物理ai训练消耗多少token
国内每周要消耗十三万亿托肯,而美国一周要消耗三万亿托肯,我们日常生活当中使用 ai 都需要消耗托肯,而托肯它是有价格的,目前我们的托肯每周用量是美国的四倍,但我们的花费却只有美国的三分之一, 因为在国内一百万托肯约等于一百五十块钱, 我们来算一个总额,相当于国内一周花掉一点三亿元,而美国一周要花四十五亿元,我们用的最多,花的最少,这就是我们 ai 的 核心优势之一,借此会有很多的一些机会,这些我们在评论区交流。

粉丝1056获赞660
相关视频
 00:37查看AI文稿AI文稿
00:37查看AI文稿AI文稿你每天的投肯的使用量的确反应不出来你创造了多少用户价值,但是它一定程度上能够反映你使用 ai 的 程度有多深。如果你每天消耗的投肯量的话是一个亿以上, 你是 c t o 级别的 ai 用户,如果你每天的消耗投肯量是一千万以上,你是专家级别的 ai 用户, 如果说你每天消耗的通费量是百万以上几百万,你是资深工程师级别的 ai 用户,如果说你每天使用的通费量几十万十几万,你很危险。
89程序员康健 02:20查看AI文稿AI文稿
02:20查看AI文稿AI文稿项目中装很多 skill 会不会加速你的 token 消耗?答案是会,因为它不小心就可能执行了某一个 skill。 每一个 skill 都有它的一个范围定义,有时候你可能不需要它,但是它的定义标准会额外的给你执行了更多的指令, 这个时候就会消耗更多的 token, 所以 skill 是 按量索取,尽量不要装全局,尤其是堆的越多的时候,那么一个普通的命令可能会消耗你大量的一个 token。 分享一下我真正的体验吧, 昨天那个视频我拍了十八个 skill, 其实我原始的项目只有两个的,也是我自定义自己训练的,根据项目自定义出来的, 但是装了这一些网上热门的 sqs 之后,你会发现它的表现还不如我自身原来的 sqs, 在 执行过程中尤其不小心命中了一些 sqs, 执行的消耗会非常的多。所以说这一些 sqs 的 出现对你来说有没有好处呢? 对于完全不懂的人来说,装那么一个两个体验一下就行了,如果你自己能做规范的话,还是建议用自己的 skill。 如果是你的 ai 不 怎么聪明的话,你只需要给他十行八行的好的提示词就行了,并不需要装一些技能进去。所以 装了很多 su 四并不能让你的 ai 变聪明,你的标准提示词才是让它变聪明的根本,所以大家不要被这个地方给误导了,就是想通用是比较难的,都要根据自己的项目去调整, 所以大家看到一个好的 su 四的时候,你在用的过程一定要用你的项目去调整一下它,让它发挥出它的效果来,不要盲目的听别人说哪个好,就哐哐的往项目里面装。 但是如果你装了之后,你要做检测,问一下你 ai 他 识别出这个是六十没有,如果识别出来之后,你可以问他,你现在是有作用的吗?目前命中率怎么样?记录一下他的命中情况,如果第一个命中很差,第二个没有执行到,你可以把它给移除掉, 也可以按照项目的情况去配置一他的的执行方案,他的一个出发条件,这样也可以有效的去解决,这样也非常有效的节约你的头,肯,让你的头肯续航时间更长。
 06:01查看AI文稿AI文稿
06:01查看AI文稿AI文稿hello, 下班了,我今天想聊一个话题,哈,叫当 skating law 撞上了物理限制,或者撞上了现实世界的限制。为什么想讲这个事情呢?因为我们最近在看 open 经济相关的这个结构哈, 一个比较明显的感受哈,现在我们说大模型的 skating law 一 直都还没有撞墙啊,特别是前一段时间 astropics ceo dario, 他 也又说没有看到这个墙啊,没有 hitting the wall, 也就是说大数据,大算力, 大模型它还是可以带来更好的效果的。像他们最近的这个 missiles 这个模型也再一次验证就是智能的这个上限还可以进一步的提升。 呃,那就是说在训练大模型的过程中,这个数字世界训练模型它没有上限,但是呢,你训练模型是需要芯片的,你需要数据中心,你需要 hbm, 需要夜冷,对吧?需要各种各样的东西,需要资本开支,这些都是物理世界的带来的这种限制。那现在物理世界的这个资源的扩展,它并不是指数的,因为你建数据中心,你是需要 去做人力的投入的,包括变压器,包括很多的,就是比如 b、 h、 b、 m 吧,就它也是最近这几家,呃,三星和海力士,然后还有镁光垄断价格,造成各种价格上涨,对吧?它也都是物理限制,为什么?就是因为它的能耗跟不上, 包括数据中心也是一样,也是需要去扩建,那数据中心的扩建就需要电工,然后电工的培养又需要好几年的时间去做认证之类的,也不是说随随便便就可以找一个,所以当所有的这样的一些 现实世界的限制堆在一起,因为像老黄当年说的那个五层蛋糕的结构、能源、 基础设施、芯片、模型应用,这五层蛋糕,前三层它都是涉及到了物理世界的局限,所以这个时候即使是我有更多的钱,我想去训练更大的模型,想推高这个智能的上限,也都是需要去抢这种现实世界的资源的。 这也是为什么赛蒙奥特曼看到了这样的一些限制,所以他把很多的算力等等一些存在自己的手里,还是做了很多储备的。然后像 dario 也是在三四月份吧接受一个采访的时候,他就说 他们其实需要非常谨慎地去预判未来一两年需要的这个数据中心,包括算力的规模大概有多少, 包括他们也给美国政府去提建议,需要应该是四十几瓦的电力的增加,才能够去支持未来模型的这个扩展。 但是呢,这些重资产也是有折旧的,如果你算的不好的话,其实会带来非常多的资本开支投入,你后面如果用不上的话,就打水漂了,就相当于闲置,对吧?这也是非常大的浪费。所以就是如果 算的不准,那就有可能这公司就崩了,这现金流就跟不上了,但如果灯也没电了, 那如果是不够的话,你就捉襟见肘。