claude怎么回到之前的会话
cloud code 已经有一百万 togg 上下文了,但用不好效果反而变差。大家好,我是 ai 学习的老张, ospec 刚发了篇官方博课,专门讲 cloud code 的 上下文管理策略,看完我觉得很多人,包括我自己,之前的用法都太粗放了。先说一个关键概念,上下文腐烂。 ospec 官方术语, 意思是上下文越来越长,模型注意力被分散,早期不相关的内容开始干扰当前任务。说人话就是聊的越久,模型越容易犯迷糊。 一百万托克是把双刃剑,能干更大的活,但不管理好,效果反而变差。核心来了,美文对话结束后,你有五条路可以走,继续回退,清空,压缩。子弹里大部分四个才是拉开差距的关键。 重点说两个,一个是 rewind 的 回退, cloud 走歪了,别纠正,直接双击 s 卡跳回去。那些失败尝试留在上下文里会干扰模型回退,直接把垃圾丢掉。另一个是子代理,把工作丢给独立的上下文窗口去做,只拿结论回来,中间大量输出不会污染主绘画。 最后一个建议别等自动压缩触发,那时候恰恰是上下文最长,模型最不聪明的时候,趁状态好,主动用 compact 的 命令压缩。 记住三条一百万 token 不是 让你无脑堆的。每轮对话后,想想该瘦身还是继续,主动管理永远比被动触发好。觉得有用,帮我点个关注,我们下期见。

粉丝2086获赞1.2万
相关视频
 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿一定要快点试试这个 kol 的 战,感受一下 kol 的 强大的代码和写作能力。他真的跟官网一模一样,不是账号迟不会被封号,还不限制托肯。接下来准备给他发一下丸子的别录,我看一下他的文件提取的能力,我看出来他的回答速度还是相当快的,写出来的内容还是比较准确和靠谱的, 比我自己读要快非常多,也没有出现像 cologne 之前常出现的断联的情况。接下来再让他帮我读一下科研图,以前我自己要是读这种英文的科研图,真的是要花很久时间,现在你只需要发给 cologne, 它就瞬间可以把这个科研图的全部的流程以及内容都给我分析清楚, 方便非常多。而且你看他还可以把整个流程都帮我梳理清楚。接下来再让他帮我改一下之前的这种石山的代码,可以看出来他把问题在哪里都指的明明白白的。重新给了我一遍,他修改之后的一个代码,看起来比我写的代码要好太多了,这真的是我目前能够找到最好用的 closed 站了,没有之一。感兴趣大家点点关注。
6008六粒的世界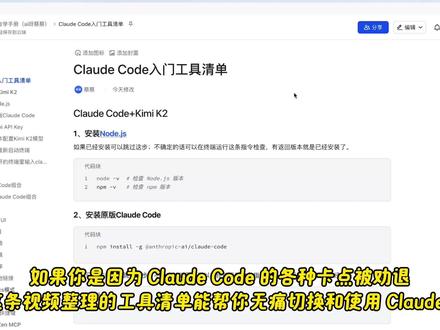 06:301942Next蔡蔡
06:301942Next蔡蔡 08:042.0万珍妮丁丁说AI
08:042.0万珍妮丁丁说AI 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿很多使用 color code 的 人都不知道这个简单的技巧,但它能为你节省大量的时间和避免浪费宝贵的 token。 你 是否遇到过这种情况啊?你精心构建了上下文,让 color code 帮你修复 bug, 结果没有修好,然后你让它再试一次。结果 color code 又构建了更多的上下文,但是还是没有修好。 那接着你开始用 compact 的 命令来压缩对话,然后问题依然没有解决。最后啊,你意识到可能 cloud 已经没有足够的上下文空间来继续修复 bug 了。 最终,你决定运行克里尔命令清除上下文,或者新开一个绘画,从头开始等。这样做的后果。是啊,你必须重新构建上下文, 你之前投入的时间和消耗的头壳全都被浪费了。那如果我告诉你有一个简单的方法可以将上下文恢复到 cloud, 尝试修复 bug 之前的状态呢?你下次想要清除上下文并从头开始的时候试试这个技巧。 在卡拉扣的终端中,连按两次退出键,回到 cloud, 尝试解决 bug 之前的状态。在这里啊,你可以尝试重新构建提示词,或者为 cloud 添加更多的上下文,这样就会避免浪费透坑和节省你的时间。那下次遇到这种情况,一定要试一下。
53起哥的AI实战 01:22查看AI文稿AI文稿
01:22查看AI文稿AI文稿在你开始使用 cloud 之前,先把这三件事给做了。现在越来越多人已经从 gpt 转到了 cloud, 但如果你今天就开始做这三件事,你可以直接甩开百分之九十五的人。第一件事,开启全局记忆。第一步,进 cloud 的 设置页面,把记忆相关的两个功能全部打开, 这样 cloud 就 能记住你是谁,你之前聊过什么,你的习惯偏好是什么。第二步,如果你是从 excel gpt 转过来的,点一下 start import, 把它给你的提示词复制粘贴,然后到 excel gpt 里跑一遍,然后把 excel gpt 输出的结果完整粘贴为 cloud, 它就能自动把你过去在 gpt 上积累的记忆全部继承过来。 第二件事,连接 google 服务,打通你的工作流,把你的 google drive、 google 日历、 gmail 全部连上去。这一步做完, cloud 直接变你的私人行动助理, 它能帮你规划日程,整理文件、发邮件,那些重复性高但又不得不做的琐事可以全部丢给他。第三件事,为 cloud 装上你的专属技能 skills, 你自己的方法论喂给他。比如你写文案的框架,你做短视频的选题逻辑,你跟客户沟通的话术,整理成文档传上去 之后,每次对话,他就能直接按照你的套路输出你真正能用的东西,而不是一堆正确但没用的废话。如果你想要一套真正能落地能赚钱的 ai 工作流,把我现在每天在用的方法直接发送给你。
204不是小丁- 02:05查看AI文稿AI文稿
02:05查看AI文稿AI文稿cloud code 现在是地表最长智能体啊,这个是毫无争议的,但是他到底有没有办法在国内使用呢啊?我充了钱之后会不会把我号封掉,让我血本无归,浪费钱呢?如果说你也有这个疑问啊,你可能跟四个月之前的我是一样的, 今天就给你讲清楚啊,其实 cloud code 呢,和 cloud 它是两个事情,虽然说它是一家公司的,但是是不同的两个产品啊。 cloud code 呢,它是免费的,它是开源的,你使用它不需要花一分钱的, 甚至你可以用别人家的产品来使用它啊,你可以理解为它是干活的躯干,它是没有一个大脑的啊,有了大脑之后它才能够干活。那么大脑是谁呢?大脑它就是 cloud 啊,这个东西是普通人不容易去买的,你比如说啊, cloud ops, 四点六四点七啊,这个是最好的模型,你写作啊,编程啊,你直接上四点六四点七啊就好了。 那么普通的编程任务呢?具体干活你用 solo 来完成也是可以的。嗨酷呢,我现在是基本上不怎么用的啊,基本上是 solo 起步, 你像我现在订阅完了之后基本上只用 os, 这个感觉真的是太爽了。所以说,如果说你有条件啊,直接上 os 直接工作就可以了, 但是如果说你开不到原厂的模型,用国内的模型代替可不可以啊?啊,完全可以的,国内的我只推荐一家啊,我推荐智普,这个是我身边朋友反馈下来,跟 opps 能力很像的。 所以说呢,就是如果说大家你也想接触到 ai, 我 就推荐最强的智能体和最强的模型啊, 智能体就用 cloud code 啊模型,要不你就用 cloud 的 os 或者索尼,要不然就有国内的智普,就这两种组合。 然后如果说你不会安装 cloud code 啊,你可以关注我啊,我下期再出一个零基础如何安装 cloud code 的 教程,其实也非常简单,普通人看完五分钟也就能安了。
