
粉丝5318获赞2.9万
相关视频
 02:48查看AI文稿AI文稿
02:48查看AI文稿AI文稿你如果用这个 open cloud, 肯定会消耗很多 token, 那 最好的方法就是用免费的模型,这里它就会支持 onigravity。 千问还有 open code, 咱们这里就教一下怎么设置这个 onigravity。 用它里边的免费模型装上了之后就 out bought config, 这里边就点选 logo, 这里边儿选 model, 这个再选里边儿的模型。因为 onigravity 是 谷歌的,所以这里边儿选谷歌,选 onigravity。 当然你可以选这个 google gemini c l l, 这个也是因为 gemini c l l 也是免费的,但是 onigravity 它有更多模型,包括 cloud code 的 模型,还有 gemini 的 模型,所以这个 咱们选 onigravity, 它会跳一个网页让认证,所以这里你就选你的谷歌账号儿就可以了。 三音这很快就认证成功了,就可以选模型了。这里它选的模型比较多,所以就会需要一直往下拉, 它在谷歌 on the gravity 里边往下走,走走走,这是 coco 的 get up, 对, 这里就是大家可以看到谷歌 on the gradient。 我 这里边是把谷歌 on the gradient 下边的模型全都选了之后选,直接按空格就可以选和反选, 选完之后按那个回车就可以选定了,这里话直接跟 t 钮,然后它结束之后就可以自动地使用 anti gravity 模型了。这样 clubbot open cloud 就 可以免费使用 anti gravity 里边的 cocoon 了,就不用自己买 cocoon。 当然你可能配置完之后想选自己的首选模型,因为 integrative 里边儿有很多模型,咱们可以在这里边儿配置。在这个尼加目录点 cloud bot, cloud bot, 点 jason, 我 这里边儿直接打开,咱们就往下走,这里边儿你可以看 a 阵词,下边儿这有一个 default, 这就是你默认用的模型,这里有个 primary, 就是 它首选的模型。就是啊, google on the gravity 里边儿这个 color whoops, 四点儿五 thinking, 这个比较慢,所以我想要把它改成 gemini flash 这个模型,咱们呢? sun flash 对 这个模型会比较快,所以我想把它改成这个模型,当然你可以自己改,它就会首先尝试的模型是这个,如果不行,它会用 fallback。 这边的模型我现在已经改好了,之后我就可以保存重启一下 clubbot, 它就可以 clubbot play the gateway start, 我 又拼错,然后这就重启了,就可以开始用我新设置的这个 drama 三 flash 这个模型了。咱们看一下它具体的情况, 你就会看到你的模型已经开始用。呃,首选模型,这个有时候它算比较慢,但是总体来说它会遵循你的配置的。今天就到这来谢谢大家,希望可以帮到你们。
3949AI鹅鹅鹅 06:23查看AI文稿AI文稿
06:23查看AI文稿AI文稿最近玩智能体啊,实在太消耗 token 了,所以我们今天要来讨论说啊,哪里能搞到便宜的甚至是免费的大模型 token 呢?首先我们来看一下,如果正常使用 token, 大 概是个什么价格呢?像我们日常最常用的这个网页版的聊天机器人啊,类似于豆包、 jammy 这些网页的服务, 一问一答,大概每一次呢会消耗几千到几万的 token。 一个月下来呢,大概可能就是三百万的 token, 数量也就是几块钱。但 agent 就 完全不一样了,它要自己规划,自己执行,自己反思,一个任务跑下来呢,可能会调用几十上百次模型。像我们最常使用的 cloud code, open code、 open cloud 这些智能体啊,每一次跑起来都要消耗几万甚至上百万数量级的 token。 我 也翻了一下我自己的使用日志啊,然后大概估算了一下,我每个月的使用量呢,大概是三亿个 token 左右。然后我们来算笔账,如果你使用的是 cloud sum 的 四点五这个模型, 它的价格呢,大概是每一百万的 token, 输入呢是三美元,输出呢是十五美元。考虑上一些这个缓存啊,折扣啊,平均价格呢,你可以认为是每一百万的 token 五美元左右。那这么一算啊,其实你跑一个 agent, 每个月其实要烧掉一千五百美元左右, 就算是换成便宜的多的国产模型啊,一个月也要用到两百到三百美元,这个价格呢,我觉得还是蛮离谱的。所以这期视频啊,我就来跟大家聊聊,怎么才能搞到便宜的甚至是免费的大模型接口。先说好,这期视频呢,是没有任何的广告的,全是我自己实测 实际使用的经验。在正式开始之前啊,我想先给你一个这个思考框架,省钱这件事情呢,本质上其实就在做三个维度的取舍,价格、稳定性、模 的能力。你不可能三个都要,如果你想要最强的模型并且稳定,那肯定就会稍微贵一点,如果你想要便宜,那肯定就要牺牲一些模型的能力或者是稳定性。我们带着这个框架呢,然后再来逐个看各家的方案。先来说这个 cloud 买套餐到底能省多少钱呢?官方没有公布套餐的实际使用量,但有人测过了数据呢,放在这个网址里面,我给大家总结了一下,如果你订阅一百刀的这个套餐,用到极限的话,就能用掉价值一千三百五十刀的这个额度, 相当于打了不到一折,换成人民币算的话,差不多就是零点五元的人民币就能买到一美元的这个使用量。但 cloud 的 官方有两个大坑啊,大家也都知道,第一呢就是国内的用户特别容易封号。第二个呢就是不允许介入其他第三方的服务, 只能在这个 cloudco 的 这些官方应用里面使用,没有办法拿它去接入 opencloud 或者是其他第三方的这个智能体。如果你又想要这个按量付费的这个灵活性,又想要这个套餐的折扣价,那怎么办呢?我觉得唯一的选择啊,就是中转站,中转站呢,你可以把它理解成为这个零售商,就他们会去批量的向 cloudco 的 官方购买 这个套餐,然后呢在中间加一些价格再卖给你刚才说的,比如说零点五元的人民币兑换一美元以上, 市面上有上百家的这个中软站,那怎么挑呢?有人做了一个中软站稳定性的监测,大家想要购买,想要具体了解的,其实可以看这个网站,上面呢监控了几家比较大的这个中软站的稳定性。不过说实话,这个中软站呢,基本上还是一门比较灰色地带的生意, 所以呢,建议大家每次别充太多,这里呢就不具体展开了。然后我们来说第二家那个 check gpt, 相比较那个 cloud code 的, 动不动就封号啊,然后不让接其他的这个工具 open i 呢,其实就大方了很多, 它不仅能接自家的这个 codex, 还允许你去接 open code, 允许你去接 open cloud 这些第三方的项目,而且额度啊,要比 cloud 的 要给的多,大概是零点三元人民币就能买到一美元的使用量。更香的是啊, open i 的 活动特别多,比如说像那个 gpt 开通团队套餐,首月免费,你可以去某鱼搜这个 team, 新车几块钱呢,就能用上价值二十五刀一个月的会员。如果你拿这个会员去跑 codex 啊 token, 相当于说完全白嫖。 codex 的 缺点呢,就是它写代码的速度啊,会相对来说比较慢一点,不过呢,你可以开多个 agent, 让它并行去跑 数量去换取速度。然后下面一个是这个谷歌 gemini gemini 系列模型写代码的综合能力啊,普遍来说稍微比这个 cloud 和 gpt 弱一点,但有个骚操作啊,就是可以通过教育活动拿到免费一年的谷歌 ai 会员,然后用这个谷歌的编程 i d e anti gravity 来跑这个 cloud 模型,然后还有一个更狠一点的玩法,就 使用这个项目 cloud proxy api, 它可以把 antigravity 里面 cloud 的 模型转接出来给 cloud code, open cloud 这些工具去用。因为谷歌会员啊,几乎都能白嫖,所以它对应的这个 token 啊,也约等于免费。不 过这么玩的人啊太多了。谷歌最近呢,在频繁调整这个 anti gravity 的 额度,所以这个方法我也不是太推荐,因为它可能之后就不太稳定了。聊完了预三家之后啊,我们来聊一聊国产的这些模型。国产的模型呢,本来零售价就只有海外模型的一到两折,购买套餐之后呢,就会更便宜了。在国产模型里面啊,我觉得当下最强的可能就是最近推出的这个 kimi k 二点五,我实际用下来它的能力其实跟 cloudsonic 四点五几乎没有什么差别。有兴趣的朋友啊,可以去 kimi 的 海外版看一看, 有个首月零点九九美元的活动,能拿到原价九十九元的套餐,还可以支持这个接入第三方的 cloud code open cloud。 国内版 kimi 的 活动呢,就稍微差点意思了, 每周大概五元左右。但是 kimi 我 觉得最大的问题啊,就是套餐额度给的比较抠,控制台里呢,只显示了使用的百分比,看不到具体的 token 使用量。我实际测下来呢,比下面两家我要介绍的这个国产模型啊,给的量都要少得多。 