java未使用导入语句

粉丝3723获赞1.4万
相关视频
 03:45查看AI文稿AI文稿
03:45查看AI文稿AI文稿感谢参加我的面试,如果有结果你将会在一周之内通知你。嗯,好嘞好嘞,谢谢。我假如说现在线上的数据库突然出现了问题,他的现象就是慢慢查询数量变多, 嗯,这个曲度它本身的这个响应变慢,内存就变多, cpu 变多。嗯,但是它大概有两分钟左右它有回复的正常。那现在呢?我事后想去定位一下问题在哪里, 就是如果这个这个事情排给你,你怎么去做?就是慢日制会记录这个慢搜口出来是吧? 嗯嗯,但是慢日制记录搜口这些搜口不一定准。它这些搜口语句有可能是在数据库里面其中某一个,比如说批量导入的,这过程当中可能有这种类似于长事务的情况,出现的情况下,它正好去查了,然后会把这种 连带的,在这过程当中会把这些搜口语句给记录下来,有条件的话就可以在生产库上去去看一下到底是不是真的慢。 然后其次的话就是就是会用这个 explain 吧,来去看一下 circle 语句它的一个执行计划, 然后来分析当前缩影的一个使用情况。除了这些的话也需要考虑,因为您刚刚说到较长时间的这种停顿嘛,也有可能是这种数据库连接池,这种连接资源,资源紧张的这种情况。在 ok 数据中间线有用过吧?啊?用过哪几款?除了 roky 其他都用过。 嗯,我看看为什么能能能达到百万级的这样一个性能比其他消息中间件快那么多,原因是什么? 官方的介绍,他自己的定位,他并不是一个消息中间件产品,是一个流势处理的一个框架定位,他已经发生变化,基于这种 topic 加多分区这种形式吧,他可以将一个主题关联成划分成多个这种 partition, 那 partition 多了之后它所能够同时处理的这个数据量号称是这个百万病发嘛?它外界是依赖这个组 keeper 来去保证它的一个因本身组 keeper 是 一个 c p 系统来去保证它整个卡夫卡在运行过程当中这种悬浮呀,它的一个稳定性。还有的话就是分区嘛,分区它也有这种储藏嘛? 啊,主存的话也有这种 i s r 分 区,还有这个普通分区分区多副本的这种形式,保证它这个选举的一个过程,它的一个效率问题。还有一个的话就是消费者这块他们设计的也不是, 也跟其他的不一样,它是以通过这种消费者组的方式啊来去进行这个消息消费的,这样就可以提高这个消息消费这面的一个吞吐量的一个处理吧。那 ok, 如果现场我这使用了看不看?嗯,呃, 之前正常运行的突然会发生的数据的一个堆积,那这个时候呢?堆积已经影响了我正常业务的运转。嗯,那比较着急的一个时候。 嗯,那个我现在需要去解决这个问题。没有呢?或者生产者那边的话可以通过这种限流吧,然后像消费者这一块的话,去增加消费者的这个组的这个数量,来去提高它的一个病发 消费能力队列这一块的话就可以适当去调它的一个分区的这个数量。还有一个的话就是那个在确保消息可信呢?有一个 ack 嘛?就是他把那个 ack 设置为 s r 副本 确认同步,不需要等到所有的副本全同步。刚刚说到这个生产者这块限流的话,比如说采用这种呃令牌桶这种方式,入口这边就基本上就可以保证了吧?差不多这些, ok。
731面试小达达 03:14查看AI文稿AI文稿
03:14查看AI文稿AI文稿我们直接开始第一课,第一课共有八个知识点,都非常简单,首先是第一点,这一点啊,背就完事了,请大家暂停一下,背下这两段代码。 考试的时候,只要遇见编程题,我们都先把这个开头给他写上,再把这个结尾给他写上,这样就能拿几分。 好,这就是第一点。接着是第二点,更简单,都不用背。在扎瓦程序里,除了固定的开头和结尾外,在中间部分里,我们经常能看到类似他们这样的涉及计算的语句,相信大家都能明白这几条语句的意思。 比如他是让 a 等于九,他是让 b 等于 a 加八,他是让 c 等于 a 减七,他是让 d 等于 a 乘以六,他是让 e 等于 a 除以五, 他是让 f 等于 hb 的余数。大家能读懂这些语句,也会使用这些语句就可以了。可能有个别同学对取余有些陌生,取余的算法是他,我们给大家举了两个小例子,不会的同学可以暂停一下,结合例子一看就懂,这里就不啰嗦了。 好,这就是第二点,大家注意,每条语句后面都有分号,不要一漏就可以了。 接着我们学第三点,我们看一下这些语句。在这些语句里,我们用到了变量 a, 变量 b, 变量 c、 d、 e、 f。 其实啊,这些变量在扎瓦里是不能直接拿出来用的,要想使用变量,我们必须先用这些单词开头的语句对变量进行定义。我们需要先在前面定义 a, 后面才能使用 a, 先在前面定义 b, 后面才能使用 b, 以此类推定义 c、 d、 e、 f, 后面才能使用 c、 d、 e、 f。 如何进行定义呢?最常见的方法就和这几条例子一样。 具体点说,就是通过在开头使用这些单词中的一个来定义要使用的变量。比如这一行在开头写上一个 int, 后面写上这一堆东西。它的意思是说,定义 abc 均为 int 型变量,同时顺便让 a 等于五, c 等于二。 int 定义的变量特点是整数。 这一行在开头写上一个 double, 后面写上这一堆东西,它的意思是说,定义 a 二 b 二均为 double 型变量,同时顺便让 a 二等于二十点二三三。 double 定义的变量特点是可以有小数这一行, 再开头写上一个叉,后面写成这一堆东西。它的意思是说,定义第三易均为叉形变量,同时顺便让第三等于大写字母 a。 叉定义的变量特点是只能包含单个字符。 这一行在开头写上一个 string, 后面写上这一堆东西,它的意思是说,定义意思 f 均为 string 型变量,同时顺便让意思等于必过。 string 定义的变量特点是可以有多个字符。
