dimi的token从哪里来
假期财经圈直接炸锅了,所有投资人都在聊的全新风口 token 出海,彻底火出圈。先给大家说透什么是 token, 它就是 ai 时代的核心基础单位,是人工智能处理信息的最小单元。简单说,谁的 token 消耗量最大,谁就是 ai 竞赛里的绝对头部。还记得互联网时代,我们拼的是日活月活流量,到了 ai 时代,规则直接变了, token 才是王道。 全球投资人都死死盯着 openroot 这个全球平台,就想从 token 数据里找出 ai 时代的新巨头。 而就在最近,这份全球榜单直接刷新认知,榜单前三名被中国大模型公司包揽, mini max、 kimi、 智浦直接登顶冠亚季军。再看海外科技巨头, gemini 排第四, cloud 第六,马斯克的 grog 才第七,这是什么概念? 中国大模型正在批量输出到海外,直接拿下 ai 基础设施层的主导权。而且 open router 是 完全开放的全球竞争平台,每一笔调用数据都是用户真金白银的使用,绝非实验室跑分空泛调研。 全球最火的 ai 智能体创人都公开为 mini max 站台,直言它是最好的开源模型。 mini max 新款模型发布仅一周,直接冲上掉用量榜首 周掉用量暴涨三零七 t tokens, 这个数据超过了另外三家头部模型的总和。更厉害的是,这波增长根本不是内卷,排名靠后的厂商掉用量没有下降,反而整个市场都在涨, 足以证明 ai 市场远没到天花板。 token 成本持续下降,应用层创新就不会停,行业增长飞轮已经高速转起来了,这里提醒大家赶紧关注博主最新财经热点,第一时间给你汇报, 绝不放过任何行业关键信息!先看 token 出海赛道实现逆袭!核心看 token 成本的三大关键人才,能源、算力。人才方面,咱们直接断层领先奥塞,金牌数量遥遥领先,工程师规模数倍于西方 华人,更是大模型领域的核心力量, gpt 核心团队里百分之三十五都是华人,硅谷技术小会都开始用中文交流。能源方面优势更是碾压中国电力成本不到美国的一半,而且电力供应充足稳定,数据中心想扩容就扩容,完全没有缺电困扰。唯一的算力短板, 顶尖算力卡只是用于模型训练,推理环节根本不需要。如今 ai 行业进入推理时代, tok 成本就是核心竞争力, 咱们靠着人才和能源的双重优势,直接量变引发质变,才有了霸榜全球的奇迹。谁能想到,两年前还在感慨国内 ai 产业调队两行冲进全球第一梯队, 现在 token 出海的新增长范式已经到来。现在 token 出海的新增长范式已经到来,国内算力、能源需求将被全面拉动, 中国 ai 产业彻底走出内卷,成为全球 ai 军备竞赛的核心受益者。这波中国科技的强势崛起,真的太提气了, ai 时代的中国力量已经站在了世界舞台的中央!

粉丝846获赞3866
相关视频
 01:31查看AI文稿AI文稿
01:31查看AI文稿AI文稿二十四个疯子三千万美金打造出了一款恐怖的怪兽级 ai 硬件。近日,塔拉斯公司发布了旗下最新的 hce ai 芯片,该芯片可以极高的效率运行 lama 三点一的八 b 模型,运行速度达到了恐怖的每秒一万七千个 token。 你 没有听错, 对比其他硬件产品,它的运行速度提高了十倍以上,制造成本降低了二十倍,而能耗也仅为十分之一。 从图中可以看到, nvida 的 最先进的 h 二百和 b 二百在它面前简直就像上个世纪的产品。塔拉斯芯片之所以能实现这么恐怖的运算效率,是因为它是一款完全定制化的硬件产品。它 把 ai 模型用硬连线连接到了专用芯片,模型指令和硬件电路设计是完全一一对应的。你可以理解为芯片把大模型的功能一比一映射到了专用硬件电路里。 虽然这样做避免了传统硬件带来的数据延迟和性能损失,但代价是塔拉斯芯片不具备通用性,它只能对应单个模型, 如需运行新的模型,则需要重新设计整个芯片电路。而且由于容量限制,目前塔拉斯芯片还只能运行三比特或是六比特的量化模型版本。塔拉斯的产品设计可以说是颠覆传统 ai 推理逻辑的革命性创新,但是否有客户真的愿意为自己的模型去购买专用芯片来提升产品竞争力,这仍需市场验证。 目前,塔拉斯正在筹备第二款芯片 h c r, 预计在年底前可以实现硬件部署。如果你对这款神奇的芯片感兴趣,可以访问 demo 地址来实际体验它在真正意义上做到了毫秒级回复。网址在评论区,欢迎各位实测并给出您的反馈。
