Python怎么和agent聊天

粉丝74获赞316
相关视频
 00:30查看AI文稿AI文稿
00:30查看AI文稿AI文稿大家好,我是龙博,今天鼓捣了个新玩意, vlog 远程 webcoding 工具。微信官方的产品啊,一键就可以安装,而且完全免费。微信扫个码就可以直接连接到你本地的 agent。 我 现在人在泰国的街头,但我已经写了很多代码, 就像跟人对话一样,我在微信的聊天框里面把我的需求发给我的本地 agent, 我 本地 agent 就 可以对我电脑上的代码进行修改。哎呀,随着这个 ai 的 发展,我们又感觉自己的这个工作变轻松了,反而感觉自己有更多的机会和更多的时间去工作了。
 07:03查看AI文稿AI文稿
07:03查看AI文稿AI文稿今天我们一起把你的 openclock ai 员工们拉进一个群聊,让他们互相讨论并且实现任务的交接。项目已经开源了,你可以直接拿去用,我们首先展示一下效果,然后我们说一下如何根据你的任务,你的风格和你 ai 团队的情况进行定制。好,我们开始我们首先来到我们的 openclock 控制中心,那么这个项目已经开源了, 如何安装?我们展示完马上就会讲,不要着急。那么来到之后,我们发现有新的一页叫做群聊,就是我们点击群聊页 进来之后,我们可以点击一个点新任务来进行群聊任务。我们首先看一下这个页面,啊啊,左边是我们所有的群聊县城,看到我其实测试了很多次,包括 ai 的 测试,那么点击这个左上角的新任务呢,就会触发一个新的群聊, 那么右上角呢,是我六个待命的 agent 智能体,那么每个人有不同的角色,比方小鸡负责情报,狮子呢,它是我主要的对话 agent 啊,猴子呢,它负责一些写文章的工作,然后熊猫它是程序员等等等等。这之前我也介绍过了, 那我可以看到他们都是灰色的状态,处于待命,而没有正在工作。比如这里我抛出这样一个话题,我们一起讨论一下,我想做一个视频介绍我们这个 open call 服务中心,然后一起讨论一下怎么做。这时候可以看到小鸡 gog 正在输入,那么他是第一个回答的 agent, 那 么之后呢,就会有另外一个 agent 来补充他的观点, 那么我并没有默认让所有 agent 都回答,因为这样很可以 talk, 但你拿出我之后,你的想法,你的 agent 进行改了。这里我就是默认两个 agent。 首先回答, 如果你在 openclaw 里有这样一个 ai 的 团队,那么每一个角色,每一个 agent 可能有不同的模型,他们有不同的记忆,还有可能用不同的工具,那每个人都有自己的角色,那么也适合做不同的动作。那么这里我们首先看他们两个的回答呀, 我们看一下他们两个怎么回答的。首先是小鸡,他的意思是你要证明你的价值,这个视频你不能说把所有东西堆在一个面板里,你要说的高大上一些,对吧?就他这句话, 那么 monkey 猴子的意思是他同意啊,你要是说明咱这个面界面真的在推进任务,你不要抱,把它拍成导航栏,而且拍成一个任务被推进的连续过程等等。他给出了很多细节, 那么相当于是猴子在补充小鸡的一些观点,他可以同意,可以不同意,那么他们之间互动变成互相杠精的状态。好吧,这里我是主要是一个补充的状态, 这是讨论的状态,你也可以直接安排任务,或讨论或不讨论,让这几个不同的 a 阵之间进行执行任务,并且交接任务。这里呢,我们可以点击这里的安排后续顺序 啊,还没有执行者,我们点击每一个 a 阵就是把它作为执行者。比如我先点击潘达,潘达是我的程序员,我给他的任务就是你去扫描审核代码,先总结一下我们整个控制中心的功能。 然后呢,我们可以往下继续加不同的 agent 来交接任务,比如这里,如果我们点击啊,下一个是 may, 可以 看到呢,盘打会自动地把这个任务交接给 may, 我 们可以再点击三个 monkey。 好, 那么第一个判断的任务是扫描代码,然后总结所有功能,然后它的交接条件就是所有功能的总结,对吧? 然后闷呢,我希望他根据总结的功能呢,给我想一下视频的开头,给我三百不同视频的开头,而第三个 monkey, 我 希望他拿到三个不同视频的开头之后,生成三个啊封面图这样的一种想法。 好,那我们安排好这个任务的执行数据之后啊,那么我们这里就可以点击保存顺序,然后呢,我们点击开始执行, 我们等待一会之后会发现,哎,我们的熊猫把他的一步任务就做完了,他总结了整个代码,然后总结了我们整个控制中心的所有的不同的功能, 然后他呢把这些信息给到了我们的 man, 我 们的狮子,狮子呢,就给我生成了三个不同的视频开头,然后呢,他 at monkey, 就 让 monkey 继续这个工作,根据这套的开头生成三个不同的视频的缩略图,然后给我们 url。 好的,然后 monkey 呢直接把我们的 url 给到我们了,他做了三个不同的缩略图,那么仅仅是为了展示流程,我是让他用代码生成了前端网页来给我缩略图的想法,那么最好的效果当然是接入 ai 生图软件,让他直接给你生图了。好的, 我们继续。刚才呢,我们是自由讨论,然后呢,我们给了一个任务,三个 agent 通过交接完成这个任务,对吧?现在呢,我想展示一下另一个功能,我们艾特某一 agent, 通过交接完成这个任务,对吧?现在呢,我想展示一下另一个功能,我们艾特某一个 agent 的 时候,就是指定他来回答我们的问题, 或者我艾特多个 agent 呢?就这两个哎,顺序轮流回答我的问题。那么这里我们先从一个开始,比方这里我艾特一个 man, 就 刚才这三个想法,我喜欢第一个,所以我希望它展开。 那如何根据自己的团队和你想要的风格来定制这个群聊功能呢?有两层,第一层就是我开放了一个入口,就在这个控制中心的根目录下面,有一个叫号点 m d 的 这样一个 markdown 文件, 它呢是所有群聊成员一个共享的上下文,也是整个群聊的写作协议。比方说大家是偏配合还是偏互相反驳,还是大家的发言风格是什么,互相之间如何交接任务等等。 然后这是我默认的提示词,我发现成中文了,看到还是比较中庸的,比较偏鼓励写作的,那你呢?也可以啊,用我这个提示词来给你的 open, 它把这个号点 m d 这个写作协议改成比方说偏互相反驳,互相 challenge, 这样一个风格都是可以的。 第二层就是每个 agent 啊,自己的个人层,这就是其实大家可能都知道每个 agent 自己的 workspace 里面的那些 markdown 文件,对吧?那每一个 agent, 所有 workspace 文件都可以在我们的控制中心里面进行查看和直接修改, 点击这个文档的页面,然后这里比方说我们的 man, 主要的 agent, 他的回答风格,他的人设,其他的啊, markdown 文件都可以查看和修改。 那么除了我们的群聊功能和修改人设文件 workspace 文件之外呢?控制中心还可以让你看你花费了多少 tokin, 以及每个任务花费 tokin 的 百分比,非常的细节。除 此之外,你还可以看你每一个 ai agent 员工,他正在工作吗?还他正在干什么工作,以及他上一次最近的产出。 除此之外呢,你还可以看,呃,不同 agent 之间啊,它是互相的协助,比方说这个 agent 和它的子 agent 之间的协助,还可以查看不同 agent 的 记忆和修改它们的记忆 以及总览。我们可以有一个健康分来评判你目前 open cloud 的 运转是不是健康的,有没有问题。我会和 github 上的小伙伴一起继续优化迭代群聊功能以及 open cloud 控制中心和我们大家去使用,去提一秀以及做贡献。 pr 好, 我们下期再见。
1685木子不写代码 08:37查看AI文稿AI文稿
08:37查看AI文稿AI文稿一直呢就是想做一个微信聊天机器人,但是呢没去做,这两天我把它做出来了,嗯,我们先直接看演示效果,后面我再详细的说是如何实现的。在正式演示之前呢,我们先 我先说一下,我在 open core 里面创建了一个 agent 叫做谦尔,他专门就是用做聊天的。然后呢这边我们将脚本运行起来,看实际运行效果,把上面给清理掉,清理掉过后我们直接运行这个脚本, 它首先会去检测我们整个列表是否有新的消息,如果有新的消息的话,它将会把消息发给我们的倩儿,让倩儿给我们自动进行一个回复,而且是每一个用户就会创建一个不同的绘画。好,上面没有消息,我们看到了,所以它全是零。 这是做完了一次的轮询,我们再来,我们现在这边用手机给这个微信发送一条消息,你好, 给他发送一条消息,大家可以看到这边微信这边已经收到消息了,收到消息过后,这边的轮询马上就过来,会检测到消息,然后让 open core 进行一个回复。 好,这边收到了消息,用百度飞讲进行了一个消息内容的识别,然后 open core 那 边也新创建了一个绘画,根据这个用户 大家看到我的鼠标是没动的,它自动的进行了一个鼠标的操作,这边它是回复了一个内容,我们再对内容进行回复,让它接着继续。 我也在成都,你在成都哪里啊? 好,这下边会马上就收到消息的,马上就会好的,已经收到了消息,让它自进行自动一个回复, 待会看到消息已经回复过来,我们进入这个绘画里面看一下。在进入 open core 绘画过后呢,我们可以实时的看到这个消息, open, 我 们 open core 收到了什么消息,然后 open core 给他回复了什么消息,我们再来给他说一下。 不喜欢逛街太麻烦了, 看一下 openclo, 马上马上又又会抓取到消息过后进行一个回复 啊,大家可以看到这里, openclo 收到了消息,不喜欢逛街太麻烦了,然后生成一个回复,然后发给微信过去了,这个是支持多用户的,就是这个列表里面有多个用户给你发消息啊,它支持多个用户一起聊天,然后根据每一个不同的用户 去创建一个绘画,独立的绘画就不会导致串台了。好,我们结束的脚本, 好了,这就是演示,就这么多, 前面呢我们进行了一个效果的一个演示,下面呢我们来对这个整个文件进行一个分析,我把所有的脚本都放在了这个 w x 这个下面,我们运行脚本是这个 就是 no repel teams, 就是 说未读消息列表的一个回复,在这里呢,它主要首先第一步它去调用这个这个脚本,这个脚本里面呢去进行一个桌面的截图, 在这里我们给他一个窗口的名字,他就会去截取我们电脑专电脑上面桌面上运行的这个窗口, 把它一个图截下来,截下来过后呢,我们在这边进行了一个识别, get 整数这个函数进行了一个识别,识别过就识别是否有未读消息,在列表里面识别我们的微信列表有没有未读消息。好,我们再回来,如果我们在这边 识别到了有未读消息过后,我们首先进入这里,我们看一下这边,我们将这个列表进行了一个循环, 循环就是说这边就是说我们一个先给了它的一个序号,就是 index 一个序号,序号给了过后呢,我们给他一个 i team, 就是 每一个 i team 就是 一个对应的一个绘画一个人,说白了就是 过后呢,我们去检测他的头像,看头像中是否有未读的消息,这里我采用的是 omar, 用 omar 检测的,检测了过后呢,如果是我们检测到了有未读消息过后,我们进行进行下一个操作,就是进行鼠标移动的一个操作,还有鼠标的点击, 点击到过后呢就会识别到它的,通过它的头像我们进入到了一个,我看一下这里 find user, find user 呢,就是说在用户这这个函数呢,就是在我看一下在上面, 就在这个里面它会读取这个 user index 这个文件,在这个文件我们为为每一个用户创建了一个唯一 id, 如果有的用户他就直接调取这个 id, 然后将这个 id 传给 openclo, 作为一个绘画 id, 也是唯一标识的规划 id, 那 么这就是上下文连过来就可以,那么如果是没有用户在这个列表里面,那么它就会在这里面加一个,我们看下这个地方就进行 right gt。 