计量经济学中平稳性检验结果步骤

粉丝1.2万获赞3.4万
相关视频
 02:40查看AI文稿AI文稿
02:40查看AI文稿AI文稿平稳性检验第一步,打开变量,在窗口中选择 view unit, root test, taco 表示平稳性检验。方法通常选用默认的 adf 检验。在 selection 中一般选择 sake 或者 ache。 弱得下三个选项表示原序列,一接序列,二接序列 include。 下三个选项表示洁具象、趋势象,两者都不存在。用 adf 检验判断序列是否平稳,需要将这三个的结果一起做出 其他默认点击 ok, 结局向结果表示 adf 对应的 p 值大于零点一,说明在百分之十显著水平下原序列不平稳。 freeze 保存一下结果, 继续做韩趋势像的 adf 检验,保存,再做不含洁具像、趋势像的 adf 检验。 从结果看出,结局象、趋势像二者不存在的三个 adf 值对应的屁值都大于零点一,说明原序列不平稳。第二步,做一阶差分后的 adf 检验,选择 will unnatural test, 选择 istreat difference 之后结局像、趋势像,二者不存在的。三个步骤与之前的操作一致, 只要三者结果中有一个 p 值小于零点一,则可以说一阶差分后的序列是平稳序列。 从结果可以看出,结局像、趋势像 nandaadf 直对应的 p 值都小于零点零一,说明经过一阶差分后的序列是平稳的。第三步,选取合适的数值,填入最终结果, 将个 adf 复职复制到 word 表格。如果所有的序列均通过平稳性检验, 通过对比拮据像、趋势像和不存在三者的百分之一、百分之五、百分之十对应的值谁最小,来确定最终写在报告或论文上的数值 本力中,趋势向下对应的数值最小,所以最终选择趋势向下四个对应的数值写在报告中。
703热爱散步的蟹鲸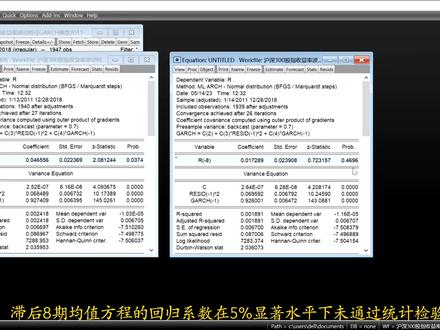 08:35查看AI文稿AI文稿
08:35查看AI文稿AI文稿基于 gark 模型的沪深三百股指收益率波动分析。一点一描述性统计打开收益率序列, 绘制实序图、直方图描述性统计表,点击 view 选择 graph 末日 ok 持续图表明大部分数据以零为中心值,上下波动,大部分处于负零点二、零点二之间。 点击 view 选择描述性统计 histogram and stats 直方图 stats table 统计表 看均值及大及小值,标准差,标准差小,说明选取的数据差距小,数据呈现聚集趋势,存在聚性特征。 从直方图可以看出,大部分数据聚集在正负零点零一二五之间, 风度为负,说明数据又偏,风度九点五二三大于三,说明比正态分布数据陡峭。 g、 b 统计量的伴随概率 p 值为零,说明选择的数据不服从正态分布。 据偏度、风度 j、 b 统计量分析可以看出,收益率具有右拖尾减 分布,不服从正态分布的特征。 一点二平稳性检验对收益率进行 a、 d、 f 检验,选择其他检验也可以 依次选择检验形式。只要存在一种平稳情况,都可以说该序列是平稳序列。 为了使结果好看一点点,尽量选择最小的结果,比如 a、 d、 f 值最小或 p 值为零。 基于 a、 d、 f 检验法及 sig 准则,收益率系列的原系列的 a、 d、 f 统计量是负四十四点八七九一三,伴随概率为零,体值 小于零点零五,可以认为该序列通过了平稳性检验。一点三二 g 效应检验第一种方法直接看该序列的自相关检验结果, 直接看 a、 c、 park p 值,先找 p 值小于零点零五十对应的至后期 本例中滞后六七开始 p 值小于零点零五,说明可能从滞后六七开始存在二级效应。 其次看 a c 和 pack 中是否有一项的数值的绝对值超过零点零五,超过零点零五说明在某阶存在二级效益。 本例中,之后七七时 pack 超过零点零五,之后八七时 a c 和 pat 的绝对值超过零点零五。最终选择七阶还是八阶,需要建立 gark 模型,通过技术显著性判断 第二种建模。利用残差判的 arch 效应模型可以按论文情况构建。本例只举例两种初步回归模型,在回归窗口中选择一方叉检验中的 arch 检验, 观测至二方对应的伴随概率 p 值为零,说明在百分之五显著水平下存在二级效应。利用第二 种模型判断二期效应, 重复 r g 检验步骤,伴随概率 p 值为零,存在 r g 效应,可以建立 gag 模型。 利用残差项判断 gark 模型中自变量应选择之后多少期, 和第一种直接利用收益率序列判断接触的方法一致。 在 p 值小于零点零五时,对应的至后七期 pack 大于零点零五,至后八期的 a c 和 pack 大于零点零五。 一点四 bark 模型结果命令 l s r 二七和 l s r 二二负八。最 massive 的选择 arch auto regressive 比较之后七七和八七模型的回归系数, 之后八七均值方程的回归系数在百分之五显著水平下未通过统计检验本例模型中的变量,因去之后七七收益率。 关于 dark p q 模型中 p 和 q 的取值,常用取值为一和二, 建立 gark 幺一, gark 一二, gark 二一、 gark 二二这四个模型对比系数显著性,并利用 age, s, c, h, q, c 最小 原则选出合适的模型。只需要改变 arch 和 gark 的数值 对比 a 一个 s, c, h, q, c 干儿个一一模型中的三个数值最小, 且 gark 一一模型的系数均在百分之五显著水平下显著。本例选择 gark 一一模型分析收益率波动特征。 一点五模型结果分析,上半部分是均值方程,下半部分是方叉方程。 reside 一二的系数表示二取项系数, gark 幺的系数表示 gark 项系数。二取项和 gark 项系数之和接近一,说明收益率的冲击存在持续效果或条件方差,所受的冲击是持久的。 gark 项系数零点九二七四零四,说明早期的收益率波动对后期的收益率波动具有显著影响, 存在风险溢价现象,波动越大,风险越高,收益率越高。 一点六 h a m 检验, 检验结果,线上建立的 gark 模型已经不存在二期效应,说明 gark 模型是有效的。一点七伏二值计算,点击 prag, 选择 make gark variance, 建立一个新序列。 根据新序列计算,在百分之九十五致信水平下的 var 值。 一点六五为百分之九十五制性水平统计值。 将计算出的 var 值复制到 excel 表格,用 var 预测值减收益率的绝对值筛选出结果为负的情况, 结果为负代表当天的预测失效。
152热爱散步的蟹鲸 03:37查看AI文稿AI文稿
03:37查看AI文稿AI文稿大家好,这里是博哥讲计量,我们今天看一道真题,采用比对法啊,进行计量标准的简定或教的结果的验证时,参与比对的。同等级的计量标准共四套,这个含被考核计量标准, 被考核计量标准测得值的扩展不确定度为零点零二零 t 等于二。在被考核计量标准测得值的方差接近于各实验室的平均方差, 包含因子均相同的条件下,该套计量标准测得值与四套计量标准测得值的算数平均值之差绝对值应不大于。 我们首先看到这个,这道题是干什么的?它是进行 鉴定或教职结果的验证啊。这个方法呢,有两种,一种是传递比较法, 那个具有溯源性,这个是比对方没有溯源性啊,这个就是要靠好几家的实验室用他们的平均值作为参考值的啊。这道题呢,就是考的就是一个基础的公式, 我们知道采用比对法的时候,我们应该用的是我们自己的,自己的实验室的数据 啊,减去一下,你参与比对啊,用这个比对的方法,我们把各家实验室的数据的平均值作为一个参考值,要求小于什么呀?小于等于根号 下啊,上面是 n 减一,哎,上面小,下面是 n, 就几次啊,有四加的话,就是啊,就是 啊,总共就是四套啊,因为这个四是包含备考核计量标准,也就说他们总共是四, n 是四,四加啊,然后呢?四加的什么呀?扩展不确定住啊 啊,这是,这是他们最考核计量标准的扩展不确定度 啊,用的是这个公式,不能和后面的那个比对法啊,尽量比对啊,音值相混 小,这是最容易过桥的地方。然后呢,人家问的是什么?该套计量标准测的值与四套计量标准测的值的算数平均值。哎,恰好。然后还有一个绝对值,恰好就是这公式的左边部 等于右边部分,小于等于右边右边部分呢,那么这是一个四, n 是四,那么这就是四分之三。嗯,你这个 到 u lab 是乘以一个零点零点零二零。哎, 好,这就行了,这算下来大概就是一个零点零一七,零点零一七。哎,这个答案就直接出来啊, 这道题,也就是说,考考察一下咱们这个比对法,还有计量比对区别啊,公式不要带错。 好,感谢大家的关注,也可以参与我的一对一的辅导,谢谢大家。
258博哥讲计量 06:51查看AI文稿AI文稿
