Minitab中grr怎么转换表格
你。

粉丝230获赞2750
相关视频
 08:39查看AI文稿AI文稿
08:39查看AI文稿AI文稿我们来看一下,一个是要表里面的数据结构是什么样的,这个就是一个加的,一个是要表的格式,那我们来分析一下这里面的一些数据, 然后这个是十个零件啊,一到十个零件,这个是 a 测量员,测量商是一二三 啊,这里面是测量的数据,然后这里面有一个均值,均值就是对于第一个零件的三次测量的均值,这里有一个极差,三次测量的极差啊,这个是呃一到十个零件的均值,一到十个零件的极差 啊,下面其实这个也是一样哈,这是 b 测量员,这是 c 测量员啊,然后我们来看这个,一个是阿爸吧, x 八, x 八第一个测量员,他是,他是多少?他是三点九三,就是这里面的所有的均值 啊,相加除以十啊,就是等于这个值,这个叫。还有这个阿坝 a 是所有级差的均值,就等于这个啊, 那这个也是一样哈,这个是 b 测量元的均值, b 测量元的这个积差的均值啊,这个是一样 c。 然后再来看这个, 看这个数据啊,这个数据是比较重要,这个数据是什么?所有零件,这是呃三个测量员的零件的一个均值啊,三 个测量员对于呃第一个零件的均值,第二个零件均值,第三个零件均值,那这里面所有均值里面最大减最小就是等于这个 rp 值, rp 值一会会用到哈,它是代表的是制造过程的变差, 然后再来看这个值,这个值叫极差的君值,极差的君值指的是什么?就是 这个 a、 b、 c 三个人的呃均值啊,其实这个代表的就是重复性, 如果重复性很好,这个值应该非常的小,重复性很差,这个值会非常的差,这能理解吗?因为这个值是等于三个测量员的这个值的平均,那 这个值又会跟这里面每一个产品的级差值有关,所以这个值其实就是代表了我们的重复性好不好啊?那再看这个值,这个值代表是什么?这个值代表的是 a 测量元的这个均值, a 测量元的均值, b 测量元的均值 和 c 测量员的均值,他们最大减最小就等于这个值,这是代表在线性, 那怎么理解他呢?你看这个值啊,这是所有零件的这个均值啊,就等于这个值,那我们说在线性就是不同的能测它的数值是不是一样加 a 测的这个数, 数值跟 b 测的数值啊,如果是一样的话,他这个均值应该也是一样的,你来看这个是三点九三,他测出来的,那第二个是三点九四,第三个是 看一下啊,第三个在这,第三个在这里,三点九一,那你其实如果是他们都是一样的,说明这没有在线性,如果相差比较大,说明在线性比较大,那我们来看一看啊, 三点九三,然后三点三点九四,那这两个人差不多哈, 然后三点九一,说明这个人 c 测量原测的总体的均值要比 b 和 c 要小啊,这是代表在线性,就是三个人的均值的相 相差,相差了多少就代表再相信啊。 然后这下这几个数据啊,做什么用的啊?这是给你计算控制线用的。 像这个君子的上线,就是我们刚才在 ppt 里面有介绍了啊,君子上线他是这么算的,然后机叉的上线是这么算的,然后君子的下线怎么算的?刚才也提到了,这个就是系数啊, 就是实验的次数,他用到了三个系数啊,第一是第四,第三和 a 二,他跟实验的次数都是相关的啊, 测量两次还测量三次,那现在我们是测量三次嘛,所以都用这个系数啊,都用这个系数。然后这两个图刚才也告诉了大家怎么看哈,这个的 字图要百分之五十的点在外面,这个是 a 测量一元的君子图,这第一个零件的君子其实就是这个值啊,就是这个值三点八三啊。第二个点是四点零四,就代表了这个点三点八三,四点零四。 那评价的方式就是百分之五十的点在外面,所以我们评价下去看一下,一点,两个点、三个点、四个点、五个点、六个点,百分之五十在外面嘛,所以这个图是 ok 的。 那这种方式也是一样啊,一个点、两个点、三个点、四个点、五个点、六个点,没问题,一个点、两个点、三个点、四个点、五个点、六个点、六个点,没问题, 然后这个图就过了,然后再看这个极差图,极差图这里看 a 评价原极差,那 这个是没有点超出外面 ok 的。那这个第一个代表是什么?就是代表了这个值,极差 a 啊,代表这个啊,这个是代表这个极差零点零四零,对吧? 然后他这第一点,第二点、第三点,那他画成了这个图啊,所以你刚才看到第二点是零吗?对吧? 啊?他是这样的,然后这个不能有点操作控制线吗?如果有点操作控制线,刚才说了,就是说明有特殊原因的存在,然后测量过程就不能继续评价我们的积压的值,就应该要找到这个特殊原因是什么原因导致的,把它找出来, 然后解决这些特殊原因。你看第七个点是操作控制线的,说明有特殊原因存在了啊,那我们来看 下第七个点到底什么原因会这么大? bb 车辆原因的第七个点应该是看一下这是第七个点,那应该是这组数据有问题, 然后这个数据有问题,你看这吉他只是特别大,零点一六,那别的吉他只有零点零八、零点零二,你看他一下子零点一六的,这个是什么什么问题呢?那最大的是四点零四, 然后最小的是三点八八啊?那就是说重复性有问题的,所以 你要找到他的这个原因到底是在什么地方,然后重复性呃有问题,有可能是我们刚才也提到了,比如说听错了,记错了,还有可能就是说呃测量是被松动的, 还有就是测量设备磨损的,还有可能就是呃测量设备上有一些杂物、脏东西,都可能会导致这个问题。所以呃,我们在呃测量过程中,员工在测量过程中你一定要做观察,还有最好的方式是要做什么? 需要做这个录像,因为如果是你不录像的话,你光靠这看这个数据,你就不知道到底是什么原因导致的,明白吗?所以你只是看这个数据有时候是不足够的啊。 好,这个下最下面这个图,最下面这个图其实就是这个 a、 b、 c 三个测量员的君子图,把它 画在一张图上的,那这个是不同的测量员的君子图,这个三条线嘛,就代表三个作业员,他测量的只是把它放在一张图上的 啊?这个图,这个一个是要表,就是这样这样子来看的啊?
