即梦ai生成人物如何更像真人
像这样超真实的 ai 人像是怎么制作的呢?今天三步教会你做出超真实的 ai 人像,摆脱僵硬塑料感。先上传三到四张人物照片,让 ai 精准融合五官特点,这是做出自然脸庞的关键一步。第二步,给人物加上真实质感 buff, 再提示词结尾,加上佳能八五定焦胶片质感这类专业摄影 参数,还原真实成片的细腻画质。最后再补充真人细节,比如鼻翼微张、高清毛孔、皮下血管纹理,真实度直接拉满。这样生成的 ai 人像瞬间鲜活逼真! 你学会了吗?赶紧动手试试看!

粉丝385获赞3135
相关视频
 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿纯干货 cds 二点零真人过审的八种方法,每个方法的详细提示词我都整理好了,然后过程中咱们就不看这些提示词,只看具体的这个呈现的结果。这是我们的原图,虽然是 ai 生成的,但是 cds 二点零一定会把它给识别成一个真人。 那么第一种方法是做这样的,一个简单的一个素描图,一句话提示词就可以搞定,但是缺点是有时候会影响最终画面的呈现的效果,他可能会视频有点那种油画的质感,不够真实。第二个方法是这种现稿的多式图, 可以看到,首先还是人物以现稿为主,但是他的服装以及面部的细节给提取出来,这样的话更加能还原到这个人本身的样子。第三个方法是分离身体与面部,我们用提示词先做一个只有身体的图,再做一个只有面部的图, 这样的话他就会规避到真人审核。第四个办法是用面部遮挡的方式,首先是把这个图做成一个三式图, 然后用提示词去遮挡面部,每个图遮挡的部位不一样,最终可以拼合成一个完整的面部,那么他也会把这个判定为非真人。 第五个办法是用这种网格遮罩的形式,也是一句提示词,给这个人物的面部增加上网格遮罩,那最终 cds 二点零会把这个人物的完整的面貌给呈现出来。第六个方法是三式图,把它做成这种人物形象卡片的形式,但这种方法成功率不高, 怎么样更高呢?我们做到九式图,这是一个人物形象的卡片,确保了各个角度的人物一致性,但是成功率也不是最高的。想要做的更高,可以用这种多式图的方式,更加详细的去固定人物的服装的细节,比如说鞋子、嘴部、眼睛、手部、服装等等发型。 那这个方法是适用于做一些比较大制作的项目,就是你可能要经常的附用这个人物。当然现在官方是有真人的渠道,很多网站也上了对应的 a p i, 然后价格会稍微有些贵。我看有网友总结了这样的一张图,就是这种企业端的价格的 明细。如果是大批量的需要用真人去做漫剧的话,肯定是用这种方式更加简单直接,价格可能也会稍微贵一点。
891AI课代表 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿你用寂寞 cds 做视频,人脸总是审核不通过,经过我的实测,这两个邪修办法能够稳定通过,亲测有效。先告诉你一个核心问题,能听懂这一个就能解决一半。他并不是不让你用人物,而是他不让你用真人照片,明白了吗?真正能够解决这个问题,就是把人变成 ai, 人怎么变就两步, 先上传你的照片,注意这里是生成图片,不要傻乎乎的去做视频,然后写一句提示词,保持人物特征,保持五官比例,生成 ai 人物定妆照,你想固定表情,加上提示词就可以,最后看看效果,脸还是你的脸,但是已经是 ai 画的。以 后你转到 c 弹四里过审,固定角色就随便你用第二个方法,模型选择 c 弹四二点零,这里会显示不能用人脸。你随便打开一个能够生成图片的 ai, 把原图丢进去,第一步, 让他生成人物的四式图。第二步,让他把图片拼成四宫格。第三步,保存四宫格图片上传到季梦刚刚上传的人物图片是不过审的,现在能够秒通过,因为系统识别是 ai 画出来的人物,不是真人照片。接下来看看效果。
1589菜芽的AI笔记 01:20查看AI文稿AI文稿
