k8s treafik如何访问现有项目

粉丝1516获赞6660
相关视频
 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿嗨,大家好,我是小雨老师,不知道各位因为,因为兄弟们有没有搞过这 m t r s 双向认证啊?那么一般会应用在这种金融领域,或者说这种车端的,对于科曼端的强教练的这种领域,下面 一般怎样去做呢?我们会用同一套域名,然后比如人正常浏览器访问的是走的这个,咱们的这个,比如说这个数字证书,这套认证的机制, 对吧?过我们的网关,那么当车端过来请求的时候,他会携带他的证书,然后我们这边是网关上是配置,有私有 c a 的, 进行一个 m t r s 的 一个校验。 呃,一般他会怎么样去做呢?就是说,嗯,是两种情况,比如说我们可以单独拆一个域名,被这个 m t r s 单独去做,那因为开启 m t r s 这个策略是一个域名级别的,他不是一个 pass 级别,比如我针对一些呃安全的,有 这个交换需求的这些 pass 进行一些。呃,配置,这个东西在网关上是不太好去配置的,你只能去做判断,或者说我们让它透彻到后端,比如说我们,比如说 a p i v e, 比如说 security, 需要去较验,那么让后端去判断它有没有去传,当然你传的时候它有那个策略,比如说你开启 on off 或者什么 off option, 对 吧?等等这些东西,那么这个其实还是一道东西,就是私有 c a 的 这个管理,对吧?你可以用云的,也可以用自己的做一些签发的服务,对吧? ok, 嗯,所以总体下来的话其实不是很复杂,但是呢,也对,你也考验你对于这个 kbs 集群,包括网关应用程序 a p s x, 然后双向认证这些东西的 管理理解,对吧?然后这些东西在拍咱们的这个,嗯,集军网啊,集军网课程就可以, ok 这么多。
 01:45查看AI文稿AI文稿
01:45查看AI文稿AI文稿k 八 s 里面 r、 b、 a、 c 是 什么?我们来看张图片啊。 k 八 s 集群比做一个公司用户或服务账号,就是公司里的员工角色,如 rooster rooster rooster 就 像是岗位权限说明书,规定这个岗位能干哪些事情,比如说读报表啊,修改文件,重启服务这些绑定 robedding, closer routing, 就 像给某个员工分配了某个岗位,让他可以拥有岗位里的权限,这个和我们平时系统里的 r p a c 是 一样的,首先有用户,然后有角色,还有就是把角色和用户绑定 r p a c 里面的权限有哪些呢?可以从三个维度来说。第一个维度就是动作维度,表示你可以干哪些事情,比如 get, list, watch, update, great 这些动作。第二个维度是资源维度, 包括 public, service, 概概, map 这些资源,就是说哪些人可以对这些资源进行什么操作。第三个维度是从操作范围减,是 name space 级别的还是集群级别的,如果是 name space 级别的话就是 ro 加 robedding, 如果是肌群级别的话就是 cluster row 加 cluster roboting。 我 们来看个势例,首先我定义了个肉,然后这个肉被操作的资源是 o 的, 然后它拥有的动作权限是 get, create, delete。 然后我们再创建一个 roboting, 表示把用户和角色绑定在这个 robotin 里面。我们看 subject 下面 can 表示用户类型, name alice 是 具体的某个人,表示这个人可以进行哪些操作。下面的 ro i e f 就是 引用的上面定义的 ro, 这里就将用户和角色绑定到一起了。 如果是操作基区维度的,我们把它的 can 定义为 close ro, 然后 robin 定义为 close robin, 这就是 k b s r b a c。
56小北爱编程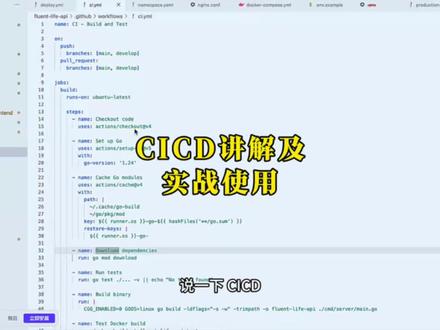 08:43查看AI文稿AI文稿
