如何用matlab打开文件数据

粉丝688获赞4919
相关视频
 18:58查看AI文稿AI文稿
18:58查看AI文稿AI文稿今天主要介绍一下把它的加载和处理 tst 文件数据的一个实力和程序啊。最近的话有一个好朋友,他也呃是化工专业的,嗯,在读研,然后他们要处理一个化工实验 tst 的一个结果数据, 然后呃里面的话会涉及到一个 tst 数据的一个处理,然后他的一个 tst 数据的话啊,比如说我们双击一下的话,我们看一下 啊,这是二零二零年九月二十五日他的实验数据,那里面的话刚开始这里会有这个文字,然后文字的话可以替换成这个空白, 然后呃实验处理的话,这里面是第一列是它的一个封号,封号的话就是它里面会有些图形,会有些拨封,然后这里是呃保留时间的话,它是一个啊封 风就是这个风值时间面积的话就是他的一个类似于通过定积分计算的,呃他这个图形和这个横轴他的一个面积,然后呃这个 哦面积的百分比就是,然后里面嗯就是要筛选掉他有些杂质,杂质的话他有一个啊对应的一个峰值的范围大概会估置,比如说他的峰值时间是在二点二五五二,二点六六五的时候,他就是第一个杂志,然后以此类推, 总共的话会有呃这这么多杂志,然后就是在根据他的一个峰值时间先去筛选,筛选是在这个范围内的啊,他就是杂志就要把这个数据给呃删掉,然后再把剩余的这个产物的面积 啊,把它累加起来。这然后这里面呃处理的难点的话是在哪里呢?呃首先的话它里面的这个数据的话,因为它有这个呃文字和这个数数据物分,所以的话就要进行一个转化啊,先用这个加载着他的 嗯转化,然后而且他每一组的一个数据,因为这里的话算是一组,这里的话也算一组,就是每一个组里面他的实验的数据个数是不一样的,那这样的话就是要呃,对,呃,要甄别是每一组的一个数据,然后嗯, 所以的话目前的话就是呃通过一个程序进行的一个处理,然后里面的话会涉及到一个 tst 类的这个 这个函数,这个函数的话主要是加载 tst 数据的一个函数,然后里面的话,嗯,他能够读读起文本文件中的一个数据,写入多个输出,然后 tst 函数的话是以指定的,就是以指定的这个风板头,风板头的就是他这个数据格式,将文件 将数据从这个文件啊非常嫩读取到这个 abc 变量中,比如说,呃,我们这里是它有两个输入,第一个输入是文件名,第二个输入是它的一个格式,以怎样的格式去读取这个文件啊?里面的一个封,呃封麦的话, 呃,当然后面的话后面的版本还有 ststs, 看这个函数,然后丰满的格式的话,比如说我们的百分之一,他就是读取有符号的整数,值百分之一的话是读取整数,呃,值百分之二十的话读取附点,数,值百分之二十的话就是读取一空白或者分格符分格的这个 文本,然后他输出的话是制服限量元包,呃,速度,他前面的格式化是输出双击度,速度那百分之 q 一直在推,然后今天用的是这个百分之二十,因为里面的话会有这个文本, 我们可以看到它里面的话会有这个文本信信息啊,比如说这里文本还有就是一些其他的,那我们的话就可以根据这个文本读取之后他的一个值,然后去判断他每一组他的是在哪里去开始在哪里结束的。 因为我们可以看到他每一组的开始呃和结束的就是开始的时候他有个标题,然后结束的时候这里有一个总计,然后后面会有数据,然后我们主要是以这个作为这个嗯判断的,所以的话要求的话就是刚刚讲的,他要在所有峰制度筛选出出风的一个范围,并删除对于 杂志的实验数据,统计画后的摄影面积,然后这里的话就有呃这些杂志他的一个出风时间。呃,当然手动,手动也可以,但是如果每天他的有这个实验数据处理的话,那就是可以通过程序进行处理啊。我们来看一下这个程序,嗯, 先看一下他对应的一个呃实现的一个效果,比如说我要去处理这个呃十一月三号的这个实验数据,它里面的话比如说二十五,嗯,二十八。 然后运行一下这个程序的话,这个程序会筛选出对应的杂志以及统计杂志的个数,还有对应的杂志出现的位置,以及对每一个组的数据会产生一个一个色。我们来运行一下, 然后这个四角 c 是清除命令行的窗口,命, 这个肯定哦的话是清除工作区的变量可落,之后的话是关闭一些图形窗口,然后这个非要内的话,我们就可以去修改啊,这里的话出现了一个结果,嗯, 可以看到,我们先看一下这里的文本输出结构,这里会输出实验数据一共有多少组?八组,然后第一组他的杂志个数有九个,然后第一组的剩余面积,是啊,这么多第二组的杂志个数, 呃,剩余面积,呃,第三组、第四组依次类推,然后这里面会输出主数,就是第一组的第二个数据,他是打字,第一组的第三个数据他是打字,那这样的话你可以去实际的去看一下这个程序的有效性。那实际上看完之后的话,那就可以发现啊,这里面的这个杂志的位置,他就是在这个 他的一个风之时间,出风的时间就是在这个范围内,所以的话啊,这是对应的,然后对应的 的话,我们可以看到右边他会自动的生成对应的 tst。 