多模型token的用户有哪些
使用 tokken 除了程序员和做慢剧的创作人员之外,谁用的多吗?昨天在 tokken 沙龙给我们演示如何使用 workbobby 的 学校经理给出的答案, 和另一位在我们楼下举办 ai 应用课程的徐老师观点是一致的。现在使用 workbobby 或者龙虾还有一个很大的群体,就是传统的制造业。传统制造业都在转型,都在享用 ai 来降本增效, 也都在学习使用 ai 不 同大模型的 top 来提高自己的管理效率,财务效率,客服效率和生产效率。这个现象是真的吗?传统的制造业老板真的这么焦虑?已经都开始养虾养马了吗?欢迎大家在评论区告诉我。

粉丝3.7万获赞16.5万
相关视频
 04:27查看AI文稿AI文稿
04:27查看AI文稿AI文稿我拿到小米二十三亿 token 的 时候,其实是有点懵的,不是兴奋的那种懵事就这就这也能过迪那种懵?这个是 max 套餐的十六亿,这个是 pro 套餐的七亿。先交代一下背景,小米最近搞了个活动, 叫咪蒙 over 的 百万亿 token 创造者激励计划,三十天免费送一百万亿 token, 最高给到 max 上十六亿 cash, 等值六百五十九块钱。 这个话题已经有很多博主写过了,活动也快到尾声了,五月二十八日截止,还剩不到一周,按理说不该再蹭了。但我之所以还是写,是因为我发现了一个特别简陋 特别巧的方法,几乎百分之百能拿 max 档。这个方法我一会儿说,先把活动本身聊透。咪猫是小米自研的大模型,最新版本 v 二点五 分两个模型, pro 版面向复杂任务深度适配 a 剑客和编程,在 gdp v a l a a 和 clever 榜单上开源第一。还有一个是全模态版,文本、图像、视频、音频都支持 v 二点五, pro 用的 mo 架构,总参数三零九 b 激活十五 b, 原声支持一百万 to k 上下文推理成本只有国际币源旗舰的百分之二点五, api 定价大约是国际竞品的五分之一。 你可能觉得这不就是个国产模型吗?但坦率地讲,这次小米的成绩确实够硬。 texturina 全球综合第五, labyrinth 全球第四。 open route 上周以百分之三十多的试战率登顶第一 周条用量四点八二万亿 token, 而且它是开元的 mit 协议商用自由。说真的,全球前十开元模型里,中国占六席, 小米是第一个登顶开元榜首的手机厂商回到活动,这次 over 的 计划分两部分,一部分是面向开发者的百万亿 toc 创造者激励,另一部分是面向 ainc 框架团队的生态共建。我们聊的是前者,申请流程不复杂,去 mimo 填个表单,三个工作日出结果, 通过后邮件通知、登录开放平台等权益到账就行。但很多人卡在评估这步,拿到的是赠金,而不是 tiktok plan 或者档位很低。网上常见的建议是要写详细的项目描述,要有 github 链接,要做完整的项目, 有些教程甚至建议你前后端数据库齐活,搞得跟融资 b p 似的。我一开始也这么想,然后我发现了一个更聪明的路子,就是只做一个前端,一个用歪不扣定搞出来的非常非常厉害的前端不需要,后端不需要数据库,不需要部署上线, 就是一个纯前端页面,但视觉要炸,交互要丝滑,让人点开第一眼就觉得,卧槽,为什么这招管用? 你想啊,评估的人一天看几百份申请,大多数是 github 仓库链接和 api 文档,他点开一个仓库可能还没看完 readyme 就 关了,但你给他一个牛逼的前端,点开就是成品,视觉冲击力直接拉满,谁都能一眼看出来这东西好不好。后端逻辑写得再复杂, 评估的人不懂你的业务逻辑啊。但一个漂亮的页面,不需要专业知识就能判断质量。我自己 pro 档就是这么拿到的项目就一个纯前端页面,没写一行后端代码。我朋友按照我的方法拿到了 max 档。 噗儿当倒是我实打实拿作品申请的,自己写的 app, 还有几个 skill, 两者加起来一共二十三亿 token。 再说一个很多人踩的坑,一定要先注册好小米账号,绑好邮箱和手机号,申请表里填的邮箱必须跟小米账号绑定的邮箱一致, 如果不一致,或者你用的是手机号注册的账号,没绑邮箱,通知邮件根本发不到你手上,全一批了你也拿不到。 我一开始就翻车,在这折腾了好久才搞明白。所以正确顺序是先去小米官网注册账号,绑好邮箱,然后再去申请。操作上也不复杂,用 cloud code、 科斯尔或者任何顺手的 ai 编程工具,让 ai 帮你 vibble 扣度一个炫酷的前端页面,重点放在视觉效果和交互上,动画动效,享意识布局,这些能让页面看起来很贵的东西。多搞深情表里,把截图放上去, 项目描述写清楚,用了什么工具,做了什么功能,解决什么问题,就这样。最后说说这个 tucker 值不值得薅。 mmo v 二点五 pro 的 编程能力,我自己用下来的感受是比我日常用的 g l m 五车报强不少,跟 g l m 五点一比也差不了太多。 a p r 能直接对接 cloud code 浏览器, oppo 跨这些主流工具。十六亿 tucker 免费活动五月二十八日截止,池子部等人免费的羊毛,而且是比较厚的那种,不薅确实亏了。
