DeepSeekV4续写效果
dipps 跟 v 四表现到底怎么样? dipps 跟 v 四出来已经有一段时间了,我相信大家在我们看到非常多关于它的讨论。 dipps 跟 v 四官方是说可以对标到今年 二月份发布的双内四点六,但我个人实测下来,尤其在包括 bincloud 里面,我也用了一段时间,我发现它实际上能对标的是去年九月份发布的双内四点五的水准, 差不多有一年左右的差距,我觉得这个是符合当前中美的差距的。第二个是 deep sea v 四 pro, 它的参数达到了一点六万亿,那也是 deep sea 体现了它在 a g i 这个实现思路上的小步快跑的一种节奏和方式。

粉丝70获赞302
相关视频
 06:33查看AI文稿AI文稿
06:33查看AI文稿AI文稿deepsea v 四 pro 王炸来袭啊!朋友们,万众期待的 v 四版本终于发布了,那么 deepsea v 四 pro 的 网文写作能力,写小说能力到底如何呢?今天我一条视频全部告诉你, 并且我整理了关于 deepsea v 四写作能力的注意事项文档,感兴趣的朋友们,我们评论区见。话不多说,我们直接进入正题啊,今天我从正文、大纲、审稿三个方向给大家来分析一下 deepsea v 四的写作能力到底是怎样的 啊。我先说结论吧,综合对比来讲是比之前的 deepsea 好 太多了,但是整体能力还是不如智慧版,细腻版还有氛围版,包括奇想版的整体效果。 直接来给大家展示一下生产的实际案例就明白了。我们可以看到啊, deepsea v 四 pro 已经上了二十四号刚刚发布的 deepsea v 四版本,那么我总结了一下呢啊,它有一个比较强的优势,就是发散能力比较恐怖,不过换句话说就是它不会做关于网文事项的正确判断,需要大家增添主要的大纲内容加以辅助。 我们直接跳转到创意工具箱里的大缸生成器啊!在这里呢,我们从 ai 模型里面选择我们的 deepsea v 四 pro, 给大家来实际操作一下,这里有很多大佬们预制好的提示词供大家选择,大家可以自行去尝试选择一个最适合自己的提示词 啊。我们这里拿以文成新老师的这个提示词来举例,比如说我去创作一个历史脑洞题材的小说大缸,大概的灵感呢?我们可以减速一下,比如说携带超市便利店系统穿越到 大明王朝这个世界观人设,这里我们就写一个两界导爷吧,这里我们都可以根据你自行的需求去填写,我这里就先不添了,直接给大家生成一下,展示一下 deepsea v 四 pro 的 实际生成效果。 可以看到啊,他现在就已经开始进行大缸生成了,那么主要的核心设定也给出来了,大家可以仔细的看一下。有很多朋友问,为什么我用官方的 deepsea v 四去生成的效果,很核心的一个点就是因为星月有非常多所适配的提示词, 这是直接去官方生成你没法拥有的,这也是 ai 写作真正的核心。如果说你让 deepsea v 四直接为你生成一部小说,基本上不可能的啊, 可以看到啊,世界观也给出了非常详细的内容,还给出了我们的主要势力,包括主角的设定以及反派的设定,全部都给出来了,这是我们之前所说的 deepsea v 四擅长的就是 已有信息点进行发散,比方说我们可能之前智慧啊,细腻啊,可能只给出两到三个角色, t c f a 四可能给到五到六个角色。我们再来看一下他的故事梗概啊,其实整体的内容呢啊,因为我给的题材并没有什么太多的创新点,所以说整体的内容我们可以看到还是比较平淡的。已 经开始到了卷钢规划,可以看到生成的字数是非常多的,来到了第一卷,包括的卷钢剧情也是给出来了,那我们就来等他生成完毕, 可以看到到现在为止他还在生成,那我们已经到了十一章的章纲了,我们这里就直接停止,目前为止他已经生成了一万三千三百一十七字,他还可以再根据这些文本接着往下生成,也是我们提到的他的发散能力非常强,我们这里呢,直接把它推送到我们的备忘录里, 这样我们之后就可以关联好我们的大纲,我们直接跳转到我们的作品页面啊,新建一个章节,来看一看他的正文字到底如何 啊,这里我也提到了啊,它的正纹生成的优点就是语言自然,长线稳定,量产高效,也是它生成的字数会非常的多,但是呢,它缺乏智慧版、细腻版、奇想版的人化感情,也就是我们所说的真人味儿,它容易越写越平, ai 味比较浓重,这也是 deepsea 最大的缺点,我们直接从 ai 写作这里选择我们的 deepsea v 四, 我们就不关联最近的章节了啊,因为我们前面的章节是与文本句型无关的,我们先选择好我们刚才生成好的备忘录, delete v 四,选择一套喜欢的句子,我们直接从本章句型这里简单来概括一下吧。根据大纲内容直接生成 番茄小说黄金开篇内容啊,在本章剧情这里,应该是放我们的戏纲或者是我们的章节主要内容啊,我所给的这些内容呢,一般是我们要加一个括号,在前面加上我们的主要剧情,这样的话生成的内容会更加好。我这里就不填写主要剧情了,直接让它生成,看一看效果。点击生成 我们使用的 deepsea v 四版本,这里的中文呢,就生成完了,我们直接把它复制到中文的面板里,我们来看一下中文生成的内容,可以看到所生成的内容属于是我们 ai 的 通病了,像这段的多余的形容词描述都是可以直接删除的,包括我们让他开篇对话入局也没有达到, 不过我们往下接着看,形容描述还是太多了,不过整体的剧情人设好像是立住了,包括这里我们的对话 他肯定也是完成了我们的要求,多对话内容。那整体往下看呢?系统出现的还是比较早的,生成的内容呢,可以说是中规中矩啊,不过 情绪拉扯给的还是挺到位的,我们简单可以看一下实际内容,缺点也是很明显,都不需要我多说,大家就明白了,我们一直放到最后,整体的文章是不是比较平淡,我们这里再用智慧版去生成一下,看一下和 deepsea v 四对比下来有什么区别。我们选择智慧版,点击使用 生成。智慧版一生成出来,我甚至还没往下看,但是开头我就已经感觉到了巨大的区别了啊,大家可以看一下这情绪冲突和生成的文本质量。所以说整体来说呢,智慧版、吉祥版和新一版还是要优于 deepsea v 四的生成能力的, deepsea v 四可以去处理一些我们接下来要提到的内容, 等它生成完毕,看一下生成的内容,进行一个对比。好,这里智慧版所生成内容也生成完毕了,大家看一下啊,生成效果我就不用多说了吧,对话的情绪,真人感,还有行文之间的剧情连接,包括情绪起伏,更加牛逼, 大家可以自行看一下效果。所以说推荐大家在生成正文的时候呢,还是去使用我们的智慧版、吉祥版、细腻版这些比较大热的模型,我们可以简单看一下生成的正文效果啊,非常牛逼,非常牛逼, 我真的不用多说了,大家自己看就能看出来,对比出来效果,只要你是懂网文的朋友。那么 g p c v 四我们可以用来干嘛呢?我们可以用来进行 ai 审稿, v 四的逻辑能力虽然比不上智慧版,但是它在审稿上有自己的键数,我来生成一下大家就明白了,我们直接从这里呢选择一个,呃,选择一个打分版, 来看一下这四个 v 四给我们这个智慧版生成的内容能评到多少分。可以看到啊, v 四的评分已经出来了,它给这篇文章综合评分给到了一个六十八,会根据我们的内容进行分向扒皮,包括我们的扣分点在哪,以及我们的爽点密度节奏的分析,包括信息节奏与趋势效率等等,这些内容 我们都可以根据他所诊断的内容进行更改,后面还会对开篇的核心段落进行一些改稿修正,我们都可以选择自己 喜欢的内容放到中文里,还会给你指出必改的硬指标。所以说每个模型都有自己的特点和优势,大家可以根据自己的喜好去选择,根据自己文章所需要的文风去选择搭配不同的提示词呢,则有不同的生成效果。对 a i c 所感兴趣的关注私信我即可。
