claude code如何蒸馏
最近写了一个快速搭建 web 应用的一个 skill, 然后这个 skill 的 话它有几个核心流程。第一个就是选择这个 web 的 项目类型,比如有 ai 对 话,然后 dashboard, 还有多的页,还有萨斯系统的等这些项目项目类型。第二个的话就是选择这个 web 项目有哪些页面, 第三个选择的话就是每个页面有哪些组件之类的,然后就是选择这个 ui 框架,还有选择这个设计规范,这样设计规范的话也是使用最近开源的这个五十二家这个大厂的设计规范,然后使用哪些图标注, 选择了这个之后就是到生成呃这个 web 项目,还有一些参考,比如呃这个权杖框架的一个最佳实践,然后这个设计规范的一个映设表,还有一些技术相关的一些文档链接。然后就是呃生成的时候使用的这个模板,大概是这么一个 skill, 下来我给大家演示一下如何去操作, 比如打开 cloud code, 然后再搜索这个 skill, 发送 demo web build, 这时候我会等待它加载来确认我们的一个要生成的 web 的 一个效果。比如我选择落地页三项这类型的,然后是单页面 所有的组建组建库,我们使用推荐的方案风格的话,我们使用 open ai 的 设计风格,然后使用默认的, 然后它就收集好所有的信息,让我们确认是否要开始生成。接下来就是开始去生成这个 web 应用了, 现在就无脑接收就行了, 经过等待已经生成好了这个项目,然后我们打开一下这个项目, 这个的话就是使用 open i 的 规范,然后生成的这个官网的落地页,基本上效果看起来还呃,还可以的。 然后我也用这个 style 生成了另外的一些 web 页面,这个使用的 cloud 的 规范设计去生成页面一个官网的页面,然后这是一个 dashboard 的 页面数据,看看这是这是一个磨玻璃的效果的规范,这个是一个萨系统, 总体看起来这么个页面是效果还是不错的。然后基于当前这个设计规范,可以在这个页面之上开发,继续开发功能都是能够进行统一的。然后这个 style 的 话我也上传到这个 glop 上面了, 大家可以使用龙虾,然后下载这个 skill 去搭建一个属于自己的一个 bug 页面,大概就这些。

粉丝39获赞528
相关视频
 07:16查看AI文稿AI文稿
07:16查看AI文稿AI文稿大家晚上好,然后今天前面跟大家有讲过要做数据分析,首先推荐的是 cloud code, 那 其实一开始上手的时候我们是很茫然的,那 cloud code 怎么用,对吧?然后就跟大家演示一下 怎么用 cloud code 去分析我们的数据啊,然后首先的话我们就连接上了这个 cloud code, 然后我这里是订阅的是一个 max 套餐,对吧? 然后我们本地呢,其实是已经安装好了这个 mimic for 的 一个数据库的,那然后我们发送我们的 prompt, 这 prnt 呢,就是跟他说我们我们要做一个 mini 4 的 一个浓度证的一个探索性数据分析啊,然后我们的信息给他,然后我们这里是跟他讲就抽象做一个 demo, 然后目标呢就是 table one 啊,然后要做一个 excel 文件,还有 k n 曲线啊,然后 e d a 的 话就是所谓的探索性分析, 我们要看一下一整个年龄分布啊哈,这个受法评分的一个分布的一个情况,还有关键的生命体征对比,然后还有缺失值,热力图、相关性热力图等等应付得过来的,如果再多的话,确实你的一个认知的一个贷款会跟不上啊,跟不上这 ai 的 一个脚步。 然后其实写代码,你说这,那你有些人就问,就说那你这个代码你信任他吗?对吧? 呃,不能完全信任啊,不能完全信任那,那也会在探索过程中会发现很多一个踩坑的点,然后不断的去纠正, 那你有了足够多的上下文的之后,他的表现就会好很多。所以其实跟爱的交互是一个积累的一个过程,不是一次性的说,我一次性就要得到一个很完美的一个版本这样子, 然后我们这里看到他已经给我们写了一个 e、 d、 a 的 一个啊拍摄脚本,对吧? 然后这些啊,对,前面,前面这个都是我们的规范数据源啊,队列抽样输出,对吧?这都是要有记录的啊。这里有很这个脚本很长, 一般我不会去 review 再去 review 这个脚本,因为太长了我们也看不过来。然后就是通过一些,比如说断言啊,然后他去做,那我们看到他这里对他自己运行成功了,他还自己去读了一下这个图,他说中文显示变成方框是字体的问题, 然后做了一下修正啊,做了一下修正,然后这里自己在跑。所以 cloud code 它这种工具的好处就在于它自己有一个反馈循环,它自己跑了,数据它自己要去看的, 出了图它自己要看的,然后有问题它会自己去解决,那这个是理想状态啊。但是如果说有一些,呃,你虽然跑通了,一些潜在的问题你没有发现啊, 就比如说一些数据的错误啊,队列的错误啊,这种也是会发生的,这种潜在问题没发现,那就可能会导致灾难性的后果。所以这个只能是自己在分析的过程中啊去体会。 但是你说这个从效率的角度呢?这个肯定是比我们自己手写要大了很多。那以前,呃,在 agent 比较流行之前,就是我们比如说不会写社库脚本,那么我们就会 copy 到 呃空白的网页端,然后一个一个自己去,对了,自己在中中间担任一个呃信使工作啊,那那那本本来就是我们一生的话,本来写代码能力是比较弱的,那你 你主要要掌握的就是啊,就是你的一个判断你的科学问题的一个选择,而不是在写代码上啊。话我们看一下我们的一个结果,然后在这里 我们先看一眼这个脚本啊,看一眼这个脚本,那么是一个很长的五百多页的一个脚本,然后我们看五百多行的一个脚本,对吧?然后 这个我们一般就没法再看了啊?然后我们就看一下它产生成的一些图啊,生成的一些图,它总共有六张图啊, 一张表,那这个是一个 table one 的 一个预览,预览的图啊,我们因为我们是一个两千个队列嘛,对吧?一个两千个 demo 的 一个队列,按人口学特征、疾病严重程度、住院天数、手术室也是检查啊,做了一个排序,对吧? 还是非常好的。然后我们看一下它 excel 的 一个 table one 啊, excel table one, 你 看这个排版啊,也是相当不错,对吧?第一张是一个 k n 曲线,一个非常常用的一个东西 啊,轻度的手法啊,中重度的一个 k n 曲线,成一个梯度的一个排排序,那我们看看这 e、 d a 嘛,我们主要是看一下年年龄的分布,对吧?呃,然后我们这里可以看,对吧?他在二十左右,那因为我们是筛选的是十八岁以上成人的队列,那如果说你有一些 ag 是 在后面 有异常的值的话,比如说十八以下,或者说在,甚至在零复制都有可能,那这个时候是什么情况呢?就是有些数据的录入的错误,那我们这个要把这些样本呢排除掉,那我们去看一下它整个成一个,呃,成一个这个 啊,就是一个单峰的一个分布啊,这个是比较正常的。那我们看这年龄组的一个情况,就大概预览一下我们整个一整个一整个数值,一整个数据的一个情况,让我们看看这心率、收缩、压、呼吸频率、体温这些情况啊, 然后有一个大概的概概念,然后就是一个缺失变量啊,比如说第一天的一个白蛋白缺失太多了,那如果你想以白蛋白作为一个特征的话,那你就要想怎么去处理这么这么高的一个缺失变量,你去做差补可能就不太合适, 对吧?你是去做完全分析的话,又是会闹着某些偏移,这个就要取决于你的一个自己的一个科学问题了。 然后这个关键变,那呃后续的话肯定会有一些更更 高端的,也不说更高端,更深入的一些用法就是怎么用好它,那就是因为其实 模型去他去扫扫一遍这个表,说每个表有哪个质段是非常非常快的,那人的话你一个看一个,一个看一个,一个去理解哪个质段是什么意思,那是非常呃费时间的。有一个好的方法就是我们可以 先去扫一下字段,然后让它呃把它列出来,然后我们再去理解,那对后续整个分析自己心里会更有数一点。好,今天的分享就到这里,然后欢迎大家关注刷到实验室 呃,以后再跟大家分享怎么用 cloud code 进一步做我们的数据分析啊,不仅仅是 mini k4, 可能也包括多主学的一个分析好。
30双脑实验室 01:35查看AI文稿AI文稿
01:35查看AI文稿AI文稿总结了几个在使用 cloud code 的 过程中可能会忽略的事实,或许能够避免你的误用。内容来自 cloud code 的 官方文档以及原代码泄露以后,业内很多大神的解读。 第一,中断当前的任务成本很低,并且不会丢失上下文。这归功于 cloud 所采用的流体架构和异步生成器。 所以如果你在 ai 运行的过程中发现问题,请干脆利落的按下中指键,而不是等待这个已知的错误结束响应以后再去修改。第二,对话是可以持久的,可以恢复,不用重新开始。大多数人打开 cocoode 会创建一个新的对话,这会导致之前所有的操作和上下文信息全部丢失。 你学会使用 continue resume 和 fork session 这几个命令,充分利用和 ai 对 话的过程中积累的记忆和学习成果。第三, ai 的 上下文压力可能比你想象的更严重,所以压缩上下文非常重要。 主动使用 compact 命令,不要等待系统自动压缩,以免丢失你所关心的上下文信息。压缩后继续对话比开始新的对话要更好。 可以使用 context 去检查你实际的上下文使用情况,获取按类别划分的实时细分数据。你还可以用 compact 加 focus on blah blah blah 告诉 ai 你 想保留的上下文重点是什么。第四,学会使用 cloud dot md cloco 会在你每次发消息的时候重新读取这个文档,所以你可以把你的架构、决策文件、规范、测试模式等一系列规则都放进去。很多人这个文档是空的,但恰恰这个文档是最能够提高你生产力的配置。下期聊聊剩下的。
