大家好,我是土豆,今天想跟大家聊聊另一个我最近在用的 skill, 专门用来生成性能测试分析报告的。事情是这样的,做性能测试的兄弟姐妹应该都有过这种体验,押测跑完了, jimitter gatling 或者云押测平台里一堆曲线和数据,结论得自己总结,报告得自己写, 而且报告格式还不统一,有时候用 word, 有 时候贴几张图加几段话,领导和开发看起来全凭悟性,更头疼的是指标解读响应时间多少算正常, tps 到多少才算合格?瓶颈到底出在操作系统中间件还是数据库调优建议怎么写才不显得像套话? 再加上时间本来就紧,既要盯着压测执行,又得赶在评选前凑出一份能看的报告,加班凑文档都快成常规操作了。 所以我就想,能不能让 ai 帮我干这件事。你提供压缩结果的截图,再加几句简单的文字说明,比如什么场景用的什么工具,重点关注什么, ai 就 能帮你做指标解读、瓶颈推断、优化建议。最后输出一份结构固定、可以直接分享的 html 报告, 这就是我今天想分享的 performance test report skill。 在 cursor 里面,通过这个 skill 把截图加描述,变成一份专业的性能分析报告。它主要做三件事,第一,读取你的压缩结果,支持一张或多张截图, jmeter 聚合报告、 getling 云压缩平台的大盘都可以,再加上你补充的场景说明。 第二,做专业分析。他内置了一套性能测试知识库,包含指标含义、行业参考值、平静分析顺序,调优方向,他会从截图里提取关键指标,按操作系统中间件、数据库应用的顺序做分层推断,最后给出可操作的优化建议。 第三,输出标准报告。一份 html 格式的报告,包含压测、概述、截图与说明、瓶颈分析、优化建议、总结与后续建议。版式固定,给领导看、给开发看,或者打印成 pdf 都行。这个 skill 解决的核心问题有三个, 一、报告产出效率。从自己整理数据手动码字变成提供截图和说明,然后拿到一份完整报告。二、分析规范性分析,逻辑和表述方式,由内置的知识库约束,减少遗漏和随意发挥。三、格式统一。每次生成的报告都基于同一套 html 模板,团队沉淀和对外呈现都方便。 好了这个 skill 的 完整配置,提示词模板,还有我用的性能分析报告、 html 模板,我都整理成了一个 md 文件,需要的小伙伴可以关注我。

粉丝1.2万获赞10.5万
相关视频
 03:13查看AI文稿AI文稿
03:13查看AI文稿AI文稿最近半年使用 cologod 安装了近百个 skr, 最后发现真正能提升工作效率的其实只有三个技能,今天免费分享给大家。第一个, superpowers, 这个 skr 改变了我用 cologod 的 方式。以前我是直接把需求交给 cologod 的, 让他来写代码,写出来虽然能跑,但是经常跑偏,改来改去浪费大量时间。 装了 superpowers 之后,我养成了一个新习惯,每次开弓前先跑一遍,不认英斯德尔敏。这个技能能让可洛的反过来问我问题,你打算怎么处理并发数据库选什么 等等等等。问完一圈,他会把讨论结果写成设计文档存到本地。听起来多了一步,但这一步帮我拦住了无数次的反攻。有些问题你自己都想不到,但是可洛替你想到了。 注意, superpowers 包含了二十多个紫技能,千万别全开,我只用 breamstorming, 头脑风暴, 其他的按需加载,要不然会浪费大量上下文。第二个技能, playing with fails, 这个技能解决了我被坑过无数次的问题。 cloud 有 个问题,它做到一半就失忆。不知道你们有没有遇到过 一个复杂的任务,聊了半个小时,可乐突然说,好的,让我们开始吧,然后就把之前做过的事情又重来一遍。根本原因是对话太长了,上下文被压缩,之前的计划全丢了。普莱因维的 flow 的 做法很聪明,就是别把计划写在脑子里,它是存在纸上 克拉的扣的。每次动手前会先建一个计划文件,每完成一步就在这个文件里打勾,就算上下文清空了,重新读一下文件就能接着干。 这个思路跟 minnes 很 像, minnes 做常任务为什么玩?因为它所有的中间状态都存在本地了。第三个技能, roughlop, 我 给这个技能起了个外号,监工 sky, 你一定体验过 cloud 的 摸鱼模式。写到一半突然说基础框架已经搭好了,你可以在此基础上继续完善。 翻译过来就是活我没干完,我先下班了。 raflopp 通过一个或可拦截 cloud 的 退出动作,他退出的时候或可会检查。你说的完成标准达标了吗?没达到,回去继续写。 我用它写过,完成过一个 c r u d 模块,设了条件,所有接口测试通过加 redmi 写完才算结束。 kloth 中间响停了三次,但都被塞回去了,最后确实把活干完了。但要注意的是,完成条件一定要写写具体做完用户模块这种话等于没说, kloth 分 分钟说服自己已经完成了写成。完成登录接口可用 单元测试,覆盖率百分之八十。加 redmi 包含 api 文档,它才没法浑水摸鱼。以上就是我常用的三个技能,今天希望能够对大家有所帮助,感谢观看,拜拜,下期见!
2.6万PM.姜同学 02:09查看AI文稿AI文稿
02:09查看AI文稿AI文稿这个 skill 可以 让巴菲特直接变成你的私人助理,配置好后,在 ai 里输入任何一只股票,他就会用巴菲特的思维结合专业的分析,最终给你输出一份机构级的深度报告。这跟那些针对别人说话风格的 skill 完全不一样,使用起来也非常简单,直接看下怎么操作吧。 首先我们打开 github, 在 里面输入这个叫 buffet oracle analysis 的 项目,它的中文名叫巴菲特神域分析师。然后我们可以看一下这个项目的介绍, 你未给他任何一个公司的名称或者股票代码,他都将输出这些维度的专业分析,底下是他的一些分析流,让我们直接上手开始操作吧。 然后回到上面,我们直接点击这个绿色的 code, 然后来下载它的压缩包,把它下载到桌面,然后我们回到 cloud, 这里我建议大家直接创建一个 project, 方便于后期的使用。 我们直接点击 new project, 然后名字里直接叫巴菲特分析师。底下这个 what are you trying to achieve。 我 们可以直接让 cloud 给我们写一段 md 文档,复制粘贴进去,然后创建项目。创建完之后,我们直接把刚刚下载的压缩文件发给他,让他学习这个 skill, 然后可以看到他解压分析,学习总结。等他安装好了以后,我们也不多废话,直接让他开始分析。就以腾讯为例子,我们可以看到他在分析,他在解锁。下面我直接给大家看这个分析过程的醇香版,非常牛逼,不需要多余的解释。 然后我们可以回头看一下他这个分析,他列出了一个非常详细的看板,对于他的一些收入,毛利率,包括 roe 都是非常清晰的列在上面,以及他的护城河分析,多维度估值汇总,包括巴菲特的分析卡,对他进行了一个评分。 下面是风险矩阵,投资决策,在多少价位的时候买入多少的市场比例,我觉得还是非常有价值的,大家如果有什么感兴趣的股票也可以去搜一下。 最后这个项目还在持续的迭代更新中,未来肯定有更多功能有待开发,那么今天的视频就到这里,希望大家喜欢,这里是 bryce。
1996碳基玩家Bryce 02:52查看AI文稿AI文稿
02:52查看AI文稿AI文稿大家好,我是土豆,今天想跟你分享一个我最近一直在用的东西,一个面向测试工程师的 cloud skill。 它可以做什么呢?很简单,你丢给他一份需求文档,他给你吐出一整套。测试用力 不是那种泛泛而谈的势力,是真正能直接用,能对起你公司模板的那种。我知道,你可能会想,又是标题党吧, ai 生成的用力能靠谱吗? 别急,今天我不仅会告诉你它怎么用,还会把完整的配置文件、提示词、模板都整理成一个 md 文件,放到最后, 你可以直接拿去用,或者自己改。先说说我为什么要做这件事。做测试的都知道,拿到需求文档之后,最耗时的环节是什么,不是执行,是拆解。你得把文档里那些业务规则、接口、约束、边界条件一条一条拎出来,写成正向、反向异常的用力。 文档短还好说,赶上那种五六十页的需求,翻来覆去看,生怕漏掉一个点。而且最烦的是,不同人拆出来的风格还不一样,有的人只写正向,有的人边界写的细,有的人异常想的全,最后合到一起参差不齐,反攻改到想摔键盘。 所以我就想,能不能让 cloud 帮我干这件事。我给他设定了一套固定的测试设计策略,什么意思呢?就是不管扔进去什么文档,他都会按同一套逻辑来拆解。 第一,正向流程主路径必须覆盖。第二,反向异常输入错误,流程阻断、权限不足都得想到。第三,边界条件,数值的上下线列表的空余满时间的临界点一个不漏。第四,场景组合多个条件同时变化时有没有冲突?而且我让他区分接口、功能、性能三种类型。接口用力, 他关注参数、错误码、返回值,功能用力,他关注加载并发响应时间。 最关键的是,他可以对齐你公司的模板。你在配置里告诉他,我们的用力格式是用力编号模块、前置条件、步骤、预期结果类型,他生成出来就是这个格式, word 也行, excel 也行,直接复制粘贴,不用二次整理。你可能想问,真的能直接用吗? 我拿最近一个真实的项目试过,需求文档大概三十页,有接口描述,有业务规则,有交互说明。我把文档贴进去 cloud, 大 概用了几十秒吧,生成了六十多条用力。 我一条一条看下来,正向的都覆盖了反向的他想到了手机号已注册这种场景边界的他,列了密码,最短六位,最长二十位这种临界点 漏掉的,当然也有大概百分之十左右需要我手动补充。但你想啊,本来我要花两三个小时从头写,现在只用花十几分钟过一遍补一下, 效率翻倍不夸张。所以,这个 skill 的 本质是什么?不是让 ai 替代你,是让他帮你干那些重复耗时但又必须做的事情。你把精力解放出来,去做更有价值的事,比如复杂场景的设计,比如质量体系的搭建,这才是一个测试工程师该有的成长路径。好了,今天的内容就到这, 我把这个 skill 的 完整配置、提示词模板,还有我用的测试用力格式范例,都整理成了一个 md 文件。需要的同学可以在评论区回复六六六,或者私信我,我直接发给你。
