langchain上下文存储在哪里
一天学一个变态的大模型知识点,今天讲的是蓝田像量存储。 好,我们接下来看一下这个像量存储啊,它属于这个六个模块里面这个解锁的这里,那我们接下来看一下像量存储里面会给大家讲到什么?第一个就是我们要去安装一个模块啊, 因为我们要呃完成一个简单的本地存储的一个 fast, 好 吧,我们之前在讲 r g 的 时候给大家讲过 r g b, 对 吧?然后我们这里面呢,就给大家用这个 fast 来给大家举例啊, 首先大家要安装一下这个发色,然后 cpu 啊,当然它有 gpu 了,就是你的电脑里面有 gpu 的 话也可以安装,然后我们还要安装一个这个模块啊,就是这个,然后它的版本呢?大家也尽量跟我保持一致啊,那发色的 cpu 的 话,它那个版本的话就暂时无所谓啊, 然后我们这个做一个像样的一个存储,那我们直接来看这个代码 唱板这里啊,我为什么要引入这些模块?其实我们想把一个就是网页的这个文件啊,把它把它存下来,然后呢把它扒下来,然后存到我们的这个项链里面去啊,项链数据库里面去,好吧, 就是给大家做一个相当于做一个什么完整的 ig 的 一个演示啊,我们之前给大家说那个他的这块啊,他的六个模块里面的, 来这里数据检测啊,你看数据检测里面是不是就是给大家构建这个 r g 的, 对不对?那我们来看啊,我们从这里面导入一个叫 document loader, 里面有一个叫 webbase loader, 它其实是一个什么做爬虫的, 做爬虫的这么一块,然后 wifi 的 话就是一个,呃,路径,是吧?我们可以看一下这个 uld 纸,它是一个咱们啊中华人民共和国的一个就是森林防火的一个条例啊,是这样的一个文档,一个链接啊,当然大家换成其他链接也可以啊, 然后呢?下面是一个什么,下面就是它那个就是你要哪些数据,对吧?我只要什么,只要 base。 呃,这个 b s 下面的什么 id 等于这个,这个其实需要一点这个 爬虫的知识啊,大家如果说老师我对爬虫不是很了解的话,那这里大家听一下就可以啊,就是我想把这里面所有的文本数据给它获取到,然后它这块里面啊有一个 div 啊,就是在这, 你看它所有内容都是在这个 diy 下面,那这个 diy 我 如果说把它干掉,我把它删掉啊,你看所有内容就没有了,是不是?然后把它恢复回来呢?就有了,是不是?那就是说我把这里面的所有的文本内容呢,把它获取下来,好吧?然后呢我们可以在这打印一下, 那就是我们让代码 e s i t 停到这,然后呢运行一下,给大家看一下打印出来的一个结果。看,这就说打印出来的一个就是获取到的一个结果啊,获取到的一个结果看到吗?他把那个文档里面,就是链接里面的所有的文本内容都给它获取下来,是吧? ok, 那 接下来的话我们要把它存到我们这个项链里面,对不对?要把它做一个编辑,然后把它存到我们的项链数据库里面,是吧?那你还是要做一个分割的, 对不对啊?这块我们用什么?用 oki 的? 或者说用这个国内的千问的这个编辑模型都可以啊,如果说你有这个呃 oki 的 api 的 话,就可以用 oki 的, 那我们没有,是不是 啊?不是,我们没有,我们现在用的大多数都是国内的这个模型啊,我们用的是千万这个 text, 尼克尼,高 v 三,我们之前在讲 r g 的 部分的话,也应该呃用到过这个模型,是吧? 然后接下来的话就把它存啊,这是做了一个尼克尼,对不对?然后把它存到发色里面啊,你还要去做一个什么?还要去做一个这个这个切分啊,这个是用的 text server 里面,这个就是呃地归的这么一个切分,然后切分的规则就是串 size 五百,然后呢这个滑动呢,重叠的部分呢?就是五十,是吧?然后把这个啊,把这个 这个文档呢给它传进去,对不对?然后给打印一下文档的一个长度,接下来的话就是把 embedding 和 document 啊,把它存到我们的 files 里边,是不是?我们之前用那个图码的时候是不是也是一样文档,然后 embedding, 对 吧?啊?就比较方便。大家看我们现在如果说用这个 用咱们 lincoln 的 话,是不是就比较方便了,对不对?上面是文档,就是老师我这块理解不了。是,如果说大家实在理解不了,你准备了一个什么啊?你准备一个纯文本也可以,然后放在这里,然后用这个把它切分,切分完成之后 直接往里边存,然后现在大家看他这个文档被切割成了二十一份啊,被切割成了二十一份,那如果说老师我想每一份都看一看啊,这个切割完成之后到后面呢是什么样子?大家看这,这就是,这就是一个 document, 然后下面这是一个 document 啊,这是一个 document 文档里面有什么?每一个里面有什么? macdata 就是 s 这个目录,对吧?这是它的原链接,然后这个就是它切割完成之后的一个文本的一个内容,看到了吗? 啊?这就是它文本的一个内容, ok 啊,那这个呢?我们给大家看完之后,接下来的话,其实我们就可以什么这个已经存起来了,接下来你是不是可以基于这个来去做什么? 来去做一个 r g 了,是吧?来看这啊,我们来看这怎么用啊?这是我们之前讲过的一个文档,对不对啊?然后请根据提供的上下文,是不是这个模板呢?你要这么写啊,就是固定要这样写, 为什么呢?后面因为我们要用到这个链啊,这个链式的一个操作,所以说这个文档你必须要包含啊,必须要包含这个东西 里面的 ctrl 就是 你的上下文,然后这是我们的问题,对不对?模型呢?我们用的是这个纠错,然后啊这个链,对吧?这有一个链啊,创建一个叫文档组合链, 将文档内容呢和用户问题组合成一个完整的题词,对不对?他需要把什么,需要把大模型和这个啊传进去,为什么我刚才说这块一定要有 ctrl 啊?就是这个链,对吧?就如果说我们想用这个文档组合链的话, 它必须里面有这个东西,然后它才能把剪索到的上下文呢放到这里,好吧? 然后接下来这是向量数据库对不对? add retrieve 啊,就是去要去剪索了,是不是你剪索里面你要剪索限制?我们添加了一个条件,就是你剪索出来的文档最多啊,你只要 top 三就可以了, 是不是?然后接下来啊, create 又创建了一个链儿对不对?这个链儿是干嘛呢?是解锁的,就是把你解锁到内容和这个 document check 啊,就是文档对不对,把它放在一起 对不对?结合了剪辑器和文档组合链儿啊,实现了从向量数据库中解锁相关的文档,然后并且将文档和用户的问题呢做了一个结合。大家发现 在 launch 里面,它其实做了 r g 的 话,就是它只通过了两个链啊,我们是不是就完成了?那接下来的话,我们只要掉了这个链,把问题往里面一传,然后呢我们要去它的一个回复,这样就可以了,大家发现原先我们还要怎么样? 拼接提示词对不对?然后再去检测,这样的话是不是就更方便一点,就是我们用了这个链之后,大家发现,哎,特别方便对不对?当然这会大家有人说,老师我有点现在有点懵逼,对吧?也没有关系,我们后面基于这个链呢,我们也会详细的再来跟大家讲啊, 然后这个呢,就是它的一个回复啊,是吧?我们也可以运行一下,看一下它的一个回复结果。 我们这个就是问的森林火啊,这个草原火灾的一个扑救,然后这是一个答案对吧?然后根据上下文啊,这个是 就是及时疏散群众啊等等,这个回答问题应该也没有什么问题,对吧?但是可能是说效果有多好呢?不一定,对吧?因为它里面有很多的问题,对不对? 我们还没有给大家来去解决,那这个呢?就是一个从向量的一个存储到他的一个解锁啊的一个基本的一个使用。为方便大家快速入门大模型视频文档和超详细大模型学习路线图,感兴趣的同学留个学习抱回家。

粉丝1.7万获赞3.7万
相关视频
 08:03查看AI文稿AI文稿
08:03查看AI文稿AI文稿本地知识库就是从向量数据库里面获取这个外部的知识,跟大木星结合的时候啊,他的这个外部的这个 sos, 这个数据员怎么跟使量数据库的数据员进行同步的这样的一个技术问题,有一个解决方案跟大家一起来聊一下啊。 当前里面的话呢,目前已经整合了这样一个创建质量数据库所引,并且跟外部数据人做一些同步的这样的一个 a p i 啊,我们一起来看一下他这个是怎么来实现。我们在做质量数据库的时候,我们会发现这个 外部的文档有很多,我们把大量的文档同步到史量数据库的时候,因为光有史量数据库是不够的,那你有可能的话,你还要做一些关系型数据库啊, 要做一些啊,有一些文档要放在关系性数据库里面,因为,呃,因为你每次做文档如果你都是全量的话,那它的效率是非常低的啊。而且如果你要通过 chat g p t 做一些适量化 inbiting 的 这样一个操作的话,那么他要消耗大量的这个 token, 他要花费费用啊。那么有没有一种方案,就是说,呃,我们只是把我们这个外部的数据员,呃, 不是有变化的时候,我们才在这个时量数据库里面去更新,或者我不需要的时候就把它给删除掉,我有新增的时候,我再插入到这个时量数据库里面,就相当于做一个增量啊,这样的一个操作啊。目前的话,郎欠的话,他提供了这样一个解决方案啊,他他提供的这个叫 indexing hi 啊,大家可以看一下它这个官方文档上面啊,它已经把它给放出来。嗯,那我们来解释一下它到底目前是怎么来实现的啊?它怎么来实现啊? 本质上来讲需要把这个每个文档他会产生一一个哈士,一个哈士的一个编码啊,这个编码的话呢,就是代表这个文档,当你这个文档发生变化的时候呢,他这个哈士值就不一样了,他会把这个哈士值和这个文档的唯一的编号放在关系 数据库里面啊,他有个叫 sos id, 他会被把每一个文档都有一个唯一的编号,然后把这个哈序值和 sos id 进行关联,他就去判断啊,你这个时时量数据库里面的这样的文档他到底是不是有变化,或者你这个时量数据库里面的这个 sos id 是不是已经有了,有了的话呢?那么他就 不会重复的去插入。如果这个文档的哈确实跟原来的不一样的话,那么他这个文档发生变化,那么他在矢量数据库里做一个修改的这样一个动作啊,如果这个文档没有了的话,他就作为一个删除的这样一个操作啊, 它的主要是这样来实现的啊,原来我们在做这个外部本地知识库的时候,我们这些代码都要自己去写啊,现在他就提供了一个类啊,叫 record manage 啊,他这样一个类啊,专门把这一些的功能都实现出来了啊,而且呢他也有三个 model 啊,他这个 record 的有,他这个叫 clean up more, 他有三种啊,一个叫 non, non 的话呢,他是他会,他不会去处理删除的这个操作,他只会去判断你这个文档是否是是重复,如果是重复的话呢,他就不会 重复的去往你的食量数据库里面去插啊,但是如果他发现你这个食量数据库里面这个文档已经没有的话,他不会从食量数据库里面做一些删除的这些动作啊,他等于是这样。第二种模式的话,他叫增量模式啊,增量模式的话大家可以想象得到啊,那么他不是全量的去 做这个更新的啊,增量的话呢,它就是呃,把对比啊,你现在的这个 eatsos 跟你的矢量数据库做一些对比,如果发生有变化的时候,如果有新增的,那么就他就插入,有删除的他就删除, 修改的他就更新啊,他主要是做这样一个事情啊,所以还有一种的话呢,他就是全亮,全亮的话呢,他就不会刮了啊,他把你的这个锁隐全部删除掉啊,删, 删除掉之后呢重新再插啊,当然他也会,如果你这个文档在但是重复,他也不会重复的在这个实量数据库里面去创建,他有这样的一个好处啊,那么他这个 h i 的话呢,目前在这个 郎欠的这个版本里面已经发布出来了,已经发布出来了,他这个就是我前面讲的,我们一起来再来看一看啊,他到底是怎么来用的啊?他怎么来用的?他这个里面举了一个例子啊,他举了一个他的时量数据库是用 elastic 设置的啊,作为一个时量数据库的啊,我们小工以以的那个 本地知识库的话,也是用 elastic 社区的啊,用 elastic 社区的话呢,它也有一些好处啊,比用 fas, 呃,会,呃,如果数据量大的话,它的性能会更好啊。 fas 的话呢,它主要是把所有的这个 质量数据库都放在内存里面,这样会导致如果你的文档很大的话,他需要要非常多的这个内存啊。我们曾经测试过将近有七十亿的这样的一个啊,七十 gb 的这样 的一个适量数据库,如果你把它转化成 elastic 社区的话,它它的内存大概只需要七个 g 啊,它就够了啊。而且随着你的文档再增加它, elastic 社区里面也不会增加太多的内存,因为它会把磁盘和内存就结合起来啊,作为一些适量的这些数据库,它 catch 需要的时候呢,它才会装载到这个内存里面。 同时 elastic 社区它也是个分布式的架构啊,所以做是量数据库的话,相对来讲性能也会非常不错啊。那这个是。嗯,所以他举的这个例子也是用 elastic 社区的,因为只有 elastic 社区他这种创建的文档非常需要非常多的时候,他,呃,用这个 index, 你 call the manager, 他才会有真正的价值。呃,否则的话,如果你本档量少少的话,你每次都重重新建一次就可以了。他这个里面这是标准的用法啊。这个是,呃,他用了一个 invading, invading, invading 的话呢,是用 oba ai 的 invading 的这样的一个操作,当然我们也可以用本地的啊,据哈根 face 的 这样的一个项目大模型也是可以的啊。这个是 elastic 设置的这个一个服务服务的这个 url 啊,这个是锁引的这个名称啊,它这里面名叫 test index, 下滑线 index。 好,那么它这个 record cycle record manager 的话呢?它是把这个相关的一些数据要存在 cycle 数据库里面的,它用的是一个 cycle light 啊,是一个轻量级的一个内置的这样一个数据库啊,它放在这个 数据库里面,我一般是用 micro 的这个数据库啊,你只要 d, b, u, i, l 这个地方改一改就可以了,然后它在 record manager 里面就创建这个 c 个码。嗯,创建完了之后的话呢,那么它就要开始 这个就是标准的这个文档的拆分,这个就要开始了创建,所以创建,所以他这个里面定义了一个如何处理这个文档,这个他定义了这个 record manager, 就是前面定义的这个 index, 然后这个就是 victor, 就是矢量数据库,然后这个就是他的 model clean up the model 它有三种,它目前是做一个全量的。然后这个是 source id 的这个 key 啊,你在 circle 这个表结构里面,跟你的这个食量数据库的 elastic 社区里面的所有里面,它有个 menadata, 它这个 source 它要指定一下你这个 source id 的这个 menadata 的这个 type 一个 name 是什么?好,这样他就可以创建了,用起来还是会比较简单,用起来会比较简单啊,那么他这个所以创建完了之后,那么他就可以开始引用,引用 创建的这个锁引进行结合这个用户问的这些问题再进行。呃,到下面数据库里面去检索,再结合大模型去回答这个问题,他是这么来做的, 这个是个基础的用法啊,如果有详细,大家还是可以看看他的这个官方的这个 document 啊,官方的这个文档啊,他这个里面讲的会更清楚啊,因为他,他这个,他这篇博客里面只讲了一个模模式 啊,只讲了一个负的模式啊,全量的一个模式。他这个文档里面他会介绍三种模式,一个 not, 一个增量,还有一个是全量啊,他这个三种 clean up 的模式他都介绍。这个就是前面讲的那个 south 啊,他在 mental data 有个 attribute, 它包含一个扫词啊,就在这个地方,它是确保你这个数据的唯一性啊,它是怎么来确保的啊?这个可以用一个 document 的 id 啊,来确保这个关系型数据库。 c 口里面的这个 document 的 id, 跟你的食量数据库里面的这个文档的这个 id 进行一一的对应啊,这个是可以好 使用的话,也是比较简单的啊,所以连线他是不断的会添加一些新的功能放在放在整个框架里面的,让我们的开发变得越来越容易啊。原来我们要做这样的一个本地数据本本地知识库,他的开发量是非常大的,现在他创建 类似的这些类啊,那么我们开发起来会更加简单。这个是他原来没有加锁引的时候,他是这样的,如果加了锁引的话,他就会变成这样的一张图,就在这 他做了一个 record manage, 他这个地方要建一个关系型的一个数据库啊,要连两个,让你的关系型数据库跟你的矢量数据库里面的文档进行关联啊,他只要实现的是这个事情,你的文档做一些增量变化的时候,他不需要重新建所有的锁, 所以他需要的时候他才会剪啊,这个就是今天介绍的这样的一个解决方案,好吧?啊?好啊,今天的话就跟大家就聊到这。
283小工蚁 06:23查看AI文稿AI文稿