111carol 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿兄弟们,你们要的 cloud code 大 师速成指南他来了,我自己做了一个这样的一个测试,就是我用斜杠 scares 命令去统计我的技能, 然后我用 cost 去看一下我用这条命令所花费的 token 是 多少,查询结果发现他没有花费任何的 token, 然后我再用自然语言的方式去跟 cloud code 进行对话,让他告诉我我目前有多少个可以使用的 scares。 查询结果出来之后,我再用 cos 的 命令去查看一番我现在这个交互自然语言的交互用了多少的 token, 它这里是以一千个 token 为单位的啊,所以说这里是零点零七五,那我们就会发现,当我们在 clock cos 使用中能达到同样的效果的情况下,使用斜杠命令比我们用自然语言的方式要省 token 的 多。 那么既然它这么好用,那么我就整理了一份整个关于 class code 的 完整的命令行手册。这里除了习惯命令之外,还有我们的快捷键和如何去拓展我们的工具,也就是 m c p 的 命令。 第四块就是如何去管 ai 的 记忆。其实 class code 的 这些资料哈市面上有很多,但是你真正要说如果完整足够系统的这种的话,目前还是没有的,如果大家有兴趣的话,可以把它当成我们一个使用过程中的速查手册。 第五块把我们去调用或者是构建 scale 或者 engine 的 效率直接提升了十倍。第六部分是我们 cloud code 总常用的配置,文件的一些配置几乎都在这里。第七部分,当我们没有进入到 cloud code 的 时候,也能够通过终端命令行的方式去给它下达命令。 最后第八块还有我们的高级使用的一些高级的技巧,比如这里控制大模型思考的一些高级的技巧,比如这里控制大模型思考了一些高级的技巧,比如这里控制大模型就变得十分的简单。
158叶秋大大 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿最近有一个基于千问三点五二十七 b 的 cloud 蒸馏版大模型,在开源圈刷的很猛,号称本地最强大模型。很多人已经下了,更多人还卡在第一步,不是下载慢就是装玩跑不起来,或者跑起来以后发现根本不是自己想要的东西。 这期我只解决三件事,它到底藏在哪?什么人该装? windows 显卡和 mac 到底分别用什么方案?还有国内网络环境下,怎么把最实用的版本拉下来,别在第一步就耗一晚上,先把话说死。这个模型不是拿来陪你聊天的, 你要的是情绪价值,自然闲聊,写点轻松内容,它不占优。它真正有价值的地方是代码、数学和硬逻辑。 你可以把它理解成一把偏科,非常严重但是刀口特别锋利的工具,用对地方效率很夸张,用错地方你会觉得它怎么这么拧巴。很多人对它评价两级,不是模型不行,是场景没对上。 他最能打的地方不是打的多花,而是思路更像干活的人。很多模型碰到复杂问题,前面看着挺唬人,后面就开始绕,换个说法,把同一句话讲三遍。 q opus 这一类蒸馏的好的模型,价值就在这里,他会更快进入拆任务的状态, 先抓目标,再拆步骤,再看边界条件。这个差别在代码场景特别明显。比如你让他改一个项目里的报错,不只是让他给你一段代码,你要的是他先判断问题在哪一层,是依赖冲突,是输入格式不对,还是你整个调动链写歪了。 他如果会把思路按步骤展开,后面给出的修改方案就更稳,不是玄学,就是因为他少了很多来回打转的废话。再说那个最直观的标志就是 think 结构,你会看到他不是直接甩答案,而是先把过程铺开。这个过程本身就很有用, 因为你能看见他是不是走偏了,他要是第一步就理解错题,你马上能发现,不用等他输出一大头结果再返工。 对于做代码、做逻辑题,做复杂规则判断的人,这个透明度很值钱。还有一点容易被忽略,他不是只会做单一题型,社区里对他评价高不只是某一道 benchmark 分 高,而是他在逻辑、数学、编程这些需要连续推理的任务里表现比较均衡, 这种跨任务稳定性才决定他适不适合真拿来干活。如果你不是单纯在终端里问答,而是拿它接近 agent 流程, 这个模型还有一个很实用的点,它原生支持 developer 角色翻成大白话就是你少折腾很多俄式兼容和模板修补的问题。对于接工作流的人,这种省事比参数多两分少两分更重要。实际用法也很直接,你可以把它看成一个本地代码,大脑 挂到 defy 这一类工作流工具里,或者放进骗代码的执行链里。以前你可能接的是云端模型,现在只要机器带得动,就能把一部分代码任务搬到本地。这样做的好处很实在,响应稳定,隐私可控,而且不依赖外部接口受封。这个点对写代码的人吸引力很大。 最后直接给结论,你手里如果是三千零九十、四千零九十这一档的显卡,或者是三十二 gb 内存级别的 mac, 就 刚好需要一个离线的代码和逻辑助手,这个模型值得装。它的强项很明确,干活能力也够硬。 如果你主要是聊天解清内容,想要一个说话自然又会陪伴的模型,那就别把时间花在他身上,他不是这个方向的优等生。这期先把定位讲清楚, 后面的下载部署和参数设置,按简介群的内容直接照着做就行。跑起来以后第一件事不是闲聊,先拿一道代码题或者逻辑题试它,你会很快看出差别。
378AI技能教学网 07:40查看AI文稿AI文稿
07:40查看AI文稿AI文稿说实话,大多数人用克洛克的就像花一万块买了 iphone 十六 pro max, 结果只用来打电话发微信。 今天基于 cloud code 的 创始人 boris chany 的 推文家主包本人自己的纯主观体验。瑞评一下克洛次十四个被严重低估的功能。不过首先叠个甲,这里面每一个功能就算是拉完了也是非常有用,只是说没有那么被低估而已。好,现在开始。 第一个, a d d r 跨仓库访问 a d d r 添加的文件夹,允许 cloud 在 同一个上下文中同时看到并操作多个文件夹。 有了它,单次绘画直接多开地图,跨仓库操作,行云流水,让它在真实企业级复杂项目中的实用性直接起飞。但对于一些出街开发者,所有东西放在一个工作区直接起飞。但对于一些出街开发者,所有东西放在一个工作区里去用。这里给到顶级。第二个, voice mode, 口述复杂需求比打字快三倍,并且这也更像是你作为产品经理去一边看着 clod 做出的效果,一边提出改进建议, 确实快,确实爽。但很难想象一个公司的开发人员都同时口喷代码的升倍。而且要是个人开发者在咖啡厅语音编程, 林舟可能以为你在玩什么沉浸式剧本杀,这功能是为那些有独居办公室的人准备的,但问题来了,这种人大概率同时使用多个 ai 工具。那为什么不直接专门注册一个语音转文字的软件呢? 这里给到 npc。 第三个,牢记, md 团队知识库,这是 antropic 内部公认的复利核武器, 记录团队的代码规范,踩过的坑项目特定配置一个不断吸收你的开发习惯的 cloud md 是 最好的复利资产。不过有一说一, cloud md 本身还是有存在感的,但是考虑到它实际开发中的出境频率,这里给到吭。第四个, branch 绘画分支,就像 git branch, 但针对的是对话历史,创建分支后,你就可以在不中断主线的情况下平行探索多个方向。不过现实中 大多数人的 cloud session 通常就持续一到三小时,要么任务完成,要么 context 乱掉后直接重开。不过它在某些场景下还是有实用价值的,比如长时间复杂重构, 需要并行验证多个技术方案,总体评价不算鸡肋,但也远没到必备级别,更多是给喜欢精细管理对话流程的人准备的。 这里给到 npc。 第五个, gitworktree 并行执行。这是 boris 本人多次强调的最大效率解锁之一,核心优势在于并行加隔离, 这确实能把开发效率从单核提升到多核水平,不少人反馈用起来后整体速度有显著提升。 当然,并不是人人都有必要这么做,有人觉得脑子管不过来,开多了容易乱出现技术上并行、 大脑单行的病历情况。关键在于你是否经常同时处理多个独立任务,以及你对 git tree 的 熟悉程度。这里给到顶级。第六个, auto memory 加 auto gene cloud code 的 长期记忆系统,模仿 r e m 睡眠自动整理记忆。 auto memory 会把交互中的关键偏好项目动件转化为持久笔记, auto 字母则在后台定期清理,进行合并优化。问题是很多用户用几天就忘了他在后台运行,不如直接编辑 cloud d d m d 来的直观可控 auto memory 你 得时不时检查一下, 才不会觉得 cloud 突然变笨了。这里给到人上人第七个 hooks。 这是目前最确定、最深入的挂载到扩展的生命周期的方式,但确实只有少数人真正了解和使用。 抛速 tux 可以 自动格式化输出代码, session start 能动态加载上下文。你需要深入理解 cloud 的 完整生命周期, 还得具备一定的工程化思维。