06:51查看AI文稿AI文稿同学们大家好,我们今天开始学习计量经济学第一章的内容。第一章是课程的一个导论,我会和大家一起探讨计量经济学的诞生,并且帮助大家对计量经济学的研究方法、研究过程有一个最基本的了解。 第一章节内容比较简单,题型呢主要以选择题为主。基朗经济学这个名词的首次出现是在一九二六年被挪威经济学家弗里西提出, 而一九三零年世界计量经济学会的成立则标志着该学科的正式诞生。这里可能会考察一些选择题,两个时间和创始人的名字。同学们一定要记住,计量经济学是以经济理论和经济数据的事实为依据,运用 数学统计学的方法,通过建立数学模型来研究经济数量关系和规律的一门经济学科。研究步骤遵循从模型设定到估计参数、模型检验最终实现模型应用的范式。 然后在模型检验这边,我们需要知道的是这以下四个检验,其中的统计推断检验与计量经济学检验是我们接下来需要重点学习的。而计量经济检验的话,其实更加偏向于考察你的经济学基础知识。 数据类型方面同样也包括四种,这里需要大家看到一个数据时能够准确判断出它的类型。下面我们详细来看一下四种检验类型。经济意义检验 检验模型是否符合经济意义,既需要我们检验参数估计值的符号大小,参数之间的关系是否符合人们的经济学常识。统计推断检验需要检验参数统计值的可靠性,它包括你和优度检验、 变量显著检验、方程显著性检验等等。计量经济学检验检验模型的计量经济学性质, 他又包括随机扰动项的序列相关检验、一方差检验、解释变量的多重贡献性检验。而模型预测检验指在检验模型参数估计量的稳定性以及样本容量变化时的灵敏度。 我们一起来看两道例题。第一题,一个计量经济学模型用于预测前必须经过 的检验,包括大家可以看到这里给出的是四个孔。这道题考察我们的就是刚刚学过的四种检验类型,题目比较简单,但是需要同学们一字不错的记忆四种模型检验的名称 来看。第二题,现有模型 i 等于零点三四加 a r, 其中 i 为投资, r 为利率, a 为未知参数。 以下 a 的取值能够通过经济意义检验的是。相比前一道题呢,这道题就需要大家思考一下了, 其实只要仔细思考,我们不难发现,这道题很明确的告诉我们,他考察的是一个经济意义检验,那就需要我们选择一个合适的 a 值,让他的符号大小符合经济学常识。 大家先看符号,同学们学过经济学应该可以很容易就能判断出投资 i 和利率 r 是具有相反关系的,利率越低呢,投资就会越多。所以我们首先就能排除 a、 d 两个选项, 再来看大小, b 选项虽然是负的,但是这个值过于大了,利率上升并不会引起这么多的投资变化,这个是不合常识的。因此这道题的正确答案选择 c 选项。 接下来我们一起来看计量经济学的数据类型。数据类型主要包括时间序列数据、洁面数据、面板数据、虚拟变量数据这么四种。时间序列数据是对同一对象在不同时间连续观察所取得的 数据,比如说北京是二零一八年到二零二零年的 gdp, 而洁面数据呢,就是同一时间内对不同对象进行调查所得来的数据。比如说二零二零年一年之内,北京、天津、河北的 gdp, 因为 gdp 均处在二零二零年这一同一时点,因此呢,它是洁面数据、面板数据。我们可以简单的理解为是我们前面时间序列数据和洁面数据的结合。 以下面这张表为例,它既包含了北京、天津、河北这三个省份,同时呢还囊括了这三个省份二零一八年、二零一九年、二零二零年三个年度的数据,其中每一年的数据都是一组洁面数据。最后呢,就是 虚拟变量数据,虚拟变量数据是我们在设计模型的时候自己设立的一个数据,他通常取零或者一。比如说考察性别时,我们可以把男生取作零,女生取作一。 而考察文化程度时,我们可以把有文化去做一,没文化去做零来进行分类。 我们再来做两道题来练习一下吧。例题三横截面数据是指 a 选项同一时点上不同统计的单位、相同统计指标组成的数据。 b 选项同一时点上相同统计的单位、相同统计指标组成的数据。 c 选项同一时点上相同统计的单位、不同统计指标组成的数据。 d 选项同一时点上不同统计的 单位、不同统计指标组成的数据。让我们来回忆一下刚才课件上出现的表格,洁面嘛,他肯定是一个十点,而一个十点内不同对象的数据正是对应本道题的 a 选项。因此我们来选择 a。 例题四,统一统计指标按时间顺序记录的数据称为 a 选项,横截面数据。 b 选项,时间序列数据。 c 选项,虚拟变量数据。 d 选项,面板数据。 时间序列数据和面板数据都可以按照时间顺序来记录,但是面板数据他可能对应多个统计指标,比如说我们统计北京历年的 gdp 和人口, gdp 和人口就是两个指标。因此我们本道题只能选择 b 选项时间序列数据。以上呢,就是本章的全部内容了,内容不太多,大家记得课后及时回顾。
67期末帮 11:21查看AI文稿AI文稿
11:21查看AI文稿AI文稿好,接下来再看一下,又是差又是离的,在我们的离散程度的测度指标当中,还有一件事叫做离散系数啊。离散系数,从含义上来讲,它又叫做变异系数, 或叫做标准差细数,这叫离散系数啊,也就是说,标准差和均值的比值叫做离散系数啊。标准差和均值的比值。好,那我问你,均值,我能不能换一个名词,均值叫平均数,对吧?他是不是叫平均数就是均值呀, 对吧?平均值嘛。好,离散系数又叫变异系数,或叫标准差系数。是他,是他还是他?三个名字一件事,离散系数,首先要知道,他是测度数据的离散程度的重要指标,他主要用于不同类别的数据离散程度的比较。好, 重点系他的计算公式。离散系数,标准差评,标准差评,看明白了吗?标准差与平均数的比值叫标准差评。所以如果用 cv 来表示离散系数,用 s 来表示标准差, 好, x 八来表示平均数,所以上面是标准差,下面是平均数,这叫做离散系数的计算方式。标准差评,记住口诀,直接得分。那你就想你与我分离,你与我分散, 我非常不开心,我非常不快乐,我要给你标准差评啊!记住这个口诀,与我分离,与我分散,我要跟你标准差评,所以他是标准差除平均数。标准差评, 口诀记下。好,那么视力呢?比如说啊,呃,利用本节前面的五名营业员元旦当天的 这种销售额的案例述职计算日销售额的立三息数。在刚才两问当中,我们已经算出来了,标准差是一一点四五标准差,也就是方差开过根号的那个标准差是不是在处以刚才求得的平均数五百七十? 好,所以标准差除平均数。标准差评就是离散系数的计算。掌握好,来看一下特点。标准差的大小呢,不仅与数据的测度单位有关系啊,也和测观测值的均值大小有关,它并不能直接来用标准差比较不同变量离散程度 好,离散系数呢,他消除了测度单位和观测值水平不同的影响,他可以直接用来比较变量的离散程度。注意啊,不同类别变量的离散程度的比较只能用离散系数。就记这么一 句话就可以了啊。说呢,他消除了这个测度值,他消除了测度单位和观测值的水平不同的影响啊,他能够用来比较不同的变量之间的离散程度。把这句话做到简单的记忆就可以了。 好,来看这道题,标准差细数是一组数据的标准差,与其相应的什么的比值。标准差评,标准差除平均数应该是与均值的比值,是不是选择 a 啊?我们求的是均值,也就是算数平均数,不是几何平均数啊,这个什么叫几何平均数,我到后面会讲 好与均值也就与算数平均数的比值选 a, 正确选项。好,来看这道题,某学校学生的平均年龄呢,为二十岁,他的标准差为三岁啊,某学校的教师的这 这个平均年龄为三十八岁,标准差为三岁,这叫不同类别的变量之间。我们要用离散系数来比较他的离散程度吧,比较该校学生的年龄和教师年龄的离散程度。好,这道题目注意了啊, a 应该选择谁呢?谁先算离散系数呗!离散系数标准差评学生的离散系数标准差评学生标准差。三岁,学生的平均数是二十岁,这是学生的标准,差评离散系数。 好,老师的标准差三岁,老师的平均数是三十八岁,这是老师的标准差出平均数标准差评老师标准差评学生离散系数两个有了好,这两个谁大谁小你分不清楚吗? 三除以二十三除以三十八啊,分子相同,分母小的分数大,所以学生的 离散程度是更大的对不对?因为他离散系数求得的值更大。于是我们得到重要结论,学生的平均年龄离散程度要大一些。这道题目就是考察离散程度的计算题是不是小学数学题,离散系数选择地就是我们要的正确的选项。 好,这道题目下列离散程度测度值当中,能够消除测度单位和观测值水平的不同影响的,是能够消除不同影响来区别不同类别对离散程度的比较。我们应该选择是离散叙述,选择 b 才是正确的答案。 好,以上呢,就是离散程度和集中趋势的测度,我们就全讲完了,老师呢,给你一张综合的表格,叫做横看成岭侧成峰,远近高低各不同,大家要相对比相区别的 重点掌握啊!一张图解决所有的问题。好,首先啊,我们有集中趋势的测度指标,三个数,均值、中位数和重数,这三个都是代表一组数据的一般水平或重心所在,是集中趋势的测度两分。 而离散程度的测速呢,是又是差又是离的,就是离散程度了。方差,标准差,离散技术 是否受极端值的影响?来纵观下面的内容,均值因为需要用每个数来计算,所以他非常容易受到极端值的影响,来个大的来个小的都会计算到他的过程当中,所以影响很大。 好,中位数和中数只是一个中间位置数,你偏大的,老子来了,不影响我的位置,跟我无关,明白吗?我不正眼看你一眼。好,中数呢? 不影响,我是出现次数最多的那个就行了,我管你是谁。好,所以这两个啊,都不受极端直的影响。 而离散程度,方差、标准差,离散系数呢?这三个在计算的过程当中是不是都需要用到均值来计算?方差是离差平方和的平均数, 标准差是方差的平方根,离差平方和的平均数。再看一个平方根,离散系数是标准差,平除平均数。你说这三个是不是都和平均数有关系?好,平均数适合他们就适合,听明白了吗? 平均数,均值容易受到极端值的影响,所以方差、标准差,离散系数这三个也容易受极端值的影响。掌握了好,再看一下他们适用的情况。均值能计算,求平均的 仅限于定量数据,也就是数值型数据,能有具体的数值来计算的才能算平均数。所以均值只适合于数值型数据啊,它不适合于分类数据,也不适合于顺序数据。分类数据男女求平均,半男不女没意义。记住了, 顺序数据本科生、研究生、大专生求平均等,以啥没意义?好,所以他只适合于数值型数据,他不适合于另外两个不能计算的,明白吗? 好,方叉标准叉离散系数,我说过均值是如何他们就是如何,因为他们计算都是跟着均值走,他们是包括了均值在内的,对不对?所以啊,这三个也同样只适合于定量数据,数值型数据能计算的才能求方叉标准叉离散系数一样 和他一样。好,那他同样这三个都是不适合于分类数据和顺序数据的,就是他们所有的特征都和均值相同。 好,接下来来看一下中位数。中位数呢,是一个中间位置数啊,他适用的是能排序就能找到中位数,谁能排序就能找到中位数好,一二三四五六七八九十。数值型数据能排序好有中位数,顺序数据能排序好,有中位数,但是男女之间没有中位数 啊,没有顺序对不对?不分大小,不分优劣的,只分类的分类数据,他用不分顺序去哪找中美数据?半男不女没意义是不是?所以呢,他不适合于分类数据,但是他适合于两个数值型和顺序,能有序他都能适用好。