agent 后端能用什么
程序员所谓的转 ai 一 阵,百分之八十的知识其实还都是一些传统软件开发,尤其是后端的那套东西,业务流的处理,异步的处理,高并发的处理,数据库的处理,其实都是这一套东西。那么真正你要说有门槛的无非这么几块, python 语言, 因为你要先把这个编程语言扭过来。第二个,其实来讲,因为大家对于 ai 丝毫不了解,那么你在整个 agent 的 这个过程中,可能会对很多地方有困惑。第一,我这块掉了一个大模型,那大模型到底能给我一个什么样的反 馈?我什么时候该掉大模型,什么时候该去掉小模型,他心里没有数。第二, agent 的 项目里边一个核心,现在来讲,工业界默认的其实就是上下班工程,而所谓的上下班工程, 我们是要消除大冒险的幻觉,把更多正确无误的知识灌输给我们的 a 着的,那靠什么呢?靠经典的 r a j, 那 么 r a j 这套东西怎么去搭?如果你完全没有,比如说深度学习的基础,没有大冒险的基础,那么这块对于你完全是个黑箱。有很多小伙伴一想,我有大量的数据,我直接灌进去,听说切分怎么切,这细致的东西它都没有概念, 而且没有做过 ai 的 小伙伴,他甚至对于这种所谓的招回率、精确率没有概念,而且因为都是黑箱,一旦出问题了,你都不知道该改哪。所以说这些小伙伴真正的在企业的现实中,你去搞几个项目, 甚至我觉得对于这些 java, 老鸟,嵌用式老鸟、 c 加加老鸟 ai 这块的应用层面的开发项目,尤其 a 镇的这块开发项目,挑两个领域、两个不同的技术站从头到尾跑下来,这基本来讲就切换过来了。我觉得小白转行如果难度系数是一百分的话,这些老鸟转过来的难度系数最多就是五 十分,对于一些传统开发很熟的小伙伴,可能难度只有三四十分,就是把这些东西搞定了之后,做应用层面的开发没有那么难。

粉丝1.4万获赞9.8万
相关视频
 05:43查看AI文稿AI文稿
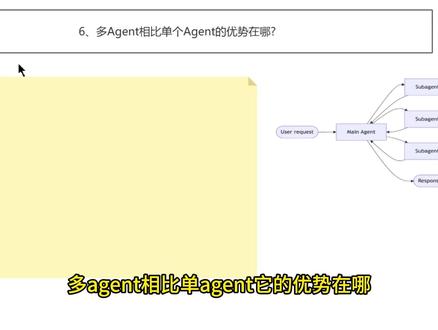
05:43查看AI文稿AI文稿多 agent 相比单 agent, 它的优势在哪?我们知道啊,多 agent 它的模型大概是这样一个架构给大家看一下, 这个架构是这样的,就是说因为我要完成很多的任务,比如说为我规划一个三天的北京文化之旅,包括预算,包括美食推荐。 那么这个时候呢,就会有一个主 agent, 称之为 main agent, 然后啊,他就是你的团队经理或者是项目经理,他负责接这个复杂的任务,然后他接到了这个复杂任务,他的核心就是进行分解,然后分解完之后呢,他就将大任务拆成需求,然后不同的子任务来执。执行这个子任务交给我们的 sub agent 就是 子 agent。 主智能体的话呢,将子任务交给各个子智能体,他们就像团队当中的这一个专业顾问。那么这个 sub agent a, 他可能是行程规划专家,他负责安排景点交通日历。我们的 sabbatical b, 他 可能是预算管理专家,他负责查价格,他负责制定计划表。我们的 sabbatical c, 他 是美食文化专家,他负责推荐餐厅特色小吃。 每个子智能体专注于某个领域,然后呢,拥有该领域的专属工具或知识库,执行效率的话呢,他的质量他就会更高, ok, 所以呢,这个子智能体啊,他们可以并行 或者是按序按顺序完成自己的工作,之后的话,将这一个结果,哎,这一节的结果可以返回给我们的这个主智能体, 然后组织人体了,他就扮演这个整合或者审查者,他需要将各个子结果,包括你行程啊,预算啊,美食列表啊,汇总一个连贯的方案的同时,同时还要检查你的逻辑是不是自洽,是不是信息完整。如果整合时发现有缺陷,比如说你的预算 不够了,或者预算超支了,或者你推荐的美食不匹配了,那主制人体的话,他会再次协调相关的子制人体再进行调整,所以他也会形成一个审查改进的这样的一个闭环,从而去确保高效的出输出。最后的话, 我们的主制人体将所有的工作整合成一个完整的、统一的最终响应交付给客户,这就是我们的多制人体啊。当然多制人体相比于单制人体,它的优势在哪里呢?我们前面看到的这种就是单制人体, 比如说我们前面讲过的自动化运为故障加诊断 agent, 那 这个时候他内部的话需要调很多很多的这种工具,第一轮、第二轮,第三轮、第四轮,然后这是第五轮,也就是他调到第五轮的工具, ok, 那 么你可以看到这个这个 agent 他 就做的非常庞大了,那你可以认为这个单个 agent 他 就是一个超人, 他是一个尝试解决所有问题的全能超人。而相比而言,我们的这个多智能体的话,他就是一个专业分工、高效团队的一个啊,高效协助的一个团队, ok, 所以 你可以看到他的优势点在哪里啊?优势点我这个地方给大家讲,给大家讲啊。 第一个单个的 agent, 它就类似于全科医生,而我们的多 agent 就 类似于专科医疗团队, ok, 单个医生的话,全科医生的话就是什么都会,但是什么都会必然会带来另外一个问题,什么都不精, 然后全科医生的话啊,这个多 a 针的话,那它各有专长,并且可以进行深度协做好,这是一个简单的类比,除了这个类比之外的话,我们再看第二点,就是多 a 针它的优势, 这个优优势的话呢,还有一个优势非常明显,它可以去降低上下文负担, ok, 你 通过多 a 针,它里面的这一个是隔离的,它可以通过隔离和信息过滤去解决上下文爆炸的问题。 因为在前面的单个 agent 里面的这个上下文传递给他,传递给他,传递给他,上下文的话,量是比较多的。而如果说我多 agent 的 话,我可以去实现那个叫做上下文,是隔离的 下文隔离啊,同时的话也可以做信息过滤,解决这种上下文爆炸这种问题, ok 啊。然后第三个的话呢,就是说他还可以去解决什么啊?解决这个多 agent 的 优势。 多 agent 的 优势还有一点,它可以去怎么说啊?就是说避免这个单 agent 的 单一个大脑处理所有的任务,然后呢,你就成一个脑袋就成浆糊了,所有的信息混在一起,形成了上下文的一锅一锅粥,对不对?所以,嗯,就解决注意力 分散啊,就解决这一个幻觉率高的问题,幻觉概率高的问题啊,还有包括刚才的 talking, talking 的 话呢,就是超长, 所以这是多 agent 它的一个优势啊,因为它的一个优势就是分工明确嘛。同时的话,多 agent 它的这个拓展性, 它的优势是什么?它的这个稳定性也强啊。先说稳定性,为什么说稳定性强呢?就是你单个 agent 如果出现了一个 bug, 它影响的是所有整个系统啊,如果说你是,你是,比如说 sub agent c, 它出现了 bug, 那 你可以用故障来隔离, ok, 所以呢这个就是它的稳定性啊,同时就是稳定性可以单个 bug 的 影响小, ok, 然后呢?你去开发的时候,那个代码的这个冲突率也小, ok, 所以 它可以带来我们的这个效率的提高,维护成本的这一个降低,所以这是多 agent, 相比于单 agent, 它的优势在哪里?