06:23查看AI文稿AI文稿在之前的四期视频里,咱们一起精读了 anthropic 关于上下文工程的深度长文。这个系列的核心是帮咱们建立了一个战略性的认知,它深入剖析了 ai agent 在 长任务中为啥会出现认知衰退,还从理论高度提出了高级架构的必要。 今天呢,咱们要开启一个新的系列,来精读 luncheon 关于同一主题的官方文章。如果说 anthropic 的 文章回答了为什么要这么做,那 luncheon 作为领先的应用框架, 它的视角更偏向于具体怎么做,它把抽象的架构思想拆解成了一系列具体的能操作的设计模式。在本期内容中,咱们先学习 luncheon 提出的一个基础思维模型, 也就是操作系统类比,再了解它规范的四大核心操作,这能为咱们后续理解所有具体的实现技巧打下坚实的框架基础。要理解上下文以及上下文工程, lanchain 引用了 andridacapacity 提出的一个特别精妙的类比,就是把大语言模型系统看作一台计算机。在这个比喻里, l l m 就 相当于 cpu, 它负责所有的计算推理和生成,但关键是它本身是无状态的,每次 api 调用都是一次全新的独立的计算过程, 这就意味着每次调用的时候,你都得把它需要知道的一切重新提供给它。而上下文窗口呢,就像是计算机的内存,也就是 ram, 它是模型的工作记忆区, 它的特点是速度特别快,但是容量有限,而且内容容易丢失,不像硬盘,信息一旦超出范围就会彻底没了。这就体现出咱们作为构建者的核心角色了,咱们得像操作系统一样, 设计一套高效的内存管理机制,来决定在每个计算周期该从庞大的硬盘,也就是所有可用的信息原理,加载哪些最关键的数据到宝贵的内存中。所以说,上下文工程 本质上就是扮演操作系统的内存管理器角色,它负责在作为 cpu 的 l、 l、 m 和外部世界之间高效的调度信息。既要保证 cpu 在 任何时候都有正确的思考依据,又要确保内存空间足够高效、干净,这就是上下文工程的精髓,让模型始终在正确的信息环境中思考。 那作为操作系统,咱们要管理的数据具体有哪些类型呢? lincoln 把它清楚地归类成了三大类。第一类是指令, 这是模型的行动原则,决定了模型该怎么做。它是一个集合包括核心的系统提示,用于行为较准的 few shot、 视力工具的定义和描述,甚至还有对语气和风格的约束。咱们可以把它理解成模型的操作手册和身份设定。第二类是知识, 这是模型推理和回答问题所依靠的事实和信息,回答了我知道什么,它的来源可能是知识库、外部检测数据库,或者是用户直接提供的文档等等,是 agent 做决策的现实依据。第三类是工具反馈, 这是模型和世界交互后得到的观察结果。 agent 不 只是靠语言思考,它会调用工具、 api、 文件,系统每次调用的返回结果都会写回到上下文中,成为下一轮推理的新输入,这是它的感知通道和外部记忆的来源。所以咱们可以把这三类信息的关系理解为 指令,确定了目标知识提供了依据,工具反馈形成了感知与行动的闭环,他们一起构成了 ai agent 生存的信息生态。理解了要管理什么之后, luncheon 做了一个很棒的总结,他把上下文管理浓缩成了四个关键动作,分别是写入、选择、压缩、隔离。 要强调的是,这四个动作不是按顺序一步接一步的流程,而是一套能动态组合调用的信息管理机制。就像系统管理员一样,在 agent 的 每次思考循环中,实时维护模型的思维空间。 首先是写入,这是信息生命周期的起点,当模型得到新的信息或者观察结果,比如一次工具调用的返回一个关键的中间结论,就得把它记录下来,写入到临时的草稿区或者更持久的记忆中。然后是选择, 这是上下工程的核心动作,每次模型推理前都得执行。系统要决定从所有可用的信息原理挑选哪些最相关的内容,放进当前有限的上下文窗口。比如最近几轮对话 最相关的文档片段或者刚刚的工具,结果选的准,模型就能专注,选的乱,他就会混乱。接着是压缩, 当信息越积越多,选出来的内容还是放不进上下文时,就得进行清理与总结。比如说把时轮对话整理成一段简短的摘要,或者保留关键结论,删掉过程细节。这一步既能节省宝贵的空间,又能大大降低噪声,让系统能持续思考而不崩溃。 最后是隔离,这是一个架构层面的策略。当一个系统里有多个任务或者多个 agent 并行工作时,必须保证它们各自的上下文互不干扰。比如,一个负责处理订单的 agent 和一个负责处理客服的 agent 不 能共享同一个记忆区。 隔离是确保系统在复杂协助中保持稳定的基石。对于产品经理和开发者来说,理解这四个动作不是为了死记概念,而是为了在设计 ai 产品时,能清楚地界定信息流的边界和策略。 咱们要明白,系统的智能往往不只是取决于模型本身有多聪明,更取决于咱们怎么组织上下文,规划信息的流动路径。写入决定了系统能不能积累经验,选择决定了它能不能专注重点, 压缩决定了它能不能长期工作。隔离决定了它能不能安全扩展。这就是为什么 line chain 把上下文工程看作是操作系统层的能力。只有掌握了这一层的设计 agent, 系统才有可能具备真正的持续性智能。咱们今天学到的是上下文工程的系统框架,在这个框架里, l l m 是 计算核心,上线是工作内存。 而上下文工程就是在有限的内存中让模型保持清醒、专注、高效的艺术。它管理着三类核心信息,也就是指令、知识和工具反馈,还通过四个核心动作,也就是写入、选择、压缩和隔离,让 ai 的 思考有了连续性和秩序。 下一期,咱们会继续精读 langchain 的 下一部分,如果上下文理不到,系统会以哪些具体的方式出错,包括污染、干扰、 混淆和冲突。同时咱们会把这些现象和咱们之前精读 anthropic 文章时学到的唱下文腐烂概念做一次深度的对比分析。如果你觉得本期视频对你有用,欢迎一键三连,你的鼓励对我很重要。
38曼道AI 05:32查看AI文稿AI文稿
05:32查看AI文稿AI文稿在上一期里,我们搭建起了上下文工程的框架,并把核心操作归纳为写入、选择、压缩、隔离这四大系统指令。今天我们要深入探讨这个框架的起点。记忆的写入。 写入操作背后有两大核心记忆系统,分别是草稿纸和长期记忆。接下来我们会详细剖析他们的实现机制和设计模式。简单来说,写入这个动作其实是在为智能体 构建两种功能和生命周期截然不同的记忆系统。我们可以用一个形象的类比来理解这两个系统,那就是办公桌和档案柜。办公桌是你处理当前手头工作的地方,上面堆满了草稿、便签和临时资料, 一旦工作结束,桌面就会被清空。这就好比草稿纸,它服务于当下的短期过程性记忆,而档案柜则是存放重要结论、经验总结和项目规章的地方,方便未来随时查找。这就如同长期记忆服务于未来的长期结论性知识。下面通过表格清晰呈现二者的区别。 从目的方面来看,草稿纸是为了确保当前任务能够成功执行,而长期记忆则是为了服务未来的所有任务,助力智能体实现学习与进化。从生命周期角度而言,草稿纸的生命周期是任务级别的,具有意识性。 而长期记忆是永久性的,并且可以跨绘画使用。从内容力度来讲,草稿纸记录的是详细的过程和原始数据,长期记忆记录的则是经过提炼后的结论和高级知识。 从核心作用来看,曹丕保证了当前任务的逻辑连贯性,长期记忆则让智能体能够学习、 进化并实现个性化。接下来我们详细解析曹丕的核心机制,其核心在于存储与使用的分离,这意味着 草稿纸中的完整信息存放在上下文窗口之外的应用程序内存中。只有在每次调用模型时,我们的上下文工程代码才会智能的从中选择、压缩最关键的部分载入上下文窗口,这正是它对抗上下文腐烂的核心手段。在工程实现上,主要有两种模式,模式一, 显示工具调用。在这种模式下,智能体会主动调用类似 right note 的 工具来进行记录,具体流程如下,第一步,智能体思考并形成计划。第二步,它开始行动,明确的调用工具,将计划写入草稿纸。 第三步,在获得新信息后,他再次进行思考。第四步,再次行动,调用工具更新观察结果。这种模式的优点是行为完全透明,非常便于我们调试和理解智能体的决策过程。但缺点也很明显,他对模型遵循复杂指令的能力要求更高, 而且每一次写入都是一次额外的工具调用,会增加 token 开销和延迟。模式二,隐式格式驱动。这是目前更为主流的方式。我们不再提供专门的写入工具,而是在系统提示中强制要求智能体的输出必须遵循 stop action 的 格式。智能体的输出是一个包含了思考和行动的完整文本块。接着我们的框架会接入处理, 它会自动提取出思考部分的内容,存入后端的草稿纸,然后再提取行动部分去执行。对于模型而言,他并不知道草稿纸的存在,只是在出生思考。这种模式的优点是高效、自动化, 更符合模型的自然推理流程。但缺点是记忆的写入过程由框架封装,对于开发者来说不如显示调用那样直观。接下来我们详细解析长期记忆的写入。如果说草稿纸解决了任务内的连贯性问题, 那么长期记忆则是为了解决长期任务的连贯性问题。这里的核心挑战在于如何从海量观察中智能地提炼出高价值信息。业界主流有两种著名的生成机制,机制一、 reflection。 reflection 的 核心思想是从错误中学习提炼规则,它是一种事件驱动的纠错型记忆。具体流程如下,第一步,框架检测到一次失败情况,例如智能体搜索苹果,收入返回的却是手机新闻。 第二步,框架自动触发一个原提示,要求大语言模型复盘这次失败,并生成一条可附用的规则。第三步,大语言模型生成一条类似当我搜索公司财报时应加入季度收益等关键词这样的行为策略,然后由框架将其写入长期记忆机制。二、 generative agents 这种模式的核心思想是从观察中总结合成洞察,它是一种周期性的认知升华模式。 其流程为,第一步,系统在一天中持续收集原始的、零散的事件日记,比如张三提到预算紧张和李四发了成本削减的邮件。第二步,在每天结束时,框架自动启动一个 prompt plan, 通过多轮提问,让大语言模型对这些原始日制进行层层对照和提炼。第三步,大语言模型 最终生成一条类似洞察项目 x 正面临显著的预算风险这样的高级事实,并由框架将其写入长期记忆。总结一下,今天我们深入探讨了写入上下文这一核心操作,了解到它包含两个层次,一是草稿纸,通过显示或隐示的方式管理着任务内的短期记忆。 二是长期记忆,通过反思或合成这两种高级机制,实现跨任务的知识积累与进化。掌握了写入操作,我们的智能体才真正具备了记忆的能力。不过,信息存进去只是第一步,如何在需要时从浩如烟海的记忆中精准快速的找到那条最关键的信息呢? 这就是我们下一期要深入探讨的核心操作选择。如果您觉得本期内容有用,欢迎一键三连。
23曼道AI 05:16查看AI文稿AI文稿
05:16查看AI文稿AI文稿在上一期,我们学习了 luncheon 为上下文工程提供的 wsci 核心框架,也就是写入、选择、压缩、隔离这四大操作。这套框架就像一个系统级的工具箱,能解决 agent 在 运行中可能出现的各种问题。今天 我们要深入探讨这个工具箱究竟要治疗哪些具体病征。要理解这些病征,我们得先回顾 agent 的 核心工作循环 推理行动贯彻。正是这个循环,让 agent 能持续工作,但也导致了信息不断累积。我们把这种累积的未经管理的信息称为上下文债务,当这份债务过高时,系统就会从健康状态滑向病态。 lanckken 的 文章引用了 drubinic 观点,将长上下文可能引发的性能问题归纳为四种典型的可被诊断的失败模式,就像是 ai agent 的 临床症状。第一种是上下文污染,它指的是一次幻觉或错误信息渗入到上下文中,还被后续的推理当做事实依据。 这就好比信息员被投毒,一旦有毒的数据进入 agent 的 认知循环,后续基于此的所有决策链条都可能被污染,导致最终结果严重偏差。第二种是上下文干扰,它指的是上下文中的信息过多,压倒了模型自身的预训练知识。 这就像信噪比过低,模型强大的常识和非理能力源于其庞大的预训练数据。但如果我们在上下文中填充大量低价值的预训练数据,这些噪声就可能淹没模型固有的知识信号, 让他在噪声中迷失,做出违背常识的判断。第三种是上下文小,他指的是多余的不相关的语境信息影响了最终的回应。这就像注意力被分散,因为上下文中有太多看似相关但实际无关的元素,模型的注意力被稀释,无法清晰。追综合新逻辑, 从而把两个不相关的概念错误关联,造成逻辑上的张冠李戴。哎。第四种是上下文冲突,它指的是上下文中的不同部分,包含相互矛盾的信息。这就像指令级冲突,比如系统提示要求模型保持简洁,但历史对话中却有很多涌长的例子,或者 从两个不同数据源检测到的信息相互矛盾,这会让模型陷入决策困境,导致行为混乱或犹豫不决。接下来我们要搞清楚这四种具体症状和之前在 anthropic 系列中学到的上下文腐烂这个概念有什么关系。 这很重要。弄清楚它能帮助我们建立一个从根本原因到表面现象的完整诊断模型。上下文腐烂是描述底层状态的术语, 它是说由于 transformer 架构在处理长序列文本的内在限制,导致注意力被稀释,而且训练数据中长序列样本缺乏,使得模型在上下文长度增加时,整体认知能力包括信息召回精度和长距离逻辑推理能力会系统性呈梯度的下降。 这是一种和信息数量直接相关,不可避免的物理现象。而我们刚才讨论的四类性能问题是,这个底层状态恶化后,在具体任务中表现出的可被诊断的失败模式,更多和上下文的内容质量有关。二者的因果关系可以从三个层面理解。第一, 直接引发上下文腐烂导致的注意力稀释和信噪比降低,会直接引发上下文干扰和语境混淆。约模型没办法有效区分信息的优先级和关联性,自然会被无关信息干扰或者错误关联信息。第二, 催生与放大风险。但已经处于腐烂状态的系统中,模型的推理能力下降,更容易产生幻觉,从而主动制造出上下文中毒的源头。同时,对于外部输入的错误信息,它也因为判断力下降而更难识别。第三,屏蔽问题发现在腐烂状态下, 模型的长距离记忆能力衰退,这让他可能发现不了上下文中早已存在的语境冲突,因为相隔较远的两条矛盾信息已经超出了他当前有效的注意力范围。我们用一个精准的类比来加深理解,把 a i a 证想象成一个开长途车的司机。在这个类比中,驾驶员就是 l l m, 本身 是执行任务的主体。司机的疲劳状态对应着上下文腐烂,它不是具体的驾驶错误,而是长时间驾驶,也就是长上下文导致的内在的、 系统性的能力下降,这时司机的反应、判断、注意力都在全面衰退。而我们刚才讨论的四类性能问题,对应着驾驶中遇到的烂路或由此引发的具体驾驶失误。通过这个类比,因果关系很清晰了,上下文腐烂是根本病根。 四类问题是具体并发症,一个精神饱满的司机,就算遇到烂路也大概率能成功应对。但一个疲劳的司机因为内在状态衰退,处理烂路的能力大大下降,出车祸概率大大增加。总结一下,上下文腐烂是因为模型架构限制 导致其处理长,上下文能力下降的底层现象。而我们今天讨论的四类性能问题是腐烂状态下 在具体任务中表现出的可被诊断的失败模式。上一期我们学习的 w s、 c i 四大操作,也就是写入选择压缩隔离,正是为了从架构层面系统性的对抗上下粉腐烂这个根本病菌预防和治疗这四种具体的并发症而设计的。 下期我们讲解 well cc 中写入记忆具体的工程实践。如果您觉得本期视频有用,欢迎一键三连。
41曼道AI 04:41查看AI文稿AI文稿
04:41查看AI文稿AI文稿在之前的几期中,我们学习了上下文工程的写入、选择和压缩,这些操作都只在优化单一信息流的信噪比和效率。今天我们将进一步探讨隔离上下文, 它要解决的是一个更复杂的问题,当系统需要同时处理多个任务或者一个任务过于庞大时,如何防止不同的信息流之间互相干扰?隔离的本质就是分而治之,它不再是优化一个上下文,而是创建多个独立且互不侵犯的上下层空间,以实现复杂并行的工作流。 本期我们将深入探讨实现隔离的三种核心架构,分别是多智能体、环境沙箱以及运行时状态。 首先是最直观也最强大的隔离策略,多智能体,它的核心思想是将上下文的隔离级别从 agent 内部提升到 agent 之间。其核心机制是一种团队协助模式,由一个主 agent 进行顶层规划与任务分解, 并将具体的子任务派发给多个并行的专家。子 agent 关键在于每个子 agent 都在自己完全独立的上下文窗口中工作,实现了清晰的关注点分离,避免了主 agent 被海量细节所污染。但这里存在一个非常现实的工程权衡,这种模式虽然强大, 但原文也提到其 token 消耗可能高达十五倍。那么,作为产品或技术负责人,我们应该在什么情况下才值得付出如此巨大的成本呢?关于单 agent 还是多 agent 的 关键决策我之前已经制作过一期独立的视频单 agent vs 多 agents, 一套清晰决策框架。在那期视频中,我们建立的核心思路是默认应该采用单 agent, 因为它的成本和复杂性都更低。只有当单 agent 遇到了明确的瓶颈时,我们才启动对多 agent 尬购的评估。而评估的核心标准有两个,第一, 任务是否高度可并行,且子任务需要深度探索。第二,架构升级带来的收益是否远大于其高昂的成本。如果大家想深入了解这个决策框架,强烈建议回顾一下那期视频。第二种隔离模式是环境沙箱,这是一种在技术上极其聪明的架构, 它的核心思想是分离思考与执行,它的机制是让大语言模型的上下额只负责思考生成代码或指令, 而将所有重资产的操作,比如代码、执行文件 i o 都交给一个外部隔离的执行环境来完成。这里可能会产生一个疑问,如果沙箱也只是返回一个简短的结果,那它和我们之前讲的草稿纸机制本质区别是什么?不都是把大块信息放在窗口外吗? 它们的区别在于信息的借制和交互的方式。曹丕本质上是一个文本日记,他隔离的是思考的痕迹,存储的是自负串, agent 对 他的操作是读写文本。而沙乡是一个动态环境,他隔离的是真实世界的状态, 存储的是真实的对象。 agent 对 他的操作是发号施令。通过这种方式, agent 可以 通过操作沙乡中对象的原数据和样本, 实现对海量数据的盲人摸象式分析,而它自身始终工作在一个轻量级的上下本中。最后一种模式是运行时状态对象,它发生在单个 agent 内部,它的核心机制是通过结构化来隔离 agent 的 内部状态。我们将 agent 的 完整状态设计为一个包含多个字段的对象,如 messages、 internal notes 等,并由开发者代码暗虚暴露给 l l m。 这又引出了另一个问题,这个模式听起来和上一期讲的从运行时状态中选择几乎一模一样,它们的界限到底是什么?答案是, 它们是同一枚硬币的两面,但视角和意图完全不同。隔离是架构式的视角,强调阻挡。它在设计之初就通过 scram 设计预先定义了信息边界和访问权限。选择是操作员的视角,强调拉取。 它是在运行时根据隔离预设的规则,动态地从不同分区中拉取所需的信息。简单来说,隔离定义了信息的边界,而选择在边界内活动。至此, 我们已经完整地学习了 luncheon 提出的写入、选择、压缩、隔离这四大核心操作。回顾整个精读系列,我们从 antropica 的 理论出发,理解了上下文腐烂的根本约束,再到 luncheon 的 工程实践,我们掌握了管理上下文的 wsci 框架。最终我们得出一个结论, 构建一个真正强大、可靠、可扩展的 ai agent。 其核心挑战已经从算法和模型本身转移到了系统性的上下文架构设计上。这正是我们作为产品经理和开发者在 agent 时代的核心价值所在。谢谢观看,如果觉得对您有用,欢迎一键三连!
