蒸馏模型先生使用方法

粉丝38.8万获赞140.6万
相关视频
 05:21查看AI文稿AI文稿
05:21查看AI文稿AI文稿如果告诉你有一种技术可以花学霸百分之三十的成本就拿到学霸百分之九十的分数,你想不想学一下?那我们今天就来一聊 ai 大 模型领域里边最热门的一种偷师的技术, 叫做蒸馏,我保证这里边涉及到技术原理的部分,连我奶奶都能够听得懂,但是听懂了这部分的内容呢,对于每一个人的学习都有用,那我们现在开始啊, 蒸馏这种技术呢,是现在大家都熟悉的 ai 三巨头里边的那个 hinton 提出来的。 hinton 老师的故事在我以前的那个视频里边,其实我就跟大家说过,出生于科学世家啊,他们这个科学世家厉害到什么程度呢? hinton 的 老爸是这么评价他的, 说,以你的聪明程度,只要花我两倍的努力,然后在我现在两倍的 岁数的时候,就能够达到我现在一半的成就了。问那 hinton 的 老爸的成就是 hinton 的 多少倍? hinton 老师在提出来蒸六这个技术的时候,他就指出,哎,有没有一种办法能够让训练大模型不那么费钱,能够让一个小模型以相对低的成本 和代价就能够学会老师的大部分的知识呢?所以呢,他就提出了这种技术背后的原理并不复杂,主要就是通过让 那个大模型的老师模型去教那个小模型的学生模型,最终让学生模型学会老师模型的大部分的知识。同时呢,小模型可以以更低的成本,更短的时间和更少的 代价去训练出来,这个就是蒸馏技术后面本身的想要解决的问题,那他是怎么做到的呢?关键在于这个老师模型需要把老师学到的知识里边 的那部分暗知识表达出来给学生。对于一个大模型来说,他所学习到的知识其实是一个 超级高维度的特征向量,这个特征向量在数学里边表达为神经网络的权重,权重的定义在之前的内容里边我也讲过了,大家可以自己去翻当啊。老师他对于这个世界的理解都体现为一个非常复杂的特征向量的时候, 这个时候老师去教学生,他就可以以不同的方式来教。这个方式呢?在呃,大模型领域里边有一个参数叫做 temperature, 叫做温度,当这个老师的教学生的温度比较低的时候,就意味着他比较保守, 当温度比较高的时候,就意味着这个老师比较活跃。哎,比较浪一点,可能举的例子会比较多一点。当老师模型再把温度调高的时候, 那老师就可以把对于这个世界的客观规律等那部分暗知识充分的展示给学生。当学生能够学会这个世界的暗知识的时候,学生就能够以更低的成本,更快的方式来理解 这个世界的规律,最终实现小模型在更短的时间里学到老师的更多知识的一个效果,而且他的表现不会大幅降低。那有了蒸馏这种技术了以后,大模型就不用再部署到那么几千台 gpu 的 机房里,而可能 他就能够很轻易的在未来走进你的手机里。这个就是蒸馏技术在大模型领域里的一个应用方式,但是实际上这个技术在我看来,他对于我们普通人的学习其实更有启发,关键就在于 我们每一个人或许在这个世界上都是学生,我们可能也有比较旺盛的求知欲,想要去了解更多的东西啊,我们怎么样去向我们的老师去学习?这个其实是与我们每个人都有关的。那其实刚才我已经说到了诀窍, 关键就在于我们要去学习到老师的那个认知体系当中的那部分暗知识,当你能够理解这一点的时候,其实你的学习就可以加速。那什么是这个世界的暗知识呢?我可能只能跟你举一个例子,是当年释迦牟尼佛像家业传法的故事,当佛祖像 弟子们传法以后,他看向一众弟子,其中只有一个人就是家业,就是现在的禅宗初祖,微笑的看向释迦牟尼佛,然后释迦牟尼佛就明白了,哎,禅宗初祖听懂了,从此家业 祖师就成为了禅宗的初祖。这个和暗知识有什么样的关系呢?我想说的是啊,这个世界的规律,他未必 都藏在语言当中,所以作为学生的我们,实际上可以向人学习,也可以向大自然学习。重要的不是我们向谁学,而是我们能够通过现象看到了 本质,看到了道的多少。这个其实是对我们每一个人的学习真正重要的事情。那今天我们聊完怎么样向聪明的人的学习真正重要的事情。那今天我们聊完怎么样向聪明的人的知识的话题。 你想不想知道,如果你是一个老师,你应该怎么样更好的去教会自己的学生呢?如果你对这个话题感兴趣,我们下一期可以聊一聊。
