officexmlhandler在哪打开
卸载 office 二零零七安装二零一零时经常遇到缺失, m s x m l 给大家演示下如何安装 m s x m l。 我们需要准备两个文件,可以私信联系我获取。我们依次安装 m s x m l 和注册表。 根据电脑系统安装六十四位或三十二位, 安装完 m s x m l 后运行注册表。

粉丝70获赞161
相关视频
 01:03
01:03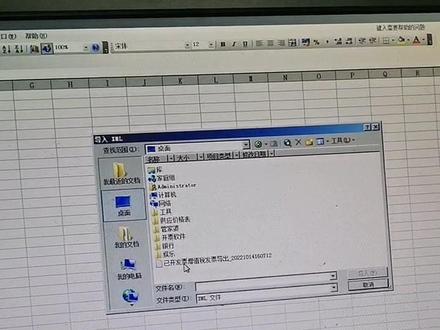 00:21
00:21 08:51查看AI文稿AI文稿
08:51查看AI文稿AI文稿今天我们要来介绍一个非常强大而且十分实用的函数,叫做 filter s m l。 这个函数呢原本是用来提取网页数据的,它有两个参数,第一个参数呢,是指有效的 sm l 格式的字物串,第二个参数呢,是指标准的 spass 格式字物串。需要注意的是,这个函数只适用于 excel 二零一三级以上的版本, 如果光是这么介绍的话,你可能会觉得很懵,所以呢,接下来我们要进行更详细的介绍。那什么叫做有效的 s m l 格式的这串呢啊?我们先把隐藏的内容给显示出来, 这个呢就叫做有效的 s m l 格式的这串。关于他的相关知识我们并不需要 进行深入的了解,我在这里呢也只是介绍几个跟菲欧特 s m l 第二个参数书写相关的几个特点。就比如说这个尖括号包裹的一个字母 moxed dot, 就是所谓的根源数的标签, 一般来说,标签都是成对出现的,开始的时候呢,就是这样直接包裹起来,结束的时候呢,就是在字母前面加一个斜杠,那根源数里面包裹的内容就是他的指元数了,他们也是以标签的形式一对一对的出现呢,就比如说这个 price, 然后后面的斜杠 prise, 这样呢就是一对标签,不知道你发现没有,根元素里面可能包含多个紫元素,而紫元素里面也可能包含自己的紫元素,这样呢就形成 多层级的一个结构。而 filter s m l 函数的作用呢,实际上呢,就是把某一个层级中结构的数据啊,也就是某一个标签中包裹的数据给提取出来。 在这么多的标签中,如何精确的定位到我们所需要的标签呢?就比如说,我想把 yet 这个标签里面的数据给提取出来,我们用 filter s m l 函数,我们可以这么写, 第一个参数,我们选择所谓的标准的 sm 格式的周串,然后呢,它的一个路径啊,就是从根目录开始写起 bus stock, 然后呢,接下来这个 book, 他把这个 yet 都包在里面嘛,所以接下来的字母是 book, 接下来呢 才是 yet, 然后我们按回车,你看他就以宿主的形式把我们所需要的年份呐都提取出来,就二零零五,二零零三。 这种写法呢,看起来是很直观,但是呢,他要求我们对成绩结构非常清晰,先后顺序不能搞错,否则函数一定不能错。所以呢,接下来我们要介绍另外一种写法,这种写法呢,他就是不管你在哪一个层级, 哪一个标签,就比如说,我们要提起 yet 标签里面包裹的内容,我们不管他哪一个成绩,我们只需要在标签的名称前面加上两道斜杠, 然后回车也是同样的一个效果哦。又比如说哦,我想把 prize 里面的内容给提取出来,我们把 prize 复制一下, 然后呢,把这个 yet 改成 price, 然后按哦回车,他就把价格都给提取出来了。这个呢,就是 filter s m l 的最基础的用法了。 正是因为函数有这样的一个特点,所以呢,我们在实际的使用过程中,要想方设法的构造出所谓有效的 sm l 格式的自由串。 所以呢,就由我们下面这个最常见的套路了,一般情况下呢,我们是用 smteachu 这个函数把单元格中的自如串中的分隔符进行替换, 然后呢构造成标准的 sm l 格式的字物串,嗯,就是这样的,可以看得出来啊,我们构造出一个简单的两层结构,由 a 标签和咪标 签组成,其中 some titty 的作用呢,就是为了生成多对的 b 标签。