啊,就是这个一个四号文件,他因为总共有八组吗?每一组他有一个实验数据,我们可以双击一下啊,看他的一个实验的一个结果, 我们可以看到这里的话,我们这是第一组的实验数据,结果我们把这个数据文件也打开了,然后我们可以看一下第一组他的实验数据的话,实际上是有多少组呢?啊?第一组他的实验数据一共有二十五组,那我们三选完之后的话,这是符合要求的一八九立此类推, 然后这里面的话,嗯,那就是把这里的面积加起来,然后以此类推, 然后来看一下这个程序,这个程序的话实际上就是通过这个 tst 类的这个函数将因为他 里面的数据,我们可以看到它这里实际上就有四列吗?每一列的话我们把它复制给一个变量,把每一列的数据复制给一个变量。 呃,通过这里面的这个呃,我们可以单独执行一下,比如说我们先执行一下这里的话,我们呃可以看到这里是非常冷的,把这里每一列的数据复制给 aeaaasi, 那就可以看到他是实际上是一个原包类型 啊,二百一十三,但是我们可以看到它这里面文字读取的话会出错,然后这里面是依次类推,那这里都是啊,既有对应的左数,又有这个文字,那这时候的话我们就要进行处理, 可以看到这里面啊,那这时候的话我们就是要将数据从原包内形转化成数字矩阵,那我们在转化的过程中遇到 到了他这个文字部分,他实际上就会转化成为空值,就是 ngm 不确定等值。那这时候的话我们就通过一个 clcltw, 然后这里是输入的数据,我们处理过程是将 cel 类型转化成啊,举生类型,再转化成双精度负离类型。 首先的话我们就是对这个输入进行处理,我们要看他是有多少行,多少练,然后这个 is 的话就是这个结果啊,最后这个结果就是 n 的话一,然后我们进行处理的话是就是通过这个 ceopoomat 这个函数的话,我们对他的每一个 数据进行一个处理,呃,进行一个操作吧,进行一个操作,呃就是原版类型转化成举证类型,然后再将这个呃里面的字符啊,里面不是有那个 st 啊,因为他转化的这个结果的话可能还有 制服,制服的话就是 st 啊,图这个大大宝啊,那这样的话,呃运行之后我们可以看一下他的一个结果,我们通过这个函数我们再单独执行这几个, 我们可以看到这里面的话,实际上里面的文字部分的话就转化成 nan 类型的话,那这里面啊,那里里面的话,我们呃这里面的 nn 的话就把对应的删掉,那我们可以以一个 nn, 嗯他作为这个间隔,比如说, 呃连续正面是连续的数据吗?如果出现了,嗯嗯,那就是下一组的数据,那就可以通过这样的形式去筛选, 然后我们去呃,因为他每一组的数据是个数一样的,我们就是计计算他的一个啊有多行多练。然后我们这里是定义了这个出风的位置,通过这个 lb 和 ub, 那这样的话就可以 他那个出风范围,如果在这个之内的话,他他就是打字,我们就是要找出对应的 nn 数据的下标,我们运行一下我们就可以得出他的对应的下标,因为它里面,呃我们要筛选的是 第二列的数据吗?第二列我们是要对它进行这个出风时间进行一个操作吗?我们就是要对这里的这个 nn 数据进行处理,通过这个范的去呃判断,呃椅子 nnn 就是判断,呃如果是这个 nn 的话,他就会返回一啊,如果不是的话就返回零,我们就是可以找到对应的下标, 下标的话我们看一下,那这里的话就是有对应的一个下标,然后我们将这个 nan 的数据进行删除,然后我们就是呃将这个空空的矩阵去代替,嗯,我 我们可以看到他里面一开始二百一十三,后来变成一百九十七,但是我们可以看到他依然啊,依然的话,还有呃呃 其他的这个数据里面有第二类的话,就是已经没有空的了,已经没有 nan 数据了,这时候我们可以去了解,然后 然后我们将不同的数据进行分组,每组数据占一列,我们就可以呃通过通过第一列就进行一个筛选,我们可以看到第一列它的数据其实很有意思,它就是呃一还剩下一个 nn, 呃进行一个处理之后,因为我们是将啊这个 n n, 呃就是根据第二个第二个出风时间的 n n q 三 筛筛选的,然后去删除的,通过这个控制针,但实际上他的第一列的话,实际上他还有还有一个 nnn 的话,呃这个就是间隔,间隔伏 就可以看到他的一个数据,实际上就是这个 n, 这里面证明呢总计他这里面的 n n, 但是根据根据这个总计的位置去判断他是每每个组的,然后这样的话我们就是呃每个组的个数可能不同,但是用这个元宝类型存储不同组的大小, 那这样的话我们就是进行个分组,一到这个闹一减一,然后这里的话就是呃通过这一行,通过范的的话,我们可以呃看到呃我这个分组他出现嗯嗯的位置,那就是从二十六 开始,后面他就是第二组的数据,以此类推,那这样的话就找出了这个断点,那我们的通过这里的话,我们就可以 因为他每一组的数据不一样吗?不一样的话你通过举证去存储的时候的话,他举证的数据他的一个行数和列数要一样,那这时候的话就可以通过这个原包类型去存储。