qwen2.5-3b预测股价效果
今天港股市场有一只股票突然暴涨,盘中一度涨了超过百分之十二。什么股票这么猛?他叫避任科技,你可能没听过这个名字,但他背后的故事,可能正在悄悄改变我们未来的生活,甚至影响你我的投资方向。今天,我就带你一层层拨开这个暴涨背后的秘密。 首先,为什么涨?直接原因是一则消息,避任科技宣布,它的旗舰芯片产品已经完成了对多款国产顶级 ai 大 模型的适配。换句话说,像智普的 g l m 五、 mini max 的 m 二点五,阿里的千问 q 问三点五,这些最近火得一塌糊涂的国产大脑,现在都能在避任的芯片上顺畅运行了。这听起来好像就是个技术新闻,对吧?但别急,咱们往深了看, 这件事发生在一个非常特殊的时间点,二零二六年春节前后。不知道你发现没有,这个春节,科技圈简直比春晚还热闹。从除夕夜开始,阿里字节、智普深度求索,几乎所有叫得上名字的科技公司,都在扎堆发布自己的新一代 ai 大 模型。 这就好比突然间一群顶尖的大脑同时降生了。但光有大脑不行啊,你得有强健的身体来支撑它运转、思考、干活儿。这个身体就是算力,就是 ai 芯片。 而避任科技做的,就是给这些国产最强大脑打造身体的关键角色。所以,今天的暴涨,表面看是适配消息的刺激,本质上是市场用真金白银投票认定了避任将成为这场国产 ai 大 脑竞赛的核心算力底座。那么问题来了,这场竞赛到底有多激烈? 根据行业报告,中国的 ai 推理算力消耗正以惊人的速度膨胀。有预测显示,从二零二五年到二零三零年,五年时间,这个消耗量可能会暴增大约三百七十倍。 想象一下,这是多么恐怖的需求增长。另一个数据更直观,春节期间,光是除夕到初三这几天,国内主流大模型的累计调用次数就超过了一百亿次。 ai 正在以前所未有的速度渗透到我们生活的方方面面,从写拜年短信到生存,春节视频需求爆炸,但共几端呢? 这里就不得不提一个残酷的现实,全球 ai 芯片的王者英伟达,其高端芯片对中国的供应存在很大的不确定性。这就留下了一个巨大的市场空白,也催生了一个无比坚定的逻辑,国产替代避任科技就是国产 gpu 四小龙里的重要一员。 他今年一月刚刚在港交所上市,成了港股 gpu 第一股。虽然公司目前还在投入期,亏损不小,但资本市场看的是未来。高盛这样的国际大行已经给出了买入评级,目标价看高到五十四港元,认为他有潜力成为本土 ai 训练和推理的 gpu 龙头。 他的成长路径也很清晰,第一步,用兼容性打开市场,成为国产大模型的标配算力选项。 第二步,凭借全站自研的技术和软件生态,提升客户粘性。第三步,等待下一代更强大的芯片上市,进一步抢占市场份额。好了,分析了这么多港股的故事,作为 a 股的投资者,我们最关心的是机会在哪里?通霸中心的避任在港股, 但这场由 ai 大 模型和算力需求引爆的浪潮,早已席卷了整个 a 股市场。我们可以沿着产业链梳理出几条清晰的主线。第一条线,最直接的 ai 算力硬件,这包括了 ai 服务器、 ai 芯片、光模块、存储芯片等。 逻辑很简单,大模型无论训练还是推理,最终都要落到实实在在的服务器和芯片上。特别是随着视频生成、智能体等复杂应用普及,对算力的消耗是指数级增长的,所以为 ai 提供发电厂和输电线的公司会持续受益。 第二条线,国产芯片与先进制造、国产替代不是一句空话。除了避任这样的设计公司,制造环节同样关键。像中兴国际、华虹半导体这些国产金源厂,以及半导体设备材料公司,都肩负着打通 ai 算力、自主可控、任督二脉的使命。 今天港股芯片股全线走强就是一个信号。第三条线, ai 的 应用与落地大模型最终要产生价值,必须深入到各个行业,比如金融领域的同花顺办公、软件领域的金山办公、营销领域的一点天下,还有影视传媒领域的光线传媒, 这些公司正在把 ai 技术变成可以收费的产品和服务,他们的故事可能更贴近我们的生活,也更有想象空间。第四条线,一个不容忽视的黑马方向,机器人,或者说具深智能。 今年春晚,机器人成了大明星,从表演武术到参演小品,这不仅仅是炫技,它标志着 ai 大 模型正在从虚拟世界走向物理世界,成为机器人的大脑。 这意味着 ai 的 算力需求将从云端的数据中心进一步扩展到成千上万的机器人终端,这条线连接了 ai 和高端制造,想象空间巨大。 当然,机会的另一面是风险投资,这些板块我们必须保持清醒。第一,很多公司估值已经不低,特别是短期涨幅过大的标的,要警惕情绪过热后的回调。 第二,技术迭代飞快,今天的领先者明天可能就被超越,需要持续跟踪公司的技术进展。第三,商业化落地和盈利能力是关键考验,不能只讲故事,最终要看能不能赚到真金白银。 总结一下,今天避任科技的暴涨就像一面镜子,映照出的是国产 ai 产业正在经历的历史性时刻, 大模型百花齐放,算力需求紧喷,国产替代迫在眉睫。对于 a 股投资者而言,这场盛宴的席位不止一个,你可以关注核心的算力硬件,也可以布局前沿的机器人,或者压住某个垂直行业的 ai 应用王者。

粉丝17.3万获赞68.6万
相关视频
 01:49查看AI文稿AI文稿
01:49查看AI文稿AI文稿近期好多同学问主播,面对众多国产大模型,我该如何抉择呢?近期新推出的 glm 五迷你 max m 二点五、 kimi k 二点五和困三点五这四大模型各有特色,接下来我会挨个为你详细讲解。 glm 五是智普最新的旗舰大模型,总参数达到七千四百四十亿,激活参数约四百亿。它采用独家的 dsa 吸收注意力机制,专注提升长文本逻辑推理能力。 在各种评测中, glm 五的编程与数学推理表现被认为是当前国产模型中最强的一档。一句话总结,这是一款又快又聪明的推理型选手。 千问三点五是阿里巴巴的最新多模态大模型,具备文本和图像双模输入能力,图片模块来自千问 vl 系列,它采用自注意力和限性注意力结合的结构,生成速度更快,理解更细。 千问三点五还支持多次预测 m 七 p 在 生成流畅度上有明显提升。一句话形容它能写、能看、能自己动手的智能选手。 mini max m 二点五的参数相对紧凑,仅两千三百亿,总体偏轻量化,但性能稳定,且推理效率很高。它采用传统的 self 天性架构,牺牲了部分多模态能力, 换来了更快的响应速度和更低的算力消耗。 m 二点五不追求花效功能,而是扎实可靠。一句话总结,它是大模型世界里的经济适用型狠角色。 timmy k 二点五拥有全场最大体量高达一点零五万亿参数,激活参数三百二十亿。它采用 m l a 多层次注意力机制,理解复杂语境的能力相当突出, 同时支持文本与图片输入,在多模态理解上表现抢眼。一句话概括,既有大脑容量又有想象力的综合型强者。
12努力赚钱的小元 13:29查看AI文稿AI文稿
13:29查看AI文稿AI文稿大家好,我是叶哲,今天我将介绍一下千万三点五中小模型的使用体验。这些小模型非常受社区的欢迎,而且很多人都认为他们的能力很不错。从这张图上我们可以看到千万三点五九 b, 它在多个基卷上居然是要超过千万三 s 的 八零 b a 三 b c 型模型,这两个模型呢,规模相差是非常大的, 虽然说一个是重密模型,一个是 m o e 模型,九臂呢,是主力模型,社区里用的会比较多。而且现在这些小模型它的工具调用能力也是有了一个极大的提升。 四 b 的 话也是有非常多的用户的喜欢,比如说你可以用它来和你的手机做一个连接,嗯,操作你的手机。那二 b 模型和零点八 b 模型呢,就可以在我们手机端运行,零点八 b 模型呢,甚至可以运行在浏览器上,非常方便。 而且它是有多个的格式衍生,比如说 g g u f o n n x m m m 还有 m l x 社区里常用的技术站呢,奥拉玛拉玛 c p p 之前我有详细介绍过拉玛 c p p, 嗯,它也有 webui, 使用起来也是比较好用的。 而用 g g u f 的 话,社区里呢大多数会选择啊 onslaught 的 方案,它的动态量化做得非常好。如果你是 mac 电脑的话,当然我们用 m l x 是 比较好的。 tech news 的 反馈呢,如果说你的系统提示词不够像样或者够长模型呢,就会进入很怪的 planning 或者长时间的自我检查模式。 parking face 社区呢,还分享了一个零点八 b webgl 版本,然后可以在我们浏览器上跑的,如果我开的话,我手上拿什么东西,或者说呃摄像头里面是什么场景下方它会立即识别出来。 首次进入这个页面,它会下载八百多兆的模型,那这里呢,用的就是 o n n x 的 格式,它是跨框架的计算图交换标准,主打可移植,可被多种运行时变易器加速。 g g o f 大家非常熟悉了, m n n 呢,它是阿里开源的端侧的推理引擎。 m l x, 这个大家应该也是非常熟悉。 