skyreels v4怎么安装
大家好,欢迎来到 skyreal 四教学系列,我是你们的 ai 教学助手。今天这集我们从零开始,带你全面了解 skyreal 四这个革命性的 ai 视频生成工具。 无论你是内容创作者、短视频运营,还是对 ai 视频感兴趣的新手, 这一集都会给你一个清晰的入门指南。准备好了吗?我们开始吧! skyrose v 四是由 skywork ai 开发的全球首个统一音视频生成模型, 二零二六年二月二十五日正式上线,目前在 artificial analysis 排行榜上排名第二。它最大的突破是什么?一句话,它能同时生成视频和音频,而且是天然同步的。 以前的 ai 视频工具只能生成无声画面,你需要另外找音效配乐, 再手动对齐 scratch v 四,直接把这个流程省掉了。 scarci 是 此有五大核心功能,第一,联合音视频生成, 输入一段文字描述,它同时输出一千零八十 p 三十二帧,最长十五秒的视频和匹配的音频。第二,多模态输入,支持文字、图片、视频片段遮罩和音频参考五种输入方式,可以灵活组合。 第三,统一编辑界面,生成修复、编辑三大任务在一个界面完成,不需要来回切换工具。第四,电影级画质,一千零八十 p 分 辨率,三十二帧率,画面流畅自然。第五,多镜头生成, 可以一次性生成风格统一的多组镜头,方便拼接成完整内容。让我们来看最基础的操作,文字生成视频 打开 sky rails 官网,注册账号后进入创作界面,在提示词框中输入你的场景描述,这里有个关键技巧, 用具体的动词来描述画面和声音。比如不要写一个下雨的场景, 而是写大雨敲打金属屋顶,雨滴溅起水花,远处传来雷声。越具体,生成效果越好。你还可以加入声音锚点, 比如古典在第三秒响起,帮助模型更好地同步映化。接下来是图片生成视频功能,上传一张静态图片,比如产品照片或场景截图。 skyros v 四会将其扩展为动态视频, 实色效果非常惊艳,它能保持原图的光影角度,添加自然的镜头运动。比如上传一张桌面照片,它会生成轻微的镜头漂移效果,阴影变化也很真实。 小技巧,如果第一次生成有物体变形,可以在提示词中加入,保持物体刚性来改善效果。 pos 盖如丝丝的编辑功能也很强大,它采用通道拼接技术,把修复、扩展、编辑统一在一个界面里。 你可以用遮罩选择视频中的特定区域进行修改,比如替换背景中的某个物体,或者修复画面中的瑕疵。最棒的是编辑时不会丢失上下文,不需要反复导出导入。最后给大家几条实用建议。 第一,十五秒时长限制其实是优势,它迫使你聚焦核心内容,非常适合短视频创作。第二,每次只做一个意图的修改,不要同时要求改运动、改色调、改时间。 第三,善用音频参考功能,上传一段参考音乐生成的视频,会自动匹配节奏。第四,先用低分辨率快速预览,确认方向后再生成高清版本,节省时间。 skyros 目前处于限量预览阶段, 官网提供免费额度,建议你立刻去试试三段提示词,就能判断它是否适合你的工作流。 好了,今天的入门教程就到这里,下一集我们会深入讲解提示词写作技巧和高级工作流。记得关注我们,下期见!

