ai skills agent入门

粉丝31获赞181
相关视频
 11:43查看AI文稿AI文稿
11:43查看AI文稿AI文稿你是小阿八,正在用 ai 开发网站,为了让 ai 生成的效果更好,你告诉 ai 界面不要使用蓝紫渐变色,不要生成一大堆没用的文档,你要遵循公司的代码规范。阿八阿八,洋洋洒洒几百字 之后,每次开发网站时,你都要写这么一段又臭又长的提示词,太麻烦了。于是聪明的你开始想办法, 先把常用的提示词保存到单独的文件,每次手动投喂给 ai。 然后创建了资源文件夹,把公司的代码、规范、设计素材都塞进去,告诉 ai 参考这些去写。 接着你还写了一些脚本,让 ai 生成代码后自动执行格式化运行测试,提交代码到 get 仓库。最后再写着 agent 点 m d 文件,把所有规范和工作流程都写进去,让 ai 自动读取,你沾沾自喜, 嘿嘿,俺这套工作流堪称完美。但很快你发现了问题,随着规范越写越多,文档越来越臃肿,每次对话都要占用很多 ai 上下文空间,浪费 tokens。 于是你找到号称没有人比他更不懂 ai 的 鱼皮,求助阿爸阿爸,俺还能咋办啊?不是有 agent skills 吗?为啥不直接用呢? 呃,啥玩意儿?这可是最近 a h r 爆火的技术,下面我来带你玩转 agent skills, 让你知道它是什么,怎么用,有什么魔力,怎么自己开发。点着收藏,我们开始。 agent skills 是 astropic 推出的一套开放标准,目的是让 ai 能够学习使用各种专业技能,而不用每次都重复输入提示词。简单来说,它就是给 ai 装备的技能包,技能包里有精心设计的提示词、代码、脚本,还有各种资源文件, 把 ai 想象成一个职场小白,给他装上文档处理技能,他就立刻知道怎么生成 ppt 处理 excel 表格。装上代码规范技能,他就知道怎么按照公司的标准写代码。 你挠挠头,呃,等等,这不就是俺在做的事吗?把教 ai 做事的文档和 ai 要用到的文件打包成文件夹差不多,但 osropet 把它做成了一个通用标准,而且在实现原理上有一些新花样。 可恶啊,俺差点就改变世界了,这能有什么新花样?下面我先来带你用一下 agent skills, 再跟你说说其中的奥秘。 目前对 agent skills 支持最完善的工具是 asteroid 官方的 cloud code, 我 们就以此为例,安装并使用 skills, 先打开 cloud code, 并输入命令,添加官方技能市场。这就像是在你的 ai 助手里开通了一个技能商店,接下来你就可以从商店中获取技能了。 然后在 toloud code 中输入命令,安装官方提供的技能包。这着 example skills 包含了一堆官方势力技能,包括前端设计、网页测试、动图制作等等。 装完之后,你就可以直接让 ai 使用这些技能了。比如你要做一个网站,以前没装技能的时候, ai 生成的代码又是那个熟悉的蓝紫渐变色,千篇一律的 ai 审美。 现在安装了 front design 这个教 ai 生成专业设计版网站的技能后,你输入提示词,帮我开发个人作品及网站。 ai 会主动问你,我发现你安装了前端设计技能,需要用它来生成证据设计版的页面吗? 确认之后, ai 会利用技能生成代码,告别篮子渐变,生成独特风格的精美页面。我们不用每次都给 ai 输入一大堆相同的提示词,装一次技能就行了。 除了代码相关的技能,官方还提供了文档处理技能包,同样在 cmd code 中输入一行命令安装。 这只技能包里有 ppt 制作、 word 文档生成、 excel 数据分析、 pdf 解析等技能。接下来,如果你让 ai 做着 ppt, 它会自动调用 ppt 制作技能,直接生成排版好的 ppt 文件,帮你节省几个小时。 你好奇道,咦,为什么 stills 能做到安装即用?技能包里面到底有啥? ai 又是怎么知道该用哪个技能的? 好问题技能其实就是一个包含 still 点 m d 技能说明文件的文件夹,还可以包含可执行脚本资源和参考文档。 由于每个技能的复杂度不同,结构也会存在区别,我们可以在本地目录中找到已安装的技能文件夹。以官方的 ppt 制作技能为例,它的结构是这样的,包含一个核心的技能说明文档, still 点 m d, 还有脚本参考文档和各种资源文件。 而 front and design 前端设计技能只有一个, still 点 m d 文件。 still 点 m d 文件是每个技能的核心,它包含两个关键部分,第一部分是原数据,用 yam 格式写在文档开头, 其中 name 是 技能的名字, description 是 技能的描述,告诉 ai 什么时候应该使用这个技能。 描述写得越清晰, ai 就 越容易在合适的时机调用它。第二部分是指令内容,就是一套经过精心设计的提示词,指导 ai 具体怎么做。以前端设计技能为例,它的指令内容包括设计思考、前端美学指南和必称指南。 你挠了挠头,如果有多着 stux, ai 怎么知道该用哪个技能呢?如果把每个技能说明文的都塞给 ai, 不是 很占用上下文吗? 这就要说到渐进式批漏这个核心机制了。当你让 ai 执行任务时,它会先扫描技能目录,但不会把所有内容都加载到上下文中,而是只读取每个技能的原数据, 发现描述和任务相关,就知道该用这个技能了。然后才把完整的技能说明文档读进来,按照里面的指令执行,并根据需要加载技能包中的其他资源,用到哪个查哪个,既精准匹配又节省上下文,这就是渐进式纰漏的精髓。 所以 agent skills 的 本质就是把专业知识打包成一个文件夹,让 ai 按需读取并使用。呃,那除了 cloud code 之外,其他 ai 工具支持 agent skills 吗?俺平时用 curser 比较多, 当然能, agent skills 已经成为通用标准, curser、 west code code、 dex 等工具都支持。 skills 的 社区也非常活跃,你可以在 cloud skills、 hub 市场开源的 awesome、 cloud skills 等地方找到很多现成的技能, 比如有着叫 uiu 叉 pro max 的 技能特别火,专门用于提升 ai 的 设计能力。用法很简单,首先按照开源仓库文档的指引,安装官方提供的命令行工具, 然后进入到你的项目目录下,根据使用的 ai 工具执行对应的命令。比如我这里用 cursor, 它会自动把技能安装到 cursor 的 配置目录里,安装完成后,可以看到它的文件结构。接下来当你让 ai 开发一个网站时,可以使用斜杠命令手动触发技能,或者让 ai 自动识别技能。 ai 会根据你的需求识别出产品类型和需要的页面类型,然后调用设置点 p y 搜索脚本,在 data 目录里进行多维度搜索,找到适合的配色、字体、布局风格。接下来综合搜索结果,生成完整的设计方案。最后 ai 再按照设计方案生成代码, 这样一来,生成的界面既专业又有设计感。 ai 不 需要把所有规则都背下来,而是用到哪个查哪个,这就是 agent skills 的 精髓。 用了很多别人的技能后,你产生了一个大胆的想法,哎,能不能把公司的周报折式封装成一个技能,以后推荐给新来的同事,还能卖几个钱,嘿嘿嘿。嗯,有点东西,那你打算怎么做呢?当然是发挥程序员最擅长的事情。复制粘贴。 俺先复制一个官方的技能包,修改目录名称为自己的,然后修改技能说明文的 still, 点 m d 的 原数据指令内容这些关键部分。最后把公司的 logo、 ppt 模板爆照样例放在子文件夹里就行了。妈妈再也不用担心我的周报了。 不错不错,但其实有更简单规范的方法。在前面安装的 example stills 官方势力技能包里有一个叫 still creator 的 技能,专门用来帮你创建新技能。你只需要跟 ai 说,帮我创建一个专门生成公司周报的技能。接下来 ai 会问你几个问题, 你希望周报包含哪些主要部分,以什么格式输出?你通常会如何使用这个周报技能?希望周报的语言风格是什么?很快,一个完整的技能包就生成了,你会看到一个点 scale 为后缀的文件,本质上是一个压缩包,你可以把它解压到你的个人技能目录下,你的所有项目都能用。 如果你想让技能只在某个项目生效,可以把它放到项目的 cloud, 同步给项目组其他成员 测试。没问题后,你还可以把它开源到 github, 或者上传到 chaleo 的 stokes hub 这样的社区平台,让所有用户都能用,你开心极了。原来开发一个 stokes 这么简单,但是这玩意儿跟之前火爆的 mcp 和邪道命令有啥区别? 好问题, m c p 就 像给 ai 装上了手和眼睛,让 ai 能够连接外部工具和数据源,比如搜索网页、读取代码、仓库、查询数据库,适合需要获取数据或操作外部系统的场景。 而 agent skills 正像是给 ai 发了一本工作手册,把专业知识和工作流程打包起来,教 ai 在 特定领域该怎么做。 至于斜杠命令,它就像是快捷键,是需要你手动输入常按的命令来触发的固定操作。而 steils 的 特点是, ai 可以 自动识别该用什么技能,不需要你显示调用。对了,其实 mcp 和 steils 是 可以结合起来的。 举个例子,如果你想让 ai 帮你发周报, m c p 负责获取数据,从任务管理数据库拉取这周的任务列表。 skills 负责加工数据,把获取到的原始数据整理成老板爱看的格式,一个提供食材,一个提供配方, 你看这技能文件夹的结构,突然怪叫一声,阿爸,哈!等等,俺突然意识到一个问题,这不就是我们程序员玩烂的封装附用、模块化懒加载那一套吗?写几个代码文件,打着包发到网上,让其他程序员下载下来用 不是一回事吗?为什么 agent stux 能突然让整个 ai 圈为之疯狂?好问题,从技术的角度来看,它并没有发明什么惊天动地的算法。在我看来,它能火主要是两个原因。第一,它是开放标准,封装一次技能包后就能在各种 ai 工具里附用,还能通过社区共享。 更重要的是, stux 能立刻让 ai 的 工作更专业可靠,让普通人无感地享受到技术带来的价值。以前想让 ai 变聪明,你得学提示词、工程配置各种工具链。现在只需要像装 app 一 样安装技能包, ai 就 立刻变专业了。 一项技术的成功不在于它有多复杂,而在于它能让普通用户在不关注技术细节的情况下感受到技术的价值。 你点点头,学会了,学废了。降低门槛才是技术走向大众的钥匙。没错, agent skills 不 仅仅是个技术概念,更是一种新的工作方式。 你可以把它融入到自己的日常工作中,比如把重复的任务封装成技能,把团队的最佳实践固化成技能,让 ai 真正成为你的得力助手。 在这个 webtopod 盛行的年代,技术的门槛正在崩塌,而想象力的边界正在无限扩张。你可以在我免费开源的 ai 编程零基础入门教程中学到更多 ai 编程技巧,也欢迎关注鱼皮,学习更多 ai 和编程的技巧。那么问题来了,你最想让 ai 学会什么技能呢?