08:43查看AI文稿AI文稿说一下 c i c d, c i 的 英文全称是 continuous integration, 表示持续集成,它表示一有代码提交就自动合并到指定分支, 然后自动跑测试验证没问题。 c d 的 英文全称是 continuous deployment, 它表示持续部署, 表示测试通过以后会自动上线。 c d 是 依赖 c i 的, c i 通过之后才能 c d。 那么我们项目中该如何做 c s d 呢?首先我们在项目的根目录下要新建一个点, gitlab work flows 目录,然后在这个目录下去写 c i 和 cd 的 压文件。 写完之后我们把代码提交到 gitlab 上,然后它之后再提交代码时候,会自动触发 c i 和 cd 的 执行流程。我们来看一下 gitlab, 这是我的代码仓库,你看在 action 这里有刚才我们写的 c i 和 cd 的 代码流程。我们来看一下 ci, 这里点到 c i 的 亚默来看一下。来解释一下 c i 里面每个步骤的含义。首先这个 name 表示自动化工作的名字,显示在我们 actions 的 页面上,我们刚才在这个左侧是看到的这个名字的,它就是取的 name, 这里 框表示定义触发器就是,它会定义什么时候会自动运行这个脚本。 表示当有新的代码捕食到 may 分 支或者 development 分 支的时候,会触发后表示当有人创建针对 may 或者 development 的 分支的代码合并请求的时候, 会触发下面的 job, 表示定义要执行的具体任务。 runs on, 它表示指定运行的环境,这里表示在 gitlab 提供的最新版的 ubot 编辑机上去运行下面的代码。 我们看 steps, 它里面包含具体的执行步骤,内部表示拉取代码,使用官方的插件把仓库里的代码下载到虚拟机中。内部表示安装 构员环境,这里表示指定安装的版本。内部表示配置缓存, 用官方的缓存插件加速后续的构建过程。这里表示指定要缓存的文件夹,包括 go 的 偏移缓存和下载的第三方依赖包,这步表示下载依赖, 它会执行 go mode download 来下载项目中需要的第三方包。这一步表示运行测试,它将会递归运行所有的单元测试。这里的或表示 即使没有测试文件或者失败也打印提示并强制通过, 防止流水线意外中断。我们看这里表示翻译二进制文件,所以最后步它是要测试 docker 的 构建, 这个就是完整的 ci, 它的过程就是从指定分支上拉取下来代码,并且进行单元测试,然后来翻译,翻译通过以后给它打包到镜像里面。然后我们再看一下 cd, cd 它的作用是用来自动化部署到服务器上。 好,我们继续来看一下 cd 的 流程,我们看这里是表示 cd 工作名的流程是生产环境部署, 然后我们 on 表示触发部署的条件。这里表示代码推送到末分之以后会自动部署,然后这个表示它支持手动点击按钮部署。我们看 jobs, 它下面也是表示要执行的任务, 这里也是表示它是通过 u 半途的虚拟机上运行,其实它仅仅是用 u 半途来连接服务器,然后我们之后的这些操作它全都是要在我们的服务器上去执行,那所以这里的第一步 就是去连接我的服务器,这里是表示连接我的阿里云 e c s 服务器,那通过这个工具,下面这些表示要连接的服务器的信息, 看这有个 set 杠 e, 这 e 表示退出的意思,它表示如果出现错误了,就立即停止,避免错误继续执行。我们看下面在 script 里面的代码,在 script 里面的这些命令全都是在我们的阿里云服务器上去执行的。首先进入到我的项目目录, 然后去啊取到最新的代码,这里是去检查我项目里面的环境变量,这里是看我的服务器上有没有启动刀口服务,如果没有启动的话,就给它启动刀口,这里表示给刀口配置镜像。下面这些表示去清理我的瓷盘, 然后停掉旧的容器,等旧的容器完全停止以后,去清除我用的 vlog, 然后再去构建和启动新的容器。我们看一下这里在构建启动新容器的时候,这里用了 docker compose, 它并没有指定 docker compose 的 压文件, 其实它是在找当前目录下的 docker compose 文件。我们来看一下这个左边是我的项目,这是它的根目录,然后在根目录下有一个 talker compose 的 样的,所以在这里去启动容器的时候,它会它会自动的去找项目目录下的 talker compose, 然后去执行。