ai绘图触发词是什么意思
他是奇异博士、时间宝石的守护者、复仇者联盟的好朋友,现任至尊法师。他是哈利波特、邓布利罗君领袖、死亡圣心的主人、霍格沃兹的传奇人物。 而他是一个不会画画的设计师、创业行业打工人。练习时长两年半左右的知识区小透明 up 主。没错,就是我。他们之间看似天南地北,毫不管理,但却有一个共同点,就是都被人称作魔法师。 你现在正在收看的是我们的零基础 stable diffusion 入门课的第二节。在上一节课里,我们已经通过二十分钟的快速梳理,解决了 stable diffusion 的本地安装,并成功绘制了属于你的第一张 ai 绘画作品。 ai 绘画和魔法念咒有什么关系?记得吗?作图的过程中有一个必不可少的环节,就是像 ai 输入用于描述画面的 prompt 提示词。因为大部分 ai 绘制作品的提示词是用英文书写的,很长很乱,而且穿插着各种奇怪的数字符号,就像是高深莫测的重 咒语一样。因此,大家形象地把写题诗词的这个过程叫做念咒。而我们就像那些魔法师一样,要通过吟唱咒语来变出我们想要的结果。虽说 ai 是人工智能,但他和真正意义上的人类智慧还是有一定差距的。很多时候,他并不知道你想要的是什么。因此就需要详细的题诗词来帮助你更好地指挥 ai 作图。 这也是为什么念咒这件事情,在 ai 绘画盛行的今天,已经慢慢形成了一门独立的、可以去探讨研究的学问。你想学念咒吗?那不妨花上十分钟看完这期视频, 我将带你系统梳理一遍提示词的基本逻辑、提示词的分类、提示词的书写方法、正面和反面提示词的区别、权重及优先级逻辑。顺带再聊聊生成图的基本参数设置、批量出图设置的含义。 学完了这些,你就能成为一位呼风唤雨的大魔导师了。课程内容很干,也很充实,我建议你先点个赞再开始学习。本课讲解题诗词逻辑的时候使用的是 stable diffusion, 但我知道有很多朋友用的是另一款非常 流行的 ai 绘画运动 journey。 这节课的大逻辑框架其实是通用的,而 m、 j、 b、 s、 d 要更依赖好的提示词来做出作品,在提示词的应用层面更具深度。如果你希望看到一期关于 m、 j 的提示词教程,可以在弹幕敲个一,做出来之后,我再来通知你。准备好就开始我们今天的魔法之旅吧。 这节课我们来接触 stable diffusion 中的文生图功能,也就是经由文本生成图像。这里面的文指的自然就是提示词 prompt 了。广义的解释, prompt 是指用户输入的文本或图像信息,目的是指导模型根据一些特定需求生成艺术作品。 直白一点说,他是我们用来告诉 ai 我要画什么,画成什么样的一种语言。上节课里我们也提过了 s、 d 里进行绘制的两种基本方式文声图和图声图。文声图就是主要以文字来实现这个沟通过程的,而图声图还可以依赖图片来传达信息。但图声图里也有提示词,而且同样重要。提示词包括的 内容是非常广泛的,它可能包括作品主题、画风、形象特点以及一些具体包含的要素。以我绘制过的一张图片为例,它的提示词足足有十几行那么长。不同提示词分别像 ai 描绘了画面的风格、人物体貌、服饰特点、场景内容和一些额外的修饰性元素。 别看这么多字,其实很多关于风格和画质把控的提示词是固定的。在这期视频的结尾,我也会向你分享一个我书写提示词的基本模板,你可以参考套用。虽然说提示词并非越多越好,但很多时候,写多点比少写点出来的效果肯定要更好。写在特定的需求上,控制会更为精确。 所以,要想让 ai 按照我们的需要去铲图,提示词到底应该怎么写呢?放轻松,其实写提示词的过程是非常自由的,无论你写什么, ai 都可以给你画。在 stable diffusion 中,可以输入提示词的区域就是左上方这两个文本框了。之前也提到了,它被分为了上下两部分,上面是正向的 提示词,下面是反向的提示词。虽然自由,但提示词有些基本的语法规则是你应该掌握的。首先,提示词需要英文书写,所以如果你英语水平足够好,可以直接用英语组织你的描述语言。如果不太行,就跟上节课里说的一样,求助翻译软件吧。 其次,提示词是以词组作为单位的,他不需要像真的英语句子一样有完整的语法结构组从句之类的东西。就像如果你要跟 ai 说,画一个又长又宽的面和一个又大又圆的碗,那可以直接把它分解成面长宽和碗大圆。这样 ai 也能听懂,甚至有时候听得比前一种更懂。 词组与词组之间需要插入分格符。基本的分格符形式是一个英文里面的绊脚逗号。在输提示词的时候,最好把输入法切换到英文,因为里面涉及的符号基本都是英文的。提示词可以换行,但每一行的行末最好要打上分格符。你可以输入一些东, 直接点击。生成出来的图片是这样的,他有可能很符合你的需要,也有可能变得奇奇怪怪。 ai 绘画是具有一定的随机性的,点多几次生成,每次生成出来的东西都会不太一样。之前也有人把 ai 绘画比喻为抽卡,想要出好的图片,得靠运气来抽。 一个女孩在林中漫步,这其实只是一个非常概括的描述这个女孩长什么样子,森林里有什么东西,时间是早上还是晚上?天气如何,这些东西 ai 都不知道。你的提示词太过于笼统,那他就只能瞎蒙抽卡了。 但也别担心,提示词很多时候不是一下子就写好的,而是先有一个初心,再慢慢细化、补充和微调的。上节课里,我们在后面加入的提示词,更多的就是在一些具体的方面对这个画面去做控制。要加些什么呢?提示词有很多不同的分类,这里我把它简单的概括成了如下几个大类,方便你对号入座,找到逻辑。首先, 基于人物或者主体特征的,例如女孩穿的是衬衫还是长裙,头发的颜色和长度,以及脸上的表情、肢体的动作。具体一点,越具体, ai 的思路也越清晰。你可以加入一些形容词,例如 beautiful、 happy 等。他们虽然比较抽象,但也能在一定程度上让画面往你想要的感觉倾斜 几次。是关于场景特点的,比如森林里有树木,但可以加入一些白色的花,或者是一条小路。还有一个要点,如果你描述的是户外场景,最好加入 outdoor 的提示词。反之,室内是 indoor, 它会很显著的影响整个画面的氛围。 关于环境的描述,也可以算作场景的一部分。比如画面的发生时间是在白天,有阳光,天空多云,这些都可以写进去。这些东西其实都很好理解,而他们也算是具象化的。我们在画面里能看到的东西,我把他们又归结成了一个大 类,就是内容性的提示词。然而,如果只有内容性的提示词,你画出的东西有很大概率是不会让你满意的。像这些作品,你会觉得他很模糊,细节也不清晰。这里我们就需要引入其他的提示词,来给这个画面打一记强心针。 首先是画质。