16曼道AI 09:25查看AI文稿AI文稿
09:25查看AI文稿AI文稿大家好,我们今天继续讲解 ai 开发 launch, 我 们今天讲解的题目是角色以及保留上下文,然后我们看看今天要点,其实是模板角色保留上下文。首先其实是模板,就是 我们之前讲的那个模板,今天模板稍微不同。然后角色呢?什么叫角色?就是我们在给 ai 对 话中,嗯, ai 他 默认的常最常见,分几种角色,首先第一种角色就是系统提示,就是 你要告诉 ai 他 是什么,然后他的能力、边界以及规则,就像这个你是一个专业的客服,你是温柔的陪伴型助手。然后就是这样的意思,就是你告诉 ai 你 是干什么的, 就是给他定了个信,然后剩下两个角色,一个是用户,用户就是咱们你在那个向 ai 请求的问题,这就叫呃用户角色, 就是下面写的这种呃学生开发者,然后还有一个助手,这个助手角色其实说白了就是 ai 给你返回的问题,这个就叫助手角色。然后今天的代码呢,也是在这个老虎网盘资源,然后搜索 ai 角色,就上下保护就行。 然后我们直接看看代码的部分,首先代码部分呢,这一块是我们配置 ai 的 一个连接, 就是要访问大模型的连接,前面已经讲过,这块就是今天不一样的地方,之前的我们的提示词呢,我们可以看一下,初体验的时候,我们提示词就直接写了一段话,没有带任何的角色,这种直接问他,他就给你回答,这是通用的。 然后你看我们今天的提示词,他就变了,也是提示词模板,但是模板里面他不一样,他分了几种角色,第一个就是 system, system 就是 刚才说的,你告诉他你是一只小猫, 然后你的名字叫什么?这个待会我们参数传进来,我是你的主人,你每天都有和我说不完的话,下面请开启我们的聊天。然后这有三个要求,那么有了这个 system 呢? 那么我们这个 ai 它的一个角色设定就已经定好了,它只能在咱们这个设定的规则以内,它会跟你说话,你说后面你跟它再对话的时候,它就会像一只小猫一样跟你说话。 然后下面 human, human 就是 我们就是刚才说到的 user, user 就是 我们向他提问的一个角色,这有些同学说,刚才不是说三个吗?为什么这只有一两个?先别着急,因为一开始呢,就只有两个,后面 回 ai 回答了问题才有 ai 的 角色。你看我们现在把这题词填充一下,就这定的 chart template from formate message, 你 看这个 name 就是 传进去的,就是你告诉他你的小猫叫什么名字,叫咪咪,然后下面这儿你问了他什么,想我了吗?然后我们先看看这个提示词组合起来是个什么样子。我们先不让它发给大模型,我们就看看,单纯的看看提示词是什么, 这样很快执行完,你看它的提示词就带有角色了。 system message 就是 这个 system, 然后再往下走, human message 就是 user, 那 它这是用 hum, 然后这就是提示词,然后我们看看我们把这个提示词发给大模型,它会怎么回答,然后你看 大模型怎么发呢?这前面不定义了大模型的连接大模型客户端吗?然后 invoke 一下,然后我们就用普通的括号返回,我们看看它给我们的返回是什么样子的, 哎,看,返回回来了,它说话是不是就按照小猫看?它说,喵主人回来了,开心的蹭主人的腿, 今天我可想主人了,我一直趴在窗台上看外面等你回来呢。今天看到三只麻雀,还有一只长得特别像小鱼干。然后 这个时候你看他的回答,是不是就是按照咱们系统给他定义的奶声奶气的小咪咪?然后给咱们回答的问题是不是就这种语气?这个 system 最主要就是干这个事的,然后 这是角色设定,我们讲完了,然后前面刚才说的角色为什么只有两个?然后别着急,我们再往下走, 然后延续上下文关于这个呢?嗯,先说到,先说一个概念啊,大家觉得 ai 到底有没有记忆?可能很多人都说有。 然后这个问题呢,我跟我的朋友也讨论了,争论了很长时间,不算讨论吧,他是一个非计算机人呢,我们先看一看啊,问题就是这个是 ai 大 模型,大语言模,大语言模型,把它字体放大一点, 这是我们 ai, 然后我们人相当于在这这吧, 咦,没了,我只画一个小圈吧,椭圆,这是我们人,我们向他提问题,发了个问题,然后他给我们回答了,然后我们再给他发问题的时候,他能不能记住我们之前提的问题和他的回答? 先说答案,他肯定是记不住的,这个时候大家可能都会有人要反驳,哎,不对啊,我们用的这个大模型,他明明能记住。我前面问他的问题啊,是的,但我们用的那个,呃,叫 ai 应用, 他不是最原生的这个大模型他为什么能记住呢?然后我们下面通过的讲解你就知道了,我们先记住 一个知识点,这个大模型它本身它是没有记忆功能的,我们只能跟它发一次绘画,它告诉我们再之后再跟它发前面的绘画,它是没有记住的。那么我们平时应用的豆包 tipsix 它是怎么记住的呢?我们看看 今天要讲的内容,就是保持绘画,就是把上下文都怎么保持住。我们刚才那个代码走到这里就问了下他咪咪给他起个名字,然后问他想我了吗?就是这样的一个过程。那么后面我们再问他, 你看这块,我们把这个返回的 message 就 前就前面我们提问的 message, 再加上 ai 回答回来的内容,这个就是我们想讲的第三个角色,刚才之前一直没有讲的 ai 回答的问题,这个就是 ai message 直接用它 ctrl 就是 它返回的内容,我们把它加到这个 message 里面,这样的话我们的提示词就变成了 这一块系统提示词,然后用户说的话,刚才说的什么?想我了吗?然后又加了一个 ai 的 回答,回答是什么?就是刚才看到的这一段, 这是一个回答以后的提示词,然后再问他问题的时候,我们怎么问? message 里面再增加新的消息,今天遇到了一个小偷, 然后这个是新的提示词,你看这是二三的提示词,然后最后把这个问题都发给他。也就是说我们每次 向大模型追加问题的时候,实际上是把前面跟 ai 的 绘画内容,就是你你给他发了什么,他回答了什么?都再一次发给大模型,这样大模型他才能 有记忆,就让你觉得有记忆,实际上它是没有记忆的。这个问题讲清楚了啊,然后我们下面运行一下代码,看一下它的第二次加了,嗯,这个 ai 回就是 ai 给你回答问题的以后的提示词是什么样子?我们打出来,然后我们又又增加了个问题,是什么样的打出来啊?我们看看啊, 这个是第一次请求的初识的提示词, 然后第二次你看,第二次他就带了角色,你是一只很粘人的小猫,是不是?我们前面定义的?比如我们发第二个请求的时候,是把前面的回答内容也给他加进去了,然后再往看关键点,最后 um system message, 我 找一下看,这个是第一次问的,然后它又回答了 a i message 又回答了, 这是前面的第一个提示词,然后这个第这个提示词又加了新的。今天遇到了一个小偷, 这今天遇到了个小偷,也就说我们为了让大模型有看起来是有记忆的,那么我们每次新提问,其实是把之前的对话的内容都告诉他了。
29it大神 06:09查看AI文稿AI文稿
06:09查看AI文稿AI文稿在上一期,我们深入探讨了写入上下缝的两种核心机制。通过写入,我们已经为智能体构建了一个庞大且可供查询的信息库。今天我们要解决一个更为关键的问题, 当智能体需要做出决策时,如何从信息庞杂的库中精准找出当下最需要的信息并放入上下文窗口呢?这就是上下文工程四大核心操作中最高频、最核心的一环。选择上下文, 我们用操作系统来类比。如果说写入是把文件保存到硬盘,那么选择就相当于操作系统的内存调度算法, 它的优劣直接决定了整个系统的响应速度和智能程度,其核心思想是从加载数据进化到注意力调度。本期我们将逐一解析如何从草稿纸、长期记忆工具集和知识库 这四个关键信息源中进行高效选择。我们首先关注智能体的内部信息源,也就是它的草稿纸和长期记忆。 一、从草稿纸中选择草稿纸记录了智能体在一个任务中的完整思考上,不过它会不断变长。这里选择的机制取决于写入的实现方式。如果草稿纸是通过显示工具实现的,那么智能体可以在思考过程中主动调用类似 scratpad 这类工具来回忆和选择它需要的历史步骤。如果草稿纸是作为运行时状态的一部分,这也是更主流的方式,开发者就可以通过代码进行精细化控制,在霉菌循环中按需暴露草稿纸的不同部分。常见的策略包括使用滑动窗口只加载最近 n 轮的思考传,或者进行状态 总结,只加载上一步的行动与观察结果,又或者在失败时进行错误复盘,专门加载所有失败过的步骤。这种由开发者代码主导的程序化筛选过程,是 保证智能体在复杂任务中不迷失方向的关键。二、从长期记忆中选择对于长期记忆, land chain 引入了人类记忆三分法作为分类和选择的框架。程序性记忆对应智能体的行为规则,也就是系统提示。 有人可能会问,系统提示不是每次都必须加载吗?为什么说是可选的呢?在传统提示里,系统提示固定不变。但在 lanchen 架构里,程序性记忆是多模板可切换的。系统可以根据当前的用户意图,动态地选择并加载一个专门的指令模块。比如 一个客服智能体在识别到用户意图时才会去选择并加载关于退货流程的详细指令及情景。记忆对应智能体的过往经验, 最典型的就是少量本视力,这也不是静态的,高级的策略是动态少量本提示。系统会根据用户当前问题的语义,从一个庞大的视力库中动态检测并选择最相似、最相关的几个成功案例,注入到本次的上下文中,实现具体问题具体分析。 这样做的好处是每次调用的少样本都与任务相关,能节省 token, 避免上下文腐烂。语义记忆对应事实性知识,这是最庞大选择挑战最大的一类,单纯依赖欠入或知识图谱进行缩影,这是第一步, 真正的挑战在于确保选择的记忆是恰当的。文中引用了一个失败案例,一位用户要求 chat gpt 生成一张图片,但 chat gpt 却从他的地理位置信息,并将其注入到了图片中。 这个案例给我们一个深刻的警示,一个错误的选择有时比没有记忆更糟糕。它揭示了选择机制的核心难点,犯法不仅要判断与意相关性,更要判断任务意图的世界性。 现在我们来看智能体如何从外部世界中选择信息。一、从工具集中选择当一个智能体拥有上百个工具时,如果把所有工具定义都放入上下文,会造成巨大的上下文干扰和偷看浪费。这里的核心高级策略是工具的解锁增强生成。 它的实现机制是为所有工具的描述建立一个独立的 r a j 缩影。在智能体每次思考前,系统先根据当前的子任务意图进行预剪索, 选择出最相关的前 k 个工具,只将它们的完整定义加载到本次的上下文中。这种方法的价值在于,它极大地降低了模型的决策难度,能显著提升工具调用的准确率。这里值得进行一个扩展讨论,也就是工具选择的架构权衡。 lion chain 推荐的动态选择策略 优先考虑的是扩展性与精准度。它特别适用于那些工具及庞大且开放的场景,比如插件系统。 而 menace 的 文章构建 menace 的 经验教训中建议的做法是,固定工具级加遮蔽策略,保持提示前缀不变。利用 cv 缓存可以降低成本,提高速度。适用于工具级小而稳定且对响应速度要求极高的场景。这两种策略没有绝对的优劣, 而是在不同产品约束下的工程选择。有机会我们可以再精读一下 minus 那 篇关于唱下文工程教训的文章。二、从知识库中选择最后我们来看知识选择。这里的技术趋势是从简单的向量搜索引进为由智能体主动迭代探索信息的智能搜索,其核心痛点在于 对于代码库等结构化信息,单纯依赖向量的语义相似度是不可靠的。因此,一个强大的知识选择系统必须采用混合解锁策略。这套策略通常包含三个步骤, 首先是多路召回,并行使用多种技术,比如用向量搜索查找语义相似的内容,用关键词搜索来精确定位实体名,用知识图谱来查询复杂的关系。其次是智能体探索,允许智能体在思考行动的循环中主动使用这些解锁工具进行多步骤的 有逻辑的推理和信息挖掘。最后是重排序,再召回大量后选信息后,再用一个更精细的模型或规则进行二次筛选和排序, 最终选择出信代比最高的几条放入上下文。总结一下,本期我们掌握了上下文的选择方法,包括从草稿纸、长期记忆工具以及知识中选择最合适的信息进入上下文。但如果经过我们精挑细选之后,发现这些关键信息加起来仍然超过了上下文窗口的长度限制,我们该怎么办呢? 这就引出了上下文工程的第三个核心操作压缩。下一期我们将探讨如何以高保真的方式为上号箱进行瘦身。如果您觉得本期视频有用,欢迎一键三连。
8曼道AI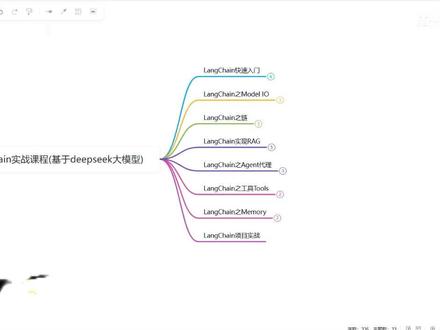 01:02:01查看AI文稿AI文稿
01:02:01查看AI文稿AI文稿一天学一个变态的大模型知识点,今天讲的是来看从入门到精通。 哈喽大家好,欢迎来到浪铲实战课程啊,那这个课程呢,是基于 deepsea 这个大模型来给大家讲解浪铲这个 框架以及一个项目实战。那咱们浪铲的版本呢,是基于零点三的这个最新的版本,那在浪铲这个课程里面会给大家介绍到这些方面。首先第一个是浪铲的一个快速入门, 那在这里面会给大家把 longchain 的 整体啊,全都给大家过一遍,比如说 longchain 的 一个基本使用,提示模板输出的一个解释器,以及我们怎么用这个向量存储,以及一个简单的 ig 实现,还有我们的 agent 代理的一个基本使用。 那我们在第二个模块的话,就是 longchain 的 一个 model io, 那 这一部分呢,总共分为三个大的模块,就是提示模板,我们的 model 模型以及输出解释器啊。那在第三个 章节呢,我们回家讲到 log 键的链啊,首先第一个就是一个 log 里面链的一个基本使用,以及链的调用方式,还有我们 log 键中啊,内置的常见的一些链的使用。 那接下来呢,我们回家讲到这个 log 键的实现的一个 r g 啊,这是一个简单的 r g, 没有经过任何的优化。那这里面回家讲到文档的加载,对吧?我们怎么加载本地的,怎么加载这个在线的?然后呢,文档的切割文本,向量化的模型啊,以及向量存储,还有我们的这个 retwo 解锁器。 那接下来我会给大家讲到 luncheon 里面的一个 agent 代理, agent 的 一个基本使用啊,我们的 openai function agent 以及这个 react agent 啊,这个是咱们呃 agent, 也就是智能机里面用的比较多的一种这个框架。 然后接下来就是 longchain 的 这个工具啊,那在这个工具里面,我们会给大家讲到 longchain 的 一个工具的一个初步认识,以及更多的工具的使用。那接下来的话就是 longchain 里面的这个 memo 的 记忆管理,那在这一块会给大家讲到两方面,第一个就是最基础的记忆管理方法, 然后再会给大家讲到更高级更灵活的记忆管理,那把这些所有的模块给大家讲完之后呢,我们会通过一个 luncheon 的 项目实战啊,来给大家把所有的知识点呢,给大家穿插起来,也会给大家做一个项目实战啊,那这个课程呢,就是我们啊整体的一个知识点的一个架构。 那我们接下来正式的进入到 luncheon 的 一个框架的学习啊,那我们在讲课的时候用的是这个主比特,然后也给大家准备了这个 pdf 的 一个课件啊,大家可以方便课后去看, 然后当然推荐大家用这个注册这个方式,那我们进来看一下快速这个初识 luncheon 的 一个快速入门。那 luncheon 呢?首先它是一个框架啊,主要就是用来做咱们这个大模型这个应用, 那它的好处就是什么呢?我们用这个框架啊,它本身提供了一系列的工具套件以及接口,那可以让咱们的开发者啊使用语言模型来实现各种各样的任务,比如说文本啊,到图像的一个生成文档回答,聊天机器人等等啊,但是我们现在可能用这个 luncheon 做的比较多的, 还是啊这个基于文档的回答以及聊天机器人啊这些应用,对不对?那下面给大家看一个它的一个官网啊,这是 long chain 的 一个官网,然后它官网上这里都是英文的,对吧?大家如果说英文不太好的话,这里面也不需要担心啊 啊,这里面有一个中文的这个一个文档啊,然后它基本上就是照着翻译过来的,而且它的版本呢,也更新到了最新的一个版本,所以说啊,大家如果英文不是特别好的话,可以去看一看这个中文的啊,它基本上就是照着官网去原版不动的翻译下来的, 你看大家看这里旁边基本上都是一模一样的。好吧,那我们接下来借用这个官网里面的这句话啊,来看一下这到底是个什么东西,我们来看这里啊 啊,这个大家如果说看一些啊,想看这个英文的,但是又看的不是特别懂的话,然后大家可以下载一个浏览器的一个插件啊,叫这个沉浸式翻译啊, 你看 lunchin 是 一个什么东西对不对?一个简称 lunchin 是 一个用于开发单元模型驱动的应用程序的一个框架,咱们用框架的好处就是人家给咱们开发写好了,对吧?而且 lunchin 简化了大模型应用的生命周期的各个阶段啊, 比如说什么开发阶段对不对?生产阶段,部署阶段啊,这三个阶段其实都需要我们去完成对不对?那开发阶段的话,我们使用浪线的开源的构建, 这个组建对不对啊?来开发咱们的应用程序,利用第三方执行和这个模板可以快速的开发出来。那生产阶段我们使用这个 lsmith 可以 去检查评估啊 啊,监控您的链儿,包括我们的提示词对不对?然后最后部署啊,最后部署的话,我们可以使用这个 lasso 将咱们的任何的链儿呢转化为一个 api 啊,就是咱们现在做的项目的话,一般可能都是前后段分离的对不对?那我们用 lasso 的 话,可以把这个链儿转成 api 的 一个形式啊。 那接下来的话,我们来看一下 lasso 里面的核心组件儿,它的核心组件儿的话一共有这么大概六个,第一个就是咱们的提示模板,第三个是咱们的数据解锁, 第四个是这个记忆 memory 啊,第五个就是链,第六个就是 agent。 大家先对这些核心组件有一个简单的印象就可以,等我们把这些所有的都讲完啊,然后大家回来再看。哎,这个时候大家就会啊,知道 luncheon 里面的核心组件总共有哪些,然后它分别是干什么的, 咱们现在分别跟大家说,比如说模型干什么的啊,铁木板是干什么的,对吧?大家可能现在也是有点模糊啊,但是这个基本上如果大家之前接触过大模型的话, 这个模型啊,其实包括提示模板,这个两个大应该不陌生啊,但是对于后面的,比如说数据剪辑呀,记忆啊,链啊,或者或者咱们那个 agent 啊,这个可能不是特别的一个熟悉是吧? 这个没关系,我们后面呢都会给大家一一的讲解到啊,包括它里面封装的一些这个模块啊,比如说模型 i o 的 一个封装,它包括什么代码? model, prompt、 output, password 啊,这个输出解析 对不对?以及这个 retou 啊,就是我们的一个向量解锁,是吧?它包含了什么模块啊?这些模块呢?我们后面都讲,都会给大家讲到,大家先有一个眼熟就可以,对不对?比如说 retou, 咱们的向量解锁, document loader 是 我们的啊,各种各样的文档的一个文件的一个加载器,比如说我们要加载 pdf 的 啊,加载 word 啊,加载这个 macdunk 啊等等。然后接下来的话就是咱们的 imagine model 啊,这个大家看到这个东西就知道它肯定是为了 r g 做准备的,对不对?包括这个向量存储啊, vitry story 啊,就是向量的一个存储,还有最后一个对文档的一个日常操作啊,比如说我们要切割呀,对不对? 然后最后啊,它的一个模块里面还有什么?还有咱们的 agent, agent 的 话就是一个智能体,对不对?