协方差分析的意义和原理
斜方叉分析干什么用?怎么用?当 xa 定类数据、外围定量数据时,通常使用方叉分析进行差异研究。如果方叉分析时需要考虑干扰项,此时就称之为斜方叉分析。第一步,先进行平行性检验,选中平行性检验进行分析,查看交互项是否呈现显著性。批值大于零点零五,说明通过平行性检验。 通过检验后取消勾选,再次进行斜方叉分析。斜方叉分析结果智能分析与分析建议让你更懂数据分析,你学会了吗?

粉丝3.9万获赞18.9万
相关视频
 06:08查看AI文稿AI文稿
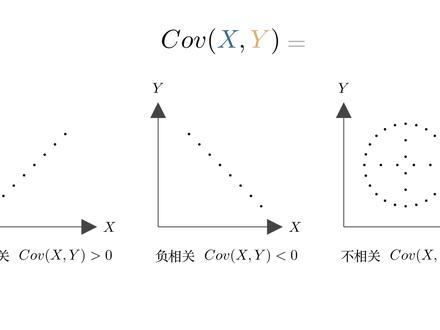
06:08查看AI文稿AI文稿同学们大家好,今天我们来学习斜方叉。简单的说,斜方叉就是用来描述两个随机变量的相关性。随机变量的相关性分为三种,当 x 增大时, y 也增大, x 减小时, y 也减小。 x y 同向变化,此时 x y 正相关,斜方叉大于零。当 x 增大时,歪减小, x 减小时,歪增大, x y 反向变化,此时 x y 负相关, 斜方叉小于零。当 x 增大时, y 可能增大,可能减小。当 x 减小时, y 可能增大,可能减小。或者 x 变化时, y 没有变化, y 变化时, x 没有变化,此时 xy 不相关, 斜方叉等于零。也就是说,我们可以通过斜方叉描述随机变量的相关性, 那他的数学表达是该是什么样的呢?下面通过一个例子来简单分析一下。 我们来考察一下身高与体重的相关性,为此采用了以下样本。下面以身高为横坐标,体重为自动坐标,建立坐标系,然后将第一、二个样本表示在坐标系中。 很显然,对于第一个样本而言,第二个样本横坐标增加了,纵坐标也增加了。此时身高与体重正相关,我们用这两个点构成的一个红色举行来表示,然后将第三个样本点表示在坐标系中。相对于第一个点,第三个点的横坐标增加了, 纵坐标也增加了。此时身高与体重正相关,我们也用一个红色举行来表示。相对于第二个点,第三个点的横坐标增加了,纵坐标却减少了。 此时身高与体重副相关,我们就用一个蓝色举行来表示,最后再将第四个点表示在坐标系中。用同样的方法,他和其他三个点会生成三个红色举行。 在这幅图中,红色代表正相关,蓝色代表负相关。很显然,红色比蓝色多,因此整体上身高体重是正相关的。 这个方法虽然直观,但比较麻烦,每个点都需要和其他点比较一次,比如这里再增加一个五号样本,他就需要和前面四个点都比较 一次,再生成四个。新的举行有没有办法对此进行简化呢?既然要和所有点都比较,那么就和与君之比较的效果是一样的, 计算出均值,将他在坐标系统表示出来,然后只需将每个点与均值比较就可以了。可以看到结果仍然是红色占多数,说明身高体重总体是正相关的。 如果把坐标远点移到均值的位置,我们还能很容易的知道一三相线是正相关的,二次相线是副相关的。 下面我们用红色区域的面积减去蓝色区域的面积,通过其结果来判断相关性。首先看第一个红色区域,他是由第一个样本点和均值构 组成的。将第一个样本点用 x 一 y 一表示,均值用 x 一八, y 一八表示,则第一个区域的面积为, x 一减 x 一八,乘以 y 一减 y 一八。将第二个样本点用 x 二 y 二表示, 则第二个区域的面积为, x 二减 x 一八,乘以 y 二减 y 一八。将第三个样本点用 x 三 y 三表示, 则第三个区域面积的相反数表示为, x 三减 x 一八,乘以 y 三减 y 一八。加上它,就相当于减去了蓝色区域的面积, 用同样的方法表示出第四和第五个区域。需要注意的是,在这个式子中,表示红色区域的象是正的,表示 是蓝色区域的相是负的。将这个式子用连加符号简写,若结果大于零,则他们正相关等于零,不相关,小于零,负相关。对这个例子而言,带入数据可以算出结果为正, 因此身高体重是正相关的。虽然通过这个式子,我们判断出了身高体重的相关性,但他还不是斜方叉,因为他还有点小问题。 假如我再加入以下两个样本点,因为此事均值并没有发生变化,所以坐标远点还是这个位置。然后将新加入的两个点表示在坐标系中, 他们分别在二、四相线是副相关的。这时候蓝色区域大于红色区域,按照算法, 身高体重变成了副相关。身高体重成副相关,明显与我们的直觉不符,那是出现了什么问题呢?观察后发现,新加入的两个样本要么是又矮又胖,要么是又高又瘦, 出现的概率极低,也就是说,我们少考虑了概率。加入概率因素求得的平均值,我们称为加权平均。将原点移到加权平均的位置, 世子里的均值就被替换为家权平均。因为此时坐标系和各个点已经不重要,所以将他们引去对每一项乘以其相应的概率。 此时每个区域都有不同程度的缩小。为了让同学们看的更清楚,这里将他们放大一点, 可以看到红色区域仍然占多数,身高与体重仍然是正相关的。 通过这个式子,我们就可以判断出随机变量的相关性码。将式子改写为期望的形式,这就是斜方叉公式。
2624马同学图解数学 09:41查看AI文稿AI文稿
09:41查看AI文稿AI文稿大家好,这节我们一起来学习斜方叉分析,我们先看一下这个案例,为了研究三种不同饲料对于生猪体重增加的影响, 将生猪随机分成三组进行喂养不同的饲料,这是三三种不同的饲料,那么我们另外还有个数据,就是生猪在喂养前的体重,那么这里我们就有三个变量了,一个是生猪的体重的增加, 一个是不同的饲料,这个是不同的水平,对吧?那还有个就是喂养前的体重,我们有三个变量, 那么所谓的斜方叉的分析,他就是将无法或者很难控制的因素作为斜变量,在排除斜变量影响下来分析控制变量对观测变量的影响。那么在这个例题里面,三种不同的饲料,这个 就是控制变量的三个不同的水平,对吧?那么体重的增量,这个是应变量, 这就是我们要看的观测值,那么在这里初始的体重是这样,对于这个小猪的体重的增加,他是非常重要的,对不对?但是这个我们是不能够控制的,因为给我们的样本提供给你的小猪,他的体重就原来已经是固定的了, 那这个初始的体重,那么就把它作为鞋变量,那鞋变量的分析方法,实际上他是结合了方差分析和回归分析,那么在我们的书上他后面有做了 三组的这个回归方程,大家可以用 excel 或者用 evo 式,或者用其他的软件去做,做的答案是一样的,我们在这里老师只是演示在 spss 里面怎么做斜方 方差的分析,那斜方差的最重要的是要引进斜变量, 那我们还是认为观测变量他是受四个方面的影响,一个是控制变量的独立作用,对吧?另外一个控制变量,他们如果不同的控制变量他有个交互作用,那么第三个我们就引进了协变量的作用,那最后一个是随机因素,那方超分析中的这个圆角色是什么?我们认为 斜变量对观测变量的线性影响是不显著的,这个是 h 零,记住啊,如果 h 一的话,那就是斜变量对观测变量的线性影响是显著的。 那斜方叉分析包括什么内容?第一包括 spss 的斜方叉的分析,第二个包括他的 均值分析,第三个我们可以做一个图形的分析,当然你还可以再做一些其他的分析,那现在我们来看一下案例。好,我们现在在 数据编辑器窗口,我们已经打开了生猪与饲料这个数据文件,那现在我们首先来做一个斜方叉的分析,还从分析这里进入,我们选择一般线型模型,看到没有?