这也是为什么资本市场现在非常喜欢重资产投入,或者说在 ai 方面有非常激进的这样的一些表述的公司,就大家也可能看到了这一点,就是你需要去提前去抢物理世界的资源,如果 没有抢到的话,也许你未来的这个 scaling 就是 你模型本身的 scaling 就 跟不上,这也是一个平衡啊,因为有可能未来这个 算法带来的改进还是会出现一个显著的成本的下降,或者说需要的算力规模会变小,包括中国的芯片等等,也会带来一些产业上成熟,所以现在的这个去一味地扩大资本开支也不是一个必然的选择,所以各家公司其实都有在平衡这个问题啊。但是我想说的是, 数字世界的 skating law 确实是撞上了这个现实世界的天花板。然后呢?我还想到一点,因为我们最近不是一直在跟 ai 磨嘛,就是人的精力和时间是非常有限的,然后你天天跟这些 multi agent 在 一起, 磨得你呵呵,就还是挺痛苦的。你的精力是跟不上的,实际上人的局限也是 ai 的 局限, 因为人是有精力限制的,包括我们的组织也是有限制的,就说 ai 在 生产中去推开它,还需要遇到这个组织能不能推动的考验, 那这里面摩擦就大了。来自现实世界的这种摩擦,比如说人不愿意接受的这个问题,惯性,包括组织中的这种,你怎么让 ai 进到一个组织中来?其实摩擦是非常大的,所以其实不考虑模型的偷看的生产, 我们从偷看的应用角度,现实世界也是 ai 落地的一个非常大的阻力,就是虽然有一些前沿的用户他会比较密切地去用,但是更多的人还是习惯于在自己传统的工作场景去使用 ai, 或者说非常少量地去使用 ai, 还没有体会到它带来的巨大的竞争力的增益,所以我也非常理解现在出现的这种所谓的两极分化的情况,前沿的用户每天都开几十个 agent, 同时在跑 opencloud 的 那个创始人 peter, 他 每每个月的抽空消耗是一百多万美元,那像他这样的和我们日常可能也就是用 chatbot 对 话的这样的一些群体,就形成了巨大的差异。 所以这个还挺有意思的啊。就数字世界的指数增长遇到了现实世界的限性增长,就带来一个非常有意思的现象。我想到刘思新之前曾经说, 他觉得现实世界人类的这种局限性会限制 ai 的 发展。可能看起来确实是这样的啊。呃,这样也好吧,就是也不会发展的太快,导致我们非常焦虑跟不上。这是今天跟大家分享,拜拜。
1150晓辉博士 02:55查看AI文稿AI文稿
02:55查看AI文稿AI文稿兄弟们,今天聊一个大多数买托肯的人还没有意识到的事情,你现在理解的 ai 是 什么?聊天,写文案,画图、做 ppt, 哎,这些都是虚拟 ai, 活在屏幕里,但是下一个阶段, ai 要从屏幕里走出来啊,进入到现实世界了, 机器人、无人机、自动驾驶、 ar 眼镜,这些都叫做物理 ai。 虚拟 ai 解决了脑子的问题啊,那物理 ai 呢?解决了手脚的问题,那这跟用 mac token 又有啥关系啊?那你想一想,你问 ai, 一个问题,消耗几千个 token, 几秒钟就完事了。但一个机器人在工厂干活,他要实时感知环境,判断障碍物,规划路径,做出决策啊,执行动作,每一秒都在调用模型,每一秒都在燃烧 toker。 那 一辆自动驾驶的汽车跑一公里消耗的 toker 可能顶你跟 ai 聊一整年。马斯克呢?他说机器人可能是特斯拉最重要的产品,今年七八月份,那就要启动量产。那一旦从展示阶段进入到量产, toker 消耗量直接 上一个量级。无人机也一样啊,那以前靠人来遥控,未来是靠 ai 自主决策,每一架无人机就是一个天上飞的 toker, 消费终端、 巡检、物流、农业救援,七成,二十四小时不停歇,那虚拟 ai 时代构想需求两年涨了一千倍,物理 ai 全面铺开之后,再翻一百倍都不夸张。那现在你的客户是写文案、搞编程的开发者,未来呢?你的客户可能是管五百台机器的 工厂啊,运营两千架无人机的物流公司跑上万辆啊,自动驾驶车的出行平台, 每一台机器,每一架无人机,每一辆车,都是永不停歇的 token 消费终端,而且这些客户啊,跟现在完全不同哦。啊,开发者一个月用几百块的 token, 工厂一个月可能用几百万啊,当客当 当,客户价值啊翻了几千倍。但他们一样需要中间商来聚合,风发来做多模型的调度,做成本的优化。那我知道 token 中间商的逻辑从来没有变过, token 就是 产品, 人群广啊,消耗高,复购强物理、 ai 只会让这三个特征更加极端啊。人群呢,从开发者扩展到了整个制造业,消耗量从几百万级跳到了百亿级,复购从每天变成了每秒。 那这个赛道呢?现在才刚走完上这个赛道呢,现在才刚走完上半场,下半场的盘子大到今天无法想象。我是大卫,深耕 ai 大 模型的聚合服务, 想了解这个生意怎么做呢?评论里面扣 ai, 送你一本我写的磁源经济, ai 时代普通人的黄金赛道电子书。
982大卫讲Token经济 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿用 ai 编程,爽是爽,就是账单看着心疼。每次问个小 bug, ai 都要先给你写一大段客套话。今天介绍这个六万星标的神器,教你如何从大模型嘴里抢回美金。 caveman 这个插件的逻辑简单粗暴,强制 ai 用原始人的方式说话,没有废话,没有寒暄,只说核心逻辑和代码,直接砍掉,大量偷肯消耗。 他甚至内置了文言文模式,利用汉字极高的信息密度,把百字解析压缩成一句话,省钱省到有点离谱。如果你是高频使用自动化工具的极客,或者公司内部跑了几百个 a, 整这个插件,一周就能帮你省下非常可观的 api 费用。 他不只是一个梗,而是一套完整的提效工具链,完全免费,一行命令就能装到你的开发环境里。 ai 时代,真正昂贵的不是模型本身,而是每一次被废话浪费掉的上下文等待时间和推理预算。赶紧把这个神仙插件装上,把省下来的 api 费用拿去喝杯咖啡吧!我是带你每天半小时看透前沿 ai 的 酋长 andy 下课!