1284杨大哥 02:19查看AI文稿AI文稿
02:19查看AI文稿AI文稿春节之后的市场应该是有两种可能,第一种是继续围绕着 ai 相关的科技板块进行炒作,这里面春节假期里面讨论度最高的就是托肯出海的逻辑。第二则是风格切换,市场炒作跟 ai 完全无关的方向,比如军工,比如消费,比如贵金属等等, 到底是哪一种可能上后面几天应该就会给出答案。首先指数会要在春节之后选择方向,这应该是一件大概率的事情,但问题是从哪一天开始明确方向,在向上或者向下变盘之前,市场还会不会在三天内上方震荡一段时间? 如果是这种情况,那操作上就应该是一个轻指数重个股的指导方针。所以关键呢,就看盘面上能不能形成一条具有持续性的赚钱主线。 比如春节假期里面,市场发酵的比较多的是托肯出海的这个逻辑,可能很多人是第一次听说这个逻辑,所以呢,我简单的介绍一下, 托肯是 ai 时代的一个计量单位,你可以把它理解成人工智能处理外界信息的流量,谁的托肯消耗量最多,就说明谁的用户使用量最多,这家公司在 ai 竞赛的排位就越靠前。 而根据最新的数据,譬如三家中国大模型公司, mini max、 kimi 和智普包揽了全球前三,这就说明中国的大模型正在批量的输出给海外的消费者, 而海外的消费者在使用这些大模型的时候,消耗的其实是我们国内的算力,所以呢,它就会带来大量的国产算力的需求。而刚好 mini max 以及智普这些公司,它们的大模型是适配国产芯片的,所以发酵的主要就是云计算、 cpu 以及服务器这些方向, 而且指数如果能够在这些方向的带动下,摆脱现在的震荡格局,出现主升浪的话,那市场呢,就会继续围绕着科技这条线进行发散,但如果走不出来,市场就会出现第二种可能,就是大家对于科技股的审美出现疲劳了,资金涌向一些跟科技完全无关的方向,比如军工。 这段时间国产 c 九幺九大飞机这条线其实也是在慢慢的上升趋势,所以呢,这也是一种可能。 总而言之,节后的走势可能会非常的复杂,而我们现在能够做的就是充分的考虑到每一种情况,然后观察上的反应,看哪一种情况的可能性更大一点,祝大家好运。
132韬韬进化了 05:47查看AI文稿AI文稿
05:47查看AI文稿AI文稿我们来聊一个话题啊,如果人工智能的终极目标根本就不是要取代我们,而是为了把我们从那些繁琐重复的工作里解放出来,那这个世界会变成什么样啊? 今天我们就来深入解析一下这个构想,一个关于怎么释放我们每个人潜能的未来,你看,就是这个词的转变,替代,变成释放。这一下子我们看待 ai 的 整个感觉就完全不一样了,对吧?它不再是那个让我们焦虑、害怕被淘汰的东西,反而成了一种嗯,解放我们,给我们带来无限可能性的力量。 好,那问题来了,这种新的自由,它的能量是从哪来的呢?其实核心就源自一个东西,叫做 token, 你 可以简单的把它理解成 ai 在 思考在生成内容时消耗的计算单位,有点像它的脑细胞,关键是现在这种脑细胞正变得越来越多,多到几乎是无限供应。 没错,就是因为 ai 技术发展的太快了,这种强大的计算能力已经不再是什么稀缺资源了,它会变成像我们家里的电,我们手机上的网一样,是一种基础资源,用来支撑我们每天的思考和创造心灵的外骨骼。这个比喻我觉得特别有意思, 你想想,如果 ai 真的 成了我们思维的一个外部延伸,那我们的创作方式得发生多大的变化呀?咱们先从最熟悉的,也就是文字创作,来看看这到底意味着什么。 你看这个对比,一下子就明白了。以前我们写作很多时候是在跟海量的信息作斗争,费老大劲去查资料、理逻辑。但现在呢?这个过程变成了一场和 ai 的 思维共舞,就像玩爵士乐一样,你给出一个想法,他马上给你回应。你们俩一来一回,即兴的就把作品给创造出来了, 光说可能有点干,咱们来个具体的例子,这样感觉就来了。