个人开发者如果不是特别享受深度折腾和系统优化,可能最大的作用就是设置一个任务完成之后的震动铃声。这里给到顶级第八个贝尔 s d k 加速。 s d k 的 启动优化版,能把启动速度提升最高十倍左右。它会跳过自动搜索本地 cloud, 点 m d m c p s 等配置文件的步骤,直接以精简模式快速启动, 对经常用 sdk 斜角本的人,能显著减少冷启动等待时间。对普通用户来说,这个功能基本没啥影响,就像给 f 一 赛车换上更轻的碳纤维部件,对每天开代步车上下班的你来说,听起来挺高级,但实际用不到。现在不用特意去折腾,等它变成默认就行了, 只适合重度 s d k 和自动化用户。这里给到 n p c。 第九个 loop schedule 定时任务。思路上应该借鉴了不少小龙虾的心跳机制,通过 croncreate 实现间隔执行, 比如五分钟检查一次部署状态。但是路普局限性很大,不能关闭会话,也不能超过七天。 c k 九则是在云端运行,而且能让 klod 自行启动任务还是很不错的。这确实是把 klod 从单纯的编码工具升级为具备一定自动化平台能力的显著进步, 但还有继续完善空间。这里给到人上人第十个, mobile app 加 teleport。 早上在手机上启动任务到办公室,在电脑上继续,可以让你在电脑、手机、平板上面丝滑切换,继续筛选。不过在地铁上语音输入代码, 旁边大爷可能会觉得你是个都下班了还要给程序员下任务的万恶产品经理。而且咱都下班了,不能有时间多读读书锻炼锻炼身体吗?一定要每个月提前十五天用 buckle 的 那点额度吗? 这里给到人上人下一个 agent。 agent 是 强大的元语,但经常被忽视。你可以给每个 agent 定制工具及权限模型颜色。 ri 动力 agent 只读分析,避免误删。 security agent 专门做安全审查,当然 agent 最核心的作用还是上下文隔离。这里给到顶级。第十二个, plan mode, 几乎所有三审都应该从 plan mode 开始,而不是直接让 cloud 写代码。计划阶段多花时间让 cloud 依次实现, 如果执行重出问题,立即回到 plan mode 重新规划,而不是让 call 帝继续无脑修补。 shift 加 tab 就 能进入主包。之前说过很多次, plan 模式是最简单但是最复利的功能。 先花十分钟让 cloud 把架构和步骤想清楚,一次搞定,节省的总时间远超计划时间。虽然其实不算被低估,但是考虑到其出境频率、 实用难易程度等等,仍然要给到吭。第十三个, bypass permission 很多人觉得 auto accept 格几分钟就要跳出来一次刷存在感很难受,但其实在插件设置里可以点开 bypass permission, 在 终端里则是 cloud dangerously skip permissions, 这消除了点允许点到手抽筋的情况,而且对于大部分个人开发者来说足够用了。让人类把注意力解放到其他地方。对于长时间运行的任务,批量操作,这是必备功能。这里给到顶级第十四个 chromecastation 给 cloud 的 一个验证自己前端工作的方法。 cloud 可以 自己打开浏览器看自己的杰作。 cloud 写代码,自己测试,修复再测试,直到完美。这个是提高前端质量的一个不错功能,毕竟如果你雇了个前端写代码, 但是又不让人家看写完的效果,那大概率最终产品比较滑稽。不过架不住有人直接截图发给酷傲的手动循环,这里给到人上人, ok, 结束了。注意到这里没有一个啦,因为这些其实都是相当不错的功能,给啦实在有点不礼貌。
3375没有token的mav 06:17查看AI文稿AI文稿
06:17查看AI文稿AI文稿astropic 的 cloud code 哈,是如何防止别人蒸馏它家的大圆模型的?大家如果有印象的话,二月份的时候我记得它指的中国的那些厂商嘛,包括 deepsea 啊,或者 moose ocean 那 一些去蒸馏它家的大圆模型。 我来先讲一下大圆模型,大圆模型其实它就是一个函数,它大概有个上亿个参数。 我们开源的话,我们就说呢, deepsea 这些是开源模型,实际上就是把这上上一个参数啊,给大家看。 b 源模型的话,实际上就是不给你看这些参数哈, 这跟我们所说的开源实际上是不一样的,传统的开源,比如说 linux 开源,它是源代码要给你的大源模型说开源,它只是把这些参数值给你,给我们来看叫更确切的说应该叫开放权重,而不是开放应用的这些源代码哈, 这些训练用的元代码,对公司来说,包括 deepsea 所有的都不开放的,因为他们要训练,即使这些元代码给了我们普通人也是没有什么用的。为什么?因为我们就算有了元代码,我们没有那么多的资源来训练这些东西,对我们来说最主要的可能就是, 呃,没有硬件来训练,当然也没有数据啊,对这些厂商的话,它可能是有硬件,但是它也没有数据,这些数据是从哪里来的啊?简单来说全是偷的, 他会把所有互联网上的东西,包括微几百科呀,或者你上到哪个帖子,你发到哪个博客,他都偷去了他,他不会经过你授权的。这些呢,实际上是不够的,他们还会做什么事情呢?把这些书我们人类一直以来的所有的书他都买一本过来,包括他们会下载盗版的书, 也会下载哈利波特这一些哈,包括他们会呃正经出版的这些书,他会把它切掉,然后用计算机扫描了,然后让大元模型来学习。就按说这一件事情已经被人罚了十几亿还是几十亿了, 因为以现在训练的规模的话,所有的印刷品都已经没有了,都已经不够了,现在高质量的数据已经是没有了,你说怪谁呢?有可能怪秦始皇,因为秦始皇把书都烧了嘛。 那现在我们训练的话,其实这些大元模型啊,当数据都没有的时候,很可能就要去训练别家大元模型的,但大元模型的这种东西就叫蒸馏,但是蒸馏一般 一般都是蒸馏自己的,包括比如说千万啊,它会蒸馏自己的,或者 dipstick 也会蒸馏一些自己的,出一个更小的,在低一点的硬件上也可以跑的。 既然他指责嘛,我就去看一下这 cloud code, 它也不是泄露了,我就对这个很感兴趣,我就想看一下它有没有, 有没有它有一些方法如何阻止别人蒸馏它家的大圆模型的哈,第一个我是用 cloud code 去分析 cloud code 的 圆的嘛,分析一下哪些是蒸馏啊?第一个就是伪造工具注入是什么,它就撒谎嘛,它这个这个文件里就是 code 的 这个文件里,它 它是要做一个判断,你要同时满足四个条件,比如说你要是官方的 api 或者是什么东西,满足这个条件之后啊,比如说 说,我说帮我查一下天气嘛,现在啊,它就会湖州嘛,它可能已经查到了这个天气,但是呢,它会胡乱编出一个工具来说,我调用了 visors 去查这个工工具, 但这个工具很可能是不存在的,因为爬虫的话,其他的人去读它的话就会觉得,哎,它竟然有个爬虫。久而久之呢,它实际上就会了什么,学会了幻觉嘛,因为 surface cloud code, 它本身它就在 撒谎,因此呢,你去读这个东西啊,反而读出来都是假的。第二个呢,就说它会把自己的思考的链路都给清除掉啊,这个在第二行这个代码里,那模型它会 先叫什么?先思考的话再去回答想的这一段呢?思考快的话,它里面实际上隐藏的推理的过程,但是呢,这个函数呢,它发给服务器, 服务器在思考内容的时候它都删掉了,因此呢,思考过程很有可能是 模型最重要的那一部分。蒸馏价值最高的,实际实际上是蒸馏他的思考过程,但是呢,他已经删掉了。所以呢,你就是只能拿到一些干巴巴的答案,但也学不到推理能力。再就是他返回数据,他不是返回好几个吗?可能他要从五个文件中返回, 比如说五个文件能返回,但是他会,比如先读文件,然后再把文件内容如下,这五个应该是做起来吧,但是他不会的,他会直接把这个所有五个文件先压缩一下,压缩过度成就过度,文字呢,我完全搞成一个栽药,你爬虫肯定是没有办法看了吗? 第最后一个还客户端的输出去改造他,我也写在这里,他比如说说,我要调用一个方法去调用文件 a 吧,又调用另一个工具去把它写入文件 b, 我 就模糊了这一点, 比如说他只可能是说我读了两个文件,写了一个文件,但是呢,他也不告诉你他用什么文件去读的,也不告诉你他用文件什么去写的。因此呢,你也没有办法去知道他具体的文件名,读了哪些内容,做了什么事情。爬虫呢?他只是统计一下数量觉得,哦, 好吧,他读了一个东西,读了一个文件,你也不知道他读的哪个文件呢。总之呢,整套方案的解决思想其实就是这样,你爬是可以的,他也阻止不了你爬嘛。但是呢,你爬到的数据都是我湖州的, 我,我乱编的吗?假的工具呢?我胡做的这些东西,就让你的爬爬虫学一些错误的行为吗?删除思考的话,你也学不到他的推理过程,但据和统计的话,他已经统计好了,你也学不到什么东西。最后的话,其实你爬虫去爬的话,最终呢, 你也爬不到什么东西啊,收益是非常低的。我看他指责的中国的这边是用了多少次,大概用了是十五万次,调用就是你,你大家,如果你没有用过这些东西,你可能觉得十五万次好多,实际上非常少。十五万次,你如果装个小龙虾的话,两天给你跑十五万次, 所以呢,这是非常少的一个数量,而且他说用了个一千七百多个账户,爬了十五万次,也就是说每每每个爬不了几次吗? 其实这个指着还是蛮搞笑的,是吧?因为如果爬塔的话,为什么不去找一点盗版书呢?其实找盗版书其实会训练的结果会更好一些。
