AI教程分享(姿料)

粉丝24获赞131
相关视频
 00:39查看AI文稿AI文稿
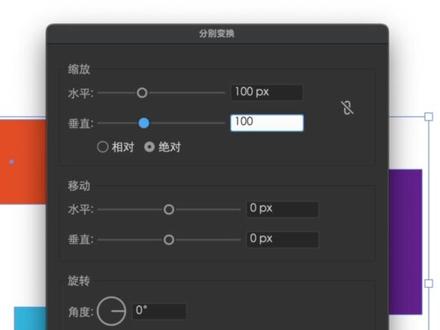
00:39查看AI文稿AI文稿ai 中大小不一的图片如何一步调整为同样大小呢?首先选中所有图片,打开对象变换,分别变换, 勾选绝对,这是新版本增加的功能。然后点击约束比例,把水平缩放,设置一个数值,这里以宽度一百为例,最后确定,这样所有图片就被设置为一百。宽度且比例保持不变, 大小不一的矢量图形也可以设置为同样大小。首先需要勾选绝对,把水平与垂直数值都设置为一百,最后确定,这样所有图形就会被设置为同样大小了。
203Ai设计 07:30查看AI文稿AI文稿
07:30查看AI文稿AI文稿左边是我在网上随便找的一个产品原图,右边是用 ai 精修后的结果。 这些适用于亚马逊平台 a 加页面的搬了图都是由 ai 生成,不用寻找任何素材。生成这些图片只需要用到两个 ai 工具,一个是豆包,另一个就是 chat gpt。 使用这两个工具是完全免费的,不需要充值任何会员,就可以达到刚才我做出的效果。 哈喽,大家好,我是正在找工作的小张,今天给大家分享用 ai 制作亚马逊平台 a 加详情页面的一个教程。在视频的结尾,我会总结 ai 生图的一个步骤,大家记得保存就行。 由于我没有产品,就打开亚马逊平台,随便找一个产品,当做我的一个产品的竞品,大家直接寻找自己公司的产品的竞品就可以。 我随便选了一个用来给头发定型的一个造型霜,接着在网上随便搜一个头发的造型霜,下载保存下来,当做我的一个产品。有了产品图之后,我们要先对其进行精修,打开豆包,上传我们的产品, 让豆包进行一个抠图,并直接生成 p n g 格式。经过我对各种 ai 工具的测试,豆包是抠图最厉害的一个 ai 工具,现在把豆包抠好的产品保存下来。 接着我们打开 chat gpt, 从左下角可以看到,我们使用的 chat gpt 是 免费版,没有升级任何会员。如果我们要对产品进行精修,首先要让 ai 明白我们要做什么以及如何去做, 所以我们要首先喂养 ai, 直接询问 chat gpt。 我是 一个电商美工,要对产品进行高品质精修,该如何去做? gpt 很 快就会给我们一个答复,然后上传我们的产品,让 gpt 根据他的答复对我们的产品进行一个精修。唯一一点的缺陷就是文字可能有一些乱码, 这点我们用 ps 简单修改一下就行,这里我就不再做演示了,相信大家都会 回到亚马逊平台,找到我们产品的竞品。可以看到 a 加详情页面的第一张版本图,我们将其保存下来。接着回到 chat gpt 在 一个全新的聊天框内再次喂养 ai, 让他知道我们的目的是要做亚马逊平台的 a 加详情页面。 