粉丝40获赞357
相关视频
 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿本周四的时候看到国产的 scariest v 四模型在国外的 artificial analysis 测评网站上登顶了,想着来和 cds 二点零对比一下试试。本次对比使用了相同的图片 作为首阵和相同的提示词,不过 skyreals 官网目前仅有 beta 版本可以测试,这个应该不是用于打榜的正式模型,如果后续有正式版本可试用。再重新对比一次。先看看 skyreals vs beta 版生成的效果, c dance 二点零依旧是日常排队。看看 c dance 二点零生成的效果。 目前个人来看, skyreal's v 四 beta 版还是没有 cds 二点零的效果好期待后续 skyreal's v 四正式版能够测试。
57farer 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿兄弟们,天宫开元 skyreal 四 v 四啊,音画同步模型杀入全球榜第二啊!基于双流 mmdt 架构,首个统一多模态输入啊!因视频联合生成重绘编辑任务, 模型输入就是在通道维度上拼接三个张量啊,所有任务啊,看作填空题啊,图片转视频的第一帧一致啊,续写后面呢,视频编辑就马斯克告诉模型呢,改哪一部分呢? 然后超分生成啊,低分辨率生成全程草图啊,高分辨率生成关键帧啊,利用超分模型呢,把草图变清晰啊,利用叉帧模型呢,把动作变丝滑,采用缩放 对齐啊!音频和视频旋转位置编码,利用视频吸收注意力,降低计算复杂度啊。
121龙哥紫貂智能 14:31126云桥网络
14:31126云桥网络 04:38查看AI文稿AI文稿
04:38查看AI文稿AI文稿很多人质疑,昆仑万维单日百分之九点四五的股价涨幅只是 ai 概念炒作。但事实上,这波上涨背后,是 skyris v 四已经跑通的技术加商业化比环, 是市场对国产纹身视频技术商业化价值的认可。不同于很多只发论文不落地的实验室模型, skyris v 四早已实现规模化变现,构建了完整的商业化比环。一方面,开放全能力 a p i 接口,面向电商、教育、影视等弊端客户 提供定制化视频生成解决方案,无需自研大模型即可接入顶尖能力,大幅降低企业内容生产门槛。另一方面,依靠昆仑万维旗下 java web 短距矩阵,将技术与流量深度绑定,实现技术产品变现的闭环验证。 数据显示,截至二零二六年一月, drama wave 加 free reels 短剧矩阵月活突破八千万,年化流水超四点八亿美元,单部 ai 短剧制作成本不足两万美元,而爆款单日投放收入可达十万美元, roi 极高。 skyrealus v 四作为核心技术底座,不仅支撑了短居业务的规模化盈利,还在广告营销、游戏场景、教育视频等领域快速落地,商业化潜力持续释放。更重要的是, skyrealus v 四的登顶,打破了海外模型在文声视频赛道的垄断格局。 在此之前,全球 ai 视频生成市场的技术话语权几乎被 openai、 google 等海外巨头掌控, 国产模型只能在中低端市场挣扎。而 skyreal 四的出现,标志着中国 ai 多模态技术已经实现从跟跑到领跑的跨越,成为全球纹身视频赛道的核心玩家。这种技术突围带来的长期价值, 正是资本追捧的核心逻辑。 skyreal 四的登顶不是终点,而是国产纹身视频技术爆发的起点。结合当前行业趋势和技术引进方向,我们能清晰看到, ai 视频生成的下一个风口将围绕更长时长、更优交互、更轻部署三大方向展开。而 skyreal 四已经提前布局。第一,长时长视频生成。 目前 skyreal 四已能稳定生成十五秒商用视频,下一步将向五分钟以上长视频引进,支持完整剧情生成,彻底适配影视预演、长视频广告等更高级别的商用场景,这也是突破 sora 两局限的关键方向。第二,实时交互能力升级。 未来纹身视频将从被动生成转向主动交互,创作者可在生成过程中实时调整镜头角度,修改人物动作,实现 ai 导演示创作。而 skyris v 四的统一任务框架,为这种交互升级提供了核心技术支撑。第三,边缘端轻量化部署。 目前 skyreal 四已实现四卡 a 一 百步数,下一步将推进轻量化版本研发,未来可支持手机端实时生成,彻底打破硬件限制,让 ai 视频生成走进普通创作者, 实现人人都是视频导演的场景。值得注意的是, skyreal 四的突破并非昆仑腕为一家的胜利,而是国产 ai 多模态技术整体崛起的缩影。 