7294程序员鱼皮 04:29查看AI文稿AI文稿
04:29查看AI文稿AI文稿大家好,我是成风,我花了一周时间用剪辑 skills 做了一个剪辑的 agent, 发到外网上,这个也火了,真的很爽,十分钟就可以剪一条半个小时的视频。这是我剪出来的一个案例。做这个东西的原因是我经常用剪映剪口播视频,但用久了发现了几个问题。 剪映的智能剪口播,他无法理解我的语义,导致有些重复的片段他没有识别出来,如果我一口气说二三十分钟自己剪就非常累。 第二个是字幕的质量非常不好,自己生成的字幕错别字特别多,所以我用 cloud code 的 skills 功能做一个剪辑 agent 剪映它是没有学习能力的,它没办法了解到我的一些习惯,但我的 agent 它是能够越来越了解我的一些使用习惯的。三个核心设计, 第一个是我们的 a 技能,我们首先要去下载视频技能素材,然后再安装环境,根据口播来剪辑整个视频,然后给我们的口播加上一个字幕,视频经过这个流程就会达到我们想要的结果。 第二个是 skill 技能系统,以前我会把所有的功能都做成一个大的 skill, 需要添加指令才能区分不同的任务和麻烦。把剪辑的五个核心任务分别做成了五个独立的 skills 放在目录里面。当我们输入斜杠 v 的 时候, cloud code 就 会自动列出这五个可用的技能,你选哪一个, ai 就 会执行哪一个技能,这是不是更加简单呢?所有的方法论都写在 skills 里面,你不用去重复说明。为什么我会做成单独的 skills 呢? 因为每一个步骤人都需要去检查阶段性的产出,比如说我会去检查审核稿式文件,再执行剪辑的步骤。第三个是自更新的机制,它会越来越懂我们,这个是我比较得意的设计, 每次我们执行完任务后,我们都可以给到 ai 反馈,告他这是对的还是错的,然后 ai 就 会把反馈永久的保留到 skill 里面去,最后这个 skill 就 会从一个通用的规则逐 渐变成只属于我们个人的定制化方案。用了十次,他可能会知道我们百分之八十的习惯,那我们用了更多,他最后就会完全符合我们的需求,这就是自更新的魅力。具体怎么做呢?我们首先复制这个提示词,打开我们的 ai, 告诉他去下载。 然后呢,他就会在这里的 skills 文件夹增加了这五个技能,选择斜杠你,我们就可以看到这里的五个技能,剪辑、剪口波、自更新、字幕安装,我们首先要去安装, 为什么要选择安装?因为我这里面会有两个模型,我们要执行这个步骤,我就下载这个模型。第一个是放 a s r, 它是阿里的模型,它对于口误的识别特别厉害。第二个是 openai 的 vesper, 它是用字幕的, 他对于生成字幕非常有优势。我们接下来开始去做一个剪口播,我们这边录入一个视频,然后拖动到这里面来,让他来剪口播,这中间 ai 就 会自动转入我们的视频,去识别我们的口误, 识别里面的语气词,识别里面的静音,最后生成一个审查稿,然后他就会给我们形成这样的一个口播稿,我们就可以去校验,他在这里标注了静音是要删除的部分,还有一些比如说这里的口误,我这个说了很多遍,他也识别出来了。 如果说你对于这个有疑问,我们可以把这个复制给他,告诉他这里要怎么做,然后去修改这个文稿。执行完我们就可以看到 原来一个四分四十七秒的视频,他检到了,只有两分四十秒之后,他还会重新进行检查,去审查一下文案,等到他确认好没问题就行了。如果他还检查到有口误,他还会继续去删除,比如说这里他就检查到了还有两处口误, 他就进行了第二轮的剪辑,直到他认为满意了,这边已经没有口误了,我们就可以看到这里新的视频了。之后我们就可以执行字幕,在加字幕之前,我们可以看到这里的词都放到里面去当做一个词典, ai 就 会根据这个词典去整理好我们的字幕。然后呢我们就能看到这里有一个字典改过了,我们自己再仔细的看一遍。当我们匹配好文稿了以后,确认好没问题, 我们就可以让 ai 进行烧录,最后我们就能看到这个完整的视频了,上面是内容,下面会有字幕,这都是完整的视频。这中间如果说 我们有什么地方需要让 ai 改的,或者说我们执行的是正对的,我们可以执行这个自更新的机制,通过这个自更新的,它就会去优化我们的, 让我们的 skill 变得更加个性化,因为我们每个人的说话特征其实都是不一样的,所以是需要让 ai 去学习的,自更新就是用在这个地方。关于这个完整教程,我已经放在了 agent 的 叉一百上面,大家可以去这里看。
4428AI产品自由 19:18查看AI文稿AI文稿
19:18查看AI文稿AI文稿梅猴王朋友们, agent skill 最近真的太火了,但很多朋友肯定还是很困惑, skill 到底是啥?有什么牛的?没关系,草旅从 skill 大 全它来了。 今天呢,我们会通过一个逐步升级的案例来理解 skill 的 结构和原理,然后我们还会学会定制自己的 skill 这个 skill 呢,只需要我们说帮我做一个促销海报啊,优惠券,员工服装,它就会生成符合我们品牌风格,带 logo 的 物料图片。 另外,我也会推荐给大家一些好用的必用的 skill, 比如说帮你的文章配图,把杂乱的知识变成教学网页,一句话处理表格等等等等。 我还做了个秋之技能生成器,大家只要回答一下 ai 给的选择题,为你量身定制的技能就轻松完成了。并且今天所有的资料链接以及补充资料我都做成了一个网页,大家只需要一步步的跟着做,跟着看,就一定能搞定, 非常值得一个点赞收藏关注哦!来吧,准备好我们 go go! go! 首先,到底什么是 skill skill 呢?翻译过来就是技能呗, 它其实和人类的技能是类似的,比如说你是一个厨师,那你就有炒菜的技能,处理食材的技能,摆盘的技能等等等等。那每个技能里面,比如说炒菜技能,这里面就包含了你的流程,你要先炒什么,后放什么, 还有你的配方,你的油温多高,盐放多少。有了流程和配方呢,你可能还会需要一些工具,需要煤气灶什么的, 甚至你可能还会有一些独家的材料,有一勺秘制辣椒酱什么的。那 agent 的 技能也是同理,它要来做菜,它也得有流程、配方、工具和材料。 所以在 agent skill 的 术语里面呢,它就是 skill 点 md, references, scripts 和 assets 这些东西打包成一个文件夹,这就是一个技能,一个 skill 了。我们先来个简单的, 比如说我们要做一个写作 skill, 那 我们就在 skill 里面可以要求他先去啊这些网站去搜集信息,然后再按这个爆款原则去写个大纲,然后再参考这个语气来写稿啊,最后按照平台要求来审稿等等等等。那有朋友就很疑惑, 那这不就是写提示词吗?哎,本质上还真是的,毕竟啊,我们跟大模型的交互其实都离不开提示词, 但是呢,这并不是 agent skill 的 全部,它在工程上是有很多优势的,能做的肯定比我们拷贝粘贴提示词要多很多。好处我们后面都会说到,那先让我们通过创建一个 skill 来理解它的结构和原理, 我这里用的是谷歌反重力来做编辑器来看文件,然后呢,用的是 cloud code 来做 agent 来处理任务。这俩东西的下载方式呢,我也都放在资料里了,非常清晰简单,大家一步步跟着做就行了。 接着你只要在反重力的这里创建一个项目,比如说我的就叫丘之 project 吧,然后呢,我们调出终端, 输入 cloud cloud code 就 调用出来了,这个界面大家看着会有点复杂,但是不要怕,跟着我一步步来就可以了,之后我们跟 agent 的 对话都会在这里进行。 ok, 那 我们开始创建, 那我们先要做的是一个最简单版本的 skill, 后面呢,我们会逐步升级的哈, 那现在假设我是一家轻食店的老板,那这是我们秋之餐厅的一个品牌 logo, 那 我希望做一个 skill 呢,能够按照我的品牌调性和视觉规范,帮我们去想各种物料的创意,做一个创意生成器。 那按照 cloud 的 规定,我们创建一个 skill, 得在规定的点儿 cloud skills 文件夹里面去创一个 skill 文件,那我们用最原始的方式,直接手动的来创建这些文件夹哈,点儿 cloud skills, 然后我们再创建一个文件夹,这个文件夹的名字呢,就是我们 skill 的 名字,我们叫它秋之创意吧。那这个 skills 的 文件夹里面呢,必须规定有一个 skill 点 md 的 文件,这个大写的文件,那文件里面放啥呢?我已经写好了, 粘贴进来,那就是这么些文字。好了,这就是一个 skill 了,大家先压住脑子里面的问号,我们再来细看一下,那这个文件里呢,上面这两个横线里面的它叫做元信息 matlab, 写着两个东西啊,一个呢是 skill 的 名字,一个呢是 skill 的 描述,这两个东西专门用来告诉 ai 这个 skill 叫什么名字,是干嘛用的,什么时候可以用它,那我这就写着是做创意物料用的啊,当用户说要做个海报什么的物料,他就自己触发它了。 而下面这些信息呢,叫做指令 instruction, 其实就是具体告诉 ai 怎么样做的一些提示词喽。 ok, 那 我这写了我们的餐厅叫做秋之餐厅,品牌的风格有这么些要求,输出的格式让他是这样等等等等,非常的简单哈,那我们保存好一个 skill, 真的 就创建完了?来,我们启动 cloud code 来问问他,你有哪些 skill? ok, 你 看,他现在就已经识别到了我们的秋之创意 skill 了。 ok, 我 们直接问他,我要做一个秋之餐厅的春节促销海报,让他给个创意 好,他这里就开始提示我们,他正在加载这个 skill 了,我们同意 ok, 他 就输出了创意,并且是按照我们的要求和格式来的。 那有朋友就受不了了,哎呀,这一通操作不还是提示词吗?跟我自己写一段这个提示词存着给 cloud code 看有什么区别呢?最大的区别之一在于它是按需加载的, 什么意思呢?其实啊,当我们正常的这样跟 cloud 去聊天的时候,大模型它只会看到我们这个 skill 里面这两行短短的圆信息。 只有当我们说我们要做一个秋之物料的时候,他才意识到,哦,该看具体的指令了,他才会去加载这下面这部分的完整指令,否则这些他都不会看到。 这样的好处就是方便我们可以同时拥有很多个 skill。 每次 a 正的都会看一遍所有 skill 的 简短的原信息,但是只有当 a 正的意识到他要去具体调用一个技能了,他才会去看下面的一大堆指令,而且 ai 的 回答也会更精准, 因为他没有了其他提示词的干扰,那 ai 加载的少了, open 自然也就省了一堆。那这是他按需加载的第一层。 当然了,刚刚这个 skill 实在是太基础了啊,就算一口气把它下面的指令都加载完,好像 token 也不多哈。 但是如果我们的要求变得复杂了呢,比如说我们秋之餐厅的物料其实分很多种, 常规的呢,有海报、菜单,也有比较特别的一些实体物料要设计,比如说餐盒、杯子,员工服装,还有一些社交媒体的物料,比如说公众号封面,微博配图等等等等,他们的尺寸都不一样,配色要求也不一样, 还得符合各平台的一个规范。每一个物料呢,我们都假设它有详细的长长的说明,那这时候我们如果把所有物料的要求都写进 skill 点 m d 里面,那这个文件就会变得巨长。 但是很多时候呢,我只是想做一个,比方说实体餐盒的设计大模型,根本就不需要知道公众号封面的规格,但是 ai 还是得把整个文件都读一遍,那这就造成了 token 的 浪费,也可能会造成一些信息干扰。那怎么办呢? isopec 就 又规定了一个文件夹叫做 references, 我 们呢可以把实体的物料和社交媒体的物料这个两个规格单独拆出来,单独的给它放到这个 reference 文件夹里面去。 那这个实体物料规格点 md, 我 们就写一些线下的工服呀,餐盒之类的要求, 那这个社交媒体物料规格呢,我们就去写公众号封面呀,微博配图这些的尺寸和要求,甚至我们都可以拆得更细。 