24有韵之离骚 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿我一定要推荐你用 cloud code, 因为这是走向 ai 时代的一条最快的路。那么用 cloud code 能做什么呢?第一个,它能帮助你部署 opencloud 大 龙虾,它能帮你去部署,帮你去修复 bug, 给大龙虾安装各种插件,它还能跟大龙虾一起协作,去做更多的事情。第二个,它能帮你部署任何软件,比如 docker、 rackflow、 tiktok 上任何开源软件都能部署,还能帮你修复 bug, 调参数。第三个,它能帮你编程,做出你想要的工具、软件、网站,帮你链接各大平台,打通各个平台与网站,甚至是通讯工具之间的连接都能实现。 cloud code 有 一个非常重要的功能, 就是真的能帮你收集并下载东西,我就用它收集了一千多份规范,帮我收集了房屋体检时相关的全国所有资料,甚至收集各种国外的规范文件。 做信息收集一定要用它,它能真正帮你收集并且翻译,它甚至能帮你工作提效,比如自动填表,帮你填 word、 excel, 甚至做 ppt 都能实现,而且它能根据你现有的知识库,你的资料进行精准填表。 cloud code, 甚至是你这个内容分发工厂,能自动帮你写文章,自动排版,自动分发各大平台,甚至还能帮你的文章直接转成视频,我这个视频就是 cloud code 帮我做的,完全是它帮我做,我没有写银行代码, 它还能帮你在实际中干活,自动帮你做标书,监控招标信息发布,自动审核招标资料,还能帮你对图纸进行分析算量。你在评论区说一下你能想到的在电脑上的操作, 我都能用 cloud code 帮你实现。我觉得 cloud code 就是 一个让你的想法转变成真实,能帮你干活的 ai。 如果你真的想用 ai, 强烈推荐你用 cloud code。 接下来我也会开启教程系列,让大家一步一步用好它。
9710阿森编程日记(AI自动化) 13:10查看AI文稿AI文稿
13:10查看AI文稿AI文稿各位,先问你们一个问题啊,你们有没有想过,为什么 colotco 的 能够完整的理解一个几万行的项目,改起代码来贼溜,而一般的 ai 写代码就经常出错呢? 你们可能会说,哦,肯定是因为模型牛啊,参数多啊,对吧?但其实我今天要告诉你们的是,你们完全想错了,更多大模型学习物料和全套面具可在这暴走。大家好,我是彭宇。这个答案远比你们想象的要深刻的多。二零二六年三月三十一号凌晨, 发生了一件特别有意思的事儿, anthropic 这家公司在发布 cloud code 二点一点八八版本的时候,不小心犯了一个超级低级的错误,他们把一个叫 sourcemap 的 文件没删掉,结果呢,整个项目的五十一点二万行 type script 原代码 就这么完整的暴露到了网上,你们想象一下这是什么概念啊?相当于一个堡垒的建筑图纸被全网公开了。更疯狂的是,这件事在二十三分钟内就被发现了一个安全研究员,他一看这个 npm 包的体积特别大,就觉得不对劲。然后他用逆向工程工具一扫, 一千九百零六个完整的 type script 文件加五十九点八兆的 source map, 就 这么被还原出来了。没多久就有人上传到 github, 结果这个仓库被 fork 了四万多次, 全球开发者都看到了。那为什么这件事儿这么重要呢?因为里面包含了什么呢?系统提示词?工具定义?全线逻辑、 agent 编排、系统记忆管理机制?还有最关键的是,这整个项目完全没有依赖 land chain, land graph 这些框架, 全是 ansorepic 从零手工打造的,这意味着什么呢?意味着全世界的开发者第一次能看到一个顶级 ai 公司是怎么真正构建一个超级工程助手的,这简直就是一份最好的 agent 开发教材啊!好的,那咱们现在进入核心了, 这个源码最厉害的地方在哪呢?在它的五层分层架构,看屏幕啊,从下往上数,第一层是用户交互层,你们知道吗? cli 命令解析, r e p l 对话界面流逝,输出渲染, markdown, 代码高亮,这些全都是自己写的,不仅仅是套皮啊,每一个细节都经过了精心打磨。 第二层呢,这才是真正的大脑,我叫它 agent 核心层,这里面有什么呢?有 react 循环引擎,这是 agent 的 心脏,然后是系统提示词的动态构建,这不是固定不变的,而是根据每一次对话动态的去调整。还有上下文窗口管理,这特别关键, 因为 cloud 的 上下文有限嘛,所以怎么在有限的上下文里让 agent 还能理解项目的全貌,这就考验工程水平了。 最重要的是,这一层还支持什么呢? coordinator agent 加 sub agent 的 多 agent 写作,你们想想啊,一个大项目来了,主 agent 不是 自己一个人逐行去改代码,而是先分析一下这个任务能不能拆解,拆成几个子任务, 然后分别派给不同的 sub agent 去处理。有些 sub agent 是 teammate 类型的,就是伴随式的协助,有些是 fork 类型的,就是独立分支之行,还有 background 类型的,就是后台异步之行,甚至还有 remote 类型的,就是远程调用, 这样的多 agent 编排,才能够处理真正的大型工程项目。还有一个特别关键的东西叫 kyros 后台代理,这个东西特别有意思,它会持续地在后台监听,看有没有新的测试结果,构建日制,然后自动反馈给主 agent, 让主 agent 形成自愈循环。 第三层是工具执行层,这是 cloud code 最强大的武器,你们看啊,有什么呢? file system 工具组可以读写文件, bash 执行器可以跑命令, web search 和 fetch 可以 搜索网络, grab 和 glob 可以 搜索代码, edit 和 multi edit 可以 精准地修改文件。还有 notebook 工具可以操作 jupiter, 甚至还有 computer use 可以 进行桌面操控。这些工具加起来大概有四十多个, 关键是什么呢?每一个工具都有一个属性,叫 defer loading, 就是 说这个工具不是一直加载的,而是用的时候才加载,这样可以大幅节省上下文的占用。而且啊,特别值得注意的一点,所有这些工具的调用、注册参数、校验、分发、执行,全部都是 astropick 自己手工写的, 零框架依赖啊,这意味着他们对每一个细节都有完全的掌控。最后一个亮点,所有工具的执行结果,不管是 read 的 输出, bash 的 日制, grip 的 搜索结果,全部都会完整的写入到本地字盘,形成一份可审计的完整执行轨迹。 这对企业用户特别重要,因为他们需要知道 agent 到底在干什么。第四层是权限安全层,这太关键了,你们想啊,如果一个 agent 连什么都能做,那就太危险了。所以 cloud code 这边设计了一套四层权限链。 第一层是企业级策略,就是说 operator 可以 在局配置文件里定义组织级的权限边界。第二层是项目级的规则,这些写在 cloud 点 md 这个文件里,就是项目跟目录的那个约定文件。 第三层是用户级偏好,就是你在运行时可以交互式的确认。第四层是工具级的默认策略,每个工具自己有基础的权限配置。那这四层怎么写作呢?简单说就是像只读的操作,比如 read l s, grab 这些在信任目录内就自动执行,不用问你, 但是文件写入网络请求,这种就会弹窗显示一个 def 预览,让你确认。特别危险的操作呢,比如删除系统文件、访问 ssh 密钥,改 etc 这种,这些会被硬编码拦截,任何配置都绕不过去,这就是安全第一的设计理念。 第五层是记忆持久层,各位啊,这一层太重要了,很多人都忽视了 cloud code 为什么能够记住一个项目的所有细节呢?就是因为这一层项目跟目录有一个叫 cloud 点 md 的 文件,这就是项目的长期记忆, 用户可以在这里写下项目的架构说明、编码规范、历史、重要决策。每一次对话,这个文件都会被注入到 prompt 里,还有完整的对话历史,所有内容都会被保存在本地词盘上。更牛的是 ansorepic 用了一个叫 prompt cash 的 技术, 这个技术特别重要,简单说就是那些不变的部分,系统提示工具,定义、项目规则,这些会被分段缓存起来,第一次生成缓存可能要花一点代价,但之后的每一次调用,这些部分就不用再计费了,这样的话, 长期的大型项目上,成本可以降到直接调用 api 的 几分之一。还有一个特别的设计叫上下文压缩,当对话的 token 接近上限时,系统会自动触发摘药压缩,把关键的信息提取出来,不重要的细节就删掉。但要注意啊, 这个压缩是很智能的,不会丢失任务的关键状态。现在咱们来看 agent 的 循环过程。这个流程分成六个步骤,首先是输入感知,用户给一个指令,系统就会加载上下文,包括 cloud 点 m d 和历史对话。 然后是提示构建系统,根据这次的任务动态的拼装一个提示词,注入工具定义和权限规则。然后呢,这个提示词就被发给 cloud api 进行模型推理, cloud 会用流逝的方式返回它的思考过程和决策。 接下来就到了第四步,工具调用。 