codex怎么剪短剧
做这样的 m g 动画,这样的小包装,以及这一些都是我让 codex 根据我的口播稿生成的。之前你想做这种动效视频,至少要会 a e, 会关键帧,会调时间线。但现在你只需要把 logo 截图文案丢给 codex, 它就能给你做出一个直接可以用的视频。那么话不多说,让我来教会你 codex 怎么做动效视频。 要用 codex 做动效,有两种方法,一种叫 remotion, 一 种叫 hyperframes。 你 可以把 remotion 理解成一个一个组建来组成视频。 比如说 logo 入场是一个组建,截图卡片是一个组建,数字增长是一个组建。比如你每期视频有固定的片头固定动画, 你只需要更换文案、换截图、换颜色,用它就可以批量生成一整套风格统一的视频。我直接在 codex 里面说,帮我创建一个十秒的产品。 mg 动画演示生成之后,就可以在右侧的浏览器打开,如果哪里不满意,也不需要手动脱关键帧, 你就继续给它 p 住。不过当然它的局限也很明显, motion 更加像是 ae 里面用代码生成动画,它比较依赖工具,而且不够灵活。 但是如果你只是想快速做一条简单的动效用于分享,那么就可以用到第二种方法, hyperframes。 hyperframes 的 思路很神奇, codex 先把你的画面需求转化成 html, 然后用 css 做动画来做出视频效果,最后再把这个页面渲染成 mp。 四。这种方法就特别 ai native, 因为大模型本来最擅长的就是代码能。 比如说这条影视巨峰的 m g 动画,我直接跟柯黛斯说,帮我一比一复刻这条视频的 m g 动画效果以及色彩搭配,生成一条一模一样的 m g 动画。这个时候柯黛斯就会生成一个完整的 html 以及 一个视频成片,虽然成片还是会有很多崩坏的地方,但是能让一个连 a e 都没有听说过的人做出这种视频已经很让人惊讶了。然后你也可以让柯黛斯帮你打开这个 hyperframes 的 工程, 这样你就可以在工程中修改文字,拖动元素等等等等。还有个问题是,你怎么能保证每次生成的视频都是同一种风格呢?我习惯的方式是先让 codex 给我提炼我之前做视频的 动效特征,然后帮我总结成一个 motion 点 md 的 文档,最后把我这套做动效的方式打包成 skill。 我 每次制作视频的时候,就可以让 codex 来调用 motion 点 md 里的动效配色以及动效库来进行操作。那么我已经整理好了我在用的 skill 以及我的 motion 点 md 的 文件,有需要的话欢迎来我的知识库了解。

粉丝8275获赞10.0万
相关视频
 02:45查看AI文稿AI文稿
02:45查看AI文稿AI文稿codex 太厉害了,给你们看一下啊,就是我跟他说我的需求啊,就是自动化生成图片,然后对应的 cds 二点零的分镜提示词,然后直接生成视频,你看这个流程,直接他就能帮我做了啊, 他先让我啊,登录授权我们这个呃节目的账号啊, 然后我登上去之后啊,他说让我确认,我说我的意思是用 image 二模型生成图片啊, 就是目前来说最强的生图模型,然后好,他用了 gpt 的 生成了这四张啊图片看,然后他就写好了这个完整的分镜提示词, 点进来看一下啊,我对他这一版其实是不是很满意啊,我就又上传了我的塑身形象和这个音频音色一起给他生产啊,他就直接啊添加进去后啊,升级后的,其实是看见没有啊, 他的运镜啊,他的音频音色,还有啊他的模型啊,比例, 分辨率描述,他都会一并成交,让我确认,确认之后,好,你看八分钟之后生成完成, 虽说非常的厉害。你看到这边我自己来剪一下。看这套新中式 主楼加旁边小院房,一进门就是双层挑空门厅气场一下就出来了,面宽十三米,进深十一米五,屋檐声带一亮,晚上比白天还好看。细节看这里,门厅线条,灯光,院子比例,这房子盖的讲究,老家准备建房的评论区打别墅,我把这套思路讲给你听, 怎么样,是不是非常的厉害,就是现在哦,如果说你还没有体验过这种 and just give 就是 这种自动化的啊, 模型就真的是,呃,你现在所有的工作方式都可以通过它给你复制出来了,不信你你问一问他,他都能给你复制出来, 真的。所以如果你还没有体验过的可以好在评论区啊,打个一啊,或者说想体验我会教你怎么去做。我真的想在 ai 时代啊他们大家一起无限进步啊。
2414呈鸿 01:43查看AI文稿AI文稿
01:43查看AI文稿AI文稿你现在看到的这条视频就是 codex 加 hyperframes 做出来的,包括所有的动画字母以及里面的图片生成内容,包括这条视频也是 codex 自己发出来的。接下来我给大家拆解流程。首先我把这个视频的文文本案复制到 index t t s 去做配音生成,没错,这个视频的配音 也是 ai 的。 接下来在 codex 当中找到插件,下拉找到 hyperframes 白黑键,点击加号,再点击安装,然后就可以到对话窗口艾特这个插件,再把这段音频 一起放到聊天窗口,然后把要求给到它, codex 就 会根据 hyperframes 这个插件做出对应的动画。值得惊讶的是,当我看到这条视频的成片时, codex 居然自己去文件夹看了我的录屏素材,然后自己剪进了成片当中。所以你们会看到鼠标动画,但是我从来没有告诉过 codex, 我 提前录了屏。 这就是 codex agent 的 聪明之处,整个动画都是由 ai 自己调用技能做出来的,包括你看到这里可能会觉得这个动画有点看腻了,那这个时候应该有点真实的动画有点看腻了,比如一个玩美女的滑板,或者一个正在喝帅哥的咖啡, 是因为这个部分啊,调用了今天的 emerge 二生成图片,所以你看起来这个视频才不会那么枯燥。包括这期视频的封面也是 codex 做的, 视频发布也是他自己发出来的,既 computer use 功能发布之后,随之又上线了 chrome 的 功能,所以我就提前登录了视频后台,你才能看到这条完整由 aint 全流程制作,自动发布出来的视频。