喂养完 ai 后,我们就上传刚才从竞品页面下载的斑点图,让 ai 拆解这个斑点图,分析这张图片的色彩构成,等 gpt 拆解完毕,再上传我们自己的产品精修图, 要求 gpt 按照它对竞品图的一个拆解,结合我们的产品生成一张类似结构但是不侵权的斑点图。 可以看到 gpt 生成的图片的质感和色调都是挺在线的,唯一不足的地方就是尺寸不太对,经过我的多次测试,发现 gpt 只能生成这个尺寸,没有办法完全符合我们净品的一个斑点图的尺寸。 想要解决这个问题,我们就得再次回到豆包,在豆包上传 g、 p、 e 做好的斑点图,输入我们对图片尺寸的一个要求,并且要求图片原内容不能发生任何改变和形变。 可以看到豆包在原基础上完美修改了尺寸,符合了我们的一个要求。唯一的问题就是豆包保存的图片会在右下角自带水印, 这个时候就需要我们打开 ps, 使用污点修复画笔工具把图片右下角的水印给去掉就行了。这样我们 a 加详情页面的第一张斑的图就做好了。 回到镜片的页面保存第二张斑的图,使用同样的步骤,先让 gpt 对 这张图片进行拆解, 然后再让 gpt 根据拆解的结果,结合我们的产品生成一张结构相似但不侵权的半大图。 这里要注意的是,每一次生成图片都要重新上传一遍,我们的产品精修图 是为了保证 ai 生成的图片中的产品不会发生任何改变。我们的第二张图片生成好了,但是仍有很大的问题,首先就是模特的手很怪异,不像正常人类, 其次就是图片下方还有一些多余的介绍,并且模特还是采用的原来竞品图的模特,这些都是我们需要修改的地方。 再次上传我们的产品图,告诉 gbt 重新进行修改。首先就是模特不要重复,接着就是去掉模特的一只手臂,一只手臂应该比两只手更容易生成。 果然, ai 再次生成了图片后,模特的样貌发生了改变,并且只剩下一直手持产品的图片,虽然还是有一点不和谐,但比之前的图片要好很多。首先用 ps 将图片底部多余的部分给裁剪掉, 接着打开豆包,上传裁剪后的图片,输入我们的一个尺寸,要求经过两次细微调整,得到完美符合我们需求的一个图片。下一步就是用 ps 消除右下角的水印即可。第二张图片就这样做好了, 回到竞品页面,下载对方的第三张版的图,依旧是先让 gpt 进行拆解, 然后再上传我们的产品图,让 gpt 根据拆解后的结果,结合我们的一个产品,生成结构相似但不侵权的全新版本图。图片生成之后保存下来,再次打开豆包,对这一张图片进行尺寸上的调整, 这里可以看到图片中的葡萄从青色变成了紫色,不太符合我们产品的一个色调, 所以需要让豆包把颜色重新改回去。细节调整完后,我们就可以把这第三张斑点图给保存下来,去除掉右下角水印就可以正常使用了。 剩下来的图片我就不再演示了,大家可以自己去操作练习一下。下面展示一下 ai 生成的一个结果, 最后做一个总结,大家牢记这些步骤就行。如果大家觉得我的分享对你提升工作效率有很大的帮助的话,麻烦点点赞和关注一下,谢谢!