我们看构想完成以后,去删除我用的数据,这里去检查一下服务的状态, 在这里是对后台 api 的 服务去做了一个健康检查。好,我们看这里是调用了一个 else 接口,如果检查通过的话,提示部署成功,部署成功之后,我们要做的最后一步就是去给发送通知,这里我用了钉钉去发送通知,我们看一下这里是配置的钉钉的 talking, 在 这里配置 talking 以后,就通过这个 webhop url 去给它发送通知,这里是写通知的文字, 这里表示通过 http curl 去调用钉钉的 web 服务器发送通知,然后发送成功以后去打印发送成功,然后退出。 这就是完整的 cd 流程。我们看 cd, 它的全过程,就是拉取了分支最新的代码以后,去给执行 docker compose 去部署我的服务,然后通过健康检查来确保服务部署成功。部署成功以后,再通过钉钉去发送部署成功的通知, 这就是 cd 的 全流程。我们来演示一下全流程,看一下它是怎么部署的。这是我的代码,我现在是在内存值,我修改了一个地方以后,提交到 部署到内存值以后,它会自动触发 get up 的 action, 会自动执行 c 和 cd 流程。好,现在来修改一下,我随便修改一个地方,我在这里修改了以后, 我给它部署到内存之上,我们看部署成功。部署成功以后,在我们的 kidhub 这里的 actions 里面, 它就会自动触发我们的 ci 和 cd。 这里的前面这个绿色图标,它表示之前已经 运行成功的,这里的转圈表示它正在执行的,这个表示 ci, 下面这个表示 cd。 我 们来等一下,就在执行的过程中,我们可以点进去 来看一下他执行的详情,这里的执行步骤都是这样,我们 c i、 c d 里面写的代码一步一步去执行的,我们等待他执行完成。好,我们看过了三分十八秒以后,他执行完成, 执行完成以后这里会显示必设的图标,这个是 ci。 好, 我们看 cd 也是执行完成的。在 cd 执行完成以后,我们是可以在钉钉上去收到一个部署成功的消息的, 我们来看一下是不是有这个消息,但这里是有消息显示部署成功的,这就是 c 和 cd 的 全过程。
246小北爱编程 06:43查看AI文稿AI文稿
06:43查看AI文稿AI文稿大家好,我是小刘,今天给大家讲一讲 kpi s 到底是什么呢?作为一个从开发转运维的老兵,我深知技术术语有多晦涩,咱们今天就用大白话来帮你建立一个更直观的理解。 kpi s 它的全称是 kublates, 因为 k 和 s 之间正好有八个字母,所以说简称 k 八 s。 它是一个开源的容器编排平台。用大白话来讲, k 八 s 就是 用来管理容器的一个大管家。在讲容器之前,咱们来先说说容器。 你可以把容器想象成一个打包好的应用盒子,里面装着你的应用代码、 运行时环境,比如说 jdk, 还有配置文件和衣袋裤。这个盒子在任何环境下都能够开箱即用,不会出现我本地能跑,生产跑不了这种尴尬情况。 另外需要注意的是,容器它不等于虚拟机,容器更清亮,启动只要秒集。 那为什么需要 k 八 s 呢?想象一下这个场景,比如说你有十台容十个容器跑,在三台服务器上,突然某个容器挂了,谁来重启?它?流量变大了,谁来自动扩容?一台服务器宕机了,上面的容器谁来迁移? 新版本要发布时,咱们如何不中断服务呢?这些都是 k 八 s 要解决的问题。 k 八 s 就 像是一个智能调度系统,它能够帮助你 自动恢复挂掉的容器,根据流量自动扩缩容,把容器调度到合适的服务器。还有服务发现、覆盖、均衡配置和密钥管理,全部都能够搞定。 接下来咱们来说说 k 八 s 的 核心概念。我们先从 pod 开始。 pod 它是一个最小的调度单元,你可以把它想象成一个豌豆角,里面装着一个或者多个豌豆。 关键点有三点,第一个,同一个 pod 里的容器共享网络和存储。第二个,通常一个 pod 只放一个容器。第三点, pod 它是临时的,随时都有可能被销毁重建。 第二个核心概念是 development, 翻译过来就叫做部署 development, 它是用来管理 pod 的, 你可以把它想象成一个应用管理者,他告诉 k 八 s, 我 要运行三个副本,用的是 ng 镜像, 如果某个 pod 挂了,他立刻就会拉起一个新的。