然后呢再用 fielter s m l 这个函数把 b 标签中包裹的内容给提取出来,也就是分格服之间的数据给提取出来。 我们先把里面的内容给复制出来, ctrl c, 然后赶紧来看一个例子吧, 就比如说我们有这样的一串文本,其中的姓名啊,科目的名称啊,成绩啊,都写在一起啦,那如何把这些数据单独给分离出来呢啊,最常见的一个做法是,我们选中这些数据,然后切换到数据选项卡, 点击这边的一个分裂,按分格符,然后填入分格符的名称。如果我们不想要覆盖元素 数据的话,我们可以选择目标区域,我们选择的是这里,然后点击完成啊,他就分离出来了。这种分组的方法呢,看似简单,但是呢,跟公式比起来,他还是有许多缺点的。就比如说后续如果我们有新增数据的话,你 必须把原来分离出来的这个数据啊清空,然后呢再重复进行一遍,那如果新增多次的话,那你这个操作就要进行很多次。 同时呢啊,这个深层的结果啊,不能直接被函数所引用。就比如说啊,我想直接通过这个文本计算出一个总成绩,那 你只能分组后,然后呢再选中这两个单元格,然后再进行一个求和。那如果用公式就不一样了,我们直接可以用一个公式把它计算出来, 我们先把这个数据清空一下,然后呢来看一下函数究竟是怎么写的。用的组函数就是今天介绍的 filter s m l。 我们先把刚才复制的文本给粘贴进来,我们先来看一下我们构造的第一个参数究竟是长得啥样。 可以看得出来,我们通过 sometitu 这个函数呢,构造出一个标准的 sml 格式,所以呢,就可以用这个函数来进行提取啦, 这样呢,就提取出来,可能你会说这不是竖向的竖组吗?那如何把它变成横向呢?方法也很简单,那就在前面套一个 transport 啊,这样呢就调转方向了,然后我们选中他往下拉啊,搞定。至于刚才说到的这个直接求和呀,我们可以直接这样子写,我们先把下面的数据给清空掉,我们先把这个全是 pold 给删除掉, 然后点击一下回车,确定这个数字啊,是处于第三行和第五行的这个位置嘛,我们可以用 index, 呃,把这个第三行和第五行的数据啊给取出来,然后呢它产生一个新的数组,然后再用 sum 进行求和就 ok 啦,所以呢,我们是这样子写的, 对吧?把这个第三和第五行取出来,然后用 some, 然后点击一下确定,然后再往下拉, 嗯,这样呢,就求和完毕了。接下来呢,我们来讲一道更难的,就是没有这个明显的分隔符,但是 那我们可以用 test join 来构造出一个分隔符,然后呢再用 future s m l 函数进行提取啊,也就是这一道题了。这道题呢是看见星光训练营里面的一道题, 它的含义就是这里面呢有这么多个图形,然后呢要算出在这一片区域中每个图形的数量。这道题呢有很多种解决方法,这里呢我要介绍的是如何用 filter s m l 这个函数来解决。 首先呢,我们通过 ts join, 用一个分隔符,把这些所有的图形都给连接起来,分隔符就是这个了, 然后一呢就代表忽略空格,这个呢就是这一片区域了,我们点击一下回车啊,这样就连接起来了, 然后呢用刚才的套路啊,把分隔服中的数据给提取出来,用菲尔特 s m l 点击一下回车,这样呢实际上就是把多列啊转化成一列,然后再把唯一值给提取出来,我们只需要用 unique。 最后呢要算出数量的话,就非常简单的,我们只需要用 call if 就可以啦, 然后往下拉。
162阿武教程 15:59查看AI文稿AI文稿