925解码IATF16949 11:28查看AI文稿AI文稿
11:28查看AI文稿AI文稿这是一个加一个是要表头这种格式,十个零件, 然后 a 作业员测量三次, b 作业员测量三次, c 作业员测量三次这样的数据结构。但是在我们的密利太本里面,他数据结构不是这样的,要进行转换,他是这样的一个结构, 这个是 a 做元测量十个零件的第一次, a 做元测量十个零件的第二次这样的,嗯, 第三次。然后 b 座椅也是一样的, c 座椅他是数据结构是这样的,那我们要建立这样的一个结构的数据,一个这个一个是要 表的数据格式,然后再打开我们的这个密集特表,密集特表你刚打开软件页面是这样的,你看这边是一个很大的这个空白页,我们需要把这个把鼠标放到这里, 然后变成这种形状的时候往上拉啊,这样就变大了,这个就有这个有点类似于可是要狂。然后我们就把这个刚才转换好这个数据 全部烤过去,然后复制烤到这一台。 你应该应该记得这个零件号,测量纸和测量也是在上面的话,在上面 单元格下面才有数据。然后我们再选这个统计,统计 这个质量工具,质量工具,然后再点量去研究,选啊啊交叉这个啊, 不是圈套也不是扩散,是交叉, 然后他就会出来一个对号框,这个部件号,部件号就是我们一到十个零件,那就我们刚才的对应的这个是零件号, 然后操作语文就测量语音选他,你要你,你点到这里的时候,要选中双击左边的这 一个相应的直啊测量数据就测量值,那这边有两个选项,下面一个是方叉分析,一个是一个是霸,一个是君子吉他图的分析方法,一个是方叉的分析方法,两种都可以啊。然后 你点这个良具信息里面,这里可以编辑一些基本的一些数据,比如说你到底是什么样的测量设备啊?什么时候研究的?然后谁来编制的良具的工厂,这些可以可以写,可以不写啊? 然后这边可以不用动他,就这样不用动他也可以,你要写也可以,但是不影响这个家的这个最终借口。那我们选君子吉他法吧,好,再点确定, 点完确定以后他就会生成一个表,当你看不见这个东西,你在这里可以。呃, 查看这里啊,查看这里是数据和输出,如果我们要看数据的话, 点点这个紧输出啊,紧输出。好啦,切到切换到另外一个页面,那你就能看到这个他分析的一个结果,然后他分析结果分为这个数值,数值有两个数值,一个是方差的分量,一个是良具的评估。 那实际上按照我们手术的要求,方叉你不评估他也可以哈,我们看两句评估就可以了。然后两句评估这里 里面有啊啊,藏种就是良具的重复性、战性性变差,藏种变差的多少就在这里就能看见, 那其实我们核心的就是这个指标啊,这个你看现在就是三十八点三八,那我们要求是十以下,他这个有点大了。然后这个就是对应我们以前的 ndc 可区分内别墅,就有点像我们 家里面一个手表里面那个 ndc, 那这是数值。然后这边有图形,有六个图形, 六个图形我们来看一下,把它放大,看看能不能放大,可以放大,然后这六个图形怎么看呢?这个就是变异的分量, 是重复性账总变差的百分比,在线信息账变差的百分比,还有重复性在线信息账总变差的百分比,还有零件变差账总变差的百分比。 这是一个柱状图,让你更直观的容易看出到底哪个变差是比较大的。 那比较好的情况下就是重复性变差,再行进变差和啊啊的变差,柱子越短越好,就是相当于这三个占总变差,越小越好, 那这个柱子越高越好,就是是零件的变差或者部件之间的变差,占总变差的占比是越大越好的。 然后再看下面这个急刹图,急刹图有要求, 就是不能点,有点超出控制线,这是上控制线,这是下控制线。点不能超出控制线。很明显这里必做有缘的第七。第七个点是超出去的,那说明测量过程中是有异常的,重复性是有问题的。 那这是一个君子图,君子图就是一到十个零件啊,十个零件每个质量原,这是 a, 这是 b, 这是 c 质量原,三个质量原他们的君子的分布。 那我们要求一般是百分之五十的点要在控制线以外啊,这是上控制线,就是他是下控制线,这上控制线大多说点要在控制线外面,如果有很多点都落在控制线 里面,那可能说明我们测量系统分辨率是有问题的,不能够识别我们制造过程中的一些变差啊。那像这种情况,像这个图,你看大多数是在外面,而是百分之五十点在外面就可以了, 那这个是一个十个零件,十个零件三个测量员测量的值 在在什么地方?就是我们希望呢,就是大家的点都在一起,就是 a 作业员、 b 作业员、 c 作业员测量的这个值 啊,都一致的,这比较好。如果很分散,你像这种像第七个点,他很分散,那就说明在三个测量员里面测量这个零件的时候,有很大的值,也有 很小的值,那他这个就会比较大,这个越越大,说明重复性越差啊。 那这个图就是看三个人测量的值,你看这个最好是三个人测量值,大致是相等的, 那如果有一个座椅员相对于其他两个座椅员或者车辆员,他车辆的值。 如果是,就像这个图,你能看出 b 测量员他测量的值总体情况下会比 a 和 c 测量员值要大一点,所以你看他就往上,那他如果往下,就说明 b 测量员 测量的值总体是比 a 和 c 要小的。所以如果是有一个呃测量员,他 他的值跟另外两个测量员差异的非常大,那可能要注意,说明这个测量员可能手法上有问题,或者说他的操作方式是有问题的, 那这是一个交付作用的一个图,最好的方式就是说你看这个是十个零件啊,然后这个是 abc 测量员测量的值, 那最好的情况下,就三个人测量的值都应该差不多的啊,那是比较好的,如果差异的特别大,你像这个, 你这个 b 作业员测量的值就会比 a 和 c 测量测量员的值要大,他就会跑到上面去,知道吧?就像这个是 a, a 测量员,他的测量第四个零件的时候,他的均值就要比 c 和 b 测量的只要小,他就会跑到 b 下面 就给你看了。那如果有一个作业测量员的时候,有一个测量员他老是所测量所有零件的值都是比其他测量员都偏大或者都偏小,那说明这个 这个测量员他总体发生了偏影,要么偏大要么偏小,这是简单的帮大家分析一下。 那其实我们如果操作的时候,可以把这个图表复制到一个设有表里面,做完了以后啊,如果想要输出的话,你可以把这个图表复制复制出来,把这个图表复制啊,是可以复制的, 你直接按 ctrl 加 c, 点点中,他按 ctrl 加 c 就可以了,然后我们再建立,比如说把它复制到这里粘贴,他就会过来,这个图表就会过来, 比如说我们可以这个数据加上这个图表,然后再把这个也拷拷贝过来,以 ctrl 加 c 给他拷贝过来, 把它扛进来, 这可以把它放大一点啊, 然后我们只要看这个就可以了,然后你再给他设定一个表头,这里跑过来, 然后你再设给他设定一个表头,其实这个就可以做一个 gir 分析了,比如说这个就像就像这个表头一样,就给他弄一个表头, 类似这样的可以把烤出去, 那这个就就往成分系了啊。
825解码IATF16949 12:35查看AI文稿AI文稿