接下来是重数 种树呢,我说他是最具包容性的种树呢,其实他是都能够去适用的对不对?种树都能够去适用的 啊,但是呢,我们教材当中呢,说他不适合数字型数据,因为他容易出现双重数,多重数,无重数,不稳定,所以说他不适合数数,数值型数据,我们按照教材当中记一下行不行啊?但是重数依然是最具有包容性的,因为只有他能够适用于分类数据,男女知识 啊,众生平等,是不是只有他众分平等啊,只有他能够适用于分类数据,包容男女知识 啊,这是他特别的亮点和考勤。剩下呢,他也适合于顺序数据,本科生研究生本科生最多呀啊,男女男生最多呀,对不对?他都适用啊,其实他也适用数值型,但是 教材说他不适用,咱就不适用吧,他也很少考,不用管,你就记住他。这就行了啊,只适用于集中趋势分类数据的只有中暑。 好这一页呢,我们就全讲完了前两节,这张表格全部概括了前两节所有的内容。好,这些大家在去重点区分,重点记忆,重点掌握 好。来看一下这道考题。下列指标当中,数以描述数据的集中趋势并且易受极端值影响的是谁? 集中趋势并且易受极端值影响,我们应当选择的是均值平均数对不对?首先啊,啊,三个数,平均数,中位数和重数容易受极端值的影响,而平均数呢,他是一个呃,更容易受极端值的,他们都是这个集中趋势,凑读对吧, 但是重,但是平均数呢,更容易受到极端之影响。选择 a 正确好,数字型数据的离赞程度测度的指标。 数值型数据啊,只是说数值型,离散程度,离散程度都是数值型数据,只适合于啊,叫做又是差又是离,对不对?离散系数方差都很差啊。这三个就是离散程度的测度指标,选择两分, cde 两分。 下列统计量当中是用描述分类数据集中趋势,从集中趋势的三个数当中选,又必须描述分类数据,只有种数能包容分类数据男女知识种数才是我们要的正确的答案。 下列统计量当中容易受到极端值影响的事,容易受极端值影响的事,需要用 每个数来计算的均值,还有通过均值来计算的方差、标准差,离散系数都会受到,都会受到极端值的影响。而重数呢,只是出现最多的那个中位数呢,只是中间位置的,他们两个都不会受到 极端值的影响。这道题选择 abc 正确答案好。以上呢,就是第二小节,希望大家能够重点掌握。
119慧考智学 26:14查看AI文稿AI文稿
26:14查看AI文稿AI文稿哦,大家好,我是山东大学的陈强,那么这一期视频号呢,继续跟大家介绍中介效应的原理与检验下, 那么在上一期的视频号中,我介绍了中介效应的检验方法之一,也就是这里的逐步英国法啊, coco steps approach。 那么在这一期的视频号中间,我将啊继续介绍第二个方法以及第三个方法。 那么在此之前呢,我还想回答一下这个观众在评论区所提出来的几个小问题, 那么一个问题呢,就是说有些观众还是不理解,为什么在我举的那个例子中间,那个年龄于性别不可以作为中介变量。我举的那个例子呢,就是想研究 管理层的这个支持是如何去影响员工的业绩啊,那么在那个例子里面呢,我也考虑了这个员工的年龄与性别,我们假设他可以用来作为中介变量,那会是什么样的后果? 首先呢,我们要注意的就是说这个中介变量它是一个专有的术语啊,最好不要从这个中介这个词它通常的含义上去理解, 因为中介效应是一个装有的术语,所以其实它的定义就是说你要有一个因果的链条,也就是从你的自变量影响到中介变量,再影响到你 的结果变量,有这样的一个英国链条的存在,这是它最本质的定义。那么我们来看一下,有没有可能你把这个 h 或者 这个性别作为 media 的放在这里。那么首先一个问题就是说,你的管理层的 support 无论如何是不可能去影响员工的年龄或者性别,因此呢,这个从 x 到 m 的这个 a 的这个路径其实就不存在, 因此呢,性别或者年龄就只能够作为调节变量,就是说他可以去调节 x 对外的作用,也就是一种意志性的效应,就是说 x 对外的作用呢,会因为这些员工的年龄或者性别的不同而不同,但是年龄和性别是不可能作为中介变量的。 那么评论区的观众还有另外一个问题,就是说这个总效应的方程一,也就是这个方程是不是会存在有遗漏变量的偏差啊?那么我们也来 来探讨一下这样一个问题啊,从表面上来看,似乎是存在一个遗漏的变量,因为如果你跟第三个方程去比的话,那么明显它是遗漏了这个 bm 这一项,也就是遗漏了这个中介变量 m 啊,但是呢,因为这三个方程是我们所假设的,所以呢,这个其实这里的 m 它是由这个自变量 x 所决定的 啊,如果我们把这个 m 的这个方程第二个方程给他带到第三个方程里面来,我们就会得到不一样的一个结论了, 那么也就是这里啊,我现在做了一件事情,就是说这是我的第三个方程啊,然后呢,我把这里的 m 用第二个方程的这个表达是给他带进来,那么就变成这啊,这是我的第二个方程, 也就是把我的 mediatorm 对自变量 x 去做回归的方程啊,然后呢,我把它这个沉进去,再给它合并同类下,那么我看到说现在我的新的这个结局线呢,就应该是 i 三加上 b i 二, 那么这个其实就相当于翻成 e 的那个 i 一了,而这里的这个 x 我同样也可以和平同类一下,那么就是把原来的 c pry x 和这里的 a 乘 b 的这一项加在一起, 那么因此呢,这个 x 前面的这个回归系数呢,就变成 cprn 加 a 乘 b, 那么这个呢,其实就是翻乘一里面的那个 c 了,也就是这里的这个 c, 那么同样的我现在这个劳动像呢,就变成什么呢?就变成你把这个 b 成 epio 二以及这个 apio 三加在一起,那么这个就是我的新的老动向,也就是这个翻乘一的一手一,其实是这样的一个表达式啊。 那么现在的问题就变成说,我既然可以把方程一写成这样的一个表达式,那么我要回答的一个问题就是说,对于方程一我能不能够得到一致的估计, 那么这里面就取决于什么呢?取决于这个方程一的劳动像,其实里面是有两个部分,有包括了 b 一手二和一手三,那么他会不会和这个方程里面的这个解释变量 x 有相关性, 那么这里面搭呢?我们是需要一定的假设,那么一个很自然的假设就是说方乘二和方乘三都没有遗漏变量,也就是说我们假设方乘二和方乘三呢,都可以得到一致 的估计,那么这就意味着什么呢?意味着 f 手二和 x 是不相关的,和方程三的一致性意味着 f 手三和 x 也是不相关的, 那么这样我们就会马上得到一个结论,就是说方程一的这个老动向里面的这两个组成部分, 也就是一手二和一手三,他们其实跟这个 x 都不相关啊,因此我们马上可以得到结论,就是说,其实呢, 这个方程一他也是可以得到一致的估计的啊。那么这里面的一个唯一的我们需要的一个条件就是说你的方程二和方程三能够得到一致估计, 那么你就不用担心方程一会存在一路变量,他也可以得到一致估计啊。当然了,如果方程二和方程三无法得到一致估计,那么方程一肯定就 就得不到一致估计了啊,那么这个是非常显然的,因此呢,就是说你为了保证方乘二和方乘三能够一致估计,那么你在实践操作中间通常是需要加入比较多的这种控制变量,从而来保证方乘二和方乘三不存在内生性。 那么从刚才的那个问题,我们也可以隐身一下,就是说另外一个观众提出来一个问题,就是说可不可以用除了 os 以外的方法来检验中介效应啊?那么简短的回答就是说是可以的啊, 比如说你可以用 logic 啊,如果你的这个 m 或者 y 这里面有任何的一个变量是,比如说是虚拟变量当 b b, 那么你可以用 logi 或者 pro 比去估计他,而不见得非得要用最小的乘法。另外呢,就是说刚才我们谈到了已漏变量问题, 那么假设说翻成二或者翻成三存在遗漏变量偏差,那么这种情况下,为了解决内生性呢,你可能就需要去找一个工具变量。 那么因此呢,这里面其实你用工具变量法,像比如说二阶段最小二乘法或者 gm 去估计这样的三个方程是完全没有问题的啊,只不过呢,大家最常用的还是用最小二乘法去估计啊,如果用 iv 的方法或者 probe logo 都相对比较少见一些。 接下来呢,我们就言归正传,就来介绍今天要讲的这两个方法啊,其中的方法二呢,就是叫做系数差异化, defense off 扣一,非常 smasher。 那么是什么样的系数之间的差异呢?我们可以来看一下这个逐步英国法里面的这三个方程。那么从第一个方程我们知道,这个适应的 是表示一个总的效应啊,也就是说,把这个直接效应以及通过中介变量所起的这个间接效应,他俩的之和其实是通过 c 来体现了。而这里的第三个方程呢,他是同时把这个自变量以及这个中介变量都放入到回归方程里面去了。 我们来考虑一下,就是说如果这个中介变量是存在的,那么其实呢,这个 cpry 我们会期待他应该只是 c 的一部分啊,因为这里的 cprine 呢,它度量呢是一个直接效应, 如果 c prim 和 c 它俩就完全相等的话,那么就意味着这个中介电量其实是不起作用的。因此呢,我们可以通过 c 和 c prime 之间的差别,这两个 违规系数的差异,我们来判断是否存在中介效应,那么这个就是所谓的系数差异法,也就是说我的原角色呢,现在就是去考察 c p n 减去 c 是否是等于零, 那么这里的 c 呢,就是偷偷与 fight, 而 zpry 呢,是一个 draft, 那么你把这个 total infant 减去 draft, 那么自然就是剩下的那个作为间接效应的中介效应了, 那么检验的方法呢?