结构体查表代码怎么写

粉丝1.7万获赞4.0万
相关视频
 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿四零八考研这些知识在第一遍不用重点学,首先就是数结构的代码部分了,很多同学有这样一个疑问,我在基础阶段要掌握所有的代码吗? 并不是这样的,大家只用掌握一些结构体的代码怎么写和一些简单的算法就可以了,比如说数和图的存储结构的代码怎么写,还有列表的头叉尾发这些算法怎么写就可以了。像一些难的算法, 比如说 d f s、 b f s 和快派的代码,大家只用理解其算法思想就可以了。这些代码怎么写,我们放在强化阶段去重点学习就 ok 了。还有就是记组的两个章节,第一个就是定点数的乘除运算,这部分的知识非常抽象,但是整体的考察规律和解决套路是非常明显的, 大家在技术阶段学习的时候,只用看一遍基础课程,然后我们放在强化阶段,通过真题去重点学习,有针对的学习就可以了。还有一个章节就是四点三程序的机器一代码,表示这一章节除了知识点比较抽象之外,他考察的题目主要是大题, 我们真题目前没有考察过选择题,所以我们第一遍甚至可以不用学,放在强化阶段做大题的时候再重新学习这一张就可以了。如果我们第一遍学的话,没有相关题目练习的情况下,我们吸收知识点的效果比较差。然后操作系统和记网的话,没有什么特别难的章节。
541跑个不停 02:25查看AI文稿AI文稿
02:25查看AI文稿AI文稿辛辛苦苦用 c 语言写了一个列表,突然发现需求改了。之前列表保存的是 int 类型的数据,现在要改成 double 类型,那是不是要从头到尾修改代码?这个工作量确实太大, 于是聪明的你在写代码的时候稍微做了点改进,用 type define 把类型重新命名,这样后面不管是存储 int 还是 double, 只要修改成一个地方就行。恭喜你,你已经具备了泛型编程思想,懂得数据和算法的分离。 不过这种写法还是有点小儿科,实际用途不大。如果把类型换成非标准类型,比如结构体,这一套逻辑还得大改。 于是你又对代码做了改进,把数据直接改成 word 新类型的指征。这种指征在 c 语言里面俗称万能指征,它可以指向任意类型的数据,不管后面想要保存什么类型都不影响。 当然,对于链表的增删改查,一系列操作都跟之前有点区别。比如链表的插入操作,既要给节点分配空间,也要给具体的数据分配空间,赋值得改成 memory copy。 这样一套代码实用性就非常高了。 正当你沾沾自喜的时候,我不禁要给你泼一盆冷水,所以,一山还比一山高。 linux 内核还有性能更强的写法,轻入式链表。 他把链表的前后指征直接切入到用户的结构体中,这种设计最灵活,节点和用户数据完全结偶。我把这种实现方式尽量用最简洁的代码还原出来。首先是定义,链表结构只包含两个指征,一个指向前面的节点,一个指向后面的节点。 用户在定义节点的时候,直接把链表时针嵌入到结构体中,而对链表的初识化也是通过红来实现,虽然看起来有点乱,展开后就是这样的,不管是向前的时针还是向后的时针,都指向了节点本身。 列表的插入操作只涉及指征的移动,不涉及数据的拷贝。编辑列表的时候稍微有点复杂,这里的 list entry 通过成员的偏移量反推结构体的地址,然后再去访问结构体其他成员。有点类似内核里面的 intokenof 红函数, 代码不长,但是看起来确实有点复杂。聪明的你又突发奇想,既然想实现范型编程,那把 linux 内核换成 c 加不就行了?有了 s t l, 什么链表站队列,几行代码通通拿下。所以为什么 linux 内核不用 c 加来写?
321嵌入式编程 03:10
03:10 01:00
01:00 10:49查看AI文稿AI文稿
10:49查看AI文稿AI文稿结构体,我是组长何玉静啊,我们先来看一下什么是结构体。 呃,在编程中,我们经常需要处理复杂的事物,这些事物往往有多个不同数据类型的属性。就比如说一个学生,他有学号、姓名、年龄、成绩四个属性,呃,学号是整数,姓名是字母串,年龄是整数,成绩是复变数。 如果说我们单独用一个变量,一个变量来组织这些呃属性的话,就会很混乱。呃,你看,比如说一个学生,他就会出现四个变量,要有四个变量明确命名, 呃,会造成相关联的若干项数据量非常零散,呃,一个一个对象还看不太出来,假如说是一个班的学生,或者说一个学校的学生,这个时候变量就会特别多, 然后呢?逻辑代码,逻辑就会非常混乱,所以说我们就产生了结构体。结构体就说将这些不同类型的变量打包成一个整体,呃,一个对象就会有一个,这个整体是一种用户自定义的复合数据类型。 呃,结构体的核心思想是数据封装,就是刚才讲的,把若干的变量给打包在一起,就是数据封装, 他像一个专属容器,其实就是一种语法。结构,呃,将描述同一个对象的所有相关数据打包在一起,把零散的数据整合为一个整体,呃,结构体的优势就在于逻辑清,逻辑清晰,呃,便于管理,代码附用。 逻辑清晰,就是说,呃将一个对象他的所有属性聚合,然后这个时候你每次使用的时候,你就针对那个整体去使用,不需要使用单个零散的变量,所以代码一图就会很直观易懂。 定义管理就是说知识将整个结构体作为一个单元进行传递或存,存储代码费用就是你定义一次你之后的对象都可以用这个结构体类型去定义。 像我刚才讲的就是说把学生定义为结构体的话,在我们做这个班级学生信息管理系统的时候, 呃,如果没有结构体的话,我们假设有五十位同学将他的姓名、学号、成绩组织起来,需要一百五十个独立变量,会非常的困难。