llm怎么调用skills
agent skills 最近的热度真的太高了,如果说 m c p 定义了 ai 调用工具的规范,那 skills 就 能让大模型将复杂的任务按规定的流程稳定运行。现在不少国内的 ide 都将 skills 集成到了自己的工具中。本期视频我会以 code 为例, 介绍什么是 skills, 以及如何通过 code 加上 skills, 让 ied 的 能力再上升一档。 skills 由三块内容组成,原数据、指令以及资源和代码。原数据用简短的描述说明了这个 skills 是 干什么的。 这部分数据会始终加载到模型的上下文中,原数据的内容很少,意味着可以同时配置很多的 skills, 而不会产生太大的上下文成本。 第二部分是指令。如果大模型觉得应该使用这个 skill, 这部分指令的内容才会被加载到上下文中。指令中会存放这个 skill 的 主要内容, 比如这是一个处理 pdf 的 skill, 指令部分的内容就定义了拿到一个 pdf 后如何处理 pdf 的 方式。指令和原数据都会放在 pdf 文件中。第三部分是资源和代码,在第二部分的指令中可以引用其他的文件, 比如要使用高级功能,就让 ai 去读 reference dmd, 要填写表单的话就读 form dmd 也可以指定当遇到某种情况就运行某个脚本,脚本一般都是拍存文件或者是有脚本, ai 会直接拿到运行之后的结果。通过这样一个 skill, 能让 ai 直接多了一个遇到 pdf 之后的处理能力。 同理,我们还可以写数据库迁移的 skill, 但把 review 的 skill 或者视频文案标题分面全部自动生成的 skill, 接下来就是怎么把 skill 在 ai 版本。先来看 ai 版本, 比如我现在想把这个 pdf 的 skill 做成用户级的能力,就在这个目录下创建 pdf skill, 里面放的就是 skill 相关的文件了。我现在手上有一个 pdf 文件,我通过这个 skill 让 code 将 pdf 转成图片,一行说明,直接搞定,完全解放双手,把 skill 集成到 id 中就更好用了。 code ide 最值得关注的特性就是它的快捷模式,这是一种完全的自主编程能力,特点就是无需持续人工介入就可以长时间持续执行。现在这个功能也可以通过 skills 扩展自己的能力了。就以这个 pdf skills 作为例子来演示,如果只想在当前项目下使用 skill, 就 可以在项目的点 code skills 目录下将刚刚这个 pdf skill 放进去。 现在我们要做一件事情,通过快捷模式模仿叉叉 u drop 生成一个定时任务管理页面,再通过 pdf skill 直接将产品使用文档整理成一个 pdf 文档。快捷有三套不同的模式可以选择,选择的场景不同,执行的方式也会不一样。我们这次主要是做个网站,那就选择构建网站就可以了,如果要做复杂项目的话, speak 会更加严谨。 另外,快捷模式还支持本地执行、并行执行和语音端服务的执行,我们这次就选择本地执行。快捷在执行前会自动根据需求对任务进行拆分。我们刚刚已经把 pdf skill 配置到项目中了,可以看到任务的最后一步就是通过 pdf skill 创建用户使用文档 quets 对 skill 的 支持是内置的,只需要把 skills 放到对应的目录中, quets 在 执行的时候就会自动去调用。现在通过前面五步任务,一个 web 项目就生成出来了,大家可以看一下生成的效果。第六步,通过 pdf skill 生成的文件也放在了项目目录内,内容十分详细。 代码能自动生成, pdf 文件也能通过 skill 自动生成。现在你就得到了一个完整的权限项目, 以及一份完整的产品使用说明。 pdf 文档所有你能想象出来的,能用代码写出来的功能,现在都可以作为一个个 skill 了。另外,如果你长时间使用 quick 做项目,会发现它对项目的理解会越来越深,这其实是 quick 的 一个技术突破点,可以做到自主进化,快速学习。以上就是本期视频的全部内容,我是鱼仔,我们下期再见。

粉丝6.6万获赞65.6万
相关视频
 08:26查看AI文稿AI文稿
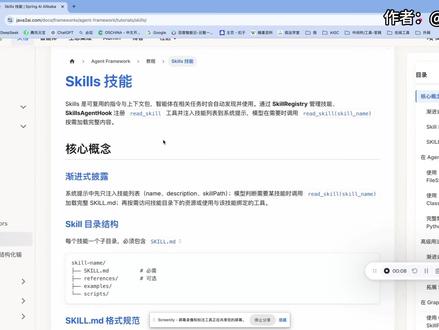
08:26查看AI文稿AI文稿大家好,我是 map。 今天我们按照扎瓦图 ai 上的 agent framework 的 skill 教程,把技能这套机制讲清楚。 skills 本质是一套可附用的指令和上下文包。智能体在做相关任务时会自动发现按需加载,而不是一次性把全部说明塞进提示。你先说核心的概念官方文档里,官方文档里强调一个词叫渐近式。譬如意思是系统提示 先指注入技能列表,也就是每个技能的 name description 型和 skill pass 模型,据此判断要不要用这个技能。但他认为需要时再调用 reader schema 并传入技能名,这时才加载完整的 schema。 点 md, 也就是 skill 的 markdown 文件。 之后可以按需访问技能目录下的资源,或者使用和该技能绑定的工具。这样既能让模型知道有哪些能力,又不会把大量说明一次性塞进上下文,对 token 和效果都更可控。负责这一套的主要是 skill register 和 skill aren't 户口 registry 管理技能的注册 以列表互可,负责把 read skill 譬如成工具,并把技能列表注入系统提示,技能在词典上的组织方式很简单,每一个技能对应一个 目录,目录里必须有一个 skill 等 and d, 当然还可以有 reference, 简谱 script 等子目录放参考和脚本。那 schematics md, 它的规范式有两个必填的,第一个是 name, 第二个是 description, 也就是描述 name。 建议小写字母数字连接连字母,最长是六十四个字母,那 description 的 话过长它是会被截断的。 那下面就是它的一个正文,主要写功能说明、使用方法,可用资源等。文档里建议单份 schema 点 m d 控制在一千五到两千的 token 左右,长内容要放在 reference 里面,并在正文里列路径。这是一个建议。经验, 这是一个经验的建议,那便于模型快速扫一眼再决定是否 these skill。 在 agent 里 skill 是 常见的,有两种注册。第一种的话就是 file system skill 文件 registry, 从本地文件系统加载,那构建时可以指定项目的一个 指定这个 project skill directory 和 user skill directory。 那 对应项目级和用户级的技能目录不配的话,用户即默认式当前用户目录下的 啊。想想欸,斜杠 skills 那 项目级默认是当前工作目录下的 skills 同名的技能以项目级为准,然后拿这个 registry 去去见 skill agent hook, 把 registry 传进去,再把 hook 挂到, 再把这个或可挂到这个 react agent agent agent 启动的时候就会在系统提示里带上技能列表,并暴露 read skill 工具。第二种是 class pass skill registry 技能,它主要是放在我们的这个 main 路径下面的 resource 目录下面的 skills, 或者说随价打包。那构建时指定 class pass 雷。呃, scuse 那 可选的像这个 bash pass 那 指定解压或复制到的一个目录,同样用这个 register 编辑 skill aire 的 付款挂到这个 react in 的 上面。那两种方式都是 register registree 管技能从哪里来,然后赫克管怎么注入提示,怎么暴露 reader skill, 那 文档里也给了我们一个完整的视力。 呃,主要是这个 skills 加排行榜加 shell 流程是先用 class pass 奎,当然是 pass skill register, 当然 gans pass 的 skills 目录加载技能,再建这个赫克, 当然这边是 skills agent 库克和 shell errant fork 就 这两个 fork。 shell 的 工作目录是当前的工作目录,然后 react errant 上同时挂这两个 fork, 先挂一个叫做 python 的 一个 tool, 最后是 enable login 启动日制方面排查。