 05:54查看AI文稿AI文稿
05:54查看AI文稿AI文稿今天这个视频厉害了,教你怎么做这种很火的真人 ai 转场视频,更重要的是通过这么一个小的案例来教会你,我们在做 ai 视频的流程架构准备好了吗?开始上课。 首先我们需要用手机拍这么一段视频,然后把它导入到剪映里面来,我们把它拖到剪映里面来之后啊,裁剪掉多余的部分啊。这个时候我们移动到最后一针,我们点击右上角的这里,点击导出安全针。 那除了这个竞争之外,我们还需要再准备两张照片,一张是自己最近五官清晰的照片,我因为好久没有拍照了,就拿了一张自媒体的截图。那还有一张是转场之后你想穿的服装的照片,我这里是准备了一套藏服。接下来我们就要用到 banana banana 了, 有很多同学上课不认真啊,一直在问我是用什么工具作图的。那再强调一次,像现在生图,我只推荐一个工具,就是 nano banana。 首先因为它效果最好,生成出来的照片最真实。 那第二个原因是它的修改能力特别强,你画面里面哪个有问题?改个服装,改个背景,都是用哪把掐?第三个是它最便宜,你们可以去某鱼搜一下 jennon 三 pro, 买一个独享账号,基本八九十块钱就可以用一年。 买完账号之后,登录上你买的谷歌账号,你就可以使用香蕉了。点击这里的工具之后,选中这个制作图片,然后一定要把这里的快速改成 pro, 你 这样生成出来的照片效果才会好。你可以看到这个地方官方已经给了我们很多的预设,你可以直接选择你想要的效果,就可以随便点击一个新建项目, 然后我们把这里的视频改成 mag, 就是 图片,我们这里是一个横向的图片。好,这里一下选择生成四张,然后把我们刚才准备好的三张照片拖到这边来。注意在这个地方检查一下你照片的顺序,一定要第一张是能看清你脸的照片,然后第二张是你想穿的服装的照片, 第三张是我们刚刚导出的竞争截图,然后回到我这个文档里面,把这一段提示词直接给他复制,然后在我们的 flow 界面里面粘贴, 然后点击生成,看到没有他就会同时生成四张照片,然后选择一张你觉得不错的照片就行,你可以看到这是我们刚刚重新生成的照片。好,我们得到这张照片之后,点击这里的下载。 好,我们这里点击。 ok, 那 当然如果你不想要雪景的话,你也可以把这段提示词直接喂给 ai 呢,不管是豆包千问或者下载 g p p 都可以。你跟他说若仿照这个提示词结构,把里面的场景从雪地换成其他你想要的场景,比如说沙滩, 并且提供你想要穿的服装,你就可以生成你自己想要的画面。 ok, 我 们现在拿到了第一张照片之后,我们就可以在 pro 界面里面。好点击这个加号,把刚才生成的不错的那张照片,你说这张还行,点进来,然后再点击您面部的近景, 并且回到刚才我们的文档里面,把这段提示词给他复制粘贴进来,然后点击发送,可以看到继续生成四张新的照片,这段提示词的效果是镜头往前稍微推进一点,然后我们来一张我回头看的中近景的照片,来,我们看一下他生成的近景的照片, 我觉得这张效果还是不错的。那这样的话,我们上来就得到了两张照片,分别是我们想要生成 ai 视频的首尾帧, 然后有了首尾针之后,我们就可以随便选一个视频模型,那不管是可灵或者 v u 啊,都可以。我们点击这个右下角的 nano banana pro, 然后把它改成 video 啊,这个时候我们把视频的数量改成乘一视频的模型,还是选择 v u 三点一 quality 啊,这个质量比较好。我们再回到刚刚的文档里面,把最后这个视频指令里的英文提示词给它复制一下,好,回到我们的 v u 模型里 粘贴进来。好,这里的手针,我们就选择刚刚的中景镜头啊,转身之前的,然后尾针,我们就选择刚刚新生成的效果不错的这个画面,我们只需要点击生成即可。如果你用可灵这种国内的模型的话,你就可以直接粘贴我们刚才文档里的中文提示词。 ok, 现在已经生成了,我们大概看下效果。 好,我们点击下载幺零八零 p。 好,我们把刚才下载的片子导入到我们的剪映里面来,然后拉到时间线上,我们稍微做一下变速,然后再剪切一刀。 ok, 我 们最后随便找个转场音乐,比如说这里放个旋律卡上点。 因为今天正好北京下大雪,所以我最后可以给他打一个字幕,然后配上一个好看的字体,把它变小一点,那我们给前面这个视频加一点缩放,再给它加一个叠画的转场,好,一起来看一下成片吧。 那最后我们总结一下,因为现在吉梦 cds 对 人脸的限制,所以像这种首尾帧来升视频还是非常好用的,因为所见即所得, 我们在视频出来之前就可以来把控整个片子的质感。同时我在这个文档里面,除了刚才这么忧郁的看着镜头,我也放了一个笑着看镜头的版本,你们也可以试一下。期待看到你们最后的成片。 那还是老规矩,点赞收藏评论区打上学长细节来领取这个文档。那做出来的片子你们可以发视频艾特我。 ok, 我是 学长,一个持续分享 a i g c 干货的博主,那我们下期再见,拜拜!