如果使用结构体的话,每个学生的信息打包成一个整体,然后呢,每一个整体又作为一个数组元素形成学生结构体,数组最后就需要关注一个数组就行, 管理会变得很精益求好。呃,这个是本次课程大纲。首先我们先讲结构体基础,就是如何定义、创建和使用结构体。其次呢,我们就会讲结构体数组,还有结构体时针,结构体函数,就我们会对本节课的内容做一个总结。 第一部分就是结构体基础定义、创建和使用结构体。首先我们先来看定义结构体, 呃,在使用结构体之前必须先定义,你定义一个结构体类型,其实就相当于定义了一个新的数据类型,就和平时我们使用整数啊,浮点数这些是差不多的。我们来看定义的语法, 定义的语法首先是这个 stat, 就是 这个关键字,然后呢你再给你的结构体取一个名字,然后呢再用括号括起来,括起来里面的内容就是,呃,我刚才讲的一些属性,比如说学号啊,成绩之类的, 然后呢,它里面的结构是这个样子,就是数据类型,然后空格乘以零,然后呢注意末尾必须要有一个分号,定义结构体末尾必须要有分号,不然结构体是无效的。 好,然后那边是一个市里,就是定义学生类型,就像那样定义,呃, stack student, 然后呢括号里面就是它的属性学号的命名成绩,这样就把它很好的组织在一起。 好。然后我们就在讲创建结构里面,你定义了一个类型之后,你就可以像使用普通数据类型一样去使用结构体类型。 呃,创建方式有三种,就是初学者最常用的应该是第一种就是先定义后创建,就假设前方已经定义了结构体之后,然后你创建每一个变量的时候,应该是这个格式,就是 text, 然后呢带上你刚刚的结构体零,然后呢再是你的变量零, 如果把这遮住的话,其实就和普通的数据类型是一样的,但是呢你前面得加一个这个来表示的是你自定自定义的结构体类型。 然后第二种就是定义时直接声明,就是在前方定义结构体类型的时候,你在那个花炮的最后直接带上你想创建的那个变脸结构体,变脸就是那个 typeface, 是 一种别名的色彩,这个不就不了解。 然后呢,第三个就是使用结构体,使用结构体一般有两种使用的用品,第一种就是呃初识化的结构体变量,刚才我们只是创建了这个变量,现在我们初识化这个变量就是说给它复制。 呃,一般我们是使用花括号进行一次性初识化复制,就比如说你创建这个变量的时候,你用一个花括号把它所有的属性的值全部扩起来,然后呢可以一次性复制给他。 注意,如果出实化的时候,假如我们有三个属性,出实化的时候,你里面只用了两个值的话,就会有一个被赋值为空,空的话对应每个数据类型是不一样的,可能是零,可能是呃空串。 然后再注意就是说你赋值的时候,你那个幺零零幺张三和九十二点五得和你定义的时候,你里面的 id 和 name 和 score 的 顺序对应起来, 然后呢也可以在不创建式复制化,就是如果你没有这样统一,说实话的话,你就会在后面逐个复制,逐个复制就相当于就是说普通变量的复制, 这个其实相当于一个普通数据,普通普通的编码,然后呢你给他复制幺零零幺,本质上就是访问结构的生成,然后复制我们接下来讲的就是访问你结构体,访问结构的生成表,就用那个点号,那个预判符去访问,用这个 s t u, 然后呢去打一个点,然后呢再 呃重列名,这样子之后 s 六点 id 就 相当于是访问 id, 这个呃变量可以进行写入和读取,比如说看这下面的代码,呃 九点一点 id 等于幺零二,就相当于给他这个成员变量写入了,然后呢还可以读取我新创的一个变量是待卡,然后呢读取卡的 id, 然后呢呃读取之后还可以打印了,这是第三个。第二部分就是结构体数组, 结构体数组其实就是呃数组,但是呢就是说它里面原料元素是一个,一个结构体 也是一个数字,然后呢定义结构的数值就是这样的,就是说呃,假如定义一个整数数字呢,就是 int 数字名,然后这时候前面定义变量一样,也就是说你要用结构定义,然后前面 定义一个元素的学生数元素就是一个结构体变的就这样三个, 然后呢结构体的速度定义就是这样,然后再促使化,促使化的话也是像我们前方说的整体复制,但是说呢,因为你里面是三个元素,所以说你要有呃,有三组,三组花括号去复制,然后外面还嵌套一个大括号,就是中间那个。 然后呢最后就是访问结构体数组元素就是你方向,你组织把它们组织成一个数组之后,你想访问一个这个结构体应该是怎么样的? 就是呃,也是数组名下标,然后点成员名,就数组名下标,就是平时访问数组元素的惯常的英文嘛,但是说因为它是结构体,它里面有成员,它不是一个单独的变量,所以说还要打点去掉用那个成员名,然后呢才能访问到具体的变量。 好,第三部分就是结构底纸质,结构底纸质的那个做法是一样的 啊,指尖是 c 语言的精髓,然后结构体指尖能让我们更高效、更灵活的操作复杂的结构体数据类型 啊,结构体指的赋值啊赋值。首先是你必须先定义一个结构体变量,这样才能让指尖去指向它。 第一个结构体变量就是前面讲过的第一行的,然后呢后面我们就定义一个指向结构体的指征,我们注意你定义这个指征的时候和之前的原理是一样的,就是你这个前面的类型必须和你指向不变量的类型是一致的。好,然后定义了之后呢,这里要加一个这个符号,代表是指征, 然后定了之后呢,再用取地址操作符去把他的地址取出来,复制给这个纸,嗯,和普通纸一样,结构体纸图层的是结构里变量在内层用的手地址,通过这个地址我们可以在其他地方,就比如说函数内直接操作原数据,避免了拷贝整个结构体带来的感性。 呃,结构体直径的。第二就是说我们通过这个结构体直径访问它指向的结构体成员。呃,是使用一个箭头的操作符,其实就是一个横杠加一个大口, 用这个纸针,然后呢用这个操作符就相当于是。