caffeine缓存为什么快
哈喽,今天给大家分享本地进程缓存咖啡,咖啡呢是一个基于加瓦吧开发的,提供了近乎最佳命中率的高性能本地缓存库, 那我们首先呢要引入这样的一个依赖叫咖啡,我们来看一下测试类,那我们首先通过咖啡点妞妞的,我们拿到这样的一个 cat 对象,我们存数据呢,也只需要用我们的一个铺的方法,然后比如说我的女朋友是赵丽颖, 那我们取数据呢,通过这样的一个 api 去取,如果存在呢,我们拿到这样的一个数据不存在呢,返回的就是那开粉还提供了这样的一个 api, 比如说我们先通通过 k 呢去缓存中取, 如果取到的话就直接返回数据,那如果缓存里没有这样的一个数据呢?我们这边提供了一个方可审的一个接口,也就是会拿到这样的一个 k, 然后我们可以用这个 k 呢去查数据库,查完数据库呢,我们还是 会帮我们放到这样的一个缓存里面,那这样的一个 api 呢就实现了,先查缓存,缓存命中直接返回,如果没有命中,我们去查数据库,查完数据库之后再放到缓存中再返回,那这样呢就特别的方便。 我们来看一下咖粉的一个去除策略,比如说我们可以设置缓存大小上限为一,然后如果说你存入的数据大于了一条的话,那我们会把最老的两条呢给他删掉,咖粉他删数据啊,他不是立刻删除,他会有一个延迟, 那如果说给他延迟一会之后啊,我们会发现最后我们这个里面就只有迪丽热巴,那除了刚才我们可以设置缓存的大小之外呢?我们还可以设置缓存的一个有效期,比如说我们这边可以设置一秒钟, 如果你存入的数据一秒钟之后呢,他就会被删除。我们来看一下在实际的代码中是怎么用的,比如说我这边要查一个商品的一个信息,那我们通关 id 去查,那我们正常的流程,比如说我们会去先查缓存,缓存有直接返回,没有去查数据库,存入缓存再返回,那我们就可以用这样的一个 apr, 我们可以通过 id 去查缓存,如果有的话直接返回,那如果没有的话呢?我们就去查数据库啊,查完数据库之后放到缓存中,然后再返回。 那我们来看一下这样的一个 catch, 比如说我们就直接给他注入进来啊,当然我们会在配置类这边呢,给他构造这样的一个 catch 对象,然后再放到容器中,那今天的分享呢就到这。

粉丝2.4万获赞27.3万
相关视频
 04:05查看AI文稿AI文稿
04:05查看AI文稿AI文稿今天我们说一款本地缓存组建 caffeine, caffeine 是基于加瓦一点八的高性能本地缓存库, spring 五开始默认缓存实现使用 caffeine 代替刮网有四大特点,第一,四种淘汰策略,基于大小 低权重,基于时间,基于饮用。今天我们着重介绍大小权重、时间三种 catch, 普通 catch 以及 loading catch 以及 a sing catch 两种概的方式,一种是 get, 一种是 get if present。 get 方式在多线程情况下会阻塞我们的线程,也就是必须等待前一个线程更新完缓存才能获取到更新后的值。而 get if present 呢,不会走色线程,而是直接返回,但是可能会返回闹。一种自动刷新机制, refriation after right n 秒后 自动刷新缓存的策略来看一下。第一种基于缓存大小淘汰的,我们创建一个 catch, 缓存最大值为十,也就超出十,之后就会基于我们的 lfu 算法进行淘汰。来,我们先只给缓存里面添加二十个值,让主线成休眠外毫秒。 我们可以看一下淘汰之后的元素是六七八九十四十五十六十七十八十九,可以看出来 其实被淘汰的元素也是比较随机的啊。第二种权重淘汰,我们设置一下总权重大小为一百, 当缓存的权重大于总权重的时候,就会淘汰权重小的缓存,我们的权重值我们就设置成我们的 k, 然后给我们的缓存添加二十个元素,让主线绳休眠五百毫秒去淘汰我们需要淘汰的缓存元素。