因为 ai 学习的图片里面有些是高清的,有些质量比较模糊。我们就可以用这样的题诗词,让他盯着那些高清的去看,从而让你的作品也产出类似的画面特征。常用的题诗词包括 best quality、 ultra detailed、 masterpiece、 high res、 八 k 等等。 也有一些比较具体的,例如什么 extremely、 z、 c、 l、 c, g、 unitsy、 market water、 paper、 unreal engine rendered。 他们指向某一种特定形式的艺术作品,而他们往往都具有更为细节化、真实化的特征。其次是画风,也就是作品的艺术风格,他也是多种多样的。如果你想要画的是一幅比较偏超 画风的画作,那常用的画风提示词包括 painting、 illustration、 drawing。 想偏二次元一点,可以考虑加 reanym、 comic game。 cg 的关键词。 小照片。真实系的画风其实也有对应的风格关键词,例如 photorealistic、 realistic 等等。但真实系的创作更依赖基于真实照片训练的模型。这一点在完成了后续的学习之后,你会有更深刻的体会。 我把这些提示词统称为标准化的提示词,因为他们能让画面更趋近于某一个固定的标准。加了这些标准化的提示词,画面的质感和细节是不是一下就丰满起来了呢? 分析到这里,该怎么写提示词的初步框架就清晰了。一个 ai 能读懂的好咒语,应该是内容充实丰富,且画面具有清晰标准呢。这里我也提供一个基本的模板框架,你可以按照这个方式对号入座的修改里面每一段的内容,从而让你的画作变得更符合需要。 内容型的提示词,多数时候是因你想创作的内容而异的,每次都要改成不同的东西。如果你只是需要微调,那提示词词组化的一个好处就会体现出来。当你想要修改某些具体的细节时,不需要重新来组织语言,而是直接找到对应的词组,更改成不同内容。画面内容就会针对这一项产生变化。 但标准化的技师词组是相对固定,可以抄作业的。所以只要你想画的是比较二次元的高质量插画,你可以每次都把上节课我教给你的这段咒语原封不动的复制进去。 但在这段咒语里,你可能会看到很多像这样的括号和数字,他们又是做什么的呢?其实这些内容是用来增强或者是减弱某些提示词的优先集合权重的。以我们刚刚绘制这个画面为例,虽然我们输入了 white flower 白色的花,但画面上并没有出现白花。这里面的原因就在于你输入了很多不同元素, 送给 ai 都要他画。但他在处理的时候不一定 get 到你最想要的是什么,所以可能优先去画了树和森林。如果你就是特别特别想要白花,那就可以用类似的方式把白花的权重和优先级增强。 据增强的基本方式有两种,第一种是加括号,在提示层两侧加上这种圆括号,注意还是英文绊脚的,他的权重就会变成原来的一点一倍,相对于其他元素就会更突出。 你还可以套多层括号,每套一层就再乘以一点一倍,三层就是一点三三一倍。看在我们加了三层括号以后,哗就出来了。 另一种方式是括号加数字权重。加了一种括号以后,你可以直接在后面加一个英文引号,然后打一个数字,数字可以直接定义他的权重。比如一点五,就是原来的一点五倍。看白花变得更突出了。所以,当你觉得这个画面里有你告诉了 ai, 但他 有没有画出来的东西时,就可以借助这些方法来强调加数字的方式明显更准确。而加括号在进行微调的时候就更方便。比起圆括号,还有这种大括号代表一点零五倍,调节的效果要更细微一点。 而如果你想削弱某一个提示词的影响,就可以赋予它一个小于一的权重。数字或者用方括号会把权重削成原来的零点九倍。 调节群众的时候也要注意一件事情,就是尽量避免个别次调的权重太高。我体验里的安全范围在一上下的零点五左右。当你赋予个别次调一个二左右甚至更高的数值时,他就容易扭曲画面的内容。 这个时候我们一般需要改换思路,通过更多同类性的字条来协同增强它的效应。还有很多跟我深入的语法规则,例如词条的混合、迭代、迁移等。如果你想学,就在内幕敲一个二,我会 准备一些额外的教程在和你讨论。提示词的另外一个重要构成部分是负面提示词。通俗点说,你希望这个话里出现什么,就往正向提示词里丢,而不希望他出现什么,就往反向提示词里面丢。 反向的提示词是可以没有的。但一般我们也会选择加入一些通用的项目,主要也是基于标准化的考虑,比如上节课的魔咒 low quality。 low rest。 之前的目的是杜绝低质量的学习样本。 monochrome 和 great scale 的意思是单色灰度的目的是为了保持画面的色彩鲜艳。 at proportion 代表激情的身体比例。 ugly 不解释,你也知道了。后面这些 missing hands, extra finger 之类的有点悬乎。之前不是一直说 ai 不会画手和四肢吗?画的时候偶尔会多只手多跳腿,少根手指之类的。这些提示词也就是为了避免类似的情况发生。虽然时间用起来, ai 有时候还是左耳进右耳出的。反向提示词,通常情况下也是可以抄作业的。但如果你想要一些特殊一点的风格,偶尔也可以反其道而行之。比如把 monochrome 搬到正向提示词里,再给一个相当的权重,就可以画出单色风格的画作来。 如果说题诗词是咒语,那下面的一系列出图参数就像是魔法师的魔杖和魔导书一样,控制了这个咒语的具体释放形式。 看到这一大堆参数,是不是头都有点大了?别担心,我们从本质出发来快速梳了一遍。首先是采样的步数。我们之前说过了, ai 生成图像会经过一个加造再去造的过程。而去造就是在用像素一点点的模拟你最重要生成的这个图像。每模拟一次,画面就会变得更清晰一点。 之前我有向你展示过的这种一步步生成的过程,其实画面每闪一下,就代表他迭代了一步。理论上采样步数越多,肯 最终效果越清晰。但实际上,当步数大于二十步以后,后面的提升不大,就像八十分再到九十一百分一样。而增加步数肯定意味着更长的计算时间,所以默认的采用步数一般都是二十。 你算力充足且想追求更高的细致度,就设置为三十到四十,最低不要低于十,不然你可能会被自己产出的作品吓到。采用方法其实可以简单解释成 ai 进行图像生成的时候使用的某种特定算法。 外比 ui 提供的算法选项非常多,足足十几个,但其中我们常用到的估计也就四到五个。这其中 eui 的两个适合插画风格,出图比较朴素。第 pm 二 m 和二 m carras 速度较快, s d m carras 细节会较为丰富。这些评价并不一定绝对准确,也因提示词和模型的不同有所差异。