19老猿的世界 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿前面两题咱们聊了,蒸馏是大模型当老师教小模型,这个教到底是怎么教的?很多人以为啊,就是把大模型的答案抄给小模型。错, 真正的蒸馏教的是思路,不只是给答案。我给你举个例子啊,比如一个复杂的路口,有行人,有电动车,有加载的车。大模型处理这个场景的时候,他的大脑会经过一系列的过程,先感知到所有的物体,然后推理他们可能的意图,最后会画出一条安全的路径。 蒸馏要做的不只是告诉小模型最后往左打了多少度方向盘,而是把中间那些思考步骤,为什么判断那个人要过马路,为什么需要提前减速,也一并的交给小模型,这叫思维练蒸馏。 大模型把自己推理过程一步一步拆解成小模型能理解的教材,小模型学习完之后,遇到类似场景,就能模仿老师的思考方式去处理,这还没完,现在的蒸馏技术更高级, 比如咱们上个视频提到的 jfk 多教师蒸馏什么意思?就是找好几个不同的老师,有的擅长感知,有的擅长规划,有的擅长推理,各有所长,把他们的本事都提炼出来,合成一份综合教材,交给一个学生。 所以现在的自驾,表面上是代码在跑,背后则是一整套的名师辅导班。大模型在云端当老师,小模型在车里当学生,一代一代的迭代下去, 郭小鹏说过一句话,大模型加大算力,加大数据,共同作用,带来接近 l 四的质价体验。而对那些算力不够的车,真流就是那座桥梁, 这个真流三部曲就到这,听懂的朋友,以后看到轻量化质价的宣传,你就知道背后是谁在当老师了。我是彭于晏,也说车,咱们下个系列见。
63鹏宇焱也说车 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿朋友和你们分享一个非常炫酷的事情,我调出了一个推理模型,它是 deepsea 二 e 的 极简版,我给他起名叫做 tina 二 e, 那 账号规矩,先展示效果,问他几道小学数学题,他不仅给出了答案,还给出了详细的推理过程。 页面显示了它的基础模型是千万二点五杠零点五 b。 那 看介绍就知道它是二四年的模型,没有推理能力的,非常清亮的模型。那这个版本的推理能力是用模型蒸馏训练出来的?废话不多说,直接展示过程模型蒸馏的效果。我是看 dipstick 二 e 这篇论文,它提到用 dipstick 二 e 生成八十万条样本, 对小模型千万二点五进行微调,会比直接在小模型上做强化学习训练效果要好。换句话就是说,大模型的推理能力是可以蒸馏在小模型上的。那我就上手试了试, 我用的大模型是千万三 max, 它是千万系列最新的推理模型。那先训练什么数据呢?我给了七十四道数学推理题,我的电脑性能有限,那就先小范围的测试, 其实此是要求他写出推理的过程,还有答案,把这些数据保存下来,那这些数据就相当于千万三 max 这个老师对题目的解析思路嘛。然后我用这些数据去训练千万二点五杠零点五 b 这个学生模型,让学生按照老师的思路去思考 这个过程,和普通微调没有任何区别。之前几期我都分享过,你们可以去看往期内容。那他得到的也是一个 adapt 文件夹,把 adapt 文件夹和千万二点五到零点五 b 这个小模型融合,就可以让原本没有推理能力的小模型长出推理能力。 那这里要说一个实话,他只能回答简单的数学题,因为电脑性能受限,我没有给更多的数据集。 deepsea 二 e 这个论文他也说了,他们蒸馏的数据样本有八十万条,那完全不是一个量级。关于模型蒸馏的内容就是这一些,关注我,我会分享更多的智能组玩法。
51鸣姐.AI进阶 00:36查看AI文稿AI文稿
00:36查看AI文稿AI文稿大型双标现场来了,让我们回顾 antropic 的 经典语录。这些实验室使用了一种名为蒸馏的技术,即通过在更强大模型的输出结果上进行训练来提升一个能力较弱的模型。蒸馏是一种广泛应用且合法的训练方法,但蒸馏也可能被用于非法目的, 竞争对手可以借此在远低于独立研发所需时间和成本的情况下,从其他实验室获取强大的能力。这前后反差也太明显了吧,合着自家用就是合法,广泛应用,别人用就成了非法获取,这双标程度简直了,大家怎么看这种说法呢?