12:35查看AI文稿AI文稿大家好,这一期网络课程主要是教大家怎么样使用迷你 type 的时期,这个软件来帮助我们做家的分析。 那我们很多企业在做 gir 分析的时候,一般是用一个色的表的这种模式来进行分析的,那这一期呢,就教大家用软件来做分析。那介绍一下迷你特别软件, 那这个软件是一九七二年就已经发布了啊,一到现在已经是五十多年了,他是有一个国外的一个软件,那现在很多公司都在用哈,比如说通用啊,机翼啊,福特啊都在用这个软件, 他不仅仅可以帮助我们去做这个加分析,他可以还可以帮助我们做一些 spc 的分析,以及生成各种各样的图表,是非 非常有用的一个质量统计的一个软件,有兴趣的小伙伴可以把这个软件下载下来体验一下啊,我们正式的进入我们今天的主题啊,那这个是我们企业经常用的一个,一个是要表格式的加 的分析表格啊,这里是数据,这边是数据,这个图大家应该都比较熟悉啊。嗯,这一期课程不会去讲 这个加分析的一个操作流程和步骤,如果大家对操作流程和步骤不是很熟悉,或者是对加的原理也不是很熟悉,希望你能上一下我的其他的一些网络课程,就专门讲加的分析的一个流程步骤和原理。也有 这样的网课的啊,那这节课我们不说。嗯,那这是十个零件啊,我们一般选取十个零件,然后三个作业员, a、 b、 c 作业员,然后每个人测量的次数一二三这样测量次数, 然后在这个数据填上去以后,我们就一般会去看这个呃值两项,我们比较关注的就是这个按啊的值是二点四,那二点四呢?我们的准则是小于十二点四是可以的,然后这个是 ndcndc, 我们要求大于等于五,他五十九也是可以的。 好,那用一用这个一个 ceo 表格式,他有一个什么样的缺陷呢?那呃,因为这个这个表格有可能很多小伙伴是从网上下载下来的,或者说他客户给 给他的,以及他的同事给他的,然后这里面像这种加的这个值啊,你点他,你会发现他会, 他会涉及到很多链接到很多公式,那你也不确定这个公式到底是对的还是不对的。那我们以前发现有很多公式都是不对的。那第二个就是这个长数,你看比如说这个 k 一、 k 二、 k 三的长数,他不同版本的这个,呃, mac 里面的这个长数也是不一样的, 那就是有时候就会有这种遇到这种情况,嗯,你把这个家的表给你客户,让你客户去 说你算出来的价值,怎么跟我的算出来价值不一样呢?当他挑战你的时候,你对自己的这个数据,其实你是也没有这个信心的,因为你也不知道自己的这个公式是不是对的,常数是不是对的。那这个 时候如果我们有一个迷你特别软件去验证一下啊,你心里就,你心里就更有底了。所以这就是我们呃讲课的一个目的啊,也也告诉大家有多种的一种分析方法。 然后我们要把这个数据放到 mate type 的软件里面去分析的时候,我们要有做一个,呃,做一个转换啊,因为 money type 软件里面的那个数据结构跟我们的一个色的表的数据结构它是不一样的,你像这个 一个射手表的格式,他是这样的,数据结构是这样的啊,但是迷你太他就不是这样的,迷你特是另外一种方式,所以我们要对这些数据进行转换。那怎么转换呢?简单的说一下,那我们这 个是零件号,一二三四五六七八九十,就是十个零件 a 最圆,对十个零件测量的第一次。啊,是这是这样的结构,然后这下面这一个是 a 最圆,对这个十个零件测量第二次, 然后 a 座椅对这个十十个零件测量的第三次。那那接下来由此的推就是 b 座椅和 c 座椅总共有九十个数据,对吧?你把它数据结构转换成这个,然后再把它拷贝拷贝下来, 接着我们就打开迷你太婆这个软件, 我现在用迷你特别的软件的版本是十七哈,当然也有更高的版本我没有用,我觉得十七又已经挺好用的。 拿这个软件打开的时候有一点需要一点时间啊,不是那么快好打开来了。 那接着我们就把这个刚才转换过的这个数据把它拷贝一下, 把它复制复制,然后再粘贴在这里。啊,这样就深,这样就是就可以了啊,数据结构就可以了。 然后我们再选这个统计质量工具良具研究,然后选这个,呃,良具按按交叉研究,交叉这里点它 他嗯,部件号我们就选中 c, 那就这个零件号我们把它选进来, 操作员就是这个 c 三,然后这个测量值就是指这个啊 c 二,我们就把它选出来,然后分析方法,这里面选这个啊, s 八杠二,然后点确定, 那迷你特别软件就把我们生成了这个数据了,那这边数据分成两部分,一部分是这个,一部分是这个啊,那我们来讲一讲这个大字。讲一下啊,那这里数据我们只要看这边就可以了, 那这里看第一个就是按二,按二,我们看最后一个是二点三八,那他的意思就是说,呃重复性在线性按二的这个变差占总变差的百分之二点三八,那我们按照我们这个呃 准则来看啊,小于十是比较好的,他二点三八也是 ok 的。那我们再来看我们的这个一个 ceo 表里面,一个 ceo 表里面他是二点四, 二点三八,其实他是两个小数,如果是约等一下也其实也是等于二点四,那就跟我们这个一个这个表是一样的,那说明我们这个一个这个表的这种公式是对的。 然后再看重复性,重复性的变差是占总变差是一点九六,百分之一点九六,占用性变差是占总变差是一点三六,然后零件变差占总变差是百分之九十九点九七,那就是这个意思,帮助这么去分析他, 然后可区分的区别数等于五十九,就是我们这个 ndc, 也就是我们一个是要表的这个数值, 这个看完了以后,我们再看这个图表,就刚才那个图表 就这个,那这个也这是一个图形,图形展示,刚才是这个数据展示,那这个图形展示怎么样去看他呢?啊?我们要去了解他这个是什么意思,要看得懂。 然后这个图我们一开始要看,这个是阿图,阿图,这个是 a 作业的阿图、 b 作业的阿图和 c 作业的阿图。 阿图的这个要求是不能有点超出控制线,你看到没有? b 做圆有点超出去的, c 做圆有点超出去的, 那如果是有点超出,呃,这个阿图说明测量过程是不受控的,就是重复性是有问题的,如果 重复性有问题,然后这个积压的最终的结果是不被认可的,就是没有用啊,就必须测量过程要受控,重复性要没问题,你积压的值才有意义啊,所以这点请要注意。 然后再看这个君子图,叫 a spa, 控制图也是分成 a、 b、 c 这个作业员,那他这个判定准则跟阿图是不一样的,他百分之五十点要落在控制线外面 啊,如果是百分之五十的点控制点落在控制线里面,那可能是我们的测量系统的分辨率可能是不足够,不能很好的去发现我们制造过程的一些变差 啊。那像这种 abc 都是可以的,因为他百分之五十点住在外面,他是这么判定的。 然后再看这个,就是呃,测量值和零件,嗯,他的这个分布情况, 那他主要是讲的是不同测量人测量某个零件的差异图,这种差异档次相当的啊。就是呃,不同的人,他测量这个 这个零件的时候,他均值应该是大致差不多的,也不能偏差很大。他重合的时候是比较好,像这种是比较好的,像这种就不好。这种就是说明就是大家测量的值差异比较大,三个作业员的这个测量的均值比较大,不太好啊, 像这个也不好,差异的特别大啊,这是这么看的,然后这个这个图呢,叫测量值和测量员之间的这个图,就是能能看出不同测量元素 所有的测量均值,这是 a 作业员和 b 作业员, c 作业员测量的均值到底怎么样?