01:20查看AI文稿AI文稿吸电二点零,很多人都没办法上传这个真人的这种素材照片了,那么都会显示失败,那么我今天总结的有两种解决方案。先说第一种吧,你们可以看到我这里上传本人的照片都是失败的呀,然后呢?后面我为什么这里就成功了呢? 这里成功了是因为我做了一个三四图啊,这是我三四图啊,用这个纳洛本纳的把它合并成三四图,合并完之后呢?嗯,直接上传就可以了,他就识别你是 ai, ai 的 这种三四图就可以生成了。 对了,忘了说,你们这里最好这个分辨率选择这个四 k 啊。然后呢,这个提示词就这样子,很简单的把三张图片合拼为一个三四图,非常简单。 然后如果你们不会用工作流的话,你们也可以用别的这种 ai 的 模型去把它这个素材给转一下,变成 ai 的 素材,它就可以生成了。 然后剩下另外一种方法我就先不说,我也不知道说这种方法他会不会马上被下架,所以你们能用即用吧,好吧,等有需要我再更新第二种,好吧,哈哈哈哈。
624张从文 00:54查看AI文稿AI文稿
00:54查看AI文稿AI文稿积木 c d 二点零卡人脸又升级了!像之前用的很好的全员采稿人物的三式图,四宫格、九宫格的形式,昨天晚上开始全都不好用了。 于是我花了一晚上时间给大家又找到了目前为止积木百分百能过人脸的方法,而且生成的人物效果 比之前的任何方式都要好。说真的,这玩意太省妈了,以前哄睡半小时起步,现在放上哄睡模式,十分钟自己就睡着了。不用联网生成的视频里的人物形象跟本人几乎都一模一样,一点都没有 ai 味。就是这种人像定型图,包含了人物的三种仕图,还有脸部跟身体的各种特征, 把它们集合到一张图上。大家看,我连续用这个图生成了这么多条视频,条条都过人脸。而且生成这种人像进行图,只需要提供一张本人的照片发给吉梦,然后输入我这段题词,就可以自动帮你生成。想用吉梦去做,真出现在我视频,同学一定要试一试啊!
2307隋校长Ai短视频带货 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿你用积木 cds 做视频,是不是一传人脸就失败?试了几十次,全卡在审核。今天分享一个邪修办法,亲测有效。现在积木审核有多严?真人不行,长得像 ai 的 真人也不行。 其实底层逻辑他非常简单,就是真实度太高了,他怕侵权。解决方法也非常的简单,就是让图片像人, 但又不像人。把图片做风格转会,保留五官特征,但看着像画的,我反复试了几十种风格,目前最稳的就是豆包自带的彩铅画,跟原图最像, 又能稳定过审。你拿这张彩铅画当参考图,他就不提示包含人脸的违规了。然后再给一段真实视频当风格参考,让他生成真实的效果。两张图一结合,就是你想要的实测相似度在百分之九十以上, 你做视频完全够用。这才是真正的邪修办法。觉得有用点赞收藏,记得关注,不然你找不到我!
140菜芽的AI笔记 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿你上传正人人脸用 cds 生成视频的时候,是不是总是遇到这样的这样的这样的提示?那我之前分享了,我用我和我女儿的形象做了一个短片,这个短片其实是用了三条十五秒的视频拼到了一起,但是验证了我的方法可以做到让多条视频相对的保持人物的一致性。 很多朋友也在评论区留言,让我去分享一下,那这条视频就是讲一下具体的方法。我先说清楚,极梦的 app 和豆包的 app 我 不懂,我这十几天一直在用的是极梦的网页版和小圆圈,尤其是小圆圈的网页版和 app, 我 觉得他们的模型能力会更加强一点, 用的最多,所以说我讲的仅限是我知道的方法。我先给大家看一下,我今天上午为了做条视频,专门又验证了一下我的方法管不管用,又在疾风网网页版跑了一条视频,他是明确说不让使用真人人脸的。 大家好,今天我给大家带来一个数字,那这条视频我用的就是我的形象,我的声音,怎么做的呢?方法就是把自己的人脸照片生成一个四宫格就可以了,先自己拍几张照片,最好是不同角度的,然后用美图秀秀拼个四宫格 c 单词的题时词就直接说人物形象,参考艾特你的照片就可以了。我女儿呢,用的是三宫格,反正就是两张以上的,应该都都是可以的。目前是极梦的网页版和小园区的网页版,使用下来都是没问题的。 很多人也说用素描,我觉得真人照片效果更加好,素描是 solo 的 玩法,那这个小技巧呢?我也不知道能够管用多久,如果说有其他更好的方法,欢迎各位可以分享一下。