但如果说之前接触方式拷定的啊,就是咱们 agent 中的一部分啊,它要为了实现某些,对吧? 比如说它可以调用外部功能的函数啊,谷歌搜索呀,对不对啊?文件 i o 啊,查天气啊啊等等等等。那这个它是怎么实现呢?大家可以简单理解,就是通过那个防身 call 用来实现,然后下面是它的开源的 code 组成啊,比如说 lanchang code, lanchang communication 啊,这个 这个我的发音不是特别标准啊,但是然后大家知道啊,这是个什么东西就可以,然后包括 lanchang, graph, lan solo, lan smith, 对 吧?可能我们在开发阶段用的比较多的其实是上面几个 啊,上面几个 luster 和 lsmith 的 话,是这个项目开完成之后,咱们要部署的时候才会用到。那上面给大家简单介绍了一下 lunch 这个模块,以及它里面的一些这个开源库,还有这个啊, 它的核心组件。那我们接下来看一下 lunch 的 我们要用的版本到底是哪个呢?啊?就是我们要指定它去安装的一个版本啊,就是我们通过 pip install lunch, 大家去安装这个零点三点七这个版本,然后后面这是什么意思啊?后面其实是换源啊,大家如果不换源的话,可能安装会比较慢。 然后还有一个版本,我们要去指定的就是这个 p i p install launch open i 啊,零点二点三,然后大家也去指定一下这个版本的去安装,那为什么要指定这个呢?这个其实是,呃,并不是 launch 最新的一个版本啊,它它我指的最新的是什么? 不是这个零点三除了零点四,而是什么?而是它后面的一个小版本,对吧?比如说零点三点八,零点三点九,零点三点一几,对吧?它现在后面的小版本呢,其实是不断在更新的,但是 啊,没有说从 longchain 零点二更新到零点三,零点三更新到零点四,现在零点四还没有出来这个最新的版本呢,大的版本呢,就是零点三,所以说我们用零点三这个版本来给大家讲,好吧, 那这个呢,就是啊 longchain 的 一个基本介绍,我们接下来看一下 longchain 的 一个基本使用,我们通过 longchain 来调用 openai 来进行对话,当然这个 openai 的 话,它其实内部啊,我们可以调用的模型是比较多的,包括这个国内的 deepsea, 我们先来导入这个模块啊,然后这个呢是加载咱们的点 e v 文件啊,咱们的点 e v 文件里面存了很多的这个 key, 对 吧?然后这个呢就是 chat open i, 我 们要进行对话,对吧?大家不要看它的名字叫 chat open i 啊,是不是只能调用这个 open i 的 然后一些这个 模型啊?其实并不是,接下来我给大家看一下怎么去调用咱们国内的 deepsea 的 一个 key 啊,这个 key 呢,现在在官网去申请就可以了,但是现在基本已经停了啊, 他现在也已经不让充值了,所以说大家现在应该申请不到了,但是大家可以通过其他的平台啊,比如说手速流量 api 对 不对? bc l 然后 k 这个 k 呢,大家现在应该申请不到了,就是因为他不能充值,不能充值的话,嗯,我们是没有办法去用的,对吧? 但是我们可以看一下代码,可以看一下它的代码,首先第一个就是它的一个 k, 然后第二就是它的倍速 l, 所以 说这个相对来说其实是比较简单的,我们只需要拿到它的 k, 把这个 k 呢写到哪里?写到这个点 e n 文件里面,然后接下来呢就可以把它获取到,获取到之后我们的模型啊, model 的 话,这里面指定啊叫 这个 deep secret 啊,它它的模型名字不叫阿姨,大家要注意啊,我们通过代码调用的时候,它的模型名字啊,不叫阿姨, 它现在的模型就是那个 chat 叫 v 三,然后它的推理模型呢?叫什么?叫这个 r 一 的模型啊?咱们在通过代码在调用的时候,它其实叫这个东西,所以说大家在用的,在这里面写模型名字的时候,不要写 deepsea 跟 deepsea 啊,这个它的模型名字是这个, 然后接下来 open ikey 的 话就是这个,然后贝斯源呢,也换成这个 deepsea。 那 接下来的话,我们这个模型在 long chat 里面啊,就相当于 更换完成了。如果说大家不写这里面的东西的话,他默认的话用的是这个 g p c 三点五,当然我们也可以用 g p c, 其他的比如说 g p 四四 o 啊,都可以,大家在这里面去直接去换就可以了,然后我们要去调用,对吧?那通过什么方法呢?通过这个 in google 啊,问他什么是大模型,对吧?然后打印这个 response, 然后这面打印了五十个等线,然后又把他的内容取出来,那大家看这个是他的直接的返回啊,这是他直接的一个返回,好吧,他基本上返回都是用 markdown 的 这种格式,然后呢?这是他的 content 取出来了, 看没有 content 取出来,对不对?大模型啊,是什么?然后大模型的核心特点举例,对吧?然后应用场景啊,什么挑战正义,然后未来方向,这个所有的他基本上都给你列出来了,看到没? 这个就是这个 i e 推理模型。但是如果说咱们换成什么,呃,咱们换成这个 oki 的, 他可能回复就没有那么多了,而且他可能并不,他可能回答啊都不是特别的准确,可能 那如果说我们要用这个 open i 的 话,可能我们我们就把这两行代码分开,因为我们要用这个代理,对吧?然后大模型通常指的是啊,深度学习吧啦吧一堆啊,大模型指的对不对?这个回答照 deepsea 的 回答可能就稍微差点,然后当然我们也可以去换模型,对吧?在这里面指定模型就可以了,比如说把它的 model name 指定是指定为这个 gpt 四啊, 这时候我们再来看它这个回答,可能就会比这个默认的 g p 三点五要好一点。这里如果大家什么都不写的话,它默认就是这个 g p 三点五,当然大家在那个点英文文件里面写上它家的 k 和 bc l, 这个我在我的点英文文件里面其实是有的, 然后这里啊继续学习,对吧?答模型通常是指,是不是啊?这个回答相比刚才三点五那个回答呢?可能就更准确一些, 对吧?这个是单轮对话的一个,咱们调用 deepsea 的 这个模型啊,因为大家可能现在这个 deepsea 现在调用不了,对不对?然后我们剩下的啊,咱们用这个大家可以自己去换啊,咱们课堂上用什么用这个 t v t 啊,或者说用这个 deepsea 都可以, 那这里面默认的话就是三点五杠 turbo, 那 咱们刚才进行的是这个单轮的对话,对吧?那其实我们也可以进行多轮对话的一个封装,首先还是先导入,然后来实例啊,里面什么都不写,默认就是这个三点五, 然后从这个,从 lancan 这个模块里面导入什么?导入 ai message human system, 这个其实相当于啊,如果大家之前学过 open ai 的 话,相当于这个 open ai 里面的 assistant user system, 对不对?像那个角色,对吧?那我们的 message 的 话就可以封装啊,比如说 sitter 木封装,你是这个于老师的个人助理,你叫小木,对吧?然后黑幽默呢?就叫我叫同学小张,是不是?然后这个又说了一句啊,你是谁?是不是?问他你是谁,对吧?那没那个我们正常的回答应该是什么? 应该什么?这个你是对不对? saturn, saturn 相当于什么?相当我们给这个 ai 附了一个角色,对吧?那我们现在在问你的话,你其实是指的应该是那个 ai 的, 对不对? saturn 这个 user, 所以 说他的回答应该是个人助理,叫小木,对吧? 啊?这个时候我们来运行看一下正常的回答,对吧?你看我是于老师这个个人助理,对吧?有什么可以帮助到你?那这个呢?就是一个啊, launch and 的 一个对话啊,它的一个单轮对话和多轮对话的一个简单的一个基本使用啊。 我们接下来看一下 launchchain 里面的一个提示模板的一个使用啊。首先我们要从这个 launchchain 点 code, 点 prompt, 然后导入一个叫 chat prompt timet 这么一个啊模块,然后我们要用的话 怎么用呢? chat prompt timet, 然后,然后 from message 这里面的话我们可以去传啊,传一个这个源组,那第一个呢,就是 system, 也就是它的一个角色,我们定义给这个 咱们的一个 ai 的 一个角色,比如说告诉他你是一个世界级的文档编写者,然后这个 user 呢?就是我们啊,我们自己输入的, 对吧?用户输入的,然后这里我们可以打印一下这个 prompt, 那 接下来的话,其实我们要把这个提示词发给谁?发给咱们的大模型啊?怎么发呢? 在浪差里面有这种操作,叫练式操作,什么意思啊?就是把它处理啊,经一个竖线,然后呢交给大模型,这个大家怎么理解啊?如果大家学过内个词的话,其实应该见过,这叫管道服, 比如说在 list 里面它有命令。 ps, aux 对 不对?查看现在所有进程,但是我不想查看那么多,我只想查看什么?查看 register 进程,那大家就在中间可以加上一个竖线,就起到什么?起到一个传递的作用,就是把它处理的结果传给他, 对吧? ps, a o s, 查看所有进程,但是我想在这些所有进程里面过滤出来,过滤出来是吗? reddit, 所以 说就把所有进程交给这个命令,然后再去处理一下,那其实在 longchain 里面也是差不多的,我们写好的这个提示词,对吧? from message 啊,这个,当然这是其中的一种用法,我们这个提示模板也不止这一种,我们现在是一个给大家把 longchain 里面所有的指点啊,先给大家快速过一遍, 这个练式调用的话,我们后面也会给大家详细讲解,也就是把这个题模板交给大模型,对不对?但是有一个变量没有什么还没有传啊,有时候用户输入的还没有传,那这时候怎么办呢?我们可以通过嵌件 excel 格式去调用,然后呢在这里面写 input, 对 不对?把我们的问题写上啊?什么是大模型?那这时候我们来运行一下, 上面就是它的一个提示模板,看到没有?上面提示模板,这个是我们要输入的一个变量 input, 然后 input 这个 type 啊,剩下的基本上 message 里面,呃没有什么东西,对不对? message 里面唯一一个就是 system 嘛, system message, 然后这块 time 就是 您是一个世界级的文档,对吧? 那这个接下来是他的一个回复啊,接下来其实就是他的一个回复了,比如说 content 大 模型指的是指的什么东西?然后后面,呃,但如果说你只想你只想去获取内容的话,直接也可以点 content, 对 吧?如果说你想看的比较全,他这个里面什么都有,比如说 我们的总共的头肯是多少,对不对啊? prom 的 头肯是多少?总共的头肯是多少,是不是?然后它用的模型的名字是哪一个啊?它这个 user 啊,这里面它每个其实都有记录,所以说如果说大家想看到比较全的信息的话,可以直接这样,如果说你不想看到的话,直接点 ctrl 把它取出来就可以了。 那这个就是 lanchen 的 其实模板的一个基本使用啊。那我们接下来再来看一下这个输出显示器啊,这个输出显示器的话,其实就是控制咱们 lanchen 的 一个输出,好吧,那我们来看一下它具体是怎么来控制这个输出的,那上面还是一样的,我们要去导入,对吧?这里面还是从这个 lanchen 点 lanchen 下弦扣的 来导入这个 output pass 里面有 string 啊, jess 啊等等啊,然后我们具体讲到这个输出显示器的时候,会给大家每一种都介绍一下, 那最开始还是一样,我们要来抽象这个模型啊,默认还是三点五,大家如果想要 type c 的 话就换成 type c, 咱们在之前的视频里面也都跟大家讲过,那接下来的话,我们就要创建一个文档,对吧? type prompt, 然后第二行 message, 那 这里 system 给它定义的就是你是一个啊,擅长编辑技术文档,对吧? 其实我们可以让他做一个什么,作为开发者,是不是啊?你是一个擅长编辑技术文档的一个开发者,或者说产品经历啊等等,这个角色呢?大家可以自己定义,对吧?根据大家的一个需求,然后这个 user 呢?同样是音库的,这是我们用户要输入的一个问题,对吧?比如说我们要去问他啊,这个 launch 是 什么呀?对不对?大模型是什么呀? 然后接下来的话,我们听一个输出解释器啊,这个输出解释器是一个叫词顺啊,叫 putpasser, 也就是说我们最终想让 lange 输出的一个结果呢?是一个字串,对吧?那我们怎么把这个啊,这个输出解释器和这个 lange 最终那个输出把它结合在一起来呢?就是通过我们这个链,对吧? 我们的这个 prompt 啊,模板,对吧?要传给大模型,对不对?那大模型现在有了回复,有了回复之后呢,我还要经过输出解释器的一个处理,就是相当于什么?相当于一层一层,像那个啊,像那个生产的链一样, 对不对?咱们这个工厂里面是不是有那个链,对吧?第一个工人组装一下,第二工人组装一下,第三工人再组装一个,对吧?最终呢把这个成品呢给它拼接起来,对不对?给它组装完成,那这个链呢?其实跟这个就非常的像我们的 problem 的 创意大模型,对不对?大模型处理完成之后,哎,我最终的一个输出是要输出成一个租串,对吧? 那我们来看下浪欠,然后这个欠点一维口啊,这个还是问他这个浪欠是什么?那我们来看他的一个输出到底有什么不一样的一个地方, 哎,大家发现两千,对不对?这是他的一个回复啊,他的回复现在其实就是一个字母串,那有人说这里面和我们之前其实没什么区别,对吧?那如果说我们把它去掉,大家就能看到区别了, 我们刚才这个回复就是什么?就是一个纯字母串,那你像现在他是不是有 amessage, 对 不对?是不是有这么多的信息,对吧?如果说你不想要这么多信息,你也不想自己去取的话,其实我们可以通过一个叫输出解器,直接扣上它的一个输出啊,这种是比较方便, 那包括我们也可以,比如说让它输出一个 json 啊,但是如果说是一个 json 的 话,那我们的音符其实也要变,也就是说我们的回复啊,我们的回复的时候就要指定大模型回复一个 json 呢,对不对?如果说你本身回复的还是像这种 啊,正常的一个字串的话,那我是没有办法把字串啊,是没有办法它这个输出解释器是没有的话,把字串直接变成 json 的, 所以说如果说我们想让它输出是一个 json 的 话,那你必须要告诉它, 那最终呢?你的输出呢?是要用 json 格式进行回复的,那这个时候我再用什么?再用这个 json output password 来处理一下,对不对?那我们先来看一下这个效果, 然后前面问题用 question 回答,用 answer, 这个大家可以指定也可以不指定,不指定的话它就默认,对不对?那 你看我们看指定了 k 之后的话,开头就是 lancashire 是 什么,对吧?然后这是他的回答,那有时候说我都用 jason 回复了,对吧?我都指定用 jason 回复了,那这里你这个 autoplaster 是 不是没有什么用啊?对吧?我们来看一下区别啊,看一下区别 就是我们让他用 json 回复,看到了吗?他其实回复的是不是 json 格式?是的,但是啊,并不是我们想要那种,他其实还是在这个 a m s h 里面,我们还是要通过 ctrl 把它取出来啊。这个就是我们用了这个输出解释器它的一个什么好处? 它可以直接获取到你想要的这个数据的一个格式啊,就不需要我们再去做任何的一个处理了,对吧?包括这个 k 对 不对? y 六啊,我们都可以去去定义, 这个就是我们的一个输出解器的一个简单的一个使用。好,我们接下来看一下这个向量的一个存储啊,那如果说我们想把这个数据啊,把它保存在这个向量数据库里面,那我们要怎么去存它? 那这里面我们选择一个这个 fast 这个向量的一个数据库,那么首先要去安装一下,就是通过 p i p install fast cpu 啊,当然他有这个 gpu 的 版本,但是大家可能电脑里面并没有这个 gpu, 对 吧?那我们就选择安装这个 cpu 啊,然后我们还要去安装一个模块,就是这个 lanchang 啊 community, 然后它安装那个版本的零点三点七啊,大家去尽量安装跟我一样的这个版本,那我们这里面去啊,把它数据保存到那里面,我们这里面用到了一个叫 web loader, 来去找一个数据啊, 啊,它是一个,大家看这个模块的名字叫 web loader, 对 不对? webbase loader, 它就是从网页上去加载数据的,那接下来剩下还是一样了,走代理,对吧?然后接下来啊 webbase loader, 首先它第一个参数有一个叫 webpass, 也就是说它要把哪里的数据呢?给咱们 抓取到啊?他要抓取这个网站,对吧?他抓取到这个网站上的一些数据啊,那我们看他是怎么抓取的,他是通过什么呢?他其实通过这个 b i 四,然后去获取这个 id 啊,这个其实涉及到一点爬虫的知识啊,大家如果说没有学过啊,爬虫的 b i 四的话,咱们可以这样 就直接选中它,然后这块有个 d i v, 看到了吗?我稍微放大一点,它的 d i v 有 一个 id, 然后呢大家发现啊,这里面当我把这个 d i v 删掉的时候,就整个页面啊,它其实没有东西了,对吧?那比如说它所有的文字其实都是在这个 d i v id 为这个 d i v 下面,对不对?那所以说我们就解析啊, 通过 bs, 然后呢 id 等于它这样的话,其实我们就可以把这个数据呢,把它获取下来,好吧?那这个时候其实我们可以来测试一下,比如说我们来运行啊,打印,对吧?这样直接运行, 然后大家看啊,这个其实这个时候呢,它其实就已经获取到了这个数据,看到没有配置 content, 然后这里一大堆啊,这这数据就特别多了,咱们就不看了,好吧, 那接下来的话,我们继续往后看来这个代码我们怎么把这个数据保存到咱们那个向量数据库里面呢?对不对?那首先啊,你既然保存到向量数据库里面,那我们首先要做一个向量化,对不对?那这里我们选择什么呢?选择这个 open i 的 你白领来做向量化。 那接下来的话就是导入这个 fast 以及什么 retou 啊,它是一个什么 text split, 对 不对?就是文本切割啊?我们不可能把啊整个的所有的文本,对不对?一次性的全都存进去啊?我们一般是要做切割的, 而且去做编辑的时候,它的数据的长度其实也是有那个啊,它的 token 的 长度其实也是有这个要求的,对吧?所以说我们一般的做法呢,都是先把这个文档先把这个加载文档呢做一个切割,切割完成之后呢,然后我们这个时候才去什么啊?再去保存, 对吧?那切割的时候就会有这个串 size 和这个串的 overlap, 这个串 size 的 话就是说每一块切多大,然后这个 overlap 呢?它是其实是一个滑动窗口,也就说两个啊,你切的这个两个块之间的重叠部分有多少?这个我们呃在讲那个 r g 的 时候会给大家详细的讲到, 然后接下来的话其实就是切割,切割完成之后的话,我们看一下它切割了多长啊?就是我们刚才加载那一堆文档,它把它切割成了两百四十八块,然后接下来的话其实就是一个响亮的存储啊, fast 点 from document, 然后把这个 document 切完块之后的这个 document 呢,把它往里面一传,然后对应的这个编辑啊 存进去,对吧?