从阿里通一千万、三点五 max 登顶国内大模型榜首,到小米 mini v 二落地端测,再到 skyris v 四领跑全球文声视频赛道,国产 ai 正在从单点突破走向全面开花,逐步打破海外巨头的技术垄断 a 国 ai 赛道从不缺概念炒作,但若想长期立足, 终究要靠技术硬实力说话。昆仑万维股价单日暴涨百分之九点四五,看似是一则登顶全球的消息引发的短期狂欢,实则是市场对技术落地加商业化变现双重逻辑的认可,是国产文声视频技术突围的必然结果。 skyreal 四的登顶告诉我们一个道理,国产 ai 的 突围从来不是靠模仿跟风,而是靠自主创新,针对行业痛点,打造核心技术,结合场景实现商业化落地,才能在全球竞争中站稳脚跟。 随着 skyreal 四的持续迭代,以及更多国产多模态模型的崛起,中国 ai 正在逐步掌握全球赛道的话语权。 而对于投资者而言,真正值得关注的从来不是短期的股价波动,而是那些能持续突破技术瓶颈,实现规模化变现的硬核企业。 对于创作者和企业而言, skyreal 四的出现不仅降低了视频创作的门槛,更打开了全新的商业想象空间。国产文声视频的时代已经到来,这一次我们不再跟随,而是引领。
21AI邪修钱宝宝 15:181072有趣的80后程序员
15:181072有趣的80后程序员 03:36查看AI文稿AI文稿
03:36查看AI文稿AI文稿还在为 ai 视频门槛高、效果怪异而头疼吗?告诉你一个秘密,现在连你家猫都能用 ai 拍个雪山救狐的二创短片,而且是那种离谱到飞起的版本,这背后是中国模型 skyreal 四的强力助推。 先说个刺激的,就在今年二月, skyreal 四还只是全球第二,跟 solo 二里有三点一,这些大佬掰手腕。结果呢? 不到一个月,他在带音频的文声视频领域直接冲到了世界第一,这速度简直是开了挂!这说明什么?咱们中国团队在 ai 视频这块,是真的有两把刷子,而且迭代速度快的像坐了火箭。 从追赶者到领跑者,这波操作够不够酷?那 skyways v 四到底牛在哪?美美,它的基础能力那叫一个稳!以前 ai 生成的视频,要么细节拉胯,要么逻辑混乱。 现在不一样了,它通过全模态强化学习,让模型更懂你的意思,理解更透彻,逻辑也更清晰。 再加上多帧和网格参考技术,保证角色形象不崩坏,长镜头修饰也流畅。你看他生成的战争场面,镜头切换行云流水, 再看赛博朋克飞船穿城,光影速度感十足,妥妥的科幻大片既视感。连 hello kitty 滑雪这种复杂动作都能稳稳接住,不掉链子,这电影级的完成度,谁看了不说一句?哇塞, 光有基础还不够,还得能玩出花样! skyreal 飞四的进阶功能,简直是短剧创作者的福音。想拍多镜头对话,上传几张人物照片,再给点题诗词,模型就能帮你搞定。连微表情、手部动作、口型都抓得准。 想让角色说不同语言,英文、法文、日文甚至台湾腔,他都能精准生成,正反打镜头切换自然口型同步得让人挑不出毛病。 更绝的是,它还能做视频编辑,局部添加、删除、去水印,甚至把删掉的部分合理补全。这不就是个 ai 版的 premiere pro 吗? 还有那个九宫格,参考专门给短剧设计的,上传最多九张关键帧,就能生成全程连贯角色场景不变的完整故事,效率直接起飞。当然,这么强的功能背后是硬核的技术支撑。 skyreal 是 v 四最大的突破在于它的全模态强化学习体系。这玩意儿解决了传统扩散模型只盯着像素点,忽略整体语义的大问题,让生成内容更有大局观。 同时,它还采用了创新的 mmdit 双流架构,通过双向跨注意力机制实现音画完美同步,还能理解复杂的组合指令。 为了应对高分辨率长视频带来的计算挑战,他引入了带偏移的三 d o p 来解决因视频对齐问题,并用视频吸出注意力。 vs a 机制把计算成本砍掉了大约三分之一, 这技术含量杠杠的。而且这可不是实验室里的花架子,它已经深度应用在昆仑纬和 free ros, 月活用户超过八千万,月流水高达四千万美元, 这数据就是最好的证明。所以你看, ai 视频生存的世界,正在被 skyreal 四 v 四这样的中国力量深刻改变,门槛越来越低,功能越来越强大。