但实际使用的时候,我推荐你用最下面几个带有加号的, 他们是改进过了的算法,无论如何应该都比上面的更稳定。另外,大部分模型也有推荐使用某一种特定的算法,这可能是模型制作者自己测试过的。比如深渊局的作者最推荐使用的就是 s d e cars, 这个时候照做就好。下面的宽和高,他代表的就是你最终出图时候的分辨率。分辨率的设置存在一些隐性限制, 个人的分辨率是五百一十二乘五百一十二,但这个分辨率下的图片,哪怕细节再丰富,看起来可能都是很模糊的。设备允许的情况下,我们一般会把它提到一千左右。相同的提示词用更高的分辨率跑出来,质感是不是就完全不一样了呢? 但是分辨率设置的太高也是会有问题的。一是你的显卡显存抗不住,我的三零七零就只能跑到一千五百像素左右的宽和高。其二则是分辨率太大了,很容易出现多人多手多脚的情况。 这个问题我有特意研究过,他的原因是 ai 在进行模型训练的时候用的图片分辨率一般都比较小,如果你的分辨率设置太大,他就会认为你是多张图片拼接而成的,那出现多的人就不奇怪了。要避免这样的问题出现,一般我们会采用低分辨率先绘制,再靠这个高清修复来放大。 它本质上是进行了一次额外的图升图。我们会在第五课里面详细讲解。你也需要通过反复试验,了解在你当前的设备条件下,什么分辨率是既能保证质量,又能兼顾效率的。 旁边的这两个选项,面部修复一般都会勾选上,他会采用一些对抗算法识别人物的面部并进行修复。和我们用的美图 app 里面智能 p 脸的功能差不多。平铺是用来生成那种可以无缝贴满整个屏幕的纹理性图片的。如果你没有需要,千万别勾。也是一个会让你画面变得很奇怪的东西。 提示词的相关性好理解,他的数值越高, ai 忠实的反应提示词的程度就越高。但和权重一样,我们一般不会互动太多,七到十二之间是比较安全的,数值太高容易变性。随机种子也是一个可以用来控制画面内容一致性的重要参数。但我打算放在下节课里再和你慢慢讨论。 成成的批次和数量是这节课的重点之一。因为 ai 绘画的不确定性,即便是统一组提示词,你也需要反复试验,期待他在某一瞬间给到你一个完美符合你需要的画面。 这个实验过程有时候会很漫长,可能会经过几十次、上百次。如果你想让 ai 一直不断的按照同一组提示字和参数去出图,那就把批次数调高, 绘制的过程会不断重复进行。结束了以后,他会生成两样东西。除了每个批次出的图,还会有一张像这样拼在一起的格子预览图,方便你进行对比。所以你完 可以让他一口气来上个十次、二十次,甚至几百次。你自己去吃个饭,睡一觉,让显卡在这里打黑工。之前,我就用这个功能控制 ai 去批量重绘了我的头像,然后在几十张里面挑了一张自己喜欢的。在细化下面的每个批次数量。我一般不建议你挑增大,它可以让你每批次绘制的图像数量增多, 理论上效率会更高。但他同一批绘制的方法是把他们拼在一起,看作一张更大的图片一次去画的。所以如果你的设备不好,非常容易爆显存,不如单批画少一点,再用更多的次数去解决问题。了解了这些参数的具体含义以后,你应该就更清楚的知道自己想要去做什么样的图片了。 讨论了这么多关于提示词和参数的知识,你现在会写提示词了吗?会了的请敲一,不会的,请把圆周率的前十位数打在公屏上。不用猜,我也知道你打的是什么了。因为就我自己的摸索经验来看, 单纯掌握这些理论上的方法,其实很难一下子就摸到写提示词的窍门。所以我还为你准备了几个非常适合新手的在写提示词方面取巧的方法,一定要记牢了。我总结出来的方法一共有三条,用起来都非常简单。第一条翻译大法。其实无论这些提示词再怎么复杂,他们说的还都是人话。 因此,当你不知道该如何表达的时候,就用自然的语言去把你想要画的东西一件件的说出来就好了。还是那句话, sd 不认中文。所以你得先用翻译平台把它转成英文。 你可以像上节课一样,先描述一个确切的场景,然后再按照我们刚刚的逻辑,想到什么就把新的词组翻译成英文,再加到后面去。虽然这些词语表述有时候不绝对准确,但他至少是在帮你接近那个你想要的画面。而有一些功能插件也会帮助你把不准确的音像矫正成 ai 的词典。里面有的东西我觉得也蛮实 用的。目前也有一些国内开发者做出了可以用于翻译题诗词的插件,我也挺感兴趣的,探索完了以后也会第一时间做成教程分享给大家。 第二条借助工具 ai 绘画也流行了一段时间了,能意识到提示词难写的人肯定也不止你我而已。因此有些人专门开发了一些可以帮助你更好的去书写提示词的工具。在这里我推荐两个可以用于辅助书写提示词的网站。他们的用法都很简单, 可以像选参数一样勾选那些你需要的。他会帮助你自动按照刚刚我们说的那些语法规则整理到一起,然后你再复制粘贴到自己的 sd 里面就可以了。使用这些工具像是在经历一个更方便的翻译的过程,但要注意思路不要被他已有的一些词汇限制住了。 如果有其他你想要加进去的东西,也可以尝试自己撰写添加。第三条抄作业是的,在 ai 绘画领域里,操作 作业并不是什么不光彩的事情。在一些模型网站和绘画分享网站上,有很多创作者还会主动分享自己作图使用的咒语和模型,帮助大家获得类似的出图效果。同样,推荐两个可以用来搜索记录提示词的网站,一个是 open arts and ai, 里面有很多基于 sd 官方模型和欧美主流的模型生成的作品。 另一个网站记录的二次元作品和亚洲审美的内容会多一些。像这些作业帮网站的时候,也记得按照我们刚刚说的那个大概的逻辑框架,对里面的提示词进行仔细的筛选。例如这幅作品,如果你喜欢他的人物表现形式和背景元素等等,那主要就抄内容性的部分。 如果只是喜欢这种画风,或者是希望有类似质感就超标准化的部分。这三条办法一一梳理下来,现在再做一个选择,你是不是觉得写提示词也没那么难了呢?好了,以上就是本节课的所有内容了。在今天的这期教程 成立,我们简单探讨了文生图功能以及其中的提示词书写逻辑,了解了提示词的基本逻辑、语法规则、群众调整和负面提示词的作用,梳理了 sd 的出图参数设置里面的各项含义,并整理了三条对于新手非常有帮助的书写提示词的辅助方法。完成这节课以后,你就是一位会念咒、能指挥 ai 的出色魔法师了。 在下一节课里,我们会继续探索 stable defusion 图声图部分的内容,了解一键开启 ai 世界的奥秘,在二次元和三次元世界间自由穿梭的关键。 上次讲了这么多,也基本没喝过一口水的份上,大家就给一个三连支持鼓励一下吧,才能让我以更充足的动力来玩剩下的视频,从而带给大家更多听得懂也学得会的使用教程。感谢你看到这里,这里是冷磊,我们下期再见面,拜拜!

