别再随便给 hermes 装 skill 了,如果你还在调戏 ai, 让他乱烧 token, 那 你根本没用对方法。今天我给你整理出 hermes 生态里最硬核的五个必装基础设施神器,装好它们,你的 hermes 才能真正从玩具变成生产力引擎! 一、 repomix 上下文碎片化,项目结构读不准,把整个仓库一次性喂给 hermes, 一 次性读懂项目 npx repomix 再也不用分段喂代码。二、 tokus kill token 消耗失控成本看不清, 实时监控 token 支持多 agent 格式化, dashboard 最稳的成本管家。三、 hermes workspace c l i 操作太黑框框 c q 管理混乱, web 工作台加聊天加终端加 c q 管理加内存浏览器,一站式直观体验。四、 handset hermes 老忘事情, 装上长期记忆,跨绘画、自动召回架构决策和项目偏好再也不是陌生人。五、 mission control 多 agent 写作太复杂, 大项目的终极指挥中心、任务分发、成本追踪、全流程编排、自托管 dashboard, 这五个工具覆盖了 hermes 核心短板、上下文成本交互记忆、工程编排。装好了,你的 hermes 才是真正的生产力怪兽!

粉丝1162获赞4.8万
相关视频
 03:15
03:15 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿目前 hermes agent 的 token 日军消耗达到了两百二十四币,把 open core 牢牢按在了第二名的位置上。那么今天来盘点下 hermes agent 有 哪些神级 skill, 建议收藏视频慢慢观看。一、 riphomix 上下文碎片化,项目结构读不准,把整个仓库一次性喂给 hermes, 一 次性读懂项目 npx, 再不用分段喂代码。二、 token 消耗失控成本看不清, 实时监控 token 支持多 agent 格式化, dashboard 最稳的成本管家。三、 hermes workspace c l i 操作太黑框框 c q 管理混乱, web 工作台加聊天加终端加 c q 管理加内存浏览器一站式直观体验。四、 handset hermes 老忘事情, 装上长期记忆,跨绘画、自动召回架构决策和项目偏好再也不是陌生人。五、 mission control 多 agent 写作太复杂, 大项目的终极指挥中心、任务分发、成本追踪、全流程编排、自托管 dashboard 这五个工具覆盖了 hermes 核心短板、上下文成本交互记忆、工程编排。装好了,你的 hermes 才是真正的生产力怪兽!
124DAHE 02:29查看AI文稿AI文稿
02:29查看AI文稿AI文稿如果你现在用 hermes, 还是把所有需求都塞给一个 agent, 那 你很快就会遇到两个问题,第一,上下文和记忆越聊越乱,研究、写代码、查资料、回消息全混在一起。第二,一次只能处理一个任务,你让他跑研究的时候,别的事只能干等着。 真正把 hermes 用顺的人,往往不是把单个 agent 掉得更猛,而是尽快把它组织成一个有分工的团队。你可以把 hermes 团队理解成一个小型数字工作室, 有的 agent 专门做规划,有的 agent 负责研究,有的 agent 负责执行,还有的 agent 只做复合和交付。每个角色只处理自己那一段,上下文就会干净很多。而且团队化以后,你终于不用再等单个绘画慢慢排队, 而是可以把任务拆开分别推进。如果你已经有一个能跑通的 hermes, 四步就能把团队骨架搭起来。第一步,克隆 profile, 继承你已经调好的基础配置。第二步,给每个 profile 写思路, 把它是谁、擅长什么、不该碰什么讲清楚。第三步,在项目根目录放 a j s, 让整个团队共享项目结构、协助规则和当前进度。 第四步, and profile 单独调用,让每个 agent 只处理自己该处理的任务。真正上手时,命令并不复杂。先执行 profile clone, 把你已经调好的基础配置复制出来,然后进入不同 profile 单独工作。重点不是命令有多花, 而是每个 agent 的 记忆和绘画都已经独立了。后面你再做研究、规划、执行和复合,就不会全部挤在同一个上下文里。这里最容易被忽略的反而不是命令,而是两个文件。 so 负责定义单个 agent 的 人格和边界, 告诉他该做什么,不该做什么。 agents 负责定义团队共享背景,把项目结构、协助规则和当前进度统一下来。一个管我是哪个角色, 一个管我们正在做什么项目。这两个文件分开以后,团队合作才会稳定。所以这套方法真正的价值不是让 hermes 看起来更高级,而是让他终于能像团队一样稳定,工作 任务拆得更细,上下文更干净。每个 agent 都有自己的角色边界,你也终于可以同时推进多件事。如果你现在已经有一个跑通的 hermes, 下一步最值得做的不是继续往单绘画里塞更多需求,而是尽快把它团队化。
917沐晨AI笔记 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿hermes 装上这五个 skills, 直接起飞,不装 skill 的 hermes 能力直接砍掉百分之六十,很多人把它当普通模型用,简直是暴填天物。 装上这五个 skills, 它才成为完全体。第一个, d stack, 九万八千星, ycombler 总裁 gary tan 亲自打造二十三个工具,覆盖从 ceo 到 qa 的 完整工作流,让 hermes 学会自我净化,越用越聪明。第二个, blend, 一 万六千星, 同一位大佬出品的 ai agent 知识铺,专门优化记忆层,让 hermes 拥有长期记忆跨灰化,记住你的偏好和项目上下文。 第三个, hermes yee 七千五百星,清凉级 web 界面,手机和浏览器都能用,不用装客户端随时随地访问,你的 hermes 体验丝滑到不行,用过就回不去。第四个, one song hanzacient 三千星,全网最全的 hermes 生态导航 skills 工具集成方案,搜什么都有,新手入门第一站,老手找灵感的宝藏库。 第五个, hunts agent self evolution, 三千三百姓 nasrisix 官方出品的自净化增强版,用 desp 和 gepa 自动优化技能和提示词, harmis 自己改,自己越跑越强,五个项目加起来星数超过十二万。
68第二观察者 03:29查看AI文稿AI文稿