gim 呢,应该是国内三家里面我觉得最大方的, 然后套餐的额度给的非常的足,最低档的套餐呢,是每个月二十元,每年两百四十元,但价格是真的香,我自己也买了。接口方面呢,也很开放,可以支持接入各种的工具。缺点呢,就是现在 g i m 四点七啊,它的模型效果暂时不如 kimi, 而且高峰时间段呢,因为顾忌它 套餐卖得太多了, token 的 吐字呢,我觉得巨慢。另外一个 mini max 呢,我觉得它的套餐跟 g l m 很 像,然后这里也不跟大家重复了。然后还有一家呢,大家可能没想到,就比较小众,就是英伟达。英伟达呢,其实它也提供这个完全免费,额度不限的这个开源模型, 包括前面说的 kimi k 二点五,然后 jimmy 四点七, mini max m 二点一。但是呢,因为可能门槛太低了,然后用的人实在太多,热门模型的速度呢,慢得离谱。所以这个呢,我就更不推荐了,只是跟大家介绍一下,英伟达,它其实也有这个免费的接口。最后啊,来再帮大家整理一下思路,如果你想追求最强的效果, pro 的 中转站呢,是目前性价比最高的选择。如果你的预算有限啊,那国产模型里面 g i m 的 套餐最实惠。 timi k 二点五的效果最好,但是有传闻呢,说这个月会有大批的这个模型,会推出新一代的模型,到时候呢,我再跟大家更新。然后如果你想白嫖呢? openai 的 这个 timi 拼车几乎是完全零门槛的, 效果也不错。这期盘点里面当然肯定没有包括说这个百分之一百所有的方案,市面上还有很多我没发现,或者是我没有测过的这个方案。如果你有更好的渠道,欢迎在评论区补充,大家一起交流。好了,今天视频就到这里了,我是迪总,黑心李超,我们下次见。
1.9万第四种黑猩猩 05:15查看AI文稿AI文稿
05:15查看AI文稿AI文稿兄弟们,大家最近有没有被这只小龙虾刷屏名字从 cloud bot 到 multi bot 再到 open cloud 火爆全网,你们是不是也想拥有这样一个私人助理,每天早上打开飞书,让他整理 ai 圈发生的大事儿发送给我, 提醒我女朋友生日买花和订酒店,每天帮我关注和整理持仓动态,是否有重大利好利空等消息, 并且能够通过我常用的飞书给他下达指令,这就是 openclaw, 被称为真正能干活的 ai 助手。本期视频给大家带来 openclaw 的 保姆级教程,包含模型选择、安装部署、接入飞书以及如何配置使用 api 聚合平台 crazy router, 节省百分之五十的 token 费用。首先我们来看模型选择 opencloud 实现效果的核心在模型,虽然它支持很多模型,但是官方推荐使用 cloud ops 模型,效果比较好,建议使用。 然而 opencloud 非常费 token, 同时 cloud ops 四点五的官方 api 价格确实也让人生味。本期视频里也会教大家如何配置 opencloud, 使用 crazy router api 聚合平台,实现省钱百分之五十。调用 cloud ops 四点五。 接下来是安装部署,为了避免 ai 误操作导致悲剧产生,这里不建议部署在日常工作,电脑可以选择部署在云主机上,我这里用的是 a w s 送的半年免费云主机,大家可以根据情况自己去薅。 这里我们打开终端,直接登录到 a w s 的 云主机,输入 open c 号官方提供的一键安装脚本进行安装即可。 安装完成,进入初步设置向导选择模型,这里可以先跳过,后面会进行配置,选择 channel, 这里默认没有飞书也可以先跳过,后面会配置 skills 也可以后面根据需要再配置,后面一路 no 和跳过即可,之后根据实际使用情况再进行配置。 这里使用 openclaw gateway status 验证一下状态,再用 curl 看一下状态是不是两百,这样我们就完成了基础的安装配置。如果需要远程访问 openclaw 的 管理界面,还需要安装 x x 进行反向代理,这里可以使用 e r m 进行安装,配置文件可以参考我这个, 重启 n g s 即可。接下去配置 openclaw 信任代理和允许 http 认证, 然后重启 openclaw, 再获取认证的 token, 将 token 拼接在 url 的 后方,即可访问 openclaw 的 管理界面。接下来我们配置 ai 模型,这里使用 api 聚合平台 crazy router 提供的 api key 进行配置,它比官方 api 便宜近百分之五十。 模型使用这个 called open。 四点五,我们点击令牌管理来创建和复制我们的 api key。 接下来打开 openclaw 的 配置文件,找到 model 和 agent, 这里按照我这里面的配置完成 crazy router 的 api key 和 cloud ops。 四点五的配置,重启 openclaw, 完成配置。 最后一步,配置飞书渠道,飞书使用 webbed 长连接模式,无需域名和公网回调地址,配置简单,个人用户也可以免费使用。首先在开发者后台创建企业自建应用,然后获取应用凭证 app id 和 a p c secret, 同时开启机器人能力 开通相关权限。在 opencloak 中安装飞书的插件,设置飞书中我们刚才获取到的 app id 和 app secret 再次重启 opencloak 事件配置中使用长连接接收,同时添加事件和事件权限, 再创建一个版本并发布,就完成了飞书的配置。接下来我们实际看一下效果,看看 opencloak 能帮我们做些什么, 很快就帮我们生成了一份高质量的总结报告。 接下来可以给他布置一个任务,每天早上帮我们搜集持仓股票的动态信息,分析财报、产品发布、监管诉讼、高管变动等重大利好利空消息。这样他每天就会把详细的分析报告发送给我们,方便我们第一时间了解持仓动 态,也可以很全面地分析多个同类产品的情况。 最厉害的来了,可以让他给立即帮我们写一个专业的程序,然后运行这个程序,得到我们想要的运行结果。整个过程我们完全不需要关心代码文件和运行环境。对了,这里要配置下 a 阵字的权限才能使用编程代理, 他会直接把程序的运行结果给我们,结果也完全符合程序的逻辑和预期。 最后总结一下,我们首先进行了 opencloud 的 安装配置,接着配置使用 crazy router 的 api key 注册来调用 cloud opens。 四点五,使用飞书机器人作为接入渠道进行通讯。最后演示了几个常用的应用场景, 像 opencloud 这么全能的助理,每个人都值得拥有。再把我踩过的几个坑给大家分享一下。好了,本期视频就到这里,有问题留言问我。
5296Geek Leo独立开发者 01:45查看AI文稿AI文稿
01:45查看AI文稿AI文稿那这几天看到有博主说 open clock 可能在很短的时间内就会消耗你上百万的 token, 今天抖音私信又有一个朋友在跟我确认这个事情,他也很担心,就是怕用上了 open clock 之后 token 负担不起。那刚好今天早上我遇到了这个问题,我最后也找方法去避开了,所以我给大家分享一下。首先 给大家看一下这个统计图,我用的是腾讯云的,之前我接过那个腾讯云的 deepsea 的 模型,也就是让 openclaw 去用这个模型。 那我今天上午问了他一个问题,确实不多啊,他就问题很少,但是他消耗了我七十五万的头肯,大家看一下,也就是今天 那短短的也就是不到一分钟时间,所以这个是事实,但是也不用太过于焦虑。因为什么我给大家看一下,我最后把它切换成了 mini max, 我 买的是它一个月的套餐, 我不是给 mini max 做广告。那它这里呢?你可以用任何的这种订阅式的模型,它这里是五个小时有四十次的对话。那任何的这种订阅式的模型,它几乎都是这么去定量的,按照你的对话次数, 所以我把它切换过来以后,他只会按照对话次数去计算,而不会按照你的 token 数量。所以如果五个小时我超出四十次对话了,那大不了这个模型我现在用不了了,他不会让我有更大的损失。 所以我觉得如果大家真的担心说 token 负担不起,那就去买一个这种按月订阅的模型就可以了,所以我觉得避开这一点就可以了,其实也没有那么恐怖。
1045自说自话的江哥 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿不懂代码的普通人怎么不熟 oppo clone 呢?根本不需要花几千块钱去买一个 mac mini, 今天看了我的这条教程呢,直接让你白嫖一百万。 talking, 咱们打开阿里云的官网,在这里点产品,然后选到清亮应用服务器, 然后呢,在这里可以选这个啊, open club 啊,然后一个月啊,一个月大概是这个二十多块钱,一年大概六十多块钱,咱们选个二十多的直接付款啊,付款之后呢,可以看到我们这个实力马上准备好了,咱们点我这个实力,点进去有个音乐详情啊, 因为详情一共有三个步骤啊,第一个步骤啊,就执行这个命令啊,可以放通这个端口啊,第一个已经成功了,第二个呢,就是配置这个 oppo 的 这个 mate 啊,咱们这里呢,直接使用这个百炼 callinplay 啊,确认开通就行了, 免费赠送一百万 token 推理额度啊,这个是阿里云旗下的一个百链平台。然后呢在左下角有个蜜柚管理,创建 a p o a p i k, 创建一个 a p i k, 然后呢勾选用户名称描述一下,随便填一把啊, opcode, 然后确定, 然后大家可以看到啊,这个庙已经生成了。然后呢,右上角有一个地区啊,我们现在是在华北啊,就在北京地区,然后复制这个,然后复制 api k, 然后在上一个页面,然后回到上一个页面,粘贴我们的 api k, 然后呢选北京。那就可以看到奥鹏哥老配置成功。 然后呢就是第三步了啊,就直接呃,可以给我们一个网站,让我们去访问我们的这个龙虾机器人, ok, 点开我们的龙虾机器人,直接问他用中文介绍你自己 啊,你看他已经回答了,下一期我会让 oppo cola 自动帮你干活,大家有遇到部署的问题可以随时问我。