这样用户问请从某路径的文件里提取关键信息时,模型可以先 reading the skill, 拿到对应的技能的 skills 点 m d, 再根据说明去拼路径跳 python 或 shell 处理技能目录下的文件 技能列表理会带每个技能的 skill pass 模型可以用它拼出文件文件的绝对路径。这个就是典型的技能描述加工具执行的 我们法令法,那进阶用法里有两块值得我们去看的。第一个是工具和技能的一个绑定,嗯, 叫做 group 的 group 的 druse, 那 把一批 to 拷贝克,按技能名分组,那在 skis 迎刃帖 fork 里用 group to 也传进去。只有模型 对该技能调用了 readers q 之后,这批工具才会加入单次的请求,实现暗叙的暴露,那同一次绘画后续轮次里,这些工具仍然可用。第二个是生产环境,可以给或可配一个 auto 配一个 auto reload, 这样子每次 agent 执行前会尝试调用 re, 支持就 reload, 若实现支持就会加载最新智能文档也提醒了 reload 只在一次执行的首次推理时作保证同一次执行内行为是稳定的。 那在基于呃 graph 和 chat client 的 链路里,用 不用 react int 时,可以用 skype promta argument aviator aviator, 它是 spring i 的 aviator, 在 请求的 before 阶段把技能的原数据注入系统提示实现技能发现这部分,但它不注册 read skill。 若需要模型,按需读完整的 skill 点 a 要自己在 check client 或者 ins 里再挂了 rescale 工具和对应的节点。构建时可以用指定目录让 avira 内部建这个 fire system。 skill register 也可以先建好 skill sir register 再传给 advisor 那 文档里,文档里他明确说了,技能通常还要再配合脚本执行和 shell 才能在生产里真正用起来,所以和前面的 skill, python 和 shell 的 视力是对得上的。 架构上我们可以记成一条线。首先 secure registry 决定技能从哪里来,比如说文件系统或 classpath, 然后 skill agent 库克或者 skill prompt argument advisor 决定怎么把技能列表塞进系统提示 接定 skill, 决定何时加载完整的 skill。 四点,能递,然后 group toots, 决定哪些工具跟着技能做间接式 p o 落地时三点注意技能的名称。 skill read skill 参数, cropped toots 的 key 要保持一致,指对必须随技能激活的工具用 group toots, 其余的用 agent 的 toots 即可。 那 skill 点 m d 要控制它的体积。长内容拆到 reference, 这是我们当地给的呃经验建议。好了,以上就是我们今天的所有内容,感谢大家观看,我们下期再见。
46Map 08:34查看AI文稿AI文稿
08:34查看AI文稿AI文稿在本视频中,我将向你展示如何在 cloud code 中设置自我改进的技能。目前,大型语言模型存在的一个问题是,它们实际上并不会从我们这里学习。举个例子,假设你正在开发一个网页应用程序,在他尝试做的第一轮中,你所用的代码、执行环境或模型可能会犯一些错误。假设你想添加一个新功能, 并且这个功能中包含一个按钮。一个简单但相对常见的错误是 l l m。 实际上并不知道你可能想要使用的那个特定按钮。一般来说,你可以通过某些输入和按钮判断出哪些内容实际上是由 l l m 生成,这时你可能会纠正这个错误。 说好的,我其实是想让你引用这个按钮,但问题在于,当你在当前绘画中纠正了这个错误后,下次开启新绘画时,它还是会犯同样的错误。你又得重新纠正,或者记得明确指定要引用那个特定的按钮。 下一次绘画也是一样。这个循环会一直持续下去,每一次对话实际上都是从零开始的。而这个问题的关键在于,它影响到市面上的每一个模型 以及每一个编程工具。在我看来,如果编程工具本身没有一个良好且有效的记忆机制,确实会带来各种各样的挫败感。这种挫败感可能会以多种不同的方式表现出来。他可能不会遵循命名规范, 也不会使用正确的日期记录规范。他可能不会像你在其他组建中那样以正确的方式验证输入。你是否有过这样的经历?心里想着,我昨天才告诉过你这个或者我上周才跟你说过。问题在于这里没有记忆机制,你的偏好设置不会被保存下来。 实际上,如果没有某种记忆机制,你就会一直重复同样的事情。这个问题的解决方法其实相对简单,我们实际上可以设置一个反射技能来分析绘画、提取、修正内容,并更新技能文件。 我最近在尝试的一件事是把我在整台机器上使用的全局技能全部在 github 上进行版本管理。 随着我对这些特定技能进行反思和迭代,我可以随着时间推移看到所有不同的记忆。如果出现了回推或者我想要回滚也很容易。因为所有内容都在 get 的 版本控制之下。所以现在我设置的方式是有几种不同的机制, 而且相对来说很简单,我可以开启反思,关闭反思,还可以查看反思状态。我们有两种不同的方法可以实现这一点,一种是手动方式,另一种是自动方式。首先我们来讲一下手动流程,有一个叫做 reflect 的 技能,然后还有个斜杠命令。当你进行对话时,如果有你想让他记住的内容, 你只需调用那个斜杠命令,他就会获取对话的上下文,然后引用特定的技能,并相应的进行更新。 手动更新的好处在于,你可以更好地控制实际在技能文件中被更新的内容。我们来举一个假设性的例子,所以你可能会利用这个技能。他可能会说,这是我对认证模块的评选,而你可能会意识到哦,他实际上并没有检查 c 框注入,我们可以进一步指定始终检查 c 框注入。 然后从那时起, cloud 会在当前绘画中检查 coco 注入。就像我之前举的按钮示意一样,理想情况下它会返回并向你展示已经完成了。而这其中非常棒的一点是, 所有的修正都是可以成为良好记忆的。信号批准则是进一步的确认,而 reflect 命令和技能会提取这两者。然后在这个过程之后,我们所需要做的就是实际运行 reflect 命令。我们有两种不同的方法可以做到这一点。我们可以运行 reflect 命令, 或者也可以显示地传入技能名称。但如果你只传入 reflect, 它会因为处于该对话进程中而具备上下文感知能力,从而知道该技能实际被调用的时间。 实际上, cloud 会分析并扫描对话内容以查找修正。它会识别成功模式技能更新后的情况,并且这种设置方式会为你提供不同致性度级别的详细分析。致性度会分为高中和低。如果我说 绝不要做 x, 比如在这个项目中绝不要自己设计按钮样式。你完全可以像这样具体说明。中等执行度会是那些表现良好的模式,而低执行度则是需要后续复查的观察结果。而所有这些功能都只通过这个技能文件来实现。你可以编辑它对其进行调整。如果你想要版本控制或者不需要, 也可以直接添加 git 机程。另外,如果你不想用它,也可以直接移除。我会把所有这些内容放在视频描述里。在实际更新相应技能之前,审核和批准流程是这样的,我们可以看到检测到的信号, 提出的更改,以及如果我们接受这些更改后将要添加的提交信息。此外,在这里我们还可以直接进行更改,而且可以用自然语言来修改,这就是这个功能非常棒的地方之一。至于如何将这些更改实际应用到我们的技能目录并推送到 git, 我们可以点击 y n, 也可以用自然语言输入我们希望在 cloud code 中进行的不同更改。然后,一旦你做出了这些更改,或者你接受了 cloud 提出的建议,它就会编辑相应的技能,并在 get 中提交这些更改,接着再推送上去。 关于这个流程,有一点是我在自己的设置中非常想要实现的,那就是对于它在技能中做出的所有不同更改,一定要确保你也对这些更改进行了版本管理。 接下来,你其实可以采用同样的流程并将其自动化。你可以通过 hooks 钩子来自动触发反思操作。如果你之前没有用过 hooks, 实际上它们就是在不同事件发生时运行的命令。现在有一个 stop hook, 通过它你可以让 clod 持续运行并自动执行。 你实际上可以绑定一个 shell 脚本,每当 stop hook 被触发时,就调用它让 clod 继续运行。但它同样也非常适合用于绘画结束时的分析。 就像这现在这里势利中的语法是有问题的,但实际上它的作用就是在 stopbook 上我们会去触发那个 shell 脚本来进行反思。如果你打算让这个过程自动运行, 你确实需要对反思机制以及它实际执行的内容有很高的信心,但它的作用是,你会像之前一样经历整个流程,然后一旦绘画结束,这个后壳就会分析并自动更新所有不同的学习内容。 