来看 下总权重大小是一百九十,就会将我们权重小的元素进行淘汰掉,留下我们权重大的十一,十二,十三,十四,十五,十六,十七,十八,十九。 还有基于访问后到期的淘汰策略,通过 expand after access 设置,我每一秒钟去淘汰那些没有现成去访问的对象。我们往这一个缓存里面塞住一个对象 过去一次,然后让主线成休眠三秒钟进行淘汰,等待我们的 skydo 定时任务去刷新缓存,再打一下我们这个缓存对象的值 来第一次,程序员老郭过了三秒钟之后将我们的缓存对象淘汰清除了,获取出来就是 no。 有一种刷新机制就是 refreshing after right, 写入之后,每一秒钟去更新一下我们的缓存 record status, 开启我们的统计。如 如果你不开启我们的 caffein 就不会帮我们统计对象的淘汰情况以及加载情况以及加载时间等等。然后我们模拟一下,每刷新一次我们的 numbers 加一。首先我们通过 get 获取,如果没有,他就会帮我们填入第一个值, 也就是一,让主线能休眠两秒去刷新,然后再次获取。但是这里有一个问题啊,就是第二次获取的时候,你会发现获取出来的值还是一,这是因为我们的 refreshing after the right 并不说你 n 秒后会自动刷新,而是 n 秒后,而且第二次调用的时候才会被刷新。我们的开启统计就会帮我们统计所有对象的执行情况,有,命中缓存次数,未命中次数,心值加载成功次数,心值加载失败次数,总共加载时间被淘汰出去 的缓存总数据,被淘汰出缓存的那些数据的总权重来,第一次是一,然后执行了之后,第二次你发现他还是一直到我们的 过了 n 秒,而且第二次才获取到的是二,同时可以帮我们统计我们的缓存数据的执行情况。还有一种是 unseen loading cat, 他这种是一步的缓存,一步缓存,当你去 get 的时候,返回的是一个 compliable future 对象不了解 compliable future 怎么使用的,可以去看一下我之前做过的一个视频,那个视频对 compliable future 介绍的非常详细。好,今天呢, confine 组建的使用我就介绍到了这里,谢谢大家。 nice。
334程序员老郭 00:35查看AI文稿AI文稿
00:35查看AI文稿AI文稿release 作为缓存性能非常高,单机 q p s 可以去到十万,那么还有比 release 速度更快的吗?答案是本地缓存。 下面我们来对比一下本地缓存和 release 的性能。我们可以看到,从 release 获取数据是毫秒级,而从本地缓存获取数据是微秒级,时间相差了几十倍。本地缓存有多种选择方案,比如用类的成员变量只有一个,抗 carethasmat。 企业里面一般主流是用开粉来实现,它是瓜娃的升级版的,性能更高。如果你需要用到本地缓存,推荐使用开粉。
396架构师贤哥 02:56查看AI文稿AI文稿
02:56查看AI文稿AI文稿搞程序开发,那肯定要有缓存,因为毕竟数据库的性能实在是太弱了,没有缓存,我们的代码性能是无法提升的,尤其是搞加瓦编程的人啊。这个缓存呢,基本上都是常用的。呃,包括我们大家所熟悉的单机缓存,以及分布式缓存等等。 我在这本词普润的图书中啊,写的是卡飞印的缓存组建。那选用这个组建原因是在于这个组建是现在性能最高的单机的缓存组建。 不过呢,我今天有点高估自己的写作进度了,毕竟呢,我们在写这个缓存的时候出色基本使用还要去研究他的算法和元旦码。我今天在缓存算法上花的时间不少,因为大家知道对于缓存 算法能说出来的有什么呢?