566Yapie程序员哥 04:06查看AI文稿AI文稿
04:06查看AI文稿AI文稿还在为龙虾消耗滔天而发愁,那么这个视频给你讲一种方法,让你的龙虾能够免费的调用商用模型,这里面有两个关键点,第一好用,第二免费。那是啥呢?接下来给大家揭晓啊。大家都知道,这两天智普发布了智普五的模型, 在性能上已经达到了 a 公司四点五的模型的能力了,并且超越了 g 公司三 pro 的 能力了。但是大家有没有发现,随着智普五的发布,在官网上咱们可以惊讶地发现它的四点七 flash 免费了,也就是说咱们可以在 opencloud 里面 免费的去调用它的次新模型四点七了,那么这样咱们就找到了一个免费的并且效果还不错的一个模型了。好,那怎么对接啊?啊?给大家来说一下,首先呢,你得确保你已经安装了 openclaw 龙虾了,安装完成之后呢,首先啊,先把你的龙虾服务先结束掉啊,结束掉之后呢, ok, 这个时候 打开你的龙虾的配置文件啊,配置文件呢,就在你当前登录用户底下的 opencloud 文件夹底下有一个 opencloud 点 jason, 把它双击啊打开,然后打开之后呢,咱们去找到三个地方啊,一个呢是 model 啊,在 model 底下去添加一个智普的 model, 这是第一个,然后第二个呢,在 agent 底下将上面你配置的智普的四点七啊添加到你的 model 和 models 里面就行了。 好,那么接下来呢,咱们就添加一下,这时候呢,我去添加到底下,然后加一个英文的逗号啊,然后给它随便去起一个名字,这个名字呢就叫做 j m l 吧。啊, 好, ok, 然后完了之后呢,哎,使用 jason 这种格式,先给它包包装上啊,然后包装上之后呢?好,这个时候咱们需要打开一个之前已经配置好的内容,然后将里面的内容啊复制到字谱里面就行了啊,好,那这时候呢? ok, 粘贴啊,粘贴完了之后呢,就长的是这样啊,当然里面的 base u l 需要改成咱们连接的四点七的地址,然后 api k 呢,需要改成 api k, 然后里面的这些模型呢,也改成现在的模型就行了。 好,那么咱们回到这边啊,它的地址是啥呢啊?地址是这串叉叉之前的,复制它,然后更新到 bash 里面。好,粘贴了,然后完了之后, api k 呢?咱们需要找到你的 api k 啊,然后在界面上咱们去创建一个 api k 啊,比如说啊 test, 随便就几个名字啊,就有了,有了之后呢,把它复制,复制完了之后呢?哎,粘贴到这就可以了啊,然后粘贴完了之后呢,那么还有 id, 模型的 id 和名称啊,那模型的 id 和名称的话,咱们就回到这边,在哪?在这啊,这是模型的名称,复制,然后把它进行粘贴, 然后粘贴就行了,那么这样咱们的 model 就 已经配置完了啊,咱们就有 g l m 这个模型了。好,那么有了它之后呢? ok, 复制它的名字啊,在咱们的 agent models 的 默认模型里面给它换掉,那么咱们是它加上斜杠啊,加上咱们的模型名称,复制它, 然后进行粘贴好,然后完了之后呢?哎,同样的,把整个内容全部复制,来到 models 底下,好找一个地儿啊,随便找一个地儿,使用英文的方式来给它进行粘贴啊,然后它等于啥呀?等于一个括号号就行了,这是一个标准的 get 格式,这个配置完之后呢,意味着咱们整个 open class 对接免费的模型就已经 ok 了。好,那么接下来咱们来看一下效果啊,那么看效果的话,咱们首先先打开命令行窗口,然后输入这一行命令来启动咱们的 open class 啊。好,那么咱们等它启动好了之后呢,问一下大模型它目前连接的是谁啊?好,那么这时候就启动了,那启动好了,启动好了之后呢,咱们可以在页面上去访问啊,也可以在其他对接的,比如说某书上去访问,都是可以的。好,那这时候呢,咱们就输入一下,叫做我给你配置了一个新的模型, 告诉我你现在连接的是啥啊?那么这时候呢,它很快就给我响应了,它目前连接的是啥呀?四点七 flash 啊,它是可以快速响应的,并且是免费的模型到这儿咱们就对接完了,这样的话,咱们再也不用担心 talking 的 消耗量了,既能食用龙虾,同时又没有 talking 的 烦恼,一举两得啊,我是磊哥,每天分享一个干货内容。
3559磊哥聊AI 02:50查看AI文稿AI文稿
02:50查看AI文稿AI文稿老铁们好,又见面了,前两天我们部署了小龙虾,以及部署了飞书机器人,将小龙虾导入了飞书机器人来帮我们干活。但是很多老铁他更关心的问题,但是很多老铁他更关心的不是如何布置飞书,也不是如何布置小龙虾,而是这个每天爆表的头肯要怎么办? 今天我们介绍一个神奇的工具,它能提供无限的国产模型的 token, 这个工具就是 iphone。 先简单介绍一下 iphone 颗粒,它是阿里旗下的一个编程工具,它这里明确写着 free ai models, 包括最新的模型。 根据实测,它现在能提供 g l m 五的模型,还有最新的 tim 二点五,而且它承诺是无限量的供应,所以基于这点我们可以把它, 基于这点我们可以尝试把它接入小龙虾,这样就可以供我们有源源不断的 token 来驱使小龙虾。先说怎么安装 iphone, 我 们打开 iphone 的 网址,然后将这一个命令复制下来,在 mac 上打开终端,如果是 windows 电脑就参照以前的视频,如果是 windows 电脑,就按照以前的视频在 npm 下进行安装。我们把命令复制进来, 回车它就会自动安装 iphone。 安装好以后,我们就进行登录,我们在目标盘符或者地方建一个文件夹, 右键选择在终端打开这个文件夹,输入 iphone。 如果是第一次运行,它会跳到 os 去进行验证登录,根据提示注册扫码登录即可,然后它就会跳到命令行,那我们的登录就完成。 下一步我们就需要使用一个编程的 ide, 不 管你是使用,不管你是使用哪一个 ai 编程工具,你只要下载一个就好,我这里以字节的翠的做示范,我发现有很多老铁还不会使用翠, 我这里给大家做一个简单的教学。其实有了这种编程工具,它能实际解决我们很多的问题,在某些程度上它会比豆包更好用。我们下载为翠以后,将一个文件夹拖入这个程序, 你可以拖入,也可以打开文件夹,只要导入一个文件夹即可,这样他会将写生成的内容保存在这个文件夹,再将这个教程拖入到右下角的这个对话框,这时他会引用这个文件。在翠的右下方,我们可以看到这里有 kimi k 二点五, 实际上他提供了很多的模型,有豆包最新的豆包二点零的模型,还有 mini max 二点五, g l m 二点五等等,我们都可以选择一个来使用,我们用最新的 g l m 五。我们就跟翠说,阅读这个文档,将我的 open cloud 接入 iphone, 翠就会去自动给你部署这一个配,就会自动去帮你完成这一个工作,因为我已经部署好了,我就不再部署了,我们可以看一下。
1061林浩Ai工具库 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿今天给大家分享一个项目,让你用最少的钱去用上最好的模型来使用这个 open curl, 因为我们都知道这个 open curl 小 龙虾,它的性能很好,而且非常有意思,但是它的 token 消耗太恐怖了, 如果你要用 open i 的 这种 codex, 五点二,五点三这种模型的话,或者用 cloud 的 这些模型的话,它可能跑一晚上,你明天就欠费了。 今天来给大家分享的这个项目是什么?可以让你把这些 cloud code, 把这种 etgrity 这种应用 它里面的会员额度给它套成 token 来使用这个 open curl。 当然你如果要用在其他地方也是可以的,比如说你想用这 codex 这个模型去在 cloud code 里面使用也是可以的。这个项目本质上就是一个怎么样把这些会员的 token 给它套出来, 把它弄成一个标准的 a p i 的 格式,标准的 open i, a p i 的 格式,让所有的这种应用都可以去调用。 ok, 我 们来看一下,我直接给大家看一下出来的结果是什么样。提起来这个服务,就可以直接到这个网址里面去配置了,这是它的一些仪表盘,你可以配置上你的这些会员 ai 提供商是什么? 一般我们用的话,用这个 codex 的 会比较多一点,像其他的是这种 jammer 或者 ideographic 的 cloud pro, 这种会员基本上就不用考虑了,因为在国内是非常容易被封的, 所以说基本上是不用考虑的。