238Ac的ai打工日记 01:02查看AI文稿AI文稿
01:02查看AI文稿AI文稿十三亿免费头啃,十四个大模型免费用,很多人不知道,上周我用 ai 写方案,写到一半给我来一句额度不够了。后来发现了这个开源项目, 把十四个大模型的额度聚合起来,满足日常使用,不会有额度焦虑。每次你问他一个问题,他会帮你挑一个速度更快的来回答, 谷歌 grog、 mister、 cloudflyer 等十几个,哪个更快,哪个还没限速,他自己看,你不用管,以前只能靠一个,用完就断,现在十四个在背后撑着,轮着给你用。某个大模型突然断了,不会有任何提示,直接切到下一个,这个叫故障转移,你那边根本感觉不到。 就像你不知道服务员换班了,但菜一直在上,今天用了多少,谁更快谁快,不行了,全有记录,随时看清清楚楚,你知道哪个快到上限了,提前换,不会写到一半突然断掉。还有一个我觉得很聪明的设计, 你跟他聊一件事,他认准同一个模型三十分钟不换,为什么?因为换了他就失忆了,前面说的全不记得,他帮你守着,聊完这件事再换。 ai 时代,信息差就是钱。
2456开源项目盘点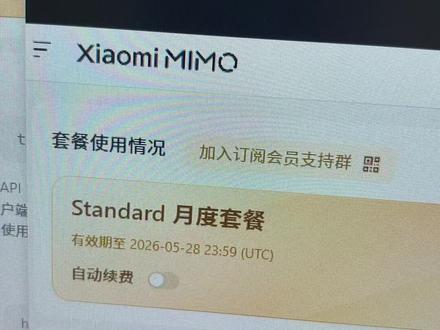 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿用不完,根本用不完。一开始我申请的第一个账号五月二十八号到期,用完了之后他给我重置了,但是五月二十八号就截止了,就没有时间可以用它了。然后呢?现在续费只要一分就可以拥有一百一十亿的额度。 我有两个号根本用不完,根本用不完。 它这个显示九十九,不用管它,直接点学费,它直接只付,只需要付零点零一元。
 02:52查看AI文稿AI文稿
02:52查看AI文稿AI文稿豆包要收费这事我其实一点都不意外,就很多人其实没有意识到, ai 对 话他不是免费的 token, 他 是有成本的。以前我们用微信呢,抖音呢,那多一个用户呢?平台只是多承担一点服务器成本,编辑成本没有那么夸张。但大模型他不一样,你每问一句,他背后都是在烧 token 的, 你让他陪你聊天和他视频,那本质上都是算利的成本。五一我回老家,看到我爷爷奶奶都在用豆包跟豆包聊天视频,我当时就在想,在普通人眼里就这么玩一玩的事,但在大模型公司,就是钱一直在往外哗哗的流。 所以说大模型他很难照搬以前互联网那套逻辑,先圈免费用户,以后再想办法变现。以前免费用户不怎么烧钱,用户越多呢,平台想象力空间越大。但现在是不一样,每个免费用户都在持续消耗成本, 以前是人越多越好,那现在是如果这些用户不能产生价值,可能越多越亏。所以我觉得啊,豆包收费这事,本质上不是突然想赚钱了,而是他开始必须要算账了。我自己其实是愿意为 ai 付费的。 我现在每个月花在大模型上的费用大概在八百块钱左右,贵不贵?贵,但是它为我节省下来的时间和创造的价值远远超过这八百块钱。对我来说哈,时间成本比会员费贵多了, 而且还有一个很多人看不见的成本,叫工作流迁移成本。我的 promote skill agent, 很多东西都是在一个固定的模型里调出来的, 你换模型不是就接个接口那么简单,后面一堆细节要重新打磨的。所以我不是不愿意为 ai 付费,我是愿意为生产力模型付费,但我很难为一个陪我聊天、陪我娱乐的模型付费的。 这也是豆包比较尴尬的地方,他现在很多用户可能只是把它当做陪玩的工具、娱乐的玩具。这些用户数量看起来很大,但付费意愿未必很强。而真正愿意持续为 ai 付费的人群,可能大多数都是用了很顶级的模型,把 ai 用在生产力上。 所以说,大模型这门生意,最后可能会比短视频平台更残酷。短视频平台可以共存,是因为内容风格不一样,有人爱看图文,有人爱刷视频, 有人喜欢热闹,有人喜欢安静。但模型他不一样,处理重要的事情时候,很少有人说我要用一个啊,差不多点的模型就行。嗯,只要他不太贵,没有关系,他笨一点都没有关系。那真正用在生产力上的模型,大部分的人都要用一个更顶级的模型。 所以大模型公司最终都要想清楚一个问题,就是到底赚谁的钱。我的判断是,哈,不是赚所有人的钱,而是赚那些能把 token 变成生产力的人和公司的钱。所以豆包收费,我不觉得意外。