153清湛AI程溥 03:57查看AI文稿AI文稿
03:57查看AI文稿AI文稿给大家介绍一个开源的项目,叫 this easy distil, 这是一个大模型蒸馏的开源的项目,这个项目是阿里开源的,今天给大家来介绍一下。那首先我们看一下这个项目的框架,它这个项目包含了一些数据的合成, 这里面都介绍了,它能够合成一些简单的 c u t, 当然它也能合成一些复杂的一些 c u t 的 这样的一些指令,那么是基于 系统一简单回答,也能够合成一些基于系统二复杂的推理的整个一个过程,它这个都能够实现。另外大模型蒸馏我们一般给大家之前也介绍过,只要是把这个老师的这样一个知识蒸馏到学生的这个大模型里面来, 他这个项目他的蒸馏也支持两种方式,一种方式叫黑河蒸馏,另外一种方式叫白河蒸馏,黑河蒸馏它主要是把呃老师的最终的这样的一个回答蒸馏给这个学生。 白盒蒸馏它还会更复杂一些,它主要是把老师的深层的是说 top 二十个 open 的 这个 logics 引含的知识蒸馏给这个学生的模型。这个我们之前也给大家介绍过,特别是现在那个 deepsea v 四的那个版本,它就是通过蒸馏的方式,把强化学习玩的专家模型这些老师 蒸馏给一个统一的一个学生模型,那让这个学生模型具备所有这些专家的这些模型的能力,所以这个项目应该来讲是非常好的一个项目,它就可以实现把各种各样老师的能力蒸馏给这个学生,它也能够支持。这个我们前面讲的叫白盒蒸馏,白盒蒸馏就是把这个 logitex tok 的 logitex 蒸馏给这个学生, 它这个项目训练过程它也能够支持我们之前讲的 g, r, p, o, d, p, o 这些都能够支持的, 包括它也能够支持一些增流的一些算法,我们前面给大家介绍过,那么它里面它还有针对这个通一千万二点五,通一千万二这些模型的一些增流的方法,它写了一些命令行和脚本,它可以通过这个命令行就直接生成这些增流的这样的一个配置的一个 脚本,或者叫配置的一些配置文件,他直接能够生成出来。那么这个配置文件我们可以看到他这个地方就是一个黑盒的一个蒸馏的方式,他使用的这个 it'scent 包括他是怎么 推理的,他的推理的一些方式,包括他目前的老师模型有哪一个学生模型用哪一个,他这里面包括他整个一个催眠的整个一个过程 都可以生成配置文件,你就很方便地通过这个 ez distil 这样的一个命令行去运行,它就可以快速地把这个七 b 的 模型的能力增留给这个零点五 b 的 这个模型。那么这个项目里面它也有很多的这种论文,他们做了很多的增流的这些能力,包括 视觉多模态的能力增流给这些模型,当然它也内涵了一些数据这部分,所以这个项目应该来讲对于我们大模型做增流它会非常简单,那么这个项目依赖它也是非常少的,它这依赖它主要是依赖 v i m 零点八点五这个版本,另外它主要是依赖这个项目,叫 trl 零点幺七点零这个量, 主要是依赖这两个项目为主创这个 transformers 它主要是依赖于四,当然目前 transformers 已经更新到 v 五版本了,那这个项目它有一个不好的地方,就是它更新度还不是很高,一般更新它是两个月前它在更新 应该,但是对我们去学习如何把这个模型的能力,老师的这个能力增留给这个学生,它的这一部分的代码,原代码还是可以做一部分参考的, 甚至来讲你可以拿这个框架直接来用,那它这个项目里面它还包含一部分能力,把这个 edit 的 这样一个能力,就是模拟这个 edit, 虚拟调用这个 edit 工具的这个能力,也可以生成相应的数据,让这个大模型能够得到强化学习的训练,这个也可以。 那么这个项目应该来讲能力还是不错的,特别是当前的这些小模型,如何具备这个大模型的这些能力的话,它都可以通过这个简单的 easy industrial 这样的一个框架能够学习到这个大模型的这个能力。好,今天我们这样的一个视频给大家就介绍到这。