所以为什么要用这个?它的二十美金 plus 这种会员它有一些渠道,它会比较便宜,并且最近最划算的是什么?去买那种 team 的 账号, team 的 母账号,它还可以拉四个子账号,只要几十块钱,它相当于你一共有五个这种 plus 的 二十美金的会员账号,然后你有五个 codex 的 使用量,你只要登录授权, 登录了之后,它的这个网址里面有一个 token, 你 就直接复制到这里面提交就可以了,它可能会报错,但是不用管它,你直接砍看这个配额管理,这后面就可以,只要它这儿是有的,都可以使用, 就是正常可以使用的。还有这些配置面板这些,这个提起来也很简单,大家用 cursor 或者说用 cloud code 直接全选 给它复制,让 cloud code 的 去给你做配置就行了,就 cloud code 的 这些直接给你做配置就行了,但是它还是有些坑,但是 cloud code 呢?这 coser 这些它自己就能解决,它需要自己去配置一个 key, 这个 key 随便是什么都可以。还有一个坑就是我这 cloud code 第一次登录的时候,它把这个这个东西它搞错了, 他以为不需要这个后缀,他一直告诉我这个,我让他检查,他检查了半天才知道他是要要这个的才能登录进这里,提起来也是非常方便。总体来讲这个项目还是非常不错啊,他可以把这种 codex 可以 套出来,甚至你可以把你的端口 去做个内网穿透,或者搭在服务器里面,这个项目你就可以去卖 token 了。我也用这个 codex 这个模型在我的 cloud code 里面去跑了一遍,它是真的有点慢。 codex 这个模型,但是它的准确度这些没太大问题了,感觉跟 cloud code 是 没有本质的区别的,但是效果都还是蛮蛮不错。
871jesse 00:44查看AI文稿AI文稿
00:44查看AI文稿AI文稿大龙虾还没有明白,百万 token 先没了,别急,一起来薅老黄羊毛。无限 token 免费用。首先在英伟达这个网站用邮箱注册个账号,接着验证一下手机号,就能调用 api 了, 关键是支持国内手机号,不用绑卡。然后随便选一个大模型,进入聊天页面, 这里可以切换各种大模型试试,白嫖的人太多,热门模型可能响应很慢,找一个速度还过得去的,这里查看视力代码,可以直接复制模型相关配置。然后打开你龙虾的外部页面,修改配置, 保存之后建议重启一下服务,现在就再也不用担心托肯消耗了,之前配置好的飞书也能直接使用。
1938小蚂蚁爱折腾|搞AI 10:20查看AI文稿AI文稿
10:20查看AI文稿AI文稿最近为大家做了多期 openclaw 相关的视频,而且昨天我还发了一期 openclaw 的 高级用法的视频。但最近我发现几乎每期视频的评论区都会有留言提到 openclaw 调用 cloud code 会非常消耗 token。 因为在之前的视频中,我有为大家演示过,用 openclaw 来调用 cloud code 进行编程开发,我们只需要为 openclaw 全程操作 cloud code, 为我们实现编程开发。 但是我们如果采用传统的方式,也就是常规的方式让 open cloud 直接调用 cloud code 的 话,那么 open cloud 每隔几秒就会轮循一次,检查一下 cloud code 的 状态以及 cloud code 的 输出。使用这种传统方式的话, open cloud 必须时刻盯着 cloud code, 所以 openclaw 就 会消耗非常多的 token。 所以 我发现在评论区大家抱怨 openclaw 调用 cloud code 会消耗更多的 token。 因为大家采用的是这种常规的传统方式, 所以 openclaw 要采用不断轮询的方式来查询 cloud code 的 状态,也就是 cloud code, 它执行的任务越久,在 openclaw 中它轮询的次数就越多,所消耗的 token 也越多。 所以我们可以完全不需要用这种传统的方式直接让 opencloud 来调用 cloud code。 因为无论是 opencloud 还是 cloud code, 它们都非常非常的灵活,所以越灵活就越强大,就越有利于我们去自定义一些功能,从而轻松解决用 opencloud 调用 cloud code 的 时候, 产生大量的 token 消耗。尤其是 cloud code 在 前几天新增了 agent teams 这个新特性,因为 agent teams 相当于在 cloud code 中随时可以创建一个完整的开发团队, 而且每个 agent 呢都是独立的进程,所以是真正的并行执行,而且每个 agent 之间还可以相互通信,还能共享任务列表,能自动认领,还能实现专职角色分工,比如说负责开发前端的 agent, 负责开发后端的 agent, 还有负责测试的 agent。 所以在 cloud code 中有了 agent teams 这个最强大的新特性,在 open cloud 中就可以更加轻松地向 cloud code 委派任务,让 cloud code 全自动完成整个开发工作流。 想让 open cloud 以更节省 token 的 方式来调用 cloud code, 其实非常简单,我们只需要用到 cloud code hux 功能, 在 open cloud 中可以结合 cloud code 的 hooks 功能,真正实现调用 cloud code 进行自主开发,并且能够实现真正的零轮询,而且还能非常节省 token。 当开发任务完成之后, 我们还能在聊天软件的群组中自动接收到任务完成的通知,包括实现的是什么任务, 项目存储的路径,还有耗时,还有 cloud code 的 agent teams 是 否已经起用,还有具体完成的功能,还有项目的文件结构等内容。下面我们就看一下我是如何通过 cloud code 的 hux 来实现了整个流程。 下面我们先通过这个流程图,让大家更直观的感受一下在 cloud code 中通过 hux 回调来实现的整个步骤是怎样的。 首先是由 opencloak 将我们要开发的任务委派给 cloud code, 像这个委派只执行一次,而且它是后台运行,不会阻设 opencloak 的 对话窗口和它的主 agent。 当 cloud code 接到任务之后,它就会进行自主开发还有测试,当任务完成之后,它就会触发 stop 事件。 第三步就是 cloud code 中 hooks 自动触发,它会先将执行结果写入到这个文件中,然后再发送 wake event 来唤醒。 open cloud 在 这里采用了 stop event 以及 session end event 实现双重保障,来保障在聊天软件中,我们能够真正收到它的任务完成的通知, 然后 opencll 就 会读取这个文件中的这些结果和状态,当它读取完这些结果和状态之后,它就会回复给我们,也就是通过我们的聊天软件来回复给我们这些状态。 像这个流程的话, opencll 只在给 cloud code 派发任务的时候调用一次 cloud code, 然后这中间的流程不需要 opencll 参与。在最后这里, opencll 再读取一下这个执行的结果,并且将执行结果发送给用户。 所以在第一步, opencloud 只是给 cloudcode 下发一个任务,它下发任务的过程所消耗的 token 几乎可以忽略不计。在最后这里,它只是读取一下结果,将处理结果发送给用户,而且这个结果里的内容非常少,甚至不超过一千字, 所以在最后一个步骤,它所消耗的 token 也几乎可以忽略不计。在 cloudcode 的 自主完成这个任务的过程中, opencloud 不 需要对 cloudcode 进行轮询。 好,下面为大家讲解一下我是如何实现的。在 cloud code 中通过 stop hook 来达到任务完成自动回调的效果。在刚才也提到了我们使用了 stop hook, 还用到了 cloud code 的 session end。 下面我们简单看一下为什么要用到这两个 hooks。 在 cloud code 中一共有十四个 hooks, 之所以我们选择这两个, 是因为我们构建的这个工作流,在 cloud code 中,它完成开发之后才会触发这个 hooks, 所以 使用 stop hook 作为主回调,就可以保证 cloud code 的 真正完成开发时才会触发。在这里我们还用到了 session and 作为兜底回调, 也就是假设 stop hook 它没有触发成功,还有这个 session and 它能够作为兜底。像这样的话,我们就能够真正保证 open cloud 向 cloudcode 发送一条开发任务,然后 cloudcode 独立运行。在 cloudcode 独立运行的这个过程中,它并不会消耗 opencloud 的 上下文。当 cloudcode 完成开发后才会触发 hux, 然后我们的聊天软件就会收到通知, 下面我们就可以看一下具体的代码。