35马士兵教育马小鱼 02:39查看AI文稿AI文稿
02:39查看AI文稿AI文稿很多人打算做 a 镜的项目,但是不知道从哪里开始,我呢就跟大家讲解一下如何使用外部焦点,一步一步的去做 a 镜的项目,都是干货,建议收藏。这里先说一下,如果直接去开发 a 镜呢?这可不是很合理的。 我们知道 a 镜呢,一般是部署到后端中的,因此正确的顺序是先做后端,然后在后端的基础之上再去开发 a 镜呢。步一步来,如果只单纯的开发一个 a 镜呢,是没有用的,就像你造好了船,不把它放到水里是没有用的。 设计一个后端,首先要考虑的是基础选型以及开发部署方式,还有架构设计,好的架构设计有利于提高网站性能和开发效率。 第一个基础选型以及开发部署方式,框架选择 pos 边, o m 选择 circle。 alchemy 数据库是 pos 数据库缓的是 radis, 任务任务是 celery。 这套基础选型比较适合 ai 项目后端开发 pos 一 边适合快速封装接口。 pos 数据库负责结构化数据存储, redes 负责缓存和状态管理, siri 负责处理异步任务。对于 ios 密集型场景,合理使用异步能力可以提升系统病发处理能力,但是系统性能最终还是取决于数据库缓存、任务队列和模型调用链中的整体设计。 技术选型确定了,就要确定开发步骤方式,也就说我们在什么样的环境下进行开发,也就是开发环境的确定。建议使用 docker compos, 在技术选型中包含了多个技术,不用 compos 的 话,就需要逐个手动启动并配置端口和网络,很麻烦。用多个 compos 使用一条命令,也就是多个 compos app, 就 可以全部拉起服务间的依赖和网络自动处理,这是很方便和高效的。 二个就是架构设计。第一点,前后端分离。前后端分离是外部开发中非常常见的一种架构方式,尤其适合需要独立部署、多人协助、多个端共用一套接口的项目。 对于 ai 项目,可以把 ai 能力分装成后端接口,前端统一调用。除了常规 h、 t、 d、 b 接口外,很多 ai 场景还会涉及到流势输出、任务和结果轮询,因此接口设计要结合具体业务场景来确定。 第二个三层架构设计,也就是路由层、业务逻辑层和这个数据库层三层是分开的,值得清晰。它的优点如下,路由层保持简洁,只做接受请求,调用 service 业务逻辑层 反馈结果。 service 业务逻辑层可以被多个路由层附用,然后数据库层与业务逻辑结构方便单独设置和迁移,互不影响。 第三个就是双端设计。很多商业化项目会同时设计两个端,一个是面向普通用户的客户端,一个是面向管理员的后台管理端。因此可以提前规划他们的基础骨架,把注册、登录、权限、密码修改等通用功能先抽出来, 具体业务功能呢,再根据项目需求逐步补充。可论的客户端面向普通用户,也就是让普通用户使用的 back office 管理端,面向管理员,也就是让管理员使用的。总结,上面讲解了后端项目架构设计的一些思路,大家呢可以参考一下,然后设计出自己的架构,当然建议使用 ai 帮你实现你的架构设计,因为效率高。
 02:03查看AI文稿AI文稿
02:03查看AI文稿AI文稿这个 a i a 的 项目运行起来是这样的效果,可以给它进行提问,要大模型,根据我的提问给我规划一条完整的旅行路线, 这个项目怎么跑的啊?大家拿到代码之后注意啊,这里面是分前端的部分和后端的部分,我们是基于 long chain 和 long graph, 后端是 nice g s。 这是一个全站的项目啊,都是基于最新的版本。在这个点英文文件里面有两种运行方式。第一种方式我们本地要用欧拉网模型, 部署千万的模型也好,或者其他的模型也好,而且怎么部署,你之前也讲过啊,在这里面我们可以选择我们的模型在本地安装,这个 tokyo 是 免费的,本地的。还有一类是我们调用云端的,云端的话我们可以调用 deepsea 啊, deepsea 的 话,那你这地方你要配置你的 k, 创建你的 k 啊,这你里面得有余额,要不然调用不通的。然后这里面要配置你这个 k, 配置完了之后我们直接启动就行了,启动完了之后就运行起来就是这样的一个效果。第二天提问可把这个所有内容都给你返回到这里面来了, 对吧?所有的整个旅行,包括你这个饮食预算,景点推荐,天气情况,整个这个项目的完整的工作流程。说一下,这是一个 agent 啊,用户在这里面去输入,输入你的问题,输入完了之后,这时候会基于 long graph iex 模式,然后调用我们大模型对话,然后分析意图,然后再决策调用哪些工具。对工具的话,比如行程的工具,天气的工具,预算的工具,那么这时候再给流逝的输出给前端,整个流程是非常简单的,那我们这里面大概有十一个接口, 整个项目你可以作为公司的项目包装到简历里面,也可以作为找校招啊,找实习啊,也可以作为自己 学习的项目包装到 g m 里面,你可以直接应聘 a 业前端, a 业应用开发 a a n 的 a 业全段的岗位啊,那就是在 nice g s roundabout 大 模型,还有香香裤前端是用 v 三脸内里面,你就这么描述就行了,直接这么去描述。还有我们整个的项目的难点和亮点都给大家整理了, 怎么样包装,具体怎么样实现,这里面都有,包括这个原码,大家一定要跑一跑整个核心时间,就要整个 ai 的 项目的话,大家可以评论区留言。
 07:41查看AI文稿AI文稿
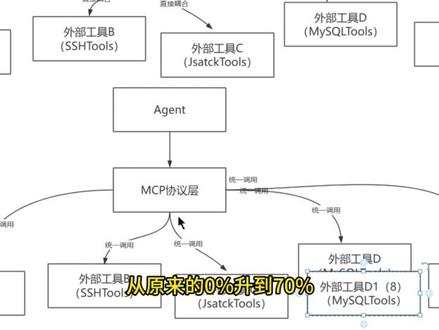
07:41查看AI文稿AI文稿m c p 如何和 agent 来进行对应的一个结合?首先我们来抛出第一个概念, m c p 是 什么? m c p 英文全称叫做 model 啊,叫做 model contest, 然后 pro talk 啊,也就是说它是模型上下文协议, 模型上下文协议啊,它的本质是什么?就是 agent, 你 要与外部工具与这个外部工具之间的一个标准化的通讯 学。 o k, 那 我们来讲一下,这是这个工具的话,主要是为了去解决一个什么问题,比如说我们可以把它理解成啊, 这个假设我们没有 m c p 啊,那这是我们的一个 agent agent 之后呢,你要去调各种工具,比如说我们的工具 a, 或者是工具 b, 或者工具 c 啊,说的简单一点吧,我们把上一节课的内容可以进行结合,把上一个问题,这个 agent 的 react 机制,那你把它看成是什么?我的智能体这一边的智能体要去掉外部工具,外部工具有拼投影,有 htv 投影,还有其他的投影, 对不对?那么其实就理解一下,也就变得非常简单。那我们刚才的这个 agent, 如果说你要去掉外部工具,这个工具是第一个工具,叫做 ping 命令的,或者是 http points, ok, 这是一个。然后除了这个之外的话,你还有外部工具啊,这是外部工具 a, 我 记得啊,然后这是, 这是外部工具 b b 的 话呢,那有,比如说 s s h 的 这种,这个 toys 好, 那还有外部工具 c, 外部工具 c 的 话呢?分析 java 进程的 destruct toys, 外部工具低,那涉及到的可能是 myicycle, 那 如果说外部工具低,各种各样的工具 啊,一二三四,那就 e 了,外部工具 e, 那 可能对应的就是比如说 d b points 好, 那么这个地方你的这一个大模型,你去钓的时候就相当的容易了,或者是相当的藕合了。 那你看到没有?就是我去调各种外部工具的时候,要调外部工具 a, 要调外部工具 b, 要调外部工具 c, 要调外部工具 d 和 e, 那 它是直接藕合的 啊,为什么说是直接藕合的?你推到我们前面的项目,前面做的那个大致的这一个 agent 去完成我们的四步核心推理叫 reaction 模型的时候,那你去写这个智能体的时候,那你这个地方要写一个工具,工具 a, 工具 b, 工具 c, 工具 d。 啊,工具 e, 你 要写很多很多的工具, ok, 这样的话带来的问题很明显就是非常麻烦, 或者是说你传统里面的,你得为每一个 agent 去单独配置他的工具提供,然后每个工具要单独集成,并且有可能接口不统一。所以在这个之间,我们的如果加入 mcp 的 话,就是这样的一个优化, 加一层啊,这个叫做 m c p 写一层,然后让智能体去掉我们 m c p 写一层,然后这里就是完成一个统一的调用, 就这样的一个优化啊,大家可以看到这种优化的话,呃,它其实就会做的 做的非常的舒服,或者非常的爽, ok 啊,你进行统一调用,统一调用的一个好处是什么?我举个简单例子,比如说这个外部工具升级了 啊,我这个,呃, mexico 升级了啊,这个叫做八的版本,或者是我这个工具升级了一个叫第一或者第二的版本,那如果你是原来这个的话呢,你的这个 agent 里面的调用逻辑你也得改, 你的智能体里面也得改。但如果说我这个地方要升级的话啊,那我进行一个对应的替换就行了。有这边的话, mcp 的 协议是提供统一的, 然后你这里是统一去调它的,你在 mcp 层做一做一个处理啊,你说你升级成支持八的,那换个工具就可以了,所以这样做起来的话呢,就非常非常的爽,或者是说工具升级它不影响我的 agent, 然后 agent 升级同时也不影响你的工具, 所以呢,这是作为架构一个方向需要考虑的,不然的话呢,就工具的变变动会影响我们的调用方,对不对?你的系统稳定性,你的维护成本就会上去,那加入 m c p 的 话呢,我的系统稳定性提升了,同时还去降低了我的一个维护成本。 另外的话呢,就是我的这一个集成效率也要比原来这种方式要高很多,因为通过标准的 m c p 层的统一接口去调用所有的工具,成本要低很多。 