15:59查看AI文稿AI文稿接下来我们给大家分享的是 excel 导入 xml 数据的内容,那这个数据的内容的话,听起来会觉得,嗯, excel 还能导入 xml 数据, 他和我们的平常数据好像有点不一样哦,他怎么老呢?那其实一下我在做我们的一个 xm 数据的一个处理的时候的话,遵循的我们点内的的一些方法来实现,那我们来看一下啊,就是我们看 首先来了解一下 s m 格式是什么,那 s m l 格式呢?目前来说的话,在进行我们的数据的传递的 这个呃层次化的一个数据方面的话,使用的不是我们传统的一个什么,就数据库的一个语句的传递,那么它非常适合用来做我们 一个数据交换。为什么?因为我们在在做数据交换的时候的话,我们出来的数据是一个相对的格式化的数据, 但是 xm 也有缺点。什么缺点呢?就是啊,我不管我传递过去什么数据,我得到的如果是他本身是一个空数据,他也要把我们的相对应的一个格式还有我们的一个节点传过来。 所以第一次呢就出现了一类的数据叫节省数据。这位节省数据的话是目前来说呃用的最为广泛的一种类型啊,因为节省数据相比我们 sm 数据的话,传递的内容要少很多。 呃,像另外的话有一个叫做亚马数据,那亚马的数据的话其实是我们的节省数据的一个变种,那么它非常像我们的一个什么呀?拍摄的 这样的一个基于我们的一个位置的一个定位,节省的数据他有大括号啊,但是压门是没有这个大括号的, 那目前来说常用的啊,就是我们在呃我们的 excel 中常用的,基本上前面两种,一种 xml, 另外一种是节省的数据。压门的话在我们的一个 xxxl 中处理的非常少, 非常少,所以我们至少需要了解到这两种的一个数据的一个格式的这个内容。 那么大家看一下这里面的一个数据啊,那这里面的话,像我们的 seven meet, 然后 seven meet 的这个数据里面有两条我们的 seven meet 的数据。对数据,那这数据的话,其实在我们的一个点亮的一个格式里面,它其实就相当于什么一个表 格的一个数据记录,那这里面相当有两条数据的记录存在,那我们在做 xm 的解析的时候一定要了解到哦,我们怎么样去描述我们的一个 xm? 那 sm 和我们的前面的 htm 有什么不一样的地方呢?我们为什么要导入我们的 xm 呢?其实原因很简单啊,就是我们的 html 的这个语句啊和标签呢,都是规划好的,比如说我要描述横线,我们就是 h h, 往描述回车,我们就是 b r, 对吧?描述回车就是 b 啊,那描述认可的话呢,毫无疑问的就是 a, 然后什么什么什么,那这个的话,其实就是我们说对应 的这样的一个数据,但是 xm 的话具有更大的灵活性,大家看一下啊,这里面像我们的一个萨米特,那这里面的话,这个数据呢,会有相对应的一个呃,不是我们一个预定好的,因为它可以任意的数据, 那这首的话我们定义的一个呃封闭的标签呢?那这里面大家看一下啊,就是这里,这里面是杀 meet, 以杀 meet 为结束, 那这个 name 他以 name 的一个 b 标签结束,然后中间用我们的一个字符来描述,那么 h 的话是用 h, 然后用 h 的 b 标签结束 捐的,你捐的的必标先结束,那这个来说的话,就是我们所对应的一个什么呀?所对应的一个呃,一个解析的一个内容,那这样来说的话,其实就是实现了一个什么 一个内容呢?就是我们非常清楚明了的可以了解到我们的整个的 xm 的语句用来描述的这些信息,比如说我描述了 他姓什么,名什么,然后年龄多大,如果说我们这里面把节点扩展的话,可以填充更多的信息。 所以说 xm 的话,格式的话,相比我们的一个 htm 的话,他的一个差别,我刚刚已经说过了,就是说他可以任意的定义我们的一个解析的一个节点, 比如说标签的话,是不不再是我们的一个类似的,呃, html 里面的话,用必须预定好的,我的任意的标签都可以实现我们的一个呃定义。那么在我们的 excel 等跑快瑞导入 sml 的数据, 我们通常人来说有两种方式啊,那第一种方式的话,我们通过获取数据,然后从 xm 去把我们的数据导入进来。 那么另外一种方式呢?就是进入到我们的 paro carry 的一个编辑器当中,然后再选中新建语言,然后文件选中为 xm。 那么这两种呢?适用的场景,通常来说的话,这是是这个适用于我们没有到任何的数据在里面,或者我们这里面没有任何的查询在里面, 但是如果说一旦有查询的话,我们其实不用退出这个界面,我们直接点击新建文件,然后 sm 就可以把我们的 sm 数据来做导入进来说这是我们通过 excel 的一个 powquarry 导入 sm 数据的格式。