在这个代码中,我们先看一下这一个脚本,它的作用就是将要开发的任务来写入到这一个文件中,然后再通过这个脚本来启动 cloud code。 当 cloud code 完成开发后,这个 stop hook 就 会自动触发,然后就会调用这一个脚本,我们可以点开看一下, 这一个脚本就会将任务发送给 openclaw, 所以 这个自动回调流程,它会读取这两个文件里的内容,并且写入到这一个文件,然后 openclaw 就 会将这些信息推送到我们的聊天软件,这样的话我们就能够实现 在 open cloud 中向 cloud code 下达开发任务,然后由 cloud code 自主完成开发。当完成开发之后再触发这两个 hux, 最后我们的聊天软件就会收到推送通知。好,下面我们可以先用一个简单的开发案例来测试一下。在主 a 选项这里,我们直接在对话框中输入我们的任务, 我是为了是用 cloud code 的 a g and team 协助模式构建一个基于物理引擎还有 h t m l c s s 的 带材质系统的落沙模拟游戏,然后我们直接发送,看一下这个效果, 这里很快输出提示,它已经将这个任务派发给 cloud code 的 agent teams。 这个开发模式就是调用 cloud code 的 agent teams 多智能体写作,这里还给出了这个工作路径,然后这里它提到完成后会自动通知到群里, 像这样的话,这个主 agent 的 线称并没有被阻塞,它还可以继续为我们执行其他的任务。比如说我们在这个主 agent 中继续输入任务,比 比如说让他查询新加坡今天的天气,然后我们直接点击发送,看一下最终的效果。像我们如果采取传统的方式在 open cloud 中来调用 cloud code, 在 主 agent 中必须等到 cloud code 真正完成开发之后,这个主 agent 呢才会继续执行我们的其他任务。 像我们采取了现在这种方式,这个主 agent 的 进程并没有被阻塞,所以我们让他查询新加坡的天气,然后这里他就很快查询了一个天气,然后我们还可以继续输入其他人物,比如说讲个笑话,然后这里他就很快输出了一个笑话。而 cloud code 在 后台完全是自主运行,不需要我们去干预, 然后我们只需要等待 cloud code 完成之后,将完成后的消息推送到这一个群组里就可以了。之所以设置为将完成后的消息单独推送到一个群组,是因为我们在这个 agent 中可能还在进行其他任务的操作, 比如说让他讲个笑话,他在讲笑话的时候突然多出来一条任务完成提示,这样会导致这个上下文窗口比较混乱,所以我们就将他完成后的这个消息推送单独推送到一个群组里,这样的话就不会占用这个主 a 智能的这个聊天窗口。在这个群组里我们就看到了这个消息推送,我们点开群组 查看一下,在这里我们就看到了这个任务推送,这里提示 cloud 的 任务完成。这里是开发的这个游戏,然后这里是游戏的路径, 在 cloud 的 code 中使用的就是 agent teams, 这里就是给出的项目文件,然后这里它还推送了第二条消息,这里还给出了完成时间大概六分钟,然后这里还包含一百八十四个测试通过, 然后这里就是给出的交付,然后这里还给出了这些性能,下面我们可以输入提示词,让他将代码文件打包发给我,这样的话我们就可以在本地打开进行测试,因为我的 open cloud 是 运行在云端的 好,这里他将为我们开发的这个项目文件发送给了我们,这里还提示解压后在浏览器中就可以打开使用,然后我们直接点开,然后我们在浏览器中打开看一下这个效果,就是他开发的这个落沙游戏,我们可以先测试一下,我们选择这个沙子 好,这样点击之后这个沙子就落在了底下,然后我们再点击这个水 好,可以看到水落在了沙子上,然后我们再给它加一把火,可以看到这个火会往天上飘,再给它加一些木头, 然后再给它加一些蒸汽,可以看到这个蒸汽飘到木头上会变成雨。像这样的话,我们就真正实现了在 open cloud 中调用 cloud code 进行开发。大家就不用担心在 open cloud 中调用 cloud code 非常浪费。 token, opencloud 所消耗的 token 几乎可以忽略不计,哪怕我们不在电脑前,也可以通过手机向 opencloud 下达开发指令。当完成开发之后,我们就可以在群组中查看推送的这些消息。
593AI超元域 05:37查看AI文稿AI文稿
05:37查看AI文稿AI文稿嗨,大家好,今天给大家分享下基于 openclo 搭建本地 ai 员工的部署教程,不用花一分钱托肯, 这次我们基于汪派能用为面板来搭建搭建完全本地化的 ai 员工助理,核心是部署欧拉曼本地服务以及 gpt 模型,再搭配 openclo 作为交互入口, 数据全程保存在自己的服务器,既省钱又安全,不管是日常办公还是个人使用都超方便。话不多说,咱们直接上实操。整个实操过程分为六步, 第一,准备 gpu 服务器。第二,运维面板万帕诺安装。第三, gpu 资源配置。第四,奥尔玛模型平台安装。第五,完成 gpt 模型加载。第六, open club 个人员工构建。 我们先来完成第一步,基于腾讯云申请一台带 gpu 的 云服务器,这里选择创建一个竞价实力进行操作演示。首先我们保证服务器为 gpu 架构,为本地模型提供算力。其次,磁盘记得设置为一百 g, 方便大模型下载到本地 并开通公网 ip, 方便后续访问。最后记得提前开通应用的默认访问端口,欧乐玛应用端口、 one panel 应用端口、 openquad 应用端口。服务器创建好以后,我们直接登录腾讯云服务器,默认会享 gpu 相关驱动。安装好首次登录需要耐心等待下,登录后,首先我们通过 sudio 命令切换到 root 用户下, 然后到 one panel 在 线文档中获取一键安装命令,直接复制执行即可。进入安装过程时,先检测完成 dawk 的 安装,需要确认安装目录并下载安装 dawk, 安装完成后,开始设置镜像加速器和面板访问参数,其中输入 yes, 完成镜像加速器配置, 面板端口号输入我们已开通的端口号,最后获取面板账号及面板密码即可。登录 one panel, 登录后我们确认下 gpu 卡的驱动情况,紧接着配置好面板访问地址,方便应用直接跳转访问。配置完成后,我们进入终端开始 gpu 资源配置,首先再次输入命令行,确认英伟达显卡驱动,然后逐个输入命令,完成英伟达容器镜像安装 配置 dolphin 镜像使用英伟达的 gpu 资源配置完成后重启 dolphin 镜像,这样我们就完成了 gpu 资源使用的配置。 到这里我们基本准备好了我们的资源,接下来我们开始欧拉玛的安装,我们进入应用商店,选择 ai 就 可以快速看到欧拉玛应用,点击安装输入相关参数即可。 这里我们需要确认好版本,零点一五点四当前最新版本端口号一一四三四开启端口外部访问,最后一定记得勾选开启 gpu 支持,其他保持默认,点击确认开始安装。这里安装包含镜像拉取以及应用安装两部分,大概需要一分钟左右, 这里我们快记下。安装完成后我们到已安装应用中确认欧拉玛已经正常运行, 点击链接地址页面显示欧莱玛 is running 即可。到这里我们就完成了欧莱美开源模型管理平台安装。下面我们急于欧莱玛完成开源模型 g p t 杠 o s 二零 b 模型的加载, 大家跟上节奏,在 one panel 中找到 ai 管理,进入模型管理,点击创建模型,在模型配置页面点击快速跳转进入欧莱玛官网, 输入 gpt 杠 o s 快 速搜索到模型,点击获取模型 id。 然后我们再回到 one pan 面板,输入获取到模型 id, 点击确认开始模型下载,该模型下载大概需要十到二十分钟,这里我们快速跳过模型,加载完成后,我们就为我们的个人 ai 员工准备好大脑了,我们通过模型先验证下能否正常对话,太棒了,可以对话哦, 这样我们就为 ai 员工准备好了大脑。下面我们同样基于 one panel 来安装我们最近特别火爆的 openclaw, 进入应用商店找到 openclaw 应用,点击安装完成参数配置确认,默认端口号已经开通,下拉选择欧拉曼模型供应商并输入相关参数,具体参见如图所示。其中 gptos 二零 b 对 应我们下载的本地模型 a p i t 输入任意字母 base u r i o 对 应我们部署的欧拉姆地址。最后同样记得开通端口外部访问, 其他参数保持默认,点击确认即开始安装。安装大概一分钟左右,我们同样快速跳过,安装完成后通过安装目录获取 opencloud 访问 token, 获取后与 ip 端口 token 等于 token 值,拼接后输入 web 访问地址中, 最后点击跳转,直接选择带 token 的 访问地址就可以体验啦。让 ai 助手帮忙创建一个文件清单,到服务器对应目录查看,完成操作啦。 接着我们让他网上查询一些信息,他也可以轻松帮我们搞定。到这里我们就完整构建了一个本地的 ai 员工啦,大家速来体验呀!完全可以用 one panel 作为 ai 员工的管理员,本地,重点是本地!本地就等于安全! 同时再也不用为 token 着急上火啦!小伙伴们快来快速构建,抓紧体验啦!