431大麦AI笔记 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿有什么 ai 技巧能迅速拉近你和专业创作者之间的差距呢?我发现百分之九十的人都不知道如何保持 ai 视频中人物的一致性。 要知道, ai 视频它生成人物的形象前后不一,成片自然是没法使用的。而掌握其中的技巧其实特别特别简单。大家在制作视频前,大都会先生成一张人物图,其实能做到这一步,你已经超过百分之七十的人了。但是对 ai 而言,这只是一种弱约束,想要保持人物的一致性还远远不够, 需要掌握以下三个进阶技巧。第一是拆分人物和场景。生成视频时,如果将人物和场景混在一起生成,会大幅增加保持人物一致性的难度。因为在 ai 的 预算逻辑里,人物和场景会被视作统一的参考画面而变化。 但是现实中拍摄视频的时候,人物和场景本来就是相互独立的,人物的样貌始终是保持固定的。所以我们要做的就是把人物和场景拆分开来, 先生成人物的多角度,试图让 ai 充分理解角色的完整形象,才能将人物转化成为一个稳定可附用的视绝对象。第二是先定动作,再进场景。当需要人物做出某个动态的动作时候, 先单独把人物的动作效果生成出来。注意,这里不是抛开背景和绿木扣像一样单纯生成动作,而是先把动作的首尾帧制作完成。比如说要呈现人物从画面的左侧走到右侧的效果, 那要先确定好走之前和走之后的两个关键帧,再通过首尾帧生成完整视频,这样整段视频的人物形象就会流畅,自然,不会变形。第三个是把镜头拆的越细越好。 对 ai 来说,视频生成的过程本质上是持续的推理预算,预算的时间维度越长,画面的信息越复杂,推理偏移的概率就会越高,人物形象也就越容易失真。因此,一定要把镜头拆的足够细致, 一次只生成一个镜头的内容。说白了,这些技巧都是在复刻现实中的视频拍摄方法。毕竟现实里的视频创作本身就是一个镜头一个镜头拍摄完成的,我们只是把不仅和拍摄的工作交给 ai 来完成而已。如果你对用 ai 创作也感兴趣的话,关注我,带给你更多实用的 ai 创作技巧。
1885谢非说科技 01:25查看AI文稿AI文稿
01:25查看AI文稿AI文稿最近呢一直在研究这个寂寞带货视频,为了实操落地啊,我们研究了一套非常非常牛的提示词,生成出来的效果呢,真人感跟素颜感特别强,而且就像实拍一样,待会呢我会把这整套方法论告诉大家,首先我们要准备三套我们要推的产品, 然后呢我们打开季梦的视频生成全能参考模式,把这三套衣服导入进去,输入我们这一段提示词,生成出来的效果就是这样的,人物的微表情动作,还有这个换装的切换,都是非常流畅,非常有真人感。 那我们怎么样才能产出这种狂人感特别强的带货视频呢? 首先我们要知道的是 ai 生成出来的视频,他是要有一个明确的指令的,你的指令越明确,他产出的内容就越精准。首先第一点就是我们要给他一个固定的画面风格, 那第二点呢,就是我们要给他一个固定的场景细节,那第三点也是最重要一点就是要固定人物的微表情跟动作,那这三点搞定以后呢,我们再给他一个具体的切换 服装的时间就可以了。那如果你还有什么不懂呢,你可以在评论区留下你的行业,我都会一一给大家解答提示词呢,我也会在粉丝群毫无保留的分享给大家。
3936牛牛AI 01:01查看AI文稿AI文稿
01:01查看AI文稿AI文稿没有用三式图,也不用把照片上的人脸涂掉,只需要上传一张正常的带人脸的照片,就可以在极梦的官网上生成你想要的有电影感的有活人感的 ai 视频。 看到这个艾特服了吗?他在这里新增了一个创建主体,你可以在这里上传自己预先生成好的角色图,而且可以上传多个角度,这样可以保持人物高度的统一性。 你看我这个只是上传了一张照片,不用涂脸,也不用额外的去生成他的三式图,你只需要在提示词里艾特你刚刚创建好的这个角色就可以了。那么现在 就只剩排队的问题了,什么时候吉梦能把这个网站亲生的高级会员的排率待遇提升一下就好了。现在在人家第三方十分钟就能生成的视频,在你这要等六个小时,这对吗?这真的对吗?
