power query如何获取txt数据
粉丝33获赞96
相关视频
 02:41查看AI文稿AI文稿
02:41查看AI文稿AI文稿欢迎和我一起学习第五章中的第一讲,获取外部数据从 excel 二零一六版本起,数据选项卡第一个命令组以前叫获取外部数据,后来变成了获取和转换数据。获取和转换其实就是 procreal, 它比之前一个少版本导入的数据接口更智能。有时或许的数据不规范,还需要整理数据, procro 可以帮忙转换。 点击获取数据命令,可以从文件,从数据库还有其他地方获取数据,几乎提供了无缝数据导入。 首先选择重文本,找到练习材料,找到需要导入的数据,点击导 入文件原格式是简体中文 g b 二三幺二, g b 二三幺二是中华人民共和国国家标准简体中文字符集数据类型检测这里我要导入 t x t 文档中所有的数据, 选择基于整个数据集,点击加载,加载数据会应用智能表格, 打开 t x t 文档,把产品 a 的数量改成三千,保存 t x t 文档。在 excel 中,在表格工具设计选项卡点击刷新,产品 a 的数量也变过来了。 我不想 excel 的数据与 t s t 文档再发生关联,就点击取消链接命令,弹出提示,这将有 永久删除公众表中的查询定义是否继续,我单击确定 要把这个网站的数据加载到 excel 中,先将网址复制一下,来到数据选项卡,选择自网站, 将网址粘贴过来,点击确定。打开导航器,在导航器中选择 table 零,不需要全部导入这些数据,只导入排名、球队胜负胜率,点击转换数据。 按住 shift 键,选中前五列,点击删除列,选择删除其他列,最后点击关闭并上载 好。以上就是本节课所讲的内容,最后按照课程惯例打开这个公众表,看看这些问题你都会了吗?
202office945 01:3224龙哥教你学电脑
01:3224龙哥教你学电脑 22:06查看AI文稿AI文稿
22:06查看AI文稿AI文稿好甜蜜,从这节开始呢,我们就正式进入我们本套课程的学习了,那么在我们正式学习之前呢,我首先啊做一个简单的自我介绍,我叫无名,大家可以叫我吴老师,老吴啊都可以, 我们这道课程的主题啊,是零基础,速成 party 高手,也就说即使同学们之前未接触过 party, 或者是呢未曾使用过 party, 那么都可以借助本套课程的学习啊,快速成长为 party 高手。那么我们废话不多说,我们接下来啊,就直接进入我们第一节课的学习。 我们先来了解一下,我们为什么学习 party。 在这个数据时代啊,无论我们从事什么工作都会遇到啊,需要对数据进行分析,从而呢去支撑业务决策的工作任务场景。那么既然数据分析这么普遍,它的工作流程有哪几步呢?我们接下来啊,就来熟悉一下,那么对于数据分析的工作 做流程总共有四步啊,分别是获取数据源,数据清洗,数据分析,数据可视化。那么我把这几个步骤呢分别啊来解释一下。第一步啊,就是获取数据源,也就是获取啊所有我们数据分析工作所需要的数据, 那么我们获取的这些所有的数据啊,他的规范可能并不统一,所以呢,我们就进入第二个步骤,也就是数据清洗,所谓数据清洗呢,就是将不规范的数据呢,我们要把它进行规范,也就是数据规范化。 那么当我们把这些数据清洗干净之后呢,那么接下来我们就可以针对啊,已经清洗好的规范的数据,我们来进行各个维度的数据分析工作,也就是进入了第三步,当我们分析好之后呢,我们的分析结果啊,并不直观,这个时候呢,我们可以通过图表的方式,将数据啊可视 话的方式来进行呈现,也就是制作报告,从而呢方便别人呀,来去易于理解。那么这就是工作流程的四个步骤。那么当我们呀再去做数据分析工作的时候,在这些工作流程的过程中, 我们有可能会遇到什么问题呢?我们接下来啊,也来了解一下,我们来看一下常见的工作难题有哪些。那么第一个难题啊,就是数据原分散, 我们所需要进行分析的数据啊,有可能是在文本文件中,也有可能呢是在 excel 工作部文件中,那么还有可能呢,在数据库中,那么所有这些分散的这些数据员,我们如何来进行整合呢?那么这就是一个问题了。 再然后呢,就是因为啊,我们所获取的数据啊,并不规范,他的数据员可能都不统一啊,那么这个时候我们就需要来去进行数据的清洗,将数据进行规范化,同时呢方便 进一步的进行数据分析,那么怎么样来进行规范呢?好,这也是一个问题啊。然后第三个呢,就是在有些分析工作中啊,我们所拿到的数据量有可能是非常大的, 如果我们使用传统的工具,比如说 excel, 我们去处理几十万条的数据,我们就会发现他就已经开始频繁的卡顿了,导致工作非常的低效。所以第三个问题是数据量大, 第四个呢是重复操作,在这个时代啊,那么数据每一刻都在产生,而我们呢往往需要快速计时的来进行分析, 那么当我们的数据发生变化的时候,那么我们希望立刻得到分析的结果,如果我们使用普通的工具啊,那么当数据发生变化的时候,我们每一次啊都可能要重新的来进行操作,导致浪费大量的时间,所以呢,对于啊,这些各种各样的工作 难题,我们到底怎么样来去进行解决呢?