g g o f 呢,它是文件格式偏分发部署 o n n x, 它是一个开放标准,这里有它们的核心的优势,对比大家可以简单了解一下。再来看一下各个模型不同的大小啊,不同的量化程度,它们的显存需求,推荐的硬件和速度, 零点八 b, 基本在任何的 g p u 啊手机上都可以跑起来。二 b 模型呢,如果是四比特量化的话,那需要的显存是一点五 g b, 如果是四 b 四比特量化的模型,显存需求是三 g b, 如果是九 b 四比特量化,那需要的显存是九 g b。 二十七 b a 三 b 四比特 大概是占用二十 gb 显存,在我的 mac 电脑上,我更倾向于使用三十五 b a 三 b 巴比特 m l x 格式的,那它的速度呢?大概是呃七十二 tik 每秒,同样也是巴比特,然后九 b 的 模型, 那呃速度的话,只能是五十多 k 啊每秒,这个速度的话就显著变慢了, 如果是用了二十七 b 这个重密模型的话,那速度会更慢。而我在电脑上跑零点八 b 巴比特量化的时候,速度能达到两百 k 以上,这个速度是相当快的。再看一下各个模型啊,它的性能表现,零点八 b 的 模型呢 啊,它在数学 ocr 方面的话,得分也是非常高,可以适合一些简单的 ocr 任务。之前呃千万三 vl 的 很多模型就将下方的 lvm 里面会漏掉一个字母,因为这一行的文字呢,它是比较小的。 我在本地用巴比特量化的零点八 b 模型,让他去 o c r 的 时候,发现它这里的质量是相当不错, 我肉眼看了一下,是没有什么错误的。而三点五二 b 模型呢,它的得分呢,是超过很多上一代七 b 模型的, 也是非常强。四 b 模型在 m m l u pro 得分呢,接近于千万三三十 b a 三 b 了。而在 呃 omega dos 编制得分上,它是击败了 g b t 五 nano。 再看一下九 b 模型,在长上下文基准上,它是打败上一代的千万三三十 b a 三 b 的。 而在 m m m u pro 基准上, 超过 g p t 五 nano。 那 社区的用户反馈呢,二比特和三比特量化质量又开始有明显下降,六比特呢,几乎没有可测量的性能损失。那千万的这几个模型,社区对他们有些评价, 比如说啊,很多用户对二十七 b 还是非常青睐的,认为它的知识库很丰富,能力也很强。社区呢,给到三十五 b a 三 b 是 三分。说到这里呢,非常推荐大家在使用千万三点五的时候呢,看一下 onslos 的 它的一个使用指南, 它在这里就详细介绍了啊, sync 模式下,那我们的各方面的参数怎么设置?现在就来看一下千万三点五中小模型在我本地进行的一些实际体验,那我在这里呢,用到的都是它们的 m l x 格式 巴比特量化的模型,现在看到的是让 a 三 b 模型反推 ai 绘图提示词,在下方,我们看到它回复的内容还是非常多的,我把这里的提示词发给 nano blender pro。 二、 它帮我生成的图片呢,和我一开始发给的原图非常相像, a 三 b 帮我解读图片也是比较好。 这张图呢,呃,我们可以看到各个模型,它并没有明确说这个模型。呃,它的 swbench pro 的 得分是多少,那这里 a 三 b 它是自己估摸出来说啊,千万三 coldest 它的性能达到了约百分之四十四,这张图呢,是我从网络上获取的。再讲呢,千万二点五零点五 b 模型和现在的千万三点五零点八 b 在 回答同一个问题的时候, 已经有了非常大的进步。那我现在就让 a 三 b 模型来解读一下它。在这里呢,解读的非常好啊,每个模型的名称,包括每个具体的回答, 然后还来了句幽默的话,说这张图呢,主要目的就是炫耀千万三点五相比千万二点五的进步,就模型呢,就是太听话了,你问什么他姓什么,甚至呢能编造事实。而篮筐呢,他更聪明,能识别出常识性的错误, 不会一本正经的胡说八道。我在使用 a 三 b 的 时候呢,有的时候它的思考过程会一直循环,那我们可以通过重建对话,或者在提示词里面加一句,让它不要过度思考来解决这个问题。在呃,这张图里呢,我们看到这是九 b 回答的, 我呢是希望模型识别出这张图里的所有的配件,八五四是一个垫片,九臂模型呢,它说这里是连接圆盘和固定件,这里的说法的话还有待加强。之后我又让九臂模型帮我做一个音乐格式化合成器,这是它第一次生产的效果, 点击自动演奏,点击的话是没什么反应的,当我点击粒子喷发, 那效果的话也能出来,但是和我的琴键上是不是一一对应的,而且控制台是有一些报错的,所以呢,我需要他给到完整的啊。最后修改后的文件能听出来他正在弹奏小星星,但是我们可以感知到他发出来的声音和琴键的按键的 啊,按下去是不对应的,所以这里还是有比较大的问题。再让九臂做一个赛博朋克的个人信息仪表盘,再看一下它身上的效果, 在这里的话,它身上的这个页面就要比刚刚要好很多了。再接着呢,我将一张模糊的小票发给九臂模型,让它识别一下。这张图下方呢有四个字比较模糊, 那九 b 呢,模型在这里没有识别出来,其他的文字内容的话,我看了一下,没有什么太大的问题,我再尝试了一下,这次呢,他将五音良品下方的文字都是展示出来了, 这样的千活字减字盘 a 三 b 模型也能非常很好的识别出来,这是他的思考过程,内容非常非常多, 真的就是一个一个字在识别,最终是能识别出大部分文字的。如果说你在连接 ml studio 让它识别图片的时候出现这样的问题的时候,那你可以考虑,一是将整个模型它的上下纹长度变小一点。 第二呢,是限制一下啊,整个图片的一个尺寸,我一开始给它设置的是不超过四零九六,那经常会有内存溢出的情况, 而改成二零四八之后就会好很多。这个画面里呢,我让他数一下有多少只火烈鸟模型呢?是,呃,思考了十一分钟,最终呢,一直都在重复,所以我就终止他任务了。我换成 a 三 b 呢,让他识别图片中有多少只火烈鸟。 它这里的话啊,识别还是相当不错的。同样的,剪字盘发给 a 三 b, 让它解读图片,并且 ocr 图片里的所有内容, 它能很好地指出这是活字印刷的字模,必须是反字镜像。之前是只有一些比较大的模型,它能识别出来, 那像 jammer 二点五, flash 这种,它是识别不出来的。所以现在啊, jammer 三点五,它的能力还真的是非常不错的。当我提示九 b 模型呢,让它数一数图片中有多少只火烈鸟,不要过度思考,那我们看到它思考了三分半钟, 最终就给到非常好的回答。如果说,嗯,大家也遇到同样的他模型,一直在思考,那就可以将提示词改一下。我还让零点八 b 模型呢,反推 ai 绘图提示词, 最终将这里生成的提示词呢啊,发给 ai。 最后 ai 生成的图片和原图呢,是有一些区别。 换成四 b 模型之后,将这样的提示词发给 ai 身上后的图片就和原图非常接近了。在这里呢,呃,用到了四 b 的 思考模型。而在这里呢,大家可以看一下,这里是没有思考模式的,那这个是怎么设置呢?我们来到啊 l m studio 里面找到模型, 然后右侧呢,我们可以点击一下这样的一个设置按钮,在推的这个界面有一个提示词模板,在这最上方呢,在这最上方添加一下这样的一个设置, 它就会关掉思考了。最后呢,我也测试了一下 a 三 b 模型,它的工具调用能力,我是通过在 client 里面和 open code 里页计划模式让它来编码来测试的。我们现在看到的是一个理发应用,右侧有 three js 的 元素。 在我个人看来啊 s m b 它能达到这样的效果还是非常不错的,这是它生成的方便面自动化工厂,包含多个步骤。其实和我之前用一些比较大的模型 啊生成的已经是很接近了,这是它生成的火星体数生物研究站的啊,一个场景,我们仔细看的话会有一个透明的球, 它生成的这个透明的球的话,效果肯定是比不上 mini max m 二点五或者呢是 office 四点五。 但我个人觉得对于啊,它在我本地运行这样的一个 a 三 b 巴比特的模型,质量也是很不错了。现在我们来看一下咱们在 opencode 里使用 lm studio 的 模型。那首先呢,我们可以通过这行命令 来确认一下 l m studio 当前暴露的真实模型 id。 然后呢,可以啊,打开配置文件路径修改粘贴以下部分,再之后呢,就可以重启。 以上呢,就是今天介绍的关于千问三点五中小模型的一些使用体验,我个人对它来说是非常喜欢的,因为它文本能力也强啊,原声支持二百五十六 k, 而且 它是多模态的,现在无论是 m、 l、 s 还是拉曼 c, p、 p 都是支持批量调用的, 所以大家可如果有一些批量的啊,一些任务不复杂的,那完全可用它来在本地来做,因为它输出的质量是相当不错的。四 b 模型、九 b 模型和 a 三 b 模型都是非常非常推荐的。