2935Karma看世界 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿好了,大家好,这段时间 codex 相信很多小伙伴已经上手,开始用了一个非常好用的 openai 的 桌面端的一个 agent 工具。那么今天我想推荐一个 codex 里面的一个很强很厉害的一个做视频的插件叫 hyperframes, 它可以帮你按照网页的形式去做成一个视频,相当于用写前端的代码去做一个视频。首先我们知道 ai 在 写前端代码这块已经是非常厉害的,所以说这个插件就可以帮你 让你的 ai 像写代码一样去做视频。好的,那么我们就直接来试一试这个插件到底有多厉害。使用是在这边点击这个插件下面找到这个 hyperframes, 安装之后我们直接右上角点在对话中使用。这里我把 cloud 的 一个官网给他,我说一句,请根据这个网站做一个产品的宣传视频。好的,我们这里让他开始执行。好的,可以看到他跑了一段时间,他去官网去拉取了一些他需要用到的素材, 他接着在执行。好的,现在他已经生成好了,他已经跟我们说宣传视频已经生成好,在这里只需要点开就可以去预览。 并且他除了宣传片以外,他还使用了官方的素材,产品的文案,他还有动画的分镜,他还给这个宣传片加了旁白的阴鬼。让我们来一起看一下 the ai for problem solvers breakdown complex work together research write analyze data and code with expert level collaboration bring code to your desktop browser tools and team code by anthropic think bigger work clearer。 可以 看到整个效果还是非常好的,除了可能画面中有个别的小细节, 有一些排版上的问题,整个的效果你敢相信是我只用了一句话,没有经过任何修改它就出来的一个结果。随着 ai 进一步的发展,一开始的文字、 图片、视频以及到现在的全自动的生成视频以及剪辑, ai 的 发展只会越来越快,而且这个工具对于很多想要制作一些宣传视频、科普视频的人来说非常的有帮助。
1791Yuuhann 00:27查看AI文稿AI文稿
00:27查看AI文稿AI文稿家人们,扣代词现在可以直接做视频剪辑了,我只在扣代词里敲了一行字,装上嗨客 friends, 敲键一句话就能生成想要的任何视频。动效、转场、字幕配音全自动,不满意继续打字改就行,秒出新版本,还可以批量生成。下面这个视频是我让扣代词生成人类编程史的视频,太酷了!又会扣代,你就真 正打开了 ai 内容创作的新世界大门!我强烈建议所有自媒体人、内容创作者都要学会扣代斯这套玩法,真的能把效率直接拉高十倍!关注我以后分享更多玩法!
2.7万杰哥AI实验室 20:30查看AI文稿AI文稿
20:30查看AI文稿AI文稿用 ai 剪视频,真正花时间的不是剪辑。过去半个月,我深入的研究了 hyperframes, 得出了一个结论,大多数人出片效果差,不是因为工具不行,而是因为跳过了最关键的前期准备工作,脚本怎么写,素材怎么准备,节奏怎么定,这些都是要提前想清楚的,不然后面全是反光。 所以这一期我把我的整套方案拆解一遍,从 ai 剪视频的原理到成片走一遍完整的流程,里面涉及到的所有的内容都已经开源了,你可以装上直接跟我一起操作。所以这一期又是一期非常干的视频,希望对你有所帮助。那我们现在开始 ai 剪辑到底在干什么? 其实就是让 ai 写代码, ai 用 html、 css 和 javascript 在 网页里面搭画面,动画、字幕、转场,全都靠代码, 然后浏览器一帧帧截图拼成 mp 四。所以你听到的 html 渲染成视频,说白了就是先在浏览器里把画面跑出来,再一帧帧录下来, 那代码能做到什么程度?网页上你见过的所有的交互效果、动效、转场、字幕、动画、三 d 适量图,它全都能做,但它也有做不到的,比如说实拍视频、图片这些它就不能实现,所以必须靠提前准备好素材,或者让它上网帮你来搜索。 hyperframes 就是 这种工作原理,从 html 渲染成视频,它能做的事情非常多, 画面可以分层叠加,视频文字图形往上垒就可以了。它内置了 coco 语音模型来帮你合成配音,还内置了 whisper 语音模型,帮你生成带时间戳的字幕,还能合成背景音乐和音效,甚至能一键扣掉人像背景。 功效方面,三 d、 a e 动画、 gpu 特效这些都支持生成完成后,它还会自动做一轮质量检查,扫代码结构、跑浏览器测试、抽关键帧截图,确保画面没有明显的问题。 hyperframes 的 完整的工作流大概就是这样的,先出使画一个项目,然后一个镜头一个镜头的去搭载画面,搭载完成后,检查和焦验 没有问题就预览,预览通过后输出渲染。我们在这个流程里其实就做两件事,告诉 ai 我 们需要什么样的视频,以及提供 ai 自己造不出来的素材,比如配音图片、视频设计文件等等。 但有个问题,你直接跟 hyperframes 说,帮我剪一条 spacex 的 视频,他大概率做不好,因为什么主线、什么风格、什么节奏、什么素材,他完全不知道,只能靠瞎猜。所以我写了 video spike builder, 加在了 hyperframes 前面,他专门干一件事情,通过追问,逼你动手之前,把所有的决策都想清楚。怎么追问呢?分五个阶段。 第一个阶段是锁定视频的基本盘,他会问你几个问题,包括视频的目的是什么,给谁看,发在什么平台,时常是多少核心,想传递什么信息,以及品牌的调性是什么样的。 第二个阶段是盘点素材,把你可能需要的素材分成六类,逐项跟你确认文案有没有配音,用真人还是 ai 有 没有实拍画面, logo 有 没有高清透明底,需不需要三 d 模型,还缺什么素材要去找等等这些事情。 