1.9万数字生命king 05:05查看AI文稿AI文稿
05:05查看AI文稿AI文稿现在有很多朋友问我就是 cologold 怎么样接入本地的大模型?今天给大家说一下本地大模型是怎么接入的?然后有两种的方式,第一种方式是通过 cc switch, 这个之前的视频也给大家说过 cc switch 怎么使用的。 然后第二种方式就是我们通过欧莱玛装了本地大模型之后,直接呃对接我们的,通过 setting jason 的 文件直接对接我们的 cologold 的 文件。先说第一种方式,通过 cc switch 来对接本地大模型, 我这边的 cc switch, 因为我之前是通过对接了三种方式,第一个是我是用了 deep seek 的 deep seek, 然后第二个就是用了字节的火山方舟 coding plan, 然后第三呃那个 cloud official 我 没用,因为我没买它官方的 a p i。 然后第四个就是本机的 alama 模型,我也安装了这三种方式都跑通了。先一一给大家说一下,呃, 先说怎么样对接本地大模型吗?然后本地大模型其实非常简单,就是大家在这边添加一个新的供应商,然后新的供应商之后,这里面的填写方式像我这样填就可以了,就比如呃我们的供应商名称随便填一个欧拉玛,然后这边呃上面的标志也可以随便选一个, 因为我这边随便选一个,他就是欧拉玛。然后呃官网的链接,因为我们欧拉玛是本地的模型,这边是填空的,什么都不用填,这个 api k 的 话也不用不需要随便填,大家只要填欧拉玛就行了,你随便设置一个就行了。然后另外就这边比较关键,这边就是需要填写一个本地的端口,然后这个端口是什么意思呢?也给大家说一下。 它这个 http 就是 指的是本地服务,然后 local house 就是 我们自己的电脑嘛,它始终指向我们本地的 ip, 一 二七点零点零点零点零一嘛, 然后这个一一一四三四,它就相当于我们本地的端口号嘛,就是我们奥拉玛呃,本地运营大,本地大模型的工具,它是默认这个端口的,所以就是当我们安装奥拉玛之后,会提供一个 api 服务来监听这个端口,所以我们这边要设置呃,在 cc switch 里面要设置这个东西,就它的是请求地址, 这个就是像这样原声的填就可以了,认证自盾也是这个。然后另外这个这边模型的话,就是我们本地安装的模型,你要看一下我们本地安装了哪些模型,比如我这边就是运行了奥拉玛里斯,这边可以看一下,比如运行这个,他这边就我我之前安装了四个模型啊,就是千问三点五九 b 的 千问斯,呃,伽马寺那个 e 四 b, 然后还有干妈四三十一 b 以及干妈四 e two b。 因为我的只有一个独立显卡,就是八 g 的 显存,所以我只能一般是用切分三点五和 e two b 的。 然后这边的设置就是直接把你需要设置的模型,比如复制两过来就行了,然后底下这个东西就会自动生效, 保存好之后就行了,然后我这边就会在使用中给大家看一下效果。我这边就刚问他们,我是他什么大模型,他其实就是干妈四 deep 呃,谷歌 deep money 的, 然后我们可以切换模型的,就是我刚这边安装了是千万三三点五九币和干妈四 e two b 嘛,然后这边就可以选择嘛,你可以选择不同的模型, 我这边就可以切换到切切换三点五九 b 这边之所以能切换是因为我这边只设置了这两个模型,你看只设置这个,当然我这个也可以设置一四那个一一一 four b 都可以, 这是本地大棚型的设置,这是呃,我觉得通过 c c c v 是 最方便的,我们也可以切换到 deepsea, 我 这边切换到 deepsea, 然后就可以很方便的从本地切换到云端了。我就说你好, 它这边是因为呃切换模型之后需要重启一下 cloud, 我 们重启一下就行。 比如我这边重启一下,它就会呃启 用我们的 dips pro, 很 方便的一键切换。然后这个前面就是我之前装的 cloud mail 那 个插件,就它每次启动它都会查取呃最近五十次的 通话内容,就是回忆一下我们之前的那个记忆,这个我就记个记忆插件,非常好用,它是自动自动启动的,然后它上面有你的新增功能啊,还是重构啊,还是改变,它都会给你标出来你之前做了什么样的东西。 我觉得这个非常好用,然后比如它当前它就会告诉呃 vr obv observation 在 这个端口就相当于在这个端口,这就跟我们刚刚那个呃奥奥拉玛端口不一样了。 然后给大家说一下,就是呃关其他的大模型厂商他们的 apis 怎么对接的,其实也很简单,就是我们的 a, 我 拿 deepsea 举个例子,这边顺便说一下,比如 deepsea 这边,他的 u i 只需要填 u i l 啊,就是我们的 u i l 就是 open i 或者 osrogic, 因为 cloud code osrogic 吗?我们只需要复制这个链接,把它填到这就行。然后 apikey 就是 我们自己设置的,这边主模型的话就是 v s pro flash 三点二、三点三点二都可以, 因为马,因为那个三点二后面不是要七月二十号要弃用了吗?就是之前的 chat 和 reason, 一个是 syncing, 一个 on syncing 的 模式,在里面 ipikey 只要设置一下就行了。 然后还有一种方式就是通过线上的,这个我觉得是同样的道理啊,大家就是相当于之前的那个接收文档,就是它这边也会写好的,就是主要就是这个,呃, 这个 anastropic base u i l 给它填好就行了。然后这个这个 token 也是随便填的。然后这个模型就是我们刚设置的那些模型,其实是一个道理,这边就不细说了。
145马斯洛AI智能体 01:25查看AI文稿AI文稿