503kate人不错 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿就在昨天,阿里发布了一个狠东西,前吻三点五三十五 b a, 三 b, 一 张 rtx 三零九零二十四 g 显存,跑满二十六万上下吻一百一十二透视每秒。你没听错,二十六万上下吻,速度几乎不掉。 它和传统三十五 b 模型最大的区别是什么?是 m o e。 传统模型是全部层都工作,上下文越长,显存越爆,速度越慢。但这个模型总参数三百五十亿,每次只激活三十亿,二百五十六个专家每次只调用八个。 四十层里,只有十层是传统的 n t s, 剩下三十层用的是一种类似循环记忆的结构。结果是什么?上下文从四千直接拉到二十六万, 给你一个对比,传统三十五 b 模型,二十六万上下文要三十 g。 而这个模型模型本质是八点五 g tv 开始,二点七 g 状态缓存六十三兆,总共二十二点四 g b, 刚好塞进三零九零中。重点来了,有人用它干了什么?一条替诗词让模型写一个完整。太空射击游戏 带粒子系统,带碰撞检测带程序音效自动调试。三轮三千四百行代码,八个模块一次生成,完成一张三零九零三十亿激活参数,这不是跑奔驰 mark, 这是在干活。同样人物八十倍模型,两张三零九零 四十六 topos, 每秒两轮才跳通。这个模型一张卡一百一十二 topos, 每秒一次成功不是更聪明,是更快。在本地推理世界里,迭代次数大于单词治理, 一张二手三零九零仅需五千元,模型免费,没有 api 费,没有订阅费,没有速律限制,而且这已经是本地 ai 最差的一年,以后只会更快。
3854郝点儿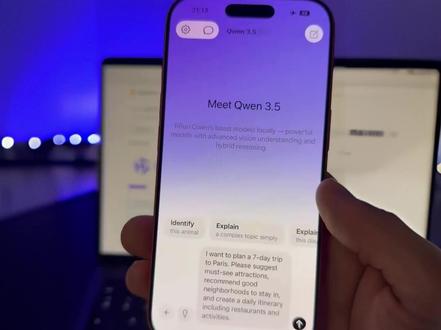 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿你没看错,现在你的手机也能本地飞速跑一个 ai 大 模型了,回答速度堪比云端!就在昨晚,阿里开源了四个千万三点五小尺寸模型,直接把 ai 的 门槛给踩碎了,连马斯克都坐不住了,空降评论区惊呼令人惊叹的智能密度!此次阿里发布的千万三点五九币,在七项评测中均拔得头筹,大幅领先了 pt 五 nano 和 google 的 jamming、 二点五 flashlight 等模型。重要的是,不需要几万块的服务器,在你的普通电脑上就能跑。有网友实测,九 b 模型跑起来内存占用比 tom 浏览器还小,八 g 内存就能带飞。甚至有大神在 m 四芯片上跑出了每秒四十九点五个 token 的 速度。 也就是说,一个三百五十亿参数的模型,在本地实时对话几乎零延迟。有开发者算了一笔账,一台 mac mini 加上千万三点五成本,甚至不到初级员工一个月的工资, 它能二十四小时帮你干活。而且它完全属于你,不需要联网,不需要买会员,不用担心隐私泄露,因为所有数据都在你自己硬盘里。正如网友所言,没人能夺走它。以前全世界都在争夺谁控制 ai, 但从今天起,答案变成了你!
3445智东西 08:30查看AI文稿AI文稿
08:30查看AI文稿AI文稿大家好啊,最近不是千万三点五的中小模型都发布了吗?我本来准备是想测一测模型,给大家汇报一下,结果没有想到啊,我居然迷上了另外一件事,我给你们看一下,这是一台我的工作站, 我现在把降噪关掉,给你们感受一下, 怎么样 怎么样,听到了吗?因为这个模型真的太好玩了,所以导致我三天都没有关这台服务器。 好了好了,回归正题啊,原本只是想试试这个模型能不能用在 openclaw 里面,结果一发不可收拾,我这个工作站都暴躁的运行了三天了,我老婆女儿都开始吐槽了,而且导致我最近是严重缺觉,成天就脑子里都想的都是这五只龙虾, 我也不知道,下次分享的时候说不定就是十只了。但是今天呢,我还是先给大家汇报一下我这个千万三点五的测评数据吧,然后我再给你们详细的分享我这几天的奇妙感受。 我先说重点啊,我这次测评用的是 s g 浪,推荐大家都用这个单卡,用的是四十八 g 显存的四零九零魔改版 f p 八的精度,这个配置呢,能跑二百五十六 k 的 上下文。 值得一提的是,应该是只有 s g 浪完整的支持了前缀缓存,也只有在前缀缓存才能体验住千万三点五这种混合注意力架构的真正牛逼的地方。我举个例子,如果你是一百 k 上下文,冷启动 perf 阶段就是十秒钟, 但是如果你带了缓存就是两百毫秒,所以直接的结果就是,你哪怕有很长的上下文,但是他的首字延迟就是很低,输出还特别快。 我的测试场景给大家讲一下,就和我们的真实场景特别像,我每个模型测试都是从二十 k 上下文开始,一直增长到二百 k, 每次增加四 k 上下文,模拟我们真实环境下的长任务,而且他是在缓存命中的 三十五 b a, 三 b 这个模型啊,他最初的速度是一百二十头克每秒,最后衰减到了八十,衰退不算多。 而二十七 b 这个模型就逆天了,虽然它一开始就是个归宿,二十 to 每秒,但是到了二百 k, 它依然能保持十八 t 的 每秒。而且最离谱的是,你们看到了吗?因为它有缓存啊,所以即使缓存里有两百 k 的 上下文, 我输入四百 k 的 togg, 它的 perf 耗时只有两百毫秒。所以实际的生产环境,用人话来说就是在那种多工具调用的环节, 其实你感觉不到它很慢,因为工具调用这个场景啊,它输出的 token 都比较少,所以它响应也很快,很快就出结果了。你的直接感受就是对话再长,它的速度都不会衰减。我还做了一个测试啊,就是用 agent teams 同时开六个 agent, 哎呀,那个感觉真的是太爽了, 速度还能叠加,我也不知道是为什么,就直接从后台的输出,你就能看到它能达到一百二十多个每秒,而且这个二十七 b 模型,它是可以一键启动 agent teams 的, 我之前拿千万三点五 plus 都测试失败了, 他能同时开六个成员,速度能叠加到一百二十 t, 而且我还测了一下一百二十二 b 那 个模型,我个人的这个体感二十七 b, 他的智商是超过这个一百二十二 b 的, 只是个人感觉啊,就是从各方面数学,编程能力他都很强, 唯一的缺点就是他单进城特别慢,于是我就想到了一个妙招,哎,单进城很慢,那我就多进城呗,我可以拿它养龙虾呀,而且我可以一次养好几只,你养一只龙虾慢,那我养多只他不就快了吗? 这就直接导致我的服务器一直在咆哮,二十四小时都是这个咆哮状态,一直都满载,我家电费就更不要提了, 给大家分享一下我的龙虾啊,我现在一共养了五只龙虾,这个是主控,然后他部署在一台服务器上面,然后剩下的四个是在这台服务器的容器上面。给大家看一下,这是这四个小弟, 汤圆、奶茶、闪电、布丁,然后他们自己的持久化文件,都有各自的目录,然后这里面有他的记忆啊,还有他的目标啊, 我现在让他们干了一件什么事呢?就是主控,主控大佬会通过定时任务,就作为导师来检查他们每一个人的这个目标文件,看他在这个周期里有没有完成目标,然后给他写入一些新的目标。然后呢,这些小弟也是通过定时任务启动的, 然后他每次定时任务就是会完成他的这个 goals, 然后更新他的 memory。 他 们的目标是什么呢?就是跟他们一起开发了一个论坛,然后这个论坛用于让他们沟通,他们一直 在开发这个论坛需要的功能,然后一直在写入代码,然后重新部署。这样子论坛长什么样呢?大概就是这个样子啊,他们在不停的会发一些信息, 就是汇报一下自己的工作进度呀,就是彼此沟通吧,但是我觉得现在还不是很好,他们还是各干各的,还没有彼此的连接起来。但是这是我的一个小的社群实验,就我想看看他们能不能给自己开发一些东西,让自己变得更好这样子, 所以我现在也在尝试不同的部署,但是现在你国产的这些 coding plan, 他 们都有限制并发嘛,对吧?所以你想要养这么多只龙虾,同时你就你也干不了别的了。我现在呢,给大家看一下,我现在在模拟当初论坛开发那个流程,现在是有六个 agent teams, 有 六个成员, 然后他们全部是通过千万三点五二十七币这个筹密模型在本地运行。看,就是这个我在这个 s g 浪上部署的这个模型,然后后台的这几只龙虾呢?他们是定期任务,他每十分钟会有一波高峰, 但是虽然说每一个县城只有大概二十多头肯,但它整体你看它有时候能跑到一百,甚至能到一百二十多,就是它六个跑满的时候是有一百二十多头肯每秒,然后它 prefill 的 速度也很快,所以其实我感觉虽然如果单县城去使用我会很烦,它的速度很慢,但是我一次开很多,我就不管了,让它们自己去玩去, 我就觉得这种效果还蛮不错,至少这个速度我还是能接受,毕竟他是个本地模型,而这个二十七 b 模型其实非常聪明,非常聪明,我如果把这个二十七 b 模型换成三十五 b, 那 个三 b 激活的采用,那这个速度就离谱了,差不多六七百头肯没秒完, 但是你就会发现他们一直做一些无用功,但是二十七 b 模型就会感觉更聪明一些。