665慕课期末加油站 02:44查看AI文稿AI文稿
02:44查看AI文稿AI文稿我问你啊,给你一个百万行的 excel 文件,怎么高效稳定的去导入数据库?当你听到这个问题的时候,如果第一反应是用 p、 u i 这些工具来 读出来,然后一条一条的音色,那么你可能正在掉入一个导致内存溢出、数据库崩溃任务跑一整天的天坑。这不仅是考在 java 基础的 api 使用,更是一场对大数据的处理能力、工程化思维和系统稳定性设计的一个综合考验。今天我带你从零去 构建一个能扛住百万数据,保证数据一次性的企业级 excel 导入方案。对于这个问题,我们面临的挑战有五个,第一,如果把整个 excel 文件加载到内存,一个百万行的 excel 文件轻松占用数百兆甚至是上 g b 的 一个内存,直接可能会导致 o m 问题。 第二个,导入耗时的时间等于文件解析耗时,加上数据库写入耗时。如果是串行处理,单线成竹条插入,假设每秒插入一百条 一百万数据可能需要三个小时时间,而且数据连接池可能会被耗尽。如果你担心简历上的东西讲不出来,我已经把面试经常问到的一些技术站场景题都整理在两百万字的面试文档了,里面针对每个知识点都有很详细的解析思路,只要你是我的粉丝,留言六六六就可以打包带走。第三,导入过程中中途失败了怎么办? 是全部回滚还是部分回滚呢?如何保证不出现重复数据呢?第四个,如果 excel 数据本身的格式有问题,比如说日期格式错误、字符串超长、业务逻辑处理冲突等等,那程序如何优雅地去处理这些非直接的崩溃呢?第五个,导入任务动辄运行几十 分钟,用户无法感知到进度,也无法在失败之后快速定位问题,所以针对这些问题,我们需要全方位的考虑和解决。第一个工具选型,可以用 excel 使用简单,内容控制更稳定,非常适合海量数据。第二个,把文件分编,比如按照 shift 或者按域读的行范围,由不同的县城并行 解析。然后呢,使用生产者和消费者的模型解析县城,作为生产者,把数据快放入到有界组织队列,一组消费者的链子里,取出数据进行一个批量入库, 同时确保数据库连接池的最大连接数足以支撑你的并发写入限速,避免线层因为获取不到连接而产生等待。第三,导入任务应该提交到限层值,一步执行,立刻返回一个 test id 前端,在后续可以通过 test id 来去轮询后端获取导入进度成功或者失败的记录,这解决了用户体 验的问题。第四,对于超大数据量或者系统解偶的需求,可以将解析后的数据先发送到消息队列,然后由独立的消费者服务 来去消费入库,这样上传解析服务和入库服务完全隔离,抗压能力和可扩展性更强。最后,对于事物的处理,我们可以按照一个批次一个失误,失败以后回滚当前批次,并记录后续从事或者补偿。以上就是这个问题的分 析,我是麦关注,我每天收获一个加我硬核干货,如果内容对你有帮助,记得点赞收藏,我们下期再见!
 04:46查看AI文稿AI文稿
04:46查看AI文稿AI文稿面试官问,如何处理百万级 excel 数据的导入?在 java 开发中, excel 数据导入是常见的需求,但面对百万级数据规模时,传统导入方式会暴露一系列致命的问题。首先是内存溢出, o o m 一 次性加载全量 excel 数据到内存,即便根本无法承载, 直接就会崩溃。其次是超时等待,同步处理模式下没有分页异步机制,用户上传文件后页面常见,处于加载状态,提 体验极差。再次是数据丢失,导入中途一旦失败,因为缺乏数据回归与重试机制,以导入的数据无法恢复前预操作全部白费。再者是格式错乱,影响你的日期,会自动转成数字,长数字还会显示成科学计数法,导致导入的数据格式不符合业务要求。最后是性能低下,单条数据插入数据库会引发频繁 i o, 哪怕只有几万条数据导入场景。这些问题在电商、 erp、 c r m 应用等需批量导入数据的系统中尤为突出,成为资源系统规模化应用的关键瓶颈。这些导入问题产生有明确的根源,首先是内存溢出,根源在于传统 r 八级矿工工具会将 excel 全量数据加载到内存,百万问题数据下内存占用飙升至几百兆,直接超出 gps 对 内存限制。其次是超时问题, 原语,同步处理模式下,数据解析校业插入全程堵塞主线层,且无分页分批式机制,单次处理数据量过大导致响应超时。再次是数据丢失,核心原因是缺乏事物管理与 批次化处理逻辑,导致中途失败时无法回滚,以插入数据也没有失败数据记录与重置机制。再者是格式错乱问题出在未针对日期、 数字等特殊数据类型做专门格式化处理,仅依赖 e c r 默认解析规则。最后是性能低下,本质是单条数据插入数据库,引发 i o 频繁且同步处理,未充分利用 cpu 与 i o 资源,缺少批处理优化手段。针对上述导问题所 首先在技术选型上精准匹配场景需求,选用阿里的 e z e c r 替代 ipad point, 利用流式解析特性转换处理数据,从根本上控制内存占用。借用 my blade plus 批量插入能力,提升数据库操作效率。通过 h o t r 简化日期格式化数据调研等工具,调用 swagger 辅助导入接口调试核心流程设计遵循分而治之加流式处理思路。