那如果是我们希望的最好的结果,就是三个作业员,三个测量员的均值应该是一样的,这是最,这是最好的,那一样的话,他就会成一条直线, 他如果是呈这种线,就说明 a 作业员和 c 作业员测量的君子要比 b 作业员要大一些 啊,这个 b 作元测量均值要比 a 和 c 要小一些啊,他就可能是成一个这样的一个形状,或者是这样的一个形状,都不是很好啊,最好是一条直线,这是大家均值差不多, 那这个图就是交互作用的一个图哈,就是最好的方式就是大家的点啊,都是大致相当的,就说明,嗯,所以 的作业员跟这个零件之间是没有交付作用的啊,如果有一个这个点啊,跟这个值差的很多啊,这说明可能这这个这个这个作业员跟这个零件可能有交付作用,就这个意思啊。 然后最后一个图,就这个图,这个叫变异分量,指的就是呃两句啊啊的这个占总变差的这个比重是多少?从无形变差占总变差的比重,在线性变差占总变差的比重, 那我们希望的就是呃重复性,这样总变差比重很小。再性性这样总变差变差很小,零件这样总变差越大越好,也就说我们测量系统分析的这个变异主要来 来自于零件和零件的变差,是是是,比较好的,那我们就测量系统分析一般是没问题的,所以部件之间,零件之间的变差,这个柱子是越高越好,然后两句啊啊的这个柱子越小越好,越低越好,重复性也是越低越好啊,在线性也是越低越好。 那一看像这个像这个图啊,就是良具的啊啊,占总变差的这个比值是比较高的,你看看这把达到快百分之五十了,说明这个测量系统肯定是不行的啊,这点大家要学会看啊。 然后这一批这一期的这个呃,简单的教学啊,就到这里,希望大家懂怎么样去用这个 mate type 来 来做分析啊,那如果需要没特别软安装软件的时候请联系我啊,谢谢大家的观看。
386解码IATF16949 02:33查看AI文稿AI文稿
02:33查看AI文稿AI文稿今天我给大家介绍如何转制列, 转制列可以将工作表中的行转制成列,而列转制成行,行列数据实现转制。 我们看这个案例啊,某工厂收集使用四种配方油漆在产品上喷涂烘烤后的硬度数据, 每天各收集一次,收集了六天,这样总共得到二十四个数据。现在我想把 所有硬度数据行列转制保存在新工作标准,这应该如何操作呢?我们可以点击菜单栏的数据,选择转制列, 在弹出的对话框中再转至以下列,这里我们把 c 二到 c 五列选择进来 存储。转至这里我们就选择存储在新工作表中,下面使用列创建变量名,这里 我们啊,要把 c 一日期列选中去,填进填选进来,否则啊,行列转制后,数据就没有列名了。 最后点击确定生成了新的工作表, 这个这个新的工作表里我们就都得到了行列转制后的数据。原本行是日期, 列呢是配方,现在行变成了配方,列变成了日期。 好的,以上就是转支力的操作方法。
13刘金恒讲质量 06:51查看AI文稿AI文稿
06:51查看AI文稿AI文稿好,今天我们来讲工作表数据的录入方法,那使用 metibo 对数据进行统计分析的时候,我们首先要将数据录入到工作表中, 如果你的数据呢,是直接采集或者是记录在纸上的,那么可以在工作表中直接的手动录入。但是很多时候啊,你的数据是记录在 excel 表额当中的, 那么我们可以直接复制粘贴就可以了啊,比如说我们这里啊,有一个啊, excel 工作表,那这里呢,有四列数据, 有撕裂数据,呃,这撕裂数据啊,都是带有列名的,那么我现在啊,想把这些数据录入到 minitable 工作表中去进行统计分析, 那我只需要全选数据啊,也可以全选这四列,点击 ctrl c 复制粘贴啊,切换到 b table 工作表, 鼠标左键,点击你想要的起水位置, 比如说我的空白空白表,我就选择啊最左上角这个位置, ctrl v 粘贴好,这样数据 就完全的粘贴过来了。这里要注意啊,如果你是将列名一起复制的,那起始位置呢,要选择列名那一行。 有的时候啊, excel 复制粘贴过来的数据啊,它的格式不是我们想要的, 那就需要啊,按 ctrl 加一啊,进行数据类型的调整啊,比如文本数据转化为数字数据啊调,还有调整小数,点位数等等。 那对于只有一个工作表的数据,这样操作啊,是简单方便的。但是 如果我想把这个 excel 啊文件里所有的工作表都录入到 mini type 工作表中啊,大家看有这么多呢啊,非常的多, 一个一个的复制粘贴就太慢了,那我们可以啊,点击工具栏里的工具栏里的,打开,点击工具栏里的打开, 好,选择我们想要的,想要录入的啊,选择我们想要录入的 excel 文件。 好,我们点击确定,在弹出的对话框中 啊,我们可以看到他包含了所有我们想要录入的工作表都在这里。对于不想录入的工作表呢,我们可以啊,把这个录入词表前面的对勾呢取消掉。 另外,如果我们不想录入啊, excel excel 工作表里的啊,前几行,比如说前两行啊,我们想从第三行开始录入, 那么可以在要导入的第一行里面啊,就这里把默认的一啊改成三, 改成三,这样啊,录入的时候他就从第三行开始录入。那么另外,如果我要录入的数据 没有列名,没有名称,录入后啊,列名这一行呢,要先空着啊,那就需要把数据具有列名称啊这个选项呢,前面的对勾取消掉, 这样我们的录入的数据啊,就直接从啊数据列开始。好,那么现在啊,我们点击确定,我们点击确定 啊,现在我们发现所有的啊 excel 工作表都录入到了 mini tap 当中啊,我们点击这里,点击这里可以看到啊,所有的工作表都已经录入成功啊,但是这里啊, 有一个点我要提醒大家,我们看 excel 的这个工作表,这个工作表,这个工作表呢,和我们的 excel 工作表是有区别的, 大家看 excel 表里的这个工作表,它并没有这么多缺失向,并没有这么多缺失向,而而咱们实际录入的 meteor 的工作表里面出现了很多的缺失向 啊,这个问题是什么?我们重新打开啊,重新打开 mini type, 再录入一次, 我们还是重复操作,打开, 选择我们要录的这个 style。 大家看啊,这里有一个选项啊,我们点击选项进入, 有一个说明是添加缺失值,以使所有列中的行数相同啊,很明显啊,这个这个点不是我们需要的, 那么我们现在呢,就把它前面的对勾取消掉,好点击确认啊,再点击确定 好我们的,我们来看好重新录的啊。 工作表呢,就没有之前的问题了,好好的,这就是工作表数据的录入方法。
71刘金恒讲质量 05:00查看AI文稿AI文稿