然后我们执行一下的话,我们可以看到这里面的啊,一,他是二十五乘以一,呃, 二二三四,二十五, 呃,我们可以看一下这个啊,一里面的话是一乘一的啊,二里面也是一乘一的,以此类推, 嗯,根据这个每一个组数不一样, 那相当于把第一组,把第一组分分出来了,然后第二组的话我们就可以继续进行,他有一定的规律了啊,因为我们里面要涉及到他里面的一个位置 位置,如果是比如说我们这里的啊 i s 二啊,我们这个第一组,第一组他是开头的话没有前面的进行一个对比,然后后面的话我们就可以根根据这个呃,这个出现的这个恩怨的位置去进行一个判断,通过一个放循环区替代, 嗯,相当于第一组他的一个数据分类的啊,分组的话就是要通过这个手动的形式,第二组的话之后的话我们可以去判断这个浪里面,浪里面他实际上记录的是什么呢啊?比如说我们第一组的话,二十六之前的话就是第一组 啊,五十五,二十六到五十五的话就可以是这样,那我们的话可以通过这个循环去判断这个,当这个 i 减一的时候,让我这个让 i 减一,然后这里是要加一,然后一直在推,然后这样的话我们单独执行之后的话,我们可以看到那这里面 按一按二,它实际上是一个一乘以八的一个,呃,赛尔类型面包类型,那这里面的话就是第一种, 然后这是第二组,然后这是阿姨的第一列的这个数据,这是我们需要的这个第二列的这个时间,然后他有八个吗? 可以看到它的维度是不一样的,那可以通过这个圆包类型去存储,然后我们去计算圆包的尺寸啊,求出每一组它的一个尺寸,我们单独执行一下,我们可以看到那里面二十一里面的话 啊,他就是二十五,一乘以二十五,一乘以二十八,一乘以二十二、二十二、二十一、二十二、二十四、二十五,那这样的话就根据,呃,这样的话我们就可以进行判断,那这样的话我们就可以去计算杂志个数以及杂志出生的位置,就是通过去放循环吗?外层啊,我这里总共有多少个 元包?我们是要对阿罗进行处理吗?啊?总共有八个,然后每个元包,呃里面通过放循环啊?二十一里面, 因为我们这个二十一是记录他元包每个元包里面的一个大小吗?我们就可以去去缩影。然后呃我们在对每个元包里面进行处理的时候,我们要判断啊,他是属于哪哪, 是不是在这十二个范围内?十二个杂志内,我们就要判断阿鲁二他的第啊,比如说,呃,他是一乘以八,一乘以八, 他的第多少个数据就是阿鲁二原包的,呃第多少个数据是不是在这个呃出风范围的下届或者是上届里面,因为他有十二种杂质,所以每一 个每一个数据,比如说里面的这个 is 啊,里面的这个不是阿鲁二,比如说这个第一个元宝吗?我们所有的时候就是阿鲁二,括号一,都号一,那这里 他的话他就会获得,我们可以呃双击一下,那这里的话就会可以获得他里面的这个第一个元包他的所有的数据,那这里面的数据,然后比如说第一个数据我们要进行所有的时候,那就是一,那可以看到我在返回的十一,那这样的话就是通过这样的形式对每一个他的一个出风范围进行判断, 然后如果在这个范围内的话,我们就是这个要加一,然后把这个位置保存,这个位置就是啊,你是第几个原包,然后啊原包的第几个数据, 哦,保存之后我们运行一下,我们可以看一下他得到的一个对应的一个结果啊, 就是通过这个 in 杠 s 可以看到这是啊第一个元包有第一组,第二个是杂志,第一组第三个第四,然后以此类推,一共有六十六个杂志,然后我们要计算杂志出现的这个次数吗? 嗯,就比如说我要统计每一组出现的次数,那不就是相当于啊,如果 如果这个第一行第一列他的数据为一的话,他就是第一组的啊,第一列的数据为二的话就是第二组的,我们要统统计每个组他出现的次数 啊。最后的话就是将杂志的数据啊复制为这个,嗯嗯,然后再进行一个删除, 嗯,然后对数据进行一个删除,然后呃进行一个 处理,处理完之后把这个结果复制给一个新的元宝,那这样的话就是把对应的结果进行一个输出啊,这个 dota 里面的话就是输出对应的一个结果, 然后把这个结果复制给这个,因为里面我们这个文件名的话是第这个,那哎的话就是有多组,然后第几组数据?呃,就是通过这个这样的形式支付串连接, 最后这这通过这个啊,是 read 去把这个文件名和这个数据,这个数据的话就不好了,带他和带他一,这个带他的话就是,呃,我们里面的这个删除之后,删除咋做?之后的第一列、第二列、第三列、第四列的数据,然后把它运行,然后输出对应的信息。比如说我这里第几组啊? 有多少个杂志,点击住他的一个剩余面积是多少,然后输出杂志他对应的主数和位置,那这样的话实际上他一整个流程就已经走完了。 那这样的话每次的时候我们啊只需要比如说我们把这个文件名更换一下幺幺零三吗?我们就改成零九二五, 买成这个文件名,然后运行一下,它就会出现它对应的。呃,你当前这个文件它的一个结果,那可以看到它这里面的实际上就是不一样的嘛,我们可以用它揪揪揪啊,这样的话实际上就是一个完整的一个处理的一个过程, 然后里面包含的这个数据的话,就是原包类型转化成最后只是运行的一个结果。 然后这我今天的话主要是一个世界例子去讲解他这个,呃马特勒本加载和处理 tst 文件数据的一个实力啊,主要是拥有了这个 tst 类的,以及呃这个数据的一个转化,还有就是一个范函数, 呃,本来这个程序可能写的时间也会比较长一点,因为都是根据你的这个实际的一个输出去调试去判断,最后的话把这个结果输出来了,然后,嗯,谢谢大家。