然后呢,我们只需要在 skill 点 m d 这个总指令里面只留下那几个常见的物料要求,并且我们还需要写上一个指引 啊,告诉他如果用户要做线下物料的话,那就要去读这个实体物料规格点 m d。 如果要做社交媒体类的图,那就要去读社交媒体规格点 m d, 那 现在同样的一句话, 他给出的方案就更精准了。这样当我们只做常规物料的时候,这两个 reference 的 文件大模型压根就不会看。然而当我们说做实体参合的时候,他也会通过 skill 点 md 的 指引,只去看 reference 里面的这个实体规格文件, 那这就是它的进一步按需加载了。那我们可以想象,我们可以有好多种不同情况的 reference, 反正它只会在需要的时候自己去看指定的文件。 但是现在我们的秋之创意 skill 呢,只能输出创意,还得我们自己去做图,所以呢,我就还想让它可以按照我们的品牌规格,直接帮我们把图做出来, 也没有问题。那这就要用到 skill 的 另一种文件夹了,叫做 scripts, 那 这个 scripts 里面呢,一般放的是一些可执行的脚本, 那我这里呢,实际上也就放了一个非常短非常简单的脚本,其实就是在调用 nano banana 的 api 来生图的一个脚本。那有了这个脚本之后呢,我们还得去 skill md 里面在指令里说一声,告诉他,如果用户要求直接生成图片, 那他就得把之前我们想的这个创意转化成生图的提示词,然后按照这个命令去调用这个生图脚本,这样他就能一句话自动去生成精准的图片了。 不然我们还得自己去拷贝提示词,打开软件再粘贴,再生成,再下载保存,现在我们一句话就搞定了。 另外我还有个需求,我希望深层物料的图片能保持秋之餐厅的 logo 不 变, 所以我们还得给他几张 logo 图作为深图的这个参考。那我们就可以再建一个 最新规定的一个 s s 文件夹,我们把两张的 logo 图片放到这个文件夹里,当然我们还要回到 skill 的 md 里面,告诉他参考图在这个 s s 文件夹里面,如果要深图的话,需要把这个图片当做参数给脚本传进去来执行。 好朋友们,现在这个 skill 就是 一个完整的官方完全形态了,其实有点像我们在用自然语言写程序,对吧?那我们先来试试效果,来帮我做一张周六饮料免费的一个实体海报, 你看它发生了什么?它先是加载了这个 skill, 然后它内部可能发现啊,要做的是这种实体物料,它就要去看另一个解说,于是它去检查了这个实体物料的规范。那并且它意识到我们需要的是直接生成图片, 所以呢,它又生成了提示词,把这个提示词和 logo 图片一起给到,并且运行了这个脚本。那最后它输出的图片告诉我们,在这里我们看看结果, 你瞧瞧它这个尺寸,配色 logo 是 完全符合我们这个品牌规范的啊。那为了防止这个是一次性的结果,我还多试了几次,它这个深层的效果都很不错。 然而如果我们的要求还跟之前一样,我们只要创意并不要直接深图的话,那他的这个脚本他也不会被执行。 而且呢,刚才我们说到这个 scripts 脚本,这里面其实还有一个重点,这个脚本里的代码它是写好了的, agent 根本就不需要去看里面写了什么,它只要知道我们在 skill 点 m d 里面写的那些指引,告诉它传什么参数,会输出什么,它只管运行脚本就行了。 所以不管我们在 scripts 里面写了多少行代码,大模型它都不会去读取,一点 token 都不占。 当然了,如果我们在 skill 点 md 里面的那个指引写得不够清楚,大模型不知道怎么用这个脚本,那他有可能也会不得不自己去看一下这个脚本,但他的机智和园艺是不需要去读这些脚本的。 好,那我们来回顾一下,其实创建 skill 就是 在指定的文件夹下去创建一些文件,那最简单的 skill 呢?只要一个 skill 点 m d 就 够了,里面有这个原信息和指令,而完整形态的 skill 可以 加上 references, script s s 这些可选的文件,那这些东西是怎么配合工作的呢?这就是 skill 最重要的设计。按需加载的三层结构,第一层,源信息。 这一层呢,是始终加载的, ai 的 每一次对话都会看一眼所有的 skill 的 源信息,它去看到自己有哪些技能,就像一个目录。那第二层,指令层, 这层是只有当 ai 判断并且决定我要用这个 skill 的 时候,它才会去加载完整的 skill 点 m d 文件。第三层,资源层, 这层包括了 reference 里面的参考资料, scripts 里的脚本, assets 里的资源。只有当 ai 进一步判断任务需要更详细的信息,或者它需要执行某个脚本的时候,它才会去按需加载,并且脚本它是只执行不读取的,完全不占用托克。 好了,这下我们完全理解 skill 的 按需加载,也就是官方定义的渐进式批漏机制和三层结构了。可是对于普通人来讲,这又是写 markdown 又是脚本的,好像创建一个 skill 还是挺复杂的。 no no, no, 现在谁会用手写呢?我是用这个创建 skill 的 skill 啊,秋之 skill creator 创建的。 那这个呢,是我基于很火的 skill 创建器改良的一个更加互动式,更加小白的一个 skill 创建器。那大家把它下载下了以后,放到这个点儿 cloud skills 文件夹里面就好了。那下好之后,我们想要创建什么 skill, 直接打开 cloud 直接跟它说就行, 或者我们也可以斜杠来调用他,那他呢,会开始一步步的引导和追问我们,来帮我们梳理这个需求。而且我特意设计的是这种用选择题的方式来追问我们整个过程,我们就只需要用大白话回复他的问题,以及按一按上下键做一做选择题就好了。 他这个追问的过程啊,到时候大家问题可能和我现在这个不一样,因为他会根据你的需求去做灵活的调整啊,他都是现编的。 然后呢,这个过程中因为我们要做图片,所以我们还需要给他提供 logo 图的参考,以及那个 nano 不 nana 的 a p i 和文档。那我也给他直接拖到了这个项目文件里,然后告诉他了一下这个文件的路径, 他就会自己去参考和把它们放到 excel 文件夹里面。那这两个素材我也都已经放在了我们的课后网页上了,大家可以去用做练习来试试复现它。 那问完这些问题之后呢,他还会给我们核对一下方案,如果我们看着方案没问题,那他就会自动帮我们生成所有的 skill 文件了。 那做好 skill 之后呢,他还会帮你想几个例子来跑一下测试。我们这里其实测了好几个,风格都很一致,很好看。大家在这个调整的过程中,也可以去点开他写的这些 skill 文档来手动的修改一些,反正都是提示词嘛。 所以总之只要你有明确的输出要求,或者有明确的方法规范流程知识,创建器就会指引你帮你来写出一个定制的 skill。 而且除了自己创建,网上也有很多现成的 skill 资料里,我也整理了一些集合网站和 skill 仓库,成千上万的 skill, 大家可以去逛逛。并且我也给大家打包了几个普通人常用的必备 skill, 比如做 ppt, 处理文档, excel, pdf 这些基础的,我们直接把它拖进 skill 文件夹就可以,一句话让它帮你把乱糟糟的表格梳理得整整齐齐。 还有这个官方的前端设计 skill, 这是直接让 cloud code 生成的前端网页,而这个是挂载了这个前端 skill, 做出来的网页,效果明显大幅提升。还有这个动画生成的 skill, 用这么一段提示词就可以做出这样一段演示动画。 当然大家也不用去装一堆自己根本用不上的技能,一个游戏英雄也只需要四个技能 q w e r 就 能杀遍全场。所以最有效的还是把你最最高频做的几件事,打磨成一个你独家的稳定产出的 skill。 尤其是你对结果有明确的要求,你有经验和方法,你验证过的事情。 比如说打工人,你的周报每周都要写,那就做一个让 ai 来主动采访你,然后出周报的一个 skill。 比如说老师每节课都要背课,那就做一个你只要给出课题,就能给你一整套课件习题和 ppt 的 skill。 又比如说,你总是要给你的文章配图,那就做一个给他一篇文章,他就按你的风格做配图的 skill。 又比如说,你总是在审核,那就做一个按照你的规矩自动批阅合同来写备注的 skill。 因为大多数的人都不需要成为一个技能开发者, 我们只要先把自己掌握的小技能交给 ai, 让他替你重复劳动。好了,资料链接都在评论区了,大家动手试试吧!这个时候呢,点赞、收藏、关注的技能就该出发了,我们下次见了!
3.7万秋芝2046 14:59查看AI文稿AI文稿
14:59查看AI文稿AI文稿打开这个平平无奇的命令行窗口,输入 open code, 回车,现在就激活了 ai 神力的模式,把公司一堆财务数据表格直接拖进去, 然后输入对表格数据进行摘要分析,并可识化为车。不到一分钟,他就自动帮我们生成了一份包含六张专业图表的分析报告,甚至连相关性分析都做好了。 把喜欢的视频链接扔进去,输入下载视频到当前目录,回车视频自动下载到了本地, 本地文件乱的像猪窝。把文件夹路径给他,让他整理一下文件夹回车,文件瞬间归类的整整齐齐,甚至还能直接帮我们拣写学术综述论文,只需要将题目发送给他, 让他帮我们剪辑总结刊写。现在我们只需要喝杯茶,一万多字,一百多篇参考文献的综述 就生成了。这些操作全都归功于最近火出圈的 agent skill, 可以 说是近期最能提升效率,最值得折腾的 ai agent 了,我亲测呢,非常值得拥有。 那今天我们就手把手带大家配置和使用,并且毫无保留地分享我私藏的十个超好用的 skill 视频。最后我还会教大家定制专属于自己业务的 agent skill, 点好收藏关注,赞! let's go! 那首先要拥有这个绳力,我们需要一个代替,就是 open code, 它是近期呢热度最高的 ai 编程终端,你可以把它看作是一个免费版,开源版的一个可乐的 code, 最大优势呢是对咱们中国用户呢特别友好,不需要魔法呢,也能顺畅使用。而且内置的像 glm、 四点七、 mini max 二点一这些很强的一个免费模型,安装起来呢也非常简单, windows 用户呢,我们推荐使用 note gs 方式, 我们先来安装 note g s, 下载对应的安装包,直接双击安装一路 nex 呢即可。接着呢,我们来安装 open code, 我 们首先进入 open code 官网,点击右上角的 free, 我们直接复制第二行命令,然后 windows 加二,输入 cmd 回车,然后粘贴我们刚才拷贝的命令回车,这样我们就安装完成。输入 open code, 出现 open code 的 界面呢,就代表我们安装成功。 open code 最棒的呢是它内置了一个免费模型。我们输入杠 model 可以 看到右边带 free 的 呢,就是我们的免费模型,这里面有 g l m 四点七以及 mini max 二点一。 这两个国产模型的编程能力和中文能力呢,还算是比较强,我们直接使用上下格选择即可。当然了,如果你想使用更强大的一个模型,有个神级插件 open code and gravity, 我 们直接访问它的 github 主页,然后复制这行命令粘贴到 open code 中执行。我们等待 ai 自动完成安装, 显示需要登录的时候呢,我们直接打开新的命令行窗口,然后拷贝命令粘贴,然后回车。模型供应商呢,我们来选择谷歌 登录方式呢,选择 antigravity。 我 这里呢已经登录,大家第一次登录的话,在浏览器中会自动跳转到谷歌浏览器,让我们来登录谷歌的账号。 我们登录完成之后,复制生成的 u r l 粘贴到命令行的选择回车,就完成了一个配置,然后输入杠 model。 