cloud 决定了要用哪些工具,系统就开始并行或者串行的执行这些工具,这些工具的执行结果回来了之后,第五步,权限校验,系统会根据那四层权限链决定这个操作是自动放行, 弹窗确认还是硬拦截。最后是第六步,结果持久化,把所有的工具结果对话内容都写回到次盘,这样下一次就能恢复状态。在这个循环的核心有一个特别重要的特性,叫多 agent 协助。如果是一个超大项目, 可能有一个主的 coordinator agent, 他 负责任务拆解和调度,然后他可以派发给多个 sub-part agent, 有 的是同步等待结果,有的是异步后台执行。还有那个叫 carras 的 后台代理,他会持续地在后台监听,看有没有新的测试结果。 构建日制,然后自动反馈给主 agent, 让主 agent 看到自己的问题,然后自动去修复,这就形成了一个闭环的自愈循环。好的,现在咱们看一下这四十多个工具。系统屏幕上可以看到,这些工具大概分成三种权限等级, 第一种是只读安全的,比如 read, lua, script, 这些可以自动执行。第二种是需要用户确认的,比如 edit, write, web fetch、 notebook 这些会弹窗。第三种是高风险的,比如 bash 命令和 computer use, 这些是桌面操控,需要二次确认。 每一个工具都不是简单的一行代码,而是包含了完整的参数校验、错误处理、权限检查。比如说拜式执行器,它不仅要执行命令,还要捕获输出,还要检查这个命令是不是试图访问敏感目录, 如果是就直接拦截。这就是为什么 cloud code 这么安全的原因,不是因为模型有道德,而是因为工程做的太细致了。权限系统的四层链妙处就在于它的渐近式渐企业级策略定义组织边界,项目级规则定义项目边界。 用户级偏好可以加额外的限制,工具级默认是基础配置,关键是只要任何一层有更严格的限制,就会按照最严格的来执行,这保证了安全性。现在讲一个特别重要的新概念,叫 harness engineering。 你们有没有想过, cloud code 之所以比网页版的 cloud 强这么多,真的是因为模型本身不一样吗?其实不是,它们用的是同一个模型啊,关键的区别在哪呢?就在于围绕这个模型构建的软件脚手架,传统的做法是什么呢?叫 prompt engineering, 你写一个 prompt, 然后不断调整它,看能不能从 ai 里搞出更好的结果。但这样有问题啊,因为再好的 prompt, 碰到复杂任务还是容易出错,而且没办法自我纠正。而 harness engineering 的 理念呢?完全不一样。他说 与其去优化模型本身,不如去优化模型运行的环境。怎么优化呢?第一是上下文工程精心设计,每一次进入 agent 的 信息结构,让 agent 有 最清晰的视野。第二是工具约束设计, 不是给 agent 所有工具都用,而是只给他需要的工具,而且对工具的权限做严格限制,这样 agent 就 被引导到正确的方向。 第三是反馈回路闭环,一旦工具执行完了,比如代码写好了,要测试一下测试结果,不管成功还是失败,都要反馈给 agent, 让他看到自己的问题,然后自动去修复, 这就形成了一个自愈的循环。第四是可观测和审计,每一步操作都要记录下来,这样你就能追踪 agent 到底在干什么。对企业用户来说,这特别重要,那 cloud code 的 原码恰好完美地印证了 harness engineering 这套理念, 这就是为什么他这么强,为什么他的成功可复制。现在给各位总结一下,从这个泄露事件里,咱们能学到什么呢?我想提出六大启示,第一,拒绝框架依赖 cloud code 的 四十多个工具,零 land chain 依赖,这说明什么呢? 说明框架虽然提供了方便,但也意味着失控,对核心的 agent 循环保持完全的掌控,这才是稳定性的根本保证。第二,安全是第一,设计 cloud code 的 全线系统贯穿了整个架构的四层,这不是事后加的补丁,而是从一开始就在系统的 dna 里。 如果你要构建企业级的 agent, 一定要把安全放在最前面。第三,上下文记资产, cloud 点 md, 加上 prompt cash 这两个东西,让项目知识完全持久化了。 上下文工程的质量决定了 agent 输出的上限,相比之下,调 prompt 反而是次要的。第四,多 agent 是 未来单 agent, 能力再强也有限, coordinator 加 sub agent 的 编排才是处理大型工程任务的正确姿势。第五,闭环验证驱动 那个 caros 后台代理特别重要,它让测试结果构建日制,能够自动反馈给主 agent, 形成自动修复的循环。没有这个闭环, agent 就 只是一个聪明的一次性执行器,不是真正的 agent。 第六, npm 安全警示异形点 npm ignored 缺失,导致了价值数十亿的技术资产泄露。这说明什么呢?说明构建流水线的安全审计和代码安全本身一样重要,每个公司都应该吸取这个教训。好的,各位,咱们来做一个最终的总结。 这次泄露事件揭示了一个朴素但深刻的真相,那就是 ai 时代的护城河不在参数量,不在算法,而在工程。 ansorepic 用源码告诉全世界,一个顶级的 ai 编程工具到底应该怎么构建。 harness engineering 是 方向, cloud code 的 源码就是最好的教科书。所有这些细致的工程设计,反复权衡的架构决策,对每个细节的原因,它不是简单的套上 cloud 模型就完事了, 而是围绕着这个模型,从用户交互、 agent、 核心工具、执行权限、安全、记忆持久五个层次都做了极其细致的设计。这对咱们开发者来说意味着什么呢?意味着我们不用再盲目的去优化 prompt 了,我们应该把更多的精力放在构建更好的运行环境, 设计更清晰的工具约束,建立更完善的反馈回路,这就是 harness engineering 告诉我们的方向。所以啊,感谢 ansorepic 这次的意外开源,它给了全球的开发者一份最好的工程教材。我想随着时间推移, 会有越来越多的开发者意识到, agent 时代真正的竞争力不是模型,而是工程。那么下次再见了。
110AI大模型学习 00:24查看AI文稿AI文稿
00:24查看AI文稿AI文稿现在我每天的工作变成了蒸馏自己。以前脑子有东西,好歹别人拿不走,以为那就是自己的护城河,现在老板扔下来十倍的工作量,然后 toking, 管够,你说干不动,看来你不会玩 agent, 下一位。这下好了, 主动学习,把自己蒸馏成 skill, 然后把活分给 agent 来干。不是想蒸,而是不得不蒸。今天你蒸馏自己了吗?我是阿图,每天分享蒸馏技巧,下个视频见。
299阿图AI 03:13查看AI文稿AI文稿
03:13查看AI文稿AI文稿最近半年使用 cologod 安装了近百个 skr, 最后发现真正能提升工作效率的其实只有三个技能,今天免费分享给大家。第一个, superpowers, 这个 skr 改变了我用 cologod 的 方式。以前我是直接把需求交给 cologod 的, 让他来写代码,写出来虽然能跑,但是经常跑偏,改来改去浪费大量时间。 装了 superpowers 之后,我养成了一个新习惯,每次开弓前先跑一遍,不认英斯德尔敏。这个技能能让可洛的反过来问我问题,你打算怎么处理并发数据库选什么 等等等等。问完一圈,他会把讨论结果写成设计文档存到本地。听起来多了一步,但这一步帮我拦住了无数次的反攻。有些问题你自己都想不到,但是可洛替你想到了。 注意, superpowers 包含了二十多个紫技能,千万别全开,我只用 breamstorming, 头脑风暴, 其他的按需加载,要不然会浪费大量上下文。第二个技能, playing with fails, 这个技能解决了我被坑过无数次的问题。 cloud 有 个问题,它做到一半就失忆。不知道你们有没有遇到过 一个复杂的任务,聊了半个小时,可乐突然说,好的,让我们开始吧,然后就把之前做过的事情又重来一遍。根本原因是对话太长了,上下文被压缩,之前的计划全丢了。普莱因维的 flow 的 做法很聪明,就是别把计划写在脑子里,它是存在纸上 克拉的扣的。每次动手前会先建一个计划文件,每完成一步就在这个文件里打勾,就算上下文清空了,重新读一下文件就能接着干。 这个思路跟 minnes 很 像, minnes 做常任务为什么玩?因为它所有的中间状态都存在本地了。第三个技能, roughlop, 我 给这个技能起了个外号,监工 sky, 你一定体验过 cloud 的 摸鱼模式。写到一半突然说基础框架已经搭好了,你可以在此基础上继续完善。 翻译过来就是活我没干完,我先下班了。 raflopp 通过一个或可拦截 cloud 的 退出动作,他退出的时候或可会检查。你说的完成标准达标了吗?没达到,回去继续写。 我用它写过,完成过一个 c r u d 模块,设了条件,所有接口测试通过加 redmi 写完才算结束。 kloth 中间响停了三次,但都被塞回去了,最后确实把活干完了。但要注意的是,完成条件一定要写写具体做完用户模块这种话等于没说, kloth 分 分钟说服自己已经完成了写成。完成登录接口可用 单元测试,覆盖率百分之八十。加 redmi 包含 api 文档,它才没法浑水摸鱼。以上就是我常用的三个技能,今天希望能够对大家有所帮助,感谢观看,拜拜,下期见!