一般线型模型单变量在这里我们可以看到, 那应变量是什么?应变量显然是喂养后体重的增加值,对吧?那么固定的因子我们要做的是 不同水平的饲料,也就三种饲料,那在这里的话,我们又多了一个协变量在这里,那喂养前的体重我们 做一些变量,那这样的话我们可以直接来做一个确定就可以了,这样我们就得到了一个 伸出体重的斜方叉分析结果。我们看一下这个主体筋兼效应的检验,在这里的话,我们可以看出喂养前这个是作为一个斜方叉,这个是饲料,这个是控制变量的这个影响水平,那这是误差,这是总计,那在这里我们可以看到 f 统计量的观测值,还有他们的概率在这里,那概率是零的话,我们可以是什么? 我们刚刚讲的好,我们看饲料后面的这个坯子是零,那是拒绝演假蛇,也就是说饲料的不同的水平,也就是不同的饲料 对于观测变量是产生了显著的影响啊。再看一下喂养前的这个体重,这个斜变量,他的体脂也是零,那这个是代表是什么呢?那也就是 也是我们也是拒绝原假设,那就代表鞋面呢?对于观测变量的线性影响是显著的,那么在这里的话,我们就是如果要进一步研究的话,我们要把 喂养前的体重,这个鞋变量的因素,他的影响因素剔除了之后,再去研究饲料的不同水平对于喂养后体重增加的影响程度。 那接着我们来做一个君子对比,还从分析这里进入一般线性模型单变量,那在这里的话我们选择对比,那对比,在这里 我们可以看出只有因为只有一个因子,就是一个控制变量,那我们在这里的话,我们选择简单就可以了。简单,那现在先选最后一个,因为他是这个三种饲料,我们看一下这个我们先, 然后点击,我们先把变化量这里点了以后我们点继续这样点确定好,这里我们可以看到对比的结果, 这个是参考类别是三,也就是用级别一和三来对比,级别二和级别三来对比,这个是指三种的饲料, 那那我们可以看出第一种饲料比第三种饲料增加了多少?就是平均多增加了体重十二点七九三,那第二种比第三种平均多增加了十七点三三六, 那这里我们就可以看出第二种比第一种平均多增加了四点五四啊,那第二种饲料是比较好的,然后其次是第一种,那第三种这个饲料是不好的啊,那这是一个结果,那我们也可以再再换一下,我们是用试用, 这个是用第三组作为标准的,对不对?用第一和第二和第三组是错对比,那我们现在也可以用第一种为标准,用第二和第三组来进行一个对比。我们还是从分析这里进入 一般现行模型单变量那对比,那这里的对比我们可以换一下,我们换成第一个啊,第一个这变化量看这里已经变成了 饲料简单分析法的这个第一个我们继续,那 我们可以看到一个新的一个表格,这个对比结果这个参考类别是一,我们书上面他也有这个 表格,但他没有说怎么做的啊?这里老师演示一下是怎么做的,那这里我们就可以看出来,第二集和第一集的这个相比的话,他是一样的四点五四二,那第三集和第一集相比,这里是负的十二点七九三,他的结果他是一样的, 对吧?啊?你也可以看一下检验的结果,这个显著性水平,还有刚才的这个显著性水平,他都是小于零点零五的。 不支持原假设就是拒绝原假设,也就是说他们是有显著差异的。 当然我们也可以看一下这个书上他也讲到了,就是说基本描述统计量,我们可以看一下基本描述统计量,我们再来看一下 这个是描述基本的描述统计量,从基本的描述统计量来看,我们看一下这个平均值,也就是喂养后体重增加的平均值,这里说是 第二种饲料是最好的,第三种是饲料是其次,第一种饲料是最差的,对不对?这个是一般的这种的描述性的统计量,我们是这样来看的,但是我们看了一个这个 对比分析了之后,我们结果跟他是不一样的,对不对?描述统计量里面第一种饲料的效果是最差的,但是我们经过方差分析, 我们发现这个对比结果里面,那实际上是第三种饲料它的效果是最差的,所以说这个两种的结果它是不同的。 最后再来做个图形的分析,一般线形模型单边量,那我们看下这个图形,那图形的话我们直接做个水平轴,水平轴的分析添加那。呃,这个折线图可以从平均参考线,这个也可以选一下。 好,我们来看一下这个结果,从这里看,看到的话可以看出来了,这是第一种饲料,这是第二种饲料,这是第三种饲料,所以我们从这里可以看出来是什么。 第二种这个饲料效果是最好的,对不对?第一种饲料是第二好的,第三种饲料是最差, 他的是不是这样子?这个和我们描述性统计量是不一样的,但是和我们做的这个君子的对比结果他是一样的, 也就是说我们做这个斜方差分析,大家刚才看了,我们可以做三步,一个做个斜方差分析,第二个做个君子对比的, 然后看一下他的结果。第三个我们可以做一下这个图形的分析,那么这个图形的分析书上面没有写,但是这个因为很直观,我建议大家做的时候要加上这一步啊。那这节我们就一起学习到这里。
73何晓琦老师 06:54查看AI文稿AI文稿
06:54查看AI文稿AI文稿大家好,我是赛蔻小白,今天给大家介绍方叉分析,要是觉得这个视频有用的话,爱心点赞关注,这是对更新的最大动力。 方查分析的英文为 analysis of various, 缩写就是 anover。 看这个视频的同学们要是没有学过体检验的话,可以先学习体检验,之后再看方查分析。方查分析主要是用来比较不同组之间的均数是否存在显著差异。我们在体检验的时候讲过,之前的体检验只能检验两组, 方扎分析能检验多组。一般情况下,在比较三组及以上的组建差异的时候,我们会用方扎分析。我们首先举个例子,我们想知道医学、心理学、生物学的学生之间在推理能力上是否存在差异。于是我们抽取了十个医学、九个心理学和九个生物学的学生,让 他们去进行推理能力测试,最后得到了以下分数,一、学生的平均分数是八十一分,心理学的平均分是八十三分,生物学的学生是八十 七分。我们发现分数差最大的在医学和生物学之间有六分的平均分差异。那么我们能说生物学的学生推理能力显著大于医学吗?不能,因为有人会说你的车样只有十个医学生,这十个人可能刚好不是很擅长推理。确实如此,所以我们需要引入方差分析,从统计的角度来得出能否给出更合理的答案。 所以首先我们先提出我们的零假设,零假设是医学、心理学、生物学的学生在推理能力上是相等的,而被责假设是至少存在一组的均数与其他组之间是不同的, 那么这里需要值得注意的是,贝德假设不是需要医学、心理学和生物学的学生推理能力都不相同,而是只要存在一组与其他任何组军数不同即可。在确定的假设以后,我们就需要确定显著性水平 up 值,并找到 f 零介值。那么首先我们来介绍一下方叉分析的统计量 f 值。 f 值的公式不复杂, 公式的具体细节之后我会在视频下方写上,但是在这里我会简单的解释它的构造,以更好的理解方差分析 f 值等于组间均方,除以组内均方分母, msw 关注的是多组之间的组内差异。样板量不同的时候求的是汇合方差,当样板量相等的时候,就正好等于各组的方差的均数。 分子部分在体检研中我们应该记得分子是用两组均数相减获得了组件差异,而对于多组情况应该怎么办呢? 有一个统计量是专门描述数据的离散程度的,就是方差。要是我们想知道三组以上的组间均值离散程度,只需要求他们的方差,就知道他们之间的均值差异是大还是小。所以组间差异相比于组 内变异越大,则 f 值越大,越能够拒绝零假设。回到之前的 f 零界值查找,我们设定阿法值为零点零五,然后根据自由度来找到我们的临界值。