ai怎么发指令节省token
有没有发现,刚问 ai 两个问题, token 就 烧没了?钱包在滴血,到底哪出问题了? token 的 本质,你可以把 token 理解成 ai 识别信息的最小语义单元,类似我们日常说话时的词、词组、标点甚至断句符号。中文场景下通常一到二个汉字对应一个 token, 英文场景下三到四个字母对应一个 token。 换行符、空格、特殊符号也会被单独计算为 token。 很多初学者误以为 token 就是 单个汉字,实际上,不同模型的分次规则差异很大,比如生僻词可能单个字就算一个 token, 常见的词组可能两个字才占一个 token。 计算消耗量时,不能直接用汉字数简单换算 token 计费逻辑呢?目前所有商用大模型的计费规则都以消耗的 token 总量为核心标准,类似快递计费,按包裹重量算,和你包裹里装的是什么内容没有关系。 不管是你输入给 ai 的 问题对话历史,还是 ai 输出给你的回答内容,全部都会记录 token 消耗。 很多人以为只有 ai 深沉的回答才需要付费。实际上,输入册的 token 消耗量占比往往更高,尤其是带长上下文的对话,输入消耗的 token 可能是输出的三五倍。上客家依赖 大模型,本身没有记忆能力,要保持对话的连贯性,每个对话都需要把之前所有的历史聊天内容,连同新的提问一起全部喂给模型。类似你每次去熟悉的理发店剪头,理发师都要先回忆你之前的发型偏好,才敢下剪刀。 很多人以为历史对话只会存在本地设备,不需要重新传给模型。实际上,每类对话的输入 token 都包含了全部历史内容。对话轮次越多,单轮的基础 token 消耗就越高。 长文本开销当你给 ai 投喂 pdf、 论文代码等长文本内容时,整篇文本都会被拆成 token 输入给模型。类似你请人改稿子,先要把完整的稿子全部交给对方看完才能改。 如果后续你针对这篇长文本多次提问,每一次提问都会重新把整篇长文本算入输入 token, 不 会因为你之前传过就免除费用。很多人误以为长文本只在第一次上传时计费,实际上,只要上下文里保留了长文本内容,每一次调用都会重复计算这部分 token。 多轮累加消耗多轮对话的 token 消耗是累加式增长的。比如你先问 ai 北京的景点推荐,再问住宿攻略,再问交通路线。第三次提问的输入 token 就 包含了前两次的所有对话内容。类似你连续找同一个律师咨询三个问题, 律师每次都要先把前两个问题的背景梳理一遍,才能回答第三个。很多人聊完一个话题,不新开对话窗口继续聊无关的新话题,之前的历史内容还是会被算入 token, 平白多花几倍的开销。 响应勇于消耗大模型的输出默认会尽可能保证内容完整通顺,很多时候会输出很多非必要的内容。类似你问店员附近的地铁站在哪儿,它不光告诉你地址,还要给你讲手摸班车时间、站内有没有卫生间。尤其是你没有在 prompt 里限制回答长度时, ai 的 输出 token 量可能是你预期的二到三倍。 很多人以为 ai 输出的内容都是必要的,实际上只要在提问时明确要求,简短回答,只给结论,就能减少至少三十的输出。 token 消耗。工具调用开销现在大部分商用大模型都支持联网查数据库、调用第三方插件, 这些工具调用的过程也会产生大量 token 消耗。比如你让 ai 查今天的北京天气, ai 首先要把你的问题转成天气接口的调用指令,这个过程要消耗 token 接口返回的天气数据,还要全部未给 ai 转成自然语言回答,这部分返回数据也会全部算入输入 token。 很多人以为工具调用只花接口费,实际上中间来回数据处理产生的 token 消耗往往比直接提问高二比四倍。 流式输出计费很多平台的 ai 回答是逐字蹦的流式输出,不少人以为中途打断 ai 输出就能省掉没生成部分的 token 费用。实际上,不管是不是流式输出模型,都是先在后台生成完整的回答内容,再逐段传给前端展示, 你中途打断只是没看到后面的内容,已经生成的部分还是会全部计入 token 消耗。除非你在 ai 刚开始输出的一秒内就会全部计入 token 消耗,除非你在 ai 刚开始输出的一秒内就会全部计入 token。 token 优化边界日常使用中,可以通过压缩上下文、定期清理无关历史、限制回答长度等方式减少 token 消耗。但优化是有边界的,不能为了省 token 删掉关键的上下文信息。比如你让 ai 改论文, 要是为了省 token, 只给他传你要改的那一段,他很可能因为不知道上下文逻辑改得完全不符合要求,反而要多花好几轮的 token 纠正错误反而更费钱。优化 token 消耗要平衡成本和回答准确率,不要为了省小钱浪费更多成本。以上就是今天关于为什么用 ai 的 时候 token 消耗这么快。

粉丝2.0万获赞9.7万
相关视频
 00:27查看AI文稿AI文稿
00:27查看AI文稿AI文稿离谱一条指令直接省百分之九十 token! 记住这个开源项目名字,在 get up 拿下了五一 k 的 四档。它是 ai 与终端之间的过滤中转工具,在生成上下文的同时,自动清掉无用信息, 智能精简文本数据。一条指令直接省下百分之九十 token, 无感运行不卡顿。适配,各大主流编程 ai 完美适配 open clock code 等全程免费开源商用,自用随便用!关注我,带你学习更多 ai 技术知识!