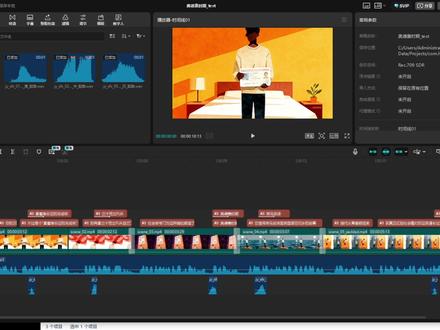 03:52查看AI文稿AI文稿
03:52查看AI文稿AI文稿搭一个让 ai 自动生成这样视频的 skill 真的 很容易,咱们先来看一下效果。承认吧,你的二十多岁不过是个拿着身份证的未成年,别再拿三十而立 pua 自己了。社会学专门为这种尴尬期造了个词,奥德赛时期,他借用河马史诗里英雄漂泊归乡的故事,只待从青春期结束到真正扛起社会毒打的这段漫长过渡。 这条视频呢,我没有加背景音乐,只是让它实现了 tds 配音,然后根据我的文案去生成分镜的提示词, 用提示词去生成对应的图片,再用对应的图片去生成视频,它只是经历了这样一个三步的 api 的 调用,就可以批量的产出这样的视频。然后加入了一些基础的功能,比方说关键词的提取,这是它自动识别的, 在关键词动画效果出来的时候,配上一个对应的音效。在这里我先说一下 ai 生成视频目前成本还是比较高的,它主要有两种方式,一种是调用 api, 而电有 a p i 的 话,现在最强的模型,那就是字节旗下的 cds 二点零。如果你的电脑配置足够高,比方说有一个九零系的显卡,那你就可以考虑本地生成,如果是这种风格的话,本地模型也是可以出的。咱们来看一下它的流程。第一步呢,就是来 读取你的文案,你可以把文案放在你电脑里边,用 txt 保存就可以,你可以保存一份文案,或者十份一百份 都可以,他都可以批量的帮你去完成。然后我这里有五个预选的风格,刚才的这种画面,这种卡通风格的画面是一种,你可以去选其他的,你喜欢的,包括现实感的都可以。如果你有对标账号,想参考他的风格,截一张图发给你的 ai, 让 ai 反推风格提示。 然后第二步就是把咱们的文案用 tps 配音,配音的方式模型有很多,有 api, 有 本地,这个就你们自己去选择就行。 第三步就是让 ai 根据你的音频产生的准确的时间轴去把它分分镜,然后生成提示词。生成画面的这里有一个重点, 因为你要和你的画面做时长的匹配,所以这里你要用 tts 返回的准确的时间处,你不能靠文字让 ai 去大概分,这样的话就可能对不上。第四步就是根据你刚才的分镜生成参考图。现在 ai 生成图片和视频的质量已 已经是非常的高了,所以这两步你就是根据你的提示词去调用返回的结果,如果不满意,你再调整风格类型的提示词就可以了。 其中最长的一步就是图声视频,除了耗时最长,也是它的费用最高。前边的所有的这一套流程, 一条视频跑下来可能就是几毛钱或者一块钱,但是徒生视频的这个环节,一个一分钟的视频,如果调用 cds 二点零的话,可能就是十块钱,二十块钱,甚至更高,所以这里一定要注意根据你们自己的需求,你们能承受的一个范围。我这里测试用的是 cds 一 点零, 一点零,我让他帮我估算了一个费用,一分钟的视频大概是十多块钱,这里只是做了一个测试,你也可以选择便宜一些的模型,或者考虑本地去跑,最后一步就比较简单了,就是按咱们的要求,根据一句话,然后匹配对应的画面,导入到剪映的草稿, 然后加一些转场的特效,加一些音效,包括背景音乐都可以让他直接全部加入进来。现在有很多认知类的视频都可以用这种方式去批量生成。 有很多小伙伴关注的 ai 生成短剧的 skill, 其实也是这样的一个流程,只不过你里边会把你的文案划分成剧情,然后让他去拆分分镜的提示词, 最后也是生成图片,图片再去生成视频。最后一个拼接流程都是一样的,只不过中间的步骤需要按你的需求去调整,有时间的话我会出一期专门的教程。最近更新的比较少,因为一直在调试各种视频的,有直播切片带货的, 还有一些帮小伙伴们定制在他们电脑上去远程调试的。大家有想做的视频不知道怎么去搭建的,可以评论区告诉我。
350老郑的ai干货站 04:41406对对十十
04:41406对对十十 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿昨天我帮一个朋友二十分钟从零写出了他第一个 skill, 方法啊,就五步。很多人以为 skill 很 复杂,要写代码,其实不是, skill 本身就是一个文件夹,它核心只有一个,就是 skill 点 m d。 他 只做两件事, 第一定义我是谁,通过 name 和 description, 以及我要怎么做。至于脚本和 reference 文件,那只是做事情需要的材料而已。 第一步,先找问题,这步最关键,如果你每天重复的次数大于三次,那这个事情就值得做成 skill。 比如说朋友每天都要看做 a d 实验的数据分析,这种就是典型的 skill 的 应用场景。第二步,定义需求,把流程说清楚,比如说我要从 big 查数据,我用了哪些的 circle, 以及关注哪些指标和场景,让 ai 跑一遍,把不符合预期的地方直接告诉他应该怎么改。 第三步是自动生成,记住一句话,用 skill creator 这个 skill, 把刚才的整个过程封装成 skill, 这时候 ai 就 会自动帮你生成 skill, 点 md, 执行流程以及所需要的脚本,你啊基本不需要动手。 第四步就是测试加调试,用刚才生成的 skill 再跑一遍,然后看到它的执行,找到偏差,再修改这个 skill 点, md 一 边改两到三轮就稳定了,本质就是 prompt 调试加流程校准。 最后一步就是发布,把 skill 整个放到点儿 agent 的 skill 目录下,这一步很关键,你一次配置到处都能附用。 最后记住一句话, skill 就是 重复工作的 s o p, 找一个你每天都在重复做的事,花二十分钟把它变成一个 skill, 你 会发现 ai 这不是工具,它是你的执行系统。
215建斌聊AI 05:09查看AI文稿AI文稿
05:09查看AI文稿AI文稿同样是小龙虾,别的龙虾勤奋在线,你的龙虾昙花一现,别的龙虾干活利落,你的龙虾总是报错,别的龙虾审美拔尖,你的龙虾审美跑偏, 这中间大概率就差一个东西, skill。 我 拉大家上期呢,教大家怎么零门槛安装小龙虾,但想让它真正的替你干活,还得给它配上好用的 skill。 那 接这期呢,我用五分钟带你从头到尾搞懂什么是 skill, 哪些是必装的 skill 及它的安装教程,记得点赞关注收藏,我们正式开始! skill 就是 小龙虾能调用的一项能力,简单来说,它俩的关系就像是哆啦 a 梦和口袋道具的关系, 你想要缩小就打开缩小灯,你想要飞起来就带上竹蜻蜓。你想要瞬间移动就打开传送门。口袋里有什么道具,哆啦 a 梦就能做什么事儿。你装上什么 skill, 小 龙虾就拥有什么能力。 从查天气、写表格、追热点到自动化操作,这些都需要 skill。 有 了专门的 skill, 小 龙虾才能从一个会聊天的 baby 虾变成一个会干活的效率虾。而 skill 能做的也远不止单个功能, 还可以把多个功能聚合到一起。比如说我之前做的 ai 升视频的工作流,涉及到升脚本、升分镜、升图,也可以直接做成一个全链路的 skill。 那 这样的话,我就可以很从容的只发一个产品卖点和产品图过去,小龙虾就知道一二三,每一步该怎么做,直接跑完全程非常的省心, 那你的经验就变成了他的能力,这样一个 skill 还可以高效的赋用到团队的其他人用。 想要养出效率虾,这四个 skill 必须第一时间安排。第一个 skill waiter 技能审查就是你的电子保安,你要安装新 skill 的 时候就会触发 skill waiter, 他 就会给出一份风险评估。如果说啊,他弹出说这个是高风险的,咱呢还是别撞了。第二个 tively search 搜索技能 是给小龙虾联网冲浪用的 skill, 那 opencloud 自己呢,是没有办法直接联网的,有了 tively search, 他 才能找到最新的资讯。 第三个 agent browser 浏览器的操作技能,比如说呢,帮你打开浏览器啊,抓取网页信息,填写表单,全程都不用你动手, 这样呢,一个自动抓取的表格就给你做好了。第四个是 self improving agent 自我改进技能,遇到了问题,它会复盘,会改进,会自动迭代,所以这是一个越用越强的养成系 skill, 也是 graphhoop 上面最热门的 skill。 以上就是养龙虾必备的四个 skill, 那 国产龙虾一般都会默认安装好这几个 skill, 大家可以查漏补缺看看。 完成了 skill 的 基建,我再跟大家分享,非常好用好看,能快速提升工作质量的 skill。 