seedance2.0动漫效果

粉丝1.1万获赞8.6万
相关视频
 04:02查看AI文稿AI文稿
04:02查看AI文稿AI文稿为什么二零二六年视频创作者必须要学会 ai? 刚好最近字节呢,也是杀疯了,他们上线了一个超级厉害的视频模型, c 档是二点零,有多强呢?这种慢剧广告, 这是短剧,怎么还没出来?四根全是阳性,什么 vlog 都是用它一句话生成的, 接下来我给大家用几个案例测试一下啊。然后最近这种仙侠漫剧不是特别火吗?然后呢,我上传了三张图片,让他帮我生成一个十五秒的仙侠高燃战斗视频,最终出来的效果呢,是这样的, 哼, 动作呢,其实是非常复杂的,但是它也能够非常流畅的去完成它,它能够自动去生成风景音乐音效,在特效上呢,也非常高级,而且镜头的切换,全景中景特写啊,这些都有 c 杠子。二点零呢,目前可能是 ai 界最强的视频模型。然后呢,我就拿出了人类最强打斗分镜鸟山明的龙珠出战, 让他参考分镜,生成一段大斗视频,看下效果啊, 你看到分镜切换非常流畅,节奏把控到位,音乐音效呢,也很合适。然后呢,我又翻出了龙珠的动画对比了一下, 不愧是人类最强动漫,打斗情绪渲染力,还有打斗的力量爆发感呢,也是 ai 目前没法比的,所以我觉得 ai 还需要再卷一下下,但如果你要做二改或环外篇呢,我觉得是够了, 虽然离人类最强还有距离,但是像这种真人感的短剧怎么还没出来? 四根全是阳性,什么?天呐,我们怎么养得起四个孩子?其实从质感上面来看啊,你说他的画面还是声音是真人的,我都会相信。其实这一段我只是在网上找了一个段子,然后直接让他帮我生成一个短句就可以了, 以后你刷到的短剧可能都不一定是真人,我连本带利全部拿回来。然后呢?我想试试他到底能不能一句话做商业广告。我上传一张图片,然后一句话让他帮我生成一个 t v c 自改的广告,而且必须是快节奏, 快节奏,慢节奏他都能听得懂。 我数了一下,一共是差不多十八个镜头,这让我真的感觉到 ai 的 进化真的太快了,学习能力、复刻能力远远超于我们人类, 包括剪辑上的卡点都是由他自己来完成啊。用了我们专业剪辑,里面的跳切质感和我们平时看到的 t v c 广告其实已经差不多了。关键是它只需要一句话呀,一句话,甲方都不止对你说一句话。 回到我们最开始的问题,为什么二零二六年视频创作者必须要学会 ai 呢?因为技术门槛儿正在降低,审美门槛儿正在重建。这一反逼着我们去思考我们要做什么。未来的超级个体呢?是一个人,就是一支队伍。那这期视频呢?先到这里,下期视频再见。拜拜。
1.3万南门录像厅 01:58查看AI文稿AI文稿
01:58查看AI文稿AI文稿被 cds 刷屏了,阿婆看到后就是慌张,于是试了试,之前阿婆不是做过 ai 视频吗?那个时候用的是 banana comfy, ui 做的差不多是这样, to realize, i got a feeding but i。 当时 ai 还不能理解什么是镜像,就很艰难,疯狂抽卡,一个镜头前前后后要抽几个小时都只能勉强用。而现在用 cds 不 抽卡,一次性出效果是这样的, 太强了呀!就是他的分镜效果,还有角色定位以及对镜子的理解都太强了,还自己配音,配乐逆天!然后阿婆又试了试其他的效果,比如权宗哲大战剑修夜顺光的二 d 动画,也是一次性不抽卡 呀。哦哦,最后是一张图和场景的结合,三小只的混战,我还没弄人设图,就一张海报图,场景就是游戏里拍了一下,结果。啊啊 啊啊啊啊啊啊, 别打了别打了,给动画行业留一条生路吧!还说啥呢,如此低门槛的就能出这种动画视频,这一切都太恐怖了。四杰这种大企业的 ai 实在是太强了。 这话不是广告,而是感叹。还有一句感叹是人类一败涂地,发展太快了。阿婆也陷入了深深的思考,今天本来是更新其他视频的,被时代浪潮冲击的有一种脱力感。最后来点正能量吧。祝大家新年好! 新年快乐!祝各位新年快乐,万事如意!哎,这也别愣着呀,给大家拜年!新年快乐!愿你在新的一年里心想事成,万事如意!