03:29查看AI文稿AI文稿你有没有想过,每次启动一个代理,他其实什么都不知道,不认识你的项目结构,不了解你的编码习惯,更不知道你 prefer 什么风格。 但如果你在项目跟目录放一个 agents 点 md, 或者在家目录写一份 so 点 md, 代理一启动就会自动读进去,瞬间从失意状态变成一个懂你项目的老手。这就是上下文文件干的事儿。 hermes 支持五种上下文文件,每种角色不同点 hermes 点 md 优先级最高,是项目指令的终极来源。 agents 点 md 是 主力写项目结构、编码约定和特殊指令。 cloud 点 md 是 cloud code 的 上下文文件, hermes 也能检测到 s o u l 点 m d 比较特殊,它定义代理的个性语气,只从主目录加载,不属于任何项目。 cursor rules 是 cursor ide 的 编码约定,都抵使用。 这里有个关键规则,每个绘画只加载一种项目上下文,按优先级从高到低,第一个找到的就赢。顺序是, hermes 点 m d 大 于 agents 点 m d 大 于 cursor rules。 所以,如果你项目里同时有点 hermes 点 md 和 agents 点 md, 只有 hermes 点 md 会被读进去。但 solo 点 md 是 个例外,它始终独立加载,作为代理的身份层,不会跟项目上下文抢位。 更巧妙的是,渐进式发现机制,启动的时候, hermes 只加载工作目录根部的 agents 点 md 到系统提示里。 但如果你在绘画中读到了 frienden 的 子目录的文件, hermes 会自动发现 frienden 下面的 agent 点 m d, 并注入对话。每个子目录每绘画最多检查一次,而且会向上便利复目录。 好处很明显,系统提示不会在启动时就被称报子目录的上下文,只在需要时才出现。 s o, u l d m d 跟其他四个文件有个本质区别,它不在项目目录里,只从 armes home 主目录夹载。它控制的是代理的个性和语气,比如回复是用中文还是英文,语气是严肃还是轻松。 不管你打开哪个项目, s o, u, l d n 都会作为身份层加载到槽位一号。如果文件为空就不注入,如果有内容就逐字放进去,它是你给这个代理实力定义的灵魂。 实际用起来很简单,大多数情况下,一个 agents 点 md 就 够了。写上架构约定和重要说明。 如果你想让代理在不同项目里保持统一风格,就加一份 solo 点 md。 如果团队同时用 cursor, 放个 cursor rules, 可以 让两个工具共享。约定 需要覆盖所有其他上下文的时候,采用 hermes 点 md 兜底。渐近式发现是自动的,你只要在子目录里放 agents 点 md 就 行。 所以上下文文件的本质就是给代理两样东西,持久记忆和独特个性。 项目上下文记住你的架构和约定,扫点 m d 定义代理的回答风格,优先级即联,确保不冲突。渐进式发现保证提示不会膨胀。五种文件,一套优先级,一个独立身份层。这就是 hermes 把失忆代理变成懂你项目的老手的方式。
24AI观察 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿在上一集讲解了 hermes web ui, 本集继续看另一个入口, hermes desktop。 如果 web ui 更像浏览器里的控制台, desktop 就是 原生桌面应用,它把聊天、 sessions、 profiles、 tools、 memory 和 office 都放在一个窗口里。这一集只看使用体验怎样把 hermes 变成一个常驻桌面的 ai 工作台。 hermes desktop 的 第一层价值是把常用入口集中起来。 chat 负责对话和任务推进, sessions 负责回看历史上下文, profiles 负责把不同角色分开。 tools 决定 agent 能调用哪些能力。 skills 管可附用工作流, office 管可释放状态,所以它不是多一个聊天框,而是把 hermes 的 日常入口整理成一个工作台。 office 是 hermes desktop 很 有辨识度的地方,它用三 d 工作区展示 agent、 任务和状态。 当你只是临时问一句话, chat 就 够了。但当任务开始变多, office 会让后台发生的事情更直观。你可以先看整体状态,再回到 chat, 继续追问或处理细节。这也是桌面端相比纯命令行更上产品的地方。 setting 是 桌面端的设置中心 主题, provider、 model 和常用偏好都在这里管理。 hermes desktop 支持 open router、 anthropic、 open ai、 google gemini、 new potao、 quin、 mini max、 groku 等供应商。 如果你用奥莱玛 lm studio 或 vl lm, 也可以走本地兼容接口。桌面断槽处是把常用设置变成可检查、可回看、可调整的面板。 用久以后,这里就是你管理桌面工作台偏好的地方。 chat 是 日常使用最频繁的入口,它支持 sse 流式输出,回答会一段一段出现。工具、执行进度、 markdown 渲染代码高量和 token 用量都在聊天流程里,直接可见 桌面端的价值。不是替代 hermes 的 能力,而是把这些能力变成一个更稳定的日常工作台。你可以把它当成主操作区,提出任务,观察进度,继续追问,再把结果沉淀到后续工作流里。接下来要理解两个日常路口, profiles 和 tools profise 是 隔离环境,你可以给不同角色创建不同 profile, 比如默认助手、财务分析、市场经理。每个 profile 都有自己的配置记忆和技能。 tools 决定 agent 能做什么。 web search, terminal file, operations code, execution, memory, skills 都可以按需开关, 第一次使用,建议少开一点,只给当前任务真正需要的工具。 skills 和 office 是 桌面端很有辨识度的两个入口。 skills 页面用来浏览和管理,可附用技能。当你开始沉淀常用工作流,这里会变成能力资产库。 office 是 可丝化三 d 工作区,用来呈现 agent 和任务状态, 一个偏能力管理,一个偏可丝化写作。这是 desktop 相比纯 c l i 更像产品的地方。这一集我们把 hermes desktop 的 桌面工作台体验讲完了,如果你想继续看 hermes agent 的 完整系列,可以关注我,我会继续分享更多 agent 的 工具和工作流内容,我们下集见。
462小勉 02:45查看AI文稿AI文稿