有 fi f、 o, 还有我们的 l r、 u 以及 l f u, 包括还有我们这个叫 tiny 的 l f u, 还有我们 w timid, l f u。 这个缓存算法实在是太多了。 我为了给大家解释一些算法呀,花了大量的时间去绘制这个图形。每一张图呢,画的时间差不多都要达到四十分钟左右。呃,虽然不难,但是呢,就是你要把一些抽象的概念, 形成一个非常具有直观性的图像,还是有一定的时间是需要多思考的。如果你们认真去回味一下的话呢,会发现很多的计算机的图书上,图饰都是特别少的。因为什么?因为计算机原本就是一个学术性的学科 科,但是这个图是少呢?对于初学者而言,又感觉非常的难受,毕竟很多概念很抽象,看不懂。所以我为了解决这样的困难呢,就加了大量的图形,自然而然,我们这个写作的时间就拉长了。呃,对于他的这个卡飞印的圆码呢, 我们也是在编写之中,因为要跟我们的缓存算法对应上,所以我们也是要去里面不断的刨魂,去找到里面所有的程序位的结构,包括他的处理方法,也是需要花时间的。 如果没什么意外呢,应该是在明天就能把卡飞印的原代码的核心部分呢,给大家分析完了。说到这个地方啊,我再说一下我在书中所涉及到的原码分析呢,真的只能给大家分析核心代码,如果 果全部都分析,那基本上一个组建就一起一本书,关键是没有什么人能看懂他。所以大家呢,对于我们这些圆码的东西呢,是掌握他的阅读的方法,跟着我的视频学,对不对。然后呢,而后自己有需要再去不断的翻阅。 希望明天能够顺利的写完圆码部分。而后就可以开始写 sprin catch 的具体操作了。
 01:28查看AI文稿AI文稿
01:28查看AI文稿AI文稿缓存有三位清除算法,你是否清楚呢?在实际的开发之中,缓存是提升项目运行技能的重要技术手段,而缓存是一块内存空间,当空间不足的时候,我们就需要将一些无用的数据清除掉。 而面对这些无用数据的驱逐,我们有三类的常用算法,分别是 f i, f o, l u 以及 l f u。 其中啊, f f o 采用先进先出的算法,最早保留的数据会被首先驱逐, 而 lru 会根据最后一次访问时间戳来进行排查。那如果你最后一次访问的时间戳已经非常靠前了,数据就会被清除掉。在 reddis 和 memor catch 中使用的非常多。 还有一种呢,就是 lfu 的算法,是依据访问的频次来决定是否清楚。同时呢,考虑到我们性能问题,在 lfu 中又提供了两种扩展,一种叫天命 lfu, 以 wtonyfu。 这两种扩展主要的目的是为了解决稀疏流量的访问。 当然了,像我们 wtfu 呢,是在我们卡飞印的组建之中,提供了大小区的概念。具体怎么讲呢?我们可以等到我们课程直播的时候,咱们再做进一步的实现分析。
 01:35查看AI文稿AI文稿
01:35查看AI文稿AI文稿手机中的缓存为什么最占内存?你被手机缓存占过内存吗?换存是 cpu 的一部分,它存在于 cpu 中,而 cpu 存取数据的速度则非常的快,而内存就慢很多。 缓存是为了解决 cpu 速度和内存速度的速度差异问题。为什么说最占内存?以缓存的内容只要不主动清除, 会长期储存在手机里,当内存接近饱和时,手机运行就会出现卡顿的情况。尤其社交类的 app, 缓存的内容还是非常多的, 也是占内存比较多的。那么如何清理缓存呢?打开手机中的设置,找到应用,应用管理页面就显示了手机上所安装 的所有软件。选择缓存最多的软件一般为社交软件,然后选择存储,就可以看到清除数据和 清除缓存两大功能,这里点击清除缓存按钮即可。或者安装的有第三方清理软件,直接一次性清除缓存也是可以的。需要知道,缓存是手机操作系统自带的优化功能,无法关闭。 以上的方法也是治标不治本,因为只要打开手机使用,就会有新的缓存内容出来,所以在购买手机还是优先选择大储存的版本,使用体验也会更好一些。