这将成为你在 cloud code 中可以拥有的持续自我改进循环。你同样也可以在其他代理系统中利用这种持续学习的策略。所以他会做的事情是,比如在那个按钮的例子中,他会继续进行并从绘画中学习。在 cloud code 中的表现是,我们会看到一个从绘画中学习的提示, 并且会显示它更新了哪个技能,所以这实际上更像是一种静默通知。但就像你在屏幕上看到的这种提示一样,它确实更新了那个特定的技能。然后,关于在停止钩子上被调用的 reflect shell 脚本, 我们可以将其开启。有一个机制可以开启或关闭 reflect, 这实际上会以和我们之前的 reflect 模式相同的方式工作,只不过现在是自动的。让我觉得兴奋的一点是,你可以利用这些技能做很多不同的事情,这可以用于代码审查, api 设计, 测试,文档编辑以及许多其他用力,而且让技能能够从你的对话中学习。我认为这是一件非常强大的事情, 而且把它集成在技能中,你就不必担心嵌入记忆以及我们常见的典型记忆系统所带来的各种复杂性。所有这些内容都会保存在一个 markdown 文件中,你可以直接用自然语言阅读。我喜欢的另一点是把它放在 get 里, 因为你可以看到系统是如何随着时间学习的。如果你有一个前端技能,你可以看到在使用过程中学到的所有不同内容,而不必每次都从零开始。 我认为更有趣的一点是,你可以看到这些技能是如何随着时间演变的,以及随着你与系统的对话,系统是如何变得越来越智能的。如果你也在 get 中利用这个功能,你将能够看到针对特定技能的所有不同学习过程。最后总结一下, 如果你对代理技能还不太熟悉,我会在视频描述中放上一些链接。我也可能会在这个月内做一些关于这类主题的其他视频。所以,如果你对这类内容感兴趣, 欢迎订阅我的频道。好的,最后,但同样重要的是,我们来总结一下刚才讨论的内容。有几种不同的方法可以实现这一点。你可以通过自动检测的方法来做,也可以通过手动的方法,或者你也可以切换开关,结合两种方式使用。如果你想利用自动检测的方法看看它的效果,也可以尝试一下。 另外,我建议你熟悉一下实际的 reflect 机制,然后我们还有切换机制。所以,如果你想结合手动和自动两种方式使用,你需要在 hock 触发时开启自动检测机制。 好的,总的来说,这一切的目标就是只需修正一次,之后就再也不用修正了。这只是一个开始。我并不是说这一定是最终的解决方案,但希望它能为你在技能提升、自我改进以及持续学习方面带来一些启发。
1449一蛙AI 06:59查看AI文稿AI文稿
06:59查看AI文稿AI文稿大家好,今天我们来聊一个特别酷的话题,怎么给你的 ai 助手装上超能力? 没错,我们要深入聊的就是一个核心概念,叫做 agent skills。 通过今天的讲解,你会发现,把一个普普通通的 ai 调教成一个能搞定你特定需求这专家级助手,其实没那么难。 咱们当程序员的是不是经常会想,哎,要是我的 ai 能直接看懂我们团队内部的 api 文档,或者能百分之百遵守我们项目的代码规范,那该有多爽啊! 我们想要的早就不是一个什么都懂点,但什么都不精的通用工具了,对吧?我们需要的是一个真正融入我们工作流的团队专家。那么想让 ai 变得这么懂行,关键在哪儿呢?答案就是 agent skills。 简单来说,这玩意儿就是一种能把特定的专业知识,工作流程,还有各种能力直接打包起来,然后安装到 ai 身上的方法。 你可以把一个 agent 的 skill 想象成一个嗯,一个专家技能包,这个包里啊,装满了搞定某个特定任务所需要的一切东西,比如说有详细的操作指南,有重要的参考文件,甚至还有能直接跑的脚本代码。 ai 一 旦装备了你这个技能包,它就能非常稳定,而且是可重复地完成这项工作,不会再瞎发挥了。 这里有个比喻,我觉得特别形象,一个通用的 ai, 就 像一台刚出厂的电脑,预装了个操作系统,能干很多事,但干啥都不专业。而给它加上一个 skill 呢?就好像是给这台电脑装上了一个专业软件,比如 photoshop 或者 final cut pro。 你 想想,一旦装上了一个叫财报分析的 skill, 那 ai 处理起相关任务来,是不是一下子就变得又转主又可靠了? ok, 我 们现在知道了它是什么。那问题来了, ai 到底是怎么发现并且在需要的时候聪明地用上这些我们给他的强大 skills 呢?咱们来看看它背后的工作机制。 这里面最巧妙的一个设计叫做 progressive disclosure, 翻译过来就是渐进式批录,这是一种效率极高的上下文管理方式。 你看啊, ai 它可不傻,不会一股脑儿地把所有技能的说明书都读一遍,那太浪费资源了。第一步,它只是快速地扫一眼所有技能的名片,也就是它们的原数据,知道个大概。 然后第二步,当你的指令发过来,它发现,诶,这个任务好像和某个技能的描述很匹配,这时候也是只有在这时候,它才会去加载那个技能的完整指令,这样一来,宝贵的计算资源就被大大节省了。 那我们怎么来激活一个 skill 呢?其实你有两种而法,第一种叫 explicit invocation, 也就是显示调用。这个非常直接,就跟你抄命令行一样,用一个 dollar 符号或者 slash skills 命令,明明白白地告诉 ai, 哎,就用这个 skill 来干活儿,别的别碰。 第二种呢,叫 implicitinvocation, 也就是引式调用。这个就更智能了,你就像平时一样下达指令, ai 会自己分析你的任务,然后去技能库里找看哪个 skill 的 描述最符合当前任务,然后自动调用它。 所以你看一个清晰准确的技能描述,对于能不能实现这种智能调用简直是太关键了。这些 skills 放在哪儿也决定了它的作用范围。我们管这个叫作用域, 这张图表就展示得很清楚。比如说你把一个 skill 放在 ripper 这个作用域里,那它就和整个项目的代码库绑定了,团队里所有人都能用,特别适合团队协助。 而放在 user 作用域里的呢,就是你自己的私人工具箱了,不管你在哪个项目里,都能随时调用。在网上还有 adim 和 system 级别,那些就是给整个系统或者所有用户配置的通用能力了。 好了,理论知识铺垫的差多了,是不是有点手痒了?别急,现在我们就进入最激动人心的环节,亲手来创建我们自己的第一个 skill。 你 可能觉得创建一个 skill 会很复杂,但实际上它的门槛儿低到你可能不信,你只需要两样东西,第一,一个文件夹,随便你起什么名儿。第二,在这个文件夹里创建一个叫 s k i l 点 m d 的 文件,对,没了,就这么简单。 而这个 s k i l 点 m d 文件就是你这个 skill 的 心脏和灵魂所在。当然,光有一个最基础的结构还不够酷,我们还可以给它加点装备来升级它的能力。 比如说,你可以建一个叫 scripts 的 文件夹,把可执行脚本放进去,这样 ai 就 能直接运行代码了。 或者建一个叫 references 文件夹,放一些参考文档给 ai 当背景资料,还可以弄个 assets 文件夹,存放一些文件模板。这些可选的组建能让你的 skill 变得更加强大和灵活。 现在我们把镜头拉近,仔细看看这个核心文件, s k o 点 m d。 在 这个文件的最开头,必须。我是说必须要有两个关键字段,一个是 name, 它就是这个 skill 的 唯一 id, 记住得是小写字母加连制服的格式。 另外也是最重要的一个就是 description, 你 可以把这个描述看作是你写给 ai 的 一份招聘启示,你得用最清晰的语言告诉它 这个技能是干嘛的,适合在什么情况下使用。这个描述写得好不好,直接决定了 ai 在 关键时刻能不能慧眼识珠,准确地找到并用上你的技能。好了,学会了怎么搭架子,那下一步自然就是怎么把这个 skill 做得更高效、更可靠。 接下来,我们来分享几条非常关键的最佳实践,想让你做的 skill 成为精品中的精品。记住这几条黄金法则,第一,保持专注, 一个 skill 就 让它干好一件事,别贪多。第二,多用私然语言指令,少用写死的脚本,是让能给 ai 更多的灵活性去应对不同情况。 第三,指令要写得像说明书一样清晰,最好用起始句一步一步地告诉他该干嘛。最后,也是最关键的一步就是测试,疯狂地测试,用各种你能想到的提示词去试试看,确保 ai 总能如你所愿地被准确唤醒。 好了,关于 agent skills 的 基本干练和用法,今天就介绍到这里,现在发挥你想象力的时间到了,不管是打造一个能帮你自动整理会议资料的文档助手,还是训练一个帮你的 bug 的 编程专家,这里的可能性真的是无穷无 尽,那么屏幕前的你想交给你的 ai 的 第一个新能力会是什么呢?
