tensor.detach()什么功能?

粉丝7678获赞2.5万
相关视频
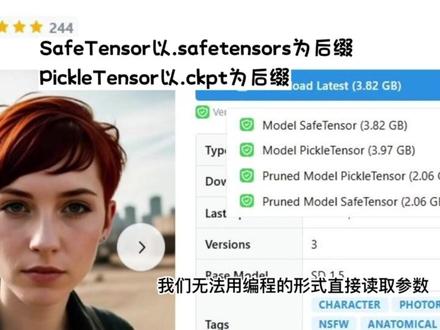 02:09查看AI文稿AI文稿
02:09查看AI文稿AI文稿了解了这几种模型的概念后,我们接下来再试着区分一下模型的后缀名语、版本名称,这里还要再学习几个专业名词。我们点击 c 站模型的下载按钮后,有时候会看到模型提供了多个版本供使用。 safe tensor 代表下载后模型以 safe tensors 为后缀。 pq tensor 代表下载后模型以 c t p t 为后缀。这两种模型本质上是一样的,只是 safe tensor 是受到加密保护的,我们无法用编程的形式直接读取参数,除非获得开发者提供的密要, 而 pique tensor 是不受加密保护。换句话说, pique tensor 模型是开源的。 safe tensor 是不开源的,我们下载时任意选择一个即可推荐用 pique tensor 的模型,至少未来还留有查看模型参数的权利。 是指经过减脂 proning 的神经网络模型文件。减脂是一种神经网络优化技术,他通过删除一些勇于的神经元或连接来减少神经网络的复杂度,从而提高模型的运行速度和泛化性能。 推荐使用 pro 的模型,它不仅泛化性更好,而且简直意味着参数的减少,模型文件需要的储存空间更小。此外,当我们去 hotting face 下载 stable diffusion 一点五版本或二点一版本的模型时,还会看到 e m a 或者 e m o 里的字样。 ema 也是一种常用的优化神经网络的方法,它可以平滑模型的参数更新,降低训练过程中的震荡和波动,提高模型的鲁棒性和泛化能力。一般选择 ema 优化后的模型会更好,有时候模型的文件名上还会看到 f t f t 十六、 f t t 三二这类单词,这代表模型数据使用了不同数据类型进行储存的 f t 十六、 f t 三二分别代表了单经度和半经度浮点数简单理解就是 f t 三二相比于 f t 十六保留了更多小数。 由于 ft 十六的数据精度较低,可能会影响模型的性能和精度,但它可以减少模型的存储空间和计算量,从而提高模型的训练和推理效率。如果电脑内存足够,那就选择 ft 三二吧。
21AI科技树 07:20查看AI文稿AI文稿
07:20查看AI文稿AI文稿好了平平平大家好,欢迎来到智炼探索,今天给大家介绍一款 stable defusion 的平替在线 ai 绘画网站,这个网站可以在线编辑生成自己想要的图片,包括各种模型,随便使用,再也不用担心电脑配置不行的问题,非常方便。 下面我们打开网站,这里有很多模型供大家选择,想用哪个点哪个。这个网站支持中文,对新手非常友好。点右上角小地球,然后选择简体中文,再点旁边的登录,可以选择一种合适自己的登录方式。 我们做测试,随便打开一个模型,这里看下要注意的事项,是否可以商用, 点击运行打开模型,这里之前已经测试过,所以有的地方已经填好了,这里是基础模型,可以根据自己的需求和要做的风格 选择相应的模型,上面也有很多分类可以选择,看好哪一个直接点击即可。选择好以后还可以继续添加自己想加的 lower 风格 模型,随便选择一个 ben san torko, 这个数值调到一,这个数值越大,你所生成的图片风格越接近所选模型, 如果有需求还可以继续添加,在这里建议最多添加一个 lora, 添加多了生成出的图片比较乱,也可以添加 control net, 这个模型不支持,所以这里是暗色的 提示词,这里我都填好了,直接复制就可以自己填写,也可以 lin sound dot com 这里选择生成图片的大小,有已经设置好的尺寸,也可以根据自己的需要尺寸填写。 