01:25查看AI文稿AI文稿今天呢给大家介绍一款解决 cloud code 思域的一个插件, cloud m e m, 它能够自动的呢捕获编码绘画中的所有的操作记录,通过 ai 呢智能压缩,并在未来的绘画中注入相关上下文。 这款插件呢解决了 ai 编程助手最棘手的问题之一,上下文的连续性。在传统的这个 cloud code 的 使用中,每次开启新绘画 ai 呢都需要重新了解项目背景,这不仅仅浪费了时间,还容易导致信息丢失。 通过一套精密的记忆系统,让 cloud code 能够记住之前的对话和操作,实现真正的智能辅助编程。 我们来看一下它的核心功能呢,主要呢就是自动获取上下文。第二个呢就是智能的压缩与存储,使用伺候奈的数据库呢,存储绘画,观察和摘药。 第三个呢就是强强大的这个搜索能力,自然语言查询支持,支持渐近式信息展示。第四个呢就是 web 可丝化界面,内置呢 http 的 一个服务,提供直观的这个 web 查看器的一个界面, 安装好以后呢,就可以在这个界面当中可以看到我们对应的这个绘画。
75老码AI驿站 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿在 cloud 中接入 deep sec v 四,直接使用 cloud, 用不了?别慌, deep sec v 四是刚发布的全新大模型,在数学 stem 竞赛型代码的测评中, deep sec v 四 pro 处于领先水平。现在有个完美方案,在 cloud 中接入 deep sec v 四,直接使用 cloud。 安装完毕后,再登录界面,点击左上角,在 help 中打开开发者模式,在开发者模式中选择进入配置, 在这里填入你 deep seek 的 信息。这里需要注意下方需要手动填入 deep seek v 四的模型名称,否则只能加载 v 四之前的老模型,填入后选择确认同意。 右下角可以看到我们添加的模型,现在可以正常对话了。关注我,带你学会更多 ai 内容!
3.3万九机实验室 04:53查看AI文稿AI文稿
04:53查看AI文稿AI文稿大家好,我是安逸,今天咱们来深入拆解 cloud code 的 第九章,记忆系统,看看它是怎么实现跨绘画的信息积累的。主页有更多架构解析,感兴趣的朋友可以点个关注。那咱们直接开始。 如果一个 ai 助手每次新对话都从零开始,他就会不断忘记用户的长期偏好,之前纠正过的错误,还有那些不容易从代码直接看出来的项目约定,用起来就像每次都是第一次合作,非常割裂。所以需要记忆系统来解决这个问题,让 ai 能够跨绘画保持对重要信息的记, 但这里必须先立一个边界,记忆不是什么都存,如果什么都往里塞,很快就会变成垃圾堆, agent 还会开始依赖过时的记忆,而不是读取当前的真实状态。所以记忆系统的第一条原则就是,只有那些跨绘画仍有价值,而且不能从当前仓库状态直接推出来的信息,才值得进入记忆系统。接下来我们具体看哪四类信息最适合存储。 记忆系统最核心的就是区分什么值得存,什么不值得存。适合优先存储的有四类,第一类是 user, 也就是用户偏好,比如喜欢什么代码风格,希望回答简洁还是详细,更偏好什么工具链。第二类是 feedback, 用户明确纠正过你的地方,比如不要这样改这个判断方式之前错过。 第三类是 project 保存不容易,从代码直接重新看出来的项目约定或背景,比如某个设计决定是因为合规而不是技术偏好。 第四类是 reference, 外部资源的指征,比如某个问题单在哪个看板,某个监控面板在哪里?这四类的共同特点就是跨绘画还有价值,而且不能轻易从当前代码重新推导出来。说完了该存什么,更重要的一张表是什么?不该存 这张表比该存什么更重要?绝对不应该存进记忆的有这么几类,文件结构、函数、签名、目录、布局。这些完全可以重新读代码,得到当前任务进度。这属于 task 和 plan 的 职责,不属于记忆 临时分。支明当前 pr 号 n 快 捷为过时修 bug 的 具体代码、细节代码和提交记录才是准确系。还有密钥,密码凭证存在安全风险。这条边界一定要稳,否则记忆系统会从帮助系统长期变聪明变成帮助系统长期产生幻觉。理解了存取边界之后,我们来看一个最小星智模型。 最小心智模型是这样的,当用户在对话中提到一个长期重要的信息,系统会调用 save memory 工具,把它保存到 memory 目录下的独立文件里。 每条记忆一个文件,里面有 frontmatter, 原数据记录 name, description type, 然后是正文内容,同时维护一个 mervo m d 锁影文件,帮助系统快速知道有哪些记忆可用。下次新绘画开始时,这些记忆文件会被重新加载进上下文。 这就是记忆系统的核心工作流程。那记忆系统和其他几个概念, task、 plan、 c、 u、 d、 d 的 边界在哪里?很多人容易混淆 哦,这是最值得反复区分的一组概念。 memory 保存跨绘画人有价值的信息。 task 保存当前工作要做什么?依赖关系如何?进度如何? plan 保存?这一轮我要怎么做? c、 l d d 保存更稳定,更像长期规则的说明文本。一个简单的判断法,只对这次任务有用就用 task 或 plan, 以后很多绘画可能都还会有用就用 memory, 属于长期系统级或项目级。固定说明就用 d、 d、 d 边界清楚之后,我们来看初学者最容易犯的几个错误。 初学者常犯的错误主要有三类,第一是觉得项目结构、函数位置这些信息值得存进记忆,其实完全可以重新读。第二是把我现在正在改认证模块这种当前任务状态存进去,这是 task 的 职责,不是 memory。 第三是把记忆当成绝对真相,这是一个很大的误区,记忆记录的是曾经成立过的事实,不是永久真理。 正确的工作方式是先把记忆当做方向提示,再去读当前文件。当前配置如果和记忆冲突,优先相信你刚观察到的真实状态。 说完了基础概念,如果想把系统做到更稳,还有六条进阶边界需要补上。第一条,不是所有记忆都该放在同一个作用域,至少要分清。 chipboard 只属于当前用户和 team, 整个项目团队共享 user 类型几乎总是 privileged, project 和 reference, 通常更偏向 tip。 第二条,不要只存,你做错了也要存,这样做是对的。 feedback 字不仅来自副反馈,也来自被验证的正反馈。 第三条,就算用户要求你存,有些东西不该直接存,比如本周 p r 列表、当前分支名,某个函数现在在什么路径,这些太容易过时,更适合存在代码和记记录里。 第四条,记忆会漂移,所以每次回答前要先核对当前状态。第五条,用户明确说忽略 memory 时,就当它是空的,而不是一边说忽略一边继续用。第六条,推荐具体路径函数外部资源之前要再验证一次,因为命名和路径都是会变的。 记忆先告诉去哪里验证,验证完再给结论。这六条边界理解了,记忆系统就真正稳了。最后来一个一句话口诀帮你记住这张的核心,但当前代码里不容易直接重新看出来的信息, 只要这个原则立住了,记系统的存取边界就不会乱。学完这章,你应该能回答,为什么记,不是什么都记。什么样的信息适合跨绘画保存,为什么代码结构和当前任务状态不应该进 memory memory 和 task plan c l a do d m d 的 边界是什么?这几个问题能答上来,说明这张就真正掌握了。我是安逸,我们下期见!