那举个简单例子,那我可以说我在服务器内部的话,我就可以去自研我的 m c p 的 服务层啊,如果说你去面试的时候 m c p 的 话,我 m c, 我 比如说用 fast 的 m c p 这种框架比,比如说像像我们去讲过的这个, 这个 fast 的 mcp 对 不对?也可以用 java 来开发 mcp 服务,也可以用 python 来开发 mcp 服务,也有很多的开源的 mcp 的 这样的一个服务项目,那它提供了一种简单高效去构建 mcp 的 服务,为开发者提供强大的工具和资源, 所以我们就可以用这种方式啊,当然你也可以去用第第三方的什么地图的话,就用高德 m c p 服务,然后呢,搜索的话,天气里有天气的这种什么集成的天气,中国天气网或者是中国的一些天气的频道的服务, ok, 比如啊,同时的话,你可以自研一些根据系统定制的一些公单系统服务,一些日制查询服务,一些监控报警的服务 啊,同时也可以用第三方 m c p 的 服务,所以在项目当中的话,你的工具费用率就提高了。原来你做这个 agent 的 话, 你十个 agent 的 项目,你要重复开发三十个甚至五十个工具,那现在的话呢,有 mcp 的 这一个层的话,我十个 agent, 我 共享的十二个或者十五个工具就可以完成。那我工具代码的这个赋用于从原来的百分之零升到百分之七十,升到百分之八十,开发效率的话呢,也是减少了,因为新的 agent 它集成工具的时间就要减少,工具影响的这个范围啊,也减少了你如果工具要更新 你原来 agent, 那 每个 agent 里面都要改,现在的话呢,就是基本上影响的很少很少,团队的病发能力也进行了一个提升,系统的稳定性也进行了一个增强。所以啊, mcp 和 agent 怎么去结合的?本质上面它是将 我们的这个 agent agent 本身是个智能体嘛,你可以认为它是一个大脑,然后呢外部工具就是行动,就是将你的大脑和手脚的行动通过标准化的一个协议连接起来, 这样的话呢,就是让我们的智能体他专注于去做我的智能决策,而工具就专注于去做我的工具能力实现啊。工具一次开发多处附用,是不是跟 java 当中的那个 gvm 观念概念是一样的? 一次开发工具一次开发,到处附用,对不对?然后呢,也构建了开放的生工具的生态圈,可以去促进团队的一个切落,也可以引入外部的这些工具啊。 所以呢,这就是让 agent 它能够像人的专家一样的结合各种工具解决复杂的问题,所以这也是 ai 应用从单一功能走向生态化比较复杂功能或者是智能生态非常关键的一步。
42马士兵教育马小鱼 04:15查看AI文稿AI文稿
04:15查看AI文稿AI文稿我们再来看第七个问题,就是 agent skills 和我们的这个 multi agent 有 什么区别? agent skills 是 说的很好理解啊, skills 就是 通用的 agent 的 拓展包, 就好比是说我们 agent 是 一个通用型的底座的话,那它可以加载不同不同的这种技能啊, skills 包,然后具备不同的专业知识和工具的能力啊,完成特定的任务。比如说 啊,我们的这一个智能体,他想要具备综合的功能的话,我可以加 skills 的 拓展包一,他专业知识有法律和医学的,那加载完之后的话,他就变成了法律专家,他具备专业的法律知识, 然后同时他还可以加载我们的 skills 拓展包。二,这个他具有搜索或者是绘图的功能,加载完之后的话呢,他就能够去利用我的工具,人手使用我的专业工具去进行对应的操作,然后我的 skills 三, 比如说我去特定的任务里面,我要去订票写邮件的话,那下载这个 skills 包的话呢,它就可以进行任务执行者去稳定完成一些特定的任务啊,所以这是我们的这个 agent skills 和我们刚才的多智能体 multi agent 的 它的一个呃,一个差别。那首先的话呢,他们的理念就不一样啊,这个 我们可以看出它的一个差别。 agent skills 啊,它的一个是什么?它的就是让单个智能体变强大, ok, 然后你原来的这个 multi 多智能体的话,它就是通过任务分解或者是写作的方式啊,让它去完成。第二个的话呢,这个 agent skills 它其实是让, 就是给一个全能专家,然后配置多功能工具箱, 你在要用什么东西的时候,拿着这个工具箱就可以使用了啊,这种 multi agent 的 话呢,很明显它就有点类似于一个项目经理带一个团队,然后下面的成员的话就是我们的子 agent 啊,很好理解。那第三个的话就是在于啊,这个 agent skills, 他 能够去根据任务自主去规划,比如说自主规划的时候,你到底是要用一个还是多个 g 的 啊?它具有规划能力啊。然后那个 multi agent 的 话呢,说白了就是它是由我们的负 agent 来去协调了。 那么第四个的话呢,就是说啊,它的上下文管理,比如说 agent skills 里面有一个点叫做渐近式路由,渐近式路由的话,呃,也很简单,就是仅仅需要根据什么?就是仅你如果要预加载的话,就是 预加载那个技能描述,需要时再加载 技能详情,还有包括上下文共享,所以它是渐进的,这样的话就不会导致我们一次加载的内容过多。 然后站在另外一个点的话呢, agent skills 里面还有一个优势,就代表我的 multi skill, multi agent 它就是通讯的这一个成本比较低,为什么?因为它所有的思考都发生在单个 agent 里面, ok, 或者单个模型的一个类,单个模型调用的内部,而如果说你是 multi 的 话, multi agent 它就需要去通信协调,存在网络延迟啊。所以呢, agent skill 的 好处是什么? 它的好处它就非常的高效,同时的话呢,也比较的简洁,另外的话呢,它还有一个低延迟的这样的一个特性, ok 啊。不过呢,嗯,也有一个问题,就是说它会存在一个加载技能包过多,也会导致认知过窄,也会导致这样的一个问题啊。那所以对比我们的 agent skill 和我们的这个 multi agent, 它有些有些什么样的试用场景呢?试用场景的话一般推荐啊,就是如果你是复打架构,那你还是走我们的 mike agent 的, 你要开发成本高。对,然后你需要去处理我们 agent 之间的一个协调。 ok, 那 如果是 agent skills 的 话呢,就是说白了它就是它的优势点啊,也有它的一个比较明显的优势点。就是 啊,你如果说,呃去技能没有那么多的话,比如说小于五十个的话,那它还是比较好的,所以推荐的话走我们的 agent skills, 你 的任务是限行的啊,所以这就是 agent skills 和 multi agents 它的一个差异,或者是它的一个差别。
31马士兵教育马小鱼 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿你的 ai 还在靠截图点鼠标这个项目? c l i f anything 让任何软件变成 agent 填充工具,让任意软件接入 open call、 nano bot、 cursor、 cloud code 等 agent 框架。一定要看到。最后,我拿自己的全站项目实测, 一条命令添加插件市场,再一条安装完成,指向你的项目一键生成完整 c l i 所有后端 api, 前端逻辑自动变成命令行工具,包括启动服务器,管理生命周期, 一条命令取回 json 数据, ai 直接理解让任何软件变成 agent 的 原声工具。下面看一下实操展示。 这是本地的一个开源项目,包含对项目的增删改查功能。我们首先在 cloud code 中安装好 c l i anything 插件,然后跟 cloud code 说,帮我把这个项目使用 c l i anything 做成 c l i 命令,等待 cloud 运行 成功后,可以看到结果。他把我们项目的操作全都做成了 c l i 命令,还贴心地写好了 skill。 我 们直接安转这个 skill 就 可以让 ai 操作软件了,是不是特别棒?
 03:55查看AI文稿AI文稿
03:55查看AI文稿AI文稿今天来唠一唠,如果要是想干这个 ai 应用或者是 ai 的 开发的,这个都需要会一点啥呢?我这方面确实没啥了解啊,所以说我就找来了我身边的大神啊,就是通过三个问题来给大家一个大概的了解吧。啊, 那你首先先做一个自我介绍。大家好,我是栀子的同事,我其实是一个后台开发,但是最近一直在研究 ai 落地的相关的技术吧,所以主要还是看栀子有啥问题想问。我就是 先问第一个问题吧,就是现在我们如果只学一个 java 呀,或者只学一个前端,就你感觉还够用吗?其实从以前来说都不太够用,因为你现在看到市场上的招聘,那全都是全站的一个开发嘛,然后特别是 ai 来了之后,你不仅要写前端,后端你可能连测试和运维都要干了,所以如果你单纯只 学一个 java 或者 python, 或者是前前端的 real, 肯定也是不够用的,你可能都要有设计,就即使你不要,你不要了解很深,你也是要有一个全面的认知, 是一个项目的从零到一的落地的每个流程你可能都要略知一二,但也确实在我感觉就是啥呢,在 ai 时代就是人少活就变多了。 那我想问第二个问题,就是你看咱们学了这么多东西是吧?啊,我头就很大呀,就我天天背八股文,我还要写一些算法题啥的。那你说我,我现在还用整这么细完了,我是不是只会用就行了呀,你说 其实我也很讨厌刷算法题被骂过人吧。就是,但是呢,但是呢,如果你是想进大厂的话,据我了解啊,现在除了可能除了阿里有些部门是考察 web 扣顶之外, 呃,像别的大厂可能还是以立扣还是一个必选项吧,就如果想进还是得刷算法题,但是我个人认为现在性价比不高。