放上分去的自由度有两个分子,部分的自由度为 df between 等于 k 减一,其中 k 是组数分母部分的自由度, d f v c 等于 n t 减 k, 其中 n t 为总样本量。根据自由度公式,我们知道 d f between 为三减一等于二, d f v c 为二十八减三等于二十五。然后我们再查表, 这张表是在 off 为零点零五十对应的 f 临界值。这里只截取了部分的表,所有的自由度都能从一到正无穷。每一列对应的是 d f between, 而每一行则对应不同的 d f v z。 在我们这里找到了 d f between 等于二, d f v z 等于二十五, 则我们可以确定 f 零戒指为三点三九。找到零戒指以后,我们就可以通过公式计算 f 值,然后对比 f 值与 f 零戒指之间的差异,就能够确定组间是否存在显著差异。 那么假如我们得到的 f 值为五,那么我们就能够拒绝零假设,说明医学、心理学和生物学的学生在推理能力上是存在显著差异的。而如果我们得到的 f 值为二点五,那么我们就 没有能够拒绝零假设,说明目前的条件下,医学、心理学和生物学的学生在推理能力上是不存在显著差异的。在这里需要注意两点,第一,我们需要注意当 f 值大于 f 临界值时,我们能够说拒绝了零假设。我们的数据支持倍值假设。当 f 值小于临界值时,我们不建议说接受零假设, 而最好说没有能够拒绝零假设,因为我们只能说明我们当前的证据没有证明某件事情,但不能证明他完全不存在,比如可能是因为研究的某些原因疏忽而导致的。第二 方查分析是无法告诉我们具体哪两组之间是存在显著差异的,比如,当发现结果显著,我们只能说三组之间是存在显著差异的,但是我们不知道到底哪组和哪组之间是差异显著。 回到之前的例子,我们不知道三组之间到底是医学、心理学,还是心理学、生物学,又或者是其他可能的情况,所以我们需要进行伺候检验,才能够知道具体的均 差异是什么样。这一部分可以留到之后再讲。放大分析有许多用法,之前讲的是单因素放大分析,因为只有一个资源量,并且组之间是相互独立的,除了单因素,还有两因素、三因素等。在这里我先介绍一下两因素放大分析。比如除了看三个学科学生的推理能力,那么还想再加一个角度,就是咖啡习惯, 可能喝咖啡的人推理能力会更好。又或者是只有生物学的学生喝了咖啡会提高推理成绩,医学生和心理学的学生就不会提高推理成绩。那么这些发现似乎是更有意义的。 这也是引入第二个自变量的关键,就是可以探讨交互作用,对于交互作用,大家感兴趣可以之后再查。而对于重复测量放大分析是当一个自变量的时候,我们采用的是重复测量。比如我们有一个专门的推理训练, 想要看他对学生的推理能力是否有帮助,于是我们就测量他们在训练前、训练后和训练一个月以后的成绩,然后比较这三组之间是否存在显出差异, 就能用到重复测量方查分析。接下来是混合设计方查分析。混合设计方查分析一般是当我有两个自变量的时候,一个自变量是不同学科,比如医学、心理学和生物学。另一个自变量是重复测量,比如我对不同的学科学生进行推理训练,然后测量他们训练前、训练后和训练一个月以后的成绩, 这时候就能用到混合设计防沙分析。接下来是防沙分析的前提假设,因为防沙分析是参数检验,所以需要遵循其他类似的假设。首先,单一束防沙分析和两一束防沙分析是需要遵循独立水机抽样正在分布防沙起线。 除此以外,重复参加方扎分析,在单一数方扎分析的基础上还要遵循斜方扎分析。混合设计方扎分析,在单一数方扎分析的基础上还要遵循组间斜方扎分析。最后做一个总结,方扎分析主要是用来比较不同组之间的均数是否存在显著差异。方扎分析得到的结果显著,只能告诉我们在这几个均数之间是存在显著 差异的,但是无法告诉我们具体的差异情况是怎么样,必须结合事后检验才能得到具体的差异结论。方章分析的统计量为 f, 当零假设为真实,服从的是 f 分部。这一部分知识可以进一步掌握 社科医学的领域应用到的方法分析,比如单因素方法分析一个字变量且三个及以上的不同水平背时间设计,例如学科式字变量、医学、心理学、生物学三个水平,每个学生只能在一个水平内。两因素方法分析两个字变量主要是关注两个字变量之间的交互作用,交互作用不显著的时候,也能同时关注到两个字变量的主效应。 重复测量方扎分析,一个字变量,且是三个及以上的不同水平背时内设计,例如时间训练前、训练后和训练三个月以后。接下来是混合设计。方扎分析,一般情况下,两个字变量,一个为背时间变量,一个为背时内变量。最常见的就是不同组的人在多个时间被测量收集数据。由于方扎分析涉及到的内容很多, 一直在这里简单的介绍一下方扎分析的原理和应用场景,要是有任何疏漏还请指正。视频制作以分享知识为主,要是大家觉得有帮助还请点赞关注。
1925Psycho小白 07:05查看AI文稿AI文稿
07:05查看AI文稿AI文稿大家好,今天要讲的内容是方叉、斜方叉和斜方叉矩阵。 方叉、斜方叉和斜方叉矩阵是重要的数学概念,很多机器学习算法,例如 pca 主成分分析、 lda 线性判别分析、多元高次分布等等都要依赖他们。 方叉描述了一组随机变量的离散程度, 它等于每个样本值和全部样本的平均值。差的平方和再求平均数记作 v a r。 如果有 m 个 样本,每个样本都有一个特征值 x, m 个样本的平均值是 mill, 那么 x 的方叉等于 m 分之 sigma x i 减 mill 的平方。 例如,计算数字一到五的方差,首先计算出平均值三,然后计算这些数字和平均值差的平方和再除以五,得到方差是二。 很多时候,为了后续计算的方便,会对样本进行去中心化的处理。 将全部样本按照平均值进行平移后,可以得到方叉 x 等于 m 分之 c 格满 x i 的平方,这样就可以 在不影响样本分布的情况下简化计算。 例如,一到五,每个数字都向负方向移动三个单位得到负二,负一零一二,计算他们的方差,结果仍然是二。 斜方差描述了不同特征之间的相关情况。通过计算斜方差,可以判断一组数据中的不同特征之间是否存在关联关系。 说样本有两个特征, a 和 b。 训练集中一共有 m 个样本, a 和 b 之 之间的斜方差记作 c o v a b, 它等于 m 个样本的特征 a 减均值谬 a 乘以特征 b 减均值缪 b 的乘积,然后累加到一起,再除以 m 减一。 例如,在平面上设置一一、二、二等等到五、五这五个样本,每个样本有 a 和 b 两个特征, a 的平均值是缪 a, e 的平均值是缪 b, 他们都等于三。 从整体上来说,当 a 大于平均值 mill a 时, b 也大于平均值 mill b, 或者 a 小于 mill a, b 也同时小于 mill b, 这时计算出 a 和 b 的斜方差就是正的,这说明 a 和 b 的变化趋势相同, a 和 b 是正相关的。换句话说,就是 a 变大的时候, b 也变大, a 变小时, b 也变小。 如果有一负一、二负二等等到五负五这五个样本,我们会发现 a 小于谬 a 时, b 大于谬 b, 而 a 大于谬 a 时, b 小于谬 b, 此时计算 a 和 b 的斜方差就是负的,这说明 a 和 b 的变化趋势不同, a 和 b 是负相关的。