那么这个时候我们就需要使用 parquery 了,使用 parquery 我们就可以轻松解决啊,那么所有的这些工作难题,那么接下来我们呀就来了解一下,到底什么是 parquery, parquery 我们呀见明知义,可以把它理解为啊就是一个超级查询工具, 那么它实际上本质上是一个优质的 etr 工具。好,这里呢有一个新的词汇啊,叫做 etl, 这个词呢看起来啊好像很复杂,但是呢实际上非常简单,我来给你们来解释一下, etl, 也就是 extract, transform, load, 那么这三个单词的首字母的结合啊, 那么这个 extract 就表示意思,就是抽取的意思,而 transform 呢就表示转换的意思, load 呢就表示加载的意思,也就是说当我们从数据员获取到大量的数据之后呢,那么接下来我们就需要把这些分散的数据员呢来 进行整合,来去抽取出来啊,我们数据分析工作所需要的数据,这一步呢就称之为是抽取, 那么当我们把这些数据抽取出来之后呢,那么这些数据啊并不规范,所以呢,我们可以借助于转换,那么这个步骤呢,来去执行数据清洗的操作,将数据呢进行啊规范化,再然后我们呀需要把我们清洗之后的数据呢,去加载到其他的数据分析的工具中, 那么这些数据分析的工具啊,那么也就是我们加载的目的端,比如说 excel, power b i, 它们都是典型的数据分析的工具, 再然后我们就可以进一步的来进行数据的分析,从而呢,最终啊把分析的数据啊进行数据可视化呈现给啊我们的领导或者是其他的同事。那么在这个过程中啊,那么准备来看抽取,转换和加载,那么就是 属于啊 party 可以去承接的工作,而且呢,在我们数据的分析的工作中啊,那么这几步我们把它归结为啊,就是数据清洗的工作,他会占用我们大量的时间,而借助于 party, 我们就可以节约我们大量的工作时间,来去提升我们的工作效率。 所以对于 part part 来说,那么它的优势到底是什么呢?我们来看一下,第一个就是它可以连接上百种数据源,无论你的数据啊,是在文本文件中,还是在 excel 工作部中,又或者是在数据库中啊等等,那么它都可以啊连接上去,那么这样的话,是不是就解决了我们数据源分散的问题啊, 再然后就是无需编程也可以啊,对这个数据进行快速的清洗,在 party 中啊,存在丰富的数据清洗的命令,我们很快啊就能够看到,再往下那么就是支持大量数据的快速 处理,也就说使用 party, 当我们遇到大批量数据处理的工作场景的时候,那么不会出现这种频繁卡顿的情况,然后再往下,那么就是记录所有的操作步骤,一旦数据源发生变化,我们只需要刷新就可以了,也就是像刷新网页一样,非常的简单。 那么当我们的数据啊原如果他的数据进行了更新,那么因为啊 party 可以记录我们所有的操作步骤,所以呢,当这里的数据发生变化,我们点击刷新,那么他就会把新增添的所有的数据啊去执行同样的记录这些操作,那么这个时候我们就可以及时的得到分析的结果了。 所以同学们对于啊 party 现在有一个大概的了解之后,我们可以这么来总结一下,就是 party, 因为它强大的功能可以轻松的解决啊我们工作中遇到的所有的难题,同样呢去节约我们大量的时间啊,让我们 能够专注于业务分析本身。那么这么强大的 parquery, 那么它到底是在哪里呢? parquery 啊,它实际上是直接植入到了那么这些数据分析的工具中,比如说 excel 和 part bree, 我会在后面的课程中啊逐一给同学们进行演示啊, 那么我们只要知道 powerpoint 很强大,而且呢是植入到这些数据分析的软件中的,所以呢它是非常易于获取啊和进行使用的 啊。那么接下来呢,那么我们呀来讲解一个案例啊,通过这个案例,我们来感受一下 park query 的强大的功能,那么从而呢去提升啊同学们学习 park query 的兴趣。 这个案例呢,我说明一下,不需要同学们现在立刻就能够掌握,只需要观察老师的操作呢,去感受 party 的强大功能就可以了。那么接下来我们就来看一下这个案例哈,这个案例的需求呢,是让我们呀去整理 qq q 号以及呢 qq 的邮箱地址,那么我们来看一下这个原始数据啊,可以看到在这个原始的数据中,是不是这些数据啊都特别的零散啊,好,那么经过 parker 的处理过之后,那么我们就可以啊能够整理出来 qq 号以及呢 qq 的邮箱。 那么接下来我们呀就把这个案例呢,我们呀来去完成一下,我再重申一下,就这个案例并不需要颓废,立刻就能够掌握,只需要观察来感受啊 party 的强大就可以了。 那么接下来我们就来找到老师所提供的素材文件啊,我们来找到零基础速成 party 高手,找到第二个文件夹,也就是素材,我们来选择第一张,然后呢找到第一节课的素材, 那么现在我们来去双击打开这个邮箱的采集数据一啊,那么这是呢我们采集的一些邮箱的数据,那么现在呢这个任务啊,就是想让 我们呀来去把这里的 qq 的邮箱以及他对应的 qq 号,然后呢把它整理出来,那么怎么去操作呢?