呃那个结构体,然后呢再用那个再把程序变量写上去之后呢,就是那个程序 区别一下那个点和那个箭头,点是说你那个前面直接是你结构体变量的变量,然后但是那个箭头呢,就是说你前面是那个对应的值。 第四部分就是结构体和函数,其实重点就是讲它怎么进行数据传递,就是说我怎么把一个结构体去传进一个函数,然后这样进行操作。 呃,方式一就是直传递,但是呢这个直传递基本上是没什么用的,因为像你把结构体像这样传进去之后,函数内部他就会创建一个副本,就相对于说把原来那个结构体复制一份, 然后呢你在函数里面操作的时候,他就不会去改变原来的那个结构体,他只会改变里面创建的副本。 哦,然后呢?然后第二个方式就是地址传进去,就是说把指真传进去,把指真传进去之后,在函数里面去更改的时候,就相当于直接操作那个地址,操作地址的话就可以修改到原变量。 看这两个群。呃,初学的话是先理比较好的是先理解制传递吧,但是用的比较多的还是低质传递。总结一下今天讲的内容就是首先是结构体的定义与使用,然后后面是结构体数组,结构体矩阵,然后最后是结构体与函数交互。 呃,结构体不仅是 c 语言面向对象编程的熟悉,也是处理复杂数据,编写大型程序的基础。呃,所以大家要好好掌握结构体。
 24:20查看AI文稿AI文稿
24:20查看AI文稿AI文稿hello, 大家好,立刻公控。呃,我们来回顾一下我们之前 呃这一节课的一个内容,在我做这个西门子从入门到精通这个课程以来,呃已经呃半个月了。然后我们来回顾一下这一个这节课程我们现在已经讲到哪些了? 呃,目前呢,我们已经把呃西门子从入门到精通这节课程的入门篇 已经讲完了,入门篇里面就包括了一个呃课程介绍,对吧?西门子的一些框架啊,包括一些我们学习这门课程的一些学习路径啊。第二节课呢,我们会讲到西门子 plc 啊,家族与硬件的一个选型 啊,所让大家熟悉的从幺二零零到幺五零零的主流系列。然后第三节课呢,我们又从呃 tia 博图的一个软件安装和授权。呃,因为博图它是非常大的一个软件,它 它的更新频率也很快,就比如说像我们现在已经从十二、十三、十四、十五、十六、十七、十八、十九,包括现在的二十二十一啊,都已经更新完了, 所以更新速度很快的。然后如果大家对于薄图的呃有哪些版本的有问题需要哦,就是软件或者是授权啊,都可以去找我。这节课我们在呃安装和授权这节课我已经跟大家讲的很清楚了。 呃, ok, 第四节课我们讲到了薄图软件的一个界面简况,呃,熟悉,让大家熟悉了那个薄图的一个工作界面和相不素。 然后在第五节课我们讲到了啊怎么去创建第一个项目啊,在薄图的一个软件里面去做一个硬件主态啊,怎么去做主态一个啊? cpu 对 吧?啊,跟大家讲到了去主态 cpu 的 一个啊,一个部署, 嗯,然后在第一阶段入门片的最后呢,我们带大家认识了 plc 的 一个 io 模块和地址的一个分配 啊,就涉及到了一个啊 i o 的 一个分配和地址呢,包括 ip 地址。在这节课也讲到了,如果对大家对于我现在讲的这些有疑问,可以翻看我之前的一些视频 啊,大家在看视频的时候,大家希望大家能够帮忙点个关注啊,你们的关注就是我们持续更新的一个动力啊,谢谢大家。然后在第二阶段,我们在基础篇里面 讲到了核心的一个调试的一个编程思想,对吧?就第一个呢,会跟大家讲到了 plc 的 编程基础, plc 的 一个工作原理是怎么样的,它在扫描周期和工作原理包括理解 plc 底层运行逻辑。 然后在第二节课的时候,我们讲到了基本的一个逻辑指令,还有常开常闭指令和线圈指令,然后掌握了最基础的与或非的一个逻辑。 然后在第三阶段呢,我们讲到了常用进阶指令啊, set 啊,置位指令,还有复位指令,以及上升延和下降延的一个脉冲响应。那在第四节课我们讲到了定时和计数的功能啊, t o n t o f 还有 t p 定时器的一个区别。 呃,在第五节课我们讲到了程序下载与监控啊,让大家掌握程序的一个下载和监控,怎么去下载,怎么去监控呢?然后在第六课课也是比较重要的,就是我们用 plc simmer 啊,这个软件,就是 plc sim 这个软件,我们去呃告诉大家去怎么去仿真,其实在每一个每一款薄图的里面都有一个对应的 sim, 比如说薄图 v 十二,它就有一个对应的 plc sim 二 v 十二,薄图 v 十三,有一个对应的 v 十三, 都有的啊,只要大家啊去装对应的版本就行了,这也是对于,嗯,就是我们在运行薄图的时候非常关键的一个工具啊,都是需要用的。 然后在第三阶段呢,我们讲到了境界片啊,就是西门子的一个独特的一个编程化思想,就是结构化编程。嗯,在第三节课的第一节课,我们讲到了为什么需要啊结构化编程,研究了那个结构化编程与传统编程的一个区别。 然后第在三点二阶段我们讲到了 f b 啊,就是我们嗯经常要用到的 f c 块和 f c 块的一个功能的创建和使用。 在三点三阶段呢,我们讲到数据快, db 的 分类和应用啊,详细的讲了一下 db 快 与背景 db 快 的一个区别。在第四节课的时候我们也讲到了三点四,里面就是多重背景数据快的应用啊, 就是怎么样啊?单纯的背景数据快,还有多重背景数据快,他们有什么区别?还有什么?嗯,特点,对吧?在这一节课我们都讲到了, 然后,呃,嗯,这两天后台呢也有大家去问我,比如说问什么呢?问的就是 西门子 plc 的 一个结,嗯,在那个经常容易出错的一个问题,就是什么是啊,结构体啊,什么是 udt, 然后它们两个之间有什么区别?那 ok, 我 们今天这节课就跟大家详细的讲一下啊 plc 的 结构体与 udt 的 一个 区别。