88Cheery 02:41查看AI文稿AI文稿
02:41查看AI文稿AI文稿销售是任何一个行业的底层核心,多模型聚合的 talk 分 销也是 ai 发展的底层核心。 talk 分 销不是低价买,高价卖, talk 分 销的核心是多模型聚合的能力, 你的客户,他需要的不是一堆看不懂的 ipr 秘书,他需要的是解决问题的具体能力。 当他需要写文案的时候,自动路由到性价比最高的文案模型。当他要做数据分析,自动切换到数学最强的模型。 当他要生成视频,直接调度图文,生成最优的模型。 就像我们购买商品,我们会选择去超市和互联平台,因为他们能给我们带来三种能力,第一种是能够将成千上万种商品分门别类的展示, 第二个,明码标价。第三个,保质保量。 对应的多模型聚合的 top 分 销也同样能够为客户带来三种能力,一、场景适配。 当我们要完成一项工作的时候,他的场景一定不是单一的,而是连续的。比如我们要生成一段短剧,那我们首先要写剧本,做脚本,定人物角色, 根据提示词生成视频,它是需要多种能力的聚合,而多模型聚合平台能够满足客户在复杂工作产品下的各类需求。第二个,成本最优, 不同的场景匹配不同的模型,永远用性价比最高的 token 来解决问题。第三个,客户粘性强。 当多模型聚合平台能够满足客户的使用习惯和场景,那么客户将很难再迁移。 所以未来的 talk 的 分销不是比谁更便宜,而是比谁的模型池更大,调度更智能,服务更稳定。看好你哦!
8闲人老戴 05:17查看AI文稿AI文稿
05:17查看AI文稿AI文稿大家好,今天是二零二六年的五月二十六日,然后今天跟大家聊一聊大模型啊,你敢相信吗?其实我们用了七年的大模型,最底层的工作逻辑就要被淘汰了。现在所有的 a 大 模型,不管是 gpt 还是各类的国产模型,本质上就在干一件事,就是一个字一个字的往外 拼,也就是说足字 top 生成,这套 top 生成的架构,撑起了过去七年来 ai 的 爆发,但是最近两篇顶刊论文的发出,让整个行业意识到,其实纯 top 的 套路基本上是走到头了。 一句特别火的哲学观点啊,就是认知的边界放在 ai 身上也很贴,也很贴切。 我们脑子里想一个东西的时候,比如想这个苹果,是画面,是口感,是味道,是触感,其实在一起的是连续的完整的一个感觉。但是到了这个方,为了方便交流或者到了表达这个层面,其实我们就硬生生的把这个丰富的感受压缩成了 呃,苹果这两个字。但是为了方便交流,我们硬生生的把这么丰富的感受压缩成了苹果这两个字。那么重点来了,语言本身就是人类的有损,那么 ai 学的就是这种压缩之后的文字符号。 呃,这就会导致一个天生的缺陷,就 ai 一 直在学人类的表达,从来没有真正的去去学过,真实的世界, 他只会去模仿。呃,从认知上线,其实早就被 tokun 所锁死了,那么日内最顶级的两个人,其实早在公开 警告过这件事。呃,第一个是 openai 的 前首席科学家 alan, 他 在二四年的那个顶会上就明确说过,纯靠数据预训练的路线已经接近极限了。 第二个便是那个同龄奖得主杨丽坤,他一开始就一直批评这个大运模型的路线有问题,认为只靠文本训练永远做不到真正的智能 ai, 所以 一直在推进世界模型的发展。 两位最懂深度学习的人,其实共识非常一致啊,是 open 范式,有天然天花板,也不是绝对的唱空。 呃,因为今年的顶级团队也已经给出了新的解法, m i t 的 霍霍海明团队,包括自己的 c d s 实验室。首先我发布了两套新的模型架构,然后他们的核心的突破就特别好懂,就是不再需要独自的突破人拆解,而是独自的生成。 传统的文字生成要上千步的踩样,又慢又死板,新的架构全程在内,就是在连续向量空间里面去理解,去推理, 最后一步才会转化成我们能够理解的文字。简单来说呢,就是旧的模型是一步一站一站的,慢悠悠的,像绿皮车,绿皮火车,而新的模型是直拉的高铁,效率更高理,理解也更连贯,也更接近与人的真实的认知。呃,全球大厂的布局其实现在也已经彻底分化了, 谷歌很早就坚持多模态统一向量呃向量空间,然后图文的音频的视频全部打通,不让文本单独的拖后腿。而那个四 g 的 space 团队已经把连续潜空间技术落地 在视频生成这个模型上啊,是国内其实最快做的最快的团队之一了。 open i 这边也很理性,其实其实知道阶段性的视频算力成本太高,然后技术也不成熟,所以他们其实就输出了骚扰骚扰的问题,最后大家知道您已经开始完全输出 了,然后优先打打磨核心的文本和动态融合。