jason 调取这个像这个 jason user, jason 里面加一行, 然后结束过后呢,我们中间有一个过程,需要一个 new, 我 看一下是在哪里 find user 里面,对 find user 里面,因为我们用的识别,对昵称的识别的话,用的是百度飞讲的一个昵称识别识别的时候,所以我们有一个 message check 这么一个来对比两个 用户了,已经有的用户昵称和现在当前识别到列表的用户昵称的相似度有多大,因为有时候百度飞讲这些啊,也会识别错误的,比如说将呃 某些汉字吧,可能会识别的有错误,但是呢它通过对比识别度,因为不可能每个汉字都识别错误,通过对比就可以了。对比结束过后,我们这个地方就需要进行消息回复,我们就进行 new message o r c 这里面, 在这里面我们这个地方给他划了一个区域,在这个位置就识别那个区域的消息,消息识别过后,在这个位置就发给了 open curl, 就把消息发发给了 open curl 这个位置位置 message to open curl 这个脚本调用,我想是这个 message to open curl 这个地方就通过,因为 open curl 是 支持 open i 的 api 接口,所以我们就直接通过 open i i 的 接口就直接向 open curl 进行一个交互。 然后在这个地方呢,重点说了一个,就是这个地方就是叉杠 opencl, 杠 sense 杠 key 这个,这个就是为每一个用户创建独立的一个绘画,这样就不会将要给王哥发送的消息发送给了你李哥。然后我们再到再回来一下, 再回到这个主主运行文件夹里面来,回到 new message 这里面,当我们收到了消息过后,我们就会在这里执行这个操作。 mouse check 到 mouse control 里面去,我看一下 press ctrl 这里面就会,这是鼠标的位置,这是消息的内容,将消息内容复制粘贴到,这是执行复制粘贴和鼠标点击的这个是复制消息,然后这下面就是粘贴消息,粘贴了过后,这下面执行回车就把消息给发送出去了, 这个程序运行的流程的反大致就是这个样子。嗯,有喜欢的可以大家一起交流,谢谢大家。
13何止于静 05:24查看AI文稿AI文稿
05:24查看AI文稿AI文稿各位开发者朋友们,今天我要给大家介绍一个真正改变游戏规则的工具。大家都在谈 ai a 键有多强,能规划,能推理,能写代码。但有一个问题被反复忽视, a 键他根本用不了大多数真实软件想让 a 键,他帮你批量处理 g i n p 图片, 没有 a p i, 让它操控 blender, 渲染一个场景得靠截图点击,脆弱的一碰就崩。想用 agent 自动生成 libraface 报表,只能用残缺版的拍散封装,丢掉了百分之九十的原声功能。这就是 ai agent 的 最后一公里难题。 agent 再强, 也用不了真实世界的软件。香港大学数据智能实验室 h k u d s。 的 研究团队提出了一个不同的答案, c l i anything c l i anything 是 一个开源的 cloud code 的 插件, 核心能力只有一句话,把任何有源代码的软件自动生成一套 a j n。 原生的命令行接口 c l i。 它的底层逻辑来自一个朴素的洞察, 可以是人类和 ai agent 共通的万能接口。为什么 c l i 天然适合 agent 呢?第一,结构化。可组合文本命令天然匹配 l l m 的 输入格式,可以自由串联成复杂工作流,就像搭积木,每个命令都是一块积木, 可以随意组合。第二字描述,一个 help, 就 能让 agent 在 运行时自动发现所有可用功能,无需手写 api 文档,就像你拿到一个新工具,看一眼说明书就知道怎么用。第三, agent 友好,内置 jason 标志,每条命令都能输出结构化 jason agent 无需任何额外解析,就像两个人交流,用结构化的语言比用方言更容易理解。第四,确定且可靠, 输出稳定一致。 a 键的行为可预测,经过验证, code code 的 每天通过 c l i 执行数亿千亿的真实任务。 clean anything 的 核心式,一套全自动气阶段生成流水线,即分析架构设计 c l i 实现模块规划、测试、编辑测试生成文档发布,整个过程无需人工介入。最终产出一个包含以下特性的 python 交互模式,支持逐步迭代的绘画式操作。 就像你和朋友聊天,可以一句一句地交流,而不是一次性说完所有话。第二, jason 输出模式。 jason 标志让 agent 直接消费结构化数据,就像你给 agent 发送一份格式化的报告,它可以直接读取和处理。第三,撤销重做。完整的绘画状态管理, 就像你在编辑文档时,可以随时撤销和重做,不用担心出错。第四,全套测试覆盖单元测试加端到端测试。目前九大应用共一千四百三十六个,测试通过率百分之一百。就像你盖房子,每个环节都经过严格检查, 确保质量。第五次描述文档,每个命令都有完整的 help 说明, agent 可在运行时自主发现,就像每个工具都自带说明书,随时可以查阅。 c l i anything 已经为大量主流开源软件生成了现成的 c l i 接口,覆盖范围相当广。创意工具、 ai 平台、办公套件、数据工具、开发工具、 图标格式化等等一应俱全可以。 anything 的 安装非常简单,在 cloud code 的 绘画中运行两条命令即可完成安装。第一步是添加插件市场,第二步是安装插件,无需任何额外配置,装好即用。安装完成后,只需将软件的本地路径或 git 部仓库地址传给插件 期阶段流水线自动运行。比如为本地 g i n p。 源码生成 c l i, 全期阶段自动完成。生成完成后,将 c l i 安装到系统 pass, 全程交由 cloud code 替你完成安装就好了。如果生成的 c l i 还不够完整,你可以叠代优化 c l i, 扩展覆盖面,并补充缺失的功能。 除 cody code 外,克里安尼尔森也支持其他主流 ai 编程工具,如 open code codex 等。 c l i anything 提出了一个相当有钱占性的命题,今天的软件是为人类设计的,但明天的用户将是 a 卷 t, 我 们需要提前为这个迁移做好基础设施。 它的核心价值在于,第一,彻底绕开 g u i 自动化的脆弱性,不依赖截图,不依赖点击直接对接软件的真实,后端保留百分之一百的原声,功能稳定可预测。 第二,一个命令通吃。所有软件只要有源代码,无论是 g i n p blender、 libreoffice, 还是你内部的私有工具,统统可以一键生成 a 阵的可用的 c l i。 第三, a 阵友好的设计哲学贯穿始终,结构化 j 四输出, help 字描述, r e p l 模式完整测试覆盖。每一个设计 决定都在降低 agent 的 使用门槛。第四,多平台多工具胜肏 code code、 open code code x clean anything 的 设计是平台无关的,正在向更多 ai 编程工具延伸。如果你正在构建需要操控真实软件的 ai agent, clean anything 值得认真评估, 它很可能是目前这个方向上最系统、最完整的开源解决方案。各位开发者朋友们, ai 舰的时代已经到来。今天的软件是为人类设计的,但明天的用户将是 a 舰艇,我们需要提前为这个迁移做好基础设施。可以, anything 就是 这样一座桥梁, 它让任何软件都能被 ai agent 直接操控。彻底解决了 agent 的 最后一公里难题,一个命令通知所有软件。这不是科幻,这是现实。如果你正在构建需要操控真实软件的 ai agent, cleanything 值得认真评估。为 agent 的 时代做好准备,从 cleanything 开始。
 04:08查看AI文稿AI文稿
04:08查看AI文稿AI文稿哈喽,大家好,我是 qk, 那 么呢今天给大家讲一下,怎么让你的 code 叉变得越来越聪明啊?那么为什么讲这个呢?就我之前有个电脑,就是它一直不知道 python 怎么去调用,然后每次新的绘画呢,都需要我去指定说你要通过这样这样子去调用你的 python, 所以 说我那时候就想,那我能不能把这个弄到一个全局的一个记忆里面,让它每次呢每次一个绘画呢,它就知道怎么去调用了。 那当然呢,我这台电脑是有这个拍摄环境的,所以我问他,他就说有,首先我们需要下载一个小龙虾的一个插件,就是一个 agent, 它你就直接下载这个就行,这个是专门用来自己去学习,让它变得越来越聪明的。 那么下载完之后呢,你就直接让酷狗叉帮你去安装就行哈,你就说添加到 skill 里面,然后学习一下这个 skill, 那 它自己就安装了,那这些呢,就是你大概看一看就行, 然后啊添加完之后呢,就跟他说你帮我配置一下,然后每次新的绘画,你就第一时间去学习这个技能,然后读取全集的记忆, 然后这个时候呢又看次看次的,他又给你去啊,帮你去弄了,其实这个东西啊,你不看也没事啊,这个不太重要,你我们主要目的就是让他啊自己去配置完就行。 那么最后呢,就我比如说我说把这个啊调用 python 的 这个东西寄到全区的一个记忆里面,要放续后续的一个那个绘画里面,能够啊,直接执行这个, 知道怎么去执行这个 python 脚本哈,那他就说就写到全区记忆里面了,那怎么知道说啊?我这个 东西是确实记到了全区记忆在新的绘画里能用的,比如说我这里,呃,打开一个新的绘画,我就说测一下当前系统是否可用,就随便输入个东西。然后呢你可以看到说我现在在仓库里的话,先自己去读取了这个东西, 然后呢就是说他就自己去检测了这个全区的记忆,就说这个东西已经记录到全记忆。那么其实这两个文件呢?这个 门襟大概就是一个啊,全区记忆的一个相关的一个东西啊,比如说它这个全区的一个记忆,它就写到这个 m d 里面,那么它它这个我们添加的这个自学习类技能也添也放到这里面, 然后这个全息,就比如说我们之前添加的这个 pad 怎么调用,所以说它就记录了。然后你每次新的绘画, 就是比如说我这里要我再问你一个新的问题,那么这个时候他就有了这个 python 的 一个啊记忆,说我怎么去调?当然你一些其他的东西,比如说啊,你的 ida 是 吧?放大了怎么调?你的一个 js 的 怎么怎么去调这个这些东西你都可以 跟他说,你就说直接像我之前这样子,你说直接就啊写到全区记忆里面,还有一些其他的技能,比如 比如说,嗯,你的一些习惯,你说啊?我,我研究安卓的,是吧?安卓逆向的,然后我的 feed, 这你通过什么命令能执行? feed 这种你都可以, 就配置好之后,你就让它记忆到全区的记忆里面,然后这样子的话它以后的一个工作就会更加的一个方便。对,就是其实就是一个 多了一段记忆,就是让你的一些关键东西进行一个共享了。那还有个问题就是,呃,他记忆的之后呢?他有可能是会把让你的 token 向后会稍微多一点, 因为他比如说他每次新的绘画他都会,但这个量应该是还好,就是你一个新的绘画他都会读一个这个东西, 然后大家这读的这个东西肯定会消耗,相对来说是消耗多一点点头感,所以说你也不用什么东西都让他去记到这个拳击记忆里边,你只需要把一些关键的东西就记到这里,然后方便你后续的一个 操作就行。大家你如果头肯比较多的话,那就当我没说过哈。好,那么呃,今天介绍大概就这样,我们下期再见。
 02:26查看AI文稿AI文稿