743Tony讲实话 02:05查看AI文稿AI文稿
02:05查看AI文稿AI文稿一天就烧了四亿 token, token 都去哪了?该怎么节省 token? 先看看 token 是 怎么没的。第一个就是你各种的记忆文件、 skill 技能文件,你以为它是用哪个就发哪个吗?不,它是全部打包发给大模型,然后去决定该用哪个。 另一个就是上下文智能体,其实是不会分析上下文的,跟你的记忆文件一样,也是一起全部打包给大模型去处理。 记文件和上下文加起来基本上就是几万字,再加上各种的工具,还有你的处理的任务文件,加起来差不多每次对话就有十几万字。 像可乐扣的这种编程工具,虽然没有复杂的记文件吃 token, 但是这仅限于你刚开始做的时候,等项目做久了,尤其是动辄几十万甚至上百万行的时候,你的需求表述还很模糊,这时候大模型就只能扫一遍你整个的项目文件,哪怕扫完还不确定,再扫两遍, 然后你的一亿 token 就 没了。所以我就做了一个逻辑整理的 skill, 把整理上下文和文档解锁这种特别消耗 token, 但又不需要太强能力的事儿,交给 minmax 这种便宜且量大管饱的大模型去做,等整理好之后,再切换 deepsega 去执行,或者 cloud code 去编程。 平常我每天的 token 消耗至少一亿多,这两天更是到了三亿,但是前几天在用这种方式的时候,只有一两千万的消耗,节省了不止十倍。但是为什么没一直用呢?因为这种方式就像黑箱一样,你看不到 clock code 和 codex 的 实时输出,改了什么,有没有瞎改你都看不到。 然后我又做了一个能让 hermes 实时广播 clock code 运行过程的 skill。 当然你不想用这种方式的话,你就得做好项目管理。首先要有目录和剪辑,每次修改的时候把目录发给大魔行,它会直接定位到插入点,非常的快。 写小说也是,你得做好章节大纲,两三百字一个章节大纲,到时候未给大魔行的时候,字数就会减少十倍。
73薛铁柱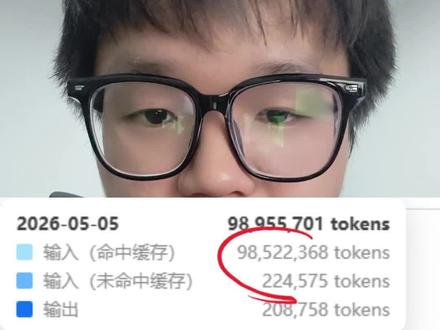 01:38查看AI文稿AI文稿
01:38查看AI文稿AI文稿几个简单的小技巧就可以让你的 ai 命中缓存达到惊人的百分之九十九,其托肯消耗和成本其实可以锐减百二十倍。这真不是夸张,是我消耗了整整一亿托肯得到的一个实际经验结果。第一 点,善用记忆系统。其实我们知道现在大部分市面上主流的 i can, 它都是有自己的一套记忆系统,无论是 open card 还是它都扣的。只要我们善于利用这个记忆系统,其实可以大大的增加这个缓存的命中率。举个例子,我最近在做一套自己的 ai 面试助手,但是这个任务他不是一天两天我就能够完成的, 所以我每天会在任务完成的时候,我会告诉我的 autodrive, 让他自己去保存当天的这个记忆。这样的话,在我明天或者后天重再开启这个任务的时候,他能够直接读取自己的绘画内容,从而大大的降低这个拓客的消耗。 第二点,制造边界和原则。布置一个任务的时候,如果没有明确的规则和原则的话,你可能需要跟你的爱多次交互,他才能够真正的明白你的需求。 就算他明白了你的需求,你没有制定一个明确的边界,你的 ai 也可能会做出越界以及难以预期的一个结果。所以制定边界和原则是非常重要的,你可以直接将这个工作原则喂给你的 ai, 让他传进他的记忆系统。 