也根据我自己的观察吧,就二六年上半年的时候,其实大家对考察算法题的兴趣也不大了,就主要还是要深挖吧。就二六年上半年的时候,其实大家对考察的会比较深一点,但是 传统的八国文还是会问的,包括像我们做后端的话,有一些什么中间件啊,然后有一些啊,场景题啊,可能以后会更加偏向于一些系统架构设计的一些题目, 但是如果你想要一个拿到一个比较好的 offer 的 话,可能还是得刷,虽然是很痛苦,但是我就感觉就是碰上一个好项目真的很不容易,就像咱们天天就写那老破登山改茬,我都写烦了, 就感觉挺恶心的。这所以说就第三个问题吧,就是说就是现在有这些 ai 这些新岗位啊,就相较于传统开发来说吧,就我们还需要再多学一点啥呢啊,就在能够了解到什么程度呢? 你要知道我们现在像 ai 港的开发语言不是很重要,包括 java, python, 这都无所谓,是最最重要的可能就是你要去了解 ai 应用相关的一些内容,可能会更加有助于在二十年找到一份心仪的工作。就比如说, 呃,我要了解 ai 的 对话的一个逻辑啊,包括 ai 的 知识库的一个增删改查,包括啊剪辑呀,向量化啊,召回啊之类的一些东西。首先你得是会用 ai 工具,其次你得去了解每一个 ai 工具的原理。就比如我举个例子吧,可能在二六年的话,面试官可能会问你很多什么 啊,一个 ai 对 话的一个从零到一的设计是怎么样的?就比如说防身扣啊,一些你爱的一些范式啊,一些内容,这些可能需要了解,但是你其实并不需要了解的特别的深,因为没有人是专家,因为,对吧,从二零年开始才慢慢火起来,但是确实,但是很多的很多的组建就是你起码要知道别人问那你,你要,你要能打出来, 然后你还要去明白这个坑在哪,就是你的基础选型,你的理由是什么?所以这回回到刚刚的问题上,其实这还是要深挖项目,就是你可能就需要去做一个 ai 应用相关的一些项目,你才有东西去跟面试官聊,不然最后可能还会回归到刷散发的地步。其实你可能你学的东西可能比面试官还懂 啊,是吧,其实很多时候是这样的,因为面试官他并不需要面试,嗯,所以他只需要做自己业务,万一他的业务跟 ai, 他 可能刚开始转 ai 应用了之后整个公司刚开始写 ai 应用相关的东西, 那你肯定肯定是比面试官还多,确实,所以说我感觉还是要选很多技术的。行吧,那最后就不知道大家还想看点啥,想看我俩的多唠点啥的,再有机会再继续唠啊。
3949吴所知 01:01查看AI文稿AI文稿
01:01查看AI文稿AI文稿这是一套系统的大模型 agent 学习课,专门帮你解决学习过程中最耗时间的问题。不是学不会,而是不知道该学什么,按什么顺序学。很多同学学大模型都是在到处拼资料,今天看一篇 r i g, 明天收藏一个 agent 框架教程,后天又刷到 prompt。 工程资料越攒越多,但脑子里的知识还是散的,没有一条清晰路线, 最后就会出现一种情况,你明明看过很多内容,但面试官一问, r a g 和微调怎么选? agent 怎么调用工具? land graph 和 land can 有 什么区别? agent 成本太高,怎么优化生产环境?怎么做安全控制?你还是很难完整回答。 所以我把大模型 agent 应用开发需要掌握的内容,整理成了十三大模块,一百九十九个小模块,每个知识点都有动画、视频讲解,再配套五十万字图解文档。你不用在自己到处找资料、筛资料,也不用纠结哪些该学哪些,可以先放一放,直接按照路线,从基础认知、核心能力一步步学到工程落地和项目实战。 这套内容适合零基础想入门大模型 agent 的 同学,也适合有开发基础想冲 agent 开发岗位的同学。想节省找资料、拼路线、反复试错的时间,可以直接看小黄车。
51小哲讲大模型 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿计算机专业想转 a 证的工程师,别再瞎摸索了,我见过太多人刷了两百篇 ai 文章,收藏了五十个教程,结果连一个能跑的 ai 都答不出来。 问题不在你再没有一条清晰的执行路线。下面这条三个月路线是我带过三百家学员验证过的,每一步都有具体产出,不搞虚的。第一个月,搞懂大模型调用工具,调用记忆机制,直接动手用 api 做一个能查天气记日程的对话助手,不是玩具,真能用。第二个月,学 react code 解决 a 证的胡说八道和工具调错两大坑。 上个月的助手升级成能自动分析 pdf, 生成摘掉的 a 阵。第三个月,多 a 阵,协助加 prompt 调优,搭一个双 a 阵的内容审核系统,一个斜港,一个审核,互相叠带。三个月,三个项目面试直接演示,不是我学过,是我做出来了。上期学员后端转方向,四面拿两个 offer 运维,用 a 阵子做巡检,工作量砍一半。你现在是什么 方向?不管你是后端运维测试还是前端,告诉我你的方向,我给你一份针对你方向的三个月专属规划加时代圆满留学习就行。
 07:15查看AI文稿AI文稿
07:15查看AI文稿AI文稿这条视频讲 codex a subagent, 小 白也能听懂的版本。它不是一个新软件,也不是神秘功能,而是 codex 处理复杂任务的一种用法, 你会看到它什么时候该用,什么时候别用,以及怎么用它。 review 一个真实项目,先给 subagent 下一个最朴素的定义。一个复杂任务,你可以让 codex 拆成几块,分别交给几个子代理并行处理。 每个子代理跑在自己的 agent thread 里,最后只把结论交回主线成汇总。官方术语听起来会正式一点。 sub agent workflow 指同时跑多个并行代理在汇总。 sub agent 是 被派出去做某件事的代理, agent, thread 则是每个代理自己的线程,你可以在 cli 里查看和切换。 sub agent 主要解决两件事,第一, context 被污染,读文件跑命令看报错,猜原因,全塞进主线城,后面判断就容易乱。 第二,该病型的事被串行,做安全测试风格可维护性本来可以同时看,却被一个代理从头查到尾。判断要不要开 sub agent。 可以 先问一个问题,任务能不能拆成几块?互不依赖的小事, 能拆就适合试,拆不开就别硬上。任务很小,子任务紧咬在一起,写入范围重叠,或者你自己都还没想清楚怎么拆,这些情况开了反而添乱。不适合的情况也要记住,任务本身很小,没必要开多个代理。 几个子任务互相咬的很紧,并行也不省时间。最危险的是多个代理同时改同一篇文件,这时候省下来的时间很可能被冲突和反攻吃掉。 真正适合练手的场景大多是 rate heavy, 比如大型代码库探索 pr, 多维 review 几个 bug 方向, b 型排查,长文档和长日制分块分析。官方也建议新手起步时先选探索测试、 treeash 和总结这类任务。 codex 默认不会主动开 sub agent, 你 要在 prompt 里讲清楚。常见说法包括 spawn two agents, delegate this work in parallel use one agent per point。 中文直接说启动三个 sub agent, 分 别检查安全测试和可维护性也可以。如果拿来 review pr, 可以 直接用这个模板,一个 sub agent 检查潜在 bug, 一个检查测试覆盖,一个检查代码质量和可维护性, 最后要求主线程等三个都完成后再输出高风险、中风险可选优化,以及建议优先修什么。 这个模板真正值钱的不是文字本身,而是里面的控制点。每个子代理的职责不重叠,避免大家都泛泛 review 一 遍,明确等全部完成再汇总,可以避免主代理拿着半成品就下结论。最后加一句,优先修什么,可以把排序工作也交给主县城。 接下来用 ship ready 这个小项目做例子,它是一个 s s landing page audit 的 mvp, 后端 api 在 s r c app 点 js, 审计规则和 rewrite 在 s r c audit 点 js, 存储是 s r c store 点 js, 前端是 publ i c 斜杠 app 点 js。 代码量不大,正好适合演示怎么稳妥的开 sub agent。 在这个项目里,最稳的开法不是让三个 agent 一 起改代码,而是启动三个 read only sub agent runtime risk agent 看运行风险 q a coverage agent 看测试缺口, architecture agent 看模块边界, 所有子弹里都不要改文件,等全部完成后,主线程再决定要不要修。三个结论里, round time risk agent 最有价值。他发现 handle request 里 in sync 路由没有 await, 外层 try catch 接不住 a sync handler 抛出的错。 这种 bug 在 happy pass 测试里不容易暴露,但线上可能表现成请求挂住或者 unhandle rejection qa coverage agent 的 结论也很实用。 他没有泛泛说测试不够,而是列出 invalid json 未付费 share 过早 follow up。 若 brief 绕过 rewrite 这些副路径, 这些用力不一定都要立刻补,但摆在面前,主县城就能快速挑出最该锁住的状态流。 architecture agent 的 结论最容易让人冲动, 他说 src app 点 js 可以 拆成 page extract checks brief 和 rewrite 几块 判断没错,但这次目标是写测试加修 bug, 不是 重构 auditing, 所以 这部分建议最后先记下来,不立刻动。