好想象一下,现在有一位历史小说家,他想写一本关于中国宋朝的小说, 这就有意思了,你看作者,他不是冷冰冰的问 ai 送床晚宴有哪些菜不?他把一大堆数字化的屎料都喂给 ai, 然后像跟一个博学的老朋友聊天一样,问的是感觉和氛围。 哇,你看这些细节,热气腾腾的菜,街上的叫卖声,诗人眼里的倒影。 ai 做的不是携手的活,他扮演的是一个超级资料员加上气氛组的角色,他把一张活生生的充满感官细节的画卷铺在你面前,把作者从繁琐的考据工作里彻底解放出来,让他可以全身心的投入到故事和情感本身。 好了,文字聊完了,那视觉呢?咱们能不能把同样的原理应用到图像和视频上?比如说,那些我们做过的一闪而过的梦,有没有可能把它给保存下来呢? 咱们每一个人可能都有过这种经历吧,做了一个特别奇幻的梦,醒来以后那个画面还在脑子里,但没几分钟就忘了。可现在有了强大的视觉 ai, 这个梦境或许真的可以被我们捕捉下来。 你看看这个过程,简单到有点不可思议,你只要张开嘴,把你的梦描述出来,然后可能再调整一下参数,比如重力是地球的一半,接着背后数万亿的视觉头肯就会开始疯狂计算,把光影动态全都给你模拟出来,这已经不是在做视频了,这简直就是把你的想象力直接变成了现实。 这句话真的说到了点子上,你想啊,当一个工具快到你几乎感觉不到它的存在,那工具本身就不重要了,你脑子里的想法和现实之间那道墙就没了,剩下的就是你最纯粹的,最想表达的那个东西。任何人都可以成为自己世界的导演, ok, 除了帮我们搞创作, poke 的 力量还能做什么呢?嗯,它还能触及一些更柔软、更人性化的地方,比如说陪伴。 咱们再来想象一个场景啊,一个想学法语的人,他不再是打开一个 app 背单词,而是随时可以召唤出一个 ai 伙伴。这个伙伴可能是一位住在巴黎非常有耐心的老太太,他会陪你聊天,纠正你的发音,还会给你讲讲塞纳河班的故事。 这体验的核心其实已经不是为了追求那种机器般的精忠了,而是因为背后有海量的 token 支持, ai 的 反应几乎没有延迟,让整个互动感觉特别真实,特别自然。尤其是在你一个人觉得孤单的时候,那种被理解、被连接的感觉才是最重要的。所以说, token 未来的一个重要方向就是去计算情绪价值, 这种庞大的算力会被用在各种特别细微的关怀上,比如他会记得你昨晚没睡好,或者知道你最近在减肥,然后给你一些贴心的建议。所以问题来了,既然这种 ai 力量的核心已经不仅仅是为了提高工作效率,那我们到底该用一个什么样的新标准去衡量他对我们生活的价值呢? 这个对比我觉得特别好。工业时代,我们用马力来衡量机器工作的速度有多快,核心是效率。而现在呢? ai 时代的 tock 力量,它衡量的应该是我们人类生活的自由度,它的核心是解放。 这个比喻我太喜欢了,就像今天,我们没有人会去赞美电力本身有多了不起,我们赞美的是我们在灯光下读的书,看的电影,和家人共度的时光。 tucker 的 力量也是一样,它最终会成为一种看不见的基础设施,重要的是我们用它来做什么。 那么聊了这么多,最后其实就回到了一个,我们每个人都得问问自己的问题,当那些繁琐重复的事情真的都不需要我们操心了。你一直想做,但总觉得没时间做的那件虽然没什么用,但特别美好的事到底是什么? 是不是想把那首写了一半的诗给写完?还是说想给家人策划一场真正完美的旅行?甚至有没有可能用 ai 帮你重现一个和已经离开的亲人在一起的瞬间?当技术和时间不再是障碍,唯一限制我们的想象力和渴望了。 所以说,瘦到底啊,这根本就不是一场我们和机器之间的赛跑,它更像是一场我们和自己内心的和解。 ai 技术发展的最终目的,可能不是为了让我们跑得更快,而是为了给我们自由,让我们能慢下来,去做一个更玩着更像人的人。 所以在我们今天解析的最后,我想用这句话来结尾,最重要的也许真的不是去追赶 ai 的 速度,我们更应该做的是去拥抱它带给我们的这份自由。所以我不祝你快马加鞭,我祝你信马由缰,愿你的想象力能在这股新力量的帮助下,去到任何你想去的地方。
3乔氪智造 01:45查看AI文稿AI文稿