最后一个点,整理和提炼工作流,让他按照工作流的方式输出结果以及产出文档。当你需要他完成一个周期较长的任务的时候,一个合理的工作流是非常重要的,他不仅可以让 ai 快 速理解和解决一个问题的流程,并且可以通过产出一些文档来极大的提高一个缓存的命中率。举个例子, 你需要做一个文档,那么你可以先跟你的 ai 交流想法,让他去产出做出这份网站需要的一份产品文档,然后你再根据他的产品文档去优化,之后让他去根据产品文档去完成功能,这样他有了依据而不会天马行空,每次产出都会根据文档来做,而不会浪费脱坑又产出垃圾。
424欧拉欧拉欧拉z 02:32查看AI文稿AI文稿
02:32查看AI文稿AI文稿如果你在用 codex 却还没装这个 skill, 就 别怪你的额度总是不够用了,因为在你使用 codex 的 时候啊,它不可避免的要去网上搜索各种信息,比如查找文档,做用户调研、爬 github 仓库,甚至我之前的 ai 捡爆系统, 也是需要 codex 去帮我搜索搜集 ai 资讯的。但搜索其实非常消耗头肯,因为 agent 每打开一个网页,都可能把大量的皱纹、无关的网页代码、广告信息都带进上下文里搜索,轮次一多呀,你的额度就吃不消了。 agent 这个 skill 就是 专门用来解决这个问题的, 因为 agent 在 使用这个 skill 的 时候,会自动调用 agent 的 a p i, 所有搜索工作搞定后,再通过 markdown 的 格式传回给 agent。 这样一来,最重的那些活全部交给 any search 了,我们自己的 agent 就 轻松很多,使用方法也非常的 ai 原声, 我们在它的官网上复制这个 skill 的 命令,粘贴发给 codex, 它自动就会安装好了。我们只需要在对话中调用它, codex 就 能自动使用。我们立刻来测试一下,首先引用 any search 这个 skill, 然后让 codex 帮我们对比下过去一周 cloud code 和 anti gravity 这三款主流的 ai 开发工具,在国内的社媒和论坛中哪个更受欢迎。 最后用一个简洁美观的 html 网页呈现给我们,我们先看一下额度啊,现在是百分之九十八,点击发送 any search 收到请求后,会从海量的信息渠道中精准路由到最相关的数据源。 我们来看看结果。首先他给出了结论, codex 综合第一,下面有一个评分表,然后就是比较重要的量化样本表, any search 追踪了 npm 下载量、 reddit 评论和 hacker news 的 帖子, 下面还有一些基于搜索结果定性的分析。从样本来源我们看到他搜索了非常多的网站,从安装源到国内的社区、论坛到官网都涉及到了, 搜索质量很高,整体消耗了我 codex 五小时额度的十八个点。同时我还让 codex 在 不使用 any search 这个 skill 的 条件下,用同样的 prompt 跑了一次,这是最终的结果。 整体呈现上信息简略了一些,搜索员也大幅减少消耗的额度,还比之前多出了五个点,这就是低效搜索带来的隐性成本。 所以 any search 的 价值呢,就是把这类重活儿专门交给搜索技术设施来完成。当然它也可以直接在网上进行初步体验,从专业维度到普通生活的各个领域都能覆盖,非常推荐。好了,我是阿朱,关注我,让我们一起在 ai 潮头冲浪!