其实挺简单,我们可以去构造一个 t 统计量啊,也就是说,当你有了样本之后,你得到这个 c hi 与 c pranhai 的 os 的估计值, 那么你可以把这个 zhead 减去 cprinety, 这个样本估计是作为分子,然后除以他的这个标准误差,也就是说你去算一下 c head, 减去 c prine head 这个 variance, 然后去估计一下她的这个 variance, 再给他开根号,那么其实就是处于他的标准物了 standard arrow, 那么可以证明呢,这个 t 统计量他是服从渐进正态的,也就是说他在大眼本下会收敛到一个标准正态的分布啊, 因此你就可以用标准正态的那个零借值一点九六去检验 c 减去 cpry 是否显著的不等于零, 那么这个就是一九八八年由他们俩所提出来的一个方法,就是说给出来了计算这个标准物的一个具体的公式啊,也就是说这里呢,就是你可以去把这个啊, c 的自己的标准叉算出来,然后 c prim 的标准叉算出来,再减 减去他们俩的这个两倍的 covariance, 那么这里的啊,其实就是个相关系数啊,而这个 sc 跟 scp, 那么就是他们俩的标准差。 因此通过这样的一个方法,你可以算出来 c head 减去 c prime head 这个样本翻插,然后开根号之后就是一个标准物,由此你就可以得到这个相应的 t 统计量,然后做这样的一个 t 检验。 但是呢,这个检验的方法就是稍微有点绕了,就是说我本来是要关心的是中介效应这个间接效应到底是否存在, 那么他的这个 approach 呢?就是说我把那个总效应减去直接效应,看一下是不是等于零,所以他等于是有一些绕远了。也就是说如果回到我们这张图的话,那么其实呢,他考察的就是说 看一下这个 c prime 这个直接效应是不是和我的总效应,也就是这里的 c 他俩是相等的啊?那么这个还是稍微有点烙远了。那么实际上更加直接的去检验是否存在中介效应的这个方法呢,我就直接可以去看 a 和 b, 那么我们知道这样的一个因果链条如果要成立的话,那么必须要有 a 是不等于零的,而且 b 也得不等于零, 那么如果我们想要直接度量间接效应是否存在,也就是说我们是需要 a 和 b 他俩都得同时不为零才可以, 也就是这里的这个原角色,就是说 h 零, a 等于零或者 b 等于零,那么只要 a 等于零或者 b 等于零,这个因果链条中间的任何一段如果是不成立的话,那么 那么这个中介效应就是不存在了。但是呢,这个检验呢,有一点麻烦,因为它不是一个联合检验,而是一个 a 等于零或者 b 等于零,那么怎么办呢?我们可以把它转换成一个单一的检验,也就是说我可以把它写成他一个等价的形式,就是 a 乘 b 等于零, 因为如果 a 或者 b 等于零的话,那么很显然 a 乘以 b 一定要等于零。反过来,如果 a 乘以 b 等于零的话,那么 a 或者 bb 蓝至少有一个,要是等于零的, 那么这个约束呢,条件就变成只有一个了,那么这也就是所谓的系数乘机法,因为它是 a 和 b 这两个回归系数的乘机,作为我们检验的远角色和统计量。那么这里呢,我们会看到说它其实是一个非线性的约束啊,因为并 不是 a 和 b 的一个线性组合,而是他们俩的一个成绩,所以呢,做起来的话就稍微有点麻烦。那么 berlin can 一九八六年的那篇经典的论文呢,他就推荐说使用手表一九八二年的方法, 也就是说针对这样的一种非限性的约束啊,那么啊,我们是需要把它做一些泰勒展开啊,也就是所谓的 dota messer, 然后来推倒出它的一个大样本的分布啊, 那么这个就是这个 sober 在一九八二年的那篇论文 as entire confidence intervals for indirect effect instructual equation models。 那么我们同样可以去构造这样的一个 t 土地量,也就是说我把这个 ahan 乘以 bhan, 也就是 a 乘 b 的样本估计值,然后呢,除以他们俩的标准 差,那么我可以证明呢,这个系统计量也是服从渐进标准正态的分布。那么这里面的一个关键问题就是说,我是应该如何去计算这个 a 乘 b 的标准误差啊?那么因为它是分线性的,所以这里面就稍微有一点麻烦 啊。那么在讲这个如何计算标准物之前呢,我们这里先回过头来看一下这个系数乘积法与系数差异法的联系啊, 其实从前面的那个推倒中间我们可以看到,就是我们刚才在推倒那个考虑是否存在一路变量偏差的时候,其实有得到一个这样一个结果,就是说 c 减去 cpon 其实是等于 a 乘 b 的, 我们可以回过头去看一下,也就是这里啊,我们当时的推倒结果就是说这个方程一的这个 d 呢,其实是等于 c prang 加 ab 啊,因此呢,你只要一把它移向,把这个 cprine 给它移到这个 c 的这边,那么马上就会得到一个结果,就是说 c 减去 cpran 其实就是等于 ab, 也就是说这个是因为我们写下了这么三个方程,他们自然这个三个方程的回归系数之间就存在这样的一个关系, 而且呢,就是说,只要你用的是 os 去估计,那么我们可以证明说,在你的样本里面,这个等式依然是存在的, 也就是这里的 c 害减去 c prank 一定会等于 a 害乘以 b 害啊,那么这个是只要你用 os 去估计他,那么他是一定会成立的这么一个等式啊。但是呢,就是说,呃,你用这个系 数差异法 c 害减去 c prank 去做检验的话,那么你所估计的那个标准物和你用这个系数乘机法 a 害 b 害去作为检验统计量,那么他们俩那个标准物的计算结果是不一样的。 那么对于系数乘积法,也就是说,如果我们用 ab 等于零作为原角色的话,那么他的这个标准物到底应该怎么样来计算呢? 那么可以证明 a 害跟避害他俩其实是相互独立的随机变量,而且都是服从渐进正态的分布啊,因此呢,要计算 a 害成避害的这个方差,其实还是相对容易的, 那么这里面我就给大家稍微介绍一下,譬如说,我可以把 a 害做一个标准化,也就是说把它写成他自己的那个均值,这个啊 mua 加上他的标准差成 以 z 一这样的一个随机变量。而 z 一呢,就是服从一一个渐进标准正态的分布啊。其实这个 z 一呢,就等于是说把 a 害这个随机变量给他做了一个标准化,也就是减去他的均值除以他的标准差。 那么同样的,我可以把这个 b 害这个随机变量也做一个标准化,可以把它写为这个 mub, 也就是 b 的那个期望,再加上这个 c 个码 bb 的那个标准差,再乘以 z 二这样的一个,也是服从渐进标准正态的这个随机变量。 而且呢,我们知道说这个 z 和 z 二,他俩是相互独立的,因此呢,我们就可以很快的得到这个 a 害乘以 b 害的这个翻叉的表达式啊,那么你把这个上面的这个柿子带进去, a 害是用这个 mua 加 加上 c 个码 a, z one 带进来,然后这个比害呢,用 mu b 加上 c 个码 b, z 二给他带进来,然后呢,你把它盛开来就变成四项。那么这里面呢啊,虽然有四项,但是我们知道第一项只是个长数,其实你可以忽略啊,因为加上任何的长数不会改变方差。 而这边呢,剩下这三下呢啊,其实他们的这个斜方叉都是零啊,因为呢, 这个 z 和 z 二是相互独立的,而这边呢,虽然这里 z 乘 z 二似乎跟前面的 z 或者 z 二有相关性,但是如果你去算他的斜方叉的话,其实很快就会发现他也是等于零的, 因此呢,我们就只需要考虑他的这些翻插的这些像就够了,那么你把这个翻插球进去,就会得到这个 c 哥吗? a 方没有 b 方啊,然后是 z 一的这个翻插,也就是这一项的翻插,那么第二项的翻插呢,就是这个 c 个码 b 方 mua 方,然后再乘以 z 二的翻插, 然后呢,最后一项,你把这个前面的系数就会变成 c 个码 a 方,乘以 c 个码 b 方,然后呢,是把 z 一的方差乘以 z 二的方差,因为 z 和 z 二是相互独立的, 那么这里面,因为我们刚才说了,这个 z 和 z 二都是渐进标准正态,也就意味着他们俩的分叉呢,其实在大样本下是收敛到一的, 因此呢,这个啊, z 一的方叉, z 二的方叉以及 z 一的方叉和 z 二的方叉相乘,在弹幕下都可以直接把它忽略掉,所以就会得到这么一个结果,那么这个就是在大样本下的一个近视了。因此呢,如果我们要估计这个 aip 害的翻叉,那么你只要把这个表达式里面的这些 c 个码和 miu 给它换成相应的样本的对应的那个表达式就可以了,就是说这个 c 个码 a 方,你就给他换成那个小 sa 方啊,也就是用 a 害的样本翻插来替代就可以了。 而这个 mu b 方呢,其实就是 b 的那个样本均值,那么因为这个 b 其实他在样本中间就只有一个观测值,也就是逼害,所以这个地方其实他就是逼害的平方啊,那么剩下这些像同样的是可以这个用样本的相应的观测值去替代, 因此呢,我们就可以得到标准物的表达式。那么当年这个收表在一九八二年他提出来的表达式就是这样的啊,他其实是把刚才我们看到 这个第三项给他忽略掉了,他认为这个是相当于一个二次项,因为是两个翻插存在一起,那么可能就很小了,所以他就直接把那一项给他忽略掉了啊,然后就会得到这样的一个表达式啊, 那么有一个更早的一个哥们,他在论文里面其实把这一项也给他放进去了啊,那么这个就相当于是做了一个二阶的泰勒展开手表。一九六零年的这篇论文呢,其实他还提出另外的一个估计标准物的方法,也就是这里, 那么为什么要提出第三个呢?也就是说他发现说,其实呢,你把这一项加上去,他其实是一个有偏的估计,也就是说是有 buyers, 那么如果要把它变成一个无偏的估计呢,你不仅不能够给他加上这一下,你反而要给他减去这一下,那么这样才能够得到一个安白。 那么因此呢,我们就会有这么三个不同的这个标准物的计算方法啊,那么他在大样本下都是有效的,也就是说如果 n 足够大的话啊,那么他们都会瘦脸到同样的那个真实的标准物。 但是呢,在有限的样本下,这三种啊计算标准物的方法就可能不太可靠了啊,那么现在比较流行的做法就是说直接使用 booster, 也就是自助法, 那么就是你每次都做有范回的在抽样,也就是说,比如说你从这个样本中间抽出来一个观测值,然后记一下你抽的是什么,然后再把这个观测值给他放回去,也就是 reset replacement。 然后呢,你再继续再抽一个新的观测值,然后再记一下啊,然后再把这个观测值再给他放回。 