那 第一个呢,叫做 front and design, 是 一个审美极好的 skill, 我 让它生成了一个拉拉面包店的网站,可以看到呢,它的配图非常的有质感,整体都是淡黄色的配色和色系,排版也非常的清晰和高级。 我还用它生成了一个拉拉服装店的一个面向二十到三十岁欧美女性的独立站,网页整体是非常有活力的,多巴胺的渐变风格,最戳我的是这个鼠标的设计细节,你看它是一直会跟着这个鼠标,有五个彩色的圆点,你鼠标移动起来,这个圆点一起移动,看起来非常的有交互感。 front and design 呢,是 anthropomorphic 推出的 skill, 大家可以相信 xfopy 的 审美出来的效果都非常的有独特的质感。第二个 remote skill, 一个用来升高级视频的 skill, 那 比如说啊,我想要做一个介绍 openclaw 和 skill 的 科普视频, 它呢就能很快地给我做出一条视频,二十秒的时间,里面的图文格式化动效都非常的丝滑高级,也非常适合做数据的格式化,像这种让周报图表动起来的效果是不是也蛮不错的?或者呢是做一个产品介绍的视频,可以看这条 看整体是不是非常的有质感,感觉是那种直接能用的视频。那 remotion 呢,是以图形元素为主体的视觉风格,非常适合去做一些比较冷静的或是高级的一些视频内容。 最后呢,我们就要讲一讲 skill, 它的安装方式大致分为三类,第一种的话就是手动安装,因为 skill 本质是一个文件夹,所以呢,你可以直接从 github 或者是 clonehub 上面下载这个 skill 的 安装包,解压之后直接就拖到小龙虾的文件夹下面重启一下就可以直接使用了。 那第二种是半自动的安装,你只要找到了这个 skill 的 在线链接啊,直接丢给小龙虾,让它自己去安装就更省事一些。 第三种是全自动安装,你甚至都不需要知道这个 skill 叫什么或它的链接是什么,你只要提前的安装一个 find skill 的 skill, 就是 让它自己找 skill 的 这个 skill。 那 比如说现在呢,我需要你做我的投资顾问,你呢?先去搜索一下需要具备哪些 skill 才能做好这件事儿。 好的,就可以看到它自己会去技能库里巴拉巴拉巴拉的一通搜索,然后找到最匹配的几个 skill, 最后我们确认一下想选哪一个,一般呢选个星比较高的那几个 skill 啊,直接就下载安装就可以直接用起来了。 好的,以上呢就是 skill 的 全部实操介绍, skill 的 本质呢,其实就是让你的小龙虾叠各种 buff 啊,技能叠齐了,只要你敢想,它就能帮你搞定。 今天这期视频呢就到这里啦,欢迎在评论区里分享你用过的神奇的 skill。 下期我们再聊一聊怎么手搓一个你自己的 skill。 那 如果这期视频帮助到你的话呢,记得点赞收藏关注。
4280Lala罐头 01:59查看AI文稿AI文稿
01:59查看AI文稿AI文稿今天给大家分享三个超级有趣且实用的 scale, 每一个都能让你脑洞大开。首先第一个 pua 点 scale, 这是一个可以让 ai 在 调试和写代码时更有压力,更高效的技能。 不止人会被 pua, 连 ai 也要被 pua 了。它的亮点是在于把阿里字节、华为、亚马逊等互联网公司的文化抽象成十三种 pua 话术,然后用这些话术去 pua ai, 让 ai 在 写代码时更努力、更主动,更能提升效能。 触发方式很简单,就是斜杠 pua, 然后加上加油,别偷懒,你怎么又失败了等等 这些技。这个技能适用于所有场景,尤其是在 ai 多次失败卡壳的情况下。 第二个技能更牛逼,叫吹牛逼点 skill, 这个技能的作用就是让你能够在任何场合下都游刃有余的吹牛, 一句话就能帮你搜索分析、下载图片、视频片段,模拟对应的场景绿化,让你能够在短时间内成为某个行业的行业专家,并且知悉各种行业黑话。 他的出出发方式也很简单,就是斜杠点吹牛逼,输入快速帮我了解某个行业,或者说我要去某某行业吹牛 等等。第三个技能非常有意思,叫人格蒸馏点 skill, 它其实是一个合集,它的原则是万物皆可蒸馏。比如把巴菲特、乔布斯、马斯克这些名人的思维框架、决策风格、表达习惯蒸馏成 ai 技能, 一键加载就能让 ai 用他们的思维方式去帮你思考、决策、写东西。甚至还有人把同事、老板、前任也蒸馏成了 scar, 太搞笑了, ai 时代,你想蒸馏谁?好了,今天的分享就到这里,感谢观看,拜拜,下期见。
312PM.姜同学 02:23查看AI文稿AI文稿
02:23查看AI文稿AI文稿我刚学完 open cloud, 发现呢,其实打造一个属于自己的 skill 根本就不是很困难的一件事情。我现在用一分钟左右给你讲明白, skill 它不是一个提示词,而是一套工作方法。 这个时候呢就需要你回到自己的一个业务或者工作流程中理顺它。比如说我的这个工作是摄影, 那你假设你要去产出一篇爆款的文章,你需要经过哪几步?首先去收集热词,收集现在这一两个月行业内的一些关键词或者一些爆款的文章。我们收集好这个之后呢,我们再去 根据这个去写出文案。我的一个思维方式是怎么样呢?要去怎么优化它的开头,优化它的结构, 然后这个我要教给他,因为你要把 open cloud 呢当做一个人,就比如说你公司新来了一个员工,如果说你什么都不教他,让他用自己的方法去发布这个报文,那很可能就是出现一个错误的情况,你要先教给他一个具体的工作流程。 而且 open cloud 有 一个非常厉害的点是在于它可以定时或者是固定的帮你去完成一些重复机械化的工作。就比如说像收集选择题,你可以让它每天早上的几点几点钟帮你去整理好,然后发送到你的邮箱,或者是帮你放到电脑的一个表格里面。 你搞清楚了自己的工作流之后呢,可能很多人的表达能力比较差,或者是说你自己的总结能力比较差, 你把它写出来的那个 skill 呢?它的文字描述非常复杂,比如说你让它第一步怎么怎么做,第二步怎么怎么做,它是写的很庸常啰嗦,可能有很多无效的关键词,这个时候怎么去优化呢? 在 ai 时代,你要学会就是去多用 ai, 帮你去完成学习 ai 的 事情, 就比如说你可以去问豆包或者是各种的大模型,就比如说你可以帮我做一段直接能给 open class 使用的提示词。这里我再分享一个平时我自己修改文案的一个小窍门, 就是呢,你可以做好文案之后呢,你去让 ai 作为一个挑剔的用户去给你的文案挑刺,让他去批判。 然后呢,改出来的内容呢,你再丢给另外的一个大模型,让他又以一个挑剔的观众去改,这样你反复往复呢,就能把你的文案给优化的非常好。 ok, 今天学到这里,明天学什么再给你们分享。
97靖宇的追梦日记 02:29查看AI文稿AI文稿
02:29查看AI文稿AI文稿如果你用 openclaw 但从不装 skill, 那 你等于在用一部没装任何 app 的 智能手机。系统很强,啥活也干不了。但 clawhub 上技能超过五万个,怎么选?过去一周安装量断层领先的五个 skill, 今天我直接给你标准答案。 先说怎么装,一分钟搞定。我们打开永冻虾七二四 claw, 打开后点击右上角的兑换码输入一一一输入后即可免费使用。接着我们点击左边的技能,就可以看到所有的 skill 了。再说 skill。 首先第一个 find skills 总结,技能导航仪, 它能从超过二十万个 skill 里精准筛出你需要的,按场景、技术战热度排名、几秒定位、高匹配工具,筛选时间从几小时缩到几分钟。它是公认第一个该装的入口级技能,没装它,你连有啥好 skill 都不知道。第二个, superpowers 总结,开发全家桶, 内置 t、 d、 d 系统化调试、代码审查、子代理、驱动开发等二十多个子技能,覆盖从理清需求到写完自检的完整开发链路,社区公认,这是最值得装的单 skill, 装了它,其他 skill 才能真正串联起来发挥威力。第三个, caveman 总结,省钱压缩包,通过智能压缩 prompt 来减少 token 消耗,让上下文窗口容纳更多有效内容,直接降低 a p i 调用成本。 github fifty three six k stars 日均新增一点八 k, 适合所有觉得 openclash out token 太快的用户。 第四个, versatile react best practices 总结, react 代码规范器, versatile 官方出品,内置四十五条以上分级规则,强制 ai 遵守、组建、拆分、状态管理、性能优化等最佳实践 实测,起用后 react 项目 bug 率降约百分之四十,页面加载时间平均减六百毫秒,稳居编程类 skill 安装量第一。第五个 skill creator 总结技能定制工厂 anthropic 官方出品,你用自然语言描述工作流,它自动生成标准 skill 文件封装、团队规范和个人调试流程 社区反馈。用后重复性工作自动化率可提升约百分之八十,把个人经验变成可附用技能。这五个技能是层层递进的关系,先用 fine skills 找到合适工具,再用 superpowers 搭起开发主干,靠 cavemen 压低成本,用 react best practices 保证代码质量。 最后用 skill creator 沉淀你自己的经验体系,五个技能够成完整闭环。关注我,每天分享 openclaw 生态真正能用的硬核干货,让你不再被五万多个 skill 淹死!