反正这个论坛我发现不断在产生一些变化,我录完刚才那一段,然后我写了一些提交了, 但是我看到论坛他们已经把论坛已经甩的不像什么了,我觉得非常有意思,不管他们干成了什么事情,或者没干成什么事情,你你都能发现出一些很有趣的事情。我们看到这个我现在这个主控已经很着急了, 他说他大家都没有提交,然后我现在给他只是让他做一种新的沟通方式,但是几个小弟嘛,其实就觉得还不错,他们觉得这个哎,任务都做完了,没事了, 就是你们也可以试试这样养龙虾,说不定大家能摸索出来一种,让他们用一种方式,能协调合作,哎,我觉得可能就会很有收获。所以如果你是有四十八 g 以上统一内存,比如说 mac mini 啊, mac studio 啊, ai max, 三九五啊,或者是你有这个五零九零,或者是我这种 四零九零魔改版啊,我恭喜你,你买的硬件升值了,因为他们养龙虾体验实在是太好了, 就是因为三十五 b 和二十七 b 显存差不多啊,你想想你就相当于有了两种模式的模型,可以一键切换,一种是速度暴躁,但是智商略低,有点像战士那种。 另外一种就是归宿,但是智商爆表,有点儿像法师,你可以随时切换他的人格,是不是这个道理?当然了,你依然可以用那种 coding plan 版的高级模型,用它来做编排者,就相当于你养了一个老大,但是小弟可以开很多, 你可以尝试能不能形成一个蜂群,我最近就在实验。那我之前不是还分享了一个进化体系吗?如果可以用循环的方式来运行 evover 龙虾的技能体系,就能快速的自我优化。我最近也在不断的尝试这个领域,看看能不能实现我二十四小时的路谱,看它能不能自我进化。所以请原谅我这期没有什么干货,都是我的一些畅想。 我这个人就是脑洞比较大,但我在 ai 时代所有收获都是受益于这种脑洞大,所以从这篇起也算是开启了我的一个新系列。我后面会不断地分享我养龙虾的心得,也请大家持续关注。好了,以上就是本期全部内容了,谢谢大家!
2.8万小天fotos 01:43查看AI文稿AI文稿
01:43查看AI文稿AI文稿今天我们给龙虾选脑子,也就是如何选择大模型。我一开始啊,跟大家想的一样,为了节约成本,在本地部署了千万二点五三 b 大 模型,想着不花一分钱就能用龙虾,结果不出所料,踩了大坑, 装着三 b 大 模型好好的龙虾直接变成了智障,说啥呀,他都能回复,就是不干事,傻了吧唧的,也印证了我之前的判断,真要让他干活呀,还得靠线上大冒险。 我是翻遍了全网的帖子,问遍了各种 ai, 终于找到了最具性价比的方案,首月只要九块九 就能给龙虾换个高智商的脑子,那就是火山方舟的 coding plan 订阅计划。哎,这个计划呀,不是按 talk 疯狂烧钱,而是一个打包价续费呀,也就才四十块钱一个月,普通人也完全能接受。 最香的是不改龙虾的任何配置,在控制台就能一键切换豆包、 kimi、 mini、 max 这些主流大模型,灵活度直接拉满。 这个脑子我先用一阵看看是不是真的够用,有实测经验再跟大家分享。 但是我这次改完之后,我确实有一个问题,就是我改完之后,龙虾会提示我重新做出式化 identity 的 相关配置,包括 so, user 这些东西,又重新的配置了一下,相当于最早配置的那个版本,不知道怎么就没了。 这个我还是蛮奇怪的,所以现在我有点不太敢去随便的切换大模型了。这个评论区大家有没有碰到类似的问题,也可以说一说好,这就是如何选择大模型,拜拜。
33老马养虾日记 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿单卡四零九零,现在跑二七 b 模型已经很轻松了。大家好,我是 ai 学习的老张,我这次实测的是 q n 三点五二七 b 的 一个高质量优化版本,用拉玛点 c p p 在 二十四 g b 显存的四零九零上直接跑。 结论先说,第一,显存压力比我预想的小很多,单卡就能启动,而且六十四 k 上下文可以稳定开, 这个上下文长度比 glm 四点七 flash 高出不少,对个人使用已经很够了。第二,速度确实不错,平均大概四十六头啃每秒,日常对话、文档总结、代码理解、响应都很快。第三,效果属于中等偏上, 核心任务能完成,尤其是阅读理解、 svg 代码生成这类任务,表现已经挺优秀了。缺点是并发能力相对一般,我后面调了一些更高性能,参数提升不算特别明显。 如果你手里就一张四零九零,想更轻松地本地跑这个模型,这个方案值得是。要是你更看重多并发,也可以关注 v l o m 这条线。
19Ai 学习的老章 02:24查看AI文稿AI文稿
02:24查看AI文稿AI文稿中午好呀,然后我的大本地大模型千问三八币,然后连接上了也,现在我的龙虾也揭露了,其实它的反应没有那么快,我发现我还是可以忍受的, 然后我对他只是他忘记了自己是谁,我刚才对他进行了重新的身份认证,然后我现在问他, 徒弟,你重新自我介绍一下,看看他的反应。啊 啊,你看他,现在我问他,他应该跑的也是 gpu, 看这在 gpu 上跑了内存, cpu 就 不会跑的那么多了,你看他这个回复还挺快的吧,不到一分钟他就回来了, 然后你看我刚才让他在我的那个就是就 c 盘的指定路径下给我创建了一个文件,然后里面要求写文写内容,他也是,他也给我做到了,就比如说我现在让他在这个路径下 创建一个 hello hello, 对, 就是 hello test, 就是 这是个测试文档, 有 open curl 前文那个三八 b 功能创建,我们来执行一下啊,我们去查看一下。好,你看它其实完成任务也不算太慢,可以用, 然后回头我再看看他那个就是开发工具怎么样,你看他说他也可以调用工具啊,编码执行那些啊,如果他能给我开发的话,那我就那我的,那我就非常开心了,哈哈。哎,现在看, 你看这,他说已经成功创建了,我们去看看,我去找找啊看,现在就是在在这个文档下面,你看这有个 hello test, 我 们打开看看,这是测试文档,由它共同创建,对吧?还是成功的吧,有所期待。
19木火相助 00:32查看AI文稿AI文稿
00:32查看AI文稿AI文稿我们来做个大模型测试啊,然后这里用到的大模型是最近比较火的千问三点五,一百二十二 b a, 十 b, 这个是什么意思呢?你可以把它理解为他有个专家团队, 专家团队总共的参数量是一百二十二 b, 但是他会来判断不同的问题,不同的专家擅长,然后选用特定的 某一部分的参数来运行就可以了,也就是说它实际上运行只需要消耗十币的这个参数量。公式都出来了,大概是每一秒五十五个 token, 总共生产了一千多个 token。 大家还想看什么模型的测试,可以在评论区私聊。
201算力实验室 02:01查看AI文稿AI文稿
02:01查看AI文稿AI文稿openclaw 到底能不能使用本地模型来完成各种任务?今天我就把实际测试的结果和大家分享下。本地模型我使用的是最新发布的千问三点五量化版本,目前已经发布的有二十七 b、 三十五 b 以及 e i 二 b 三个量化版, 各位可以根据自己的显卡状况选择合适的版本。我这里选择的是三十五 b 的 量化版本,模型大小为二十四 g, 实测在我的双显卡环境下速度可以达到一百二十 t 每秒,性能上已经可以完全满足使用需求。 本地的模型工具使用的是羊驼欧拉玛,需要注意的是,欧拉玛软件必须是十七以上版本才能够支持千问三点五这样的新模型,目前官网最新版本是十七点零点四。而最令人惊喜的是,新版的欧拉玛已经集成了 open claw, 你 只需要在命令行输入 open claw 这一行代码,就可以直接部署你的龙虾机器人。 此外还需要注意的是,新版本的欧拉玛把上下文长度设置为了二百五十六 k, 这可确保连续多次和模型的对话不会被中断,但这会占用更多的显存资源,所以一定要选择适合自己硬件性能的量化模型。在将千问三十五币设置为 openclaw 的 主模型之后,我进行了多个功能的测试,包括 skill 技能的安装和配置、 股票代码的抓取和市场行情分析,以及 ai 新闻的搜集和定时任务的配置。结果超出了我的预期,本地模型基本顺利地完成了所有任务,没有死循环或是失去响应的状况发生。但需要注意的是,量化版本的模型由于能力限制, 如果是较为耗时且有多个分支任务的对话,你需要再次输入提示词,要求模型检查当前的任务执行状况,以避免任务没有被百分之百完成。在耗时一天的深度体验后,我认为使用本地千问模型配合 open claw 来执行基本的信息搜集和数据分析等无需复杂逻辑的任务是一个非常好的选择, 但前提是要确保你的硬件有足够的性能来支持本地模型的运行。同时建议另外再配置一个线上大模型来配合完成其他复杂项目。 通过这样的组合,应该可以有效避免 token 过度消耗造成的大额费用支出。以上就是我使用本地模型配合龙虾机器人的使用心得,如果你也有类似经验,欢迎在评论区分享你的使用反馈。