3471阿朱星际漫步 02:25查看AI文稿AI文稿
02:25查看AI文稿AI文稿这是一期教你如何正确并且省钱使用 cloud code 的 视频,关注我时间长的朋友应该都知道,我是 cloud code 的 死忠粉,作为一个每天使用八个小时,并且用 cloud code 变现了几千块钱的用户,今天我将跟大家分享几个帮助大家省钱而且提高效率的隐藏命令,也许你从入门到精通就差这几个隐藏命令了, ok, 话不多说,我们直接开搞。首先就是 model ops plan, 大家熟知的我们都是通过 model 进行切换嘛。 但是这个命令对于二十美金的 pro 用户来说实在是太友好了,因为它会自动地在你进行一些复杂推理和写计划的时候使用最强的 ops 模型,然后在执行的过程中使用第一档的 sonata 模型,这个就能帮助 pro 用户显著地节省头肯, 你的一倍头肯,能用到三倍头肯的效果。第二个就在命令行输入 remote control, 就是 我们在养龙虾的时候终极梦想,就是我们躺在床上,然后让 ai 自己写代码,那么这个命令就能很好地帮你实现。这一点能够通过手机来操控 cloud code, 你 只需要在对话框里面打斜杠 r c, 它就会生成一个网页, 你用手机打开这个网页的时候,你的整个 cloud code 就 会在你手机上同步,这个功能是让你的手机变成遥控器,远程的遥控 cloud code, 我 只能说憨爆了。第三个命令行是斜杠 export, 它会把我们所有的对话上下文打包成一个 m d 文档。如果没记错的话,我觉得 cloud code 的 上下文窗口应该只有两百 k, 经常出现那种你跟他聊着聊着上下文窗口满了,你需要开一个新窗口的问题, 那么这个命令就能很好地帮助模型去知道啊他现在做到哪一步了,他接下来要做什么?此外,你可以导出到其他的 ai 产品嘛,比如说 codex 上面,然后你继续搞。最后我想讲的这个不是命令行,但是如果你要想在你睡觉的时候让模型继续帮你工作,那么就一定要勾选上这个 permission, 它叫 bypass permission。 我 们是不是很多人在使用 cloud code 的 时候,一会儿一个弹窗,一会儿一个弹窗,你要点击去确认这些权限,但是你选择 bypass permission 的 模式之后,它自己就会去执行所有的命令了。其实我今天本身还是很想讲一个,就是 agent team, 你 一个人怎么去组建一个 agent 军团去帮你干活? 我经常搞十几个 agent 同时并行的帮我完成任务,这种感觉实在是太爽了。但是因为这个篇幅比较长,而且今天时间有限,可能讲不完,所以说大家如果想听的话,可以在评论区里面提需求,如果想听的人多了,我们下期直接安排上,那么我是 holland, 关注我,带你分享更多 ai 变现和省钱玩法。
2341浩兰德 02:09查看AI文稿AI文稿
02:09查看AI文稿AI文稿一个工具让 ai 别说废话。这个工具叫 qmail, github 上有六万多颗星,四月初才上线了,一个多月就涨到了这个数。我是松哥,今天来给你拆解一下这个工具到底是 什么,能帮我们省多少头,肯什么场景上该打开点赞收藏好,看完你直接装上就可以用。举个例子,你扔给 ai 一 份二十多页会议纪要,让它总结, 他呢,先给你梳理出整体的结构,再分章节铺垫背景,最后才说重点。装完案 q 漫之后,他直接说三条进度延后两天补色,再审批下周决策渠道方案。同样的事情,一个铺垫了半天,一个一句话就给出答案, 那最终能帮我们省多少呢?作者自己拿了十个真实的任务场景来测试输出的头,肯平均就能省百分 分之六十五,那其中最夸张的一个啊,是直接省到了百分之八十七。这里我要强调一下,省的是 ai 嘴里说出来的 token, 也就是它的输出内容,它脑子里的思考过程是不动的,所以回答的质量大家不用担心它呢。总共有四个压缩等级,爱的最轻, 去掉一些客套话,适合我们日常使用。 for 是 默认的电报风格,大部分场景都够用了。 out 是 极致压缩的效果,适合你第八个看日的时候看。那还有一个呢,叫文言文风格,最省头等,但是可读性比较差,这个就看你 自己接不接受了。安装也特别简单,一个扣耳命令就搞定了,大概三十秒就能装完。装完呢,可乐扣的里面是自动生效的,也不用我们手动去打开,想看自己省了多少,敲一个命令就可以了, 它呢,直接告诉我们这次省了多少,累计省了多少?总共换算算钱,它又是值多少?那顺便提提嘴,它呢,不只是考了 code 可以 用, 像 codex、 jimmy c r i、 cursor、 windows 几乎这些主流的三十多个编程 agent, 它都可以来使用。说实话,省 token 是 附带的好处,对我们自己来说, 最核心的是节省我们阅读的时间。 ai 回复的越短,你抓住关键信息就越快。像总结文档,抓重点,看数据这种场景, ai 越短越好,真的要写方案,要解释思路的时候,我们再切换回正常模式就可以了。好了,今天的分享就到这里,你平时上 ai 干活,最受不了的是他的哪种废话?欢迎评论区聊聊,关注松哥,一起少加班!