69媒企融创 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿天天刷视频,手机越刷越卡,到底为什么呢?因为我们看过的所有视频都会被缓存下来,特别占内存。那么应该怎么办呢? 一、进入你的抖音主页,点右下方的我,点右上方的三条杠,找到观看历史,这里面就是你之前看过的所有视频,我们直接清空。 二、回到刚才的三条杠,点击设置,找到下面的清理占用空间。三、如果你不在乎观看历史,也可以直接关闭掉,这个功能更省事。 操作方法,还是先打开三条杠,点击设置里面的通用设置,找到观看历史记录,关掉它就好了,你也赶紧去试试吧。
 00:37查看AI文稿AI文稿
00:37查看AI文稿AI文稿本周六的加我直播开始进行缓存技术的讲解了。首先会为大家讲解卡飞印的缓存组件,而后再过度到 spring kits 缓存服务。 需要提醒大家的是啊,这个缓存服务是迄今为止我们在业务开发中最为常用的缓存组建,其也支持有 gsr 幺零七的缓存处理规范。 如果你想编写出高性能的代码,就一定要学会使用缓存。明早八点半,我们不见不散,继续我们的加网工艺变成直播,让我们将共享的传播精神坚持到底。
 12:27查看AI文稿AI文稿
12:27查看AI文稿AI文稿为什么会有缓存这玩意其实特简单,因为 cpu 的速度比内存的速度快的多,有同学说具体快多少,一百比一。 当然我们想起剖析这个概念, cpu 速度比内存速度快一百倍,什么意思呀?你 cpu 做计算的,我能理解, 你内存是做计算用的吗?你内存是做存储用的呀?大哥,你说你一做计算呢,跟人家做存储的比速度是怎么比呢? 听清楚这概念,所谓的计算,所谓的 cpu 速度比内存速度快,指的是这个意思, 通过我们的计算单元去访问我们内部计算器,如果这个速度是一纳秒,那么通过我们计算单元能够访问到我们内存的这个速度。一百纳秒 是这个意思,这是他的速度啊,速度比的一个概念,一百比一。好。当你理解了这件事之后,你就会发现啊,我们 cpu 速度比内存速度实在快太多了。假如我要从内存读个数据过来的话,我发出一条指令说你给我读过来, 然后我就等九十九那秒,等着他读过来,我才能继续能理解了吧。那我怎么充分利用这九十九那秒啊?大哥,你能不能别这么慢呀?啊?我读个数据你要浪费我九十九那秒,读个数据又浪费我九十九那秒,那我 cp 我简直实在是没有用武之地了。 所谓现在的高性能充分,就是充分把 cpu 的性能给他挖掘出来啊,给他燃烧出来,就干这件事,就让他充分利用起来。怎么才能利用利用呢? 最容易想到的就是中间加一层缓存,就这个缓存啊, cpu 返到这里的速度会比较快,这里速度比较快,比方说我要返回一个数据的时候, 我呢访问这个数据的时候,我会首先从最快的里面去找啊,如果没找到的话呢?我在内存里面再去找,找到了之后把这个数据读过来,表示数据是三放到这里,当我下次再访问这三的时候,我就不用内存找了,我内存是一百个纳秒,我这是五十个纳秒。 好,我去直接这个缓存里找就可以了。 ok, 这个是缓存的概念。好,当你理解了这件事之后, 如果说我,我就再问你,如果我觉着五十那秒我还不够爽,速度还不够快,来,你告诉我怎么办?怎么办?多急缓存。对,再来一个,对, 再加一层缓存。哎,瑞丽是个数据库的关系。说的很对,没错,再加一个缓存不就可以了吗? 那如果还不够呢?再加,那到底我加多少个缓存格式啊?如果说加的,呃,缓存的数量太多,你说 cpu 到内存之间,我加一百层换存太多了,然后呢?浪费也浪费硬件是吧?然后你每读一个数据都在中间存一百次 啊,这个也不太好,那如果太少了的话呢?