116小工蚁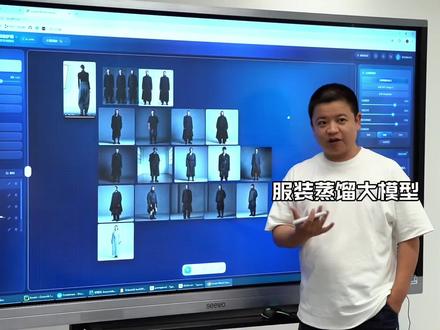 00:55查看AI文稿AI文稿
00:55查看AI文稿AI文稿现在搞得我心里慌慌的,因为这款产品马上就要退出市场了,我也不知道这个产品是否涉及到侵权,那这个呢,就叫服装设计师的蒸馏大冒险,我现在给大家看一下三本钥匙,我是我们是怎么蒸馏它的,镜头近一点, 我们把三本钥匙的呢,所有的经验手法,大脑思想文献图片,产品,所有的把它打包成文件夹,通过这个窗口一一的把它打进去,打进去之后呢,它的所有的内容就进入到向量, 进入了项链之后,我们再进入的知识图谱,去把它的所有的思维给它结构化,我们再通过指令就能设计出这样的一套产品了,简单呢设计了几款羽绒服,呃,大衣,夹克, t 恤之类的,我们把所有的产品给大家看一下 啊,这个产品马上就要上线了,现在呢也有很多人在私下呢,说的我心里慌慌的,说我们是侵权,这个东西是违规的,是不合规的。
938张奇.服装人AI圈 11:47查看AI文稿AI文稿
11:47查看AI文稿AI文稿今天就给大家讲一个就是大模型蒸馏相关的一个知识啊,就是什么是大模型蒸馏呢?其实就是说把你的大的模型进行一些压缩啊,然后压缩成一个小模型,但是它实现的能力呢,并没有变,这样就可以节省我们的一个成本资源。 其实一句话概括就是让小模型继承大模型的一个智慧啊,对,然后先说一下什么是模型蒸馏啊?模型蒸馏它主要是就是像刚才说的,就是用一个小模型来实现大模型的能力,就比如我们原来有一个大的模型,我们称为 teacher, 就是 教师的模型,然后 我们需要把它蒸馏成一个小模型,也就是学生模型,就是用大的模型作为老师来教小的模型,它的一些能力,从而就是把那个大模型里我们需要的这部分能力转移到小模型身上 啊。它的那个好处就是说我们大模型原来可能说我们用的非常就那个参数非常多,比如我们用一些千问七十二 b 啊, deep sync 这些啊,它的那个参数都是非常多的, 当我们训练成小模型,他可能就是七币或者是零点七币,就是量级就残数量非常少了,然后他的训练成本啊,也是非常快 啊。然后在实际生产步手中也可以节省很多的资源吗?因为现在我们的卡存储都是非常贵的吗? 所以你如果能节省,就是有一百多币到七币的话,可以节省很多张卡的。正常一个七十二币的,一个千万的模型,可能就得要四张四零九零去部署了,而你七币可能一张就 ok 了,所以说它的成本节省是非常非常大的。 然后再说一下这个关于他这个模型蒸馏怎么做的,就是说你输入这个就是一个问题,假设就是天空是什么,对于那个原来这个大模型,也就老师这个模型呢,他输出了是天空的几种那个 概率。因为对于呢咱们大模型来说,他其实就是一个神经网络嘛,他最后会输出每种分类的一个概率,然后通过这个结果呢,我们用去训练这个学生模型,就是这个问题,学生模型可能训练的就出来的概率呢?是 就是概率分布是这样的,大模型是这样的,那么我们通过一个交叉商损失函数,也就是一个 k l 散度,让我们的学生模型更接近更逼近教师模型,从而就是 让最后就是二者输出的结果,就是他的那个交叉上就是差距越来越小,从而这个时候我们保就是保存学生模型此时的一个结构,那我们就认为他可以就是代表我们的一个原来的大模型了,也就是教师模型 啊。