05:00查看AI文稿AI文稿大家好,今天呢我们学习 mantap 统计分析的第三张数据整理变换呃裂变量, main type 系统的变换裂变量或者称为转制,就是将将裂变量呢,转变为行变量,或者说呃交换这个裂变量为行变量, 也就是对举证的列和行进行对调,或者就称为举证的转制。那在实际工作中呢,我们需要对 呃裂变量和行变量呢,同时进行统计分析,或者是绘制图形。呃变换或者说转制裂变量呢,会给我们带来很多方便。那我们先看看例子, 我们这是打开了我们的一个面站和一个呃这个项目文件, 在这里我们看一下这个是三个啊,四个人的三个科目的成绩。我们看第一列就是文本列 tax, 它是个科目,包括数学、物理、化学。那 cr 的 c 五呢?为为这个三个为四个同学,四个人嘛。然后下面是它的各科成绩。 那我们在做啊,这些警力列取了什么呢?列取了三个,如果我们可能十多个人或二十多个人呢,能往 c 六 c 七进牌。当然呢,我们需要对比如对某一颗成绩,比如数学啊,做他的一个统计分析,比如看一下他是是否符合正态分布或均值。那像 这样的话,数据数学这个成绩呢?在一行中那不利用统计分析,因为我们我们没有在我分析的时候,他的数据是按列来分析的。所以说这个时候我们考虑怎么将这个数据进行转制,也就是数学、物理、化学作为我们的这个列的标签 是吧?那这个时候我们要行和列定对调一下,这个时候就需要进行一个转制,转制呢,我们在数据,然后点击 这有个转支列,看到没有转支列,大家把鼠标放在这,他会有提示,就是重新排列数据,也就是使物业变为行,使行变为列。 ok, 大家点击这个,在这里 点击之后,那这个是看我操控的装瘦的。点击之后呢,大家呃选哪几个段吗?你选哪几个呢?也就选择这几个性, 点击 c 二列, c 三列, c 四列和 c 五列是吧,这是四个同学,当然如果你的人数比较多,可能十几个,你这样一个点比较麻烦,你点一个 c 二,点击一个肯,再点一个肯触 点最后一个啊,不点上点 shift, 我们点第一个第呃,点第二个就是这个人名之后点去,再再点击键盘上的一个 shift, 点,再点击 c 五,这样这样就同时选中了。我们再点选择这样的话,这四个同学呢,就放在了这个里面。 那下面呢,我们就是选的时候以后就是可以是在最后使用啊,在最后使用的一点之后,就是我们转这个数据呢,放在这个已展现的这个数据。我们现在数据不是放在只有 到 c 五列吗?我们转制之后的数据呢,是从 c 六列开始排,所以说大家可以选这个。当然了,你也可以把转制之后的数据呢,放在一个新建的这个三样表格里。当然了,这里有一个什么呢,使用 啊,创什么呢?使用列,使用列,创建表演名。那个就是我们点击默认的这个科目。行了,在这个时候啊,点确定, 点确定之后看到没有,我们这个 c 六列, c 六, c 七, c 八, c 九就是我们前面的呃,转至之后的, 哎呀,我们这个这就是我们转了之后的看到没有, 这是 c 六列,是有四个同学吗?四个人,然后 c 七, c 八, c 九就是什么呢?三科成绩是吧?转之后下面你如果说分析的话,就可以对我们这个成绩分析了。比如我们看数学,看看均值多少是吧?点击统计基本统计,有个图形化会所, 不要我们选择我们的这个数学 c 系列,这样的话就可以看到我们的这个图案汇总,比如均值啊,方差,售后和正态分布啊等等就可以了。 ok, 那这就是我们。 这就是我们这个第三张数据整理的某一小节,也就是变量的啊,变换的裂变量。 ok, 那大家如果呃有需要有需要这个软件或者说数据的话可以呃,我会分享在这个视频的下方,大家可以进行啊,自行下载。
12木木及格 10:29查看AI文稿AI文稿
10:29查看AI文稿AI文稿好,下来呢,还有上一次第二讲呢,给大家布置的数据作业啊,大家可以打开第二讲数据啊,我们把这边的练习一二三四五六七快速的给大家说一下啊。 首先呢针对这个数据啊,这次,呃,我就直接用 manita 二十一版本跟大家演示了,如果说各位你们有其他版本也参考来用就行了啊,因为差异不是很大。 好,我们先把它粘贴过来啊,它的规格是六百正负,我们对 c 二到 c 六的数据来做分析, ok, 呃,这边有两种方法,一种呢是把数据堆叠啊,一种呢就是直接对这个数据分析啊,我们先讲堆叠的方式,那堆叠注意这块呢,我们就要用行堆叠啊,那我可以把堆叠的数据放到 c 十列, 我先在 c 十列呢敲一个标识啊,标题列点数据堆叠列加要堆叠行。 sorry, 这块是要用行堆叠啊,这块是要用行堆叠 啊,把 x 一到 x 五选起来啊,堆叠后的数据呢,我们存到这次啊,下标就不存了。然后呢直接点确定啊,堆叠出来了,你会看到呢,这五个才是这五个, ok, 他就是这样放置了,所以呢,呃,航队结之后呢,用 n 等于五,我们来算一下六百正负五的。 当然呢,在这块呢,我们仍然建议呢做一下正态性检验啊,看一下数据的正态性如何。 好,我们这个数据呢 是呃服从正态分布的,因为它的 pv 六呢是超过零点零五,并且这些点呢是比较靠近这条线的。 那接下来呢,我们就可以考虑呢来做这样的能力分析啊。呃,对对的,这个数据自助大小呢输五,然后呢规格线是六百正负,呸,看规格是多少,我没记,应该是六百正负五,印象中 好,让我们用康初加字母 e 或者点这个快键按钮,可以把你刚刚的命令调出来。好,这块要输那六百正负就是五百九十五和六百零五, 然后我们点确定啊,这块呢就会给出我们的分析结果,那这边有 cpkppk 这个案例呢, cpkppk 使用哪一个都可以,因为它的过程是稳定的 啊,而他的数据也是服从正在分布的。当然呢,你也可以直接用一个命令,就是六合一的图,这样的话正态性和那个上面都有啊,所以我是推荐大家呢使用这个命令 啊,我操作比较快啊,然后各位如果跟不上可以点赞停键啊啊,正态性啊,过程也是稳定的啊, cpkppk 相差不大,那用谁都可以啊。 ok, 那我们再教另一种方法呢,就是直接对这个数据做啊。呃,当然呢,这两个命令都可以直接做能力分析,正态这个也可以直接做,这个呢,也可以直接做我们用这个六合一啊,呃, sqsn 啊,点开之后呢,我们勾子组跨数行 啊,然后呢把 c 二到 c 六选进来,然后规格, ok, 这 这个做出来跟刚刚是一模一样的啊,这个就不多解释了啊,我们快速进入练习二啊,练习二呢,这个是 n 等于一的一个数据啊,就是间隔一定时间呢,抽一键啊,它的规格是幺幺五零。 ok, 我们对这个数据来做一下同样的给他 ctrlc 和 ctrlv 啊,你也可以用文件新件工作表啊,如果是老版本的呃,十五到十八版本,你是要用这样来新件工作表好,然后粘贴过来,那这块呢,同样上来呢,我们仍然要先做一下正态性, ok, 数据又近似正态了,下来呢,我们来算他的能力 啊。当然呢,也有些人习惯用这个六合一,你就不用做正台信了啊,直接点啊,这样吧,我后面都尽量用这个六合一,这样就避免去每次都去做这个正台信了啊。这样 起来这个是一啊,那他的规格呢?是单边规格要求小于幺幺五零啊,然后我们点确定 好,我核对一下啊,规格是啊,对幺幺五零,对的啊,那这边你会看到数据服从正在分布,这边有 cpkppk, 你会看到 cpkppk 差异比较大,这两根线也 这边的异常点比较多,所以这个过程是不稳定的,那这个时候呢,我们就建议用 ppk, 当然呢,一般我们的 ppk 的要求呢是大约等一点三三,他做到了一点五五,所以他的过程能力呢还是非常好的, 但是他这个过程是不稳定的啊。