粉丝9.1万获赞31.7万
相关视频
 04:04查看AI文稿AI文稿
04:04查看AI文稿AI文稿在人工智能生成图像里边呢,因为只有你会使用核心关键词,才能用更少的词表现出更加丰富的场景。假如你和一个漂亮的女生去野营,那如何才能将这个场景表达的更加有氛围呢?那如果让我来定义这个场景,他的核心关键词就是篝火女孩, 那核心关键词的应用呢,会让你尽可能少的在使用关键词的前提下,把整个的图片表现的更加的淋漓尽致。 另外尽可能少的关键词呢,也会使每一个词他的意图更加的明确,权重呢也更加的有效。那下面呢,我们就来看一下如何绘制这个篝火女孩本次实验的主模型呢,我们依然选择 brow。 首先呢,我们需要定义一下这个女生的身份,在这呢,我们把它定义成女高中生, 于是呢,我们用下面的提示词来生成我们今天的美女模特,点击生成一个非常不 错的效果。下面呢,我们就增加这个场景的核心关键词。首先在你的脑海里呢,需要对这个画面呢,有一个相对完美的构图,比如我们想表现美女在傍晚野营时候的一个场景,那有一个关键词就非常重要了,那个就是篝火, 因为有了这个词之后呢,有很多环境因素呢,我们就不用额外去描述了,于是呢,我们增加这个词来看一下效果, 那你会发现,虽然篝火呢是有了,但是整体的氛围呢还是不够,所以说呢,我们需要对环境进行进一步的渲染。由于是晚上嘛,所以说我觉得傍晚的效果呢会更好。 那如何来表现傍晚呢?我们可以增加这样两个词,一个叫做 set, set, 点击生成来看一下效果。这两个关键词的加入呢,使夜晚的这种氛围呢,表现的 特别的强烈,但是呢,我觉得整个图像的通透感是不够的,所以说呢,我们希望拿远山来作为背景,于是我们增加下面的关键词, heal in background, 点击生成再来看一下效果。整体的氛围呢,已经差不多了。 最后呢,我们来增加一些特殊的效果,那就是晚风吹过了美女的头发。于是我们增加下面的关键词, when the effect, 点击生成来看下效果。最后呢,我们调整一下光照啊,为了让人脸更加清晰呢,我们需要给这个人物增加一个面光,所以说呢,我增加 front light 到这呢,基本的构图就完成了。那后边呢,我们需要做一些后期的加工,让整个的图片更加的有质感,看起来细节更加的丰富。首先呢,我们需要将这个竖屏的图片转成一个横屏的,目前这个图片的尺寸呢是五幺二乘五幺二,这样呢,我们把它扩 重乘幺零二四乘七六八。那我们将图片发送至图称图,然后将它的尺寸调整成幺零二四乘七六八,重绘幅度呢或持持成零点七五。同时呢,我们使用 ctrl net 打开完美像素模式, 将相同的图像拖拽到 ctrl nice 当中。控制器的种类呢,我们选择 inpent。 预处理器呢,选择 inpent n 类,加上莱马模型,选择 inpent 模型,权重选择零点七五。 缩放模式改成 resize and feel。 还是那个观点,由于我们现在要重绘未知的区域,所以说一定要选择 feel 这个选项, 生成图片的数量呢,选择六,点击生成,这个时候呢,我们得到了六张效果都不错的图片,那你挑一张你最喜欢的就可以了。后面的就是一些城市化的操作了,我们使用 utimate sd upscale 来放大图像,然后使用局部绘制功能 对人脸呢进行重绘。注意在重绘人脸的时候呢,你可以加入你希望的捞染模型,这样的话呢,生成的人脸呢也会有一个比较大的变化。那我们来看看最终生成的这些图片,浓浓的火光照在美女的脸上,夕阳呢还没有完全落下, 远山绿树晚霞构成了完美的背景,那我个人看的呢,都美得慌。还是那句话,如果你选对了核心关键词,整个图像的生成呢,就会变得非常的容易,而且调节起来呢也会更加的简单。 反倒是那些使用了又臭又长的关键词之后,你才会觉得这样对图片的控制呢,反而更加的麻烦。当然这只是我个人的一些见解啊,如果有不同的看法呢,欢迎评论区交流,关注我,让知识变得更有意思。
428有趣的80后程序员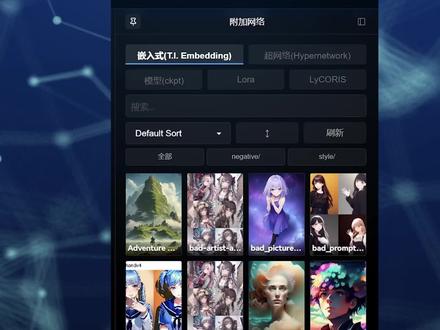 00:59查看AI文稿AI文稿
00:59查看AI文稿AI文稿在使用 stable diffusion 的过程中,会经常用到各种 lower 级 embedding, 这些模型一般都需要有触发词来使其生效。一旦保存的 lower 或者 embedding 一多,触发词的管理将会变成一大难题。 今天我就来分享一个可以快速调用触发词的方法,大幅提升你的工作效率。我是利用 stable diffusion 已经有的风格模板来进行管理的,你可以看一下我的风格模板里的有常用的质量提示词 laura in bedding 的触发词,还有模型对应的 vae 以及主模型的特殊触发词。 这样管理你就可以按照你的绘图的需求,快速的引入你所需要的提示词及触发词。操作的方法非常简单,你只需要打开 stable diffusion 的根目录,里面有一个 styles 点 csv 的档案,使用记事本类型的软件打开它,记得千万不要使用 excel 去打开,否则格式会出问题的。 里面内容的处理格式我打在屏幕上了,每次你下载了一个新的 lora, 就可以按照这个格式去记录,然后就可以愉快的使用了。好了,今天的分享就到这里了,咱们下次再聊。
 05:03查看AI文稿AI文稿
05:03查看AI文稿AI文稿如果只有一个提示词,你会相信他能生成无数高质量的图片吗?那你现在看到的这些图片呢,就是用一个提示词生成的,这呢我们会用到一个神奇的插件,叫做 one button prompt, 那这个插件是干什么的呢?简单的来说呢,是帮你来扩充提示词的,当然说起来简单,但真正用起来呢,还是有些讲究的。老规矩,我们先说他怎么用,然后再讲他怎么安装。首先呢,我们先来准备一个提示词来作为基础,这个呢是我们之前设计好的一个提示词模板, 那在之前有一期视频呢,我们用这个提示词模板生成了各种各样的美女,这个提示词呢比较长,那你真正在做实验的时候呢,可以用你自己的提示词,因为这个提示词具体是什么其实不太重要。但是这样呢,我们还是强烈建议这个提示词要遵循我们之前说的那个 tsdl 这个结构,那这样的话 话呢,会非常方便我们后续的操作。下面呢,我们就来利用这一个提示词来生成无数张的图片。点击脚本的下拉列表框,选择 one button prompt 这个脚本。其实呢,这个脚本的使用呢,还是非常复杂的,但是呢,它的一些高级功能我们其实用不到, 所以说呢,我们今天只来介绍它的基本功能,那这个差价呢,可以用在四个不同的场景。我们先来看第一个, 那就是我们来固定图片的风格以及相机的视角来生成不同的图片。在这个界面当中呢,我们首先需要先指定好你要绘制什么东西, 那我们可以在这个下拉列表当中进行选择,这呢我们选择人物,而在这个阿提斯的下拉列表框当中呢,我们可以选择艺术家,那由于我对艺术家呢不太熟悉,所以说呢,这我们选择奥,也就是所有的他在生成的时候呢,会随机的选择一 一个。而图片的类型呢,这我们选择照片 photography。 主体重写的部分呢,我们选择 one girl。 这样的话呢,人物的主体可以被固定下来,在正向提示词的前缀,也就是 perfects 的部分,我们将图片的类型和人物的描述呢给他添进去, 这样人物的表情和背景虚化的一些特点呢就被保留下来了。后缀的部分呢,我们暂时留空,那其实回头如果你有需要的话呢, lora 是可以写在这个地方的, 别的默认就行。这样我们点击生成六个批次,一次两张图片,也就是十二张图片。不得不说生成图片的都比较漂亮,所有的图片不管是配色呀,风格呢,可能都会有一些变化, 但是你要注意,图片的背景呢,都是模糊的,整体的对比度呢都比较柔和,人物都是深情的看着镜头。那这些呢,就是 我们在刚才的提示词里边固定下来的部分。那这种方式呢,是我们在实际当中探索图片生成里边的一种常用的技法,那就是我们会把一些固定的元素固定下来,剩余的部分呢让它自动去发挥。 第二个应用场景呢,就是我们在图片的后缀部分增加 lora, 这样的话呢,人物的长相也会被固定下来,比如我们在后缀,也就是 surfax 部分增加上下面的 lora 模型,零点四个权重的 cute girl, 零点三个权重的韩国风格和零点三个权重的俄罗斯风格, 点击生成。这次生成的图片,除了保持原来图片的一些风格之外,你会发现他们的人脸呢,也会比较像,而且呢长得都比较靓丽。这个呢就是我们固定了 ora 的结果, 那是 这个脚本的第三个场景呢,就是用来制作冲突和不合理性,比如我们将图片的尺寸设置成五幺二乘七六八,然后呢,我们在提示词当中增加裙子和鞋子的描述,这样呢,提示词当中既有人脸的描述,也有裙子和鞋子的描述, 这样会制造一种冲突,那就是人脸的描述会要求镜头离人脸比较近,而裙子和鞋子的描述呢,会要求镜头离人比较远。那此时哎该怎么处理呢?我们来看一下。 那这个时候呢,你会发现生成了很多蹲着和坐着的照片,这个呢也是人工智能的一种折中的处理手法,那这种制造冲突的方法呢,也会使人工智能呢存在很多的变数,生成很多你意想不到的图片。其实上面的三种方式呢,都是在将图片生成的范围呢给他减小,当然 我们也可以让图片生成的范围呢变得越来越大,比如我们保留图片的最基本的类型和质量的部分,将其余的部分全部删掉,那你会发现这次生成的图片呢就五花八门了。 那最后我们来说一下这个插件怎么安装呢?你现在看到的是它的 github 的主页地址,我们进入到 stable defusion web ui 的 extension 选项卡当中,选择从 url 当中安装, 将这个地址填入到输入框当中,点击生成,等待安装就可以了。那使用这种方法呢?我们可以让一段固定的体式词生成出来各种各样漂亮的图片,这样的话呢,有助于激发你的灵感。还等什么,赶紧试一下吧,关注我,让知识变得更有意思!