导入流程分为上传文件转换提取、数据调研、批 次积累、批量插入进度反馈。其中文件上传支持大文件分片上传,避免单次请求超时。主款读取通过 e z excel 的 专属鉴定器,主款解疑数据不换成全量数据,大幅降低内存占用数据焦虑,缓解过滤弊点向缺失格式错误、 重复无效数据。每积累一千条有效数据,触发一次批量插入,平衡 i o 效率与内存占用,同时实时返回已处理条数成功率剩余时间,提升用户体验。性能优化从多维度展开,固定一千条批量插入大小,避免批次过小导致 i o 频繁或批次过大,占用内存为数 据库查询插入至五百一十二兆,最大值一千零二十四兆,使用记忆垃圾收集器记忆, 一步控制内存占用未验证白安吉 excel 数据导入的解决方案的有效期,开展了专项测试。核心验证结果显示,白安吉数据导入处理耗时约二十八秒,内存分子控制在三百八十兆,数据成功率达百分之九十九点五。小体量数据一万条、 十万条、五十万条,导入耗时分别为一点二秒、六点五秒、十五秒,内存分子均未超过二百五十兆,成功率均在百分之九十九点八以上。整体验证结论为,采用 e z excel 加多线层加 p 处理加异步处理的组合方案,可稳定自身百万级 e c r 数据导入内存占用始终控制在四百兆以内,处理耗时均在三十秒以内,成功率超过百分之九十九点五,完全满足生存环境的性能和稳定性要求。 从面试角度来看,该百万级 e c r 数据导入方案的核心亮点在于放弃传统的 apache palm, 选用 e z e c r 流式解析特性,解决了大文件导入内存溢出问题, 这是方案的核心优势。通过批处理封面上传,将百万级数据拆分为小批次处理,将你单次导入压力,结合事物管理失败重置机制,保证导入数据的完整性。通过实时进度反馈优化用户体 验,面试加分点体验的能精准定位,穿透 excel 导入的核心痛点,并给出针对性解决方案。轻易尝试 excel 相较于 party poin 的 选型和理性考虑,事物一 场处理等生产环境关键诉求,体现工程化思维,从数据拆分、资源调度、底层调优层面展开优化,展现完整逻辑。该范可广泛应用于电商商品批量导入、 e r p。 员工信息导入、 c r m。 客户数据导入、教育学生成绩导入、金融交易记录导入等场景 处理。百万级 e c l。 数据导入的核心在于通过 e z e c l。 流利上传一步处理,提升导入效率,结合完善交易事务反馈机制,实现稳定高效、大规模数据导入。 刷题面试不用慌,发古文宝典,进群免费领!谢谢观看,关注我,求知不迷路!
167小Q每日八股 02:09查看AI文稿AI文稿
02:09查看AI文稿AI文稿说一下这个 clik 语句,它在 micro 里面的一个执行流程吧。啊,好,就史莱克语句,它首先会查询缓存,就如果缓存里面有,就直接返回, 如果没有,就继续执行,生成一个执行计划,最后就由这个存储引擎按照这个执行计划去读取数据。嗯,你 提到了这个缓存和执行计划,方向是对的,不过这个流程其实可以拆的更细一些,也更容易在面试中体现你的个系统性思维。我帮你捋一捋整个 c 的 一个执行过程呢,其实是可以清晰的划分为六个关键的阶段。第一是连接器, 很多人会忽略这一步,但它其实是在所有 circle 执行的一个起点,这个环节会验证你的个用户名密码,还要检查你对目标数据库有没有访问权限。第二,查询缓存,你刚才提到了这点很好,但要补充一个重要的一个变更,从 mc 八点零开 开始查询,缓存功能已经被彻底移除了。为什么呢?因为在高兵法写多读少的一个场景下,缓存命中率极低,而且每次写操作都要清空相关缓存,维护成本反而成了性能的瓶颈。 三、分析器,检查你的一个思考,它是否符合语法规则,比如关键字有没有拼错,括号是否匹配,表明字段是否存在等等。如果通过了检查,分析器就会生成一棵解析树,你可以理解为思考的一个语法骨架,这棵树结构后续会被优化器和执行器反复使用,是整个执行流程的一个语义基础。 四、优化器,这是性能的关键啊,它决定用哪个锁影多表,捉影顺序是否用临时表?比如先过滤小表再关联,能大幅减少中间的一个数据量。第五,执行器按优化器的一个计划调用存储引擎 提取数据,如果走锁影,就通过 b 加数定位数据页,如果是全表扫描,就顺序提取数据块。第六,返回结果。把查到的个数据分批分装为网络包发给客户端,结果极太大时还会流逝返回,避免内存溢出。如果能把整个链路串起来,尤其是强调优化器的一个决策作用, a server 与引擎 那个协助机制就能展现出更强那个底层理解力理解了吗?嗯,好。最后视频配套的面试题答案都整理在评论区了。另外,如果近期面试受阻,没有面试机会,我们也有面试突击陪跑服务,可以私我咨询。从简历优化、项目包装、技术突击、面试、突击、项目业务难点亮点梳理、模拟面试、面试复盘并向内推等。
 15:06查看AI文稿AI文稿