也就是说, a 变大的时候, b 变小, a、 b 变小时必变大。 如果样本整体的斜方差刚好等于零,那么就说明 a 和 b 不相关。例如有二、二、二、四、三、三等五个样本, 根据公式计算, a 和 b 的斜方叉刚好等于零。从图中也可以看出, a 和 b 的分布没有规律。 为了更方便的计算斜方差,我们同样可以将数据进行去中心化,得到的斜方差不会有变化。 总结来说,斜方叉表示了不同特征之间的相关情, 两个特征之间的斜方差大于零,则正相关小于零,负相关等于零不相关。 最后来看斜方叉矩阵。斜方叉矩阵计算了不同维度之间的斜方叉,它由方叉和斜方叉两部分组成, 其中对角线上的元素是各个随机变量的方叉,非对角线上的元素为两两随机变量之间的斜方叉。斜方叉矩阵是一个对称矩阵, 例如矩阵 c 一是 a 和 b 两个 特征的斜方叉矩阵。矩阵 c 二是 x、 y、 z 三个特征的斜方叉矩阵,而矩阵 c 三是 x、 e 到 x, n、 n 个特征的斜方叉矩阵。 在计算斜方叉矩阵时,需要将 m 个样本的特征按照列向量的方式保存到矩阵中,然后计算矩阵和矩阵转制的成绩,得到斜方叉矩阵。 例如 m 个样本,每个样本有 a 和 b 两个特征,将这些样本按照列项量的方式保存到矩阵 x 中。计算 m 个样本的斜方叉矩阵,它等于 x 乘以 x 的转制,再除以 m, 它是一个二乘二的矩阵。 那么到这里,方叉、斜方叉和斜方叉矩阵就讲完了,感谢大家的观看,我们下节课再会。
387小黑黑讲AI 02:11查看AI文稿AI文稿
02:11查看AI文稿AI文稿sbss 操作步骤讲解系列第十五课,斜方叉分析斜方叉分析检验在斜变量控制下应变量在分类变量上的差异情况。 第一步,将需分析得数据导入 spss 中并复制后点击分析一般线性模型单变量。 第二步,进入图中对话框后,将变量放入对应的变量框中后点击选项,将因子放入右侧平均值框中,勾选比较主效应描述统计其性检验,点击继续确定。 然后单因素斜方叉的主体间因子描述统计来闻其心 检验、主体间效应检验和成对比较,结果就出来了。第三步,多因素斜方叉分析操作步骤,数据导入并复制后,点击分析一般线性模型单变量。 第四步,进入图中对话框后,将对应的变量放入对应的变量框中,点击选项,将因子和因子交互相放入右侧平均值框中,勾选比较主效应握描述统计其性检验,点击继续确定。 然后多因素协方差分析、主体间因子描述统计来文其性检验、主体间效应检验估算值分类变量凉凉比较最重要的交互 互相的凉凉比较检验啊!根据多因素方差分析交互相凉凉比较的操作步骤类似,均需要通过修改语法进行检验,结果就出来了。 将主体间效应检验结果粘贴复制到 excel 表格中,并将凉凉比较的结果整理放在表格的后面。 学会了吗?记得点赞关注呦,可带坐指导交流学习!
57艾吖法数据 04:07查看AI文稿AI文稿
04:07查看AI文稿AI文稿大家好,下面呢我们继续讲解,我们讲解一下我们的斜方叉分析。 当研究者知道有些斜变量会影响因变量却不能控制和不感兴趣的时候 啊,或不感兴趣的时候。对,比如说,当研究工作时间对员工绩效的影响,员工原来的工作经验、能力,职业素养,就是鞋面量,可以在实验处理前予以观测,然后在统计时运用鞋方叉分析来处理。 斜方叉分析呢,是将回归分析同方叉分析结合起来,将斜变量对音变量的影响从字变量中分离出去,从而呢,可以进一步提高实验的精确度和统计检验灵敏度,以消除混杂成混杂因素的影响,是对 实验数据进行分析的一种分析方法啊。斜方叉分析不仅可以使用分类变量,还可以使用连续变量。通常情况下,斜方叉分析将那些难以控制的因素作为斜变量,从而在排除斜变量影响的情况下,分析因子变量对响应变量的影响。 根据斜半量个数的不同,当模型当中只存在一个斜半量的时候,它就叫做一元斜方叉分析。当有两个或两个以上的斜半量的时候呢,它就叫做多元斜方叉分析。 在这个 skate 十六点零版本当中呢,斜方扎分析的基本命论语句与多因素方扎分析也是一致的啊,也是这一个,呃,这个命令当中呢,呃呃,具体的这各个选项也是一样的,它的区别在哪里呢?在 于我们这有一个 tom list, tom list 当中呢,斜方叉会用到一个连续的变量,连续变量呢,大家再注意,在我们的这个方叉分析当中呢,一定要加上 c 点儿 啊, continue 啊,英文的简写, c 点开头的变量如 c 点 h, 比如说我们的年龄就是一个连续的变量啊,呃,就是 c 点 h 啊,我们还还是基于这个数据四进行一个斜方向分析的一个讲解 啊,这个呢,就是我们除了除了这三个之间的这种量量交互作用之外啊,这就是我们前面的那一个,呃, 多因素防查分析的那个命令啊,在后边再加上一个连续变量啊,是一点信任, 那可以发现加上这个信任的这一个显著程度还非常高,加上信任之后呢,我们的这一个可见系数和修正可见系数都得到了一个非常显著的提升,都接近于满分了现在。是啊,然后呢,我们这个信任程度也是这个非常重要的一个斜面量, 然后呢,我们还可以进行一个回归分析,针对这个叫 regress。 关于这个回归分析呢,我们后续的在各个章节当中呢,也会讲到啊,也是很重要的很基础的一种分析方法。 这个回忆分析啊,其实相当于就是把它把 这个消费度,消费者整体接受的评价作为音变量,把这三个变量它的因子及其交互向以及这个斜变量,它呢作为字变量啊,呃,这一堆作为字变量进行了一次回归分析啊, 其实这就是它的一个为什么在一开篇的时候讲到就是我们的这一个斜方叉分析,它的本质啊, 本质他是这个将回归分析同方法分析结合起来啊,将斜变量从对音变量的影响从字变量当中分离出去,进一步提高了实验的精确度和统计灵敏度,消除了混杂因素的影响, 是吧?这就是我们斜方叉分析的一个讲解,谢谢大家。
 10:32查看AI文稿AI文稿
10:32查看AI文稿AI文稿当你的变量内形里面有一些是分类变量的时候,特别是你要探索两个两个分内变量之间 是一个什么样的关系,或者是两个分裂变量与另外一个连续性的变量是一个什么样的关系。这个时候呢,我们就可以用到下面的这些方法, 主要是交叉表分析、卡方分析和这个方叉分析。其实方叉分析在呃各个领域,在在生物学啊,在这个心理学啊,都运用的还是非常非常广泛的,所以说呃方叉分析也是非常重要的一个重要的一个分析方法。 那么方向分析的,其实有时候我们也把它叫做 f 检验,也是把它叫 f 检验,它在本质上呢,实际上是比较两个或者两个以上的样本均值是否存在显著的差异。 虽然他叫方差分析,他本质上比较的是两个和两个样本之间的均值,因为跟均值相对应的还有一个是方差,对吧?而且他在分析的过程是御用的一些方差,所以我们把它叫做这个方差分析,他本质上是比较几个样本之间的这个均值。那么我们说方差分析的目的就是实现梳理出 各个不同的这个分类变量。分类变量就说我们质变量是一个分类变量,然后阴变量呢,可能是一个这个呃数值性的变量, 我们要看不同的这个分类变量对一些事物是否具有显著性的影响,特别是连续性的变量是否具有显著的影响。比如说我们这个里面用的分类变量,用性别,用不同广告的类型,都是我们所说的这个分类变量,对吧?