 03:21查看AI文稿AI文稿
03:21查看AI文稿AI文稿之前我又给大家分享一期如何去从零到一写自己第一个 skills 的 视频。后面呢,有很多学习圈的朋友都在反馈,用 cloud code 写出来的 skill 要么就是太啰嗦, 要么就是不好使。那今天我呢,来分享一下 cloud code 创始人团队亲自总结的写好 skill 的 核心技巧,帮大家呢避开去写 skill 的 雷区。 ok, 我 先破一个最常见的误区,就是很多人以为 skill 就是 一个 markdown 的 文件,写几行说明就完了。但 skill 本质是一个完整的文件夹,可以去包含脚本、数据、资产配置文件,甚至是动态钩子。搞清楚这一点,我们再来去看具体的编辑技巧。首先第一条,不要去陈述显而易见的内容, code 本身对编程啊已经非常了解了,你不需要去教他什么是函数,你要做的就是告诉他那些打破他默认思维的方式和信息。 我举个例子,比如 antispac 内部在写前端设计 skill 的 时候呢,不是去教 cloud 怎么去写 css, 而是明确告诉他不要用 enter 字体不要用紫色渐变。就这一句话,设计品味呢,立刻就不一样了。第二条呢,一定要有易错点的部分,英文叫做 gorgeous。 官方呢,透露,任何一个技能里面,最最核心价值最高的部分其实就是易错点。因为 ai 经常会在同一个地方翻车,你只要把你平时发现他最爱搞错的地方给他记下来,当成错题本塞进技能里面,而且随着日常使用,发现新坑就往里面去填,这个技能就会越来越好用。 官方呢,有很多很厉害的技能,一开始也是几行字加一个易错点,后来呢,再慢慢的去长大,变得更多的。第三条呢,就是要利用文件系统去做渐变式,譬如什么意思?就是不要把所有内容都堆在一个文件里面,你可以把详细的 api 说明放到 references 杠 api 点 m d 里面,把模板文件呢放在 excel 目录里面。 主文件只需要去告诉 cloud 这些文件在哪里,他会在需要的时候呢,主动去读,这样既保持了主文件的简洁,又不损失任何的信息。第四条就是不要去把指令给他写死。 六是要被反复使用的,每次的场景都不一样,你需要去给 cloud 提供完整的任务的核心信息,剩下的让他根据具体情况自己判断, 管太死呢,反而限制了他的能力, ok。 第五条也是很多人去忽略的一点, skill 的 一个描述字段不是给人看的,是给模型看的。每次对话开始的时候, cloud 会扫描所有 skill 的 描述,来判断当前这个请求要不要去触发某个 skill。 所以 描述字段必须精准的回答一个问题,什么情况下应该用这个 skill 写成工作总结,哎,没用,写成触发条件才有用。当然了,官方呢,也分享了很多的进阶玩法,比如说给 skill 去加记忆, 用日历文件或者 seeklight 存储历史数据,比如内置现成脚本,让 cloud 把精力放在决策,而不是写模板代码里面。 比如呢,设置按需激活的动态钩子,比如杠 careful 模式,专门去拦截 r m 杠 r f 这类的一个温写的删除命令。最后呢,官方也说了一句很实在的话,它们内部有很多强大 skill, 最开始也就只有几行指令,加一个避坑的列表,是在不断使用,不断踩坑,不断补充之后才变得越来越好用的。 所以先动手,边用边叠带才是叠好旧的一个正确姿势。 ok, 如果你对 ai 感兴趣呢,也欢迎去了解啊江学长, ai 学习圈里面呢,聚了一批真正在玩 ai 的 朋友,平时呢一起交流,一起折腾。我们也刚刚结束了我们的玩扣定的训练营打卡,目前也有两千多位新友了。那如果感兴趣呢,也可以去在评论区回复。
725清华姜学长 04:18查看AI文稿AI文稿
04:18查看AI文稿AI文稿这个是我用一个 skill, 一 句话让 ai 按照我的品牌标准直接输出的电商详细页文案。这个是另外一个 skill, 每天呢自动帮我生成 ai 行业日报, 有招标,有来源,打开就能看。还有这个 skill, 我 把一份三十页的合同丢进去,它自动的按照我们公司的红线标准标红了所有的风险条款。那在以前,这些事情每一件都要折腾半天,现在装上 skill, 一 句话就搞定。哈喽,大家好,我是冉冉,那今天这期视频呢?我们一起来看一看。 skill 去哪里找? 五大玩法,还有怎么样自己去做一个,把自己的工作流程自动化。我也做了一个文档,总结了所有的资源。再说一下 skill 是 什么,那白话来说呢,就是一份写给 ai 的 sop, 你把干什么,怎么干,参考什么资料,按照什么标准输出,打包成一个文件夹, ai 拿到以后就自动照着执行了,就像你给新员工了一份岗位手册,他照着做就行,不需要你每一次口头交代。而且呢, skill 是 一个开放标准,写一次,你导入到任何其他的 ai 都是可以用的。 先说一下像 deepsea、 豆包、 kimi 这些能不能用 skill, 如果你用的是网页版,那目前是不行的,因为它们是纯对话模型,没有本地文件的读写能力,没办法直接加载 skill 的 文件夹。但是呢,有两个变动的方法,第一个是用 kimi code, 它可以像 cloud code 一 样来读写本地的文件。那还有一个是,比如现在有很多的开源平台是支持 deepsea 的 a p i 作为底层模型的,同时呢,又有 skill 市场,相当于用 deepsea 的 脑子加上了 skill 的 专业能力。 接下来呢,来说一说怎么样去找到好用的 skill。 我 帮你整理了几个最好用的 skill 商店。首先是 lophop skill 市场,收入超过一万个。 skill 有 中文界面, 按照分类浏览,包括但仅限于像 ppt 制作, pdf 处理,网页抓取,写作优化都有。每一个 skill 都有评分和安装说明。 skills m p 目前是最大的 skill 聚合平台,收入超过七十万个开源 skill, 支持按照职业来筛选,每一个都标注了四大数和质量评分。 c 社的官方 skill 仓库也在 github, 质量最高,那 github 也有社区整理的 skill 百科全书, star 超过一万三, 按照领域分好的类提醒一下哈,如果你用的是个人开发者分享 skill, 在 你直接让 ai 学习之前,最好先让 ai 帮你扫描一下代码, 避免有一些安全病毒隐患。优先使用 star 数高的官方维护的仓库。我们再来说一下 skill 怎么装,我们一般来分为两种方式,一种最快插件命令一键装。比如说你下载一个 skill, 打开 cloud code, 直接出驻一行指令,回车就装好了。 然后你直接说帮我做选择题调研, cloud 会自动调用这个 skill 来处理,不需要你手动地来指定。第二种,手动来装,这个适合从 github 下载的第三方 skill 下载解压之后,把整个文件夹复制到 cloud 的 的路径下面就可以, cloud code 启动以后自动发现,不需要额外配置。但问题来了, 如果说你找不到自己用的 skill, 或者说你每天的工作也比较 special, 没有一个通用的 skill 能够去覆盖,该怎么办?答案呢?就是自己做。 a 社官方有一个 skill creator, 专门帮你生成 skill, 装好以后直接说你想要做什么。 skill creator 会自动地帮你生成全套文件。 skill md 写好了,角色设定和回复流程, reference 和 scripts 的 结构也搭好了, 但是呢,这个只是一个八十分的通用模板。你再把你的售后政策文档、产品参数表拖进 reference 的 文件里,跟克拉克说,回复时候必须严格参考 reference 里面的售后政策,它就自动地把你的资料引入到提示词里了, 从零做晚五分钟,说几句话而已。那正确的姿势就是 skill creator 来出题稿,你用你的经验和资料喂成一百分,你的行业经验越深, skill 越好用, 因为这些经验是 ai 在 互联网上学不到的。最后呢,来说一下 skill 的 文件结构,你搞懂了呢,就可以去改任何的 skill 核心呢?其实总共就三样东西, skill md 是 灵魂文件,写了干什么,什么时候触发执行步骤。 这个就是岗位说明书。 reference 文件夹放参考资料,品牌手册、公司规范、行业数据。 ai 在 工作的时候会查阅 scripts 的 文件夹,放执行脚本,自动刷数据,自动格式化输出,你不用自己写, 让 cloud code 写就可以。任何开源 skill 都是这三样东西的排列组合,现在就去试试吧。我是冉冉,欢迎大家关注我,一起用 ai 升级自己的人生,下期见了,拜拜!