34龙行天下 03:22查看AI文稿AI文稿
03:22查看AI文稿AI文稿嗯,哈喽,大家好,这一节我们先给大家介绍一下 mateleg 的一个软件的一个布局。首先我们可以看见在他的上面这一部分是他的一个菜单栏,正面可以选主页,选绘图,然后选 app, app 里面就有很多的一些工具箱,然后大家可以自己来尝试着玩一下。好,然后呢那我们左边这部分有当前文件夹,当前文件夹就是说我们在当前的文件夹来创建程序, 在这里面是命令行窗口,命令行窗口可以自己来数一些命令,比如说一加二,让他返回一个三。然后右边呢是工作区,工作区 就是我现在有哪些变量,比如说我有 x, 有 y, 在我们主页的时候, 这里面的绘图会提供我们一些绘图的工具,比如说我选择 x, 选择 y, 然后点这个绘图,他就帮我绘出一个图像来, 这比较好用的一个方式。 ok, 那布局大家给大家讲好了之后,那比如说我想掉一个历史记录怎么办?那历史记录我就可以在这里面布局,然后选有一个历史记录, 然后可以选停靠和弹出,比如说选停靠,那他就在这个位置, 对,这样就有个历史记录, ok, no, 我还想知道的一个事情,就是说我的命令好 窗口里面的字太小了,以及我当下文家里面的字太小了,这时候可以选择一个预设像,在这预设像里面我们可以对字体进行更改,以及对自己大小也进行更改。好, 这边有编辑器和调试器,还有当前文件夹,我们可以打开字体,然后 选择选择这个自定义,然后命令航窗口是不是在这呢?那我们选择文本的这个大小,比如选择自定义,那我想要一个十二的, 然后选择一下应用,这个时候再看一下这个字体又变大了。然后还有就是命历史的,就是命 命令历史记录的这个字体如果显小的话,我也可以改成个自定义,但如果用左边代码就默认的好。还有就是编辑器,编辑器里面的字体我们也可以进行更改以及更改大小, 还就当前文件夹就是这个字,那我使用自定义,我希望他大一点,选择十二, ok, 他就变大了。然后还有就是在右边的工作区,我也希望他的字体大一点, 我就选择十二,然后选应用,就这样的话,你看就所有的字都变大了,那十二有点大,我就选十吧。 嗯,这样就可以了。当然还有其他的一些设置,比如说颜色设置,这个大家可以自己再来摸索,目前我只设置这些就够了。 ok, 我点下确定。
2034MATLAB-DataWork 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿平时我们在处理数据的时候,我们会用到 mat love 来进行对 csv 数据的读取, 这是一个震动的波形,当我们有多数数据的时候, 比如说像这么多文件的文件夹,里面有这么多组的数据,我们就可以用批处理来进行处理,比如说写了一个批处理的脚本,这样的话我们就会对每个数据逐针分析, 这样他就可以自动来分析了。 累掉数据分析之后,我们会生成一个这样的 文件夹,然后里面是每次分析得到的图片, 记录的图片,然后上面是我们生成的一个数据表,把每次分析的结果写在数据里。
 10:29查看AI文稿AI文稿
10:29查看AI文稿AI文稿介绍一下 etit 啊, tst 文本数据如何导入那个麦特乐本以及 mate 遇到 tst 里面含有字符,比说英文字母和数据的时候怎么导入?然后,然后介绍一个实力, 然后嗯,首先的话建立一个嗯 m 脚本, 然后保存可以随便输比 啊。保存完之后,比如说我这里准备了啊两个类型的,一个是呃就只有纯数字的,还有一个就是这种既含有数字又含有这个啊智 串,就是制服英文的。然后去怎么导入?比如说呃,先看导入第一个纯数据的,那就我经常用的是两种方式, 比如说导入那个矩阵漏的 led, 漏的漏的漏的函数,他是呃比较常常用的啊,这的话就比较好用的话,就是直接输入他那个文本文件内容就可以了,文件名 d a t a 对着点 tst, 然后呃双引号连接起来,然后保存一下,点击运行, 然后这个数据就已经在里面了, 然后这就是 a 的内容, a 就证明已经导入进来了,同时也 可以用啊。第二个函数的话,比如说也是同样的啊,音 pos 对着就是啊,这个函数 音坡的对头也可以直接啊导入那个 啊,最好就直接复制一下,在后面他的输入也是一样的,就直接是输入这个,然后我们看运行一下 a 和 b 的内容是不是一样,是不是 tst 里面的内容 啊?