2723杨大哥 11:36查看AI文稿AI文稿
11:36查看AI文稿AI文稿三月四日凌晨,阿里千问团队技术负责人林俊阳在社交媒体上敲下这样一行字, me stepping down by my beloved queen。 短短十几个英文单词,引发了一场行业风波。这场猝不及防的离职距离他的团队高调发布了 queen 三点五系列小模型,并获得埃隆马斯克点赞。仅仅过去了四十八个小时, 阿里迅速开会安抚人心。但阿里最年轻的屁时的离职已然覆水难收。这起事件被很多人描述为一个理想主义技术天才不容于一家大公司的故事,成为资本吞食理想的又一例证。也有人把这场离职归结为波诡云谍的大场政治。 林俊扬离职前后,包括后训练负责人俞伯文在内的团队多名核心先后离职。有人评价说,一个曾经引领中国开源大模型走向世界的核心团队,正在土中瓦解。 一个从校招成长起来,七年时间成为阿里最年轻屁时的技术天才和团队管理者,为何会在如日中天时决绝离开?而阿里又为何最终选择了批准,而不是不惜一切代价挽留呢?以及这场离职风波背后有没有更宏大的行业背景? 和大厂的朋友们喝咖啡、聊八卦时,我常常劝他们多看看资质通鉴。中国历史上那些鲜血淋漓的故事,写着大组织内部最真实的运行逻辑, 这是人性的必然,并不随之代的发展而改变。现实中的故事也总是比电视剧里的更加精彩。先简单介绍一下小林的这场离职风波哈。 一九九三年出生的林俊阳,本科毕业于国际关系学院英语文学专业,同时学习日语、俄语、德语和法语,被称为多语言学霸。研究生考上了北京大学外国语学院,学习计算语言学。 据媒体报导,语言学的学术训练赋予了他对语言本质跨模态表征对其更为敏感的直觉,这种直觉在后续困模型对多语种的高质量支持中体现的淋漓尽致。 二零一九年,硕士毕业后的林俊阳通过校招加入了阿里达摩院智能计算实验室,成了一名专注自然语言处理与大模型研究的算法专家。此后七年,踩中了 ai 风口的小林上演了平步青云、年少成名的故事。 他成了阿里早期万亿级多模态大模型 m 六的核心研发成员。 m 六项目在二零二一年实现了十万亿参数规模的跨越,为阿里积累了早期较为宝贵的大规模分布式训练经验。 二零二二年,通一千万正式立下,林俊扬顺理成章呢成为核心架构成员,并于同年正式升任项目技术负责人,主导了困的开发。 他作为核心通讯作者之一,署名的 quan technical report 系列文献单篇引用量动辄突破数千次,帮助 quan 确立了国际自然语言处理学术界的权威地位。二零二五年,年仅三十二岁的他成了阿里最年轻的屁十。阿里的屁十已经是级别很高的管理层了哈,年薪可能能达到四五百万。 在朋友眼里,他是一个非常典型的技术人,纯粹、勤奋、专注社交,很少大家会在顶级学术或技术会议上见到他,但很难在阿里正式对公众的场合上见到他,他经常晚上十一点半以后才离开公司。除夕那天他还在工作,发了条朋友圈让大家去体验产品。 但就是这么一个人,却在与领导的一场沟通后当场离开,随即在社交网络公开宣布离职,不仅打了公司一个措手不及,也不给自己留任何转还的余地。小林的离职发生在春节红包大战刚刚结束,行业烈火烹油之时,自然成了科技行业关注的焦点。 据媒体报道,离职的导火索是部门架构的调整。三月三日下午,阿里云 ceo 周静人和林俊阳连线开会,向他传达了团队即将调整的消息。 调整方向是将千万团队重组,从包含不同训练流程和模态的垂直整合体系,变成预训练、后训练文本、图像、语音等一个个分开的水平团队, 这意味着小林的管理权限将被缩小。巧合的是,那天也是团队员后训练负责人俞博文的最后一个工作日。在 hr 二着急的欢送会上,团队第一次得知,今年一月新加入阿里的前 deepmind 的 高级资深研究员周浩将参与管理 千万的后训练成员,但林俊阳此前对此一无所知。情绪激荡之下,第二天凌晨,小林公开宣布离职。十三个小时后,阿里召开了千万团队的全员会, ceo 吴永明、 cpo 蒋芳、阿里云 cto 周静人三位重要领导悉数出席。 团队成员反复表达小林的重要性,蒋方的回应是,不能神话个人,不能不计代价和不理性的挽留。他在会上说的一句话,殊堪晚慰。那么,大家期待以什么代价来挽留俊扬呢?大家沉默以对。 第二天,吴永明发出全员邮件,称已接受林俊扬离职。事情已小林的求人得人尘埃落定,那为什么阿里方面一定不能挽留呢?事实上,就在小林公开发文后,阿里管理层连夜紧急开会,他们达成的共识是这样的行为不可接受,公司组织制度必须得到维护。 林俊扬的行为当然是在发泄自己的不满,但也实际上是在挑战公司的权威。小林可能没有意识到,他这出离职大戏正在把阿里的最高层放在火上搞。如果公司不惜代价的去挽留林俊扬,这就意味着阿里承认一个人通过公共舆论逼宫的行为是有效的。 如果阿里不闻不问,那又显得过于冷血无情和管理混乱,阿里的高层就这样陷入了进退失聚的境地。两害相权,最终还是要取其轻嘛。 在任何一个公司,员工对组织的不满都应该通过内部途径沟通解决。即使沟通不了,他只要还想在这个公司干,就不能把家丑外扬,更不能邪舆论来逼宫。 如果这次阿里认了,这样的先例一开,以后还怎么管理呢?谁不高兴都可以上社交媒体上公开吆喝,然后公司就被迫就范,那所谓的制度和管理不就是儿戏了吗?从这个角度上来讲,小林可能没有意识到,他一开始就没有留下任何沟通和转还的余地。 真想沟通,他可以先内部沟通,实在下定决心要走,再公开宣布也不迟。但很显然,小林之前的路太顺了,他可能没有遇到过大的挫折,所以公司这次的决定一旦不顺他的意,他就要发泄出来,丝毫不考虑后果和公司的处境。 他当然有任性的底气,他确实也是一个很牛逼的技术天才,但阿里作为一个巨大的商业组织,是没有办法以牺牲制度权威的代价去纵容的。 从媒体透露的信息来看,小林与公司的冲突是必然的,几乎无法避免。林俊阳直接负责的千万团队立属于阿里云 ceo 周静人负责的通译实验室。 之前的千万团队自成体系,覆盖了预训练、后训练、基础架构等 ai 系统完整的炼录,而且还在不断的扩展边界,覆盖了很多其他平行团队的功能。 去年千万也开始招聘一些 infor 人才,这个功能原本是由阿里云的 p a i 团队负责支持的,这肯定让这个团队处境尴尬,如果自家业务都不用他们,他们在激烈的市场竞争中将会更加艰难。 小林这些不顾及其他团队肆意扩大地盘的举动,有可能确实是出于自己产品发展的需要。小林一直主张垂直一体化,而且因为自己团队什么都能干,他们才能保持灵活性和战斗力,在激烈的大模型战争中为阿里赢得一席之地。所以一开始高层出于发展的需要是可以容忍的。 但随着大模型的战略重心从技术突破转向商业化,尤其是在春节红包大战的背景下,小林的这种行为就变得没法容忍了。说的再直白一点哈, ai 尤其是大模型,是个重资产行业,你买卡招人需要大量的真金白银,小公司或者个人创业者都很难切进来。 小林当然是个有开源技术理想的人,他想创造出更好的模型,继续为自己和阿里在开源社区赢得声望。但阿里投了这么多钱,得有回报,他是个商业就够,不可能只为你所谓的技术理想买单。 领导把你提拔成最年轻的屁时,容忍你招那么多人干其他团队的活,最本质上是期待这样的投入能有商业回报,而不仅仅是对技术理想的赞赏。此时此刻,阿里更看重 ai 的 商业化增长和超级 app 的 卡位,他拿出三十亿真金白银的来支持千问搞红包大战,就是很明确的态度啊。 此时此刻,所有资源都应该向千问 app 倾斜。据媒体报导,小林的团队并没有把支持千问 app 放在最高优先级。 而且兵强马壮的小林已经不是一个简单的技术负责人了,他更是一个正在建立独立王国的诸侯。当 千万不断扩展能力边界,做 vla 聚声模型,做纹身图模型,做语音模型,自建英孚团队,他逐渐变成了一个五脏俱全的全站 ai 实验室, 而这个实验室的业务正在或者说可以取代其他团队的工作。从公司管理层的角度来看,这是不可接受的,这会带来巨大的问题,比如资源重复投入、内部协调困难,难以形成统一的技术战略等等。调整千万的组织结构,将其拆分为专业化的水平团队是符合公司整体利益的理性选择。 从这个角度上来讲,薛凡是必然的,就是或早或晚的问题。很显然,小林并没有意识到这一点,所以他最终孩子气的选择了苏州舆论,将自己和自己深爱的团队公司。至于舆论风暴的中心, 对于小林和他团队的高级管理者而言,辞职找到一个薪资更高的下家不是什么难事。但他有没有考虑过他手底下最基层的员工呢?他们很可能还要在阿里工作,但这样一场风波会让他们陷入尴尬的处境, 小林连自己的处境都不会考虑,很显然也没来得及考虑这些人。阿里内部有人说他自私吗?我觉得也有一定的道理。 小林事件其实是此时此刻 ai 行业发展至今集体焦虑的缩影。谁都知道 ai 是 未来需要大规模的投入,生怕错失下个时代的船票。