130EMMYSYNC 03:20查看AI文稿AI文稿
03:20查看AI文稿AI文稿这可能是你目前见过的最强的 ai 数字人自动生成,最接近真人,随意调节语速语调,甚至能模拟呼吸声和细微的情绪起伏,告别呆板的机械音。这是我刚刚用 ai 制作出的虚拟数字人。女友,嗨,我是你专属的 ai 生成女友, 今天我只陪你一个人,不会被别人打扰。你现在最想让我为你做什么呢?聊天?陪你放空?还是乖乖待在这里只看着你就好, 那今天我会以最快的素材带你上手 ai 视频制作, ai 的 工具整合包模型我都为大家准备好了,我们要生成这种视频的话呢,主要有以下几个步骤,第一呢,获得一张让你欣喜若狂或者小鹿乱撞的美女或者帅哥的图片。第二呢,我们这张图进行图身视频,把视频生成出来。 好,废话不多说,我直接开始操作。那我们输入这么一段指令啊,让他帮我反推一下图片的提示词, 好,然后直接发送大家去推送一下。好,我们看到这里提示词已经反推出来了,然后把它反推出来之后呢,这个提示词我们可以看一下啊,如果觉得这个词还可以,我们直接把它复制。复制之后呢,来到我们的 ai 平台,在这个平台这里呢,我们看到这里有个图片生成,可以看到吧 啊,在图片生成这里呢,我们直接复制刚刚提示词给他,然后进行生成。如果是点击这个之前呢,你可以选一款模型,你可以选三点一,也可以选四点零。 三点一理论上来讲的话是比较好用的一款图片模型,如果你觉得它生成效果不好的话,你可以稍微降一降,得到一个比较好的效果,然后选好尺寸,点击生成。然后我们看到这张图啊,其实我感觉中规中矩吧,可能还没有达到我们想要效果,对不对? 那为什么没有达到我们想要效果呢?那因为我们这个平台呢,是一个比较绿色的一个平台啊,比较绿色平台,既然它是绿色平台呢,所以对于图片的尺寸有一个把控,所以呢,我们如果想要生成一些这种哎比较满意的图片的话呢,可以来到我们的这个 comui 啊,因为开 v u i 是 一个开源软件啊,开源软件如果是你自己看的话呢,生成的图片的话呢,是不需要有这些东西的啊,可以直接不需要,我们电脑里不需要遵守这些规则啊,那我们直接用到我们的 flex, 一个纹身图,工作流,配合上一款 lora。 至于尺寸呢,如何挑选呢?看大家自己的一个选择了。好,我们看一下,我们去选一下,然后选中这款 logo 之后呢,我们可以简单设置下尺寸 啊,我这里设置的是一零二四乘一五三六啊,为什么我会设置一零二四乘一五三六呢?因为我想得到一个清晰度比较高的一个图像啊,所以我设置了这样的尺寸,咱们也可以去做一个参考。最后点击生成之后呢,它可以生成出这么一张图,哎, 这个图就符合我们那个审美了,对吧?好,然后把这张图保存下来,可以在我这个生成的页面节点这里呢,点击右键,然后找到保存图像这样一个选项, 然后我们点击一下把它保存下来,保存下来之后呢,回到我们刚刚的这个 ai 啊,然后我们再回到这个首页,在首页里呢,这里看到一个图片生成,我们可以点它把它改成视频生成, 然后把刚刚那张图拖进来。啊,然后呢我们怎么样去输入刚刚的提示词,比如说刚刚美女跳舞的一个视频生成啊,点击生成。好,看到我们已经生出来,我们简单看一下,还可以看到效果质量还是非常高的,对不对?而且他没有出现什么差错,如果说想要去啊做一个帧率的放大,可以点一个补帧。 好,那么这种质量的视频呢?我们可以发我们的这个某音啊,或者说其他短视平台去获取一定流量。好,如果你看到这里呢?本期视频我会以文档的形式把制作 ai 视频所用到的工具,核心词还有创作思路全部记录下来了。