现在是 tst 里面的内容,然后现在的话,因为呃有的那种实验设备输出可能是 tst 的格式,它里面就会遇到这种啊,既有中既有种英文就是,然后有这些数字,然后也有这种 数字的时候如何提取数字?提取完这种实验处理的一个结果的一个数据之后,删除一些不符合要求的结果,然后再把它保存回去,然后这里的话就是有一个例子 啊,这例子的话主要是讲这个程序怎么来的,然后我是他为了可视化,我就把它加在一个 gui 里面,然后这里的话,这个文件的话,就是呃读取一个 tst, 然后对里面的数据,比如说他的 sy 有一些数据点 啊,输入一个呃线叉,比如说如果 x 大于二或者是大于几,这个数字由我这里输入决定,那他就把这个数据删掉, 同样弯也是就是呃三种情况,如果输入,比如说输入二,这里输入二,那就是如果 当 s 大于二的时候,绝对是 s 绝对是大于二的时候,那就把这个点去掉, y 大于二的时候去掉,同时大于的话同样也要去掉。然后就是对数据进行一个处理,然后把它输出,比如说输出成一个 聚三啊,聚三点 tst 的一个格式,然后保持原来的顺序,就是把那种点上去,然后点击这个计算 啊,先要加载,加载这个数据,加载啊,然后 加载完之后,读取完之后,这里会弹开一个打开机,读取数据完毕,然后输入线插,之后我们就可以计算了,就是输入 x 关,他要大于某个值,他就删除数据点,然后输出,最后输出会在以以聚餐点 tst 命名的一个文件里,然后点击计算,然后这里会有个进度条, 然后啊计算完毕,然后就可以显示啊,这些点就是超过了不符合要求的点,比如说这个点,这是他的序号,这是 sy, 这个点是二点二,他的绝对值也是二点二,然后他大于了二,那他就是不符合要求,同样的这上面可以画, 然后这里的话就是点击这个输出,超出线输出出这些点之后保持原来的顺序,然后的一个 tst 啊,然后这个 tst 就倒出了,然后 可以重复,比如说我可以改成一啊,改成一,如果这个文具名不变的话,他就会重复覆盖里面的内容,比如说点击计算 ok, 然后显示,哎,这里的话就是显示只要大于一的,我就把它删掉, 然后点击输出,那我们可以看一下里面有没有章鱼的,就是这个就是生成的文件啊,看 x, 这是 x, 这是 y 啊,这里面都是小于一的,绝对值小于一的,同样的他也是按照原来的顺序,你看后面也有 老乡的话,这个这个界面就可以批量的处理这个类似的文档。如果格式是一样的,那我就可以清除,然后继续输入,也可以清除这里面的显示,然后点击关闭,然后这里的话就主要是讲一下那个怎么实现 啊?这样的话就是用那个音音,音音 boot 对他这个函数的话,他的第一个输入就是这个文件名,我这的话文件名的话就直接啊 这个这个程序的话就直接默认了,就打开这个,然后这里的话就是第二个输入函数的话,就是列分隔符啊, 就是每一列是通过怎样的方式去判断他是换了,换了一列,呃,然后就是通过空格,然后这里的话就是输入 h i 的话,就是 比如说这里第一个这是一个循环,如果挨等于一的时候就是 h 一,就是取得二十三,呃,因为呃这个原始的数据是在, 比如说这里是我的 x, 是从二十三行、二十四行开始取的,所以我就取二十三,他读取的时候他就会读取下一列,从下一列开始,从下一行开始读取同样的,然后这里这里的话,因为后面还有那个文字,哎,这里这里的话,这 分我又是呃文字部分,我就继续要取这里,所以第二个的话就是二百一,然后分段的话,如果是只只有上面一开始只分一段的话,那就还就不用循环, 然后这就是循环操作,然后对他进行导入,导入之后他就最后结果是一个圆包类型, 就是可以点击这个 a 一看情况,这 a 一的话,因为他有三十六段,就有三十六个结构题,每一个结构题里里面有两部分,一个是对的,就是 f、 y、 f 和序号,然后引用的时候就只要 a 一 大括号,一逗号,一逗号点,对的就是引用,就是在原包类型里面引用结构体,然后这个是文本类型,也就是如果后面要保持原来的顺序 写录的话,就要把这些文本信息也要写录,然后这里是然后这中间的一个程序的话,啊 长时间比较短,就主要他的主要作用就是啊把那个删除,删除的那些数据要计数,比如说我一开始原始数据每一段有多少个,因为每一段有一些不符合要求的点,删除之后删了多少个数据,然后删了之后那个每一段之间的分界点是在哪里? 然后然后这里的话就是呃这一部分程序就是实现这个功能,然后这里的话就是把结果输出成一个 tst, 然后这个名字的话是这是设定,如果是在那个界面里面就可以自己定,然后他是以 w 加的形式,就是如果这个文件名 题原本存在,他就会覆盖,就会把那个内容清空,然后如果不存在,他就会创建一个以这个名字命名的 tst 文本,然后把他把他的一个巨柄复制给 f id, 相当于我只对 f id 处理,就是对这个文件处理, 然后这里的话就是一个循环,呃就是因为他这里啊 a 一括号一点对号一,这这条语句的话就是引用啊那个原包数组里面第一个结构题的一个文本信息,因为我要把那个保持原来顺序输出, 然后这里的话这个语句的话,这这后面,嗯这几条语句,这个的话就是啊这个是计数的。