38安逸Ai 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿这只八十秒教程带你把 cloud desktop windows 版接入第三方大模型。 api 安装完成后,先点击右上角菜单,选 择 help to troubleshooting enable developer mode, 点击 enable 后应用会自动重启,耐心等几秒。重启后,再点右上角进入 developer configure third party inference。 以 kimi coding 为例,模式选 gateway url 和 api key 继续下滑,先点 add 模型名称 kimi coding, 再点右下角 apply locally 弹窗里选择 relanch now 完成应用重启。 重启回到交互页面后,右下角能看到第三方模型已接入,点击左侧 new session, 新建一个对话,再输入框上方点 select folder, 然后在资源管理器里选你的工作空间, 完成后就可以正常开始对话了。想接入其他模型,只要替换 get 为地址 key 和模型名即可。
66杨卓科技 04:03查看AI文稿AI文稿
04:03查看AI文稿AI文稿前两期我们讲了工具使用 write file, write file edit file 加 to hellenas 分 发,再加 save path 沙箱。今天进入第三期,代办写入这一章解决的是 agent 聪明了之后一个更高级的问题, 他的计划能不能从脑子里拿出来放到外面。到了工具,使用这一步, agent 的 已经会读文件、写文件、跑命令了,但问题马上出现, 多步任务容易走一步忘一步,明明已经做过的检查会重复再做,一口气列出很多步骤后,很快又回到即兴发挥。说到底,模型虽然能想,但它的当前注意力始终受上下文影响,如果没有一块显示稳定,可反复更新的计划状态,大任务就很容易飘。 在拆解实现之前,先把这张涉及的几个名词理清楚。第一个绘画内规划不是长期项目管理,而是为了完成当前这次请求,把接下来几步写出来,并在过程中不断更新。第二个 to do, 这里它只是一个在体,是模型用来写入当前计划的一条入口,不要把它理解成某个特定工具名。 第三个 active step, 就是 当前正在做的那一步。教学版里用 in progress 表示,这么做是为了帮助模型维持焦点,同一时间先把一件事做完。第四个 提醒,不是替模型规划,而是当他连续几轮都忘记更新计划时,轻轻拉他回来。这里我要特别强调一个边界,这张讲的是当前绘画里的清亮计划,用来帮助模型聚焦,下一步, 可以随任务推进不断改写。它不是持久化任务版,不是依赖图,不是多 agent 共用的工作图,也不是后台运行时任务管理,这些会在任务系统后台任务定时调度里再展开。如果现在就把这张讲成完整任务平台初学者会很快混淆当前这一步要做什么和整个系统长期还有哪些工作。想把这张先想成一个很简单的结构,用户提出大任务 模型,先写一份当前计划。计划里有三种状态还没做,用中括号空格表示正在做。用中括号大于号表示已完成。用中括号叉表示每做完一步就更新。计划更具体一点就是先拆几步,选一项作为当前 active step, 做完后标记 completed, 把下一项改成 in progress。 如果好几轮没更新,系统提醒一下, 记住了吗?这就是最小版本最该交清楚的部分。来看具体的数据结构。 plan item 是 最小条目,包含三个字段, content 表示这一步要做什么。 status 表示现在处在什么状态。 pending 或 in progress or completed。 active form 是 当它正在进行中时更自然地进行式描述。除了计划条目本身,还需要一点最小运行状态,叫 planning set, 里面有 items 列表和一个 rounds since update。 计数器记录连续多少轮过去了,模型还没有更新。这份计划教学版推荐先立一条简单规则,同一时间最多一个 in progress。 这不是宇宙真理,它只是一个非常适合初学者的教学约束。强制模型聚焦当前一步。那具体怎么实现呢?先准备一个计划管理器类, 允许模型整体更新。当前计划在更新时校验,如果 in progress 的 数量大于依旧抛异常。教学版让模型整份重写当前计划,比做一堆局部增删改更容易理解,然后把计划渲染成可读文本。 panda king 是 中括号空格, in progress 显示中括号大于号 completed 显示中括号差。 这章之后,矩阵不再只维护 messages, 还开始维护一份额外的绘画状态,叫 planning state。 也就是说, agent loop 现在不只是在对话,它还在维持一块当前工作面板。 messages 是 模型看到的历史, planning state 是 当前计划的显示外部状态。这就是这张真正想让你学会的升级。把当前要做什么从模型脑内移到系统可观察的状态里。提醒机制说明了一件很重要的事,主循环不仅要执行动作,还要维护动作过程中的结构化状态。 最后说几个初学者最容易犯的错。第一个,把计划写得过长,如果一上来列十几步,模型很快就会失去维护意愿。第二个,不区分当前一步和未来几步,如果同时有很多个 in progress, 焦点就会散。第三个,把绘画计划当成长期任务系统, 这会让这章和任务系统的边界完全混掉。第四个,只在开始时写一次计划,后面从不更新,那这份计划就失去价值了。第五个,以为 reminder 是 可有可无的小装饰,不是。提醒机制说明主循环要同时维护动作和动作过程中的结构化状态。来。 最后一句话,记住这一章,这一章的偷的不是任务平台,而是当前绘画里的外显计划状态。核心就三件事,让模型把计划写出来,让计划保持更新, 让主循环能观察到计划状态。下期我们继续讲子代理,把局部任务放进独立上下文里,做完只把结果带回来。欢迎点个关注,我们下期见。
52安逸Ai 08:01查看AI文稿AI文稿