呃,首先我们用一句,我们在这个我们 ppt 里面用到了五个阶段啊,分别是一句话去区分,第二个是图文深度比对比, 第三个呢是生活场景的一个比喻啊,我们就是喜欢用一句话或者是生活场景这种比喻去让大家能够通俗易懂的去理解。然后第四呢,就会核心的核心要点的一个总结。那我们首先看一句话的一个区别, 一句话区别呢?先继续这个核心什么呢? u d t, 对 吧? u d t, 它就是用户自定义数据类型, 嗯,然后它的本质就是相当于一个全剧的一个模板,它是一个数据类型啊,大家注意一点,它就是一个数据类型,我们把它标注一下, 它是一个数据类型,然后它就相当于一个模板和模具啊,这样能理解一点。然后 s, 呃结构体呢? streak, streak 的 一个呃结构体,结构体的话它就是一个临时的局,局部临时组成的一个组合。 我们来在程序里面去看一下什么叫嗯? u d t, 什么是叫结构体?它两之间的用户其实是完全是不一样的,首先我们在那个结构体里面,嗯, 结构体里面,我们可以在它呢,一般都会在美国,在 db 里面去新建一个,对吧?我们可以打开一个全局 db, 然后在这里面呢,我们可以选择啊,直接选这个结构体的这个名字啊, streek, streek 这个名字,然后如果说你想学啊,怎么去新建的, ok, 我 们来直接新建一行啊,我们直接新建一行,然后在这个全句 d b 里面, 对吧?我们直接新建一行,然后比如说结构体二,我们直接选一个名字啊? okay, 然后这个时候我们可以选择它的 streak 类型, streak 它就是一个结构体,嗯,它就是,呃,在西门子薄图里面 啊,它都是用这个 streak 这个名字啊,我们只需要知道它是怎么用的,然后选择 streak 之后呢?这个时候它会在下面会,我们在这个下面会让它新增它的指向。 什么叫指向呢?就是它的说白了它的一些子目录,对吧?它你在这个结构体里面,这个圈圈里面它有哪些东西?然后我们可以选择,比如说,呃,有启动,对吧?我们可以选择一个波尔量启动,然后也可以加个注字启动按钮, 对吧?这就是一个,然后我们也可以新加一个啊,对不对?新加一个停止,对吧?停止,嗯,对, 然后停止,然后停止按钮,我们可以选择用做起跑停的一个啊方式去展示它, ok, 然后我们可以还可以做一个啊输出,对吧?输出,点击输出,然后这里面都可以在这里面啊,这个字后面写, 然后这就是一个结构体,嗯,结构体呢?它都是在这里面,它可以直接在里面去新加很多东西,不一定是只有这一些它都可以去加进去的啊? 我们今天就是主要做个演示,所以我们现在只加了三个东西,对吧?然后结构体是在 d b 里面去新建的,对不对?然后我们再看一下用户是定义数据类型 u d t, 它是在哪里写的呢?我们是在在薄图这个软件的一个下包里面, 我们可以在左侧这个目录,我们选择这个 plc 数据类型点开, 然后在这个 plc 数据类型里面,我们有一个添加新的数据类型啊,新的数据类型,我选一个,我们选一个,然后把这个数据类型的名字呢改一下,比如说改成 udt, 测试电机, ok, 然后选一个电机的 udt, 这就是一个电机的 udt, 然后同样的我们也可以选择启动, 然后这里面会选择库尔类型,然后停止,然后点击输出, ok, 然后在这个 u d t 里面我们也定义了它三个变量,然后大家会可能就会问, 那既然都可以,对吧?在 d b 里面这个结构体里面,我们也可以定义这三个变量,然后在这个,呃,嗯,叫什么 u d t 里面我们也可以定义这三个变量,那它们有什么区别呢? 首先第一个核心的区别就是它们在新建的位置不一样,对吧?新建的位置一个是在结构体的话,它是在 d b 里面啊,去新建的这个变量,包括 f b、 f c 块也可以去新建,它就是在这里面去新建的一个变量,对吧?然后这个变量的数据类型叫 啊史密克。那这个 u d t 呢?我们是在数据类型啊,自己编辑的一个用户数据类型里面选择的,它就叫 udt, 所以 说它们两个用的啊,用的地方啊,新建的地方是不一样,就是这第一个区别就已经很明显了,对吧? ok, 所以 说你我们大家可以看到用户数定义,用户自定义数据类型啊,就是 udt, 就是 它是用户自定义的数据类型,然后这个瑞可能它是一个局部临时组合的一个结构体,嗯, 然后通俗比喻呢,就像一张电机图纸啊,一旦画好,整个项目都可以用它来造造电机,它这个是怎么说呢?说白了就是 udt, 它就相当于一个数据类型,数据类型的话,你比如说我们现在可以用用使用 u d t, 对 吧?我们在 d b 里面选择一个,选择一个使用 u d t 的 一个变量,然后这个时候我们选择,对吧?选择电机 u d t, 我 们这个数据类型里面就可以选择电机 u d t, 我 们选择它, ok, 是 不是它就这个 u d t 的 数据类型呢?就跟这个 streak 是 一样的 啊,我们可以在这里看到它是不就相当于我们直接可以调用它了,对吧?所以它就相当于一个电机啊,电机图纸啊,整个项目都可以用它来,就是做。 然后这个史瑞克呢,它是就像房间里面临时用零件加起来一个架子,这个架子只能在这个房间里面用啊,就是我们在这个 d b 里面新建了一个这个 d b 里面去使用,对吧?它的局限性就很明白了。 然后我们再去看一下深呃,图纹深度对比 u d t u d t 用户对自定义,然后它这个有什么区别呢?它就是全局的一个模板,一个模具,它的定位位置就是独立创建的啊,数据片创建的一个 plc 数据类型啊, 所以这那个 u d t 就是 我们说的自己创的一个模板,我们自己创一个模板,比如说你要去加工的东西,你自己建了一个模板,这个模板之后呢,你可以通过这个模板去批量生产同一类型的东西,对吧?