28松哥的AI办公室 02:26查看AI文稿AI文稿
02:26查看AI文稿AI文稿嗯,然后很多人可能用了 ai cloud 上来的话,就会先去生成一个图片了,生成动画了,其实 我觉得这种是一种浪费钱的行为。哦,那个,因为现在如果你经常上网搜的话,你可能会看到像那个,嗯,像现在什么千问了,豆包了,他们都有自己很好的一个动画生成工具,比如什么快乐小马了, 然后那个 deep cds, 这些我之前试过,真的非常棒,生成大概十秒钟左右的视频。嗯,免费的,一天能有十次,那如果两个软件一起用的话,你可以有二十次了,这还不考虑其他的一些软件?所以说你用 ai cloud 去生成的话,呃,我觉得是很很不划算的,因为 ai cloud, ai cloud 你 去生成视频,它是非常消耗头肯的,但是生成的质量说实话我觉得跟 deep space 还有快乐小马生成的差不多, 然后再做一些嗯,编程类工作啦,或者是一些长期的一些工作的时候,你用 icloud, 我 建议你先别着急去使用它,你先自己拟好一个大纲, 然后你再和 a a i cloud 去沟通我这个大纲有什么问题,然后 ai, 你 是否理解了我这些里面的每个细节,然后你们俩对齐,然后如果你在对齐中发现啊 ai 可能理解错了,那你就在初期阶段,你就可以指出它, 指出这个问题,然后再去研究解决方案,最终整个,呃,这个解决问题的整个逻辑全都梳理通了,各个细节都没问题了。哎,咱们再去探讨后续的代码啊,或者是详细的步骤怎么去做啊,这样的话能够把你这个 token 节省到 啊,相当于是做一个最大的节省啊,不然的话你每尝试一次重,每尝试就重新跑一遍,这个烧 token 是 比较快的。嗯, 然后当然最好的省秃根的办法,那就是想办法薅薅羊毛这样的。其实我觉得可能未来每个人每个月花费五十到一百块钱去去买秃根应该是一个很常见的事情,因为这个 对自己来说是一个很大的帮助。嗯,好,今天就到这里。嗯,拜拜。
24不吃鸡贼🛵 00:48查看AI文稿AI文稿
00:48查看AI文稿AI文稿这个霸榜 get 榜月榜第一名名字就叫 skills, 专门设置 ai 写代码的各种毛病。我给你们讲三个最炸裂的。第一个,你给 ai 一个需求,他会反过来像面试官一样疯狂追问,你问道,你把所有细节都想清楚了,他才开始写代码,这一步就能砍掉百分之八十的反攻。 第二个, ai 写代码最大的问题是什么?废话太多,这个技能能让 ai 只说人话,干掉百分之七十五的废话,还能节省 a p i 调用费用,一举两得。第三个就是测试驱动开发,但它不是写完代码再补测试,而是先写一个失败的测试,再让 ai 去实现, 每一步都有反馈,代码质量直接起飞。还有诊断 bug 的 重构烂代码的,把需求拆成独立任务的。一共二十多个技能,全是实战级的, cloud code code, excercer 都能用链接我放评论区了,三十秒就能装好。
3153哇哈哈哈 03:51查看AI文稿AI文稿
03:51查看AI文稿AI文稿我相信百分之九十九的人都不知道这八个可乐扣子的隐藏指令,大家耐心看完这个视频,绝对会让你大开眼界。 第一个, btw 命令,今年三月份刚出的,就是让可乐扣子在干活的时候插一个问题进去,但这个问题不会被写进历史上下文。以前你问一句可乐扣了就停下来了,上下文被污染,干活就容易跑偏。现在问完直接回车,这对对话直接消失,任务照跑, 历史干干净净,并且几乎不费掏开,用完了就回不去那种命令。第二个,瑞万的命令,可以理解成 ctrl z 撤销,打开这个命令,会弹出一个菜单来,让你选只回退代码,还是只回退对话,还是两个一起, 还是压缩上下文释放空间,这个命令非常实用。第三个,隐菜的命令,这个命令我觉得被严重低估了, 他会生成一份 h t m l 报告,分析你过去一个月用可多扣的习惯,看你常用哪些指令,有哪些重复的操作,然后给你推荐自定义的命令,说白了就是可多扣可多扣的在反向观察你, 给你优化建议。这个我建议人每个月都要跑一次,他会让你重新认识你自己的工作习惯, 非常有意思。第四个, see you plan 命令。你打开这个命令, cloud code 会同时启动三个平行的 agent, 分 别从代码附用、代码质量、运行效率三个角度帮你审核改动,然后汇报结果,相当于找了三个同事帮同时帮你 re 要代码。 我现在的习惯就是每次写几个大功能,更新之后顺手跑一遍,因为 ai 的 代码经常有种鱼,这个命令基本上都能把那些种鱼挑出来,写代码的一定要用这个命令。 第六个半尺命令,原来他是叫 fork, 现在改名了打,但是打旧名还能用,会自动跳转。作用就是把当前对话分叉出一个新的绘画来,原来的绘画不受影响。他跟 rewind 的 的区别就是, rewind 的是后悔药,半尺是平行宇宙, 如果你想同时试两种不同的方案,就是分叉一下,两边各走一边,最后就是选一个效果好的就可以。 