三个 sub agent 的 优先级其实不一样, round time risks 想让你先修服务端 qa coverage 想让你先补测试, architecture 想让你先理边界。主县城不能给三票打平均分,而是要挑确定性高、改动小、能被测试所注的事情先做,最后真正落地的改动其实很克制, 异步路由统一加 await, 让外层错误处理生效。 rewrite 必须 brief ready 才能解锁, follow up 增加还没提交 brief 和非法字段校验。 read json 加 body size 限制 invalid json 返回四百,最后补 note test 回归测试。 这个案例最有意思的一课是两个代理的结论拼在了一起, round time risk agent 告诉你哪里坏了。 q a coverage agent 告诉你怎么用副路径测试把它锁住, 这就是 sub agent 真正的价值,不是替主线城做决定,而是把几个方向的结论同时端上桌。跑起来之后也要会管理 agent thread codex c l i 里可以用 slash agent 查看和切换线程,如果某个子任务偏离方向,可以让 codex 停掉那个负责性能分析的 sub agent 跑完的线程,也可以让它关闭已经完成的 agent threads。 给新手的练手顺序,不建议一上来就五个 agent 一 起改权。项目先并行阅读,让多个 sub agent 各自理解不同模块,再并行 review, 把 bug 安全测试,可维护性分头看。 第三步是单写,多审一个代理或主线成改代码,其他子代理做 review, 最后才是小范围并行修改。 下一次让 codex review pr, 你 可以直接从这个短 prompt 开始。请使用三个 sub agent 并行检查,当前 pr, 一个看 bug, 一个,看测试一个看可维护性, 等全部完成后,按风险等级汇总给我。就这几句话,已经够你完成第一次 sub agent 练习。 最后记住, sub agent 不是 替主线城做决定,他真正干的活是把几个方向的判断同时端到桌面上,让主线城更快做取舍。新手先从 rate heavy 的 探索和 review 开始,等你能清楚拆分任务,再尝试让多个代理并行改代码。
64沐晨AI笔记 06:15查看AI文稿AI文稿
06:15查看AI文稿AI文稿我们来看一下第三个面试题, workfloor 和 agent 就是 我们的智能体,它最大的区别是什么? ok, 就是 你面试的时候极有可能会问到这个问题啊。第一个我们要从这个维度来说,从核心的这个设计啊,设计首先那个 workfloor 的 话,嗯,你可以认为它就是工作流啊,比如说你工作流的话呢,你对应的框架里面完成工作流的东西,比如说像 spring ai、 阿里巴巴, 阿里巴巴,还有包括 python 当中的这一个 long graph 这个框架,哎,工作流的话,它很明显的一点就是它会通过一个叫做开发者进行一个预定义,哎,就是预定义当中,那明显就是通过这一个图中的这一个什么它的图结构嘛?它图结构里面有节点与边, 它的一个构建。 ok, 这样的话我们就运行逻辑,你可以认为它的运行逻辑就这样了啊。运行逻辑就是比如说你去输入,然后输入完之后的话呢,那就是按照预定的或者是预设的 预设的步骤来进行处理好,做完之后的话呢,进行对应的一个输出,那它的一个特点就是说如果你是相同的输入执行,它是必然有相同的路径,所以这个地方就是一个确定性,确定性很好理解,就是相同的输入必然 执行相同的路径。 ok, 就是 即即使你引入了大模型,但是呢它大模型当中它也是一个固定的节点,本质上面它也是属于预设逻辑的一个部分啊,就是你大模型当中也是预设的节点嘛。然后第二个的话就是 agent h 呢,就是智能体啊,智能体它是流程,由 l l m 动态控制,要注意了,动态控制的话呢,就是我们的这个大模型的这一个处理,它可以去根据我们的环境这个反馈,比如说我们的这个工具调用的结果,比如说用户的输入,然后自主去 决定下一步它的动作,下一步动作,比如说我又是去调用工具,又进行我的这一个调整的策略啊,它的运行逻辑是这样的,首先第一个是输入好,输入完之后的话呢,那这个由 l l l 来进行决策, ok, 决策完之后再进行执行,执行之后再来看反馈好,反馈之后的话再来再决策, ok, 所以 这里面他强调的是一个什么?是一个动态性,他强调强调实时的响应和自主的替代。举个简单例子啊,如果说你按工作流的话,那今天你干一件事什么事情,然后想干什么事情,然后这个时候输出是相同的。那如果是大模型的话,他考虑到外部调一个工具,比如说看今天的天气,比如说今天今天要出门 啊,他调了今天的天气,那没有下雨好,那可能跟工作流的执行是一样的,如果今天的天气要下雨, 那他的输入里面可能就加上我还要带把伞,或者我决定不出门,他由这个工具调用外部的,就比如说工具调用外部的天气的这一个啊,函数或者是个方法得到他的这个结果,再自主决定下一步对应的一个动作, ok, 所以 这就是工作流和这个 agent 比较大的一个区别啊。当然说到工作流的话呢,必须要去说到工作流怎么去玩的, 你如果说要玩工作流的话呢,推荐就是说可以去用迪拜先做一个快速入门啊,迪拜里面的话呢,基本上啊,这里面都是玩工作流的。 ok, 大家可以看到这个里面的包括啊,这个开始进行一个对对应的执行,包括这里面去快速去掉这种多模型,还有包括这里面去掉我们对应的一些智能助手,然后还可以去进行数据查询的一些智能 api 的 一些对应的操作啊, 所以呢,你可以认为这个 beyond 它就是一个开源的大约模型 lm 的 应用平台,它做了一个低代码或者零代码的一个对应的开发啊,这里面是很好去给大家去展示工作流具体怎么去做的,比如说像这种条件分支节点, ok, 像这种条件分支就是在我们的界面里面进行拖拽啊,就形成这样的一个条件啊,这是输入,然后做完之后呢,这中间是条件, 条件做完之后的话呢,然后再可以去维护。 ok, 它是一个对应的预设流程啊,它跟这个智能体的话还是有一个很大的区别,所以这是 bookfloor 和 agent 它最大的一个区别在哪里啊?当然因为它的最大区别在哪里,之后的话呢,它的适用场景就有差异了,所以第二个的话呢,就是适用场景, ok, 也不是说动态的一定是好啊,就是很多小伙伴说那 agent 是 动态的,那就比 workflow 要好不是,那 workflow 有 它的适用场景, agent 也有它的适用场景, workflow 的 话呢,它适合于那种流程固定是固定,然后呢可拆解 的一个啊,拆解的,拆解的确定性任务啊,就是说你在做这件事情的时候,你却知道他任务的一步、二步、三步、四步,或者是 a 向 b 向 b 向 b 向 ok, 然后呢智能体它是适合于功能单一的,然后呢,需要工作和需要工具去协助的不确定性的任务, ok, 就是 你有一些开放问题的分析,然后多部多步骤的一些创业的生成,然后这个时候呢,你就需要去根据需要 l l m 去根据实时的这个反馈去进行一个动态的调整。所以呢,你也知道在这个 agent 不是 用来取代 work flow, 因为 work, 因为有些甚至有些业务场景,它需要通过 work flow 按照固定流程去生成基础内容,然后再由 agent 智能体去动态 去动态化结果。但某些步骤是固定的,某些步骤是动态化的,所以有些在确定的地方引入 walkthrough, 在 不确定的地方或者是需要思考的地方加入 agent 的 自主决策能力 啊,因为这样的话呢,它的这个效率和灵活性来说还是有差别的。那如果说固定的流程的话, walkthrough 它这个流程效率肯定会更高,然后 agent 的 话,它需要依靠 l l m 的 一个反馈,所以在实际的这个项目当中, 比如说像多智能体结合,比如说任务复杂的一个拆解啊,这个都需要,比如说像 workflow 和 agent 去进行一个灵活的调配,这样才能够达到一个最优。
39马士兵教育马小鱼 01:25查看AI文稿AI文稿
01:25查看AI文稿AI文稿你的 ai agent 想同时操作 s 三、 gmail、 slack 和 github, 要写四个 sdk, 现在一个 bash 命令全搞定。 每次接新服务 agent 都要学一套新 api mcp 工具 sdk 认证服务越多, agent 越猛,工具条用链越写越长, token 越烧越多。 maros 把所有云端服务挂载成一颗统一虚拟文件系统。 s 三挂在斜杠, s 三 slack 挂在斜杠 slack, github 挂在斜杠。 get up。 你 的 agent 只需要会 bash, 就 能跨服务操作一切。 一条命令,从 s 三复制文件到本地 c p 斜杠 s 三,斜杠 report 点 csv 斜杠 data, 斜杠 report, 点 csv, 一条命令解锁 slack 频道的告警消息。 grab alert 斜杠 slack 斜杠 general 信号点 g s o n 竖线 w c 减 l 一 条命令读取 github 仓库文档。 cat 斜杠 guess up 斜杠 morris 斜杠 readme, 点 md, 不 用学任何新 api, 因为 bash 就是 它的 api。 五月六号刚开园三天,一千二百九十四星,直接冲上 github 趋势榜。支持 python 和 typescript, 已经接入 open ai agents sdk, lineage、 versa, ai 等主流框架。 一个文件系统所有后端。追星不盲从实测出真知,点赞收藏,下期实测!