6402亚食人 04:51查看AI文稿AI文稿
04:51查看AI文稿AI文稿首先这不是一条广告,而是我用 cds 二点零测试的一套打斗画面。怎么说呢,嗯,我真的被吓坏了。 过去要做这么一套效果,先不说能不能实现吧,从角色设定到分镜设计,再用 ai 辅助构思动作提示词,再手动反复修改, 运气好一点的,抽个三十次就能拿到一个五秒的可用镜头,而现在一口气全都给解决了。今天这条视频,我们就一起来看一看他都更新了哪些既好玩又好用的神奇功能。 首先还是要拜访一下吉梦老师。选择视频生成,我预先设计了两名角色形象,把它们分别上传上来。选这个模型,全能参考模式比例,选择十六比九十五秒的视频, 我把题词分成了三段,第一段零到四秒打艾特,选择对应角色图,以图一为手针,用西区苛刻变焦从正面推进镜头,交代第一个人的状态, 四到八秒交代图二角色出场动作和环境。最后八到十五秒详细描写两个人的打架细节,用了什么招式,再指定一个运镜效果走你。 我们看模型,会通过分析画面质感、风格来判断他属于什么类型。这条视频很明显他理解成了是游戏画面,整个的打斗感特别像某种赛博朋克动作类游戏的效果,挥刀的动作有点慢,但是该有的特效都给到了,有点意思。 同样的原理,我们换成这种仙侠风格的图片后,效果就完全不一样了,明显感觉人物的动作更流畅,特效也更丝滑了。就单凭这个影视级音效这一点,就不知道节省了多少时间,真是越刷越上头, 咱们换个机甲的试试。我准备了三张图,分别是机甲、越野车和杀虫。同样是拆分成三段,零到八秒描述越野车和沙漠的背景,让他完成在空中变形成机甲,最后发射激光炮消灭杀虫这么个剧情。 这越野车岁数也是有点大了,变个身零件丢了一半。你别说,这机甲变身的味还真挺对,我以前试过很多模型都做不到这个效果。 仔细看,他开炮之前会有一个蓄力充能的过程,从头到尾一镜到底,没有任何多余的环节,就是最后杀虫没打爆,换成这个结尾就完美了。 这次的一大亮点是视频参考,所以我准备了一条骑自行车的视频作为素材,注意时长不要超过十五秒,否则就上传不上去。玩法很简单,还是选全能参考。注意首尾针虽然也支持这款模型,但是想要上传视频参考,你就只能用这个。 我分别上传了一张人物形象图和这条参考视频,我们将视频中的运镜和人物动作,把故事背景放在古代街头看效果, 这真是太丝滑了。注意看,我并没有指定分镜,他会根据视频参考自主设计,并且给出的地理环境和围观的这些路人的状态也太到位了吧。十五秒切了十二个镜头 放在过去,升分镜图就够合一乎了。并且我同样把主角换成熊猫,把背景设定在动物园里,用同样的一条参考视频,给出的却是完全不同的感觉。真的从来没想过 a i 还能这么玩。 我准备了一条只有两秒钟的视频,开头我让 ai 给我续写,后面的剧情延长到十五秒,然后按照我给他的剧情继续表演,看看他的演技。 哦买噶,线索是什么? c dance 二点零发布了以后傻子都会做视频了,这演技确实够浮夸的。注意,我只是提供了一个思路,至于怎么运镜和如何表演,基本全是靠 ai 自己脑补的,我甚至自己都不知道是什么效果,这实在太可怕了。 最后咱们来模仿一个动作,我分别找了五个男团演员来替换原视频中的五个跳舞的男生,题词很简单,效果更炸裂。 关于玩法真的是太多了,在这篇文档里列举的很详细,我大概一个多小时才给他看完。感兴趣的同学记得在评论区里大声喊出那三个字,咱们回见!
3.1万Ai训练师大宇 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿真的太炸裂了,我随便把凡人传说中的一段小说文字喂给 c 弹四二点零,而且是直接是喂给他,不加任何的这个提示词,看什么效果, 朋友们是不是非常的炸裂啊,我们一句看啊,看他这个好地方和这个不完美的地方啊。首先第一句,韩丽转身来伸出一只手指, 转身,伸手指非常的这个蓝色光球附在手指尖上, 这里有个小问题就是有蓝色光球啊,但是呢,他真的是给了你一颗核桃,咱们都知道核桃是一个比喻嘛,其实这里的话有一个建议,这种比喻的东西可以把它给去掉啊。 ok, 我 们继续看抚弦的手指尖,没问题,去这里没说去,我没注意,但他哼了一声啊,听到没? 你注意听这个 bgm 还有配乐哇,非常的好。然后呢轻轻一弹是不是射向这个远处的 b 罩上,没问题,因为它是前来宾宴,所以它是非常冷的,直接把整个这个血罩呢变成这个蓝色的, ok, 整个血罩温度即将变成了严寒的世界,温度之低可以变成呼吸。 然后呢,看到这些之后呢,韩丽声音一晃到这个蓝色的 b 罩面前闪现,闪了好几次,其实闪个一次就够了啊,这个有点多余,然后一抬手一道金色的剑气击在了厚厚的冰层上,破碎之声传来, 击上去破碎哇,真感觉真的是一气呵成,除了一点点不完美的地方,比如这个核桃啊,我们赶紧用你自己喜欢的小说去喂给鸡八二零看是什么效果,真的是太震撼了。
2.1万科技暴龙 06:53查看AI文稿AI文稿