那么 呃连续性面料或者我们所说这个数字性面料有什么呢?比如说这个用户对于产品的购买意愿,用户对于产品的购买意愿, 对吧?这个都是我们所说的这个连续性的这个变量。呃,连续性的变量或者是数值性的变量。好,它的原理是什么呢?它原理呢?实际上就是说利用主内及主间这个偏差平方与自由度,呃计算出主内主间的这个军方的这个值,从而计算出 f 值, 然后依靠这个 f 分布去判断呃变量之间的这个关系是否存在变量之间是否存在显著的这个差异。说的相对来说有一点偏专业哈,相对来说偏专业。但是如果你完全没有学过统计学,也没有学过概念论,你就理解一点,就是不同组织他的均值是不是一样的? 方才分析就是要做这个不同组建的均值是不是一样的,但是为了从统计上判断他的均值是不是一样的,他可能他运用了一些其他的一些指标,比如说主内组建的这个军方,呃,这个军方的这个值啊等等等等一些其他的那些 判断。那么从操作上呢?显著差异是否是等于显著影响?是的,我们说显著差异就是说他的他 a 对 b 的影响,他 他存在显示他就说 a 对 b 的影响,他不是等于零,他是大于零或者是小于零的,所以说 a 对 b 就有显著的影响。好吧,那么方叉分析他有一些要求。要求呢?首先是这个质变量和这个音面量之间的这个关,呃,这个类型是有要求的, 首先是要要求分析分类变量与数值性变量这样的关系,我们刚才已经给大家强调过了。第二个呢,就是说他对样本的要求,他是两组或者多组之间 数据之间的差异进行呃进行检验。就像如果我们进行这个,如果只有两组的话,他在本质上他实际上也是一种 t 检验,是本质上也是一种 t 检验,对吧?我们说 f 检验和 t 检验他本身是有一个关系的,本身是有一个关系的。也是这里其实也是可以反 根据自备量的这个类型,我们可以把方差分析分为单一组方差分析、双一组方差分析和这个多一组的方差分析。当然这个分类其实跟我们前面讲这个,呃,回归分析的是我分类方式,实际上是有一些类似的哈,有一些类似的 回归分析的时候,我们有一元现金回归和这个多元现金回归,对吧?然后这里呢,我们有单因素分叉分析和双因素分析分析,还有多因素分叉分析。 呃,我们这里面在进行分析的时候,都是说质变量是一个或者是多个,但应变量肯定是只有一个的。在统计分析里面,如果应变量有多个的情况下,有多个的情况下,也可能会存在,也可能会存在。但是这种呢,比较复杂,比较复杂,不建议那种基础不是很好的同学去使用。 如果基础不是很好的话,你就去做一些比较常规的分析,比如说这个回归分析啊,方向分析也是我们今天要讲的这一些目,主要 目的哈,就采用一些比较简单的方法去得出你们需要的结论,而不是说上来就会说,我会,会,我会很多分析方法,我来把我所会的分析方法全部来一套,那没有这个必要,没有这个必要。 好,那么方叉飞机怎么去操作?呃,首先呢,我们要去计算这个方叉飞机的这个主内方叉和主尖方叉,然后通过主内方叉和主尖方叉呢得出这个 f 值,根据 f 值去查对应的借零借表 临界表,确定这个临界表的这个值。然后呢去根据我们的这个呃 f 值和临界表的这个值 进行比较,然后以及去看去判断,如果 f 值是小于零戒值的话,一般就说明他的 p 值肯定就是大于零点零五了,一般就说明他们之间是没有显著差异的。 如果 f 值大于零借值, f 值比零借值大,然后就说明变量之间存在显著的差异,也就是说这个分类变量对我们这里所说的这个数字变量是有显著的影响的。呃,有同学问到说方拆分析、卡方检验都是大于零借值的时候显著,对吗? 实际上啊,不管是方差分析还是卡方卡方分析,还是我们所说的回归分析,他都是一样的。就是说你根据你算出来这个 f 值或者是这个 t 值去跟你的这个零界值进行比较,当你的 f 值 t 值越大大于零界值的时候,那么你的 t 值是会越小的,这个是我们说是存在显著差异的。 如果你的 f 值 t 值或者是 p, 呃,或者是这个卡方值他都是小于你的零戒值的话,一般他的这个 p 值就会大于零点一五,就说明没有显著的差异,这是我们从原理上,从原理上进行了这个 讲解。那么从操作上呢?操作上一样的,我们还是按照我们之前的这个思路,从操作上给大家讲一下。从操作上我们在分期数据或者收集数据的时候呢,我们有两类变量,一类是分类变量,也是我们所说的质变量,对不对?分类变量或者质变量, 我们呢就可以去啊,把这个质变量放到这个分析分析的这个质变量方框里面去。然后呢?呃,因变量呢?可能是连续性的变量,可以是购买意愿或也可以是信息性,或者这个趣味性。假设我们看这个购买意愿, 我们就会发现这个性别,这里面性别呢,就说女性对这个购买医院的均值是五点三二三五,男性的是五点一九三九,对吧?这个值好像是有差别,因为从这个数值上看,女性的这个值是比男性的这个值大的,但这个值从统计上 是不是一定是女性的这个购买医院比男性的统计医院大?我们需要去做这个方差分析,做这个方差分析,我们读出来这个 f 值是多少呢? f 值是零点四五八七, 零点四五八七,零点四五八七,得出来这个 p 值呢?可能就是呃,因为这个值已经比较小了哈,已经比较小了,一般你至少要呃大于,一般要大于二或者大于三嘛,这才会显著。好,那么在这个零点四五八七的这个情况,你的 p 值就会 大于零点零,我们说这个影响是不显著的,影响是不显著的,那么影响是不显著,有可能是什么?有可能是 因为你分析的时候,你的这个样本的这个样本的这个男女比例不协调,对吧?有可能是你这个分析的比例不协调,或者是什么样子,要去找一下原因。所以说我们在分析的时候哈,一般是一般是这个样子的,我们在收集数据的时候再给 给大家强调一下,分析的时候呢,为了平衡,为了平衡这个性别啊,平衡这个地域,一开始的时候,你不要一开始就比如说我要收集一千二百分问卷,或者我会收集收集四百分问卷,我一开始咔就把四百分问卷给设置了。 你如果这样设计的话,首先你的这个人力成本和这个人力物力财力就发挥很大的,这个人力物力财力,结果一收起来发现啊,要么你们问,就你们有一项有问题, 问题里面有一项有问题,那么你需又需要全部重新推到全部重来,这个对你来说是有很大的损失。 所以我们建议,我们建议大家在做的时候呢,做的时候做这个,呃,做一次前侧,做一次前侧,也就是在正式发布问卷的时候,你做一次前侧,前侧就是在发布之前测一下你这个问卷,测一下你的这个收集收集数据的 方式是不是合理的收据收据是不是合理的,如果不是,你可以稍微进行修改,这里的损失也只是少部分。我们说 t 检验是可以,但是 t 检验,因为我们说 t 检验是 f 检验的一种,对不对?不是说 t 检验不是 f 检验,他只是一种,这实际上是我们所说的单因素方差分区,不是说他不是方差分析,好吧? 如果是有多个变量的话,那么你就需要做什么?如果有多个变量,你就需要把多个变量放在一起做这个方差分析就是多因素方差分析。多因素方差分析呢?可能还会有一个,呃,可能还会有一个更复杂的情况,就会出现这种交叉,就是交互的影响。 就比如说这一个是性别,那么一个是性别,一个是年龄,那么性别和年龄他们除了这个性别会对这个购买意愿产生影响,年龄会对购买意愿产生影响,那么他们才会有一个交互。