1219大象学长(AI有课) 02:15查看AI文稿AI文稿
02:15查看AI文稿AI文稿分享八种 ai 手尾针大片玩法不限 ai 工具提示词结尾总结给大家, 物品全部上货!手针拿着手机拍摄一张照片,尾针将手机伸出去,再换一个位置,两张图片先交给 ai, 去除掉手臂, 再导入 ai 软件连接首尾针,输入这一串提示词,既可以得到物品的悬浮效果。二、机械避孕镜对着物体拍摄一张平视图,然后再拍一张俯视图,首尾针相连接 就能得到丝滑的机械避孕镜效果。再也不用对着产品费力拍了,塞起一颗颗变焦,我们可以靠近主体超广角拍一张,然后再后退一点,焦距放大,再拍一张, 首尾针相连接,就能够得到细微刻刻变焦效果。延时效果,拍摄一张城市白天的照片,然后让 ai 帮你变成夜晚的照片,白天和夜晚首尾针相连接,就能得到一段城市日转夜的延时视频,大大减少实拍的工作量,同理还能够得到四季轮转的延时视频。 五、物体生成效果手针拍摄一张积木散落的照片尾针拍摄一张积木搭好的照片,手尾针相连接,输入这一串提示词,就能得到积木从零到完成的视频。六、文字书写效果准备一张空白绿幕照片,然后在空白绿幕上面手写设计一个标题, 手尾针相连接,输入这一串提示词,就能得到文字的出场动画。最后放到剪辑软件面,抠出文字,就能得到手写的 vlog 标题。 七、口播场景切换我们在两段不同的场景口播里面分别导出片段的最后一针和片段的开头针。首尾针相连接,输入运镜的提示词,把生成的片段连接在两段素材中间,这样就能够在口播的过程当中自然的切换场景 无人机视角。像这样的无人机视角镜头也可以通过首尾帧实现,只需要模拟无人机的穿越视角,在场景中多拍几张不同角度和高度的照片。首尾帧两两连接,输入这一段提示词,最后把生成的视频拼接在一起即可。 当然使用智能多帧的功能也可以。好了,提示词我全部都已经整理出来了,大家收藏好可以去试一试。
35潘大嘴(数码版) 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿这是我用 ai 做的广告, 今天一分钟教会你。本期设计的工具跟提示词我都整理到文档中了,需要的朋友自取就行。仔细观察你会发现视频的主要元素就三个,模特、口红及爱心。所以第一步我们先来确定主体形象,模特提示词你们可以参考我这个, 如果有喜欢的明星,也可以增加一句模特面容,参考谁谁谁。然后准备好你的产品图跟装饰的元素元素,记得要跟视频的整体风格相统一。第二步是分清策划,如果你直接让 ai 帮你写一个脚本,出来的效果可能不是你想要的, 因为随机性会很强。这里教你一招拉片拆解,找一个你喜欢的或对标的广告视频,让 ai 以专业的分镜脚本格式对视频进行系统化的拆解,每个画面的内容、运镜时长、景别它都帮我们列好了。 接下来我们上传我们准备好的参考图,也就是模特图、产品图跟元素图,让 ai 根据画面生成九宫格的分镜提示词,再把提示词转化成图片, 然后我们在里面挑选出我满意的一个镜头,然后把它裁剪出来使用。如果你觉得九个画面还不够的话,还可以继续生图。挑选好分镜画面后就可以做视频了, 这里我用的模型是视频三点零点击创建主体,这里有我已经创建好的模特跟产品人物可以选择固定的音色,这样有利于整体保持一致性。然后我们上传分镜图,输入提示词, 参考之前拆解的脚本去写就行了。我们可以打开这个智能分镜,它会自动帮你拆分镜筒,如果你有自己的运镜想法,也可以选择自定义分镜。 视频支持三到十五秒,我们把每个视频下载后拼接起来,再加上背景音乐,就形成了完整的作品。这里是公软优社,我们下期见。