呃,这边我们要说明一下,如果你是单边规格的话,你会看到这边的 cp 和 pp 是算不出来的,这个大家知道一下啊,我们继续往后练习。三啊, 第三呢是我们的这个呃记件的数据的批控制图,他每次的检验样本量是相同的啊, 同样的方式呢,我们快速的给他粘贴过来,然后呢这块呢是要做批控制图啊, 呃,不是,呃 sorry sorry, 这块是要错 sorry 啊,二项的能力分析啊,我们点二项, ok, 点开,那缺陷数呢是 是瑕疵品啊,他这块呢长量,其实你可以手工输两百啊,当然你也可以点实际样本量,然后呢把这个一键一键敲过来,这两个方法都行,你只要选一个,那我就用这个长量两百啊,然后点确定 好。这边呢,哎。呃,是他的一些数据,那你会看到在尾端呢,基本上波动还不算大啊,所以呢,这个样板量基本上够了。 那他的这个过程的 z 呢?是一点六,加上再加一点五是三点一,所以他还是小于四啊,所以过程呢,呃,能力呢,并不好,好,这个了解一下。 呃,我们来看练习四的数据啊,同样的把它指过来, 呃,这个呢也是 p 图啊,这这个呢也是做二项分布的能力啊,当然呢,它的控制图就是 p 图啊,能力分析,那我们仍然用二项, 然后下面是不良数。哎,这块呢就只能用实际样本量了啊,因为他每次的抽样量是不一样的 啊,点出来之后的话,我们也可以看下面这边波动不大,所以呢,它的过程零点九六啊,如果直接过程 z 呢,是要跟二点五比较,如果说我们给它加一点五啊,变成了多少二点四几 啊?二点大概二点五左右,那他是小于四的,所以过程能力也是不好的。 这个数据呢,呃,是记点的数据啊,这是记点的数据,他一个产品可能出现多个亮点啊,那我们来给他放到我们的数据里面,那这个时候就要用坡松分布 啊,找到 sqao 啊,缺陷呢,就是缺陷数啊,这块的样本呢,它不是一个长量,它是一个 a sir, 这个是一个样本啊,然后我们点确定 啊,同样的我们可以看到哦,这个尾端可能还没有在,可能数据量还要再维持一些,因为看起来好像这两个点波动不达,但是其他的其实还是在持续下降,这个稳妥点的,我们还要 再增加一些数据,所以这块的 dpu 零点六八九四呢,可能并不是准确的啊,所以还要再持续追踪数据 啊。我们来看练习六啊,这个是也是一个经典的数据,它的 n 呢,等于一 好,我们的路径仍然是 sqao 坡冲分布啊,然后这块呢是污点,这块就勾长量,然后说一点确定好,我们来看一下效果 啊,这个尾端的数据可能还是建议再收集一些,因为他这边在持续增加之后又开始下降了啊,所以再收集一些看看。如果说, 呃,连续五六个数据呢,正当不大,那我们基本上就可以呢,认为数据量是可以的啊,这块看起来这个还是有点问题,所以数据量还是要再补充啊。我们来看练习期啊, 好,练习期呢是杂志率啊,它是 n 等于五啊,它的规格也是单面规格小于十五啊,我们来做一下分析 啊,这个呢是,呃,这次呢,我们直接用六合一的图,然后用正太 sqsn 啊,点开之后, 杂志率这个用途它是要小于十五的啊。刘树老师,你没剪它的正态性,没关系,这个六合一的图里面有正态概率图, ok, 大家会发现 这个数据呈现了非正态啊,你会看到他这个离这个直线是比较远的,他的 pv 六是小于零点零五的,所以这个数据是非正态的。那这块算出来的这两个值呢,就不是很精确啊,比如说老师,那这怎么办好? 呃,当然我们这一讲还不讲,那我们会在下一讲就是 spc 的进阶课程里面呢,会跟大家来讲这部分内容啊,所以这个题目呢,我们且听后续分解, ok。
 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿今天教大家如何用 meantable 制作脂肪土和过程能力分析。 首先将需要分析的数据录入 c 一栏内,然后点击图形, 选择直方图,点击包含礼盒,点击确定,选择 c, 点击此度,选择参考线,在数据值输入上下线和中心指中间用空格分开, 点击确定,点击确定,直方图就做完了。要注意的是,在这个直方图中间 呢,我们并不能看出不良率以及这个 cpk 和 ppk 等相关的值。如果你想知道这个数据的 cpk 和 ppk 以及 ppm 是多少,那么我们就要进行过程能力分析。 点击统计质量工具 能力分析正太,在单列里面选择 c 一,因为我们所有的数据都在 c 一列里面,直组大小输入五, 然后输入规格,下线和上线,点击选项, 在目标里面输入三幺零,点击确定,确定, 过程能力分析就做完了。在这个图中间,大家可以看到 cpk, ppk 以及 ppm 分别是多少。 想学习更多这方面知识的家人们请关注我,关注我学习质量知道。
3476老张说管理 05:22查看AI文稿AI文稿
05:22查看AI文稿AI文稿大家好,我是石老师,今天分享 mini 胎宝小技巧。图形生成器这个功能是从二零版本开始才有的,是一个集成化的数据可视化工具。 与以前的图形菜单相比,图形化生成器初步具备了图形推荐的功能,在您不知道使用什么工具的时候,他可以给你推荐可能的几种图形供你选择。 另外在制作完成的图形报表中增加了交互功能,为图形编辑和查看带来了新的可 这个就是图形生成器的界面,打开软件一起操作一遍。 现在你看到的是从国家统计局网站上下载的客运量相关的一个数据,这个数据表是从二零一九年三月份开始记录,记录到了二零二二年的二月份, 这里呢主要体现出了客运量当期的值和累计的值,包括铁路的、公路的以及航空运输这几个方面。那么如果你想可实化这些数据的话,你可以通过 图形图形生成器来进行数据的可视化操作。比如你想 想看一下公路客运量当期的数值,把公率客运量当期值放入到变量中即可,这时选中的是图库。如果说你选中的是掐的,比如说脂肪图、概率图或者是单支图等等, 那你如果是没有这些,也就说我不知道该用哪个图,那你可以默认选中图库。当你选中图库的时候,他可以给出一些推荐的值,告诉你这些值如何去 生成相应的图形,那么我们也可以把时间放进来,那这时他也能生成一些图形出来。那我们看一下时间序 列这方面的操作,在看到时间序列这方面操作的时候,因为他的分组变量变成了时间,那这个呢?显得不太合适,把分组变量拖动到时间尺度这里 就可以了,这时你看到你能拖动这些标签,来点创建, 单击创建之后,这张图就创建出来了。这张图创建出来之后,与以往的图形不同的是,当你的鼠标放入到相应的位置的时候,他能给你指示出来, 比如说啊,这里二零二零年五月份,呃,公路客运量当季值是五万四千两百三十四万人, 然后呢?二零二零年的二月份,大家都知道这是疫情的原因,导致了公路客运量急剧的下滑,虽然说后期有一些增长的趋势,但也挡不住下滑的 这样的一个趋势。当然你说我不看二零二零年之前的,我只看二零二零年之后的,从底下你可以通过的这个滑块来进行调节,那这个时候你就能看到二零二零年之后的一些数据,比如说二零二零年十一月份,从这里可以看出 客运量的下降是非常的严峻的。那有的人说这个时候我想编辑一些图形,怎么编辑?那你只需要点在图形上,点右键,单击图形选项,在你的右侧栏 就出现这样的一个文本注视的内容,当然这这个图形呢,只能参增加文本注视,所以在这里你添加标题,这个标题可以写为 客运量在猪年下降。在标题打完之后,你也可以点击副标题,当然副标题的内容可以根据你的想数据来源或者是其他的 数据来源,国家统计局,好,那这样的话你就得出来了一个这样的一个图表,这里是 图形交互式图形,这边呢是图形的内容,那这样你就可以使用 数据的图形生成器做成一个 图形了,当然图形生成记中还有很多相关的内容,如果你有兴趣的话可以去尝试一下。这里是石老师的课,喜欢的话关注点赞。