因此呢,你这样用这个 boss 出来这种自助法呢,就有可能会把这个观测值,有些观测值呢会可能抽到多次,和有些观测值呢,可能就没有抽到啊,但是这个都没有关系啊,那么这个就是自助法的一个标准的做法。 那么假设比如说你通过自助抽样得到了一千个不同的自助样本啊,然后每一个自助样本的他的样本容量跟原始的那个样本的样本容量都是一样的, 因此呢,比如说如果你有一千个自助样本的话,你就可以得到一千个 a 害和比害的观测值啊,因此呢,你就会可以得到这个 a 害和比害的一个自助的这样的一个分布, 就是一个 boost dragon。 然后呢,你就可以根据一千个 a 害成 b 害的样本观测值去 计算他的样本标准差,那么这个是自助法现在是比较流行,他特别适用于样本容量不太大的情况下, 而且呢,这个 soba test 他这个用的是大样本理论,也就是说这个提桶剂量在大样本下会收敛到一个标准正太,但是呢,对于有限的样本,可能他未必就能够收敛到标准正太, 换句话说就是说他有可能这个踢土剂量的这个真实分布离标准正态还有一定的距离啊,特别是当你的要么容量不太大的情况下, 那么你这里的 a 害成 b 害,虽然 a 害和 b 害都是渐进正态的,但是呢,两个正太分布的成绩,他也未必就是和这个正太分布很接近啊,因为这个 a 害和 b 害,他们俩的期望和方差都不一 一样,那么有一些做了一些蒙迪卡罗是一名类型啊,这些模拟就发现说,其实在有限样本下, a 害成 b 害可能是非对称的啊,通常会有一个比较长的右边的尾巴,也就是说这个分布可能是在有限样本下会是向右偏的, 那么这样的话,你如果去用这个标准正太的那个临界值,比如说一点九六去做检验的话,可能也会导致偏差。 因此呢, soba test 在当代的做法就是说,我就直接用这个自助法去构造他的一个百分之九十五的自信区间,然后用这个去做检验,而不一定非得通过那个提统计量去做这种假设检验。 那么另外一个想跟大家交代的就是说,当你把这些啊, abcc plan 这些我们关心的系 给估计出来之后,其实就很容易去计算这个直接效应和间接效应,以及他们俩占这个总效应的比重了, 那么这里给他写出来,明确的写出来这个公式啊,那么比如说你如果想考察直接效应占总效应的比重,那么其实就是 cprine 除以 c, 那么 cprine 就是那个直接效应,而 c 呢,就是那个总效应, 那么当然的这个 c 呢,其实就是在数字上,他就等于 a 乘 b, 再加 c pray 啊,所以呢,你在这个分母,你也可以给他写成 cprint 加上 a 乘 b 啊,那么结果是一样的。 那么啊,我们可能更关心的是这个中介效应,也就是这种间接的中介效应,他占这个总效应的比重啊,那么这个在做中介效应这种 啊,时政分析的论文中间一般都会汇报啊,就是说你所关心的这个中介效应,到底在这个总效应中间占了多大的比重啊?那么啊,也就是这里的这个表达是,你就把这个中介效应,也就是 a 成 b, 除以总的效应 c, 那么就可以得到中介效应占总效应的比重了。那么这个中介效应为什么是 a 乘 b 呢?其实很简单啊, 就是说,比如说我们看到这边 x 到 m 的这个回归系数,这个斜率是 a, 对吧?那么也就是说这个 x 增加一单位,会导致 m 增加 a 这么多, 而呢从 m 到 y 的这个啊,关系呢,它的回归系数是 b 啊,那么换句话说, m 这个中介变量如果增加一一个单位的话,那么这个 occumberry 这个 y 呢,就会 增加 b 个单位,因此呢,你把这个两个给他串起来,那么就是说我们会得到一个结果,就是当这个 x 增加一个单位,那么会通过这个 m 这个中介变量使得外增加多少呢?这个中介效应到底是多少?那么就首先是一个单位要乘以一个 a, 然后使得 m 增加了 a 个单位,那么 m 增加了 a 个单位之后呢,还得再乘以 b 啊,那么才是最后能够使得这个外增加的那个量, 所以呢,这个中介效应其实它就是 a 乘 b 啊,也就是我们这里 soba test 的他所关心的就是 a 乘 b 是不是等于零,因为这个其实 a 乘 b 度量的就是这个中介效应到底等于多少。那么更多的细节呢?我会在下一期,也就是 中介效应的 stat 操作中间做进一步的介绍啊。那么这一期的视频号就介绍到这。好的,谢谢大家,再见。
 04:16
04:16 10:59查看AI文稿AI文稿
10:59查看AI文稿AI文稿同学们大家好,欢迎大家来到计量经济学速成课,在接下来的两个小时里,我会和大家一起去学习计量经济学的考点内容,争取让大家用最短的时间学会这门课的知识,顺利的通过期末考试。 现在开始,请同学们跟着老师的上课节奏,认真学习每一章节的考点知识。课后呢,再通过每一章节配套的讲义和题库,及时巩固练习,相信通过这两个小时的学习,同学们都可以轻松通过期末考试。 我们的复习课主要包括以下几个考点,首先呢,就是导论部分,主要是让同学们对计量经济学有个初步的认识,主要同学们要了解一下发展历程。计量经济学所涉及的数据类型等概念。 第一章概念难度比较小,同学们主要要有一个大致的印象即可。一元线系回归模型这部分考点相比第一章难度是有所提升的,也是计量经济学学科十分重要的一部分。 一元部分掌握清楚之后的考点掌握起来就不是很有难度了,大家这部分一定要认真跟着老师好好听讲。 这部分需要同学们理解整体与样本回归模型的定义区别,掌握最小二乘估计的含义、性质,掌握离差平方和可诀系数间的关系以及设定原假设,运用模型检验是否接受该假设 内容呢,是比较多的,但是只要顺利公关这部分内容,后面的部分就会轻松不少。多元线性回归模型这部分与上一章节一元 线性回归模型学习思路是一样的,换汤不换药,如果有两个及两个以上的自变量,我们就称为多元回归,只是比一元多了几个自变量。所以呢,同学们不要过分紧张,跟着老师思路还是可以轻松掌握的。 多重贡献性这部分内容很多教材是放到比较靠后的位置去讲的,这部分内容会比较考验概率论学习的功底,如果同学们概率论的知识已经忘记了,建议大家回过头再简单复习一下。 这部分呢,主要围绕多重贡献性的定义,产生的原因,有什么后果以及诊断方法和补救措施,理解起来还是有一定的难度的。不过需要记忆的就那么多知识点,大家一定要跟紧老师的节奏,注意听老师为大家总结提炼的知识点。 一方差这部分呢,是相对前面章节讲的同方差而言的随机误差项,具有不同的方差,我们就称为一方差。理解一方差性的实质,记忆一方差产生的原因,掌握检验和修正的方法,难度是比较大的,同学们要认真听讲,做好笔记 字。相关,我们也叫做序列相关,指的是随机误差项的各期望值之间存在着相关关系。 同样和一方差多重贡献性,这两部分考点的学习思路是一样的,需要同学们首先了解自相关的定义,理解自相关产生的原因,建议自相关对参数估计以及模型检验的影响, 掌握 dw 检验的前提检验统计量统计规则,掌握广义差分法的含义和计算。 总的来说呢,计量经济学难度是有的,但是整体也是有迹可循的。第二个和第三个考点呢,主要是教大家建立什么样的模型,掌握估计方法是在满足一系列假定之下比较完美的一个模型。 而现实生活中数据可能并不完全符合第二、三章提出的假定,会出现多重贡献性、一方差字相关等问题。因此呢,需要对这些问题进行检验并修正,所以就有了我们后面的章节。 其实呢,既然经济学一共就这么多考点,而且难度不大,解题都有一定的套路。平时上课掌握的不够好的同学也不用紧张,只要跟着老师一起学完这两个小时的内容,一定可以轻松通过考试。那话不多说,接下来就跟着老师一起进入具体章节的学习吧。 同学们大家好,我们今天开始学习计量经济学第一章的内容。第一章是课程的一个导论,我会和大家一起探讨计量经济学的诞生,并且帮助大家对计量经济学的研究方法、研究过程有一个最基本的了解。 第一章节内容比较简单,题型呢,主要以选择题为主。基朗经济学这个名词的首次出现是在一九二六年被挪威经济学家弗里西提出, 而一九三零年世界计量经济学会的成立则标志着该学科的正式诞生。这里可能会考察一些选择体,两个时间和创始人的名字。同学们一定要记住,计量经济学是以经济理论和经济数据的事实为 依据,运用数学统计学的方法,通过建立数学模型来研究经济数量关系和规律的一门经济学科。研究步骤遵循从模型设定到估计参数,模型检验最终实现模型应用的范式。 然后在模型检验这边我们需要知道的是这以下四个检验,其中的统计推断检验与计量经济学检验是我们接下来需要重点学习的,而计量经济检验的话,其实更加偏向于考察你的经济学基础知识。 数据类型方面同样也包括四种,这里需要大家看到一个数据时能够准确判断出它的类型。下面我们详细来看一下四种检验类型。 经济意义检验,检验模型是否符合经济意义,既需要我们检验参数估计值的符号大小,参数之间的关系是否符合人们的经济学常识。 统计推断检验需要检验参数统计值的可靠性,它包括拟合优度检验、变量显著检验、方程显著性检验等等。 计量经济学检验检验模型的计量经济学性质,它有包括随机扰动项的序列相关检验、一方差检验、解释变量的多重贡献性检验。 而模型预测检验旨在检验模型参数估计量的稳定性以及样本容量变化时的灵敏度。我们一起来看两道例题。第一题,一个计量经济学模型用于预测 课前必须经过的检验,包括大家可以看到这里给出的是四个孔。这道题考察我们的就是刚刚学过的四种检验类型,题目比较简单,但是需要同学们一字不错的记忆四种模型检验的名称 来看。第二题,现有模型 i 等于零点三四加 a r, 其中 i 为投资, r 为利率, a 为未知参数。 以下 a 的取值能够通过经济意义检验的是相比前一道题呢,这道题就需要大家思考一下了, 其实只要仔细思考,我们不难发现,这道题很明确的告诉我们,他考察的是一个经济意义检验,那就需要我们选择一个合适的 a 值,让他的符号大小符合经济学 常识。大家先看符号,同学们学过经济学,应该可以很容易就能判断出,投资 i 和利率 r 是具有相反关系的,利率越低呢,投资就会越多。