5.0万OpenClaw开源社区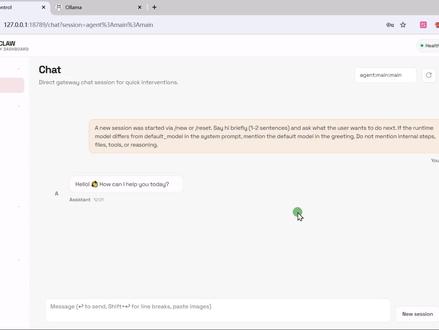 16:56查看AI文稿AI文稿
16:56查看AI文稿AI文稿我们在前面安装这个 open 可露的时候,所使用的模型是智普的模型以及还有阿里百联的模型,但是这些模型的话都是属于在线的呃,它会需要很多个 talking, 那 这些 talking 呢,我们是需要花钱去买的, 那当然呢,也有人去反映这个在线的模型啊,它所消耗的 talkin 很多,所以说这个时候有人就想我们能不能使用本地的模型来部署 这个呢?当然是可以的,我们可以先到那个欧拉玛的网站上面去看一下啊,在他的首页这里面有一个 openclo, 我们点击进来啊,这里面没找着,没关系,我们往下拉一下,往下拉一下之后,因为这个 clubbot 已经改变为了这个 openclo 了,我们在这里面选择这个 openclo, 然后呢我们往下面拉,往下面拉的话,这里面的话呢,他就会有一些他所推荐我们所使用的这些模型。那么我们就建议呢,各位就是使用的时候就直接使用他所推荐的那些模型 啊,现在在我的环境这里面呢,我已经是把这些模型呢给它拉取下来了,那你使用其他的模型的话,可能还是会有一些问题的。 那下面的话呢,我们就开始去配置一下这个模型,点击这个 open clone, 然后呢我们点击这个 config, 点击 config 之后呢,继续找到这个 modus, 然后有一个 private, 然后这里面咱们就开始去添加一个模型 and you try, 那 这里面我给他一个名字叫欧拉玛好了, 这个名字你自己可以自己随便去取都可以。然后呢我们这个 api 的 这个位置呢,你可以选择这个是 compilation api key 的 话呢,这个可以随便去写 啊,因为我们的这个欧拉玛它不需要这个 k 去验证,这个你随便写什么都可以啊。 然后呢这里面我们选择 i p r k os header, 勾选上 bios ysl, 这里面的话,你就加上我们的这个欧拉玛的这个地址, 那么这里面的话,我现在的地址是端口是幺幺四三四,那这里面我们写的时候就是 h g d p 冒号本机,你你可以写任何的,你主机上的任何的一个地址都可以,零点零点幺, 这里面的话我们写上端口幺幺四三四,这里面一定一定要把这个 v e 给它加上去。 如果说你不加这个 v 一 的时候,那我们去访问的时候,他可能就是,对吧?你问他问题,然后呢他就回复的时候就是一个空的,什么都没有,所以说这里面一定要加上一个 v 一 才行。 然后呢我们继续往下拉,找到这个 modus, modus 的 话,然后呢我们选择这个 and, 选择 and 的 之后,然后在这里面 api 的 这个位置呢,我们也是选择 open i, 它的这个我们就选择 max talkings, 然后它的这个上下文的这个窗口呢,我们给它设置一个比较大的一个值就可以了,随便你去设值。 继续往下拉好,然后这里面有一个 id, id 的 话呢,就输入我们的这个啊模型的名字就可以了,比如说我这里面就直接使用 gptos 二十 d。 好, 那么然后呢我们继续往下拉,这里面有一个 and, 把它选择为这是一个 text 的, 然后这个 man talking 的 话呢,你也可以随便去写,我就直接写上一个四万就可以了。这个你随便去写, 然后给它起一个编名,我们就写成这是为一样的就可以了。这是我增加了一个模型。 那然后呢,我们你看啊,在它的官方网站上呢,给我们推荐了好几个模型,其中还有一个是 glm 四点七的,对于 glm 四点七,它这里面的话使用的是一种语音环境,我们这里面点击这个 mod 的 话,它不是让它是直接使用的,是在线的一个模型, 我们在这里面的话呢,也来给它加过来。在我的环境这里面的话,你看有一个 glm 四点七 club 的, 这里面的话,这里面呢,我也是给它拉取下来了。好,所以说我这里面再次增加一个新的模型,这几个我都给它加过来。 好,在这里面我们再次点击一下这个 and。 好, 然后呢,这里面我仍然选择的是 open i complexions。 然后呢这里面也选择 manage tokens。 窗口的话,我们在这里面你随便去写一个都可以 继续往下拉。然后这里面 id, 我 们把我们的这个镜像来给它加上去,就是 g, p, d, o, s s 的 这个 y 啊,这个是应该是选择的是 glm 四点七的,这个我们加第二个镜像。第二个模型 input 的 这个位置呢,咱们也选择 text 的, 这个位置的话,就随便去写一个比较大的值就行了。 这个名字的位置呢,我们也给它起一个命名,也叫的是 g m g r m 点 g cloud。 好, 第二个模型呢,我现在也是给它添加过来了。 那当然了,我们也可以再次去添加一个我们这里面添加的模型都是官方它所推荐的模型。 然后呢我现在再来添加一个其他的模型,这个呢,他并没有出现在官方推荐的这个文档这里面,咱们现在来看一下是否会有什么问题。我这里面选择枪顶三杠十四 b。 好, 这次去添加一个模型。好 and, 好的,现在这里面来给它收起来。好吧,这里面的话,我们仍然选的是它。好了之后,这里面选的 max tokens, 这个呢,我们就随便的去写一个比较大的值就可以了。 然后这里面 id, 我 们就把这个谦问三十四 b。 我 再说一次,谦问三十四 b, 这里面并没有出现在它的这个推荐模型这里面。 input, 这里面点击 text, 这个值呢?我们也直接输入一个比较大的值就行了。好,这样的话我现在添加了三个模型,点击 save, 咱们现在去看一下它的这个配置文件,点击打开 点击之后呢,这里面你看有一个 private 的,是百炼的,这个是我们在前面的时候已经添加过的奥拉玛。这里面的话呢,我增加了三个模型,一个是 gpt osss 二十 b, 还有一个是 grm 四点七克拉的,那还有一个是铅汞。三十四 b, 然后呢我们往下面拉,找到这个 agents, agents 的 话,这里面的话,这个模型的话咱们现在继续来给它添加过来,把这几个模型现在来给它加过来好了。好吧,呃,这里面的话,我就直接啊往后面去写, 这是一个这是一个,这是一个。 那这里面的话,我们直接选择的是维欧拉曼、 欧莱曼的这几个模型,咱们现在来手动的来给它加过来,然后 g p t o s s s 二十 b 二十 b, ok, 这个是添加过来了一个了,然后呢我们再把剩下的两个模型也来给它加过来。呃,还有一个叫做这是为 g r m 四点七 cloud 的 这个呢,我们现在也是把它的名字记 r m。 好, 那然后呢我们再次来给它增加一个,还有一个是千问三十四 b 的 铅汞三十四 b, 这个边名的话呢,我也给它起名叫做这是为铅汞三十四 b 就 可以了,那这里面的话,我现在额外的额外的增加了三个模型,那然后呢,我们现在使用其中的某一个模型,把它设置为是默认值, 比如说我这里面就是这是 default, 就是 设置的是它的默认值。 ok, 好, 我现在使用 g p o s s s 二十 b 的 这个模型保存一下,咱们现在开始去做测试,点击这个 chat, 好, new session, 打开一个新的脸际,新的绘画。 好了之后呢,咱们现在来跟他去沟通一下。你好,请问你是哪个模型? 它这里面的话,因为使用的是比例的模型,它这里面其实是会消耗比较多的这样的一个 gpu 的。 好,它这里面的话告诉我们说使用的是欧莱玛 gpt 二十 b 的 这样的一个模型。好,然后你可以随便的去交流就可以了。 好,请问是哪个模型? 好?这里面告诉我们说是欧拉玛 g p t o s s 二十 b 的 这样的一个模型了, 那当然呢,我们现在去换一下,我刚才讲咱们刚才看到的时候,它这里面实际上是会消耗比较多的 gpu, 那这个时候有的同志说我笔记本上面跑不起来,对吧?跑不起来,那么大的这个,呃,那么大的这个,呃这个模型,那没关系,我们可以直接使用什么呢?我们可以直接使用它的这个云端的这个模型, 也就是直接使用 g m 四点七 cloud cloud 的 话,它本地并没有去下载什么模型。 那这里面的话,你首先你得你要是想使用这个模型的话,首先的话你得要在欧拉玛的网站上自己去注册一个账号,记住了,你得要注册一个账号,注册一个账号之后呢?然后我们在命令行里面 去登录一下,在这里面有一个登录的这个名字。 好,欧莱玛,我们现在去登录一下,那这里面的话,你看我现在已经是登录了。那如果说你没有登录的话,比如说我举个例子来说,我现在把它给退出来,我不登录了, 不登录了之后呢,我重新去登录,你看他这里面的话是会给我一个链接,给我一个链接之后,我们在这里面把它切到我们的地址栏这里面来,他会问我们是否要去链接,当然了网站这里面你得要先去链接一下才可以, 这种方式就算是连接成功了,连接成功了之后我们才能够去使用这个云端的这个模型,我们可以试一下,好让 你好,我们来看一下他是否能够正常的去回复,你看此时是可以正常的去回复的, ok, 退出来就行了。那这里面的话,他啊我们这里面直接使用免费版的就可以了,你不用去花钱去购买什么,直接使用的是这一块免费版的,他也够我们去用的了。 那这里面的话呢,我们现在去换一下这个模型, glm 四点七 cloud 的 这个模型。好,我把它给换掉。换掉之后呢,然后我们现在重新的去跟它去做一个沟通,点击这个 new session。 好,我们现在开始跟他去交流。你好,他这里面的话就可以跟我们正常的回复了。请问你是哪个模型? 