32六堂课-时老师 11:40查看AI文稿AI文稿
11:40查看AI文稿AI文稿质量人经常需要对一些数据进行分析,有时不一定需要实际测量的数据,只需要一些符合条件要求的数据进行模拟分析,这些数据不仅要符合尺寸要求,可能还要服从正态分布,甚至是特定的标准差或 c、 b、 k, 如果只能自己手动一个一个编,那就太费事了。这期视频就分享如何快速的生成一些符合特定条件的数据组,不多话进主题,其实要生成符合特定条件分布的数据并不难, x 或一些专业的统计分析软件都能做到。 这期视频分成有钱的跟没钱的做法进行说明。先说有钱的做法, mini tab、 jmp pro、 spss 等专业软件都有提供生成随机数的功能,就以 mini tab 来说,假设要生成一组随机正态数据,只要到功能区中的计算 功能找到随机数据,并选择正太,然后在对话窗口中输入相关的条件设置即可。 先来生成一组有三百个数据且平均值五点零,标准差一点零的随机正态数组,来看一下这组数据的正态检验,其实这有点多此一举,身为专业软件,生成的数据如果无法通过检验,岂不可笑? 另外,看到基础的序数统计均值五点零五,标准差零点九七,并不会完全与设置条件相同,只能做到尽量靠近, 顺便看一下过程能力的指标。 cbk 是零点六五,如果没有特殊用途, cbk 的值并不重要。但若要特定 cbk 值的数据组进行模拟分析时,那要如何处理? 假设现在有个五正负二的尺寸规格,所以规格上下线就是七跟三,希望生成的样本分布中心跟规格中心重合,也就是样本平均值是五,那标准差该设置多少才能生成一组 c、 b k 符合要求的数据? 这是大家已经很熟悉的 c b k 公式,公式里面共五个未知数,规格上线 u s l 规格下线 l s l 样本均值 x double bar 标准差估计值 sigma 以及过程能力 c b k。 值刚刚的假设规格上下线 让本君值都已知, c、 b k 则是看要求给定,因此只剩下标准差是未知数。这样只要简单的把公式进行推导,就可以知道标准差的公式。先讨论双边公差的部分,为了方便 推导公式,再假设样本均值无偏移,就是样本均值 x double bar 等于规格中心,这样的话,规格上线减样本均值就等于样本均值减规格下线令它等于 s l。 所以 c b k 的公式就变成,但是要除以三倍的标准差。接着等号两边都乘以三。再来是把等号右边的分母与分子的三倍上下相消,就变成三倍的 c b、 k。 等于,但是要除以标准差,然后等号两边都乘以标准差, 就可以把等号右边分母的标准差消掉,变成三倍 c b k。 乘以标准差等于 s l。 接着把三倍 c、 b k 移到等号右边,就可以得出结果,标准差等于 s l, 除以三倍 c b k。 所以在样本分布中心无偏移的条件下,标准差等于 s l, 除以三倍 c b k。 最后看到,若样本均值不等于规格中心时,把 s l 换回来,就是 s l 等于规格上线减样本均值,或等于样本均值减规格下线,因为计算 c、 b、 k 只有用到这两个其中一个较小的值,所以就可以写成最后这样。 假设需要一组 c、 b、 k 一点三三的随机正态分布数据,就按这个推导出来的公式来计算需要的标准差,只要使用 many 函数套用公式即可。 计算的结果,标准差零点五零一二,改变一下,样本均值为五点二零,其他条件不变之下,标准差需要变成零点四五一一三。接着用这个结果到 mini type 生成一组随机正态数据, 再用这组数据进行过程能力分析,可以看到,平均值标准差 cbk 虽然没有与要求的目标值完全相等,但也非常接近,因为软件只是根据设置条件进行估算,基本上很难得到完全相等的结果。如果要得到非常接近目标条件的数据组, 可能需要经过多次生成数据找到最接近组。接着看让人头痛的单边公差问题,把原先的规格要求改成单边有上限的规格。这里看到,当规格下线被改成五之后,标准差变得很小。那是因为目前计算标准差的公式 是从计算双边公拆 cbk 推导过来,在规格上限与样本均值差及规格下限与样本均值差这两者之间取交小值。把规格下限改成 乘五之后,就会让原本的计算 cbu 变成 cbl, 但有上限的单边公差只能计算 cbu, 所以可以把规格下线的值改成与规格上线相同,等于让公式只能计算 cbu, 但这样计算的结果会出现复数, 所以需要在计算标准差的单元格中,在原本的函数前面再加上 abs 函数,就是让单元格显示计算结果的绝对值。但这样的结果跟前面双边公差是一样的。 因为尽管可以推导出标准差,但无法限制随机生成的样本分布范围,所以生成的数据中会有一些超规格线的值。 因此想要在 c、 b、 k 或标准差不变的条件下生成在规格线内的随机正态数据,只能想办法把整个样本分布往融差中心移动, 这样只能不得已采取折中的方式,就是在相同的规格容差条件下,把单边公差改成双边公差。这里就是把规格要求改成六,正负一点零,规格上限维持原来的七, 规格下线变成五,然后把样本平均值尽量往新的规格中心靠近,或直接等于规格中心。也可以一样用计算的结果到 mini tab 生成一组随机正态数据, 再用这组数据进行过程能力分析,可以看到平均值标准差 cbk 也非常接近设定的目标值。然后样本分布并没有超过六正负一的范围,也勉强等于是原先单边公差的范围。 因此遇到要生成单边公叉的随机正态数据,就只能选择这种折中方式处理。如果各位 有更好的方法,欢迎在评论区留言建议。以上分享的是有钱的做法,但万一遇到老板打算换车买房子,不愿意花钱买这些专业软件,那就只能选择没钱的做法,便宜的笑或 wps 同样也可以做到这些功能。 先在 excel 工作表中先把设定条件改回原来的双边规格。先介绍第一个函数, r a and d red 函数可以在单元格中随机生成一个介于零到一之间的数值。 如果把这个函数稍加变化,在 run 函数后面乘以某个数值,就会变成在单元格中随机生成一个零到这个数值之间的数值。例如,在 run 函数后面乘以 七,那就会在单元格内随机生成一个零到七之间的数值。