3.0万PM.姜同学 03:51查看AI文稿AI文稿
03:51查看AI文稿AI文稿我相信百分之九十九的人都不知道这八个可乐扣子的隐藏指令,大家耐心看完这个视频,绝对会让你大开眼界。 第一个, btw 命令,今年三月份刚出的,就是让可乐扣子在干活的时候插一个问题进去,但这个问题不会被写进历史上下文。以前你问一句可乐扣了就停下来了,上下文被污染,干活就容易跑偏。现在问完直接回车,这对对话直接消失,任务照跑, 历史干干净净,并且几乎不费掏开,用完了就回不去那种命令。第二个,瑞万的命令,可以理解成 ctrl z 撤销,打开这个命令,会弹出一个菜单来,让你选只回退代码,还是只回退对话,还是两个一起, 还是压缩上下文释放空间,这个命令非常实用。第三个,隐菜的命令,这个命令我觉得被严重低估了, 他会生成一份 h t m l 报告,分析你过去一个月用可多扣的习惯,看你常用哪些指令,有哪些重复的操作,然后给你推荐自定义的命令,说白了就是可多扣可多扣的在反向观察你, 给你优化建议。这个我建议人每个月都要跑一次,他会让你重新认识你自己的工作习惯, 非常有意思。第四个, see you plan 命令。你打开这个命令, cloud code 会同时启动三个平行的 agent, 分 别从代码附用、代码质量、运行效率三个角度帮你审核改动,然后汇报结果,相当于找了三个同事帮同时帮你 re 要代码。 我现在的习惯就是每次写几个大功能,更新之后顺手跑一遍,因为 ai 的 代码经常有种鱼,这个命令基本上都能把那些种鱼挑出来,写代码的一定要用这个命令。 第六个半尺命令,原来他是叫 fork, 现在改名了打,但是打旧名还能用,会自动跳转。作用就是把当前对话分叉出一个新的绘画来,原来的绘画不受影响。他跟 rewind 的 的区别就是, rewind 的是后悔药,半尺是平行宇宙, 如果你想同时试两种不同的方案,就是分叉一下,两边各走一边,最后就是选一个效果好的就可以。 第六个落魄命令,他可以让可乐定时重复执行某个任务,用法就是在这个命令后面跟上时间间隔和你和你要他做的事。比如说每五分钟检查一下部署状态,他就自动跑,不用你盯着, 默认时间间隔是十分钟,并且结果直接在上下文里。可乐可以基于结果做判断和后续操作, 但是要注意,定时任务在创建三天后会自动过期,最后触发一次,然后自我删除。第七个 remote ctrl 命令,就是打 r c 或者是完整的命令。 remote ctrl 它会生成一个 url, 手机打开这个链接,你整个 cloud 的 绘画就出现在手机上, 完全同步。你在手机上发指令,终端那边也能看到你在终端操作,手机实时更新终端代码,始终在你电脑上跑。手机只是个遥控器,所以很安全,非常好用,这点就像那个龙虾。 第八个 export 的 指令,打开这个指令,当前整段对话直接导出 markdown 文档,听起来不起眼是吧?但是有时候你会发现这个功能真的很实用。你跟可乐扣了讨论了半天的架构方案,中间有大量的来回推敲, 如果不保存,回头找起来非常麻烦,直接导出来存着,作为更详细的上下文,下次直接用这八个隐藏的指令,非常实用,建议大家使用起来。好,今天的视频就到这里,感谢大家观看。
217PM.姜同学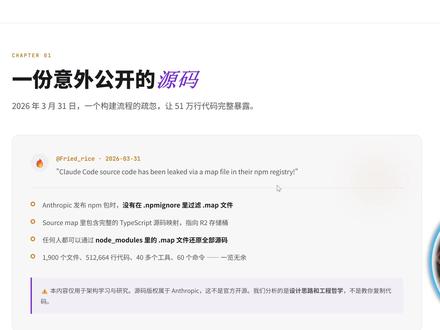 06:20查看AI文稿AI文稿
06:20查看AI文稿AI文稿给大家分享一下 cloud code 的 一个核心的架构,我们起源于三月三十一号的一次构建的一个疏忽,让他的所有的元旦码进行了一个包录,我们可以看一下 在 azurepic 发布这个 npm 的 包的时候,没有过滤这个文件,导致了他所有的文件我们都可以进行一个还原,可以进行一个下载学习, 这是他的一个原码,大概五十余万行。然后我们进行了一个分析,首先这就是他的一个架构的一个全景五层架构,十五个核心的模块。然后我们可以看一下,首先就是他的一个颗粒的入口,他在终端输入 cloud 回车就可以进入这里面可以进行解析问题,可以进行传达我们的一个参数。 然后接下来就到了我们的接口层,比如说终端的界面以及 s d k 的 模式,以及桥接,桥接的话我们完全可以使用插件进行,比如说像微信进行一个沟通,所有的云代码在我们的一个悬浮的界面,比如说这个终端的界面,在 s r c 里面的一个这个文件 多少行,我们也标记出来了,这个文件的话我们会共享在视频的仓库。然后接下来就是我们的引擎层核心的一个调度中心,这是绘画。然后接下来是 api 的 一个客户端,然后接下来就对到我们的一个执行层, 比如说我们最基础的一个工具的调用命令系统以及我们的执行编排。所有的我们分析完之后会有一个文件进行一个管理。 接下来是我们的安全层和上下文层,只作为一个安全,我们不再追溯,接下来是它的一个拓展层,比如说像 m c p, 无论是 open class 适配的。然后接下来是我们的一个插件以及技能,我们现在举一个最简单例子,比如说以整理桌面为例,我们进行一个图解, 首先我们会在终端进行输入一个帮我整理一下桌面,然后他会调用主文件,然后进行解析参数,比如说指定的一个模型,以及我们可以选用的一个工具。 然后接下来他就是他 cloud code 比较快的一个架构,我们分析出来的就是一个并行的乐曲, 在同时开始的时候我们可以读取,然后加载命令以及这些东西都是一个并行的,而不是说一个串行的。接下来就是他的一个注册的工具以及命令,在这个文件里面都很类似。然后接下来就到我们的一个启动的页面,进入一个循环, 这里面的话就是我们的 src 一个一整个的一个核心的部分放在了这里面,具体的话我们可以进行克隆这个仓库进行看一下。然后接下来给大家一起图解一下。 他不是一个聊天的机器人,他是一个自主行动的助手,我们可以看到他不仅是回答问题,他可以思考、执行、检查,直到任务完成。 首先他在思考,然后会调用一些工具,然后创建了一个分类的文件夹,最后整理完成,这就是他的一个处理,我们模拟的一个动画效果。 然后接下来就到了我们的一次请求六步旅程,我们进行分析它的核心架构,我们比如说找到我们项目里面的要做的事情,然后生成一个文件,看一下数据怎么流转。我们首先用户进行输入,然后进入了这个问题的引擎, 然后接下来他就会组装一下题句词,比如说需要用哪些工具,在哪个目录之前聊了什么,然后组建成一个上下文发给 cloud api, 这就是我们的一个元代码,具体我们可以看一下。然后接下来第二步就是 close 思考,帮我搜索 ai, 它并不是直接回答的,而是说它要判断一个先搜索什么,然后返回一个工具的请求,然后这个是流逝的,并且是个并行的。然后接下来就是权限的检查,执行搜索, 然后我们进行一个匹配,然后返回 ai, 然后再次思索,所有的这个类的都是使用 react 结构思索执行,思考再执行,然后接下来就是需要确认的事情,那最后这就是它的一个流程,类似于 open class, 然后接下来我们看一下它为什么这么快? 首先第一个就是它的一个全链路的流式,传统的系统 ai 全部响完,然后再显示,现在的话是现在是边响边显示,然后第一层是用的是这个零缓冲,然后接下来是它的一个工具的边出边执行, 我们可以看到他并不是说三个,说完了,第一个就开始执行,他是说是一个并行的,然后接下来就是并行,然后写入排队,这个就是我们演示的一个界面, 看一下,比如说像传统的方式是 ai 的 输出,这是时间线输出,完成之后,然后进行执行工具,然后进行读写,然后进行操作。对于 cloud code 的 话,它是一个流,对于 cloud code 它是一个流逝的一个并行处理,我们可以看到这是时间上的一个优势。 然后接下来就是它的一个安全性,每层操作都会精准经,每个操作都会经过八层的检查,然后安全的会自动通过,危险的话就会问你,极度危险的话会直接拒绝, 然后比如说像这个违例,我们可以看到它会经过八个审核的入口,第一层是它 是 play 模式,第二个就是他的一个命令,然后接下来我们看一下,然后这就是他的一个优势,比如说我们反复对话一百轮也不更崩溃。 a 的 记忆是有上限的,因为我们的一个上下文 c c 采用的是四层的记忆系统进行管理, 第一层是历史的消息在这个文件夹里,然后接下来是带一个自动压缩,然后是我们的一个压缩后的一个关键信息,最后是一个持久的记忆, 当然的话我们可以进行我们的 graph memory 进行一个插件的管理,然后接下来这就是它总体的一个设计的哲学,比如说流逝优先、安全闭合等等, 这就是我们的一个源码,接下来我们会进行开源,一个直接可以用的一个,接下来我们会开源一个 cloud code 的 直接的一个适配的版本,谢谢大家。
126AGI_Ananas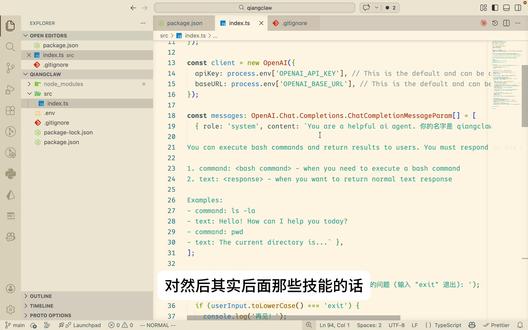 34:25查看AI文稿AI文稿