如果命中率不够的话呢?他这个速度还提升不起来,所以他 同学们记住中间有多少多少层缓存。到目前为止,工业界是一个权衡利弊的结果,是一个妥协的结果,是一个成本和效率互相之间妥协的结果。到目前为止,一般来讲是三级缓存, 也不排除将来内存的速度会变来,变得越来越快,那么这个时候可能两级就够了,也不排除将来 cpu 速度越变越快, 这个时候三级不够会变成四级、五级,但是不管怎么样,在目前的工业界用的基本上是三级缓存。看这里,一般来讲呢,我们第一级缓存被称之为 l one, 第二级来个 two, 第三级来个 siri, 经过中间的三级缓存,我们才能达到我们的主内存 访问寄存器已纳秒小于已纳秒,访问直接内存八十纳秒 好了。讲清楚这件事之后,还有一个最基本的概念,就是我们这三阶段分为什么位置, 听我说,每一集缓存,第一集和第二集是和我们的合在一起的,第三集 是多和共享,因为我们的一颗 cpu 里面会有好几个核,也就说一颗 cpu 里面会有一个 l 三级缓存, 然后才是我的内存啊。红中说了个特别有有用的问题啊,我觉着得把红中这句话呢给大家交代一下,没有什么价格我是加一层解决不了的,如果有的话就再加一层。我告诉你,计算机到现在为止,软件到现在为止,这句话实际上是核心中的核心, 是金科玉律,这句话就是软件开发和硬件解决问题的易进京, 没有什么架构是夹一层解决不了的,实在不行就再夹一层,你记着这个就行啊,你不信你去找去 说。我这 vm 好多操作系统,我屏蔽不了,没关系,我加一层,这 vm 我是不是搞定了?所以呢,在我们真正的多和 ppu 里面,他是这么一个物理结构,这个结构是什么样的呢?我们有一个 i u, 他访问计算器的速度是最快的,当然计算器也是最贵的。然后呢,中间权衡的结果,我在中间加了一层缓存, 又在中间又加一层缓存,我两个和 cpu 共享同一个 l 三,我两颗 cpu 呢,共享整个的内存,有同学说中间还有没有可能会加呀?你要愿意的话呢?也可以啊,也是没问题的,随你。 下面我们来琢磨。如果在多级缓存的架构里头,我们开始读一个数据过来,从内存里面读一个数据过来,比如说这个数据就放在这三, 我们现在 ar u 呢?要用到这个三,我们怎么做?我们当然首先是去哪找啊?是去一层一级缓存里找,有没有啊?没有 没有呢?找二级缓存还没有找,三级缓存还没有。好了,这个时候我们从内存里找好,我们往回读的过程什么样呢?他会首先往 这放一个,往这又放一个,往这又放一个。 ok, 这是我们就读到这个三了,然后把它读到计算器开始做计算。当如果我们下次又用到这个三的时候,我怎么办? 我突然间发现二万已经有了,我还有没有必要走剩下的步骤呢?没必要,这样的话呢,我们的效率就提升了, 一盒 cpu 对应一个 luok, 当你理解了这个概念之后,我们好好琢磨一件事。 呃,我每次读这个数据的时候,比方说我用到了数组里面的第零个位置上的数据, 我对这个数组做一个循环访问,当我读他第零个位置,我发现没有,然后呢,我把这第零个的位置的时候呢,在每一个缓存里面放一遍,然后我马上要用第一个数据,我发现还没有。怎么办?我又把这第一个数据往这放一遍, 你发现没有,这个效率反而变低了。原来我只要直接直接读内存,现在呢,我美读的一个都得往中间缓存放,一个反而变低了。 那我有没有什么提高效率的办法呢?你,你好好给我琢磨琢磨,有没有有提高效率的办法吗?提高效率办法很难想到吗? 听我说很简单吗?就是当我要读取这个数据的时候呢,我不是只读那个,我用到的,我会把这个数据周边的一些数据一块读进来。比如说我读这 输组的时候,我用到第两个位置,我顺带着把后面七个位置一块堵过来,不是零一二三组,六七八,我全堵过来。 