84炼云 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿怎么在本地电脑上部署最近火遍全网的 modbot, 并在不写一行代码的前提下,组合串联多个 skills 技能包,让它帮我们实现一个小案例。首先根据你的电脑选择对应的指令脚本,然后在命令行窗口粘贴执行, 等它执行完会自动进入配置流程。第一句是告诉你,虽然我很强大,但也会有风险,问你是否继续,这不废话吗?选 yes, 然后选快速启动。在配置大模型,国内国外都有,根据自己情况配置,我用的是 g l m 四点七粘贴模型, key 模型版本就选当前版本。在配置使用它的途径有 telegram、 whatsapp 等,不管哪一款,对国内用户来说都有点难搞,所以我这先跳过,然后是配 skills, 我这也跳过。配置完后启动项目,在浏览器的对话框里输入你是谁,看到有回复内容,就说明安装配置成功了。接下来调用 skills, 让他帮我们实现一个小功能。很多人不会写 skills 怎么办?没关系,他内置了帮你创建 skills 的 技能包,所以只需要告诉他调用 skill creator, 创建一个新的 skills。 从 github 的 trending 榜单中获取热门项目清单,并读取每个项目的 readme 文件,形成一份项目报告。报告内容需包含项目名称、 star 树、解决了什么痛点等等。最主要的是,这个 skills 需包含两个脚本文件,第一个脚本用于获取页面内容, 第二个脚本用于发送邮件,再把报告发送到指定邮箱,没一会就创建好了一个新技能,此时直接告诉他邮箱地址,并调用新技能看看效果,等他执行完登录你的邮箱。 ok, 已经收到了一封新邮件,并且里面有今日热门的五个开源项目,但内容排版不太好看, 我们可以使用最近很火的另一个 skills 美化一下。根据官方文档说明,把现有 skills 集成进去,有三种方法,我这选择第二种直接文件拷贝的方式,到 c 盘用户目录下找到 cloud bot, 新建一个 skills 文件夹,然后粘贴,再回到对话框,请使用技能包美化邮件内容。 好的,又收到一封邮件,这个排版看着就很舒服了。最后重点来了,如果想定时收到这封邮件,怎么弄呢?直接在对话框里输入,每隔三分钟执行一遍上面的任务,等待六分钟后,邮箱里就有了两封邮件,因为这款工具自带了定时任务功能。好了,如果觉得有用,别忘了点赞关注我们,下期视频继续!
764阿甘探AI 03:53查看AI文稿AI文稿
03:53查看AI文稿AI文稿很多人在争论 ai skills 是 不是涌现行为,但我发现这是个假问题。真正的问题是,你给 ai 装了一堆技能, 他不知道什么时候该用。大家好,这里是 l l mx factors, 一个专注于拆解大语言模型时代底层逻辑的频道。今天我们聊一个 ai a 阵的开发中最容易被忽视的困境。先看一条真实的开发者反馈。有人说,我问一个我知道应该激活 skill 的 任务, cloud 直接做了,根本没用。 skill 能力有了,出发没了,这才是问题。我们先搞清楚 skills 到底是什么。社区里有人一句话,破功, skills are just prompts the agent can choose to load that's it。 不是 什么黑科技,就是预加载的 prompt 关键词在哪? can choose to load, ai 可以 选择加载,问题是它会选吗? skills 和 m c p tools 有 什么区别? tools 是 函数调用,静态绑定的, m c p 是 动态工作流引擎,复杂但强大。 skills 呢? 可选夹子的 prompt, 简单但靠人设计。有人说得好, scales 是 更用户友好的 m c p 精简版 scales 组合使用确实有价值,就像工具箱里的扳手、螺丝刀、锤子,组合起来能完成更复杂的任务。但问题来了, ai 知道工具箱里有什么,但它不知道什么时候该用哪个。这就是触发困境的本质。要让 ai 正确激活一个 skill, 需要三步, 识别、场景匹配决定现在该用。执行加载使用第一步就经常失败, ai 不 认为当前场景需要用这个 skill。 有 人想出一个办法,用一个 router skill 来管理其他 skills。 听起来很聪明,但问题是 turtles all the way down。 你 需要 router 正确激活 route 需要什么来正确激活另一个 route 无限欠讨。还有人用 hooks 就是 不断提醒 ai 有 哪些 skills 可用。问题是太通用,缺乏针对性消耗上下文窗口,治标不治本。这告诉我们什么 agent 开发的核心困境是能力不等于可用。 你以为 agent 的 开发是给 ai 更多工具,写更强的 prompt, 增加能力,实际上 agent 的 开发是让 ai 知道什么时候用设计出发条件,增加可信。好的 skill 设计不只是能力描述,需要包含清晰的出发条件,什么时候用明确的边界,什么时候不用 原子化设计一个 skill 做一件事。这就是为什么 demo 爽上线崩 demo 的 时候,你手动告诉 ai 用什么工具。 production 的 时候, ai 需要自己判断用什么百分之九十的 agent 项目死在这一步。给你三个实操建议,第一, 设计 skill 时先写触发条件,不要只写这个 skill 可以 做什么,要写当用户提到什么关键词且场景是什么条件时使用这个 skill。 第二,测试触发比测试执行更重要。设计十个应该触发的场景,十个不应该触发的场景, 跑一遍看成功率。如果激活率低于百分之八十,先修出发逻辑,别急着优化执行。第三,组合 skills 要设计协议。 skills 之间的调用需要明确的入口,出口状态传递规范失败处理机制,否则组合只会增加混乱。回到开始的问题, skills 组合是不是涌现行为?这个问题不重要,涌现是系统产生设计之外的行为, skills 组合是设计内的能力叠加,叫什么不影响你的 agent 能不能用什么才重要, 可能性大于能力。一个能稳定触发的简单 skill 好 过十个触发不了的复杂 skill。 agile 工程的本质,让正确的能力在正确的时机被正确地调用。所以今天的核心判断是什么?争论涌现是假问题, 真问题是 ai 有 了技能,不知道什么时候有。这是 agent 开发最难的部分,也是区分 demo 和 production 的 关键。原文链接我放在评论区了,你在开发 agent 的 时遇到过 skills 触发的问题吗?欢迎评论区讨论。这里是 l l mx factors, 我 们下期见。
 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿上期视频,很多朋友追着问博主,你的 ppt 到底怎么做的?今天压箱底的方案全部公开,干嘛要收费? not book lm 导出 pdf 不 能编辑,国产工具千篇一律,我全测过了都不够用。直到我用 gemini 搭了一个自己的 ppt 智能体, 零成本,无限页数,高颜值,可编辑一次成型,给大家看看实际效果, 基本每次一轮就能让你满意。觉得某页不合适,告诉他只改那一页,想加图标说一句就行。他是一个可以对话的设计师,不是一个只能用一次的工具。方法很简单,三步, 第一步,打开 gemini, 创建一个 g e m, 相当于你的专属智能体。第二步,写着我这套提示词,里边封装了一整套电影级设计规范,高级转场,智能配色,不对称双蓝布局,数据图表动态生长,而且指定默认用 canvas 输出。这一步很关键, cass 输出的内容可以直接导入 powerpoint 的 编辑。第三步,丢进去一份文档,一段大纲,甚至一句话,一键生成题旨词,我放评论区置顶了直接复制就能用。拿到之后记得回来评论区告诉我效果怎么样,我们一起来优化这套题旨词,越叠代越强。
1436LIGHT 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿这是一个让你实现 skill 自由的网站,让你使用 ai 的 效率提升十倍。每天一个强大的网站。第五十六期,今天要讲的是, 这里有四千多条各领域的专业 skill, 包括写作、前端、后端、营销、自媒体、 ppt 制作等,内容超级丰富,需要哪个用哪个。使用也很简单,以创意为例,找到对应 skill 地址,在创意里点击克隆 get 仓库,输入 skill 地址,等待十几秒,你的编程工具就拥有了这项技能。没有编程工具也可以使用扣子 输入请安装这个 skill, 附上地址就装好了,使用时直接调用就行了。重要是这个网站上的资源免费使用,持续更新,不用注册。恭喜你,离超级个体又近了一步!