61未来设计师由乃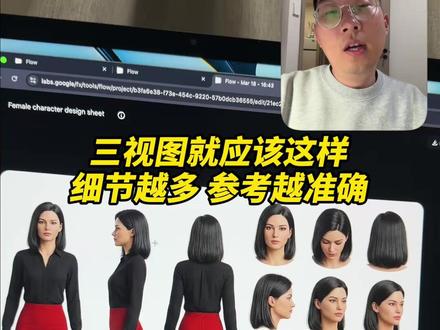 00:54查看AI文稿AI文稿
00:54查看AI文稿AI文稿如何生成这样的人物三十图呢?其实很简单,这里呢我为大家准备了一份题诗词,直接把这个题诗词放到节目里面去,然后放上你的人物图片就可以了。 那这里呢,我用我的真人照片做了一份参考,然后呢生成出了这么一份三十图出来,我觉得这个已经完全可以用了。 生成这样的三人图有什么好处呢?第一就是你在生图和生视频的时候呢,你参考的角度越多,它生出来的越准确,减少你抽卡的成本。第二呢就是在吉梦 c 档次二点零中呢,你用这样的三人图就可以完美的规避掉这个不能用真人形象的问题, 如果现在你不想用你的真人脸,或者说是你现在没有一个合适的虚拟形象的话。这里呢我也为大家准备了一份这样的题词,你先在节目当中去,你把你的这个人物形象生成出来,然后你再把生成的单张的人物图片你放到这个题词里面去,生成三十图,就可以直接去使用了。
3686不搞传媒的小老王 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿鸡梦 cds 二点零的人脸检测又升级了,之前的彩铅、转会三式图、九宫格全都不管用了。我研究了一周,终于找到这个最新通过人脸检测的方法, 来看看生成效果吧!隔离霜、干皮提色、粉红和粉红对不对?来我跟大家说一下,实在了,我不想我自己用打在公屏。欢迎来到我的直播间,我是你的好朋友。那今天呢?我在直播间里面我今天喷的香水呢?是一款非常非常方法,就是用这段提示词生成这个人物的全部信息,将它们整合在一张图上。 我用这个已经生成了好多条视频,每条都能通过人脸检测。一直被卡人脸检测的宝子快去试试吧!
221希希说 01:19查看AI文稿AI文稿
01:19查看AI文稿AI文稿一天得罪一个麦克博主,今天得罪豆包,他仅发布了两条作品就涨粉了一点二万,粉丝,获赞更是高达二十一点四万,第一条视频就获得了二十点七万赞,真的是太厉害了。咱们先看案例。不是吧, 最近怎么老有人说我长得像什么豆包,我照了半天镜子也没看出来啊,今天我们一起拆了它。首先我们将模式切换为图片生成模式,使用极梦 a i 四点五模型上传一张豆包的头像,输入这段提示词,比例我们使用九比十六,高清两 k, 点击发送生成。为了方便大家,我已经把完整资料上传至在线文档了。 图片生成好后,我们选择一张自己喜欢的,选择智能超清,将它放大到四倍,这样子我们在对口型的时候画面感会更清晰一些。高清完之后,我们将模式切换为数字人模式, 选择高清素材作为引用图。此时大家会发现我们还缺少一段以豆包说话方式的音频文件。 ok, 我 们来处理它。我们回到应带四 tts, 上传豆包音色的音频文件,下面部分也要进行上传。上传完之后,我们在红色区域输入我们想去克隆的文字内容, 点击运行,稍等。十秒钟后,我们的音频文件克隆好了,我们点击下载,回到数字人对口型界面,我们上传音频,点击发送生成。最后让我们一起来看一下最终结果吧。不是吧,最近怎么老有人说我像什么豆包, 我照了半天镜子也没看出来啊,你们说说到底哪里像了?是脸?是表情?还是?我一说话就很 ai? 关注星途 ai, 每天分享不一样的干货内容。
89星图AI







猜你喜欢
最新视频
- 1.2万岳母阿蹲