02:45查看AI文稿AI文稿分享一个今天调用 ottoclaw 整理它的上下文时的工作过程。最近 openclaw 和 hermes 打得有来有回, ottoclaw 是 智普推出的国产小龙虾,四月份 ottoclaw 在 openclaw 机座上增加了 hermes 的 记忆功能。我就是那个时候从零开始捣鼓小龙虾,今天就发了几句话,他 就鞭挎着自己开始哐哐行动了。感慨一句, openclaw 加 hermes 真的 很好用,正常对话速度也不慢。没有他自己在后台默默进化的时候,我在拉玛 c p p 里跑三十二到三十五 topen s, 在 他这里能跑二十六到二十九 topen s。 除了新家在对话,几乎就是我刚发完消息,他就开始回复了。我关闭了模型的思考模式,今天主要展示一下他这个主动的调用工具过程。
12今日兴趣: 03:56查看AI文稿AI文稿
03:56查看AI文稿AI文稿还在使用命令行来玩 hermes 吗?对于新手小白来讲,命令行确实是一个非常不友好的工具,今天这条视频我就来教你如何安装 hermes 的 官方的 web ui。 使用这个工具,你可以查看智能体状态管理任务,查看日期,调整配置,鼠标点一点就能使用, 界面干净功能一目了然,比存命令行简单好用。下面我们就来学习一下如何安装使用 hermes 的 官方 web ui。 首先我们来看一下如何进入帮助文档,这是 hermes 的 官方文档,虽然显示有简体中文的选项,但是进入之后其实还是英文, 所以我们只能选择国内的 hermes 的 中文社区,点击这个文档,然后我们找核心能力,这里的管理 里边有 web 仪表盘,在这里我们就能找到启动 web 仪表盘的命令,就是这个 mister dartboard, 点击复制,把这个命令复制到我们的剪贴板里, 然后我们打开 wsl 的 命令行儿,粘贴这个命令,打回车,提示我们需要安装如下的主键,包括 fast api 和 uic, 同时也给出了安装方法在这里,那么我们就按照他说的这个进入这个文件夹儿, 再来运行这个命令,系统提示我们已经安装成功了,下面我们再来复制一遍 permes dashboard, 这个命令钻到命令行里运行 还是不行。相同的提示,先来检查一下当前的版本号 permes vincent, 看看它的版本号零点幺三,最新的版本号是零点一四,我们来升级下版本试试, 我们看到已经升级完毕了,这里显示 unico 也已经成功的安装了。这回我们再复制一遍这个 hermes dashboard, 再来运行一下看看 它。这里提示给我们了一个网址,幺二七点零点零点幺九幺幺九,我们来访问一下试试, 已经可以访问了,这个就是 hermes 的 官方 web ui, 默认它是英文版,我们先把它调成中文版,点击左下角这个 e n 按钮,在这里 点击简体中文就可以切换到中文版了。我们来看一下它都有哪些功能。首先看第一个功能绘画,绘画就是你跟 hermes 的 聊天记录,包括你在命令行里和通过聊天软件进行的聊天 模型,就是你目前正在使用的大模型都有哪些?在我这里有两个模型, glm 四点五、 flash 和 minimax 二点七。 第三个是日制功能,这个是运行的日制。第四个是定时任务,这个是目前有哪些计划任务,可以点击右上角这个创建按钮,手工创建计划任务。 下一个是技能,这些就是目前系统内可以使用的技能 skill, 包括系统自带的和我们安装的,这是全部的技能,这是工具级。下一个栏目是插件管理,在这里我们可以对我们已经安装的插件进行查看和管理。 下一个是 doident 配置,这里是目前我已经设置好的 ident, 也可以点击右上角的创建按钮,添加新的 ident。 下一个栏目是配置,在这里可以查看 hermes 的 各种详细配置。 下一个栏目是密钥,这里可以查看系统内正在使用的密钥,我现在使用的密钥包括智普 这两个大模型的密钥。文档就是跳到官方的文档,这里由于是国外的网站,有点慢, 我们这个就不看了。然后这是它的插件看版,这个是很重要的功能,以后我们会讲到的。下一个 example 实力连不上,这个我们不看了。最后一个 achievement 成就好像跟我们也没有什么太大的关系,这 就是 hermes 的 官方 web ui, 今天就讲到这里了,谢谢大家的观看,再见。
21波哥的AI课 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿别再给 hermes 随便装 skill 了,真正影响效率的不是装得多,而是有没有补上五个基础设施短板。这条视频用九十秒讲清楚上下文,成本交互、记忆编排分别该用什么工具。 第一, repo mix 项目结构读不准,代码分段未到崩,用 npx repo mix 把仓库打包成 ai 友好的上下文。第二, talk skill 抽肯花到哪里,哪个 agent 最烧钱,一眼看清它就是多 agent 场景里的成本仪表盘。第三, hermes workspace, 别只盯着黑矿 c o i web 工作台,把聊天终端、 skill 管理和记忆浏览放到一起。第四, handsight。 hermes 老望项目偏好和架构决策,长期记忆会跨绘画自动召回,但它不是每次都像新同事。第五, mission control, 大 项目多 agent 协作,用它做任务分发、流程编排和成本追踪,适合自托管团队工作台。这五个工具不是玩具插件,而是补 hermes 的 五个短板,上下分、成本、交互、记忆、工程编排。 先装基础设施,再谈花哨 skill, 这样 hermes 才能从调戏 ai 变成真正的生产力引擎。
 05:14查看AI文稿AI文稿
05:14查看AI文稿AI文稿想象一下,你开了两个终端,两个 hermes 代理都指向同一个代码,目录都在改文件,一个代理刚写好的接口,另一个代理直接删掉了。绘画历史在打架,记忆存储在互相复写,你根本不知道哪次改动属于哪个实验。 这不是假设,这是在同一个 checkout 里并行跑多个 harmis 的 真实风险。解决方法只有一个, getworktree, 每个代理自己的目录,自己的分支,自己的检查点,历史互不干扰。 要理解为什么要用 work tree, 先得理解 hermes 是 怎么感知世界的。 hermes 把当前工作目录视为项目根目录,运行 hermes 命令的那个目录就是它的全部。上下文 在这里找 soul, 点 md skill, 点 md context, 文件在这里执行,代码在这里写入更改。 c l i 模式下,那就是你运行 hermes 的 目录。 messaging gate 位模式下,由 messaging 下划线 cwd 环境变量指定检查点历史也绑定在工作目录路径上,不同目录完全独立的回滚历史。 所以想让两个代理真正隔离,最简单的方式就是给他们两个不同的目录。 get work tree 专门解决这件事 来看。实际操作从你的主仓库跟目录开始,一条命令就能创建 worktree git worktree add some ripple feature feature, hermes experiment。 