01:45查看AI文稿AI文稿你知道吗,现在使用百炼 ai tocun 消耗最多的根本不是什么大公司,而是一群你从来都没听说过的一些小角色。今天跟那个百炼的市场的聊,宇哥啊,他们自己都很惊讶, tocun 用量最大的不是银行,也不是五百强,也不是那些大型的头部企业,而是可能是二十人的财务记账公司,还有一些可能是学生哎,或者是其他的一种小角色。 这个现象啊,其实不得不让我们重新来审视一下 a i a 技能啊,为什么会出现这种现象?我们都是做软件的,我们是做企业服务的,写软件,写代码,做解决方案是我们引以为傲的工作。 但 ai 这个时代,我们的软件赢家或许真的不是写代码能力最强的那一个。通过跟宇哥交流啊,在他们这些大厂眼里边,以后是没有传统意义上我们看到的那个软,那个写软件的那个代码的,那个那个软件呢?是没有的,都是一个一个的智能体。 尽管现在我可能还不太相信啊,但是智能体可能会取代很多很多事情啊,但这些智能体的开发呢,可能就是一个大学生,一个仓库管理员,一个门店的一个店长,因为他们离需求太近,那如果按照这个逻辑啊, 他们有可能就是来跨界过来的人啊。当 toc 被无名之辈大量的调用,说明 ai 的 战场可能已经从实验室转移到了车间、门店、仓库,谁离真实的业务场景最近,谁有可能就掌握下一代的软件的话语权, 这可能真的是一个颠覆。兄台,你身边有没有这样的无名 ai 玩家呀?
21选软件网@老张 07:19查看AI文稿AI文稿
07:19查看AI文稿AI文稿面试官问 embedding 到底是什么?这道题怎么答?我们从一个最基础的问题开始,为什么需要 embedding? 模型的输入是 token, 但 token 本质上只是一个 id, 一个编号,比如猫在词表里的编号是幺五二三四,狗是八千七百二十一。 问题来了,幺五二三四和八千七百二十一这两个数字之间有语义关系吗?没有,它们只是缩写,和语义毫无关联。 你不能说幺五二三四减八千七百二十一等于六千五百一十三,所以猫和狗的语义距离就是六千五百一十三,这完全没有意义。 模型需要一种表示方式,让猫和狗之间的数学关系能反映语义关系,这就是 embedding 要解决的问题。在往下讲之前,先澄清一个概念上的混淆。面试中说到 embedding, 其实有两个层面, 第一个是模型内部的 embedding 层,它是 transformer 的 第一步操作,把每个 token id 映射成一个向量,这个向量是 token 进入模型的起点,后续每一层注意力计算都会在这个基础上不断精练。第二个是独立的 embedding 模型,它接受一整段文本作为输入,输出一个代表整段文本语义的向量, 这是 reg 系统中做检测的基础,也是面试中被问到最多的那个 embedding。 两者的底层原理是相通的,但应用场景和训练方式不同。下面主要讲文本级别的 embedding, 也就是第二个 一个 embedding 模型,接收一段文本,输出一个固定长度的数字向量,比如七百六十八维,这七百六十八个数字一起编码了这段文本的语义信息。但这里就遇到了面试官的第一个问题,这七百六十八个数字分别代表什么?答案是,每个维度没有独立的可解释的含义,这和传统的特征工程完全不同。 传统做法里,你可能手动定义特征,第一维是是否是动物,第二维是情感即兴,第三维是是否包含地名。 每一维都有明确的语义标签。 and betting 不是 这样,它是一种分布式表示,意义分散编码。在所有维度的组合模式中,你没法看着第四十七维的数字说这是动物维度。任何单一维度都不对应任何可解释的概念信息是以整体模式的方式存在的。一个经典的例子可以帮你理解分布式表示的威力。 在早期的 war to veck 实验中,研究者发现,向量减去男人的向量,加上女人的向量,得到的结果最接近皇后的向量。 这说明 embedding 不 只是记住了每个词的大概意思,它编码的是词与词之间的关系结构,国王和皇后的关系,与男人和女人的关系。在向量空间中表现为近似平行的方向,而这种结构不存储在任何单一维度上,而是涌现于所有维度的协同模式中。 那这些向量是怎么训练出来的?