12捷讯技术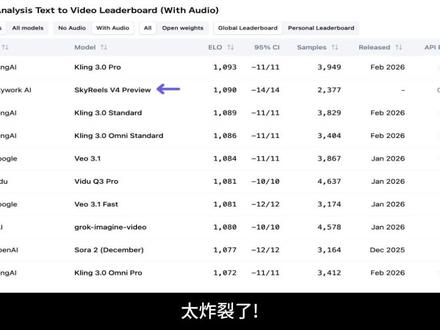 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿太炸裂了!就在刚刚,全球最权威的 ai 评测榜单 artificial analysis 更新,谁也没想到,来自中国团队昆仑天宫的视频模型 scariest v 四以黑马之姿直接杀入全球前二,超越 google will、 三点一、 openisora 二、 grok 等主流模型。 scaryos v 四到底有多牛?这个视频告诉你,第一,照片变短剧。以前你想拍个霸总短剧,得找演员对台词拉后期,折腾半天。现在用 scaryos v 四,只需要两个角色的静态图 输入对白,他自己就能直接开演,表情到位,台词入戏,连声音都给你同步配好。我说我现在回来。好, 那我让二妹过来,让他送你回去。第二,主体替换。想让家里的狗跳爵士舞?没问题,你只需要给一张狗的照片,再给个舞蹈参考,轻松搞定。第三,全维度视频编辑一句话就能改天气、换背景、去水印,甚至插入新的形象主体, 所有编辑操作打打字就能完成。而过去这些操作,你需要在 pr、 a、 e 各种 ai 工具之间反复切换才能完成。现在, scario 四 v 四一个模型就能全部搞定了! scario 四 v 四登顶榜单,是中国 ai 力量的一次集体爆发,这样的国产大模型,才是真正能改变你工作方式的生产力工具。
3900来去AI 00:27查看AI文稿AI文稿
00:27查看AI文稿AI文稿二月二十七日, skywalker ai 重磅发布全球首个多模态视频基础模型 skyless v 四,实力刷新行业天花板。在权威机构 artface 了 nelson s 评测中,它排名全球第二,超越 google v o 三点一、 open ai、 sorry 二等主流模型。 它集多模态输入、音视频联合生成、统一编辑、修复于一体,以双流 i d i t 架构为核心,可生成一千零八十 p 三十二 fps 十五秒影院及音视频,可实现专业级修复、权威度编辑、中文语音合成表现突出。
27今日人工智能 03:55查看AI文稿AI文稿
03:55查看AI文稿AI文稿昆仑 tiangong skyreal 54 has successfully made it onto artificial analysis global text to video ranking。 该模型在全球现役模型中位列第二,展现出卓越的性能。在所有历史模型中, 昆仑天宫 skyreal 四 v 四排名第四,此排名表明其在国际 ai 视频生成领域已取得显著地位,这一成就凸显了昆仑天宫在 ai 技术创新方面的实力。 skyreal 四 v 四是一款先进的短距生成工具,具备强大的视频制作能力。该系统能够通过简单的输入及两张角色图片和相应的台词快速生成视频内容。其输出视频分辨率高达一千零八十 p, 帧率达到三十二帧每秒,确保了视觉流畅度。 生成的短距视频时长可达十五秒,足以呈现一个完整且引人入胜的微型故事。 skyreal 四的生成效果达到了影院级别,画面质量和细节表现力极高。 其生成内容高度逼真,几乎完全消除了传统 ai 生成视频中常见的 ai 痕迹。 skyreal 四模型支持多模态输入,能够处理多种类型的数据信息。 例如,它可同时接收角色图片作为视觉参考,以定义视频中人物的外观特征。此外,模型还能输入舞蹈参考视频,提取并学习其中的动作训练和风格。同时, 音频输入用于捕捉节奏信息,确保生成视频与音乐节拍同步。通过这些多模态输入,模型能够忠实地将角色外观与参考视频中的舞蹈动作结合。 最终, skyreal 四能根据所有输入信息生成高质量视频,展现其跨模态精准融合控制能力。 skyreal 四系统提供手帧参考功能, 允许用户输入特定图像作为动作起始帧。同时,该系统还具备运动参考功能,支持用户导入运动视频作为动作指导。 通过这些功能,用户可将不同角色如兵马俑或动漫角色带入到预设动作中,此过程确保了角色在复杂动作系列中保持高度一致性与精确性。 skyreal's v 四提供一站式全流程视频修复与编辑功能, 用户可通过简单的提示词指令实现视频内容的精细化处理。该系统支持去除视频水印,保持画面纯净无暇。同时, 它能够精确移除视频中的特定人物或对象。 skyreal 四还具备一键修改角色服装的功能,提升视觉多样化。用户甚至可以将视频风格从写实转换为乐高积木风,极大地增强了创作灵活性。 skyreal 四技术能够将静态画面转化为动态的电影级运镜效果。 该系统为原本平淡的镜头注入蓄势张力与节奏感,提升视觉表现力。创作者无需在多个视频编辑工具之间切换,即可完成复杂的视频操作。 skyreal 四简化了视频制作流程,实现了高效且专业的镜头语言转换。 skyreal 四系统采用双流 mmdt 架构,指在高效处理多模态数据。该架构通过独立的视频处理分支和音频处理分支并行工作,视频流与音频流共享,一个文本编码器实现信息整合与理解。 系统利用双向跨注意力机制,促进音视频数据间的深度交互与融合。结合 rope 频率缩放技术,确保音视频在底层实现毫秒级的时间对齐。这种精确的时间对齐是实现精准唇形同步的关键技术基础。 skyreal 四采用通道拼接加持续拼接的双维统一范式,将所有视频任务转化为修复问题,此范式实现了模型在不同视频生成任务间的无缝切换,提升了处理效率。 七、低分辨率全序列加高分辨率关键帧联合生成策略,优化了视频生成过程。结合自研 vsa 机制, skyreal 四 v 四在保证视频质量的同时,高效生成影院级规格视频。