也就说咱们项链数据库里面现在存的是文档,然后还有什么?还有这个项链啊,还有那个项链,那项链长什么样?就是比如说是一堆数字啊,这种数字的都是, 好吧?文档和向量它是对应的啊,它为什么要对应呢?对吧?因为我们将来可能要查询,对不对?我们查询的时候查的什么?查的是向量,但是最终返回的是要文档,对吧?我们最终给给这个用户去返回的是文档,而不是一堆这个向量,对吧?因为你给用户返回这一堆向量的话,它是看不明白的, 对不对?那这个呢?就是用 logite 啊,怎么去做一个向量的存储?我们接下来看一下如何用这个 logite 啊?怎么去做一个向量的存储?我们接下来看一下如何用 logite 啊,怎么去做一个剪辑。 那这里面其实我们借助到了一个链啊,叫 create steve document 键啊,这个链我们后面也会详细的跟大家讲, 然后接下来的话我们导入这个模板啊, from tammy, 然后呢?这里面这句话很重要,就是仅根据提供的上线文回答一下问题啊,这个其实可以最大程度的避免幻觉,以及这个啊就是回答的问题呢,和我们的文档呢没有关系,但是这个只能说最大程度的避免啊,不可能说完全的避免。 然后这里面有一个 content 啊,然后 content 这个标签啊,是为什么要写呢?这个其实是我们后面那个链里面它必须要写的。我们如果说用这个链的话啊,你的行私模板里面必须要有这个东西,然后问题的话,这个就是我们自己要去写的了, 那接下来的话我们来实地啊,这个导入对不对?菜单, ok, 然后来实地啊,这个当然大家可以换其他的模型,对不对?换咱们国内的啊,都可以,比如说这个 deepsea 啊,对不对?质朴清颜呢? kimi 啊啊,这些都可以。 然后接下来的话我们要创建一个啊文档的一个组合链 create, 这个把大模型往里面一传, lm 往里面传,然后 prompt 往里面一传, 对不对?将文档内容和用户的这个问题组合成一个完整的提示,然后我们接下来要给谁呢?给这个大模型来生成回答,对吧?那你在生成回答的时候,大家知道 i g 的 话,它要去剪辑,对不对?那这个时候呢?哎,我们又用到了一个链啊,叫 create 编辑,是不是? 那这个东西是什么?其实就是我们上面这个项链存储的啊,把这个数据啊存到这个项链里面,对不对?存到这个项链数据库里面,发到这个项链数据库里面,然后接下来的话他要去解锁,对不对?那现在的话他其实就是这个,其实就是那个解锁器了, 然后 i 子设置这个 k w a r g s 的 话,就是说设置了最多我解锁三个文档,那接下来的话我们就来创建这个解锁链,那解锁链的话它需要两个参数,第一个就是刚才我们的解锁啊解锁的这个,然后第二的话就是我们那个 dongle 的 check, 就是 文档的一个链,然后它把这个 两个链组合在一块,对不对?他就实现了什么?实现了从咱们这个向量数据库中来解锁相关的文档,而且将这些文档呢和用户组合成最终的一个提示词啊,就可以发给咱们。行了, 那这个时候我们去问他,比如说建设用地啊,用地使用权是什么?然后我们来运行一下这个代码,当然这个代码现在的回答呢,可能不是特别的好,对吧?他说啊,这个什么地表的对不对? 现在他做的不好,这个是也正常了,因为我没有做任何的啊,其他的一些优化,对不对?所以说这个 r g 的 话,只让大家去看一下实现的一个流程,就是我们用 lange 怎么快速的实现了一个 r g 啊?通过了两个链, 对吧?那这个链呢?其实也是我们后面会详细的给大家讲到的一个知识点啊,这个大家不用担心,好吧?这两个链我们后面也会给大家讲, 这个 create 和这个他其实相当于什么?第一个链相当于将文档和这个用户的问题对不对来做了一个拼接。那第二个呢?其实就是将解锁器和什么和这个文档那又做了一个拼接,好吧?然后最后呢交易大模型跟跟咱们那个正常的 ig 的 这个程序啊,基本上也是一样的。 好,那我们接下来看一下这个 luncheon 里面的 agent 的 一个使用啊,也叫代理,那在 luncheon 的 框架中呢? agent 呢?是一种利用大模型啊,来执行任务和做出角色的一个系统,那在 luncheon 的 世界中, agent 就是 一个智能代理啊,我们也管它叫智能体,对不对?咳, 那它的主要任务呢?其实就是提取我的需求,然后分析当前的一个情景,从它的工具箱呢,选择最合适的工具来执行操作,对吧? 那它具体可以干嘛呢?比如说它可以使用工具对不对啊?它有各种各样的推力引擎,对吧?它 a 轮它在使用,它还有什么?还有一个叫可追溯性啊,当然还可以自定义啊,交互啊,记忆啊,执行器啊,这些的话,大家现在可能啊,看不懂,对不对?先有个印象就可以啊,一样的,先有个印象,等我们详细的讲到的时候, 然后大家就知道啊,这些工具怎么去用啊?对不对?它的记忆能力,我们怎么给它添加对不对?以及它的这个 agent execute 啊,我们怎么去用,对吧?那我们还是以刚才那个案例来快速的看一下它的代码的一个实现啊。 首先呢我们创建一个工具,叫什么?叫解锁器的一个工具,对不对?我们把这个解锁器啊放在这里,然后这个是什么?这个是解锁器工具的一个名字,然后下面其实就是一个描述了,对不对?接下来这就是工具啊,我们有了工具就可以给这个 agent 去使用,对不对?那怎么去用呢?来看这啊, 那这里其实是导入了一些模块,然后呢我们这块啊这个模板大家发现,哎,我们的模板呢写的什么?我们这个 prompt 呢?写的不太一样,对不对?那这个 prompt 它的模板是在哪里啊?它其实是在这个浪, 这个浪颤的一个官网啊,官网里面,然后呢我们可以去找它各种各样的模板,好吧,那如果说大家想看一下这个模板是个什么样子呢?大家可以直接在这里搜索 啊,直接在这搜索,然后点进去,点进去之后呢大家就可以看到它完整的一个这个模板是一个什么样子了,看到叫 system, 然后这个就是聊天记录,对不对?这 human 的 话就是咱们的一个输入啊,那这个呢,就是 agent 的 执行的一些信息。 那接下来我们有了模板之后呢,我们可以干嘛?实体化 chat open i 对 不对?然后 create open i function agent 啊,就是通过这个 function 创建一个 agent, 然后把大模型一传,工具一传, prompt 一 传,对不对?接下来其实就可以执行了,把这个 agent toys 工具啊,这个是什么意思?就是打印执行过程, 打印 agent 整体的一个执行过程,我们在刚开始的时候,建议大家把这个参数都给它加上,就是能看到它执行的整体的过程,那这个时候我们去啊运行这个代理,好吧,我们再来看一下,就是我们通过 agent, 然后让去问一些问题, 就是他要去搜索啊,他其实也是通过这个工具,你看他开始执行,对不对?然后呢这是他这个执行结果, 那,那我们再执行一次,这个其实我没有看到他的执行的一个过程,那来看这里,这个时候大家注意看啊,他其实用到了这个东西,看到没有?用到了这个东西,那这个东西是什么?是不就是我们上面自己定义的这个工具啊, 对不对?这是不是就是我们自己定义的这个工具的一个名字,对吧?那他用这个 工具,然后呢?去什么?去检测,对不对?检测出来了这么多的信息,然后呢?哎,有答案了,最终把这个返回,大家发现用 agent 要比 r g 啊,它的一个结果要好得多,是不是?起码它查出来这些东西的话,信息呢?其实是比较多的,对不对?那这个呢?就是在 longchain 里面啊,咱们怎么使用这个 agent? 好 吧, 快速的简单的一个介绍啊,我们是通过这个 function, 通过这个 function agent 方式创建了一个 agent, 然后通过 agent execute, 然后去执行了这个 agent, 那 最终的一个执行结果,那第一次为什么会看到啊?第一次那种情况呢?就是它这个 agent 判断了一下 它没有什么,它其实没有用这个去解锁,它正常来说的话,我们去问的这个问题啊,它是什么?它应该是用这个解锁器, 应该是给我先去解锁,而不是说用模型直接返回。我们刚才第一次那个看到的应该是模型直接返回的信息,但是这个我们知道并不对,对不对?应该是去这个相册数据库里边去解锁,对吧?用这个工具去解锁,你把解锁到信息给我返回啊,这个才是正确的,对吧?那这个呢,就是一个 agent 的 一个简单使用啊, 我们接下来看 logon 的 第二部分, modelio, 那 modelio 的 话可以把对模型的一个使用呢拆分成三个块啊, 那第一步呢就是咱们的输入提示 prompt, 第二步呢就是咱们的调用模型啊, predict, 然后第三步呢就是咱们这个输出啊, pass, 对 吧?那这三部分呢,我们会分别的来给大家讲,在第一部分的快速入门呢,这三部分呢,其实我们都有提到,但是没有讲的特别详细,对吧? 那接下来的话,我会把这三块啊,把大家讲的把这三块呢分别的给大家讲的详细一点。那我们先来看这个第一个提示模板, lunch 的 模板呢,它是允许这个动态的选择输入啊,根据实际需求来调整输入内容,适用于各种各样的特定的任务和应用,对吧?那语言模型这个就不用说了,对不对?它提供了各种各样的接口,对吧?我们可以通过不同的这个 接口去调用不同的模型,对吧?比如说最近特别火的 deepsea 啊,我们也是可以去通过 longchain 去调用的。那第三部分的话,就是我们的一个输出解析,那利用 longchain 的 输出解析功能的话,可以准确地输出模型所需要的信息啊,避免处理用于的数据,比如说你输出了我们想要的数据,是一个 json, 对 吧?那我们可以通过输出解析器直接输出一个我们预期的 json, 一个数据啊,就避免了模型的输出,之后呢,我们还要自己去处理,对不对? 那这三块呢,形成了一个整体啊,在浪叉的过程中呢,就是他被统称为什么叫 modelio 啊?他每一块呢,每一个环节呢?浪叉都提供了这个模板和工具啊,他可以啊,帮助我们快速的调用各种语言的模型的接口。那我们先来看一下这个图片啊, 那这个图片呢,其实是浪叉官方的一个图片啊,比如说这个 modelio 第一部分 format, 对 吧?就是他看这 x y 啊,对吧?相当于一个, 他直接把这个 x 放这,把这个 y 放在这里,对不对?然后把这个拼接好,那这样做的好处就是 x y 的 话,其实我可以根据用户动态的输入啊,来去变化,对不对?或者说啊,可以通过其他的方式来获取到 x y 这个值,不是说每次都是去固定的对不对?那这里面我可以传给大模型啊,也可以传给这种聊天的,对吧? 然后输出,那输出的话我可以让它输出成帧这种格式对不对?那这三部分呢,统称为 model l 啊,就过程对吧?那我们先来看第一部分,就是咱们的一个提示模板, 那在浪颤的 model i 中,提示模板呢?是其组成之一,这个当刚才大家看到了,对不对?那语言模板的提示呢?是用户输入了一组指令或者输入,对吧?这跟咱们正常的使用那个 prompt 的 提示词其实是一样的,对不对?它主要是用来指导模型的一个响应,帮助模型理解上下文,并且生成相关且连贯的 啊,基于模型的一个输出,对吧?比如咱们回答问题啊,完成句子啊,或者说对话呀等等。那 这个 problem time 也是浪颤中的一个概念,通过接收用户原始的输入啊,并且返回一个准备好传递给语言模型的一个信息啊,就说我们组装好的这个 problem, 把它拼接好,对不对?接收用户原始的信息啊?接收用户原始的信息对不对?然后准备好一个传递给语言模型的信息,就是你把它拼接好,然后再发给这个大模型, 是不是?那我们接下来看狼菜模板的一个特点啊,首先第一个的话就是通俗易懂,对吧?第二呢可啊增强它的可重用性,第三个简单维护,第四个是智能的处理变量,第五个呢就是弹性化生成,当然这几个特点啊,其实我觉得个人觉得 啊,哪个更实用的?其实就是第二个增强他的可重用性,对吧?比如说你在这里写好了一个提示模板,你在项目中啊,很多的其他地方你可能都要用到的话,那其实你可以把这个模板定义好,然后呢重复的去使用啊,就不需要你每次在使用的时候都要去再定义,对不对? 而且他的就是用了模板之后呢,我们的模板的维护呢,就相对来说就比较简单了,那我们就不需要去改,在每一个地方呢,我都要去改这个题词词,我只需要修改模板就可以了,是不是这样对于咱们项目开发来说的话,是一个比较好的 一个地方,因为如果说你每次啊要改这个题词词的话,你都要去找到具体的文件,然后再去修改,对不对?那这个其实是相对来说比较麻烦,能有了模板之后的话,我想在哪里用啊就在哪用,而且我可以多个模板 对不对啊?比如说有一二三四五个,对吧?在不同的场景下,我去运用不同的这个提示模板,而且我只要修改,你不管用了多少次,对不对?我只要修改这个基础的模板就可以了。那接下来我们看一下它的类型,那大方型提供了这个模板 有哪些类型?就是朗善给我们提供的。首先第一个啊,提供了一个叫 plunk time, 然后就是我们聊天嘛, plunk time, 然后还有这个样板提示啊,就 feel short 少样板提示的样板。 那第四呢?第四个就是部分的格式化,然后第五个就是管道,第六个是自定义模板。那其实我们用到比较多的还是前三个啊,前三个包括第二个,其实用的最多这个,好吧,那我们接下来看一下 这几个模板啊,分别是什么?好吧,首先我们来看一下模板的一个导入啊,首先我们从哪里导入?从 linc 点 pro, product, 对不对?第二 part, 然后导入,对吧?然后这个呢? photoshop 的 话就没有后面那个了,对不对?然后 padlock 对 不对? chat tomt, 然后导入这些,这个是 chat message, 是 system 之 ai 之 friend 啊,这个分别对应的其实就是我们那些角色。那模板导入之后的话,我们来我们需要运行一下, 然后接下来的话,我们就可以创建题词模板,对吧?那这个题词模板的话,我们先创建一个这个原始的,比如说你是一个专业程序员,对什么描述?那这个 test 呢?肯定就是我们去输入的, 那这个原始模板我们要去什么创建一个啊? longchang, 用 longchang 给我们提供的来创建一个 longchang 的 体式模板,那怎么创建呢? from tom t, 然后点 from tom t 从哪来,对不对?然后把这个 tom t 往里面传,那这个时候 tom t 我 们就创建好了,对不对?我们可以打印一下,这时候其实我们可以打印一下,打印它其实就是这个样子,来我们运行一下 input 啊,这个就是让我们输入的,对不对?然后呢?这个就是我们的原始的这个 time thing, 对 吧?那我们怎么把这个 text 传进去呢?通过 prompt 点 format, 然后 text 等于 luncheon, 那 这个时候呢?其实我们就把 luncheon 呢相当于传进去了,它的 提出模板啊,必就变成了什么?您是一位专业的程序员,然后对于信息浪产进行剪短描述,对吧?那这样的话,其实我们下次比如说你想对于什么啊?对于大模型啊,对不对?或者对于 r g 啊,对于其他的这种技术的关键词进行剪短描述的话,那我只需要去改这里就可以,我在使用的时候,其实我不需要去改这里,对不对? ok, 这是创建其实模板,然后我们接下来其实也可以什么?上面这种方式的话,是通过我们创建了一个原始的其实模板,然后呢来创建出来一个 long chain 的 其实模板,那当然我们也可以直接去创建,直接创建怎么创建呢?来 problem time 啊,就直接往里面写就可以了,对不对?你需要什么?需要 input 的 一个变量,对吧?然后叫 type, 那这个提示模板呢?我们就直接写到这里面了,那直接写到这个 prompt temp 里边去,您是因为专业的程序员对什么信息进行描述,那用的时候其实还是一样的啊,我们用还是还是这样点 format, 然后 text 等文档,那这样的话其实就是更直接,好吧,那这个就是如何来创建我们的提示模板, 我们接下来看一下如何来使用这个 t s 模板,对吧?我们写好了这个 t s 模板的话,我们要传给大模型,对吧?让最终返回这个结果,那我们接下来看一下它是怎么去使用的。首先上面还是一样导入这个模块, 然后走代理这个 type, open i 的 话,模型默认的话就是三点五杠 turbo 啊,这个大家可以不写,然后也可以换成其他的这个模型,比如说咱们国内的快速入门的时候,也跟大家介绍过怎么去换。 然后这里就是我们的这个输入题词啊, input 对 不对?输入了什么大模型?这个 long chain prompt, 那 它这个 prompt 其实用的就是这上面这个,然后得到模型的一个输出,我们怎么去得到呢?就是这个 model 点 in local 啊,通过这种方式,然后 input, 把我们的这个什么,把我们的这个提示模板啊传进去,对吧? 那这个时候呢,这个 input 就是 什么?就是它啊,就是那个提示模板,那这个时候呢,我们就可以得到一个什么大模型的一个回复啊,来运行一下, 然后呢?现在就在正在运行啊,然后大家可以看一下下面这行代码,就是 model 点 emoji, emoji 就是 去调用嘛,对不对?呃,然后我们来看一下报错啊,这报错是报 我们往上滑一点啊,这个报错是报了一个 connect error, 对 吧?就是连接错误啊,连接错误这个一般跟我们的节点有关系啊,然后大家可以这个 看一下自己的这个代理啊,有没有打开,或者说他这个节点啊?有没有问题?如果说你确认了你的这个代理打开了,而且节点没什么问题的话,对吧?他网速正常的话,那大家只要重新运行一下这个代码就可以了, 这个不是代码的问题,大家如果说运行这个代码,如果说你自己买了一些 k 啊,遇到刚才我那个问题的话,大家重新运行一下代码就可以了,或者说看一下自己的代理没有打开, 然后这个时候呢,它其实就已经生成了这个答案,对不对啊?让 chat 是 大模型的,是一种信息大模型对不对?用于处理什么文本的语言模型啊? 那这个时候呢,我们其实就已经把这个题模板啊翻译给了大模型这种方式,对吧?那我们接下来看一下,叫 chat prompt timet, 对 不对?很明显它和我们刚才讲那个 prompt timet 是 有区别的,对不对?那 chat 它多了一个什么?多了一个聊天嘛, 对不对?那模板它和那个具体有什么不同呢?就是它可以有对应的一些角色,比如说我们的原始模板是一个什么?是一个,你是一个,你是一个数学家, 你可以计算任何形式,然后呢?这个是 human 啊, tempet 对 不对?那我们用这个 chat prompt tempet, 然后点 from message, 那 这个时候呢,大家注意看我们里面传了一个什么,传了个 system system 呢?是这个 tempet, 然后 human 呢? human 就是 什么 human? 它对应的模板呢?其实就是我们输入的, 对不对啊?那其实就相当于我们如果大家学过提示词的话,这个相当于 system, 这个相当于那个 user, 对 不对?还有一个 assistant 的 那个助手, 是吧?