02:26查看AI文稿AI文稿今天教大家怎么去使用 i 聊天,首先还是打开讯雷搜索,小韩是小白,点击我的资源,找到 i 这个文件夹,下载好这个压缩包后解压出来,解压的路径里面不能有中文, 解压完成后,我们先用管理员打开开放,然后跟着我的步骤来安装, 安装完之后来安装这个版本的微信,全部弄好后,打开第一个文件夹,找到 ren, 双击打开,等待下载配置, 然后浏览器会自动弹出来这个网址,点击模型配置,点击注册地址,这里会让大家注册,因为我注册过了,所以就不演示了,跟着步骤一个一个来就行了。然后点击令牌管理,添加令牌,这里弄过了就不演示了。都弄好后,我们就可以点击上方的按钮, 如果启动不成功就关闭微信,重新打开并登录, 登录完成后重新点击,会自动弹出来这个聊天窗口,请不要关闭,这里我发条消息演示一下。 这里的 i 模型什么的都是可以更改的,不懂就用默认的就行。 prompt, 这里可以更改 i 的 性格,记忆等等,按你自己的想法来更改好后点击保存,之后就会按你设定性格进行辅助回复,这里有主动的消息配置,让 i 主动给你发消息,按自己需要来更改就行了。
5涵 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿ai agent 可以 理解为一个能替你完成任务的智能助手。普通聊天机器人主要是回答问题,而 agent 会先理解目标,再拆步骤,调用工具观察结果,然后继续调整行动。 它的核心不是会聊天,而是一个循环,想一想,做一步,看反馈,再决定下一步。比如你说帮我整理一份竞品报告, agent 可能会搜索资料,读取网页、提取重点,做成表格,最后生成总结。 这和传统自动化也不一样,传统自动化按固定流程走, agent 可以 根据中途发生的情况重新规划。 所以一个 ai agent 通常需要四样东西,目标、记忆工具以及判断下一步的能力。它适合处理有步骤、需要查资料、需要使用软件或者需要反复修改的工作。但它也不是魔法。 目标越清楚,工具越可靠,检查机制越严格, agent 才越稳定。一句话, ai agent 是 会围绕目标自主计划使用工具并持续推进任务的 ai 系统。
 05:49查看AI文稿AI文稿
05:49查看AI文稿AI文稿pencil 爬虫教程第二章二点八, cookie 使用学 python 我 只看糯米哦,通过上期视频呢,糯米已经讲解了有关 cookie 的 基础知识点,那么本期视频呢,我们就继续深入学习一下爬虫是如何使用 cookie 的。 上节课我们说过, cookie 可以 让一个网站保存你的一些基本用户信息,等你下次重新访问这个页面,就不用再次输入账号密码了。 我们之前用爬虫去爬取网页数据的时候,都是直接在请求头中加了一个 user agent 的 信息,这样可以避免让网站服务器识别出我们是爬虫的请求。但是这些请求都是没有在用户登录的状态下发出的,因此我们无法拿到登录后的一些详细信息。 那么我们该怎么办呢?一个爬虫除了能模拟客户端,能不能也模拟一下用户登录呢? 当然可以了,我们只要在爬虫发出请求前,在请求头中加入我们的 cookie 信息,让网页服务器认为这次的请求是一个真正的用户发出的,这样我们就可以爬取一些登录后的数据信息了。 在莫米实际演示代码前呢,我们还是要先回顾一下 cookie 的 一些基础知识点,这对后续理解爬虫行为起到很大的帮助。 cookie 一 般分为两种类型,一种是临时 cookie, 它没有设置过期时间,只要我们关闭浏览器, cookie 就 会自动删除。 就像你访问一个网站,但是没有登录,这时候网站会给用户浏览器发送一个临时的 cookie 来记录所有的浏览行为,但是用户关闭浏览器再次重新登录这个网站,之前的浏览行为就会丢失。 另一种就是持久 cookie, 它设置了 expires 或者 max edge 属性,这样 cookie 就 会保存在本地硬盘上,直到这个有效期结束才会失效。就好比我们登录了一个网页,我们可能几天甚至半个月都不用重新登录, 直到这个 cookie 失效后,我们才需要重新输入登录信息,这时候服务器会返回一个新的 cookie 供浏览器使用。 我们知道 cookie 这么重要,它是由服务器生成的,那么我们可不可以自己模拟生成一个登录的 cookie 信息呢? 这是当然可以的,但是模拟一个登录可能要涉及到验证码、加密滑块、安全验证等,对于初学者来说难度还是挺大的,因此我们不如直接用 cookie, 这样省时又省力。 当然,如果你的 cookie 过期了,你需要重新登录,重新复制,所以更好的方式是使用 requests session 结合模拟登录。但是今天糯米先把 cookie 的 使用讲透,那么我们怎么去拿到浏览器中的 cookie 呢?糯米这里打开了一个百度页面,并且登录了自己的账号。 接着我们右键选择检查按钮,进入开发者选项页面,或者通过键盘上的 f 十二键也可以进入到当前页面。这里糯米选择了网络选项,也就是 network 选项卡 页面已经提示了我们需要重新加载页面,我们点击这个按钮或者按键盘的 f 五键,刷新一下页面。我们网上翻找主页面的请求,一般是第一个请求, 宝宝们看,这个就是我们想要的请求了,在它的右侧我们可以找到这次 http 请求的请求头以及网站返回的响应, 我们可以在 request headers 里面找到 cookie 一 项,我们可以直接双击它,全选复制这个文本,这样我们就拿到了想要的 cookie。 既然拿到了这个 cookie, 我 们该如何使用它呢?我们回到代码页面,这里糯米已经把这些代码写下来了,我们一步步看。首先我们要导入这 request 库,这里面我们就可以用到它的请求方法。 接下来我们把想要访问的目标网站写下来,用一个 url 变量保存, 这里就是最重要的一步,我们之前会在请求头内放一个 user agent, 就 可以让网站服务器识别不出我们是爬虫发出的请求。 同时呢,我们把刚刚复制的 cookie 也放在这个请求头中。下面的代码呢,就是我们发送一个请求,并且把响应的内容保存下来,写成一个 html 格式,那么我们运行一下看看结果如何。 宝宝们看,我们已经成功请求了百度页面,并且我们在左侧也能看到生成的 html 文件,我们可以在这里右键选择浏览器打开,这样我们就能跳转到百度的页面了,并且这里面已经有了我们的登录信息。 但是呢,有一些信息我们是拿不到的,因为有部分信息他是没有写在 html 文件里。在这里我们还需要关注一下 cookie 使用的注意事项, 我们不要轻易泄露自己的 cookie, 我 们的 cookie 里可能包含了登录凭证信息,别人拿到了你的 cookie 后,可能会冒充你登录页面做一些不好的事。 cookie 里还有 h t t p o n e 属性,有些 cookie 会被标记为 h t t p o n e, 这意味着它无法通过 javascript 读取,这主要是为了防止 x s s 攻击。有一些标记为 secure 的 cookie 只能通过 http 传输,爬虫也要使用 http 网址。 最后, cookie 有 过期时间,一旦过期我们就要重新获取。好啦,以上呢,就是本期的所有内容啦, 相信宝宝们已经掌握了 gucci 的 使用,我们的爬虫也能突破登录限制,抓取到更丰富的数据。下节课呢,糯米继续演示一下爬虫代码,实利用爬虫爬取视频素材,关注糯米,持续带你掌握拍 some!
132糯米姐姐 04:57查看AI文稿AI文稿
04:57查看AI文稿AI文稿今天给大家带来用开森制作聊天机器人。好的各位那么今天呢给大家分享一个聊天机器人的小案例啊,来,我们先来演示一下, 我们点击运行,欢迎来到聊天室。 ok 啊,那么你的名字这里呢,就出现了一个输入名字对吧?来我们这里叫小笨。你好,我是你的聊天对象,请为我取名字。 ok 啊,那现在呢就要输入一个对方的名字啊,就叫做小葱啊。 好,那么现在呢我可以提问啊,比方说我想问一下那个,呃三国演义的作者是谁对吧?来我们跑一下三国演义的作者是谁?罗贯中。好,那我们再来问啊,罗贯中的 出生朝代是什么?罗贯中的出生朝代是什么?元末明初。 ok 啊,那我们再问啊, 就说是谁吧,元末明初的皇帝是谁? 元末的皇帝是元顺帝妥欢帖木耳,而明初的皇帝是明太祖朱元璋。呃 ok 啊,呃那么基本上呢你问他什么问题啊,他都会按照这一个呃相关的 要求啊去回答你。呃那如果说你不想问了,呃那就直接输入您啊。但最后我还想问一个问题就是 a, 呃你觉得,呃我帅吗? 你觉得我帅吗?哎呀呀,我又没看到你呀,你可以先给我描述描述你的样子呀,或者发张照片让我看看我才能知道你帅不帅。好, ok 啊,那么现在呢,我们就停下啊停下。 好,那我们稍微的讲一下它是怎么去实现的啊?首先呢我们用了一个语音接口啊,叫 talker 啊,它就可以去实现这一个语音播报。呃然后呢我们还调用了一个豆包的 ai 接口啊。 呃那具体怎么去调用呢?呃代码的话啊,代码的话都会在那个 robot 里边啊,重点呢,你要搞清楚两个点啊,来,在这里啊。呃第一个点呢就是这个 访问的一个密钥啊,第二个呢就是一个接入点。好,那这两个点呢,你不能用我的啊,因为我把它配置到这个 config 里面,对吧? 留用自己的啊,到时候你去接触就行了。那么这里就是提了一些要求,对吧?那这里的要求有个什么呢?就是因为就是 ai 的 回答,如果你不做要求的话他会回答很长的一大一大片,对吧?那你对他做一个简短化的要求啊,那么基本上啊,你发这个请求就能得到你想要的结果。 好,那么这里讲完之后呢,我们再来看一下你怎样去申请这一个,呃 ai 的 这一个, 呃那个访问权限啊,那我们打开这个网站就是豆包的啊,那为什么推荐这个啊?因为你只要注册了他就会送你五十万个托尔斯啊,五十万个托尔斯,那这个呢?可以用一段时间,对吧?啊然后啊 按照这里面呢,呃我们去搞定两个关键的,这个,这个,呃密钥啊,一个呢是访问密钥啊。呃我们不妨去点开这个开动管理点开它啊。 好,呃我们是这个啊,是这个对吧?好,那个访问密钥。呃我看一下啊,这是在 开通管理里面啊,稍等。访问密钥不在这里啊 在这里啊,这里是一个访问密钥啊, apikey 啊,当然你这个地方把它点开啊,就是你的 apikey 啊。 好,然后呢?另外一个在开通管理里面啊,它找到是一个接入点来,我们点点击它,然后呢?这里面如果你点那个体验,对吧?它就会给你一个接入点啊? 那比如说这个话题,对吧?来,在这个话题里面呢,你输一个什么呢?哎,是不是有个接入点是他啊?你直接复制就行了啊?复制就行了。好, 把这两个搞定啊。呃,作为那个参数传递给这个访问密钥和这个接入点。哎,那你就可以成功的去访问了啊。当然,我说的是啊,你在豆包里面去申请啊,就是抖音的那个, 申请的话会有五十万条这个 tokens 啊。好, ok。 那 么这个分享到这里就结束啊,厉害。
11会飞的来财 02:24查看AI文稿AI文稿
02:24查看AI文稿AI文稿天都快亮了,沉了啊,我沉了。我用格拉格的让他帮我用 python 写了一个这个脚本,然后呢,他会通过这个脚本去读取这个文件夹里面的文文本档,这个文文本档里面的东西可以是 你的记录啊,或者是你的知识库,或者是你对一,你对下一个项目要做的一些 s o p, 你 把它放在里面以后,内容是这样,内容是这个样子的,内容是这个样子的成文本形式,它会读取通过这种格式整理成 bug, 然后再放进 oc 的 里面。像这一个就是我的大脑,这里面包含我对跨境的所有认知,还有我自己这个人 做过的项目,成功的那些 sop, 我 都会把它写进去,让他以后本地的 id 再去做。工作流的时候,都会先读取我的这个大脑里面的数据,通过我的 sop 去做这件事情是绝对不会出错的。比如说这个, 这是我做的,真做我做的项目,比如说这个我自己在做美特的广告投流,所以我会拿真实的数据,以及去搭建广告系列广告组,广告中间的所有素材,所有步骤,包括账号的风控,账户的风控该充多少钱,预算该怎么拉,我都会放在里面。 在本地的 a 证工作流在做这件事情的时候,我都会先让他读取我这个 sop, 我 不知道你们能不能听懂我在说什么啊? 我所有的 a 证以后只需要读取我的这个文档,以后做的事情一定是正确的,都不需要我再二次审核,也不需要我再去跟克拉扣子再去发二次指令,也不需要我去跟 jamal 去发第二次指令,他只要读取我的这个 知识库就可以了,相当于我的第二个大脑,属于一个高净值的数字资产。太重要了,你像这个就是自己做的项目,我会不断的完善它。我正在做着 在跨境电商方面,我怎么样加入 ai, 让它可以更轻松的实现自动化,可以省去一些人工,让 agent 去帮你去呃,监督你的实操盘,或者是人工帮你,或者是自动化帮你上品。直接省去人工,我才完成了这一点一晚上时间。