27Qiuming 04:19查看AI文稿AI文稿
04:19查看AI文稿AI文稿最近 ai 圈又炸出一个大新闻,咱们中国的 ai 大 模型在全球最硬核的视频生成赛道拿下了双料世界第一。昆仑万维旗下天宫 ai 的 skyreal v 四先是在三月十九日登顶文声视频加音频赛道,紧接着三月二十一日图声视频加音频赛道也拿下了全球第一, 把 google、 open ai 这些国际巨头都甩在了身后。今天咱们就来聊聊这件事背后的技术突破和行业意义。先给大家划重点,三月十九日, scariest v 四在 art facial analysis 的 text video audio 文声视频加音频赛道登顶全球第一。三月二十一日又在 image to video with audio 图声视频加音频 赛道拿下第一,实现双榜领跑,它直接超过了 clean 三点零、谷歌 v o 三点一、 v 六、 q 三,甚至包括 openai 的 solo。 二是目前全球 ai 视频生成能力最强的大模型。 不管是文字生成带音频的视频,还是从一张图片生成带音频的动态内容, skyreal 四 v 四都做到了全球顶尖,这在行业里是史无前例的。很多朋友可能会问,文声视频和图声视频到底是啥? 我用最简单的话给大家解释,纹身视频,你输入一段文字指令,比如一只可爱的柯基在海边追着浪花跑, 配轻快的背景音乐, ai 就 能直接生成一段完整的音视频,从画面到声音全靠文字驱动。图声视频,你先给 ai 一 张静态图片,比如一张风景照,一张人物照,然后告诉他,让照片里的人微笑着挥手。 配上鸟鸣声, ai 就 能把静态图片变成连贯动态的视频,同时生成同步音频简单说,文声视频是从零到有,图声视频是从静到动, 两者都是 ai 视频生成的核心赛道,也是现在内容创作最刚需的能力。可能有人会好奇,这个 artificial analysis 到底是什么榜单?为什么它的排名这么有分量? 他是全球 ai 领域最权威的独立第三方评测机构,不依附任何科技公司,所有评测都基于真实用户盲评和客观技术指标,结果非常有公信力。 他的榜单不是简单看生成快不快,而是从画面质量、音画同步、逻辑连贯性、细节真实度等多个维度大分,甚至会测试唇形对齐、场景一致性这些行业难题。他细分了文声视频、图声视频、带音频、不带音频等多个赛道。 这次 skyreal 四登顶的带音频赛道更是贴近真实商用场景,含金量极高。 skyreal 四拿下双榜第一,绝对不是一个简单的排名变化,背后藏着三个关键信号。一、中国 ai 视频技术实现全球引领 过去 ai 视频领域一直是美国公司领跑,这次咱们的模型在两个核心赛道同时超越 google、 open ai, 证明中国在多模态生成、音画同步等关键技术上已经走到了世界前列。二、商用价值大幅提升。 双榜第意味着 skyreal 微四能直接支撑短距电商、教育、品牌营销等真实场景, 比如快速生成广告片、短剧,内容效率比传统制作提升几十倍。三、技术路线得到验证。它采用的双流 mmdit 架构、全默态强化学习等技术,证明了音化同步生成加多模态参考是 ai 视频的正确方向,会成为全球行业的标杆。 最后再说下我们前两个视频着重强调的 cds 为什么没出现在榜单上,核心原因有两个,一是合规问题导致功能受限。 c dance 二点零上线后,因为训练数据版权问题被好莱坞制片厂起诉,字节跳动紧急暂停了真人参考、 电影级生成等核心功能,模型能力大幅下滑,无法以完整状态参评。二是赛道与参评机制不匹配。这次榜单聚焦带音频的文声、图声视频,而 c dance 之前主要在纯视频赛道发力,且因为合规问题没有主动提交新版本参评,自然就没有出现在排名里。 简单说,不是技术不行,而是没去参赛。总的来说, skyreal 四双榜登顶是中国 ai 视频的一个里程碑事件,它不仅证明了中国大模型的技术实力, 也让我们看到未来 ai 内容创作的话语权正在向中国企业倾斜。好多今天的视频就到这里,欢迎点赞、关注、转发,我们下个视频再见!