此时呢,我们就可以在谷歌这一栏就可以看到有 cloud office 四点五以及 dreamline 三 pro 的 一个免费模型。 好了,重头戏来了,我为大家精选了十个呢,能让你的工作效率原地起飞的一个 scale。 第一个 scale 是 数据分析神器,这呢也是我常用的一个 scale, 不 管是销售报表还是科研数据,丢给它呢,它不仅能总结,还能自己写 python 代码来画图。这是公司的一个财务数据,包括产品收入、利润等信息。 我们直接拖动到 opencode, 然后输入对表格数据进行摘要分析和格式化。 opencode 呢,会直接输出这样包含六张格式化图的一个财务数据分析报告,甚至呢,连相关性分析图呢,也是一目了然。 第二个 style 呢,是文件整理助手,如果呢,你跟我一样下载文件夹呢,永远是乱的。 这个 skill 呢,就必装,它能理解文件名,把电影文档、安装包等等各样的一个文件呢,进行自动的一个归类,甚至呢,还能帮我们删除重复的一个文件。我们只需要输入帮我整理一下下载文件夹 回车。然后呢,它就会自动地进行分类,重命名,清理重复文件。我们无需花精力呢进行繁琐的手动整理了,这是 ai 帮我自动整理后的一个效果。 第三个 style 呢,是视频下载器,这个功能呢,简单粗暴呢,但超级好用。我们把喜欢的视频链接呢粘贴进去,然后输入下载视频呢,到当前目录 回车。我现在呢,就用它来下载视频,不用到处再来找下载器,命令行里一句话呢,就能搞定,干净呢又卫生。第四个 skill 呢,是知识库问答, 这个 style 呢,我也是非常喜欢。如果呢,你把一堆的 pdf 文档, youtube 链接呢,都丢给了谷歌的 notebook lm 里,就可以让 oppo code 直接去读取你 notebook lm 里的知识库,然后基于你的知识库呢,给出待引用的一个答案, 这样呢,就有据可依,减少的一个瞎编。使用前呢,我们需要先进行身份的一个验证,复制这行命令,然后输入到 opencode 中回车。通过身份验证之后呢,我们就可以直接进行提问了, 我们拷贝自己 notbook 的 一个链接,然后粘贴到 opencode 中, 比如我问他深度学习模型呢,如何通过政策化技术来防止过紧核,可以看到它是基于我们笔记本的知识库的内容来进行的一个回答,这样就完全杜绝了 ai 瞎编乱造的一个毛病。 第五个 scale 呢,是医学影像 ai 文献综述 scale。 这个 scale 呢,对学术研究者来说简直是神器,它可以拷写医学影像 ai 研究领域的一个文献综述输入,帮我拷写医学影像大模型研究综述, 它能自动地把我们检索文献,总结摘药。最后呢,生成一个一万多字的一个综述,出稿 八个章节,一百一十篇参考文献,甚至呢,还推荐了八个复图以及后续计划和目标期刊的一个建议, 这就很离谱了。当然这个 scale 的 思路呢,完全是可以迁移到我们自己的研究领域,大家呢只需要修改一下配置呢就行。 第六个 scale 呢,是 word 文档处理 ai 生成的内容呢,通常都是马克当的一个格式,转 word 呢,还有排版就非常的一个麻烦。而这个 scale 呢,就可以让 ai 呢去自动地进行 word 生成,编辑和分析。 我们直接将一个马克当的文件呢拖入进来,然后让它转化成 word。 现在呢,可以看到它已经自动地在调用我们的到可技能。 我们打工人的周报合同一键生成 word 呢,对经常需要交付 word 文档的职场人士来说呢,确实是,还是非常实用的。第七个 scale 呢,是 ui 设计大师。 这个 scale 呢,在 github 上呢,已经收获超过一万多个 star 了。它能够分析我们的项目需求,并生成一套完整且量身定制的一个设计系统, 配色、字体组建规范,甚至 css 代码呢,都给我们准备好了。这是我前期开发的一个 ai 专利,写作智能体的一个界面, 我直接输入帮我设计新的一个 ui 主键和页面,然后这是一键优化后的一个效果,我们再也不用担心 ai 做出来的网页呢, ai 味儿太浓了。第八个 scale 呢,是 scale 创建器。如果你觉得以上的 scale 呢,仍然无法满足你的需求, 这时呢,我们就可以用这个 scale, 它是 arropic 官网出的一个原技能, 通过对话式引导的方式呢,就可以帮助我们生成符合官方规范的一个自己专属的 scale。 比如呢,作为自媒体博主,我想让 ai 根据我的视频脚本呢,自动地推荐爆款的标题,转载视频简介以及推荐标签。此时呢,我只需要告诉他我的需求,他就能够帮我创建一个专属的 scale, 输入我的需求。 然后呢,将我之前自己写的一个提示词呢直接拖入回车,这是 ai 帮我直接生成的一个结果,然后这是他帮我写的 scale, 点 md 的 一个文件。第九个 scale 呢, 自媒体神器,这就是我用上一个 scale creator 做出来的我自己私人的 scale, 它可以根据脚本或者字幕内容的一个标题,视频简介以及 时间轴和标签。以前呢,我都是自己写提示词,拷贝到 ai 中来手动执行。现在呢,我们把字幕文件呢直接拖进来,这是一个字幕文件,我们直接拖入到 open code 中,输入帮我生成视频的标题和简介。 回车可以看到 open code 呢,会自动地识别任务来调用我刚才创建的一个 scale 进行分析,这是他帮我推荐的十个标题以及视频简介,时间轴和标签。今天的视频标题呢,我就是通过这样的方式来生成的。最后呢,来给大家介绍一个宝藏的仓库, 在这个仓库中呢,收入了有六十多个主流场景的一个 skill, 包括各类文档的一个处理,开发工具的一个集成、创意设计辅助、学术研究、写作支持、安全取证分析等等。强烈建议大家呢收藏。 说了这么多 scale, 我 们来看看具体到底应该怎么部署 scale 呢?是从放在点 open code gos 文件夹下的一个功能模块,如果我们是使用局部技能的话,就放在当前项目根目录下点 open code gos 目录之下, 此时呢,所有的技能呢,就仅当前项目可用。如果我们想所有的项目都通用的话, windows 用户呢, 直接放在用户主目录下的一个点, config open code scales 这样的一个目录之下,我们直接演示一下新建一个项目的一个文件夹,我们命名为 scale project, 然后打开文件夹,接着新建一个点 open code 这样的一个文件夹,再新建一个 scales 的 文件夹,大家注意这里有一个 s, 现在呢,我们就可以将 scales 文件夹直接 copy 过来, 这就是本期视频中涉及的所有十个 scale。 我 们要在当前项目之下使用 scale 的 话,直接进入项目的一个文件夹,右击点击,在终端中打开,然后输入 open code。 接着呢,我们输入我有哪些 scale, 此时呢, iphone code 呢,就会显示当前我们项目中存在的 所有的一个 scale。 我 们再来看一下 scale 的 一个文件规范,每个 scale 的 核心呢是 scale, 点 md 文件,我们任意打开一个 scale 看一下, 其核心呢就是这个大写 scale, 点 md 这个文件我们直接打开可以看到呢,首先是原数据层,六个横杠包裹的这部分,它包括两部分内容,一个呢是技能的一个名称, 另外呢就是对技能的一个简短的一个描述,应该会根据这个来判断是否需要加载该技能。第二层呢是指令层,这个呢是必须的。 第三呢就是资源层,包括 script, 它里面呢是可执行的一些程序脚本,参考文件夹会放置一些参考文档, asp 文件夹里呢会放一些图片等资源。那最后呢,关于怎么来用这些 scale, 其实逻辑非常优雅,你把这些 scale 文件放在项目里,或者配置成全局技能, 当你提问时呢, open code 会先扫描这些技能的一个目录,也就是原数据,如果有需要,它才会去加载详细的一个指令, 这种按需加载的方式既省 tokyo 呢,又让 ai 变得巨聪明。我把今天提到的所有 skill 的 下载链接, 还有详细的配置教程呢,都会放在评论区。好了,以上呢,就是本期视频的所有内容,如果这些 skill 对 你有帮助,记得点赞收藏关注,我们下次再见!拜拜!
664AI 博士嗨嗨 10:211.8万技术爬爬虾
10:211.8万技术爬爬虾 03:28查看AI文稿AI文稿
03:28查看AI文稿AI文稿这是你朋友给你发的神秘工具,有的能生成好看的照片,有的能让 ai 越狱,还有的能一键复活。老大,离谱的 ai 用法总是离不开离谱的提示词和工具,渴望学习的你是在评论区找大佬分享,还是晚上偷偷来我家让我教你呢?其实这些都不用,因为这个 game 上爆火的 skills 项目可以解决一切问题。 不过在说它之前,我们首先要知道,最近全网吹爆的 skills 真的 那么万能吗?它背后的原理又是什么呢?小白又要如何用它?本期视频将带你一探究竟,同时也会分享几种离谱的玩法,建议各位在父母的陪同下使用。在使用之前,我们先来诉通一下 skills 究竟是什么。 二零二五年十月份的时候,一家叫 ansopik 的 公司先提出了名为 cloud skill 的 技术,然后基于这个技术又推出了 agent skill 开放标准,让起初只能在自家软件上使用的 skill 也可以在其他软件上使用。不 过即便这么良心,这个标准制作完成后,它还是不温不火。但是随着时间的流逝,它的好处也在慢慢显现,因为 skill 可以 很方便地分享给别人使用。于是有不少人自发的将自制的 skill 上传到 github 上,吸引网友下载, 结果好评如潮。有人夸他的功能非常离谱,有人夸他非常节省偷啃。这是因为他用了一种叫做渐进式批漏的技术, 也就像洋葱一样,一层一层一层的把提示词给 ai 看。例如,这是一个 pdf 处理技能,可以分为三层,第一层叫做原数据,包含技能的名字和描述。第二层叫做指令,这里写着给 ai 看的工作流,比如让他用什么工具从 pdf 中提取文本。 第三层是参考资料和代码,让 ai 在 执行工作流的时候按需阅读。所以相较于传统提示词按需加载的特性,让它不仅能实现复杂的功能,而且占用上下文的长度会更小,也就更节省。头等, 如果你没有听懂的话也没有关系,会用就可以,除非你对 skos 的 底层细节非常感兴趣。那么你可以看看这篇官方文档和架构图, 我在这里只讲它最核心的几点。那么接下来呢?我们讲讲 skills 有 哪些离谱的用法和技巧。我们先来看几个案例,例如你想做一个产品动画,只需要像这样抒你的需求,完全不需要你懂剪辑就可以达到很好的效果,还可以拿来做软件宣传片, 或者那种高大上的数据动态演示,是不是非常香?再看这个剪辑技能,它能帮你下载播客这类长视频,再剪辑出其中的精华,然后生成带双语字幕的短视频,还能配上发布文案,非常适合做切片。另外还有这个漫画技能,想要批量生成漫画,只需要输入一个编好的故事, skill 就 会将 ai 加载特定的提示词,让 ai 一 连串的执行操作,生成这样的效果,看起来是不是画面非常精美,还有分镜和对白。 最后再推荐一个去 ai 味的技能,要比我之前推荐的提示词会智能不少。这里还有一个技能,下载的排行,热门的 skill 都可以在这里找到。以上提到的技能链接以及安装教程我也都整理好了,放在了视频的下方,你可以自取。 看到这里,想必你对 skyo 有 了一定的了解,但我还想提醒的一点是, skyo 并非适用于任何场景,因为简单的任务提示词就够了,复杂的系统需要写代码才行。而 skyo 适合处理中等难度的任务, 当流程繁琐但又不值得为它开发一个 app, 使用它就好了。好了,以上就是本期视频的全部内容了,如果你觉得有所收获的话,不要忘记点赞收藏。最后,我是元宝,一台 ai 和黑科技的挖掘机,我们下期见!