就比如说男性在年 的时候是什么样子,女性在年轻人什么样子,这个时候就会有一个交互影响,那么交互影响的他这个 他这个分析方法。呃,我们在后面可能会讲到这个是我们对于这个方差分析的一个基本的这个讲解。当然我们也可以分析这个不同年龄对这个购买医院的对不同年龄对购买医院的影响,不同年龄对购买医院的影响。这个时候呢?呃, 我们就会发现不同年龄层呢,他的购买意愿是存在这个显著差异的,因为 p 值是等于 f 值是大于三的,大于三,而且 p 值是小于零点零五的, p 值是小于零点零五的,对吧?这个时候我们就说年龄对消费者的购买意愿存在显著的差异 啊。有同学问到,就是说啊,刚刚讲的这个交互影响是不是属于双因素分析?呃,双因素一般就是说我们讲双因素区别于单因素,就是说你的影响因子啊,是有两个,就是你的分 那边呢?是其实是有两个,对不对?但是交互交互影响是说这两个背量之间,这两个背量之间是存在相互的这个影响的,好吧?在后面的时候呢,呃,后面的章节里面老师会讲到如何去做这个调节效应。调节效应的分析在这里只是给大家简单的提一下,就是, 呃,你在做这个双因素分析的时候,或者多元呃,分析的时候,你要注意到可能会有这个调节效应,就是我们所说的交互效应。
 16:30查看AI文稿AI文稿
16:30查看AI文稿AI文稿嗨,大家好,我是孜然,今天我们来学习基金科目二第七章投资组合管理。本章分值在十二分左右,是一个超级重点章。本章的核心内容就是我们作为基金经理,如何去找到最优的投资组合, 以实现投资者的目标好。而关于如何找到最优的投资组合呢?各路学者也做了非常多的研究,其中比较经典的就是这么几个理论,其开山鼻祖就是马克韦斯,他在一九五二年提出了君子方叉模型,哎,开始用期望值来度量收益,用标准差来度量风险。通过一系列的论证, 最后得出的结论说,投资者应该进行分散化的投资,也就是我们经常说的不要把鸡蛋放在一个篮子里的早期理论。但是这个理论呢,他比较偏定性,没有定量的给出风险和收益的关系,也没有为证券估值提出解决方案。因此,从一九六四年开始,威廉、夏普等人就 先后的提出了看模型啊,给出了收益、风险以及他们俩之间的关系的精确描述。那么这个模型呢,它属于是一个单因子的模型,其表达式是这样的,单个资产的收益率,他是等于无风险的资产收益率,再加上风险溢价, 是这样的一个表达式。这个模型中能够解释资产的收益率的因子就是 r m 减 r f, 这个叫做市场溢价因子。 相对来说,他只用这么一个因子去解释单个资产的收益率的话,还是比较简单的,也比较好理解。但是他在统计上来讲的话,其解释程度是不高的,也就是说应该还会存在其他的因子影响资产的收益率,于是一九七六年 steven rose 提出了套例定价理论 a p t 多因子模型,也就是存在多个因子去影响单个资产的收益率,但是他也是没有去具体的给出多因子,每个因子他的经济学含义到底是 什么?所以说这个模型呢,到目前为止一直都还在发展中的,后面呢,又又出现了像三因子模型、四因子模型、五因子模型,到现在为止,很多同学的毕业论文还是以这个为方向不断的去充实和发展的,可见这个理论他在财会金融领域中占有非常重要的位置。 在这些理论中呢,经常都会谈到一个问题,就是市场的有效性。而关于市场的有效性呢,一九七零年牛津砝码他提出了市场有效性假说,将市场分为了三种类型,分别是弱有效、半强有效、 强有效市场一会我们会展开去讲的,在这里呢,我们就只需要大概了解到这个层次就行。首先呢,就先来看马克维斯,他的头 组合理论,其中他用到的一个重要的分析方法就是君子方叉模型。这个模型主要解决的问题就是投资者如何从所有可能的证券组合中选择一个最优的组合。前面我们说过,投资者的目标是 两个,一个是风险,一个是收益,那最好的目标就是这两个目标都同时得到满足,也就是说在风险一定的时候收益最大,并且收益一定的时候风险最小。哎,如果我们能找到一个这样的投资组合满足我们的这个目标的话, 那么这种组合就是我们的最优组合了。知道这样的一个逻辑之后,我们就怎么去表现风险和收益呢?哎,马克维斯他就提出了用标准叉 c 码去衡量风险,用期望 去衡量收益,通过一系列的推到,他就会得到一个这样的一个有效前沿,这个是投资者在市场上能找到的满足投资者目标的一系列的组合, 然后再结合效用函数找到一个缺点。哎,那么这个缺点所对应的组合呢,就是最优的组合了,这就是君子方插模型它的主要思路。那我们来看一下书上他是怎么说的,哎,他说在回避风险的假定下, 也就是马克韦斯他假设的是我们投资者都是理性的,投资者是厌恶风险的。在这种情况下呢,他就建立了军事方向模型。他的分析要点是这样的,首先投资组合具有两个关键的特征,一个是预期收益率,就是我们讲的收益目标,那收益目标呢?他是用期望来表示的。 另外一个呢,就是各种可能的收益率围绕其预期的偏离程度,这种偏离程度可以用方差来表示。这个 c 吗?方还有方差或者标准差都可以啊,因为标准差其实就是方差开根号码啊,他们的大小得出的结论是一样的, 这是第一步,他用数理统计的方法开始来量化风险和收益了。第二步,投资者将选择并持有有效的投资组合。什么叫有效的投资组合呢?其实就是满足投 投资者目标的组合,所以他是指在给定的风险水平下,使得千万收益最大的投资组合,并且呢,这个投资组合也是给定的千万收益率。水平上使得风险最小化的投资组合, 同时满足这两个条件的组合呢,就是有效的投资组合了。这第二步找到有效投资组合。第三步呢,再通过对每种证券的期望收益率,收益率的方差,以及每一种证券和其他证券之间相互关系,也就是用斜方差来度量的这三个统计量进行分析,可以在理论上识别出有效的投资。 最后呢,再对上述的三类信息进行计算,得出有效投资组合的集合,并根据投资者的偏好,也就一会我们会讲到的效用函数,从有效投资组合的集合中选择最适合的投资组合,其实就是这个缺点,效用函数和你的有效前沿之间的这个缺点,这就是最优的那个。 好,我们具体来看一下是怎么去分析的啊?首先我们要做的第一步就是要去量化风险和收益,那么就需要用到期望来表示收益,方差来表示风险,斜方差来表示各个资产之间的相互关系。那我们先来看 期望,哎,分单个资产的期望收益率和多个资产的期望收益率。哎,这块呢,是要求大家必须要会计算的,非常简单啊,咱们在第一章的时候也讲到过关于期望的计算,所以这块其实是对第一章讲到统计学知识的一个 应用。首先单个资产,单个资产的千万收益就是资产的各种可能收益率的加犬平均值,因此他又被称为是平均收益率。如果以 r 代表收益率,那么 r 的期望就可以表示为一, r 等于这么多,其中 p i 表示第 r i 种收益率出现的概率, 所以就是单个资产的千万收益率,就是这里所讲的用各个可能收益率作为权重来进行加权,平均得到的这个期望 就是期望收益率。那么我们具体还是看例题会比较清晰一些。比如说这道例题说某金融产品下一年度如果经济上行,年化收益率是百分之十,经济平稳的话,年化收益率是百分之八。经济下行呢,年化收益率是 百分之三,上行的概率是百分之十,平稳的概率是百分之五十,下行的概率呢是百分之四十。那么问你下一年度该金融产品的期望收益率是多少?