239旭哥AI笔记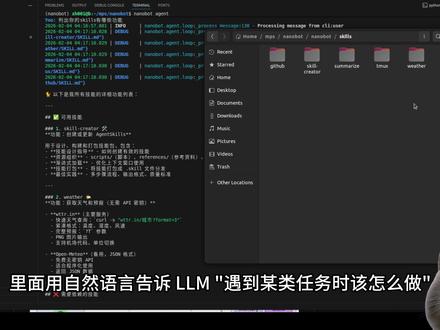 06:12查看AI文稿AI文稿
06:12查看AI文稿AI文稿最近香港大学开园了一个项目,叫 nano bot。 nano bot 是 一款超轻量级个人 ai 助手,仅用约四千行代码即可实现核心代理功能。 nano bot 内置了五个 skill cq, 本质上一个 markdown 文件,里面用自然语言告诉 l l m 遇到某类任务时该怎么做。它不是代码插件,而是提示词工程的模块化封装,把人类的最佳实践写成 markdown, 在 需要的时候喂给大模型。 这个设计很聪明,你不需要会写代码就能给 ai 加能力。我们让 nano bot 列出它的四 q 和对应的功能。 skill creator 技能作用是让 agent 自己创建新技能,它会自己生成 skill, 点 m d。 自我进化微的天气查询,用于获取天气和预报,无需 api 密钥。 还有一些需要额外依赖的 skill summarize, 内容摘要总结或提取文本转入内容。 team x 终端绘画管理,用于远程控制 team x 绘画。 github 与 github 交互。这里我们提问,让他帮我们查询当地的天气。 l l m 会调用 read file 读 read skill, 点 md, 按照 skill 指令执行返回结果。我们看查询结果。今日二六年二月四日,温度十一点八摄氏度,天气多云阴天。我跟他说帮我做一个翻译技能 c q, 文件夹下多了一个 translate, 它会自己生成 skill, 点 m d, 写好触发条件,放到 workspace 目录。下次你说让它翻译这段话,它就自动加载使用了。下面我们来一起本地部署 nano bot。 它用了 lightlam 做模型路由,理论上支持一百多个模型。 openai, 智普 d p 格莱玛本地模型,我们按照官方命令克隆项目并安装依赖,安装依赖完成后运行驶使化命令,它会生成 config 点接收文件。这里我们用的是性价比高的智普 glm 四点七模型。 需要注意的是前缀过时问题。 nano bot 代码里用的前缀是基普,但来铁来来米已经在二五年十二月改成了 z i i。 智普不认识老前缀处理后的 api 了,所以报令牌已过期。错误, 我们需要修改 schema 点 py 和 linux provider 点 py 文件。原来字段叫 gpl, 改成 gai 后 nano bot 才能正确读到你 can fake 点 jason 里 z i 下面的 api key 深度对比 opencloud 和 nano bot 架构 下面是我觉得最值得聊的部分。 opencloud 和 nano bot 架构下面是我觉得最值得聊的部分。 tik 经济学用 ai agent 做事,每一次对话都要把系统提示词、工具定义既能描述打包发给大模型,这些东西,哪怕你只是问一句,二加二等于几。 opencloud 系统提示词大概一万四千个 token, 工具定义八千个 token, 您还没问问题呢,光底噪就已经两万两千 token 了。 nano bot 系统提示词压缩到三千到五千, token, 工具只保留了九个核心的定义,开销两千五百 token, 同样的简单查询大概六千六百 token, 省了百分之七十二。再看复杂任务,比如读文件、分析内容,搜索网页跑五轮工具调用 open core 要烧掉十二万 token 的 输入, nano bot 只要三点五万,差了三倍多。为什么差距这么大? 我叉了七个维度来看第一个系统提示词, openclaw 是 全量注入,不管你问什么底噪固定一万四千 token, nano bot 做了精简核心指令压缩,既能只放一个 xml 锁影加样。第二个,反射循环, 这个差异非常关键, openclaw 有 深度 reflection 机制,出错了会反思,反思完重试,重试失败再反思,听起来很智能, 但最坏情况下五轮反射成本直接放大十倍, nano bot 没有反射失败就报错,好处是绝对不会成本失控,坏处是复杂任务的自愈能力弱一些。 第三个,工具加载策略, opencloud 是 二十多个工具全量注入,加上所有 skill 原数据,假设你十次对话只用了一个 skill, 剩下九次全是浪费,会白白浪费。十万 token, nano bot 用了一个巧妙的两级加载 系统提示词里只放技能的 x m l 锁影大模型,看到锁影后自己决定要不要加载完整内容。 第四个,上下文压缩, openclaw 有 autocompaction, 但预值设在五万 token, nanobot 完全没有压缩消息,只会追加敲现了 api, 直接报四百错误。第五个,工具返回结果, opencloud 的 浏览器工具可能返回完整网页 html, 动辄几万 token, nano bot 用 brave search api 返回结构化加载,不过是要和文件读取,两边都没做截断, 但是这个 brave search api 申请需要绑卡,大家有条件的可以尝试一下。第六个,塞设历史管理, openclaw 保存完整消息,包括中间的工具调用列五十轮对话后历史可能超过五万 token, nanovo 只存问答,对中间的工具调用过程不存, 所以增长慢很多,五十轮也就一点五万 token 左右。再看 skills 系统两边都用四 q 点 m d 文件定义技能,但加载策略完全不同。 openclaw 是 全量注入,所有技能都塞进系统提示词, 好处是模型随时能用任何工具,坏处是不管用不用都占 token。 nano bot 在 系统提示词里只放一个技能,所以列表模型看到所以后判断需要哪个技能,再用 red file 工具加载完整内容, 多花一轮调用,但省了大量偷看。你看现在 cloud 的 system prompt 里也有类似的 siegs 列表, mcp 协议本质上也在做同样的事。 skills 这个模式以后一定是标配,不管什么 ai agent 框架,最终都要解决怎么把领域知识高效注入给模型这个问题。 最后总结一下, openclose 定位全能但昂贵,它的功能覆盖确实最全,反射机制让它处理复杂任务时有自愈能力,但代价是每次对话的固定成本高, 存在成本失控风险。 nano bot 代码量只有百分之一,但该有的 react 循环工具调用技能系统一样没少。它不适合所有场景,但对于个人开发者和小团队来说,性价比极高。这期就到这里,觉得有用的话点个赞收藏一下,我们下期视频再见!