1363-星月凌云- 04:30查看AI文稿AI文稿
04:30查看AI文稿AI文稿大家好啊,我是瑞克老张啊,那个五一期间接着给大家聊,因为事比较还挺有意思。昨天晚上呢,我们的那个开发团队给我们反馈啊,就说那个 dvd v 四 pro 特别好用,然后我们就在 callix 里边就接着进来了,接进来以后我也测了一下, 哎,我发现一个很有意思的问题,虽然说啊,他自己说,他跟那个,呃,就是包括我们说的,呃这几家,像那个,呃, 那个 cloud oplus 四点六啊,啊,包括啊,这拆 gpt 五点五啊,还差三到六个月。但是你知道这里面有一个很好玩的事啊,就是 dspic v 四 pro, 它的缓存命中率极高, 什么意思呢?就是大家要知道这个大模型的这个 api, 它分两种价格,一种缓存缓存命中,一种缓存没命中。 缓存命中的话,就意味着它之前跑过类似的这些东西,所以它有结果,有结果它可以拿下来改一改就给你用,那这样的话它价格非常低, 缓冲没命中呢,那就意味着要重新计算,那这个价格就非常高啊,这个要要知道。所以呢, deepsea 呢,我们查了一下,我们测了四个啊,就是我现在正在做的小东西,测了四个,呃,大概每一个的话呢,都都给我写了不到八百行的这个命令啊,基本上缓冲命中率呢都在百分之八十五以上, 这意味着什么呢?意味着我非常省钱,我们看看,我整个把这所有东西都跑完了,大概跑了不到一个亿的 token 啊,我花了多少呢?花了不到十二块钱,这个这个,这个性价比就非常高了啊,真的性价比非常高,它比那个 cloud 包括那什么的缓存命中率都高。 我们之前也用 kolld, 但 kolld 现在不给中国人用了嘛,是吧,那个我们就敢用,折磨你啊,这个但折磨你的缓存命中率非常低,低的让人发指啊。然后就是花钱花的比较多啊,这搞那么不到一个亿的,差不多一个亿的 token 吧,这折磨你得花到二十美金左右。但是 deepstack 的 话呢,基本上就十几块钱,十几块钱解决问题啊,十几块钱解决我们四个四五个问题,而且它那个 bug 吧,它自己找起来就很快,我们怀疑就是在 deepstack 的 从那个 n 卡,就是英伟达的卡迁移到生成的卡上做训练,这个过程中啊,他们另外的那些做啊,这个呃案例的部门并没有闲着,他们在不停地用各种的代码去测试,然后把这个代码各种的去修正,然后形成这样的缓存库, 所以现在的效果非常好。哎,我没有想象的效果的话,你们都可以去试一试,真的都可以试试这个 v 四 pro, 我 认为这恰恰很可能是它未来的一个最大的杀伤点,因为这样的话是所有人发现它的成本进一步降低。如果都用缓存,这个这个东西相当于呃这个 cloud 的 五十分之一的价格呀, 就如果都是缓存命中的话,它相当于 cloud 的 五分五十分之一的价格,非常夸张。那这个事的话呢,后续的东西很可能会引发。 是啊,包括美国这个开发者在内的一个一系列的海啸啊,它意味着大幅度的节省成本,效果还不错啊,这个事就就特别有意思了啊,所以它背后可能引发的是一个是 taco 出海,一个是酸碱锌铜,还有一个的话就是整个的在全球啊, 不管是开源还是闭源的啊,包括编程在内的这样的一个大模型使用的大范围的变化,它这个变化很可能是行业性的啊,是扩散段的,而且这个扩散现在看越来越快,越来越快, 所以呢,大家一定要关注这个趋势,这个趋势可能会引发整个产业链的变更的,这个变更的时间不会超过一个月。他后续的东西他不像上一次,上一次是立马就显示出来了,这次是在慢慢的显示出来,他显示出来的话,那他这个如果你提前不布局,你到那个时候你可能就晚了,那个时候的话机构大量入场,你就没有什么筹码, 需要的话赶紧先来看啊,真的赶紧先看好不好?如果需要的话,看看我们的这个季度会员科普课,我们准备在下个星期开始的五月份,我们会安场安排最少三次关于 deepsea 的 啊,这个深度的拆解,一次直播两次的这个复配的内容啊,如果需要真的好好看一下咱们的季度会员科普课啊, 九十天四十五个视频最多啊,四十五个视频最少,四十个视频八场专门的直播,非常的超值。而而且咱们的月卡呢,本身呢两百多块钱是吧? 机卡的将近八百块,这是因为一个是老张给大家补贴,还有一个是平台虽然没有那么大的,那也给了几十块钱补贴,所以现在价格是六百多块钱,非常的超值啊,需要的真的好好看一下,而且呢内容的话呢,是非常的覆盖的全面,都是围绕大家所关心的这些话题展开的,毕竟的话我们还有很多专业团队在干这个事, 非常的超值,需要好好看一下啊。链接在底下点击即可啊。稍再说一句,一定要记得接助教老师电话,不然你不知道该怎么看课。好,今天就到这,我是瑞克老张,关注我,咱们投资的视角,看科技背后的精彩,我们下期见,拜拜。
335瑞克老张有话说 01:38查看AI文稿AI文稿
01:38查看AI文稿AI文稿最近被 defc 威斯搞的有点无奈啊,就我目前呢是一边用 ai 写文章,一边用 ai 写代码,对吧?写代码写的是一个写作业的,我写文章用的就是那个写作 a 阵台写的两边的模型都是 defc 威斯,然后首先在代码这边, 这次这这个 v 四的表现呢?我觉得跟 glm 五点一没有起赶上的区别啊,就是所有简单任务全是一遍过,然后所有复杂任务呢?最多两遍啊,最多两次,几十次就完了,然后到目前为止没有犯过任何就是比较堆积的错误啊,什么都没有, 非常厉害。但是咱写作这边出问题了,哎,就是他写一篇文章,然后我觉得不好,我让他改,改完了我觉得还不好,再让他改,改了我感觉受不了了。我,我把整篇文章全删了,让他重新写, 结果他写出来是完全一样的内容,就我已经明确告诉他刚才写的不好了,对,也不要那样写了,然后他还是,然后他输出的还是完全一样的内容, 然后呢?我就继续删,然后再让他写他写的还是一样的内容。然后我就换了一种策略,我就说一段一段写,我不让你一次性输出一整篇文章,一段一段写。好,先写第一段,写完了我让他改,结果他没有改第一段,他又输出了后面的内容, 然后我就直非常直接的问了他一下,我非常直接的问了他一下。 无奈了,无奈了。
80嘉豪 05:50查看AI文稿AI文稿
05:50查看AI文稿AI文稿deepsea 的 影响力还在继续放大,今天一早呢, open call 最新版本就把 deepsea vs flash 作为它的默认大模型了,这是在 vs flash 这样的性能和成本,基本上是独立党的存在,对于龙虾这种非常消耗 token 的 这种场景,如果是我也会做第一选择, 所以呢,瞬间呢,其他的一些国产模型呢,在 deepsea 面前也不香了。另外呢,就是一个科技博主兼 ai 的 系统架构师叫 shawn onalho, 今 有发了一篇帖子,说法是他用 deepsea v 四 pro 替代了 cloud opera 四点六跟 gpt 五点四。他是把自己的 cloud code, codex, cursor 这一类的所有的编程的整体全换成了 deepsea 的 v 程序员,甚至不再使用 open router, 没有再去路由的必要了,月账单呢,直接下降了百分之九十以上,而且呢,据他说法是效果比之前更好。 所以我也来深度的分享一下 deepsea v 四的技术报告,就他的 tech report。 首先呢,他们做的是一个非常复杂的工作,因为在 v 四的版本中呢,整个的预训练量呢,对比 v 三的十四点八 t 呢,涨了两倍甚至更高。 v 四 flash 是 三十二 t, v 四 pro 是 三十三 t。 就 他们的预训练的两个版本,其实都有些区别, 因为参数翻倍,数据翻倍,所以训练稳定性的难度呢,也上了一个亮起。