那么 导入数据的话,其实我们来看一下这里面的话有两种不同的一个案例,有一种案例我们叫简单案例,那么简单案例有什么特点呢?就是他的数据啊,只有单层,大家看一下,就是负的外面是有一个单层的数据,然后这里面其他的话就是直接是负的数据本身了。 那另外的话有一类的类型呢,就是像我们这样,那最外层是一个 people people, 然后的话里面有一个 students 的这样的一个双层的一个节点,大家看一下,所以说这里面有这是一节点,这是二节点,然后 student 三层节点, 所以说他这里面的话,同时在这里面还有一个二层节点,所以说这里面的话是我们的一个多节点的 xm。 那昨天我们多节点的 xm 导入 会有什么样的一个呃问题呢?因为单节点的话我可以直接导入进来,没有问题,但多节点的话他会出现了一个什么样的状况,我们来看一下 他会出现一个什么在这里面 student, 大家看一下,这个 student 的话,其实是有一个这里面是我们的一个所对应的数据,然后这里面是所对应的数据,也就是它忽略掉了什么往外层的 student 标签,然后只拿到了我们的最里程的 xma 数据, 说这个的话正好是我们所要的,所以说这里面的话,他在这里面的话,他出来的是一个什么,是一个胎宝,所以胎宝的话其实可以通过 就是扩展的方式啊,就是然后把它扩展出来,然后他就把我们的数据全部都列出来了,就通过展开的这种方式呢,我们就可以把我们的一个数据啊,就是实现一 个非常简单的扩展来实现我们的这个内容。那最后的话,我们可以把我们的数据作为一个表保存或者是紧创建连接,然后将数据模型添加了,因为我们很多时候的话需要的话是利用他的这个数据啊来做一个数据模型的一个创建, 说这点大家需要去特别注意一下。 ok, 我们来实际来给大家来演示一下这个例子啊,我们来通过一下来导入我们的一个跑边, 听到这里面之后的话,我们到我们的数据,那这里面的话我们找到我们的一个文件来自 xm, 来自 xm 的话我们在这里面选中我们的一个文件 高级课程跑快,那这里面的话 sm 数据有一个简单的 sm 数据,我们就直接选中一层就好了, 然后这里面的话我们就直接有这样一个负的的一层,我们来直接看一下这个数据啊,就是我们的数据有什么不一样的地方?基本数据这个的话我们打开, 那么大家在这里面看啊,最开始的最外层啊,其实是一个什么呀?就是 breakfast 门六 那 breakfast menu, 它这里面是以 breakfast menu 作为一个毕节点结束的,那这时候的话大家看起来可能会觉得有,但是我们把这个 就是这样看,我觉得应该是大家可能都能看的明白,因为他 其实是一个我们的层次化的一个结构的数据啊,就是说他的结数据非常的一个层次化,这个层次化的话他有一个所对应的当,当你看不清楚的时候,你把它放到这样的一个我相信谁都可以看,看的非常的清楚明白 代表什么意思。可爱的各位, okay, food, okay。 那这里面的话,当我们把所有的这个 foud 的这个节点呢,全部都放到这里面,大家可能就很明白了,这里面包含了什么呀? 包含了内幕是,呃, baker, bedroom waff waffle, 然后这里面的价格是多少?然后它的描述以及它的一个 clarice。 这个的话是什么呢?我很多我不太知道它的英文代表什么意 意思啊?然后这里 foot 就是 strawberry black wolf。 然后这里面的话,然后这里面的啊,这应该是华夫饼啊,这个应该是 bel belgian wolf, 就是华夫饼吧,然后这里面的话是 belbury belgian wolf。 那这个的话其实就是相当于是这里面有描述了,是一二三四。呃,五个商品,这里面也叫五个商品,那么五个商品他的分别的名字描述、价格都在这里 说。