70张然冉 15:22查看AI文稿AI文稿
15:22查看AI文稿AI文稿现在都二零二六年了,你是不是还在用 k l q b id 一 来去开发 stm 三二单片机呢?很多新手同学想快速通过 ai 来学习单片机,却卡在了环境配置和软件安装上面。那 前几天呢,我分享了一个强制开发对比的视频,很多朋友也过来问我怎么才能让 ai 自动地去编辑下载到开发版上,不需要借助这些图形界面的软件。那这两天我也专门优化了一下自己的 stm 三二工作流,并且将它分装成了一个 skill, 彻底告别了 qbit 一 和 qbitmix, 让 ai 从 环境安装项目搭建,编辑下载,全链路自动处理。那我们的关注点只需要放回到编码本身上就可以了。那接下来我就和大家分享一下这个 skill, 并且演示一下如何去使用。 oh my god! 好, 那先跟大家介绍一下我们的硬件准备啊。首先第一个是我们的这个 st link 啊,这个是一个破解版,十块钱左右。然后这个是 st m 三二单片机啊,适合新手的。呃, 是 f 幺零三 c, 那 这个开发板大概十五块钱左右。那今天呢,我们就用这个和这个来跟大家演示一下。嗯,首先呢,这个开发板上面有一个灯,然后我们还准备了一个 usb 转串口的 工具啊,那今天我们主要是用我这个 skill 给大家演示一下如何创建一个这个单片机的工程,然后呢,让这个灯闪烁起来,并且在串口中输出它的闪烁频率。那我们现在就先把线接起来啊。然后这个单片机呢,是没有 reset 的 引脚的,我们只需要把 三点三伏还有肩带和两个通信的胶 clock 和 s w 加上去就可以了啊,然后这里正好这个线序就是这四个并排的,然后这个 reset 不 接,我们就把这四个直接插上去 好,因为我们这个供电呢,直接是用这个 st link 供电,因为我们今天演示的是一个非常轻量级的东西啊,可以看到我这个里面现在是有程序的,它已经是在上树了,并然后把我们的窗口也接上去啊,然后我们来看一下它是 com 三,我们这些都准备好啊, 好,我们已经创建好的一个这个测试工程啊,我们今天还是用这个 tree 来跟大家演示,然后我这个 skill 已经配置在 tree 里面了。 然后先跟大家简单介绍一下它整个的一个流程,就是做环境检测,然后,嗯,有一个交互式的去和用户去讲,然后去配置,因为我们知道在 s t m 三二中啊, 我们要开发什么单片机,我们的时钟啊,一些基本的硬件配置,比如说用 q b mix 是 可以配的,那是否要起用这个 hell, 然后是不是要用这个 atos 这些啊?如果大家不装官方这些软件的话,那我们还是得去配这个啊,但不一样的是我们这里使用的是 c mix 去编辑,最后呢我们会把这个烧录也给完成。 那整个这个过程呢?首先第一个环境检测呢,这个 scale 呢,是走了两条路啊,那首先他会去看你的电脑啊,如果你电脑是 windows 的 话,会推荐去装这两种 linux 终端,这样的话 ai 在 执行这个炫命令的时候呢,就相对来说友好一点啊,整个比 c m d 和 power 要好很多啊,如果你没有装这个的话,那你肯定是得到的是 windows 的 一个 power, 那 有可能我这个 scale 会去帮你去安装这个东西啊, 这里跟大家补充一下,怎么去改这个 tree 的 这个 bash 啊?这里可以看到我默认的 bash 不是 power shell, 然后每次加新的,包括 ai 用的呢,它都不是这个 power shell 啊,就是在这里选这个默认配置文件,如果你装了的话,你可以去切,那我现在切到这个 m s v s two, 然后这里有一个终端配置文件。这里我们装了以后呢,我们要把这个加上去啊,自定义的 就可以了。这样的话,我们基本上 ai 默认是在使用这个终端,但是在群里面呢, ai 有 时候会用这个终端去写 power shell 的 这个指令哦,那这个时候你就需要在这个规则里面,你要去添加一个全局的,然后你就要告诉他 默认的终端是一个什么什么什么,然后要使用什么什么什么。因为这里我没有加,是因为我每次都是到我的项目规则里面去加的,这里我们可以加一个全局规则, 这个加一个这个啊,我们把这个保存成一个全局的,那 ai 就 不会出现第一次使用的时候在这个里面输 power。 呃,为什么不推荐用 power 呢?因为这玩意权限管控太严了,然后你会发现 ai 经常会第一次会报错,然后再去修改。这个无疑是对我们 token 和时间的一个最大的浪费哦, 而且很多的命令也没有资源呢,也不是很好,所以建议大家用这个啊。 好,我们让它加载这个 skill, 然后帮我们出画一个 stm 三二的单片机项目,还有我这里这个 bios 默认已经是这个了啊,这个我之前已经装过了,所以我这里是 msvsto, 这个大家可以早点去装了,然后这里它会去检测我们的 需要这个环境啊。首先第一个是我们的编辑器交叉编辑工具链,然后还有一个是 cmake 的 程序,还有一个是拎讲,然后是我们 s t link, 就是 我们这个烧录器的这个烧录的程序,然后 open ocd 也是一个烧录程序啊,这两个 都推荐大家去装,然后有可能都会用到。好,这里他已经看到了我所有的这个 g c c 的 这些东西啊,然后现在是因为我的电脑里面我已经把这个 q b mix 和 q b i d e 都给卸了,所以这里它没有检测到这两个软件,那工具呢?就会走这个命令行的去安装,然后这里已经所有发现了我之前安装的所有的,如果大家没有的话,呃, scale 会自己去帮大家去安装哦。然后这个就是我们的交互式对话,就是刚才的第二步 项目配置,那我们现在使用的是这个最入门的就是这个幺零三 c 八 t 六这个,然后我们就选择这个就行了,如果你有别的型号,你就在这里去输就可以了。然后这里我们就使用这个 hell 加 c 啊,大家可以用 c 加加,如果你不用 hell 的 话,就使用原声的 arm 指令的话,也可以去选这种组合。 这里我们做一个简单演示,我们就用 hell 加 c。 然后这里是配时钟源啊,因为我们外部是 八兆的,然后它的主屏是我们要配这个 hse 啊,我不确定它能不能配到七十二兆,大家可以去试一下,要不我们给大家试一下吧,我没记错应该是最高是四十八兆,我们可以试一下,然后我们因为刚才是说要演示 led 和串口啊,这里我们可以选上,比如说其他的大家可以去想,比如说 s p e, 然后比如说还有什么 iphone c, 这个都可以写啊,那没有的话我们就先不写了,这里是一个开放性的问题啊,比如说你可以去说我想用这个开发一个 带屏默德硬件设备啊,我们可以去讲这个话说开发一个,然后这种开放性的回答呢,他就会进一步的去跟你去提问啊,你可以提交一下让他看。 这里就会给到你一些建议啊,比如说你的定时器, p w 脉冲啊,这些 g p l 的 方向,就就和你一键相关的, ai 就 会协助你去配置啊,这里我们就再告诉他,就 我们就不配了,就是给大家演示一下啊, 这里其实对模型的要求还蛮高的,因为我自己是比如说用 kimi, 呃,还有其他应该是不行的,包括这个 deepsea vs flash, 我 还是要用好一点的模型,那有空呢,我也可以跟大家去。嗯,测评一下国外的模型和我们国内的模型 各家的模型能不能完成同样的任务,大家有兴趣的话可以去阅读一下我这个 scale, 其实我们用的还是开源社区和官方提供的一些资源,因为官方的 github 里面,其实它所有的 help 资料都是开放的, 然后对于阿姆的一些看上社区资源是非常丰富的啊,因为阿姆的交叉面工具链本来就是一个很容易获得的东西,然后 stm 三二单片机呢,它又是一个阿姆单片机,然后 c 面肯定价,这些都是非常容易获得的,我们只需要 合理的将它组合起来,就可以完成我们这个 stm 三二的这个开发了啊。那这里整个过程实际上是帮你下载了一个叫做 stm 三二 cmake 的 一个开源仓库啊,然后这个库里面包含了所有的 stm 三二芯片, 包含了所有的 stm 三二芯片的 hell 的 这个抽象层的这些接口,还有还有它所有的组建啊功能呢,就类似于我们的这个 qb mix 这个软件,因为 qb mix 是 一个图形化,大家可以在上面勾勾选选就可以,就可以把我们整个 stm 三二这个 hell 的 所有的配置全部弄完,最终生成代码,然后在 qb ide 里 面去使用啊,那原来我们的整个开发方式呢,有可能我们的代码是用 vsco 的 或者说其他东西去编辑的, 但是我们的编辑和整个的稍后下载可能还是要用到官方的这个 ide。 那 整个在我们的 ai 开发的这个工作流里面 呢,实际上很不方便哦,我们仍要去点它,但是实际上它也有一些 c i 的 命令,可以让 ai 去跟这个 ide 去交互,但这个前提我们还是要去下载这个 ide, 并且用 q b mix 去手动去配置项,最终呢要去点一下这个生成代码, 然后后面才可以由 ai 全部去介入啊。那我探索了一下呢,实际上也可以绕过这个 q p mix, 如果下载了这个 q p i d e 的 话,实际上它对这个便宜的这种飞镖的 s t link 支持还是比较友好的,并且还能给它升级。呃, 也包含了我们需要的所有的工具链啊,大家可以去下载一个,但是你可以放那不用它,只是用它里面的工具,当然不下载也可以,我们的 skill 会给大家自动去下载其他的工具啊。