13欧公子买单 01:51查看AI文稿AI文稿
01:51查看AI文稿AI文稿当 ai 还在为音画不同步挣扎时,昆仑天宫以用 skyreal 飞四掀起革命,这款国产全模态视频大模型,强势杀入 artificial analysis 全球榜单 top 二,超越 vo sora 等巨头,以音画双生硬实力重新定义创作边界。电影级质感一秒生成 一零八零 p 高清画之下滑,学者腾跃学姐的雪雾翻飞、兵器碰撞的火星四溅,皆与音效严丝合缝。 低角度跟拍、慢动作特写、复杂镜头调度如行云流水,模型对电影级质感的全是让专业导演都惊叹。全模态融合创作零门槛。全球首个打通文本图像视频音频的瑞士军刀来了!只需输入两张人物图加一段文字,关公与秦书宝就能在荒野对吼, 中文口型与台词情绪完美了合,更可让北极狼秒变 m j 舞者。编辑指令如魔法般精准替换角色,消除字幕底层突破,根治行业顽疾。双流 m m d i t 架构,让音视频如双胞胎般共生, rap 旋转编码彻底治愈时间错位。 当其他模型还在后期配音, skyrose 已实现扩散过程中的原声音化同步角色怒吼时喉结颤动,低语时眉峰微蹙,生命力扑面而来。创作者的焦虑终结者,从十五秒电影级短片到六十秒长视频,从局部重绘到全片生成,他将素材剪辑升级为羽翼创作, 正如影视巨峰听所言,这是推导行业流程的海啸。当 ai 能理解镜头语言、情绪、纹理,人类创作者将真正成为驾驭工具的舵手。 skyross 发布,标志着 ai 视频从单点合成迈入全站创作新纪元。言 巨头称拍强行视频编辑碰撞的火星四溅,皆与音效严丝合缝的角度跟拍慢动作特写复杂镜头调度如行云流水,人类创作者将真正成为驾驭。
12励志 06:55查看AI文稿AI文稿
06:55查看AI文稿AI文稿三月, a 股 ai 圈最大黑马非昆仑万维莫属。一则 skyreal 四登顶全球纹身视频模型榜首的消息 直接引爆资本市场,昆仑万维股价单日飙升九百分之四十五,市值单日增加数十亿,成为 ai 赛道逆势上涨的核心标杆。 但这波暴涨从来不是偶然,更不是资本的短期炒作,而是国产文声视频技术从追赶到领跑的硬核,证明是 skyreal v 四用四大底层技术突破,撕碎海外模型垄断的标志性一战。很多人只看到股价的狂欢,却忽略了一个关键事实,文声视频赛道 长期被 openai、 sora、 谷歌、 vivo 等海外巨头牢牢掌控,国产模型始终处于跟跑状态。而 skyreal v 四的登顶,不仅是一个模型的胜利, 更是中国 ai 多模态技术从单点突破到全站领先的转折点,其背后的技术逻辑藏着国产 ai 突围的核心密码。 在 skyrealus v 四登顶之前,全球纹身视频赛道的话语权一直被海外模型牢牢掌握。 bobo ai 搜索二凭借物理模拟和长时长生成能力, google real 三点一靠多模态融合占据一席之地,但两者都存在难以突破的技术瓶颈,音化、割裂、逻辑脱节、任务碎片化,难以满足商用场景的核心需求。 而 skyreal's v 四之所以能在 artificial analysis 权威榜单中脱颖而出,超越苏瑞二、 vivo 三点一等全球主流模型, 核心在于它没有走跟随模仿的老路,而是针对行业痛点,实现了四大技术重构,每一项都直击海外模型的短板。传统纹身视频模型,无论是苏瑞二还是 vivo 三 一,都采用视频生成加音频叠加的分离模式,这就导致生成的视频常常出现口型对不上、台词、背景音乐与场景脱节的尴尬,后期修音成本极高,难以实现商用落地。 skyreal 第四,创新性采用双流多模态扩散 transformer mondo 的 架构, 将视频分支与音频分支协同建模,共享多模态语言编码器,实现文本图像、视频片段与音频参考的联合控制,让音视频从生成之初就实现原声同步,而非后期平接。 