如果再进一步做些变化,让 ren 函数加上某个特定数值,例如三加上 ren 函数乘以四,这样就等于三加一个零到四之间的随机数。 结果就是会产生一个介于三到七之间的数值。但 ran 函数生成的是平均分布的随机数,如果生成的数据量够多,就可以容易的看出来数据是呈现均匀分布形态。 如果要生成的是随机且呈现正态分布的数据,就需要使用 normal 函数。使用 normal 函数需要提供三个参数,第一个参数是正态分布的概率,第二个参数是平均数,第三个参数是标准差。平均数是决定 生成的正态分布数据的样本分布中心。标准差是决定生成的正态分布数据的区间宽度,概率则是决定生成的数值在正态分布区间的位置。例如,概率越靠近零或越靠近一生成的数值越接近正态分布两端的位置, 概率零点五就会生成落在正态分布中间的数值,基本上就等于设定的样本均值。 样本均值与标准差在工作表中已经有,可以直接填选代率,这里先填入零点一。按前面的说法,代率越接近零或一生成的数值越靠近分布的两端零点,一是往零的方向靠近, 所以会往分布的下线靠近,以这里的案例,应该是会往三的方向靠近。由于刚刚输入的概率是一个固定值,所以复制工是到其他单元格 格产生的数值也是固定的。如果要生成很多数据,这样做就的逐个单元格更改概率值实在是太麻烦了。回到 normal 函数的对话窗口,可以看到下方的说明,概率参数是介于零到一之间的数值。 前面介绍的 ryan 函数刚好可以随机生成零到一之间数值,那就把 ryan 函数填入概率这里, 这样就可以利用复制粘贴的方式,快速的生成很多随机正态的数据。 因为概率是由 rain 函数决定,所以生成的数据位置也是随机产生,并不会依序排列。如果想要直接生成依序排列的随机正态数据,就必须对函数 的内容进一步修改。首先设置一个需要的样本数量,再回到 normal 函数的对话窗口中。这次利用 row 函数来设置概率, row 可以返回单元格的所在行数,随着单元格越往下, row 函数返回的数越大,因此概率也会越大, 这样 normal 函数就会随着单元格往下生成生序排列的随机正态数据。复制之后似乎有点问题, 确认一下函数的内容,原来是样本数量的单元格。第五没有写成绝对引用,这样复制公式时,其他单元格里面的公式就不会是引用第五。要改成绝对引用,只要在公式内的第五前面加上前符号, 或者在公式中鼠标点到第五的文字,再按下键盘上的 f 四,就会自动加上前符号。接着再从新复 布置公式到其他单元格,这次就没问题了。可以看到生成的随机数据是由小到大依序排列,且呈现左右几乎完全对称的正态分布。 最后是单边公差的随机正态分布。跟前面谈到使用 mini tab 生成随机正态数据的处理方式相同,直接改成双边公差的规格,然后把样本平均值尽量往新的规格中心值靠近。 以上就是使用笑生成随机正态分布数据的方法,学会了这个没钱的做法,就可以帮公司省下一笔买专业软件的费用,也可以帮老板更快的把五菱宏光换成大奔。 最后要声明的是,请正确且正当的使用这些数据。
342Aron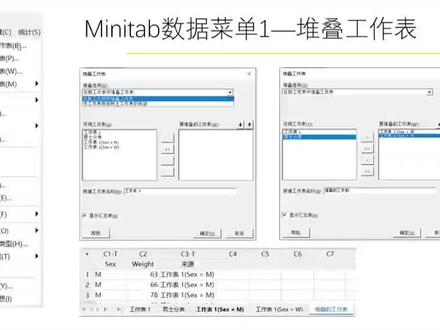 02:33查看AI文稿AI文稿
02:33查看AI文稿AI文稿今天分享对叠工作表和合并工作表两个功能,首先可以看到我这边打开了一个对叠工作表的菜单,在对叠选项里面有一个在新的工作表中对叠 以及将工作表附加到主工作表的底部两个选项。 这里的第一个的意思呢就是合并到一张新的工作表里面,第二个的意思就是在现有的工作表底部最佳其他工作表的内容 可以看到,我这边打开堆叠工作表菜单,然后在可用工作表里面选取要堆叠的工作表,我选 选择了 sex 的页面与 sex 的物们两个工作表,然后新工作表明为堆叠的工作表,然后我点击确定, 看到生成了一个新的名叫对叠工作表的工作表,里面包含了前面两个工作表的内容,这个就是对叠工作表,然后看合并工作表。 合并工作表下面呢有两个分支,一个叫匹配列, 一个叫并列。先说一下这个,呃,匹匹配值这个功能理解 列起来呢稍微难一点,呃,我这边打开匹配值菜单,然后选择暗列,然后在可用列中选择 wait 作为匹配列。点击确定, 可以看到在我这边下面新生成的工作表中,都将两个之前的工作表中的 wait 的内容按照顺序进行了排列, 然后最后还有一个并列,这功能比较简单,就是把多个工作表合并在一起。
 05:41查看AI文稿AI文稿
05:41查看AI文稿AI文稿今天为大家介绍复制列道列, 复制列到列,可将当前工作表指定列中的数据复制到指定工作表的列中。 大家可能会觉得,哎,这功能有什么用啊,我直接选中列,按 ctrl c 复制,然后在指定位置按 ctrl v 粘贴不就行了吗? 其实啊,复制列到列最好用的地方是它可以划分数据子级,去复制你想复制的数据, 删除这你不想复制的数据。我们看这个工作表,这个工作表里呀,有两列数据,分别是 c 一油漆列和 c 二硬度列。 我现在啊,想把这两列数据复制到当前工作表后面几列,直接复制粘贴当然是可以的,但是如果我其中有些类型的数据呢,是不想复制过来的, 这应该如何操作呢?我们可以点击菜单栏的数据选择复制, 选择列到列。好,在弹出的对话框中,我们再从列复制这里把 c 一油漆列和 c 二硬度列加入进来, 将复制的数据存储在哪里呢?我们可以选择在新工作表中或指定的另一个工作表中,也可以在当前工作表指定列中 啊,有这三个选,有这三个选项,我们就选择存储在当前工作表指定列中 哦。那么我们指定存在哪两 两列中呢?我们就自定义存在 c 三和 c 四列吧, 输入 c 三空格 c 四,大家注意别忘了用空格间隔开啊,否则是会报错的。 这时候啊,如果我们直接点击确定,那就和 ctrl c 和加 ctrl v 功能一样了,区别啊就是我们可以点击下方的划分数据自己 在弹出的此对话框中。首先上面我们可以选择复制的数据,是要 包括某些特定的行,还是要删除某些特定的行,就选择指定包括的行吧, 比如我想复制所有的硬度列中硬度数据大于等于十的数据,小于十的数据呢,我不打算复制。 那么在下面指定行里要包括的行里,默认是包括所有行,我们可以选择匹配的行。 然后在后面的条件框里,我们点击进去,弹出 弹出计算器。在这个计算器当中啊,我们不要去管右边的函数,因为一般划分自己的条件都是很简单的, 我们啊,就在条件框里啊,选择 c 二硬度列,然后呢,找到并点击大于等于再输入十 这个计算器啊,建议大家用鼠标点击按键去输入, 不建议啊,自己键盘输入。如果因为格式问题啊导致报错, 那,那就需要重新来过了。好,我们设置完毕,点击确定,再确定,再确定。 这样啊,我们在 c 三和 c 四列就生成了复制过来的列,并且呢,在输出窗格注明了,包括硬度数据大于等于十的数据,不包括五行数据。 好的,今天我们先讲到这里。
12刘金恒讲质量