就比如说第一段是从呃第一行到多少行,这个号 的三就是那个结果,呃他是一个项链,他的第一个数据就是第一个分段的一个第一行到亢的山,呃就是第一行到某一行就是第一段的,然后对他进行一个晒子,晒子的话就是因为他是呃,晒子的话,他就是 呃返回 a 的一个尺寸,因为 a 是一个矩阵,因为他的数据有三行, 呃就是三列,三列,所以他就会返回这个是行数,这个是列数,然后相当于这后面的话就是对矩针进行一个呃存存写进去, 写进去的时候,然后就要判断如果他买了,买了一一行的话,他就要换行,换完行之后,然后就要,呃,把这个换到那个光标 移到啊最开始,然后再写,然后这这个循环主要是这个,这个这个过程,我主要那个君安的话,主要是把这个过程写入了,写入那上面。 哦,具体的话,呃,程序的话会在我们的公众号里面,袁隆判里面,然后呃,有,然后那个文文件的话就是改其他名字也可以,然后今天就讲到这。
84龙行天下 06:04查看AI文稿AI文稿
06:04查看AI文稿AI文稿分享一个用 matalev 你和你想要的曲线的一个方法。嗯,这里用的就是网页版的麦特莱,就是这个网址,然后打开之后建立一个新的脚本,新建脚本 这里重名为 face, 然后把它打开,打开,我们第一行还是进行一个初始框, 然后建立一个 x 数据和一个 y 的数据, x 轴和 y 轴, x 轴呢?就举个例子吧,就是生成一个零到二排之间的一个项链,用 nice space 零到二肽之间, 然后一百个数据外呢是三 x 函数, 那么就就是这两组项链,我们可以先给他输成一下看一下, 然后运行一下,也就是我们这样的一个正前曲线。对这样的曲线我们应该怎样去拧拧合呢?这运用的一个命令就是 polar eggs, 你把 xy 填上,这 对我们不知道他是几次你和,所以我们先去试一试,比如说一次,一次当然是个直线,我们已经知道直线,但是我们这里呢去来试一下,演示一下, 对你你和后的这个 p 呢?他是一个,嗯,权重系数,你这个权重系数怎么去给带入到原来的 x 当中去逆和出新的外置呢?新的外置是为外衣, 那么新的值的计算就是 polar value 这个值批举证,然后还是原来的 x, 然后是新的万一 对新的外衣我们进行一个绘制后档, 万一我们在运行,所以看到红色线是礼盒的,然后这个蓝色的是原来的原来的数据,可以看到这个偏差是非常大的,所以我们改动这个,呃,这个几次项,把这个一次改成二次看一看, 现在还是没有效果,那我们继续改比说改成四次,这个次数相越高呢,他跟原来的数据吻合程度越大,但是过高呢,他会反而会过,你和就是 离原来的数据比较偏远了,所以当四次的时候,我们看你和效果还是比较好的。那我们继续,比如说,比如说到五,我们再运行一下, 这个是完全拟合的,那为了看出这个效果呢,我们这里实际演示的时候改成四吧。 ok, 那么这个我们为了区别你这里加一个 legend, 加一个加一个标题吧,第一个是实际的,然后第二个是你喝的, ok, 这里个标题就出来了,那我们为了评价我们礼盒出来的这个纸跟原来是一的纸,他的偏差常常用到两个指标,一个是阿尔方, 这个阿芳指标呢,通常是衡量预测值和真实值,它接近成 度的一个指标,这个阿方越接近一说明这个预测值是更加完美的,贴近于真实值的,越小说明是越偏离的。我们这个二二方的函数呢,我们这里给出来了,这就提前写好了, 等于一减去残差平方和,比上一个总力差平方和。然后是这样的一个公式,我们直接 用阿斯乖尔这个函数,然后第一个第一项是,嗯,真实纸,第二项是,呃,预测纸,那我们带入这个函数就 ok 了。 us there, 真实纸是外,然后预测只是外衣,那另外呢,我们还用 mse 这个函数,也就是平方差,平方差函数衡量, 这是纸和预测之间的偏差大小,第一个是外,第二个是外衣。 来运行一下,可以看到二方是零点九九零四,那么这个值越接近一说明他的预测效果是越好的, 那么这个 mse 就是军方误差,他这个值越小,说明离合效果是越好的。因此我们当前得到的这两个指标 他都比较完美,所以说明我们四次相的时候你和效果是比较完美的,那么当然这个具体问题还要具体去分析是多少次。
7062Endless科研分享 01:58查看AI文稿AI文稿