而 snoop 其实走的完全是不同的差异化的路线啊,短时间内不卷这个话说多模态此刻文本推理和代码能力, 然后这个靠着成熟的商业商业模式来稳定的赚钱。但是所有人都是心知肚明,未来的竞争一定是从 一个统一的连续空间的痊愈认知的能力来竞争。一旦 token 范式慢慢的退场,那么三个行业的变化其实会变得非常的现实。第一个是专业做视频图像 token 的 技术和公司,嗯,价值不大的缩水,因为未来根本不需要把内容拆解成离散的 token。 第二个是现在大家吹捧的多模态的能力,以后会被成为所有 ai 的 标配,也不再是所谓的高端的卖点。第三个是按 token 计费的商业模式,未来大概率会要存够,因此生成不再和字幕的这个数量强绑定了,你再按这个字幕收费,其实就非常不合理了。 最后来跟大家谈一谈大家最关心的这纯大模型到底能不能得到 a g i。 客观来讲,只靠这个 token 的 文本生成范式,基本上不可能得到真正的通用通用智能, 因为他学的本质是压缩了简化过的二手信息,永远补不上真人世界里的物理逻辑和细节认知。当然取消偷看也不等,也不等于说真的就是能够直接实现 agi, 因为现在的行业的新方向其实很清晰啊,不再死磕数据,然后也不而是让模型主动探索,这个是错, 接受反馈。自我替代,也就是大家常听到的 rsi 低轨自低轨自优化,这才是下一代 ai 真正的专场, ai 的 底层逻辑正在悄然的变化。 嗯,所以呢,其实下一期要想讲讲一讲这个 ai 的 自我替代,包括自我进化到底是什么样的一个原理啊?点赞关注我们下期呢,接着再聊。
18静哥哥拆书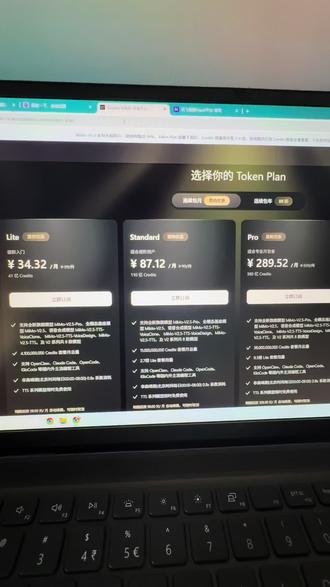 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿用 ai、 大 模型、小龙虾编程这些可以考虑一下。小米的这个大模型,现在降价了,三十四块,三毛二,续费是三十九块钱一个月,四十一亿的 top, 这个九十块钱的九十九块钱,一百一十亿,以前这个四十块钱,三十九块钱的只有七个亿,只有两个亿, 这个九十九块的,七个亿,可以高频率的编程,可以用七天, 那现在一百一十个亿用一个月问题不大。还可以考虑这个讯飞的口径,可能三十九块钱可以用到 glm 五点一,有多个模型可以选择。
 01:50查看AI文稿AI文稿
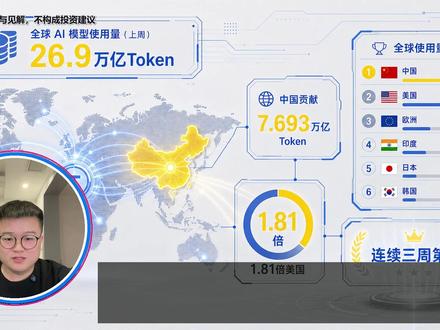
01:50查看AI文稿AI文稿上周,全球 ai 大 模型的总调用量达到了二十六点九万亿 token, 其中中国贡献了七点六九三万亿,是美国的一点八亿倍,这也是中国连续第三周拿下全球第一。我今天不是来跟你吹这个数字有多厉害的, 而我从这组数据里看到了两个普通人可把握的商业机会。第一个, token 赛道的确定性。有人问我, token 赛道到底是不是真需求,还是一阵风? 你看看这组数据,它不是某家媒体的预测,是 openroute 平台统计的真实消耗量每周更新。而且这个数据连续四周都在涨。二十六点九万亿 token 是 什么概念?如果把每个 token 换算成文字,这一周全球 ai 处理的信息量相当于把国家图书馆里的所有藏书 翻来覆去读了不知道多少遍,而且这个数字还在往上走。腾讯 h i 三、 preview 钓用量单周暴涨百分之两百一十, deepsea 减 vi 减 flash 暴涨百分之八十六。不是某一家模型在跑,是整条赛道的量都在起来,需求是真的,增长是真的。第二件事,出海市场的确定性。 这里要先解释一个背景, openroute 是 海外平台,用户大部分是海外的开发者和企业,所以这个钓用量榜单统计的海外用户在选择哪些模型?中国模型的钓用量超过美国, 说明的不是中国国内用 ai 的 人有多多,而是海外用户正在大规模转向中国。模型为什么?很简单,价格, opinaanthropica 这些美国模型定价以美元计,海外用户用起来成本很高。 deepsea、 kimi、 high 三,这些国产模型定价以人民币计,换算成美元之后便宜得多,性价比在海外有天然优势,同等能力,价格可能只有美国模型的十分之一,甚至更低。 这个价格差不是补贴出来的,是汇率和成本结构带来的,短期内不会消失。对做 token 聚合分发的人来说,这意味着你的潜在客户不只是国内的中小企业,还包括海外市场。 两件事同时被一组数据证明了, token 赛道是真需求,出海市场是更大的蓝海。我是牧野深耕算力与磁源赛道,专注分享行业干货,咱们下期再见!