我们来看哈,首先我们来去选择这一片数据中的任意一个单元格,我们来单记一下,然后呢我们来去点击这个数据选项卡, 那么这个书呢,我们来看在这个获取和转换数据这个命令组中啊,我们看到这里有一个来自表格和区域,那么我们来去单击一下, 当我们单击过之后,我们会发现他想要去创建表啊,并且呢询问我们表是否包含标题,我们看到我们这个表中啊,是不是没有任何的表头啊,所以呢,我们不需要进行勾选,我们直接点击确定就可以了, 当我们点击确定之后,我们就会发现,我们是不是就进入了 powerpoint 的编辑器啊?所以我在之前就给同学们讲过这个 powerpoint 编辑器啊,它是直接植入到 excel 中的哈,所以我们可以直接来进行使用。 那我们来看一下,在这个 park car 编辑器中啊,是不是有很多的命令啊,那么这些命令呢,都是属于数据清洗的命令啊,那么这个 park car 的功能非常强大,就是因为他有这些非常强大的数据清洗的命令啊,那么我们接下来来看一下我们加载过来的数据啊,这是不是就是我们刚才数据原中的数据, 我们来观察一下这些数据,然后紧接着我们对这些数据啊来去进行清洗。那么咱们来看一下,在这些数据中啊,是不是有很多的这些数据啊,他的左侧都是有一些空格的, 那么这些空格呢,没有任何的意义,我们想要把它处理掉,那么这个时候怎么做呢?我们就可以啊,把所有的列先给他选中啊,怎么去选中呢?先去单击那么上方这个表头,我们来单击一下,选择第一列,然后我们按住 shift 键,再去选择最后一列,我来去单击一下,那么这个时候是不是又把所 所有的列来给它选中呀?也就说借助于 shift 键,那我们就可以选择所有的列,然后紧接着我们来去点击啊这个转换这个选项卡,我们看到在这里啊,是不是我们可以来找到格式啊?然后在这个格式中,人们有没有看到这里是不是有一个修整的,那么这样一个命令啊? 我们来去点击修整好,这个时候我们会发现,是不是所有的这些没有意义的空格是不是都已经消失了呀?那么非常的简单哈,操作起来非常的简便。而我们再来观察一下我们这个数据啊,我们会发现我们要处理的这些数据啊,那么在五页, 那么现在我们想要把它转换到一列中,是不是处理起来更加的方便啊?那么这个时候怎么样来去把它转换到一列中呢?同样还是选择所有的列,因为我在之前已经选中了,这次呢我就不进行选择了,我们呀直接来 点击转换,在这里有没有看到有一个非常强大的功能,叫做逆透试列,我们来去单击一下,当我们单击之后,我们就会发现哇,是不是所有的数据都已经成功的转到一列中了呀?当然了,他还生成了另外一列,那么这一列我们并不需要啊,所以呢我们把它给清除掉, 我们来去点击他的表头,是不是单独选中了这一列,然后我们按一下键盘上的第一个按键,那么这个时候是不是就把这个无用的这一列来进行删除了呀?然后我们继续来进行观察,然后我们来看一下,在我们这个数据中啊,有没有发现有些呢,那么是属于 qq 邮箱,比如说在这里是不是有 qq 邮箱啊? 但是呢再往下我们看到还有很多的非 qq 邮箱,好,那么这个时候我们就需要来进行筛选了,那么我们进行筛选的话,那么我们是不是就要去把这个 qq 邮箱给它筛选出来呀?但是在筛选之前, 我们需要先来观察一下,看一下我们这个数据啊,是不是还有一些其他的问题哈?当我们往下来去进行滚动的时候,我们来看在这里,哎,是不是又出现了一些空白的一些数据啊?那么我们也需要来进行筛选, 所以我们将来有两个筛选任务啊,一个呢是把这些空白的数据给它清除掉,另外一个呢就是把 qq 那么这样一个邮箱啊,我们需要给它筛选出来,所以我们先把空白的数据啊,现在筛选掉, 我们可以点击这个小三角,我们来看在这里是不是有一个删除空啊?我们来去点击一下,当我们点击过之后,我们再往下来就进行滚动啊,来看一下我们的数据,可以看到是不是空白的这个数据啊,就已经消失了呀? 好,再然后我们需要来去把 qq 有项,我们来给它筛选出来,那么这个时候我们再次来进行筛选,我们点击过之后,有没有看到这里是不是有一个文本筛选器啊?那么我们在这里 看到有这样的一个命令啊,就叫包含,那么我们来观察一下,对于我们所有的 qq 的邮箱来说,是不是它都包含有 qq, 那么这两个字母啊,也就是 qq, 所以呢我们这里来去点击它,然后呢找到文本筛选器,我们来去点击包含, 那么这个时候我们呀来看一下,他所弹出这个窗口中是不是就使用包含呀,让我们去介入或者是选择一个值啊,那么我们呀在这里就来去输入 qq, 然后呢点击确定, 那么这个时候我们来看,是不是这里啊 qq 邮箱就被筛选出来了呀?但是呢,在这些 qq 邮箱中,我们看到有一些并非是 qq 的邮箱,比如说这里啊很明显是一个新浪的邮箱,而在这里呢也是新浪的邮箱,那么为什么他们没有被删除掉呢?那我们来看一下,在这个爱的符号的左侧啊, 看到这里是不是也有 qq, 然后再往下,在这里是不是也有 qq, 也就是说在这里因为它的 id 符号的左侧那么也有 qq, 所以呢它就没有被筛选掉, 那么这个时候我们怎么样来进一步的进行过滤呢?那我们思考一下,我们是否可以把我们筛选的条件设置的更加严格一些,因为对于所有的 qq 影像来说,是不是 qq 的右侧都有一个点啊, 所以我们只需要再去加一个点不就可以了吗?