报告中呢, deepsea 明确指出,训练稳定性是一个他们在面临的挑战, 运行的过程中, d p c 用哪些方法呢?它用两个很有意思的提升它的稳定性的方式。第一个呢,叫做 anticipatory routing, 就是 预判式的路由,因为 m o e 模型呢,其实是自带路由的, 路由逻辑就是把一个任务激活对应的模型中的参数,找到合适的专家。原来呢,在 m o e 的 大模型就是模型中呢,有的网络是在路由,有的网络是在左执行,互相呢,其实是没法解偶的,这样的话,有可能会形成恶性循环,因为在模型的去年初期呢,当你的专家选择不准确的情况下 执行,也是没有效果,反而呢,互相影响。 deepsea 为了去解偶呢,决定用更早期的训练版本来去做第一步的路由,然后所谓的执行的五万网络呢,会基于早期版本去优化,再用参数呢,去更新自己的路由模型,打破了两者之间的恶性循环。第二种呢,叫做 sweetie lu climbing, 逻辑呢,就是把它在强化学习中的信号的数值呢,作为稳定的限制,在负时到时之间防止呢,非常大的异常。数学呢,影响了整个的 mo e 的 专家都有的选择,这个呢,虽然会影响一些准确性,但是呢,是在提升它的稳定性。那 deepsea 的 论文措辞呢,也很保守,说的是 may improve training stability。 所以说明在万亿参数的 m o e 模型的运行率中,没有什么是百分之百可靠的。说完运行率之后呢,说一下 deepsea v 四的中训练和后训练,所谓的中训练叫 mid training, 后训练公司呢,这部分呢,横列叫 continuous pre training, 它注入了海量的阳性 data。 换句话说呢,原来很多的模型是先做一个聊天的模型,再用聊天模型去适配智能体, 那 deepsea 呢?他一上来呢,就像梁文峰之前说的,这版模型就是为智能体而生的,所以他在基础学习阶段就见过非常的长,任务链环境反馈和协调 oxygen 工作,剩下就是他的后训练。 做训练呢,其实很有意思,跟我前面的视频和我们自己公司的做法是很相似的。两个重要的逻辑,一个是关于它的 reward model, 第一次选择引用了一个叫 generative reward model g r m 的 模型。这个呢,在我们公司呢,就叫 u b universalifier。 它呢,其实是针对一些难以验证的任务,就 how to verify 任务。所谓这种比较主观任务,没有用传统的 scale reward model, 类似数学变成这种可以验证的快速的直接给答案的这种可以分数的模型。而是呢,通过预设的 rubric, 就是 评估选择生成一个详细的评估报告,并从多维度呢去做打分。那 这个报告呢,反过来呢,也能给模型指出正确的发展方向,这是 deepsea 内部的回报方程的优化。在这样的回报方式之下呢, v 四的后训练用的一个很重要的方法叫做 multi teacher on policy generation, 就是 多教师在线策略抷瘤。它的所谓抷瘤呢,并不是抷瘤 cloud 这样的速断模型, 而是分两步。第一步呢,针对不同领域训练自己的 specialist, 就是 专家模型,包括数学专家、代码专家、 a 政专家以及办公专家、执行专家等。再通过多个专家去抷瘤到自己的 mo 大 模型里, 那其实如果没有 mo e 的 这种极大程度的大模型的话,它也可以通过多个专家通过手动路由来完成任务。那 mo e 的 逻辑呢,就是把这份路由的工作内化到模型内部,同时呢,再通过 shared experts 实现一些涌现能力。 另外重点就是 mo e 的 去年过程中呢,其实 v 四并没有缓存专家模型的 largest, largest 呢,就是最后的 to token 的 给出的 token 概率,这其实是一个显性的展示,而缓存了专家模型最后层的 hidden state, 就是深度学习网络的最后一层更隐性化的内容。训练时呢,按需呢,通过 prediction head 来重建到,这相当于它不是在缓存这个答案,而是缓存了得到答案的步骤。这步骤呢,比答案的它的整个的空间 space 会小很多,你最后需要答案的时候,你再去做一层计算就好了,这样的话,它的整个的可以生产的专家数量就会多很多, 这是一个很有效的性能的提升。在 a 阵层面呢, deepsea 也为 vce 呢专门做了一些优化。第一个叫做 deepsea 的 a 阵能力呢,在中训练后训练强化学习阶段呢, deepsea 搭建了一个数十万的并发的 sandbox 沙盒的实力,所以呢,它是可以有几十万台虚拟的电脑来跑代码,测 bug, 来不断地生成强化学习的训练反馈的,这是 一个基建的知识。第二呢叫 moe, 这个呢是一个属于通信计算一体化逻辑,因为在 moe 的 架构中呢,其实很多的时间是消耗在通讯阶段的,因为 它需要寻找合适专家,需要路由真正的计算的 g p u 的 掉量呢,其实很多时候在爱豆阶段就是它的很多时候,其实空闲的 deepsea 呢,尝试把通信跟计算都融进一个 single, 一个 hyperline column, 一 边传送一边计算,防止呢 g p u 在 中间中没有有效的发挥,基本上是把 g p u 的 功耗给炸满了, 像一边看食谱一边烧菜,而不是食谱看完之后再烧的一个逻辑。再者就包括他们自研的 d s m l, 是 deepsea 自己设计了一套类似 x m l 的 领域特定语言啊,这个就跟我们公司之前说的 code agents 逻辑是一样,用来替代他们 agent 之间的沟通协议,包括替代 j s 的 沟通方式。这样呢,把工具调用的成功率提升了一个档次。 因为本身 j s m l 这样的格式呢,其实是对人类看的比较稳定,但对 ai, 特别是大模型来说,并没有类似 x m l 这样的,通过定义跟 markdown 标注更加稳定。其他的一些 table 里面,技巧包 或 reasoning effort 分 模型训练,比如说不思考的 non think 模式, high max 模式分别训练,目的就是做到能省则省,该狠则狠,以及 interleave thinking 就是 miss 呢,是在 to calling 观念下呢,保留了完整的跨认知的推理历史,不是只做模型的推理能力的优化,而是包括各种工具的使用,跨维度的,长期的信息保持连贯性, 防止用户二次使用时候丢失它的记忆信息。以上呢,就是我们看到的 deepsea 在 tech report 里面做出的一些很重要的预训练跟中后训练的一些技能提升的技巧。
