压完,解压完了就是这么一个效果啊,直接双击啊,这个点 x 一 啊, 双击完了之后他就会出现一个安装界面啊,然后点下一步,然后你要选一个你安装的一个路径啊,这个软件还是比较大,尽量不要装到 c 盘里面啊,我就装到我的 d 盘里面去了, 然后点那个 id 二,然后我这有两个目录啊,两个目录的原因是什么?一个是他安装了墨镜,一个是为了我后续方便,如果说我有些插件要在这里面的话,哎,我就把插件给他放到这下面,到时候好找啊, 然后的话我就下一步,然后点,点上这个关联点,加完你可以点,可以不点啊?创建快捷方式啊这些这些可以点,可以不点啊,我就把这三个默认的给点上, 然后出现这个界面的话,就是已经安装完成了啊,我们直接点完成就可以了,然后来到桌面上啊,这个就已经有了啊,给大家来看一下啊,然后这里啊点下一步 啊,点确认点继续啊,然后就可以了啊,然后的话大家也可以啊,要激活的话,大家这里给大家 搞一个别的东西啊,退出不激活啊,然后的话,哎,这里的话给大家看一下这个东西啊,这个东西解压完了之后啊,我的安装包解压完了之后,然后这里面有一个 怎么去激活它的啊?来看一下,直接点点两下这个啊,这个就 short size 啊,就是成功了, 然后双击两下这个 idvbs, 然后的话你要记得这个看一下你是哪个操作系统啊?然后的话你是哪个软件,然后再去激活就可以了。好,那现在我们再重新打开一下 啊,现在就可以了啊,然后的话, 呃,现在可以了啊,现在可以了,大家,大家双击这个的时候一定要把这个网络给断开啊,网络给断开就可以了啊,然后就是这样的话,我们这个开发工具就已经装好了啊, 然后的话我们那个 java 的 一个环境变量也已经装好了,然后 java 那 个 id 的 这个开发环境我们也已经装好了,然后这样的话我们来看一下 啊,我们新建一个项目啊,文件新建新建项目啊, 新建一个加瓦项目,那我们就叫 s t u d y 加瓦啊,学习加瓦的一个这个,那我们就直接选,我们要选 jdk 啊,这里我要选我们 jdk, jdk 我 们就选一点八啊,直接点 点创建就可以了啊,然后我们就选择一个单全窗口打开,打开,打开完了之后啊,这里面就有一个很简单的一个视例啊,就是编程的时候入门啊,学习的一个 一个案例嘛,然后使用现有的 gdk 版,然后配置一下它, 然后呢?我们现在它这儿不是有个 demo 吗?我们就来运行一下这个程序啊, 现在是怎么写的?我们不需要管它,我们只需要运行一下它,看一下,哎,这儿控制台已经输出了什么?输出了 hello world。 说明什么?说明我们环境变量,包括这个工具你也已经准备好了啊?后面。
39Java研究僧

![[教程向]如何在安卓手机(或平板)上运行我的世界JAVA版#我的世界 #教程向 #教程 (fcl下载链接将在视频发布后一天发出)](https://p9-pc-sign.douyinpic.com/tos-cn-p-0015c000-ce/oAI06BEV5An1AesxwIi6zYnBcfjApqDiEAByYI~tplv-dy-resize-origshort-autoq-75:330.jpeg?lk3s=138a59ce&x-expires=2092046400&x-signature=A5BYg5M6iguolO45EPpg2x6m6OE%3D&from=327834062&s=PackSourceEnum_AWEME_DETAIL&se=false&sc=cover&biz_tag=pcweb_cover&l=20260420204616A7A775D978765EDF868D)