556Git源宝(AI版) 04:15查看AI文稿AI文稿
04:15查看AI文稿AI文稿最近 ai 圈爆火的 agent skills 到底是个啥?今天用三分钟给你讲,看完直接上手用。我们先上结论, agent skills 呢,就是给 ai agent 配了一个工具箱,里面呢全是你常用的工具和操作流程, 关键是这个工具箱它是你自己设计的。我们先来看一下这张图,以前呢, agent 它只有单技能的这个 mcp 可以用,它没有操作手册,我们呢,就只能自己手把手地去指挥 ai, 去调工具干活。在这种情况下呢,遇见相同的任务,就会经常地给 ai 发送重复的指令, 你说一句他动一下,而且每次都得重复说。现在呢,我们有了 agent skills 这样一个组合技能以后,我们就可以直接把那些常用的重复的操作写进这个 skills 里面,我们就像给 ai 做 sop 的 手册一样,下次呢,再遇到同样的活, ai 呢,它就会自动帮你干了, 你也就再也不用重复的折腾了。比如我这里列了三个技能,第一个技能,你看我们每日的热点筛选, 以前呢,我们都是逐个的让 ai 去做,或者自己搭一个工作流去弄,那这样的话门槛就高了。现在呢,直接可以把搜索分析、写报告、发邮件这样的步骤给他按照步骤执行就搞定了。 还有第二个技能,财报分析,找数据分析,评估预判风险,用代码生成报表。还有第三个技能,海报设计,你把你的公司的品牌规范设计要求都放进去,然后让 ai 按照要求去设计海报,我们呢,就可以把这些常规的动作都给他 打包进这个 skills 里面。如果这个不太好理解呢,我这里再举了一个游戏的例子,这张图呢,玩过王者荣耀的应该都比较熟悉了,你看王者呢,每一个英雄都会给他三到四个技能, skills 呢,相当于就是把这些技能给他配了一个固定的连招,比如三一二 a。 编好以后呢,我们再给他绑定一个咒语,下次呢,只要你一念这个咒语,他就会自动释放这个技能的。当然啊,现在的王者是没有这个功能的,我这里呢,就举个例子,方便大家理解。接下来呢,我们再来看一下这个 skills 他 具体长什么样子。 一个完整的 skills 呢,它主要包含以上四个文件,其中它的核心文件就是这个 skill md 了,我们来看一下它具体长什么样。那一个 skill md 呢,它主要有两部分构成,这个以上部分呢,是它的第一部分,也就是它的核心,然后第二部分呢,就是这一块, 就是他的内容。像第一部分这里呢,主要我们就要描述他的技能名称,还有这个技能的功能有哪些,以及什么时候去调用他。那下面这个部分呢,我们就描述指令使用场景,具体执行步骤,还有以什么格式输出,然后给他一个 demo 例子作为参考。 这里呢,我们就不详细的去聊了,感兴趣的小伙伴可以截个图。这里呢,我再补充一点,看,我这里提到了热点,需要根据我的人设进行匹配分析,那这个人设呢,我们就可以把它写进这个参考文档当中,那 ai 呢,就会从这个参考文档去读取人设内容去进行分析了。 如果你想对 skill 进行深入的了解,我们还可以打开这个 cloud 官方开源的 skill 的 仓库,自己进去看一下,它提供了很多模板,大家可以看一下它具体是怎么写的。那最后呢,我们说一下如何使用啊? 像现在除了 cloud code 以外呢,像 coser 去 open code 还有 codebody, 它们都已经把 skill 集成进去了,而且呢官方都有说这个东西具体怎么用,今天呢,你就可以把这个工具下载下来, 然后把你反复使用的那些操作写进 skills 里面来解放你的生产力。如果你用的是确的话,你看用这个就很简单了,你可以直接通过提示词告诉他,帮我去创建一份能审查我的代码效果问题的 skills, 然后呢 他就会去给你生成一个 skills 的 模板文件,看这里面的内容都写了,你遇到不符合的你自己修改就可以了。如果你觉得用代码来处理比较麻烦呢?他也提供了这种直接新建文件的方式, 就按照他的要求去填写就 ok 了。好了,我们今天的分享就到这里了,你也可以在评论区把你想写进 sketch 的 东西在这里分享出来,我们大家一起讨论,我们下期再见,拜拜。
543老雷AI洞见 01:40查看AI文稿AI文稿
01:40查看AI文稿AI文稿先给结论,剪辑式的 skill 本质是专业提示词加工具接口的组合器,同时通过渐近式提示词让 ai 按步骤完成整个剪辑流程, 这不是未来,而是正在发生的现实。 skill 的 两点核心本质,一、加 a 专业提示词加工具接口组合 提示词告诉 ai 风格节奏、剪辑规则,工具接口让 ai 调用剪辑软件素材库、音频处理工具执行操作。二 d 渐近式提示词展现 skill 不是 一条一次性指令, 而是分阶段分步骤驱动 ai。 比如先筛选素材,再剪辑片段,再调整时间轴,再添加转场,再处理音频,再生成字幕,再生成字幕,最后输出多版本。每个阶段的提示词都有明确目标, ai 根据前一阶段结果逐步完成下一阶段任务。第一次点名剪辑师的具体工作内容, 你每天做的事包括 skill。 将每一步拆解成可执行模块, ai 自动按步骤执行,几乎不需要人工干预。 skill 拆解流程示意,一 john 上传素材并选择风格。一、 ai 根据提示词筛选高质量片段。二、抵 a 时间轴排列, ai 按节奏自动剪辑。三、 它我转场特效处理耶, ai 自动添加符合风格的特效。四、 ro 音频处理耶自动匹配音乐和音量 五、 g a 字幕生成一,自动生成并嵌入六天它多版本输出杀不同平台尺寸和格式自动生成,每一步都是渐进式提示词驱动,确保 ai 完整理解目标并执行智能体协调。多个 skill 同时运行,全天候处理几十条视频, 输出,质量可控统一,无需疲劳,企业效率提升数倍,成本大幅下降。最后一句话, skill 的 本质决定了它能逐步替代剪辑师的重复工作,这是不可逆的趋势。
2042三阳LINK【AI视界】 00:31查看AI文稿AI文稿
00:31查看AI文稿AI文稿太炸裂了!创业居然跟玩游戏一样简单!这个工具可以把你所有的 skills 转化为格式化的三 d 地图。就像游戏界面一样,每个 agent 都是一个独立的小人,你喝着咖啡,这些小人就帮你把活干了。 拖拽就能分派任务,执行过程中,谁在干活,谁在待命也看得清清楚楚。你可以缩小查看大局进度,也可以放大聚焦每个细节。而且你想调整组织架构,只需要几秒钟的点击。拖拽可以遇见的是,以后你只需要选定了一批 skills 丢给他,立即开工,一个人就能支撑起一个庞大的公司。
9228吴越AI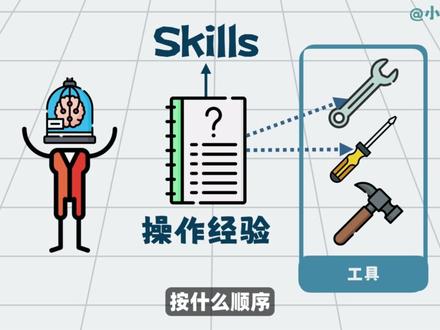 07:31查看AI文稿AI文稿
07:31查看AI文稿AI文稿这两年的 ai 领域,具象化体现了什么叫用概念的堆砌来演示技术能力的匮乏。最近又又又出现了个很火的新词 skills, 它的本质是什么?跟 workflow、 prompt、 mcp、 command 又有什么关系?接下来我们就一次性将这些概念串起来,带大家看清楚。看之前你点赞了吗?关注了吗?谢谢! 提示词我们知道,要让 ai 干活,最简单的办法就是给他发一句指令,也就是 prompt 提示词。比如帮我写个简历,但 ai 吐出来的结果可能在格式和内容上都不太符合我们预期。 为了让效果更好,你可能会加入很多规则,比如个人信息要居中、教育经历要用表格列出,项目经历要用 star 法则拆解。这种详细规定步骤的提示词,我们称为结构化提示词。 come 的是什么?但提示词这么长,每次都说 手敲,不太现实。所以很多 ai 客户端,比如 cloudcod, 会支持把常用提示词固化成文件,需要时就通过类似快捷键的命令换出。这种用短命令替换一段固定内容的功能就叫 comend。 system prompt 是什么 come on 让我们更方便输入长提示词,但提示词变长后,我们会发现 ai 越来越不听话。让他用表格,他给你纯文本,你让他居中,他直接忽略, 那有没有办法让他更听话?有,我们在输入框输入的内容在大模型领域叫用户提示词 user prompt。 他还有一层优先级更高的指令,叫系统提示词 system prompt。 一般来说,同样的要求放进系统提示词,大模型的指令遵循效果,遵循效果会比用户提示词更好。但我们平时用 ai 的时候,就一个输入框,敲进去的内容默认都会被当成用 提示词发给大模型。系统提示词都是 ai 客户端在背后发的,怎么才能将输入的内容作为系统提示词发给大模型呢?一些 ai 软件特地留了个口子,让我们可以用文件的形式记录要发的系统提示词,比如 cursor 的 ctrl cloud code cloud 点 m d, 最常见的里面可以放,请用中文回复我看爽了吗?那来个一键三连不过分吧? met data 是什么?我们平时需要面对很多场景,比如写简历、写周报、写邮件,对应的要求各不相同,将他们全塞进一个系统提示词文件里,明显不合适怎么办? 最直接的做法就是按场景拆成一个个独立的 m d 文件。那问题就来了, ai 怎么知道该用哪个文件?将文件全部给大模型读一遍再做判断也不现实,毕竟文件内容会转为数字,也就是 token 文件阅读 多,运费脱肯太贵了,怎么办呢?我们可以在每个文件的开头加一段很短的描述信息,写清楚这个文件是干什么的,什么情况下该被调用。这种提示型的数据叫原数据 met data。 这样,当用户在 ai 客户端里发送帮我写个简历时, ai 客户端只需要将这些 mate data 发给模型。由于 mate data 很小,所以也不费什么 top 模型,判断出是简历场景并返回 ai 客户端,就会自动加载简历专家的全部内容进系统提示词发给 ai, ai 根据提示词开始生成简历内容,然后返回给客户端,这样既保证了提示词效果,又省下很多 token。 看到这里,还没睡着的弹幕扣个零,让我看看还有多少人? reference 和 script 是什么?随着需求越来越细,单个文件依然会变得很大。比如同样是写简历,不同岗位 有不同写法,产品需要突出业务理解,开发岗要体现工程复杂度,算法则更关注论文成果怎么办?继续拆,我们可以在写简历点 md 中留一个岗位入口,不同岗位路由到不同文件。 如果单个岗位文件还是太大,那继续拆,这样 ai 客户端就会用 cat 等系统命令读取文件总纲,再根据岗位方向一路下钻,只查看需要的那一小撮文件,用不到的文件完全不消耗。 tok 这种按需加载数据的读取方式,也就是所谓的渐进式披露。 这些被拆分出来的文件,我们可以作为参考资料,放入到一个叫 references 的文件夹底下。顾名思义,只要大模型有需要,就可以参考里面的材料。既然能调动系统命令读文件,那按理说也能执行命令跑代码,那写个 python 脚本,将文本写入 word 文档里,再导出成 pdf, 也就顺利 成章了。同样将这些代码文件放到一个叫 scrap 的文件夹里,在提示词里写清楚什么情况该执行什么脚本。这样大模型就能和 ai 客户端配合,通过代码脚本实现纯文本聊天之外的功能。看到这里,你已经超越百分之九十九的观众。扣个一,让我看看到底有多少人 skill 是什么?到这里,我们已经把自己常用的用户提示词变成了一段段以文件形式存在的系统提示词,再通过 metadata 和拆分文件,实现按条件和场景加载数据,大大减少托肯消耗量。 并将提示词可能用到的参考资料和代码分别放入 reference 和 script 文件夹,一个负责读参考资料,一个负责跑代码。将提示词文件主入口改名为 skill, 点 m d, 再将他们共同打包为一个文件夹给个命名。比如写简历的叫 resume writer, 写文章的叫 article writer。 这个被外化为文件夹形式存在且可动态加载的系统提示词,其实就是所谓的 skill。 我们来看一下 skill 的完整工作流程。首先将它放到 cloud code 的 skills 目录底下,这样就算完成了安装,此时 cloud code 就能识别到它的命令。 然后我们像往常一样在聊天框里发送自己想做的事情。比如帮我写个简历 pdf, cloudcod 就会加载本地的多个 scale 文件,将他们的 met data 一起发给大模型, 大模型识别返回当前需要哪个 skill, 告诉 cloud code。 cloud code 加载对应 skill 文件到系统提示词里发给大模型。 大模型根据需要,让 cloudcod 依次读取可能需要参考的多份资料,甚至是执行本机代码脚本,生成 pdf, 并将结果给到大模型,大模型最终输出完整结果给用户,完成整个流程。那 skill 跟 mcp workflow 的区别是什么呢? skill 和 mcp 的区别我们知道,大模型就像大脑,为了让他能够操控外部工具,大佬们引入 mcp 协议,他就像给大脑配的手一样, mcp 插件就是手上的工具, 给一个大学生一堆工具,他也不一定能修好车,毕竟他缺的是经验和流程。所以才有了 skills。 你可以将它理解为是操作经验,规定在什么场景下,按什么顺序组合,使用哪些工具。注意,这里提到的工具既可以是 mcp 插件,也可以是本地的 script 脚本。 看上去 skill 像是编排工具,那他跟 workflow 又有什么区别? skill 跟 workflow 的区别我们知道,很多任务其实可以拆解成好几个步骤,比如做视频,可以分为找选题、写文案、做分镜等几个步骤。为了解决这类流程化需求,不少大佬开源了一些低 代码工具,比如 n 八 n, 通过拖拉拽的方式快速构建一条流水线。这种通过规则配置,把多个步骤进行编排和调度的流程就叫 workflow。 skills 本质上也是做逻辑编排,但跟 workflow 不同的是, workflow 的流程结构在设计阶段就确定好了,而 skills 的执行流程则由大模型驱动,灵活性相对更高,两者最终都能做到类似的功能。所以不那么准确的说, skills 可以简单理解为是大模型驱动的 workflow。 现在大家通了吗?好了,如果你觉得这期视频对你有帮助,记得转发给你那不成器的兄弟。文字版的笔记见评论区最后遗留一个问题,哎,算了不留了,提前祝大家新春快乐呀,祝大家暴富暴美暴帅! 评论区告诉我你还想了解什么?这里是小白的 bug, 我们聚焦一切可能影响人类历史进程的技术,如果你感兴趣,记得关注我们,下期见!嘟嘟嘟嘟嘟嘟嘟嘟嘟。