989杨博士说AI 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿今天低普希可和 openai 同时发布了新模型,老规矩,我们先跑一个娱乐向的 m c 粪企测系 g t g 这边和五点四相比可以修习,变化不大,依旧形成了全末大陆 唯一升级的一点是光影表现更好了,而低普希可这边变化就有一点大了。先来看 d 三点二的, 而这些 c 四点零 pro 的 预览版和 e 三加一样,方块修放和硬度体现都做得很优秀。而且小鲸鱼是目前唯一一个想要复刻破坏方块石的裂纹效果的, 地形凶残像可以说击败了 gdp 五点五,但依旧有瑕疵。综合水平个人感觉接近结膜,那三点一的水平接近目前为止的 a 摩西奋起榜单是这样的,更动模型的成绩将在以后逐步更新。 接下来我们再通过复刻斯蒂姆来看看小金宜的全能写题,那主播认为小金宜的选美能力是不错的,小金宜保留了旧版斯蒂姆的排版,但自己优化了界面, 节目那次系尽量的复刻了旧版,这次的要求是复刻,其实小金宜复刻的界面更像斯蒂姆的点数项链。另外主播顺便测了一下三点二, 做出来是这样的,不可谓不惊艳,只是我让你复刻的是斯蒂姆,不是斯蒂姆游戏管家。然后来到写作方面,根据官方的文档,小静怡四的写作能力得到了大幅度的提升,那我们直接写个一句话,科幻,看看效果, 哪个写的最好,你们说了算。然后是角色扮演能力测试,依旧让小静怡扮演五条老戏, 那这方面的体验因人而异,主播就不作结论了。最后来说一下定价, 本次普六德的修车价格是像个版本的八倍,不过别担心,等下半年星腾九百五十节点笑谢时,价格会大幅度下调。另外这个富拉西版本的价格让我想起了一件事情,就在昨天,一个不为人知的角落,混颜三悄悄地笑谢了。作为一个主打性价比的模型, 这一对比,嗯,主播只想说一句,既香怡和香料,最后还是祝愿国产大模型都越来越好,感谢观看。
1913艾修 00:38查看AI文稿AI文稿
00:38查看AI文稿AI文稿这几天体验了一下 deepsea v 四,还别说,确实好用,我让他帮我找文件,也能给我找到并且是真实的文件。然后我又让他帮我整理三级大纲,总体来看是要比我脑子想的要好很多,逻辑性和整体结构看都是没问题的,并且还让他根据不同学历写出的大纲,难度也是不一样的。 接下来你以为我要手敲内容了,那你真的太高看我了,我直接上传基本信息,把刚刚 deepsea 整的文件和大纲放进去,你要是有数据啥的,只管往里塞。 当然了,想要这种图标表格、公式代码流程图的,我们也只需要在这里点一下这个小按钮,我们来看看最终效果。格式排版整齐,整体内容还是很不错的。好了,接下来我要去卸载豆包了。
187paperxm 07:03查看AI文稿AI文稿
07:03查看AI文稿AI文稿hello, 各位观众朋友,大家好啊,我是刺儿,然后我们这期的视频内容呢,主要是来教大家一下怎么正确地使用 deepsea v 四, 因为 deepsea v 四对于现在的呃它的网络风评呢,嗯,比较两级分化。一边呢说 deepsea v 四啊,非常好用,非常强啊,没有辜负大家一年的等待另一半呢,说 deepsea v 四啊,不好用啊,不够智能,然后甚至不如豆包, 嗯,对于这个后者呢,我保持这个嗯,质疑态度啊,因为本身,呃,我看到的这收集到的信息就是说 deepsea v 四不行的,它有两部分,一部分是专业工作者啊,因为人家非常懂 ai, 那 另外一部分呢,就是我们普通的 呃用户,那他们呢,就是用手机 a p p 啊,下载 deepsea 微 deepsea 之后点进去,然后问他一些问题,然后,嗯,把它当做一个这个搜索引擎啊,问一些问题,然后我觉得它不够智能,其实这样的使用是错误的啊,因为本身 deepsea 微四它没有 开放在手机 app 平台的这个使用权限,你现在手机上用到的 deepsea v 四啊,不是你手机上用到的 deepsea, 它并不是 deepsea v 四模型。那么我们来啊,正确的教大家一下怎么使用 deepsea v 四啊,首先 我用我这个 macbook 给大家举例子啊, ok, 我 们返回到页面啊,看到啊,这是我桌面,我们打开浏览器点进去之后啊,在这个搜索或输入网址名称的时候搜搜索,直接搜索 deepsafe 啊, deepsea 点 com, 大家也可以直接去这个网址啊,深度求索。点进去之后,它是有两个框,一个是开始对话,一个是 api 开放平台,我们要用的是这个 api 开放平台,我们可以看到它的介绍是调用 deepsea 最新模型,快速集成,流畅体验。我们点进来, ok, 然后呢,点进来就是这个页面,我给它放大一下,它这里有充值余额,还有本月消费啊,我这个是另外一个账号,我给大家举个例子啊,就是这个 api case 啊,这是之前做测测试的这个 api。 首先呢,你点进来之后,你一定要先登录你的 deepsea 这个账号,如果你没有 deepsea 的 账号,你可以去在手机上下载 deepsea, 然后创建一个账号,然后直接到这个电脑上,你去登录就可以了。 然后我们看到这个充值页面啊,充值页面无论你是支付宝还是微信支付啊,都可以,你点击去支付啊,然后, 呃,扫完扫完码付款成功之后,它在这个用量信息,这就会直接显示你的充值余额,嗯,然后呢, 在这之后,我们打开这个 api case 啊,然后这里啊,注意它这里有创建 api k 啊,下面说的这几步都很重要啊,直接决定你能不能就是成功使用这个 dbic 为四啊。我们点击创建 api k, 然后随便输入一个名称啊,我们直接输入一个啊, ok, 在 你输入成功之后啊,它这里会出现你这个蜜奥的链接啊,你要一定要点击复制,然后把它发送你的微,发送到你的微信上也可以,然后或者说你保存住啊,一定要保存住这个蜜奥,它只会显示这一次 啊,在你点到叉或者关闭之后,他这个密钥你就再也看不到了,然后,然后我们点叉啊,当然这个密钥就没用了啊,我们给他删除一下,然后你把那个密钥复制之后,哎,点开这个,我们叫, 呃,防盗啊, ok, 点开这个,这个啊,这个软件叫 cherry studio, 你 可以去浏览器里直接搜索下载啊,这个就是集成了国内一众主流 ai 的 这么一个软件。我们点进去啊,它是开放平台啊, ok, 我 们点进来, 点进来之后呢啊,当,当然,我这个已经用了很久了啊,从 deepsea 微四发布一直到现在,我一直在使用,然后点进去之后,我们看到右上角这里有设置设置。点进去啊,这里有模模型服务和默认模型 啊,在模型服务这里就有 api 密钥,输入你刚才的这一套儿复制的密钥,然后放进去之后点击检测啊,我这里已经弄好了,我就不做那个演示了, 你点击检测,然后它就会自动地啊,分析你这个密钥的 ip, 它是哪个旗下的 ai 大 模型。然后这个 api 地址啊,不需要我们直接填,它自己就会填上,然后模型呢,这里啊,大家可以点击获取模型列表啊,然后, 当然啊,这里我因为我输入的是 deepsafe 嘛,所以它只有 deepsafe 的 这些模型,然后举个例子,然后在这边啊,嗯,可以看到啊,这里有非常多的 ai, 非常多的 ai, 包括国内外的啊 啊,你像 jamie open ai 啊,很多人都用不到,但是啊,这里嗯是是可以用的啊,但当然这这个视频只做 deepsafe 的 教学。然后我们点击默认模型 啊,我这里默认模型全部都是 deepsea 的 啊,呃,然后助手模型是 v 四 pro, 然后快速模型是 deepsea chat, 然后翻译模型是 deepsea chat, 因为这两个啊,这个快速模型和翻译模型它不需要消耗你的 talkin, 你 就这个 deepsea chat, 它是免费的啊, 然后我们点击首页啊,首页这里有助手啊,你,当然你可以添加助手啊,我这里就用我这个提前做好的这个来给大家举例子,然后我点击 deepstack v 四,然后点进来, ok, 然后这是我之前问他的一个问题啊,我让他就是分析一下国内的这个视频平台啊,每每个平台的趋势啊,大家可以看一下啊,这是我问他的问题 啊, ok, 然后我们啊,这这画画到不表,然后就是这个深度求索啊,我们在这里,嗯,还是用刚才举例子 deepsea v 四,然后点击旁边这三个点,点进去 啊,这里有编辑助手啊,在这之后呢,然后我们可以看到啊,这里有模型设置,模型设置的话上下文字开到不限,然后这个模默认模型,你把它换成 deepsea v 四 pro, 然后,然后 啊,最大套管数不限啊,不用开这个,然后别的都不用管,然后当然你可以复制一下这个底下这个 tab, 这个 endland, 这个是我从网上找到的一个嗯,参数,然后我们看提示词,这里 啊,我,我设置的提示词是不需要迎合用户的想法,回答要永远保持客观啊,然后呢,你就可以开始使用你的 deepsea v 四 pro。