第三个阶段是我觉得整个 skill 里最有意思的一步叫做激发表达手段,大多数人根本不知道自己想要什么效果,那他就会主动的告诉你 html 可以 实现哪些效果让你来选。 第四个阶段是定视觉主题,你可以从 hyperframes 里面预设的八个主题你选一个,也可以描述你想要的风格,让他来帮你生成一套。 第五个阶段是收集参考和返利,让 ai 有 一个具体的参考,或者明确说你不希望视频里出现什么内容,让 ai 知道哪些原则是不可以违反的。 五个阶段走完,所有的决策都会落到一份叫 video spike 的 markdown 文档里,等到 hyperframes 接手的时候,它只需要照着这份文档执行即可。 这个 skill 里还内置了六十九个预设的画面组建,包含了数据图表、流程图、思维导图、 ui 模拟、大字海报和各种场景,也不需要自己去想这一境用什么形式来表达,它会根据你的内容自动去匹配。 说白了, video spike builder 就 干一件事情逼你想清楚,你前期想得越透,后期出片的质量就会越高,返工就会越少。好,那知道了原理和流程之后,接下来我们来安装 hyperframes。 打开 codex, 点击左上角的 plugins, 在 搜索框里输入 hyperframes, 找到之后点一下右边的加号,弹出窗口后点击下方的安装就可以了。装好了之后,你可以再点进 hyperframes 的 插件页面,看看它的详细介绍。 这里有一点要注意, hyperframes 不是 一个单独的 skill, 它其实包含了十五个 skill, 但在这个页面里,你可以自由地管理这些 skill。 装好了怎么用呢?点击右上角的 tryinchat, 系统就会帮你新开一个聊天窗口, 里面已经预设了一段生成视频的提示词,示意跟着它就能快速上手。接下来我们还要装我专门为 hyperframes 写的一个 skill, 它的作用就是在生成视频之前,帮你先把脚本和分镜梳理清楚。在 github 上面搜索 video spike builder, 找到这个开源项目。 往下滑到安装部分,你会看到两条命令,第一条是安装 hyperframes, 我 们刚才已经装过了,所以跳过。第二条是安装 video spike builder, 复制这条命令, 然后回到 codex, 把命令贴进去。稍等片刻,它就会从 github 上面把项目拉下来进行安装。装好了之后,可以看到它默认安装到了 project level, 也就是项目级, 只在当前这个项目下才能使用。如果你希望在任何项目里都能调用这个 skill, 那 就需要把它装到大局。操作其实很简单,你只需要跟 codex 说一句,帮我把它装到 user level 就 可以了。 hyperframes 和 video spec builder 都已经装好了,不过在开始生成视频之前,我想先让你看一下 video spec builder 里面到底写了些什么。在 cursor 里打开项目左侧,可以看到 video spec builder 这个 skill 的 所有文档已经从 github 上面拉下来了。 我们先打开 skill 的 md 看一下介绍。当用户想制作视频、宣传片、产品演示或者动画的时候,这个 skill 就 会自动启动。它一共有两种模式,第一种是零到一模式,第二种是迭代模式, 启动的时候, skill 会自动检查项目文件,家里有没有现成的 video spike 文档,如果没有或者是空的,那就走零到一模式,如果已经有了,那就进入到迭代模式,让你通过对话反复的打磨视频脚本, 再往下看文档结构,整个 skill 的 文件组织一目了然。其中最重要的是 reference 文件夹里面我准备了几份核心文档, 包括沟通风格、零到一工作流、迭代工作流、视频组建的使用方式、节奏设计指南,以及最关键的一份 question bank, 也就是问题库。我们打开问题库看一下, codex 在 使用这个 skill 时,就是按照前面讲的五个阶段来追问你,一步步逼你把需求想清楚, 每个阶段该问什么,追问的逻辑是什么,什么样的回答可以接受,什么样的回答必须打回去重答,全部都写在了 question bank 里, 可以说 question bank 就是 整个 skill 的 灵魂。看完了 skill 的 内部结构,接下来我们就要开始做视频了,不过在正式开始之前,还有一步准备工作一定要做。 前面我们讲到 hyperframes 里面有八个主题,那如果你想用自己的自定义主题该怎么办?所以这次实操我就带你走一遍。比如我提前整理了 spacex 和 grog 的 设计语言, 纯黑白的硬科技风格,然后提炼成了地址按点 md 设计文档和 tokens 点 css 这样的样式代码,把它们一起复制到了项目文件夹里。 hyposhop 检查自定义主题的逻辑是,如果项目文件夹里已经有了 design, 点 m d 就 会问你要不要使用这份自定义的设计风格。准备工作做好了,接下来我们开始第一条视频。 在聊天框里面输入 slash video spike builder。 使用这个 skill, codex 做的第一件事就是扫描项目目录,他发现里面没有现成的 video spike, 于是就进入到了零到一模式,从零开始引导我们。 他先抛出来两个问题,这条视频讲什么?投放在哪个平台?横屏还是竖屏?那我告诉他,我想做一条关于 spacex 发展历程的视频, 时长大约是一分钟左右,横屏格式 codex 收到了之后,并没有急着往下走,而是上网搜索了一圈 spacex 的 资料,然后又追问了两个问题。第一个是时长,他觉得一分钟,这个回答太模糊了,因为七十五秒、九十秒、一百一十秒的视频节奏是不同的, 所以希望我给一个精确的。第二个呢,是受众,这个片子到底是给谁看的?这决定了内容的深度。那我回答他,时长就一分半左右。