那接下来的话,我们的对话的这个模型定义好了,定义好之后的话,然后来导入这个 chat 后台这个接口,对吧? 那接下来呢? chat prompt 对 不对?然后点 from message, 这个时候我们需要把这个 text 传进去,对不对?我今年十八,我舅舅三十八,然后爷爷七十二,然后算一下我和舅舅一共多少岁了,那这个时候是我们的 message, 对 吧?那我们要把什么?我们把 message 啊,这个信息传给什么?传给咱们的这个大模型,对不对? 也就是说我们要把这个信息啊,放到什么?放到这里,对不对?那最终呢?我们是不是就有了一个完整的 prompt, 对吧?完整的 prompt 它是要得到答案的,我们是要发给大模型的,调用大模型,那怎么调用呢? model 点 emoji, 然后把 message 一 传,那这个时候呢,我们需要打印它的 content 啊,就是你不想看到这一堆东西的话,你就打印它的 content 就 可以了, 然后我们来运行,看一下这个结果啊,来看这首先上面打印的是什么?上面打印的是这个, 来上一栏呢,是 message, 这个信息看见没有? saturn message, 你 是一个数学家,可以计算任何的这个计算形式,然后黑猫的 message, 这是我们自己输入的,对不对?今年十八,然后一共五十六啊,没有问题,对不对?你看舅舅一共多少岁啊?五十六岁 是吧?那 longchang 提供不同类型的 message, 这个 problem timetable 啊,最常用的就是 ai 啊, saturn 啊,对不对? human message 对 不对?那 ai 的 话就是人工智能消息,那系统的 saturn 的 话就是系统消息,人工的话就是咱们的 human 啊,这个和词典模板里面基本上就是对应的。 来啊,那接下来我们看一下导入啊,首先还是一样的去导入,对不对?然后模板的一个构建啊,那这个时候的话,我们可以怎么去做呢?来啊,看看,这我们写好了,一个,对不对? system entity, 然后呢? system message 对 不对?就是我们可以给它这个角色嘛, 对不对?给他定一个角色啊, sitemessage prompt, 然后 from tempet, 把这个往里面一传。你是一个翻译专家,擅长将什么语言翻译成什么语言,对不对?然后这样 啊,那这个时候的话,我们的 sitem 就 写好了,对不对?那 hello 是 一样的,对不对?然后呢? chat prompt tempet 点 from message, 这个时候你把 sitem 一 传,把 hello 一 传啊,其实跟上面是一模一样的, 跟我们上面这种写法是,就是它的达到的效果其实是一样的,但是这种写法呢啊,它更看起来呢,稍微的更复杂一点,但是它有好处啊,就是能让我们的整体看的更清楚,代码逻辑看的更清楚啊,它有有利有弊,对不对? 那接下来的话,我们把这个 problem 他 们给编辑好之后的话,那我们要往里面传信息,对不对?你要翻译什么是吧?那 input 就是我们要把英语翻译成中文,然后你要翻译到这个文本是什么呀?是不是这个 text 啊? text 等于,对吧?我爱大模型,然后点 to message, 对 不对?那这个时候我们去打印这个 prompt, 然后呢?接下来去调用啊,这个就比较容易了,是不是?那我们来运行一下啊,你看这是我们的 prompt, prompt 就是 system message, 对 不对? 然后 result, 这是结果啊,这是结果。我喜欢大模型,对不对?就是英文翻译成中文嘛?我们输入的,我们输入的是一个什么,对吧?我们输入是一个英文,然后他要把英文翻译成中文嘛,对不对?擅长将英文翻译成中文, 那这时候呢?我们就得到了结果是不是?那如果说你不想看后面一堆的话,你就直接点 ctrl, 像我们上面这样,对吧?直接点 ctrl 就 可以了,就能获得到这个结果了。 我们接下来看一下这个少量本视例的一个提示模板,这跟题词的一个少量本提示基本上是类似的,我们都是通过给少量的一个提示来让大模型生成更好的一个恢复。那基于大模型和聊天模型的话,那我们分别可以使用什么? 这个 fieldshot 和这个 fieldshotchat message prompt 啊,它基本上使用是一样的。那我们先来看一下这个怎么来创建这个视例集, 那这里面创建了一个列表啊,这是一个列表,一个单跑,然后音符的二点二, alt put 四,然后用的是一个加法,那五减二呢?是一个三,对吧?然后这是一个减法,我们在给势利的时候,其实不是给的越多越好,给三到五个就可以了啊,给三到五个大模型基本上就能学习到这个 样本的东西了,那接下来的话我们来创建这个 int 模板,那首先还是一样的,从这个点 prompt 里面导入这个 prompt time, 然后接下来的话 写啊完原始的,对不对?你是一个数学专家,算式啊,音谱的,然后值什么对不对?使用了什么,跟我们上面是一样的对不对?你输入是一二加二,那 out 谱的就是四,对吧?然后使用了加法运算,对不对?那 from 它的 创建咱们这个模板对吧?那这个时候其实我们可以啊,通过这个方麦的点,方麦下角线 prompt 来试一下怎么往里面传,是不是啊?比如说我们可以这样, 可以这样我们直接传,对吧?直接传一个,比如说二加二对不对?然后 output 四,然后这次这个描述啊,这个 description 描述啊, 打印,对吧?你看你是一个数学专家,然后算式呢?二加二值四,使用了加法,那除了这种方式呢,我们还可以通过这种啊,这种的话就是一个解包操作啊。 example, 咱们先看这块 example 一 对不对?然后呢就是这个, 那它是列表的下标是从零开始的,一取的是它对不对?那前面星星是什么意思呢?就是它把这里面的每个参数和这里面是相对应的,看没有阿普夫的 destruction 啊,这个时候我们可以运行一下 哦,我们来看一下啊,他说这个没有定义啊,那我们先要先要运行一下它啊,先要运行它,然后再来运行它,那这个时候大家注意看五减二对不对?然后三使用的是一个减法,这没有问题。那么接下来这个其实模板创建好了,那我们接下来开可以创建这个叫 feel shot。 首先导入啊?还是先来导入?然后呢? example 是 我们上面的 prompt sim, 对 不对?就是上面这个啊,就上面这个,然后这个, 这个,这个 steve 啊,啊,不是 steve s u f f 这个 fact 啊? s u f fact 对 不对?那它是什么意思啊?就是你是一个算学数学专家,然后算是值,对吧?它表示在咱们那个生成的其实模板末尾会加上,会加上这句话, 然后我们要输入什么?输入的是 input 和 output, 那 其实我们想让它干嘛呢?我们想让大模型啊,这个输出,什么 输出?你的这个描述用的什么算?算这个算式对不对?你看二加二是四,对吧?然后呢?五减二是三,它使用减法,那二乘五,比如说我们输入的是一个二乘五,然后数值三的话,那它应该输出的使用的是一个乘法,对不对?那这个时候呢?我们的 prompt 就 拼接好了啊?我们的 prompt 就 拼接好了, 然后接下来的话我们可以调用大模型,对不对? model 点 input, 然后呢?把这个传进去啊?把这个传进去, 对不对? prompt 点这个 format, 然后 input 二乘五, output, 那 这个时候它输出的话,大家想想输出应该是一个什么?应该是一个乘法运算,对不对啊?找我们要先学一下上面这个,然后再用它, 他正常如果输出的是一个乘法因子的话,那这里是没有问题的,对不对?比如说我们再输出一个啊四,然后除二等于二啊? alt put, 那 这个时候呢,他应该输出的是一个什么?哎?除法是不是就没有问题了,对不对啊? 就是通过大模型啊,让给了一些实力,然后让他来预测啊,他使用的是什么啊?这也不叫预测啊,对不对?因为我们给了这么多实力,他应该能学会了,对吧?如果输出的不是乘法啊,这个才有问题,对不对?当然如果说输出的真的就不是乘法,而是其他的, 那这块有几个方案。第一个就是大家把这个模型改掉,因为三点五的话,现在这个模型能力呢,不算强了, 对吧?现在已经出了很多的新的模型了,是不是我们可以通过 g b 四啊,四 o 啊,对不对? o 一 啊啊? o 一 迷你啊,是它现在最新的是 o 三,对不对?那我们可以通过这个更换模型啊,来去达到我们最终想要的一个效果,那这个呢,其实就是我们这个少量版的一个提示模板的一个使用啊, 我们接下来看一下这个 modelio 的 第二部分模型。那 longchain 知识的模型有三大类,第一大类就是咱们的语言模型 r m, 也叫 text model, 那 第二呢,就是咱们那个 chat model 聊天模型。第三个呢,就是咱们那个文本签入 embedded model 啊,这个也是我们啊经常去 r g 经常会用到的,对吧? 那我们先来看第一个大语言模型啊,那 longchang 的 核心组件呢,就是咱们的大语言模型,它提供了一个标准接口,以字母串作为一个输入并返回字母串的形式啊,与多个咱们的大模型呢进行交互。 那这个接口呢?比如说 openai 啊, hack and face 啊,其实多个厂家都提供了标准化的对接方式,对吧?那我们先来看这个文本补全的方式啊, 我们导入这个 open i, 那 这个时候大家注意,我们用的就不叫 chat open i 了,对吧?用的就是 open i 了,那文文不全的,然后 max token 呢?我们指定二十,最大的 token 呢就是二十,那这个时候呢,我们通过 inlocal 这个方法呢,我们就直接把这个 text 传进来啊,那这时候我们来运行一下,当然它中文的话可能会出现乱码啊, 哎,我今天真的好想你的,好想和啊,想和你一起看电影呢,这个是没有问题的,对吧?那这个呢,就是我们的一个大元模型的一个使用啊,比较简单,对吧?我们进来看一下对话模型啊, 这个对话模型的话,我们用的就是 type open i 啊,之前其实也用到了挺多回,对不对?比如说我们的 type 大 元模型是什么?然后我们下面呢调用着吗?调用这个 deepsea 啊,那 啊,为什么在这里去叫呢 deepsea 啊?这个 deepsea 呢,现在是已经可以充值了啊,到今天呢是已经可以充值了,它那个充值接口呢,终于是放开了,所以说的话,大家可以去啊充一下这个 deepsea 啊,基本上充一块钱的话就能使用很久,对吧?如果大家不是特别这个频繁的使用的话,基本上个人使用的话,一块钱真的能用一个月,至少啊,然后我们获取它的这个 那个 key 啊,这个 key 呢?我是写到哪里呢?是写到点 e n v 文件里面了啊,写到点 e n v 文件里面,然后呢就是这样等于啊,这个就是大家去那个官方去申请就可以了,那这个时候呢,我们其实就可以把这个换成什么,换成我们的 tipsy 了, 然后 deepsafe, 这是按一那个模型 api base, 对 吧?那那接下来我们就可以问他大模型是什么?它,当然它这个现在速度可能会啊稍微的慢一些,虽然说它恢复充值了,但是它其实调用的时候速度也不会特别的快,因为它要推底,而且啊它其实内容还是挺多的, 就是他返回的内容比较多,然后如果说在他没有返回之前呢,其实我们看不到这个结果了,我们可以通过那种流逝的啊,流逝的输出就是他有多少返回了模型给我们返回了多少内容的话,我们都可以啊在这打印出来那种流逝的方式,这样我们就可以看到 模型的一个就是给我们的回复啊,就是一个字一个字蹦,像那个 disco 那 个官网似的,我们问他一个问题,他不是说啊,在那卡着,咱们现在的代码运行看起来像卡了一样,对不对?其实并不是啊,而是他在一个字一个字的往外蹦,对吧?他在推理是不是 他推理的过程,思考过程,只不说我们看不到,我们在这个程序调用的时候是其实看不到的,对吧?当然我们可以通过流势输出,就是他输出一个字就打印出来,对不对?就像那个网页一样,当然现在是看不到的啊, 然后我们因为我们没有通过流逝的那种方式去调用啊,那我们现在就可以看到了大模型是什么,对吧?而且它返回的都是这个 markdown 的 这个格式啊, 然后往下翻啊,打模型什么一堆,对不对?然后它价格呢?这个大家可以自己看一下,它现在就两个模型,一个是 v 三的,对吧?啊?一个是 r 一 的, r 一 主要就是推理嘛,对不对?而且它的头盔呢,也特别便宜,现在也放开了,那大家可以去那个用一下,然后接下来我们看一下这个智普模型,就是这是国内的,对不对啊?除了 deepsea 呢,我们还可以 用什么呢?用智普啊,用这个通讯千问啊,还有用那个按月啊,都可以,我们这里用这个智普啊,智普啊,同样的大家要去那个智普的官网去申请一个 apikey, 然后它现在有个模型呢,是免费的,免费去调用,就是 g m l 四 plus, 这个 这个模型是免费的去调用的,然后这个时候我们来运行看一下啊,但是它需要安装这个模块叫 p y g w t 啊,这个模块大家去那个 c m d 里面去安装一下就可以了, p i p 音符,好吧,那这个时候我们可以看到它也给我们返回了这个内容, 好吧,那这个呢,就是我们怎么去调用这个国产的一些模型? longchain 它其实是支持一些国产的模型的啊,可以通过这种方式,就是我们可以通过直接这种方式换 api, 换这个备份,然后模型名字把它换掉,然后也可以通过模块直接导入啊,这个 longchain 也是有这些模块的, 对吧?我们国内的现在做的大一点的这个模型的话, luncheon 里面其实都是有专门模块可以去用的,比如对不对?我们其实就不需要像啊 open i 的 就是调用 chat, open i 的 那种方式,直接就是智普 ai, 对 不对? chat 同意,对吧?还有我们的那个安岳的 kimi 的。 好,我们接下来看一下这个聊天儿模型,那聊天儿模型呢?也是 luncheon 的 核心组件儿之一,对吧?它使用聊天信息呢,作为一个输入,并返回聊天信息做一个输出, 那 longchang 呢?有一些内置的这个消息的类型,比如说 saturn 对 不对啊?启动 ai 行为,那 human 呢?就是呃用户的一个输入,对吧?那 ai message 呢?就是聊天的一个信息啊, 聊天模型那个信息对吧?可以是文本,也可以是调用工具的一个请求啊,其实和我们那个提示词它是一对应的。 saturn human 对 吧? user 啊, human 就是 对应的 user, 然后 ai message 的 话,对应的就是那个 assignen, 那 我们先来看一下这个怎么去用啊? 其实和我们上面那个用法基本上是一致的,对吧? message 对 不对? human message 和 sitter message, 那 这个时候呢?比如说我们输了一个 text, 对 吧?你好啊,然后 chat open i model 三点五,是不是?然后这个 human message 的 话,我们把这个 content text 往里面一传,是不是?这就代表着我们用户的一个输入,那把这个 message 呢?只要发一大模型啊,就 ok 了,那这时候我们来运行一下, 你看返回的就是你好,有什么可以帮助你嘛,对吧?然后聊天模型也可以支持多个消息作为一个输入啊,比如说 system, 就是 你是一个定一个角色,你是一个乐于助人的一个助手啊,你叫什么对不对?然后问他,你是谁啊? 你好,我是于老师,对吧?那这个聊天的其实相对来说比较容易,而且我们前面多次的用到过这个 chat opi, 对 不对?那接下来的话,我们来看一下文本的一个切入啊,这个文本切入的话,在咱们在做那个 i g 的 时候是经常用到要用到的, 对不对?那 importing 呢?它是用于嵌入和主要用于嵌入的,对不对?做那个文本向量化的,那比如说它提供了这个有很多的啊, open i 的, 对不对?哈根 space 的 啊等等。那这些其实都给 longchain 提供了一些标准接口,我们看怎么去用啊? 那 longchain 里面它集成了什么呢?集成了这个就是 open i importing, 对 不对?我们可以直接导入,然后直接这样去用,然后它默认的模型呢?就是这个 text importing 三拉直, 当然大家可以去指定对不对?可以去指定一些 open ai 支持的编辑的模型,那我们比如说我们这里 excel 等于大模型,对吧?那有了编辑之后我们可以什么?比如说迁入文档, you want the document, 然后这里大家注意啊,它是一个列表啊,它是一个列表,它要放到列表里面,对不对?我们打印它是一个二维的 啊,他是一个二维的,然后零,比如说打印前五,他不需要,我们不需要打印那么多,对不对?他的维度可能很高,如果说我们不这样打印的话啊,打印出来东西可能很多,对吧?然后我们可以也可以去查询,对不对?那查询的话就是这个 qry, 然后把 text 往里面传,对不对?我们在查询的时候可是肯肯定是用文本去查询, 是吧?然后也打印前五,那这个时候我们可以运行看一下它的一个效果,你看这个是我们编辑把文本变成什么,变成这个数字这么一个过程,是不是?然后这块是什么?这块是我们根据这个文本查出来的,编辑啊,它能是对应上的,对吧?能是对应上的, 对不对?那这样的话,我们在根据语义搜索的时候,才能找出来对应的一些文本,对吧?然后我们也可以去调用什么,通过这个方法叫 hank face bird bindings, 对 不对?我们可以去啊,去调用这个本地的一些模型, 对吧?那本地的模型的话,这个其实就涉及一个问题,大家要去下载,对不对?下载本地的这个 embending 模型,那这个模型大家可以从哪里下载呢?第一个就是 hand face, 让 hand face 大家可能需要翻墙,对不对?然后这里面有一个国内的镜像的一个地址,大家打开之后的话就是可以在这去搜索, 对吧?比如说我们用的模型是这个 embending 的 模型,这个就直接在这搜索就可以了, 在这里搜索,如果说没有搜到的话,大家可以把那个去掉啊,把前面那个去掉,你看这里面是不是又有了,对不对?然后大家可以也可以在这里面去搜索啊,它有下面的各种各样的任务,对不对?然后你找到那个 in bending 啊,它下面有,嗯, in bending e m。 我 们直接在这搜一下,搜一下 e m b d 啊?哎?没有吗?呃,我们 ctrl f 去搜一下啊? e m。 哎,我们去看看它的自然源啊,应该就在这里 text text 翻译, 它这个还真没有,那这个其实就是我们的,大家可以看啊,这个如果说我们在这个网站没有搜到的话,没关系,我们再给大家介绍一个,好吧?这个也是咱们国内的一个叫达摩达 啊,摩达摩达社区,摩达社区的话,然后它这块有一个模型库,我们可以搜一下这个,看能不能搜到啊? in minding, 没这个时候它就有了,是不是啊?那我们可以通过这个,如果说在这个网站上没有搜到那个一模一样的啊,就没有搜到一模一样的话,然后大家可以来到这个网站去搜索一下, 对吧?那这个时候呢?我们就搜到了,是不是搜到了这个模型,是吧? enigma 的 模型啊?