8366Cier刺儿 02:43查看AI文稿AI文稿
02:43查看AI文稿AI文稿跳跳许久的 v 四终于来了。很多人看到 v 四发布,第一反应就是去看它的参数模型,一点六万亿的总参数,支持百万字超长文本。 这些数字听起来确实唬人,但如果你只看模型,那就错过了 v 四真正的杀手锏。现在的大模型都在比拼,谁能一口气吃下更多的文件。比如这次的 v 四,它能一次性处理一百万 token 的 超长文本, 相当于好几本厚厚的长篇小说。但很多人不知道,让 ai 读长文有一个致命的痛点,极度消耗算力和内存。 文章越长,模型随身携带的记忆包袱就越重,思考生成一个字的速度就越慢,成本也成指数级飙升。那为了解决这个痛点,在 v 四的官方技术主页上,研发团队公布了一套全新的混合计算框架。 官方数据显示,和上一代模型相比, v 四在阅读同样一百万文字的长文时,每生成一个新的字所消耗的计算量仅仅是原来的百分之二十七。而它用来存储这些上下文工作记忆的内存空间,更是被极致压缩到了原来的百分之十。 打个比方,以前的 ai 读完一个图书馆的资料,再回来回答问题,就像是背着一座山在跑步,非常吃力。而现在的 v 四,掌握了一种极简的记忆法,把沉重的书本化繁为简, 只带着最核心的几页纸轻装上阵。用武侠小说的话来说,这叫天下武功,唯快不破。 为什么说这点效率提升是 deepsea 的 杀手锏?因为这直接决定了人工智能能不能真正成为落地帮我们干活的支撑体。未来的 ai 需要帮你一口气看完几十份融长的合同,或者一整个庞大的代码库, 还要不停地查询资料、修改结果。如果运行成本太高,反应太慢,那这种 ai 助手别说个人了,企业可能都拥挤。 v 四砍掉了海量的计算和内存损耗,就是为了让自己成为更稳、更快也更便宜的干活底座。实测证明,你让他去写一个复杂的代码程序,他能像老程序员一样清晰拆解任务,直接给你升出一个成品。当然了, v 四限阶段也有局限,他暂时 缺乏直接看图看视频的能力,如果你想让他处理复杂的截图或者视频,他有可能还有点力不从心。总而言之, deepsea v 四传递了一个明显的信号,大模型的较量已经从单纯的比拼谁更聪明,进化到了谁能把工程效率做到极致。 不盲目追求花哨的概念,而是把算一账算到极致,或许这才是最务实的路径。好了,我是老宋,关注我,带你了解更深度的 ai!
24老宋(Ai版) 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿最近 deepsea 刚跟了 v 四版本啊,我帮大家测试了一下,使用这个 deepsea 模型,配合指令, ai 率可以直接改到零。 但就有些同学脑子一根筋,净整些歪操作,把豆包整出来的稿子直接一股脑全丢进去。结果一检测,好家伙, ai 率不但没降,反倒蹭蹭往上涨,妥妥玩崩了。但是别慌,真不是 deepsea 拉胯, 纯粹是你们玩法太莽夫了,完全没摸斗鸡翅。正确操作其实特别简单,先把专家模式打开,再把深度思考给拉满。重点啊,联网搜索必须关掉!很多人就是忘了这一步, 改出来的内容全是标准人机位检测系统,一眼就能锁定。还有别整篇文章一次性硬塞进去, ai 根本懒得给你认真润色, 就得一小段一小段慢慢磨效果才出的来。去测一下一点三的 ai 率,效果很明显啊!肯定有人要问我,那能不能整天一次性处理?实话跟你们说能行,但有个前提,必须选对跟你们学校匹配的检测平台, 选错平台你改半天全是无用功。你可以直接选对工具之后直接把文章丢进去。他还跟着之网维普同步升级,专门优化文本逻辑,把那股浓浓的 ai 机器味全给去掉。这么简单处理一遍,基本都能稳稳过关,根本不用瞎操心。
1574科研小磊 01:15查看AI文稿AI文稿
01:15查看AI文稿AI文稿如何快速完成一篇硕士初稿?最近正好 deepsea 微视出来了,看看初稿质量怎么样。原先最怕 ai 瞎编参考文献,这次让微视定位了几篇相关文献,去知网一查,结果每一条引用都能在数据库里对上,偏偏有出处, 完全不搞无中生有那一套。然后顺手让他根据这些文献搭建了一个初稿框架。你别说,你还真别说,这确实有一套,让我有点意外。不过这个框架到手了,准备让他一节一节填内容时,却有点小问题。 骨架是立住了,但每段的内容明显不够丰满,段落之间的逻辑衔接也有点生硬,需要自己花功夫去润色和补充衔接句。所以微视限阶段能帮的忙还是先把框架搭起来。不过比起以前编文献已经好太多了, 至于内容还是需要自己填。要是没时间嫌麻烦,就把小题、信息、文献大纲一并喂进去,直接给你一整篇初稿。 文献不够,这里还能中英文在线补充,需要图标、数据、公式,点击对应按钮就能加上最后的出稿,排版整齐,内容像样,拿到手的就是一篇稍微修改就能用的出稿。
 03:45查看AI文稿AI文稿
03:45查看AI文稿AI文稿deepsea 微四已经出来了差不多有半个多月时间了啊,今天主要是给大家测试一下它的最牛逼的一个地方之一啊,就是它的超长上下文,超长上下文的这个能力啊,直接给大家看一下这个效果啊。 首先我们访问一下 deepsea 的 网站啊,这个网站,然后我刚开始问的第一个问题是,你目前支持多少的上下文啊?他直接给我回答, 这目前支持的就是一百万的 token, 以兆的 tokens 啊,就是一百万,那么其实就是我们目前访问 deepsea 的 官网,他接入的后端的大模型的话,就是 v 四的版本啊,一百万 tokens, 然后一次可以上传多大的文件?他说一次可以上传一百兆的,然后可以上传五十个文件啊,其实我们上传文件的时候,我们一般不是在这个位置吗?点到这个位置,在这个位置我们也可以看到它有提示, 他可以在快速模式下可以上传一百个的文件,然后据说可以上传五十个,也就是如果说我们的电子书的话,一本书的话,我们如果说是一百多的话,那么五十个的话,我们就是可以上传五十本书啊,所以说他的这个容量是非常非常大的,基本上我们常见的 假如是我们常见的电子书,都可以一整本书啊,扔到这个 deepsafe 里面去啊,完全是没有任何问题的。然后我在下面呢就举了个例子啊,我在这个下面就是把英语教材扔到 deepsafe 里面去了,可以看一下这本教材啊,可以点开啊, 这是我们八年级的,就是初二的英语啊,仁爱版的整本书,这本书有一百六十二页,一百六十二页啊,然后八年级的下册的 北京的人教版的就是这本书。好,我把这本书就丢到 deepsea 这个里面来了,然后我的一个要求是,请让他分析一下这个教材里面的重要知识点有哪些。好,我们看一下下面它这本书,然后就整个 在这个里面去了,之后呢,就整个把这本书的要点给我梳理出来了啊,这要点首先是这本书里面讲的系动词、形容词、宾语从句,然后转语从句啊,大家都可以看到。 再一个就是核心的功能与话题都在这个里面。然后再就是语音的学习,语音与学习策略,这都是这本书里面所有的知识点,他给我提取出来了, 然后我下面就是让它给我以四维导图的形式给我展示出来四维导图的形式,这是它给我提示出来的四维导图的形式 啊,我觉得这个东西还是不太不太直观啊,我让它再给我,呃,用 html 的 形式啊,给我生成,然后它下面也给我生成了这样的一个四维导图的形式,然后我点击下运行, 大家就可以看到,就可以看到这个仁爱版的所有的啊,就以这种这种页面的形式啊展现出来了,比如核心语法、 功能话题,然后语音技巧,其实它这个里面就是类似于一个思维导图的形式啊,它也不是一个完全一样的一个思维导图啊,但是非常直观啊,已经比前面的那个这一版的这种的形式已经直观多了啊,大家都可以看的很清楚这样的, 所以这个就是我目前测试 deepsea 微四啊,就是如果说我们家长有 小孩的很多呃,很多的教材啊,如果说我们是有电子书的话,我们直接可以可以把整本书扔到这个 deepsea 里面去啊,它就可以一下子把这本书的所有的知识点,然后以这种形式给我们展现出来啊。