原来使用的是我们一开始刚刚所做的练习,使用的是这个 gpt osss 二十 b, 那 现在的话使用的是 grm 四点七 club 的。 那这里面你看它告诉我们说现在用的是什么?叫做是欧拉玛里面的 glm 四引擎 cloud 这样的一个模型。 那我们现在再次来给它换一个模型,我本地这里面,在我本地这里面有一个千米三十四 b 的 这个模型呢,实际上是可以正常去使用的,我们现在来打开看一下。 好,请给我写一篇两千字的作文。 那你看啊,我这里面使用的时候它是可以正常去使用的,看到了没,它消所消耗的 gpu 其实也是蛮多的,跑起来也是蛮快的,没有什么问题。我 ctrl c 终止了,对吧?你可以等一下也行。好,我们退出来吧。 好的,反正我现在就想说明的是什么呢?说明的就是我的这个千万三的这个我的千万三的这个模型啊,是 正常是可用的,对吧?然后呢,我们现在把它换到哪里面去呢?换到我们的这个 opencloud 里面来,我们看一下能否正常去使用。好,我选择这个千问三十四 b, 把它换成是默认的, 找到这个 agent 千元三十四币,那这个呢,就是我们的加载过来的这个模型呢,已经保存退出,然后这里面的话呢,我们现在再次去跟他去沟通 new session。 好,那这里面咱们现在来问一下你。好,他这个不稳定,我们也就是说使用千万三的这个模型的话,呃,他可能就不是很稳定,有的时候你看现在可能是正常的,但有的时候呢,他可能回复的时候就不是很正常。 好,你看这里面回复的时候,现在就已经是不正常了,也就是有问题了已经,对吧?那在我本地跑起来的话是正常的,但是呢,我们在 open clone 这里面去引用它的时候,运行起来的话,则可能还是会有问题的, 所以说我们在使用模型的时候就直接使用它所建议的这些模型就可以了。 那当然了,如果说你本地的这个啊机器配置的比较高,你可以直接使用千万三 q 的, 那如果说你所使用的这个配置不是很高的话,那这里面的话呢,我们就可以直接使用是 glm 四引擎的,这是属于是语音环境上的一个啊模型,那它这里面的话并没有什么限制, 对吧?你可以看一下,它这里面并没有告诉我们说可以免费使用多少 talking, 超过这个 talking 就 不能使用了,它这里面并没有这些要求,所以说我们直接使用在线的也是非常方便的。那如果说机器配置不高,那么我们就可以选择它机器配置比较高,对吧?你就完全使用本地运行的这个模型, ok, 你 就可以选择它。 这是我们如何让 open globe 使用欧拉玛所部署的模型?大家可以自己来尝试一下。
 04:05查看AI文稿AI文稿
04:05查看AI文稿AI文稿我跟你们说啊,中国的电力正在以一种前所未有的方式出口到全世界,而且它不是通过电缆输送出去的, 它是通过一个你每天都在用的东西。就 ai 对 话里面这个 talk 能想象吗?你知道根据现在全球最大的 ai 聚合平台 open router 单周前十名的模型消耗总 talk 里面中国的模型占了百分之六十一,就前三名全是中国的公司, mini max、 kimi、 智浦的 g r m 五, 还有我们熟悉的 deepsea, 就 这些模型啊,已经把美国的 cloud grog 挤出了前三。就一年前大家还在讨论能不能追上 open a, 现在数据已经给出答案,当然了,我们也要客观看待啊,就这个 open router, 它统计的只是公寓的这些,其实就是我看了另外一篇报告,它统计的这个数据其实只占全球总的消耗量的很小一部分。 其实你美国很多公司,他们是在思域里面调用这个托管,这个没有计算在内啊,但不管怎么说,这其实是一个趋势啊。 但是你想一下这个电力它是怎么通过这个 token 出海的?你想象一下,比如说在加州啊,或者在佛罗里达任何一个美国的地方,一个程序员,他 调用了中国的一个大模型来帮他写代码,帮他去计算。哎,这个模型它消耗的这个 gpu 和电力其实是在咱们国内完成的,对不对?那你其实它没有离开咱们中国的电网, 那其实他通过这个电力转换成了一个算力的服务,通过托肯完成了这个跨境支付,其实说白了是数字时代的一种服务贸易。 而且更巧的是,这种通过 api 进行的电子传输,它受 wto 的 电子传输关税豁免规则保护,嘿嘿,这意味着这是一条数字的免税高速公路。我们把视野拉大一点,你会发现,托肯出海在中国四十年的出口史上,其实具有里程碑的意义。 八二年代,我们出口的是衬衫、鞋子。到两千年时代,出口电子家电。到了二零一零年,智能手机走上了全球。到了二零二零年,我们出口的是什么?是新能源汽车。每一次升级,其实产品的附加值都在提升,但你卖的始终是实实体的货物,对不对? 直到了这个托肯出海啊,是这条升级链的终极形态。我们出口的其实已经不是在任何实体了,而是纯粹的智力和算力。 这个其实有点像美国了,美国他们其实一直以来出口的都是高精尖的这些软件啊,包括微软的这些 office 啊,这些 windows 啊,对不对?还有苹果的这些软件。那到了今天,其实我们的软件在以 talk 的 形式在出口, 你可能会问,凭什么是咱们呀?这模型的技术,其实中美现在也差不多,甚至我们其实还落后一点,但其实真正的胜负手啊,藏在最底层的电力。二零二五年呢,我们的全国用电量首次突破十万亿千瓦时, 我们的体量超过美国的两倍。更重要的是,我们通过东数西算的战略,把数据中心建在了内蒙啊,贵州啊,等可再生能源丰富的地区,那里的电价可以低到每度两毛钱左右,这就是一个巨大的一个优势了。而你知道现在美国的电力有多紧张吗? 连这些谷歌啊, ams 这些巨头都开始涨价了,因为 ai 推理的本质就是烧电换智能,谁的电又便宜又更低,天然的竞争力就更强。 而今天我们已经建立了一个结构性的优势,除了电力便宜呢。其实中国的模型啊,其实在性能上面已经具备了极大的性价比和强大的开源生态了,这也是我们能够出口 token 的 一个核心原因。 有数据显示啊,一些我们顶尖的模型的输入成本可能只有同类的国外产品的十六分之一,这还不是牺牲性能换来的便宜,而是在工程效率上做到的极致。也就是说,你花更少的钱就能买到接近顶级性能的模型体验,你谁会拒绝呢?对不对? 在哈根廷、 face 等开源平台上,中国模型的下载量已经超过了美国。当一些国外的公司在收缩他们的开源的时候,我们的 deepsea 啊, mini max 等却在持续的开源高速迭代,把全球开发者生态紧紧地握在手里。 总之呢,中国的 ai tok 出海啊,表面上是模型技术的竞争,中层是算力服务的贸易,底层则是电力体系的比拼,它也标志着我们从出口实体产品升级到出口电力、出口智能的一个阶段。
6237蛇口费雪和不二家 02:56查看AI文稿AI文稿
02:56查看AI文稿AI文稿参照 openclo 各种教程一顿操作猛如虎,仔细一看原地杵,今天一个工具搞定 openclo、 欧拉玛和飞书开源运维管理面板 one panel 来,咱们直接开始部署。进入 linux 服务器,输入这个命令,一键安装,一路点回车,直到出现这个页面就安装好了, 从这里拿到相关信息,在浏览器中就可以进入到工具了,点击这里,然后点击 ai, 选择欧拉玛,点击安装,输入容器名称和勾选端口外部访问,然后点击确认就开始自动安装,等出现这个页面的时候就完成安装了。 然后点击模型,点击添加模型,输入需要安装的模型名称,点击添加就自动开始加载了,等到出现这个页面就加载完成啦。然后再次点击这里,点击 ai, 选择 openclaw, 点击安装,选择欧拉玛,填写加载的模型,输入任意字母的 key 和欧拉玛的地址, 输入容器名称和勾选端口外部访问,然后点击确定就开始自动安装了。等到这个页面出现就完成 openclaw 的 安装了,然后点击已安装,点击 openclaw 进入安装目录,点 击 data 目录,点击 com, 再点击 openclaw 配置文件,就拿到 openclaw 的 token 了。然后回到已安装页面,点击 openclaw 的 参数, 按照这个格式填写对应的地址信息,点击确认,然后点击跳转就可以进入 opencloud 开始使用了。好了,我们开始配置飞书。首先进入飞书的开发者后台,点击创建应用,输入名称和描述,然后点击创建,然后添加应用能力中的机器人,并设置好机器人名称, 然后分别选择好应用和用户的消息权限,就完成了飞书的基础配置了。然后返回 one panel, 进入 opencloud 的 安装目录,然后点击终端输入这个命令,然后开始配置飞书。是否配置,选择 yes, 这里对接的消息工具,我们选择飞书,这里飞书的插件我们选择本地的就可以了。然后添加账号 id, 填写飞书中这个 id 即可。这个版本你用哪个就选择哪个,这里再次输入前面的那个 id, 这里输入这个 secret, 这里选择 finish, 就 完成飞书的基本信息录入。现在是否配置访问策略,选择 yes, 选择 open 就 好了。是否添加显示名,选择 yes, 点击回车,完成配置更新,至此就完成了 openclock 的 所有配置了。回到飞书,点击事件配置,选择长链接,点击回掉配置,也选择长链接,然后添加事件,选择接受消息,点击确认添加。最后创建版本, 输入版本号等必要的信息就可以提交了,我们就可以在飞书中看到对应的信息。点击这里完成必要流程后,就可以开始使用啦。大家在使用的过程中如果遇到了问题 或者有想要实现的场景,欢迎打在评论区,后续视频会为你们解答。点赞、收藏加关注,让你学习不迷路!亲爱的同学,你学废了吗?我是爱学习的小南,希望我的分享能对你有帮助!