06:53查看AI文稿AI文稿金杰呢,也是杀疯了,他们上线了一个超级厉害的视频模型 c dance 二点零有多强呢?这种慢剧广告 断剧。苏里今年的桃花好美啊。 我把这次用到的工具,完整的工作流和操作步骤都打包好,专属 ai 提示词,免费工具包和入门课程我已经全部整理完毕,感兴趣的三三三。那我们来讲一下 ai 视频的制作流程,主要分为这几步,首先第一个就是脚本的生成, 第二个角色设定,再就是分镜图片的生成,再来就是视频的生成,最后是视频的剪辑,那我们先来看一下分镜脚本的生成,那我们可以先来再打开 ai 这样一段话。国漫三 d 打斗的仙侠风格大概是一个什么情节?要求它结构清晰, 故事情节情节引人入胜。好, ok, 当我们觉得这个这情没有问题之后,我们就可以再来给他发送第二段话,当然我们也可以适当的去修改一下,把这个直接发送给他, 那这个时候我是要求他按照我的表格去生成,这里面会有 ai 升图提示词,以及画面的内容,影碟时长信号等等,我都需要他直接给我。好,那我们得到这个之后,可以直接把表格下载下来,放到自己的本地就可以去修改, 那比如说我这边把它打开,打开之后他就在自己的本地也是这样的表格,这样方便我们后期去查看。像这里他是直接给的 ai 升图提示词,那我们可以根据这个提示词去升图,或者说我们也可以去修改 好, ok, 那 这个就是脚本的生成,主要就是这两段提示词,像上面这一块我们是可以去修改内容的。 好, ok, 当我们表本生成之后,接下来就是角色的设定,角色,我这边给的两个角色是这样子,大家可以看一下。首先提示词,第一个我们要给出风格,国漫三 d 风格, 下面这里就是他的一些描述,那这个提示词我也打包好了,大家可以在评论区留言领取。 那有了人物之后,我们就可以去生成分镜图片了。我们先来看一下大概的剧情,就是一个反派和一个正派打斗的过程,先是反派发起攻击,然后正派在受到攻击之后将能量全部吸收,然后再发起反击的一个情节。好,那我们就来看一下对应的分镜图片。 首先第一个镜头就是这一个反派发起攻击的一个镜头,那我们要得到这一个镜头的图片,所以这边写的提示词就是根据我们之前得到的人物上传上来,再给他一个特写镜头,人物近景的呈现, 再把背景描述一下,比如说天空阴沉,环境是白雪,大概就是这样一个描述,最开始的这一针,我们就直接把生成的这一针发给 ai, 然后跟他说去掉他的这个符文,手放下来,这样我们就得到了首尾针,我们再用首尾针来去生成这个视频, 他就能够得到一只手举起来,后面我们要对他进行一个加速,那我们再来看第二个镜头,他开始要去运功了,大概是这样的吗?所以这里的镜头描述给的就是镜头跟随角色双手结印,全身汇聚无尽的能量, 展示角色强大的气势,额后一只手掌向镜头射出巨大的能量光柱的攻击,镜头拉远一段时间后,能量光柱撞到一座巨大的山上,发生剧烈的爆炸,大概就是这样一个过程,那这里我们就只用到了手针去生视频, 这里有一个圆视频,因为我们的视频是要经过处理的,就取一节去加速,大家可以看一下去做一个对比。 接下来就是我们第三个镜头比较简单,这个镜头我们只要让风去吹动他的衣服和眼神就可以了,所以这里就直接给了一个男子姿态保持不变,眼神坚定的看向前方,头发被风吹动就可以了。 我们再来看一下第四个镜头,相对来说就会有一点点难度了,这里我给的提示词是男人全身汇聚无尽的能量,一个手掌向镜头射出巨大的能量光柱,这里其实我是用了一个倒放的, 他最开始生成的镜头是这样子,是这一个能量他直接发出去,就跟我们前面最开始是一样的,是发出去我们给他倒放一下,那他得到的效果就是他受到反派的攻击。那这边来演示一下倒放,这里我们直接把生成好的视频放到这里来, 我们选中它在剪映,这里会有一个倒放,我们就直接倒放一下,那这样它就是光波打到这个人物身上,我们再用它的尾针去作为下一个的手针,我们可以把这个尾针直接在这里导出竞争画面,这样就可以把这一个图片给它导出来, 导出来之后我们可以来看一下,我们在做镜头五的时候,就直接拿这一个作为镜头五的手中画面,大家看一下这个镜头五,这里我们就直接让它生成两个镜头,首先第一个镜头他直接去吸收这一个紫色的光效, 第二个镜头就直接特写到男人的眼睛里面,大概就这两个镜头,那这个镜头我们可以直接打开 ai 上传这一个手中图片,这里直接给他镜头一,镜头二这边时长给个十秒,这样他就会给我们生成两个镜头, 那生成出来之后就会是这样一个画面,最开始是一个紫色光照被男人吸收,第二个就是一个特写,好,当我们把镜头五生成完之后,接下来就是最后一个镜头,那最后一个镜头也比较简单,直接这一个 反手回去的一个画面,所以这里我们直接拿之前的这一张呈现图,给它的提示词就是男人全身汇聚无尽的能量,展现角色强大的气势, 然后呢一只手掌向镜头射出巨大的能量光柱攻击,跟随镜头拉远,大概就是这样一个提示词。那最后我们再把这六个片段直接放到剪辑软件里面, 直接拉进来之后调节合适的长度,包括进行变速,最后再配上合适的音乐以及音效,最后导出成片,整个过程就完成啦。好, ok, 那 这就是这一次的分享。
959AI-七七 03:35查看AI文稿AI文稿
03:35查看AI文稿AI文稿hello, 各位小伙伴们大家好,今天给大家演示一个吉梦的最新的功能啊, cds 二点零啊,它的最新功能叫全能参考。然后呢它可以做什么样的动画呢?就特别厉害的动画,大家看一下。 对,这样子的一些动画。好,大家可以看到呢,它是一个非常连贯的一个动作啊,然后所有东西都是准确的,呃,然后整个呃逻辑啊,各方面的东西都是对的。好,那么我们直接开始。 好,首先的话呢,我们到这里来做这个分镜图,这个是我以前做的一个片子啊,就是在这个雪地里边啊,有一些这个怪兽啊,追着这个 一辆车啊,然后这车里面的话呢有人啊,然后呢他们飞走啊,这是然后这些啊,怪兽掉下去啊,然后呢这个最后啊,他们这个逃脱成功的故事。好,那么首先第一张图我们直接来到这里面 啊,这第一张啊,然后第二张啊,我们放到这里面,第三张啊,这他逃脱成功的这样的一个故事。好,这样子就有三张图,大家可以看到,呃,第一张啊,然后呃第二张, 第二张的话呢是这个他飞到天上,然后这一些这个怪兽掉下去啊,第三个的话呢,就是这一个汽车啊,呃,逃离成功的一个故事啊,然后的话呢,我们就说啊,汽车被怪兽包围 包围,然后汽车猛加速啊,然后飞向啊,冲向悬崖,怪兽掉下去啊,汽车稳稳的啊,落在悬崖 对岸的平台。好,就这样子就可以了。然后呢你还可以直接给他艾特各种图啊,这个怪兽啊,这被包围,这个是第一句,那么我们可以在这里艾特一下,第一句啊,被这个我们包围了,然后汽车猛的加速冲向悬崖,这是第二句。 好,这个第二句,然后怪兽掉下去,汽车稳稳的落在第三句。好,这样的话呢,我们就通过三个分镜,直接就非常连贯的啊,实现了这样子的一个动画。这个如果说我们用分镜的方式来操作了,他的难点在于速度很难保持, 但是如果说能够在一段里边直接就给他做完,那么我们的这个效果呢,就特别的厉害啊。好,那么我们直接点击啊,生成好,这个速度还挺快的,大概也就是个一分钟不到。好,已经可以了,大家看一下。 哇塞,效果 很好。