所以说这块的话,就是涉及到一些就是那个神经网络算法类的一些知识啊,如果大家学过就积极学习神经,学那个神经网络这些东西的话,就深度学习的知识的话,其实理解这还是非常快的啊。 然后关于那个蒸馏,它是分为两部分,第一个叫硬蒸馏,第二个叫软蒸馏啊,二者有什么区别呢?就是第一个硬蒸馏,就是说我通过教师模型输出的那个结果,我只取就是概率最高的那个答案。 比如像刚才那个问题,天空是什么颜色的?比如蓝色,那么我们就把蓝色作为标准答案,然后让小模型去训,拿这个答案去训练那个小模型,也就是我蒸馏后的那个模型 啊,就是说这个结果就是固定的,就让他输出这个。比如我问小墨镜填充了什么颜色的,那小墨镜必须得输出蓝色,那这样是符合预期的啊,其他的颜色就是概率都是零,这时候我们就用一个交叉上的反然数来实现这个能力啊。 就比如呢,我们就就抄答题卡嘛,就是说每个每四个选项只有一个是对的,其他都是错的,只有一根零啊,没有什么刚刚才看的那个概率啊,这就是硬蒸馏啊, 就是说只告诉他最正确的答案就 ok 了。然后什么是软蒸馏呢?就是说我们要把就是原来大模型的输出呢?它通过一个 softmax 嘛,然后也输出一个多分类, 有每种类别的一个概率,我们拿这个概率去那个训练这个小模型,其实这时候他小模型是学习我们原来大模型的一个思考能力,因为天空是什么颜色的,可能说他需要就是内部进行一些思考学习考,最后输出了这个结果, 我们是通过一个 k r 散度来用这个就大模型输出,结果去训练小模型, 这个就是他有了思考过程,其实对于一些问题啊,他就有了一些比较好的结果,因为你像有一些知识啊,他没那么明确,没有所谓的一跟零就对与错。他可能说像我们在竖仓中的一些工作,就比如竖仓分层,你是分几层呢?你是分四层他也 ok, 你 分三层他可能也 ok, 你 分一层就留一个,其实有时候他也 ok, 这时候你就需要结合我们实际的场景,实际的一个业务发展去说了 啊。所以你对于这种那个软蒸馏在我们实际中的应用还是非常非常多的,因为这个可以就是有自己的一个思考过程,并且输出一些就是各种可能性的一个概率啊。 就这样他可以学到我们每个类之间的一个相似性,也就是之之前那个论文说的叫那个 dark knowledge 啊, 这个其实我们实际用的就是如果你是那个就是那个,就是对于大模型的要求可能高,就让他有些思考能力,大家可以用软蒸馏,而硬蒸馏呢?是什么情况下用呢?比如说就让商品就对于一些固定的模式,比如 啊像其实他就类似于之前给大家说过的大模型的微调 sft, 我 给出最定固定的答案,然后以及输入的那个数据有输入什么,他输出什么,我把这两个给那个已经有了,然后来训练小模型,然后让小模型输出固定的一个答案。对, 其实它这种类似于那种固定的打标。比如商品,就这个商品它属于哪个类目?可能说这个结论只有一个,就是这个商品只属于 a、 b、 c, 只能其中的一个类目,它不可能属于多个类目。 这时候我们用这种 sft 去那个训练,就是软蒸馏去那个实现其实就非常的那个快啊,也是效果最好的。然后硬蒸,这个对,刚才说错了,硬蒸馏是,然后软蒸馏主要是对于那些结果有一些不确定性概率,比如你像那个 啊,就是刚才说的那个就是书仓分层啊,以及你像一个人的兴趣判断呢,就是用大模型做推理的时候,他这个输出概率都是不一致的,所以说这个时候就可以用软蒸馏了,就我们需要他输出的概率的一个分布 啊,然后对比总结,就是说我们啊硬蒸馏就是说用最后的结果也就是一个固定的值,而软蒸馏是用一个它输出的概率分布啊,标签形式就可以看,如果问号之后,你硬蒸馏这就是一,他这是取 max, 就 这里取了个 max。 