那这种情况的话, 这种期望的题目建议大家就是像我这样来分析一下题目的已知条件。我们首先看他有几种情况,他其实就是三种情况,上行、平稳和下行。我们看一下上行的概率是多少,是百分之十,平稳的概率呢是百分之五十,下行的概率呢是百分之四十。然后如果是上行的话,收益率是百分之十, 如果是平稳的,收益率是百分之八,哎,如果是下行的话,收益率是百分之三。这样一来,我们得到了每一种情况出现的可能以及对应的情况下面的收益率,我们就把他们的可能和相应的收益率先相成,最后再相加, 所以就是百分之十乘以百分之十,加上第二一个的百分之五十乘以百分之八,再加上第三种情况的百分之四十乘以百分之三,哎,最终这么一加 加总求和得出来的结果百分之六点二,这就是这种金融产品在下一年度的期望收益率,哎,他就是一个先相成再相加得到的结果值。好,这是单个人资产的期望收益率,那如果是多资产投资组合的期望收益率呢?那么这个时候组合的期望收益率就是 各个资产的期望收益率的加权平均。以什么为权重呢?以各资产的投资比例欧米伽 i 为权重来进行的加权平均。这个式子是怎么来的呢?它其实就是利用了期望的线性性。我们之前在第一章就讲过了, 和的期望是期望的和,假设我们的投资组合是 r p, 它是投资了 n 种产品,每种产品对应的就是 r 一到 r n, 然后相应的 选中就是欧米伽一到欧米伽 n, 所以 r p 可以表示为欧米伽一, r 一加上欧米伽二, r 二一直加加加,加到欧米伽 n r n。 好,那么我们如果要求这个组合的期望收益率的话,就是 e r p, 就是这一大块的一个期望,那么我们说期望它是具有线性性的,也就是和的期望等于期望的和,也就是这个 e。 我们可以拿到括号里边去,那就是 omega e e r e 加上 omega 二一二 二二,一直加加加加,加到 omega n e r n。 所以这个式子不就是上面的这个表达吗?你把它用求和符号来表示的话,它其实就是 omega i e r i i 从一到 n 求和,哎,它其实就是这么来的, 这是他的公式,那么同样我们也是必须要掌握他的计算的,我们来看这道例题,说某投资者将其资金分别投向于 a、 b、 c 三者,股票 总资金的比重分别为是百分之四十,百分之四十,百分之二十。那么 a、 c 的期望收益率分别是这么多,则该股票组合的期望收益率为多少?那么你就是用相应的比重乘以相应的期望收益率,然后再加重求和就得了,所以就是分别是百分之十四乘以百分之四十, 然后呢,对应的 b 的就是百分之二十乘以百分之四十, c 的是百分之八乘以百分之二十,最后呢,再相加加起来就是百分之十五点二,这就是这个组合的期望的收益率啊,直接带公式就行,都是相乘再相加。好,这是期望。下边我们来看的是方差, 他开根以后就是标准差,方差和标准差他是估计资产实际收益率与期望收益率之间可能偏离程度的一个测度方法。对于单一资产的,其收益率,方差和标准差的计算公式如下,方差的公式在这里他其实是 离差平方和的期望,而离差平方和的期望呢,又是用每一种可能出现的概率为权重来对离差的平方进行的加权平均。而相应的标准差呢,就是将方差将上面的这个式子开根号,就得到了下面这个式子,这个你能理解就行了,考试一般是不会要求你去计算方差标准差的啊,不用担心, 你所需要知道的就是,不管是方差还是标准差,这两个值越大表示风险越大,越小就表示风险就越小。知道这个我们考试就够用了哦,那么刚才里边用到的是 p i, 那假设我们这个 p i, p 一 p 二,一直到 p n, 他们假设都是相等,都是 n 分之一的话, 我们就可以用 n 分之一来代替 p i, 那 sigma 方就可以表示为下面的这个式子了。 p i 改成了 n 分之一,那么 n 分之一就可以拿出来了,就变成了这样的一个式子,相应的标准差呢,就是方差的开根,我们 这里就不写了,包括后边我们也不会再写了啊。而这个我们所表示出来的 sick 马方其实都是总体的方差,而实际中我们往往是不会把全部时期的数据都用上的,一个是计算量比较大,另一个是太久远的数据的话,没有太大的意义。所以我们常常是用过去 m 七的收益率来作为样本来估算该资产收益率的 方差和标准差。这个时候我们如果用样本的方差或者是标准差来估算总体的话,那么用的样本的方差的公式分布就不是 m 了,而是 m 减一。哎,这里要注意了,其实这个式子它的准确表达这里不应该用 steak 马方, 用 c 个码方表示的是总体的,而我们这里其实是一个样本的标准的,是写法的话,我们用的是 s 方来表示样本方差。而我们这里为什么用 m 减一呢?因为只有当这里是 m 减一的时候,这一块求期望才等于 c 个码方才等于总体的方差。 也就是说,只有当分母是 m 减一的时候,我们的样本方差才是总体方差的。无篇估计啊,这个是在概率论与数理统计里边就已经 过了的,而且是非常经典的一道证明题,如果你已经忘了怎么去证明,哎,当分母为 n 减一的时候,这一块他的期望等于总体的方差的话,你可以来看一下我的这一页 ppt 的一 一个证明啊,如果有不懂的话可以再来问我。那这个呢,不是我们考试的重点,考试不会考你这个的,所以呢,我们就不再讲好了。这个是方差和标准差,那么这个是单个资产的话,我们就用标准差或者是方差就搞定了。那如果是多个资产所构成的投资组合呢? 这个时候我们就还需要一个中间的工具,哎,这个工具呢,我们需要去表示各个资产他们之间的相关程度,那就需要用到斜方叉和相关系数了。斜方叉的定义就是两资产离叉的层级的期望, 这个式子也是不需要你去计算的,我们重要的是掌握下面的这个结论即可。那么有了斜方叉之后,我们注意可以看到这个式子中的表达,大于零的话,说明他们是同涨同跌的,那两资产就是正相关的关系。 而如果他们的斜方叉 x y 是小于零的,说明是一个长的时候,另一个在跌,哎,他俩之间就是互相关的关系。如果两个变量的斜方叉 是抖音联呢,说明他们之间是没有线性相关的关系的啊,这个是基本的结论。但是这个协会上呢,他存在一个问题,就是他容易受到尺度的影响,因此呢,我们还需要用到另外一个变量,就是相关系数肉,这 这个肉呢就是由斜方差除以两个变量各自的标准差得到的结果,我们也是记结论就行,也在第一章也是讲过的,肉总是属于正一到负一之间,也就是说肉的绝对值是小于等于一的,当肉大于零的时候,两个变量是正线性相关,肉小于零呢,两变量是负线性相关。 如果肉等于零呢,表示两个变量之间是无限性相关关系。但是我们书上在第一章的时候,他其实讲的是不相关。这个问题呢,在我们统计里边的话,应该是要比较严谨的去研究的,但是作为基金考试,基金从业考试来说的话,就没有那么太去在意这件事情,所以在第一章教材上他写的就是不想。 但是这个问题呢,你自己从你的意识里边应该是要知道,他只能说明的是无限性相关关系就可以了。好,那么这一招呢,他又补充了两个值,就是当肉等于一的时候,表明两个变量正线性相关,肉等于负一的时候呢,表明两个变量是完全负线性相关。那么是什么意思呢?