967C4D部落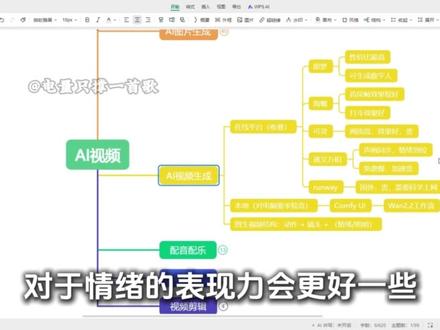 17:42查看AI文稿AI文稿
17:42查看AI文稿AI文稿自杰 ced 十一出手,慢剧圈的春天来了,现在只需一句话, ai 自动帮你顶级运镜。 那本期视频我将把 cedison 二点零使用手册和制作 ai 慢剧全流程分享出来, 相关的制作流程、提示词和 ai 工具我都以文档的形式整理好了,感兴趣的六六六带走。如何用 ai 制作出一部短片?其实非常简单,一部完整的短片,至少包含视频、台词、配音、配乐这些全部都能用 ai 轻松搞定。 而这里面最难的就是用 ai 做出符合故事情节的视频,以及保持角色的一致性。今天讲的全是技巧,我会手把手将你一条龙搞定。 写故事生人物配音、剪辑,创建一个 ai 短片视频,那我们现在正式开始吧。我这边做了一个流程图,大概分为六个部分,故事的脚本、 ai 图片的生成、 ai 视频的生成、配音、配乐、字幕以及视频剪辑。 我们先来看故事的脚本,我一共把它分成了几个模块,首先第一个我们要先去确定主题,第一种可以去跟客户沟通,第二种也可以自己去设定。就比如这一次的案例,就是以女娲补天的故事为例子去做了一个动画。那我们有了这样一个想法之后,就可以去生成剧本了。 剧本呢,我们可以借助大语言模型来生成,这里给大家推荐的就是 deep tech, 豆包和文心一言都是我们国内的,那我这边打开豆包的网站,直接给大家演示一下。 我们给他这样一段话,告诉他他是一个专业的动画故事编剧,真根三 d 动画领域,因为我现在想要做的就是一个三 d 的 动画, 那我们可以看一下这个就是他给我们写的一个剧本,比如说镜头一,镜头二大概是什么样子的,大家也可以去看一下有没有需要修改的地方。像这里他已经把场景画面和旁白都给我们了,相对来说还是比较全面的,当然我们肯定还是要去修改的。 当有了这个剧本之后,我们就可以让他直接去生成剧本中每一个人物的角色设定啊,我们可以给他发送这样一段话,让他给我生成剧本中每个人物的角色设定,需要包括这个角色的外形、服装、性格、行为特点。做这一步的目的就是为了保持我们人物的一致性, 那我们直接把这段话发送给他就可以了,发送完之后大家可以看一下,他就把剧情中出现的所有角色的设定都给我们写好了, 就比如说女娲的外形是什么样的,服装是什么样的,效果不是很好,也可以让他再去重新生成一下,不满意的部分都是没有问题的。 虽然只是一个雏形,但至少在前期我们会对整个剧本有一定的了解。到这一步我们的角色设定就做好了。那角色设定做完了之后,我们就要开始出分镜了,因为前面生成的只是一个剧本,这个剧本我们可以随时去修改, 修改完之后就要去生成 ai 能够识别的提示词,因为我们要生成图片的话,就需要把分镜脚本做出来,分镜脚本基本上就包含了提示词、旁白以及音乐这些。那我们后面生成图片的时候,直接拿这个分镜脚本里面的内容就可以了,那这个分镜脚本我给的提示词是这样的, 让他直接帮我把剧本转变为分镜脚本,每一个镜头不要超过五秒钟,角色设定也要把提示词写出来,就是我们之前生成的这个角色设定,其实你也可以直接去用,但让 ai 帮我们先整理好提示词的话,生成出来的效果会更好一些。 ai 声图的提示词让他写的详细一些,不需要具体到详细的参数,但要把风格写出来。后面这个其实就是表格的格式,我们把这个格式发送给他,那他就会直接帮我做成表格的样子,这个就是他给我们生成的一个分镜脚本, 这个脚本就是按照我们的格式来的,他就直接把运镜方式、景别是什么样子的,以及 ai 文声图提示词、 ai 图声视频提示词都给我们了。 当然这个我们肯定是要去修改的,大家可以先把这个表格直接下载下来,或者就直接让它存到这里也是 ok 的。 但如果大家后面还想要来回用的话,最好还是把它保存到本地, 那我们也可以先看一下它这里一共给了我们多少个镜头,大概是二十个镜头左右,我们可以先把每个分镜的图片生成出来,再把视频生成出来,就可以得到一个比较好的效果, 大家也可以自己去判断一下,不是说每一个镜头我们都要完全生成出手尾针,有的分镜可能只需要生成一个镜头就可以直接去生视频了。比如第四个分镜,这里讲的是人群逃亡的一个场景,我们就可以只生成一个手针,然后用图声视频的提示词生成视频就可以了。 所以这个部分大家可能要自己去斟酌一下,到底是用一个画面还是两个画面去生成视频会比较好。好,那到这里我们前期故事脚本的准备工作就已经全部做完了。 ok, 那 我们来讲一下第二个部分, ai 图片的生成, 我一共把它分成了四个模块。首先第一个选择台平台这一块我给大家推荐三个,第一个建梦,第二个是 sd, 第三个是 mj。 m g 是 最早普及 ai 图片生成平台,但它是国外的,虽然生成出来的图片很漂亮,但我们要用的话是需要科学上网的,而且成本也比较贵。 s d 它的可控性相对来说会强一些,它是可以本地部署的。 那纪梦我觉得结合了这两者的优势,首先他的图片效果现在已经非常强了,他对图片的控制和一致性都保持的很好,又没有那么难。