4028会小心的明 04:07查看AI文稿AI文稿
04:07查看AI文稿AI文稿这一期我想聊的是 slag, 如果要讲 slag 内容应该怎么做?简单说, slag 像是一个可以让你当 ai 团队的聊天空间, 它不是单纯跟一个 ai 聊天,而是你可以创建不同的 a 帧,让他们以不同角色参与讨论,甚至帮你执行一些任务。但这任务我不会,我就试了试用来聊聊天。 比如我这次做视频,就直接在 slag 里建了一群角色,技术专家、设计师、 dj、 歌手、商业分析师、批判者、用户代表,还有一些比较二次元的 npc。 然后我把问题丢给他们,这一期如果要讲 slag 内容应该怎么做,结果还挺有意思的, 技术专家会告诉我部署步骤,怎么猜,批判者会提醒我不要自嗨。用户代表会说,普通人最关心的是这东西到底能干嘛?设计师会从画面看、体验角度给建议, dj 看歌手会从节奏看、情绪上补充。这时候我突然意识到,我觉得是哪个最有意思的地方,而是它可以变成一个 ai 讨论现场, 你提出一个问题,然后让不同角色从不同角度参与进来。它有点像一个虚拟会议室,有点像你给自己搭了一个小型 npc 智囊团。当然,说实话,作为普通人,我部署完之后第一反应也是,那我到底能用它干嘛? 目前我自己用下来,它未必马上就能替代什么工作流,更多时候反而像是一个内容创作辅助工具,或者一个娱乐性质的思考空间。 比如你可以让他帮你讨论选择题,拆解脚本、模拟采访、做头脑风暴,甚至让不同角色互相反驳。所以这一期我就介绍一下怎么部署 slug, 大家一起看看能怎么玩这个东西。那么我应该怎么部署 slug? 我 演示的是 mac 版本,接的是 mini max 的 模型。 首先进入官网,是不是杠杠 slug, 点 ai 杠,然后点击 getstart, 创建好账号,进入后会让给系统建一个名字, 接下来我们创建一个 server, 填好服务名称即可,系统会自动弹出来。如何连接电脑?选择直接连接电脑即可,弹出来一串代码,复制到终端中,回车系统就自动跟电脑连接好了。 到了这一步, siri 已经跟你的本地电脑做好连接了。电脑连接好了之后是不是就能直接创建 agent? 还不完全是,连接电脑,只是说明 siri 找到了你的机器,但 agent 是 真正要干活,还需要一个大脑,比如 codex key, open code 这一类工具, 但是我都没有这些。后来发现用 open code 可以 来接 mini max。 open code 要怎么配置 mini max? 先安装 open code, 然后创建 open code 的 配置文件,接入 mini max, 弄好配置之后,再在终端中把 mini max 密钥写进去,最后就能 open code 中看到成功的页面,具体步骤我会贴出来。 这一步成功之后, slug 里要怎么做?接下来就是重新启动 slug, 让它重新扫描你电脑上的运行时, slug 的 创建 a 帧界面里就会出现 open code 这个 run time, 然后你创建 a 帧字的时候, run time, 选择 open code 模型那一栏就能看到 mini max 了。不过我发现 sark 接了 mini max 用的还蛮快的,之前和密斯都用不完, sark 给我的超级快。创建 agent 的 时候描述应该怎么写?这个就看你想让它干什么, 如果你想让它做代码任务,就写成技术助手,如果你想让它做采访,就写成记者。我自己现在比较喜欢的玩法就是把它们当 npc, 每个 a 阵都有自己的角色性格和思考方式,这样当我提出一个问题的时候,他们不是给我同一种答案,而是从不同角度参与讨论。那跑通之后,你觉得 sloc 对 普通人有什么用?如果说特别刚需,我觉得现在还谈不上, 从我这个纯小白的使用来说,它只能帮我内容创作、思路发散、角色扮演式讨论。还有一些轻量任务,因为我不会写代码,比如我这期视频就是先用 slack 里的多个 a 阵帮我讨论内容方向。最后你怎么总结这一期?这一期我想表达的其实很简单, 一个新的东西,如果你有精力可以去折腾试试,但是其他的就是目前我们还用不到,也不会用。
13Od 16:40查看AI文稿AI文稿
16:40查看AI文稿AI文稿前面第一章我们已经学过了,怎么样这个 a 准去调用一些工具,调用工具的方式,最后我们最常用用的一个方式就是通过 m、 c、 p 的 方式,那么现在我们就来到第二章节怎么样这个 a 准学会反思。那么第一小节如果课程会被意外修改,现在假设有个同事他已经写了一个 node 格式的一个课程,里面呢会包含一些 python 代码,为了让这个语言能够更生动,我们会让这个 a 准去帮助我们去呃润色整篇文档的这个风格,那经过润色之后,它的语言会更流畅,结构也会更清晰。 但是当他去运行这些数据代码时候,可能发现一些新的关键的问题。比如说现在有这样的一个原始代码,然后定两个函数,获得用户的数据,然后传的是用户 id 返回的用户的数据,那么在这一次执行的时候,正常情况下他执行,他就会输入这个东西, data for 哪个用户的,你传的参数是 u 一 二三就一二三,对吧?那可能呢?让机器人去修改这个原风格的时候呢?它不仅仅修改了这个中文的原风格,他可能把代码也给改掉了。 那把这个代码改成了什么呢?看下原来这个代码它的这个入参是不是 usrid, 它最终改成了 usrid, 是 不是多了个一原因?是因为这个机器人会认为觉得这个 user 这个命名会比这个 usrid 这个命名更加规范,所以他悄悄的把这个函数它的定义也改掉了。那你函数定义改掉了,但是可能它调用的地方这个字段入参没改,但这个地方参数定义的时候改掉了,那这样是不是可能调用的时候就会报错了?因为它没有一起同时方改变,所以这个时候就有问题, 那所以那个呢?这个问题我们要怎么解决?一个最直观的方法呢?是说要让大模型要小心一点,在系统提示里面加一句警告,就说首先呢你的角色是一个课程作家负责润色这个课程去优化文本,使得它更有吸引力。但是千万不要去修改代码块里的作用和内容,包括变量名、参数名、函数调用这些东西。但是 这样做其实它的效果不是很好,因为你没办法把所有的这个注意事项全部都列出来,即使你明确的修改这些规范,但是也有可能有一定的概率去把原来正确的东西改错了。 原因根本原因是因为大模型还是会存在幻觉的,每次生成的时候都可能引发一些新的错误,并且里面要去修正它的这个内在机制。它这种这种优化不仅仅是可能会让大模型改掉这个用户名,还可能会把它这个命令行参数多了一个横杠 a p i 的 版本,还有它的这个参考视力值,这些东西都改掉了,凡是他觉得不够规范的地方,经过优化之后却有可能引入非常多的错误,那这样就进行这个就导致这个无限的循环调试过程了,所以这个就把所有东西改错了。 所以我们自然而然就会想到一个新的思路,让大模型在输出这个优化之后,预测之后的文本之前,让它自己先检查一遍,就像在考试的时候,我们在交卷前也会先检查一遍,这种方式也是先让业界去解决它的一种办法,我们会把这种办法来做反思 reflection。 那 这个反思这种方法呢,有两种模式,第一个叫做自我反馈,校服的阅读, 然后第二种方法呢?第二种方法呢叫做外部反馈,一个是自我反馈,一个是外部反馈。那我们现在学第一种自我反馈,第一种要实现反思,最直观的思路就是让这个大模型自己去审视输出来的结果,自己去看他输出来的运色之后的结果。这里呢也有也有两种方式,就自我实现自我反馈,这也有两种,一种呢是很简单,但是结果是有限的,效果有限。一种是稍微复杂一点,但是他这个这个优化的效果会更显著一点。 那第一种就是通过单步指令进行反思,这也是一种很容易想到的方法,在我们进行这个大模型调用的时候啊,我们在提示词里面去指导这个大模型,你生成答案的时候要同时进行反思,就是生成并反思,所以你这个提示词呢就会变成这样了,你是一个作家,你的你的任务是进行这个润色语言润色,并且说出润色后的那个内容, 那你在进行润色之后,你还需要需要去进行反思,反思这个润色后的内容是否符合这个写作规范,是否会有其他内容被意外修改掉了。如果 进反思之后要给出反思之后的结果和修改建议,对照建议这个修改课程给出修改后的全部内容,所以如果是想这思路,他这个这个处理流程就这样的,这个是我们原始的这个课程的初稿,让这个大模型去生成,生成用后的结果同时进行反思,同时进行修正,所有东西都在一个节点里面去完成, 把最终导致的又经过反思又经过修正之后的结果进行输出。那所以像这个方法呢,是有一些优势的,优势呢就是在模型去生成的过程中,同时能够发现对应的问题,并且把它进行解决,能发现问题,解决问题。同时因为你你是在生成的时候同时进行反思和纠正嘛,所以可以在生成过程中发现并纠正,保持这个上下文的连贯,并且呢没有多伦网管反反去修改的这个开销去读,然后又去思考又可纠正,对吧?没有这个多伦网管开销, 它也会明显存在一些缺陷。当你把这个反思和生成绑定到同一个节点的时候,这个模型很容易使用相同的思维偏差进行自我验证,然后从而进入这个自证验证,就是自证正确的。快圈里面有像刚我们举的例子啊,他在第一步的时候会把这个 user id, 然后改成这个 user id 吧,多了个亿的 他,他现在第一步会把它改成这种,他也没优化更好的这个 id, 那 在反思的时候呢,他很有可能会把它认为这是一种规范改进的这个思想,他认为这个改造是正确的,而不是一个错误的改造,所以这样的话很容易就会有一些漏洞的开销,但是他也很有可能会有一些问题 产生。好,那所以第二个方法呢?是我反馈的第二种方法,就把这个生成和反思分开来两个步骤,所以可以把反思这个步骤独立开来,把当前的这个任务拆分成调用两次模型,第一次第一个模型专门负责生成,第二个模型专门用来负责审查。 那如果你是分开了两个 a 卷,你第一个 a 卷是专门用来写作生成运色的,那它的这个提示词就是你是个作家,负责运色课程优化,使得更有吸引力,给出它的原始的稿件是什么?这是这是这个运色的这个 a 卷,然后调用就是进行审查的 a 卷。再说你是一个严格的审查,你的任务是进行审查运色规范,并且呢,代码、配置、数据这些东西不能够被意外修改, 那请对比原始的和修改后的预测。之后的如果只改了文本的表达这个代码这些技术内容要保持完成一致,或者只有记这个注式或者格式等非功能性的变化。如果是这样只改表达,但是内容完全不变,那就可以通过。如果在审核过程中发现有些内容被改掉了,比如说他的代码逻辑被改了,变量改了,参数改了,配置线改了,就像这种情况就回答不通过,并且要指出哪个地方被改掉了,对不对?好,那你给出他原始的是怎么样的,改之后的是怎么样的, 这样它这个流程就会变成这样。首先呢是原始的这个稿件,这样呢生成,生成完了之后再让它审查,它审查就只有两个结果,一个呢是不通过,一个是通过,通过你就输出就行了,如果不通过打这个不通过的内容,以及为什么说不通过重新返回这个生成的这个 a 准,重新生成,重新审核好, 那由于这个审查的这个节点,它的视角,它就是站在审查的角度上去考虑的,因为审查的 a 准和写作的 a 准它的视角不同,这样就可以规避掉大部分的角色的偏见,因为它的角色大家负责内容不一样了。