58AI酋长Andy 00:40查看AI文稿AI文稿
00:40查看AI文稿AI文稿你们算一下这周偷啃消耗了多少?偷啃,他知道我们偷啃了,快把零食藏起来。 啊啊, 又偷啃,老板,我们再也不偷啃了,求放过了。偷啃词源 就是 ai 读写文字的最小计量单位,大概一个汉字约等于一到二个 token。 你 发给 ai 的 叫输入 token, ai 回复你的叫输出 token。 这和 token 没关系。
 01:59查看AI文稿AI文稿
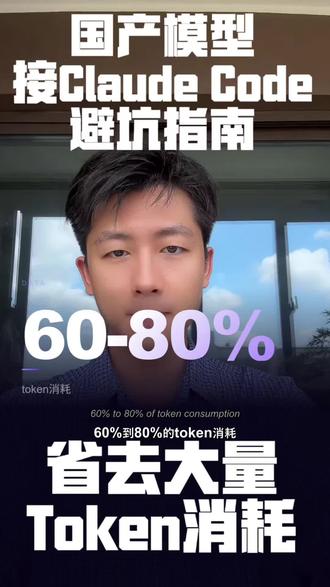
01:59查看AI文稿AI文稿cloudco 里面建国产魔性的坑你们踩了没有?今天我告诉你怎么避开这样的坑,顺便教你一个方法,能够省下百分之六十到百分之八十的 token 消耗。 先说第一个问题,大多数人装完 cloudco 的 以后呢,默认就会打开 opus 四点七,这就像打车一样,不管是三公里还是三十公里,都是用专车。同样一百万个 token 的 消耗呢, hikus 四点五和 opus 四点七的成本相差大概整整五倍。但其实呢,百分之九十的日常任务我们都可以用 hikus 去完成的。正确的做法呢,就是分档用,也就是大小模型结合使用,文件啊,格式转换啊,日常使用,我们就用 hikus 写功能写代码, debugsonit 也够了,要设置架构,能大型的重构和大型的角色,我们才上 opps, 就 这个习惯,能让我上周的账单直接省了百分之六十。也有一个开发者呢,记录了他一天三百多个工具的调用呢,通过大小模型结合的方法呢,帮他省了最高百分之八十五的头肯消耗。 那国产模型呢,它是真的便宜,最大的差价大概有三十五倍左右。它的坑主要有三个,在 cloud 的 a 键循环里面呢, 国产模型工具调用的格式经常会出错,导致它的循环直接中断,但它比较大的 代码库进行分析的时候呢,也很容易迷失方向。还有就是有一些模型,它是不完全支持 claudio 的 原生 skill 的 体系的。 一句话总结呢,就是价格便宜,但是跑得不稳定,重复修改的次数一多呢, top 也就翻倍了,它反而其实也没有这么便宜了, 所以呢,解决的方法呢,就是要尽量让他去跑简单的任务,我们大量百分之九十的任务都可以用国产模型去解决,复杂的项目呢就不建议了,这样的话也可以帮你节省不少的 token 成本。 这期的核心就一个词, token efficiency 资源效率,用对的模型比用便宜的模型更有性价比。
32超级 Evan 06:56查看AI文稿AI文稿
06:56查看AI文稿AI文稿一会 ai 就 必须了解 ai, 我 这里简要的普及下 ai 的 主要三个知识点,什么是 token? 什么是算力?什么是大模型 token? token 就是 个计量单位,就像我们用流量一样, token 就 相当于你的 kb, 你 的 mb, 你 的 gb, 它就是个技术单位。但是技术单位它的主要的计算方式是怎么样的? 一百个中文就等于七百七十个 token。 我们正常在使用 token 的 过程当中,如何判断我们消耗了多少的 token 的 数量?那我们 token 的 正常的消耗数量是分为三块的,一块是输入 输出,上下文缓存。 输入就是我们提出的问题,输出就是给出我的答案,上下文缓存就是 ar 在 记忆的过程,通常呢,上下文缓存是要大于输出的 top, 输出的 top 是 大于输入的 top。 第二个,什么是算力?算力就是芯片每秒完成的计算能力,传说的叫浮点运算能力, 英文就是 flops。 决定 ai 算力服务器的五个核心要素就是它的 gpu 的 核心数量,运行的主屏,计算的精度,呃,显存、宽带和架构工艺。 算力服务器的核心要素我们知道就可以了。我们重点呢是要了解到决定算力的成本是哪些。 决定上亿成本主要分为以下几大块,第一个是 gpu 硬件的成本,第二个是能耗的成本,第三个是网络的成本,第四个是存储的成本, 硬件成本是一次性投入成本中的大头。我们以 oliva 的 h 二百举例,一个单台巴卡的算力服务器,它的价格应该在三百万左右,那么包括像华为的九五零 还有木兮,价格是要低一些的。第二个是能耗成本,很多博主只告诉你说他的供电成本是多少,但是他不告诉你他的散热成本多少。在 ar 的 算力服务器里面,散热成本是要高于供电成本的。 第三个是网络成本,算力借房的网络不是我们家里面一根宽带接进去的,它需要接入的是高速互联的光 纤。另外一个就是存储的成本,你这样就知道,一个企业如果部署一台只调用的算力服务器,那么它初期的成本是在五百万起的。什么是大模型? 大模型就是依靠海量数据训练具备超强理解和深层能力的人工智能的模型。 我前面有一期视频专门讲解过大模型,所有的大模型都是基于 transform 大 模型的基础架构进行训练的。它主要两大模块,一个就是低 cost 模块,一个是 in cost 模块。 决定一个大模型好坏,那么是由以下七个条件来决定的。第一个是它的模型的参数量, 参数量越大,知识容量越强,但不是越好,它也取决于金条。 第二个,训练数据的量,这里包括了训练数据的体量、质量多样化和时效性,特别是质量,质量对于数据的来源的干净和正确性是有着极高的要求。 第三个,训练算力和轮次,简单的说就是反复训练越多,模型理解力越强。第四个,对齐微调, 简单的说就是这个模型好不好用,能不能说人话,能不能说对的话。第五个,上下文窗口, 简单地说,窗口越大,长文本,长推理就越强。第六个,专项领域专项优化, 这个主要是面向专业大模型的,通用模型是不等于专项模型,专项模型是需要对于细分领域的专项数据进行提纯和优化的。第七个推理优化, 这个就比较简单,就是这个大模型的响应能力是不是很快决定一个大模型的好坏,是有以下七点,那么在这七点里面哪个是更重要, 哪个是次质呢?我们总结下来说是数据的质量是大于对齐规条, 大于模型架构,大于参数量,大于算力。所以我们当遇到一个模型,说他的只看他的参数量,或者说只看他用什么样的算力来去做模型推理的,那么 你就判断说这个模型好是不对的,我们是需要均衡去看的。以上就是 ai 的 主要三个部分,呃,再简单一点的说,大模型就相当于人的思维方式, 算力是你的脑子本身好不好用,转的快不快。 talking 是 你在给别人服务的时候,你要给自己定的价格,这样理解是不是变得非常容易?这就是一样,看好你哦。
5闲人老戴 07:26查看AI文稿AI文稿
07:26查看AI文稿AI文稿英伟达黄仁勋从二零二四年就摇旗呐喊,人工智能下一波浪潮是物理 ai, 小 鹏汽车甚至抢在二零二五年底就发布了物理 ai, 却始终没掀起太大水花。 但村哥在五月份不过是喊了几句口号,物理 ai 就 刷屏,成了他科技预言家人设的又一震撼论断,不愧是连股神巴菲特都能硬撑的男人。 在这句普通 ai 落幕,物理 ai 才是未来三年唯一主线,精准迎合了当下市场。在 spacex 的 ai 部分和 open ai 连续递交了很缺现金的万亿美金招股书后,关于 ai 主线是否要从概念想象切换成业绩兑现的焦躁心态。 过去几年,享受了大量 ai 外溢估值红利的各行各业,肯定都不想现在就切换趋势,并且 ai 在 技术上也远远谈不上成熟, token 经济学刚刚开始落地,过早承受业绩压力的拷问,显然不利于生态系统的健康稳定发展。 但无奈 ai 一 点零的骑手 openai 太能烧钱,这几年从一级市场拿到的天量融资仍然填不满算力中心的头盔消耗,那就只能让 ai 二点零尽快接班,扛住未来想象的大旗。 所以物理 ai 就 赶上了历史进程。但是很多人直接把物理 ai 跟机器人乃至机器人身上的端侧控制芯片 f p g a 强绑定,把一个系统性的技术体系简单总结成了几只小盘概念股。