这就是 u d t。 呃,然后我们再看一下 u d t 的 一个比喻,统一规格的一个模具,对吧?就像这种就是一个一个模具,一次投入啊,多次产出,你把这个模具产生之后呢,你就可以同一类型的都可以去用它去产生啊,去使用就会产生很多各种各样的, 嗯,通过这个模具产生一套一模一样的相同规格的零件出来,对吧?啊?设计多个 u d t 的 一个实力,嗯, 极大地降低了重复的一个成本,这就是 u d t 的 最大的区别,它就是建了一个模板,出了一个模具出来了,然后通过这个模具我们可以产出各各种相同的啊,相同的这种模零件,所以说它就相当于一个模板。嗯, 然后再看的一个,呃, strick 啊,结构体,结构体的话它是一个嵌入式的一个表明, 什么叫嵌入式?表明?直接在 d b 啊内部和 f b 接口中定义啊?不存在啊,不独 作为独立的一个全剧类型,它就是我们自己组合的一个啊,自己组合的一个变量出来的,说白了就是我们在这个结构体里面去自己建了一些变量,把它放在一起了,然后这个名称就是一个结构体,对吧? 就自己建的,但是它它只能私有化的去使用,它不能去复制粘贴,对吧?它的那个局限性就很明显。 嗯,然后这里一个比喻就很清楚,史瑞克呢,就是像你现场临时加搭建的一个架子,就像这种啊,自己搭了一个架子,这里面有花,各种各样的花,对吧? 啊?紫色的,白色的,红色的花,每一个花都是自己搭起来一个键子,就相当于一个架子,把里面这些数据放在一个架子里面作为组合,对吧?组合起来的,所以它就叫一个嗯, street, 嗯,结构体, 这样的话一两张图就可以看得很清楚,嗯,一个是一个模板,对吧?一个是一个架子,对吧?嗯,就很区别,就很明白了。 然后在生活中的比喻中呢,更直白的理解就是 u d t, 就是 一个矿泉水瓶的一个生产模板,那它就是一个矿泉水瓶生产的一个模板,工厂设计好一套模具,所有生产出的瓶子都一模一样的。就比如说我们现在定义这个结构体使用这个电机,你看,比如说 u d t 啊,我们选择 嗯,电机一一,对吧? ok, 我 们用这个电机 u d t, 我 们可以再选一个,比如说用电机二、电机三,都选用这个啊,电机四, 每一个电机它都是调用这个电机的。一个 u d t, 然后它的每一个模板都是一样的,它就相当于一个,嗯,一个模具,然后这里面就是生产的一个矿泉水瓶,对吧?这么多一二三,每一个矿泉水瓶它都是通过这个模具生产的,所以说是它们几个都是一模一样的。 然后 streak 呢?就是用现成的瓶子搭建一个小水壶,对吧?它就相当于我现成用自己的瓶子建了一个小水壶,那这个水壶呢?只能在这个 啊,那只能这个水壶就只能在这个 d b 里面去用,就是我自己建的这个瓶子,那我就只能用我自己用,因为别人没有我这个模板,我用不了,对不对?所以说就相当于在这个结构体里面呢,我们自己建了一个啊,独特独一无二的这个结构体,我们还可以 对这个结构体添加东西,比如说我们可以添加一个电机,然后电这个电机的类型,我们选择啊,电机 u d t 啊,对吧? 嗯,就相当于在这个结构体里面,我们除了这个,嗯,波尔量的一个启动停止输出之外,我们还可以把这个电机的一个 u d t 里面也放在这个结构体里面,就是它还有很多东西,比如说啊制服,我们可以把它制服也穿进去, 对吧?我们可以放放一个制服变量,对, 对啊,制服串,选一个制服串,对吧?选一个制服串变量,对吧?也可以放在这个 u d t 里面,那就相当于一个大杂烩,对吧?还可以选整形, 对吧?选择整形,选择 int, 然后我们回顾一下啊,还有还有什么型,嗯, real, 对 吧?实型, real 类型,就是带小数点的,对吧? real 类型,所以我们可以把所有不同的变量的,嗯,不同变量类型的东西放在一个组合里面,它就叫结构体,这样大家能够很明白的一个看的很清楚, 因为,嗯,大家在使用过程中如果不能区分 u d t 和 strict 它的两个区别的话,对于大家的一个理解编程就很很累。 ok, 我 们做了一个总结,一张表背下来,我们就可以清楚地去区分。 怎么说 u d t 的 话,就是用户自定义类型,对吧?就是一个自己定的,然后它就是一个数据类型, 这句话很重点,那就是一个数据类型,然后全区生效,对吧?全区生效,然后整个项目都在运业都可以调用啊,附用性,一次定义,多处附用,它就相当于一个模板,对吧?你都可以用它,每一个地方都可以用到,然后维护成本非常低, 然后修改影响呢?修改 u d t 的 模板,所有应用的实体全部都不会变更,就是什么意思呢?我们在这个使用的过程中,如果把电机 u d t 这个类型改了,我们比如说改一下,你看我们现在的类型里面只有第几栋停止,是吧? ok, 我 们把这个电机类型 u d t 的 类型改一下,改成加一个,加一个电机停止 电机报答吧。 ok, 我 们可以看到它这里面会变,立马啊,我们调用它的 u d t 的 格式,它就立马变红了,对不对?因为我们现在 u d t 的 格式变了,这个时候怎么办呢?这个时候你只我们只需要更新啊,更新一下,这个, 快更新一下,编一下,然后它就可以了,然后再编辑完之后呢,我们再来看这里面的数据,哎,是不是 在这个电机 u d t 里面,它就有一个电机爆炸了,所以在一次使用之后,你修改了它这个 u d t 模板,所有应用的实力都会立马更新,对吧?这就是这个功能。 然后在那个 plc 的 一个,嗯,数据类型库独立存在啊,它存储,储存储的位置呢?它是在这里, 在这个数据类型里面啊, plc 数据类型里面去存储的,对吧?所以说它存在的位置呢?