所以我们首先就能排除 a、 d 两个选项, 再来看大小, b 选项虽然是负的,但是这个值过于大了,利率上升并不会引起这么多的投资变化,这个是不合常识的。因此这道题的正确答案选择 c 选项。 接下来我们一起来看计量经济学的数据类型。数据类型主要包括时间序列数据、洁面数据、面板数据、虚拟变量数据这么四种。时间序列数据是对同一对象在不同时间连续 据观察所取得的数据。比如说北京市二零一八年到二零二零年的 gdp。 而洁面数据呢,就是同一时间内对不同对象进行调查所得来的数据。比如说二零二零年一年之内,北京、天津、河北的 gdp, 因为 gdp 均处在二零二零年这一同一时点,因此呢,它是洁面数据、面板数据,我们可以简单的理解为是我们前面时间序列数据和洁面数据的结合。 以下面这张表为例,他既包含了北京、天津、河北这三个省份,同时呢,还囊括了这三个省份二零一八年、二零一九年、二零二零年三个年度的数据,其中每一年的数据都是一组洁面数据, 最后呢就是虚拟变量数据。虚拟变量数据是我们在设计模型的时候自己设立的一个数据,他通常取零或者一。 比如说考察性别时,我们可以把男生取作零,女生取作一。而考察文化程度时,我们可以把有文化取作一,没文化取作零来进行分类。 我们再来做两道题来练习一下吧。例题三,横截面数据是指 a 选项同一时点上不同统计的单位,相同统计指标组成的数据。 b 选项同一时点上相同统计的单位。相同统计指标组成的数据。 c 选项同一时点上相同统计的单位。不同统计指标组成的数据。 d 选项同一时点 上不同统计的单位。不同统计指标组成的数据。让我们来回忆一下刚才课件上出现的表格,洁面嘛,他肯定是一个十点,而一个十点内不同对象的数据正是对应本道题的 a 选项,因此我们来选择 a。 例题四,统一统计指标按时间顺序记录的数据称为 a 选项横截面数据。 b 选项时间序列数据。 c 选项虚拟变量数据。 d 选项面板数据。 时间序列数据和面板数据都可以按照时间顺序来记录,但是面板数据他可能对应多个统计指标, 比如说我们统计北京历年的 gdp 和人口, gdp 和人口就是两个指标,因此我们本道题只能选择 b 选项时间序列数据。以上呢,就是本章的全部内容了,内容不太多,大家记得课后及时回顾。
99期末帮 09:20查看AI文稿AI文稿
09:20查看AI文稿AI文稿同学们大家好,欢迎来到极乐数据课堂,我是倪老师,今天给大家介绍的一款软件叫斯贝塔,它是一款统计软件, 我先介绍一下我们的课程特色啊,相信大部分同学都去网上看过一些视频,特别是连老师的视频啊, 林老师的视频其实讲的非常好,每一个视频的时长也是比较长的,内容讲的非常的细,主要是从理论然后实践操作这么整个过程来说。但是对于刚入门学习斯蒂达同学来说啊,这类的视频我还是不建议大家去看,因为 通过一个半小时的学习下来,你可能真正掌握的内容其实只有一点点,比如说你只会导入的一个数据,对吧?但是你浪费了你一个半小时。我们这个课程的特色呢,就是经练啊,比较干货,并且偏应用。 大部分同学来学习我们这个软件主要还是为了去啊做一个实证分析,然后完成你的毕业论文,或者是头一片好的旗开。 那么我们的应用其实就非常重要。这个课程啊,我们的特色就是啊,在较短的时间里,然后让你掌握斯德塔,并且能够自己去做一篇论文。 那么我们啊讲了我们的课程特色,那相信大部分同学啊,还不知道实证是什么东西,那我这边先给大家简单的介绍一下什么叫实证实证,简单的说就是去用数据验证我们的一个结论。 那怎么用数据去验证我们的结论呢?我再举一个粗俗的例子啊,比方说我们现在有一个研究主题,就是想研究饭量对上升高的一个影响啊,我们都 知道饭吃的越多,人就长得越高,对吧?这个其实就是我们的一个理论预期,现在我们去找一份数据,比方说你把全国所有人的一个 饭量以及身高的数据被统计下来,然后我们去研究这两者的关系,基于这一份数据去研究这两者的关系,并且得到了 饭量是促进长升高的啊,那你现在做的就是一个实证分析,就是通过数据去得到一个结论。好,那么 我们现在来看一下整一个课程啊,我们会讲到哪些东西啊?接下来我们所有的课程就是按照这一个思路来的,那这个思路我主要是按照实证分析的啊,一个框架给大家梳理的。那么在做实证分析之前,大家都知 知道啊,我们需要有一份数据,那这份数据我们肯定是要对他进行一个整理和清洗,不然的话你是没有办法进行实证分析的啊,除非你这份数据是哪里买来的,对吧?相信大家自己下载下来的数据啊,都是一份一份零散的,必须要进行清洗和整理。 那整理完数据之后,我们要做的就是实证分析了,实证分析主要分为四个模块,第一个就是对于你对于你前面那份数据的一个描述性统计啊,它里面主要分为五个,一个是 n 就是你的样本量, me 就是样本的一个均值啊, m i n m a x 就是样本变量最小值和最大值, sd 就是标准差,主要包含这五项指标来对你的数据进行一个详细的描述,做完数据描述之后就进 我们的第二步主回归,主回归就是去验证我们这篇文章的一个主题结论,也就是主要的结论 还是从我们前面的那个例子来说,我们想研究饭量对长身高的影响,那么你的主回归就是要去验证你的饭量对你长身高的影响是什么?是促进的还是意志的?那当然这种影响我们必须存在于一些模型去做。 接下来我们的课程中啊,会讲 ous 模型,也叫混合回归模型, fe and r e 这个叫固定效应模型和随机效应模型, gmm iv 啊,以及 did。 did 这个模型呢,其实和前面的模型差别有点大,它是一个啊,独立的模型,就是跟前面其实没什么关联啊,为什么要讲 did 这个模型?因为这个模型现在比较流, 而且他发好的期刊非常好发,所以说我把它单独拿一块出来讲。第三部分叫扩展研究,也叫深入研究, 也就是把我们的文章的结论进一步挖掘,我们验证了饭量会促进一场升高。那么如果我把这份样本划分成两份,一份是男性,一份是女性,我们去比较男性和女性之间的一个差异,也就是吃同样的饭,男的长得高还是女的长得高, 这个其实就叫深入研究啊,也就是我后面给大家列出来的一个分组回归这么一个东西。当然我们后面还会介绍更多的一个深入研究啊,就是中介效应以及调节效应。 第四部分就是我们的稳健性检验了,稳健性检验主要是对我们的主回归进行一个进一步的验证,也就是你前面做了一次,结果其实 存在一定的偶然性,不太可靠,我们让这个结果更可靠一点,就要做一个稳定性检验。稳定性检验 啊,主要是包括以下三种方式,一个是替换变量,一个是变换模型,一个是数据样本的变换。 我们前面用吃饭,用饭量,呃呃,我们前面去研究饭量对长身高的影响,那么饭量如果我们前面是用一天吃饭的次数,就是吃一次饭还是两次饭,吃三次饭来衡量的话,呃,我们可以得到吃饭的次数越多, 你的身高越高,其实也就是验证了饭量越大,你的身高越高,对吧?那么如果我把这个次数 啊变成另一个东西,就是饭量,我不用次数来衡量,用我一天吃几斤大米来衡量,那其实吃的大米的斤数越多,也其实能够 说明我们的饭量越大,对吧?从而也是验证了我们饭量对长身高的影响,就是说把次数换成了吃几斤纳米, 这个就叫做替换变量的五金星。当然我们的方法还有后面两个啊,这个在后面的课程中我们会给大家强详细的介绍。经过上面四个步骤啊,其实我们就把 整个实证分析给做完了啊。在做完实证分析之后呢,我们其实还要讨论一下文章的一个内存性 啊,内生性它是一个问题,它会造成你回归结果的一个偏恶,所以说这个问题啊非常重要。为什么重要? 因为我们在发一些比较好的期刊的时候,神高老师只要看到你的文章中没有去讨论这个内存性,你的文章一定会被 d 稿,所以说我把它单独列为一个专题来给大家进行详细的讲解。 呃,接下来就是我们显著性调整的一个专题课,因为我们理论是理论,实际是实际,真的我们去做一份实证的时候,你做出来的结果往往是不显著的 啊,基本上两篇里面就有一篇是不显著的,那这个时候你怎么办呢?不是说直接换个题目对吧?或者是重新再找一个数据去做,我们其实是可以通过合理的计量方法给他调整到显著的啊,所以说这一个专题课程呢,实用性非常的高, 到这里为止,我们整个实证分析就已经做完了,那么接下来你就是要去写你的一个 论文的文字了,那么论文的文字其实它里面也有很多的讲究,也有很多大家不了解的东西,接下来我会给大家梳理,就是论写论文的一个重点是在哪里?就是每一个 章节里面到底该怎么去写他,你的导师才会喜欢,省高老师才会喜欢,文章才会更好发。最后就是我们的一个实战训练营,就是基于我们前面学过的一些内容,我会给大家进行一些实战训练啊,来巩固我们所学的一个内容。 最后的话我再给大家看一个呃,实证做完的一个呃案例是怎么样的? 刚刚我们讲过啊,实证分为四个模块,一个是描述性,那其实这个就是我们描述性统计的一个表格做出来的样子,就是这样子的啊,其实这个表格并不需要我们手动去做啊,斯贝塔 会给我们直接输出出来,最后就是长这样。第二块就是我们的主回归,也就是去验证 x 对外的一个影响 啊。最后做出来的表格是这样子的,这个其实软件也会直接给我们说出来,通过银行代码就可以了。 第三部分是扩展研究,其实我们这里做的扩展研究也就是对样本进行了划分,分为的 state 为零, state 为一的两个样本,然后去研究这两个核心,解释变量对你应变量的一个影响是怎么样的 啊?这里其实就是做了一个分组回归。最后第四步骤就是我们的稳定性检验,也就是 啊对主回归的结论的进一步验证。这里用的方法是替换变量啊,但是这里做了两个,一个是替换了 y, 还有一个是替换了 x。 前面我们可以看到用的都是罗恩佩特的,一,这边换成了罗恩佩特的,二替换了音变量,然后前面用的都是 siri ems, 二,一,这里替换成了 siri rms, 二, 替换了你的核心音变量,这个叫替换,呃,变量的一个文件性。好,那我们第一节课就先上到这里。