15:06查看AI文稿AI文稿嗯,大家好,今天我们就来讲一下一条马斯,呃,一条思考语句,它是在马斯口中它的具体执行流程是什么样?呃,比方说我们现在有一个 psych 语句,比如说 psych 信 from you, the well, you the id 点 e, 它的一个详细的执行流程是什么呢?首先它你在客户端写了这条思考语句, 客户端指的就是比如说你用的 never kaid, 或者说等等等等。一些客户端 在客户端写了这条 circle 语句以后,你点击执行。首先这个客户端它会和 service 层就是 my circle 中的 service 层中的连接器进行连接,也就是说,呃,下面这下面这些就是都属于是 service 层的。 然后它你客户端先和这个连接器进行这个 service 层的连接器, 三维层的连接器。先去判断啊你这个用户账号密码是否正确,判断一下你这个是否有这个权限,如果说账号密码和权限都对的话,就你可以建立这个连接。建立了这个连接以后,它会先会去查询缓存,就是看看你这个 recook 语句, 假如说,嗯,这个 cx 区完全相同,并且这个表没有被修改过,然后就可以从缓存中取到相应的数据,然后直接返回,不用进后面这只步骤。但是这个缓存,嗯,它这个效果并并不是很好,因为它维护起来比较困难, 并且它的效果也不是很好,所以说在 mesico 八以后就已经废除了,就是废除了这个查询缓存的步骤,然后假如说,嗯,连接以后,然后就开始进行解析,解析器就是对你这个 select 语句,呃,对你这个 circle 语句, 呃进行词法分析和语法分析,也就说这个解析器又分为词法分析,词法分析就是分,嗯,还有语法分析, 词法分析就是分析,分析你这个词,就是分析一下你你的 sql 语句中有没有拼写错误,比如说你这个 sql 拼写错了,你少写了,少拼了一个 e, 然后就会从这个这个阶段就会发现你这个 sql 这个拼写错误。而语法分析呢,就是分析一下你这个 呃 sql 语句中有没有语法错误,比如说你这个 from 没有写 from 啊,或者说你这个呃表表明写错地方等等等,就是分析下有没有语法错误,假如说都没有错误的话,它就会交,然后就会再进入下一步,就是预处理器,然后在这个预处理器这个阶段 去分析一下你这个 sql 语句它这个表存不存在,就是你这个表呃是否在那个数据库中存在,并且它也会进行那个 呃型号的展开,然后他把这个型号展开成具体的字段名啊等等,就是先判断一下表字段是否存在,假如说呃存在的话,不存在的话就返回错误嘛,然后如果存在的话就进入下一个阶段进优化期,优化期就是非常一个关键的阶段,在优化期里我们做什么呢?在这个优化期里面,我们对这个词汇语句, 嗯,咳,就是生成一个执行计划,具体,嗯,就是我们这 circle 语句具体要怎么样去执行呢?比如说我们要用到哪个缩影,比如说缩影用到哪个缩影?还有呃,如果是多表查询的话,就是多表 句号的时候先查哪个 表,然后还有呢? 啊?还有就是,嗯,会不会把紫查询转换成卷?就是把紫查询,把紫查询转换成卷,然后就是这就是在这个优化期这个阶段来进行, 就是来决定具体要怎么样去执行这个代码,就用那个缩影去优化一下,让它的效率性更高。比如说缩影的话,它有那么多缩影,然后用哪个?然后要不要用缩影等等。比如说有有,如果说数据库的数据量比较小的话,它有时候就是不用缩影嘛,不用缩影会更快一点,所以说, 嗯,这这这都是这些操作都是在优化器这个阶段进行处理的啊。优化器,呃,处理完之后它就会生成一个执行计划,然后它就会生成一个执行计划, 他生成了这个执行计划以后生成了一个这个优化机会,生成一个执行计划,生成一个执行计划以后,他就会把这个执行计划交给这个执行器, 然后由这个执行器由这个执行器来具体的去执行, 然后这个执行器它具体怎么执行呢?因为啊马斯克中它分为三个层次嘛,有客户端层、 service 层,还有存储引擎层,也就是说 service 层是服务层,它并不进行具体的那个数据层的那个存储, 然后这个执行器它它就是用来它调取这个存储引擎中的相应的接口,比如说它调这个存储引擎的接口,然后让它去返回具体的数据,让它去执行具体的,呃,去那个词盘中查呀,然后等等 让他来进行具体的查询,然后最后再将结果返回给,就将查询的结果返回给那个设备层,然后来就将结果返回给设备层来让设备层进行后续的,比如说嗯, 比如说一些外条件的过滤等等等等,然后这就是嗯,然后这里就会有个点,就是所以下推,然后这里有一个点是所以下推的, 所以下推,然后如果呃这个呃这个我们待会呃,等下一节再讲。我们现在先先把这个点记下来,然后就是说正常所以下呃,先大致说一下所以下推什么意思吧,所以下推,就是假如说我们这个 y 条件有两个啊,比如说 and 啊 e 等于十, 然后它,然后,然后我们有一个这个 user id 和 age 这个缩影嘛,建了,建了一个这样的联合缩影,然后我们在 service 层进行查询的时候,它只会呃,它在调用存储引擎,假如说没有缩影下推的技术的时候,它在调用存储引擎的时候只会呃,只会 只会说就 sql 用的 y user id 等于多少,然后也就说它调用的时候它执行的是这个,然后等它把存储引擎返回来的结果以后返回来的结果再在 server 层进行过滤,就是过滤一下 a 级等于十是多少, 然后呃过滤,再把最后的结果返回给可断,然后有了缩进一下。对技术的话,我们就是呃在存储引擎层就直接进行 y 条件的过滤,就是不,不仅我们直接用了 y 对 应 id 等于 g, 还直接在水清层啊,就直接来判断这个 a 几是否等于十,然后就不会再不再交给三维层进行啊,那个外过滤了,就会提升那个效率,避免避避,避免一些回表等等等等,然后这个等,嗯 嗯,那下一次,然后详细讲一下,然后最后就返回结果嘛?