而标签软蒸馏的话,它这个标签就是你那个原来大模型输出的一个概率,而损失函数也是有所区别,原来是交叉商,然后这个是 k l 散度了啊,信息量的话,对于硬蒸馏相当来说只有零根 e 就 对与错,而你软蒸馏它会包含一些关系,就是说可能是 a, 可能是 b 啊,所以这个根据场景我们去可以做一些,就是取舍去判断用哪种方式啊? 然后关于这块在树苍中的应用呢,也是简单给大家说一说,就是有很多的应用啊,就是我们经常会用的一个方式,第一个就是一个 circle 的 查询 啊,这个就是关于一些,就是那个就我们用了一个蒸馏之后,我们蒸馏出来一个写 circle 的 小模型,就是业务经常会要一些临时取出的需求吗?我们通过那个就是蒸馏蒸馏出小模型,然后他们在取树的时候,可以直接让小模型去查询树苍蝇的表,然后去那个生成一个 circle, 就原来是由六百多币降到七币了。通过蒸馏然后数据质量检测,因为现在大模型在数仓中应用非常多嘛,你想数据质量检测,我们实时的去检测数据质量,因为数据质量它无非就是那几方面嘛,你想确实只是格式异常、逻辑冲突 等等,就就其实它是固定的嘛。那这时候我们通过蒸馏其实就可以就是实现一个专门实现数据质量检测的一个模型,用来检测我们实际的一个 就是收藏的一个数据质量啊。然后智能指标解读,这个现在用的非常多啊,你像就是我们在那个报表看板上 就是经常会有一些就是指标解读啊等等这些功能其实他都是基于大模型生做的啊,就是可能说他是把这就是我们某个公司,比如抖音,他的很多核心指标,我们拿去训练去蒸馏这个小模型,让他了解这些 指标他历史的一个情况以及变化趋势啊,把这些都喂给大模,就是这个模型之后,他就学到了这些能力,然后再根据你那个看版的指标的一个波动啊等等,然后来生成一个洞察跟归音的分析,这个其实就是在实际中用的是非常多的啊,已经落地了有些场景, 然后再就数据分类脱敏,这个就是说对于一些敏感的字段,像我们在书仓中经常说的手机号、身份证号这种东西,在进入书仓中之前,我们可以通过小模型去判断这个字段的一个敏感程度,然后如果他敏感,我们需要做一些脱敏的操作 啊,但这个就是说你必须得是公司内部部署啊,你不能让数据不库啊,就不能出公司啊,这个大家要注意啊,安全性还是要保证的,因为大模型时代就是说这个安全性一定得做保证啊,不能就是说把公司内部的东西随便就给出去了,或者是通过一些渠道就是传出去了,这些大家还是要 注意的啊,之前就有人犯过那些问题啊,然后那个代码生成的话,就是说我们用代码生成一些模型 啊,就是其实就是你写一个 circle, 或者你让模型生成一个 circle, 写个 circle 可能报错了,让大模型给你改,或者是你给大模型个需求,让他给你生成个 circle, 这样它是减少我们整个一个开发的成本效率的。 对,这是几大应用场景啊,是现在用的比较多的场景啊,大家可以参考一下啊。对,然后整体来说关于大模型,这里肯定是未来的发展趋势吧,反正从现在看的话,你面试啊,还是说公司内部啊,都在推这个的大模型的使用,所以说大家在 那个面试前一定要做好这方面的一个准备啊,包括像一些大模型的一些基本的能力啊,他的一些基本原理啊,大家还是要理解的啊。 