受众是普通的知识区观众,核心内容讲的是 spacex 如何通过复用来改变航天行业的发射成本。 拿到这些信息后, codex 给出了初步的方案,九十秒大约可以插入十二到十六个镜头。时长有限,所以没有办法做完整的传记,只能走一条主线,从早期的失败,到 fokken 九的实现复用,再到成本逻辑的改变。他问我这条主线行不行, 另外他还问我有没有竹子稿。那在这一步,我把自己提前准备好的但时间错的配音文件都一起发给了他。 codex 收到字幕和配音之后,先检查了两者在时长的节奏是否对齐,然后仔细的过了一遍字幕内容,帮我做了事实核查,看看这里面有没有表达的错误,或者是事实偏差或者不准确的地方。 查完之后,他问了我一个关键的问题,音频已经准备好了,要不要根据核查的结果重新做一版,把发现的问题都改掉?因为我想快点看一下效果,所以就告诉他不用改了,直接用现成的音频就好了。 紧接着 codex 问了两个关键的画面问题,比如说发射回收筷子夹火箭之类的真实视频或者照片,画面路线是走真实的摄影为主,还是走动态的图形为主?那我告诉他,我目前还没有任何的素材需要他来帮我搜集。 视频的风格以真实的摄影摄像为主,版权先不用担心,因为我们只是测试,不会真的去发出去。现在 codex 开始工作,从竹子稿里面分析出素材的需求,整理成清单,然后去搜索。 搜索完成后,他把视频划分成段落,每个段落该配哪些画面素材都一一对应好呢?给我确认没问题的话,他就会把素材清单写进 video spike 里,然后继续追问。我看了一下没有什么要改的,所以就确认通过。 接下来 callix 问我要不要背景音乐和音效镜头节奏,他给了我一个镜头的节奏建议, 我没有太多的反馈,就让他先按照这个建议去往下执行。那字幕他也问了,是像纪录片那样的整句长注,还是整句加关键词高亮,那我选择的是字幕,需要整句长注。在字体和主题方面, codex 看到我已经有了一套黑白工业风的自定义主题, 不过他还是告诉我, hyperframes 内置的八个预设主题里, data shift 和 shadowcut 这两个也很适合这条片子,但我决定还是不换了,就用我自定义的就好了。最 后 codex 问了装饰和组建的想法,问要不要加时间码,任务编码或者是线框十字定位这些元素, 有没有参考的案例或者是反例?那我确实没有什么特别的参考和反例,就让他按照他自己的建议来设计。以上就是 codex 追问的所有的问题,问题答完之后,他就已经有足够的信息来帮我写视频的脚本了, 那这里我们稍等一下。好,写完了。现在点击右上角的 video spike, 打开它帮我们生成的视频脚本。 这份脚本里面包含了视频的整体基本盘,视频的目的、受众、画面规格、语气基调、修饰结构、表达的手段,还有素材清单,十九个分镜以及每个镜头的具体内容,还有音频的时间轴以及参考范例。最后还有一些留给 codex 自己决定的开放性问题, 所有这些都已经完整的写进这份脚本里了。你刚才看到的这个过程包括内容的主线、受众定位、画风风格、镜头节奏、字幕样式、 bgm 的 氛围、素材清单。所有这些决策在前期全部敲定了,等到 hyperframes 接手的时候,它只需要做执行就行。 如果我跳过了这一步,那直接跟 hyperframes 说,帮我剪一条 spacex 的 片子,相信我,它出来的东西根本就没法用。这就是我开头说的那句,工作量要在前期准备好的意思。 ok, 那 脚本已经准备好了,接下来就是交给 hyperframes 开始干活。在聊天框里输入 slash hyperframes, 让 codex 调用 hyperframes skill。 这个时候 codex 会接上 hyperframes 的 制作流程,根据我们刚才写好的 video spike 开始生成视频。 它会按照我们的设计规范处理字幕、旁白和音频,按照素材清单上网搜索画面素材,还会帮我们合成背景音乐和音效, 这些几乎都不用我们再干预了。因为所有的决策在前期编辑 video spike 的 时候已经全部做完了。 hyperframes 只是在这个环节负责搜集素材、剪辑画面以及最后渲染成视频。 渲染完成后,他还会自动做一轮审核,通过抽取关键帧的方式来检查画面的布局以及素材是否合适。整个过程大概需要四十多分钟,所以这里我先跳过好视频渲染完了,我们来看一下成片效果。二零二四年十月十三号, 一枚七十米高的火箭从太空飞回来,被发射塔上两条机械臂在半空中夹住了。全世界都疯了,但二十二年前造它的这家公司连火箭都飞不起来。二零零二年,马斯克拿卖 paypal 的 钱创办了 spacex, 就 一个目标,让火箭能重复使用。所有人都觉得它疯了。 火箭这东西从来都是用一次就扔了。二零零六年,第一枚炸了。二零零七年,第二枚又炸了。二零零八年,第三枚还是炸了,钱烧完了,特斯拉也在崩盘边缘, 马斯克把最后的钱全压上去。第四枚飞进了轨道。接下来, spacex 做了一件从没人做过的事,让火箭自己飞回来。二零一五年, falcon 九的一级助推器稳稳落回地面。 二零一七年,一枚用过的火箭再次升空,发射成功,火箭不再是一次性的了。今天 spacex 一 年发射超过一百三十次,比全世界其他所有国家加起来还多。一枚助推器最多已经负用超过三十次,发射成本从过去每公斤上万美元降到了两千多。 而开头那一幕,筷子加火箭,就是在这条路上。再往前走一步,火箭连着陆腿都不需要了,直接飞回发射塔,被空中接住翻新再飞。 从什么都炸到徒手接住火箭,再到每一枚都能反复再飞。这条路 spacex 走了二十二年。 刚刚播放的就是一次成片的效果,我没有做任何的干预和调整,从完成度上来说其实还可以,但是你仔细看,里面有不少可以优化的地方。 比如说片子中提到了三次发射失败的场景,其实每一次都可以用一张当时真实的照片来替换,也可以加入更多的视频素材,比如说火箭返回到着陆的画面,但是可能 codex 在 上网搜索的时候就没有找到,那这个时候就需要你来提供了。 而且说到我们自己提供素材,其实主题风格也是一样的。