甚至呢,我们可以设置多个 a 准,从事实方面、逻辑方面、风格方面、安全方面进行审查,能够提升这个审查的全面性。后面如果进行一些测试啊,指标统计都可以有一些数据的支撑,对吧?好,但是现在这种方式没有一些明显的成本,增加了一个 a 准就相当于多了一轮这个调用,那托管的消耗就会更高, 但是这个成本值不值得通过这个生成的反馈看似增加了调用次数,但是呢,我们不能简单的说拿一次低质量输出和成本进行比较更公平的事,为了获得一个可用的答案,两种路径的成本总成本是多少? 如果我们现在拿单词调用,就是把生成和这个审查单词调用没法去解决问题,无论他成本有多低,都是一种浪费。他的意思就是说如果你使用这种方法,你根本没办法去避免大多数的错误,就是错误,你没办法检查出他当前修改的错误的问题,你没把这问题发现出来,无论你成本有多低,他都是浪费。那而你通过两步调用生成的反馈,分开了之后,可以使得它的模型能达到百分之九十五的效果,那他其实就是已经能够实现相同的这个业务价值了。 那么我们有没有办法能够更加降低这个成本?在这个循环里面怎么能够在这个 case 里面降低成本?在生成反馈过程中,原始文档会被模型调的时候重复传餐,写作的那个 a 准需要用到原始的文档,那审查的 a 准也需要用到原始的文档,或到后面你要进行这个 a 准纠正的时候,文本纠正时候可能还需要用一次,那如果当前这个文本本身就很长,那这种重复的钱会增加这个库存消耗,那 其实在阿里云里面会提供这个上下文缓存 contact 来解决这个问题。首次调用的时候会缓存一些共享,如果是缓存能够命中的话,它只会按照标准价格的百分之二十来算价格, 那这样就可以重新去组织一下这个提示词的结构了。首先呢是缓存部分,是大家都需要使用的原始的文档如果会发生变化的是当前这个写作的这些指令啊,审查抽中的指令,还有修改后运输后反馈的这些内容。如果是原始的文档,可能在单次掉的时候是在首次掉的时候会按照单价计费,后面如果再使用的时候就会按照缓存的价格去进行折扣折扣,从而去降低这个成本。那这是在阿里云的时候可以用缓存来降低成本吗?好, 那要注意的是应该让这个审查的 a 准审查 a 准是只负责发现问题,而不是重写,如果让他去进行重写,可能会导致又破坏了原本的表达,又引出一些新的错误,只要让他改,他就有可能引发新的错误。所以最好是把这个审查的结果反馈给这个去生成的 a 准,让他去修改,那审查始终是负责审查生成,始终是让他生成,无论是首次生成还是根据反馈生成,这样这样就能够形成一个生成和反馈结偶的一个循环,并且呢,他回答的忠诚度呢,得到这个显著的提升。 这种使用自我反馈的这个缺陷呢?如果用自我反馈这种方式啊,那我们刚说有两种反馈,有自我反馈,有外部反馈。用自我反馈呢,它更加适合是文本层面的对比,比如说我检查当前这个代码文本有没有被意外修改,当你确认这功能能不能正常运行的时候,它只能从文本代码角度上去思考。但是如果你想要检查这个功能有没有正常的时候,这个效果就比较差。 那这是因为大模型比较擅长去判断代码看起来合不合理,但是没办法真正的去进行像编辑器一样去执行它,验证它,所以因为它没办法真正的验证它看不到运行的结果,也没办法去捕捉这些异常的报错,也没办法去感知到这个易拉罐版本或者环境配置导致的一些问题。所以呢,为了解决这个问题,我们需要引入一个外部反馈机制,也就是自我反馈,只能从静态文本角度上去考虑。那如果真正的功能角度上真正能够运行起来这个东西呢?功能方面呢,还是需要一个外部反馈的这个机制, 接下来我们看一下第二种解决方式,就是通过外部反馈的方式来解决这个模型的幻觉的问题。那像之前我们用的这个自我反馈这个方式,它更加适用于检查这个文本形态的这个对比,看它能不能正常运行,但是它没办法通过工具调用真正有一个运行的结果去感知代码是不是可以正常运行。所以呢,这个外部反馈的核心思想呢,是让这个大模型生成的结果能够真正的在现实生活中真实环境中去执行,把执行的结果成功或失败的这个错误的报错。还有这个测试报告反馈给模型,让它 让它真正的能够根据这些落地的事实去进行反馈调用。那如果说这个自我反馈是叫做让他自己去检查他做的对不对,那个基于外部的反馈就是基于事实来看我做的对不对,一个是自己从字面上去对比,一个呢是从事实角度上去反馈。好,那 接下来再回到我们这个场景的这个背景,就是说我们使用的是 jpg notebook 这个去预测嘛,那假设呢?现在这个课程里面是包含一些这个代码视力的,我们希望能够在预测文本的时候,代码依然可以正确的运行,那这就要求了我们在工具调用的时候和对应的这个反思机制结合起来。那么 最直接的一个反馈来源是让代码去执行这些工具,在这个 agent 里已经内置了一个非常强大的去执行 python 工具的去执行 python 代码的这么一个工具。 excuse? python code 的 这个工具,那他这个 agent 他 在去调用的时候,他想看到这个代码对不对?那你就可以调用这个工具去执行对应的 python 代码,那他不就可以知道这个代码能不能正常执行吗?所以呢,他就提供了一个非常安全的代码执行的环境,同时能够真正的去执行 python 代码,获取对应的执行的结果,或者 行出错了之后的错误信息。那么它具体的这个工作流程是这样的,首先呢,第一步是生成,就是这个专门用来生成的这个 a 准,他去对这个文本进行润色,同时输出包含了代码的这个 notebook 的 内容,这就是先生成润色生成。第二步呢,我们这个系统会自动去提取出代码块,哪些是代码部分的,我们会执行这个工具函数,拿这个执行 python 的 这个函数去执行对应的代码块。这第二步, 第三步执行完之后呢,这个执行生成工具会返回执行的结果,如果发生报错了,这个比如说他执行的时候报错太白了, get user data, 然后这个方法呢,他会返回一个未知的 keyword user id, 像这个是不是报错了,执行工具函数报错了,那此时这个 a 准就能够识别到这个错误,他能知道当前这个代码发生了什么问题,低于当前的这个代码的反馈,就这个错误去修正,自己发现问题自己修正,所以我是这样,它整一个流程就变成这样。首先呢是有一个用户的输入文档, 用户书文呢,我们先通过那个生成代码的那个 a 准,先生成代码的这个 a 准帮助我们去生成对应的包含了已经错误,可能会有错误的这个 logo, 就 先略色一版,可能是包含错误的你,你可能有错误,把一些正确的改成错的了。我们调用这个工具函数,调用一个代码执行的工具函数去执行,代码执行完了之后呢,会有一些报错类型,可能报错,那报错完了之后,再让这个 a 准去进行修改, 修改完之后就得到完整正确的这个执行的,又润色后的这个文就是课程文本内容了。好,那接下来我们来看一下有一个代码的例子,就是使用着 agent go 去实现的简单例子。首先呢 agent go 里面本身就是有一个内置的函数叫做 execute 啊, execute 这个 python code 的 这个工具,那我们现在呢已经有内置这个工具了,就不需要创建工具函数了,那我们就直接调用就行了。那 第二个时候呢,就是通过 to key, 这是不是一个工具函数?所以呢第二个是 request to function, 然后去调用这个执行 python code 这个方法进行注册这个工具,那你就可以使用了。好,那我们看下下面代码 啊。首先呢,我们现在这个功能使用使用这个 agent scope 这个框架去实现外部反馈的这个反思,外部反馈就调用工具进行反馈,有哪些问题呢?它的场景呢,就是去预测课程,并且用这个代码解释器去保证这个代码一定是正确正确的。好, 那首先这个这个代码里面写的什么呢?就是引入了这个 ios 超系统的一些东西,然后低等是做这个文本的这个优化的去掉一些空格,然后用的这个 agent 模型呢?还是 react agent 模型?用的这个对话的格式器还是这个 data store 格式化,然后这里呢比之前多了一些东西,就是什么多了一个 memory, 多了一个 in memory memory, 然后这个 message 也是之前一样的,就是对话里面的信息嘛,对话流程信息,这个用的函数 check 模型,对话模型,然后工具这个这个总部里面包含了这个工具箱,这个是对应的工具函数,执行 python 函数的工具函数。好, 那接下来我们看一下它先定义的第一个方法,第一个方法就是用来专门进行这个代码生成的一个 agent。 好, 那我们看一下,定义了一个这么函数 create writer agent, 然后它返回的就应该是一个 react agent agent, agent agent 是 怎么样?先思考,然后要用对应工具函数观察又思考观察好,所以我们这个这个里面有学写了,我们当前这个就是负责生成论色课程的内容的这么一个 agent。 那 现在它第一步就是先去创建对应的工具包, 先创建一个工具包好,这个是先创建工具箱,工具箱里面去把这个工具给注册进来,那就用这个数据格式这个函数来注册进来。好,然后接下来我们就开始创建一个 ras a 准这种这个模型,创建一个 ras a 准模型,因为它功能主要是用来写作的,所以呢我们把这个 a 准叫做 write, 那 我们看一下里面有什么属性,第一个它的命名呢就叫做 write, 它系统提示词呢就叫做你是专门负责预测的,第一个要优化表达,第二个不,绝对不要修改代码的东西,预测后要通过,你看预测后要通过这个工具去验证对应的代码,防止他不小心把代码快的内容改了, 如果有代码快执行失败。第四点就是如果代码快执行失败,要检查一下有没有意外修改的代码,并且要把它恢复正常,注意只改文案不能改代码。好,那这个呢?就这个这个命名这种提示词,就告诉他一定要掉工具,他决策什么要掉工具去检查我们此时用的模型来是那个 dashcode 对 吧?定义一个模型的时候呢,需要选用的是模型的名字 apikey, 然后要流失输出,这个流失输出为 force, 就 不要流失输出,如果你不写这行,也是默认是不用流失输出的好。 然后这个内容格式化也是用这个 dashcode for track for matter 工具箱注册进来的。 memory in memory 这句话带我们看一下它的作用是什么,应该是有一个记忆功能在这里的好,然后再下一个呢,就是最多的迭代的次数是十次 这个过程,如果如果他发生了这个问题的发生,问题重新生成,又去执行代码又生成,这个过程最多去循环十次,如果超过十次就就为了避免他的死循环,所以我们这个时候可以根据用户的复杂度和这个消耗的图腾去进行这个决定当前最大的循环次数是多少。好, 那这样我们是不是用定义的函数用来创建这个写作的准则,这是第一个函数创建写作的准则。那接下来我们这个主流程里面,首先第一步就是 node, 原始的 node 它的内容应该是什么?这个是原始的 node, 就是 这个课程内容,我们现在这个课程内容非常简单,对不对?就这么多课程,是不是就是这两个部分,对不对?这两部分是代码的东西。好, 这个定义好,这个函数调用定义好这个课程的内容,第一个变成课程内容,第二个开始输出原始的内容是什么?然后输出这个 origin node 了,对吧? origin node 是 我们刚定义出来的这个课程内容的这个 notebook, notebook 的 这个内容好,然后接下来我们刚说的创建一个写作的 a 卷,然后得到写作 a 卷,这接下来就是开始去发请求,那你去发请求之前,先把这个用户提示词给它,通过 message 对 象给创建出来。那首先呢,你这个用你的用户,你的 name 叫做 user, 用户提示词, 这个用户提示的内容就是这个内容,用户提示,然后你的角色就是 user, 那 这个内容应该写什么?用户提示是不是要他要要这个写作的 a 去润色,对不对?所以呢,以下是课程内容,让你去润色也要生动形象,不能修改这东西。