文本级别的 embedding 模型最主流的训练方式是对比学习,核心逻辑非常直觉。准备大量的正样本对和负样本对。正样本对是语义相关的两段文本, 负样本队是语义不相关的两段文本。然后训练模型,让正样本队的向量在空间中靠近,让负样本队的向量远离。比如北京今天很热和首都今天温度很高,是正样本队 模型被训练为让这两句话的向量尽量接近。北京今天很热和这道菜放盐了,是负样本队模型被训练为让它们的向量尽量远离。经过大规模语料的训练,模型学会了一种映射,把文本中的语义模式压缩编码到固定维度的向量中,使得语义关系在向量空间中表现为几何关系。 理解了这一点,面试官的第二个问题就能回答了。为什么鱼弦相似度能衡量与意相近?因为训练目标就是这么定义的。鱼弦相似度衡量的是两个向量的方向是否一致,忽略长度。而训练过程中,模型被反复优化为与意相近的文本向量方向趋同,所以鱼弦相似度高,等于与意相近。 这里有一个重要的推论,训练数据和训练目标不同, embedding 空间的结构就不同。有的 embedding 模型是用用户查询和包含答案的文档段落作为正样本对训练的,这叫非对称检测。 用户查询和文档的表达方式差异很大,模型学会了跨越这种表达差异去匹配语义。有的模型是用语义等价的两个句子作为正样本对训练的,这叫对称检测。两端的输入形式类似,模型学会了识别同义表达。 这不是一个无关紧要的细节。如果你的 r a g 场景是用户,提一个短问题去匹配长文档段落,用非对称模型效果会明显优于对称模型。反过来也一样,选错模型类型,召回率会有显著下降,但很多人在选型时根本没有考虑这一点。现在回答面试官的第三个问题,两个不同 embedding 模型的向量能放在一起比较吗?不能。 每个 embedding 模型通过自己的训练过程构建了自己的向量空间。同一段文本,两个模型输出的向量并不一样,这两组数字之间没有任何可比性,它们活在完全不同的坐标系中。你拿模型 a 编码的 query 向量去和模型 b 编码的文档向量算余弦相似度,得出来的数字没有任何语义含义,这在工程中是一个非常常见的坑。 reg 系统里建锁影时用的 embedding 模型和查询时用的 embedding 模型必须是同一个。如果中途想换一个更好的 embedding 模型,所有已有的向量锁影必须全部重新生成,不是调个参数的事,是全量重跑。 很多人觉得新模型效果好,就只替换了查询端、锁引端还是旧模型的项链,结果效果不升反降。排查半天才发现是模型不匹配。理解了 embedding 的 训练原理之后,我们来看一个同样重要的问题, embedding 能编码什么?不能编码什么? embedding 擅长捕捉的是主题相关性和语义相似性, 同一个概念的不同表述、近义词替换,甚至跨语言表达相同意思。只要模型做了相应的多语言训练, embedding 都能把它们映射到接近的位置,这是它最强的能力。但 embedding 有 几个系统性的弱点,面试中能讲清楚这些边界的人非常少。第一, 对精确数值不敏感,价格是一百元和价格是一万元的 embedding 可能很接近。它们的语义结构几乎一样,只是数字不同,而 embedding 不 擅长编码精确的数值差异。 第二,长文本的信息会被稀释。一段话包含十个不同的要点,压缩成一个七百六十八维向量之后,每个要点分到的表示空间就很有限, 向量变成了一个模糊的主题平均值。这就是为什么 r a g 系统中 chunk 不 能切太长, chunk 越长, embedding 越模糊,和具体问题的匹配精度就越低。但 chunk 也不能切太短,太短了上下文丢失, embedding 也不准。 第三,结构和顺序信息容易丢失。 a 导致了 b 和 b 导致了 a, 它们的 embedding 可能非常接近,因为包含的词完全一样。因果关系、时间顺序、逻辑结构这类信息在压缩成定长向量的过程中很难被完整保留。 理解这些弱点,对你设计 reg 系统直观重要。面试官问,你的 reg 系统召回率不高,怎么排查?很多时候,根源就在 embedding 这一层。 