1023牧野AI Token造物局 02:37查看AI文稿AI文稿
02:37查看AI文稿AI文稿tikub copilot, 全球最大的 ai 编程工具,几百万开发者天天在用。四月二十八号宣布了一件事,六月一日起,从固定月费改成按 token 用量计费。以前怎么收的? pro 版十美元一个月随便用,不限次数。现在呢?每月给你十美元的 token 额度,用完要加钱, 按实际消耗的 token 数量算,轻度用户没什么感觉,一天问几个问题,十美元绰绰有余。但重度用户就不一样了。 github 自己都说了, copilot 现在已经不只是帮你补几行代码了,它变成了一个 agent 平台,能跑长任务,多步骤,自主便利整个代码仓库。 一个复杂任务跑下来, token 消耗量是以前简单补代码的几十倍。十美元的月额度,重度用户可能一周就烧完了。这就像你以前办了个不限量流量套餐,每月九十九块随便用。突然运营商说下个月起改按流量计费了,九十九块,只包十个 g, 超了另算。你刷短视频一天就能干掉一个 g, 十个 g 撑几天。这时候你会怎么办? 你不会老老实实多掏钱,你会去找更便宜的方案。 call 派了底层调用的是 gpt 系列模型,按 openai 的 api 定价走,但市场上不只有 gpt, deep seek 通用前文 glm cloud, 很多模型在编程任务上的效果已经不输 gpt, 价格却只有它的几分之一,甚至十几分之一。 用户在 copilot 里一个月要超支几十美元的货,换个模型可能几块钱就搞定了。但个人用户自己去切换模型有两个问题,第一,他不知道哪个模型处理哪种任务性价比最高,得一个个试。第二,他自己去官网买 token, 拿到的是零售价,这就是 token 聚合平台的两层价值。第一层是调度平台对接了十几家模型, 哪个模型处理什么任务最好,性价比最高,平台天天在跟踪这些数据,用户不用自己一个个去试,平台帮他匹配。第二层是价格,聚合平台是批量采购,拿到的是批发价,比个人用户自己去官网充值的零售价便宜一截。 就像你自己去超市买一瓶水两块钱,但批发商从厂家一车皮一车皮拉货,每瓶可能只要八毛。聚合平台把这个批发折扣传递给用户,用户拿到的价格就是比自己买便宜。 同样的模型同样的效果,通过聚合平台调用,比直接去官网买更划算。这两层叠加起来,既可以帮你选了更便宜的模型,又在同一个模型上拿到了更低的价格,省下来的钱是很可观的。 copilot 改计费这件事,表面上是微软调了自己的产品定价,实际效果是他把一大批对成本敏感的用户推向了需要比价的市场里。 这些用户以前被锁在固定月费里,不在乎成本,也不需要别的方案。现在成本跟用量挂钩了,他们开始算账了, 一算账就会发现,外面有更便宜的模型,聚合平台还能拿到比零售更低的批发价。你做磁源聚合分发,就是在外面等着接住这波人的那个角色。我是木叶,深耕算力与磁源赛道,专注分享行业干货,咱们下期再见!
 01:01查看AI文稿AI文稿
01:01查看AI文稿AI文稿兄弟们,做头肯中间商最怕的一个问题就是客户为什么不直接去官方买?答案是两个字,聚合。 聚合主流大模型呢,有好几十种,那每家能力不同,价格也不同,接口不同,那企业自己一家家去对接太累了,只绑定一家呢?风险又高。聚合平台,一个接口进入所有的模型,自动调度啊,最优方案,客户不操心去选型,你帮他搞定。 大平台做标准化的服务,覆盖不了所有的细分需求,你在大平台技术上面做差异化,针对某个行业深度适配,针对某类的客户做定制方案。而且聚合有天然的壁垒, 客户把业务跑在你的平台上,接口啊,账单啊,用量数据都绑定了,迁移成本高,用的时间越长越难换啊。这就是护城河, 不是比谁的托肯便宜,是比谁的聚合调度更好,服务更深。那我是大卫,深耕 ai 大 模型,聚合服务,想了解这个生意怎么做呢?评论区里扣 ai, 送你一本我写的磁源经济, ai 时代普通人的黄金赛道电子书。
1230大卫讲AI词元经济 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿朋友们,你们公司开始限制偷看用量了吗?我们公司从最开始的不限量到现在每个月只有五百块钱的额度了,五百的额度用好一点的模型可能一天就用完了。然后今天我还看到一个新闻,说微软将在六月份被叫停使用 cologold, 转向用自家的 cologold, 强如微软,也顶不住天价投款的费用了。其实在微软之前,乌堡也曾被曝出全年的 ai 编程预算四个月就被烧光了。就连卖算力的英伟达自己都说,现在算力成本已经远超员工成本了。 你想一想,公司一边给你发的工资,一边还得给你报销 token 的 费用,等于花了两分钱养一个人,长此以往,公司肯定受不了。拿我们编程最常用的可乐扣子来说吧,一个重度用户月消费可能高达两千多美元,我们公司有个狠人,一天就用了五千多美元。 再说说现在最火的 web coding, 本就上是 ai 代理在反复的自我否定从事调用工具, 它消耗的托管是传统模式的两到三倍。