第六个落魄命令,他可以让可乐定时重复执行某个任务,用法就是在这个命令后面跟上时间间隔和你和你要他做的事。比如说每五分钟检查一下部署状态,他就自动跑,不用你盯着, 默认时间间隔是十分钟,并且结果直接在上下文里。可乐可以基于结果做判断和后续操作, 但是要注意,定时任务在创建三天后会自动过期,最后触发一次,然后自我删除。第七个 remote ctrl 命令,就是打 r c 或者是完整的命令。 remote ctrl 它会生成一个 url, 手机打开这个链接,你整个 cloud 的 绘画就出现在手机上, 完全同步。你在手机上发指令,终端那边也能看到你在终端操作,手机实时更新终端代码,始终在你电脑上跑。手机只是个遥控器,所以很安全,非常好用,这点就像那个龙虾。 第八个 export 的 指令,打开这个指令,当前整段对话直接导出 markdown 文档,听起来不起眼是吧?但是有时候你会发现这个功能真的很实用。你跟可乐扣了讨论了半天的架构方案,中间有大量的来回推敲, 如果不保存,回头找起来非常麻烦,直接导出来存着,作为更详细的上下文,下次直接用这八个隐藏的指令,非常实用,建议大家使用起来。好,今天的视频就到这里,感谢大家观看。
204PM.姜同学 01:33查看AI文稿AI文稿
01:33查看AI文稿AI文稿我们这里讲的不是 set token 技巧,而是直接把 token 赶到零这工具它可以把我们 ibisc, g r m 或者 kimi 等等是国内所主流的 一些网页上用的大模型都给它转换成标准的 api 的 形式,转换的是标准的 open ai 的 格式,所以目前所有的正体都能接入这个 api, windows、 mac 和 linux 的 系统它都支持。如果大家有需要的话可以在评论区留言,有用过的兄弟反馈,它的上下文只能做一轮的回答,其实是可以设置的啊,这里在我们左侧的这个 绘图管理里面有最大消息数和最大的 token 数,这都可以自定义,包括我用久了之后怕它的那个上下文窗口会超出。这里的话可以做一个 历史记录的摘要。这里我们打开 client 来做一个验证。首先我们把网页转过来的 a p i 给它接进去, a p i 的 形式和 url 照到我这里填就可以了。 a p i key 的 话在我们刚才的工具里面给它复制过来粘贴,这下面还有个 mod id。 这里我们也是打开刚才的工具, 把模型管理里面我们自己选择一个,这里为了防止他输入的时候大小写出错,所以说我就直接复制,然后过来直接粘贴保存就可以了。然后我们让他打一个百度试一下,当然这个 client 里面他已经接了一些 m c p, 这里面相当于有些工具看到他已经成功给我们打开了百度网页。我们再测试一下关于工具的功能, 让他在百度中给我们搜索一下 nba 的 今日赛况。这需要补充说明的就是他这里的搜索跟我们用 kimi 用 dsco 在 官网上搜索的 不一样,因为这个我是指定让他在某一个搜索引擎里面去进行搜索,很快我们看到他已经帮我们搜索好了,而且总结概述也是已经做好了。然后我们再问了一下哪只队赢了,如果只有一轮上下文的话,那这个问题他肯定是回答不上了,但是他是成功的回答出来。经过这一轮工具的调用,上下文的验证之后,我们看到我们所使用的金额还是零。
72叶秋大大 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿你是不是也希望你的 ai 编程助手像开了挂一样,一次陪你干完整个项目?代码不断,思路不断,结果呢?现实直接一记重锤,一个 get status 可能吃掉上千 token。 一 次 cargo test 几千 token 没了,一个大嘀嘀嘀,直接把上下文塞满。 ai 还没写几行就开始失意跑偏,胡言乱语。需求忘了, bug 忘了,刚改过的文件也忘了。你以为 ai 变笨了?不是你未给他的废话太多了, 成功日制重复输出无关信息, ai 根本不需要看,但它每读一行都在烧 token。 token 你 就理解成 ai 的 阅读额度。额度被废话吃光, ai 就 撑不住。现在 r t k 来了。 r t k 全名 rust token killer, 它不是新模型,也不是代码生成神器, 他就干一件事,命令输出交给 ai, 钱先看废话,重复的合并,没用的压缩,关键报错失败原因,文件变化留下。官方说,常见开发命令能减少百分之六十到百分之九十的 token 消耗。 get cargo p test, grab, alice find 这些常用命令都能精简, quick code, cursor, winsole, gemini c i codex 都能接。装好之后, ai 不 再看满屏垃圾日制,他只看浓缩后的重点, 绘画更长,上下文更干净,成本更低。记住一句话,别急着换模型,先别让你的 a r 被 token 活活憋死!