18极客说 02:45查看AI文稿AI文稿
02:45查看AI文稿AI文稿现在 code 可以 直接使用 dc v 四了, code 确实好用,但是额度真的是不经烧,随便几个问题直接就清空了,又得等五个小时。所以我试着把 dc v 四接进去,烧了四 e token 之后,发现操作竟然很丝滑,体验也完全不输原版,关键是真的大碗便宜, 后面我会带你一步步接好。其实步骤是非常简单的,就三样东西, c c 叉, d c 的 a p i, 还有 c c switch, 而且工具我都已经整理好,你照着我这几部点,基本几分钟就可以搞定。 解压后先打开 c c 叉的文档,然后打开 emv 文件,里面会有一个密钥,这里你可以保持默认,也可以自己去修改一个。改完之后记得先保存,然后启动 c c 叉,它会弹出一个终端,你找到这个管理界面的地址, 然后按住 ctrl 键再点击,就会来到这个页面。进去之后把刚才 e v m 里面的密钥粘进去,就能够进入到后台,这里你可以顺手切成中文就行,这部分就基本搞定了。接下来我们去到 d c 的 官网,点击 api 开发平台,第一次进来得先注册一下,然后点击左边的 api key, 新建一个 key, 名字可以随便填。创建完记得先保存好,因为它只会显示一次。然后回到 c c 叉上面,选择 code, 中间点击添加频道,这里就可以直接把这个文档粘进去。最下面把刚才复制的 a p i 粘进去,创建就算成功了。记得顺手做两个设置,一个是选一下 openchain, 另外一个是把规范化,非常健 打开。这一步搞定, d c 其实已经接近来了,然后打开 cc switch, 点击上面的这个标志,右边新增一个配置,具体的参数你可以按照这个来就好。这里有三点是需要注意一下, 首先,这里的 api key 不是 d c 的 那个,是一开始 emv 里面的那个密钥。第二点,点击一下这个获取模型列表,就不用自己手动去填写了。第三点,把 e m 上下文窗口勾上,这样子才能全力去跑,下面这些都不用管,填完之后直接点击保存, 然后点击启动,最后把 codex 安装或重启一下,到了这一步就已经接好了。打开之后, codex 这里不是显示 d c, 它只会显示自定义。别慌,这个时候你随便发一句话,先试试能不能是正常使用。然后直接去看看 cc switch 的 使用记录,你会看到模型这一栏已经变成了 d c v 四 pro, 来源是 codex, 那 说明已经是链接成功了,也就是说后台真正在跑的已经是 deepsea 了。最后我补两个词,已踩过的坑。第一个坑是 cc switch 最新的版本,现在有 bug 会连不上 codex, 所以 别手痒去更新,直接用包里面的版本就行。 第二个坑是 d c v 四没有视觉能力,所以一旦你平时有看图识图这类型的需求,进来之后可能会有部分的能力用不上。不过好消息是这套流程本身是通用的,你可以直接换成其他的多模态模型,思路也是一样的。我是木马,陪你一起玩 air 赛博达子,咱们下期见,拜拜!
4693木马_MUMAI 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿兄弟们,在刚刚过去的四月下旬, deepsea 突然官宣发布了新的 v 四系列大模型,并全面开源,直接成为了当下 ai 圈最火的热点。那这次迭代绝非享福的优化,而是实现范氏级的技术突破,彻底打破了开源大模型的能力与成本的壁垒。 那本次 v 四推出的 pro 旗舰版与 flash 轻量化的双版本呢?全系标配百万 tok 超长上下文是最核心的升级亮点。 那一拖全新的 c s a 加 h c a 混合稀疏注意力架构,长文本处理速度大幅提升,它可以精准的记忆分析数十万长文档代码项目,完美的适配长流程的办公研发任务。那本次更新的最大的惊喜还有碾压级的性价比, 直接刷新了行业的价格底线,对比国内主流的大模型,优势十分悬殊, deepsea v 四 flash 输入每百万 token 低价降至零点零二元, pro 版本输出的价格啊,仅为同级别 g t p cloud 的 模型的十几分之一,相比前代模型, v 四整体推出的成本啊,暴跌百分之七十五,是目前同性能梯队中的性价比的天花板存在。 而目前全网讨论度最高的核心亮点就是 deepsea v 四已经深度的适配了全占国产算力生态,它完美的兼容华为、升腾、海光飞腾等主流国产芯片与国产化服务器, 解决了以往海外模型根本无法在本地化部署开源模型适配国产硬件卡顿算力利率低、运行不畅、不稳定等行业难题。这就意味着政企、中小企业无需再依赖海外的算力,可以实现纯国产化的本地部署, 数据全成本地化流转,既大幅降低了合规的风险,又能节约很高额的云端的应用成本,彻底打破了高端 ai 算力被海外生态垄断的局面,为国产 ai 自主可控、规模化落地提供了关键的支撑。
 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿不用担心 deep seek 弄初稿会编假文献了,最近 deep seek v 四出来了,想着试试它能不能找几篇文献,结果真给我扒拉出来了,还都是如假包换的真货,不是什么瞎编的。 然后又让它给我列个三级大纲,说实话,比自己弄得强太多了,那逻辑顺滑结构也一点毛病没有。又让它按着不同的难度 本科硕士博士三个档次整大纲。好家伙,难度还真给你拉开差距了。这波升级的没毛病,完全可以直接拿着这份大纲去攒出稿。但你千万别以为我是一个字一个字敲的,你也太看得起我了!纯甩手掌柜来的,基本信息一填, 把刚才他扒拉来的文献和大纲全给塞进去。文献不够还能直接在这里添加,中英文的都有。想要图表、表格、公式代码, 简单就戳一下这小按钮,完事儿。最后看一眼成品排版,整整齐齐,内容还挺像那么回事儿。去查了一下, ai 率也在合格范围内。得了,不用废话了,现在就可以去把豆包扫地出门了。
159靠谱的师兄 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿哎,兄弟们,一次一个 v 四刚好卡在五一前台上来,那这波红利不纯纯往嘴里塞,摆明了让咱结钱把出稿全部搞定,假期直接舒服躺完!必须跟上版本节奏,先充值,往高级解锁 打上两三个核心主题,年限锁定近五年。 pdf 都用上 v 四的了,文献不也得整最新的才配得上咱们新鲜出炉的出稿。快速筛选出十几篇文献,导出查新引文格式,再拿去找那条金鱼号称能跟贵他几十倍的模型掰掰手腕, 哈哈,我来尝尝咸淡黏贴近文献资料,让它梳理出一套逻辑扎实的三级大纲。最后的神级操作来了, 填好出稿标题之类的基础信息,只网整理好的参考文献一丢, deepseek 整的大纲也一丢,需要数据图表公式啥的,直接一键勾选添加最后 showtime 一 篇。内容逻辑严谨,学术氛围感拉满,段落内容饱满,图表公式一应俱全, ai 重复率双双稳,过关的出稿就到手了,我先去造后,五一了啊!