好,那现在这个用户提示词,这个 message 也定好了,那接下来呢?是不是这个 a 就 开始去工作,把用户提示词传递这个 a, 让他去工作,那他工作时候因为他是异骨的,所以用这个位 等待一下,得到它这个 a 准输出的结果,那这个 a 准,它内部就会自动去完成润色,先润色再验证,验证之后如果它出报出什么问题,然后它就会修正这个问题,再重新验证,看有没有问题,如果通过的话就通过。所以像这个 a 准为什么可以实现这个功能?那你是不是已经在 a 准的系统提示词里面已经写好了,如果执行失败,要检查并修正对不对? 好,那我们看一下这个 a 准, a 准现在掉完之后得到结果,下面呢?下面呢?就是把它最终输出,输出出来,调用一下这个媚方法。好,那看一下它下面的执行结果是什么样的。学习定义函数,调用函数小节,这是原始的课程,让它变得更易懂。那现在这个,嗯,这个 python 函数呢? 怎么样变得更易懂?那是他现在就让他变得就更易懂,增加了一些表情,让你轻松的去学习,通过一些更简单的一些方式去让你去举例说明,让他更容易懂,并且这个语气更轻松了。那现在创建了一个小助手,就是函数定义,函数定义第二个就是调用函数,执行完之后就会得到输出 f 一 三,然后就完成任务。小结就是打勾,恭喜你。好,那现在假设呢?这个呢?就是这个呢,就是 ai 它定义出来的 色后的第一个版本,观察一下这个运色后的第一个版本,是不是它真的把它这个函数好像没有把它变成加了个一的,它这里也没加个一,所以它好像没有问题,它就开始验证了。它验证代码的时候,首先它用的类型的调用工具,这个工具的名字叫做执行代码,执行派森代码,它的输入是刚刚那个派森代码,派森代码它返回的是这个 id, 返回的是完整的这个工具函数,完整的这个工具函数输入这个 python 代码,输入是 python 代码,当前的 id 是 工具调用的这个 id, 当前系统提示词是类型,是工具调用的结果,调用的是这个工具执行 python 代码,它输出的是输出的这个东西。也就是说我们这里面验证的时候,相当于是要告诉我用什么工具,你要执行的代码是什么,输出这个代码执行的结果,然后会发现当前这个代码是能够执行成功的,输出的结果是完全符合预期的。 那并且我们调用工具之后,会发现它这个课程内容更生动形象了,比如说用一些比喻表情符清晰的步骤,像这种以及代码也没有问题,随便证也成功了,输出的东西是符合预期的,那所以我们这个课程都会更加生动形象。 好,那通过这种方式,我们这个 a 准呢,就可以通过一些外部工具的方式去校验这个输出,从而保证这个高效准确的自我修正。那除了这种方式就要做调用外部工具的方式,调用外部工具的方式就叫做外部反馈,那从那除了自我反馈和外部反馈之外,那我们接下来后面再下一个小节的时候,可能还有其他的一些验证的方式。就除了这个代码的验证方式之外,这种模式还可以应用于其他的。这个需要基于客观事实的场景,比如说去优化论文里面的这个图标, 比如说你现在要求 a 准为它生成一些格式化的代码,现在 a 准好像生成了一堆一段合理的这个代码,包含了逻辑处理和函数调用、图标调用,但是呢,这个代码可以运行,不代表它生成的图标效果就好了,它生成的这个图片可能会代表着这个坐标轴重叠、独立、有遮挡、字体过小、配色不适合打印这些多种问题。如果你通过外部反馈法呢,可以让这个系统自己去执行这个代码解释式工具去执行这个画图的这个代码, 然后生成对应的文件,这个 a 准也可以去接收到当前真正渲染出来的图标,能够直接看它渲染出来的图片,去发现视觉上的一些问题。比如说它坐标轴重叠了,有东西挡住了,针对性的去调整对应的代码参数,去修改它的代码,去增加它文字大小。所以经过这个生成先生成对应的这个代码,去渲染出对应的图,去观察,去调整。通过这样的一个循环,能够使得最终 ai 生成的图标能够符合我们的质量的要求,所以 我们这种基于事实的反馈的这么一种验证的思路也可以应用于这种方案。还有一种面对复杂计算的时候,比如说在一次量子医学里面,你需要出一道练习题,计算一个质子, 质子的质量是这样的,被限制在一纳米的这个无线声势线中时,其中它的这个基态能量是多少的焦耳,那在 a 准在解题的时候,可能会因为有复杂的指数运算,然后出错,那我们使用这种外部反馈的这种解法,就是系统只需要识别出它计算出来的长量的表达式,就是嘟嘟嘟,然后至于它的对应的 执行,然后就交给这个代码的解释或者工具函数去帮我们调用这一堆嘟嘟嘟,它的结果是什么?那那就不需要 a 准帮我们去计算这一堆复杂的东西,工具能返回最准确的执行结果作为反馈,让 a 准去重新修整,得到最终的答案,要不然他可能表达式也错了,计算过程也错了,那你不知道是哪里出错了。好, 那还有这个场景呢,就是当我们去结构化输出时候的校验,比如说我们像之前我们有说过,就是让 a 准生成我们想要的这个筛选配置文件,但它有的时候呢,会漏掉一些必选的词段或者类型,会出错。那外部反馈法也是通过比如说我们之前已经用过的这个 python 这个 dante 这个库对它进行校验,如果输出不符合的这个 schema 这个筛选数据的时候,就返回详细的错误的信息,比如说这个代码应该是整数,而 不是字母串,那像这种客观的精准的反馈,能够让它基于错误的 case 进行修正,直到输出这个符合预期的结构。那像这个反馈呢,其实是在时间中最常见最基础的应用之一, 那究竟是使用哪两种反馈?究竟就是让 a 准自我反馈还是外部反馈?那你就具体就看我们的需求是什么,预算是什么。那如果你只是润色一个没有代码的,你根本就不需要让这个代码执行反馈,不需要外部工具吗?所以如果是你要包含几十个代码的这个交互式课程,那你此时就可能需要外部反馈来保证这个代码的质量,避免有一些事故发生的时候的一些额外的投投入。 那所以总来说呢,我们第二节主要学的是通过自我反馈和外部反馈,让 a 准在输出的时候确保它的准确性。总来说,我们本节先是学到第一个使用直接指令时的局限性, 直接在框里面要求大模型要更小心或者不准修改此时的效果,直接在提示词里面去改它效果一般是会好的,因为他他去生成这个目标时候,他不知道你究竟这样更合理,区分不出来,所以有时候好心会犯坏事,所以第一个直接在提示词里面去改,可能会有这样的问题。 第二个我们去做反思的时候的一个核心思路是让他去模拟人的认知,让大模型自己去评估生成自己生成内容,发现并且纠正错误,比我们写的这些指令去控制他更加可靠,让他自己去发现他先执行完之后会不会改错。接下来就提出了有两种反馈的机制,一种是自我反馈,自我反馈就是让另外一个 a 准去检查,适合于主观的去验证结果,适合一些基于事实的场景去进行评估。 工程上面先生成再反馈的这个循环,那是实现反思的一个有效的方法。经过多次调,第一次生成出稿,后面呢去评估出稿,提供反馈,再去修改出稿,那像这个过程就叫做生成成和反馈的循环。 我们第一节重来再回一下我们之前的一节都是让这个 a 准学会了怎么去调用工具,那最终是使用 m、 c p。 第二节们是通过反馈的机制,自我反馈和这个外部反馈,让这个大模型学会反思,解决大模型的幻觉的问题。那你一味在提示词里面让他小心什么的,这些是没有什么用的。所以解决大模型幻觉还得是通过一些反思的机制,自我反馈和这个工具反馈的这个思路。那我们这个第二节我们会讲到怎么去构建一个工作流,去解决一些更复杂的场景。
16蒙娜丽丽 04:09查看AI文稿AI文稿
04:09查看AI文稿AI文稿哈喽,大家好,我是吉克魔导师。最近更新有点慢,让大家久等了,因为白天工作实在太忙,但一想到大家都在等着我们的 ai agent, 零基础到精通动手实践篇,我就赶紧回来了。在正式敲代码之前,我们必须先完成一件大事,搭建开发环境。 这就像上战场前得先磨好枪,备好弹,环境没配好,后面的代码可就寸步难行了。别担心,整个过程我已经为大家简化成了五个清晰的步骤,跟着我的节奏, 大概十五分钟我们就能轻松搞定,为接下来的实战做好万全准备。在动手之前,我先说一下你需要具备什么基础。三个东西,第一, python 基础,你得知道变量函数怎么写,会用 pip 装包。第二, 命令行基础,能打开终端敲命令就行。第三,就是我们的原理篇,你得先理解 agent 四大组建的概念,如果你还不会 python, 也不用太担心,我们的代码都有详细注示,但建议先花个一两个小时学一下基础语法, 这样理解起来会顺畅很多。好,我们正式开始。第一步,确认你的 python 加 r 键,打开终端,输入 python 杠杠 version。 我们要求 python 三点一零及以上版本,为什么?因为 lan graph 这个框架最低要求就是三点一零。如果你看到的版本号低于三点一零,那就需要先去 python org 下载新版本,安装完之后 再跑一次这个命令,确认版本没问题,就可以进入下一步了。第二步,装依赖包,使用下面的命令,我来简单说一下每个包是干什么的。 lanchan 是 agent 开发框架的核心, lanchan open ai 是 用来调用 open ai 格式模型的接口, deep seek 也兼容这个格式。 lanchan community 提供社区工具,比如搜索和向量数据库。 lan graph 是 agent 的 运行式框架。 simple level 是 一个安全的数学计算库。 chroma d b 是 轻量级的向量数据库,用来做长期记忆的 request, 用来发 http 请求。第三步,获取 api key。 我们需要三个 key, 但只有一个是必须的。第一个, deep seek api key, 这个是必须的。去 deep seek 官网注册登录,点 create api key, 复制保存好。注意这个 key 只显示一次, 一定要保存好。第二个 tablet key, 这个在实践二四五六会用到,去 tablet 官网注册就能拿到。第三个 openweather, 这个是可选的,只有实践四的天气工具会用到。这里我要特别强调一下安全问题, 永远不要把 api key 印编码在代码里,也不要提交到 git 仓库,我们后面所有代码都是通过 os git 来获取环境变量的,这样更安全。第四步,把刚才拿到的 api key 设置成环境变量。如果你用的是 windows, 打开 power shell, 输入这三行命令。 如果你用的是 mac 或者 linux, 用 export 命令,为什么要用环境变量呢?打个比方,把 api key 写在代码里,就像把银行卡密码写在纸上,任何人看到代码就能拿到你的 key。 而用环境变量呢?就像把密码放在保险箱里, 代码只知道以去保险箱取,但不知道密码是什么,这样安全多了。最后一步,验证环境是否 ok, 创建一个文件叫 check in v p y, 把验证代码写进去,然后运行这个文件。如果一切正常,你会看到 luncheon 和 lan graph 的 版本号以及三个 api key 的 状态,如果某个 key 显示未设置,就回去检查一下环境变量有没有设对。 我们本片统一用 deepsea chat, 它兼容 open ai api 格式,可以直接通过 luncheon open ai 调用,非常方便。如果你想用其他模型,需要安装对应的 luncheon 集成包,比如 luncheon sopic, 然后修改实时代码就行。 好,最后我们来过一遍检查清单,确认以下几项都 ok 了。 python 三点一零以上装好了依赖包装好了 deepsea api key 拿到了, tiffany api key 拿到了,环境变量设好了, check in, apiy 运行通过了。全部打勾的话,恭喜你, 环境准备完成,接下来就可以正式开始动手实践了。我是即刻模导师,我们下节代码见,拜了个拜!