489倪先生 02:38查看AI文稿AI文稿
02:38查看AI文稿AI文稿首先用奥斯法估计模型,输入 lsycx 回车得到最初的回归模型,点击内容保存。第二步,生成残差序列, 输入 january 等于 resid 回车。第三步,判断是否存在自相关。方法一,绘制残插序列散点图,从图上看到两个序列同时增加, 说明存在政治相关。方法二,利用残差相关图判断, 输入 idt 回车 接触默认水平, 点击 ok, pc 和 ac 中间的数字是接触,主要看 pc 下方的阴影部分是否超过虚线,超过虚线说明存在自相关。 本力中阴影部分超过虚线所对应的接触为一,说明存在一阶自相关。 方法三、 dw 检验,从回归结果得到 dw 等于零点六七四,样本容量三十七自变量一, 查 dw 表,查在零点零五显著水平下, n 等于三十七 k 等于一的值。如果 dw 小于查到的 dl 值,则存在一些政治相关。方法是 am 检验。在回归方程 门窗口选择 airm test 之后接触默认,也可以随意选择。如果 r 平方所对应的 p 值小于零点零五,则存在自相关。 右下面的 residy 要职为证,所以存在一阶政字相关。第四步,字相关处理方法,利用广义差分法输入 lsycx。 二、一回车, 得到广义查分方程实质后的版本会出现西格玛, 在 estimate 选择 options, message 选择 gls, 此时西格玛已删除,现在得到了最终模型结果。
1119热爱散步的蟹鲸 05:24查看AI文稿AI文稿
05:24查看AI文稿AI文稿我们开始第二点三节 stay 塔操作,实力啊,其实呢,学习 stay 塔的最快的一个方法就是说你能找一个具体的数据级,那么跟着操作一遍啊,也就基本上都懂了, 因此呢,我们就使用一个数据集叫做 greek small 啊,这个是一个 excel 表,就是原始数据呢,是在一个 excel 表里面啊,那么这个为了演示的目的的,那么这个啊,数据级呢,是比较小的啊,就是总共是包括了三十名美国年轻男子的这个教育投资回报率的数据 啊,那么这个呃,本门课程所使用的所有的数据集都可以在我的这个个人网页 www dot economic tricks 啊,然后中间一个小短横 stata com 可以下载,包括所有的课件 啊。那么首先我们讲一下怎么样导入数据啊,就是说你要用 step 来处理数据,那么应该做的第一件事情就是说把你的数据及给输入到 step 中间去啊,那么最简单的方法啊,就是我们是以这个 excel 表输入数据为例了,因为 啊,绝大多数的原始数据是以这种 excel 表的形式存在的啊,所以我们就以这个 excel 表为例,那么如果是其他形式的话也可以啊类 是的,我们后面再交代一下,那么啊,这个基本的方法比较简单的一个,就是说你可以从直接从 excel 表中间把那个你要 导入的数据给他啊选上,然后复制,然后粘贴到 stat 里面,有一个数据编辑器里面啊,那么这样就可以完成 这个这个数据的导入。那么首先呢,你打开 style 软件之后呢,那么你可以看到这个有 一一行在菜单下面有一行图标,对不对?有一些这个小卡 key 啊,快捷键,那么你看到这个有一个这个鼠标指向的这个地方啊,这个图标呢,是一个类似于 excel 表的一张表格, 然后呢上面有一支笔,对吧?这个就是叫做 detailed 啊,就是一个可以在上面编辑的一个这个数据编辑器啊, 那么旁边呢也是一张表啊,也是一个表格,只不过上面的是放着一个放大镜,那么这个是 data elite browse, 就是说啊,他是一个数据编辑器,但是是只能看的,不能改的啊,那么这两个的区别是这个,那么你就点击 这个有一个啊,上面有一支笔的这个 data editor edit 啊,那么这样话就能够打开 stata 的这个数据编辑器啊,就是这个 data editor editor 啊,然后你把鼠标呢放在这个数据编辑器的最左上角这个地方啊,因为待会你要复制粘贴过来的时候,你要从这里开始啊,然后呢我们就去打开这个 excel 表的这个文件啊,你用 啊 excel 啊,去打开我们的这个 greenix small, 然后,呃, that xls 啊,这表示说这个是一个 excel 表的一个扩展名的文件, ok, 那么这个是一个比较小的数据级啊,你看就是有商列数据啊,那么第一列呢,这个第一行就是这个数据的这个变量的名称啊,比如说第一列是 s 啊,这 表示 schooling 啊,因为这个是关于教育投资回报率的一个数据啊,这是教育年限。 然后呢这个第二列呢,是 experience e, x, p r, 这个是工龄啊,然后呢第三列是 l n, w, 就是 lockwage, 就是你工资的对数,然后这个数据呢,总共是有三十行啊, 啊,那么你就把它都选上啊,然后就是啊,这个复制啊, ctrl c 啊,然后呢,你就再把它粘贴到啊,刚才的这个 data, 艾迪特,艾迪中间去,你可以用这个 ctrl 啊,就是把它再粘贴到这个地方, ok, 那么当你选择 ctrl 粘贴的时候, ctrl v 的时候呢,这个数据编辑器会出现这样一个对话框啊, 会问你一个问题,就是说啊, the first row on the clipboard contains values that can be used as value variable names 啊,这句话什么意思?就是我刚才复制的那个从你色表里面复制过来的啊,那些三十一行商列的啊,因为第一行是这个变量名,对吧?所以他也发现了,就说你第一行并不是真正的数值型的,而是属于制服型的, 所以就是有可能这个并不是数据,而是变量名,那么他就问你说, do you want to treat the first role as well variable names all data 啊,那么你要给他个答复,对吧?那么对,在我们这个例子里面,我们应该选择就是这个 variable names 啊,那么在有些情况下,有可能你的这个数据确实就是制服型的啊,不见得一定都是那个数字型的,那么在那种情况, 大家你就应该选择 data, 如果是 data 的话就选择 data, 那么在我们这个案例中间,这个是 variable names, 这个是电量名,那么就应该选择这个, ok 啊,然后呢这个 啊,那么这个是导入数据的一个,这个最基本也是最简单的方法。
292驾猪游仙境 19:25查看AI文稿AI文稿
19:25查看AI文稿AI文稿好,同学们好,呃,今天我们呢来学习计量经济学的一个金奖内容, 那么在学习本门课程之前呢,首先给大家介绍一下我们的本门课程的一些具体章节的啊,一些知识框架,那么大家可以看到我们本门课程呢计量进行学呢,总共是包含十张, 这十张的具体内容呢,一起来看一下。第一个呢是第一张训练部分,训练部分呢主要介绍到了我们的这个计量证据学,他的产生啊,还有他的这个提出者以及他的一些发展的一些啊过程。 然后再就是我们的这个尽量经济学,他涉及到一些具体内容,他的基本呢啊概念以及呢我们 这个尽量分析行为,他的一些具体包含的内容,这是第一章,那么第二章呢是回归分析概述, 回归分析概述呢是作为我们大本门课程的一个重点,重中之重,那么他同时也是我们考试的一个高频考点。 那么回归分析概述呢,主要是介绍了我们的最小二元回归方程以及呢最小二乘法原理和他相应的这个假设,满足最小二乘分析的假设,基本假设。这个基本假设呢也是我们考试的一个重点 啊,涉及到了比如说还有我们的贝塔一和贝塔二,他的推倒有他的表达式是怎么来的,呃,我们如果是要用这个经济建造学的软件的话,怎么样去得出贝塔一,贝塔二他背后的原理是什么? 这个就是我们和一个分析概述啊,这个在考试的部分呢,他经常会出现简答,名词解释,计算题,还有我们的单选和多选, 说说他是一个重点内容。那么第三章呢,主要是违背经典假设,回个模型,那么他是一个重难点,也是我们经常会考到了啊,违背经典假设,前面我们回个分析,当中有一个满足最小二乘法, 呃,这个经济假设的话呢,那么第三张我就考虑如果是违背了这样一个假设,他会出现哪一种,哪一些状况?比如说什么是一帮差,什么是多重贡献性,还有什么是相关性啊,什么是模型设定偏误,那么他在每一种情况下啊,出 线的违背纪念假设的状况是什么?这个呢就是我们的啊,第三张水啊包含的内容, 那么第四章呢,是虚拟变量和变参数模型,虚拟变量的话呢,主要是比如说我啊,呃,考虑到了其他一些因素质的影响,比如说我这个模型当中,如果我对象是男性或者是女性,如果我的研究, 如果我的文化程度不一样,小学、初中、高中还有大学以及这个研究生和博士,那么他还要说世界变化 的不同影响。类似于这种我就要设定一个虚拟参数,那么因为这个虚拟变量他不能够,比如说男性女性,你不能够用具体的数字来衡量他是一些性质,所以呢你 只要设置这一个啊,虚拟变量,呃,模型,那么还有我们的变参数模型,就是把这个模型进行变换之后,你又怎么去啊?研究他,去设定他 好。再就是呢,我们的第五张,呃,分布之后模型,分布之后模型呢?这里是由于考虑到了我们的啊一些之后,比如说啊,这个 涉及到一个时间训练,他有一个致厚性,比如说上一期的这个啊,经济情况,收入情况,他 会影响到下一期的这个消费水平。那么如果是这样的一些情况,我们又用到的是这个分布句号模型,分布句号模型呢,就主要是介绍啊,他模型的具体的情况啊, 以及我们怎样去利用这个参数啊,这个估计去进行一个估计。好,那么第六章呢,就是我们的这个连立方程模型,连立方程模型呢,就设计到了啊,两三个模型一起,他是一个体系里面的。 好,第七章呢是微观经济啊,剂量模型,微观剂量模型呢,比如说我们研究经济行为分分为微观和宏观,对不对?