啊,那么接下来我们就来操作一下,那么怎么样来去修改,我们刚才操作呢,我们注意一下,在我们右侧的查询设置中,是不是有一个应用的步骤啊?那我们刚才讲到 party, 它会记录啊,我们所有的操作步骤, 我们刚才是不是进行了两次筛选,那么这是第一次筛选,这是第二次筛选,第一次筛选的时候呢,我们是把所有的空的数据给它筛选掉了, 而 ds 筛选是不是把 qq 之外的数据筛选掉了呀?那么现在我们想要去修改这个步骤,我们只需要点击这个小齿轮就可以了,我们来点击一下, 点击之后我们来看这是不是就是我们刚才所进行的操作啊,包含 qq, 那么这个时候我们只需要在这个后面来去加一个点,然后这个时候再去点击确定 好,那么我们来看是不是这里啊就只剩下 qq 的邮箱啊,这样的话,我们是不是就把刚才的大量的杂乱无章的数据,是不是把里面所有的 qq 的邮箱我们都已经整理出来了呀? 但是我们的工作任务是不是还需要去获取这个 qq 邮箱中所有的 qq 号呀?那么这个 qq 号是不是就爱的符号左侧的那么这些数字啊,那么我们怎么样来去给它整理出来呢?很简单,我们来看在这里有一个添加列这个选项卡,那么所谓添加 这个选项卡里面所有的命令啊,就在单独的一列中来去获取啊,那么处理后的数据,那么很显然我们呀是想保留这个 qq 邮箱这一列,并且呢把这里的 qq 号提取出来之后啊放在单独的一列中, 所以我们的这个添加列中有没有看到在这里是不是有一个提取啊?我们来去点击一下,看到这里有分格符之前的文本,还有呢分格符之后的文本,以及呢分格符之间的文本, 那么我们就要思考一下,我们是不是可以把这个 i 的符号做一个分隔符,左侧呢是一部分,而右侧呢是一部分, 那么很明显我们想要去获得的是不是分格符之前的文本啊,所以这个时候我们来去点击分格符之前的文本,在操作之前,同学们一定要注意把这一列一定要选中,那么现在我这一列呢是绿色,说明呢,我已经选中了哈,所以呢,我在这里直接 点击添加列这个选项卡,点击提取,然后呢去点击分割符之前的文本,然后这个分割符中呢,我就输入艾特。好,那么现在我们来去点击确定好,这个时候我们来看是不是又新添加了一列啊,那么现在啊,我们是不是已经整理出了 qq 邮箱以及呢对应的 qq 号啊, 但是上方这个表头啊并不直观,我们是不是要考虑把它修改一下呀,这样的话别人看起来也更加清晰,所以呢我们这里可以直接来去双击,然后呢去修改这个表头,那么第一列呢就是 qq 的邮箱,然后第二列呢是 qq 号,所以呢我们再去双击一下,然后呢来写上 qq 号, 那么这样的话是不是就直观很多了呀,我们还可以把这 qq 号然后这一例呢,我们按住鼠标左键往左边一拖,是不是调整了他们的顺序啊?好,那么现在呢,我们呀是 已经成功的整理出来了 qq 号以及啊 qq 邮箱,那么这里啊我们所进行的所有的这些操作步骤啊,那么这个结果就是查询,那么这个查询呢,我们需要给它起一个名称啊,方便我们以后啊再次来进行使用。 那么我们看到现在这个查询的名称是什么?是不是表三呀?这个名字太不清晰了,那么我们怎么样来进行修改呢?我们可以啊,在这个右侧的查询设置中看到这里是不是也是名称,我们可以来进行修改,所以呢我们把它修改一下,我们呀就把它叫做 qq 邮箱数据整理, 这样的话是不是更加直观呀?好,那么现在我们所有的操作啊,都已经操作完毕了,那么现在我们是不是应该再回到 excel 中啊,那么怎么样回到 excel 中呢?我们呀来去点击主页,看到这里是不是有一个关闭并上载的按钮啊?我们来去单击一下, 单击过之后,这个时候呢,我们就会发现他是不是自动给我们生成了一个新的工作表啊,并且呢把我们整理之后的这些数据呢,是不是放在了这个新的工作表中, 而且呢在这个右侧还有一个查询和连接的,那么这样的一个窗格,在这个窗格中,我们看到这里是不是有查询啊? 那么在这里他展示的是不是就是我们刚才设置的这个查询的名称,也就说这里啊就是我们刚才执行的一系列操作所组成的查询。如果我们需要继续啊来去进行数据清洗的工作呢,我们就只需要直接来进行双击,那我们就再次进入了 party 编辑器, 那么如果我们不需要再进行处理了呢,我们呀就直接给他关闭掉就可以了。如果同学们看不到这个查询连接窗格呢,那么可以啊,在这里来去点击数据啊,看到, 那这里是不是有一个查询和连接,我们单击一下他就消失了,我们再单击一下他就出现了啊,好,那么这就是啊,我们所进行的操作,那么我们来看是不是我们刚才执行了这么多操作,那么我们会发现是不是这个处理的结果是非常清晰的呀? 但是我们还需要考虑另外一种情况,就是如果这个数据员的数据发生了变化,那么我们还需要把所有的操作再去执行一遍吗?是不是没有必要啊? 因为我在给他们讲解 part query 的熟悉知识的时候,那么我是不是讲到我们可以啊,采用刷新的方式就可以来应对这种情况了,那么接下来我就给你们来演示一下啊, 那么我们还是回到我们的素材,看到在这里除了那么第一个文档之外,还有第二个文档,我们把第二个文档双击来进行打开,打开过之后我们会看到这里有更 多的邮箱的信息啊,那么我们先去把这些数据呢全部给它选中进行复制,然后粘贴到我们的数据园中,所以我在这里选择任意一个单元格,然后按一下 ctrl 加 a, 然后 ctrl 加 c, 是不是进行了全选复制啊?