10锋芒AI 02:50查看AI文稿AI文稿
02:50查看AI文稿AI文稿后端转大模型最容易踩的第一个坑就是以为自己会写接口,会做服务,就能很快把大模型项目跑起来。我一开始也是这个想法,结果争做项目才发现, 后端经验只能帮你解决一部分问题。真正卡人的地方在模型调用、上下文设计解锁质量工具炼录和效果调试。第一个坑是上来就啃框架,蓝尘带,飞凹头针,各种 a 件特框架,看了一堆 demo 跑的很顺,一改业务场景就崩。 后来我才明白,框架不是起点,起点应该是把最小链路跑通,用户输入 prompt 组装模型调用结果解析,异常处理日记记录,这个链路部署框架封装的越多,你越不知道问题出在哪。 第二个坑是把 rack 想得太简单。我以前以为 i a g 就是 文档切块向量化相似度照回塞给模型做完才发现效果差的时候,问题可能出在切块力度、 原数据召回策略,重排 prompt 模板,甚至是原始文档结构。后来我做知识库项目,第一步不是急着接向量库,而是先清洗文档,设计嵌客规则,保留标题层级再做检测,评测没有评测级, r a g 优化基本靠玄学。第三个坑是只会调 api 不 会调效果,模型回答不好。我以前第一反应是换模型, 后来发现大多数问题不是模型不行,而是输入太乱,比如上下文塞太多,关键条件被淹没,工具返回没结构化,模型无法判断, 系统提示词写的很空,约束不明确。真正有效的做法是把每次调用的输入输出 toker, 耗时命中片段都打日制,然后一条条复盘。如果你也正在转大模型,但不知道先补哪些基础,先做哪些项目。我之前整理过一套学习路线和实战资料,把 prompt、 r i g a、 禁踢工具调用、项目部署这些内容按顺序串了一遍,需要学习资料的可以留大模型,我同步给大家。 第四个坑是低估了工程稳定性。大模型项目不是能跑一次就算完成,线上真正麻烦的是超时限流、重试、降级、缓存、并发、成本控制。比如搜索 a 阵,踢掉三个工具,其中一个接口慢了, 整条链路就卡死。后来我给每个工具都加超时失败兜底和结果较验,项目才从演示能用变成业务能用。第五个坑是不会拆任务。刚开始我喜欢让 a 阵踢,一次性完成复杂任务, 结果经常跑偏。后来我发现复杂任务要拆成,明确步骤,先理解需求,再补充信息,再调用工具,再生成结果。最后校验输出。 每一步都要有输入输出格式,别把所有判断都丢给模型,自由发挥。第六个坑是忽略数据闭环。很多人做完一个大模型,应用就停了,但真正能迭代的项目,一定要收集失败样本,用户问了什么模型答错在哪里?解锁,有没有命中工具,有没有失败,这些都要沉淀下来。没有数据闭环,优化只能靠感觉。有了失败样本, pop 工具列录才知道该往哪改。后端转大模型不是从零开始,但也不是换个 api 就 能转型。我的建议是先做三个小项目, 一个流式对话接口,一个 pdf 知识库问答,一个带工具调用的自动化 agent, 每个项目都别直跑 demo, 要加日制一强处理评测样本和部署流程。这样学下来,你才会真正知道大模型项目怎么落地,而不是只会说我接过模型 api。
66AI大模型无涯 08:12查看AI文稿AI文稿
08:12查看AI文稿AI文稿hi, 大家好,欢迎来到今天的技术解析。今天咱们要聊点硬核的,我们将从开发者和工程师的视角来深度拆解一下由 news research 推出的开源多智能企框架 hermes agent。 咱们直接进入正题,来看看这个被圈内称为 ai agent 通用后端的技术到底有何魔力,能重塑咱们和 ai 的 协调方式。 咱们先设想一个极其现实的场景,试想一下,如果你的 i i 助手不仅能老老实实待在 i d e 里,还能无缝穿梭在 telegram、 discord、 微信,甚至是你黑乎乎的终端命令行里。而且在所有这些平台上,它共享着同一个绘画、同一份记忆,以及完全相同的工具访问权限。 是不是想想就很爽?因为说实话,咱们早就受够了现在那些碎的一地鸡毛的 ai 工具了,对吧?而这恰恰就是 hermes 想要干掉的核心痛点。 今天咱们的路线图非常直接,第一,什么是 hermes agent? 第二,扒一扒它的底层架构。第三,企业及特性和安全性。第四,成本控制,毕竟谁也不想跑破产,对吧?第五,和同类工具的硬核对比。最后,咱们总结一下为什么说它是多智能体的控制平面。 好,咱们先从最基本的问题开始。第一部分,什么是 hermes agent? 简单说,它是 non research 开远了一个 ai agent 框架,你可能会觉得这不就是个跑在端端的工具吗? 嗯,它是 cifirst 没错,但它的野心大得多。它其实是一个能直连十四种以上消息平台的通用网关服务。 咱们可以把它看作是 ai agent 的 通用后端,它是完全提供商中立的,也就是你可以无缝接入十八种以上的 llm 供应商。不仅如此,它的工具链极其丰富,从 web terminal 到最近大火的 mpvip 协议,全都能轻松搞定。 那么第二部分,咱们就来扒一扒它的架构,做个深度解析。要搞懂 hermes, 咱们得先看它精妙的三层命令系统,最底层是二进制的 c l i, 中间封装了子命令,最上层则是大家极其熟悉的 slash commands, 也就是斜杠命令。 这个设计绝了,因为它完美的统一了你的操作体验。不管是你在终端窗口里,还是在 telegram 的 聊天框里敲命令,它底层的调度和响应逻辑是完全一致的。 而真正在幕后驱动一切的,是极其严谨的 agent loop 智能体循环。你看,从 inference, 也就是推理,到托 call 工具调用,再到 observation 观察反馈, hermes 就是 靠着这个闭环不断地去执行任务,拿到反馈,然后持续推动它的推理引擎向前跑。 所以请注意,这绝对不是在简单的套壳儿聊间,这是一个真正意义上的自治运行式。说到企业即落地,我绝对要吹爆它的多族虎隔离能力。 为了解决资源互踩的坑, hermes 拿出了 profiles 机制来保证绝对的隔离。这意味着什么呢?每个 profile 都有它自己独立的配置文件,独立的 dot e n v 密钥文件 memory skills, 还有独立的绘画,互不干扰。 同时,它还自带了 delegation, 也就是委派系统,你可以直接拉起并行的子 agent, 精细地去配置委派的深度,甚至还能强制给子 agent 覆盖一个更轻量级的模型,简直不要太灵活,公口无凭,咱们直接看两行极其硬核的命令行。比如你敲 hermes backup quick label pre upgrade, 这就触发了它的 checkpoints 检查点系统。非常有意思的是,它底层竟然是用了一个共享的裸 git 仓库来处理状态回滚,极其可靠。再看另一个 hermes p alice gateway, 这就是利用咱们刚才说的 profile 机制,直接在不同端口上同时抛弃多个相互独立的 api 网管死污剂,这就是它的工程化实力。 好,这就顺理成章来到了我们的第三部分,企业级特性与安全。说实话, hermes 简直是自带了一整套企业级基础建设的重型武器, 多用户 profiles 和带 h m a c 验证的 webhook, 这些标配咱们就不废话了,我必须得提一下它的看板 boards 看板功能。大家如果玩过多 agent 的 血统,肯定遇到过一种致命的崩溃,叫死去交接,也就是某个 agent 的 中途挂了整个任务链儿,直接卡死。 hermes 怎么解的呢?它用看板机制配合心跳检测、僵尸程序识别去自动回收任务,完美填上了这个大坑。再加上绑定了特定 skill 的 chrome 定时任务,还有支持 docker、 ssh 甚至是 teton 的 端端护端,这些加起来才叫真正的生产机工具。 当然了,能力越大,这安全护城河就得挖得越深。在生产环境里,咱们可不敢让 agent 随心所欲地去执行命令,对吧?看看 hermes 的 微操,你在配置文件里加上 approvalsd mode smart, 它就会起用极其聪明的批流,再结合底层的 tyrust 策略骚扰做安全拦截。 另外通过 delegation 点 max、 concurrent children 三这种极其细力度的配置,你可以死死按住此 agent 的 病发数量,防止资源爆炸,稳如老狗。 那么既然要在生产环境跑重度任务,咱们就不得不谈谈钱的问题了。第四部分,成本控制与辅助模型。 各位如果跑过 agent 工作流,肯定对那个蹭蹭上涨的云账单心有余悸。为了省钱, hummus 搞了一套非常绝的降本架构,叫 auxiliary model routing 辅助模型路由。 简单来说就是像生成个标题了,上下文压缩视觉处理,或者刚才说的安全审批。这类杂货流水线大概占了总任务量的八十倍儿,他统统甩给那些极快极便宜的 flash 模型去干,只有剩下那二十倍儿,真正需要深度思考的硬骨头,才去调用昂贵的推理模型,这就叫好钢用在刀刃上。 此外,为了保命和省钱, hermes 还有两招必杀技。第一是 credentials pools 凭证池,它可以跨多个相同供应商的 apikey 进行无缝轮换,彻底告别恶性的速律限制报错。 第二招是 forback provider chains 回退提供商链。这玩意儿太有用了,万一主力模型突然宕机,系统完全不需要人工干预,直接顺着链条秒切到备用提供商,死死保障你的业务,高可用绝对不断断。咱们讲了这么多好话,接下来第五部分,对比与权衡。 是骡子是马,咱们拉出来溜溜。现在市面上的 ai c l y 工具简直多如牛毛,咱们先拿 hermes 和当红榨汁机 clode 碰一碰 cloud code 因为是官方亲自下场,那开箱即用的体验确实叫一个丝滑。但是 hermes 的 营面在哪呢?在于它强大的多平台网关,绝对的提供商中利性,还有深得多的企业级隔离。 这里的权衡点就很明显了, hermes 初期的配置门槛确实偏高一点,但你熬过去之后,换来的就是生产环境中碾压级别的灵活性。 那再跟 codex c l i 比比呢? codex c l i 这哥们儿很硬核,优势在于云端沙盒里的 os 内核级强制执行隔离,安全性极高。但如果拉回到生态位, hermes 在 m c p 协议的支持度上,在 chrome 调度、 webhook 触发器以及整个 skill 技能生态的丰富度上,可以说是压倒性胜出的。 如果你是奔着搭复杂的自动化基建区的,选 hermes 绝对错不了。哦对了,顺便提一嘴,如果你现在手里正用着 openclaw, 也完全不用担心沉没沉稳, hermes 官方直接给你留了条退入一条原生的迁移路径,只需要敲一行命令 hermesclaw migrate, 你 现有的工作流和状态就能被一键导入到 hermes 里丝般顺发。 好了,干货拆解的差不多了,咱们来到最后一部分,第六部分,总结一下多智能体控制平面。 各位同行,咱们其实正在经历一场范式转换,从单一的 ai 助理全面走向多智能体团结协助的工作流。回过头来看 hermes, 当他把看板、看板、 profiles、 资源隔离、 crown 定时任务还有 webhook 这些技术站全部融合在一起的时候,他就已经产生质变了。他不再是一个只会听你口令干活的端程序,而是一个真正意义上的 control plan 控制平面,用来掌控你手底下的整个 ai 员工团队。 今天整场解析听下来我最想给大家留下的一句话其实是,关键真的不在于你现在用的是哪个最牛的模型,而在于支撑这个模型的底层基础建设框架。 不管你接的是 gbt 四 cloud、 ops, 还是你本地的一头开源巨兽,模型本身的能力总归是有天花板的,真正能让 ai 深入生产业务并创造价值的,是它周围的工程生态、工具链和调度逻辑。而我想, hermes 显然是把这一点给彻底玩明白了。 所以在今天的最后,我想把这个问题抛给各位,你现在的日常是不是还停留在对话框里跟你的 ai 闲扯淡? 还是说你已经准备好去卷起袖子,搭建一套真正的底层基建,让 ai 去为你整个团队全天候地跑自动化了?希望今天的这期解析能给你一点启发,咱们下期解析不见不散!