7工软优社 00:18查看AI文稿AI文稿
00:18查看AI文稿AI文稿别再被骗了,其实这种小猫洗澡放屁都是 ai 生成的,超级简单,十秒教会你,首先跟我操作,摸一下这个跟这个,然后我们打开这个老朋友极梦在创作,这里进入选择视频生成,然后在这选择二点零时长,选择十秒,在这上传一张宠物照片,接着复制我评论区的指令看不到的截图,这个最后点生成就好了。
52刀盾 01:20查看AI文稿AI文稿
01:20查看AI文稿AI文稿今天想给大家分享一下如何用 ai 快 速搞定一整套 ip 延展设计,从角色形象、三式图、动作表情延展到周边物料、场景海报,全流程分享给你们。首先,打开新流,这是 laut 的 国内版本,没有梯子的小伙伴可以用它。 第一步,我们先把 ip 设计出来,输入这段提示词,里面包含了对角色形象、服饰穿搭、整体风格的描述,然后你就可以获得一个非常可爱的潮玩科技。建议大家在附件上传一些参考图片,这样它生成出来效果会更好。第二步,生成三式图。这一步非常简单 直接,在提示词里说你要为 ip 生成一张正面、侧面、背面的角色三式图,就这一句话就行了。第三步,做 ip 动作、表情、穿搭的延展,输入这段提示词,你就能获得六个不同风格的 ip 形象,还可以让它们动起来。 第四步,生成 ip 周边,直接在提示词里说清楚你要做哪些物料,比如手机壳、帆布袋、马克杯等等都 ok, 等待该几分钟的时间,你就可以获得非常多好看实用的周边。最后一步,生成不同风格的场景海报, 这里你可以简单描述一下自己的需求,然后让他帮你生成详细的提示词,你直接确认就好了。选中喜欢的图片后,只需要在图片框里说清楚你要的文字元素和配色,就可以得到一张非常好看的海报,对哪里不满意点一下就可以换掉,文字也是支持直接修改的。
31鹅mazing 03:06查看AI文稿AI文稿
03:06查看AI文稿AI文稿接下来可以给大家讲讲这个我们的比较难的点啊,比如说这个多人物,其实 nasa 虽然聪明,但是耐不住它量多,量多了之后它其实也会不是很听话的。对这一张图片它是它的一个问题,在于哪呢?就是呃,我们生成人之后,由于人物非常非常多, 虽然大家总体看上去这个人物的一致性还是不错的,但是我们一旦放大看了之后,大家可以看下面这些图片,他其实每一张脸都不是很清晰,甚至在这个地方他还有个蒙娜丽莎两个人的这样一个 bug 出现,包括有两个这个戴珍珠耳环的少女出现,他会有这样一些问题,那其实对于广告来说,这些质感的要求会非常非常的高, 那所以我们该做的事情,那就是将人物的脸进行一个修复。非常不好意思跟大家讲到,这个修复人脸的工作仍然是由 ps 来进行完成,但是辅助了一点 nano banana。 那 我们的做法是什么样子呢?我们从左边的这张不太清晰的图片,把每一张人的这个人脸给它采取出来, 放到 nasobanel 里面进行一个换脸啊。将人物的脸换清晰之后,用 ps 的 方式把这个人脸再贴到我们的最终的图片里面。一个人物一个人物的贴确实非常非常的麻烦啊,但是对于广告的这种高精度要求来说,这个确实是必须要去做的一个事情。 第二深层的这个牛奶,它的一个比例就是忽大忽小吗?大家看到左边这张图,在原本制作的时候,这个牛奶瘦一点,这个牛奶胖一点,那个牛奶高一点,这个牛奶矮一点,那它的一个问题是这样的,那我们怎么去把它的比例进行一个调整呢?我们这次用的一个方法叫做 我们先把手上的牛奶全部去掉,让他空着手。那第二个就是去掉之后,我们再把新的这个牛奶的资产在那洞里面描述说所有人拿着的都是这一瓶牛奶,他就能够保持这个大小,这种形状,高矮胖瘦的这样一个统一。 