不是剪辑算法有问题,而是 embedding 本身就没有编码好你需要匹配的那类信息,你去掉剪辑参数,调到天荒地老也没用,因为问题出在表示层。面试回答框架, embedding 把文本映设为固定长度的数值向量,使得语义关系转化为向量空间中的几何关系。向量的每个维度没有独立含义, 信息以分布式方式编码。在所有维度的组合模式中,文本即 embedding 的 核心训练方式是对比学习,让语义相近的文本向量靠近不相关的远离鱼弦。相似度能衡量语义相近不是数学巧合,是训练目标直接优化的结果。 训练数据和目标不同,空间结构就不同,所以要根据具体场景选择对称或非对称解锁模型。不同 embedding 模型构建的是不同的向量空间向量不能跨模型比较。 rek 系统中缩影和查询必须用同一个模型,换模型就要重建全部缩影。 embedding 擅长捕捉主题相关性和语义相似性,但对精确数值、长文本、多主题因果和顺序关系的编码能力有限。理解这些边界才能在 rek 召回效果不好时知道问题出在哪一层,而不是盲目调参。
476每日AI评论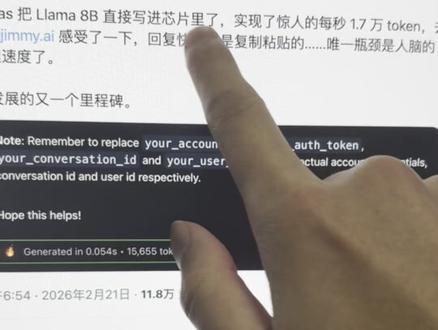 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿我刚发现一个非常重磅的这个事情啊,就是它的词把这个拉玛巴币的这个模型直接写到所谓的芯片里面去了,然后你看它的偷看速度有多快,每秒一点七万, 那这意味着什么呢?意味着我们输任何东西,这个 ai 可以 瞬间秒达。那如果说对于一个非常大型的这个文本的话,它相当于是一瞬间就可以把内容全部铲出来,效果多惊人。我刚去试了一下幻穿越题材的小说啊,背景故事是男主穿越到古代玄幻世界, 然后一路过关斩将的成为仙界至尊的故事。然后我们直接去看一下它的速度有多快,发送你看一瞬间,你看它的速度一瞬间就这么的快。 我就扒了一下他们的背景啊,然后他们看样子应该是做这种硬件加上软件类的,但他们可能主要是做硬件的。然后,呃,这已经突破我的边界了,我不大能看懂,然后有兴趣的可以自己去了解一下。我主要关注一个东西就是 api, 我 要看他有没有 api, 然后我要怎么去用 啊?他有,他现在这个 api 的 话应该是要填表单申请的。那我去弄一下试试看,有兴趣可以自己去研究一下。
1250境无止境 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿talk 到底是什么呢?最近好多小伙伴啊,听完我聊完 ai 呢,又对 ai 有 信心了,但之前呢,又没有特别关注这一块,现在问我最多的问题啊,就是这个 talk。 我是 这么说的啊,下一个 ai 的 趋势呢,一定是跟二五年是不一样的,以前的这个逻辑呢,是靠堆算力,堆硬件,但是二六年的逻辑呢,是随着对面 像 openai 啊, autopilot 啊,或者是谷歌啊等等这边的业绩呢,开始逐步兑现。那逻辑呢,就从稍前见大模型到用模型的这个实际转变,那二六年的复苏呢,就有可能是将由复杂推理带来的这个 talking 的 增长去驱动了。 那问题是 token 是 啥啊?为什么这么说 token 其实你可以简单理解他啊,就是一个机器说话办事的一个最小的积木单元,你问他问题,他不会一下子就蹦出来整句话 是先把你这句话哈拆成一份一份的小积木,然后再一块块拼,根据你这些东西啊,推理出了一个最优解,然后完整的呢,再回答出来。 但是处理 token 呢,是目前最棘手的问题,处理大量的 token 啊,数据呢,是需要在芯片跟存储之间啊,高速传输,临时存储,这就要求啊,有高宽带的这个存储来支撑,就是这个 hbm, 它比传统的 drum 这种的存储芯片啊,性能要高数倍。插一句嘴啊,是因为很多做 drum 的 这个产物芯片啊,让给做这 hbm 了,所以理解为什么最近存储芯片 这么咔咔涨价了吧。就拿一个嗯果果的手机来说吧,大概现在啊,从四十美金得涨到一百美金左右了,就是光这个存储芯片的这个成本,那这块到底能带来什么样的一个机会呢?晚上八点直播说。
160叼雪茄的金融女魔头