这条命令做了两件事,在点点斜杠 ripple feature 创建一个新目录,同时剪出一个叫 featurehermes experiment 的 新分支。 现在进入这个目录,直接运行, hermes 代理就启动了,他会把点点斜杠 ripple feature 当成自己的项目根使用这个目录范围内的独立检查点历史完全不影响你的主仓库。 需要第二个代理同样的方式,再创建一个 walk tree, 另一个分支,另一个目录,两个代理,两套状态互不相知。 两个 work tree 创建好之后,打开两个终端,分别 cd 进去,分别运行 hermes, 就 这么简单。 代理 a 在 featurehermesa 上工作,代理 b 在 featurehermesb 上工作。两者共享同一个点 g i t。 对 象库,但检出是完全隔离的。 代理 a 删了一个文件,代理 b 完全不受影响。代理 b 用了 rowback, 回退了三步。代理 a 的 检查点一针未动。这种模式特别适合批量重构同一任务的多方案对比,或者把 c l i。 绘画和 gateway 绘画配对到同一仓库的不同分支上。 并行隔离是多 agent 的 协助的基础保障。每次都手动 get worktree add, 太繁琐了。 hermes 内置了杠 w 标志,一个命令自动完成所有操作。 hermesw hermes 会在仓库里的点 w o r k t r e e s。 斜杠目录下创建临时 worktree, 剪出一个隔离分支,格式是 hermeshermes, 加上哈西后缀, 然后在里面跑完整的 c l i。 绘画。也可以和单次查询组合 hermes 杠 w 杠 q 修复问题井号一百二十三,执行完就结束。想要并行打开多个终端,每个都跑。 hermes w 每次调用自动获得自己的 work tree 和分支,完全不用协调。 手动模式给你完全控制,自动模式给你最快上手。两种用法,按场景选择。实验结束后怎么清理?先作判断。这次实验的结果要保留吗?如果要保留,像普通 pr 一 样,把分支合并进主分支,然后删掉 walk tree gate walk tree remove hence one pre feature。 注意两件事,第一,如果 walk tree 里有未提交的改动, gate 会拒绝删除,除非你强制加 force。 第二,删掉 walk tree 不 会自动删掉分支,分支还在你自己决定是否要用 gate branch d 清理 hermes, 再到 hannadhermes checkpoints 下的检查点数据也不会自动清理,但体积很小,影响不大。整套流程就是用完判断合并或丢弃。删目录,按需清分枝。 把这三层合起来看。最外层 getworktree, 每个实验一个独立目录,代理之间完全感知隔离,互不干扰。中间层分支,每个 worktree 有 自己的 get 分 支提交历史清晰。 p 二,小儿可审查 内层检查点加斜杠 rollback, 在 每个 worktree 内部操作级别的安全网工具调用,出错随时回退。 三层叠加,你得到的是多代理并行,不冲突,实验失败不影响主线,每一步都可以撤回。从一个 hermes w 开始,到把好的实验合并进主分支结束,这就是 hermes 在 大型仓库上的完整作战方式。
74AI观察 01:24412Hermes👾
01:24412Hermes👾 07:40查看AI文稿AI文稿
07:40查看AI文稿AI文稿hello, 小 伙伴们,我是拆机的老李,上一期我们安装了这个 windows 爱马仕,然后并且设置了大模型,可以进行一个正常的对话, 然后我也用了一段时间 windows 版本的一个 ems, 实际体验下来的话还是可以的,并没有发现有太大重要的 bug。 然后安装方法也很简单,直接来到这个复制一键命令,直接在咆哮上面右键这个终端,打开这个咆哮,把这一段复制到复制到你的终端,然后一键就可以安装了。 好,安装完之后我们直接进入到对话, h e r m e s 直接回车, 我们进入到一个 ms 的 一个正常对话框,可以看到我现在的默认模型是 m 二点七,然后如果你想直接回到上一回的一个绘画内容的话,我们可以 直接 hms 加一个杠 c, 就是 恢复到上一个绘画的内容。 好,可以看到这是我们上一回的一个绘画内容。那我们先讲一讲怎么在对话框中直接切换模型,直接输入杠默回车,可以看到这是我添加的一些供应商的一个 模型,那我们直接选择一个,这些字都是列出可以选择的模型,那我们随便选一个千万 回车。好,可以看到它模型已经切换成千万的一个模型,然后测试一下看能不能用, 可以看到响应是一个正常的响应。好的,那么我们在这个绘画中直接切换的模型呢?它是只对本次绘画通用,就是你在重启绘画的时候, 重启绘画的时候,它又会恢复到你的默认的一个模型, 可以看到它会附到 minimax m 二点七的一个默认模型,那我们怎么去设定这个默认模型?我们先看帮助文件,帮这种 直接看帮助文件它列出的一些命令。行,那我们找到这个是开启一个新的对话,刚刚说了杠 c 呢,就是恢复到上一回的一个对话,然后 set top 呢,就是一个, 就是设置的一个开始 mode, 看到没有?这个就是设置一个缺省模型,那我们试一下 m o d l, 然后回车,可以看到它这里有很多模型的供应商,我们默认还是英伟达的,这边有选择 keep, 还有 replay clear, 那 我们 keep 就 行了,回车,默认回车,再回车,然后再来到这个选择模型,现在默认是这个 mini max, 那 我们切换到默认的模行为 基于 m, 或者说千问的一个 a 幺七 b, 那 我们结束二十八回车。好,我们现在已经切换到千问,千问三点五的一个模型下, m e s, 可以 看到刚刚它默认模型已经由刚刚的 mini max 切换到千问三点五的一个默认模型, 这就是一个设置模型的一个方法。另外还有我们可以直接编辑这个叫什么配置文件去设定模型, 我们直接可以通过编辑这个文件可以看到这里 default, 这里就是刚刚设定的一个千万三点五的一个模型,我们直接修改这个也可以切换模型,那我们随便找一个 g l m 的, 比如说我想换到这个默认模型做 g l m 的, 那我们直接把这个替换掉,然后再保存一下,这样也可以替换默认模型,那我们再重启,再重启对话, 可以看到我们的默认模型已经变成 g l m 五点一, 好,这是设置还有切换模型的一个大致的方法,那我们假如说我们需要设定一个 forback, 就是 说这个模型失效,失效的时候自动切换模型怎么去设定?那我们还是 打开 hell, 那 我们还是杠 hell, 可以 看到它有列出一个 for bet at, 这里就是增加, 增加这个 for bet 模型,比如说我们直接把这一串复制到下面。