是在 plc 数据类型库啊,独立存在与程序逻辑简就不一样,它是脱离于它,脱离于那个程序逻辑去存在的。 ok, 应用场景呢?一般用的电机阀门轴等需要多次附用的标准设备对象, 嗯,就是我们刚刚在这里面演示了电机阀门轴,它都会用到这个,嗯, u d t, 然后这个结构体呢?本质啊,就是变相变量的一个临时打包的一个组合啊,它的本质就是一个名词打包的组合。不是啊,独立的例行 就是我们在建这个结构体的时候,我们其实说白了就是建了一个临时组建起来的一个组合啊,这个组合里面什么样的东西都有,对吧?什么样的变量都有,不玩啊,自己 u u d t 啊, string 啊, int 啊, real, 就是 一个组合, 然后在附用性呢?呃,对作用的一个范围呢?它是局部生效的,它仅在当前 dp 和 f b 接口中有效 啊,这点是完全是不一样的,他一个是全剧生效,一个局部生效,对吧?然后复用性呢?复用需要手动复制粘贴啊,多份副本相互独立啊,就是你要复制他啊, 那你只能是,比如说你要要复制这个结构体二一,那我们就只能复制复制,然后在下面添加好,然后把粘贴进去, 点一下这个粘贴啊,就这样只能复制和粘贴,它不能,是啊,不能是那种。嗯,直接选它的数据类型啊,这个不是这个,这个是我们选择这个结构体的一个粘贴,整体粘贴复制啊, 粘贴, ok, 这就叫粘贴,不是,我们可以看到整体粘贴之后这两个二和三的数据类型是一样的,对吧?这就它只能这样复制,它不能选择数据类型去复制,所以局限性很大。 ok, 然后修改影响呢?修改一个结构体仅影响它自己,不会剥离其他就是你自己改了自己的这个结构体之后呢?比如说改成添加一个,比如改成输出,直接改成电机, 对吧?注试都改了,它只改了它自己,你看我们上面这些都没有改,对不对?所以它它的局限性 决定了它的一个修改影响,它修改影响只影响自己,不会影响任何人,它就像一个组合,自己做的一个组合,然后存储位置呢?它依附于 d b 块和 l b 块,没有独立的存在形式,存储位置是不一样的。适用场景呢?只在一处使用啊, 逻辑紧闭的临时打包数据,它就是一个临时打包的一个数据,是不一样的区别。 ok, 实战指指南什么时候用到这个呢?对吧?什么时候用到这个呢?需要识别的时候,当你需要临时性,对吧?还有灵活性,就是我只改它的时候还有封装性,这是它的一个特点。 然后典型的应用场景里面就包括了啊,接口定义里面要把它组合在一起的,还有逻辑块,嗯, 还有一次性计算,它就是一次性的一个工具,附用性特别小,对吧?呃,回顾一下总览, u d t 的 话,它是全局的,可附用的,标准化的模具, 然后 streak 呢?它是局部的,临时的,灵活性的组合,所以这两个是完全完全不一样的一个东西啊。一句话的原则就是多个地方要用就用 udt, 只有一个地方用就用 streak, ok, 这个就是很方便,很方便大家能理解。 那今天的这个,呃, u d t 今天的课程就是主要讲的就是啊, string 和 u d t 的 一个区别,那就讲完了啊,我们还是用一句话去总结的,就是多个地方要用就用 u d t, 只在一个地方用就用 string, 嗯, ok。 然后它们两个之间的区别是真的明显的, 就是这张图片跟这个模具的图片两个之间,一看就懂。嗯,好,今天的这个课程就讲到这里,然后大家有什么疑问可以私信,然后最后求一下大家的一波关注,你们的关注就是我们持续更新的一个动力啊,谢谢大家。
41力克工控 02:26查看AI文稿AI文稿
02:26查看AI文稿AI文稿大家好,今天我们就来学 c i 编程,今天我要分享题目是得分排队给第二名学生的考试得分,这些学生的学号为 e 到 n, 其第二号学生的得分为 ai, 请将这些学生按照分数从大到小的顺序并输出学号序号。 若两个同学得分相同,先说出较小的学号。这道题还是要用结构体,因为数字比较大。结构体 struct 成绩 int a 是 他的分数,还有 b 是 他的学号 a s 二一二三四二的五次方再写破 c m p 成绩 x 成绩 y 判断。如果 x 点 a 不 等于 y 点 a, 那 么我们就返回分数较大的那个 x 点 a 大 于 y 点 a, 否则就 return x 点 b 小 于 y 点 b, 返回学号小的 再定义弄弄 n, 输入 n 或循环 输入 a s i 点 a, 再 a s i 点 b, 然后要等于 i, 然后一直记它那个对应的学号,然后 shift 排序排 a s a s 加一 a s 加一加 n, 然后 c m p 复制复循环 可以直接输出,输出它的学号 a, s, i 点 b, 这就是它的学号。再输出一点 d, r 运行来试一下, 再试一下, 今天题目就讲到这里,谢谢大家。
22源源小太阳 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿大家好,今天我们就来学 c c r 编程,今天我分享题目是成绩排序,给出班里某门课程的成绩单,请你按照成绩的从高到低对成绩单排序输出,如果有相同分数,则名字字典序小的在前面。今天我们依旧用结构体 structure 成绩第一个 a 还有个 string s a s 二十一分号 four c m p 成绩 x 逗号成绩 y 判断,如果 a s 如果 x 点 a 不 等于 y 点 a, 那 就 return x 点 a 大 于 y 点 a, 否则就 be ten。 返回序小名字至点序小的 x 点 s 小 于 y 点 s, 在 里面定义 n 输入 n, 负循环 输入 a s, i 点 s, 再输入 a s, i 点 a, 设置 a s 加一 a s 加一加 n c m p 复制 f 循环输出, 输出 a s, i 点 s, 再输出 a s 先输出空格,再输出 a s, i 点 a, 再输出 n d r 运行试一下 认代码。今天题目就分享到这里,谢谢大家。