前面这条视频我用的是一套自定义的黑白硬科技风格,那这套主题我是怎么设计的呢?接下来我来带你看一下, 其实很简单,你可以在 cloud design 里面进行设计,输入屏幕上这段提示词,他就会帮你生成一套主题,然后你再跟他多聊几轮,不断的调整细节,基本上各种需求就已经能搞定了。比如我这条 spacex 视频,用的黑白硬科技风格就是这么设计出来的, 它包含了一整套的设计语言,视觉的底座、中英文字体、装饰元素, a 肉出镜使用到的各种贴纸卡片,还有 b 肉讲解概念或流程时候需要用的图标、思维导图以及数据格式化,这些都已经帮你设计好了。 设计完成之后怎么导出呢?有两种方式,第一种是点右上角的 share, 然后选择 download project as a zip 下载成压缩包。那第二种是可以直接点 handoff to cloud code, 这样就可以在 cloud code 里面进行二次的开发和调整 好。实操部分就到这里,最后我来跟你聊一聊我用下来的心得,还有几个实操上的建议。 hyperframes 目前还不是很成熟,所以你千万不要指望它一次就能出成品,除非你的视频本身就很简单,只有字幕和简单的动效,不然你大概率是要调整几轮的。 问题在于,每一轮的调整其实时间成本都非常的高,赶完之后必须重新渲染,一轮就需要半个小时到一个小时的渲染时间,那大概三次也就是三个小时,这个时间成本非常的大。 所以你在使用它之前,一定要先判断一下你这条视频到底适不适合用它来做。像概念的讲解,流程演示、数据图标这类的视频, hyperframes 完全够用。 如果你的视频依赖大量的真实素材,复杂的剪辑节奏,那目前它还搞不定。还有一个问题就是它的效果不太稳定,有点像开盲盒。 虽然看起来它什么都能剪,但是实际体验下来,我觉得它的效果是时好时坏的。如果你真的想把它用起来,比如说批量的去做视频,或者是做讲解类的科普视频, 我建议你要固定一套视觉风格,几个转场和字幕样式以及贴片的动效,做成一条固定的工作流程,不然每次他都从零开始发挥这样的效果,非常不稳定。 然后是关于素材脚本里列的素材清单,不管是图片、视频、音效,我都建议你自己去准备,不要指望扣代斯可以上,我帮你搜索。找回来的素材经常和你的画面对不上,而且现在基本都有反爬 a 阵呢,是没有法下载的, 再加上搜索的过程又慢又耗 tokens, 算下来非常不划算。那我们应该去哪里找素材呢?接下来是我经常使用的素材网站,图片和视频我会常用 pixabay, 最综合 ansplash 和 paxos 的 图片资源,更多一些 bgm 和音效我推荐你用 solno ai 来合成,那这些工具都是支持 api 接入的。如果你有工程能力的话,完全可以自己搭一条自动的流水线, 配音也是一样的。 hyperframes 虽然内置了一个声音合成模型,但是它的效果其实非常的差,声音很机械,在正式的作品里根本没法用。如果你想快速的看效果,那没有问题,但是如果你想把它变成正式能用的视频, 我建议你去使用 mini max 的 speech 二点八 hd 这个模型,或者干脆自己去录好,那我的素材库差不多也就是这些了。那最后呢?我把 ai 剪辑视频这件事情拆成四层来做个收尾。最底层是大模型,模型的能力是地基, 分镜拆的好不好,素材理解的对不对,动效配的准不准全看模型。所以我这里首选 opus 四点七或者是 gpt 五点五。 第二层是脚手架 hyperframes remote, 或者你自己写的任何视频剪辑的 skill 都是脚手架,脚手架决定了你能实现什么样的效果。第三层是脚本书里怎么拆分镜,每个分镜的内容,文案转场以及整体的节奏的设计。 第四层是素材整理,你准备的素材的质量直接决定了最终画面的质量,这四层合在一起,共同决定了 ai 剪辑视频的最终效果。 以上就是本期的全部内容,如果你觉得对你有所帮助,别忘了点赞以及加入废材俱乐部,我们可以一起探索更多实操的玩法,那我们下期见了。
4180废才俱乐部Club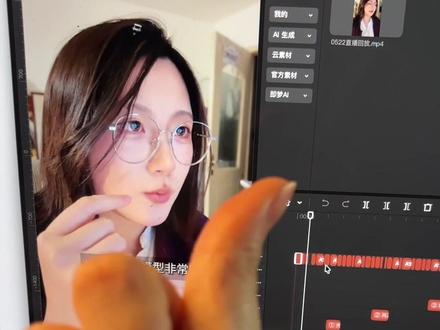 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿这些视频都是扣 test 剪的,剪了之后还有剪映的原文件,我只需要跟他说我的视频是在哪,他就可以帮我剪。大概有十个直播的切片,直播的小视频, 而且我改了字母之后,我直接跟他说字体样式样式,他就可以直接给我改,嗯,他说 a 九已经加上字体了,而且已经交对过了。嗯,给大家看一下我们的 a 九 流程呢? o d s 里面,嗯,它这个确实是跟我设定的一模一样, 而且这里面它的 image two 它也是自己校对校对过的,真的绝了。
5767喂鱼 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿要说最近特别火的 ai 玩法,那么一定是这个自动剪视频的插件了,利用 codex 加 hyperframes 的 组合玩法,让 ai 自动剪辑本期视频,就教大家如何在 codex 中使用这个神级插件。首先我们打开 codex, 在 左侧边栏中找到插件, 然后在插件市场搜索 hyperframes, 再点击安装,安装好这个插件后,我们就可以在对话中使用了, 直接新建一个对话,可以直接输入需求,比如我需要一个人工智能进化论视频,然后注意在这里直接点击输入框左下角的加号,直接选择到我们刚刚安装的 hyperframes 插件,再点击回车 发送后, codex 就 会自动调用相关的 ai 能力写字母和准备文档,稍微等待一会就能得到一个做好的视频,而且这个视频是在本地可以直接打开播放, 可以看到内容还是很完整的,包括 ai 的 一些进程都有呈现,虽然动效很直观,但是拿来做科普类的视频绰绰有余。这就是本期的全部内容。通过 codex 加 hyperframes 让 ai 自动剪视频,你学会了吗?