回车, 好,这边就是提示里增加了一个模型作为 forback, 那 我们找一下现在,比如说我们现在 dipc 比较便宜的话,我们也可以用 dipc 作为一个备用的模型去 进行一个切换,可以看到十七十七是 dipc 好 keep, 因为我已经有有 dipc 的 一个模型在里面,那我们直接设定 v 四 pro 作为一个 forback 的 模型。二,好,回车,这样就已经设定完成了 forebeat 这个模型我们在使用过程中呢,我们是看不到的,只有在你这个,比如说这个 glm 五点一,它在没有响应的时候它才会自动切换。那我们在哪里看呢? 在配置文件我们可以看到 forback, 在 配置文件这里我们可以看到有一个 forback, 刚刚添加的是 deepsea。 v 四 pro 这边可以看到已经多了一个 forback 的 模型。 好了,这一期的一个爱马仕 helms helms 切换模型的教程是到这里。
29菜鸡的老黎 02:53查看AI文稿AI文稿
02:53查看AI文稿AI文稿欢迎大家今天我们一起继续闯 ai。 上一期我们搞了一场赛搏斗蛐蛐,本期我们换个话题,让两位选手休息一下。大家可能都见过这个与 hermes 聊天的界面,说不上好看, 更谈不上好用。也可能见过 hermes 带 check 功能的 dashboard 界面,而 opencloud 的 dashboard 在 拉跟 hermes 的 一比,竟然眉清目秀了许多。 hermes 自然不愿意被小龙虾比下去,所以 hermes desktop 它来了。今天我们就来介绍一下如何安装和出场配置这个工具,帮大家避避坑。 hermes desktop 在 github 上目前接近八 k 星标的太原工具,可以从 github 页面上点击下载按钮或跳转到 hermes agent 四 cc 来下载,也可以免魔法直接到这个网站来下载,双击即可安装,然后自动进入欢迎界面。如果选择 get started, 则程序会问你是自动安装一套 全新的 windows 原声版 hermes, 还是选择使用在 windows 中已安装好的原声版 hermes? 它是无法直接识别在 wsl 中安装的 hermes 的。 因此,如果你的 hermes 是 已经在 wsl 中安装好并运行的,那么大坑就已挖好。一、 wsl 上没有 ssh 服务。 二、 windows 没有配置免密码 ssh 登录 wsl。 三、 hermes 一 般不会自行开启 api server, 那 么 开始动手填坑吧。先去 wsl 中把 api server 打开,方法是 hermes 服务器文件中设置四个参数,然后重启 gateway 端口被检测,说明 api server 已开启。再去 windows 中生成密钥对比,复制 idezer tag 到 wsl 的 指定目录中。 在 wsl 中先安装试服务检查状态,并设置开机自启动,然后把 windows 上传的 id the pop 文件内容写入 authorized keys, 这样 windows 就 能免密码 s s h 登录 wsl 了。 此时再回到 hermes desktop, 点击 connect y s s h 并填入信息,即可全功能连接到 wsl 中的 hermes。 为什么强调这个选项可以全功能连接?因为选择 connect to remote hermes 的 话,就只能聊天、查看 skills 等功能都会提示在远程模式下不可用。现在可以把每个功能都查看一下是不是完整,然后安装 call 三 d, 这个能帮我们给 hermes 安排个办公室的功能。点击 install 按钮后,由于是从 github 上下载代码,所以有概率失败。按照前几期我们提到的办法,可以手动从 github 上下载代码,放入指定目录,然 然后再次点击 install 按钮,程序会自动探测到以克隆的代码,并自动安装依赖。等待一段时间后, hermes 的 卡通办公室就出现了。 hermes desktop 的 安装和出场配置也基本完成,需要视频力命令和文档的朋友可以点个赞和关注,然后私信我。 下一期 hermes 选手将再次登场,但交给他的将是一个不一样的挑战。如果你也在用 ai 搞事情,点个关注,欢迎交流,我们下期见!
87圆满闯世界 05:02查看AI文稿AI文稿
05:02查看AI文稿AI文稿在上一集讲解了学习循环 agent, 自己给自己造江城。本集我们讲解三层记忆,从鲸鱼到老友, 大多数 ai 聊天工具的记忆,像鲸鱼,上一轮说过的话,下一轮就忘了。 hermes 想做的不是临时应答器,而是一个会慢慢熟悉你的老友, 他既记得你说过什么,也知道你是什么样的人,还会记住你做事的方法。记忆难不是因为不能存,而是因为不能乱存。一个活跃用户,每天可能就会产生几千字内容,一个月下来就是几万字,全塞进上下文只会越来越贵,越来越慢,越来越乱。 贵是因为上下文越长,调用成本越高。慢是因为模型要读更多,无关内容。乱是因为旧信息、新信息和错误推断会混在一起。 所以 hermes 不是 把所有聊天记录一股脑装进去,而是把记忆拆成三层,各司其职,相互支持。绘画记忆,记录发生了什么。持久记忆,回答,你是谁? skill 记忆保存怎么做事?这三层记忆分别对应三种完全不同的认知任务。绘画记忆像情景记忆,负责保存每轮对话工具调用和结果。持久记忆像语义记忆,负责沉淀你的偏好、项目背景和长期状态。 skill 记忆像程序性记忆,负责把验证过的方法写成可以反复调用的操作规范,存进 hermes、 skills 目录这样的 skill 文件里。 这三层也分别落在 sq、 like 加 f t s 五缩影、 memory 工具和 skill 文件这些不同在体上,三层分开之后,系统技能记的细节也不会把所有信息混成一团。绘画记忆最关键的差别 在于,到底是全量加载还是按需解锁。全量加载的问题很直接,历史越长,上下文占用就显性膨胀,响应会越来越慢,真正相关的信息反而更难命中。按需解锁的做法不一样, hermes 用 sq lite 加 fts 五只,把和当前问题相关的片段拉进来, 这样上下文占用基本恒定,关键词命中更精准,几个月甚至几年后也还能继续用下去。而且数据就存在本地的 sqlite 文件里,不需要额外数据库,也没有网络依赖。把三层放进一个真实任务里,就更容易理解了。 当你说帮我部署这个项目,绘画记忆会先召回过去发生过什么。比如上次卡在 n g x 反代失败日记里出现过端口占用,以及之前用过的 e c s 目录持久记忆。接着补上,你是谁?像是偏好 system d, 而不是 p n two。 习惯把服务放在 slash s r v。 