所以呢,我这边用到的也是纪梦。那我们选择好平台之后,接下来就要了解一下纪梦提示词的结构。 那季梦的提示词我们用连贯的自然语言去描述就行了,就是用大白话去把它讲出来就 ok 了。但风格、色彩、光影以及构图这些画面美学的名词还是需要用短词语去描述的。那我们现在要生成一个动画短片,首先要知道你想要生成的风格是什么样的。 这边我也给大家截取了一些纪梦和剪映里面比较推荐的风格,比如二 d 卡通的风格,三 d 卡通的风格,儿童画的风格, q 版的风格, q 版比较可爱一点。再来就是日漫的风格,这些都是比较常用的,感兴趣大家可以自己去深入了解一下。 那你脑袋里面应该有一个大概的想法,你想要什么样的风格?比如我们现在做的是女娲补天的,那如果我们觉得国漫生成出来的效果相对来说是偏卡通的,我们就可以在他的基础上再添加一个三 d 写实。 那大家要记住这些风格是比较难的,所以我们就可以先去找一下别人做出来的这种国漫风格大概是什么样子的。直接去搜索国漫人物,他就会给我们展示各种不同的国漫角色,选择一张自己比较满意的,直接截图或者保存都可以。 好。然后我们再来到豆包上传图片,直接让他去反推提示词发送给他这样一段话,让他生成要包含画面的风格、构图、光影、色彩, 生成出来后,再结合我们之前生成的角色设定,把设定写在前面,后面再接我们这个反推的提示词,就可以直接用这个提示词去生成图片了。 当然这个 ai 给的提示词我们肯定是要去修改的,像这种国内的模型,它对我们国内的词汇理解能力相对来说会好一些。 ok, 这个就是我们的风格。再往下面看光影这一块,我这边也给大家截了一些出来, 逆光是什么样的,侧光是什么样的,还有侧逆光、柔光大概是一种什么样的感觉,我们都要了解一下,这样去找图片的时候就会好找一些。 再来就是色彩,我们至少要知道什么是暖色调,什么是冷色调,高饱和、低饱和,高对比,低对比这种我们都可以在提示词里去给他一定的描述。再来就是构图,其实我更建议大家去找一些构图比较好的图片再去学习。 好,当我们掌握了这些理论知识之后,接下来就可以去生成人物形象了。那生成人物形象这个部分,我们可以选择生成全身像或者半身像,全身像其实就是为了把他的服装以及高矮定下来,半身像角色的五官相对来说会清晰一些。这边我直接打开季梦给大家演示一下, 大家可以看一下,这个是我之前生成的模型,大家可以都先试一下,看看哪个生成出来的效果会比较好。我这里用的是四点一的模型,生成这种国漫卡通风格的角色,相对来说效果会好一些。把提示词复制过来,比例这里选择九比十六, 提示词里记得添加上全身或者半身立绘图,点击生成就可以了。像这里我写的全身立绘图,他给我生成出来的还是半身的,这个就可以先不用管,我们先挑选一个满意的造型,最终我选择的是这个形象。那当我们得到了这个形象之后呢?接下来就是把这个半身图变成全身图了, 我们可以直接把选好的这张角色图给到他,再描述一下全身像,穿着鞋子就能够生成出比较稳定的全身像的感觉。 因为我这个角色是光着脚的,所以我就把穿的鞋子换成了光脚。生成完全身图之后,可以再用智能超清处理一下。智能超清的细节生成程度不要调的太高,调到二十至三十左右就可以了, 太高他会给你重新生成一些多余的角色设计细节。我们前期尽量把服装定好一点,这样在之后生成图片的时候,前后的一致性也会保持的更好。 那当我们把女娲定下来之后,就要去生成一些配角的角色设定图了,我们把配角的提示词复制过来,上传女娲的设定图,让他参考图片风格,帮我做出配角的形象。同样的,生成完之后,最好再用智能超清处理一下。 把所有角色的设定生成完之后呢,接下来就可以开始生成分镜图片了,我们就根据这个分镜脚本的表格去除分镜图。分镜图这里要注意的是什么?就是人物的一致性。这边我还是给大家看一下像这个分镜,它只是展示了人物的正面半身,我们就直接上传角色的正面图就可以了, 但有些场景是需要展示人物背面的,例如这个分镜,我们就需要再去生成一下人物的三式图,这个直接去豆包上传设定图,是否帮我生成这个角色的三式图就可以生成出来了。 我这里就只生成了女娲的三式图,因为只有女娲会有各种角度的展示,那关于场景的部分,我们可以先生成一张场景图,然后再放到 a 字模式里,让他帮我们根据这张图片生成一个场景变化的图就可以了,那这个就是我们图片的生成。 接下来我们再讲一下 ai 视频的生成, ai 视频生成的方式主要有两种,第一种是在线的平台,第二种是本地的,本地基本上就是 copy 与位。在线平台这一块我也给大家列出出了几个,这是不同平台的一些优势, 像纪梦性价比非常高,他可以生成数字人,就是在生成动作的同时来讲话。海螺打斗和特效做的比较好,可灵的画质比较高,但也比较贵。通赢万象是支持生化同步的,对于情绪的表现力会更好一些。 若恩是国外的平台,需要科学上网,那我这边主要用到的就是纪梦。给大家演示一下, 我们打开界面之后,可以先把图片传上来,再把提示词复制给它。提示词其实在我们之前生成的分镜脚本里面都已经给我们了,我们可以直接把这个 ai 图声视频的提示词复制,然后回到积梦里粘贴模型这一块,选择默认的就好,然后再点击生成它,就能够生成对应的动画视频了。 后面的分镜我们也用同样的方法在脚本里直接复制就好。当然并不是所有的视频提示词都能直接复制过来用的, 像这个画面呢,我就没有直接用他的镜头提示词,因为脚本这里只有动作的描述,没有情绪的描述,所以我就把这个分镜的提示词修改了一下,大家可以根据自己图片的情况适当做一些修改。 像这种比较简单的动作,我们都可以用纪梦来生成,那如果是稍微复杂一点的或者有特效动作的,我就比较建议用海螺来生成。 