这种有早没早搂一杆子再说的短期炒作,显然不利于以十年为周期的物理 ai 的 可持续发展。 于是我就想尝试用大白话把物理 ai 与数字普通 ai 的 本质区别和产业链总结一下,也是让自己的思路能跟上新的行业浪潮。大家好,我是嘟嘟,接下来我会按逻辑层层递进的方式展开完整结论。最后总结, 如果说大圆模型的本质是预测下一个字的概率,那么物理 ai 的 本质就是预测下一个动作、下一个状态的概率。归根结底是预测原子的运动概率,让 ai 能 与现实世界肉身交互。它与数字 ai 的 核心区别是需要实时互动,还不能出错。 ai 聊天等上一分钟甚至十分钟也无所谓,即便出了幻觉,也无非是撒娇卖萌,闯的祸再大还不是照样用? 但想实现 ai 自动驾驶,就需要毫秒级的实时预测自己和其他物体后续几秒的运行轨迹,还不能出任何幻觉,那可是人命关天的大事。故理 ai 不 相信营销,更流不起眼泪,这背后是无数矩阵向量的并行计算,把自然规律刻进 ai 的 骨子里。 因此,物理 ai 的 physical 不是 字面意义上的实体,而是物理学规律 physics。 换句话说,物理 ai 想要实现的是物理世界的 token 化,这对应着比目前还要超百倍的计算量增长。因为 ai 的 本质是重复压缩后的向量,对应 他在纸面上学会的物理定律,并不能对应到视频和现实,因为那只是一维文字所记载的知识,靠文本分词器所建立的头肯映射。想要影响三维世界,就需要跟三维时空建立映射,自然就需要对应的数据去训练。而被大元模型榨干的文本数据仅占世界总信息量的百分之一, 还有无数的静态图像、动态视频和连续时空流数据等待挖掘。因此,从最底层的数据层面,物理 ai 依然是大模型 skyline low 量大出奇计趋势逻辑的进一步延续。 具体来说,想让 ai 看懂视频,就需要建立二维的图像加时间维度的应用关系。如果再加一个文本提示词的维度,这就是以 cds 二点零为代表的视频生成模型在做的事儿,相当于凭想象划出一个摔倒的过程。 如果能摔出模型看过的角度,那就很像,但如果他碰到一个在训练时从没看过的全新场景,可能就摔得很浮夸。 而想让 ai 学会物理规律,不仅需要建立三维的空间加时间连续时空流,额外还得再加上大圆模型已经学会的物理常识,把摔倒所包含的摩擦力、重量、体积等等客观公式跟包含了摔倒动作的连续时空流数据建立映射,这叫做跨模态对齐。 经过这样的海量数据训练后,按大元模型的成功经验,我们就会认定这个多模态联合预测的生成,学会了物理规律。具体代表是英伟达在 g t c 大 会上发布的九千万亿 toc 预训练出的 cosmos 世界模型平台,顺带还开源了它的视频分词器以及 v s s 视频剪辑与摘药, 可以把海量视频变成 ai, 可以 随意阅读、缩影、理解和计算的超级结构化向量库,大幅提升了 ai 学会物理规律的可能性。 能做到这一步,叫做世界模型,属于多模态模型的一种,也可以称为物理 ai 的 一种。因为世界模型完全可以作为机器人的大脑,控制小脑进行活动。 比如要让世界模型学会开车,只需要再加两个维度,把它跟摄像头的图像信号以及油门、刹车等控制信号建立映射,它就能成为一个高智商司机,知道为什么要踩刹车减速,为什么要踩油门加速,还能像如今的推理模型一样,把它的思维链逻辑告诉人类, 或者听从人类的模糊与指挥控制车辆。这就是小鹏 g x 上的第二代 v l a 模型想要达成的效果。当然,现在还只是初期阶段。 再比如整合了千里之驾的阶月星辰,也成为曾经的 ai 六小龙中唯一走了大脑加小脑硬核路线的新小巨头,正在冲刺港股上市,成为以多模态大模型为核心的物理 ai 纯正标题。但是物理 ai 不 一定非要有世界模型,比如特斯拉 f s d 的端到端,它想让 ai 学会开车,只需要建立摄像头的图像信号,加时间维度、加油门、刹车等控制信号的映射关系, f s g 就 已经能控制特斯拉像草原上的猎豹一样,条件反射式的驰骋,优点是反应更快,操控更加丝滑流畅。问题是纯黑箱不可解释。 比方说 fsd 有 时会好端端的,突然加速又减速,这时你肯定想问,干嘛呢?刚才睡着了。但在端到端的技术框架下,即便特斯拉把 groc 跟 fsd 初步打通,也无法回答这种问题。 但咱不能因为猎豹不会说话,就说人家没有智能。所以端到端肯定也是物理 ai, 但它的问题是拓展性有限,让会开车的 fsd 学会打螺丝,依然需要海量的打螺丝数据,也就是曾经的名言,有多少人工才有多少智能。 跟曾经的大元模型跟视觉模型依赖海量人工标注数据一样,进场打工的机器人也有配套的数据训练,工厂真人们每天带着采集器重复抓取。但不要以为特斯拉就此落后了。马斯克作为世界首富,财大气粗,他可以选一种没有人能够复制的玩法, 预计今年量产三万台擎天柱机器人,专门用来采集数据,这将远远超出机器人行业现有的人工采集的数据规模,让特斯拉的机器人大军有机会完成恐怖的自我迭代。这个好处是,训练速度会非常快,将会很快形成垂直领域的生产力。 举例,比如让三百台擎天柱同时模拟一种打螺丝的方法,三万台就可以同时进行一百种不同的模拟,这就意味着擎天柱可以同时学一百种技巧。这个理念叫做蜂群思维,一只蜜蜂学会了,就等于所有蜜蜂都学会了。呃,手搓螺旋丸的名人直呼内行。 就是说,擎天柱只要学的足够快,哪怕一种一种慢慢学,用不了多久也能把工厂端的应用场景穷尽。因此,它形成可用生产力的落地进度可能会非常快。当然,理想状态下,世界模型的上限更高,它可以把所有场景都在虚拟环境里反复训练,这叫做数字孪生。 而且世界模型掌握物理规律,又有多模态能力,可以跟人类直接交互,这显然是成为通用机器人的必由之路,但它的难度也更高。阶段目标是优先在场景相对简单的汽车上实现 l 四级自动驾驶。 事实上,无论哪种路线,物理 ai 背后都对应着庞大的产业链,以及数据和算力的取舍和考量。今天已经太长了,咱们下期继续。
114还是大眼 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿就算你是搞 ai 的, 也逃不开绩效。最近有网友爆料啊,说有的大厂把偷看消耗和绩效挂钩,还影响转正晋升。那什么是偷看呢?简单来说,偷看就是 ai 处理文字和代码的基本单位, 只要用 ai 干活就会消耗它。那现在有的大厂把偷看消耗当成硬指标来考核,消耗不够,绩效就要垫底。 那这和当年程序员考核代码行数是一样的,都是表面功夫,不看实际的价值产出。那当年呢,程序员为凑代码行数,本来用 五十行能解决的问题,硬要写成五百行,现在员工为了刷透坑,反复生成无效内容,透坑烧了一大堆,有效产出没有半年提升, 本质上都是混淆了投入和产出本末倒置。应该怎么样科学合理的来制定绩效指标呢?我们主要看三个方面,第一, 指标的来源。第二,指标的命名。第三,指标的数量。那首先是指标的来源,指标一定是承接公司战略,聚焦价值产出的,公司推行 ai 是 为了提升效率,不是来看 谁的投坑消耗的多,而是要看最终对业务有没有产生影响,有没有真正的价值产出。那第二呢, 指标的命名方式建议大家呢,可以采用工作任务加衡量方式的这种形式来做,比如说投坑消耗,我们可以写成是 toker 消耗有效率,那这样的话,既看 toker 消耗了多少,又看能不能带来实际的有效产出。那第三呢,是指标的数量 不是越多越好,我们一定要抓住核心的百分之二十。对于普通员工来讲呢,实际上三到六个指标完全是够用的, 那比如说偷坑消耗,我们可以作为一个辅助指标,权重不用太高,以免员工呢去恶意刷数据而忽略了核心的工作。绩效考核呢,从来不是一刀切, 而是引导员工去做有价值的事情,别让偷坑消耗这样的考核重复当年代码行数 kpi 的 负责。你遇到过哪些离谱的绩效指标?评论区聊一聊,关注我萌来聊绩效,越聊越明了,下期带你了解更多绩效干货!