而且有研究表明, ai 身上的代码有一半是需要被大幅的修改甚至被丢弃的,也就是说,企业烧掉了真金白银,有一半是为 ai 的 无效创作在买单。不过冷静下来想一想,这些现象也给了我们一些提醒。 首先第一点,作为员工,我们不要再有无限畅用的幻想了, ai 工具的投入比才是根本。第二,未来公司很可能会转向使用自家模型,或者寻找性价比更高的替代产品, 就像微软强制员工使用自家的口 pad 一 样。看这里面有个关键的问题,自家模型能不能调教的像可乐扣的一样顺手好用,这才是真正的挑战。 第三,对我们个体来说,拼手速对代码的时代已经过去了,现在拼的是你每一次跟 ai 的 对话质量。当 token 变成了成本,你每一次模糊的提问,无效的反攻,不仅是在浪费 token, 也是在消耗自己的价值。
799周于川 05:52查看AI文稿AI文稿
05:52查看AI文稿AI文稿关于豆包最近打算收费这件事情,我讲几个我自己的判断。第一个就是托肯是有成本的,但是大多数用户没有这个意识,就是大模型跟过去的互联网软件它不是一回事情。就像之前的 呃软件,比如说呃抖音、微信,这些软件开发完之后的边界成本是几乎为零的,多一个用户少一个用户,它的成本差别不大,所以 之前的大量的软件都是用免费引流加后端变现的,这种商业模式是成立的,但是 token 不是, 就是每一次对话,每一次生成,它背后都是有成本的,其这个成本的确是不低。但是现在的问题是,大量 豆包的用户对于这件事情是完全没有感知的。就我五一期间回老家的时候,我发现我的父母和我上幼儿园的小侄女都大量的用豆包视频聊天,比如说我的小侄女还给豆包听音乐, 虽然我不知道为什么要给豆包听音乐,就是等等的这些行为在我看来都是极其 奢侈的,头肯消耗,但是他们就完全没有感觉。第二个就是互联网那一套先免费后变现的逻辑,在大模型这里呃不成立, 因为以前免费养用户是因为用户本身不花钱,而现在每一个免费用户都在持续烧你的钱。比如说我有一个微信号,背后接的都是我的 open cloud, 我 时不时还会删那个微信号上的人,就是把我觉得说没有价值的好友删掉,因为我 不想要他们呃浪费我的托克。你想以前都是大量的把人往死里薅,而现在我却是主动的想要把这些人删掉。 呃,第三就是我其实是愿意为顶级的智力付费的,但是不会为差不多的智力买单。比如说我现在是用 cloud, 两百美元的会员,折合人民币大概一千四左右,但是在我看来这个非常的划算,因为我 用这一千四起码创造了几十倍上百倍的价值。那国产模型呃,差多少呢?客观来讲,我觉得现在顶级的一些国产大模型,像是 kimi, 像是智浦,呃,跟 cloud 之间可能就差个百分之五,百分之十, 就是客观上来讲,它们差距并没有很大,但是就是你一旦用过顶级智力之后,你就回不去了。就说同样 一件事情,我用 cloud, 可能我花十分钟能够给我九十分的结果,那用次一档的模型,我可能花半个小时,一个小时都只能有一个。八十分的结果就是我的时间 是很值钱的,我的产出是很值钱的。而且还这里还有一个隐形成本,就是工作流的迁移成本, 虽然这个大模型是可以一键切换的,我 cloud code 我 可以接啊, deepsea 我 可以接, kimi, 这些都可以。但是当你真正的围绕一个模型打造出一套工作流之后,你 如果你换了一条模型之后,可能你的 front, 你 的 skill, 你 的每一个 agent, 很多很多大量的细节都是需要你重新去调整优化的。工作流的迁移成本对于我来讲是非常高的,这种成本让我心甘情愿,或者是说不得不每个月就是持续给它付一千多块钱。 第四是大模型是隐者通吃的生意,就是智力这个东西,它不存在风格之分, 比如说抖音、快手、小红书可以共存,因为不同的平台它的啊内容,它的风格是不一样的。但是模型这个事情不是这样子的,没有人会因为说我喜欢豆包的风格而选择一个智力差一截的模型来处理重要的事情。所以只要所以只要这个价差没有 很夸张,最强的模型都会把所有正在用 ai 创造价值的用户吸走。那豆包尴尬的地方就是在这里,现在它的用户大盘里绝大多数都是像我父母,像我侄女儿那样把它当聊天玩具的人,就是他们是绝对不会付费的。而像我这样 啊,愿意付费能用 ai 创造价值的人已经在用啊 cloud gpt 了,那次一点的可能也会选择说啊智普、智普、 kimi 等等。像 像智普现在它的套餐是每天是要靠抢的,是限量发售的,现在以前是很难想象的一件事情。这个 说明什么?这个说明愿意为顶级智力付费的人其实比想象中的哦要多很多。就是这些大模型公司已经意识到说不能免费抢用户这条路了,而是 而是开始做配额,做分层,我觉得这个是这个行业走向理性的标志。最后一个,我觉得所有大模型公司都要想清楚一件事情,要赚什么样人的钱。我个人的判断是 大模型应该去赚那些能够把托肯变成生产力的人或者是公司的钱,因为人与人之间的转化效率差异是非常非常大的。 那对于我来讲,我可能一百块的托肯,我能够创造一万块的价值,那对于有些人来讲,可能一百块的托肯他能够创造几万、十几万的价值,但是对于 呃很多普通的用户来讲,可能一百块的托肯就只能创造几百块的价值,或者就是根本也没有创造什么价值,就是娱乐一下。 所以基于这个差异,那些真正创造出价值的人是愿意为这个持续付费而付很多钱的。那至于这些 c 端娱乐场景烧出来的用户规模看起来很大,但是这些用户和 算利成本之间是负 r o i, 就是 当你的用户越多,亏得越多,且没有任何呃向上变现的路径。