这时候我们导入这个很简单的时候,我们就发现啊,他自己自动的就把这个名字价格描述以及 应该 category, 是吧?这是 category 吧?还是它是 chorus? 不太了解这个意思啊。然后这里面的话, 这是我们的一个副的,那就是我们这里面的一个个的副的,所以他已经把最外层的一个 breakfast menu 给拿掉了,只拿到我们的最里面的这个数据。因为通常来说的话,我们节仅仅是需要我们最底层的数据,其他数据都是可以被忽略掉的。 在大部分时候我这句话说的不太对,这大部分时候外面的数据可以被忽略掉,然后转换数据。 那转换数据的话我们首先要确定一下,哎,这里面好像这个开头鬼,呃,是数字不对,把它改变成为我们的一个文本, 要替换当前步骤。那这里面的 price 呢?这里面也就有点奇怪了啊。这里面的话就是按道理他应该不是我们的一个什么致富串,他应该是什么?他应该是一个我 的一个 umeric, 就是我们的一个呃,小数。那这次的话我,但是我们这里面有一个什么呢?有个美颜符号在这里面,他并没有识别出来,因为他这里面并没有我们所说的一个货币的形式啊。有货币,我们来看下货币可不可以, 但是这里面是 l, 为什么?因为他这里面的话导入过来的一个数据他没办法自动转,所以我们把这里面改一下。啊,那这里面的话我们把这里面更改类型 文本,这个已经更改了,然后这里面的话我们把它做一个。哎,看一下转换副, 应该是替换值吧,我把替换值这里面把我们的一个美元符号给他拿走。 点确定,那这次的话就没问题。然后我们再把类型做一个转换。 呃,货币,那这次的话我们就拿到我们的这样的一个价格了, 那这次的话我们的数据就已经完完整整的已经到了这个,呃,里面,那接下来的话我们就需要把它选择我们关闭并上载之,我们是把它放在我们的这个表当中呢?还是建立我们的一个连接,或者加到我们的数据模型,这个取决于我们怎么去设定它啊? 这个的话其实是没有太多的一些问题。 ok, 这是我们的一个单层的一个 sm 的数据导入,那接下的话可能会有一个涉及到,就是我们的多个节点的一个数据的一个导入,那怎么来做呢?那其实也很简, 但我们在这里面。呃,先看一下我们的 sm 数据是一个什么样的一个节点,那这里面的话,我们刚才看的一个节点就是我们的一个 啊,学生啊,这里面的话其实就是我们的一个 students 多层的这个数据,那这里面的话包含了两个 student students 的这个内容,那最外层是一个 p 破的一个标签,说这个的话其实他直接可以被忽略掉,所以我们把这个数据导入进来的时候,我们来看一下。 呃,我们来点一下获取数据来自文件 xm 外学生导入进来, 那这首的话他就会自动的会解析出来啊,就是我们当前的这个学生啊,然后的话他的数据的一个状况,我们这里点中我们的十六等字,然后点加载 转换数据,那这个的话你如果说点直接点加载,那肯定不对的,得到的结果他一定是在这里面是一个 table 的展现放到这里面来了,我们通常来说需要通过转换数据的时候把它做一个扩展,那这次我们点击这个, 把这个然后加载更多,然后点击确定,那这样来说的话,我们就把我们的一个 nh, 然后这个词全部都历史的出来了。 呃,所以说针对我们的一个多个节点的话,我们通常需要去利用这样的一种方式去做,因为,呃对于我们的一个单一的一个封闭的一个标签来说的话,他的 一个内容其实就是一个 table, 那么其实我们就要把这个 table 给做一个展开,因为他们的数据是一样的啊。 xm 的数据和节省 的一个差别,就在接着的数据的话,他可能会比较灵活,我如果有数据我就我就放,有数据就放 在我们的这个里面,没数据我就把它弄出来说这的话是是我们的一个比较大的一个差别。但 s 秒的话,我不管你有没有数据,我都要传递过去,你也必把结果汇传回来。 ok, 那这个的话其实就是我们有关我们的 xm 的这个内容的。呃, excel 传进行我们的一个内容的加载的一个方式的一个讲解。不知道大家有没有问题呢?有问题欢迎大家加入群,然后做一个聊天。 呃,我们在我们的所有的一些课程的内旁边都会有一个,呃,就是,呃目前来说的一个群聊啊,大家可以加入进去,如果购买了课程或者你想咨询一下都可以加入进去。 ok, 这节课程就到这里,我们下节课再见。拜拜。