然后我们再去回到我们的第一个文档, 然后找到他的最下方哈,然后这个时候我们来去点击这个位置,来去按下 ctrl 加 v 进行粘贴。 好,那么这个时候我们会发现是不是这个数据的颜色自动发生了变化呀?为什么?因为啊,我们呀刚才再去进入帕帕尔边际之前, 我们是不是首先点击了数据来自表格和区域啊?他会自动的把上方的这些数据转换成一张表,那么当我们在这个下方粘贴数据的时候,他也会把这些新的数据呢纳入到这张表中,那么现在呢,我们要 这个数据员现在已经啊增加了,好,那我们再来看一下,我们是否需要再次进行操作呢?没有必要啊,那么我们现在来回到这个工作表中,我们来看一下现在目前整理出来的 qq 的数据有几个啊?是不是有七十四条啊? 好,那么现在我们呀点击这个数据选项看,看到这里是不是有一个全部刷新啊,我们来去点击一下。好,这个时候我们来看是不是就新增添了很多的 qq 的邮箱以及呢对应的 qq 号呀? 为什么呢?这些数据是哪里来的呢?就是来自于啊我们新添加的这些数据。好,这样的话咱们就理解清楚了,也就说当数据园的数据啊发生变化的时候, 我们只需要在这里来去点击数据进行刷新,他就会啊把我们所添加的这些数据呢重新的来去进行处理。那么为什么会这样呢? 好,这里给你们扩展一下啊,我们来看一下,我们再去双击这个查询,然后进入啊这个 powerpoint 的编辑器。好,那么之后我们呀来看一下,在这里是不是右侧,我给你们讲到这里有很多我们操作的步骤啊,那要不这些步骤呢又已经被 powerpoint 已经记录下来了, 所以呢,当我们点击刷新按钮的时候,那么他就会一步一步的再去把这些步骤再去执行一遍,那么最后呢就把处理之后的结果呢,是不是在展示到那么对应的这个新的工作表中,好,我现在来把它给关闭掉, 我们来看,是不是就会执行完这些操作之后,再去展示到这个工作表中啊,所以呢,对于 party 来说,他是不是可以做到计时的分析啊。好,那么我们这一节课给你们演示这个案例啊,还是稍微有一点复杂的哈,但是呢,对于同学们来说啊,并不需要立刻掌握,我相信啊,通过我的演 是,那么这个案例啊,已经勾起了同学们学习 parker 的欲望,那么就让我们接下来一起啊,来去,好好学习,掌握强大的 parker 工具,来去提升我们的工作效率,将时间呢,能够花在更有意义的业务上来。 那么这节课呢,我给你们讲解了这里啊所有的,那么这些操作呢,我们会在后面的课程中啊,详细的来进行讲解,你们稍安勿躁啊。好,那么这节课我就讲解了这里。
947wumingketang 03:22查看AI文稿AI文稿
03:22查看AI文稿AI文稿如何使用 powercarry 来提取复杂的数据呢?比如在这个表中啊,要求是要提取这个原始列当中每个单元格从后往前数 第一个冒号和后面的汉字,它可以是日,也可以是月,也可以是年中间的数字,比如这边的呢,是三十日零到七日,三十月和三年。那么这个里面呢,又有符号,又有汉字,又有数字, 如果用常规的函数是不方便的,所以呢,我们需要借助我们的 powercover 来完成它。首先我们可以通过数据 来自表格或区域,把它导入到我们的 power 编辑器。首先呢,我们先做第一步工作,把它右键重复列,避免操作对原类有影响,然后搭接它之后我们可以先做 拆分列,选择分隔符,它智能会识别里面的分隔符为这个冒号。然后呢,我们选择里面的最右侧的分隔符,让它从后往前提取,单击确定按钮就完成了。第一次的 拆完之后,接下来我们就可以按照日月年来操作来答应他。我们可以继续选这边的拆分列分格符, 我们选择下拉,选择自定义,我们输入一个日好,单击第一个最左侧分割符,单击确定按钮。拆分好之后,在这个新增量上面下拉,把这个 not 取消掉,单击确定, 于是这个就是拆分为日的,那么可以待它之后添加统一的后缀,当然这边的转换选择格式,选择添加后缀,我们输一个日好,单击确定按钮,那么这个就完成了。 把这个多余的这两列单一之后,按住 ctrl 键选中鼠标右键选择删除,列好,这个就完成了。我们可以把这个查询名称改成日跑回车完成把它可以再复制一个,鼠标右键选择复制, 在这个地方我们要形成一个月这个步骤,往后的我们是不需要的,可以鼠标右键选择删除,到末尾 已删除。好,我们在这个以上来提一下你们的月,我们在单一大招选择拆分列分格符,这次的下拉我们选这边的自定义选择月,然后呢, 单击最左侧,单击确定好,拆封好之后点下拉,把这个 number 同样取消掉,单击确定,这个时候啊,我们就把它同样的格式里面选择添加后缀,输入一个越,单击确定,将多余的 这两列右键删除好,这个月搞定了,把这个查询名称改成月好,然后呢,同样的步骤再做一下年的, 在最后添加统一的后缀为粘,删除多余的列 好,那么至此啊,日月年都生成了,单击这个日,选择主页,选择追加查询,追加为新查询,然后选择三个表户更多,双击月,双击年,单击确定按钮好,就全部合并完成了。然后呢,我们可以将这边的名称可以改一下, 处理后,然后我们可以当这边的关闭并上载好,于是就可以得到刚才我们所需要提取的结果了,如果有帮助,记得点赞关注哦。