 02:46查看AI文稿AI文稿
02:46查看AI文稿AI文稿智能体产业啊,真的可能要爆发,最近有一系列的密集的催化剂事件啊,我们一起来看一下,直到今年三月份, 我们国家的日经 talk 的 钓用量突破一百四十万亿,很庞大的数据,很惊人的数据。第二是豆包呢,也开始推出收费的版本,还有呢,我们国家呢,正式出台,也是第一次出台有关智能体的专项政策。 那么这些密集事件的背后,从产业发展的逻辑来看,发出重磅的信号,整个智能产业啊,开始进入标准化、 大规模商业化落地的成长阶段。我们从产业发展的阶段的曲线来讲,产业生命周期曲线来讲,一旦一个产业进入到商业化落地的阶段,那么一些链主企业或者是关键的企业,他的弹性就会体现出来了,那么这个很关键,这个机会很多。 那么我们之前也跟大家做过拆解,智能体产业链,它有三层的架构,首先第一个是基础支撑层,包括像模型、算力、数据安全,尤其是算力,这两年是市场非常火爆。第二层是通用能力层,就包括智能体平台一些工具和框架。 第三是场景应用层,那我们注意到,这一次的专项政策主要是瞄准了十九个重要的应用场景, 每一个场景的背后,实际上都是隐藏的投资机会的。比如说这次提到科学研究有两个重要的场景,产业发展有五个关键场景, 提正消费有三个场景。那么每一个场景背后啊,我做了一些一对应的梳理,大概涉及到四十家重点上市公司,个人观点是值得去跟踪的。比如说像这家企业是前站式布局的工业智能体,搭载了二百二十亿参数的大模型底座,目前呢已经 开始聚焦像能源、电力、新能源这些场景在做,一些行业的智能体已经形成了技术开发到场景落地的完整闭环。那么真正推动 ai 落地应用,就是让 ai 真正懂得企业的业务啊,这是非常关键的, 比如说在这个早期故障预警里边,它的精度能够提升一百倍,那么像这些企业也是是首发世界物理模型支持物理规律驱动的智能体,已经实现自主学习到虚拟训练、 决策优化,已经满足科研和工业智能体的需求。这家企业的产品已经在商业航天、新能源、低空经济晋升、智能集成这些高阶级赛道开始落地应用,那么成长的路径是很清晰的。总体来讲就是 我们国家的智能产业已经从技术的导入的预期阶段,正式进入标准化、大规模商业化落地的成长阶段,那么智能体时代正在加速到来。那么这样的背景之下呢,我们要高度关注刚才提到的那些重点的上市公司。
98与学同行 03:27查看AI文稿AI文稿
03:27查看AI文稿AI文稿今天的滔凯消耗呢已经来到了四十亿,我们来看一下平台的一个更新情况,可以看到整体的 ui 布局呢,是我们重新设计了一下,所以导致里面的很多按钮、功能模块、脚本 都需要去重新的调整,因为工作量非常大,所以这个 ai 它会有这个遗忘的情况。那我们来看一下制作视频的一个任务流。 首先呢我们从这个论文爬虫这个模块找到对应的奇葩,然后再爬取页面里面去获取最新的一些文献,我们找到感兴趣的一篇论文,比如说这篇他还没有下载,我们可以点击下载按钮, 然后右上角开始下载,这里已经下载成功了,这里多了 pdf 文件。然后把这个项目呢推送到项目列表里面,我们可以按照时间进行一个排序,这是我们刚才所新建的一个项目, 这里现在只有 pdf 的 乱码。点击推进按钮,然后一步一步的去完成相 任务,这里是失败了,因为后台还有其他任务在执行,那除了单部进行执行以外,我们也可以点击一键全部,然后我们生成这个相关的视频,打开一个刚才生成 好的,这片是刚才推进好的,在 s 一 和 s 二这里需要用到 api 的 接口,这个位置呢,标注了他的 top 消耗,这是四千五,这边是一万五, 就是说我们要制作两个视频大概需要两毛钱。这个视频制作完毕以后呢,我们可以点击发布按钮,这里有推荐的标题简介标签,下面有这个自动发布的按钮,我们可以先把浏览器打开, 登录各个平台的账号,点击多个平台发布发布,然后这个平台的话需要手工去完成,因为他的管控比较严, 右边他在帮我们去做上传填充相关的素材的一个操作,那这边是从 pdf 获取到这个视频制作的一个流程。 除此之外的话呢,我们也打通了这个数字,人可多,视频那个生成,我们可以在这里去输入一个大概的吧,想象一下,你带着不明症状跑遍医院,平均要等四到八年才能确诊, 这不是科幻,这是美国超过两千五百万海豚病患者的线索,全球范围内这个数字高达三米,诊断延迟的背后是医生面对海量基因水平和复杂指南师的区别。今天我们要聊的就是如何用 ai 打破这个时间。 传统机器学习像猜谜,而大语言模型 l o m 用来学习思维推理,它能把 a、 c、 m、 g 这种长达百页的临床指南拆解成一步步, 是我们视频的一个创建工作。面对一个疑似遗传病的患者, llm 会先问症状符合哪个基因,刚才的项目呢,是单篇论文去进行的,如果想要走量的话呢,我们这里设计了批处理的任务列表,可以选中多篇,然后完成制作为推荐。 好的,以上是本期视频的内容,欢迎大家关注后续的平台建设进展。
26人工智能学术前沿 07:30查看AI文稿AI文稿
07:30查看AI文稿AI文稿三天的时间就消耗了一点二万元扑克的费用。少林绝技,天下武功,必须辅以佛法同修。一个视频,用三个最通俗易懂的比喻让你理解什么是最近爆火的养龙虾,以及如果说你也有 ai 焦虑的话呢?那么请你一定要看到最后。 首先什么是养龙虾呢?其实它指的是一个 ai 软件,叫做 openclaw, 这个 openclaw 它的标志呢,特别像是一个龙虾,所以说大家就给它起了一个名字叫龙虾。养龙虾呢,就是大家可能最近花很多时间去训练它,使用它,那这个过程呢,就可以简而言之叫养龙虾。 ok, 那 有了这个基础的概念过后呢,我再用三个形象的比喻,让你能够清晰快速的了解到底养龙虾是个啥。我也是一向对科技类的这种事物不算是太擅长,但是正因如此,我觉得我才更应该聊聊这个话题,因为这可能会跟很多像我一样的人产生一些共鸣吧, 当然我也做了很多资料的储备。那首先这个 open call 它是个啥?我觉得你可以简单粗暴的把它理解为就是钢铁侠的贾维斯,就是 你给他发出指令,他就能帮你直接完成你的很多的工作呀。呃,就用电脑啊。那第二个问题随之产生,这个 openclaw, 它和曾经的一些 ai 工具,包括像 deepsea 或者豆包等等的一些这样的 ai 产品,它到底有什么样的区别呢? 