这个是 enigma 的 模型, 那怎么去下载呢?然后呢?摩纳的话,它提供了什么?它提供了一个模块啊,就这个模块,好吧?然后通过这个模块呢?这个模块当然需要去安装的 p i p 一 扫啊,要去安装一下,要去安装一下它啊,要去安装一下这个模块, 这里写了应该是他这个模块,然后这个时候我们只需要去什么,只需要去运行它就可以了,因为我这块没有安装这个, 没有安装这个模块,所以说他会报这个错误啊,因为我已经这个用的环境不是这个,就主笔上面我用的环境是这个叫 啊,叫这个 launch model 啊,用的他这个环境里面是没有这个模块的。这跟大家说一下,因为已经提前下好了,他第一个参数的名字就是什么?就是你要下载模型的名字,然后第二个叫 case 电压的话,就是你要下载的位置啊,这个建议大家去改一下啊,如果说默认的话,他就在当前你执行这个代码的一个位置下载了, 对不对?那这个时候大家把它下载下来之后呢?哎,我已经下载过了,我已经下载过了,然后这个速度还是比较快的,那我们就可以通过什么本地的,对不对? model name 啊?去指定 我们的 embedding 模型,我现在不用 open ai 了,对不对?我可以自己用下载本地的,这样的话就不消耗 talk 了嘛,是不是?然后 hansen face 这个 bird bindings model name, 然后呢?这个参数是什么意思呢?就是生成的嵌入呢?向量呢?被归一化,有助于向量的一个比较,大家不加这个参数其实也是可以的, 对不对?那这个时候呢,我们就有了一个本地的 embedding 模型,然后也可以去做向量化了啊,也可以去做向量化了,那这个时候呢,我们就可以去试啊, 然后把这个大模型 imending, 对 不对? query 啊,我们去做这个向量化, 这个报错啊,大家看这个,这个并不是报错,而是 jupiter 啊,它的一个提示,对不对?升级你的 jupiter 和这个模块。然后下面呢,我们就已经得到这个结果了,看没有大模型的一个结果就是前五个啊,这个结果我们已经得到了,那这个时候我们在本地的话,就可以来做这个向量化了,是不是? 然后我们可以通过不通,不通过 luncheon 这个框架来做这个本地的编辑,就是通过这个模块啊,通过这个模块来去做的,好吧? 然后这个它怎么去用呢?那来我们往上啊,那它现在这个,因为我刚才运行了一下这个,我刚才运行了一下,它应该是马斯扣的啊? 啊?这个 markdown 啊,我们这个是不需要去运行的,是不是?就是大家如果想运行的话,你就把它调整成什么?调整成这个 code, 如果说你不想让它运行的话,就调整成这个 markdown 就 可以了,好吧?这个是朱比特的一个使用啊,简单的一个使用, 然后接下来的话你就可以去运行了啊,就可以去运行这个是咱们的这个数据,对不对?然后你可以使用本地的啊,这个模型, 对不对?然后把这个数据往里面一传啊?这个是一样的,是不是?然后打印这个文件,这就是这个它的一个结果了,那我们开来运行一下,你看这就它的一个结果了,是不是 我们可以通过不通过这个 longchain, 但是我们在用这个 longchain 框架在做的时候其实还是比较方便的,包括它内置了啊,就是 open i 的 这个 in bending, 对 吧?我们可以直接用 open i 的 in bending 来去做向量化,当然大家可以用本地的啊,也可以用本地的,方便大家快速入门大模型视频文档和超详细大模型学习路线图,感兴趣的同学留个学习抱回家。
53AI大模型 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿open viking 这是一个专门为 ai a 枕设计的上下文数据库,传统而 ag 系统的向量存储太碎片化了,记忆散落在各处。 open viking 用文件系统方式来统一管理 a 枕的记忆资源和技能。 我们可以像管理本地文件一样管理 a 枕的大脑。它的三级分层,上下文加载,按需加载上下文可以显著降低 copy 消耗。并且它还有上下文字迭代功能,能够自动从绘画中提取长期记忆。 a 枕用的越多越聪明。
204骋风算力 02:39查看AI文稿AI文稿
02:39查看AI文稿AI文稿上一期我们讲了强制验证,本期来看第二个真正有效的 harness 改进点上方注入。 agent 对 自己所处的环境约束条件和评估标准了解的越多,他就越能自主地指导自己的工作。很多失败并不是能力不足,而是环境信息缺失。围绕这个原则,他们做了三件事儿。 第一件事是注入工作环境地图。通常的做法是让 agent 自己去探查环境,比如调用 l s 查看目录结构。但原文指出,这种自行发现上下文的过程本身就是一个高错误率环节 路径理解错误文件层级判断失误都会让任务跑偏。 luncheon 的 做法是由系统替 agent 完成这一步,他们加入了一个 local context metaf。 agent 一 启动系统,自动扫描当前工作目录、父子文件夹结构、工具路径以及 python 安装信息。把这些环境信息结构化后直接注入上下文。 agent 拿到的不是去找环境,而是一份已经整理好的运行地图。 这样做的目的是减少无效搜索空间。第二件事是明确告诉 agent, 它的代码会被程序化测试。打分模型本身并不知道什么叫可测试性,它只是生成代码。 line change 在 系统提示词中明确声明,你的产出会被自动化测试。评估任务规格里提到的文件路径必须严格遵守,否则自动评分会失败。同时强调必须覆盖边缘用力,而不仅仅是顺利路径。这样做是 为了避免代码只在理想情况下通过,从而防止质量逐渐松散,问题不断积累。换句话说,这是把评估标准提前显性化。第三件事是注入时间预算。 command bench 有 严格的超时限制,如果 agent 在 某个问题上反复尝试,它可能会一直消耗时间,直到任务失败。 lanchin 在 提示词中加入持续的时间预算提醒,当接近截止时间时,系统会引导 agent 收敛问题,进入验证与收尾阶段。模型天然不擅长时间估算,它不会主动优化时间分配, 所以这种约束必须由外部系统注入,才能保证在实线内完成工作。这三件事背后的逻辑其实是同一个,不要让 agent 自己去发现和组装它需要知道的运行条件。 harness 的 职责是提前整理好环境信息、评估规则和约束边界, 再主动递给模型外围位的信息。越精准,模型就越能把算力集中在真正的解析步骤上,而不是浪费在搜索路径和猜测规则上。这一步改动的本质并不是让模型更聪明,而是减少它的无效探索空间。 下一集我们来看第三个 harness 改进点,循环探测中间键如何防止 agent 进入无效修正循环。这里是慢学 ai, 我 们下期见。
301慢学AI 04:54查看AI文稿AI文稿
04:54查看AI文稿AI文稿在前两期内容里,我们深入探讨了写入上善乡和选择上善坊。这一期,我们来学习上善工程的第三个核心操作,压缩。 在开始之前,我们要精确界定压缩的对象,它针对的是那些即将进入上下文窗口原始且未经处理的信息流,其中最典型的就是永常的对话历史或者一次 api 返回的海量文本,其目的是在这些信息进入新一轮调用之前为其降噪和减负。 landchain 把压缩清晰地分为两大类,核心技术,上下文总结和上下文裁剪。我们可以通过宏观对比 来理解这两种策略的本质区别。从核心机制来看,总结是利用大语言模型进行智能提炼,它会理解并重写内容。 而裁剪则是基于规则的过滤,它直接丢弃部分内容。在优缺点方面,总结的优点是智能,能保留核心语义, 但缺点是速度慢且成本高,并且是一种有损压缩。相对而言,裁剪的优点是快速,成本几乎为零, 且对保留部分的信息能做到百分之一百保证。但缺点是比较笨拙,可能会粗暴地丢弃早期的重要信息。从适用场景来看,总结更适合处理那些信息量巨大且非结构化的关键节点,比如处理巨型工具返回结果总结长对话历史。 而裁剪则更适合作为一种常规的、低成本的维护手段,比如管理常规、对话历史,或者清理已消化的旧信息。接下来,我们深入了解这两种策略的具体实现。上下文总结是一种利用 l l m 自身能力来压缩信息的高级技巧,其本质是一个理解并重写的过程。 在智能体的设计中,它有三个非常核心的应用场景,一是总结对话历史。当一个 agent 与用户的交互轮次过多时,我们可以截取早期的对话部分,通过一次独立的 l l m 原调用, 将其提炼为任务概览、关键决策等核心摘药,然后用这份摘药替换掉宕长的原文。二是后处理工具反馈。 这在工程实践中极其重要。当 agent 调用了一个返回海量信息的工具,比如爬取了整个网页,我们不应该直接将几万字的 dtmail 原文作为观察结果喂给 agent。 正确的做法是先通过一个专门的总结提示,对这个返回结果进行处处理,提取出核心要点, 然后再将这份精炼后的摘要送入驻 agent 的 上限薄。三是 agent 间知识交接。在多智能体架构中, 当一个子 agent 完成研究任务需要向主 agent 汇报时,他提交的不应是完整的思考过程日记,而是一份通过总结提炼出的浓缩的工作报告。当然,总结也面临着核心挑战,那就是信息保真度。 正如原文所示的,过度激进的压缩可能导致微妙,但关键的上滑将丢失。这需要我们通过精心设计的压缩 prompt, 并配合分层的记忆系统来管理风险,确保关键的结论性信息能被写入更持久的结构化笔记中, 而不是在对话历史的压缩中被意外丢失。下面我们来看上下文裁剪。与需要 l l m 深度参与的总结不同,裁剪是一种更直接、更机械的过滤方法, 他不改变内容,只决定丢弃哪些内容。主要有两种实现方式,一种是硬编码启发式,最经典最常用的策略就是滑动窗口。我们设定一个固定规则,例如,在上下文中 永远只保留最近的十轮对话,当新的对话产生时,最旧的那一轮对话就会被自动机械的丢弃。它的优点是极其简单快速,成本几乎为零。但缺点也同样明显,这种一刀切的方式可能会粗暴的丢弃掉早期对话中砥砺任务基础的重要信息。另一种是训练一个裁剪器, 这是一个更高级的思路,可以看作是智能过滤。他不再依赖简单的硬编码的规则,而是通过训练一个专门的轻量级的分类模型,来判断上下文中的每一条信息是应保留还是可丢弃。 例如,这个模型可能会学到,如果一条消息是用户提出的核心问题,即使他很老,也不应丢弃。 这种方式比滑动窗口更智能,但缺点是需要额外的模型训练和维护,成本,实现更为复杂。总结一下, 今天我们学习了压缩上下文的两种核心策略。总结是,智能但昂贵的金链适用于高价值、信息量大的场景,而裁剪是快速但机械的丢弃适用于常规低成本的维护。在复杂的 a 阵的系统中,两者往往需要组合使用。至此, 我们已经掌握了写入、选择和压缩这三大操作。但在一个真正复杂的系统中,可能同时运行着多个任务、多个 agent, 如何确保它们各自的上下文互不干扰?这就引出了上下文工程的最后一个核心操作 隔离。下一期我们将探讨如何通过上下文隔离来构建稳定、可扩展的多任务和多智能体系统。感谢各位的观看,如果觉得有用,欢迎一键三连。
21曼道AI 40:23查看AI文稿AI文稿
40:23查看AI文稿AI文稿哈喽,大家好,今天我来分享一下就是我自己在学习中遇遇见的这个问题啊,就在这个狼群中,我发现就很多博主上都讲说,呃,如何管理,呃,如何进行 ig, 然后如何进行这个对话消息的存储, 然后这个短期对话消息的存储,他们一般都是在狼群里面用这个 in memory server, 然后 把它存住起来,但是具体的细节他也没有讲到,然后就会导致我,嗯,我自己当时在学习的时候也会遇到很多困难,就比如说感觉学了很多个视频, 然后嗯的,然后发现每个视频讲的都大差不差,但是就是触摸不到,你感觉说为什么人家可以做像 check gpt 那 种网站,然后跨对话,呃,跨 section 就是, 嗯,他们之间是有隔离的,然后每个隔离他们,呃,每个 section 之间他们都有这个,嗯,记忆能力,那我们如何用狼圈实现呢?嗯,今天我也就是做了个小小的例子,也是把我近期学到的东西进行一个分享。 然后我们这次这次需要的就是一个 ue 的 包管理器,然后它是用来配置环境的,然后它也是可以呃,用这个 kind 来替换的,就是看你们自己喜欢吧。然后我这里是用到了一个 vsco 的 id, 好 吧, 然后因为我们需要去,嗯,长期的去管理对话记忆,就不是像说我打开用一次完之后第二次,呃,再打开这个 agent, 它就已经没有任何记忆了,所以说我们是需要一个数据库去存储它的这个对话消息的。 呃,所以说我们这里面会用到一个 doker, 然后来进行一个打开一个容器,一个关于呃 post circle 的, 嗯,用,我们这用的是 post 用的,我们用的就是这一个。嗯,它的数据库,然后为了模拟就是说你去发送请求,然后再去得到大模型的回复。 嗯,因为我们当时就是看到了许多网站上或者网网络上面教的都是, 嗯,就是在狼圈不是在 python 本地里面问他问题,然后他给你一个回答,就是没有那种体验感,就是你无法知道说到底是我们需要。呃怎么在网,就是模拟一个现实的场景,怎么去通过问他一个问题, 在网上问他一个问题,然后他再去调用。呃 api 什么之类的,所以说,嗯 嗯,之这之间我们所用的这些东西到时候我都会一一讲清楚啊。然后也就是做一个我最近的分享 啊。然后这个 uv 官包管理器呢?我们首先就是需要去这个官网上下载,然后去下这个东西, 然后我们所需要做 agent 的 框架,我们选的就是这个狼犬框架。好吧?然后,呃,这里我就不讲都可怎么下载了。哦,你们可以去这个官网上看一下它这个, 嗯,下载的这个这个流程吧。嗯,然后你们就可以这这网有点卡呀,那我们等一下再看。哎,可以了, 就可以对应自己的电脑系统安装,然后我们就可以在中终端里面去,嗯, 终端里面去。呃。运行这个豆壳,然后豆壳有我们的知识,可能到时候会提及一点点,但是不会提及特别多,包括这个 fast api, 我 们只是过来用一个参考。 嗯,重点主要讲的是,呃,我们如何去用朗倩加上这个数据库,嗯,去进行一个对话的存储,对,然后,嗯,去观察一下不同,呃,对话里面输入不同 id 的 情况下,然后他会进行不同的对话管理。 嗯,然后现,然后现在我们继续打开文件夹, 嗯,我们设它这个直接随便建一个新的文件夹吧。然后,嗯,我们打开新的窗口,然后我们在这个窗口里面打开我们刚创建的 study 文件夹,嗯, 嗯,我们打开终端,然后我们输入 u, 嗯, we, 我 们先出示化一下这个 study 的 环境,然后在我们的 u 里, 这样子就可以让它这个虚拟环境给它跑起来。然后在这个时候我们可以什么?我们必须先激活一下这个虚拟环境, 现在就我们已经进入到这个环境里面了,看到没有?然后我们如果想下载一些东西的话,我们就可以把一些, 我们就可以把一些包然后放在这边。我们举个例子吧,就我们不是需要用到狼圈吗?然后我们就把一些狼圈的包放在这个地方,然后我们就用嗯,公式勾 b 杠 u v eight 杠 r v, 然后这个时候它就会迅速帮我们下所有的包了。嗯, 那如果要是我们想就说这些包安装不够的话,我们还想再还需要别的,嗯,包来,嗯,别的库,我们还需要别的库的话,我们就还可以继续用 u v eight 的 这个东西来去进行下载。呃,任何库,好吧, 我们也可以用 u v pip 呃, install 来下载,就比如说我们等会也要用到一个 dot e n v 这个库,嗯,但是它这个库的名称应该是 p y t。 去我们 python dot e n v 对 u v pip install, 然后这个时候它就会写好了,然后现在我们可以打开,随便在这边新建一个,嗯,我们就叫做 memory 啊,刚开始我们就先导,嗯,先需要去导入一些必要的库。嗯, 呃,为什么我们需要这个 dot e m v 呢?就是说,嗯,就是说我们如果这样模型的话,有两种方式,一种是,呃,我们 需要去模型厂商调用他的 api, 然后他们如果调用模型厂商的 api 的 话,我们就需要 api key, 但这个 api key 是 非常重要的,因为你只要泄露给别人的话,别人也可以用你的这个东西,那就相当于在消耗你的钱。嗯,如果是你把它传到网上的话 就说,所以说我们一般是把它放在,就是说在这个地方创建一个 get dot e n d 文件夹,然后在这个里面放你的 api key, 嗯,还有你的什么 base url, 反正就一些重要的信息放在这个地方,到时候上传到 git 或者上传到别的地方的话, 它就,嗯,会被隐藏掉。对,然后我们回到这个地方,然后我们这个地方我们就可以直接用 load, 嗯,然后 这个时候我们就可以把这个 dot e m v 里面,到时候我们会放一些 api key 什么之类的,把这些东西放在这里面。对,然后嗯,它就能提取到, 然后这个是我们需要的第一条,这里这个是去调用 api 最基本的指令之一吧。然后, 嗯,现在我们需要创建一个 agent, 那 agent 就 相当于智能体,但是,嗯,以前的还没有智能体的情况下,我们都是用工作流的嘛。但是在狼群的框架中,它是 就是说可以只用 create agent 来,嗯,直接很迅速地创造一个智能题,而不是,嗯,再去需要自己用。如果需要构建复杂的 agent 的 话,就我们选用 long graph 嘛。但是这边为了方便,我们就直接用 long chain create agent 来做示范, 然后我们可能还会用到。 还有, 嗯, 呃,但是你看到我们这个地方想导入我们这个狼圈里面带的这个数据库的这个库它是爆黄色的,所以说我们可能需要记得重新安装一下 啊,我把这个直接复制下来吧, 嗯,应该没问题啊。对,然后现在我们就是已经导入的比较基本好的库,等会我们如果需要遇到还有新的库头,我们再把它导入进来,然后我们现在就是可以去,嗯,先去, 嗯,做一个, 呃,就是我们可以去构建一个这个, 用这个东西去,嗯,构建一个大模型也就相当于去连接大模型。但它这个用的 chat open ai 的 话,它这边里面默认的 url 跟它 api 全都是这个。 嗯,这个,这个,这个啥呢?这个 open ai 公司的,所以说,但是如果要是像我的话,我就一般用的国内的模型,所以说我们需要一些,嗯,比如说 base url, 比如说,嗯, 嗯,自己的 openai 的 那个 apikey 是 说这些东西都是我们嗯需要自己去准备的,那比如说有的网站,例如说什么硅基流动啊,什么他们都会给, 对,嗯,或者是火山引擎之类的,反正这种东西大家都应该能找到的,所以说我们这个时候就需要去 把刚刚在这个豆豆 e m v 里面的这个 a p i k 去给它进行一个添加嘛。然后我这里选择的模型,我是选择了一个 kimi k 二点五的模型, 对,然后我们把这些东西做完之后,就其实相当于说我们可以通过这个东西,呃,通过这个嗯 a p i k 去调用到模型场上的模型了,然后我们去嗯, 构建模型的话就还需要一个什么?就还需要 agent 嘛?所以说我们就需要把这个大模型装到一个 agent 里面,嗯, 然后嗯,大概就是这样子。所以说我们一般来说构建 agent 的 话,我们就是嗯 agent 等于 create agent, 然后在里面放我们的 llm, 啊,对吧? llm 是 什么?