 00:54查看AI文稿AI文稿
00:54查看AI文稿AI文稿你现在看到的这条视频就是 codex 做出来的,我只是把我的文案录了音,然后在 codex 当中找到插件,下拉找到 hyperforest by hanger, 点击加号,再点击安装,然后就可以到对话窗口艾特这个插件,再把我录好的这段音频一起放到聊天窗口,再把要求给到它, codex 就 会根据 hyperfamilies 的 这个插件做出对应的动画。这条视频整个动画都是由 ai 自己调用技能做出来的,包括你看到这里你会觉得这种动画有点腻了,那这个时候应该有点真实的照片插入进来, 比如一个玩滑板的美女,或者一个正在喝帅哥的咖啡,这个部分是调用了 gpt image 二生成的图片,所以你看起来觉得不会那么枯燥。如果再偷懒一点,甚至包括我的配音,都是可以全 ai 流程的,这样的做视频方式有没有把你爽到?
1.2万Karma看世界 06:02查看AI文稿AI文稿
06:02查看AI文稿AI文稿ai 是 怎么实现剪辑影视类混剪的?咱们今天就拿这个短剧来举例子,咱先看一下效果,你身上那股老肉味熏死人,滚,别想给我扫了我们全家的兴,我养了三十年的家,把我当温室妈,你是不是脑子不好使?我昨天千叮咛万嘱,从这个轴里边可以看得到啊,它分了很多个步骤, 这一条是通过十多集的一个短剧生成了三条视频。它是怎么分割的一个逻辑呢?就是开头用高光去抓人, 然后开始正常的去试,但是把一些平淡的过度的把它删除掉了。这样做呢,一是为了咱们情节的紧凑, 再有一个就是为了一个去除,比方说这部分就是他的第二集,一共是出了三集,他找这么大年纪的月嫂,忘了之前被老经验坑的事了,把宝宝弄红爬给你补到堵奶。同样是一个剪辑的思路,但是后两集呢,他会加了一些前情故事的一些, 你要脑子皮了?菜市场太早没开门,那你不会凌晨四点就去买,然后再开始叙述后边的内容?这个模式呢,也是跟一个做 t k 的 短剧引流的一个小伙伴去聊的,他就是用这样的思路来产生视频 剪辑。这样的视频让 ai 是 很容易帮咱们实现的。比方说我的一个短剧,或者说是一部电影,一部连续剧,咱们只要是用原声来帮它剪辑的话,只需要告诉 ai 去提取短剧所有的 s r t 的 字母文件就可以了,因为 s r t 字母文件它会有时间戳。 我现在习惯调用豆包的音频文件提取这个的费用,一小时的视频文件大概是五块钱左右,当然也有很多免费的本地部署的 软件可以实现这些功能,但是可能会有一些准确度的问题,如果咱们的时长比较长,那他前边 一段差一秒,可能等到二十级以后,他可能就有二十秒的一个误差,所以最近我使用豆包的话,他准确率还是比 高的。当有了全部的文案和时间戳以后,让 ai 去操作那就非常的容易了。咱们可以根据自己的要求去告诉他应该怎么去截取,怎么去抓取,看一下我这个 sku 是 如何设置的。它实现的流程其实就五步,第一步呢就是批量的转写, 你只需要把你的视频文件放到文件夹里面,告诉他文件夹的路径名就可以了,然后我这里调用的是豆包的 api。 第二步,我做了一个合并和转写稿,因为短剧它的下载下来以后就是一级一级的, 所以说让 ai 自己去核定一下,这些流程都是咱们不需要操作的。我加了一个向量化的和去重的场景边界,然后怎么去精准的识别? ai 现在有一个比较大的弊端就是它的上下文是有限的,当你想让它处理过多的内容的时候,有的时候它就会犯错。 举个简单的例子,你给他的一大段话,然后达到他上下文的上限,它就会只记住开头的话和最后的要求,中间的话你产出的内容就是不稳定的。 有的时候当你的工作流程你感觉设计和要求的已经非常好了,但是 ai 就是 做不好,首先要考虑一下它的上下文的问题, 所以这里我用了一个向量化的方式来解决,不用感觉听不懂,你只知道有一个这样的功能,然后告诉 ai, 它就可以帮你去实现。 然后第三步它做了一个剧情的分析,这个分析其实就是根据你个人的需求来制定的,因为我们做自媒体也好,做视频也好,每个人都有自己的一个想法,一个工作流程,这里你就需要一步一步的去告诉 ai, 你想要的内容是什么样的。比方说我的这套流程就是开头一定是高光来抓人的,这个是大家通用的一个方式,然后呢,中间 你看是不是要把这些啰嗦的过度的地方去掉,或者说像这种短剧里边可能会有一个旁白,要不要把这些拖慢节奏的旁白去掉,这都是你自己跟 ai 去要求就可以了。相当于 ai, 它识别了权威的文案,权威的对白, 那么按照你的要求,他来提取出你需要的部分。所以第四步就是构建一个剪辑的计划,就是按你的要求把这些需要的部分提取出来。