84熊王 02:06
02:06 05:07查看AI文稿AI文稿
05:07查看AI文稿AI文稿我们打开一个 excel 文件,现在我们这个 excel 文件要获取其他文件夹里面的数据,大家来跟我一起看一下如何操作。鼠标左键单击数据 获取数据来自文件从文件夹,我们现在要通过 合并文件夹里面获取,那我们就打开这个鼠标左键单击合并文件夹,打开 转换数据, 在这个地方 我们只保留 content 和 name。 鼠标右键单击删除其他列。 鼠标左键选中 content, 添加列,添加自定义列, 我们输入 excel 点 work book 括号, 括号是英文状态下的,大家不要输入拳脚或者中文状态下的符号。双击 鼠标左键双击 content。 如果我们获取的文件里面 excel 表格里面第一行是标题的,我们可以直接在这个 content 后面直接输入逗号处 单击确定。现在大家看到我们现在又创建了一个自定义列,左边的这些可以直接删除,删除列就留着自定义这个就可以了。 鼠标左键单击向左和向右,这个小箭头 下面有一个使用原始列名作为前缀,这个勾勾掉就是我们不要选择他。确定这个时 后,大家看到这个内幕里面销售出库叙事部分别有一个二,那这个时间是属于重复性的获取,那我们就只勾选一个销售出库叙事部确定, 我们现在只留着 data, 也就是数据这一列就可以了,我们选中类目删除。 鼠标左键单击 table 空白列,我们看一下下面实际上就是我们这个每个 excel 表格,这是第一个,我们再看第二个,这是第二第二个 excel 文件, 然后还有第三个,大家看到了啊,这是一一月三十号,这是不同的日期的,然后用鼠标左 键单击向左和向右这个小箭头,再看一下,使用原始列名作为前缀,这个勾我们不要去勾选确定。 现在大家看到这四个 excel 表格里面的明细,我们已经看到了,那在这个明细里面 我们实际是想要获取的销售出库明细,那现在这个里面就是有一个合计的,行,这个比如说实发数量一千一千下万两千是 合计的,那在我们需要获取数据明细的话,这个合计列我们可以不要,那这样子我们把单据编号这一列里面的 now 这个勾去掉,然后确定。那大家现在可以看到 我们这个明细已经显示出来了。之后呢?单击主页关闭并上载。 鼠标左键单击关闭并上载,现在正在获取数据,那现在大家看到这个数据我们是已经获取到了,那后面如果在涉及到这个数据需要更新的时候,我们只需要把 新增加的 excel 表格文件放在这个合并文件夹里面,我们进行更新就可以了。直接单击数据全部刷新,全部刷新我们就获取到了最新的数据, 之后我们可以对这些数据去进行数据分析,包括做数据透视都是可以的,您学会了吗?
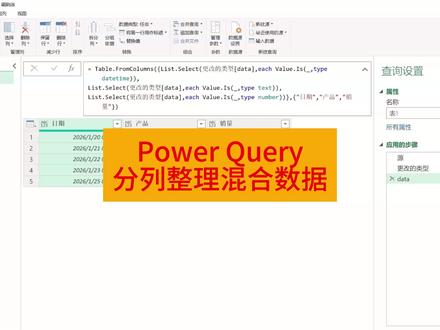 03:49查看AI文稿AI文稿
03:49查看AI文稿AI文稿大家好哈,这一期给大家来分享一下如何利用 parkway 呢,去提取不同类别的数据啊,把它整理成一个多列的表格, 现在大家看到的是一个混合数据在一列里边啊,既有日期啊,又有这个 a、 b、 c、 d、 e 这种文本啊,还有这个八十八,七十九这样的数值。现在我们把日期整理成一列啊,把这个文本 a、 b、 c、 d、 e 整理成一列啊,把它变成一个三列的表格啊,这样去做一个拆分整理 好,我们一起来看一下实现的过程。首先呢,把这一列数据呢,导入到 parkour 编辑器,打右键从表格区域获取数据。好啊,数据进来之后呢,我们在这一列上,首先把它变成一个列表啊,变成列表之后呢,我们就可以用列表的选择函数来去过滤数据啊, 打右键升化啊,这样呢,它就变成一个列表,整个表的形式就不再是 table 了啊,这个标题大家看一下,变成列表好,在这个 地方啊,更改的类型这个地方啊,就留着吧,就不删了,它是自己呃,自己侦测了一下这个数据格式啊,多了一步就是更改的类型。好,我们要用的函数是 list, select 是 来选择啊,选择的目标就是更改的类型。 data, 我们需要用到这个 each 来判断啊,这个意思就是什么值什么值。首先第一个我们要去判断啊,这个列表里边的每一个值,我们用短横线来代替啊,来循环这个列表里边的每一个值, 这个 y 六就是它每一个值是否属于叫 date 这个数据类型,如果是这个 select, 就 把它提取出来了。 好啊,这是我们的第一个提取数据类型,提取这个日期的数据类型,我们把它拷贝一下, ctrl c 啊,是回车,回车之后呢,我们来粘贴啊。第二个 list select 这个地方我们要去提取,是这个不叫 date time, 我 们要去提取 a, b, c, d, e 啊,所以叫 text 啊,我们要把它提取出来啊,这啊。 第三步,我们再去粘贴一个啊,这个其他都一样啊,我们把提取的类型呢换成 number, 就是 刚才大家看那个八十八,七十六 number 好 了啊,这是把这一列里边的数值按照不同的数据类型给他提取,来判断他是不是属于日期,是不是属于文本啊,是不属于数值。