去掉手上产品就是把这张图片丢到那里面,跟他说将人物手上的白色牛奶盒去掉就可以了,然后得到一张人物手拿着空气的照片,然后我们再把这张这个牛奶的图片跟他说,图一的人物的手中都拿着图二的牛奶,保持牛奶的大小,颜色质感统一,就可以得到后面两张图片, 它的这个大小比例就是 ok 的。 那还有刚才跟大家讲到第三个就是我们所有产品影片,不管是我们之前做的也好,现在做的也好,对于产品来说,文字、内容、包装信息永远是最为重要的, 但是非常不幸的是什么呢?就是 ai 在 这一方面它确实有能力的一个极限,那这些东西就绕不开我们的 ae 的 online 跟踪我们传统的一些影片制作的这样一个流程啊,传统影片的一些技术,所以如果在座的各位同学有需求要去做一些产品广告的话,那我们在团队搭建的时候一定要考虑到我们 的 ae 的 跟踪老师,很多时候难点镜头它还是需要一定的传统的制作技术来进行一个辅助,它才能达到一个商业级别的这样标。 所以跟大家讲到我们在制作图片的时候,我们可以通过四宫格的这样一个方式去高效的生成一组连续的这样一个分镜画面。但是前提是大家一定要制作出一张他的占位关系图, 这个是非常非常重要的,否则你切出来的四宫格这个人物一下子在他前面,这个人物一下子在他后面,一下在他左边,一下子在他右边,他就会出现这种前后不接的这样一些情况。
348与光教育 05:36查看AI文稿AI文稿
05:36查看AI文稿AI文稿却没有想到让 ai 一 键做出来的 ppt 能够有这么多人去问教程,那么授人以鱼不如授人以鱼,当然我鱼和鱼都要分享。大家好,我是彼得毯子,欢迎来到我的频道,那么本视频将会从零到一的教你如何用 skill creator 做一个符合你自己风格的 ppt skill。 我只会分享两个好用的 ppt skill, 那 么看完本期视频,你也能够一键的让 ai 帮你做出一个拥有你自己个人风格的一个 ppt 了,那么视频都这么干了,不如把你的三零也分享给我吧。那么我们现在进入一个实操的思路讲解, 我会用一个 ppt 制作的案例来去教大家如何去做一个自己喜欢的我自己个人风格的一个 ppt skill。 那么首先我们一般来说,我会先去找对应的一个一些具体案例,或说一些我比较喜欢的画面, 然后我会把这个画面截图下来,回到这个 ai 抠点的工具里面,让 ai 帮我去剖析对应的图片的一个视频画面的特点,包括一些构图啊, 元素搭配啊,配色啊这些,让他去进行一定的剖析。当然如果说你原能力比较好的话,你可以直接去用文字描述的方式让 ai 去理解,直接生成对应的效果。那么这里我让他先剖析对应的特点, 之后呢,我会让其将这些图片进行一定的杂揉,所以我喜欢像这样子的一个块的设计,然后块里面会有阴影这样的一个设计,所以说我让 ai 再次去参考这个图形进行特点的剖析,然后将这些特点都杂揉到一起,然后进行画面的格式化, 那么 ai 理解了我的一个指令之后呢,他就会去进行一个画面的一个制作嘛,可以看到他就给我做出来一个第一版的一个风格视力,那么我们可以看到第一版的风格视力他的一个效果就已经是很不错的一个效果了, 但是呢有一个美中不足点,就是我觉得它这个下面这个地方很碍眼,所以说我把这一个 d i p 给框出来了,然后呢让它去维持这样的风格特点去做 ppt, 然后以飞轮效应这一个心理的知识点去设计一个 ppt 出来,那么它结合这 ppt 再次理解了我的意思之后呢,就做出了第二版的一个飞轮效应的 ppt, 那 么第二版的一个飞轮效应 