9495小白debug 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿这个 agent skill 每天可以节省你好几个小时,直接用它和你的 ai 对 话,就能自动连接 notebook lm。 我 之前用它生成了一段播课全程,完全不需要手动操作。网页 and apple chose, google's gemini to power the next generation of siri it's not just a friendly deal i think you described it perfectly before it's a shared vote a shared vote。 安装方法特别简单,下面手把手教你。首先你需要一个支持 skills 的 客户端,目前 cloud, opencode and gravity 等都支持。然后把 github 上这个项目页面发给你的 ai, 告诉他帮你安装这个 skill 就 行。 安装完成后,比如在 opencode 中,需要把这个 skill 加载的配置文件用同样的方式把这个页面发送给 ai, 他 会按照文档帮你配置好。成功后你就能看到这个 skill 了。现在让 ai 调用定制 skill, 自动搜索近期硅谷科技动态,汇总信息,并同步到 notebook i m, 最终生成一段定制薄刻整过程完全自动化,体验非常流畅。你甚至可以设定每日定时任务,让它自动为你完成这些工作。这样一来,就不再被动接收碎片化信息, 而是每天收获一段高质量的薄刻,轻松节省下几个小时的信息整理时间。而这个 skill 的 强大还不止如此,只要是 notebook i m 上有的功能,它全都可以调用,更多好用的玩法等你来发现!关注我,了解更多 ai 干货,感谢大家观看!
442未来奇点 22:22查看AI文稿AI文稿
22:22查看AI文稿AI文稿如果你觉得现在的 ai agent 还不够好用,那很可能你还没用过 agent skills。 它是 snoop 及 m c p 之后推出的新一代 agent, 开发标准是基于通用 ai agent 的 工程扩展包。通过加载不同的 skill, ai agent 就 可以分装成具备专业知识的垂直 agent, 从而稳定可靠地完成特定领域的具体工作。比如加载一个金融类的 skill, 它就可以帮我们自动完成财务分析以及日常费用报销等等。加载一个法律类的 skill, 它就可以帮我们自动处理合同审查、 准备诉讼材料等等。可以说不论你从事哪个行业, agent skills 都能帮你把工作中重复的那些流程封装成一个 agent, 让它去自动执行,帮你节省大量的时间。而且随着它的使用范围越来越广,目前主流 ai 编程工具几乎都已经支持了 agent skills, 比如像 cursor、 cloud code codex 等等。 那这期视频我们就来为大家详细介绍 agent skills, 包括它的使用方法、运行原理、资源查找以及技术优势。好了,下面我们就来开始今天的视频内容。 接下来我们使用 cloud code 来介绍 it 的 skills, 如果还没有安装 cloud code, 可以 按照这个文档去安装,首先安装 root js, 然后如果是 windows 用户,还需要安装 git, 接着执行这条 npm 命令安装 cloud code, 安装完成以后可以执行 cloud, 刚刚默认验证一下是否安装成功。那如果是国内用户,直接使用 cloud 模型可能不太方便,我们可以给 cloud code 设置一个国产 ai 模型,比如像 deepsea、 千问 kimi k 二都可以。 那这里我们以 g i m 四点七这个模型为例来演示一下,这个 i 模型呢,有提供一些免费额度,而且效果也挺不错,那可以看到它这里支持三种配置方式,分别是自动化助手、自动化摇本,还有手动配置, 我们选择。第一步,我们需要在用户目录下的点 cloud 文件夹里面的这个 settings, 点 jason 这个文件中添加上下面这段 jason 配置。 我们先打开用户目录,那由于点 cloud 是 一个隐藏文件夹,默认是不显示的,要让它显示的话, mac 用户可以同时按下 command 加 shift, 加点这三个键。 windows 用户呢,可以在文件资源管理器中点击查看,然后显示,然后勾选上隐藏的项目, 这样就能看到这个点开了的文件夹了。然后我们打开这个文件夹,找到 settings 点 json 这个文件,如果没有这个文件,可以自己手动创建一个,那接着我们把这段 json 配置复制过来,注意这里这个 api key 要替换成我们自己的 api key, 在 这里新建一个,然后复制过来就可以了。 然后第二步,我们需要在用户目录下的这个点 cloud 点 json 这个文件中添加上这个配置参数。我们回到用户目录, 然后打开这个点 cloud 点 json 文件,我们可以在这个文件中先搜一下是否已经配置了这个参数,那可以看到这里显示它默认是包含这个参数的,那我们就不需要再去配置它了。好了,完成配置以后,我们就可以正常使用 cloud to code 了, 执行 cloud 命令,启动 cloud code, 然后选择信任这个配置文件,那可以看到它就成功绕过了这个 astropica 的 身份认证,直接进入到了 cloud code 它的对话页面,我们执行斜线 models, 那这里显示的模型呢?依然是 cloud 模型,它和 glm 模型的对应关系是这样的, cloud ops 四点五和 cloud solid 四点五对应的都是 glm 四点七,而这个 cloud hq 四点五对应的是 glm 四点六。 我们选择使用这个 solid, 也就是 glm 四点七模型来测试一下。好了,现在这个 cloud code 就 可以正常使用了。 那接下来我们来介绍一下如何在 cloud code 中使用这个 it 的 skills。 这是 esoteric 官方维护的一个 get up 项目, 打开这个 skills 这个文件夹,那这些就是 esoteric 给我们提供的一些 skills 势例,比如设计前端的 skill、 操作 pdf 的 skill, 操作 ppt 的 skill。 那这里面对我们最有用的是这个 skill creator, 那 这是一个用来生成 skill 的 skill。 没错, isrook 官方推荐的使用方式呢,就是使用这个 skill 去自动生成你需要的任何 skill。 那 要怎么使用这个 skill creator 呢?我们回到这个项目页面,点击这里,先下载代码, 可以使用 get clone, 或者直接下载这个压缩包,下载完成后,把代码解压出来, 找到这个 skill creator 这个文件夹,然后把它复制到我们当前用户目录下这个点 cloud 文件夹下面的这个 skills 文件夹里面就可以了。如果这个点 cloud 下面没有这个 skills 文件夹,可以自己手动创建一个, 那其他 skill 呢?如果有需要也可以复制过来,比如这个操作 pdf 的 skill, 还有这个操作 ppt 的 skill, 我 们也一并复制过来。好了,这样这三个 skill 就 配制成功了。那接下来我们就可以在 cloud code 中去使用它们了。 我们用 vs code 打开用户目录下的这个点开了的文件夹,那第三个就是刚才配置的 skill。 那 接着我们打开命令行,切换到这个用户目录,启动 cloud code。 好 了。下面呢,我们根据一个真实的工作场景,从零开始来生成一个 skill, 来帮助我们自动化处理重复性的工作。那具体的场景是这样的, 比如我们是一家公司,负责招聘 hr, 每天都要筛选很多份辞职简历,然后根据公司的招聘标准筛选出符合条件的简历,并根据筛选的结果生成一份分析报告,并通过邮件发送给你的上级。 这套流程你可能需要经常执行,那针对这类重复性的工作,我们就可以把它封装成一个 skill 来自动处理。回到 copy, 粘贴上相应的提示词,让它根据我们的工作场景来生成这个 skill, 要求它从一个本地文件夹读取文件夹内的所有 pdf 简历,然后分析简历内容并进行筛选。 筛选过程需要参考公司的招聘标准文档,包括销售、开发这些岗位。接着分析完成以后,要根据这个报告模板生成一份分析报告,并通过 email 发送出去,而且发送 email 的 操作要求是可选的。好了,我们来执行任务, 那可以看到它,这里提示它会使用我们前面配置的这个 skill creator 这个 skill 来完成这个任务,然后它就会引导我们去一步一步完成创建。首先它问我们是否准备了这个招聘标准文档,还是需要让 ai 去生成一个视屏模板, 那这里我们让他去生成数据模板,如果有自己公司的招聘文档的,也可以直接使用。然后他让我们选择邮件发送使用什么方式,我们选择使用 python 脚本。好了,确定方案以后,我们点击提交让他去执行。 执行结束后,我们来看一下这个 resume skinner, 就是 skill creator 给我们生成的这个 skill。 打开这个文件夹,这就是一个典型的 skill 的 结构。首先这个 skill 点 m d, 这是一个 markdown 文件,它里面存储的就是这个 skill 的 主体逻辑。 那可以看到它的内容呢?主要有两部分。首先是这个 skill 的 原数据,包括这个 skill 的 名字还有描述,那 ai 呢?根据这些原数据就可以确定这个 skill 的 功能是什么,什么时候可以调用它。比如我们给 ai 发送消息, 需要筛选某个文件夹下面的简历,那 ai 就 会去匹配所有 skill 的 原数据。当匹配到这个 skill, 通过对比它的描述信息就可以确定这个 skill 呢就能满足我们的功能需求。接着它就会去使用这个 skill, 那 可以发现它的这个匹配原理和 m c p 是 一样的, 但是相比于 m c p 呢, agent's skills 有 一项非常明显的优势,就是投币消耗明显降低,这些我们在后面会具体介绍 好了。在 skill 点 m t 中,除了原数据,剩下的就是这个 skill 的 具体执行逻辑。首先是需要准备的数据包括三个部分,一是存放这个简历的文件夹,二是这个招聘标准的文档, 它这里使用的是这个 reference 这个目录下的这两个 markdown 文件。三是一个报告模板,使用的是 size 目录下的这个 markdown 文件。那准备完数据以后,接着就是读取简历内容,然后分析简历。这里需要注意,在分析简历这一步呢, 它使用了这个 pdf 这个 skill 来读取这个简历的内容。