返回结果返回给,嗯,然后这个是这个 sql 语句的执行过程,大概是这样,但是这个 sql 语句它是一个呃查询的嘛?查询的是一个比较简单的,假如说我们有一个是更新的一些操作,比如说 update, 比如说有个 update 的 语句,或者说一个 delete 语句 啊,或者 insert 嘛,啊,这就是对数据进行更改的一些呃 sql 语句啊,它如果在进行这些数据的话,那么那么它的流程,其实前面这些流程是和呃进行这个 slack 语句是相同的,它主要不同,主要是在这个存储引擎层,存储引擎层就是来管具体的, 嗯,具体的那个数据的存储嘛,然后在 my sql 中它就是 node db 嘛, 比如说在 microsoft 中,它这个存储引擎就是挪地币嘛。然后假如说我们以一个 update 的 语句子为例吧,假如说我们来执行一个 update 的 语句,然后它先会和前面流程一样进行这个客户端,然后进行连接,然后解析预处理器、优化器、执行器,然后最后 到了这个存储引擎层,到存储引擎层以后,它在执行具体的更新操作之前,它先会它先,嗯,它先会在安都 log 中, 他先会在安都 log 中。呃,呃,记录一下就是修改修改前的值,就是记录修改前的值,因为为什么要记录修改前的值呢?因为呃避免就是呃, 如果说这个事务失败了吗?失败的话不就要回退吗?然后所以说要记录一下修改前的值,然后同时这个安卓 log 也会用于那个呃, mvcc 啊,就是那个动漫们控制的时候进行快照读的时候 也会用到这个安卓 log, 然后这个 mvcc, 然后我以前的视频有讲过,如果说大家有呃有想了解的话,可以去看前面的视频,然后这是安卓 log, 然后记录修改前的值,记录一安卓 log 以后再去记录 real log 啊。 redo log 里面呢?就是我们在呃在 update 的 这,嗯,记录修改前的值之后我们去去 redo log, 这 redo log 是 干嘛的? redo log 就是 记录修改的记录修改的操作, 因为,呃为什么要记录修改的操作呢?就是我们 因为在写词盘的时候是比较慢的嘛,然后如果说我们要等那个写词盘写完以后再返回结果的话,那么就效率比较低嘛。所以说在数据库中就是他先会把那个修改的操作,比如说 update 的 语句,他具体的操作先记录到这个 redo log 里面,然后后续的话再再新开一个进程或者什么样,然后让再去慢慢的把这个数据更新写到词盘中,比如说他会先写个 redo log 啊,然后, 然后,嗯,然后再写完了 redo log 以后还会再写一个 blog, 这个 blog 里面也是记录的修改的操作, 但是它和 redo log 有 个区别,就是 redo log 中记记录的修改的操作,它直接记的是嗯,表中。假如说, 比如说这个 redo log, 它里面直接记录的就是对哪一页进行了哪样的修改,就比如说它,比如说我们进行了一个 update 语句,然后它这个 log 里面记得,比如说它可能就会记一个配记十三,然后 offset, 然后五十四三十五吧,然后它记录就是把这个 value, 然后十改成了, 改成了五吧,也就是说它记录的是对哪一页的哪一个哪一行,哪对哪一个页的哪个数据进行了修改,然后它就是和 circle 无关的,然后它就是不管什么,它就与 circle 无关嘛,它并没有记这个具体的 circle 语句,而这个 vlog 呢? 啊,这个 vlog 呢,它它不仅它记录的修改操作,它是 circle 有 关,它并不是直接记录对哪一页进行哪页修改,它记录的是 啊,他记录是对哪张表的哪个字段进行修改,比如说他对 table user, 然后 id 等于二十,然后把他的 a 级,然后从 a 级从十改到了十五, 它这样的你会发现它们两个不同,一个就是直接记录了对哪对哪一页进行哪一页修改,而这一个是记录了呃对表中的哪一个段落进行修改。它们为什么会有这样的区别呢?因为这个 root log 它是用于啊档机档机重启的,就比如说,呃,你, 你服务器突然宕机了,然后你就可以从这个 redo log 里面,然后来进行快速的进行呃数据的恢复嘛。然后而这个 b log 呢,它是用来进行主存复制的,就是说它要呃让别的, 就说如果 log 他 是让别人,他是最容易主动复制的,他的作用是他的目的是如何让别人来复制我的操作,就让别人来复制我的操作。而 log 呢,他是如何让在到机后如何恢复,就在自己自己这这自己这个机器上如何恢复自己以前的那些操作。 然后就是相当于是一个是对内的,一个是对外的,然后两两者虽然说都是记录修改操作,他们记录的方式不一样,然后目的也不一样,这两个是不同的。 然后这里有一个两阶段提交,也就是你在执行这个 update 的 语句,在写完路由 log, 写完路由 log, 写完路由 log 的 时候,它会先处于一个 prepare 阶段, 也就是准备阶段,因为因为你这个路由 log 并 log, 它记录的都是修改的操作嘛,只不过一个是用于这个本实力本机器那个档期回复的,一个是用于主动复制的,所以说它们两个需要是,呃,就是需要, 需要同,可以理解成同时成功或者同时失败吧,比如说他们两个是一体,你可以理解成他们俩同时成功同失败吧。所以说,呃, 你这个 red log 写完以后,它就会处于一个 prepare 的 阶段,也就是说我这个事务的我这个修改的操作,这个事务已经已经可以提交了,就已经修改完了,可以提交了。