354有趣的80后程序员 03:09查看AI文稿AI文稿
03:09查看AI文稿AI文稿今天给大家分享一下 ai 绘画如何写关键词,不管你懂不懂英语,是不是小白都能快速上手。我们要知道,关键词的先后顺序是会对生成结果有影响的, 就好比近大远小,近十远虚一样,越在前面的关键词权重就越高。所以根据大佬们的实践结果,得出以下这个结论。我们来看这张表。首先是画质,也就是对画面质量的描述, 比如四 k、 八 k、 高清等等。其次是主体,也就是画面中要突出的主体,比如人物、动物或者物品。然后是属性特征, 这里的属性特征是针对主体来说的,也就是描述主体的结构特征,比如五 五官、发型、体型、姿势等等。接下来是外貌特征,这里也是针对主体而言,也就是描述主体的外貌,比如穿了什么样的衣服, 包括颜色款式,戴了什么样的耳环、项链、手链等等这些外在的装饰。好了,与主体有关的已经描述完了。接下来是对环境的描述, 首先是背景,也就是这个主体他在什么样的场景里,比如在室内的书房, 室外喧闹的大街风和日丽的沙滩,又或者是神秘古老的废墟场景。有了接下来定义这幅画的风格,想象一下不同的画家,他们的画风是不一样的,比如油画、二次元、动漫、 写实、素描等等,根据需求去定义这幅画的风格。然后是镜头,可以想象一下你自己就是摄影师,你要用什么样的拍摄手法来完成这张照片,比如拍全身,半身特写,用广角、超广角、长焦, 也可以是一种构图方式。最后把一些其他元素添加进来作为点缀,比如季节、天气、色调、光效,或者一些其他需要在画面中看到的东西。 理解了关键词的构成,接下来我们可以做一个炼丹炉,就像这样把分类做好,如果你英语好,在分类里填写对应的关键词,就不会束手无策了。如果你英语不好,那就直接用中文写,就像这样, 像我就直接用中文写,写完之后直接复制,找个翻译工具直接进行翻译,或者也可以复制到这个网站,在里面进行一些调试,最后复制翻译后的结果 到绘画软件里粘贴,就可以去生成你的图片了。至于反向提示词,就根据你不想看到的内容去进行填写,最后再根据生成的结果进行一些微调, 然后就可以得到一张美美的图片了。学会这个方法,也许下一个大神就是你了,赶紧去试试吧!
604猫腻妖妖 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿大家看到别人用 saybot diffusion 做出来的图片都这么好看,而自己做出来的却是一塌糊涂。每次想要亲自动手做图,刚要想提示词时却又无从下手呢,然后又跑到网上直接拷贝大婶做出来的整顿提示词。这样多多少少都少了点自己原创的味道。 其实用 ai 做一张图出来,虽然不用自己亲自画,但也需要付出很多的精力,才能出来一张精致满意的图片。 我们就拿这张图片为例,图片所在的环境、姿势、动作、穿什么服装装饰,头发的长短,无关的大小,表情的喜怒哀乐、眼睛等等去细节刻画,到最后还要考虑出图的质量。 所以训练出来一张高清图,说简单也简单,其实也不简单。因为依然要一步步从大环境到 人物,再到细节,都要一个个相关的提示词刻画出来。现在好了,我从网上整理了一份提示词,这里都有一些常用的提示词,以便大家下载使用,需要的可以在评论区跟我要哦,记得关注我哦!
357秋秋快跑Ai 08:28查看AI文稿AI文稿
08:28查看AI文稿AI文稿stable diffusion ai 绘画系统课程第二期全面的 ai 绘画提示词解析在我们作图的过程中,必不可少的一件事情就是像 ai 输入用于描述画面的 prompt, 也就是今天我们课程的主角提示词。因为 stable diffusion 的提示词必须为英文,其中还会掺杂各种数字等,新手看起来又长又乱。不过看完今天的课程,我相信你再也不会头大了。话不多说,让我们正式开始接触 stable defusion 的文生图功能吧。 一、什么是提示词?简单来说,提示词就是我们在向 ai 传达我们需求的一门语言。第一期课程我们提到 stable diffusion 的两种基本作图方式是文声图和图声图。文声图就是我们主要以文字的形式来向 ai 传达 我们的需求,而图声图我们还可以借助图片来传达信息,但图声图也需要提示词,而且同样很重要。提示词所包含的内容非常广泛,例如你想绘制作品的主题、画风、形象特点以及一些具体要素等等。那提示词到底应该怎么写呢? 二、提示词的分类和书写首先, stable diffusion 的提示词必须要用英文书写,如果你的英文不够好,那就求助翻译软件吧。其次,我们输入的提示词是以词组为单位的,并不需要像真的英文句子一样要求具有完整的语法结构什么的。例如, 你想让 ai 理解这段话,你看这个面,它有长有短,就像这个碗它有大有圆。你看这个面,它有长有短,就像这个碗它有大有圆,你就可以 直接把它分解成面长宽、碗大圆,这样 ai 一样可以理解,甚至比前一种说唱形式听得更懂。词组与词组之间需要插入英文的逗号,所以在输入提示词的时候,建议把输入法切换为英文, 因为里面设计的符号基本都是英文的。提示词可以换行,但每一行的结尾最好也要打上英文逗号的分格符。随便输入一段话后,你就可以点击生成他,有可能就是你想要的,也有可能奇奇怪怪。 因为 ai 绘画是具有一定随机性的,就像抽卡一样,多抽几次,如果运气够好,可能就得到你想要的图片了。一个女孩在林中漫步,这是一个非常概括的描述词,女孩的长相、森林里有什么?是黄昏还是清晨?这些细节 的内容 ai 全都不知道,所以 ai 就只能开启抽卡模式了。你可能会认为一时间我也无法想得过于全面,无需担心, 因为提示词很多时候不是一下子就写好的,而是先写好一个大的框架,再去慢慢细化、补充和调整。提示词有很多分类,这里我把它概括的分成如下几大类别,不用急着截图,后面会为大家整理出来。 一、人物及主题特征,例如穿着白色连衣裙,粉色的长发,微笑张开双臂。你描述的越具体, ai 的思路就越清晰。 你也可以加入一些形容词,例如美丽的、开心的,虽然比较抽象,但也会让绘制的图片往你想要的感觉倾斜。二、场景特点例如森林、树木、灌木丛、 粉色的花朵、林间小鹿。虽然我们都知道森林是在室外,但是在写提示词的时候,如果你描述的是室外的场景,最好加入奥特多这个词组,反之则为英朵,它会显著影响整个画面的氛围。 三、环境光照,例如白天太阳、蓝天多云的天空。