如果是就 select 就 提取出来啊,这是我们的三个 提取的过程啊,把它提取成三个不同的列,然后我们用大括号给它括起来,还要给它三个标题啊,每一列一个标题,所以我们再加一个大括号,加一对大括号啊,这里边是日期啊,是啊,我们叫做产品吧, a, b, c, e, 我 们就估且管它叫产品吧,是我们的数值,叫啊,叫销量。这样啊,给它三个题目啊,三个列表的选举,再给它三个题目啊,这样,最后呢,我们来套一层,叫是 table from columns 啊,因为现在每一个 list select 函数选出来的数据单独成一列啊,现在我们要把这三列呢这个给它合并成一个 table 的 格式,一个表。 所以这个地方呢,我们在最外边套一层 table 啊, from columns 啊,就这样呢,我们就把它合成一张表啊,这是括号。 好,在这里边呢,在最后再把另外的半拉括号给他啊,这样我们就得到了一个提取出来的一个数据啊,我们提交。好啊, 大家可以看到这里边的日期一列啊,产品一列、销量一列啊,非常清晰啊,非常规整的一个数据就出来了啊,我们把这个数据就可以加载到工作表去了,这一步就不做了。好,这个技巧给大家分享到这。
 00:40查看AI文稿AI文稿
00:40查看AI文稿AI文稿打开,从外获取,在跳出的对话框中输入网页的地址, 输入完地址后,点击确定 这些就是网页中包含的表格,找到需要的表格,点击加载就可以了, 点击一下这个加载的按钮,网页的数据就会存到打开的 excel 表格了。
11信达信息工作室 06:08查看AI文稿AI文稿
06:08查看AI文稿AI文稿啊,大家好,欢迎继续学习抛别商业整容分析系列视频教程啊,今天呢,我们来看一下 prokry 的一个技巧, 就在我们有呃每个人有多次的成绩统计的情况下啊,我们如何去始终获取他最新的最后一次的成绩或者最后一次的这个业绩吧。啊,这个试用的场景还是很多的啊,无论是考试还是这种这个工作的业绩的统计 啊,都是可以用这种方法的。好,我们来看一下他的实现过程啊,这里边呢,我有一个视力的数据啊,这个张三李四,王五赵六啊,他们呢这个每个人呢,到目前为止统计了每个人统计了五次成绩啊的不同的日期,现在呢,我是 通过帕克瑞啊这个始终获取他最后的,就也就是最近日期的一次的这个统计成绩。我们先把这个数据呢来导入到帕克瑞的编辑器啊,数据,然后来自工作表啊,在这里 这边呢,我们首先要修饰一下,要去调整一下这个日期的这个格式啊,我们需要的不是这种带时间的,需要的是纯日期 垂直去替换当前转换就可以了。好啊,现在呢,我们来做一个分组啊,做一个分组,点一下分组依据,然后点到高级啊,我们分组依据呢是以姓名来分组啊,因为你是要获取每个人的啊,所以呢,我们以姓名来分组啊,然后呢分组的第一个列呢,我们是要获取第 这个每一个人的最后的日期啊,最后的日期,最后日期,然后呢我们的操作呢是要求最大值就是麦克斯,然后呢这个麦克斯的这个对象呢,就是日期这一列 好,然后再添加一个聚合啊,这里面呢,我们就需要所有的数据啊,所有的数据我们给他起个名字叫奥,这里面不做任何运算啊,直接选取所有行, 直接选取所有,好啊,后面就不用管了,因为你选了整张表了,后边也就无所谓那一列了啊,这样的话呢,我们就设定两个聚合啊,以姓名为分组依据设定的两个聚合,一个是取最大值,一个是 啊,把所有的行全部形成一一张张的分表好,然后点确定,这样的话呢,我们就得到了,稍微放大一下,大家看 清楚一点啊,这样的话,我们就得到了这样的一张表啊,所以你看到张三啊,张三,我们点这张表的这个空白区域呢,你会看到张三,这都是张三的成绩啊,然后李四呢啊,这个都是李四的这个成绩, 每张表呢,其实都已经分开了,同时呢啊,每一个人的最后一次统计日期呢,也都出来了啊,都放在这了,这是最后一次统计日期。现在呢,我们把这张表呢做一个扩展啊, 点这个扩展按钮,然后这边因为姓名前面有了,所以我们就不要姓名了啊,这个把前缀也勾掉,就只要日期和最新业绩啊,然后点确定 好,这样呢,我们就把这个表展开了,但是你可以看到张三的最后的日期,在最后日期这一列里面,他始终是五月十二号啊,李四呢是始终是五月十七号啊,这个就为我们提供了一个非常便利的条 条件,接下来呢,我们做一个加一个自定义列啊,添加列,然后自定义列,我们做一个判断啊,等于 f, 注意这个地方,这个写 f 认 f 这个循环,不要这个把 f 写成大写啊,容易容易出错 啊,是 f 还是小写的啊?如果我们的这个日期等于我们的最后日期的话,我们给他输出。稍等啊, 调成英文的啊,我们给他输出啊,是因为因为屏幕是放大状态啊,所以他到处乱窜啊,我尽量的不再动啊。然后呢,如果不是啊, l s 的话呢,我们输出的是什么?输出的是。哎呀, 说出的是否好,就这么简单啊,就前面来判断,如果这个日期这一列就是倒数第二列啊,日期这一列倒数第二列,如果是这个等于前面的最后日期的话呢,我们就留就就给他说出一个试, 如果不是呢就是否啊,这样的话便于我们一会呢去过滤筛选啊,非常简单的一个语法啊, a z 跟 a 字号里面的这个是啊,微微里面差不多的意思啊。