也就是说多个 agent 的 skills 呢,是可以互相联动使用的。我们来看一下这个 pdf skill, 在它的这个 skill 点 m d 文件中,这个表格总结了它知识的功能,这里面包括合并 pdf, 切分 pdf, 提取 pdf 内容等等。我们这个简历筛选 skill 使用的就是这个 extract text 的 这个功能来提取 pdf 简历的内容。 在 skill 中,除了脚本文档,默认都是 markdown 格式的,如果不熟悉 markdown 语法,可以先去了解一下。在我们之前的这期视频中有介绍过 markdown 语法使用也非常简单,只需要几分钟就能快速掌握 好了。我们回到这个简历筛选 skill, 那 在新的 skill 中是否需要调用其他 skill 的 能力呢? 我们可以根据使用需求来决定,比如新的 skill 只是给自己使用,这时候就可以选择调用已有的 skill 能力,那这样可以减少开发和调试的时间,因为已有的 skill 它的能力已经经过了验证。但是如果这个新的 skill 除了自己使用,我们还要分享给其他人, 或者需要多个人去联合开发。最好就不要选择调用已有 skill 的 能力,而是应该告诉 ai 使用脚本去单独实现这部分功能,这样可以确保这个 skill 的 独立性,分享或联合开发都会更方便。分析完简历以后,接着使用这个模板去生成报告, 最后使用这个 scripts 这个目录下的 send email 这个 python 脚本来发送 email。 最后他还给了几个使用视例,只需要这样和 ai 对 话,他就会调用这个 skill 帮我们自动筛选简历。 我们可以选择只筛选简历或者筛选简历并发送报告。那可以看到通过结合 ai 模型的语义理解, ai skills 的 使用是非常灵活的,他可以通过对话内容灵活选择需要的功能,避免浪费 token。 那接着我们再来看一下这几个文件夹,这个 scripts 里面存储的就是可以被 skill 调用的脚本,比如这个发送邮件的脚本,然后 reference 里面就是 skill md 需要参考的文档, 一个是开发人员招聘标准,一个是销售人员招聘标准,里面罗列了很多细色,包括专业背景、工作经验等等。我们可以使用自己公司的招聘文档替换到这些模板,或者直接在模板中按照自己的需要去进行修改。 这个 assess 文件夹里面存放的是 skill 的 一些素材资源,比如像模板文件,公司的 logo, 字体文件等等。这个就是简历筛选后生成报告的模板,可以看到里面的内容还是很详细的,包括通过筛选的人员,未通过筛选的人员,以及每位应聘者在各个方面的具体表现, 能够帮助 hr 快 速掌握应聘者的具体情况。好了,下面我们来测试下这个简历筛选的 skill, 看一看效果怎么样。这里我用 ai 生成了两份开发人员的简历,打开来看一下,左侧这份简历的应聘者呢,没有软件开发的相关工作经验是不符合招聘标准的, 而右侧这份简历的应聘者就有比较好的开发经验,符合公司的招聘标准。我们就用这两份简历来进行测试。把这个简历文件夹拖到这个 id 号框, 然后我们让它去分析这个文件夹下面的所有简历生成报告,但是不要发送邮件,可以看到它提示可以调用这个 resume scanner 这个 skill 来进行处理。我们点击执行, 执行结束以后输出了一个分析结果,而且在这个简历文件夹下面生成了一份 markdown 格式的分析报告。我们把这个报告拖进来看一下, 点击这个预览,这个就是生成后的分析报告,那可以看到内容也非常详细,里面包括报告预览、数据汇总,通过筛选的人,未通过筛选的人以及应聘者在各个方面的评估。那通过这份报告就能帮助我们快速了解所有应聘者的具体情况, 并及时给符合条件的应聘者安排面试。接下来我们再来测试一下这个发送邮件的功能。先来配置一下发送邮件的参数,我们直接问 ai 如何配置这些参数, 按照他给出的说明,我们需要配置这些参数。先来创建一个邮箱的应用密码, 然后复制这个密码保存下来。接着我们让它修改一下这个发送的脚本,我们让它改为从本地环境变量去读取这些参数。 好了,修改完成以后,我们执行 exit, 先退出 client code, 然后执行这几条 export 命令,设置一下这个发送邮件的参数,这里面包括发件人、收件人,还有这个邮箱的英文密码,注意这个密码中间的这个空格要删掉。 然后我们再重新启动 cloud code, 再来重新执行一次这个简历分析任务。但是这次我们要求它在生成报告之后,需要发送电子邮件。 执行结束来看一下这个收到的邮件,那可以看到这里面它没有附带上那个生成的报告,而且这个邮件的内容也过于简单,我们让它来优化一下,要求还是从环境变量读取参数, 而且在邮件中要以附件的形式带上生成的报告,还有所有的 pdf 简历,并且这个邮件的内容要优化一下,需要能够体现这个邮件的用途。 好了,修改完成以后,这个 ai 它自动完成了测试。我们来看一下收到的邮件,这次就没有问题了,首先这个邮件的内容包含了这个邮件的用途,然后附件也包含了这个生成的报告, 还有这些是所有的 pdf 简历,方便去对比查看。好了,那这样我们这个简历筛选的 skill 再经过一些详细的测试,就可以用来帮我们自动筛选简历来处理一些重复的工作了。 那接下来我们结合这个简历筛选的 skill, 来介绍一下 it skills 的 工作原理。在 it skills 的 工作过程中呢,一共有三个角色参与其中,第一就是作为用户的我们, 第二就是我们使用的 ai 工具 cloud code, 第三就是 ai 工具背后使用的 ai 模型,在这里是 g m 四点七, 整个过程大概是这样的,当 cloud code 启动以后,里面所有的 agent skills 都会先把自己 skill 的 原数据加载到 ai 的 上下文窗口中,那这些原数据我们在前面介绍过, 就是 skill 点 m d 这个文件中 skill 的 名字和描述信息,那这些原数据可以用来匹配 skill 的 调用,而且这些原数据呢,通常都很短,长度只有几百个 token, 所以 它们是常住在 ai 上新闻窗口中的,不会造成负担。 然后当用户发送消息要求筛选简历,这个消息就会通过 cloud code 转发到 ai, ai 就 会检测上下文窗口中所有 skill 的 原数据,当检测到这个 resume scanner 这个 skill, 通过匹配描述信息发现这个 skill 恰好能够满足需求, 接着他就会去使用这个 skill 来完成这个任务,那这时候他才会去真正把 skill 的 主体逻辑,也就是 skill 点 md 读取过来,然后按照这个 skill 点 md 里面的设定开始进行处理。 首先调用 pdf skill 提取简历的内容,然后提取这个招聘标准的文档进行简历分析, 接着根据这个分析结果读取这个报告模板去生成报告。最后就是调用邮件发送这个脚本去发送邮件,而且这个发送邮件是可选的,这就是 agent skills 的 执行过程。那可以发现这套设计呢,遵循了一个理念, 就是只有在真正需要的时候,才会把数据读取到 ai 的 上下文窗口,这样就可以大大减少拖延消耗。 比如在 cloud code 启动后, ai 只会获取 skill 的 原数据,而只有在确定调用某个 skill 之后,才会去真正获取 skill 的 各种文档。这种工作方式叫做间接式批录或者延迟加载,主要目的就是减少拖坑的消耗。而且在这个过程中,脚本并不会全部读到 ai 上下文, 只需要读取调用脚本所需的最小信息就可以。那我们这个简历筛选的 skill 后期还可以继续扩展,比如添加面试规划的功能,但是需要注意,一个 skill 不 宜过大,最好合理划分多个 skill, 然后去联动使用多个 skill 来完成复杂的任务,这样更方便管理和扩展。 下面我们再来介绍一个可以查找 agent skills 的 免费网站,就是这个 skills mp, 这里收入的都是 github 上开源的 agent skills, 目前为止一共收入了六六五四一个。要使用它,我们可以点击这个搜索功能, 比如我们搜索关于交易类的相关 skill, 这里就返回了我们需要的。我们打开一个,可以看到这些就是 skill 的 内部文档,包括 skill md, 还有 reference 下面的参考文档 scripts 下面的 shop 脚本。 要使用这个 skill 也非常简单,只需要点击这里下载文件,然后解压出来,把这个 skill 文件夹复制到点 cloud 下面的 skills 文件夹下面就可以了。 我们执行斜线 skills, 可以 看到这个生成交易计划的 skill 就 已经配置完成了,那下面我们用它来生成一份贵金属的交易计划来试一试。 执行结束后,它就给我们生成了一份 markdown 格式的计划文档,我们拖进来看一下, 这个就是生成的这个交易计划文档了,内容还是比较详细的。我们回到这个网站,如果想要查看这个 skill 对 应的 github 项目,可以点击这里跳转到 github, 这些都是可以使用的 skill。 那除了搜索,我们还可以点击这里按照分类来查看 skill, 这里面包括生产工具类、自动化工具类等等,在这里还可以按照 star 树或者更新日期来排序。那这个网站用来快速查找需要的 skill 还是挺不错的。 最后我们来对比一下 agent skills 和 m c p 这两项 ai 技术使用起来让人感觉非常相似,那我们应该选择哪一个去使用呢?其实它们都是 astropica 推出的开放标准,两者的区别主要体现在设计理念和适用场景这两方面。我们先来看一下 agent skills, 结合我们前面这个简历筛选的例子,那可以发现 agent skills 是 在做什么呢?它是在封装一系列需要重复执行的步骤,把这些步骤封装成一个 skill 去自动处理。比如发票报销,也是一个需要重复执行的多个步骤的流程,同样可以封装成一个 skill。 那 mcp 又是怎么回事呢?我们在之前的这期视频中有介绍过 mcp, 有 需要的话可以去看一下。 mcp 的 核心设计理念是什么呢?一句话就是连接万物,也就是把各种外部服务通过 mcp 这个万能的 usb 接口全部接入到 ai 里面,比如各种软件、各种社交平台、网站以及各种数据库等等,所以这两者在最初的设计理念上就是截然不同的。 我这里总结了一个表格,来对 agent skills 和 mcp 做一个对比。先看作用上的区别, agent skills 主要解决的是一件事,就是把步骤、规则、逻辑判断封装起来,也就是说,它是把一套专业的流程直接做成一个可以附用的能力。 而 mcp 干的事情不一样,它的核心作用呢,是给 ai 提供标准化的工具接口,让 ai 可以 安全规范地接入外部的系统,比如像 api、 数据库、底层服务。 再来看适用场景, agent skills 呢,它更适合用在流程固定,需要反复执行,而且依赖专业经验的人物,本质上就是把专业知识固化下来,然后让 agent 按照规则去稳定执行。 而 mcp 呢,更适合用在 ai 需要获取外部数据,或者需要调用外部系统去完成某个操作。比如像查询数据、发送消息、调用接口这些事情,那如果看典型的应用,比如像筛选简历、报销审批、流程审核, 这些都是多步骤、规则强的任务。而 mcp 的 典型场景呢,比如像查询 github, 发送 select 消息、访问数据库,它本质上呢,是在帮助 ai 去使用工具。那再往下看一下使用门槛, agent skills, 它的使用门槛相对比较低, 通常使用 markdown 加一些脚本就可以定义清楚流程,还有能力,但 mcp 的 门槛就要高不少,你需要理解协议配置接口, 有时候还需要去自己部署 m c p server, 对 工程能力的要求更高。最后是我们最关心的偷窥消耗, agent skills 呢,采用的是见进披露的方式, 只有在需要的时候才加载对应的步骤还有信息,所以整体的偷窥消耗相对比较低。而 m c p 往往是一次性加载全部的数据,它的偷窥消耗明显会更高。所以我们可以这样理解 agent skills, 它负责的是怎么把工具用起来, 它们两者并不是替代关系,而是在一个 agent 系统里面各自解决不同层面的问题。那关于 agent skills 我 们就介绍完了,可以说这绝对是一项非常实用的 ai 技能,大家可以想一想在自己工作中存在哪些重复性的流程, 是否可以封装成 skill, 让它去自动执行,然后呢,可以去动手试一试。好了,最后感谢大家的观看和点赞支持,我们下期视频再见,谢谢!