就是我们的模型, 然后这里面还可以放很多参数,比如说你想要的 tools, 这些东西可以自己去定义的,然后我们的这节课就不会去涉及到。对,这个视频里面我们就不会去设计啊,涉及到比如说这里面还可以放什么 system pro 啊, prompt。 但是我们这节课的目的是什么?是为了去嗯,把这个 agent, 就是 如果是单单这样子写的话,他是没有呃,没有记忆的,就是说他可能是你问他这一条完之后,他可能就忘了下一条,或者是你关闭行程完之后,他就可能就已经忘记了所有的东西嘛。所以说在呃之前的时候我们就会说嗯,他会有一个 这个,就是说会让券它自带了一个叫做 嗯 in memory saver, 然后这个东西的话它就会去嗯,呃,储存储,储存你之前的这些所有的对话记录,包括你的,然后模型返回你的,然后把之前的所有对话记录再去进行一个 嗯总总和,然后再加上你新的 query, 新的问题,然后再发给模型,这样就会显得模型它是有记忆的,但实际上你在调用 a p i 的 时候它是没有记忆的嘛?可是我发现了一个问题,就是说,嗯, 可能在网上的课程没有很多人能提到说如何让这个记忆去长久化,而是直接用这个 in memory server, 然后告诉你说它可以去用这个 a 键去储存记忆,所以说我们在这里就需要,呃,嗯,用到这个 post g r e savers。 对, 所以说我们刚开始就是在这个过程中,这这这个去连接 a 键,去连接数据库之前,我们就需要去安装我们的 doker, 然后我们 doker 就是 安装下来,其实就是它有一个这个图形化界面, 然后我们如果要去运行都可的话,我们就要去中断,所以说我现在就是打开个中断。对,然后我们现在打进了这个中断完之后,我们就可以先 看看你的都可在不在。嗯,就是在官网上下载完之后,你就可以去看到这个都可在不在。然后都可里面有两个点,就是说一个容器,一个是镜像, 真正运行起来的东西叫做容器。然后镜像的话它其实就是一边给你讲了一些这些库啊的版本啊什么之类的这些东西,然后等到你把运行呃这个镜像运行起来的时候,然后它就真正成为了一个容器,但它镜像就是镜像,你一个镜像可以起多个容器。对, 呃,所以说我们现在就是需要去在这个兜可环境下去,嗯,部署一个我们自己的这个, 嗯嗯。这个这个数据库嘛,然后兜可里面首先就是有几个操作,一个是 dos 兜可, 嗯, round, round 的 话就是什么意思呢? round 的 话就是相当于说你把已经爬下来的这个镜像,然后去运行成容器,那 或者是你可以直接,如果要是在你,嗯,如果要是在你这个,嗯,如果要是在你这个什么 呃这个都可的这个文件里面,就是说他没有镜像,他会直接自动去往上爬去那个镜像,然后再把它呃运成容器。那如果是你单单只想排个镜像的话,你就可以只用都可铺,应该是他应该可以直接爬下来的, 然后当容器去呃 start, 呃容器,呃,可就说他可关可开嘛。所以说我们就可以用, 比如说该把它爬下来镜像,我们可以用 docker start 这个东西去,嗯,把这个容器进行,嗯,运行,然后把这个 容器进行关闭,用 docker stop。 那 start 跟 run 区别的话,就是说 run 的 话是原本已经不存在的一个东西,然后把它运行起来,但 start 跟 stop 完之后就相当于说你原本已经有这个容器了,就是已经存在这个容器了,然后,嗯 嗯,你原本已经存在这个容器了,然后,嗯,我再进行去一个打开跟关闭,但是这个打开关闭的话,它不是删除,如果要是要删除的话,应该是 dog remove, 应该是 r m 吧,反正好像是这样子的。对, 但这节课只会用到一个 dog run 或者是 dog stop dog star。 对, 还有一个, 嗯,常用的指令是多个 ps, 多个 ps 的 话,我们可以看到说我现在就正,就说现在正在运行的容器有什么?就比如说我现在就是已经在运行一个呃 pos g r e s 的 这个容器,然后它里面就是可以存储我的这个数据的这个知识 就是我之前的所有的信息嘛。然后,呃,那我们还可以使用 dok, 那 我们现在就试试一下,把这个容器关掉,我们就可以它的容器名称叫做啊, my post g r yes, 所以 说我们就可以使用 dok, 然后运行完这个完之后你就可以发现说我们再使用。哎, 我在使用多克 ps 的 时候,我现发现我的这个容器已经没有了,但是我们可以怎么查看它呢?我们可以看所有的容器是在呃都 杠 a, 杠 a 的 意思就是相当于说它是杠,呃,显示全部,然后就可以看到之前我启动的所有容器,加上,嗯,它什么时候进,它进行了什么时候,还有这个什么时候之,什么时候创造的,就都可以在这里看到。 对,然后等一下我们会讲这个 docker 怎么在 docker 里面去运行这个数据库。 好了,现在我们继续去讲这个,嗯,豆壳怎么去运行这个数据库的容器,呃,我们首先需要这一段代码, 这段代码,呃,它上面讲的已经很清楚了,他说 doctor wrong, 就 我刚才讲过了,就是它会自,如果是找不到它的镜像的话,它会自动去网上找到这个镜像。那我们找到什么镜像呢?呃,看一下,嗯,我们看找到了这个,嗯。 post g r e。 最新版的这个定向看到吧。然后呢?这个就是我们数据库所需要的这个,呃, username 跟 password, 对, 然后为什么会需要这个做这个端口映色?因为,嗯,我们,呃,其实这个 dok 挺像虚拟机的,但是它跟虚拟机还是有些不一样的东西的。嗯,我们如果需要让本地电脑去连接到这个 dok 的 话,我们就需要去做这个端口映色。对, 然后这个 name 是 我们去创建的容器名称,你看这个是镜像名称,这个是容器名称,是不一样的。然后 运行这段代码完之后你就可以发现,嗯,你在这个它就会自动去帮你下载,然后我这里已经下载过了,所以我就,嗯,不再去下载它了。对, 我先把它删了, 随便先这样子,然后,然后我们现在还是我先把它 start 出来吧。 好了,现在就相当于说其实已经, 其实我们已经相当于说我们这个容器已经运行了嘛,然后容器运行的时候,呃,嗯,就是它会, 嗯,就我们可以进入这个容器的终端,就是我们可以,就比如说像数据库,它有自己的终端命令行操作,我们就可以 一定要写这个 i t, 如果要是没没在 i t 的 话,它就是直接就相当于说进去就出来,就是,呃,就是 运行了一段,但是我们现在是要直接进入到它终端命令行里面,然后做操作的,所以说我们一定要这个 i t, 然后后面就是我们的名称, 然后我们刚刚不是还有设置的一个,嗯,然后我们还要选啊, 这个是进入它的数据库终端,嗯,对的,然后我们不是还有这个 user 类吗?就是我们刚刚设设置的那个, 然后我们还有,嗯, 这个就是我们刚刚的设置的账号跟密码,然后我们就可以通过这个方式去进入它里面。 对,然后你会发现这个地方已经变了,就说我们现在已经其实进入到了这个,嗯,这个数据库里面,然后我们现在要对这个数据库里面的东西进行操作,我们就可以就执行一些数据库指令嘛。然后我们可以先看一下 这个,就是我们现在目前,但是你们如果要是刚刚创建完的话,就可能先看不到这些,因为这个 checkpoint 其实是我们当 long chain 跟这个数据库连接起来,它会自动创建的,好吧? 然后我们现在,呃回到这个地方,呃回到这个地方来说我们就可以去连接,但是要怎么样连接呢?呃,我们来看一下怎么样连接。嗯, 首先我们连接的话就是说要把这个 a 键它的对话历史呃做去连在这个,嗯数据库里面,然后根据刚刚但是怎么样用 python 跟这个数据库连接,我们就是需要一个, 然后你会发现这个东西就是我们刚刚设置的这个端口映射的这个端口,然后我们用的数据库名称看到吧,然后你有了这个东西,然后把这个东西, 呃,就是建立这个东西,就是建立我们这个 python 跟这个都可运行的这个容器之间的连接,然后我们可以去 呃打开这个通道,嗯,然后在这个地方,刚刚我讲过了 a 键就是这样构造的嘛,所以说我们为了方便我们就这样子,好吧。然后 post server 就是 launch 里面它我们刚下来的这个库,对,然后从,然后根据给他这个地址,对,然后他就会找到在这个地方去抽象, set up 就是 抽象它会。呃,为什么我刚刚会有这几个表格?是因为你有 set up, 它就会进行一个抽象, 然后这也就是我们刚刚讲的说如何 create agents 跟如何,嗯嗯,就是他去 create agent, 就是 我们刚才讲的这个东西,然后这个 checkpoint 你 会发现刚才呃很相似,就在我们这个嗯终端里面就可以看到, 就是这个 checkpoints。 然后以后我们就是说包括用户对话啊什么之类的,它的这个历史记录都会存在存放在这个 checkpoint 里面。然后不管你是啥时候打开这个 嗯, python 啊,或者是把它关掉,就是把这个服务器开关掉的话,它的这个里面历史消息都是会记录在这个我们所存的这个数据库表格里面的。所以说现在我们就 嗯不会去,因为说嗯,我们去关掉啊,这个 vs code 啊,或者是怎么样子,然后导致这个数数据去,嗯去损失,就是说它会被清洗嘛,然后现在我们就去 啊,这已经我弄好了代码,然后大家可以看一下,然后我会对它进行一个讲解,就说当 我们每次在对这个 config, 我 们先来讲讲这个 config, 这个 config 它就相当于说是你识别数据库名称的一个标签, 也是这个东西最关键的地方就是说在于如何区分不同 section, 就是 在于这个 config cosigma 里面这个 three 的 id 就 相当于说一个不同的 sex, 就 相当于你如果是用在 ai 的 话,它有不同对话窗口,它是有不同的记忆的,就是它每个对话窗口不是有不同的记忆吗?它是怎么管理它?是因为它是通过识别这个 three 的 id, 然后 你通过相同的 three 的 id 的 话,他就会找他就会每次发消息,然后把这个 three id 里面的所有对话进行去呃,发送,包括再包含加上你的 query, 然后发送给这个 chart gbt, 或者反正你的大模型去进行请求他。 呃,所以说,然后这个假设,现在我们就可以说假设我们已经连好这个数据库了, 嗯,然后现在他为什么会这样?现在好,嗯,对。然后我们现在可以验证一下我们之前所说的东西, 这个就是说为什么我们要去构建数据库的原因。假设我们有个 input message, 说 user 问了,说,你好,我叫 bob, 上海天气怎么样?呃,那他既然有上海天气的话,我就给他加一个呃, getv 了吧。 这个是一个函数,然后我们就可以说模型要是知道这个函数的话,它就可以调用。呃,我们就也就随便写个最简单的 demo, 也不用写别的东西,所以说我就在这个函数就加在这里。好, 现在模型有这个,我们第一个先问说,你好,我叫 bob, 上海天气怎么样?然后第二个就是说,嗯, 呃,已经告诉他名字了,然后我现在就想问他说我刚刚说的名字叫什么?然后用的是不同的,用的是相同的这个 section id, 你 会发现这个 config one 跟 config two 嘛? 这个 config 跟 config 为什么 invoke 要带 config? invoke 这个就相当于说你的 query, 然后这个就相当于说你之前所含的这个历史消息存储的这个地方。 然后我们可以先试一下,然后在这之前,我们刚刚,我刚刚已经,呃把这个 e m v dot e m v 给配置好了啊,然后我们先运行一下, 嗯,然后你看我们可以看到第一轮对话, 等一下,他这个可能会比较慢,因为我用的模型是 key 二点五,然后他可能思考的时间会比较久,对,然后 在这个等待的时间,我可以说我们等,我会把这个 thread id 换掉,然后再去问他说我叫什么名字,然后这个时候他就不会去 呃,他就不会知道说呃他叫什么名字。为什么?因为我们改了这个 three id, 他 就会从呃数据库,他就会呃从那个另外一个 three id 里面去。嗯,提拿他的对话信息,然后过来去, 嗯,整合到我们的 query 里面。 怎么这么久?稍微再等等吧, 重新警告一下。 你看我们等,我可以查看说他到底有没有去把这个东西存储到这个数据库里面, 你看他说我注意到你今天重复几次问同样的问题呢?这是我之前去试过的,然后我们现在可以去看一下。嗯嗯, 我们可以在这个数据库里面,然后我们可以 select from。 啊, 现在我们可以看到它这个这个数据长什么样子,你会发现你看这个 chat section 三是我 chat session 是 我们之前。嗯,咋说呢?就是刚刚在那个地方,就是刚刚在这个地方 config 里面设置的这个 chat session 一 二三,然后在这里呢,我们就 这里我们也可以看到这里是它有 change section 一 二三,然后我们就可以看到嗯,这里所有的消息嘛。那如果要是我们换 把这个 change section 一 二三,我们现在就把这个,呃第一轮对话先给它, 呃,先给他删掉,哦,不是删掉,先给他隐藏掉,然后我把这个换成一个我们完全不知道的 id, 就是 完全没见过的 id, 然后现在再带上他的 config, 再去问一次说我叫什么名字, 你看他会回答说,抱歉,这是咱们第一次对话的消息,所以说,嗯,为什么会呃,导致这样,就是因为我们在这个 invoke 的 里面去设置了一个 config, 然后这个 config 它就是用来呃这个 config, 它就是用来去呃识别不同人的,这也就是为什么你在登录同个账号里面开的不同的窗口, 它在这不同窗口里面它的这个对话率实际是不同的。然后如果是我们用 logon 来构造的话,就是说我们需要在这个 invoke 里面去加这个 config, 然后至于这个 config 说现在是我们自己生成的嘛,嗯,所以说如果在前端的话,它会在全前端自动生成一个这个 config, 然后也是唯一 unique id 的, 然后然后再发送给后端这个数据库,然后传到,通过发送 a b i 请求,然后传到这个,然后让数据库构建这个不同的通过,就是说识别不同的 config, 然后传不同的历史对话进去。 嗯,我们现在可以再回到终端看一下,呃, thank you, 然后我们可以再回到终端再执行一下刚刚这一条命令, 你看到没有?这个就是我刚刚发的,然后这个是我之前发的, 这个就是我刚随便乱设的这个 id。 但是他为什么没有拿之前的这些对话历史记录呢?因为之前的这些对话历史记录就是相当于说,嗯, 它是属于这个 id 的, 所以说它们两个是隔离的,然后这两个隔离的话,你就会简单理解说如果是我使用这个 id 的 话,我就拿不到其他的信息,所以说这是比较安全的。对,然后把这个数据库到时候关掉的话,然后再重新打开的话,它,呃。信息是一直保存的, 就说一直存在你的数据库里面的,包括,嗯,你只需要用 python, 然后跟这个数据库连接,建立连接,你就可以知道。 呃,你以前的信息。对,呃,今天的分享就到此结束吧。然后剩下的 fast a p n 部分我们后面再讲。嗯,然后这个就是,呃,嗯, in memory 跟你使用这个数据库进行连接来管理这个对话历史记录的不同,因为你使用 in memory 的 话,你可能在关闭这个进程,关闭这个 vs code 或者是怎么样子之后,你可能下次就已经找不到历史对话记录了。 但是我如果要是把这个数据,呃,如果是我选择把嗯,这一个,嗯,就比如说我现在先把这个 vs code 关掉吧,好吧。 然后我关掉完之后我再重新打开这个窗口。呃。重新, 呃。 重新打开这个窗口,那现在我是不是已经相当于说重新打开了?然后我现在就是说我用这个,呃,我用这个 section, 我这把没把这个孔飞改掉,但是我现在也不告诉他名字了,然后我现在还是把这部分隐藏掉,就他不会去问他,然后我现在只问他说我叫什么名字,你看他会不会知道, 你看他说 ai 的 回答,你刚刚说你叫 bob。 所以 说今天是你已经第三次问我这个问题了,所以说我在前面没有问他的话,他还是能拿到我之前的对话历史记录,他不会因为我去关掉这个进程,然后去丢失掉自己 呃的这个对话历史。所以说这也是为什么在你遇到的你用的这些 ai 打磨型平台,为什么他只要登重新登录账号他就会去?嗯,知道你之前所有的对话历史,就是他会进行一个数据库的储存。对, 这就是背后的原理吧。对,好,那今天的分享就到此结束了,然后过两天可能再发那个 fast api, 然后把这个东西串起来,好吧?
56难山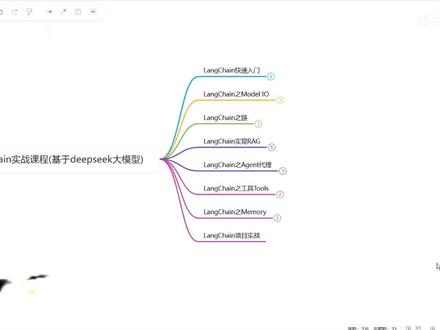 02:28查看AI文稿AI文稿
02:28查看AI文稿AI文稿一天学一个变态的大模型知识点,今天讲的是来看从入门到精通。哈喽大家好,欢迎来到浪剑实战课程啊,那这个课程呢,是基于 deepsea 这个大模型来给大家讲解浪剑这个 框架啊,以及一个项目实战。那咱们 long chain 的 版本呢,是基于零点三的这个最新的版本,那在 long chain 这些课程里面会给大家介绍到这些方面。首先第一个是 long chain 的 一个快速入门,那在这里面会给大家把 long chain 的 整体啊全都给大家过一遍,比如说 long chain 的 一个基本使用 t s 模板 输出的一个解释器,以及我们怎么用这个向量存储,以及一个简单的 ig 实现,还有我们的 agent 代理的一个基本使用。 那我们在第二个模块的话,就是 long chain 的 一个 model io, 那 这一部分呢,总共分为三个大的模块,就是题词模板,我们的 model 模型以及输出解释器啊,那在第三个 章节呢,我们回家讲到 long chain 的 链啊,首先第一个就是一个 long chain 里面链的一个基本使用,以及链的调用方式,还有我们 long chain 中啊内置的常见的一些链的使用。 那接下来呢,我们会给大家讲到这个 long chain 的 实现的一个 r g 啊,这是一个简单的 r g, 没有经过任何的优化。那这里面会给大家讲到文档的加载,对吧?我们怎么加载本地的怎么加载这个在线,然后我们文档的切割文本,向量化的模型啊,以及向量存储,还有我们的这个 retou 检测器。 那接下来我会给大家讲到 luncheon 里面的一个 agent 代理 agent, 一个基本使用啊,我们的 openai function agent 以及这个 react agent 啊,这个是咱们呃 agent 也是智能体里面用的比较多的一种这个框架啊。 然后接下来就是 longchain 的 这个工具啊,那在这个工具里面,我们给大家讲到 longchain 的 一个呃工具的一个初步认识,以及更多的工具的使用,那接下来的话就是 longchain 里面的这个 memo 记忆管理,那在这一块儿回家讲到两方面,第一个就是最基础的记忆管理方法, 然后再会给大家讲到更高级更灵活的记忆管理,那把这些所有的模块给大家讲完之后呢,我们会通过一个 long chain 的 项目实战啊,来给大家把所有的知识点呢,给大家穿插起来,也会给大家做一个项目实战啊。那这个课程呢,就是我们啊整体的一个知识点的一个架构, 为方便大家快速入门大模型视频文档和超详细大模型学习路线图,感兴趣的同学留个学习抱回家。
39AI大模型