12AI情报局 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿兄弟们, code code 为什么是烧 token 大 户?一个核心原因是它没有原生代码,所以每次搜索代码,它会 spawn 多个子 agent 去 grab glob read 大 量文件。今天分享的开源项目就是为了缓解这个问题。 它是一个在本地的代码知识图谱,它会通过 trace editor 把整个工程解析成抽象语法数,把函数类调用关系导入本地 sqlite 建成知识图谱,然后通过 m c p 开放给 cloud code、 codex、 open code 等编程 agent。 这样 agent 搜索代码时就不用忙扫大量文件,而是调用 m c p 结构化的查询,如某个符号在哪儿,谁调用了,谁改一处会影响什么。 当代码发生了改动,知识图谱会自动更新。作者在 vs code、 jango 等七个真实仓库上做过对比,同样问题,平均 token 消耗减少约百分之五十九,工具调用减少约百分之七十,并且工程越庞大,效果越明显。
1171小葱AI 00:26查看AI文稿AI文稿
00:26查看AI文稿AI文稿难以置信,只需一条指令, ai 编程就能节省近百分之八十的 token 消耗!今日最新 get 不 热点这个开源项目目前已斩获四十六 k star, 它就像架设在终端与 ai 之间的智能过滤中转站,会在命令输出接入大模型生成上下文的刹那,自动清除多余无效内容,并进行智能 精简。经过整个编程流程的转换,整体上下文成本可节省百分之六十到百分之九十。并且它完全开源兼容 call 的 等十三款主流工具,能让 ai 只读取有用信息,减少 token 的 浪费,就非常好用。
1768程序员虾仁 01:15查看AI文稿AI文稿
01:15查看AI文稿AI文稿用 cursor 和 compiled 写代码,你每花一块钱,有九毛八都被浪费了。有人晒出六周 cursor 账单,六百三十八美元,最贵一次请求烧了六百八十万 tokens。 为什么?因为 ai 编程工具底层还在用 grab 思路,先全网扫描整个代码库,再让大模型逐条过滤。本质上是搜索方式太原始, grab 只能做文本匹配,搜不出语义, 所以 ai 不 得不把所有可能相关的代码全塞进上下文,让大模型当过滤器用。今天 hn 首页的三步换了个思路,用十六米参数的静态嵌入模型做羽翼解锁锁影。一个仓库只要两百五十毫秒,查询一点五毫秒纯 cpu 就 能跑,不需要 gpu, 解锁质量跟代码专用 transformer 一 样,但 token 用量直接砍掉百分之九十八。它已经支持 mcp 协议, cloud code、 cursor codex 都能直接接。 但这事真正值得想的是,如果仅仅换一个搜索引擎就能省百分之九十八的 token, 那 ai 编程工具链里还有多少这种低效环节?我是叶哥,专注 ai 编程效率, sample 这个项目我会持续跟进,关注我后续深度拆解它的技术原理。
56叶哥说AI 02:06查看AI文稿AI文稿
02:06查看AI文稿AI文稿那你用 cloud 是 不是经常用着用着就被提示额度不够了?那今天分享六个我自己在用的省投款技巧,非技术背景的人完全能听懂。那第一个,不要发新消息,而是编辑消息。那很多人遇到 cloud, 没有理解自己的意思啊,就接着发了一条,不对不对,我的意思是什么?什么什么。那 这是最贵的习惯啊,因为 cloud 每次回复都要把整个的聊天记录重新读一遍,你发的消息越多,就越浪费 token。 那 正确的做法是啊,点击之前那条消息旁边的编辑按钮,改掉它,重新发。