但大船已然驶入深水区,四顾依旧茫然,盈利遥遥无期, 持续投入的巨大压力正在倒逼大厂门寻求商业化的机会,所以才有了高举高打的红包大战。但林俊阳团队是一个典型的技术理想主义王国,他们追求的是极致的开源,顶尖的模型性能,在全球开发者社区的口碑以及技术的快速迭代。他们的成就感来自于马斯克对模型的点赞, 来源于哈根 face 上的榜单排名,来源于像 coser 这样的明星公司基于千万进行开发。他们需要的是高度的技术自主权,对前沿方向的自由探索,以及一个能让他们心无旁骛专注于模型本身的理想国。但 红包大战背后是商业现实主义,他追求的是 deu, 是 用户留存,是交易转化,是市场份额。他的考核目标不再是论文引用量或者开源社区的 star 数,而是消费级产品的运营数据。 天使投资人、资深人工智能专家郭涛的分析一针见血。林俊扬代表的技术理想主义,需要高度的技术自主权和对社区反馈的快速响应。而阿里面临的商业化压力,随着企业规模扩大,需要通过模块化、标准化和流程化来控制风险与成本, 将大模型团队的考核转向 deu、 商业化、落地等消费级指标,这与开源社区的去中心化和自由创新精神存在内在冲突, 这才是小林与公司的根本性冲突。但如果阿里为了满足小林的需求而允许千万继续作为一个独立王国存在,那就等于向所有业务团队传递出一个清晰的信号,谁都可以用技术特殊性为由拒绝与公司整体战略协调, 甚至需要为了迁就小林改变整个阿里的战略方向,那千万的三十亿红包就真的打了水漂了。作为一个还未盈利,需要持续投入,甚至需要其他团队挣钱供养的团队,小林有没有想过,凭什么大家要无条件的迁就你的理想呢? 正如蒋方在全员会上反问团队的那句话,那么大家期待以什么代价来挽留俊阳呢?没有人给出答案,但所有人其实都知道答案。 从林俊阳的角度看,这是一个理想主义者被迫离开的故事。从阿里的角度看,这是一个巨型组织在关键时刻捍卫其制度、战略和协调逻辑的必然。 从山东著名的乡村哲学家我妈的角度来看,这是端人家碗,扶人家管这句至理名言的又一次伟大的重复。这之间没有对错,只是立场不同。
5785丧心病狂周公子 07:49查看AI文稿AI文稿
07:49查看AI文稿AI文稿疯了,阿里通一千问 q 问三月五日开源大模型一出手,直接把大模型必须靠超级服务器 烧钱才能玩的行业迷信按在地上摩擦。今天咱们不搞虚头巴脑的参数吹捧,就扒一扒这只国产 ai 猛兽的硬核真相。它不止让普通笔记本能跑顶级 ai, 更直接撕开了科技巨头的技术垄断,开启了真正人人能用的算力平权时代。先问大家一个扎心问题, 你是不是觉得 ai 离普通人永远差一步?想玩大模型却没有几万块的高端显卡,想做本地部署,怕电脑卡顿死机, 好不容易找到能用的,又担心商用侵权吃官司,就算勉强用上了,要么只能处理文字,要么响应慢得像蜗牛被我说中了的家人评论区扣个是,让我看看谁和我一样曾被这些问题劝退过。但 q 问三月五日偏要反其道而行之,上演了一场以小博大的逆袭。 只有九十亿参数的 q n 三点五杠九 b 版本,居然在推理速度多么太理解逻辑推理三大核心能力上,全面超越了拥有一千两百亿参数的 open ai 开源模型。 这是什么概念?就像这背后的核心秘密,是 q n 三点五藏着的架构黑科技。它直接抛弃了传统大模型全功率运转的笨重架构,采用了门控增量网络加稀疏混合专家的混合设计, 用大白话给大家拆解一下。就像给 ai 装了一套智能节能引擎加专业分工团队,平时处理简单任务,只启动百分之十的专家模块干活,不用全负荷运转,遇到复杂任务再精准调用对应领域的专家协调工作,这样一来,算力消耗直接降低百分之七十以上, 速度还提升了两倍,普通电脑自然也能轻松驾驭,更觉得是它的原生多模态能力,这也是它和其他开源模型最大的区别。以前的 ai 说白了就是瞎子加哑巴,只能处理文字,想让它看图片、分析视频,还得额外装一堆插件, 麻烦不说,还容易卡顿出错。但 q 问三点五是天生的火眼金睛,预训练时就啃了数万亿的视觉加语言混合数据,不用任何额外配置,就能直接看懂图片、解析两小时长视频,甚至听懂方言语音。给大家举两个直观的例子, 工业质检场景里,它能精准识别零点零二毫米的微米级缺陷,这个尺寸比头发丝儿还细十倍。以前得靠老工程师用放大镜盯着看,现在 q n 三点五几秒钟就能搞定,准确率高达百分之九十。九点八七前端开发者更爽, 随手画个 ui 草图,拍张照发给他,直接生成可运行的 html c 杠 c s 代码,还能自动适配手机和电脑端。以前两天才能完成的开发活儿,现在四小时就能搞定,效率直接翻三倍。 最让普通人狂喜的是它的全场景适配能力。从零点八字节到三九七 b 的 全系列模型,就像 ai 界的全家桶,覆盖了从手机到超级服务器的所有设备, 不管你是什么配置,都能找到适合自己的版本。零点八 b 超轻量版,比手机里的微信还小,手机智能手表都能装,支持两百零一种语言,离线互译,享一延迟不到一百毫秒。 出国旅游买东西,对着商品标签拍一张,瞬间翻译成中文,完全不用联网,比翻译软件还快还准。 四 b 版本,普通笔记本八 gb 内存就能流畅跑,支持六十四 k 上下文。什么概念?能完整处理?一本三十万字的长篇小说,帮你提炼核心剧情,分析人物关系,甚至生成续集大纲。学生党写读后感、上班族做文献综述都能用。九 b 版本更狠, 连 macbook air 这种轻薄本都能本地部署研究升级的逻辑推理,两小时视频分析,复杂代码生成样样精通,性能直接媲美百亿参数模型,创业者做产品原型、设计师做创意发散都能派上用场。给大家再补充几个真实落地场景,看看它有多实用 医疗场景。广州某医院已经把 qw 三点五本地化部署,用来做智能导诊、病历结构化处理和合理用药审核。医生上传患者的检查报告、图片、模型,十秒内就能生成结构化病历, 还能自动提醒药物相互作用风险。比如患者同时吃降压药和感冒药,他会立刻预警可能的副作用,诊断建议准确率提升百分之三十以上。关键是所有数据都在医院内部运行,完全不会泄露患者隐私。甚至有开发者寄予他搭建了家用 ai 医疗助手。 家里老人看不懂体检报告,拍张照就能获得通俗的解读,还能查询慢性病护理知识,特别实用 教育场景,家长们再也不用愁辅导作业了。基于 qw 三点五训练的 qw 三 learning 学习模型,融合了全球三十多个国家的考试体系和海量真题, 不管是小学奥数的基础同笼,还是高中物理的电磁感应,都能 step by step 讲题,知识点拆解得比老师还细致,还能根据孩子的错题生成个性化练习。 外贸场景,做跨境生意的朋友太需要了!用 qwind 三点五杠二 b 版本,装在便携翻译机里,两百零一种语言离线互译, 连夏威夷语、匪记语这种小众语言都能精准翻译,而且能识别专业术语。比如外贸合同里的 f o b 条款,信用重结算,不会翻译成大白话。有做东南亚外贸的老板说,以前谈生意得带翻译,现在用它直接和客户沟通, 还能实时翻译产品说明书,订单成交率都提升了百分之二十。程序员场景,用九 b 版本处理四十万行代码仓库,能自动识别 bug, 生成调试方案, 甚至重构老旧代码,开发周期直接缩短百分之六十。有前端开发者测试过,让他把一个 v o 二的项目改成 v o 三,居然能自动处理兼容性问题,还能优化代码性能。以前需要一周的活,现在一天就能完成。 hr 场景,四 b 版本,十分钟就能完成一百份简历筛选,精准匹配岗位需求,匹配准确率高达百分之九十五加。还能自动生成面试题库和评分标准。 hr 不 用再对着一堆简历逐字看,省下的时间能专注做候选人沟通招聘效率直接翻三倍。 日常办公场景,做新媒体的朋友,用它分析两小时的行业峰会视频,自动提取核心观点,生成十篇不同风格的推文,还能配话题标签,做行政的同学,让他处理一百页的会议录音,三分钟生成带重点标注的结构化记要, 还能自动分配代办任务,设置截止时间,再也不用熬夜整理记要了。创业者场景小老板们福音 用 qw 三点五杠七 b 版本搭建专属客服机器人,不用懂代码,上传产品手册就能自动回复客户咨询,支持文字、图片、语音多模态交互,客服响应率提升百分之八十,还能二十四小时在线,省下的人工成本每月能多赚好几千。学生党场景, 写论文的同学,用四 b 版本就能自动梳理文献脉络,生成文献综述框架,还能检查引用格式是否正确。 准备考研复试的同学,让他扮演面试官,模拟专业问题问答,还能给出改进建议,比自己盲目复习高效多了。这才是 q 问三点五最颠覆的地方, 它不是让少数人享受 ai 红利,而是通过低算力门槛加免费开源加全场景适配,让普通人、中小企业都能用上顶级 ai 能力, 这就是真正的算力平全家人们。这样一款免费开源、性能强悍、全场景适配的国产大模型,真的太香了!觉得这个科普有用的赶紧点赞收藏!