那么微观的话,比如说具体的这个某个厂商,他的这个 销售情况,或者说这个价格与销售的影响,或者是说消费者而言的话,价格呢与需求量的一个影响啊,涉及到了一些模型,那么还有我们的宏观剂量模型,宏观剂量模型呢,在我们的宏观经济当中,比如说 我们的这个消费,还有我们的这个投资,以及这个进出口政府购买,他对于国民收入的一个影响。那么这个呢,就涉及到宏观计量经济模型 啊,第九章的话呢,是经济剂量模型的评价运用,就是你在前面啊,考虑到了他的这样一些啊,模型之后,我来判定啊,最终经过这个参数的估计等等我来判定。哎,这个经济剂量模型呢, 他的这个跟我们现实他实际的,嗯,这个经济行为之间礼盒度强不强,我怎样去评价他,然后以及他在应用的过程当中会有哪一些问题,或者是哪一些优势,我就要去进行评价。那么第十章呢,是他的一个弱 若干性的发展,这个呢,就是啊,我们在啊这个金脑经济学在后期的时候,他流行一些领域所包含的一些内容。 那我们看一下重点章节部分的话,这个第二章一个重点,第三章一个重难点,还有呢第四章特别是虚拟变量也是一个重难点,那么分布之后模型呢,他是一个难点,可能有一些同学不太理解他的这个制号模型是什么样的, 以及呢我们这个年龄方程模型,重点的话呢,还有我们的微观计计,微观计量模型和我们的宏观计量模型。 这个呢,从可以来说,从第二章到第九章呢,都是我们整个这门课程的一个考试的核心。好, 那么我们接下来呢学习啊,第一章序论部分。好,那么我们再来看一下我们的这一章他的主要的一个重难点分析。 那么呢通过本账的学习的话呢,主要是要了解这个经济剂量学他的产生的一个过程,还有他学科有哪样一些特点,以及他的这个基本概念和经济剂量分析工作的一个程序 啊,就是说他有哪样一些步骤,按哪样一些流程加深呢?对我们的经济剂量学与数理经济,数理统计的一个关系的一个研究, 其中还有介绍 a, 什么是变量,什么是模型系统啊,什么又是数据啊等等,加一些概念,回归方程又是什么样的 有概念了解。好,那么我们接下来再来看一下本章的内容构成。第一节呢,主要是讲啊,这个经济技能学,他的产生和发展提出人是谁?重点啊, 第二个呢是这个经济剂量学他的一些基本概念。第三个呢,是啊,经济剂量分析的一个工作流程包含了哪一些内容?好,那么我们接下来学习第一节啊,经济剂量学的产生和发展, 经济教学的产生,发展呢,离不开一个人,那么这个呢叫做啊费,呃,这个费希里啊,那么这个有翻译的教材不同,有人说是费里希,有人说是费希里,那么啊,在考试过程当中,不管是哪一个,你只要看到爱他 心肺是心肺的这个人提出来的啊,不是马希尔啊,也不是什么卡恩斯,对不对啊?这个也不是亚当斯病,所以说大家注意啊,看到心肺的这个人哦,你就要知道他是这个计量经济学的提出人, 那么呢,他是挪威经济学家啊,是第一届诺贝尔经济学奖得主,是在一九二九年 啊,一九二啊,一九二六年,一九二六年呢提出来的,那么这个经济量学呢,他产生是在十九世纪啊,十九世纪啊,十九世纪初,那么呢,发展是在二十世纪开始发展,达到高潮的, 那么他的题处长主要是呢,起源于对经济问题的一个定量的研究,什么叫定量研究呢?就是我们 说他的这个数量关系一样的,对不对?好,那么呢定性的研究的话呢,已经不能满足经济学者了,就之前在这之前呢,有很多个经济理论分析,众说纷匀啊,比如说啊,比如说啊,这个有人认为呢,消减工资呢,他 啊这个有利于生产,因为呢消遣公司,可能啊压缩了这个成本,对不对?然后呢啊使更多的这个啊,这个资源或者说资金呢,用于这个生产材料或者是生产记忆的一个提升,然后来促进生产。 好有认为呢,增加工资有利于这个生产,因为你增加工资了,那么呢,你的人民群众他的这个收入水平提高了,然后收入水平提高了,会加 加大我们的消费,对不对?这样的消费了,然后从社会需求的角度而言,哎,需求增加了,那么是不是有进一步带动我的产出呀? 好,这个呢,是这样的一些定性分析,他各有各的观点。那么还有人认为呢,比如说这个消减利息率和提高利息率对新中企业的一个影响, 那么就是说呢,这个啊消减利息率了,那么实际上呢,就也是啊,增加一个成本,对不对?可以对企业来说可以增加利润。还有呢说提高利息率,提高利息率呢,可以增加这个元这个积极性。 那么呢这个你看一下,如果是从定性分析的话啊,你不知道哪一种情况对于这个经济影响,或是对于这个啊,另外一个因 出的影响到底是正向了还是负向了?你只能停售,在停留在一个理论的解释 啊,这个时候呢,在这样一个背景下,我们就啊这个费的啊,这个经济学家了,费斯尼,他提出了我们的这个量化的角度呢,去提出决策来看到底是谁对谁的影响,谁对谁影响多少啊?这样的一个分析。 好,那么随后呢,在一九三零年的十二月二十九日呢,我们的这个国际啊,经济剂量学家呢,啊, 啊,他们呢,在美国的这个啊,俄亥俄,克里夫兰呢,去成立了啊,一个研讨会,那么当然我们的这个啊,费西里呢,经济学家,他也参与到了, 那么这个会的主题呢,主要是啊,就是说呢,是促进啊,经济理论呢,在统计学, 还有呢数学,他们这个学科之间的一个发展应用的一个国际学会。 好,那么一九三三年啊,一首三三年,这个啊分离新的提出了啊,这样的一个经济质量学与经济统计学不一致的研究。这个呢, 所以说我们这个计量学与统计,还有那我们的数理经济啊,数理经济和数理统计,后面会有大会给大家提出的啊, 这个数理经济还有呢数理统计他们三者之间的一个 交叉关系。 好,有人会说这样学是这样学,数理经济是数理经济,数理统计是数理统计,也有人说这样新学,他涉及到了我们的 数理经济,就是社交了,数学也涉及到了我们统计学,是三者一个啊统一。那么他呢,这个我们的这个啊,弗西里呢啊,或者是弗里西啊,他提出来的这个计量经济学呢,与经济统计学不一致的这样一个观点。好, 他的观点是怎么样认为的呢?他说这个经济技能学的任务呢,是以经济学、统计学和数学之间的统一为前提,为充分条件的去实际理解呢,这个现实 经济生活当中的一个数量关系,这是他提出来的。好,我们看一下啊,看一下这个经济剂量学与这个数理经济学和顺理统计学,他们三者之间是怎样的一种关系和区别与联系。那 我们现在知道呢,这个经济剂量学,他是我们的数学和我们的统计学, 什么数理统计学,数理经济学对不对啊?他的一个有机的一个结合,就他涉及到了他们的几个内容,但并不是质量经济学就等于数理经济学,就等于数理统计学,他们之间又有一个区别,对不对? 他是他们的交叉。那我们看一下啊,这个数理经济学和数理统计学呢,他是建立经济学的理论基础,就是我们经济剂量学是在有了 数理统计学和数理经济学这样一个基础的前提上面呢,去发展而来的。 好,那么我们这个经济计量学呢,是经济学和统治学的一个交叉学科,那么他具有独立的这个研究任务。那么注重呢,我们的这个经济变量,你的一个随机特性啊, 大家看到这三个字,就在考试过程当中,选择题,他会提出送经济学和送统计学区别,那么你就注意到一个学习性好,那么借助呢,我们的统计方法呢,去建立我们的经济变量之间的一个定量关系。 那么怎么说呢?怎么说我们这个经济剂量学的话呢?他主要是研究学习性,就是说注重 限量的一个学习性好。而我们的数理这个啊,经济学呢,他是注重 啊,不是学习性,而是注重一个精确变量,他可能会设定一个未知数,或者是说会设定一个经济变量,然后呢再去求解,得到的是一个精确的,那么而我们的 可以这样理解,这个数理经济学的话呢,他更像是一个空匣子。而我们的这个计量经济学呢,他是涉及到了我 设定随机变量之后,我涉及到其中的这个参数的估计,还有的如果遇到参数估计不一致,或者是说啊,一些不太合理的情况,我又怎样去解决这种变量关系?那么他更像是在这个空奖 里面去填充的这样的一个东西。好,这个是啊,质量经济学与数理经济学的一个关系,那么我们还有一个数理统计呀,那么大家知道统计的话,我们呢,他是不仅仅是有这个自然自然的这个 现实的这一个主观的一个啊,世界为研究对象,那么他还涉及到自然界的一些啊,比较客观的,不仅主观,也有客观的一个统计的,那么他更多的是涉及到我们怎样用一些啊?涉及到一些统计资料,对不对? 那我们的计量经济学呢?他是在统计学的基础上借用这个统计的,这样就是把这个数理统计学当做一种工具,然后更好的去完成这个 空匣子。好,那么我们看一下这个啊,重点标黄的部分,嗯,这个具体界定了也是比较重要了,大家重在理解啊,重在理解, 我们看具体界定是怎么界定的?他说啊,他是啊,这个在定性分析的基础上呢,专门讨论如何用经济数学模型方法学定量的描述呢? 具有随机特性的一个经济变量关系的一个边缘科学, 或者说呢,他是数理经济学和数理统计学的一个交叉学科,所以说最终的落脚点是一个交叉学科。好,那么简单的可以理解为呢,数理统计方法 呢,是填充我们的数理经济学空匣子的一个基本工具,你们看一下,数理统计学和数理经济学的这个界点都出来了。 好,那么以客观这个经济系统中啊,具有随机性特征的一个经济关系作为呢研究对象啊,注意啊, 他是以随机特写做研究对象的,那么呢,用数学模型的方法呢,去描述具体的这个经济变量关系, 为我们的这个统计,为我们的经济计量分析工作呢,提供一个专门的一个指导理论和我们的一个分析方法。好,那么这个呢,就是刚刚 介绍完了我们的经济剂量学和数理统计,数理经济学,那么这里有一个更形象的图来表示他们之间的学科关系啊,学科关系,那我们看一下这个数学 还有呢,统聚合合经济学,他三者如果进行交叉重叠,最后你们看一下是不是产生的这样经济学啊,对不对?这样性学呢?所以说他 是我们的数理统计,数理经济和这个经济统计学的一个有机的统一重叠交叉, 所以说这个尽量进学,他不仅有定性了方面的研究,有定量的方面研究,对不对?而且他设计到了我们的统计方法,也用到了我们数学里面的一个啊,变量了这样一个关系进 关系。好,这一节呢,是关于我们的经济变经济质量学与数理经济学和数理统计学的关系的一个概述。好,本期的内容呢,到此结束,谢谢。
156自考成考课程资料





猜你喜欢
- 5236观 甘肃