那第二个,每十五到二十条消息,新开一个对话, 对话越长啊,每条消息的成本越高,因为 cloud 要重读的历史越来越长。有人统计过啊,长对话里百分之九十八的 token 都花在了重读历史上。那真正用在你的问题上呢?只有百分之一点五。那做法也很简单啊,感觉聊了很多轮了,就让 cloud 总结一下,复制开心对话,把总结粘贴进去,继续聊。 第三个,把多个问题合并到一条消息,觉得这样清晰。那很多人习惯一个问题一条消息,觉得这样清晰,那三条单独的消息, cloud 要加在三次上下文, 一条消息啊,问三个问题,加载一次就够了。那合并提问省 token, 答案还往往更准确。第四个,把常用文件放进 project。 那 如果你有一份文件,经常要跟 cloud 讨论,比如你的品牌手册,项目背景、参考资料。不要每次新对话都重新上传,上传到 cloud 的 project 功能里, 那系统会缓存,那同一个项目里面的所有回话都能够直接引用,而且不会重复扣 token。 那 第五个,在设置里保存你的个人信息和偏好。那我是一个内容创作者,我的 风格是什么什么?那这些文字啊,本身就是头肯的,浪费。那进入 cloud 设置,找到记忆或者用户的编号,把这些写进去,那 cloud 会自动带入每次对话,你不用再解释自己是谁了。那第六个啊,简单的任务,用嗨酷模型。那 cloud 有 不同的模型,嗨酷是最清亮的那一个。检查语法,翻译格式,整理错漏风暴。 这些任务不需要最强的模型来做。用嗨酷处理这类任务啊,能节省百分之五十到七十的额度,把额度留给真正复杂的任务用。那这六个习惯养成之后啊,你就能用有限的额度完成更多的任务了。那你还有哪些省投更的技巧,欢迎在评论区分享。
52起哥的AI实战 02:09查看AI文稿AI文稿
02:09查看AI文稿AI文稿第一时间跟兄弟们分享一个又能够省偷啃,又能够更加快速和精准去解决问题的一个一个组合法啊,是这样子的,我这个软件呢, 我把它封装成那个一 x 一 的文件以后,经常遇到一个问题,什么呢?就是我这个服务器啊,你看这里有五个服务器,你这个 q t b t 这个专门负责下载的服务器呢?他每次会他都会卡死在这个地方,然后呃一直没解决,那么我就 把后台的报错,每次把这个日字都发给他,都发给他,发现他的解决思路没有打开啊,现在我有一点能够看懂了哈,我觉得他的他的思路没有打开,他是看到一个问题解决一个问题,他并没有看到后面三个问题,或者说他没有看到根本的问题, 然后我就会反过来把这个问题直接丢给呃,网页版的那个 app, 或者新开一个窗口,然后把这个问题直接丢给他, 然后要跟他教会我,这很重要哈,要跟他说教会我不要问他这个是什么,只要问他教会我,然后他会分析一堆,然后就把这个 说为什么会出现这种情况说的,还说的是我没有之前没有想到,也是我这个这个克拉扣的界面没有想到的。复制过来给他复制粘贴给他,然后他你看一下有没有参考价值。 他看了这篇文章以后,他说确实是有用的,而且问题也完全符合因为什么,因为本来就是从这里出现的问题拿去问 app 的, 所以他他说有价值,而且他说他那个根治的方案有用,然后马上把它加进来,然后就进行修改啊,终于看到后台已经成功了,你看一二三四。 好了,你看确实这个组合拳有用哈。就是呃,我们有时候真的没有必要一定要在一个窗口里反复的去让他去问他去修改,有时候他真的他是只能想一步做一步, 我们直接大胆一点,新开一个窗口,新开一个窗口,但是这个呢会很很浪费 token, 因为他要重新的去看所有的代码,所有的文件,会有点骚。 token 如果只是解决单一问题的话,我觉得是呃,没有必要,可以直接尝试一下, 在这边专家模式打开问他一下,然后看他给的答案怎么样。有时候你会发现他给的答案其实是可以的,是真的可以的,因为他没有之前的上下文的误导。
24臭爸屁AI实战