简单来说,输入一句,深夜海边的海浪声中有人轻声低语,模型能同时生成连贯的海浪画面、自然的人物动作以及与场景完美匹配的海浪音效和低语声 口型同步率、音效匹配度均突破百分之九十六,彻底解决了 ai 视频音画两张皮的痛点。这种技术突破的价值的在于, 它将视频生成的后期成本直接清零,无论是电商广告、短剧制作还是影视预演, 都能实现一键生成,直接商用,效率较传统模型提升三倍以上,这也是其商业化落地的核心竞争力之一。纹身视频的核心痛点从来不是画面逼真,而是逻辑连贯。此前绝大多数模型,包括缩绕二 都存在重局部像素清整体语义的问题,生成的画面细节拉满,但人物动作违背物理规律,场景切换毫无逻辑,比如人悬浮行走, 物体凭空消失,根本无法用于专业创作。 c i reos 第四,针对性打造了全模态强化学习体系,彻底解决了这一难题。 一方面,它搭建了覆盖文声视频、图声视频、编辑音视频对齐全场景的全模态语义与 word 模行为生成过程提供全局精准的实时反馈,确保每一个画面、每一个动作都符合物理常识和蓄势逻辑。 另一方面,采用阶梯式课程学习路径,让模型从低分辨率短时长逐步升级到高分辨率长系列, 循序渐进掌握复杂生成能力。实测数据显示, skyrioz v 四能稳定生成幺零八零 p 三十二 fps 十五秒的商用级视频, 无论是海浪的波动、人物的微表情,还是复杂场景的运镜,都能精准还原真实世界的物理规律。蓄势连贯性叫苏尔二提升百分之四十,彻底摆脱了 ai 视频等与画面拼接的局限。在 skyreal 四出现之前, 纹身视频赛道存在一个普遍痛点,生成视频用一个模型,编辑视频用一个模型修复视频又用另一个模型,多工具切换繁琐,不仅增加了创作成本,还导致内容一致性难以保障。即便是 google、 vivo 三点一, 也只能实现生成加简单编辑的部分联动,无法实现全链路贯通。 sky reos 第四的核心创新之一,就是搭建了统一任务框架,通过通道拼接和野马引导机制, 将文声视频、图声视频、视频修复、元素替换、风格迁移等多种任务统一转化为修复类问题,整合在同一推理流程中。这意味着创作者无需切换多个工具, 一个模型就能完成从创意输入到成片输出的全链路创作,既能用文本生成视频,也能直接修改视频中的人物动作,替换背景, 还能修复模糊画面,迁移视频风格,真正实现一模型通吃全需求。这种架构设计不仅降低了创作门槛,更让模型具备极强的跨任务泛化性。 习德的底层生成规律可在不同任务间自由迁移,大幅提升了商用适配能力,这也是他能超越海外模型的关键加分。下纹身视频的另一个行业困局是算力门槛过高。传统模型生成一段十五秒的高清视频 需要巴卡 h 一 百集军支撑,硬件投入动辄数百万,百分之八十的中小企业根本无法承受,只能望而却步。 即便是苏热二,也因算力消耗过高,难以实现规模化商用。 c i rios b 四、通过低高分辨率联合生成策略和 vc 稀疏注意力机制,实现了算力成本的大幅优化。先生成低分辨率视频序列与高分辨率关键帧, 再通过超分辨率及插帧模型提升最终输出质量,同时降低注意力计算成本,将高分辨率视频生成的算力消耗降低三倍以上。目前仅需四卡 a 一 百即可实现业务及部署, 硬件投入减少百分之六十,让中小企业也能轻松接入全球顶尖的文声视频能力。这种技术高端化部署、普绘化的设计, 让 skyreal 第四跳出了实验室技术的局限,快速实现商业化落地,这也是资本看好其长期价值的核心原因。本期视频就先到这里,下期我将为您讲述昆仑万维的技术变现能力。
31AI邪修钱宝宝 02:04119你翔哥哥
02:04119你翔哥哥