四、画面视角,例如特写全身、从前面光脚。以上内容都算是我们可以直接从画面中看到的内容,所以以上的提示词又可以归为一大类, 那就是内容型的提示词。然而,如果只有内容型的提示词,你的作品很大概率会出现模糊、细节不清晰等问题。所以接下来我们就需要给 ai 打一记强行针,那就是加入画质提示词,例如最好质量、超详细节奏、 八 k 壁纸等提示词。因为 ai 学习的图片里面有些是高清的,有些是模糊的,加入了这些提示词,就可以让 ai 在抽卡的时候过滤掉那些模糊的图片。还有一些指向更为具体形式的质量提示词,例如 超精细的八 k 游戏、 cg、 虚幻引擎渲染等。其次就是画风的提示词,例如插画风、二次元、写实系等。但写实图片的创作则更加依赖于写实的大模型。 这个我们后续的课程详细介绍。这类画质和画风的提示词又可以归类为标准化的提示词,就是相对固定的词组。以上内容我也会在复建四中为新手提供更多的参考,大家可以下载复建查看更多。到了这里,提示词书写的基本框架是不是就很清晰了呢?可能 新手还会有一个疑惑,如果我想要的作品并没有人物呢?其实也是一样的。如果你想画一个杯子,那这个杯子就是你这幅作品里面的人物。 但是如果你想绘制一副风景移动建筑,这就需要借助不同的大模型进行创作。这些我们会在后续的模型介绍片中做详细的说明。 三、权重和负面提示词提示词我们会写了,但是提示词中的各种符号和数字又代表了什么呢?其实这些符号就是用来增强或减弱某些提示词的优先级和权重的。 因为当我们输入过多的提示词时, ai 接受了很多的元素需要去绘制,但 ai 可能并不知道你最想要的是什么。比如我们刚刚绘制的作品,我们告诉了 ai 粉色的花朵,但画面却没有出现。如果你就是特别想让画 下面出现粉色的花朵,那就可以给粉色的花朵这个提示词增加权重。增加权重的方式有两种,第一种就是加括号,记得要用英文输入法的括号。当你加了括号后,这个提示词的权重就变成了原来的一点一倍, 相对于其他内容就会更加突出。你还可以给他套上多层的括号,每套一层就会乘以一点一倍, 三层就是一点一,乘以一点一乘以一点一,等于原来的一点三三一倍。看,当我们加了三层括号后,粉色的画就出来了。另一张增加权重的方式是括号。加数字权重的方法, 加了括号以后,你可以在提示词后加一个英文引号,再直接输入数字权重即可。如果你想削弱某个提示词的权重,就可以输入一个小于一的数值。显然,输入数字可以让 让我们更好的控制提示词的权重还有很多进阶的符号规则,如果你想了解留言给我,我会准备额外的教程进行分析。但是调节权重的时候也需要注意,权重值不宜太高,在一上下零点五左右是一个比较合适的数值, 实际你可以根据自己的情况进行调节。提示词的另一个重要组成部分就是反向提示词,简单来说就是你不想出现的内容就是反向提示词了。反向提示词是可以不输入的, 但是一般我们也会加入一些标准化的词组来改善画面。例如上节课提到的反向词最差质量、最低质量、低分辨率这些主要是为了让 ai 规避那些模糊的图片进行学习。而单色灰度则主要是为了保持画面色彩的鲜艳,而后面这 些突变的手、画的不好的手坏比例、手指太多等等就比较玄乎了。因为 ai 现在还不太能处理好手部的细节,所以虽然有了这些反向词,但 ai 有时候还是会左耳进右耳出,这时就需要我们使用其他方法进行调节了, 以后的课程会继续研究。反向词正常也是可以固定化的,但是有时候为了获得特定的作品,我们也可以反其道而行之。比如把反向词里面的单色词组放到正向提示词里面,我们就可以得到一张单色的图片了。 说了这么多理论的方法,可能大家还是很难掌握写题诗词的窍门,所以我也为大家准备了很多参考的网站和例子, 让大家能更快地有自己的一套写题诗词的思路,请大家参考复建四的内容,虽然本期视频出来的作品并不完美,但想要绘制出完美的作品还远不至此,就让我们后续一起探索 ai 绘画的奥秘吧!
 00:31查看AI文稿AI文稿
00:31查看AI文稿AI文稿拆 gpt 如火如荼的当下, ai 绘画能力也在突飞猛进。这么精美的画作的关键就是提示词 prompt。 有了 promptheal, 你可以轻松搞定这一切。登录 prompthealo 网站, 你可以看到主流 ai 绘画软件迷之你 table delivering, 不喷之你 boe 的热门画作。点开图片可以查看生成使用的提示词。参考提示词来完成自己的画作。快去试一试吧!关注我,了解更多效率工具,提高生产力。
4832牛哥 01:17查看AI文稿AI文稿
01:17查看AI文稿AI文稿老板问我关键词是干嘛用的,师傅快帮帮我。那你讲一下那关键词作用吧。首先你先打开 wi ui 的这个界面,然后呢,我们点击这个图中图,在图中图上面两行 ty, 右边有两个反推提示词,这两个反推提示词的功能是不一样的,先放进去一张图,看一下这两个反推提示词, 可是他并没有把这个圆口的 的位置我们就不用再次保存了。然后我们可以打开那个 ui 里面的 人生图的面夹,在这个面夹里就可以找到你身上的图片。哎,人呢?真没拍了,别拍我呀,人会丢人的,哈哈哈哈。
18达文嘻 01:24查看AI文稿AI文稿
01:24查看AI文稿AI文稿ai 绘画提示词,犯困者的福音来了,这个最新发布的插件可以让你原地起飞,秒变大神!不得起飞了我,哎呦我的话不多说,咱们现在就开始。首先我们来到扩展,再从网址安装中输入这串网址, 然后直接点击安装,安装完成后重启 weby。 来到纹身图界面后就可以看到这款插件了。展开插件就可以看到一堆全是中文的提示词,重启手势、人物、服饰、发型、动作到面部等等全都包含进去了。 单击鼠标左键就会显示在正向提示词里,单击鼠标右键就会出现在反向提示词里。 ai 绘画最大的门槛就是高质量的提示词,这个插件直接将这个门槛给干碎了。如果没有灵感,可以在抽卡机里面随机 选择,上方还有一个随机灵感功能,更加放飞大脑,点击随机关键,灵感无限出图,直到满意为止。细心的小伙伴可能已经发现了,这款插件还为我们贴心的加上了权重,简直不要太香! 如果你想要更精准的随机,可以选择分类随机组合。先在下方提示词库中选择需要随机组合的类型,然后点击分类随机组合就可以获得特定组合的关键词。最后点击发送到提示框,点击生成就可以获得一张随机图像了。还在等什么提示词?贫困玩家快燥起来吧!