这边也给大家看一下我用海螺制作的首尾针的效果,像这个分镜就是用首尾针生成的,生成出来的效果还可以,但这个分镜我也是生成了很多次才出来的,因为他有时候生成出来的效果并不是很好,所以我们要不断的去刷图,然后找到一个相对来说比较好的。 像这种效果如果我们用镜幕来做的话,是肯定出不来的,很多镜头都需要自己去补充,包括这种特效效果我们都是用海螺来生成的,相对来说效果会好一些。 像这个镜头我是做了蛮久的,生成了很多次,发现效果都没有很理想,要不就是乱切镜头,要不就是模型崩坏。所以说可能大家看到我展示的最终成品效果还不错,但其实他都是有很多不同的镜头衔接而成的。 好, ok, 这个就是视频生成的部分,视频生成完之后呢,我们就要开始去配音了,像这个视频它是没有人物对话的,所以配音的部分相对来说会比较简单,所以我主要用到的是剪映,这里给大家演示一下。 打开剪映,点击左上角的文本,这里有一个添加口播稿,打开之后我们就可以把分镜里所有的旁白直接复制过来。下面这里是可以选择配音音色的, 选择好音色后,点击一下左边的智能分割字幕,它就会自动帮你把每段话分割好,并生成对应的字幕,能帮我们节省很多时间。参数全部设置好之后,点击添加到轨道里,配音和字幕就完成了。 好,那我们做完配音和字幕之后,接下来就可以去剪辑了,剪辑这一块我们要先导入所有的素材,然后对它进行一个初剪。 初简就是要调整各个分镜片段和旁白朗读的速度,有的可能需要加快,有的就需要减慢,还要调整一下旁白的文字表达和字数长度,让 ai 念出来的语速和韵律更加自然通畅。把不要的片段删除之后,再来做精简。 精简就是要在对应的分镜画面上添加对应的音效和整个视频的背景音乐,然后再根据不同的音轨调整一下音量的大小,字幕分段和字体样式也可以根据实际情况做一些调整,最后导出就可以了。 这边我也给大家演示一下这个镜头,我把它拆分成了两段,因为这里是一个天色变化的场景转换,需要对这两个片段进行不同的变速处理,来呈现天色快速变化的效果。 再到后面这里我对配音进行了一个减速的处理,就是在某些地方我会让他变得慢一点点,再到某些地方可能就需要加速一下,包括音效的一些速度与音轨的位置,也是需要根据画面的节奏去调整的。当然如果大家觉得需要转场的话,也可以加入适量的转场, 其实很多时候我们直接用硬切就可以了。背景音乐这个部分我们可以直接在音频音乐库这里直接去搜索,比如说我输入神话故事,那他就会给我展示很多和神话故事相关的背景音乐。 如果想根据不同的场景做出一些音乐变化的话,也可以插入多段背景音乐,做更细致的音乐处理。 当然我们也可以借助 ai 去生成一个背景音乐,在剪映这里的 ai 音乐就可以直接生成。我们可以先用大模型生成出一些背景音乐的提示词,再把提示词输入进来,点击开始生成就可以了。 因为我生成出来的这个背景音乐不太适配我这个视频内,所以我用的还是音乐库里的音乐,像音效库这一块也是一样的,大家也可以用 ai 生成适配画面的音效,这里我就不给大家演示了,大概就是这样的一个流程,当我们把所有部分编辑好之后,就可以导出了。 以上就是我们整个 ai 短片的一个制作流程。上古之时,天地祥和,历久弥明, 不易骤变突升,天穹开裂,暗流席卷天地,乱石坠落,岩浆奔涌,山林尽染。 纤民父老邪恶奔逃,在劫难中苦苦挣扎。童子之手不迟刹那分离,孑然无一,又同师徒跌倒,繁衍巨色,灾祸降临四方。女娲俯看此景,虽决意挺身而出,寻尸补天, 立于高山之巅,其依然奔赴。寻石之徒,手探赤热火山,徒手攀越岩壁,寻赤红石, 潜入幽幽深潭,穿越暗流险阻,觅青林石,登顶冰封雪山,恢复凿开兼冰采白寒石。历经重重艰险,五色齐时,尽数齐齐。 女娲立于火山练石台,以神力为引,借熔岩之威,开启催练仪式。五色奇石消融汇聚,化作流光溢彩的五彩石浆,石浆承载万物,希望古天征程即刻开启。 女娲纵身欲起,直扑天穹裂缝,五彩石浆如星河一般倾泻而出,封堵天穹裂谷。 天穹既合,风雨渐顺,万物复苏,先民重拾希望,世间重归安宁。 这一切皆因女娲一腔无私,既是大爱。女娲补天的壮举从此流传千古,成为世间最温暖的信仰。
638^O^电量只撑一首歌 02:03查看AI文稿AI文稿
02:03查看AI文稿AI文稿啊,这样一段视频啊,我们季梦季梦 ai 啊,就这个季梦 cds 二点零这两天刷屏是吧?随机测试了一下啊,做了一个五秒的这样的一个视频, 再给大家看一下,哎,我们来慢放啊,慢放我们来看一看效果到底咋样是吧?慢放变速,我们给他慢放一倍,慢放一倍都不止吧,我们再来看一下啊, 那其实还可以啊,虽然有些穿帮,但是还可以,关键是非常的快,但是呢,哈哈哈,是珍贵啊,是珍贵,我给大家看一下啊,大家看一下是吧? 呃,五秒的视频,八十个积分啊,八十个积分他就用用完了,你看我都没积分了是吧?一共就八十个积分,那么如果我们要充值的话,要开会员的话啊,我们可以看到什么基础会员 六百五十九一年,那么每个月有一千零八十个积分,那么刚才我这个五秒的视频用了八十个点,对吧?那么大概十一个视频,十个到十一个视频,你不可能不抽卡的吗?对吧?我们已经算的非常理想的,非常理想的十个视频就结束了, 对吧?那么十个视频一个五秒的话是五十秒,一个月能升成五十秒,这边一千八百九十九的一万五千个积分大概能升成多长的时长,大家去算一下,别忘了还要抽卡啊, 这个贵是真贵,是吧?他可以给我们的动画润色,给你非常的快的来生成一些我们想要去制作的一些东西啊,非常的快捷,而且效果看上去也还是不错啊,这个模型确实牛逼,但是也确实的贵 啊,这一个月没有个几千万把块钱,你要真用这个干,那是干不下来啊,干不下来。哈哈,大家没事可以去去测试玩一下啊,不管怎么样,咱们了解新的东西,对吧?了解新的模型啊。嗯,大家玩玩,没事干玩一玩,是吧?