然后就是准备提交嘛,然后这 blog 呢? blog, 然后接下来写 blog, 当这个 blog 写完以后,它会 给这个 vlog, 然后这个 vlog, 呃, vlog 写完以后,然后他,嗯, 然后他就是把这他的修改操作记录下来,然后刷到此盘中,然后就会当刷到此盘中,就说明,嗯,主库已经写好了嘛,就可以从库,从库就可以读这个 vlog 去读那个修改的操作了嘛。然后 那么既然你都可以对外公布了,那么就说明这个事务肯定是已经提交了嘛,呃,就可以提交了,所以说这时候再把这个事务提交成 commit 阶段, commit, 然后这个事务才算真正的提交,也就是说 vlog 记录, 嗯, vlog 就是 记录的是对哪一页进行哪一个操作啊? blog 就是 对哪记录,是对哪张表的那个字段进行了什么样的操作,然后 blog 是 对外的, 这个就是。然后,嗯,当这个事物 commit 的 时候,就说明这个事物已经执行完成了嘛,然后就可以进行提交了。然后这个就是。好,这这个这里还有个点,就是主重复制,这个点 主存复制,然后等后面再再讲一下这两点,做一下对和主存复制的一些知识吧。好到这里。
30想养小狗狗🐶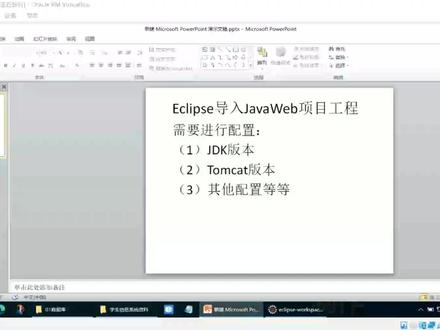 09:45查看AI文稿AI文稿
09:45查看AI文稿AI文稿大家好,这里是道哥小课堂,很多同学使用我们的 aicores 软件进行加娃娃的开发, 有些时候可能会把别人的一些加外外的项目工程 拿到我们自电脑里面进行一个进一步的一些查阅和开发,这个时候一般都会把我们这些拿到手的项目工程啊直接导入到我们的 excel 软件中去, 但是刚开始的时候我们并不知道他这个项目工程呃相关的一些版本 的配置和一些软件设置,所以直接导入之后可能会出现一连串的相关的错误。 那么这个时候呢,同学们一定要注意,当我们需要导入别人的项目工程进入我们自己的工作间的时候呢,有一些配置还是要先进行操作的, 比如讲,因为导入的项目在原来的系统中,他的 gdk 的版本 和我们现在导入之后的版本不一定一致,他们看软件的版本也不一定一致, 所以呢大家在导入别人的项目工程的时候,首先要在导入之后 手动设置一下这个项目工程的 gdk 的版本和他们的版本是我们制止电脑,制止系统里面对应的版本,这样就会讲大部分的一些问题给解决掉,就不会出现一连串的错误。 好,那么现在呃大家跟我们一起来看一下这个设置的步骤。 首先我们拿到一个项目工程这个学生信息管理系统的啊,那么这是一个项目工 跟目录,下面呢是我们一颗粒鼠软件的这个相应的结构目录,我们打开一颗粒鼠软件,然后呢点击快把它导进来, 点击目录文件夹,选择我们桌面 学生信息管理系统啊,选择他这个跟目录啊,大家双击不要双击打开进入这里面进这个这个选择,我们选择上面的这个呃,跟目录就可以了,然后点击选择文件夹, 然后点击完成,这是我们导入别人的项目工程的时候的一些步骤,那么这个时候呢,同学们会发现啊,就已经出现了很多 一些错误了,对吧? 好,那么当我们导入别人的项目工程之后呢,同学们就要得先设置一下,把他这个项目啊, 相应的变异环境改成我们系统一致的啊,把 gdk 和汤姆克的版本都调制好, 怎么做呢?我们首先鼠标点击我们这个项目工程的文件夹,然后右键, 然后我们选择变异路径,配置变异路径, 在弹出的对话框中我们选择 like you, 然后在这里面呢,同学们可以把一些已经出现差的内容把它领悟掉啊,领悟我们掉。同时呢 也要看一下啊,这里面的 jd k 和 tomk, 同学们也可以把它铃木掉, 都把它铃木掉,就是把别人是从原来的这个这个库环境啊,把它铃木掉, 那么你把别人的删掉之后了,我们要自己添加对应的 gdk 和他们开的版本,我们点击这个啊, 选择 jr 一找到这一项,点击下一步添加我们当前系统的 jdk, 点完成, 然后第二个再点加这个添加库,选择我们的 sorry 轮胎点,下一步选择当前我们系统的阿帕奇版本啊, tomk 版本, 我们这里的是八点五点完成,然后点应用, 这样绝大部分的情况下倒进来的这个项目工程就会和我们失统已经配置好的 gdk 和这个他们开的版本呢就一致了, 就能利用到我们当前系统的一些这个环境来进行操作。但是做完这一步骤之后, 可能很多同学还会遇到其他的一些问题,比如说我们 点击这个要运行的文件夹右键之后,他没有任 x 这样的一个右键菜单, 还有有些同学点击新建按钮,他没有塞外烂等等选项的添加。 所以呢,接下来同学们还可以进一步的进行一个配置,那就是在我们这个边域路径对话框里面啊,同学们再打开 下面的目标运行时,他给轮胎是 大家看一下啊,这里面他默认选择的是他们 k 七点零,但是我们系统里面是没有装七点零的,什么意思?这是七点零是 这个这个项目工程原来变异的一个环境,放到我们这里面呢,他就没有制定零,所以这个时候他在这个目标运行行动里面把它 选中的,把它取消,保证适合我们系统安装好的这个他们开的版本是一致的,把它选中啊,把它选中,然后呢点应用。 这第二个还有一个呢,就是同学们点击这个 prog f 飞雪时,这里 在这里面呢,有些时候同学们这里面都是空白的啊,都是空白的,所以呢,同学们要留意你这里面的项目啊,如果出现右键新建的时候,这个按钮是没有收, 那么同学们要至少要选中三样东西,一个呢是动态网站模块,这个要选中,第二个加把要选中, 加法要选中,还有要留意他的版本啊,留意他的版本,我们这里的版本呢是十一,对不对?所以呢,大家稍微的去改一改啊,先改还有一项呢,就是这个 xox 这一项也要选中,至少要选中这三项, 然后点应用,然后点应用, 然后应用并关闭。 那么一般选择这几项操作之后,大部分的项目呢,都是会能正常的使用和运行。 好了呃,我们今天关于这个导入加拿大相关项目的一些配置,就说到这里, 谢谢大家的观看。