那大家理想一下,当我下面在访问第一个位置,我还用剩下的步骤吗?没有了。所以呢,哎,进行一个阅读曲,就是我读数据的时候,并不是一个一个读,并不是一位一位读。哎,我是 好,这里有个专业的名词,叫做一行一行读,一行一行, ok, 这个呢,称之为缓存行,他是一行一行读好了,下面马上面临的问题就是,这一行到底应该设多大? 走不走吗?是越大越好,还是越小越好?这里面也是工业界的一个妥协, 别的结果,是一个权衡的结果,是一个统计出来的结果。听我说,当然你可以把它做的很大,你这一下读进去,恨不得把半块内存全读进去,都放二万里面,哇,这个太爽了,每次都去二万里放对不对?速度太快了,很爽。 但是很不幸的是呢,你如果每每读这么一大块的话,读这一层效率就比较低。假如我其中就用到了一个,这块不用了,你又把它给拿走,然后读另外一块, 如果你说的比较小呢?你就有好多种不可能在最近的缓存里命中的机会,说找第二个没有,没读进来,找第三个没读进来,你又得重新读, 所以叫做大有大的好处和坏处,小有小的好处和坏处,那,那这事怎么办呢?中间做一个统计,目前为止,在三级缓存的情况下, 在目前 cpu 的这样的计算力的情况下,这个数字是最合理的。好,这个数字,请大家记住, 这个数字被我们称之为六十四个字结, 不是六十四位啊,是六十四个字结,所以到现在为止,我们任何一行数据,一行数据就是六十四个字结。这么大个。好,当你理解了一个缓存行的概念之后,马上就会你就会面临的问题就来了, 你比如说大家听我说,我再说一遍。记住,作为我们 cpu 来讲,我们访问数据的时候是按照十以什么为单元来进行访问的呀?换存行一行是多大?六十四个字典, 那现在问题就来了,在哪呢?比如说我们这一行数据里面有一个 x, 有一个 y 这两个数据, 然后呢,我们左边这一盒这个 cpu 盒,他只会访问 x 啊,他,但是呢,他读的时候会把这一行数据 是不是躲到这里面自己的里面来,虽然我只访问 x 对不对?那右边这颗 cpu 呢?他只访问外,但是呢,他也会把这一行的数据放在这里来,同学们,你们看看, 虽然说这行数据在内存里头只有这么一行,但是真正让我们两颗 cb 同时访问的时候,你会发现他在中间多了好多个拷贝,多了好多个拷贝, 你竟然多了好多口碑。而且我们访问数据的时候是按照最基本的访问单元,是按照一行来的,如果说 我这个 x 发生了变化,就意味着我这行发生了变化,我这行发生了变化。由于我这一行在另外一个 cpu 里也有我,是不是或者说我要不要通知另外一颗 cpu 呢? 要呢还是不要呢?我是不是得保持这两个缓存行数据要一致呀?好,这个呢就叫做缓存一致性。 首先第一点,这个要不要一致是某些指令来决定的,有的指令我就是个毒,我一致他干嘛?不,不以不用一致, 有的指令呢?我需要做一致,那么我必须得有某一种协议来保证这个行和这个行数据是一毛一样的,比如说缓存锁,什么叫缓存锁呀?锁定某, 我在改的时候我锁定这行,其他 cpu 不去改,只能读,这个就叫做缓存一致性协议。大家听我说,缓存一致性协议这件事跟语言没有半毛钱关系, 不管你是 c 语言,你是 c 加加语言,你是加外语言,你是拍森语言,你是勾语言,随你在底层这件事情是永远存在的。 ok, 还有同学会说,老师,缓存行这件事真的会存在吗? 看个程序,我们讲这么多理论讲了快俩小时理论了,这没招啊,我必须先给你打理论基础,看程序你才能看得懂,不然你真的看不懂。好,我们来看一个小程序。
865马士兵Java 03:22查看AI文稿AI文稿