42AI新视角 00:48查看AI文稿AI文稿
00:48查看AI文稿AI文稿提示词作为 a 绘画中必不可少的一个环节,而 safg scale 就是用来控制提示词与出图相关性的一个参数。过低的 safg 数值会使图像出现低相关性,低饱和度。过高的 safg 数值会出现过多的细节,过锐的画质 甚至会让画面出现崩坏。经过测试比对,我们可以发现 cfs 该数值在六到十一还是相对稳定的。如果你想要高细节、高相关性,但又不想画面崩坏,可以使用提示值相关性修复插件。 同样的提示词,上图是未使用修复插件的,在 cf 技术值为十五时,画面已经过锐了,二十三十画面都已经崩坏了。而下图在使用了修复插件以后,在高 cf 技术值下,画面依然有很好的表现。
65AICK-KC 00:43查看AI文稿AI文稿
00:43查看AI文稿AI文稿三种高水准 stable diffusion ai 绘画提示词填写方法,萌新鼠手都能用。最后一种最简单。第一种 ai 帮你写,可以借助叉 gpt 或文心一言之类的原型, ai 帮你写提示词,你只需要说出需要的内容,然后让他帮你构思提示词,并翻译为英文复制粘贴即可。 第二种工具辅助,可以使用关键词、超市等网页辅助你的提示词填写,同样只需要选择复制粘贴。 最后一种,抄作业。可以参考一些模型网站的力图与提示词,记录网站的成品提示词,选择比较喜欢的图,直接复制提示词到 sd 粘贴即可。三种方法能让你快速产出较高质量的图,但是想成为大佬的话,还是认真学习提示词语法吧。
478指尖AI绘画 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿这个网站简直炸裂的好用,他直接把 ai 绘图的咒语给可视化了。他不仅可以用在 maide junior, 还能用在 stable defection, 简直就是 ai 绘图的魔导书。地址我放在了最后,来看一下他都有什么。首先来看一下布局,想要做海报的,添加他就行。 想要做包装设计的,点它就行。还有什么角色设计等等等等。想点什么就点什么。它还有各种不同的纹理、颜色、风格,还有各种不同的建筑学等等等等。 简直就是此战在手,天下我有啊。喏,这就是地址,赶紧暂停保存截图,关注我,用 ai 不迷路!
1467大队长聊Ai 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿这应该是 ai 绘画最好用的关键词工具,适用于 misterni 以及 stable defusion。 重点是完全免费传送门播放左上角了,搜索打开即可使用,需要的同学记得点赞收藏,有了它就能轻松拆分翻译关键词。在这里就能选择编辑米 jenny 或者 stable defusion 的提示词, 这里是输入框,比如我在这里输入一段中文关键词,他就会在右边自动分词显示,并且是翻译好的。在右侧某个关键词,单击就可以对原文或者译文进行修改。 在空白处双击就可以添加关键词,如果输入是中文,就会自动翻译成英文,反之则是中文。你还可以对关键词进行移动,调整你需要的位置,点击这里可以添加多个工作区。输入一段 英文关键词,他同样会帮你进行翻译,并自动分词显示。不仅如此,在右上角他还有提示词,词典质量、绘画画面效果等等都为你分类好了。 点击选择就可直接调用,大大方便了我们的提示词编辑。完成提示词编辑后,点击这里复制关键词,再点击这里返回 meat, 就可以提交关键词生成图片了。集合在一起后,真的就是一站式操作,以后画图再也不用一个个页面跳来跳去了。私信六六六,领取 gpt ai 人工智能学习资料!
546小门道AI 01:03查看AI文稿AI文稿
01:03查看AI文稿AI文稿大佬随便点几下就写出惊艳的提示词,而你还在到处找提示词?今天就教你使用工具,自己动手写任意提示词,找到 ai 绘图掌控感万能模板 加专属提示词工具等于优秀提示词,我们就按照这个模板演示下如何使用提字工具写出每个词都有用的提示词,并生成一张高质量的作品。 我们假设生成一张花园里坐着的女孩质量关键词能让我们生成的图片质量更高。我们在预设下找一组正向提示词。点我想要找一组负向提示词,选择我不想要主题。我们在人物下找到一个女孩和单人分别点击。我想要 我们看到提示词出现在右侧购物车了,这里可以对提示词进行拖动、排序加减、群众导入和导出等操作动作。选择坐着场景,选择花园,其他先不选。我们看下效果, 可以看到生成的图片完全符合每一个提示词。同样方法,我们可以继续选择关键词,直到生成满意的作品。觉得有用的话,欢迎点赞关注,为你分享更多 ai 干货!
311程序员AI超 01:49查看AI文稿AI文稿
01:49查看AI文稿AI文稿大家好,我是爱江子,你真的会用提示词吗?同样都是用一个这样的提示词,为什么出来的图片差距这么大?今天和大家聊聊提示词,以及如何设置专属自己的提示词。上面是正向提示词, 下面是反向提示词。虽然很多人的提示词看着密密麻麻的,但实际都逃不开一个很简单的公式,那就是画面的质量加风格加主体加场景加其他元素。对应的说明我给大家都放出来了,我们不展开细讲,直接给大家实操演示。我们可以直接打开提示词表格,复制 想要提示词的评论区评论提示词。这里我们按刚才的公式来回车,并不会影响提示词效果。写上高清古典主义女孩在街道半身照生成,就可以看下效果了,这样就基本出来了我们想要的效果。接下来我们 继续写反向提示词来优化这张照片。我们锁定种子,参数不变,加入反向提示词,重要的一个 nss double you, 然后模糊低像素,看不清,点击生成。 我们对比可以发现,不加反向提示词,背景人物有噪点,更模糊,右图人物的一些细节更清楚。讲完提示词,我们聊开头讲到的如何更便捷地使用提示词,我们要用到的是这个保存按钮, 还是以这个为例,我们把已经写好的提示词点击保存并取个名字,然后删除固定种子,这时候下拉模板风格,使用刚保存的 top 点击生成。可以看出我们没有写任何提示词就完成了目标图片的生成, 还是街道古典半身美女,这个就是自定义自己提示词的用法,作为图片质量骑手式和反向提示词来说都是非常方便的。我们可以在根目录 styles c s b 来编辑这个内容。今天的分享就到这边了,我是 ai 姜子,如果你觉得有用就请帮忙点个赞吧,谢谢!