34:25查看AI文稿AI文稿好,今天来讲一下使用 type script 从零开始实现自己的 open file, 也就是一个简单的 ai agent, 我 们会慢慢实现,过程中从简单到难,就一步一步地去了解它的底层的一个原理。呃,首先呢,我们 起个名字吧,叫强可露,然后进入数值化这个项目,用编辑器打开它。 好, 先先改一下,我们是用 type c 来写的话, 然后这边改一下 model start, 我 们创建一个音 v 文件,然后 创建一个 index 点 t s 文件。 好,其实它底层第一步肯定是需要去请求一个大模型的 a p i 的, 我们就使用这个 open open ai 的 一个接口, 可以打开这个这个 n p m 的 这个 open ai 这边的一个包,我们根据它的规范先安装一下,装一下,然后 其实我们就使用 这个这个 s d k 就 可以了。它的 api 其实大家也可以去看一下,就是其实也是一个 h t p 的 一个接口,这个这次我就先不详细看,反正先把这个代码复制过来吧。 嗯,它这个有 type script script 的 一个报错,我们把这个 node 的 这个 type 的 依赖装一下先。 好,它是从音频中读取了一个 k, 其实我们,嗯,我们因为我这边大模型是用的智普的,所以说我这边还还需要去改一个 url, 对这个,然后其实就会有两个,一个 k, 一个 l l, 如果说你是用的那个 open ai 的 这个 k, 那 其实就改个 k 就 好了,我们在这个音频的环境变量中去, 我这边是已经搞好了这个 k, 到时候我录完视频之后会删掉,所以说这边也无所谓,不过你们就是要注意这个 k 就是 不能,不能泄露出去,这个 k 的 话,其实我是在 智普的这边,我我我有购买一个 callinplay, 所以 说我这边这边点这个添加新的 api, k 也可以添加。我这边是已经添加了这次测试的 k, 这边复制一下就可以了。 然后,嗯,可以看他到智普的一个文档,其实他是说是与这个 open ai 的 api 兼容的,比如说我们直接用它的个这边的这个 sdk 就 可以了, 不过它这边文档只有一个 python 的 一个版本,不过没有关系。嗯,弄个 js 版本,我们直接看它这边的文档就可以了。好,回到这边,然后我们这边要修改一下这边的 开始 是吧?对,要加载这个音频的文件, 我们现在可以去先修改一下这个 system, 告诉他用 i have four assistant。 要 用中文吧,英文不太好。你的名字是 讲课喽,然后你是一个 have for ai ai agent, 然后这行就不要了,我们先 content, 这边先 cd。 你 好啊,来测试一下。对,这个就很简单,就是说我们就直接开始就调了一下它的这个黑片的接口,这边它的这个质补的模型是应该是这样没有补是吧? 看一下啊,它这边的模型对,应该是这个最新的一个模型。好,我们这个也是已经,我们测试一下。 你好,我是江可乐,很高兴见到你,请问有什么需要帮助的吗?可以看到其实大冒险的接口已经去 请求成功了。那我们现在第一步的话就是需要把这个 content 需要通过那个命令行去输入,就是接收它。那现在 ai 这么方便,我们就用 code code 来帮我们,帮我们去实现它,不过我们先先那个啥呢? 先 get, 先抽象了一下 get, 然后在这边。嗯,把那个 model 设 给它挪一下,然后 好抽象一下。我们现在让让他先提出第一个曲指,就是这边文本 x 这边, 然后十七和十二号,十二号 改为改为让用户输入 修改完成。它是挺,我们直接看看它的代码,它是添加了一个 middle line, middle line user input, 几乎里面的问题。 user input, 然后最后 closed, 好, 测试一下。 你好, 没问题。这个,这个第一步已经可以了,是吧?嗯,很高兴为您服务。请问有什么可以帮助的问题的吗?然后我们先做一个简单的提交吧。 嗯, it 啊,我们 我们这个信息延短一点, 先提交一下 它是输入了什么 get commit and error input。 不 行不行不行, 这个 commit 信息就只能 只能一行,不要有什么 其他的作者信息。 get commit and and user input。 好 好好,简单一点。 下一步我们就是现在的问题,就是说他,他这边就是说我们问了一个问题之后,他直接就 回答了一个问题,然后也就把这个命令给关闭了。但是我们是需要有一个循环,就是说一直不停的去问他问题嘛,对吧?那我们其实是需要一个 well 处的一个东西的。 嗯,我需要需要一个循环不断的, 然后再回答, 看一下它是怎么改的。 我要处用 the input, 用 the input 简说明了问题啊,它,它加了一行,那如果是退出的话,它就直接退出了,没问题。这个用 the input 我 们试试哈。 你好, a p u 有 点慢,一加一等于几? 再加一,这个时候它应该是没有上下文的,所以说这一步应该它回答不出来 看, 为什么呢?这个是我们下一步就需要解决的,我们现在先退出测试一下,没问题。嗯,再给它 command 一下,就是说我们看一下它这次的改动,其实也不大 at 好, 然后我们告诉他问题啊,就是说这个 u v input 是 呃循环中缺缺少上下文,让它解决一下 u v input 在 循 缺少上下文解决一下。 它应该是会创建一个数组,然后不停的推送进去 messages message 输出, 嗯,看一下它的改动啊,它是这边开始出事化了一个 message 的 一个输出,然后 这个是我们的那个 system 的 一个 promote 这个词,然后请觉得一开始的话会把这个每一次的这个 u 的 input 都 嗯输入到这个数字中,然后这边请求的话就是把这个,它这个是支持这个这样的写法。对, 它的接口是本来就支持传送这个 message 这么一个子段没什么问题,然后等到它的一个返回,返回的结果之后,它会把这个结果也 这个结果是个 string, 对 吧?对,也推推进这个数组,意思是就是说每次循环都会带上历史所有的 对话的一个消息。嗯,这个其实就是目前的一个带上下文的这么的一个解决方案。其实 color code, 或者说是 open color 其实底层都是这么来去做的。对,就是说,嗯,你如果说对话的越来越多,那你每次请求的那个 token 也会越来越快,因为他每次的 token 请求都会把所有的上下文信息,就是说你所有的历史记录的对话的一些消息都带上发给达摩型,因为达摩型其实是一个 可以把它看成是一个纯函数,就是说他并没有上下文的,所以说这个上下文是你每次请求都要提交过去的,我们现在测试一下 知识而已。 一加一等于几? 再加一。嗯, 可以看到它已经记,就是说有了上下文了,结果也正确了。那我们下一步呢,就是需要 ai engine, 肯定是可以去执行 就是一些命令的嘛,这个是肯定的,就比如说我现在要问他,我要我要列出就帮我列出 当前目录的文件,他肯定是不会帮你去执行这个命令的,因为这个 ai 帧呢,还没有这么个功能,是需要我们下一步去做的。他应该是现在只会给你返回一个,你可以输入某个操作, 是吧?就这么个意思,我先退出吧。嗯,看一下这次的改动啊,也不大 at。 那 我们下一步呢,就是需要去 让他可以执行命令。我问一下他吧,我想要添加 执行命令的功能,请帮我修改 script 这个词,我需要,需要做到 让大模型返回两种确定的返回吧, 第一个就是,嗯,我们就比如说是 amend 冒号开头表示执行某个 bash 命令。第二个是 t s t。 嗯,这是返回的结果。 看一下啊, 它自动给你把这个逻辑加上了 code, code 还是很厉害的。 看一下它的那个提示词是怎么怎么加的。英文,你可以去执行 bash, command and return results to users you must respond in one of these two from it。 或者你说你必须以里底下的两种形式去 响应,第一个是 command 开头的,没有你 to 执行一个 command。 第二个是 txt, 是 你可以,你要正你返回正常的那个文本的响应的时候,就 t txt 开头的,还给了他一个,给了 ai 一个例子, command, 然后 txt or command txt, 然后我们再看一下它对于代码这边的改动啊, 这边删了,删 前面的 message 是 一样的返回,返回了这个外层还是一个循环,然后这边返回了一个 根据这个开头的这个 command 去进行了一个判断,如果说它是以 command 开头的,它就去用这个对 child process 这个紫禁城去执行这个背时命令,然后结果的话会也存到这个。 对,我先把这个存到上下文中,然后这个是他返回的一个结果,然后再把这个执行的结果命令执行的结果也推进这个上下文中, 然后如果错误的话也是一样的,也是有把这个执行错误的推推进这个上下文中,然后如果说是嗯 txt 的 话,就 把这个把这个什么呢格式化一下打印出来,然后把这个嗯 ai 返回的结果也推介上三。文中最后的话是没有指定类型的,就是当做默认的吧,当做默认的执行, 嗯,其实现在是有一个问题的,嗯,就是说当他要执行多个命令,就是说, 嗯,如果说是它要执行多多次那个 command 的 话,它其实里面内存是应该有个循环的,就是说直到, 就是说如果说它返回的第一次是返回的 command, 第二个第二次也是返回的 command 的 话,应该也是有一个循环去处理它的,然后直到检测到以 txt 开头的,就是说它这个内存循环会结束。我现在我们可以先测试一下。 