好,然后我们点确定,那你看到这 有一列啊,这个自定义列就出来了,在这列里边呢,我们做一个筛选啊,我们不要否,只要是啊,只要 是,那么是的话,就意味着他是对应的每个人的最后的日期的啊,对应每个人最后日期的,然后我们点确定 啊,这样的话呢,我们就每个人对应的最后日期的话呢,我们就得到了他最新的业绩啊,最后的日期最新的业绩啊,现在呢,我们需要只需要把最后这一列和这个日期这一列 直接给他删除就可以了啊,这样的话呢,我们就留了姓名,然后他的最后日期啊,最新业绩,你甚至可以把最后日期给删掉啊,都不影响的。我们始终能够提取每一个人的这个最新的一个这个业绩的统计 啊,最后一步呢,我们就可以把它这个关闭并上载到一个小工作表就可以了啊,这一步我就不做了啊,这样的话整个过程呢,我们就可以从始终动态的去 对每一个人最后更新的成绩或者是业绩或者是什么。这个,呃,其他的一些这个统计的数据吧,啊,始终他获取最新的一个状态啊,来实现我们整个的这个实时监控业绩表现的这个目的。好,这节呢就给大家分享到这。
20数据分析精选 05:25查看AI文稿AI文稿
05:25查看AI文稿AI文稿今天有同学问了这么个问题,描述一下,就是怎么样通过一个公式,把多个工作部里面的数据给引用到一个工作表里? 这问题说实在的,用函数太累赘了,如果说数据在一个工作表里,那是没什么,直接引用等于 a 二,那下拉以后他就变成等于 a 三了,再继续下拉,他就是等于 a 四,等于 a 五,等于 a 六,这么以此类推的下去很方便。 如果是跨工作表呢? a 零零一, b 零零一, c 零零一三个表,我们要取他每一个表的第二行,把它给放到这个里面,看上去挺复杂的,其实也好办。当然这个再用,直接引用三个表还好一点啊,改三次公式,如果三千个表的话,那就那啥啥啥。 所以我们这里面可以用一个间接引用函数,应该 rap 工作,表明就是他。因为公司要用拉下拉,所以我们在 a 前面加点美元符号,然后连接感叹号,工作表标志。 这里面我们就不用 a 一样试了,用 r e、 c 一样试,这边用 r c 引号,逗号右拉 下拉,那这也行,那有个三个还是三十个?三千个都一个公式,用拉下拉解决。但是如果说这三个表是分别在三个工作部里面的呢? 还能用函数来解决吗? indirect 也是可以的,但有一个前期就是说这四个工作部我们都得打开,那就是引诱了三个工作 的数据,假如引用了三百到三千个,那您内桌面得有多壮观,我就不描述了。那么这里面呢?我们原来传统的试用 vba, 或者还有一个技巧的方法,多几个步骤也能够搞定, 但是现在呢,因为有了 power query, 所以这问题就变得简单多了,那我们来看一下 power query 是如何解决的。数据选项卡下获取数据来自文件,从文件夹找到那个存放了多个工作部的文件夹以后,打开, 然后这一个不用管他,直接转换数据,稍等一小,缓缓时间以后。好,我们就进入了貔貅编辑器,这里面有很多列,这些列其实都没有什么用处,真正有用的只有这个。 当然如果您那个工作不明也是有用的话呢,那把这个内容也留着啊,我这里就不需要了,只留一个康本的,选取他以后删除列,删除其他列就只有他了。接下来我们要做的事情并不是说把它合并,而是添加列, 自定义, 自定义的,这个列名可改可不改啊,改一下就是工作部, 这里面呢,用一个函数叫做 excel 点 work book, 参数就是康本的,双击一下, 左右括号都括好了,然后确定他就多出来一例,就是我们刚才添加的这个例,这时候这个康本本又没用了啊, 直接删除好。这列里面所包含的内容就是每一个工作部里面的工作表信息, 其实我们还是需要再展开的,那就展开,这里面不使用前缀吧,我不喜欢用,那么这三列是肯定没有什么用了。北大列和内姆列,如果您那个表内姆列有用,那就留着,我这也是没有用的,我只留一个得大列,确定就只剩下这个得大列了。 这里面的数据就是每一个工作表里面的具体的内容了,但是我们发现他这个工作表里的数据是完整的,而我们真正需要的就只是第二行 啊,应该是二是吧?啊,不好意思,皮球编辑器里面呢,很多数据他是从零开始计算的,所以标题这个是第零行,而这个是第一行,记住这个数字,一接下 下来我们再来添加一个列,自定义列,这个自定义改不改无所谓了啊。然后这里面用一个公式是义尺 data, 就每一个这个 data 表里面的第一行用一对大括号一确定,再来看一下,这里变成了三个记录,而每一个记录就是各个工作表里面第一行的数据, 接下来就展开就可以了,多余的列删除, 我们把它关闭并上载至。我这么做是为了让他在同一个工作表里面显示可以看到他的一个是否有差异,那么我们看到结果 是完全没有差异的。用 po aquari 最大的一个好处就是当我的数据发生变化的时候,比如说我再多一个 c 零零一的副本出来,这时候我只要数据刷新一下,他就出来了, 非常的好用啊。如果您还有什么更好的意见或者建议,欢迎杂草,谢谢!
266小妖同学










猜你喜欢
最新视频
- 2781懂哥大伟