195陶渊小明 04:57查看AI文稿AI文稿
04:57查看AI文稿AI文稿全网爆火的扣子 skills, 详细的操作 sop 流程来了,从零到一,手把手教你如何搭建 skills, 这里呢是我搭建的一个是 ai 实时抓取新闻数据的 skills, 一个文案润色 skills 包括爆款标题的 skills, 以前入色文案需要一个智能体,打开一个对话框,然后热点搜索,打开一个智能体,一个对话框,对吧?那现在有了这个 skills, 我 们只需要在一个对话框中直接三个技能同时调取 来,我们直接来上案例,比如说搜索全网关于 ai 最新热点新闻,并提炼总结爆款文案, 三条爆款,来我们看看他是怎么来工作的,你看正在加载技能热点已经提炼出来了啊,在写脚本,三条标题封面文字,你看标题封面 包括核心策略说明都给你写的明明白白,这里呢等于是调用了三个技能,一个是热点搜索,一个是文案润色,一个是爆款标题。那这是怎么实现的呢?其实很简单, 下面呢我们来一步一步来实现,首先呢就是这里扣子平台网站打开之后呢,点击这里右边有个技能,在这里用自然语言去描述就可以了,你看我们具体到我们每一条我们文案润色的技能, 那根据用户输入的话题,或者对标的文案或者新闻热点进行文案二次创作一篇爆款短视频文案,他呢就会自动的给你生成一个技能,但是呢,这个技能肯定不是你 最终想要的结果,肯定不好,对吧?那我们需要一步一步的去调整,怎么调整?这个很关键,你看下面,我说开头钩子不够好优化开头钩子爆款短视频文案最重要的标准就是看开头 有没有开好,开好了就成功了一半,对吧?那他呢,就会再根据这样的信息再去优化,那经过这样一轮两轮三轮的优化,最后呢结果呢?就差不多了,但是呢,在扣子平台呢,你这里只能使用豆包模型, 懂的都懂,对吧?你要想让他更牛逼,输出的结果更好呢?一个是你优化你的,这里你看 skill 的 就是你,其实也是贴着词,说白了还有一个呢,就是要换大模型,换大模型呢就就不能在扣子平台上去用这个技能了,我们需要跑到 本地化部署你这个技能,那具体怎么实现呢?其实也很简单,我这里呢给大家稍微简单的说一下,你看点击右边这个文件夹这里把它点开,点开之后呢,左边有一个点 skills 文件,你看直接点击下载好。 下载完之后呢,你打开这个 tree, 这个是本地话的软件,打开之后点击右边这个设置,设置下面 找到规则和技能,点开下面有一个技能创建技能,你看这里我现在已经有四个技能了,我再创建一个点击,然后我把刚才我们从兔子平台下载的那个技能呢加载上来就可以了, 你看就这个润色文案的技能呢,就加载上来,加载上来之后呢,我们可以点开看看他的这个技能里面都有哪些内容,你看角色战略,核心原理,营销 人设风格,那这些呢?发现没有,还是我们体式词 prompt, 但是这个体式词呢,又和我们智能体那个体式词还有略微的不一样,因为这里我们要把它给分层, 你看热点捕捉借势的方法,给它弄成一个单独的文件,让 ai 去调用。这样做的好处呢,就是为了节省 tok 嘛,之前 tok 太多很费钱,一个是提高效率,一个是节省钱。你看平台包含文案结构提炼出来放成一个文件夹, 然后呢这个 skill 的 点 md 呢?它就会根据需要来去调取这里面的信息, 来最终生成你的爆款文案。我们总结出来最核心的就是最少必要知识。什么意思?就是把你认为的和网上所有那些讲短视频文案怎么写的老师,把他们的核心观点,核心技能给他提取出来, 就写成这样的文档放到这里面,那 ai 呢,就会直接来拿来参考用了,那最终呢,在右边这个对话框呢,他就会是自动的去调取对应的技能 来生成你需要的内容。那所有的这些操作步骤呢,都在我们总结的这个非熟文档了,需要的兄弟直接说一下拿去。
 06:28查看AI文稿AI文稿
06:28查看AI文稿AI文稿这是 cloud code, 如果你让他开发一个美观的博克网站,他给你的结果啊,可能是这样的,这一点也不美观,对吧。于是啊,你告诉他, 不要使用蓝紫渐变色,不要使用 emoji 图标,而要使用 svg 图标。把上面这一堆要求呢,都告诉 cloud code, 让他再重新开发一个美观的博克网站。这一次啊,情况就要好很多了。 那么问题来了,我不想每次开发项目的时候,都啰里啰嗦的写这么一大段,能不能让 class code 记住这些要求,我不用每次都叮嘱呢, 哎, class code 提供了一个方法,我们可以把这一大段要求啊,放到一个单独的文件中,以 markdown 的 格式书写。那后续呢,我们再让 class code 干活的时候啊,他就把这个文件一起带上,发给 ai 了,这样呢,就不用每次都要写一遍了。但这样呢,有一个新的问题,如果我只是在 class code 里面聊聊天,提提问, 反正不是开发网站,他也要把这一堆内容发给 ai, 这不是白白浪费托管吗?能不能简化一下这个流程,只有当真正需要用到这个文件的时候, clark 才把它发给 ai 呢。我们可以这样做,给这个文件啊,取个名字,然后加个描述,放在文件最开始的地方。 同样呢,还是以 markdown 格式书写,这两个字都啊,简单介绍了这个文件叫啥,是干啥用的。然后 cloud code 在 与 ai 沟通的时候呢,他告诉 ai, 我 这里啊有个文档,他的名字和描述是这样的,如果你有需要,可以问我要具体的内容。 后面 ai 收到用户的指令,发现是要开发网站。这个时候啊,他在告诉 cloud code, 把这个文件给我发来就可以了。那经过这样一通改造呢,就避免了每次都要把这个文件传给 ai 浪费拖开的问题了。 你发现这一招还挺好使,于是啊,如法剖制写了一堆不同的文档,比如 svg 动画制作点 md, 用来详细指导 ai 如何制作网页。 svg 动画 ppt 制作点 md, 用来详细指导 ai 如何制作美观的 ppt 日报生成点 md 呢,用来详细指导 ai 如何书写符合你们公司风格规范的工作日报。那可乐扣的与 ai 交互的时候呢,只需要把这些文档的名字和描述信息作为一个目录清单发给 ai, 就像他当初把 m c p 服务清单发给 ai 那 样, ai 根据用户的提示词呢,自行决定动态加载哪些文档。 那同样的 cloud code, 同样的 ai 大 模型,因为有了这一堆文档的加持呢,你手里的这一套比别人多了很多技能,他更擅长做出好看的网站 ui, 更擅长做 svg 动画,更擅长做 ppt, 更擅长写日报,完美 nice! 刚刚这套技术啊,有一个闪亮的名字,它就是 agent skills。 这一个个文档呢,就是一个个的 skill, 也就是一个个的技能。简单理解的话,这些个 skill 呢,就是一个个的技能手册, cloud code 和 ai 根据这些手册呢,就能完成特定的工作。 为了规范管理呢, cloud code 通过文件夹的形式来管理这些 scale, 并且把每个 scale 的 主文件都统一命名为 scale 点 md, 回到我们这个网站 ui 设计的 scale, 随着你不断的迭代啊,这个 markdown 文件也变得越来越长, 因为好看的 ui 样式啊,实在太多了,各种各样的风格呢,层出不穷,你很难用一个单一的 markdown 文档来全部写完。而且,就算你能全部写在里面,但实际上呢, ai 只能用到其中的一部分, 其他大部分用不上的内容呢,又白白浪费了上下文的 talk 了。于是啊,你打算把每一种风格单独拎出来写一个文件,然后在原来这个主文件里面呢,做一个汇总,里面写上,如果要做简约风网站呢,就读取简约风点, md。 如果要做科技风网站呢,就读取科技风点 md, 如果要做小清新风格的网站呢,就读取小清新点 md。 这样一来啊,当你用 cloud code 做一个科技风的网站的时候呢, ai 发现要先读取网站 ui 设计这个 skill, 在 读取这个主 markdown 文档之后呢,再根据需要进一步读取科技风调 md, 这个文档。这样按需渐进式的加载啊,极大节省了 talkin, 让 ai 只在有必要的时候呢,才读取相应的内容。 再后来啊,你发现需要对网站的 ui 做更精细化的控制,比如按钮、段落图标、配色图标等等。用这样的单个文档方式呢,还是不太好维护。你决定啊,技术升级,把这些细力度的 ui 内容啊,全部用数据表来进行管理。那为了简单起见呢,你选择了用 csv 表格文件来进行管理。 然后,你希望 ai 在 开发网站的时候呢,按照下面这一套工作流来确定最终选择的样式。为了让 ai 知道如何搜索啊,上面的每一步呢,你都写了详细的文字说明,你还专门编写了一个 python 脚本,并告诉 ai 如何执行这个脚本,来从这一堆 csv 文件里面进行搜索。 现在 ai 大 模型在 colorado 的 配合下,在拿到你这个 scale 的 md 文档之后啊,就按照你写的流程,一步步执行里面的操作,执行拍成脚本,完成解锁,最后拿到完整的 ui 设计信息,开始为你开发网站。 事情发展到这里啊,这份 scale 不 仅是提供简单的文字信息供 ai 参考,还能指定工作流,还能提供程序让 colorado 来执行完成更加复杂的工作了。 上面介绍的这个 scale 呢,不是我虚构的,而是一个真实存在的 scale。 它在 github 上面啊,已经收获了超过十四 k 的 star 了。通过这个 scale 呢,我们可以让 colossal 的 这样的编程智能体啊,开发出 ui 更美观的产品。而这个 scale 背后的原理呢,正如我们前面介绍的那样。 最后,让我们来梳理一下整个的过程。首先,每一个 scale 呢,都需要一个 markdown 文件,并且在文件的最开始呢,有名字和描述两个字段,这属于这个 scale 的 原数据, metat 对 它 cloud code 在 启动的时候呢,加载这些原数据,并将它们包含在系统提示词中。 因为这两个字段呢,本身内容比较短,所以呢一般不会占据太多的托根。第二,每个 markdown 文件除了前面的原数据之后的中文内容呢,叫做指令,它本质上呢就是一段提示词,用来指导 code code 如何做特定的事情。 只有当 ai 需要使用这个 skill 的 时候呢,才会加载它,官方称之为触发时加载。第三,资源和代码 skill 相关的其他文件和代码脚本呢?只有当 ai 在 使用 skill 的 过程中需要用到的时候呢,才会动态加载,官方称之为按需加载。 以上啊,就是 astonrapik 推出的 agent scares 技术了,扒掉这些晦涩的名词概念呢,它其实就是一项提示词工程技术的应用,和之前的 m c p 技术呢,也有很多类似之处。如果你还不知道 m c p 是 什么,欢迎观看我的这期视频。 agent skills 也好, m c p 也好,那本质上都是属于提示词的工程,只不过是符合特定规范,相对复杂的提示词。而为了规范管理和各种工程设计考虑啊,引入了一堆技术名词而已。那现在你知道什么是 agent skill 了吗?你还知道有哪些不错的 skill, 也欢迎在评论区分享。 好啦,以上呢,就是这期视频的全部内容啦,如果觉得有帮助,别忘了点赞、收藏转发哦!我是轩辕,我们下期再见!
6727轩辕的编程宇宙






猜你喜欢
最新视频
- 1.1万时限