167非常道 01:32查看AI文稿AI文稿
01:32查看AI文稿AI文稿micro 的 事务隔离级别为啥默认使用可重复读?用读语提交不是更高效吗?可重复读到底像在哪?面试的时候遇到这个问题,你会怎么回答 啊?这个得从 blog 说起, micro 的 主重复制靠的是 blog 同步,而 blog 有 几种格式,在 micro 五点七点七之前,默认使用的是 statement 的 格式, 记录的是执行语句本身。在这种格式下,如果是用读已提交,这种事务隔离级别可能会出现什么情况?一个 update 语句在事务里面执行, 因为读已提交能看到别的事务新提交的数据,就会导致主库和重库执行的结果不一样。主库数据不一致,这生产环境绝对不能容忍的。 所以 microcode 把默认的级别定为可重复读,配合间隙锁机制,在 statement 的 格式下保证主重执行结果完全一致。这是从架构层面做的一个权衡,牺牲一点病发性能,换取数据的一致性。当然, 随着 micro 的 升级,在五点七点七之后, blog 默认使用的是入格式,也就是记录行的变更。读已提交在 micro 里面也安全了很多,大厂在高频发的场景下,反而主动改为读已提交,减少间隙所带来的所冲突。 所以你看 my circle, 选择可重复读不是因为它最严格,而是因为它和并 log 日制的历史绑定关系。每个技术的选择背后都有一套完整的架构逻辑。你在生产环境用的是 r r 还是 rc? 踩过建议锁的哪些坑?评论区聊聊,我是阿古,下期见。
137阿古在进步(Java版) 03:29查看AI文稿AI文稿
03:29查看AI文稿AI文稿今天我们讲解一道 my sql 的 高频面试题,就是 my sql 的 逻辑架构。很多面试官都特别喜欢问, 能不能讲讲 my sql 的 逻辑架构,大家遇到这个问题千万别慌,面试官其实不是想刁难你,主要是想看看你对数据库有没有一个宏观的认识,而不是每天只会盲目的写,增删改查。所以放轻松,这背后的逻辑其实特别有意思,也很好记,开始之前别忘了关注点赞哦。 想要搞懂 sql 的 架构,大家只需要记住四个字,脑手分离。这是什么意思呢?也就是说, sql 把处理逻辑的大脑和真正去存取数据的手完全拆分开了。我们可以把 sql 想象成一家运转高效的大公司,咱们可以把它上下拆解成两层来看,上面那一层叫做 server 层, 它就是公司的管理层,也就是 mycoco 的 大脑,所有跨部门的统筹规划工作都在这里完成。当你把一条 coco 语句发过去的时候,它首先会遇到连接器,连接器就像是公司的前台保安,它要核对你的身份,看看你有没有权限进这道门。进门之后,语句就交给了分析器。 分析器是个翻译官,它会把你的 coco 语句一个词一个词的拆解开,看看你到底想干嘛,顺便严格检查一下你有没有写错别字或者语法错误, 确认语句没问题了。接下来就到了核心部门,也就是优化器,这里是公司的战略规划部,他会飞速运转大脑,决定你的这条指令怎么执行才是最快的。比如他会决定走哪个缩影或者多张表,关联的时候先查谁后查谁,最后他会拿出一份非常详细的执行计划, 有了计划,执行器就登场了。执行器自己是不干搬砖这种体力活的,他会去调用底层的接口拿数据。 那么这个底层是谁呢?就是咱们要说的第二层存储引擎层,他就是真正去仓库搬砖的工人,专门负责和文件系统打交道。 到了这一层,工人们根本不关心你的 coco 语法写的有多花哨,他们只关心一件事,就是怎么把数据稳妥的写到磁盘上,或者怎么快速的把数据读进内存里。说到这里,你可能会觉得 好像也没什么特别的,那你就低估它了。买 c 口最牛的地方就在于它的存储引擎是插件式的架构,这就意味着你可以根据业务需求随时更换工人。如果你需要支持事务,还要行机锁,那就请 innooper 这位工人出马,这也是现在的默认首选。 如果你只要读写速度快,根本不需要事务,那你可以换成 my sm。 要是你想把数据全放在内存里,体验飞一样的感觉,那就直接用 memory 引擎。 那么大脑和工人是怎么配合的呢? server 层通过一套统一的标准接口和存储引擎沟通,所以管理层根本不需要知道底下到底是哪个工人在干活,直接下达标准指令就能拿到想要的数据。 接口隔离设计的非常巧妙,那咱们把核心逻辑理顺了之后,我再顺势给大家抛一个面试官爱问的连环追问那批,你讲完可能会接着问,既然优化器这么聪明,那他每次选的锁影都是对的吗? 这时候你就可以自信的回答并不总是对的,有时候底层的统计信息没有及时更新,优化器也会产生误判,选错锁瘾,咱们咱们是可以通过指令来强制纠正它的。 好了,买 c 口的架构咱们今天就聊到这里,大家在准备秋招或者春招的时候,多把这些底层概念在脑子里过几遍,面试的时候就像聊天一样自然的讲出来,绝对能给面试官留下非常好的印象。祝大家找工作顺利,拿到心仪的研发岗 offer, 加油!