表现在图像中就是这样的,这是我们的 x 变量,这是 y 变量,他们俩当肉等于一的时候, x 和 y 他们的函数关系图表现出来就是一条斜率为一的直线,那比如说是这样的一条直线,那就意味着当 x 变化一个单位的时候, y 也是变化一个单位,并且是 同样的方向的变化, x 增加, y 也增加, x 增加一个单位, y 也增加一个单位,这就是这样完全正线性相关。而如果是当肉等于负一的时候呢,他们是完全负线性相关,那么 x y 对应的图像就是一个斜率为负一的这样的一条直线,那 这意味着当 x, 哎,从这里增加到这里增加一个单位的时候, y 的相应的从这里变到这里下降了一个单位,他们是完全的方向相反的等量变动啊,这就是完全副线性相关。好,这个就是斜方差和相关系数,我们重点是要去掌握这个结论。好,那知道了斜方差和相关系数之后呢?那下边我们就要来看投资组 他的方差和标准差了,投资组合的方差和标准差取决于各个资产的方差、权重以及相互之间的相关系数。哎,这就是组合的方差的表达式,那这个公式呢,我们可以简化一下来理解,就是 假设我们的一个组合只有两种资产, r 一和 r 二来构成,那么相应的这个组合就可以表达为 r p 等于 omega 一, r 一加上 omega 二 r 二。好,那么相应的它的方差 big 马 t 方应该就等于这个求方差。这个求方差是什么呢?其实就是把这个 按照完全平方展开,那就是 omega 一的平方, sigma 一的平方加上 omega 二的平方, sigma 二的平方再加上两倍的 a b, 对吧?我们高中就学的完全平方两倍的 omega 一 omega 二 co variance 二一二二,那 coverance r 一二二,也就是它斜方叉又是等于什么呢?由刚才的这个公式你就可以看到, coverance r 一二二它是等于 row 乘以 sigma 一 sigma 二的,所以这块你其实就是 row e 二,然后 sigma 一 sig 二,对不对?你把这个翻下来,对吧?所以这个时候我们由 r 一 r 二这两种资产构成的资产组合,它的方差就是这个样子。 如果是多个资产的组合的话,那就分别做一个 omega i 的平方, sigma i 的平方,然后呢,再加上他们两两之间的一个斜方叉,而两两之间的斜方叉呢,又可以用 roij 来表示,所以呢,我们 的整个最后的一个式子就是这样的一个表达啊,同样的,我们基金同样呢,也是只掌握结论就可以,那么结论就是我们单一资产的方差不变的情况下,相关系数越小,资产组合的方差也就越小。哎,这个结论是怎么得来的呢?你看我们最终的这个表达,前面这一坨他是不是为正的?都是平方吗?那肯定是为正, 后面的这一图呢, omega iomegag 以及 sigmai sigmag 他们都是为正的,只有这个 roi j 他是不确定的,这个值呢,他是在正负一之间。好,如果这个值越大,那最终导致的我的整个的求出来的组合的方差就会越大,那表示资产组合的风险就越大。 如果我的友爱就越小,那么整个求出来的组合的方差也就越小,那么组合的风险也就越小。所以说在其他情况不变的情况下,相关系数越小,资产组合的方差也就越小,那就意味着,哎,当你的相关系数,比如他越接近于负一的时候,说明你这个头 投资越分散化,分散了之后呢,此消彼长,那相互之间的风险就会被抵消掉。因此呢,就是我们讲的,不要把鸡蛋放在一个篮子里,相关系数越小的分散化的投资组合的方差越小,整个投资组合的风险也越小,哎,他就是这么来的,哎,我们就得出了这样的一个结论。好,那么关于期望方差和斜方差这块呢? 最重要的是你要去掌握单个资产或者多个资产,他的期望收益率,这个是计算必须要会的,方差、标准差、斜方差相关系数的计算都不要求你掌握,但是结论你要知道,如果是单个资产的,那就是方差标准差越小 越小。如果是组合的资产的,那就是相关系数越小,那资产组合的风险就越小,这就是这块的内容。
87子然划重点 00:32查看AI文稿AI文稿
00:32查看AI文稿AI文稿做方差分析一定要搞懂这几个指标, f 值和批值。方差分析最终分析时,首先分析批值,如果此值小于零点零五,说明呈现出差异性,具体差异在对比平均值即可。如果批值大于零点零五,则说明没有差异性产生, f 值属于中间过程值。想要计算批值,一定要先计算 f 值。 婴儿 so 也将 f 直结果输出,用 so 做方叉分析,各类图表一应俱全,方叉分析结果可是画图形深入分析,向硬量指标表格方叉分析中间过程值,还有智能分析分析建议帮助你理解方叉分析,你学会了吗?如有其他疑问,请在评论区告诉我。
1140SPSSAU 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿如何用 spss 做写方叉分析?打开 spss, 输入数据,点击分析,选择一般线性模型单变量命令,将需要分析的变量选入对应列表框中,选择虚控这的变量,进入写变量列表框中。 单击右侧的模型按钮,勾选全因子,单击右侧的选下按钮,勾选描述统计,点击确定,潇洒结束分析验证结果收对,你学会了吗?
59纳兰程 02:21查看AI文稿AI文稿
02:21查看AI文稿AI文稿方差分析 analysis of variance annover 是一种统计方法,用于比较三个或更多组之间的平均值是否存在显著差异。它是由罗纳德费蛇尔 ronald a face 于一九二零年提出的,是实验设计和统计学中非常重要的一种技术。方差分析适用于连续型数据, 并且他将总体的方差分解成不同来源的方差,然后通过比较这些方差之间的比例来判断样本均值是否有显著差异。方差分析的基本思想是利用组间吹的们的方差与组内而日方差之间的差异来判断不同组之间的均值是否存在显著性差异。 方差分析主要有三种类型一、单因素方差分析 one way and nova 适用于一个自变量因素有三个或更多水平组的情况, 用于比较不同组之间的平均值是否存在显著差异。二、二因素方差分析。图为 now, 适用于两个字变量因素的情况。每个因素都有两个或更多水平组,用于研究两个因素对平均值的影响以及两个因素之间是否存在交互作用。三、 多因素方差分析 nvnow 适用于多个自变量因素的情况,每个因素都有两个或更多水平足, 用于研究多个因素对平均值的影响以及他们之间的交互作用。方差分析的原理是计算组间平方和 between a group some of squares 和组内平方和 would then group some of squares, 然后通过这两个平方和的比例计算 of 统计量。最后,我们根据 f 统计量与临界值的比较来判断组间 均值是否存在显著差异。在进行方差分析时需要注意以下几点一、数据的独立性不同组之间的数据应该是相互独立的。二、正态分布假设不同组的数据应该接近正态分布。三、方差其性假设 各组数据的方差应该相等及方差其性。四、显著性水平选择适当的显著性水平通常为零点零五或零点零一来判断结果的显著性。方差分析在很多实验和研究中都有广泛的应用, 可以用于比较多个组别之间的差异,帮助我们理解变量之间的关系,并做出科学推断。
27材料转AI







猜你喜欢
最新视频
- 838速龙