15源源小太阳 02:24查看AI文稿AI文稿
02:24查看AI文稿AI文稿最近在学习 rust 的 c o r m 框架,起初我也觉得它难度不小,可深入学习后发现,只要掌握几个核心组建的概念和作用,入门开发并非难事。今天就带大家认识一下 c o r m 框架里的关键组建, active model model entity relation 和 active model behavior。 咱们先来说说 entity, 它是数据库表的抽象表示,就像是数据库表在代码中的设计蓝图。不过它并不存储具体的数据,而是定义表的原信息,像表明列名、主键以及关联关系等。 inty 结构体本身没有数据,它就像是一个入口,通过它,我们可以调用例如翻递括号、 insert 括号等方法来操作数据库。有了这个入口,我们就能轻松地和数据库进行交互了。再看看 model, 它是数据库表单行数据的 rust 结构体,映设是实实在在的数据在体, 它的字段和数据库表列一一对应,并且类型要求严格匹配。我们可以通过 an t t 翻的括号点、 one 括号 or wait 等方法从数据库查询得到 model。 简单来说, model 就是 把数据库里的数据取出来,以一种符合 rust 语言规则的形式呈现给我们。 接下来是 active model, 它是 model 的 可变版本,专门用于修改或者插入数据库数据。无论是新增、更新还是删除操作,它都能大显身手。这里要注意, active model 每个字段的类型是 active value t, 而不是直接的 t, c o r m 会根据 active value 的 状态生成只包含修改字段的 c 括语句。比如说更新时只会更新处于 set 状态的列。这样一来,我们在进行数据操作时就能更加精准和高效。 relation 也是 c o r m 框架里非常重要的一个组建, 它用于定义不同 entity 之间的关联关系,也就是数据库表之间的关联关系,像一对一、一对多、多对多等。比如 hash 表示一对一关系,就像 user 对 应 user profile belongs to 表示多对一关系,比如 post 属于 user。 有 了 relation, 我 们就能实现联表查询,这在处理复杂数据关系时非常有用。 最后讲讲 active model behavior, 也就是活跃模型行为。它有一些核心的钩子方法,比较常用的有 before update 和 before delete。 before 下划线, update 会在更新数据前执行, before delete 则会在删除数据前执行。通过这些钩子方法,我们可以在数据操作前后添加自定义的逻辑。总结一下, entity 是 数据库表的抽象入口,它定义了表结构和关联规则,所有的数据库操作都要通过它来发起。 active model 是 可写的数据在内, 专门用于增删改操作,通过 active value 来控制字段的修改状态。而 active model behavior 为 active model 提供了生命周期钩子,让我们可以再插入更新删除数据前后添加自定义逻辑。
1一凡老哥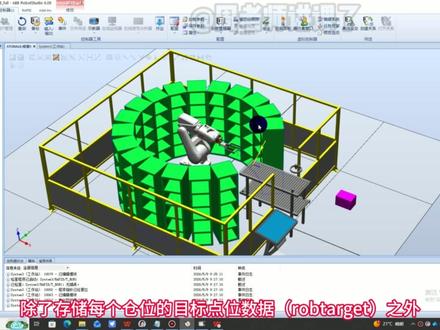 02:09查看AI文稿AI文稿
02:09查看AI文稿AI文稿什么?还不知道自定义结构体怎么做?欢迎回到十天玩转 a b b 机器人编程之第八天!今天我们讲解自定义结构体。什么叫结构体?说白了就是把一堆相关的变量打包成一个大变量,就像我们整理工具箱, 螺丝、扳手、钳子不要乱扔,全部放进一个盒子里,这个盒子就叫结构体。一、定义结构体,我们以这个环形仓储工作站为例,除了存储每个仓位的目标点位、数据, rob, target 之外,还想要存储每个仓位的状态、货物信息等,可以怎么做呢? 创建一个结构体,命名为 infor, 以 record 开头 and record 结尾。内部添加一簿类型数据,命名为 status, 用于存储仓位是否已被占用。内部添加一 string 类型数据,命名为 type, 用于货物名称 内部添加一 drop target, 类型数据,命名为 point, 用于存储仓位位置数据。二、定义变量。货架有五层十七列,我们创建一个 inf 类型的五乘十七的数值就可以了,我保存一下到试教器数据里面看一下。 数据类型里面就多了我们刚刚定义的结构体类型 inf, 点开之后就可以看到我们刚刚定义的结构体位了,随便打开数值 status、 type, point。 三、访问结构体,直接用点调用里面的内容。例,我们运动到第一行第一列的仓库位置,目标点位,这里我们输入变量名称,然后输入点就可以调用里面的数据了。 这里选择 point, 然后给定速度等其他参数就可以了。再比如我们把它的状态赋值给一个 bo 型变量,结构体我们就讲完了,下面我们就可以进行点位视角了,已知相邻两列之间的角度为十八度, 上下两层之间的距离为一百五十毫米。你可以只试叫一个位置,就算出所有库位的位置数据吗?自己试一下。 今天的课程我们就讲完了,有任何需要评论区告诉我,下个视频我们来讲解这个仓库库位的点位计算,觉得有用,点赞、收藏、关注不迷路!