好,这里我们看到基本上已经把代码已经简单的代码已经快要生成完了,这里已经把这个号的这个 配置文件生成了一个,接下来的过程就是去做这个 cmake 的 配置,当我这个调呢还没有完全的调试好,好久还会去更新,但现在已经是可用了,只是说在整个像配置过程中,可能对 ai 来说会花一点时间, 这里大家一定要科学上网才可以啊,它这个 cmake 会自动去下载你选的芯片那些资源,然后我这里刚才没有去 科学上网,所以它出现了这个网络不通的情况,但是我原来本地里面是有 ai 呢,自己去找了本地的去用啊,我们就不用去管它。接下来呢,它就会去配置这个 cmake, 然后把 cmake 配完以后会生成一个慢函数,这样的话就可以编辑,然后下载 整个项目的一个框架就搭建好了。好,我们稍等了一会呢,它全部都弄完了啊, 可以看一下他执行的什么命令啊,先是翻译啊,然后稍入验证,这个他应该是没有做啊。大家可以看到这个蓝色灯在闪啊,那是因为我这里已经有这样一个程序了,让他稍微改一下,将这个五百毫米翻转一次,加快啊,加快可能看的更明显一点啊。 好,我们再让他把这个代码里面的日期稍微改一下啊,其实可以看到他生成代码和我们用这个官方的这个 id 自动生成的没什么两样啊,记得都非常的标准啊。那整个我们这个流程做完以后呢,那我们就可以直接和 ai 写作去改代码了,那我们整个的 编辑和下载呢,就不需要再去通过原来的 id 手动去点和去弄了。这里可以看到他增加了我的这个要求的前缀啊,并且呢把这个翻转的频率呢改到了两百毫秒,这个 hell delete 默认是一毫秒,如果我们这个灯变快的话就是成功了。 好,这里可以看到我们已经检测到了,然后再刷了,已经刷完了,刷完看到这个灯是没有亮,这里我复一下也不会亮。没有亮是为什么?因为我前面是故意挖了一个坑,因为 ai 给到的这个引脚呢,和我们的硬件不一定是一样的。这里我们肯定是要去查一下我们开发版的原理图啊,我们可以看到我们的这个 led 呢, 这个红灯呢是直接接地的,所以是常亮的,因此我们看到的这个这个 red, 这个第一,这个二极管是红色的,是一直亮的,只要通电就会亮,然后我们现在是要控制这个 另外一个蓝色,就之前刚才闪烁的,那它是 p c 幺三啊,这个是直接接到我们芯片的,那它是直接接到我们芯片的这个引脚 p c 幺三上面,所以实际上我们 这个 p b 零是错的啊,因为之前 ai 给的时候呢,他只是给你一个选项,但实际上是要我们自己去确定的,因为目前这个 style 还不是很完善,没有办法去将市面上所有的硬件、主板等等等等全部都去弄了。因此呢,我们首先我们要把这个 p b 零啊,改为这个 p c 幺三, 然后告诉他这是我硬件真实的 led 灯连接的引脚,然后我们要去确定这个 p i 九和 p i 幺零是呃, t 叉和 r 叉,这里我们可以去看下这个原理图 啊, p i 九和 p i 幺零,那如何去确认呢?实际上我们是要去看这个芯片的手册,去确定这两个引脚能不能附用为 uart 接口。当然我们的这个视频呢,就跟大家演示这个 skill, 就 不 去看这个啊,那我这里因为前面我是没有把这个线接上去的,那现在我就把这个线接上去啊,我们这个串口就直接三根线,一个 t 叉,一个 r 叉, 然后接到对应的这个板子的 r 叉和 t 叉上去,然后再接一个 d 就 可以了,然后它的 t 叉是 pa 九,然后我们这里的 t 叉是这个灰色的线,然后 r 叉是白色的线,所以我们的这个灰色的线在这边是 t 叉啊,我们就要接到这个 r 叉上 p a 幺零,然后我们的白色的线是 r 叉,所以我们要接到这个 t 叉上面是 p a 九。最后呢,我们这个黑线是接地啊,我们就接到这个 d 线上面, 然后这样的话我们可以看到已经有数据在传输了,这个这个串口转 usb 的 板上面的这个通信灯是一闪一闪的,我们这个时候看我们的这个串口是已经 ok 了,为什么 led 灯不闪?是因为我们的引脚配错了,这个当时这样流是为了给大家演示一下调试啊,那我们现在就告诉他,让他去改了,然后 大家去帮我们自动下载进来。这样这种事情呢,我们可以自己去改啊,不用他去代劳,我们直接改这一句就可以了。但我们现在是跟大家演示这个 skill 和 ai 写作的一个工作流程。 好,这里已经刷进来了,刷进来以后可以看到他自动复位以后,这个灯就闪起来了,然后我们的打印这里是有催化的这个说明。好,那我们整个工作流的演示就完成了,如果大家需要的话,可以建三连私信我。 好,本期的分享到这就结束了,如果大家有需要这个 skill, 欢迎点个关注或者三连都会分享给大家。那最后我想讲一下关于这个 cy 秘密,在 c i 时代呢, c i 命令真的非常的重要,特别是在强势开发领域,实际上我们有非常丰富的 c i 命令资源,不管是我们的编辑器,还是我们的 mac, 还是我们的一些脚本等等等等,实际上这些庞大的东西都是构建在命令行 的,虽然我们用到的很多软件有图形化界面,也可以写代码,也可以去编辑去 delete, 但它们背后仍然是排量的 命令行工具去做支持。所以大家自己手头上开发的其他枪械设备,可以去让 ai 探索下自己现在的工作环境,是否可以完全的命令行话,因为未来只要 ai 能接入就可以做人机协同,所以未来一定是终端为王哦。 接下来呢,我也会陆陆续续再跟大家分享一些其他的调试设备的开发技巧和调试技巧,以及如何使用 ai 搭建我们全自动化的开发工作流。如果你对我的视频和内容感兴趣,欢迎三连点个关注。谢谢,我们再见!拜拜!
3045苦苦菜(Coding) 01:57查看AI文稿AI文稿
01:57查看AI文稿AI文稿我这半年一直在写 skill 啊,我越来越觉得就是大部分人对 skill 的 这个理解有点偏了,就包括我下面的几个技术的小伙伴,有很多人觉得它是一个插件市场,就哪个热门就装哪个,今天就是这个 superpower, 两万星,我就装这个,明天那个设计的这个, 呃,这个 skill 很 强,我就装那个,其实这个方向不太对哦。 skill 它更多的是像一个工作流程,就是你不是在给 ai 装一个外挂,你是在告诉他我在这个事情里面我应该怎么去做。强如 open ai, 它也是最近在做类似的事情, 五月十一号它发布了一个新的 deploy engineer, 说白了就是把工程师派到企业里面来, 跟这个企业,跟这个业务团队一起去看这个流程,看这个公司到底是怎么运转的,然后哪些环节啊,就耗时间, 哪些数据,毕竟必须接进去啊。强如 open i, 它也不会说给你一个 gpt, 给你一个 codex, 你 自己去琢磨吧。然后你装一个 skill 啊,就天下无敌了,所有的东西,所有的业务都能用得起来。其实不是的, 就 skill 的 话,其实也是一样的,你就是你,比如说你每周都要去整理这个会议纪要,呃,整理这个日报, 你不会告诉 ai 说,哎,帮我整理一下日报,你肯定是根据这个每个领导的这个喜好,比如说这个领导他喜欢,哎,标一二三点去这个分开给他标,有些领导他喜欢这个细节啊,写的特别多,对,每个领导不一样,然后你要针对不同的领导,你可能就会去写 这个不同的 skill, 对 吧?所以说无脑的参考别人的这个结构是没有用的,你必须要改成你自己的这么一个流程,否则他在热门 再怎么样的好的一个 skill, 它也是别人的一个工作习惯,如果大家觉得我说的有道理,就关注一下我,然后我下一条的话,我会啊,教大家怎么去生成自己的第一条 skill。
 04:22查看AI文稿AI文稿
04:22查看AI文稿AI文稿如果你接触了 ai, 你 一定听过 skill, 今天呢,就来讲讲什么是 skill。 掌握了 skill 以后呢,你就可以一句话跑完原来要交付半个小时的工作流,还可以把别的高手的流程搬到自己的 ai 上。为 了方便大家理解,我们可以用一个类比来讲解这个问题。假如 ai 是 一个厨师,每一次厨师再重新做菜的时候,他都要重新跟你对一次菜单。 ai 也一样,当你说帮我搜寻 ai 资讯的时候,他会马上反问,怎么搜集,搜集哪个方向?要近几天的还是近一周的?那么完成一个任务呢,就需要花非常多次的交互,确认具体的实现方法和实现细节,才能梳理出一版你满意的流程。 更头疼的是,下次你再让他做同一件事,他还是不记得怎么实现,于是又要重复所有的问题,每一次都要从头教。比如之前你如果已经完成了一次搜集 ai 的 资讯了,理论上来说,他应该要知道你的喜好了。但实际上,不同对话框的 ai 是 不共享记忆的。所以呢,当你跟他说再扫一遍 ai 资讯的时候,他又要再次问你, 于是 skill 就 出现了。他就像这本菜谱,厨师只要一听到要做一份番茄炒蛋,就不用再探讨多余的番茄炒蛋, ai 拿到 skill, 也不用再问具体怎么实现了。 所以你看, skill 就是 这本菜谱,一份直接告诉 ai 怎么做的说明书写一次, ai 永远记得再也不用跟它反复交互来实现这个工作流。那 skill 在 系统里面究竟长什么样呢? skill 最核心的文件就是 skill 点 md, 它本质上呢,是一个 markdown 文件,而在最上面的这一段, name 和 description 是 这整个 skill 里面最关键的部分。首先 name 它代表的是这个技能的名字,而 description 呢,会描述这个技能用来干什么,什么时候被触发。 而 ai 呢,就会根据这一贯 description 的 内容去决定我在执行的时候要不要去触发这个 skill, 而里面的正文呢,就会记载着这个 skill 具体的执行步骤。 