部署前先做健康检查, 最后 scale 记忆,再把 department checklist 拿出来,把备份环境变量构建和迁移分开跑。部署后验证接口和日期,这些步骤按验证过的方法执行, 三层各司其职之后,结果会更精准,体验也会更顺畅。除了本地三层记忆, hermes 还有一个更深一层的用户建模能力。 hong qiu。 他 关注的不是你刚刚说了什么,而是长期看下来你是什么样的人。 比如你的技术水平大概在哪一档,通常在什么时间活跃,喜欢先看结果还是先看原理?最近是不是在做数据分析项目,他甚至会发现口头偏好和真实行为之间的矛盾。比如嘴上说想要完整注式,但 review 代码时其实从来不看注式, 这些推断会被注入后续对话的 prompt 作为隐形上下文,让 hermes 的 表达和决策越来越贴近你。 claud code 和 hermes 在记忆设计上的差别,本质上是人工维护和自动沉淀的差别。 cloud code 更依赖 cloud md 和 auto memory, 写入方式更依赖用户主动维护,解锁时也更偏向启动时全量加载。项目级姓习, hermes 则把 sq lite fts 五 k 文件和 control 用户建模连成一套自动系统,既有全区记忆,也有项目级记忆,还能按需解锁。前者更像手工维护的高精度规则本,后者更像会持续进化的长期记忆网络。所以两者不是谁取代谁,而是适合不同的使用场景。记忆越强,也越要知道边界在哪。 该记的是偏好项目背景验证过的方法和反复出现的模式。不该记的是一次性细节、过时信息、错误推断和敏感数据, 长期使用之后噪声一定会积累。所以要定期检查 hermes skills 目录里的 skill, 查看持久记忆并修正错误推断。记忆是工具,不是权威,人工审查和调整必不可少。记忆系统的终极目标不是多存一点信息,而是让 a j 从鲸鱼变成老友。 鲸鱼是 ai, 每次都像第一次见面,你得反复解释背景习惯和目标。老友是 hermes 不 一样。绘画记忆提供素材,持久记忆提供画像, skill 记忆提供方法论 hongchou 再把这些碎片拼成更完整的理解。所以他不只是记得你说过什么,也知道你是什么样的人,还掌握你做事的方法? 用的时间越长,理解越深。这不是口号,而是三层记忆加闭环学习共同带来的结果。这一集先把记忆系统拆开了,下一集继续往下看。 skill 系统,如果记忆解决的是知道什么, skill 解决的就是怎么做,怎么把一次成功经验变成以后都能复用的方法。从自动提炼到跨绘画复用,再到持续改进,下一集会把 hermes 的 程序性记忆完整展开。
52小勉 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿你直接写它所有的正题都认识,因为它是开放的标准,那每一个正题也有自己的配置,克拉扣的是他啊,爱马仕是哈马仕,点 m d, 明白了吧? 好,这几个维度。好,我们看一下啊。第二层,那关于你是谁,这里边是我写的啊,你看它这里边有官方的建议。定义什么呢?定义用户的角色,你是谁?你技术的偏好是什么?写作风格是什么?注意啊,这里边不涉及到项目的架构。项目结构什么样的啊?因为它不随项目走, 跟你有关,也就说你,你在公司里边不管做几个项目,这个东西不用动,它是在描述你的,明白了吧?你看我这里边写的 架构啊,用什么技术,然后沟通风格,关注什么,这是你的,你可以改,每个人都可以改啊。第三个就是 agents 和 cloud, 这是描述项目的描述,这里边会涉及到具体的项目的架构和技术站了,解释清楚了吧?
25士心AI -志哥 06:21查看AI文稿AI文稿
06:21查看AI文稿AI文稿今天我想聊一篇关于 harmis agent 多入口架构的文章。一个 agent 的 项目做到后期,核心能力已经不只是命令型问答了。 用户希望他能跑在终端里,也能接 telegram, discord slack, 还希望有更现代的 t u i, 甚至能被编辑器或 api 调用。这时候最容易走错的一步是给每个入口都写一套 agent。 hermes 没这么做,它的核心思路是 a 键 loop, 尽量统一入口层,各自处理交互形态。 我们先看 hermes 的 核心拆分, ai ai 证负责构建 system prompt, 管理对话历史调用模型,执行工具处理上下文压缩,还有 memory to do、 session 等状态管理。 但用户如何输入,如何展示,如何审批危险命令,如何恢复绘画,这些并不属于 ai agent。 t i 点 p y 面向交互终端处理 prompt 下划线、 toki 输入和 rich 展示 getway, 面向消息平台处理平台 adapter 和异步消息。 t u i 面向液体界面, tapisk 负责渲染, python 负责 agent 逻辑。这个拆分很关键,如果把所有 u i 逻辑都塞进 ai agent agent loop 会变得无法维护。 classic c l i 是 最后的本地入堂,赫尔氏科一管的事情非常多,加载配置你人情 睡至完啦,贵惯的数据太特别,自带太特别,这种对网关的酒肯定非常的追震。 输入历史与使命 ai agent 维护对话历史处理各种 slash commands 处理图片附件和剪贴板处理审批和密码输入,退出时清理资源,写入 siit 三审。 它承担的是完整的本地产品体验,而不是 agent 推理本身。 c l i 的 一个重要特征是它和用户在同一个 terminal 里实时交互。危险命令审批、 soluto 密码、 secret 输入都可以通过 prompt 下划线。 tokyo 在 本地阻塞等待、 德瑞面向 charlie、 greg、 discord、 slack、 whatsapp 等平台。它和 c l i 最大的不同是长期运行的后台服务, 这带来很多问题。多个平台同时连接,多个聊天同时发消息,同一个 session 可能跨很长时间继续,用户可能在 a 阵正忙时继续发消息。危险,命令不能用 terminal point, 要通过消息平台审批。 其中最值得注意的是 agent cache 机制, data 会按 session 缓存 ai agent 时利用来保留 point caching。 如果每条消息都创建新的 ai agent, 就 会重建 system prompt, 破坏 provider 的 prefix cache, 成本会大幅上升。 所以 data 不是 每条消息新建一个 agent, 而是用 session key 映射到缓存的 agent 时,历 该会下。不能只用一个 session 下划线 id, 因为消息平台里同一个用户可能在不同群、不同 thread、 不 同平台里和 agent 对 话。 