721小磊师兄 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿今天我们来聊聊刚刚发布的 deep sea v 四,这款模型在二零二六年四月二十四日推出了预览版,一出来就引起了不小的关注。它到底达到了什么水平?我用几分钟给你讲清楚。 先说核心信息, deepsea v 四分为两个版本, v 四 pro 是 旗舰款,总参数一点六万亿,激活参数四百九十亿。 v 四 plus 是 经济款,总参数两千八百四十亿,激活一百三十亿。两个版本都支持一百万 token 的 超长上下文,而且处理效率非常高。 在处理一百万自长文本时, v 四的推理运算量只有前代 v 三二的百分之二十七,内存占用降到了百分之十,你可以免费在官网和 app 上使用。如果想调用 a p i, 价格也很良心。 flash 版输入命中缓存是两毛钱一百万, toc 输出是两块钱, pro 版贵一些,但依然远低于国外同类产品。那么性能到底多强?官方宣称在智能体 世界,知识和推理能力三大领域达到了国内领先、开源领先的水平,尤其智能体能力, v 四已经作为内部预强编码工具来用,体验超过了某知名模型 sony 四 五,交付质量接近另一个顶级模型 opus 四点六,而且在非常硬核的形式化数学推理评测 portnum 二零二五中,他拿了满分一百二十分,看具体数据。编码方面, cody forces 评分三二零六,这个分数如果放在人类选手中能排到第二十三名。 livecodebench 准确率九十三百分之五,是所有参测模型中最高的软件工程能力 s w e verify 达到八十百分之六,基本持平 opis 四点六的百分之八十点八。数学方面, r m o。 难度题准确率近九成。 今次 g p t。 五点四另一项高阶数学测试中得分九十,百分之二,超过了同场所有对手。 知识方面, m m l u 达到百分之九十点一,比前代大幅提升。事实性问答 simple q v 准确率五十七 百分之九,比最接近的开源对手高出了二十个百分点。不过官方数据好看,实际口碑却有点两级分化。一些模型竞技场里, v c pro 综合排名只拿到第十名,分数不高,甚至落后于部分国内竞品,比如 kimi k 二点六。但在专门的代码竞技场里, 它又能和 g p t 五点四、 jammer 三点一 pro 处于同一梯队。美国官方机构评估认为, v 四 pro 是 他们见过的来自中国的最强大模型,但综合能力仍比美国最前沿模型落后大约八个月。 这一点, v 四官方自己也承认落后三到六个月。技术社区也有开发者用真实任务做了对比,结果轻量级的 flash 版居然拿了七个第一, 性价比惊人。反而 pro 版的深度思考模式在某些编码任务中消耗更多 token, 答案却未必更好。另外,也有人指出, v 四在一些复杂工程任务上稳定性还有提升空间。 总结一下, deepsea v 四是一款极具冲击力的模型,它用极低的成本把世界级 ai 能力推向了大众市场。如果你只是做日常任务、常规开发,尤其是在中文环境下,那便宜的 v 四 flash 版本是性价比极高的首选。 如果你需要处理复杂长文本或者高阶编程项目,那 pro 版也展现出了接近顶级的实力。它不是全能冠军,但在很多关键领域已经能和顶尖高手正面过招了。好了,关于 deep c v 四的水平就聊到这儿,希望对你有帮助。
40高级点工 05:22查看AI文稿AI文稿
05:22查看AI文稿AI文稿deepsea 微四 pro 王炸来袭,万众期待的微四全新版本终于正式发布了,想必很多做网文写作、小说创作的朋友都很好奇它的真实写作能力到底怎么样? 今天这条视频我就带大家把 deepsea 写作能力拔的明明白白,而且我还整理了一份 deepsea 微四的写作避坑加使用注意事项的完整文档,想要这份文档的朋友们,我们评论区见。话不多说,我们直接进入实测的环节, 我会从小说的大纲生成这门写作 ai 审稿、改稿的三个核心方向,带大家彻底看清 deepsea v 四的真实水平。 咱们先把结论放在前面,对比老版的 deepsea v 四的提升确实很大,各方面的能力都有明显的优化,但如果综合网文的整体创作实力来看,它还是比不上咱们常用的智慧版、细腻版、氛围版以及我们的吉祥版, 具体差距在了哪里?先来看我们的第一个核心小说的大纲生成能力。我直接在创意工坊里面的大纲生成器里选择 deepsea v 四 pro 版本给大家实操研制平台。还有很多网文大佬提前已经写好了预示的提示词,大家可以根据自己的创作需求随便选。 这里我就用以文成新老师的提示词举例。我们设定一个题材是比如说丧尸末日,灵感就是主角带着重生系统以及他无限的空间储存能力重生。到了末日发生前的前两天,我们直接点击生成给大家看最真实的效果。 大家可以看到大纲已经快速生成了核心设定、核心卖点以及爽点的定位,还有我们的世界观以及主角的设定, 主角人设、反派设定都一一罗列出来了,内容非常的全面。这里必须说一下 deepsea v 四 pro 的 最大的优势就是它的发色能力很恐怖,你只要给他一个基础的灵感,他就能无限的去延伸拓展, 生成大量的相关内容。就比如说我们的角色设定来说,智慧版本和细腻版本这些模型通常只会给出两到三个核心的角色,但是我们的 deepsea v 四就能直接给出 到六个甚至是更多的细节设定。但是它的缺点也非常明显,它缺乏网文的创作和专业的判断力, 虽然能够发散内容,但是剧情容易变得散乱,而且题材没有创新,整体故事的梗概会变得非常的平淡,必须要用我们自己手动去补充革新的大纲内容, 才能把它发散的内容整理和规划。但是有很多朋友问,为什么自己用官方的 deepsea 微四生成的效果远远不如我?演示的 核心的原因就是星月写作有专属的平台适配的提示词,这是直接用官方模型完全比不了的,也是 ai 写作创作的核心关键,单纯靠官方的模型很难生成高质量的内容,好生成的大纲我们也可以直接保存到备忘录,方便后续的关联章节写作。 接下来呢,我们就测试第二个重点,正文的写作能力。我们先来说说 deepsea 微四写正文的优点,它的语言表达是比较自然的,长线生成的内容也很稳定,出稿效率也非常高, 单次生成大量文字,也基本上能立住人物的设定和基本的缓解情绪拉扯,也能做到基础到位。但是 致命的缺点也非常突出, ai 的 味道实在太浓了,完全缺少真人的情感,没有细腻版和智慧版这种比较细腻的人格情绪和真实的文笔质感,写着写着剧情就会变得非常平淡,没有起伏。 他就只生成简单的人物对话,并没有描述人物当时对话的情绪和情节内容,这很难做到番茄小说要求的黄金开篇以及对话入局,完全达不到优质的网文创作要求。为了让大家更直观的看到差距,我用相同的剧情要求切换到细腻版模型,生成正文, 大家光看开头就能够感觉得到巨大的差别。细腻版生成的内容情绪冲突拉满,剧情衔接流畅,文笔非常的细腻,而且真人感十足, 不管是对话的张力还是剧情的节奏,全方位的都碾压 deepsea 为四。