273涛哥教动画 07:43查看AI文稿AI文稿
07:43查看AI文稿AI文稿哈喽,大家好,我是日行一善,今天我们来讲解一下吉梦新上线的这个 c 单词二点零模型,这个模型刚一上线啊,就是效果非常炸裂,很多人都在用, 尤其是这个模型生成出来的 ai 慢距的效果,效果是非常牛的,像开头我们看到的那个视频,都是通过这个 c 单词二点零给我们来生成的这个模型的这个升级啊,主要有这么四点,它可以参考图像,可以精准的还原画面的这个构图,还有角色的这些细节, 以及参考视频支持镜头的这个语言,复杂的动作节奏,还有创意特效的这个复刻,以及我们可以上传视频,让他平滑的延长与衔接,按照用户的这个提示词生成连续的镜头 以及这个模型,他有编辑的这个能力,可以把我们想要编辑的这个视频上传,对已经上传的这个视频进行角色的更替删减,还有增加,这个模型非常强大。我们再来看一个实力, 这个动画效果已经非常炸裂了,这个是对哪吒二做的一个番外的一个延伸, 我们可以上传这个角色的这个图像,再生成一段提示词,就能给我们生成出这样非常炸裂效果的这种漫剧的视频,以及这个效果哪吒跟敖丙的一段打斗的一个特效, 像这个效果无论从运镜还有这个镜头的切换都是非常丝滑的,但是从细节上稍微还有一些瑕疵,但能做到这个程度已经非常牛了。 好,这次这个 s 二点零的这个能力的提升啊,主要针对于物理的这个规律,它生成出来的更合理了,还有动作的表现更加的流畅,还有对我们输入提示词的这个指令,生成出来的视频更精准, 以及风格保持的更稳定。下面我这里有些提示词啊,大家有需要的可以找我领取一下。好, s 二点零的这个模型,它支持这个多模态的一个输入, 既可以上传我们的文本图片、视频、音频这些素材都可以上传给到这个 s 二点零做参考。我们的提示词中也可以参考我们上传的这些素材做特效,还有运镜,还有人物场景声音, 只要我们这个提示词说清楚模型,他就能够理解,所以这个 s 二点零的这个能力,多模态参考的能力可以参考万物 以及强创意的一个生成,再加上我们提示词的指令响应的更加精准,他的理解能力也非常棒的。以及我们给他上传完首尾帧的这个图像,还可以上传一段视频做参考,让他参考我们视频,比如说视频中的打斗动作或者说风格都是可以的, 以及之前我们很难做到的一些视频效果,现在都可以做到,比如说这个一致性,就画面里的人物,首先要保障这个人物的一致性,还有镜头风格的一致性,现在的这个二点零都已经解决了,就是从人脸到服装再到字体这些细节,整体的一致性 更加准确,以及高难度的一些可控的运镜,还有动作的精准复刻也是可以做到的。我们可以看一下这个视力效果, 这个人物一致性保持的就非常好,以及我们做这种角色的这种参考我们上传人物的这个角色,再上传一个视频,模仿这个视频的打斗动作,好生成出来这样的效果。我们来看一下 这个效果都非常不错。以及我们还可以做这种创意的模板,复杂的特效的这种精准的复刻,好,照着这个模仿做这个创意的转场广告的这种成片,还有电影的片段都是可以的。 好,有需要这个提示词的可以找我领取一下。好,以及我们做这种 ai 慢剧,做这种剧情补充的这个模型也是可以帮我们做到的, 以及他有对这个视频做这个延长的能力,参考我们上传的这个视频,帮我们去延长这个视频后续的剧情,以及这个模型他的提升对这个音色更加准确,声音更加逼真,以及这个以及镜头的这个连贯性做的也非常好。 好,我们可以看一下这个一共是上传了五张图,一镜到底,追踪的这个镜头从街头跟随跑步者上楼梯,穿过走廊进入房顶,最终俯瞰整个城市。好,我们可以看一下这个视频的这个效果, 无论从这个角色转场,还有这个人物一致性上做的都是非常的好。以及我们可以针对于我们上传的这个视频做二次编辑,还有对音乐的这种卡点,比如我们可以看这个就是海报,我们上传几张模特还有服装的这个图片, 我们可以生成这样的这个效果, 这种对于做服装展示的视频就非常好。以及下面我们这种做剧情的,他的这个情绪演绎的也是非常到位。我们来看一下这个 啊,沉思了一会,突然开始崩溃,大叫,抓镜子,动作崩溃,情绪表情完全参考我们上传的这个视频。好,我们来看一下。 好,这个情绪做的也非常好啊, 所以这个吉梦 s 二点零的这个模型上线,代表着我们国产的这个视频模型又上了一个更新的一个台阶。好, kill the game, 大家有需要我这个全套提示词的可以找我领取一下。我们再回顾一下开头的这个视频画面。 好,今天的课我们就讲到这里啊,有需要这个题诗词的可以找我一下。好,谢谢大家。
1417日行一善讲AI 03:22查看AI文稿AI文稿