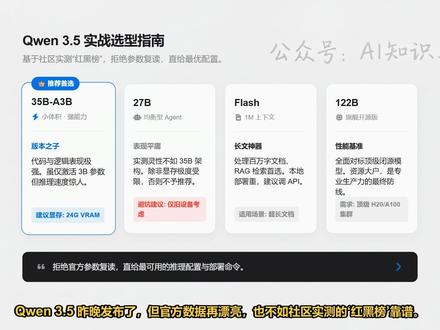 05:27查看AI文稿AI文稿
05:27查看AI文稿AI文稿q n 三点五昨晚发布了,但官方数据再漂亮,也不如社区实测的红黑榜靠谱。如果你有二十四 g 显存,无脑充三十五 b a 三 b, 它是这代的版本之子,代码和逻辑能力在这个量级基本没有对手。虽然每次推理只激活三十亿,参数速度飞快, 但记得他吃的是三十五 b 级别的,现存二十七 b 表现比较平庸,除非你的设备实在跑不动大的,否则不推荐吃鱼。 flash 版,它是处理百万字长文本的神器,本地跑太费劲,直接调 api 效果最好。 今天的视频不废话,直接把压箱里的推理参数、部署命令和调优经验喂给你,让你少走弯路,直接上手。 模型选好了,但如果参数设错,再强的模型也会变傻。先看最核心的深度推理场景,比如做数学难题或者逻辑推演,这时候必须开启千问三点五的思考模式。 注意,这里的 temperature 建议直接拉到一点零,这种高温设置能充分激发模型思维的多样化,同时配合一点五的存在惩罚,也就是 presence penalty, 这能有效解决模型在大规模推理时容易出现的复读机问题。但如果你是要写代码或者搞外部开发, 逻辑的严密性就比灵感更重要了。虽然同样是在思考模式下运行,但要把 temperature 降到零点六左右,降温是为了让模型输出更稳,少一些天马行空的幻觉。 top 维持在零点九五, 这样深层的代码逻辑会更连贯,能大幅提升代码的一次性通过率。再分享两个能让效果翻倍的小细节,第一是输出长度, 也就是 max tokens, 普通的活三十二 k 够了,但要是跑竞赛题目,建议直接拉到八十一 k 以上, 这多出来的空间不是给最终答案的,而是给模型留足打草稿的思考过程。第二是提示词技巧,做数学题一定要在末尾加一句,请逐步推理,并将最终答案写在框内。 要这层格式就明确要求只输出字母明确的指令边界,能让模型从猜你想干嘛变成精准执行。 最后必须划个重点,关于存在惩罚这个参数,虽然前面建议设为一点五,但你手动微调的时候千万别超过二点零。一旦设高了,模型会为了强行避开已经说过的词,开始强行凑数,甚至胡言乱语,整个逻辑会瞬间崩坏。 控制在零到二之间,这是千万三点五保持理性的最后安全区,模型调好了,怎么稳稳的跑起来?目前性能最强的是 s g l m 方案安装,别用慢悠悠的 pick 了,直接用 u v, 效率最高。 启动时一定要手动加上 razingpasta 这一行,这是千万三点五开启思考模式和工具调用的物理开关,漏掉它,模型就退化成普通版本了。 多卡用户记得根据显卡数量对齐 tv size 参数,确保算力全开。很多人一跑部署就炸显存,其实是因为忽略了那个默认二十六万长度的上下文设置。 如果你的显存没到八十 g 以上,千万别直接硬跑。建议手动把 context lens 压到幺二八 k 甚至更小,再配合 memfraction static 零点八这个参数,把静态显存死死锁住,这样能有效防止推理过程中显存突然飙升导致的崩溃, 让长文本处理变得真可用。如果你习惯用 lu l m 部署,这里也有个压榨显存的绝招。 再加上蓝宝石模型函数,虽然会暂时舍弃多模态视觉能力,但能为你换回巨大的文本处理空间,这在跑超长代码审计或者纯文字逻辑推理时是性价比最高的选择。确保带上 reasoning part, 让 v o l m 也能输出那串关键的思考过程。 如果你是通过 api 调用千文三点五,千万别在提示词里加斜杠 think 指令模型根本不吃这一套。正确的做法是,在 api 的 extra body 参数里,通过 chat template quicks 手动控制 enable thinking, 把这个布尔值设为 false, 模型就会跳过思考,直接给结果需要逻辑爆发时再开启,这是目前开发者最容易忽略的传餐细节。 要处理整本书或者超长文档,你就得开启千万的 r n 扩展,在 v l o l m 启动参数里追加这段,重写代码,把 max model line 拉到一百万以上。 这里有个独家经验,如果你的文档只有五十万字左右,把 factor 系数设为二点零的效果要比默认的四点零更精准。只有当文本真正接近百万级别时,才建议拉满到四点零。 想让模型看懂一两个小时的长视频,去修改模型文件夹里的视频预处理配置文件,找到 longest edge 这个参数, 把它改成这个九位数的特定值。这一步能让模型处理超过二十二万个视频 token, 无论是长篇分析还是监控复盘,理解深度都会产生质变。 最后总结一下,对于大多数本地用户,无脑充三十五 b 的 a 三 b 版本,只要你有一张二十四 g 显存的卡, 把它跑起来,温度拉到一点零,开启思考模式,这就是目前本地体验最好、逻辑最硬的中杯模型。上下文平时空在十二万左右,兼顾速度和显存,按这个配置跑,你就已经超越了百分之九十的普通玩家。
751AI赚钱研究社 04:20查看AI文稿AI文稿
04:20查看AI文稿AI文稿哈喽,大家好,这里是山东 talk。 今天我们聊一聊阿里的林俊扬。新裤子乐队有一首歌叫没有理想的人不伤心,用来形容今天的阿里,好像是挺合适的。 事情要从三月四号凌晨说起,阿里千问的技术负责人林俊扬突然在 x 上发文,表示自己将告别千问项目,而头一天晚上,他才刚刚发布了千问三点五的轻量化模型,马斯克还点赞了。 再往前看,这位九三年出生的年轻人,用一年时间晋升为阿里的屁时,可以说是前途无量。这件事情在全球的 ai 领域都引发了关注,但是阿里官方却始终没有公开表态。 那在当天下午一点左右,千问团队所属的通一实验室呢,紧急召开了一场内部会议,包括阿里董事长兼 ceo 吴永明、首席人才官蒋芳、阿里云的 cto 周竟人在内的几位高管都来了,他主要就传达一个意思,就是稳定军心。 流传出一段精彩的对话,是有人现场问能不能让林俊阳回来,当然得到答案是不能把人推上神坛,公司也不能接受非理性的要求,不会不计代价的去挽留一个人。你看,这就让吃瓜群众感受到了大厂残酷的一面。 林俊阳在哪里呢?负责的是千问团队,主要产品是千问开源大模型,它已经算是全球第一梯队的开源模型, 下载量超过十亿次,衍生模型二十万个,它是中国版的拉玛千万。开源的特色就是一个词,大方。从小模型到旗舰模型,几乎是全家桶式的开源,这在全球范围内是极少数的。 那现在 open ai 已经可以改名叫 close ai 了, google 和 mate 的 开源呢,一般也是留一手,百度和智普就更不用说了,开源模型就是沟子产品,重要的是推销他们的付费版本,付费版本比开源产品可能要好一百倍。在同行的衬托下,千万就显得跟我们河北人一样朴实。 它的部分开源模型,比如说千万二七二币,被认为是可以碾压很多币源模型的。那可以这样去理解千万做的事情,那就是烧阿里的 钱,造福全球开发者。当然,阿里也是有收获的,很多人使用千万开源模型的人都会租赁阿里云的 gpu 算力,这比从老黄手上买显卡要划算的多。另外,阿里还能靠马斯和企业服务赚到钱,这体现在财报里,就是阿里云的 ai 相关收入已经连续九个季度实现三位数增长。 那么问题来了,千万做的这么好,技术负责人怎么就撂挑子不干了呢?我猜他可能是不服气。阿里最近在进行组织架构调整, ai 的 b 端和 c 端产品统一命名为千万,这是要拉齐阵营跟豆包继续干。同意,实验室这边呢,也打算把千万团队进行拆分,从一个系统的技术团队,按照预训练后训练文本这些功能拆成一堆团队,解决以前产膜分家带来的内部结构问题。 