skill 最聪明的一个特点就是它是灯亮解锁的,比如说,当你说帮我扫一下最近的 ai 新闻的时候,它就会根据 skill 的 名片来判断哪一个 skill 可能和当前这个步骤是相关的。而这里的名片指的就是我们刚刚提到的 name 和 description 这两个字段。 那比如说,当我说帮我扫一下最近的 ai 新闻的时候,他就会发现,哎, ai radar 这个 skill 好 像有相关,于是呢,他就会读取 ai radar 这个 skill 里面的具体内容,读 取完之后呢,他就会把这个 skill 的 md 的 信息放进上下文里面,那根据这个上下文,他就很有可能会执行这个步骤。这个步骤呢,就是先第一步,第二步。哎,读到第三步的时候,他发现我们还需要去参考另外一个文件,那这个文件呢,我们就也会增量式的解锁,当当你发现了我需要去阅读其他参考文件的时候,我可能就会再去获取其他的文件, 那这样的不断增量的解锁,就可以确保我们的上下文的信息只解锁到了有关的有用的信息。通过这种方式呢,我们就可以保证上下文的信息不会过度的爆炸,而且呢,我们的 skill 也能被灵活准确的利用。 skill 的 最核心的组建是 skill 点 md, 但其实它并不只包含文字指令,它除了最关键的 skill 点 md, 这个主指令书还可以包含 python 脚本。比如说你如果想要执行一个爬虫的脚本,你可以在 skill 点 md 里面告诉他说,当你想要爬去某个网站的时候,你可以直接执行这个 python 脚本。它还可以有一些模板文件, 比如说,当你想把搜索到的信息以特定的格式存储的时候,你也可以说请参考什么什么 template 文件来填写内容。同时呢,它还可以有参考资料,比如说你想做一个网站的时候,你希望有某一个固定的参考配色,你就可以告诉他说,根据某个参考的文件,根据某个参考的网站来设计这个内容。 也就是说这个 skill 里面其实可以包含各种各样的信息,你可以把指令工具、资料一整套都打包给 ai, 存储在 skill 里面 最重要的,所以学了这些,它能帮助你什么?我总结了两个最有用的用处,第一个呢,就是通过 skill 来固化你的工作流,也就是你也可以创建一个自己的 skill。 当你在实现某一个你日常的工作流的时候,第一次使用的时候呢,你可能会比如说帮我再分类一下,帮我换个合适,帮我再精简一点,这样来来回回调了好几轮,直到得到一个你满意的版本的时候,你 可以输入这个 prompt, 帮我把刚才的这个流程整理成一个 skill, 那 这个时候呢,这个 skill 点 md 就 会自动生成你的风格格式,禁忌词,包括你在这个过程中表现出你的喜好,都会被总结到这个 skill 里面,那这个时候呢,你就可以把你反复磨合得到的最符合你喜好的工作流变成了一个你可以反复重复使用的 skill。 那第二个非常牛的能力呢,就是你可以去用别人的 skill, 你 可以直接照搬别的高手的能力。举个例子,比如说呢,我想要爬取 youtube 上面的一些视频脚本,并不知道怎么能把 youtube 视频里的脚本爬取下来,那我就直接告诉 ai 说能不能帮我搜索一下有没有关于爬取 youtube 或者是获取视频相关的 skill。 然后呢, ai 一 般呢,就可能能帮我找到一些 getop 仓库啊,或者是一些建成的 skill 可能存在某些 skill hop 里面,然后呢,跟他说帮我安装这个 skill, 那 他就会把这个 skill 安装到你的 skill 库里面,那下一次的时候呢,我们只要触发关键词,可能就能利用这个 skill 来满足我们的需求,也就是把别人的能力直接变成我们的能力, 那这就是 skill 两个最实用最现实的用处。所以如果你在用 ai 发现总是自己比别人效率低,一定要来学习这个 skill 的 用。
1044姜饼人探AI 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿codex 是 我过去几个月高频使用的 ai 助手之一,我用它做研究,写文档、做 ppt, 整理内容灵感,做网页原型。上个视频讲了 codex 基础,这期视频讲一个今年很值得先搞懂的 ai 概念 skill, 因为它决定了 codex 到底只是陪你聊天,还是能按你的工作方式反复干活。简单理解一份可以重复使用的工作说明书, 你可以把某类任务的流程规则、检查标准提前写进去,下次再让 codex 做类似的事,他就不用每次重新听你解释一遍。比如你经常让 codex 做网页,你不想每次都重复说页面不要太 ai 味,不要蓝紫配色, 这些都可以写进一个设计类 skill 里。以后你只要让 codex 用这个 skill 检查页面,他就会按那套规则去看代码、改样式,再告诉你改了哪里。 这就是 skill 最实用的地方。把你反复说的要求变成一套固定流程,那么在哪里看和怎么用 skill, 可以 去 codex 的 侧边栏这个入口里看,里面会有一个 skill 子页面, 已经添加或创建过的 skill 会出现在这个列表里。使用的时候,通常可以在聊天里输入 skill 名称,或者用斜杠跳出来。比如你有一个 find skill, 就 可以直接斜杠选中,帮我找一个适合做 ppt 的 skill, codex 就 会按 skill 里的流程去跑。那怎么创建 skill? 有 两种方法, 第一种最简单直接这样说,请创建一个 skill 以后,我给你一个网页项目时,你要先检查移动端排版按钮样式、文字层级、颜色是否太乱,最后输出修改文件和检查结果。这种叫 prompt skill, 但我更推荐第二种,先把流程跑通,再把流程固化成 skill。 举个我刚实测的例子,我想做一种白板手绘风讲解图,我先给他一个参考图,让 codex 按我的要求生成讲解图 第一版如果不满意我就继续改,比如少一点黄色纸张质感画面更像课堂白板。等到有一版我觉得可以附用,我再说。把它固化成一个 skill, 这时候 codex 会反推刚才的流程,它会把这次反复调整出来的规则写进一个 skill。 md, 这样下次我再用白板手绘讲解图, 就不用重新解释一遍审美和结构,直接调用这个 skill 就 行。如果你想让 codex 使用 skill creator, 它会按更标准的格式帮你生成可附用 skill。 我是 ai 知识派,我们下期见。
4.2万AI芝士派 02:48查看AI文稿AI文稿
02:48查看AI文稿AI文稿今天我们学用扣带斯制作 ai 爆款带货视频,一张产品白底图,用 qq 直接生成脚本达人类型,分镜头和视频提示词,做跨境都知道产品图好找,视频难做,尤其是开头的钩子怎么抓人,达人怎么设定,镜头怎么拍?英文口播文案怎么写?废话不多说,先看案例。 今天我拿一张粉底液的产品图,用抠蛋斯加 skill 加 c 蛋斯二点零这套组合拳,从零到一,做一条完整的美区 ugc 带货视频,废话不多说,上实操一共分为三个步骤。第一步,制作 skill。 我 们打开抠蛋斯,复制这段制作 skill 的 提示词, 它会根据我们的需求生成对应的 sku 压缩包,并保存到本地。这一步只需要做一次,后期再做其他产品,直接调用这个 sku, 不 用每次重新造轮子。第二步,生成 ugc 包,新建对话,再抠弹死聊天框,输入斜杠, 找到 c, 弹死 ugc 杠 c n 这个 sku, 再把产品图丢进去这里千万不要跟 ai 说帮我做一个爆款视频, 太虚了, ai 听完都想报警。我们就 sku 加产品图直接发送,然后抠蛋死会先跳出制作前的六件事。这一步不是废话,是保险,它会先确认投放地区、发布平台、成片语言、视频形式、达人类型、 视频时长与产品卖点。我们按需求填写美国 tiktok 美式英语真人口播,没有固定达人十五秒产品卖点可以让他先根据白底图去判断,再人工微调确认方向。之后扣单词会生成完整的 ugc 包,里面包括制作参数、产品与受众人物设定、图片提示词、 视频提示词, poke 钩子口播脚本和镜头清单。注意,它不是只给一段文案,它是把策划、编剧、导演、提示词工程师全部塞进一个窗口。第三步,视频生成。先纹身图,在 u g c 包里找到人物图片生成提示词, 附知道引迷局。二、点击图片生成。这一步生成的是 ai 人物手持产品。这里有个重点,人物一定要向真实的 tiktok 达人,不要精修,不要广告,不要一眼 ai 位,最好是在卧室梳妆台自然光前置手机这种感觉, 然后涂层视频,返回扣带斯,在 ug 包里找到英文视频提示词,这里我会再丢回扣带斯,让他帮我修饰一遍。重点是需要把人物和产品都标记好,并艾特出来,保持人物和产品的一致性。其实是我英文不好,怕找不到人物和产品的 位置,但不管怎样,这一步很有用,这样导入 c 单词时,就不会一句一句找谁是人物谁是产品。修饰完之后,把提示词复制到 c 单词,再加上产品图 和人物图,最后看成品。 i'm picky about base makeup because i hate when foundation feels heavy。 从产品白底图到人物出镜,英文口播镜头清单、视频提示词,再到 ai 带货视频,整套流程就好了。以前做一条跨境带货视频,要想交本,找达人拍素材,剪节奏,现在用扣袋子,至少先把百分之八十的方案跑出来, 小白也能从完全不会变成视频大神。需要这个 skill 的 评论区猪脚饭整理好了直接抄作业。最后点个关注点个赞,祝大家爆单!