它最核心的区别就是在于以前的那些 ai 工具,它可能顶多像是我们的大脑,你可以让它帮你思考很多事情。但是如今的这个 openclaw 呢,它除了有这个大脑的功能之外,它还有四肢,就是它能 先帮你想成这些事,然后最后再帮你做成这些事。呃,就举个简单的例子吧,就比如说你想要出去旅行, ok, 那 以前的像 deepsea、 豆包他们顶多就是帮你做一些旅行攻略,这个就很厉害。那这个 open cloud 呢?它是可以帮你在做成了这个旅行攻略基础之上, 还可以帮你定好这个相关的一些酒店机票等等等等的一系列操作。所以说这个就非常有意思了。那很多人就会忧虑说,那这样的话,我很多的个人信息,甚至是我的财产安全是不是会有一些隐患得不到保障? 那你如果说能想到这一层的话,那我必须得要夸夸你,因为你非常的有安全意识。这个其实也是我们当今在面对这样的一些 ai 的 时候,需要保持的一种审慎的态度,因为涉及人民币等事情就不能是小事。 那既然我们收到了钱呢?我们也就接着往下再来聊聊这个 open cloud, 它到底是不是要花钱?答案是必然的, 且还非常的,就是还比较的昂贵吧。且不论最近其实有很多人在花钱找别人帮自己安装这个 open cloud 的 这笔费用,甚至有人因为这个暴富呢,我看好像最高记录是不是赚了二十六万。有一个人就因为帮别人安装这个 open cloud 赚,呃,就是赚了二十六万, 那这个都是个题外话,关键是安装好了这个 open call, 它顶多也就相当于是通了水电,但你如果说真的要用水电的话,你肯定还是要额外的交费的,对吧? 那它这个费用又是怎么来计算的呢?其实在算力的这个运行当中,有个单位 talkin, 其实我们原本用的这样的一些 ai 软件,它也会用到,只是说它的那个量可能会稍微小一点,可能每次的话就是几十几百这样, ok, 那 如今的这个 open call, 它可能每一次运作就是几十几百这样, ok, 那 如今的这些 ai 消耗的这个 talkin 的 几倍,甚至上百倍,上千倍等等的。所以说到了如此庞大的一个量的时候呢,他的这个费用必然也就不便宜。就在前不久呢,就有一位深圳的程序员分享了自己的经历,他在安装 open call 的 第三天,在凌晨的时候就收到了邮件,就是他的 api 的 那个密钥被盗了, 在三天的时间就消耗了一点二万元。 talk 的 费用一点二万元。老铁还有另外一位大数据工程师的这个经历呢,也非常的相似,据他所描述呢,他一晚上呢就是主要和这个 open cloud 聊了几轮,然后他搜了一些数据等等的, 就消耗了一百万的 talk, 还欠费了。就如果不是邮件提醒他的话,据他所描述,他估计此刻已经破产了,而且最近 就是还没有真正享受到这个 open club 的 红利,但就已经把学费先交上了的这些案例们其实还不少。其实我回想我个人刚知道 open club 的 这个事物的时候,其实我内心是又期待又焦虑的, 我觉得期待呢当然好理解,因为我觉得它也算是一个有生之年系列,我们在如此年轻的时候,还能看到世界如此多花样的这些新的发展,我觉得是一件好事情, 但与此同时我觉得更多的是让我焦虑吧,因为我觉得像 ai 这样的工具,它的本质其实就是让强者更强,让弱者更弱,它甚至很大程度上可能会加具这个世界的贫富差距啊等等的一系列的矛盾和问题。而这种 ai 工具越强大,那么它发挥的这个影响也就 越深邃。所以说当我知道这个 open call 他 能像贾维斯一样能够直接帮我们完成很多这的时候,我就开始觉得,哇,我要是起步比别人慢了,那又得有多少人无形当中超越你? 这个其实挺让人焦虑的。就在几年前,在我们语言当中有一个词叫做数字难民,这个词当时还描述的是一些擅长使用智能手机的智能设备的一些中老年群体。 但是我觉得如果这个词放在如今的话,其实这个数字难民可能已经越来越多了,因为它甚至就包含一些在 ai 时代被落下的很多人,就是我觉得甚至可能现在有, 直到此时此刻,可能还有很多人他是没有听过这个 open cloud 到底是个什么玩意儿的人。那,那你说从这个角度来讲,是不是已经就拉开一些差距了呢?这就让我觉得在目前这个 ai 工具层出不穷的时代,我感觉我们每一个人都可能随时随地会成为新的数字难民。 就这个事情是让我有一些些焦虑的,但是我很快就想通了,因为我想起了金融先生曾经在天龙八部里边借由一名扫地僧说出的一句至理名言,我觉得非常有力量的一句话,他是这么说的,即少林绝技,天下武功,必须辅以佛法同修,方能化解利器,避免走火入魔。 我觉得这句话放到当下的这个时代语境当中,其实就是告诉我们每一个人,当 ai 的 浪潮滚滚而来的时候,我们其实更需要 去注重我们的内修,我们必须要有足够的能力去驾驭这种工具,我们才能够真正的避免被他带来的一些负面影响所侵蚀。 正是因为当今的科技发展的如此之快,我们才更应该注重我们自身的这个人文素养,包括我们对文学、对艺术、对美学等等的探索和探索,不然的我们的大脑心智就很容易被科技所占领。 而且你会发现,为什么我在开头说就是 ai 这门工具,他会让强者更强,让弱者更弱呢?那这个强者和弱者他们的差别到底是在哪里呢? 其实就包括我们自己曾经在用过往的一些 ai, 会发现可能不同的人,他用同样的这台工具,他能达到不一样的效果,这就是因为使用者本身他所具备的这个能力, 眼界、格局、思想等等的都会有所不同,而这些不同都会体现在他们给出的这个指令里。那可能很多人就会说了,那如果说未来也能让 ai 帮忙给出指令,是不是就可以磨平这些差距? 但你仔细想想,如果说未来有一天 ai 他 可以自己给自己指令的话,那还需要人干啥呢? 是不是很细思极恐?天黑也许可以帮我们做事,但是他永远代替不了我们做一些决策和判断,当然我们也并不是说完全的排斥科技,我们其实也是在这个过程当中一边观望一边接触,而且本身呢,现在这个龙虾他 自身也还有很多的漏洞急待解决,所以我觉得对很多像我们这样的普通人来说,更是大可不必被席卷到这种 ai 的 焦虑当中来,就是一个顺势而为。
35CBD男孩 02:16查看AI文稿AI文稿