 08:10
08:10 04:59查看AI文稿AI文稿
04:59查看AI文稿AI文稿好,今天来说一下科美系列 ftp 扫描的设置,首先你要知道打印机的 ip, 按菜单键,然后需要用第八个设备信息,这边可以看到打印机的 ip, 然后到电脑上,你先下载好驱动打印机的软件,比如说这个网址啊,有,然后再下载中心, 这里面有一个 ftv 扫描软件下载, 下载好了我们打开, 按右键解压, 双击打开安装。 呃,基本默认就是下一步,下一步, yes, 目录不用更改,直接按下一步就好了, 直接下一步好完成。然后在这个电脑上,桌面上他会有一个 mtv 这个软件,这个设置你文件放在哪里? 比如说我们现在设置一个,嗯,我新建一个,我要放在 d 盘啊,我 这已经有了,设置一个文件夹,一会扫描的文件就放在这里, ok, 然后选择底盘一个 scan 按,确定好,他现在就放在底盘了, ok, 然后 开机,我们那个软件开机会自动运行的,如果没运行,你看下右下角,如果没有运行,打开一下,好,他会说防火箱阻止,我们要允许访问。 ok, 然后现在 刚我们知道了打印机的 ip, 打印机 ip 是二四三 复制啊,就获得输入打印 ip, 浏览器 回车,他会进去内部的一个网页,然后选择目的地,目的地注册, 新注册 f t p 确定, 然后在这边我们输入本机的 ip, 本机 ip, 我本机的电脑 ip 是这个, 这个要设置成手动设置啊,固定 ip 不会一直变动,这样子变。好 在这边输入本机的 ip 路径,不用输。然后这个匿名啊,开启 这边名称,你可以设置一个,你喜欢设置什么,就是比如说什么什么名字啊,什么数字啊,六六八啊?选择主要 完成,按确定,哎,文件路径无效啊。 ok, 错了,这边随便输入个符号,比如说这个斜杠好,就是根目录按确定, ok, 已经注册完成了。然后我们去试一下 扫描,这边有一个 ftp, 就是我们刚刚设置的,按开始 好,现在那边显示完成,我们打开我们刚刚那个设置的那个文件,好在这个已经有一个文件了,这是刚刚扫的 好。 ok, 然后为了方便使用,你可以把这个文件夹设置一个快捷方式到桌面上,好发送快捷方式,桌面 扫描完了之后,直接在桌面上就可以打开。好的,设置完毕。
1898柯美阿宗 48:27
48:27 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿x mar 和杰森的区别啊? x mar 和杰森呢,都是交换数据的时候比较常用的数据格式,他们的主要区别呢是有这四个方面,第一个方面就是在数据大小上,杰森呢,相对于 x mar 来讲,数据的体积更小, 所以传输的速度会更快。第二个方面就是数据解析的方面,接审和 js 的交互啊,更加方便,更容易解析处理,开发起来更容易。 第三个方面就是在数据可读性的方面节省呢,数据的可读性比 xml 要差一些。第四个方面呢,就是在数据的传输速度方面,因为数据更少,所以节省的传输速度要快于 xml。
1989老猿说开发 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿利用一个公式把你的 excel 变成翻译器,我们把下面这个公式复制到 bill 单元格, 回车就可以看到对 a 二单元格的内容进行了翻译。公式能自动识别语言进行翻译。比如我们选中 a 二单元格,下拉 a 四单元格的中文就对应翻译成了英文,是不是很好玩呢?你也可以试试。
459高效办公技巧











猜你喜欢
最新视频
- 7676NANA