759AGI_Ananas 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿今天给大家分享一个开源项目 on bro, 这个开源项目特别有意思,就是它是专门用于这个 open curl 的, 但是其他的这种 skills 其实也是可以用的,那一句话概括就是它是一个扩展工具,当你用 open curl 或者其他的这种 playwrite 浏览器做动画的,呃,这种 mcp 工具的时候, 你是一个一个的进行点击的,也是我们现在做这种浏览器自动化最大的一些问题,因为它每一个页面它都要全部读一遍,再让 ai 去选择要点哪里,它速度非常的慢。所以说它这个项目就是当你执行过一次之后,它会去监控它的一些 api, 它去访问这个网址,这个网站的 api, 它会把这样的 api 自动地打包成 skills, 你 可以把这个 skills 去装在你下一个支持 skills 的 里面, 你就能快速的进行调用,而且它还是支持你可以直接上传到它的一个应用市场里面,还可以赚钱。这个项目特别有意思,就是它能自动的打包打包成 api 的 形式,让 ai 直接调用 api 就 能获取对应的信息,这样它的执行速度就非常的快了。
 26:41查看AI文稿AI文稿
26:41查看AI文稿AI文稿如何用 tree 的 技能?就是现在比较火的这个 skills 去调用扣子的这个工作流。我们今天给大家录这个非常详细的一个视频,来分享一下这个操作。操作的话也非常的简单啊,非常的简单。 在这之前呢,我们要先准备几样的原材料啊?还是一样,它既然调用肯定是通过 api 的 形式,比如说我以这个 my voice audio, 对 吧?这个是文字转音频的,为什么说这么简单的一个?因为这里有我自己录制的我的音频,我的声音,咱们一会在转换的时候可以听一下它是不是我的声音, 需要做啥呢?把工作流点完了之后复制,把这串内容给它复制下来,复制下来它就相当于工作流的 id, 其实 id 的 话,它只需要中间这一段,看见没,但是我们就假装自己不懂,我就放到这, ok, 然后这个令牌呢?令牌在哪看?我们来看一下啊, 在外面,然后点这个 api 管理,管理了之后点授权,授权了之后这有个个人访问令牌里面这是 tree skills 的, 我们再来添加一个,添加个令牌,这个是 s k i i skills 演示 过期时间,我给他选成一天,大家可以去自定义啊,你可以自定义成永久,然后这里呢我们选什么?你要是不知道,你就选选全部指定空间,我们选个人空间,确定就 ok 了。完成之后还是一样,他这有个令牌,我们把这个一复制,复制完之后还是一样给它存下来, 还是给大家讲的这个令牌自己一定要保存好,千万不要把令牌给搞丢了。这个令牌完了之后呢,如果你是一个编码的人那你可能都知道怎么去用了,但是我现在我不知道怎么用。那怎么办?我试着点一点 我点一点他咋用呢?健全方式的概述里面有没有 这里面有没有对吧?好的没有的话那我们来看一下啊我们就假装现在自己是个小白。我到这个文档中心去看看看它有没有对应的,哎。文档中心有有什么呢?有这个 api 和 sdk。 这个 api 我 点开了之后就是点左侧文档中心点 api 我在下面找一找有没有关于对话工作流的,哎还真有有工工作流的对吧我们点一下工执行工作流。注意他这里给你放的全是通过 api 的 形式如何去执行工作流的。我们在下面翻一翻 来找我们请求地址是这个对吧。咱也看不懂呀是不是看不懂 哎臣妾表示也看不懂。看不懂咋办。我看不懂就不懂了不懂就继续往下翻。我要找一个一劳永逸的东西,哎你看他这里是不是有一个同步执行的工作流的事例,哎对不对? 这是返回的事。返回我们不用管啊返回我们不用管我们就管他的请求执行就是请求我们怎么样运行对吧。 干啥了把它一复制复制完了之后还是一样你看我有多偷懒我不用懂他。不是我不懂啊不是我我不教大家怎么懂是我真不懂呀,但是我在不懂的情况下我能把它调通。 ok 好就这样这样完成了之后扣子这边要准备的东西就完了,大家跟上啊。我就不不再不再重复做了来跟上。然后呢我在这里可以新建一个文件夹,这个文件夹是干啥用的? s k i i i s gives 调用扣子 d m o demo 演示,对吧?好,放到这之后呢,这是我的翠,对吧?我要打开刚才我创建的那个文件夹,大家也是一样啊,你自己去打开它,那它那个文件夹桌面上, 因为翠它的使用的话,它就是要打开一个文件夹去用。 ok, 我 们用翠把它打开,打开了之后大家注意啊,你一定要设置一下。设置什么呢? 一定要在 solo 模式下。为啥要在 solo 模式下?因为我们这个视频要给大家分享的是我们如何用 这个吹 ide, 它的技能去掉这个这个这个这个什么扣子的工作流,对吧?你点设置完之后,它这里会有一个规则和技能,对吧?规则和技能这里是创建的,当然呢,我们不需要去在这创建,我也会用人工的方式去创建, 但是要要前提要求是啥?就你必须是在这个 solo 模式下,他才能自动去创建这个技能,而且创建完技能之后,他在哪里呢?他就在你的这个文件夹下,然后这个文件夹放这边啊,他这会有个点翠的一个文件夹。好,我们现在咋做?大家注意看,我把这个内容全复制, 复制完了之后我把它粘到这里。以上是扣子工作流调用的势力和我提供的工作流的 id 和令牌,请帮我 啊,请帮我。怎么一个技能?请帮我创建一个技能。对,创建一个技能能够调用 code 的 工作流, 我这个技能能够实现,当我输入一段文本后,调用 工作流转成音频。好, ok, 我 们就这样去给它发发,发送完之后大家注意啊,静观其变,我们来看一下。 好的,他现在去这个是什么?这个是扣子 api 调用的一个地址,对吧?他会去看,他会去理解这个内容, 然后呢说要创建一个技能,你看他在思考我的过程,思考过程的时候呢,大家再去看扣子调用这个的技能,对吧?然后他要创建一个技能,哎,重点来了,大家注意看啊,他调用的技能,他本身自身有一个技能,叫什么 skill creator, 他就用他自己自身的这个技能去创建技能,就他本身是有个技能,这个技能会根据我们的要求自动创建技能, 非常非常的厉害啊。 ok, 我 们现在就耐心等待一下这个,有人说老师教这个有啥用, 用处可大了。如果你去翻我往期的视频,你就会发现我曾经写了一个,分享一段,一个视频,对吧?那个视频就讲的是什么,我用 tree 的 skills 去掉什么,掉了扣子的 文字转音频,掉了扣子的文字生图,最后呢,他就能够文字转音频,文字生图,全用扣子的技能去帮我生成一个什么?生成一个视频,这是他能做到。 ok, 这是他完成的,对吧?好,完成了之后我们试着啊 应用到全局。好的,我们先来检查一下这个,这个,这个文件夹,你看它是不是这里有个帮我创建这个技能,对吧?这个技能的内容是什么呢?就是在这里。 ok, 好, 我是一名好老师, 正在给大家分享扣子的相关技能,相关知识,对吧?好,请帮我把上面的 文字转成音频,当我给它发完了之后,我们再看 solocoder 这块,它会提示什么内容,对吧?它会提示什么内容?它首先在思考,思考完了之后呢?它说调用技能 code text to audio, 我 们来看一下,它一会是不是会帮我生成一个音频, 当你有了这些操作了之后啊,你就非常灵活的,哎,我,我扣子里面有很多这个工作流,我想掉,怎么办?我还不会去配 a p i, 咋办?你只要会吹,我们在吹里面用自然语言让它去帮我创建技能,哎, ok, 它这样的话就能帮我生成。 好的,我们一会看一下,看,它会告诉我啊,它会告诉我这个,这个音频生成在哪里了, 我调用了音频执行结果, ok, 然后呢?分享知识,通过 debug 用了生成音频,音频在哪呢?没看见,没看着呀,反过头来看一下,哎,这里也没有, 对吧?这是一个非常典型的一个问题,对吧?常用工作流执行情况,我们点开可以看一下, 他不会让我去登录去吧,哎,你看他让我登录火山引擎去了,对吧?那肯定显然不对啊, 并没有,我没有看到你给我生成的音频文件, 请你调整技能,重新运行, ok, 遇到什么问题就给他讲什么问题,这就是我们现在用 ai 的 一个技巧。