下面是采样算法,根据自己需要选择,采样次数拉到三十,因为免费版的最大值只能到三十,提示词相关性拉到时这个随机种子我们也可以自己设置一个容易记住的数字,也可以随机生成,以后选择一个喜欢的图片,把种子记下来。 下面是高清修复,能选放大的倍数,高清修复也调到三十, 重绘调成零点三五。修复方式选第四个, 点击生成。我们用的是免费的,所以部分功能会有限制,这个提示告诉我们,高清修复的最大值不能超过一千九百二十乘以一千零八十,其实这个像素已经够用了, 我们再把高清修复调一下,放倍数调成一点五,然后生成。 这个生成的速度比较快,所以这些参数可以自己尝试填写。 这个在线的绘图网站不会像 stable diffusion 那样,一个地方设置不好就会报错,报错这个问题这里不会出现,所以说可以大胆试,一般正常一张图一分钟以内就可以了。 这里还要说一下一个账号每天送一百点的算例,每制作一张图片,会根据图片的复杂度扣除相应的算例,一般每张图片一到二个算例,所以每天大约能生成三十到一百张,一般对于普通用户来说已经够了, 这个根据自己情况而定。好了,图片生成好了,打开看一下,效果还是相当不错的。 在图片的上面还有几个选项,有做同款图生图、 高清修复、局部重绘等选项, 也可以这里进行下载,而且下载的图片也没有水印,我们点图生图可以直接点这里,把这张图片直接添加。一定要记得,如果想继续做这个风格的内容,一定要把种子复制粘贴, 这里的参数我就随便填写了, 这里忘记改提示词了,换一个提示词,这次生成看着效果不明显, 我们可以去 playground di 找一个自己喜欢的风格,复制一下提示词,当然也可以自己填写。 我们换一个原图试一下,也把尺寸改一下, 效果还是不错的。这个 animate 是制作视频的,免费版的,只能做十六帧的视频,有兴趣的可以自己试一下。这里就不做测试了,我们再换个模型试一下,这次选择做同款,看看效果, 能看到效果和刚才看到的基本一致。这是之前生成的几张图片, 如果对这些参数有什么不明白的,可以自己测试。这个不用考虑会报错、生成时间长等问题,也不用考虑电脑硬盘的尴尬,所有模型都是在线使用,即点即用。 这个网站和 stable defusion 作对比的话,各有各的好处,这个网站比较方便,但是想要更好的效果还是 stable defusion, 这个要根据自身情况选择,希望大家能用上。这就是本期内容,下期继续为大家介绍好用实用的 ai 智能软件。
16智链探索 05:52查看AI文稿AI文稿
05:52查看AI文稿AI文稿哈喽,大家好,今天给大家带来这个 tension rt 的一个加速模型的使用方式。前面我有讲过一期这个 lcm 的这个加速,他跟这个有什么区别呢?简单一点讲就是 lcm 他就是一个加速的 lower 模型, 我通过像 lora 一样的方式来调用它,就可以针对任何的模型,任何的情况去给它进行加速,所以它的使用是非常简单的,那我在第一时间就发了它的用法,但是呢,它有个缺陷,就是会降低模型的质量,所以很多人在纹身图阶段是不喜欢用它的, 都是在土生土或者放大阶段使用它。今天要讲的这个 tensen rt 呢,它是无损的,但是呢它的局限性会比较多一点,比如说我现在如果想针对麦橘的模型进行加速,那我就要提前做好麦橘这个模型的加速的 tensen rt 模型, 我如果想用别的大模型,那他又不生效了,他需要针对性的对大模型做加速。然后第二个呢,就是他在尺寸上面也有一些预设,比如说我 做好的是五幺二乘五幺二这个固定的静态模型的加速,那我就只有在生成这个分辨率的时候会有效,如果我生成五幺二乘七六八,他就无效了。