第五步就最简单了,直接导入到剪映的草稿,像这种短句的话,一般都是不需要其他的内容, 不需要背景音乐,也不需要配音,然后你可以加的可以加一些特效,可以加一些转场,或者加一些花字、关键字,包括一些驱虫的手法,其实这些让 ai 都可以直接帮你做好。当这样的一个 skyo 你 搭建好以后,比方说你这一个文件夹里边下载了三部短剧,或者说是三十部短剧, 你都可以跟他说一句话,让他用这个 skill 去全部执行,到最后你得到的就是一个一个的短剧草稿。我这里最近会比较乱,因为同时测试了很多个类型的视频,可以简单看一下,比方说像这种 直播切片带货,尤其是黑色这种,你就直接像健身人士这么外穿,你看多帅就放心拍,这个衣服的质量非常好,你能穿好几件,然后按照品类先把它进行一个拆分, 拆分完品类以后,再把每一个品也是用同样的方法把它的字幕提取出来,因为这种是带字幕的,他就比较好实现。 ai 有 一个固定的抓手,最后只是你要求把啰嗦的话去掉,然后把开头提取一个高光的片段, 一步一步按你的要求去做就行。然后像这个他就加了音频,然后还有加了视频的变速,还有加了关键字,就放心拍,这个衣服的质量非常好。这个画面的边框是因为测试,所以还没有用那种处理完 的。这种影视解说就是比较复杂的,给他一个文案,给他一部完整的剧,最后直接出这样的一个成品, 现在还是在调试当中,这个文案有也有点长,是五分钟,一抬头就发现了他们这段剧情喜感。结束准备下一个经典名梗,从警局出来营地开车来接他们,结果上车的时候一使劲把镜子给震碎了。最后还有一个很多小伙伴比较关注的,现在这种 ai 类型的内容, 怎么让 ai 一 键去生成像这条视频呢?就是给他了一个文案,然后 ai 自动调取 api 去生成对应的图片,分镜的图片,然后通过图片再自动生成视频, 然后就会有一个这样的二十多岁别再拿三十而立 p u a 自己了。社会学专门为这种尴尬期造了个词,奥德赛时期下期视频吧,我详细讲一下这个的操作流程,其实它和生成 ai 短距就是一样的一个流程。
175老郑的ai干货站 01:34查看AI文稿AI文稿
01:34查看AI文稿AI文稿这期讲一个最近很有意思的玩法,用 codex 软件接入最近很火的 deepsafe v 四模型,然后再调用 hyper 插件直接做演示视频, codex 作为软件和工作台, deepsafe v 四作为后端模型, happer 作为视频生成插件。第一步,在系统环境变量里设置一个 deep seek ipi k, 后面 codex 会通过这个变量去读取密钥。第二步,改 codex 的 config html, 核心就是告诉 codex 模型用 deep seek 杠 v 四 pro provider 叫 deep seek base url 指向 deep seek 的 epi 地址,并且从 deep seek 下划线 api p 这个环境变量里读 key。 第三步,检查 oic 召验,确认 codex 启动时真的能拿到这个 key。 配置完以后不要急着做视频,先在终端验证环境变量再启动 codex。 问一个简单问题,看它是不是走 deepsea v 四,如果这里不通,后面 hyper 再强也没用,这里有个坑。 当 codex 用第三方 api 形式登录时,官方插件能力可能会受限制,你会发现模型能用了,但插件用不了, 所以这时需要安装 codex 加加这类项目。把第三方模型调用和插件能力重新接起来。跑通以后, codex 才能一边用 deepsea v 四思考,一边正常调用 hyper 插件制作视频。 最后流程就很清楚, codex 接 deepsea v 四, codex 加加补插件能力, hyper 负责预览和渲染,这样一个视频项目就能从口播页面到 mp 四全流程跑起来。
3789不服输的奶爸 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿用 ai 自己干副业,掌握 codex, 等于掌握了豆包、集梦、剪映这三款基础软件,新手也能一晚上做出完整 ai 漫剧。今日收入六百元,今天把全套操作流程毫无保留分享出来,大家直接照着抄作业就行。原本整套流程有五大步骤,用 ai 生成剧本,再拆分镜头画面, 还要接着文字转图片制作素材,随后将图片合成动态视频,最后完成剪辑、配音收尾。现在用 codex 就 能自动解决大部分流程,从详细步骤到实操演示视频,全部整理打包好了,全程没有复杂操作,零基础也能快速上手。想要系统学习 codex 的 朋友,赶紧点个关注,跟着我一起学习!