哎,有人说有,有的小伙伴一听郝老师分享这个内容,到这之后又发现没出来,没出来他就慌,他不知道咋办,哎,郝老师,咋办?别的老师问他就怎么办?不用问, 谁给你出的问题,你就去检查谁就行了啊。你再用 tree, 出了问题,你就直接在对话框里面问他,用豆包啊,用 deepsafe 等等的都是这个思路,所以大家要转化一下,转化一下这个,这个使用 ai 的 一个习惯,对吧? 啊,习惯性去问别人的内容怎么办?要习惯性的去问 ai, ai 给你的答案反而会更精准一些。 你讲他现在做的这些工作,什么调用了?我仅仅能知道他是掉了这些内容,但是咋掉的我确实是不知道,所以我只能通过自然语言的方式去给他说,然后呢, 让他去帮我进行修改,验证参数,对吧?我看一下啊, 使用的参数名称一致哎,一致着呢呀。 text, 哦,我知道了,我知道是什么问题了,你看,咱懂上一点点的还是有点用处的啊,来, ok, 咱们回过头来可以看一下。回过头我们看一下自己的工作流, 我的工作流里面输入的这个变量叫什么?叫 input, 人家叫什么?人家叫 test 啊,我如果改的话,我就直接把这里改成 input 了,那么大家如果不会改怎么办? 工作流输入的变量名称叫 input, 请帮我修改技能。就是因为啊,在工作流调用的过程中啊,你所有的东西它一字不能查,你叫 text, 它叫 input, 它就它就不认识了,对吧?你看,我现在这么一说之后,它一会儿肯定把这就给我改了, 哎,大家看一下是不是,对吧。所以我们在学这个东西的过程中啊,嗯,也要学会去深入思考,这也是我们最近想给小伙伴们去讲这个,讲这个编程的时候担心的一个误区是什么呢?就大家就只会在这说,说完了之后,这里的东西他不看 啊,我们一定要去看,你看多了,你根据你自己的学科内容去理解它就 ok 了。好的,这样的话它就帮我改了。改了之后呢,我们再来看一下 但翔哥的 output 的 任务,可能原因工作流没有正确的配置输出,执行过程出现了问题。我们来看一下啊,工作流配置 output 的 link 没有问题啊,这个工作流的,呃,对对对,这个这个是没有问题的,因为我之前也用这个方法调过机能配置一个,一旦音频转换应该成功,对吧?权限,工作流可能需要吞进权限才能生成音频。没有问题啊, 没有问题,我们再来看一下啊,再来看一下我觉得这样的一个,我们把它发布一下,他刚说有尚未发布的这个修改,请重新帮我 运行,将内容转为音频,我再给他发。发完了之后我们再看一下,看能不能成功,反正调音的方式就是这样,我给大家分享,对吧?然后呢,大家去调,你调完了之后再去试试, 我们再来耐心等待一下,看他会不会帮我把音频生成啊。 调用成功,但返回的 auto 的 应该应 a p i 响应显示不但是由于工作流配置问题导致,请用上方链接登录扣子平台,看它的执行日期,确保正确。结束了音符的参数,我们 清它的一句券。然后呢,到这个平台,我们来看一下它的一个历史,二十三点三十六,那应该去点这个调试, 这里看不到是吧?这里看不到。呃,那它是什么问题呢?我们试着在这里直接输入一段话啊,我是一名好老师, 我这里运行一下,哎,可以生成呀,我是一名好老师,对吧? ok, 那 我继续再给翠翠说,我在工作流 界面运行了,能够顺利生成 音频链接,请帮我检查你创建的技能要求运行之后能够直接生成音频链接。 ok, 我 们再给他提要求,就是我自己也用 tree 的 编程去做了一些内容出来,在做这个内容之后呢,就发现了一些一些问题,问题是啥呢?就是他其实非常耗费时间,也非常耗费你的耐心, 就你明明知道这样能做通,他会出中间出很多很多的小问题,对吧?当然呢,还有一个问题,啥呢?上次我在用的时候是用的 tree 的 国际版。啊,我用的国际版去做这样的国际版的话,它下面用的是国国国外的一些模型,那些模型呢,可能会更聪明一些,当然这次呢,因为要给大家分享,好多小伙伴可能用不到国际版的吹,所以呢,我还是用咱们国内的去给大家分享,分享的时候可能会有一些 一些问题,对吧?可能会慢一些,可能会多交流几次, ok, 他 如果在思考中,我们就不要去打扰他。哎,耐心等待,看他一会儿能给我们做出一个什么花来。 我们来看一下啊,增加了轮询机制的说明,翻译库的时候需要使用不同的参数来确保 正确的参数名,这个已经保证了啊,哎哎,你看这个分析问题就非常到位了,说是 api 调用的时候,对吧? 我刚一调用他就要立即返回,这其实是不合理的。我,我调用完工作流之后呢,他得等一段时间他才能运行到我的结果,对吧?好, 那么我现在再给他说,请把我要求的文本转成音频,大家注意看啊,那我就说这句话,他能不能识别到?我是一名好老师,正在给大家分享 code 知识点,这是他的思考过程, 只要这个点点他是一个正方形的,他就说明一直在思考,对吧?哎,大家注意看啊,我想给大家去表达一个什么样的一个观点呢?就是我,我还要给大家去分享如何用吹去写作,你会发现他的上下文的能力非常强, 我已经说了很多轮之后,他都知道我要表达的内容是这个内容,对吧?因此请通过提供的 debug 的 u i l 我 们来看这个 u i l 在 哪呢?我没有看到它 u i l 呀,我们来看一下这里面有没有啊?复制 在哪里呢?我没有看到。 你能不能直接 生成的音频保存在项目的目录下, 他有啥问题就给他说啥问题。虽然说咱们这个视视频的内容没有一次调用成功,我觉得中间和他去沟通解决问题这个思路也能给大家带来一些这个一些启发。我们再来看一下 复制上面的链接到浏览器中,对吧? ok, 它让我复制,我又复制一下,如果它成了,那说明它就成了。 但是我咋感觉这个这个链接它又会让我再去,再去干啥再去登录呢?运行完成,哎,对对对对对,它是一个这样的一个界面,我们来看一下 output 是 空的呀,参数,哎,再给大家说一个用 tree 的 一个好的 地方啊,我们把它一截图,截图认给他之后传给他,我访问了你的 the bug 链接后, 给我这样的提示,请帮我修复。我还是想直接把生成的音频保存在 目录下,请帮我解决。大家每次遇到问题可能跟我这不一样,所以呢,怎么办?需要 text 参数,而不是 input 的 参数。 text 参数?没有呀, 我这里就是 input 的 参数呀。啊,他说这里输入的是 text, 咱不管他啊,咱不管他,让他去调,他说是什么参数就是什么参数。请帮我 把要求的文案转成音频,我们再来看一下它的内容,它又让我去访问这个 debug u i l 的 这个这个链接,请确保开始节点的输出参数设置为 test。 我明白他的意思,但是我觉得不应该是这样,你看,而且他这个 debug 链接让我去干啥?要让我去,让我去这个,这个叫什么?对对对,这个这个,这个。登录啊, 请不要用 the bug 的 形式反馈结果,你可以用你的方法帮我调用工作流, 然后我的要求是直接输出音频文件, 请你自己想办法,咱是领导,咱给他提要求,让他去想办法,如果我再给他反馈,他解决不了,反到最后人家不得用国际版的。国际版能解决,那说明还是模型之间能力的一个问题。 use context 或 input。 我们来看一下对准的呀,看一下它是什么问题,要不我就叫寄出我的这个 国际版的锤,他这次如果不成功,我们就用国际版的锤去试试一下。好的,他不行,不行就把它一关,关了之后我们试一下国际版的锤。国际版的出货好像把次数用完了啊,我不知道是那一天的用完了还是这个月的用完了, 像猫猫检查技能,我要求输入一段文本后调用 工作流输出,结果工作流的输出输入参数是字符串,名称是 input。 哎,余额不足 余额不足,不足以完成本次请求。哎呀,我们试着 扣个包吧,一百次三美三美金啊,三百次七美金, 六百次十二美金。先搞个三美金的吧,我记得上次就买了个三美金的 rate survey 哦, 不让看,好像是网络的问题,我调整一下网络啊,我们来看一下购买容量包,买个三百斤的,确定它会支付它就自己就扣了啊,我每个月的吹它就是自动扣款的 啊,已经支付完了,支付完成之后呢,刷新一下, ok, 它现在就能分析了啊,然后分析了之后我们把它还是切换到这个来看一下是不是模型的一个问题啊。