01:58查看AI文稿AI文稿matlam 软件安装常见问题解答篇有些用户安装完 matlab, 打开软件显示还要激活,出现这种问题都是前面的证书步骤自己没操作对导致的报错。点击高级选项,我要使用许可证文件。 crack 文件在你们下载的安装包中有浏览,选中 crack 中的 lessons, 自己把软件下载在哪个盘就到哪个安装,帮目录下去找到 crack, 打开激活,激活完成关闭, 双击打开 matlab 正常打开,问题 解决。第二种安装出现常见的问题,提示, lessons manager air 八秒动态库文件出错,这也是自己的原因,没有替换导致的问题出现。 无论是哪个版本的 matlab 安装包, crack 中都会有 libmar greenpole d l l 复制 limber green pole d l l 桌面上右键 matterlab 打开文件所在位置, 双击 win 六十四目录层 商机 matlab startup plugins 双击 and green poll, 把刚才复制的文件粘贴替换,替换目标中的文 建 再次双击打开 mat lab 软件正常打开,问题解决。
1395远程安装软件 01:16:34
01:16:34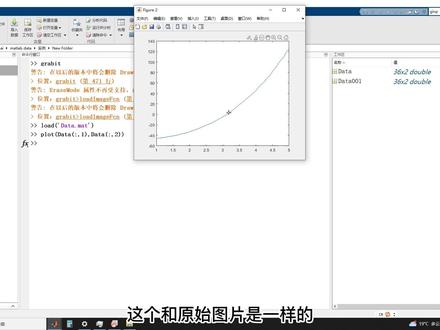 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿之前我们讲了如何用该 data 进行图片的去点,今天我们讲一下如何用 matelab 取掉,以这张图片为例,先打开 matelab, 然后输入 grab it 这个 gui 界面就打开了。首先加载图片,把这张图片给导入进去,第一步要取两个做表轴的两个端点,首先取得 x 轴的最小值和最大值,然后取得外轴的最小值,最大值, 这个步骤跟我们之前用 gatsus 是一样的,如何去操作,只要看上面的红色的备注就可以了, 比如说按住右键不动来实现放大或者缩小,按住鼠标左键不动进行图片的拖动。 点击右上角的取点工具,在图线上进行逐个点的选取,把所有的点选取完毕之后, 按回车键结束,然后这里把这个数据给保存一下, 命名为 data, 这时候已经保存了, 我们双击 data 加载数据,这个时候我们把得到的数据给绘制一下,用不到的面临即可,这个和原始图片是一样的,那怎么样使他更加的平滑呢? 这里再把我们之前学过的曲线拟和工具背部写下。首先用 x 和 y 把这两列数据给提取出来,然后用麦还赖不自身带的曲线,你和工具箱 cx 度,打开工具箱之后,把这个 x 数据和外数据给导入一下,然后点击上面的你和指数,选择三次箱, 然后这个底线很好的给你做出来了,然后我们点击左上角的生产按法,把这个工作空间给保存下来, 方便我们待会直接用代码实现曲线的离合。看到这一生成了一个 grace face 这个函数,我们把这个函数给保存一下, 然后呢直接在命令旁 入 s 数据和外数据,就可以得到我们刚刚在工具箱里看到的那个礼盒的取件,那么这个图片呢,就实现了一个很好的平滑与礼盒。回顾一下,我们先用迈特赖不自身所带的工具提取了我们想要的图片的那个数据,再用 凡凡赖布把这个数据给绘制出来,并且加以平滑和拟格。凡凡赖布取点工具还是蛮好用,你们学会了吗?
1522Endless科研分享 06:45查看AI文稿AI文稿
06:45查看AI文稿AI文稿今天我们一起来看一下迈特拉伯基本数据类型中的表 表呢,是从莫特拉部 r 二零一三 b 版开始引入的一种容器型的数据。表中的数据按列存储,每一列作为一个单独的变量,称为表变量。 表变量有名称,可以像结构体的自断名那样使用。表变量可以具有不同的数据类型和大小。所有表变量应该行数相等, 也就是所有的列应该是等长的,以使整个表保持矩形。表由行名称和列名称可以用行或列名称进行缩影。 由于有两个维度可以按名称,所以对某些数据用表来管理比用原包数组或结构题数组更直观,所以和使用也更方便。 我们首先来看一下表的创建表呢,没有专门的定义服,所以无法像原包数组或结构体数组那样直接输入,只能通过推报函数创建。推报函数的基本语法如下, 第一行和第二行呢,就是推爆的主要两种创建语法。第一种呢,先创建指定大小和数据类型的空表格,然后再填入数据。第二种呢,是准备好 数据后,用推宝函数生成表。每一种方式都可以选择是否同时指定列名或行名。 表中不同列的数据类型可以不同,但是同一列的数据类型是一致的。用第一种方式创建表的时候,必须同时指定表的纬度和每一列的数据类型。 表边量的类型可以用自伏串数组或原包数组来指定。如果用原包数组来指定的话,每个原包中的数据类型名必须是自辅形,而不是自伏串形。 变量名中类型名称的数量必须与表的列数一致。变量类型呢,可以是任意基本数据类型名 名称或马特拉伯类名称。具体可以查看推报的帮助文档。例如命令行输入这样两条指令,这是结果的输出。 可以看出,如果不指定行名和列名,默认的行名就是一二三等等。二,默认的列名就是哇,一二三等等,表示一种典型的基于迈特拉姆面向对象编程思想的类。 我们创建的表 t 呢,是推爆类的对象,继承了表例的所有属性和方法。表的列名和行名可以通过他的属性进行修改,例如咱命令行数这样两条指令,这是结果的输出。 