67极客魔导师 05:45查看AI文稿AI文稿
05:45查看AI文稿AI文稿如果你只在网页上与 ai 一 问一答, ai 只是高级版的搜索引擎,想让 ai 成为你的员工,帮你干活,就应该把 ai agent 用起来。嘿,你好,我是 bullet ai 加知识管理的实践者巨头一下视频,最后有对有设定用户超实用的彩蛋哦! 网页聊天没有跨对话的记忆,你在一个对话里聊了很多轮,终于交代清楚了项目背景、需求约束,结果新开一个对话,记忆清零,你得从头再说一遍。时间久了,有价值的讨论散落在各个对话里,找起来很费劲,也难以沉淀。汇总被附用 聊出来的文字代码只能手动复制粘贴到 word、 ppt 或者编辑器里。聊天框和工作流之间隔着一堵墙,交互永远局限在问一句答一句,不会自动到点干活。如果只是随便问个临时的问题,网页聊天没问题。但是想让 ai 真正产生生产力,就必须进入下一个阶段。 网页聊天只是这波 ai 浪潮最初的形态,就像一个咨询窗口,问一句答一句,傍晚走人不留痕迹。 以 cursor cloud code 为代表的 ai agent, 将 ai 从指挥说进化到了能动手、能读取文件、写代码、操作工具,但还是要你下指令他才干活。 opencloud 开启了第三阶段,让 ai 交互从对话式转变成了委托式。 他二十四小时在线,有记忆,能主动执行任务,能跨设备响应。在实际工作中,想要真正让 ai 发挥性能,就需要紧跟趋势,使用常驻式的 ai agent。 接下来就以国内大家都能方便安装和使用的 kimi klo 来演示如何使用全天候的 agent 打造工作流。为什么选 kimi 呢? 国内的龙虾基于 open klo, 基础能力都差不多,但用什么大模型就有区别了。而 kimi 刚刚发布了 k 二点六,整体,已经能对标 k 二点六,整体已经能对标 k 二的 opus 四点六。为了避免优质的对话成果分散在各个对话中,就可以改用 agent 来聊天, 例如 kimi curl 或者 kimi cood 的 都可以,因为 agent 可以 使用 skill, 也能与知识库工具,例如 obsidian 打通,我就专门做了一个叫 log to daily 的 skill, 一 句话就可以总结聊天内容保存到 obsidian。 例如我让 kimi cood 分 析了一下特斯拉二六年 q 一 的财报,然后我觉得这个内容还不错, 想把它存下来,那么我只需说一句,记录在案。然后 kimi 就 把财报的总结创建了一篇笔记,同时也在日记上面添加了一个日记,并且也很风趣的回答,我已记录在案。 好,我们到 obsidian 上看一下,这就是他在今天的日记上记录的这条日记,进行了一个简单的摘药,然后我们可以通过这个双向链接可以跳转到财报分析的总结页面。如果使用 kimi 的 app, 在 手机上也能一句话将聊天内容总结并保存到 obsidian, 这条就是刚刚通过手机保存过来的, 同样也是生成了一条日记摘药,然后也创建了一条总结笔记。当你收集到了较多的优质内容的笔记,就可以发挥 obsidian 的 双向链接 base 以及 ai 加 c o i 等高级知识管理的能力,做进一步的梳理与产出。 首先, kimi klo 已经有了完整的长短期记忆机制,每天会自动通过日记 memory 点 md 记录你的信息和你在做的事。你问他你最近在做什么项目,他都能回答。还可以进一步增加一个更强大的外部大脑,在 oversight 中维护一个文档,管理你的背景信息偏好 以及你当前进行中的项目或者 okr 的 skill。 在 ai 需要的时候, 根据 skill 读取你的背景信息和你的项目情况,甚至反过来去完善更新你的项目进展。要做一个 skill 其实一点也不复杂,你只需要给 kimi 说出你想做的 skill 的 名称、目标、背景、流程、参考资料是什么, kimi 就 能帮你生成。 skill 都是用大白话描述的,你只需要在这个基础上验收和优化,把你的工作方式固化下来,让 ai 按你的方式干活,越用越懂你。 kimi klo 能在电脑上创建自动化的任务也是很重要的。举个例子,我每天早上通过 follow builders 这个 skill 自动收集几十名 ai builders 的 最新推文。这个 skill 的 原作者是张咋拉, 这个 skill 汇聚了几十位 ai builders 的 推文、播客以及官方博客,每天可以把最新的信息汇总发送到你的即时通讯工具里面。而我 fork 这个 skill 的 话,主要是增加了对 obsidian 的 集成,它除了可以发送到即时通讯工具里面, 还可以自动每天添加到你的 obsidian 的 日记里面,形成一份存档。这种固定化的动作通过 agent 每天自动化的执行还是非常有用的。 之前有不少小伙伴留言,太想用 cloud 点在 obsidian 中与 ai 对 话了,但是 cloud code 因为你懂的原因,配置太麻烦了, token 也很贵。 现在我基于开源的 cloud 点插件开发了 cloud 点 for kimi 插件,现在在 obsidian 的 右边栏就可以使用。 kimi code 也包含了最新的 k 二点六模型,直接与 obsidian 进行对话了, 再也不用折腾 cloud code 了,就能在 obsidian 中无缝与 ai 进行协助。我在这个插件里面也已经实现了 to call、 skill 调用这些能力,但是可能还有一些 bug。 你 今天就可以做一件事,打开 kimi claw, 进行一次问答,把结论纯净。 obsidian 从网页聊天到用 agent 打造工作流,就从这一步开始。这是我的 ai 时代普通人必做的五件事。的第二件属于杠杆乘效率。 下一期我们讲第三件事,详细聊一聊 skill, 以及为什么每一个人都应该发布自己的 skill。 我是 blink, 你 还想听什么?欢迎评论区交流。
 02:38查看AI文稿AI文稿
02:38查看AI文稿AI文稿ok, 大家好,这是第五集跟大家分享的 ag 的 十一岗位,还有面试情况,接下来我就跟大家讲解一下他的学习路线以及怎么学习,他都是干货。先说下常见的坑,第一个呢,不会拍空单上来直接选 ag 的, 要知道 ag 的 部分知识和后单是重合的, 先学 python 呢,再学 a 技能,这样就可以学的很快,学的很好,如果上来直接学习 a 技能会很吃力。第二个,直接学 a 技能框架, a 技能是有基础阶段的,既先学基础知识,这个步骤不能跳过就让你学习,一门一元的后端是不是要先学习基础,再学框架,循序渐进的学习才符合学习规律。另外,面试的时候有不少内容来源,基础知识,基础知识都答不上来, 肯定不行。第三个,认为学 a 镜的就只是学 a 镜的 ai 开发,包含 a 镜的,说学 a 镜的其实就是学习 ai 开发,有的人都没有搞清楚 ai 开发和 a 镜的关系,所以不知道从哪里学习。让我们说一下他的学习路线。第一个, python 基础 先学 python 基础,这是第一步,如果说你是零基础,预计一个月多一点就可以把那个学完,因为 python 很 简单,所以说可以学的很快,如果说你有其他语言基础,尤其是 java, 那 么半个月就可以学完它。第二个, python 控端。有的人可能会问,为什么需要学习 python 控端,因为你开发了 ai 模块,就要使用 python 控端封装成接口, 让 python 后端去调用,或者说让 java 后端去调用,所以说需要学习。然后就是将控 plus 和 python 三个框架如何选?三个框架中直接选择 python, 这是一个异步框架,性能很好,而且专门用来编辑接口的。注意将控 plus 和 python 都是 python 后端主流框架,三者很类似,如果有时间建议把将控 plus 也学了,对于技术肯定是多多益善。 第三个 a 技能拍送他学完之后就可以开始学习 a 技能了,其实就是学习 a m 开发,因为 a m 开发包含 a 技能。第一个 a m 开发基础, a m 开发基础知识全部如下,其中 skills r a g a 技能这三块很重要。第一个 skills, 在 a m 开发基础当中, 它呢是很重要的基础,所以说呢,要好好学。第二个阿拉莫本地大模型部署,它呢就是把一些开源的大模型部署到本地,会操作就行,不用深入学习。第三个是 m c p 协议,它呢就是一个协议,了解就行。第四个就是 ig 知识库,这个呢是 ai 开发中第一个核心知识,而且呢也有岗位,所以说呢,好好学。 第五个 a 阶的 skills, a 阶的 skills 是 a 阶的基础,所以说在学习 a 阶的之前,要把这个基础给学好,所以说呢,他呢很重要,要好好学。第六个 a 阶呢,他是 ai 开发中第二个核心重点,很多人想从事的岗位就是 a 阶的,所以说要好好学。 第七个 a 阶的 team, 就是 多智能体协助,对吧,因为很多公司还处于单 a 阶的阶段,多智能体落地并不多, 了解就行,不需要什么学习。第二个学习框架,已做项目 a a 应用开发,主要框架有浪琴当寡妇粉,建议学什么用什么,因为内容很多,学不完,当你把基础学完之后,就可以直接使用框架做球类级别的项目,对于框架用到什么技术就学什么技术,既边学边用,学习框架和做项目放在一起,这个阶段完成之后就可以找实习或者说正式岗位了。
2141星辰~带你高效自学Agent 00:30AI Agent第2天:用Python让AI写自我介绍 很多人说AI Agent很难,我不知道是不是,但我试了。今天是第2天,体感正常~#跟我学AI #学AI #AI学习 #AI入门 #AIAgent查看AI文稿AI文稿