因为上次我在用的时候就用的是国外的这个模型, 用翠花钱的话一个月也得花个七十多块钱,一年下来一一千块钱,这就是一个很好的一个案例,能给大家去 去讲,去去去直观的去感受一下啊。你看它,它的这个内外模型的一个差别,咱们试着看一下,看它能不能 能不能运行成功啊,平时我们用的一些文本啊,文本类的,我你像我也,我也用国内的,但是内容不复杂,你就根本体会不到一些模型的一个差别。那我之前做的那个软注模拟申请的那个工作流啊,当你在真正的要做到 ai 去编网页的时候,你就会知道它可能不太好弄,哎,你看你看这个就比较 比较聪明,还写了一个拍子啊,但是我给我,我刚给咱国内的吹电 c n, 我 给他说,我说你有你的办法吗?我的要求就是我输一段文本,你能给我生成一段音频就 ok 了啊,你用啥方法呢?我不管, ok, 我 们在耐心等待一下啊。 名称原文本定义的是 text 单元要求的部分,这一实际已修正好。 ok, ok, 我 我我给他说一下,我是一名好老师, 致力于给小伙伴们分享最前沿的扣子内容, 请帮我把这段内容转成音频。 ok, 我 们来看一下,如果说这次他转成功了,那我就就给国际版的税再去充点钱去,哈哈,我感觉 一定要为了好东西付费呢,咱们耽误这些时间。你说一开始思路都是对的,对吧?但是你用国内的就就调不成功,你用国外的,你看好像是要成功了啊,当然还不能乐观,我们再看一下,看是不是真的能帮我把音频生成。我,那个文件夹在哪呢?文件夹在这,对吧? 文件夹在这哦,文件夹放旁边。其实这个给大家现在分享的这个只是一个思路,当你有了这个思路的之后,你就可以去做做很多的这个事情,你可以把你做的这个工作流啦,智能体用很灵活的方式去调那个啥内容啥东西,包括 他在跑这个 python 程序,咱的目标就是把音频给我生成出来, 代表我通过自然语言的方式,我能把工作留给他调成功啊,这是咱的一个目标。有小伙伴说,郝老师,你费这么大劲搞这个事情有用吗?你要相信啊,你把一个程序调通了之后,你很长一段时间你不用再去动他, 哎,我感觉有戏,对吧?你看他这个链接好像就是正正确的 删除三个文章,确定删除他是一些过程文件,测试的过程文件,咱不需要他。 ok, 来我们来看一下啊,这是他的一个音频,我们点一下,我是一名好老师,致力于给小伙伴们分享最前沿的扣字内容。我是一名好老师,这 ok, 这就说明了一个道理啊,你看这是国际版的锤还是国外的模型,在某些方面能力是要远远大于咱国内的模型,这就是今天给大家分享的一个如何用锤去掉 扣子的这个工作流。那我觉得既把如何掉工作流的思路给大家讲了,我们也很直观的啊,非常直观的感受了一下国内的 这个模型和国外模型的一个能能力,一个能力的一个差别。大家可能看到我前面沟通了很多次,但是呢,国外版的话多沟通了一次就 ok 了啊。 ok, 那 么这个视频呢,就分享到这里,也希望能给各位小伙伴在学扣子,用扣子,用最前沿的 skills 掉扣子的这个事情上面能够有所启发。好的,这期视频就到这里,我们下期再见。
 05:07查看AI文稿AI文稿
05:07查看AI文稿AI文稿hello, 大家好,这期视频给大家发布一款我现在这个呃,我们 skype 的 这个第一款产品叫 skype link, 把世间万物连接到我们的 o m 的 大脑终端,实现数字永生。 那么这整个项目都是 gpt 五来构建的,所有的代码的一个提示词都是让呃 gpt 五来做的,而我只是给了它一个命题。好,我们可以看一下整个的一个项目内容, 我做的目的就是说我们做了一个 skills, 呃,这个 skills 是 a o m 的 一个源技能系统, 把我们的所有的这个日常的工作去进行一个梳理,然后去定义它的一个关键技能,把这些关键技能交给 ai 去执行, 然后 ai 会持续优化你的技能,也就是说在未来我们不需要去做我们自己的工作,而我们只需要把我们的工作做什么内容梳理给 ai, 让 ai 去做就行了。这边是下面是它的一个具体的一个说明 啊,这边我们已经猎取了一些常见的一些实践的功能,比如说周宝编辑或者说需求评选啊,这整个 skills 的 一个 全部都是通过我们的呃 markdown 的 这个语言提示来做的,因为我们知道 skills 本身只是说对我们 ai 的 一个提示词,我们这边作为它的一个语言提示词,然后可以把世界万物全部呃,所有需要做的事情全部让 ai 来做。 呃,它整个工程都是 ai 做的,所以说这边也是 ai 提炼出来的整个核心价值,第一个是节省时间,第二个是自动化,第三个是我们的一个质量的一个提升,第四个是知识转移,然后第五个是持续改进, 其实这个我觉得对于我们来说,知识转移跟持续改进是对 ai 本身而言的,因为 ai 的 大脑会越来越聪明,因为我们这边说了,我们是连接到我们的一个大脑那么大圆模型,呃, 不同的厂商它的功能可能都有一些偏差,但基本的能力都是在不断增强的,而且这个迭代速度会非常快。 我们要知道 g p t 三也才是三年前的事情,而现在已经迭迭代了的 g p t 五跟我们新出的这个 cloud 四点六呃,智普的 呃 g m 这些能力都比原来的能力强到太多了。就我们当初上下文来说,现在最新的一个 a m 的 上下文已经能达到呃百万的 token, 而我们之前呢,可能才有 呃一百二十八 k 最早,所以说这个能力肯定是无限不断过,不断的变强的啊。现在是今年是二零二六年的二月十四,二月十三号啊,距离星级新年还有三天, 但是我觉得到今年年终或者到年末的时候,整个 a m 的 这个能力会更大的上,不断的上升,而且通过我们这种呃 link 的 方式 去创建我们每个人的 skills。 我 认为在未来这个 skills 它并不是我们要去下载或者去登录的东西,这个东西本身就是 ai 输出给我们的, 我们需要的就是说呃,我们拿到它的,可以通过我们的原体诗词去生成你自己的一个 skills, 跟每个人强相关的,每个人的工作他不一样,需要的 skills 也不一样,所以说每个人的技能包都会不一样,而这些技能包其实都是让 ai 去帮你生成出来的, 那么我们这个项目的目的呢?就是说让每个人都能把日常工作委托给 ai, 我 们去更多去思考,去创新的一些工作,去思考 ai 到底能给我们带来什么东西。然后我们这边通过系统化的一个提示词是,嗯, 可以帮助每个人去实现这个数字永生。好,那么我希望我们一起来构建未来的这个智能的工作方式,而且我觉得这个只是一个过渡阶段, 在两到三年以内,如果说我们的所有的工作功能,我们所有的技能包全部能让 ai 实现的话,那未来人类就不需要工作了,因为所有的东西都可以 ai 去做,也就两到三年的时间,我认为他是有个过渡阶段的,但目标肯定是这样子的, 好让我们来回到我们这一个工程啊,我们的工程就是在这里啊,这是我创建的一个 project, 大家都可以去 start 一下,然后可以去看一下我这边的一个描述,整个 project 都是 ai 来构建的 啊,如果大家感兴趣的话,可以给我们点个关注,然后,呃也可以跟我一起去探讨未来 ai 的 实现路径,那本期视频就到这里,感谢大家的收看。
15。T-T。




![[3.3]工具的基本语法 吴恩达Agentic AI课程中文字幕版【模块3】工具使用:工具的基本语法(Tool synyax)视频来源:DeepLearning.AI。#AI #transformer神经网络架构 #吴恩达 #知识创作人 #大学生](https://p3-pc-sign.douyinpic.com/tos-cn-p-0015/o0GBNveVDeVfkL0DATbEAL0qImQCeQgA2pZIEd~tplv-dy-resize-origshort-autoq-75:330.jpeg?lk3s=138a59ce&x-expires=2086797600&x-signature=gs9aGGKQcnrlTs7UjSl%2BnieyM%2Fs%3D&from=327834062&s=PackSourceEnum_AWEME_DETAIL&se=false&sc=cover&biz_tag=pcweb_cover&l=202602190241195CEFA06F29A03BBF3245)