当然我可以做成动态模型,比如说五幺二乘幺零二四的这个动态模型,但是动态模型的加速效果会比静态模型要略微差一丢丢。同时呢,他目前呢还在某些插件上不能进行使用,比如说 现阶段好像就不支持 ctrl net 的加速,那还停下来,他的局限很多,估计很多人已经要劝退了,但是今天我为什么还是要讲这个呢? 因为我发现很多人的使用场景是非常合适的,有些人现在已经找到了自己的工作流,他基本就在固定的某些模型下产生一些这个固定的图片, 这种情况下是用这个可以直接让你的速度提升一倍且无损质量。而且这个模型发展是很快的,创作团队已经在尽快的把这些配套的支持的插件也都完善起来,然后在后续呢他的这个这种支持的参数啊,还有针对的模型,我相信有 更好的解决办法,所以现在大家可以先来了解一下他怎么操作的之后呢,可以很快的上手,这个在未来一定是非常好的一个技术。先第一个大家要去英伟达的官网去下载这个显卡驱动的这个软件,我们先来搜索一下英伟达的官网,然后呢在他的官网找到这个驱动 程序,我们可以在这里根据自己的型号来来搜索,找到自己所需要的这个插件。然后呢下载一个这个这个驱动的这个软件, 在这个驱动软件里面大家登录进来就可以安装这个驱动程序,他的插件要求的版本驱动呢,就是在这个最新状态下更新到最新就可以了。第二个我们在 tab 里面直接搜索这个 tension rt, 进来之后按照我们的老方法来安装插件,复制他的链接到网址进行安装,这个地方应该就不用再多赘述了,后台会下载一下这个插件的这个模型,他还是相对来说比其他插件要大一些的,可以看到有个七百多招的东西要下载。 ok, 我们看到这里已经安装完毕,然后我们点击重启,在第一次重启之后呢,这里仍然要下载一些环境,大概是一个 g。 在我们重启之后呢,这里就多了一个这个 that crt, 我们打开它,右边有一个详细的操作介绍,大家有兴趣可以看一下。然后我们呢现在直接来针对麦菊的给他做一个探森 rt 的加速,如果你的要求比较简单,我们直接点击导出默认引擎就可以了, 直接就做完了。但是这里呢我想直接来做一个动态的,也就是我们用起来会相对比较简单一点的,他这里预设会有六种,上面的三个呢是静态的,一个就是只针对五幺二乘五幺二,然后只针对于单批数量为一的,这个就是七六八乘七六八,幺零二四乘幺零二四。 以下的动态呢,就是从二五六到五幺二,从五幺二到七六八,批量次数一到四,他都可以有一个兼容效果,我们就选一个五幺二到七六八的这样一个动态模型。然后 在高级设置里面呢,我们还可以手动的调整,就是他这个预设里面的各种参数动态做的越多,他的加速效果肯定就会稍微弱一点,最好就是保持默认的状态,我们这里就保持一个默认的状态, 然后呢点击导出引擎右上方的报错,大家不用管,然后就可以看到后台会开始运算,这里这个报错啊,我相信大家也许会遇到,我之前在第一次装的时候也碰到了,我们需要把所有路径当中的中文给改掉,我这里这个模型呢有中文,所以我这里需要给他去改一下, ok, 这样的情况下我们再次点击导出刚才,嗯,如果是中文状态下,他就检索不到这个模型路径,同时如果这一步无还是无法构建的话,大家需要把魔法打开 这里呢,我们可以看到已经完成了,然后这里输出位置也显示已经完成。完成了之后呢,我们可以在下面刷新一下,就可以看到我们已经做好了麦具这个模型的加速模型,接下来就是他的调用了,调用其实非常简单, 他需要在设置里面呢找到一个 unit 选项,这个 unit 选项呢其实跟这个我们的 cleve 中指层数,或者是跟我们的外挂 v e 一样,他都是不需要去经常调整的, 以至于这个一点六已经把它隐藏到了那个设置里面。我们只需要在这里刷新一下,就可以看到我们刚才做好的这个 tanshenrt 的这个模型,我们也可以不用每次到设置里面来改。