3298小哲讲八股 03:25查看AI文稿AI文稿
03:25查看AI文稿AI文稿大家好,我是大树,今天我们来彻底吃透 myico 里最核心、最底层的机制。 w i l 预写日制,全称 right headlock, 很多同学知道它存在,但不清楚它到底解决什么问题, 底层怎么运转?为什么 myico 必须依赖它?接下来从零到一,讲透 word 核心思路,让你真正理解数据库的安全底线。首先,我们先想一个问题,数据库执行增删改操作时,数据是直接写到此盘文件里吗?如果直接写会发生什么? 我们的电脑硬盘,无论是机械硬盘还是固态硬盘,随机 i o 的 速度都是远远慢于内存的。如果每执行一条 insert、 update、 delete、 sql, 都立刻把数据刷到硬盘内,高病毒下,数据库会直接卡死,性能差到无法使用。而且更危险的是,如果写到一半突然宕机断电,数据就会损坏丢失,数据库再也无法恢复。这就是没有 w i l 时, 数据库面临的性能灾难和安全灾难。为了解决这个致命问题, mycoco 提出了 wol 预写日记。他的核心思路只有一句话,先写日记,再写词盘,所有修改先记录到日记里, 不着急更新真实数据文件。这就像我们日常记账,先把收据快速记在临时小本子上,等空闲了再整理到大账本里, 而不是每花一笔钱就立刻翻大账本图改小本子,记录速度极快,大账本修改速度很慢, w a l 就是 数据库的临时小本子。 那 w a l 具体是怎么工作的?我们拆解三步核心流程。第一步,当用户执行一条更新语句, my sql 不 会直接修改词盘上的数据页,而是先把这次修改的内容写入 redo log, 重做日记。这一步是顺序 i o, 速度极快,写完就立刻告诉用户,执行成功。 第二步, my sql 在 内存里更新对应的数据页,保证后续查询能读到最新结果。第三步,等到数据库空闲日制写满,系统正常关闭时, 再批量把内存里的更新数据刷到硬盘的数据文件里,全程没有高频随机 i o, 性能直接提升百倍。这里大家要注意, wyl 里最关键的日制是 redog, 它是固定大小循环写入的文件,像一个环形队列,写满之后就从头开始覆盖旧日制,不会无限膨胀占用空间。正是因为 redo log 的 存在,哪怕 my sql 突然宕机,服务器断电重启后,数据库也能根据 redo log 里的记录,把没来得及刷到此盘的数据补回来,保证数据不丢失。 这就是数据库的崩溃安全能力。没有 w i l log 和 bin log, 这里我们用 w i l 核心思路区分一下, redo log 是 存储引擎层的日制,是 w i l 机制的核心,只负责崩溃恢复,是循环写入的。而 bin log 是 服务层的日制,负责数据备份,主从同步,是追加写入的。简单说, redo log 保证数据不丢, bin log 保证数据可追溯,两者配合,但只有 redo log 才是 w i l 的 真正在体。最后,我们总结 w i l 的 三大核心价值,这也是它能成为 my sql 基石的原因。第一, 极致提升写入性能,用顺序 i o t 带随机 i o 抗住高病发更新。第二,保障数据绝对安全,棒击断电不丢数据,实现崩溃恢复。第三,平衡内存与硬盘,让内存负责高速读写, 硬盘负责持久存储,最大化利用硬件效率。可以说没有 w a l 预写日值机制,就没有现在高性能、高可靠的 micro。
62程序员大树 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿卖 c 口锁瘾连环十八万,兄弟们是时候反击了!这些年被面试官用锁瘾场景题按在地上摩擦的还少吗?这条 c 口走不走锁瘾?为什么?这个走了那个不走?区别是啥?到底走哪个?一套组合拳下来,脑子还没转明白呢, over, 已经转给别人了。今天我就带你们把这些年的账一笔一笔算回来。第一刀,顺序不对,走不走? 面试官甩过来一条 c 口联合锁隐士,很多人一看,哎呦,顺序不对啊,不符合最左匹配啊,不走,兄弟你输了。答案是走,因为买 c 口的优化器,他不是傻子,他会自动给你调整条件顺序。调整完发现哦, abc 都齐了,最左匹配安排第二 刀,那这个呢?还是个联合锁隐?这次走不走?不走为啥?因为你压根没写 a, 最左前缀直接被跳过了,买 c 口想帮你都帮不了。就像你约饭说我和那个谁,人家问哪个谁,你说就那个谁 谁,鬼知道是谁。如果你也对这类题也答不上来的话,我这整理了能让大厂 h 二沉默的必考题目,覆盖了 jvm 夺命连环问、 spring 灵魂八谷 包并发必考场景 release 深度陷阱,点个赞,甩个 pdf 直接带走, nice! 第三刀,这两条有啥区别?联合锁影还是大家可以先暂停,想一想好公布答案。第一条要回表,第二条不用。为啥? 一条查了自断 a, 但 a 不 在个联合锁影里,所以得拿着锁影找到的主键再跑一趟主键锁影去拿 a, 这就是回表。第二条,只查 b 和 c。 巧了不是,这俩刚好在联合锁影里,锁影自己就把答案给你了,不用跑第二趟,这就是覆盖锁影,一个不用加钱,一个要加钱,你选哪个?第四道,那锁影到底怎么建?回到最开始那道题,条件是这样, 锁引怎么建?正确姿势或者位上。记住一句话,等值在前,范围在后。 a、 c、 d 都是等值条件,应该放前面,能快速过滤数据。 b 是 范围查询,要放最后,避免阻断后面的字段。等值条件可以直接通过锁引结构快速定位到第一个符合的数据,这一步就筛掉了大部分数据,然后再进行范围查询,这叫先精准打击,再范围扫荡。 第五刀,三个锁引, adx d, adx d a, d x e, id 深 c 口是走哪个? 答案不一定。从形式上看,三个锁影都满足,最左匹配理论上都能用,但实际执行时, myico 会评估成本,选一个最便宜的, 这个便宜主要看两样, i o 成本要读多少页, cpu 成本要比较多少次,谁便宜走谁。 myico 也是个过日子的人。最后送大家一句话,锁影面试题考的不是你会不会被最左匹配,是看你有没有真正理解 myico 是 怎么想的。 你以为你在答题,其实你在猜 mexico 的 心思,他会不会优化,他觉得哪个便宜他要不要回表猜对了, offer 到手,猜错了,出门左拐。兄弟们, mexico 锁影这块面试里真的太常考了,考法多,变形多,坑更多。但今天这一套组合拳打下来,下次面试官再拿锁影题,难为你,你就把这张图拍他脸上。来,咱俩聊聊成本评估。
893码力十足