comis 用 session 下划线 key 作为核心,抽象格式是 agent main 平台聊天类型聊天 id session store 会根据来源生成 session key, 再映射到真实的 session 下划线 id。 这个设计的好处是,平台路由使用稳定的 session key 数据库存储,使用 session id resume 可以 把某个 session key 切到已有 session id reset policy 可以 按平台和聊天类型生效。 session key 不是 装饰质段,而是 getaway 运行时的主键。 多路口系统很容易出现命令漂移的问题。 c l i 有 某个命令,挑了官,帮主里没有 slack 支持某个命令。 c l i auto complete 又忘了别名 hermes 用 c o m m a n d 下划线 r e g i s t r y 解决这个问题, 每条命令是一个 command def, 包含名称描述,分类,别名,参数提示,还有 k i i 下划线 only 和 getaway 下划线 only 等标志。 然后所有下游都从这里派生。 c l i help getaway help telegram 命令菜单 select 命令映设,自动补全命令解析, 新增命令的主要动作是先加 command def, 再在对应入口接 handle, 这就是中央注册表的价值定义,统一暴露可控。 hanis t u i 拆成了 node 和 python 两个进程,域态是 increact, 负责终端 ui 渲染。 t 太下划线,该位是 python j s o n r p c backend, 负责 agent 逻辑和工具调用,这不是多此一举,而是非常务实。 ink 更是合作复杂终端 ui。 python 进程已经拥有 hems 的 agent 和工具生态, 强行把 agent 移植到 node 代价太大,强行用 python 复刻现代 tui 体验又很难做好。 还有一个重要细节, python stodo 被重定向到 stare, 保留真实。 stodo 专门写 j s o n r p c 防止普通 print 污染协议通道。 t u i 里还有个 slash worker, 是 一个持久的 c l i support, 专门执行 slash command, 最大限度附用 c l i 逻辑。 horis 多入口架构的启发很实际,不要把 agent 做成 u i, 也不要把每个 u i 做成一个 agent。 更好的方式是, agent 是 能力内核工具系统是统一执行层, session, db 是 历史事实层, command register 是 控制面。 c i gateway t u i 是 不同交互外壳 入口可以继续增加,但核心能力不需要复制。代价是入口层会变厚,但这是合理复杂度, 真正应该避免的是把交互复杂度推回 ai agent, 或者在每个入口层会变厚,但这是合理复杂度,真正应该避免的是把交互复杂度推回 ai agent loop, 用统一内核承载能力,用入口适配器承载体验,这就是一个 agent 从 demo 走向产品时必须跨过的架构分界线。我是林深健, ai 我 们下期再。
66林深见AI 00:33查看AI文稿AI文稿
00:33查看AI文稿AI文稿现在 hermes agent 桌面客户端也已经出来了,支持多端, windows 端、 mac 端, linux 端也是开源免费的,所有功能都是健全的,默认英文,你可以切换到中文,在设置里面进行切换就可以了。如果你之前没有安装过,我觉得你可以试用一下这版,整体的安装过程也会比较轻松, 也能看的懂,但是里面可能会有一些 bug, 如果是你已经安装过的,我觉得你可安装也可不安装,因为你如果有之前这个版本的 y b u i 版本的话,相对功能会更健全一些,也更好用一些。
715智简 AI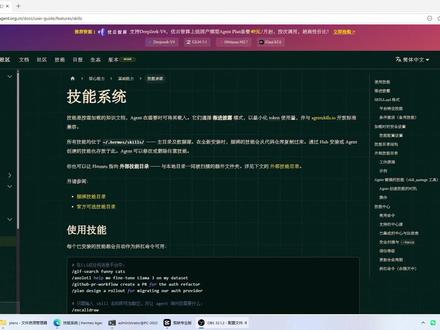 03:13查看AI文稿AI文稿
03:13查看AI文稿AI文稿想让你的 hermes 能力再升一级吗?那你一定要掌握 hermes 的 skill 技能系统。今天这个视频我手把手的教大家如何安装、管理、更新和卸载技能。首先给大家科普一下什么是 skill 六,其实就是一段提示词,它用来教会大模型如何来完成特定的任务,装上不同的技能,你就能解锁、调研、编程、文档拷写、数据解析等等这些专属的能力。我们来看一下都可以如何地使用 hermes 的 skill 功能。首先它提供了命令行,就是 hermes skills 这个命令,我们可以使用 help 参数来看一下它都有哪些命令,这里就是它可以使用的命令的列表,主要常用的呢,就有这么几个命令。我们可以使用 hermes skills list 来查看我们现在已经安装了哪些技能, 这些是我们目前已经安装的技能,还可以使用 hermes skills search 来查找相关的技能。比如说我们要搜索一个文案,那就是 search corporating 来搜索文案相关的技能,这里就是文案相关的技能,这里有名称介绍、来源等等信息来供大家参考安装。那么该如何安装呢?可以使用 hermes skills install 来安装这个 copywriting, 可以 看到这里提示我们发现了多个相同名称的技能,需要我们使用完整的标识符来指定安装哪一个技能。那么我们就运行 premise skills install 这个短一些的。这个 copying 正在下载,这里是询问我们是否确认要安装 copying 这个技能,我们输入 y, 这里提示我们已经安装成功了。我们来使用 hermes skills list 来查看一下是否有这个技能,我们来找一下 copying, 在 这里已经安装了, 那么我们下一步再来把它卸载,卸载的命令是 premise skills on in store, 然后加上 copying 提示我们是否要卸载这个 copying, 输入该提示我们已经卸载成功了。这个时候我们再来运行一下 premise skills list 啊, 我们再来找 copyright 已经没有了,那么我们再重新把 copyright 装上之后,进入 hermes 之后该如何使用这个 copyright 的 技能? hermes 中调用一个技能非常的简单,只要打一下斜杠,然后输入技能的名称,也就是 copywriting。 然后我们再接着输入我们的要求,写一个 hermes 的 介绍文案,这里就显示出来已经调用了技能 copywriting, 非常好,他已经把文案写出来了。这就是 hermes 的 skills 技能的介绍,今天就讲到这里了,感谢大家的观看,再见!