03:22查看AI文稿AI文稿各位这几天肯定都沉浸在 cds 二点零创作无法自拔吧?小餐也是小餐,这两天和朋友们交流,大家最崩溃的痛点其实很集中,就是视频段落间的逻辑瞬移。前一秒主角还在优雅喝咖啡,后一秒画面一闪, 背景桌子直接飞了,这种断存感不解决,你的视频永远没有高级感。今天小餐就实测复现,教你四招,彻底搞定 cds 二点零生成的十五秒素材衔接难题,让你的长视频丝滑的像一镜到底。 最后还有抽卡失败补救小秘籍,看完你会来,谢谢我。第一招也是小三压箱底的绝活,首尾帧锁定法。很多小伙伴为了衔接猛抽十五秒长视频,结果费用上去了,画面还是对不起,听我的,咱别硬刚!利用 cds 二点零强大的图片引导功能, 先截取第一段视频的最后一针,再截取第二段视频的第一针。关键点来了,用这两张图单独生成一个五秒的衔接短片,这五秒就是你的逻辑缓冲带,让 ai 在 两张固定图像间算出一个运动轨迹,用五秒的成本解决十五秒的难题。这波操作咱主打一个性价比拉满。 第二招,动态掩盖法。如果两段素材的细节实在对不上,那我们就用镜头语言骗过观众的眼睛,在第一段十四秒到第二段十六秒的这个衔接点,不要让镜头平移, 你要在提示词里强制引导 ai 做出大幅度的镜头运动,比如一个急速推胶,帅气的甩镜,或者让主角原地来个大幅度转身。为什么? 因为人眼对高速运动的物体分辨率会自动下降,只要镜头晃的够高级,衔接处的微小微移,观众根本看不出来。这招就叫暴力美学式转场。第三招,剪辑叠画法。咱们在生成的时候玩个小套路,千万别死卡十五秒。 比如你想做一段三十秒的视频,第一段生成零到十五秒没问题,但生成第二段时,你要把起始点往前挪两秒,开始重复,这样你手里就有两段重叠的素材了。 回到剪辑软件,把这两秒重叠部分拉一个叠化或者交叉溶解,这种藕断丝连的处理,能完美抵消 ai 生成时的随机抖动,视觉感官直接拉满。 第四招,提示词渐变法。最后一招虽然有一定抽卡概率,但也可以解决衔接问题。第二段的提示词千万别直接跳到新动作,你得在提示词开头包含第一段末尾的动作描述。比如前一段在跑步,这段开头得写保持跑步惯性并逐渐减速, 给 ai 一个心理准备。这就像接力棒,第二段必须先跑一段,第一段的路逻辑才不会断。除了这四招,小三最后还要掏出一个压箱底的独家小秘籍。大家在写 cds 二点零的提示词时,千万别只盯着画面, 记得在提示词里明确要求它只生成配音和环境音效,但千万要强调不要音乐。为什么?你想啊,每十五秒的音乐是单独生成的, 哪怕提示词里要求是同一段音乐,在衔接时也很难对齐。另外,只要没有音乐,哪怕这组镜头部分画面抽卡失败了,只要它的音效和配音是对的,你完全可以通过剪辑把有问题的部分剪掉, 能帮你挽救回无数段废片,省下的可都是真金白银的积分啊!音乐这块,老老实实留到剪辑软件里去添加,那才叫真正的丝滑。好了,这一套组合拳下来,我不信你的素材还衔接不丝滑!记得点赞、收藏、转发给你的朋友!你觉得哪一招最好用?评论区留下你的想法!
2867AI漫剧内参 02:16查看AI文稿AI文稿
02:16查看AI文稿AI文稿注意看, 这是我用 cds 两点零做的变形金刚宣传片,这个效果让我感觉传统影视制作的倒计时真正开始了。 这段十五秒的宣传片,我连参考图片都没给,就只是输入了提示词。我还记得前几天有个圈友的需求是 ai 短剧慢剧制作,今天就给安排了,就用 c dance 二点零完全可以满,一起来看看效果怎么样。 接下来解析制作过程。第一步,先找个大模型,让它帮我们生成分镜画面。我给的提示词是帮我设计一个浪漫的漫剧的片段,一共八个分镜,每个分镜都是最小单元的画面,镜头内容,每个分镜描述就一句话, 产品调性,风格考虑日本漫画。然后就生成了这样的提示词,再把这段提示词丢给 gans, 两点零选择视频生成 画面比例自助选择,时长拉到十五秒,然后大概五分钟就出来了。当然你要保持人物的一致性,就给他参考图就好了,其他的要求按需更改。接下去是另外一个圈,有的玩具机器人视频制作,同样给到大模型提示词, 帮我设计一个玩具机器人的大片广告,一共八个分镜,每个分镜都是最小单元的画面,镜头内容每个分镜描述就一句话,产品调性要高级,受众人群是儿童家长。 然后大模型就出了这样的分镜提示词,同样的操作丢给 cds 二点零视频制作,但是这次我给了参考图,因为是指定产品,五分钟后就出来这样的效果。 我想学编程,换个角度思考哦, 你们觉得怎么样?快来试一试吧!更多制作教程都放在老朱的 ai 朋友圈。关注我,老朱的 ai 朋友圈,咱们普通人一起 ai 落地。
2116老诸的Ai朋友圈








猜你喜欢
最新视频
- 5.9万冯子键