08:01查看AI文稿AI文稿招聘一个顶级程序员 cloud code, 用七天的时间,从基础入门到熟悉精通,把它一步一步打造成你的超级员工。上一期视频呢,我们学会了 ai coding 的 工作方法, 今天你让他开发一个复杂的新功能,一开始很顺利,聊着聊着,你发现它开始降智了, 聊过的信息转头就忘了,因为上下文快满了,之前的记忆被压缩或者丢失了。今天我们就解决这个问题,管理 cloud 的 工作记忆,让它始终保持在一个高效的状态。 那视频呢?最后还有几个我私藏的上下文管理小技巧。 cloud 是 最早提出来 context 这个概念的,让 agent 从 prompt engineering 到 context engineering。 那 到底什么是上下文呢? 简单的来说,上下门就是 cloud 的 工作记忆,就像是人类的大脑,你这一天你需要记住自己今天早上吃了什么, 今天的工作计划是什么,我正在做的任务是什么?以及一些临时的文件。我刚才看了十个文件,分别是什么,以及在过去的六个小时,我都跟谁开了会,讨论了什么问题。信息量这么大,你肯定记不住所有的细节,于是你就拿了一个小本本,把这些都记下来。 但是这个本子的容量也不是无限的,他就只有十页纸。当这十页纸都用完了,你要接触新的东西的时候,怎么办呢?可能就会随机撕掉某几页,或者是把某几页压缩成一页,给你腾出空间,这就是上下纹衰退。 cloud 的 上下文窗口也是完全一样的。那上下文具体包含什么呢?主要是由四部分组成,第一部分是 cloud 点 m d 就是 系统指令,它包含你的基础站的约定,编码的风格,是 cloud 的 长期记忆, 每次对话都会加载,它是不可压缩的。如果你的 cloud 点 m d 很 长,就会非常消耗头衔,那怎么写 cloud 点 m d? 可以 看我的 day one 视频。 第二部分是对话历史,就是你跟 cloud 来回的一些讨论,聊的时间越长,上下文占用的就越多。 第三部分也是占用最多的是工具调用的记录,包含你读取的文件内容、运行的命令结果、搜索的代码片段等等,是上下文快速增长的主要原因。 比如你改 bug 期间反复多次的扫描代码,那上下文就会急速膨胀。第四部分是临时的数据,包括你正在编辑的一些文件调试的信息。 cloud 的 窗口通常是二十万头克,大概是十五万个英文单词。当这四部分加起来接近限制,就会出现上下文衰退的问题。上下文衰退会有什么影响呢?当你的上下文充足的时候, cloud 反应会非常迅速,非常准确。 当上下文快满了的时候,那他可能就要搜索半天,记忆会模糊,反应就会变慢,或者改 bug, 改半天也改不对。当上下文爆满的时候,降脂感就会非常明显,甚至会出现失忆,忘记之前聊的重要信息。 同样的问题,上下文不同,效率差别就会非常大。那重点来了,上下文的影响这么大,我们要怎么管理好它呢? cloud code 提供了很多跟上下文相关的命令,行,我们一个一个来看。第一个命令是 context, 要管理好上下文,首先你就得了解它的使用情况,运行 context 命令,你就可以看到上下文的使用情况,分类占比的比例。第二个命令呢,是 compact 压缩对话, 它适合的场景是你的上下文使用量过高,或者是工具调的结构过高。那就可以用 compact 命令对上下文进行压缩,这样既可以保留关键信息,删除了一部分不需要的细节。第三个命令是 clear 重启, 它的作用是清空所有的对话历史,从头开始。上下文呢,只保留 cloud 点 m d。 那 什么时候用这个命令呢?它比较适合的场景,一个是做任务切换,比如说你上午做用户管理,下午做支付功能,那就可以用 clear 清空清空上午的记忆。 另外一个场景是对话跑偏了,你跟他跑讨论了半天跟主线开发无关的内容,也可以使用 clear 重新开始。 第三个场景是做了一些实验性的工作,你尝试了很多的方案,这样会记忆特别混乱,那也可以使用 clear 整理思路。四个命令是 btw, 这个是二零二六年三月新增的一个功能,专门用来问一些临时性的问题,用完即走。比如说你刚才说的数据表有哪些字段,你现在用什么模型在写代码,你刚才提到的某个记住术语是啥意思, 这种快速的实时查询或者是解释型的问题,就可以使用 btw, 它的特点是不进入对话历史, 问题和答案都是临时的,看完就消失,也不占用主对话的上下文空间。主对话的上下文占用零透肯,他也没有工具的使用权限,不能读文件,不能运行命令,只能基于对话上下文进行回答, 而且可以并行使用。在 cloud 工作期间,你也可以提问,互不干扰,既节省上下文,又不打断工作流。第五个命令是 resume 恢复对话。 你昨天开发了一个新的功能,干了一半,今天想接着干怎么办呢? cloud code 会自动保存,每次对话到本地使用 resume 命令,就会出现一个近期的 对话的选择器,选择你想要恢复的对话,就可以完整的恢复上下文了。那平时的使用过程中,我们要怎么管理优化上下文呢?送上八个我自己私藏的小技巧。 第一是要定期检查,在密集开发的时候,每两个小时或者每完成一个功能,就要查询一下 contacts 的 使用情况,超过百分之七十就压缩,不要等到 cloud 反应慢了,降至了再压缩。第二个是体温要具体。 cloud 的 查询是通过政策匹配进行搜索的,模糊搜索可能要搜二十个文件,精准搜索可能搜两到三个就可以了。 引用文件多用艾特文件名,指定文件,比描述哪个哪个文件效率要高很多,尽量减少 cloud 的 猜测和搜索的开销。第三个如果有多个改动,合并成一条消息发送,不要一条一条的发, 解释型的问题,临时性的问题多用 btw 的 命令。第五是调试之后要及时清理 bug。 调试的过程中特别容易产生大量大量的代码差错和日制输出 bug 调试之后要及时的 compact, 不要把噪声留给下一个阶段。 第六是长期记忆要写入 cloud 点 md, cloud 点 md 呢?建议分层管理项目的根目录放一些全局的规范子目录放 模块级的说明, cloud 会按目录层自自动读取,力度会更准确,避免每次都加载全部的内容。 第七是可以使用 sub agent 处理探索一些方向的探索,或者不依赖主流上下文的任务,比如说代码审查,就可以交给 sub agent 进行探索,会节约主 agent 的 上下文,这个后面我们会再详细的讲。 第八是善用 checkpoint 做阶段性的总结,在完成一个比较大的功能之后,可以让 cloud 输出一段当前的状态。摘要,你已经完成了什么,遗留了什么,下一步的计划是什么。然后你把这段内容保存起来, 下一次开始对话开始的时候就可以作为第一条消息贴入,等于手动的接上了上下文,比依赖 cloud 的 自己的记忆更靠谱。 那今天我们通过主动的管理上下文,让 cloud 始终处于一个最佳的状态,你已经能非常熟练高效地使用 cloud 了。 但是真正想要发挥 cloud code 的 价值,就不得不提到 scale 和 m c p 了。那接下来就是入职第四天, scale 把专业的知识封装成可以服用的技能包。
83AI产品千媚 14:35查看AI文稿AI文稿