68古法编程-小周 12:32查看AI文稿AI文稿
12:32查看AI文稿AI文稿别再纠结是 codex 还是 cloud code 了,我在实测了数十个 agent 之后,发现真正决定生产力上限的不仅仅是 agent 工具,还有你手里的 skill 配置。如果你的 skill 没配对,换再强的 agent 也是在浪费时间。 所以我根据实际开发场景和我的日常使用,筛选出了这四组最核心的顶级 skill, 包含了原能力扩展、工程化开发、前端设计和内容创作。 它们完全不挑平台,不管你以后切换到哪个 agent 装上都能用。先讲最根本的两把钥匙,我称为原 skill。 你 可以把它理解成让 ai 自我进化的能力,它不负责具体的活,而是专门用来扩展 agent 的 能力边界的。不管你用 ai 做什么,这都是你第一天就应该打好的地基。 第一个是 skill creator, 来自 antropic 官方。如果你想把一套成熟的工作流变成一个新的 skill, 便于后续调用,那么选它就对了。 以前想自己做个 skill 特别麻烦,得先去研究半天复杂的格式,不然可能写出来的 skill 还会报错。就算写出来了,使用效果也不一定尽如人意。但现在有了它,你不需要去研究什么复杂的格式,也不用手动改文件, 你只需要像给同事交代工作一样,用大白话把你的流程说一遍,或者直接把你的操作手册丢给他,他就会自动帮你起草、测试、反复迭代。在你自己完全不用看开发文档的情况下,一分钟就能写出一个既标准又好用的 skill。 安装和使用方式也很简单,在安装完成后, 只需要在 agent 里选中 skill creator, 然后输入你的需求,和它一步步地进行沟通就好。建议直接局安装,这样无论你在哪个项目里,都可以随时进行调用。第二个是 find skills, 大家千万别把它当成一个普通的搜索插件, 觉得还得自己手动去查。真正的用法是你直接给 agent 派任务就行了。比如你让他帮你做个 ui 设计,要是他发现自己不会,他就会自动把你的需求拆解成 ui 抵赞你这种关键词,然后自己去全网搬救兵。他在后台连接的是 skill 点 s h 这个平台,他会自己查看哪个 skill 安装量大,哪个作者靠谱, 然后挑出最好的那个供你进行选择。在你选择好之后,它还能直接一行命令帮你安装上 skill。 creator 是 让它能自己造工具,而 find skills 是 让它能去外面找现成的,这两个配合使用,一定能大大提升你的 agent 的 工作效率。接下来是针对具体场景的 skill。 先说软件开发, 我选了这三个, superpowers, j stack 和一个前端大神的 skill, 它们针对的场景略有区别,但核心都在解决同一个问题,就是终结那种看似逻辑闭环,实则无法落地的代码幻觉,帮你守住工程底线。第一个 superpowers, 他的杀手锏在于他把测试驱动开发这套严苛的工程标准,直接变成了 agent 必须遵守的硬规则。其实很多人刚开始用 ai 编程,最容易上手的场景就是让他写测试,而 superpowers 顺着这个逻辑直接把开发流程给正规化了,他 会强制 agent 进入一套标准的红绿重构循环,先写一个必然失败的测试,证明功能还没实现,然后写最少量的代码,让它变绿,最后再进行优化, 而且它非常稳。 agent 写完之后,它会自动开启两轮内部审计,一轮看代码,实现跟你的需求对不对的上。另一轮则专门盯着代码的质量挑毛病。这种慢思考的模式能帮你抓出很多隐藏的边界问题。 虽然看起来多花了一点点时间,但因为它第一遍就能把代码写到八十分以上,省掉了后面无数次反复抵 bug 的 时间,长期来看反而更省头肯也更省钱。它的整个工作流程大致如下, 首先他会拉着你做头脑风暴,把需求细节彻底磨清楚,先出一份整体的设计文档。然后他会把大任务拆成一个个几分钟就能搞定的小碎活儿,每个活儿都有明确的验证标准。接着就是让紫 a j 特自己去跑, 他自己写,自己查,严禁跳步,你只要在旁边关键节点确认一下就行。最后等测试全部通过了,他会把选项丢给你,是直接合并代码,还是先留着分支,或者觉得不行直接丢掉?第二个是 j stack, 作者是 y c 的 总裁 gary 谭。如果你还不知道 y c 是 什么,简单说,它就是全球最牛的创业孵化器,像 airbnb、 dropbox 这种巨头都是它孵化出来的。所以这位大佬出的工具,骨子里带的就是那种硅谷创业者的实战基因。这个工具有一点不同, 它不是那种功能单一的 skill, 而是在 agent 里内置了二十三个不同的专家角色,从 ceo、 设计师到发布工程师,你都可以通过斜杠命令直接调用,这相当于给 agent 配齐了一整支团队,让他不再是单兵作战。为什么要搞这么多角色? 因为真正做商业系统,代码行数不值钱,能跑通才值钱。有了这群专家帮你交叉审计, agent 就 能在不同的专业视角下, 把你揪出那些隐藏极深的问题。我来向你介绍一下它的实战流程。首先,在你动手写第一行代码之前,先跑一下 office hours 命令。这就是 yc 最出名的灵魂拷问。 ai 不 会立刻写代码,而是像个严厉导师一样, 反问你六个最尖锐的问题,把不靠谱的假设先掐死。接着可以用 plan ceo review 命令,让 agent 站在 ceo 的 高度审视计划,看看有没有更优解。到了代码复合阶段, review 命令就是你的资深工程师,他不光找小 bug, 更盯着那些 c i 能过,但一上线就可能爆炸的工程隐患。另一个具有实战特色的是 q a 命令,以前 a 阵呢,只能在代码里纸上谈兵,但这个命令是真的,会打开浏览器,像真人测试员一样去点击验证, 直接把 bug 抓出来修掉。最后活干完了,直接执行 shift 命令,它会自动同步跑测试、推代码、开 pr。 整套发布动作一气呵成。该瑞坦统计过,二零二六年,它的代码产出是二零一三年的二百四十倍。这不是说 ai 写的代码行数多就是厉害,而是同样的需求, 他一个人现在能顶一支小团队在干活,这就是角色分工带来的本质变化。第三个是一套前端大神 mod, 自己日常工作用的 skill, 作者是 typescript 的 布道者,如果你平时前端开发比较多,那么可以试试这个。 这套工具重点解决的是人与 agent 之间沟通对不起的问题。 mark 总结过,如果没有好的引导规则, agent 写代码很容易陷入几种困境。首先是理解偏差, agent 可能根本没听懂你需要什么,或者写得太啰嗦,废话很多。然后是执行失败,好不容易写出来的代码,结果发现根本跑不通。最后是架构隐患, 虽然代码能跑,但因为缺乏整体规划,后期维护起来会非常痛苦。所以他的这套 skill 核心逻辑很简单,宁可在前期多花几分钟对其需求, 也不要在后期花几个小时去处理这套低质量的代码。具体到这套 skill 里面的指令,我建议你重点关注这几个。首先是 graeme 系列的命令,这就是刚才提到的拷问模式,当你提了一个模糊的需求,比如说想加个登录功能,他不会马上动手,而 是会回过头来不停地拷问你细节。可能问完之后,他发现你真正想要的是 sso 环境下的多租户登录,这就把隐患消灭在开工之前了。接着是 tree 命令,也就是 aure 分 诊,他会帮你把所有的任务都过一遍, 分清楚轻重缓急,确保你不是在修一些细枝末节的小 bug, 而忽视了真正堵塞进度的核心问题。最后还有一个 improve 命令,这是代码库的架构急救包, 你可以每隔几天就跑一次,让 agent 站在大局的视角审视你的代码库,找出那些以后可能会越来越难改的地方,并给出重构的建议。接下来是前端页面设计,这是最开始编程 agent 出来时,他做的最差的一个领域之一。 agent 化 u i 出来的永远都是那些固定的套路, 固定的字体,蓝紫色的渐变背景、圆角卡片、特定的按钮样式。你在网上看到的那些 ai 生成的界面,十个里面有十二个长的都一样。解决这个问题的 skill 有 两个,第一个是 frontend design, afropic 官方出品。如果你受够了那种千篇一律的 ai 审美, 那它就是你的救星。以前的 ai 画 ui, 一 眼看过去全是圆角卡片加紫色渐变,就像是在共用一套廉价的模板。 而 front and design 的 核心是帮你洗掉这些 ai 位。它不是机械的套用组建,而是根据你的产品调性去推敲更有质感的纹理,或者尝试那种更有呼吸感的非对称布局。比如你给他提一个具体的风格要求,想要一个杂志感带点硬核感的页面,他给出的方案里, 字体的比例和模块间的留白都会处理的很到位。有了这种对视觉细节的把控,你的 ui 就 从一眼 ai 变成了真正意义上的耐看。 第二个是 u i u x pro max。 如果说前面的工具是帮你找灵感,那这个就是直接帮你配了一个设计总监。它的特点在于,它不是在靠直觉画图,而是把专业设计的那些条条框框全部变成了底层的逻辑。比如你要做一个金融或者医疗类的界面,它会非常明确地告诉你 什么样的配色能体现安全感,什么样的字体更显专业。他甚至还会给你列出一份避坑指南,直接点出哪些设计在商业场景里是绝对不能碰的。