对,然后最后的话就是说这个实战的话,就是大家可以看一下啊,主要就是说用了一个 deep, 就 由原来 deep sink, 然后蒸馏到了我们的一个七臂的模型, 然后成本就是可以看出来就是效果不变的情况下,它的成本是降低了,非非常的那个多啊,这是一个实际的案例啊,就是用的那个 sft 微调啊,说白了 因为你像一些 circle 它的那个问题,它的那个值没有什么可能,这个可能那个,其实它的那个 circle 它的写法有些时候是比较固定的嘛, 然后竖仓这个也是啊,就是说通过这些那个就是大模型与竖仓的结合啊,多了一些就是就是一些能力。 最后就是说大家在那个用这块的时候呢,就是有些东西得注意啊,比如说你蒸馏的话,就是啊一些选择呀,包括一些性能啊等等,这些大家都是要那个去注意的啊。 对,这就是关于这块的一个知识啊,如果你也对大数据感兴趣,或有转行校招咨询问题,欢迎评论区留言。
13涤生大数据 05:27查看AI文稿AI文稿
05:27查看AI文稿AI文稿哈喽,欢迎收看本期大模型最新论文分享。今天聊一个挺有意思的工作,叫 self policy distillation, 简称 s p d。 它解决的是大模型自蒸馏的一个老大难问题。自蒸馏我知道,就是让模型在自己生成的数据上训练来提升自己嘛。那这有什么难的,难就难在 模型自己生成的东西是个大杂烩,里面有你想要的能力信号,但也混着一堆风格、模式、格式套路甚至错误,直接拿来训练,等于把好的坏的一锅端了。那大家一般怎么处理这个问题?通常的做法是加外部信号来筛选, 比如用验证器打分,用执行反馈过滤,用奖励模型搜索,先让模型生成一堆后选,再用外部工具挑出质量高的来训练。听起来挺合理的,有什么问题吗?问题在于成本和可得性, 这些外部信号本身就需要额外的基础设施,验证器要单独训练,执行反馈需要沙箱环境,奖励模型也不便宜。更关键的是,对最强的前沿模型来说,比它更可靠的外部标签往往根本拿不到。那有没有办法?不依赖外部信号 也能做好自蒸馏? s p d 的 核心思路特别优雅,它不依赖任何外部信号,而是从模型自身的梯度里提取一个低质的能粒子空间,然后在自身沉的时候把 k v 激活投影到这个子空间上等等。 能粒子空间是什么意思?为什么是从梯度里提取?你可以这么理解,模型的 k v 激活空间是一个高维空间,里面有些方向跟目标能力强相关,有些方向只是风格或造声梯度。告诉我们 模型在哪些方向上对正确性最敏感。把这些方向提取出来就是能力子空间。有点像是给模型带了一副滤镜, 只让能力相关的信号通过对非常好的比喻。具体来说, spd 分 两个阶段,第一阶段是提取这个子空间,第二阶段是用它来引导自生成。第一阶段需要一个很小的校准级,只要二十到五百条带标签的数据就够了。 关键是它不用标准的全序列 loss, 而是用一个叫 correctness aligned loss 的 东西。这个 correctness aligned loss 跟普通 loss 有 什么区别?普通 loss 对 序列里每个 token 都算梯度,但很多 token 其实跟任务成败无关。比如代码里的注示,数学题里的推理过程格式, correctness aligned loss 只在决定任务成败的 token 位置上计算。比如代码任务就只看函数体,数学任务只看最终答案。没错,这样梯度信号就集中在能力相关的方向上,不会被无关 token 稀释。然后对这些梯度做 s v d 分 解取钱,而个主方向就得到了投影矩阵等等。我有个疑问, s v d 取主方向取的是信号中最显著的方向,但最显著的方向不一定就是能力方向吧?万一最大的几个方向恰好是风格或噪声呢?这个问题问得很好,关键在于 s v d 是 对什么做的。 