14:35查看AI文稿AI文稿hello, 大家好,今天来讲一下 cloud agent teams 的 一个原理,那么关于这个原理呢,也是总结了一些文档,那我觉得与其把这样的文档一个个过一遍,还不如我们直接看一下 agent teams 它们具体的请求,具体的绘画内容是什么。 所以在这之前呢,我也是自己写了一个叫做 cloud teams view 这样一个工具, ok, 包括这个代码仓库也是开源的,如果大家觉得好用,可以直接使用。那我们正式开始 cloud agent teams 的 原理解读之前呢, 我们先注意一个东西啊,我觉得我们首先要理解 agent teams, 它到底是干嘛的?在 cloud 的 设计理念里面,其实不只是只有 agent teams, 它使用 agent tool 这个工具呢,它会有三种行为,一种叫做 sub agent, 其实这个是最常用的,还有种叫 fork, 第三种才叫 teammate sub agent, 它更多的是干一件单词的任务,干完之后就退出,某种意义上它是一种同步的任务。 而且 subagency 的 理念我觉得有点像沙乡的理念,就是你委托给这个 subagency 去干一些事情,把结果返回,这个 subagency 就 被销毁。然后也是一样,你委托一个沙乡去干一些事情,沙乡销毁 有点类似这个感觉,它的适用范围是做一些比较独立的任务。那么还有种行为呢,是这个 fork 分 身, 这个呢主要是为了避免你污染你的这个主页上的上下文,在做一些脏活累活的时候 啊,上下文特别长的时候,但是这些上下文呢,其实又对整个的上下文没有任何帮助的时候,你可用 fork, 它就可以 fork 你 当前所有的上下文,然后做完事情之后,然后把这个 fork 给销毁,所以它也是使用单词任务。 第三种就是我们今天的重点是个 agent teams, 这个 agent teams 呢,其实就是主要是做一些长城任务,它的最核心的一个特点 就是它会互相之间有沟通的这么一个呃动作在里面,它适用的场景就是做一些比较复杂, 或者是做一些就是相对来说需要多个角度多个视角去看的。可以使用 agent teams, 比如说 reviewing 你 的代码,或者是对一个观点提出不同意见的时候,可以用 agent teams。 好 的,这里我们启动 teamsview 这个命令,然后这个命令是一种反代的模式。 好,可以看到在启动之后呢,我们就进入到这个页面里面,然后我们就有这样的一个 team lead 这样一个角色了,它就是主 agent, 现在它还没有实体化任何 team agent 的 成员,所以我们也看不到任何请求。呃,什么东西也没有。现在我们绘画 好了,这里我们做一个比较复杂的功能啊,我们让它使用 agent teams 功能。呃,做一个效果极好的 三 d 银河系页面。之前我们做的土星嘛,这次直接让他做一个三 d 的 银河系, 然后我这里说了一下,尽量使用 send message 工具互相沟通,因为之前的一些测试结果来看,有些时候他不沟通,他就直接把这个结果交付了。 ok, 好, 我们可以看到这边主 a 政策已经开始有请求进来了。呃,就是它的,它的请求是很正常的,一个 system message 加上 user message, 然后加上我自己刚才给的这个呃需求发给了 tipsick, 这里它调用 team criss 这个工具创建创建了一个 team 的 名字叫做 galaxy 三 d, 然后这里有个它的介绍,然后这里它其实已经创建出了两个这个成员了。 然后第三个成员分别是 star builder, 对 吧?创建星球的 planet crafter okay。 然后还有一个是 interaction master, 就是 交互的, 但到目前为止已经有非常多的信息,我们需要一个个看了,那我们慢慢来。首先我们看一下它这里有一个呃,全局的一个配置,就是关于这个 agent teams 配置,我们看一下它这个 agent teams, 就是 这个叫做呃, config 点 jason 可以 看到啊,总体的 agent teams 呢,就是配置了这个 team 的 一些基本信息,对吧?这个 team 的 名字叫做 galaxy 三 d, 然后他有哪些成员呢?第一个成员是一个 team lead 领队,然后呢就是一个 star builder, star builder 是 干嘛的呢啊?他主要是做这个,呃, create the galaxy core and star field, 就做这个银河系的这个核心。然后第二个这个成员叫做这个 planet crafter, 对 吧?它的一些它的主要任务是做,呃, create planet system 这个星球系统。然后第三个成员叫做 interaction master, 它的主要任务是 create a camera controls and interaction system, 就是 它可以控制这个镜头的移动啊,包括交互啊这些。好了,这个配置可以看出来它就是一个 agent teams 的 主要配置配置的,嗯,每个成员它到底是干什么的?然后它的名字是什么? 然后然后一些它调用的模型是什么?类似的一些配置。好第二个配置,我们可以看到这里有一个信箱,就是在这个目录下面, 这个目录下面就是我们重点要介绍的这个 agent teams 它们的交互模式。可以看到这里有三个 json 文件, 这三个 json 文件就是它们的交互通信模式。在看这个文件的具体内容前,我们先看一下它们是怎么发的,这里我详细记录了,就是除了请求之外,它们互相之间通信的这些内容。可以看一下 teammate 在 这个 九点四十五的时候给这个 star builder 发了一个消息,你看这个其实就是下发一个任务,然后给 planet craft 也下发一个任务,然后在九点四十五也给这个 interaction master 也发了一个任务。 我们看这个任务发出来之后,它的效果是什么?我们看 star builder 同时在九点四十五的时候,它接受到了一个任务,再接收到什么呢?接收到它的这个你是谁?谁? 然后你要干什么,对吧?我们现在需要注意到就是现在已经有这个四个成员了,由 team lead 的 这个领队创建了三个队员,然后我们看一下每个成员他们的上下文主要是什么。比如说现在这个 star builder, 我 们看一下, 这里我提取了他这个 task 也要,这也叫这个,这里我提取他的这个 task 也叫这个 initial prompt。 