之所以能这么专业,是因为他后台内置了一百六十多个行业的深度规则, 不管你遇到多冷门的业务,他都能拿出一套成体系的方案,从交互细节到动效走位,都给你安排的明明白白。 而且它有一个很实在的功能,就是能帮你生成一套可以持久化附用的设计系统。有了这套规范,你下次再开发新项目, 直接把文件丢给 agent 就 能用,不用每次都从零开始打磨风格。而且它的上手门槛很低,无论是装插件还是用命令行,都能快速跑起来。 这两款工具的分工也很明确, front and 底钻负责把画面画得出彩,而 u i u x pro max 负责把产品做的更专业。有了它们, ai 的 输出就再也不会有那种廉价感了。最后一类,内容创作。如果你用 agent 做内容创作,那这组宝玉老师的 skill 我 一定要强力推荐给你。 它首先解决的就是内容本身的高质量产出,比如它能帮你生成一张极具审美,完全不输专业设计师的封面图,或者把一大段枯燥的文字直接变成一张高信息密度的格式化信息图。 在内容做漂亮之后,他还会顺手帮你搞定后面那些讨厌的碎活,比如说转格式、做排版,最后还能直接一键发布到各个平台,他把从生产到发布的全流程都打通了,有了它,你就能真正实现生产和发布一体化,把所有的精力都集中在打磨好内容上。 宝玉老师的这套工具箱里包含了十几个好用的 skill, 我 这里简单带大家看几个。首先是用于生成封面图的 cover image skill, 它最强的地方在于有一套五维控制系统,从构图类型、色调方案、渲染风格到文字排版和情绪基调, 全都能精准调优。这七十七种预设组合,能让封面彻底告别开盲盒的随机感,每一张出来的效果都像是为你的文章量身定制的专业设计。 如果你平时觉得画逻辑图、架构图很头疼,那这个信息图相关的 skill 绝对是神器。它内置了二十一种专业的信息布局,像分析原因的鱼骨图、做转化的漏斗图、梳理层级的金字塔图应有尽有。更聪明的是, 它能自动读懂你文案里的逻辑结构,直接推荐最合适的布局方案。以前要在设计软件里磨半天的信息大图, 现在只需要几秒钟就能产出出版级的可量化成果。如果你经营小红书,那么可以使用小红书 image skill, 它能将长文章自动拆解为一到十张卡通风格的轮播卡片。通过内置的十一种视觉风格和八种排版模式, 如对比、清单、流程等,可以快速生成符合平台排版习惯的图文内容。针对排版环节, 这个 markdown to html 的 skill 解决的是一个非常具体的痛点,那就是在微信公众号这种不支持 markdown 的 平台上,如何保留精致的排版。它内置了多套公众号主题,能自动处理代码、高量和数学公式。 最实用的一点是,它能把文中的普通外链自动转为文末的底部引用,彻底解决了公众号里链接打不开或者被截断的尴尬。如果你平时还有翻译文章或者精读外文资料的需求,那这个翻译 skill 就 派上用场了。 他最强的地方在于提供了一个正式出版级的模式,这个模式不是直接进行翻译,而是会走分析、翻译、校正再到润色这整整四步的流程。 而且他有一个非常人性化的功能,就是能让你指定你的读者是谁。比如你告诉他你的读者是资深开发者,他就会自动省略掉那些庸愚的解释, 翻译出来的语气读起来就像是真正的圈内人写的。最后,当你把内容全部准备妥当,可以通过发布微信或者发布微博这两个 skill 来实现一键跨平台分发。 它区分了不同的分发逻辑,你可以发长文形式的文章,也可以选择只发几张图片配一段摘药的贴图模式。它把那些复杂的后台操作全都变成了 agent 里面的一行指令, 从本地草稿到最终发布,整套流程都可以在 agent 里面直接闭环完成。今天分享的这些 skill 只是个开始,其实最关键的是大家要根据自己的工作流程和使用场景,去打磨出真正适合自己的 skill。 如果觉得视频对你有帮助,别忘了点赞和订阅,我是俊旺,我们下期再见!
3.3万Juang_42号搭车客 02:07查看AI文稿AI文稿
02:07查看AI文稿AI文稿两千六百 star 上线才十六天, maras 做了一件所有 agent 开发者都在等的事,把二十多个后端服务挂在到一棵文件树上, agent 用 bash 就 能操作一切, 零新概念,零学习成本。说实话,给 agent 对 接后端服务是个噩梦。 s 三,一套 sdk, slack 一 套 github 又一套,每加一个服务就要多学一套 api, mcp server 更碎。六个服务就有六个独立的工具接口要配置, 上下文直接爆炸, token 烧得心疼。你可能觉得给 agent 搞定这么多服务,总得学一套新工具吧,但其实 bash 就 够了。 maras 把所有后端挂载成文件, agent 直接用 cat, grab、 cp 这些最基础的命令。最离谱的是管道组合,从 slack 里 grab 告警,日制 wc 技术一行搞定。 l l m 本来就对 bash 最熟悉,这是它训练与料理占比最高的部分。 maras 的 核心是三层架构,最上面是 agent 层,支持 open ai, land, chain 这些主流框架, 中间是 vfs 加 bash 层, agent 发出的 cat grab 命令被 dispatcher 翻译成对各个 resource 的 操作。 vfs 内部还做了双层缓存,五百一十二兆文件缓存加缩影缓存,重复访问,直接走本地,不走网络。 底下就是 s 三, slack github 这些后端,不管你用的是 open ai agents sdk 还是 linux 路由 ai sdk, mirash 都有官方适配器,一个 mirash sandbox client 或者 mirash tools, 五行代码接入,对现有框架零侵入, python 和 type script 双 sdk 都有。还有 c l i 模式, cloud code 直接就能用,谁在用它 agent 开发者用它一棵树搞定所有后端继承 cloud code, 用户通过 c l i 模式直接操作远程资源数据管道场景 slack 日制 grab 出来写进 s 三,再同步到 google docs 异形命令 serverless 环境下 readis 缓存,让多进程共享状态,整个工作区还能快照版本化,随时迁移 agent 不 需要更多, a p i 只需要一个文件数, maras 已经有两千六百多 star, apache 协议完全开源免费。 如果你在做 agent, 开发数据管道或者 ai 应用集成,这个项目值得关注。关注我下期继续带你发现开元宝藏。
27GiftLee 02:29查看AI文稿AI文稿
02:29查看AI文稿AI文稿你可能没想过,一个后端工程师开始写 html 之后,工作效率反而翻了好几倍。这不是什么前端框架的功劳,而是 entropy 团队一位工程师的亲身发现, 他用 cloud code 写 html 代替 markdown, 结果打开了新世界的大门。听起来有点反直觉对吧? markdown 不是 程序员的标配吗?但你仔细想想, markdown 能做什么?标题、列表、代码块到此为止了, 而 html 能做什么?表格? svg 图标、 css 动画、交互按钮?甚至完整的圆形界面?同样一份技术方案, markdown 写出来就是一堆文字,没人愿意看完。换成 html, 有 图标、有布局、有高亮,一眼就能抓住重点。 按 socook 工程师原话说,超过一百行的 markdown, 他 自己都读不下去,更别说让同事看了。但 html 文件发个链接谁都能打开。 他总结了几个杀手级场景,第一个,技术规划和方案探索,让 ai 一 次性生成六个不同方案的对比页面,排成网格,哪个好哪个差,一目了然,再也不用对着唇文字脑补。 第二个,代码审查, html 能渲染真实的。第一幅仕图带行内注示颜色标记,比你在终端里看 j、 t、 d、 f 直观一百倍。第三个,设计原型不是让你写 react 或者 swift, 而是用 html 快 速画出交互效果,甚至加上滑块和按钮,实时调餐。第四个,最实用的一个自定义编辑器, 比如三十个工单要重新排序,直接让 ai 生成一个拖拽排序的 html 页面,排完了点个按钮,一键复制结果回去,这效率谁用谁知道。还有一个关键点,双向交互,你可以在 html 文件里加划块,调参数,选颜色,调好了,把结果复制回 cloud code, 继续工作,形成闭环。 这就像给 ai 装上了一个格式化操作面板,而不是只在黑框框里打字。有人问, html 不是 更费 token 吗?他说有了百万 token 的 上下文窗口,这点开销完全可以忽略。关键是,你真的会去读一份精美的 html 文档,而不会去读一份融长的 markdown。 本质上,这反映了一个趋势, ai 越来越强,能做的事情越来越多。但人类需要一种方式保持对 ai 工作的掌控感。 html 恰好就是那座桥,让复杂信息变得一眼可读。 这篇文章在技术社区引发了不小的讨论,很多开发者表示深有同感,说他们其实早就在这么干了。也有人开始反思,我们是不是被 markdown 的 思维局限太久了,毕竟当工具进化了,表达信息的方式也该跟着进化。关注我,第一时间了解最新 ai 动态。
21硅基研究所