ppt 呢,所以看到它的一个效果就是非常重要的一步了,就是我们要回到我们的 ai coding 的 界面, 让他去利用 skill creator 这一个 skill 来去对这个功能进行一定的封装,然后呢为其命名去 diy, 那 么他就会去自动地调用这个 skill creator 这个技能,然后现学现用的把这个 skill 做出来,做出来的一个效果就是一个类似于这样子的一个文件夹,然后呢这文件夹就包含了 reference set 和一个 mb 文档, 这一个文件夹其实就是我们的 skill 本质了,只是我们要把这个文件夹进行打包,打包完之后呢,我们就可以把它放到任何一个 ai 定制的一个工具里面, 当然放的位置是基于不同 ai 定制的文档,这个就要自己去参考自己使用的 ai 定制的一个文档来去使用它,那么我们本期视频用的工具是 tree ai 这一个 ai 定制工具, 原因也很简单,是因为这个工具它内置了三个模型,包括 g m n 五 k 米 k 二点五以及云 max m 二点七这三个相对来说比较好用的模型,且它每天的一个免费的额度。 除之外,在 skill 的 装载和注入方面也比较简单,点击设置之后,在规则这里面找到一个技能表单,我们点击创建之后,只要上传相关的一个 g i p 压缩包或者 skill 注入进去了,因此它是一个相对来说比较好用的工具。 那目前 chris 这一个工具呢,也有了企业版的发布,大家如果有这方面的需求的话,可以直接点击下方的链接去进行一定的了解。 其实一个 ppt skill 的 制作呢,就分为以下五步,首先我们需要去明确自己的一个 ppt 的 一个大概的样子,把它的需求讲清楚 之后呢,把这个需求发给 ai 去生成第一版出版,我们会根据第一版的出版去不断的优化迭代,持续去改进它,直到我们满意之后,我们会让 ai 去调用 skill creator 的 一个技能,去把这个功能给它封装成一个 skill, 然后包装起来后就可以放到任何一个 ai 控件的工具里面去装载使用,或者说直接在当前的场景直接调用。 其实 skill 是 一个非常通用的技能吧,他不可能去适用到所有的场景里面,就比如说我只是让他去给我做一个心理学的飞轮效应上的一个 ppt, 他 可能做的会很好,但是如果说我让他去做其他内容的,可能有数据表格可说话分析这种 ppt 的 时候,他可能就会报一些小错误, 那么此时我们就需要在后期的绘画中不断的进行一个微调优化,那么微调优化出来的一个 ppt 效果,我们又可以把它封装成一个新的 skill, 这就是一个很有意思的点,我也可以给大家一个思路,就是如果说大家有时间的话, 也可以把让 ai 去自动的查找 ppt 中的一个布局是否正常,界面显示和页面设计是否一致, 是否合理,这样的一个技能场景,把它给封装成一个新的 skill, 然后让让 ai 在 制作完 ppt 之后,都调用一次这个 skill 去对我们的 ppt 进行一个自动化的检查,那么这样的一个流程的话,就 ppt 在 制作的过程中不用我们自己去人工去干预它, ok, 那 么本期视频就差不多到这了,相关的一些 ppt skill 分享,我会把它放到整理包里面,就叫做 ppt skill, 大家如果需要的话可以直接关注后私信整理包就可以获取了, 那么本期视频差不多就到这了,如果说对大家有帮助的话,还请给个意见,三连给咱们关注一下,那么我是别的毯子,一个专注于 ai 实战成长类型的博主,我们下一期再见。
59比特毯子