与前数的挖 taps 类似,挖内慕斯也可以用支付串或原包来指定,这里用的是支付串。我们可以列出表替的所有属性。通过这样一个指令, 这是结果的输出。可以看出,除了列名和行名,还可以设置变量单位、变量说明等默认的属性,甚至可以通过俺的 pro 和 rm pro 函数来增加和删除。用户自定义属性。 空表创建好了以后,可以通过点操作辅对表变量进行复职,就可以填入数据。例如命令行输入这样几条指令,这结果输出可以看出, 这于对结构体数组的字段进行复制的操作是一样的。不同之处在于,对表变量复制的时候,必须保证数据的类型和个数与表中定义的一致,否则就会爆错。 与修改列名类似,我们可以通过修改表的属性讲行名称修改为学生的姓名。比如在面临行输入这样的指令,这结果输出。 第二种创建表的方法是先准备好数据,再用推爆函数创建表。 例如我们可以用前面准备好的表变量直接创建一个新的表二 t 二,输入这样的指令,这结果输出可以看出表中各类的顺序与 函数参数的顺序一致,默认的列名就是变量名。但是这里由于注意第三列,第三列,由于创建表的过程当中该变量被执行了两次转制操作, 虽然数据没有变,但是末日的联名用万三来代替了别量名。所以在向推报函数传餐的过程当中,应该避免对参数的操作,这里是为了掩饰这种特殊情况而故意为之。 通过表的属性可以将哇塞改回 pe, 比如织成这样的指令,这结果输出。 我们再来看一下表的锁引。表本质上是一种特殊的数组,基本数据单元就是其中 表格。对表中的数据既可以以行名和列名进行,所以也可以像普通数组那样通过下标进行,所以还可以两种方式混合使用。 另外,与原包类似,表也有原括号和花括号两种缩影操作符,前者返回的是表中的数据单元,数据类型仍然是表,后者提取的是表中的数据。 关于表的更多内容可以执行 dog tables。 马特拉布定义了几十个推宝相关的函数,通过帮助页面上方的方可申斯可以查阅这些函数,并了解他们的基本功能。 好,关于表的内容咱们就分享到这里,关注我,咱们后面再来看一下玛特拉伯的其他内容。
34朝霞szx 04:31查看AI文稿AI文稿
04:31查看AI文稿AI文稿要这样模特了的,对,呃数据文件, fig 文件如果没有原程序的话,要如何导出数据? 然后嗯,首先的话就是呃,呃常用的一种方法就是你说先输入这三行命令行,这一行是清除 迷你窗口,这个是清除变量空间,这个是关闭所有窗口,然后啊通过这四行程序可以把数据比说是一个二维的数据啊,这是一张呃 f 点 f i g 格式的一个图, 然后他有啊二维,他有 x 轴数据, y 轴数据,首先的话就是用 open 函数,然后下括号,然后里面的话就是 fig 的一个名字啊,这是提取或 的光三光纤光点 fh 文件,它的名字哦,把它打开之后复制给一个 h, 一个 h 的话就代表了这个 fig 文件的所有句柄,所有它的内容, 然后呃再通过一个 final 函数去呃括号, g c a g c a 的意思就是当前的一个图,当它打开之后,这个 g c a 就是呃对应的是当前的图,就是这个点 f i g 文件,然后 这个是英文输入方向的单引号,然后输入这个太派,太派就是他类型,然后对这个图里的直线这种线型属性去提取,所以就是一个赖 i 一赖,然后也是用单一号引起来,然后翻啊,翻到,我就 是找到这里这条这个线的所有的一个啊元素,然后他呃给呃给一个可以看成一个变量,然后呃,然后再通过个函数去获得这个函数的一些属性啊,因为, 嗯,比如说个的这个这个变量,然后获得他的 x 轴的数据,然后复制给一个 x c, 然后这里的话就是也也用个函数,然后这个是这个提取的一个呃 呃句柄,然后对长按的 y 轴的数据进行提取,然后再通过画图,然后进行对比,这个是呃 f i g 格式,这个是画出来之后,然后数据基本上就倒出来了,然后用程序演示一下的话,就是啊,这个是 呃 f i g 文件,然后通过这几行程序啊,可以先执行执行上面的 t 恤, 然后这就是呃打开的那个 f i g 文件,就提取后的一个光山的一个 f i g 文件,就要对这个数据进行提取出来,然后后面如果做实验的话可以进行一些处理,然后他这里的话可以看这个 h 的话是一个 f i g 文件, 然后它这个 l h 的话就是一个线性线性文件,可以双击 um, 然后这个 f c 就是提取出来的数据,它有呃八百五十六个 y c 的,就是提取出来的歪轴数据 啊,就是然后通过嗯, pro pro 的函数,对啊,提取出来数据进行画图,然后执行一下这个, 好,这是提取后的,这是提取前的 fh, 这是用提取出来的数据画的图是一样的。然后还有的话就是 这个 vpa 函数,它 可以对结果进行,如果是结果含分式的或者转换成小数,然后他会默认是保持小数点后二十位,所以他的精度比较高。 哦,程序的话就在那个公众号里面云龙派。
42龙行天下