28AI不正经研究室 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿hello, 这里是小满,今天直接带你看看 codex 加 remote 最真实的效果。首先是基础开场动画,数字滚动播放滚动字幕。 接下来是一些根据自然语言直接生成的完整视频,通过这套组合,只需要输入你的需求描述, codex 就 可以自动帮你输出完整视频 来。我们再更换一种设计风格试试,这里也采用了治愈风格的配色,还让他增加了三维与二维的结合。再试试其他风格吧。这个是手绘线条风,还有一些更大胆的二次元风, 只需要安装一个 skill 以及安装插件 hyperframe 即可,而且整个视频均由 html 转换生成,所有细节均可修改。
816肥仔吃肠粉 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿我这期口播视频是 codex 帮我剪的,有了它我现在学习 ai 的 速度超快,这两天我被这个口播剪辑折磨的死去活来,我发现他们大部分适配的都是 pr 工具和达芬奇,对于我这个用剪映的人来说简直徒劳无功。 所以说我在被他折磨了这三天过后,我终于找到一个方法,利用 codex 来帮我量身打造了一个剪映的剪辑流程。我的这个 skill 核心机制其实非常的简单粗暴,就是只需要我在路口播的时候想剪掉哪一段,我就直接对他说不要, 然后我想保留哪一段,我就直接对他说 ok。 然后 codex 会智能识别到我的这些关键词来帮我进行一个初剪,最后帮我导入剪映的长号文件。 我这里大概演示一下,我就是让科特斯让他直接帮我生成一个这个监考部的视频,然后他会问你很多问题,你告诉他你自己的需求就可以了, 然后你给了他指定过后,你稍等一下,他就会直接帮你申请这个文件,然后你可以记住这个文件名,他也会告诉你,然后你要怎么去调用他。 这个时候你就打开你想要剪辑的这个视频,然后把它放到扣带子里面,然后再斜杠调用你刚才输入的那个剪口波的指令,然后按回车, 他就可以去智能帮你去出剪了。当你剪辑完成的时候,你打开你的剪映,他就会出现在你的草稿的这个位置。 有了这个 skill, 我 的剪辑时间大大缩短,它的价值不是在于 ai 去替我百分之百创作,而是将我在录制的时候已经做出来的剪辑判断,稳定高效的去转化为最终的剪辑结果,这样一来我就有更多的精力去在剪辑里面去进行精加工, 然后去真正的把自己的创意发挥到极致。那下期视下期视频,我将继续探索如何用 codex 玩转 emotion。 各位精神伙伴们,你们还想看我学习什么黑科技?欢迎在评论区里指点关注。
49蟹老板学AI 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿我这期视频的口播就是 codex 帮我剪的,我现在的剪辑速度超快,我最近做了一个 codex 剪口播的 skill, 其因是我看到别的博主做的剪辑 skill, 但是他们适配的都是像达芬奇和 pr 这样的专业剪辑软件, 但是我们日常用的最多的还是剪映,那我就去用我的方式重新做了一下。它实现的功能呢,就是在我录口播的时候说重来, codex 就 知道前面这段不要了。最后呢,它会自动来生成一个本地的剪映草稿。整个处理流程呢,分成四步, 第一步,我把原始素材给到 codex 以后呢,他用 whisper 来做中文转写。第二步,在转写结果里面识别从来和 ok 过。第三步,生成 cut list, 也就是 codex 来判断哪些保留,哪些丢弃。第四步,生成一个本地的剪映草稿文件夹。好,我们直接来演示一下,这个是我刚录好的口播素材, 我把它拖进 codex, 然后调用一下这个 skill, 跟他说你帮我粗剪一下这个口播稿,给我生成一个剪映工程。然后等一会,我们先来到剪映,点击这个大局设置,选择草稿位置后面的文件夹,然后右键在访达中显示,然后把你刚才生成好的工程拖进去,然后我们回到剪映,你看这个时候草稿就出现在剪映的界面里面了, 然后你只需要点击重新链接素材,选择一下你的素材, codex 帮你剪完的时间线就出现在剪映里面了。总结一下这个 skill 的 价值,不是让 ai 替我做创作,而是把我在录制的时候已经做出了判断,稳定地转换成剪辑的结果。对了,这期视频的动效也是 codex 帮我做的。下期视频教你怎么做。
2084光郡 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿你现在看到的这些动画转场,全部都是 codex 里的插件 hyperframe 直接生成的。以前要剪半个小时的东西,现在一条视频就解决了。在 codex 里点 hyperframe 点连接开始聊天,你会发现只要会说话就能做视频了。大字字幕图标转场说一句就出来了。 已经有录好的视频也能够直接帮你剪。上传之后 at 嗨 friend 告诉他你想要什么样的风格,贴纸、特效字幕,他自己给你加到画面上。有了它之后,你就可以畅想做视频这件事情了。比如说我最近在尝试把做视频组装成一个 ai 制作视频的 skill, 有 趣的朋友我都放到评论区了,可以先收藏再装。
39知希AI 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿用 codex 自动剪视频,效果真的很惊艳。你现在看到这条视频,就是用 hyperframes 做出来的。方法其实很简单,把写好的文案发给 codex, 然后艾特 hyperframes, 接着告诉他 帮我把这段文案做成一条视频,合适的地方可以生成真实感 ai 图片,如果你有录屏,也可以直接放进画面里。 codex 会先理解文案,再拆成适合视频表达的镜头,他会判断哪里用图片, 哪里用实录画面。 hyperframes 负责把标题、字幕、图片、录屏和转场组织起来。于是你得到的不是几个素材拼接,而是一条有节奏、有画面、有配音的视频。最关键的是,这个流程可以附用。下一次你只要换一段文案, codex 就 能继续按这套方式生成新视频。 真正省时间的地方是从第二条开始。你不用每次都重新想结构,重新找素材,重新剪节奏,先把表达讲清楚,剩下的交给流程。
4090屿鹿AI日记