00:30AI Agent第2天:用Python让AI写自我介绍 很多人说AI Agent很难,我不知道是不是,但我试了。今天是第2天,体感正常~#跟我学AI #学AI #AI学习 #AI入门 #AIAgent查看AI文稿AI文稿很多人说 ai 已经很难,我不知道是不是啊,但我试了今天是第二天,我用 python 调了 deepsea, 让他帮我写了一段自我介绍,怎么样?比我写的好太多了,很精炼,也很准确。其实今天的任务核心就一句话,学会用代码调用 ai, 让他按你想要的方式输出。 很多人问我怎么学 a i a 检测,其实我答案就一个字啊,我代码我已经上传到 get up 了,想学的具体任务步骤我也发到群里了,祝我成功,也祝你拜拜。
30老王学AI 04:59查看AI文稿AI文稿
04:59查看AI文稿AI文稿一天一个 python 知识之制作聊天机器人。好的各位那么今天呢给大家分享一个聊天机器人的小案例啊,来我们先来演示一下 我们点击运行,欢迎来到聊天室。 ok 啊,那么你的名字这里呢就出现了一个输入名字对吧?来我们这里叫小笨。你好,我是你的聊天对象,请为我取名字。 ok 啊,那现在呢就要输入一个对方的名字啊,就叫做小葱啊。 好,那么现在呢我可以提问啊,比方说我想问一下那个,呃三国演义的作者是谁对吧?来我们跑一下啊三国演义的作者是谁?罗贯中。好,那我们再来问啊,罗贯中的 出生朝代是什么?罗贯中的出生朝代是什么?元末明初 ok 啊,那我们再问啊, 就说是谁吧,元末明初的皇帝是谁? 元末的皇帝是元顺帝妥欢帖木耳而明初的皇帝是明太祖朱元璋。呃 ok 啊,呃那么基本上呢你问他什么问题啊,他都会按照这一个呃相关的 要求啊去回答你。呃那如果说你不想问了,呃那你就直接输入您啊。但最后我还想问一个问题就是 a, 呃你觉得呃我帅吗? 你觉得我帅吗?哎呀呀我又没看到你呀你可以先给我描述描述你的样子呀,或者发张照片让我看看我才能知道你帅不帅。好, ok 啊,那么现在呢我们就停下啊停下。 好,那我们稍微的讲一下它是怎么去实现的啊?首先呢我们用了一个语音接口啊,叫 talker 啊,它就可以去实现这一个语音播报。呃然后呢我们还调用了一个豆包的 ai 接口啊 啊那具体怎么去调用呢?呃代码的话啊,代码的话都会在那个 robot 里边啊。重点呢你要搞清楚两个点啊,来,在这里啊。呃第一个点呢就是这个 访问的一个密钥啊,第二个呢就是一个接入点啊,那这两个点呢,你不能用我的啊,因为我把它配置到这个 config 里面,对吧? 留用自己的啊,到时候你去接触就行了。那么这就是提的一些要求,对吧?那这里的要求有个什么呢?就是因为就是 ai 的 回答,如果你不做要求的话他会回答很长的一大一大片,对吧?那你对他做一个简短化的要求啊,那么基本上啊你发这个请求就能得到你想要的结果。 好,那么这里讲完之后呢我们再来看一下你怎样去申请这一个。呃 ai 的 这一个, 呃那个访问权限啊,那我们打开这个网站就是豆包的啊。那为什么推荐这个啊?因为你只要注册了他就会送你五十万个托尔斯啊五十万个托尔斯,那这个呢可以用一段时间对吧?啊然后啊 按照这里面呢,呃我们要去搞定两个关键的,这个这个,呃密钥啊,一个呢是访问密钥啊。呃我们不妨去点开这个开动管理点开它啊。 好,呃我们是这个啊,是这个对吧?好,那个访问密钥。呃我看一下啊,这是在 开通管理里面啊,稍等。访问密钥不在这里啊 在这里啊,这里是一个访问密钥啊 apikey 啊,当然你这个地方把它点开啊就是你的 apikey 啊。 好,然后呢?另外一个在开通管理里面啊,它找到是一个接入点,那我们点点击它,然后呢?这里面如果你点那个体验,对吧?它就会给你一个接入点啊? 那比如说这个话题,对吧?来,在这个话题里面呢,你输一个什么呢?哎,是不是有个接入点是他啊?你直接复制就行了啊?复制就行了,好, 把这两个搞定啊。呃,作为那个参数传递给这个访问密钥和这个接入点。哎,那你就可以成功的去访问了啊。当然,我说的是啊,你在豆包里面去申请啊,就是抖音的那个, 申请的话会有五十万条这个 tokens 啊。好, ok, 那 么这个分享到这里就结束啊, i'm happy。
230Python程序员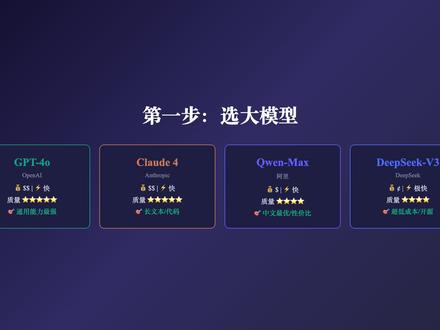 09:00查看AI文稿AI文稿
09:00查看AI文稿AI文稿欢迎来到 ai 进化录大模型科普课第三集,前两集我们讲了大模型是什么, ai agent 能做什么。今天我们来动手,手把手教你从零搭建你的。 你可能会问,市面上 chat、 gpt、 timi、 豆包这么多现成的 ai 工具,为什么还要自己搭 agent? 答案很简单,现成工具功能受限,数据不可控,自己搭的 a 枕可以完全定制进你自己的数据库,要你自己的 api, 按你的业务逻辑走。更重要的是,理解原理等于选型不踩坑。 当你知道你曾怎么运作的,你就知道哪些 ai 产品靠谱,哪些在吹牛。这是每个想用好 ai 的 人的必修课。 搭建一个 agent 其实就三样东西,第一大脑,也就是大语言模型, gpt 四 o cloud, 通用千问 deepsea, 它负责思考和决策。第二工具, a 阵的双手搜索引擎、代码执行器、数据库、 api 接口,这些是 a 阵能做事情的关键。第三,循环思考,行动观察,不断重复,直到任务完成。 这就是所谓的 a 阵 take 路。把这三样东西组合在一起,一个最基础的 a 阵就成了。 第一步,选大模型目前主流选择有四个, gpt 四 o, openai 出品,通用能力最强,中英文都很好,适合大部分场景。 cloud 四 andropic 出品,长文本处理和代码能力突出,安全性好。通用千问 quanmax, 阿里出品,中文最优,性价比很高,国内接入方便。 deepsea v 三开源模型里的性价比之王, api 价格是 gpt 的 几十分之一,适合成本敏感。场景选哪个取决于你的场景。个人建议先用 deepsea 开发调试,确定效果后上 gpt 或 cloud。 第二步,定义工具,这里要用到一个核心技术, function calling 函数调用。 原理很简单,你用 jason steemma 格式告诉大模型你有哪些工具可用。 steemma 里写清楚工具的名字,参数作用,然后把工具列表连同用户的问题一起发给大模型。 大模型看到工具列表后,会自己决定要不要调工具,调哪个,传什么参数。注意,大模型只是决定调什么,真正执行的是你的代码。这个设计非常巧妙,大模型负责脑力活,你的代码负责体力活。 第三步,搭循环,这是 agent 的 心跳,叫 agent 露。 整个流程是这样的,用户输入一个请求发给大模型。大模型思考后,如果觉得需要工具,就返回一个工具,调用请求 你的代码,执行这个工具,拿到结果,再把结果发回给大模型。大模型看到结果后继续思考,如果任务还没完成,他会再调工具,如果完成了就直接输出。最终回答。就这么一个循环,不断重复,直到任务搞定。 这也是为什么叫 agent, 而不是 chat bot。 他 不是聊一轮就完了,而是持续思考和行动。 现在来看,实际代码用 python 加 open aisdk, 一 百行就能带一个完整的 agent。 首先定义工具,一个 j s o n 格式的工具描述列表,然后哒循环一个 y o t 循环,把消息和工具列表一起发给大模型,大模型返回后,检查有没有工具调用, 如果有,执行工具把结果追加到消息列表,继续循环。如果没有,说明任务完成,打印回答, break 退出,就这么简单。核心逻辑不超过二十行,剩下的八十行都是工具的具体实现。 这里要介绍一个重要协议, mcp model context protocol 模型上下文协议,你可以把它理解为工具调用的 usbc 标准。 以前每个 ai 平台的工具接口都不一样,你给 chat gpt 写的工具到 cloud 上又得改一遍。 mcp 就是 来解决这个问题的, 它分三层, house 是 宿主,就是 cloud, chat、 gpt 这些 ai 客户端, client 是 客户端,负责维护连接和转发请求。 server 是 服务端暴露具体的工具资源和提示。最大的好处,工具开发一次,所有支持 mcp 的 ai 都能用。 如果一个 agent 不 够用怎么办?答案是多 agent 的 写作。目前主流框架有三个, line graph, 用状态图编排 agent 的 流程,精确控制每一步该干什么, 适合需要严格流程控制的场景,比如审批流、 co, ai 角色扮演模式,你定义研究员、携手审核员等角色,用自然语言描述每个角色的职责。它们自动写作最简单易用。 autopend 微软出品对话驱动,多个 agent 之间通过对话来写作,适合头脑风暴和创意类任务。 最后分享五个避之避坑指南,第一,幻觉防护大模型会编造事实, agent 里一定要加验证层,关键数据二次确认。第二, token 成本控制, 用缓存短提示词分级模型策略能省百分之八十费用。第三,安全沙箱, agent 能执行代码和调用 api, 所有工具执行必须在沙箱内,零容忍安全风险。 第四,调试技巧,打印每一步的 file 和 action, 日制出了问题才能快速定位。第五,生产部署加超时限制,重试机制降级策略,确保百分之九十九点九的可用性。 给大家推荐一个五周学习路线,第一周,学会用 openisdk 调 api 跑通基本对话。 第二周,学 fengshui, 自己定义工具搭 agent 构。第三周,学 write 增强剪索,让 agent 能查你的私有文档。第四周,用 qai ai 或 lan graph 搭多 agent 写作系统。 第五周级,以后研究监控安全和成本优化,把 agent 真正部署到生产环境。 好了,三级课程到这里就全部完成了。 第一集,我们讲了大模型的前世今生。第二集,我们解析了 ai 阵的原理。 第三集,我们动手搭建了第一个 a 阵,从原理到实战,一起见证 ai 进化。我是 ai 进化路,感谢你的观看,如果觉得有用,记得关。
84AI进化录