我们可以在用户界面里面呢找到这个快速设置,像我们可以看到大模型 v e 还有 clip 跳过层数都在这里, 在这里呢再给他添加一个 unit, 就可以搜索一下这里,我们找到 sd unit, 然后呢把它添加到这里,接下来就是保存模型, 然后重载 ui。 ok, 再次打开之后呢,我们的界面上方就得到了一个可以调整的像。接下来我们先整体的测试一下,我这里用五幺二乘七六八的呃同一个组提示词,先来测一测不用他之前的速度,我这个电脑 应该跑五张,用的是九点二秒。接下来呢我们选择这个对应的加速模型,然后同样是五张,但是一般来说他可能要预热一下,所以我们以第二次的结果为准,第一次他启动就需要点时间。 ok, 同样的几张图片,我们用了七点一秒,速度感觉没有快的特别多,因为他是一个动态模型, 这张图片的话是花了一点一点三四秒左右,如果是不用加速的话是三秒钟,差不多是缩短了一半的速度,总之是加快了一部分时间,同时他的质量没有下降。那如果说我们是换做这个静态的加速,比如说我们只做五幺二乘七六八的,不做这个动态的话,他的速度还会进一步的提升, 这个就是整体的使用。然后这插件呢,建议大家新手阶段不用去研究它,因为我们还在学习过程当中,不需要去让它多快,等我们稍微掌握了之后,然后这个技术也发展了一定一段时间之后,我们再来使用它。
338大桶子AI 00:42
00:42 00:49查看AI文稿AI文稿
00:49查看AI文稿AI文稿今天说一下客家的显卡售后,首先显卡普遍都是三年质保,售后政策这个东西并不能代表整个售后过程,同品牌不同地区的时候差距都可能会很大,要是真的遇到了聚宝这样的事,该投诉投诉,保护好自己的合法权益。 华硕平安森马个人送宝可以在华硕服务的公众号申请,微信是代理商,送宝需要个人承担邮费。七彩虹平安森马个人送宝,他家一六七到三零七的卡还支持三年的免费上门服务, 看起来非常方便啊。有用过的朋友可以聊一下。体验影池,平安森马个人送宝用户要承担单程邮费。影池的名人堂系列还有专属的 vip 售后服务,真的就是尊贵的名人堂用户啊!还有索泰明轩、应重根深,这些都是平安森马个人送宝用户,需要承担单程邮费。
150大毛的科技号 00:39查看AI文稿AI文稿
00:39查看AI文稿AI文稿这个是普通的二维的物体检测,这个是三维的物体检测,它常用在自动驾驶中。今天我们用 cg 加也来部署一下, 使用扩大加速预处理探 srt 加速推理得到物体的中心点三 d 坐标,再估算出物体的长宽、高体积以及偏航角度,便可以得出物体的三 d 姿态, 最后速度达到三十帧每秒,我们也可以查看三 d 的透视效果。
2761恩培-计算机视觉 00:471459埋头苦读
00:471459埋头苦读 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿今天我们来看一下训练好的模型如何高性能的部署。首先训练一个人体检测模型,用拍粉跑的速度是八十每秒。首先我们要提高推你的速度, 修改网络结构,转为摊萨 t 模型,使用 cg 加重写,速度提升到一百一十帧每秒。再做一下因特八量化,速度提升到一百二十每秒。再使用哭的重写预处理部分,速度提升到一百七十每秒。再改为多线程处理,速度提升到两百每秒。 现在我们来做具体的应用,在视频中选定一个多边形区域, 使用射线法判断人员是否越界,再使用 kmins 算法判断人员是否聚集。 最后我们来部署,使用 dock 容器部署并且推流,便可以在多个终端查看实时运行画面, 还可以在嵌入式 gpu 接线上部署,拿动上的速度也可以达到二十八帧每秒,在 zbl nx 上的速度也可以达到七十帧每秒。老样子圆满已开园,课程已同步更新!
1.6万恩培-计算机视觉