它不是对原始的 k v 激活做分解,而是对 correctness aligned loss 的 梯度矩阵做分解。因为 loss 只在正确性、决定性偷看上计算,梯度本身就已经被过滤过了,它天然指向能力相关方向。对 correctness aligned loss 不 只是让梯度更聚焦, 还保证了 s v d 提取出来的主方向确实是能力方向。对,这两步是配合的。如果用全系列 loss, 梯度里确实会混入风格和格式方向,那 s v d 取出来的主方向就不纯了。消融实验也证实了这一点,全系列 loss 的 效果远不如 correctness aligned loss。 差距最大的地方在代码任务上差了十三个百分点。那第二阶段呢? 怎么用这个投影矩阵?第二阶段很直接,在模型解码的时候,对目标层的 k 和 v 激活呈上投影矩阵。注意模型参数完全不变,只是中间表示被过滤了。用这个带钩子的模型生成训练数据,然后把钩子摘掉,用标准 loss 做 lor 微调。所以本质上是在蒸馏模型自己的一个过滤版本,对 spd 诱导出一个聚焦于目标能力的字策略,再把这个策略的行为蒸馏回原始模型。整个过程不需要外部教师,不需要验证器,不需要奖励。模型效果怎么样啊?在五个 bug 上测试,包括千问的零点五 b、 七 b、 十四 b, 千问三四 b, 还有拉玛三点一八 b 三个领域代码数学问答比基线模型最大提升十六个百分点,比现有最好的无外部型号字蒸馏方法提升十三个百分点。跨域泛化呢?比如用问答域的校准级,能提升代码能力吗?这是最让人惊喜的结果, 用 q a 越一较准级提取的子空间,不仅 q a 提升了,数学从百分之十一涨到百分之二十六,代码从百分之十七涨到百分之二十一,说明 s p d 捕获的不是表面格式,而是更深层的可迁移推理信号。那 correctness aligned loss 到底有多重要? 如果换成普通全系列 loss 呢?消融实验很说明问题,用全系列 loss m b p p 只有百分之十三,涨到百分之二十二,差距巨大。较准级需要多大? 二十条够吗?够。实验显示,二十到五百条的性能差异很小,说明此空间提取的数据效率非常高,这对标注资源有限的场景特别友好。那生成的数据本身质量如何?训练之前就能看出差异吗?能, s p d 生成的数据在训练前就比极限好,比如 g s m 八 k 上比贝斯生成数据高七个百分点,比 s s d 生成数据高八个百分点。定性来看, face 输出永长不聚焦。 ssd 格式规范,但逻辑有错, spd 最紧凑,最聚焦。听起来这个方法的适用范围挺广的,有什么局限吗?目前只在代码、数学、 qa 三个领域验证过,更高风险的领域,比如法律推理、医疗诊断,还需要进一步验证。另外,校准级虽然小,但还是需要带标签的数据。总结一下的话, spd 的 核心贡献是什么?三点, 第一,提出了一种不需要外部信号的能力选择性自蒸馏范式。第二,通过 correctness aligned loss 加 s v d 提取能力,子空间用投影钩子引导自生成。第三,在多个模型和领域上验证了跨越泛化能力。他给自蒸馏指出了一个新方向, 与其依赖外部帮助,不如塑造模型的内部计算,让他自己产生更有价值的训练数据。确实很优雅,用模型自己的梯度来告诉自己该关注什么, 然后生成更好的数据来训练自己,一个自掐的闭环。好,今天关于 s p d 的 分享就到这里,如果觉得有收获的话点个赞支持一下,有问题欢迎在评论区留言,咱们下期再见!
52大模型最新论文 08:21
08:21