 03:37查看AI文稿AI文稿
03:37查看AI文稿AI文稿如果你是 openai 的 拆 gpt 会员,现在我要告诉你一个好消息,我们可以在 opencloud 里不使用任何的 api key, 就 能够部署拆 gpt 最新的五点三模型进行推理了。 我知道这可能听起来有点不可思议,但事实是,现在这种方式确实处在一个 openai 末许的一个状态。 大家好,这里是熊仔学长。 codex 是 openai 的 一个 agent 代理式编程工具,类似于 antropic 的 cloud code。 open cloud 就是 借用了 openai 给 codex 设计的 oofflow 来调用你的叉 gpt 模型的。 那么你可能会说,我也可以用同样的方法,或者是使用 cloud wallet 来调用 google 的 gemini, 国内的 deep sync, 还有豆包千文这些。 那么问题就来了,这些公司实际上是不希望用户绕过他们的 api 接口的,因为 open cloud 这种使用方式对 token 的 消耗量非常大,对企业来说也是一笔非常大的电力开销。 所以在过去的一段时间,很多以这种方式使用 opencloud 的 用户在陆续地被搬掉。那为什么叉 gpt 没事? 这件事就巧在 opencloud 的 创始人被 openai 招去做个人智能体部门负责人了,这事就很有意思了哈。 但不管怎么说,目前这可能就是性价比最高的唯一的 opencloud 的 部署方案了。 部署过程也非常简单。首先我们需要以下三种安装方式来安装 openclaw, 详情可以参考我的上期视频。 然后我们在命令行输入 openclaw on board off choice open ai codex, 然后我们选择 yes, quick start, use existing values。 然后你的浏览器会弹出来,让我们登录叉 g p g 的 账户, 如果浏览器没有弹出,我们也只需要复制 terminal 里面的这段 url, 再粘贴进浏览器就可以了。 登录 openai 账户之后,我们会看到一个报错的页面,实际上走到这一步是完全正确的。我们复制这个网址,然后粘贴进 terminal 里的这个位置。接着我们继续 on board 的 过程,跳过 channel skills 和 hoax 的 配置步骤, 然后选择 restart gateway。 这一步非常关键,重启 gateway 会让我们刚刚配置生效。 然后我们先不加载模型,选择 do this later, 接着输入以下的代码, opencloud model set open ai codex, gpt 五点三 codex 来把 opencloud 的 默认模型设置成我们刚才配置好的 gpt 模型。 接下来我们输入 opencloud dashboard, 去到它的 web ui 界面,我们在 agent 这个选项卡里面可以看到叉 gpt 五点三已经成功显示了,然后我们测试一下也是正确的输出的内容。 ok, 那 么这期视频就到这里了,欢迎大家在评论区和弹幕上讨论,在 ai 飞速发展的今天,我们普通人的未来究竟在哪里? 最后求大家一键相连,收藏转发小心心,这里是熊仔学长,让我们一起成长!
1755熊崽学长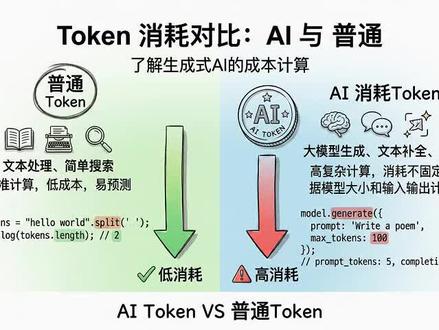 04:28查看AI文稿AI文稿
04:28查看AI文稿AI文稿写了三年代码才发现, ai 消耗的 token 和普通 token 根本不是一回事儿。今天三分钟讲透核心区别。通用 token 是 计算机系统里广泛使用的权限或身份凭证,本质是一串加密深沉的自复串,类似日常用的门禁卡、演唱会电子票本身携带了持有者的身份权限范围、有效期信息, 常见用在用户登录太校验、开放接口调用健全等场景。比如刷短视频 app 不 用每次输密码就是本地存了有效的登录 token。 要注意,这是通用语境下的 token 定义,和 ai 领域的 token 是 完全独立的两个概念,不要一开始就混淆。和 通用语境的 token 完全不同。 ai 领域提到的 token 是 大语言模型处理文本的最小计量单位,和全线凭证没有任何关系,类似印刷厂排版用的单个活字块。 不管是用户输入的提示词,还是模型深层的回答内容,都会先被拆分成一个个 token 单元再做计算。不同大模型的分词规则略有差异,但核心作用都是统计模型的文本处理量,和常说的字数功能类似,但拆分逻辑更符合模型的运算特性。 搞清楚两者的本质区别后,我们再来看他们的核心用途差异。通用 token 的 唯一作用是做身份和权限校验,核心解决的是安全问题,避免每次请求都传递账号密码这类敏感信息。 ai token 的 唯一作用是计量模型的算力消耗,核心解决的是成本核算问题, 两者的用途完全没有重叠,就像小区门禁卡和快递寄费的重量单位,只是刚好都用了 token 这个名字,实际功能使用逻辑没有任何关联。接下来我们先拆解通用 token 的 生成逻辑,它通常是服务端用非对称加密算法生成的随机字母串, 会和用户 id 权限列表、有效期、时间戳绑定,类似游乐场入场时给你发的 rfid 万代,扫一下就能知道你买的是通票还是单项目票,无法被伪造篡改。 通用 token 只有有效和无效两种状态,不存在消耗多少的说法,只要在有效期内全线匹配就可以反复使用,不会因为使用次数多而失效。 而 ai token 的 计算逻辑则完全不同,它的计算完全基于文本内容,不同语言的拆分规则不同。中文平均一个汉字对应一点五个 token, 英文平均四个字母对应一个 token, 标点、空格、换行符都会被记入 token 数量,就像打印店按打印的字数收费,不管你写的内容是什么,只看最终拆分出来的 token 总数。大部分大模型平台会把输入和输出的 token 分 开计费,通常输出 token 的 单价要高于输入 token。 我们再来看两者的使用逻辑区别。先说通用 token, 使用时只需要在每次发起请求时把它带在请求头里,服务端会先叫验 token 的 合法性、有效期权限范围叫验,通过就会处理你的请求。类似进写字楼,每次进门都刷一下工牌,只要工牌没过期,是本楼的员工就可以正常进入。 通用 token 不 会因为调用次数增加而减少,除非用户主动登出服务端手动作废或者到了有效期才会无法使用。和通用 token 可反复使用的特性不同, ai token 是 典型的消耗品,每次调用大模型接口都会产生实际消耗。比如你输入的提示词拆分后是八百 token, 模型深沉的回答拆分后是六百 token, 这次调用就总共消耗了一千四百 token。 类似去店完成玩游戏,每玩一个项目就消耗对应的游戏币,用完就需要再充值。 哪怕两次调用的输入内容完全一致,每次调用都会重新计算消耗,不会因为之前调用过就洁面。 正是因为两者同名,很多初学者刚接触大模型接口时,容易走入混淆误区,会把调用接口用的 api 密钥和 api token 搞混。 实际上, api 密钥属于通用 token 的 一种,作用是叫验你有没有调用接口的权限,不会产生消耗。而你请求里的文本拆分出来的计量单位才是 ai token, 每次调用都会扣减额度, 两者是同时存在的,一个管你能不能用,一个管你用一次要花多少成本,不要把两者的功能搞混。 最后,我们从工程设计的角度来看两者的意义差异。通用 token 的 设计初衷是降低身份叫院的安全风险,适合所有需要权限控制的系统,不管是电商平台还是内部办公系统都能用到,和 ai 没有任何绑定关系。 ai token 的 设计初衷是统一大模型算力消耗的计量标准,方便平台定价和用户预估成本,只有在涉及大模型文本处理的场景才会用到,两者的应用边界非常清晰,只是重名而已。
126小猿星星(接单中) 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿带你看看我用 oppo pro 两周之内的真实消耗,再告诉你一个技巧,让你的头壳消耗直接减少至少一半,这是谷歌官方的 api 基本系统,我们来看看这个月我是用了十二美元,我使用的模型主要是 java 三 pro、 nano 三 pro 和 sunflash, 我 用它做一切的流程,自动化、视频生成、图片生成、代码生成。再看看我们团队的差不多有三十人,这两周用了七十美元,算下来每天就是五美元,他们用文字、视频、图片的模型做类似的用途。这样算下来,我们每人每天用 java 的 模型差不多就是五到十块人民币, 这个费用远远低于大家在网上说的数字。那为什么我们能做到这么低呢?告诉大家一个技巧,首先打开你的电脑终端,确保你的 open class 是 正确安装的,然后输进去 open class skills, 这里面会告诉你你已经安装了哪些没有安装,哪些打了对号的是安装的。当你认真读清楚你安装的这些技巧之后,在你用旁边和 open class 对 话的过程中,在每次做任务的时候一定要加上一句话,就是用指定的技巧。比如在这里我让他帮我修改 pdf 的 时候,用到了 nano pdf skill, 如果你不指名的话,他会调度多个,一个一个去尝试,所以很多头衔就会浪费在过程中。 如果你已经安装部署的 oppo core, 赶紧去试一试这个技巧,你会看到明显的头壳消耗的下降。如果你还没有安装,或者你不知道怎么去本地部署安装 oppo core 的 话,我们正好有一个 ai 工具小组,里面有手把手的安装教程和进阶的 oppo core 落地应用教学。如果你感兴趣,可以看视频主页介绍,第一行会有专人给你提供更多的信息和介绍。
2318硅谷E老师



猜你喜欢
- 1784志强🎹