嗯,其实在 call 的 这个设计里面就是一个 task 对 应一个 teammate 成员,所以 task 和 teammate 是 一一对应的,所以这里也叫 task, 也叫这个 teammate initial prompt, 对 吧?这个 initial prompt 说什么?就是你是谁?然后你主要做什么内容?你要完成哪个任务? 那这个东西这段话会怎样去影响这个 teammate 的 上下文呢?我们可以看一下它的上下文是怎么构成的 啊?它的上下文其实就是首先也是 system prompt 啊,我是, 呃, cloud code, 然后我要怎么讲?这是个身份的标识, cloud code 的 标识很很简单,然后除了上面这个 system prompt 的 这个标识之外呢?在 agent teams 这个模式里面,它还会说, ok, 你 现在在 一个 agent teams 模式下面,那么如果说你要去通知你的其他队员,请用 send message 这个 tool 去说,哎,我要给谁发消息,对吧?这个是 system prompt。 好, 关键来了,可以看到 user message 里面的 这一条 teammate message, 对 吧?这个是其他的成员是,就是不一样的,或者说之前的我们在用 cloud 的 单轮的,没有用 agent teams 模式下面是不会看到一个东西就是 teammate message, 这个 team message 呢,就会把刚才从领队这里发出来这个任务给它贴到这里,就是告诉你你是谁, 你要做什么内容,对吧?你要用什么技术站,你要有什么需求,然后你要做什么东西,把它塞到了这里。所以说,呃,在 cloud code 里面,这个每一个成员其实它是一个完全独立的干净的上下文, 然后这个独立的干净上下文,它唯一的不同就是它的 user message 里面第一条是塞了一个这个任务, 所以说也就是这个 team mate 就 知道我这个这段,嗯, agent, 或者说我这个 agent 需要做什么事情,就全部靠 use message 的 第一条 信息。好的,我们看到刚才那三条信息从 team lead 发送给各个成员的呢,其实就是一个任务的初步化,对吧?这三个信息发出来之后,初步化他们的任务。哎,比较有意思的事情发生了啊,我们可以看到,就是在九点五十二二十七秒的时候, 从 planet craft 向 team need 发送了一个消息。发送了一个什么消息呢?就是 planet system complete, 对 吧?就是我这个队员,我向我们的队长发了个消息,说,啊,我的任务终于完成了,并且我做哪些事情汇报一下, ok, 这就很有意思了,然后你看它的这个 总结是这样的,对吧?任务二已经完成,然后这些是添加在这里面的一些内容。不了不了,不了不了,好做哪些事情?我们找到 planetcraft, ok, 我 们可以看到啊,它在九点五十二的时候,它本质上是掉了一个工具,然后这个工具呢,其实就是这个 send message, 然后 send message 里面有三个参数,第一个参数就是这个 to, 对 吧?我要发送给谁?其实我是发送给 team need 的, 就是我们的领队,然后 summary, 对 吧?总结,然后 message 具体的内容,所以它在九点五十二的时候,调用了 send message 这个工具, 然后发送给了这个领队。那么领队呢?同样的在九点五十二的时候呢,收到这个消息,现在最关键问题来了,领队收到了队员的消息之后,对他的上下文会产生什么样的影响呢? ok, 我 们看一下,比如说我们的队长收到了来自队员的一些消息,那么这个消息是怎么影响他的上下文呢?哎,这个就很有意思啊,我们看一下,在这个 planet craft 发出这个消息之后,下一条,也就是说九点五十二三十四秒的时候, 你对上下文发生了什么?那我们可以看一下啊,首先它的 system prompt 没发生变化,它的 user message 也没发生什么变化,我们拉到最下面 没看到诶,这个地方就很关键了,可以看到它直接塞了一条 user message, 而这个 message 就是 刚才啊 planetcraft 去发的这个 teammate message, 对吧?我说我已经做完了,然后我的做哪些事情,然后我的这个主要的功能是什么? ok 发送给他。所以说在队员之间互通消息的时候,其实你发的消息是以一条新的消息塞在 message 的 最下面的一层,发送给的另一个成员, 这样也可以保证上下文缓存的这么一个利用率。那么经过时间的推移,我们也可以看到在九点五十四的时候,从 interaction master 也发来了消息,对吧?这个也是说我的任务已经完成了。 同样的,在九点五十八的时候,从 starboard 也发来消息啊,说我的任务已经完成了,那么这个时候我们可以看到 三个队员已经停止了工作,因为他们相关的工作已经完成了,现在只剩这个队长在工作了。那么趁他队长还在工作的时候,我们也看一下,就是说这个行李箱是怎么在运作?我们注意到刚才的行为,然后我们看一下这个 leader jason 里面是什么,哎,可以看到,对吧?其实 leader jason 里面就是呃 leader, 它作为这个呃成员之一的时候,它收到了所有的来自其他成员的一些信息,包括我们刚才提到的 planetcraft 在 九点五十二的时候发了个消息说我的任务已经完成了,然后是呃 interaction master 的 时候说,呃,在九点五十四的时候我的任务已经完成了,那注意到在这里还有这两个消息,这两个消息是啥意思呢?你看这两消息是一个 idon notification 的 消息,这个消息的意思就是表示我空闲,对吧?就告诉这个领队,我现在 planet craft 我 完成任务了,我是空闲的状态。如果说 这个时候还有别的任务,呃, team leader 觉得这个 planet craft 还可以做,那他这个时候也可以只排新的任务给这个 planet craft。 所以大家可以看到其实 agent team, 它是一个相对来说比较灵活,比较好玩的一种事件。然后我们这里注意一下,刚才提到这个 idol notification, 其实是它的十四种消息类型的其中一种,对吧? 我们最普通的消息就是普通文本,就大家讲的这个呃 summary 的 消息就是我的任务就完成了,或者任务状态啊,或者怎么样的这种就是普通文本。 那还有其他十三种消息呢?你看,比如说这里的空闲表示我正在空闲呢。然后还有这个 leader 可以 下 down request, 就是 我要把我这个队员给关掉, 也有可能是有的时候某个队员需要申请某个审批,然后需要一个 permission request, 也是发给队长,然后队长来批,所以这里的消息是有十四种的, ok, 然后下一个消息就是从 interactionmaster 发来的一个消息,然后完成之后也是发了两条这个空闲的这个消息,然后 starboard 的 消息。