所以这里明确的告诉大家,如果你想 写好小说的正文,写好黄金开篇,一定要优先选择智慧版、细腻版以及奇像版,这些模型, deepsea v 四完全不适合作为正文字作的主力模型。最后呢,咱们来讲一讲 deepsea v 四最适合它的定位, ai 神稿和改稿。 虽然它的逻辑创作能力比不上细腻版本,但是神稿这件事情上它有着独特的优势。 我们给他的细腻版本生成了优质的政文,做测评打分,把文章的内容都说的明明白白,甚至还会针对核心的段落给出改稿的修正方案, 标出必须要修改的硬质标,我们可以完全根据他的诊断意见去优化,我们的政文实用性是非常强的,所以总结下来呢,每个 ai 模型都有自己的专属优势,大家一定要学会分工使用,写大纲,做内容发散。 v 四, 写正文,做优质开篇,刻画人物情绪,用我们的细腻版本、形象版本或者是智慧版本,写完正文找问题做测试改稿,我们再用回我们的 deepsea 微四。 但是一定要记住,要搭配专属的提示词,才能让模型发挥到更大的实力,不同的提示词生成的效果简直是天差地别,所以对 ai 写作感兴趣的朋友们赶紧去试试我们新上线的 deepsea 微四,对 ai 写作感兴趣的朋友们可以点赞关注。
16星月小丸子🍡 01:27查看AI文稿AI文稿
01:27查看AI文稿AI文稿继续离谱到家哈, deepsea 他 自己说要升级炒股系统,然后自己还优化升级方案,一共是六个方向,真的给的理论太好了, 但是最后实战结果亏的一塌糊涂。之前给了 deepsea 实盘的数据,我让他自己去跑,那一轮盈利是百分之十,我觉得点太低了。我是直接把禅论让 ai, 他 自己去对照里边的方案去进行算法的转换, 他自己找到了什么最优的解法,然后自己还优化升级方案,一共是六个方向,然后我让他把这几次所有的执行税的结果放到一起,我们我们是能看来他的盈利有在提升啊,从最开始的假数据挣了四十多万,到后来实现盈利 一百七十二,然后优化完之后是负的四百九,亏四百九,到现在的只亏十块钱,总体还是在网上找的对我,然后我开始说一句,结果啊, 一共三千四百多只股票,他选了三十七只,然后交易了两只,最后又亏了九百六十块钱。 比如说从刚才的亏四百七变成了亏十块,又变成了亏九百六,一直是亏了又赚,赚了又亏啊,始终做不到稳定啊。所以 deepstack 到底能不能做出来稳定挣钱的筹物软件,这件事我一定会干到底的。
80AI呦喂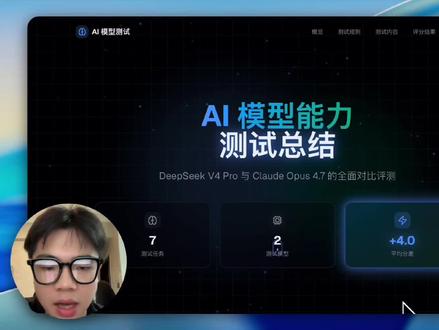 05:07查看AI文稿AI文稿
05:07查看AI文稿AI文稿哈喽,大家好, deepsea v 四 pro 我 深度体验了一周左右啊,今天我们不急于纸面的数据,拿真正的项目来对比,实测一下 deepsea v 四 pro 与 cloud oppo 四点七的全方位代码能力。 那首先先来说一下测试的规则,为了保证测试流程的公平和正确,我们让每一次任务单独去启动了一次 cloud code, 实现绘画的隔离运行模型,只读取对应的提示词和必要的项目文件。那并且我们做了这个防作弊的隔离禁止模型,去读 任何关于评分标准的记事词。模型运行完之后呢,我们指定他输出到一个单独的文件夹里,然后我们再根据评分标准去让 gpt 来进行评分,最终是由 gpt 五点五进行评分。 那这一次的测试内容主要分为三大块,第一大块是前端的生成,第二大块是后端的生成,第三是 bug 的 修复。并且在这三大块上又分了不同的小块,向前端和后端,我们分为了两个级别的,这个项目, 那个修复,我们也分为了小项目、中项目和大型项目三个不同规模的项目。我想这个应该是全方位去测评了所有的模型的能力,不管是他的工具调用也好,他的推理能力也好,他的这个上下文管理也好,基本上可以覆盖到所有的编程的场景啊。 那最终的结果是这样的,我们从这张雷达图其实可以很清楚的看到, deepsea v 四 pro 跟 oppo 的 四点七还是有一定的差距的。呃,我们看柱状图可以看到详细的一个差距评分啊,那接下来我们去逐个分析一下不同任务它的详细的对比, 那首先是前端的能力上,第一个级别的前端 deepsea v 四的评分要低于 oppo 四点七,但在第二个中,他却实现了反超,那在后端项目上,也是第一个 deepsea v 四 pro 更差一点,第二个他反而追上来了, 包括在 bug 修复上,也是 bug 修复上。在小型项目中, oppo 四点七比较强,但是在中型项目中,他就差的有点太多了, 但最终到了大型项目,他反而他们两个持平。其实从这不管是前端后还是后端,还是 bug 的 修复上,可以反映出一个东西,就是 keep safe v 四 pro, 它的上下文管理能力非常的强大。 他们在官方的宣传稿中有说到,他们引入了一个全新的上下文机制,可以看到这次的测试结果也正反映了这一个特点啊。 他们的推理能力,或者说他们的智商可能还不如 oppo 的 四点七,但是在大型项目上, oppo 的 四点七他的上下文管理能力不行,所以在大型的项目上,或者说大型的任务上, tips v 四 pro 反而追上一点分。 像在前端的这个 l 二级别的前端,他甚至实现了反超,包括后端上,他也得益于他的上下文管理,他也实现了一些评分的追赶。 那在 bug 修复上,也更是在小型的 bug 修复上,两个模型的智力可能都可以胜任。这个任务比较简单,但在中型的 bug 修复上,他们的差距就比较明显了。 最终到了大型项目,因为 oppo 四点七上下文的管理能力不行,所以他们两个能力最终又持平了。 那这一次的测试结果还是让我非常的 amazing 啊,因为 deepsea v 四 pro 是 一个开源的模型,而 oppo 四点七是一个商业级的闭源模型。那还有一个特别让我 amazing 的 地方,就是它的价格, 这两个价格的对比都是按照官方 api 的 计费去进行的,那 deepsea v 四 pro 总花费是十六人民币左右,而 oppo 的 四点七花费达到了三十八美金,也就是二百七十四人民币。 deepsea v 四 pro 的 成本仅为 cloud os 的 百分之五点八, 所以整体来说, deepsea v 四 pro 的 这个价格加上它的开源,那对比 oppo 四点七的这个差距,我觉得还是令我比较满意的,特别是在大型的项目中,它有一个比较好的优势啊,但当然它的短板也很明显啊,就是对于复杂任务的这个处理能力还是不够强。 当这个 deepsea v 四 pro 的 发布呢,我想更多的意义不在于它的 a 卷的能力有多强,它的编程能力有多强。呃,我觉得更多的意味着中国的 ai 大 模型提升到了一个全新的高度,不仅是在它的能力啊,更多的是在它的价格方面, 它的价格有如此高的优势,并且它的上下文能力又有如此的强大。整体对于模型选择的建议来说,如果你的预算充足,那毫无疑问肯定是使用 oppo 四点七的,但是 deepsea v 四 pro 真的 是太便宜了。 呃,如果各位有兴趣的话,可以自己去进行实测一下,看看 deepsea v 四 pro 的 能力到底是怎么样的。后续我也会把我的测试流程开源到此结束,感谢各位的观看。
177程序员_秃头哥