676AI江子 02:42查看AI文稿AI文稿
02:42查看AI文稿AI文稿欢迎来到小易的教学视频,当我们在进行创作时,可以分为这几个顺序,本期先和小易一起了解下如何选好模型与输入提示词 一点,如何选好模型在 ai 绘画中,不同的模型他自身学习的素材数量和处理方式都不一样,因此选择不同的模型会做出不同的图片,这些是不同模型下同一提示词生成的图片。下面小艺为大家推荐了一些不同 类型的模型。使用模型时,我们可以直接在 ai 绘画界面右上角模型处选择不同的模型,也可以在模型广场找到某个模型,直接点击创作。第二点,输入提示词。通过我们输入的提示词, ai 会生成 相对应的画面。在描述提示词时,可以有两种描述法,一种是自然语言描述法,另一种是关键词描述法。输入的提示词越少,留给 ai 发挥的空间就越多,这样得到的作品将会有更多不确定因素。相反, 提示词越多越精准,留给 ai 发挥的空间就越少,得到的作品就能更符合创作意图。输入提示词时,建议场景主题加细节特征加画面说明。我们可以利用工具栏中的提示词工具,这里能够为我们提供许多实用的提示词。 接下来我们来看看右边相关的参数设置采样步骤,也就是迭代生成图片的次数,如果次数太低,则会导致出图效果质量失控。 文本强度就是图片与文字描述相符合的程度,强度越小,图片越不受文本影响,强度越大,图片会根据文本加重绘制,一般最好不要超过十。画面说明提示词是影响创作结果的重要因素。 添加不同的画面说明提示词,我们能得到不同效果的图片。另外,在输入提示词时,我们可以加上括号,给他增加权重。比如一个括号表示一点一倍增强,两个括号时则为一点二一倍。也可以写作这样 代表对括号内的提示词一点二倍增强。最后,我们可以点击这里的重置,用同样的参数再次生成点这里能看到绘制图片的信息,包括提示词 文本强度、步骤等等。以上就是如何选模型以及输入提示词的整个流程了,关于这两方面还有什么问题,欢迎在评论区提出哦!
105海艺AI 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿这应该是最值得推荐的 ai 绘画提示词工具网站了,完全免费,适用于 made journey 和 stable defusion。 告别英文难题,用这个神奇网站可以轻松拆分翻译关键词,让你无障碍的添加自己的创意和内容 提示词你也可以直接输入中文,剩下的交给神器。你可以随心所欲的拖拽更换顺序,轻点取消关键词,还可以随意修改。 这里甚至还内置了各种各样的提示词命令,一键添加。最震撼的是,你还能打造属于你的专属提示词库,关联使用,简直是 yyds 的存在!赶紧关注我,和我一起探索 ai 生产力的无穷魅力!
83鱼总聊AI 00:55查看AI文稿AI文稿
00:55查看AI文稿AI文稿如果你想学 ai 绘画,这个视频你必须要保存。这是我为大家整理的通用核心关键词,里面涵盖各种场景、材料、事件。如果觉得有用,给个赞,我就感激不尽了。评论区留言发关键词公式。
93Ai大侠 04:11查看AI文稿AI文稿
04:11查看AI文稿AI文稿如果我说下面的这些图片呢,都是由一组提示词生成的,你相信吗?当然准确的来说呢,是由一组提示词的模板生成的,那如果你在生成图片的时候,你会发现每次你都要重新的去写提示词,那这个时候你要警惕了, 你可能没有更好的去积累提示词。这个呢是我们使用文生图呢,经常犯的一个非常大的错误,那如果你想让你的提示词能够发挥最大的作用呢?其实有几个关键点你是要注意的,老规矩呢,我们先看效果, 然后呢我们再来说大道理。这次实验主模型呢,我们使用的是 breast evil mix, 那我们先来看一段非常有意思的提示词, 我们先不用着急来看它是干什么的,你从直观上来看,它的结构呢,是非常规整的,而且这里边有一个非常有意思的提示词叫做 break。 这个词呢,其实从效果上来说呢,并不重要,而且呢有很多人呢夸大了他的作用,那为什么会有这样一个提示词呢?你有没有发现一个特别有意思的事情,你的提示词呢,其实是分组的,每七十五个 token, 那如果偷看你不太容易理解,你可以认为是七十五个单词是一组,这个呢,我可不是胡说八道啊,当你写少量提示词的时候,你会发现你右上角的这个提示词的数量呢,是这样标识的,那再多了之后呢,就是这样了。 所以说有很多人认为呢,把相关的词放到一组里边呢,就可以让他生成非常好的图像,而这个 break 就是分组的这个关键的要素, 我可以非常负责任的告诉你,目前没有任何证据能说明这个词特别的有效,但是我觉得他最大的作用呢,在于他对提示词的结构化。还记得之前我们的视频当中, 建议大家把提示词分成五个部分, tsdal, 也就是类型、主体、描述艺术和 lower。 那针对这个思路呢?上面的提示词呢,我们大致是这样写出来的。那所以说呢,我们来看第一段,他翻译出来呢,是这个样子的, 通过观察和对比生成的图片,我们会发现这段题诗词呢,主要在强调生成的图片呢,会比较柔和,包括有比较柔和的饱和度,比较柔和的灯光,以及背景模糊的这种效果。第二个部分呢是对主体的描述, 也就是 subject it, 一般是在描述人物的性别,年龄这样一些基本的特征。那这部分的中文翻译呢,是这样的,这里呢重点描述了人物的眼神和表情。 第三个部分叫做 description, 主要是对人物的一些特殊性的描述,比方说他的职业啊,环境啊,这一段呢是非常重要的,是这张图片取决于其他图片的一些非常重 主要的特点。那这部分的中文译文呢?是这样的, 你注意上面的提示词并没有第四部分和第五部分,也就是我们并没有特殊的镜头啊,视角啊,以及特殊的 lord。 但是这样的话呢,我们也能生成一张特别不错的照片,不信呢,你来看一下。 那你可以认为这个就是一个非常不错的提示词的模板了。那如果你想生成相同质感的图片呢,我们只要改第三个部分就可以了,比如我们把第三个部分改成下面的提示词, 我们就可以得到三个海滩女孩的图片,那我们再切换一下,换成下面的提示词, 就得到了一个站在老便利店里边的女孩。那我们继 需再换,换成下面的提示词,这个时候生成的你看是什么?就是传说里边那个校园里边靠窗的女孩了。不过在生成这组图片的时候,有几个点需要注意啊,第一个就是主模型, 这个呢我们刚才提到了我们使用的是 breast evil mix, 第二个呢就是我们将 clipscape 这个纸呢设成了二,当然这个呢也是一个经验之谈,如果你使用 bro v 五或者是 breast in evil mix 这样的模型的时候呢,往往倒出第二层的输出效果呢,比最后一层要漂亮很多。 那后面呢,就是你要把这些模板的提示词给他,有结构的给他存起来。那最笨的方法呢,你可以用文本存一下, 当然也可以使用 stability forumwibui style 这样的功能呢,给他存一下。当然我觉得具体的手段不重要,你的思路呢才最重要。那你是不是也有自己私藏的提示词模板呢?可以出来分享一下,关注我,让知识变得更有意思。
503有趣的80后程序员 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿先教 check gpt 写 ai 绘画提示词。第一步,定义他的角色,即扮演为 mid journey 的 ai 绘画提供提示生成器这样的一个角色任务。 第二步,赋予能力,能提供详细而富有创造力的描述,以激发 ai 创造出独特而有趣的图像,并请他记住, ai 能够理解各种语言,能够理解抽象概念。第三步,设定范围,请使用拍摄角度、构图、灯光景别、镜头色彩、纹理、背景艺术流派、艺术家名字、专业艺术词汇等。 第四步,投喂粒子概念,巴比伦塔提示俯瞰镜头、石狮般构图、丁达尔效应长焦镜头、广角八 k 最佳质量、超细节杰作照片及饱和油画、浪漫主义以及两位艺术家的名字。然后告诉 ai, 我要生成一幅中国古代都城的图片。 此刻差的 gpt 已经修炼完成,拉上 ai 绘画的小手看一下成果, nice!
233木由
猜你喜欢
- 1482第四种黑猩猩