02:16查看AI文稿AI文稿你敢信吗?全球一半 ai 数据中心正在被悄悄取消? ai 狂飙三年,突然撞上一堵无形高墙,你以为它卡脖子在芯片? 错, ai 正在被物理世界彻底锁死。训练一次 gpt 五,耗电三十八万度,足以主费一千个奥运泳池。你问 ai 一 句话,耗电是普通搜索的十倍?这不是技术问题,是 ai 的 底层基因,它本质是能源巨 ai 到头, 黄仁勋赌能源定胜负,不是他们不谈技术,而是他们看清了真相。 ai 的 增长是指数级的, 而物理世界的供给是现行的数字,跑得再快,也跑不出现实世界的物理规律。现在真正卡住 ai 的,是四道无法绕开的硬天花板。 第一,电网瓶颈。美国主流 ai 数据中心区域新建项目通电排队长达四到七年,电网扩容速度完全跟不上算力爆炸。第二,高端制造垄断, e u v 光刻机全球仅 as m l 能量产, 扩产周期长达五年,先进封装被台积电一家吃满,产能排到两千零二十六年之后。第三,核心材料短缺, h b m 内存龟片, 电子特企长期供不应求,行业预测,短缺状况至少持续到二零三零年。第四,散热与能耗,物理极限,算力越高,发热越恐怖,近百分之四十电力被用来降温,而不是计算。 一句话戳穿,算法可以一夜迭代,但发电厂不可能一夜建成。现在行业早已不卷模型,卷的是能源与算力霸权。 openai 包下五极瓦电力, 相当于五百万个家庭同时满负荷运转,谁掌控能源与制造,谁才握有 ai 的 最终话语权。中美吃掉全球百分之六十九的 ai 电力, 这场竞争早已不是代码之战,而是能源战、工业战、国家硬实力之战。没有持续廉价稳定的能源,再聪明的 ai 也只是一堆昂贵的废铁。当所有人还在追捧 agi 神话时, 真正的玩家早已下场抢夺能源与基建命脉。 ai 的 终极天花板从来不是智能,而是物理规律本身。 ai 前沿分享!
571人工智能培训咨询老师叶梓 06:31查看AI文稿AI文稿
06:31查看AI文稿AI文稿我用 ai 来通过浏览器操作店铺的视频不是火了吗?有一些网友一直在质疑 token 消耗的问题,说我这样子操作浏览器非常消耗 token, 非常不划算之类的。包括其实我在之前的视频中也经常有一些网友来询问,这样操作到底要花多少 token? 那 我现在就以程序员的角度来把 token 消耗这个问题 详细的解释清楚。首先你们要知道在什么情况下 ai 会很费 token? 简单来说就是上下文太大的时候,上下文大确实会消耗 token, 但是我要记住一点,如果上下文都是有用的消息,那这个 token 消耗就是有必要的,这种情况叫做消耗大但不浪费。而真正浪费的是什么? 是上下文中包含了太多的信息,重复的信息。那我在这里先解释一下什么是上下文中包含了太多的信息,重复的信息。那我在这里先解释一下 ai 的 那一句话, 它包括了你 ai 前面的回答的内容,你发给他的文件, ai 调用工具返回的结果,包括 ai 去网页上面去采集信息。那知道什么叫上下文之后,我们再来带入实际的场景。我们让 ai 来干活的时候,其实可以分为两种情况,第一种叫做一次性的活, 就是干完这一次就结束了,如果是这种情况,那我觉得消耗多少托肯,其实消耗了就消耗了,不需要太纠结他到底用了多少托肯,因为他只是临时的帮你解决一个问题,就好像你雇了一个临时工,那临时工平均的单次成本是不是要比你长期雇佣一个员工更高。第二种情况,重复性的活 就是今天干了明天还得干,现在干了等一下还要干。那,那我们真正要讨论的就是这个重复性的活, ai ai 诊该怎么干? 首先在第一次干重复性的活的时候,它其实跟干一次性的活是差不多的,第一次效果都会非常高,因为你主要是在调试它的整个流程,你和 ai 其实都在探索这个步骤,哪里可以自动化,哪里会出现问题, 所以第一次消耗高一点是正常的。但是一旦流程调通了,我们后面就不应该让 ai 去从头来一遍。这时候我们应该做两件事情,第一件事就是让 ai 来梳理成一个 skill, 这个 skill 呢,相当于是这个流程的一个标准作业手册,就是 s o p, 它会明确每一步该怎么执行,遇到什么问题, 遇到什么情况,该怎么解决这个 skill。 为什么要透解决托管呢? skill 本身它其实也是占用托管的 skill, 被读取或者调用的时候,它也是会占用上下文的嘛。 但是它节约的地方在于第二次之后,让 ai 执行这个流程的时候,不需要像第一次那样把所有的操作说明再重新发给他。因为你发的这些内容它其实也是上下文的一部分。 就比如说你之前说先做什么再做什么,哪些地方都能做,用什么方式去做,去遇到什么问题该怎么解决,之间所有的内容如果你每次都重复去发给 ai 的 话,那它就会每次都占用这个上下文去下 auto。 那 现在有了 skill, 你 就可以说调用这个 skill 就 完了, ai 它就会根据这个 skill 去按照固定的流程去执行。第二点就是 ai 不 需要每次重新去熟悉跟探索操作步骤,它就不用每次去重新理解这个流程,就直接按照这个 skill 里面的 sop 值执行就完了,这就是减少了重复理解、重复规划、重复返工的一些问题。然后说到 skill 呢,有一些网友也会提提到嘛, skill 能节约 token, 这些网友其实他们略懂, skill 节约的 token 是 非常少量的,而真正节约的大头 其实是把固定的流程写成脚本,这也就是我下面要说的第二点,让 ai 把固定的流程写成固定的脚本。当你们看不懂 ai 的 操作的过过程,思考的过程,其实他在非常多的步骤中,他都在写代码, 写了非常多的各种脚本,比如说渲染脚本、 python 脚本,包括浏览器的这些脚本。还有 ai 也能够调用外部的一些服务,比如说外部的 api、 c i 工具,当然这些东西可能需要我们主动告诉他去调用什么东西,那这些服务,这些方式为什么能节约多?可能因为这些脚本和这些服务 其实他们是在干活, ai 只是调用他们 ai 写这个脚本,真的干活是这个脚本,但对于很多飞机人员可能听不懂这些脚本是什么意思,到底是干嘛的。但你只要理解那么一点,脚本是负责执行固定动作的, ai 是 负责调度和判断的。当 ai 把脚本写完之后,如果这个流程是非常固定的,你真的可以不需要 ai 的 参与,你直接执行脚本,让电脑自己来操作,自最后产出结果就行了。但如果流程比较复杂,中间需要一些判断, 脚本跑完之后再把执行结果返回给 ai, ai 看完之后再决定下一步该怎么做。