03:22查看AI文稿AI文稿全世界每年会消耗十多万吨的咖啡因,相当于十四个埃菲尔铁塔的重量。大部分消耗的咖啡因是茶和咖啡, 另外一些是碳酸饮料、巧克力、药物,甚至标注了无咖啡因的饮料。咖啡因能让饮用者保持清醒、专注、快乐、充满能量,甚至可以熬夜、打麻将、补课、电子游戏。但他是一把双刃剑。咖啡因算是世界上使用最广泛的药物, 那么他是如何使我们保持清醒的呢?咖啡因是从植物中提取出来的,在某些植物叶片和种子中的含量很高,昆虫吸食过量的咖啡因会中毒。 蜜蜂吸食某些植物的花蜜时也能摄入咖啡因,好处是这样蜜蜂就能记住这类花朵了,下次再来吸。在 人体中,咖啡因是中枢神经系统的兴奋剂,原理是通过抑制一种叫腺肝的物质发挥作用,因为腺肝能让大脑感到疲惫,这要从人体获得能量的方式说起。人体获得能量的方式是通过分解一种叫做 atp 的高能分子, 在分解的过程当中将释放出线杆,而大脑中的神经元细胞中有一种兽体可以同线杆分子结合,当结合时,将激活一系列的生化反应, 促使神经元细胞减弱,从而减缓大脑中的信号分子的释放,也就是说,大脑会感觉到累了。咖啡因有同线杆相似的分子结构,它能正好嵌入线杆的兽体,可以作为线杆兽体结抗剂,能够通过结合线杆兽体,阻断线杆同兽体的结。 和兽体无法同线杆结合,大脑也就不会感觉到累了。咖啡因除了提神,还能让人感受到快乐, 这个过程同多巴胺和线杆都有关系。在神经元中,线杆兽体和多巴胺兽体是连接在一起的, 当线杆跟兽体结合后,多巴胺就无法跟自身的兽体结合了,人就会表现为情绪低落。而如果咖啡因代替了线杆的位置,多巴胺就能正常跟自身的兽体结合,人老的快乐又回来了,确实是一个很神奇的过程啊。 有证据表明,咖啡因作用于腺干和多巴胺,也会产生长期的好的效果,比如可以降低老年痴呆等一些疾病的风险。当然,咖啡因也不是只有好处,他可能让你感觉良好,保持清醒,同时 也会让人心跳加速、血压升高,导致尿量增多和腹泻,产生失眠和焦虑。此外,长期服用咖啡因也会产生一定的依赖性。 持续摄入咖啡因,人体的腺肝兽体就会一直被占用,身体会产生补偿措施,产生新的腺肝兽体。 这就意味着,即使摄入了咖啡因,新生成的线杆兽体仍然会跟线杆结合。这就是为什么你要喝越来越多的茶或者咖啡才能保持清醒的原因。 而长期饮用茶、喝咖啡后,如果想戒除,就会感受到困难,这是因为神经系统产生的下肝兽体太多了,大量的下肝兽体没有了竞争者,下肝兽体就会过度发生作用, 导致头疼、疲惫、情绪低落。一段时间后,过量的腺肝瘦体会消失。所以,要戒除茶或者咖啡,人体需要一段时间的恢复期。
2431前沿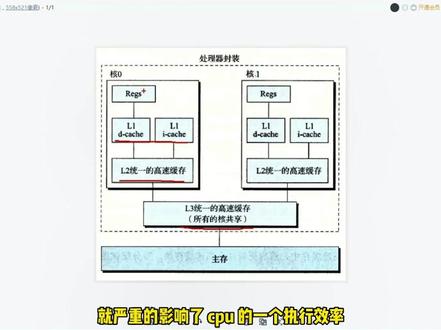 01:57查看AI文稿AI文稿
01:57查看AI文稿AI文稿请说说 cpu 高速缓存。好,我们看一下。我们看一下这张图,我们 cpu 呢,他有三级缓存啊,这是一级缓存,这是二级缓存,这是三级缓存。他为什么有缓存呢?这是因为我们 cpu 啊,直行非常快, 我们 cpu 执行的时候,他需要从内存中啊读取数据或者指令,然后去执行。但是我们从内存中读取数据的时候啊,这个读取速度比较慢, cpu 运行很快啊,读取速度很慢。 那么这样回来就严重的影响了 cpu 的一个执行效率。所以呢, cpu 他设计了三级缓存。好,我现在 cpu 要去执行。那首先呢,他去看一下一级缓存有没有数据,如果没有到二级缓存看一下 二级缓存,没有到三级缓存去看一下,如果都没有,才会从内存中读取数据。数据读取好之后,他会放到三级缓存,二级缓存和一级缓存中。好,那下次他就直接从缓存中 就拿到数据,就不需要去啊,左内存去夺取数据。那么一级缓存它分为数据缓存和代码缓存啊,或者说叫指令缓存。那我们看一下我们的这个鲁大师啊,给我们提供的我们当前这个 cpu, 来这里面可以看到, 这是一级缓存,这是数据缓存啊,这是代码缓存,然后这是二级缓存啊,然后这边是三级缓存。