2354猪脚AI短视频 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿如果你也想把自己的工作流做成 skill, 先别急着乱写提示词。 antropic 官方已经把怎么做出一个好 skill 这件事直接做成了一个 skill, 它就叫 skill creator。 这个项目最大的价值不是给你一个模板,而是把做 skill 的 完整流程直接讲清楚了, 先确定他到底要解决什么问题,再写出第一版,然后拿真实任务去测试,看结果,改文案,继续迭代,直到这个 skill 真的 稳定可用。他还会先让你把需求问清楚,这个 skill 要做什么,什么时候触发,输出长什么样, 要不要设计测试用力,这样做出来的 skill 才不会只是看起来能用。文档里还讲了一个很关键的设计原则,好的 skill 不是 把所有东西都塞进一个文件,而是拆成三层, 原数据负责触发 skill, md 负责主流程脚本参考资料和素材按需再加载,这样 skill 会更轻更稳,也更容易维护。 最后他还会继续优化描述词,让 skill 在 真正需要的时候更容易被正确触发。所以,如果你也在做自己的自动化工作流,这个官方 skill 值得直接拿来当方法论参考。
123北笙Ai 12:08查看AI文稿AI文稿
12:08查看AI文稿AI文稿openspec 和 superpowers 是 当下做 spec coding 非常出名的两个项目。在日常使用过程中,我们一定有组合 skill 的 需求,但问题是,两套 skill 的 技能命令是分散的,没办法自动触发。并且有的部分 skill 我 可能不是那么想用, 比如我更喜欢用 superpowers 的 t d、 d 执行,而不是 openspec 的 apply, 更需要用 openspec 的 archiv 能力规档 spec, 而不是 superpowers 的 一次性 spec。 怎么组合市面上的高斯大项目,让它们自动触发,互相取长补短, 怎么让整个状态扭转更可靠?这些看起来能够实现的点,在实际的开发过程中依然还有很多细节考量。 同时,两个 skill 都会产出 spec 文档,这部分也需要自然地融合在一起。 comet 就是 组合这两者产生的项目 想要做的事很直接,把 openspec 管需求的能力和 superpowers 管实现的能力接到同一条流程里,他不改这两套东西,只做组合调度。先看 openspec 这边,他很擅长管理 spec 的 生命周期, 当前需求放在哪里,变更材料放在哪里,最后怎么归导这条线是很清楚的。所以这对应于 what 部分,也就是要改什么内容。 openspec 能够很好地列出大纲,但其实 openspec 依旧有一些不好用的地方,它的 proposal 和 tasks 能说明要做什么,但不等于已经说明怎么做。 到了工程设计阶段, agent 还要补方案、补边界、补判断画面。中间这个问号就是这个的设计缺口。 openspec 的 需求澄清能力并不是那么强。再看 superpowers, superpowers 补的是 how, 是 怎么去做, 他会先澄清需求,再做深度设计,然后写计划,按 tdd 推进,最后验证和收尾。中间会不断地和用户交互沟通细节。也就是说,他把真正实现时需要的链路拉细了,两者均会产出 spec 文档。 但是如果只靠 markdown, 也会存在另一个问题,任务打勾了不代表阶段状态可靠,人事能够通过,看文档能猜出来,但 agent 下一轮回来不一定能稳定判断现在到底走到哪一步。 所以断点恢复才是核心问题。下一次绘画开始时,通常的断点恢复, agent 会先读文档,再扫代码,然后再推断阶段代码还没写, token 已经花在恢复现场上了。 comet 通过一个清亮的状态机机制来实现断点恢复,要省掉的就是这段重新找路的成本。 comet 的 定位不是再造一套方法论,它更像一条稳定轨道,把 openspec 和 superpowers 放进同一个项目流程里,让两边各做自己擅长的事,并在执行过程中对齐两边产出的文档。 openspec 管需求世界 需求是什么,题案怎么写, spec 怎么变更,最后怎么归党,这些都属于 what, 他 负责把要做的事讲清楚。 superpowers 管执行方法、头脑风暴、技术设计、实现、计划、执行、验证、收尾,这些都属于 how, 他 负责把怎么做拆细。 commit 站在中间,把 what 和 how 接起来。左边是 openspec 的 需求材料, 右边是 superpowers 的 实现方法。下面输出一条 open design build verify or shift 的 流程。 commit 不 替代 open spec, 也不替代 superpowers, 它只负责把阶段状态和 skill 出发点对齐,这样两套能力就不是两堆文档了。 proposal spec, 生命周期、 archive 状态和 brainstorming design, doc execution plan 会进入同一条 shared state, 最后落到出发规则。 open 阶段找 openspec, design 和 build 找 superpowers。 verify 阶段两边一起收口,在对应的阶段真正的触发正确的 skill, 而不是让 ai 产生触发了 skill, 但实际上是 ai 自己写的幻觉。 完整流程可以拆成五个阶段,每一段都有自己的命令和产物,不靠 agent 临场拆下一步。第一段是 comet open, 这里由 openspec 接手,打开 change 生成 proposal design 和 tasks, 先把这次到底要改什么固定住。 第二段是 commit design, openspec 的 产物会交给 superpowers 继续细划,重点不是马上写代码,而是先把边界、方案和风险讲清楚。第三段是 commit build, 这里进入工程实线, plan、 tdd、 subagent 都在这一段接上, 能按计划推进就不要临时乱跑。第四段是 comet verify, 这里 openspec 和 superpowers 会进行同步收缩,一个处理文档,一个处理代码,收尾测试要过,报告要有,需求和实现也要对齐,不是跑完代码就算验证结束。 第五段是 come to archive, 所有的需求变更同步回 main spec, change 进入 archive 状态机补充文档核心状态,这时候 open spec 和 superpowers 产出的文档会进行双向关联,到这里产出的 spec 关联文档才不会留下半截流程。所以需求不是代码写完就结束, task 勾完也不够,真正结束是实现文档和状态都对齐,使用 command 出使化之后,项目会被分成三层平台, skill 放一层,包含了 command 的 核心脚本, opensback 的 change 和状态放一层 superpowers 的 设计文档和计划放一层 斜杠。 comit 是 skill 的 核心入口,用户在使用的时候,不管当前 spec 状态如何,都可以通过这个入口进行工作。他会先检测当前 spec 状态,读取 workflow phase, 然后决定下一步该进哪个阶段。 入口先判断现场,再路由动作。当我们面对长城任务做到一半工具关掉了的情况时, 回来之后不应该重新讲一遍背景,而是直接输入 comet 继续。它会从当前 spec 状态恢复现场,不再需要重新探索项目。 如果项目里有多个活跃 spec 时, comet 会先把它们列出来。当你选择了具体的某一个 change 时,它再进入阶段判断,这样就不会把几个需求的状态混在一起。选定之后,它会定位当前阶段,比如现在是 build 就 从 build 继续,而不是重新扫描项目。 长城任务真正需要的就是这种明确的继续位置,这种设计能够极大的减轻你的使用认知负担。我们拿到 skill 不 再需要记多个命令,而是直接 comit 继续就好。 comit 会帮你把状态记住,帮你把流程走下去。支撑恢复能力的是这个轻量状态机,每个 open spec change 都绑定自己的状态,也就是说状态不是大局混在一起,而是跟着具体的状态。是 workflow 和 face。 workflow 决定走完整流程, hotfix 还是 tweak。 face 决定现在卡在 design, build, verify 还是 archive。 再往下是恢复上下文, design, doc 在 哪? plan 在 哪? build mode 是 什么?当前是否在隔离分支里? 这些字段让 agent 回来后能接上,而不是重新扫。项目验证和归档状态也需要写进去。 verify result, verified at archived, 这些字段不复杂,但足够判断下一步是不是可以继续。关键是状态不能靠 agent 手改。烟雾 commit 要通过脚本写回状态, 只有条件真的满足,阶段才允许流转,这样能减少看起来完成的状态飘逸。 commit guard 脚本就是阶段闸门,它检查文件是否存在, face 是 否匹配 tasks 是 否完成, 条件不满足就 hard stop, 只有带上 apply 才真正更新状态。 com state 脚本提供统一读写接口。 com tm validate 脚本负责校验必填字段,每举直路径引用和未知字段,一个负责改,一个负责查,状态就不容易飘。最后是 coming r shift 的 脚本,它会验证入口状态,同步 spec, 移动 change, 再把 r shift 写成 true。 需要先看效果,也可以走 dryrun preview。 安装过程如图所示,从 npm 安装之后进入你的项目执行。 commit in it commit 采用交互式命令集成,安装步骤非常简单, 说实话会先确认三件事,平台配置、安装范围。 skill 语言,你可以装到当前项目,也可以装到局目录。为了方便理解 commit 的 原理,分发的时候也支持中文或英文, 选择依赖后,相关的 skill 就 会自动就位。 open spec skill、 superpower skill、 comet skill 会部署到选定平台, specs 和 plans 这些工作目录也会一起创建好。 平台分发也交给 comet in it cloud code, cursor codex、 open code, winsole 还有其他 ai coding 平台,都按自己的目录结构放好,你不用手动搬 skill 文件。 除了完整流程,还有 comet、 hotfix, 当 bug 已经明确时,它会跳过完整 brainstorm 和 design, 直接走 open build, verify archive, 适合目标很清楚的修复。第二个是 comet tweak, 文案调整、配置调整、文档修改、 prompt 优化都可以走这条清路径,它比完整流程更清,但仍然保留 comet 的 入口和状态管理。 comet 还有一个价值,它是组合 skill 的 参考 强工具很多,但真实使用时,你常常只需要其中一部分能力,比如 openstack stack 管理、 superpowers 的 tdd 和深度设计,再加上规党能力。难点不是把文档拼在一起,难点是稳定组合嵌套。 skill 要真的触发,不能只是让 agent 看着说明访写文件,状态也要可观察,不能看起来像触发了,实际没有跑多阶段流转。 也不能看起来像触发了,实际没有跑多阶段流转。也不能看起来像触发了,实际没有跑多阶段流转。也不能每一步都靠人提醒,人工接线很容易断。 commit 把必要选择留给用户,把核心推进交给状态机和守护脚本,所以它也是一个参考,实现 skill 调度、状态机、阶段守护、规章自动化,这四块组合起来才是一套能落地的多 skill。 工作流收缩一下 openstack, 让需求有生命周期。 superpowers 让实现有方法论。 commit 把两者接成一条可恢复、可验证、可规党的流程。 从两条命令开始安装 commit, 然后在项目里执行 commit init 初步化之后就可以用斜杠 commit 加你的想法,进入完整流程。最后我想说的是, commit 留下的不是某一个命令,它证明的是一套组合范式,千套 skill。 要真正出发,多阶段流程要能自动流转 状态机和守护脚本,要让这套组合在真实项目里可靠落地。希望大家能从这个项目里学习到好用的知识,一起创造更适合自己的 skill。 接下来我们来看一段时机演示。以我本地的一个项目为例,现在我输入斜杠 compt 为我的项目创建一个电子宠物功能。我们可以看到 comet 触发了 comet open, 在 comet open 中又触发了 open spec 的 explore, 这时候 agent 会根据 explore 的 要求进行一轮项目探索。每一个嵌套 skill 在 真实出发时,都会在 cloud code 中显示 skill 的 打印。这个探索的过程比较长,我们稍微快进一下。探索完毕之后, explore 会进行多轮大碎方向的澄清,这几步需要用户进行反馈。 完成之后会生成 open spec 对 应结构的 proposal、 design、 spec、 task 等文件,并在 changes 目录下创建当前激活的需求。 然后是 comi 的 状态机核心文件出场和状态守护执行。我们可以看到,当 open 阶段完成时, agent 想要退出 open 阶段,会有强制的状态机交易,对于核心文件和状态一定得满足之后才能够进入下一阶段。 这里都 pass 通过之后, comte design 也成功被 comte open 触发了。之后 design 阶段会将 openspec 创建的文档作为上下文传递给 superpowers 进行头脑风暴,更加细化需求之后的步骤我这里不再接着展示了,欢迎大家亲自体验。下面我演示一下阶段活跃检测及断点恢复功能。 当我们在多台电脑上工作或者临时有事离开了,回来之后只需要输入斜杠 commit 继续 commit, 就 能够通过状态文件自动识别当前活跃需求。 我们可以看到不再需要重新大量的探索项目 agent 很 快就知道了当前需求的活跃状态,如果存在多个需求,也会将它们列出来供用户选择。以上就是本期视频的全部内容了,欢迎大家点赞关注 star 本项目,谢谢大家!
764Biu😉

猜你喜欢
最新视频
- 7990星探AI