2.2万瑶瑶(多agent版) 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿去年我的,然后是四三四月份的时候去那个硅谷聊的两个最大的话题,一个就是 agent, 第二个是 mcp, 当时硅谷那边的创业项目,嗯,就据说至少有数千个创业项目全都是在做 agent。 然后并且那个时候大家都是在说 m、 c、 p, 就是 就是怎么把这些大模型真正让他们通过协议能够真正协做起来。因为你大家都会发现了,说你一个大模型追求极致的聪明,这个可能 并不是未来的一个终极走向,终极走向是说我这个有好多个大模型,他们怎么能一块干活?今年这个 to b 会比较火,因为大家会发现说真正让 to c 让 c 端用户用的好,还得是说有一些,起码有一些产品本身得做的好, 但是这个你这产品还没有做的很好, c 端用户只能拿它当个 check box。 那 你想让产品本身做的好,你就得先把这个 b 端的这个生产产品的能力给提上去。 所以这个也是你刚才讲为什么现在这个弊端的应用是个大爆发,就是大家会发现它在生产力上面实实在在是能干了挺多的很多很多工作。
240生活小雷达 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿很多老板会问啊,不都是 ai 回答问题吗?为什么 agent 会比普通聊天更消耗算力呢?那区别就在于,聊天时单次反应 agent 是 连续执行。你问 ai 北京啊,今天冷不冷?他回答一句,任务结束,但 你让 agent 帮我安排一次北京出差啊。他要查日期、查航班、查酒店、匹配预算生成日程,还可能要调用日历工具和审批系统。那一个任务拆成很多步,每一步都在消耗托盘。 你可以把聊天理解成打电话问一句, agent 理解成一个助理。做完整的项目,问一句话的成本当然很低啦,但做项目就要开会、查资料、写方案、反复修改。 agent 的 底层会涉及多轮的工作流,长上下文、 工具调用、 m c p 协议、强抠顶和推理能力,这些都不是免费能力啊。长上下文意味着 ai 要读更多的资料。多轮工作流呢,就意味着它要反复思考。 工具调用,就意味着它要和外部系统交互。每增加一层, token, 消耗就会增加了。更关键的是, agent 常常不是一次调用一个模型,它可能先用一个模型规划,再用另外一个模型写代码,再用工具检验,再回到模型总结。这个过程就像一条生产线,而不是一个问答窗口。 那对 token 工厂来说呢,则意味着未来啊。需求不能只按人问了多少去来计算,而要按照什么 ai 完成了多少任务来计算。 任务越复杂,投坑越多,企业越依赖 a 井,投坑消耗就越稳定。那投资人看项目时,要问目标客户是不是有 a 井的场景啊? 如果只是普通聊天,那需求弹性有限。如果是 ai 编程、企业办公、自动客服、数据分析这些投坑工作流,投坑消耗量可能就明显放大了。一句话,聊天是在说话, a 井呢,是在干活,说话消耗有限,干活才是真正的投坑大户啊!
 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿彦祖,三年之期已到,这次我必扶你青云志胖 醒,这次我们要发达了!我有一个点子,咱们做一个 token 中转平台,对外大肆宣传,宣称我们已与多家主流模型厂商达成深度团购合作,还自研了独家 token 压缩优化技术,用户通过我们购买服务成本直降一半,再设置阶梯折扣,一年九五折,两年九二折,三年八八折,五年直接起五折。一顿宣传下来,大把公司和个人肯定抢着来买,等资金 low 过的差不多三个月后直 全款跑路。好主意,再搞个定向优惠,买过保健品,上过财商课,进过各种烧会,在理发店、健身房办过卡的用户优先购买,还能享受专属折扣精准收割。再加一个老戴新颂 tokin, 还打折活动疯狂裂变,前期更要控制成本,用国产的豆包 mini max 模型伪装成卡洛丽和 gpt 子豪。胖姐,请你俩一定要加入我的团队,到时候我再给你俩花一百万美元购买川普金卡,全款跑路,一起加入美国级享受。人 不好了,咱们预算都亏没了!平台刚上线第二天,市面上瞬间冒出来上百家一模一样的头肯中转平台,连孙九生都加入了,网友,被烧割多了根本不买上当天天就蹲咱们的新手,免费羊毛,薅完就跑,一分钱不花。更离谱的是同行直接写脚本,批量注册马甲账号,捞咱们的免费头肯白嫖咱们的接口资源,免费给他们自己的用户用。完了完了,彻底完了!