所以高频稳定客观的流程其实就是应该代码化、脚本化的去做的。那低频复杂需要理解判断主观的一些事情才应该交给 ai 去做。 代码脚本负责执行, ai 一 整负责决策。在我们电商场景下,我们绝大多数的工作其实都是非常重复的。举个例子,上架商品 有几种情况,第一种情况是你已经把你的产品的所有信息准备好了,然后你让 ai 去做自动上传的动作,其实 ai 是 会先写一个自动化的上架脚本, 那你直接就启动那个脚本,就能够通过那个脚本上架了,你就不需要再通过 ai 来启动这个脚本了,明白吗?但是我们实际运营中肯定还有更复杂的情况,比如说商品信息不全,或者说我想让 ai 来帮我去创建这个商品的标题,那在这种情况下, ai 参与的其实就是生成标题的那个步骤而已。 而真正要模拟浏览器去把你的商品上架上去,那后面的所有的工作其实是固定脚本去做的。好。再说回我视频中的那个案例,我让 ai 去五个店铺里面去采集每个店铺的订单数据,很多可能会以为它是在五个店铺里面一步一步的操作浏览器,所以一非肯定非常消脱狠, 这只是你们的意向。我在这个步骤里面, ai 真正想做很多地方在哪里,它其实就是发动了启动某个店铺的指令,启动完之后它直接就调用那个脚本去完成了采集操作。那浏览器里面每一步怎么打开,怎么点击,怎么采集,怎么保存,其实都是脚本在执行, ai 也不会每一步都去盯着浏览器看,只是每个店铺在采集脚本完成之后,它会看一下执行的结果, 截个图看一下采集是否成功。所以他真正参与主观判断的就两个步,一步是启动哪个店铺,第二个是 检查结果是否成功,中间大量的、重复的、固定的、客观的动作都是脚本完成的。所以你觉得这样的操作会很消耗脱粉吗?我希望我讲清楚,不知道你们听懂了没有?关注我会持续分享更多从技术人员出发,去用 ai 来做跨境电商的真实案例。
147凯乐AI电商创业 01:03查看AI文稿AI文稿
01:03查看AI文稿AI文稿一百四十万亿,这是中国现在每天烧掉的 toc 数量。刚看到这个数字的时候,我简直难以置信,查了一下,确实是国家统计局今年三月发布的数据, 就两年时间翻了一千四百倍,相当于 ai 每天都在替每个人疯狂打工。有人问 toc 到底是个啥? token 的 中文翻译叫做词源,简单粗暴点说,它就是 ai 时代的电费。以前大人充话费充流量,现在的硬通货早就变成 token 了。如果大家平时跑个复杂的数学模型,或者给代码 bug, 后台全是在烧 token, 未来的世界不会用 token 驱动 ai, 估计就像现在不会用智能手机一样离谱。 其实无论是写代码还是做项目,核心逻辑都一样,别只顾着在前端当个只会刷视频的消耗者,得看懂底层的运作机制,去当那个驾驭善力的人。你知道你今天又烧了多少头肯吗?
12安总家的耐鸡娃 04:12查看AI文稿AI文稿
04:12查看AI文稿AI文稿各位董事长,今天咱们再扒一扒最近火到发烫的物理 ai, 今天咱们就干四件事,第一,看看谁掌握了物理 ai 的 操作系统,这是真正的技术壁垒。第二,物理 ai 的 眼睛和触觉到底是谁家的?谁在垄断?第三, 机器人的肌肉和关节,谁是独家供应商?第四,看成品,谁再把这些技术变成能干活的机器人,谁在闷声发大财?咱们先从最硬核的开始。 物理 ai 要想牛,得先在虚拟世界里练满级,这就是底层仿真平台,相当于 ai 的 秘密训练基地。第一个出场的锁程科技,记住这个名字,国产 c a e 软件的扛把子。 啥是 c a e? 就是 给飞机导弹机器人做虚拟体检和模拟训练的,他家自研的天公开物引擎比传统软件快一百倍,你说牛不牛?关键是人家已经赚钱了, 二零二五年光物理 ai 这块就收入近六千万,还拿下了绍兴的低空经济大项目。下一个能科科技, 这家伙更狠,直接给机器人做大脑。你看那些机器狗,军工、巡检车,很多都是用的他家的 ai agent。 而且人家不仅技术牛,订单更牛,两个亿级项目落地,二零二六年第一季度订单直接涨了三倍。说完了大脑,咱们来看看物理 ai 的 五官、 眼睛和触觉,这就是感知层,决定了机器人能不能看懂世界。提到眼睛,必须是奥彼中光,国内服务机器人的 3 d 视觉百分之七十都是他家的,全球没几家能做到他这么全面的技术布局。 现在最火的人形机器人特斯拉、小米都在用他的方案。二零二六年第一季度传感器出货量直接干翻百分之一百八十。再看海康机器人,海康威士的亲儿子, 工业视觉和移动机器人双料冠军,他家的方案能让机器人在工厂里自己导航,自己干活,订单根本不愁,八十多个亿的订单在手,宁德时代比亚迪都是他的大客户, 这就是实力,有了大脑和眼睛,还得有能干的胳膊腿,这就是执行层,机器人的肌肉和关节,这部分技术壁垒最高,订单也最实在。 首先是拓普集团,汽车零部件巨头跨界来抢饭碗,人家直接拿下了特斯拉 optimus 大 长腿的独家供应, 就是那个限性执行器,单车价值好几万,二零二六年订单超四十亿,已经开始量产交货了。这哪里是跨界,这是降维打击。三花智控更厉害,直接包圆了特斯拉机器人的旋转关节和空调,十四个旋转关节独家供应,还有液冷散热系统, 单车价值近三万,订单排到二零二七年超过五十四个亿。绿的斜坡,机器人关节的心脏,斜坡减速器的龙头, 国内市场占了六成,技术跟国际巨头看齐,价格还便宜,特斯拉的供应链里也有它,二零二六年第一季度出货量暴增,产能都不够用了, 国产替代的逻辑在他身上体现的淋漓尽致。最后是汇川技术工业自动化的老大哥,他家的四福系统让机器人动作又快又准,动态响应速度提升五倍。二零二六年机器人订单预计增长百分之一百九十, 这是要把第二增长曲线焊死在身上啊!有了所有零件,咱们来看看谁再把他们组装成能干活的机器人。这就是长机与应用层商业化落地最快的地方。 埃斯顿,国产工业机器人的一哥,核心部件自己造,还搞出了国内唯一的工业机器人操作系统,订单超三百亿。排到二零二八年, 人形机器人的关节也已经打入特斯拉,供应链未来不可限量。埃福特也不甘示弱,工业机器人和人形机器人两手抓,人家已经拿到了国内车企五个亿的人形机器人订单,还有物流机器人的大单。好了,总结一下物理 ai 的 逻辑,就四句话, 仿真看锁辰,执行看拓普,三花,感知看奥比,整机看埃斯顿。今天就讲到这里,以上内容不构成投资建议,点赞关注不迷路,各位董事长下期见!
944全链情报局