81周老师讲课了 04:20查看AI文稿AI文稿
04:20查看AI文稿AI文稿大家好,今天我们就来学习下编程。今天的分享题目是交易记录,这道题的大概意思就是要我们将股票的交易后的记录给整理出来, 看一下样例输入和样例输出,它的大概意思就是输入三个数分别有败就是买入,还有卖出, 把买入从小到大牌,如果相同的就结合到一起。如果是卖出就从大到小牌相同的也结合到一起。这道题因为有三个数,所以还是用结构体 struck 股票 再定义 string, 因为 s s 是 string 吧,就是 string, 再定义 int a 和 b a s 看数的范围,十的五次方 four c m p 股票 x 股票 y 判断,如果 x 点 s 不 等于 y 点 s, 就 返回 return x 点 s 小 于 y 点 s 就 返回学号小的就是它的编号小。 复制判断,如果 x 点 s 等等于 by 加引号,哦不,是双引号 by 就 return。 返回 x 点 a 小 于 y 点 a, 就是 返回它那个数小的, 最后返回 x 点 a 大 于 y 点 a, 就 返回前大的。现在写出代码,先定动 n, 输入 n, 后循环, 输入 a, s, i 点 s, 再输入 a s, i 点 a, 再输入 a, s, i 点 b。 在复循环外面说 s 加一 a, s 加一加 n, 还有 c m p 复制复循环,再定一个代码,再定一个数,一个 k, 来数个数。 判断,如果 a s, i 点 s 不 等于 a s, i 点 s 加一 a s, i 加一点 s, 或者 a s, i 点 a 不 等于 a s, i 点 a s, i 加一点 i 点 a, 这样的话就 k 加加 就找到一个,就一直可以加加,最后输出 k, 就是 把他们全部的重叠到一起,如果不相等就加加相等的话他就不加,这样就可以将所有找到的重叠在一起,再定义一个,弄弄一个 p 也是等于零复制了,复制完 再判断前面 p 等于 a, s, i 点 b, p 加 a, s, i 点 b, 然后判断里面就输出 a, s, i 点 s, 再输出空格,再输出 a, s, i 点 a, 再输出 p, 再输出空格,再输出 p, p 就是 个数,然后 p 又从零开始运行。试一下, 通过检查我们发现我们没有输出 a, n, d, l, 输出 k, 再输出 a, n, d, l, 但是不愿意这样再试一遍。一人代码, 今天题目就讲到这里,谢谢大家。
11源源小太阳 00:40查看AI文稿AI文稿
00:40查看AI文稿AI文稿指真不会结构体稀碎,嵌入式 c 语言的死穴就在这里。很多人 c 语言考试八十分,一写嵌入式代码就崩,因为学校里教的 c 是 写数学题排顺序表嵌入市里的 c 是 直接扒开硬件寄存器, 你没见过的神奇位操作,你没用过的 volatile, 你 害怕的函数指真结构体内存对齐,这些才是嵌入式。每天吃饭的家伙 你不会这些,连别人写的驱动都看不懂,更别谈自己改 c 语言。在嵌入式这里不是语言,是扳手,扳手都不会用怎么修车?你觉得 c 语言里最恶心的知识点是哪个?我先说指真的,指当年差点直接把我劝退。
 01:27查看AI文稿AI文稿
01:27查看AI文稿AI文稿你写的 agent 代码是不是越改越乱?加个功能就要改,核心换个模型就要重写?今天介绍一个 rest 项目,把 agent 循环拆的明明白白。 clark agent 来自 clark chat 的 开源核心,它的设计哲学就一句话,一个核心循环六个扩展点,核心只有 contacts, 进 l l m 调用工具执行结果追加循环终止权交给工具自己投票决定,框架不越界。 六个插件钩子覆盖全生命周期, before to call 作安全拦截, after to call 作结果复写 context transform 管窗口裁剪 event observer 接遥测 steering source 支持运行时中途转向 follow up source 处理后续任务。一个结构体可以实现多个钩子注册一次全生效。 类型安全是 rust 的 天然优势。消息是 enum, 工具是 trait, 配置是 builder, 没有字串查找没有运行时类型错误变异器帮你拦住百分之九十的 bug。 更关键的是,这套框架已经在 clarkchat 点 com 跑了不知道多少轮。对话不是实验室产物,是生产环境打磨出来的。换模型只换 streamfm, 换沙箱只换工具,实现核心循环零改动。 apache 二点零开源。 rust 写的一百多个文件,如果你受够了 agent 框架的黑箱和臃肿, clark agent 值得一看。 github 搜 clark leapsink 斜杠 clark agent。
24锋芒AI 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿咱们今天讲一下这个分段代码当中的这些字母怎么去理解。首先幺幺幺 p 代表分段号, d k 十四 a 代表此处是一个夹板结构体, s h 二代表焊接输出量, k 一、 k 四、 k 七、 k 九、 k 二、 k 三、 k 十分别代表的是你这块十四夹板,他的一个拼板的一个料号,下方当中 s、 三他代表的都是扁体,那下方当中这些 s、 七 他们代表什么呢?他代表的是扁铁金板的意思对不对?然后咱再往后看,在这个夹板当中咱们可以看到此处结构,他这些 ai 代表的是这些拼板的板缝, ai 杠 s 代表的是他的一个需要开过度修剪破口。 好,那在这个图纸当中,比如说这个 d、 k 十四 a 杠 k 九六个厚, a 是 三,六是它的一个材质,这个对横线代表的是此处结构的一个减压线。如果对大家有所帮助,请点赞收藏。






猜你喜欢
最新视频
- 1824摸鱼游鉴