19李胖醒Plus 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿上周呢,我做了一个测试,同一个问题同时发给 g p d cloud gemini, 结果的差异比我想象中要大很多。今天我就来给你说来听一听。第一,写代码, cloud 赢, cloud 的 逻辑更清楚, bug 更少。第二,写文案, g p d 赢, g p d 的 语言更流畅,更有感染力。第三,分析长文档 gemini 赢,上下文窗口大,一本书都能塞进去。 我的结论是,没有一个模型是万能的,不同任务得用不同的模型。但是麻烦来了,如果你每个模型都订阅,一个月至少四百五十块,还要来回切换账号,效率根本提不上去。那怎么解决呢?这里就要用到我们的 api 调用的方式, 切换模型就是改一个参数的事,按量计费,哪个任务用哪个模型,不用的时候一分钱都不要花。我每天的工作流就是这样子, 早上读技术文档和国外的论文,用 gemini 帮我总结分翻译,因为它的上下文窗口最大,一篇论文丢进去,它都能消化到了下午。写代码切换 cloud 代码能力是目前最强的,而且它不会不懂装懂。 那需要写文案、做选题规划的时候,我就用了 g p p, 它的语言组织能力和创意感是最好的。一个月下来,三个模型来回换, 成本加起来还不到一百块,比以前定一个叉 cbd 还省那。总结一下我的经验,如果你只做一类事,定一个 pro 就 够了。 如果你做的事情比较杂,涉及代码写作、研究多个方向,最划算的方式就是用 api 灵活切换,而不是开多个订阅。下期让我三个 ai 分 别写一份商业计划书,看看谁写的最真实可用。
 02:55查看AI文稿AI文稿
02:55查看AI文稿AI文稿token 不是 卖给账户的,那是卖给习惯的。很多人呢,以为 token 生意就是把模型练出来, token 印出来啊,用户付钱,公司赚钱。 哎,这个逻辑反了,真实的商业面试,有人用你的产品啊,用到离不开,然后呢,才会去消耗 token。 没有第一步,后面不成立啊。不是 token 创造用户,是用户 产生 token, 这对 token 服务商意味着啥呢?你卖 token 的 逻辑也得要反过来想。先看一个反常识的现象啊, 一个人主用一家 ai 之后几乎不会切换,那习惯了他的风格欠进了工作流啊,记不住别家能干什么。换一家的麻烦远大于试一试的收益。大多数人主用一家,顶多备用一家啊,就两个名额,亿人的选择加在一起决定了几百家大模型,谁活谁死, 头部两三家吃掉绝大多数头啃的消耗,剩下几百家分残羹。这跟当年的微信的故事一模一样。米聊啊,异性啊,来往啊,非性啊,背后全是巨头,结果只有微信赢了。 tock 服务商不需要去赌哪家模型营啊,你做的是聚合多家模型的 tock 供给,不管客户主用谁啊,你都能供。那客户用 chat gpt, 你 就供呢?你就供 chat gpt 的 tock。 客户用 cloud, 你 就用 cloud 的 tock, 那 客户用 deepsea, 你 就供 deepsea 的 tock。 你 赌的不是哪家模型营,赌的是 ai 啊, 会被越来越多的人用这个确定性的趋势。 token 不是 同质化的商品啊,水是水,电是电,从哪里卖都一样。但不同 ai 公司的 token, 底层装的货完全不同, 不同模型,不同体验,不同输出风格,更关键的是 token 没有库存价值,今天没人用,这部分 token 就 废了啊,只只在被使用的那一刻产生价值。那这就意味着你卖 token 不 能只拼价格 便宜的托肯,如果客户用不上,等于零啊。你要帮客户把托肯真正切入到他的工作流,让他每天都在用,用到离不开托肯,消耗才会变成持续的收入。 你帮客户选对模型,接好 api, 进入业务流程,他每天的工作啊,就在自动的消耗托肯,你每天就在自动赚钱,那未来的风化会很明显。产出了差,会调图 ai 的 人和还在手敲键盘的人产出差十倍。 嵌进 ai 的 公司和只注册账号的公司成本差一个量级。 token 服务商的终极价值不是卖便宜 token, 是 帮客户把 ai 变成他生意里的一块肉啊,帮他, 帮他搭桶接雨,雨下的越久,你的收入就越持续。 onslipk 已经在这件事情上面把 cloud 直接嵌入到了 quickbooks, 做财务嵌入,嵌进了 cover, 做设计进入了 google 和 workspace, 还有 microsoft 三六五啊。模型厂商自己都在往工作流里钻 token, 服务商更应该这样做啊,不是等客户来买 token, 是 帮客户把 token 钻进每天的工作里,钻进去了就拔不出来,拔不出来 token 就 一直在消耗,这才是 token 生意真正的护城河。