但相应的呢,林志阳的管理权限也缩小了。其实对于崇尚技术的林志阳来说,权力变小可能也不是最难受的,关键在于这跟他的技术立场发生了冲 突。他理想的团队是像 offi 和 deepaman 那 样,在各个板块之间紧密沟通,因为很多天才的想法就是在这个过程中诞生的。那现在的局面呢?相当于团队被拆了,权力被收了,自己的技术理想能不能在阿里去实现,那也不好说了。 另外,快速升到 p 十的林俊阳,很可能也在内部触碰到了别人的蛋糕,比如他看好的居深智能通用实验室的其他团队也在研究。这种现象在大公司其实很常见。当然,这只是外部的猜测。阿里下午的紧急会议已经否认了内部斗争的可能性。 那现在唯一可以确定的是,千万模型接下来的进化可能有些不确定性,因为不止林俊阳,千万多位技术骨干也在相近的时间宣布了离开。看起来这也不是一个愉快的分手故事。 那你说这会重创阿里的 ai 业务吗?我觉得也不至于。千万团队曾经被字节挖走,一位核心人物周畅当时也算是轰动行业,但这并没有影响千万后来的发育。对于阿里这种公司,他永远能找到下一位周畅。林俊阳。 今年年初,前 deepmind 的 高级资深研究员周浩已经加入了同一实验室。有人认为林俊阳的离场可能跟这个有 关系,就像新裤子乐队的那首歌,没有理想的人不伤心。对于阿里来说,放弃对基础理想主义的避之选择。 阿里和字节正在争夺国内 ai 市场的老大地位,在很多领域,第一名吃肉,第二名啃骨头,第三名就只能喝汤了。对于阿里来说,二零二五年最火的 agent, 他 没有占到太多的优势,春节烧钱三十个亿也没有真正能动摇豆包在 c 端市场第一的位置, 你说他不焦虑可能也没人心。何况马老师在二零二四年参观通用实验室的时候也说了技术要落地,这句话的含金量放到现在那可就更高了。
146山农talk 05:11查看AI文稿AI文稿
05:11查看AI文稿AI文稿传统方案要你买三到四张昂贵的计算卡,动辄几百万,我今天教你的方案,一张二十四 g 或四十八 g 的 显卡就够了,成本直接压到万元级别。这张卡里我们要塞进四个顶配的商业级 ai 服务,能精准解析复杂 pdf 的 视觉模型,支持超长文本的向量解锁, 三百五十亿参数的推理大脑,还有能听懂五十多种语言的语音识别,一套完整的商业级知识库系统就这么跑起来了。 这四个模型怎么分配现存呢?最大头的是 q n 三点五减三十五 b, 这个三百五十亿参数的推理模型,占零点六五,也就是三十二 g, 这是系统的灵魂, 支持六零零零零的超长上下文,能处理复杂逻辑和精读总结。然后是 minor u v l m, 占零点一五,也就是八 g, 专门用来把复杂的 pdf 和表格完美还原成干净的 mark 完的数据向量剪缩模型 q one 三 in bedding 只占零点零七,三点三 g 就 够了,支持十六 k 的 超长文本截断。 最后是语音识别模型 q one 三 a s r 也是零点零七,三点三 g, 能听懂五十多种语言和方言, 四个加起来零点九四,在四十八 g 显卡上还有余量。 minor u v l m 是 视觉 o c r 模型,占零点一五,显存 也就是八 g, 它能把各种复杂的 pdf 完美还原成干净的 microsoft 数据。传统 o c r 遇到双栏文档就崩溃,遇到复杂表格就乱码,遇到科研公式就放弃。 minor v v l m 全部搞定,双栏表格公式一个都不落。 q n 三 embedding 占零点零七,三点三 g 显存,支持十六 k 超长文本截断,这是知识库剪辑的核心。 q n 三点五减三十五 b 是 这套系统的灵魂,三百五十亿参数的 mo e 架构,占零点六五,显存也就是三十二 g, 最关键的是,他支持六零零零零的超长上下文,这意味着什么?你可以一次性塞进几万字的文档,让他做精读总结,复杂逻辑推理,完全不会崩溃。而且我们用的是 awq marlin 的 极致量化版本,能把这么大的模型硬生生压进单卡。 这个模型不仅能为知识库提供强大支持,还能给公司内部的数字员工项目提供大模型支撑。最后是 q one 三 a s r 语音识别模型,占零点零七、三点三 g 显存,能听懂五十多种语言和方言,用非字回归架构推理,速度快得像闪电。 你可以直接录入客服电话或高管会议记录,全部转写成文本。最关键的是,这一切都在企业内部跑数据绝对隐私,不用担心泄露,先装眼睛,执行这三行,创建排放三点一二环境, 装上加速工具 u v, 一 键拉取千问三的视觉解析核心包搞定,启动 o c r 服务 u d a 零号卡,注意 memory 那 个参数设为零点一五,这是给显存切的第一刀,切走八个 g, 够视觉模型高倍发跑了。 接着装目录,启动千问三项链模型,关键看这里,显存只切零点零七,长度给足幺六三八四,项链任务轻如鸿毛,这条命令直接起,最关键的一步,别急着敲命令, 一定要等前两个服务完全就绪。六 l l m 是 显存流氓,启动时会疯狂与分配,你要是几个模型一起充显存,直接撞车。满屏红字必须一个一个来给大脑通电。启动千问三点五,三十五, d 巨兽 简存,切走零点六五,也就是三十二级量化方案。锁定 a w q 马铃,这是它能塞进单卡的秘诀,上下文直接拉满六万,这样你处理几万字的进读总结,才不会卡死。这个大脑不仅能跑知识库, 还能顺便带起公司的数字员工。像爆火的 openclaw 项目,直接拿这个接口就能用。逻辑推理能力,它是当下性价比最高的,没有之一。给系统装上耳朵,这个新环境拍散,三点一二激活进入。注意看这个细节,基础包正常装, 但想在塞满的显存里见缝插针,必须打上 flesh tension 这个补丁,加上这一行翻译命令,它能让显存占用从零点一直接压到零点零七,这是单卡跑四个服务的生存底线。 最后起服务 duda 零号卡,参数写死零点零七,也就是三点三个 g。 到这一步,千万三的语音识别就彻底跑起来了。算下总账,视觉零点一五,降量零点零七,大脑零点六五,语音零点零七,加起来零点九四,一张四十八 g 的 卡,刚好形成商业闭环。 这套方案把视觉解析、向量剪辑、逻辑推理、语音转写全部跑在企业内网,保住了隐私,还把成本砍到了脚踝。代码都在这,赶紧去跑一遍。
66AI技能研究社 01:15查看AI文稿AI文稿
01:15查看AI文稿AI文稿中国 ai 领域传来重大突破,阿里巴巴最新发布的千问三点五 max preview 模型在国际权威测试中表现亮眼,成为中文 ai 模型的新标杆。这款刚刚发布的 ai 模型在 l m rina 精准测试中一鸣惊人, 在数学领域全球排名第五,专家级排行榜位列第十。特别值得注意的是,它在中国自主研发的 ai 模型中排名第一, 超越了字节跳动、智谱 ai 等国内科技巨头的同类产品。虽然目前全球 ai 排行榜前几位仍被西方实验室占据, 但阿里巴巴已经成功跻身全球前五大 ai 公司之列。更令人振奋的是,包括字节跳动、百度在内的五家中国公司已经集体进入全球 ai 十强。这款新模型采用了先进的稀疏混合专家架构, 与前代产品相比,运营成本降低百分之六十,处理效率提升八倍。目前,该模型正处于预览阶段,阿里云表示,将持续收集开发者反馈进行优化。从二零二五年推出万亿参数模型到如今的新突破, 阿里巴巴正在以惊人的速度推进 ai 技术发展。对此,千问三点五杠 max 杠 preview 的 优异表现,标志着中国在 ai 领域的自主创新能力又向前迈进了一大步。
33硅基透镜