19波哥的AI课 08:39查看AI文稿AI文稿
08:39查看AI文稿AI文稿别再刷那些教你一键部署的过时教程了,如果你真的想亲手打造一个主属的 ai 助手,而不是在无休止的代码报错里痛不欲生,那今天的这期硬核解析绝对能救命! 今天我们不搞虚的,直接带你拆解一份终极避坑指南。从零开始,真正养育你的第一个主属 ai, hermes 版本,零点一,三点零。 记住,这不是流水账,这是一堂帮你避开所有新手填坑的大时刻。准备好做笔记了吗?咱们直接干货走起! 先来看看最扎心的新手陷阱。很多人刚接触 ai 诊的,那简直是两眼放光,期望值直接拉满。 你以为撬两行代码,明天就能坐拥一个七乘二十四小时全自动运转的 ai 商业帝国?自动接单、自动斜稿、多平台无缝调度、快行行。现实情况往往是一上来就把网关多配置看板全开。结果呢? 一个 token 填错,一个本地模型接口没对上,直接卡死。查了一下午,报纸日制时间全荒废在配环境和调 u r l 上了。想让 ai 飞起来,咱们得先学会怎么让它安稳落地。 要打破这种从入门到放弃的死循环,我们必须要完成一个核心的思维转变。 第一部分,咱们得明确一件事,它绝不仅仅是一个大语言模型。很多人把 hermes 和普通的 ai 大 模型混为一谈,这就大错特错了。举个最直白的例子,像 gpt 四或者 ploy, 它们的能力再强,也只是一个最强大脑。 那 hermes 是 什么呢?它是一个智能体的运行时环境,普通的聊天窗口就像是你临时拉来的外包,问完问题关掉窗口,人就走了。但 hermes 是 给你的 ai 特注,专门配了一张实打实的工作桌,这张桌子上摆着它的专属笔记本儿, 标准操作规范,有专门接收外部消息的通道,墙上还挂着一块儿管理项目进度的任务看板。你不是在简单地安装一个软件,你是在给你的 ai 安家,在一点一点养育一个能帮你打理长期任务追踪资料的超级大管家。 既然是养育第一天,咱们绝不能拔苗助长。接下来第二部分,手把手带你打下坚如磐石的地基。 听好了,上手第一天,你的唯一目标就是确认这个 ai 有 正常的生命体征。 第一步,用官方脚本安装完,立刻跑一下环境检查命令,让系统自己核对版本,别再靠肉眼盯着屏幕瞎猜报错了。 第二步,这是一个极其容易被忽略的硬指标,务必要连接一个上下文至少达到六十四 k 的 模型。为什么?因为你的 a g 的 身上要背着工具箱,历史记忆和任务状态模型上下文太小,跑到一半它就会失忆断片。 第三步,也是最关键的,关掉终端,退出绘画,然后再重新进去,看看它能不能精准恢复刚才聊天的上下文。如果不能继续工作,那这个 ai 就 只是个玩具,能完美恢复绘画,才证明你的基础建设彻底通了。这三步踩实了,你才算真正进了门。 接下来这个知识点啊,强烈建议大家直接截图保存,这绝对是新手最容易搞崩系统的罪魁祸首。配置文件大乱斗,很多人图省事啊!把所有的规则、个人偏好、工作笔记,一股脑全塞进一个记忆文件里, 信不信有你?没出三天 j ai 绝对精神分裂!看清楚这里的分类点 mv 文件,只放那些见不得光的 e p i 密钥 config 点压默,专门处理基础设置。 so 点 md, 顾名思义,这是它的灵魂所在,用来放最底层的硬规则和人设,比如执行危险命令前必须跟我确认。 而 memory 点 md 仅仅是它随时记录和修改的工作笔记。 user 点 md 才是用来存放你个人偏好的,比如你要求它凡事结论先行。 记住,各司职千万别搞混。一开始你的灵魂规则写上几行就足够了,别洋洋洒洒写两千字的小作文,不仅你记不住, ai 也会直接无视。 那你把配置文件都理顺之后,我们马上会遇到所有进阶玩家都会踩的一个超级大坑。第三部分,彻底搞懂记忆与技能的区别。 咱们是不是经常急躁地对着 ai 敲字儿?记住我刚刚说的,别白费力气了。在 hermes 的 运行逻辑里,记忆和技能完全是两码事。 对比来看,所谓记忆是用来存储客观事实和你的偏好。比如这台电脑用的是 macos 系统,或者我喜欢用中文交互,但如果你需要它帮你按照固定逻辑去总结一篇长文章,那就是另一边的技能了。 技能是流程,是标准的操作规范,也就是 s o p。 当你发现它某项任务执行的特别漂亮时,直接让它把这套流程沉淀为一项技能。 新版本里甚至还自带了一个维护工具,能帮你自动清理和合并溶于的技能。所以,别再对他喊记住我了,把成功的流程固化为技能,才是保证他下次不出错的唯一解 好了,地基打稳了,记忆和技能也分清了,现在咱们节奏加快。第四部分,带你感受一下最新版本进阶与自动化的真正火力。 新版最恐怖的地方在于,它直接把组建能力拉到了生产级别。通过 gateway 网关,你的 ai 能秒变外部通信软件里的专属社群助手。利用 profiles 配置文件,你可以无限克隆它,分化出无数个不同角色的打工人。 再加上 docker 为它提供绝对安全的沙盒执行环境。还有重磅的 canbin 任务看板,直接给你一个持久化的任务追踪器,哪怕中间宕机也能自动回复。 最后配合 chrome 定时任务,让他在你大半夜睡觉的时候,依然能默默地在后台刨脚本抓数据。这简直就是把一整个自动化公司的 it 架构硬生生塞进了你的电脑里。但是说到这里,我必须猛踩一脚刹车,给你提个极其重要的安全性。 很多新手会犯一个极其致命的错误,他们以为用 profile 创建了一个新角色,这个角色就老老实实待在安全沙盒里了,大错特错! profile 仅仅做到了状态隔离,它隔离的只是记忆、绘画和技能,但它依然拥有你这台电脑本地文件的访问权限。 如果你想限制它乱删你的重要文件,或者限制它的危险命令执行环境,你必须把它关进 docker 这样的沙盒后端里。 一句话总结, profile 管的是工作状态, docker 管的才是安全边界。这两个概念千万千万不要混为一谈。 理论,咱们铺垫的够多了。第五部分,直接上实战演练。与其第一天就做着搞全自动帝国的白日梦啊,不如跟着我做一个最踏实试错、成本最低的闭环联系。 重点来了,这是一套实战验证过极其高效的三天 ai 每日简报极简训练法。 第一天,你只需要在命令行里丢给他几篇长文,让他总结,做完之后立马指出并纠正他的排版格式。第二天,换一个完全不同的新闻主题,看他有没有长记性,能不能自动沿用你昨天纠正过的排版篇号。 第三天,当这个总结的流程彻底跑通,毫无瑕疵了,果断下指令,把这个流程沉淀成一个可重复调用的技能。你看,仅仅三天时间,它不仅学会了干活,还能自动适应你的习惯。这种低风险、高回报的慢爬坡策略,才是普通人构建稳定 ai 工作流最靠谱、最快速的捷径。 强大的工具绝经不仅仅是一堆冷冰冰的代码,它会随着你的精心调教而不断进化。 hermes 从根本上解决了 ai, 转身就忘了连续性痛点。 只要你掌握了今天咱们聊的打牢基础、区分技能、死守沙盒、安全边界这些底层逻辑,你就已经成功避开了百分之九十九的新手天坑。 那么最后问自己一个问题,现在回到屏幕前,你准备好用正确的方式去养育你的第一个专属 ai 了吗?别犹豫,立刻动手跑起来吧!咱们下期硬核解析,不见不散!

猜你喜欢
最新视频
- 1682人间变量