呃,列出当前目录 执行命令,请输入您的问题。哎,它是执行了啊,但是它,嗯,但是有个问题,有个问题,这边 这边执行的结果,对,这边执行的结果是需要再次请求,那个就是是需要再次把这个请求的结果发送给 ai 的, 就是里面应该是有个内,就是这边 这边,这边应该是内部也有个循环的,要不然,嗯,这边仅仅打印了一个执行结果,但是你没有把这个结果告诉 ai, 我 们给他说一下, 嗯, command 执执行完成之后应该要把 结果再发给,发给大模型这里,这里应该是个 是个内部的循环,就是直到检测到 没有 command 的 命令才跳出此内部循环。 改完了哈,再来看一下 这个时候外部的那个 user input 的 一个循环嘛,内部的话就是,嗯,当他的好,对,没毛病,没毛病,让他指指尖一塌,然后这边 复制了这个 message, 然后这一步再去请求。 哎,等一下,第一次啊,这个是第一次请求的,然后内部再去请求了这个大拇指的接口,把它 message 加上,然后这边 再覆盖之前的这个变量,就是说这个,对,这个就是持续会有这个 command。 如果说是,嗯, 这个 tom 的 直线完成之后会到下边这边,下面这边的话 没什么问题,就会是最终的,就是最终的响应的一个 ai 的 一个结果,响应的一个 ai 结果,然后再是外部的一个 有点 import。 好, 这么看起来好像没什么问题,我们试验一下啊。 列出当前目录的 文件, 这次是执行命令的输入,我们等一下,这边就是这边的话就是说他会把再发起第二次请求,把这个输入的结果再给到 ai, 然后 ai 再给你回复, 回复这这些啊,当前目录包含一下文件文件夹,这是一个 node js 项目,需要我帮您查看具体某个文件的内容吗?请输入您的问题,朋友们是不是?是不是? 是不是?是不是?可以了,没什么问题。那我们现在呃,看一下这个改动, 这次改动就是 这么多,我们这次 再测试一下,他就是这边测试一下这个内部循环的一个一个,一个一个逻辑,就是说刚刚是,刚刚是只有一个命令嘛?我们问他一个可以执行多个命令的问题,就是说我们 怎么讲呢?想一下, 算了,我们先退出吧,但是想不到我们今天先不得 commit 一下 at command execution loop, 没毛病。好,我们现在我想到了,刚刚,我想到了啊,想到一个它可以执行多个命令的。 帮我就是说我,我现在按下 star 就是 一个新的,一个空的一个上下文嘛。所以说我们搞它帮我查看当前项目 并补充 get ignore。 对, 因为我现当前的 get ignore 可以看到只忽略这个 note models, 其实呃,规范的那个 note 截图项目应该会有很多的。呃, get in the norm 就是 我让它去补充这么个,而且它我输入了这么一个体制词呢,它应该会,肯定会有多。嗯,多次的执行命令命令的一个 机会嘛,肯定是第一次他会列出当前的文件,然后把当前文件的结果给到达摩星,然后达摩星再让他去执行一个修改文件的一个命令。好,我们试试 好,第一次命令他是执行了这个,然后我们这边啊,这边这边的执行结果他应该会发给大模型嘛,然后大模型返回的第二第二个执行命令是, 呃,啥啊?会,这个命令是读取了这个 get ignore, 读取了那个 package 的 jason, 然后第三个命令是 是直接修改了这个 get ignore, 然后第四个, 然后会把这个输出再给到大模型,然后这边会最后最后是没有命令,没有命令就会跳出这个循环嘛?然后 说是已经成功补充了这个文件,原内容是仅包含 note models, 新内容是不拉不拉不拉不拉不拉。一堆。 提醒你,音频文件中已存在项目,现已被正确忽略。对,我之前是没有忽略这个音频文件的,而他现在可以看到啊。卧槽,那我这个音频好像,呃,好像是已经 加到了这个 get 的 这个历史中了吗?哎,不管,这个不重要。同同学,你们以后注意就说这个音频肯定是不能进到这个 get 的, 一个肯定是不能进到 get 的 提交中嘛。对,他这边已经忽略了, 这边忽略了好,这么来看是没有什么问题的。其实我我前几天去看那个 opencloud 底层呢,它是基于一个 pad 的 一个 底层的一个 ai 智能的一个包,它其实我看它底层的一个原理,其实就这么,就是这么简单,就是一个一个循环的一个过程,它会检测 最终跳出循环的,就是说我们会检测没有那个,嗯,没有命令执行了,他会跳出这个循环。就是其实就是这么的一个简单的逻辑吧。我们其实现在 这次改动应该只是一个这么改动,让 color code 给他 commit 一下。哎,其实我们, 哎,他说当前工作区是干净的。不会吧,我不是有这个限制了吗?我现在既然这个我自己做的 ai 出来,那我们让他给它 command 一下,看看行不行。 让我们现在做的这个 ai command 一下啊,你看他现在执行了一个查看当前状态的一个 一个一个一个那个啥,然后发现了当天有修改待会暂存的文件,你需要先暂存更改才能提交。你希望帮你执行哪些操作? 请告诉我需要的提交信息,我会帮你完成提交案。我们现在告诉我们现在自己造的这个 ai 哈。嗯,请帮我暂存所有的改动,并生成一行简短的 一号 it commit 信息,并帮我 it commit 我 们自己的 ai, 去帮我们去完善自己的 ai 项目。朋友们,这是不是还是很给力的 哦,他是直接一下子执行了一条命令,哎,算了,没,没关系没关系,反正我们那个多条命令的那个已经测试好了。提交成功,提交成功啊, 看一下啊,这边确实是有这个提交记录的。其实这就是它底层的 open clock 或者说是 card code 底层的一个最核心的一个循环嘛,它是可以执行 执行这个命令,然后可以去循环地去请求大模型。对, 然后其实后面那些技能的话,其实它也很简单,它你如果是有技能的话,它会把技能一开始会读到这个 system 的 这个提示词中,就是说它会把这个 content 在 不断的完善。嗯,如果说, 嗯,你们感兴趣的话,可以去抓包看一下他那个 code code 的 一开始的那个 system 提示词应该是一个很大很大的一个 content, 然后如果说,嗯,这次的这个, 嗯, ai engine 的 这个原理去了解的话,那你就会知道其实他每次的这个 api 请求都会把这个很如果是 cloj 的 话,他都会把这个很大的这个 content 在 每次请求都会给到大冒险 api 那 边,那这样的话其实他的头可能 消耗很快。就是,其实是有原因的吗?其实你如果理解到他的这个原原理的话,你就会知道一些原因了。对,看一下我录了多久了啊?什么时候开始录的?哎, 嗯,先不录了吧,后面如果有需要我再录 skill 方面的,然后录如何?嗯,我问可乐的话,它火出圈的一个原因是它有很多的,它可以接入很多的那个聊天工具,它其实只是一个。嗯, 界面层的一个改动了,我也不想去做那方面的一个逻辑,我感觉就可以了,后面如果 有其他的想法再录吧。好,谢谢大家。如果说这个视频对你有所帮助,欢迎点赞、评论、收藏、投币。好,再见。
24力气强 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿家人们还在到处找克劳德扣的教程吗?其实真没这个必要,因为克劳德自己就内置了一套很权威的学习方式,就是这个庞安 up。 官网写的很清楚,每个指令都会教你一个大多数人容易忽略的扣扣功能,打开一个,读一遍,试一遍,再标记完成。这里一共有十个庞安 up, 每一个都不是概念,而是能立刻上手的具体能力。第一个,与你的代码库对话,输入 s 就 能附加文件,让克劳德在回答前先读你的代码,还能用文件名加行号精确定位,甚至直接附加整个目录。第二个, 切换可我的工作模式,按 shift 加 type 键模式,决定他是先问你还是直接动手,可按只做分析不改代码,我透则让可我的自己判断如何执行。第三个,随时回退一切操作, 双击 s, 打开 a y, 可以 回到任意一次修改前的状态,不只是代码,连对话路径都可以一起回退重来。第四个,让任务在后台运行,命令后加就能后台执行, 你可以继续对话,不被打断。用 test 查看进度, code 还能自动根据结果继续处理。第五个,让 code 记住你的规则,把规范写进 code md, 它每次启动都会自动读取代码风格、测试方式、 限制目录都可以统一约束。第六个,扩展 ko 的 工具能力,通过马克接入 side 数据库、浏览器等外部系统连接后,你只需要一句话,它就能直接调用这些工具。 第七个,自动化你的工作流程,把常用流程写成册,一条命令就能执行整套操作,可此还能在关键节点自动触发脚本,实现真正自动化。第八个,随时随地操作代码, 用微软 control, 可以 在手机或网页远程控制当前绘画,甚至用开了帕尔塔别的设备上的绘画直接迁移过来。 第九个,让多个客劳德同时工作,通过撒贝间并行处理任务,一个人变成一个团队,还可以定义不同角色的 agent, 各自负责不同工作。最后一个,调节模型与思考深度, 用 mark 切模型,用 f o t 控制他思考的时间和深度。复杂问题用高强度简单任务,用快速模式就够了。所以 p o r o p 真正厉害的地方不是给你十个命令,而是把克劳德抠的核心能力变成一套官方学习路径。
58samlai