好,那我们现在这个 cpu 啊,是有四个核心啊,四个核心,所以这个地方一级缓存四乘以四十八 k 啊,这是四乘以三十三 k, 四乘一兆对吧?哎,这个三级缓存是十二兆。好。那么以上就是关于我们 cpu 的三级缓存,那么 cpu 的三级缓存可以提高啊, cpu 的运行效率,但是呢,他也带来了啊另外的问题。那我们在后面的视频再说一说啊,他带来了什么问题啊?怎么解决的?那么最近呢,我花费了很多时间,经 新录制了一套系统全面的加法并发编程视频课程。课程对并发编程的方方面面进行了梳理和总结,用通俗易懂的语言循序渐进,带你一步一步彻底掌握加法并发编程,让你节省大量的时间和精力。点击视频下方的链接获取本套课程。
48动力节点IT教育 01:17查看AI文稿AI文稿
01:17查看AI文稿AI文稿release 跟 mama catch 的啊,都是基于内存的分布式缓存系统,都能提高应用程序的性能,但是为什么通常情况下我们都会使用 release 而不是 mama catch 的呢?哈喽,大家好,我是专注加法干货分享的灰灰, 今天我就给大家分析一下这道题。另外,为了帮助大家应战金九银十,我准备了一份三十五万字的程序员面试题合集, 里面有两百道高频面试题,有需要的小伙伴可以在评论区扣球分享,免费领取,都是性能快。那么为什么不去用迈迈凯成呢? 相对于 map catch 的啊, redis 呢,有以下几个优势,第一个, redis 支持不同的数据类型来满足不同的场景,而 mama catch 的只支持兼职队存储。第二点, redisd 跟 map catch 的都是基于内存去操作,但是 redis 为了保证高可用,会有持久化的策略,而 map catch 的没有。第三 三点, redis 的淘汰策略相比于 mark catch 的要更加丰富,支持不同的淘汰策略可供选择。第四点, redis 的集群高可用,支持比 mark catch 更好,支持主从哨兵以及克拉斯的集群等不同的集群方案。 所以啊,这也是慢慢的慢慢开始的退出了历史舞台的原因。今天的内容啊就分享到这里,如果对你有帮助的话,请记得帮我一届三连,我是灰灰,我们下期再见!
 01:17查看AI文稿AI文稿
01:17查看AI文稿AI文稿直播间里有人问过这样一个问题,就是 cpu 的缓存到底是干嘛用的?我来举个例子吧。啊,注意看,有个男人叫小帅,小帅呢,开了一家面包店,他每次做面包就需要到面粉厂去拿面粉。这里的面粉厂啊,就相当于你的硬盘,因为你的原材料都在硬盘里,你要交给 cpu 进行处理。 小帅呢,就感觉面粉厂太远了,不如我自己建一个仓库,我把一部分的面粉拿到我的仓库里来,什么时候我用的时候啊,就直接去我自己的仓库里,距离近,方便,这就是你的内存条。后来他发现 去仓库也不怎么方便啊,我不如提上一袋面粉到我的桌子前面来,我直接从这袋面粉里拿我需要的面粉就行了。这一袋面粉呢,就是你 cpu 中的三级缓存,离你更近,容量也小了一点。再然后,小时候就觉得这一袋面粉都不好使, 我还不如直接拿一个碗舀一勺面粉放到我的手边啊,我连弯腰都不用了,我什么时候需要我直接从我的碗里拿到我的案板上就行了。哎, 这就是你的二级缓存啊,更小的可能还有一级缓存等等等等。电脑的缓存机制啊,差不多就是这个意思。总之, cpu 来处理数据,最后端的就是硬盘,中间出现了任何环节,都可以称之为缓存啊, 硬盘到 cpu 啊,你的缓存是越来越小,但是它的速度会越来越快。相应的,你的仓库,你的一袋面粉,你的一碗面粉,这些容器如果你能做大做快,那你的工作效率就会提升,你的帧数就会提高,这样说你就明白了吧。
308玩家宇宙