48周周周啊![[5] Claude Code 上下文管理,更高效工作 Context 是 Claude 的工作记忆,决定了它能理解多少项目背景、对话历史和任务细节。
在 Claude Code 中,管理好上下文非常关键。视频重点讲解了什么时候使用 /compact 压缩上下文,什么时候使用 /clear 清空上下文,以及如何避免无关信息占满窗口。
核心思路是:让 Claude 保持足够信息,但不要被过多历史内容干扰,才能让 AI 编程更稳定、更高效。#ClaudeCode #Claude #上下文管理 #AI编程 #Context #程序员工具 #AI工具 #开发效率 #代码助手 #科技前沿](https://p3-pc-sign.douyinpic.com/image-cut-tos-priv/6a1c9206c296ef0302616bc08c285bf7~tplv-dy-resize-origshort-autoq-75:330.jpeg?lk3s=138a59ce&x-expires=2095099200&x-signature=ypaJdi4BQ%2BWJ2XmNvzc%2Ff%2F4UF%2Fs%3D&from=327834062&s=PackSourceEnum_AWEME_DETAIL&se=false&sc=cover&biz_tag=pcweb_cover&l=202605260403042170E2F46F40EF467E9F) 03:51查看AI文稿AI文稿
03:51查看AI文稿AI文稿上下文是 cloud 的 记忆,它读的每个文件,运行的每条命令,你发的每句话都会占用上下文窗口。 你可以把上下文窗口理解成 cloud 能记住的信息量。每当你输入提示 cloud 提取文件,调用工具,拿到工具结果,这些都会加入上下文窗口。 而上下文窗口容量有限,所以尽量优化它就特别重要。 当你接近上限时,上下文窗口会自动压缩,压缩会总结重要细节,删除不必要的工具结果,从而释放大量上下文空间。 不过要注意,这可能会丢失之前对话里的细节。你也可以用 compact 的 命令手动压缩, 它会压缩到目前为止的所有内容。如果你想清出上下文空间,又想保留之前工作的记忆,这会很有用。 如果你想完全从零开始,不保留之前工作的记忆,也可以运行 clear, 它会清空一切,从头开始。要查看上下文状态,可以运行 context 命令,这里会显示上下文大小、占用最多的类别以及对应图标。 一般来说,如果你在做某个功能快超出上下文窗口,但还要继续就压缩, 那就压缩。继续开发时,让上下文和当前功能相关很重要。如果计划已经完成,想开始新功能,那就清空 你不希望之前的对话影响你接下来要创建的新东西。如果有些内容想让 cloud 在 其他绘画里也记住,就写进 cloud md 文件里,这样他就不用每次都从头重新发现 要写具体讽刺的是,提示写的越短,长期看越占上下文。如果说得不明确, cloud 就 得在代码库里到处找自己推理,这会比你多写一两句,说明占用更多上下文空间。 mcp 服务器默认会把所有可用工具都加载进上下文。如果你有很多和项目无关的 mcp 服务器,值得把它们关掉。 你也可以试试 skills, 它的作用类似 m t p 服务器,但不会把全部内容塞进上下文,更省空间。子代理会和主代理并行运行,但有完全独立的上下文窗口。所以有些任务只需要答案,不需要过程,比如认证接口在哪里, 就可以让子代理去查,再只把摘药返回给主代理 管理。 cloud code 里的上下文非常关键,用斜杠 compact 总结,长会话,用斜杠 clear 重新开始。 想高效使用上下文窗口,就要具体说明你的需求,查看当前上下文都被什么占用,并用子代理处理。只需要答案的任务,你 未完待续。
22V 姐深夜局 02:00查看AI文稿AI文稿
02:00查看AI文稿AI文稿我跟你们说,我之前用 cloud code 简直就是在受刑,每次我让他帮我更新周会表格,我都会像个老妈子一样跟他反复交代, 你还记得吗?上次我跟你说的那个链接,帮我再更新一遍,然后他就开始漫长的回忆,加载,找数据,一通操作下来,每次生成的格式还都不一样,真的超级崩溃,感觉自己像花钱雇了一个每天都在失忆的实习生。但是最近我打通了他的两个隐藏技能,简直是打开了新世界的大门,真的太爽了! 第一个就是 m d 文档,说白了就是你给 ai 做的一份专属的入职手册,你是谁,你喜欢什么样的风格,你的任务有什么样的规矩,全都写在里面。 ai 每次开工前都会强制的先去翻一翻这个手册,你再也不需要跟他废话去交代背景了。 第二个就是 skill, 这个更牛,相当于你给 ai 定制的一件 s o p。 比如我们经常要搞封面和视频的爆款拆解,以前每次都得先输一大段咒语啊,风格是什么样儿的,用什么字体等等,都需要去跟他交代很多内容。 现在我写了一个 skill, 我 只需要一句话,封面生成,它就全都自动搞定,生成封面了,真的太省心了!给你们看一下我的文件目录,这里就建了几个专门的 md 周会更新封面生成视频分析,我给你们演示一下现在有多夸张。以前我让它更新一个周会表格,我交代加等待的时间可能要十几分钟, 现在我只需要输入杠周会更新,哎,他就开始自动更新了,看分毫不差的更新好了,一句废话都不用多说,你牛不牛?当然,肯定会有人说啊啊,我不会写这种规则文档啊什么的。 别慌,我教你一招,你不用一开始就自己写,你先跟 cloud code 进行正常的一个聊天。呃,你告诉他你平时是怎么干这个活的,你反复的跟他沟通、打磨,等他能生成一个正常的结果,就说明他已经能完全理解你的流程了。这个时候你直接跟他说, 把我们刚才沟通的内容生成一个 skill, 它就会乖乖地自动帮你生成。好了,压根儿不需要你自己写。用魔法打败魔法,真的太绝了!姐妹们,听我的,今天赶紧跟着搞一遍,明天你就会有惊喜哦!
134Eva酱(AI版)




猜你喜欢
- 1080好创兴tv