有了 development, 你 的应用相当于就有了治愈能力。 第四个概念是 service, 也就是服务 pod, 它是临时的,它的 ip 会变来变去的。用户访问 service service, 再把流量转发给具体的 pod, 这样不管 pod 它怎么漂移,外部访问的入口永远都不会变。第四个概念是 instance, 命名空间是用来做资源隔离的,你可以把它想象成不同的房间,每个房间里的资源互不可见。 接下来咱们给大家看一个真实的案例,这是我自己生产而进的 k 八 s 集群, 三台,一共有六台服务器,三台 master 做高可用,三台 work 负责运行应用。容器运行时用的是 content, 网络插件用的是 flyer, 高可用方案采用的是 cable live。 咱们来看看部署一个应用的完整流程。首先,第一步,咱们要编辑 development 的 ymail 文件,把 pod, service, pvc 都定义好。第二步, 咱们要执行 cooper control apply apply 杠 f n g 点压默,把配置文件部署到集群中。第三步,咱们来看看部署的 pod 的 一个状态是否都是 round。 第四步,验证应用是否正常,能够正常访问,就这四个步骤,一个应用就跑起来了。 第四大点,咱们来说说怎么学习 k 八 s。 我 建议按照这个路径来,第一步,要先学会多看,这是基础。第二步,咱们搭建一个 k 八 s 的 单机环境。第三步,学习核心概念, 比如说 pod, development, service。 第四步,动手部署几个应用,不要光看第五步,再学习高级概念,比如说 english configure, map, secret。 最后才是搭建生产集群,考虑高考用安全监控。这些 我的经验是,不要一开始就上来啃所有概念,要先把环境搭起来,部署一个 n g, 试着扩缩容,滚动更新,在实践中遇到问题再去查概念,这样学起来比较快。 最后咱们来做个总结, kbs 它不是什么黑科技,它就是一个管理容器的工具。那什么时候适合用 用 k 八 s 呢?比如说容器数量多的时候,需要高考用自动扩缩容的时候,需要平滑发布回滚的时候,团队规模大,需要做资源。格力的时候,什么时候不不用 k 八 s 呢?比如说只是个人 项目,几个容器,团队小没人维护,业务量小,不需要复杂的技术,它是为业务服务的。不要为了用 k 八 s 而用 k 八 s, 一般时他其实不难,难的是坚持动手实践,不要被一堆概念吓住,先搭个环境跑起来,遇到问题再解决问题。记住最好的学习方式是在生产中使用,当然咱们要先测试环境,练熟了再上生产。 如果这个视频对你有帮助,欢迎关注小刘,后续会给大家带来更多 k 八四实战内容,咱们下期见。
86小刘运维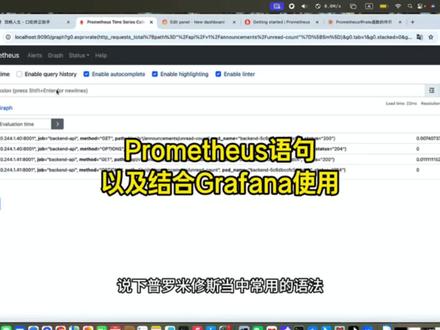 08:45查看AI文稿AI文稿
08:45查看AI文稿AI文稿说下普罗米修斯当中常用的语法,首先我想要查一个指标,我可以直接在这里输入指标的名称,然后来查询,在之前的指标中有一个指标叫做接口的请求次数,我们通过这个名称查一下接口的请求次数, 我们得到了这些所有有请求次数的接口,它的对应的请求次数后面这个数字就他们的请求次数,我该怎么样查询呢?我可以在后面加一个大括号, 在大括号里面加标签,通过标签进行过滤,就能得到这个接口它的总共的请求次数,我们来执行一下。 好,我们查到了四个,这四个他们第一个是他们的 pod 不 一样,然后第二个是他们的 master 的 请求方法不一样。那如果还想要再去继续加第二个筛选条件呢?我们可以在后面加逗号,然后继续加。执行一下得到了两个, 两个接口,一个是 get, 一个是 options。 第三个,如果我想要查询这个接口,它每秒被调用了多少次,我该怎么样查询呢?我们可以在后面加一个大括号, 大括号里面写时间五分钟,这个表示在五分钟内的所有的请求这个接口的数据。然后我们再通过对函数可以计算出来在这五分钟内这个接口每秒钟的请求率,也就是说每秒钟有多少个请求,请求这个接口 就会得出来我们想要的结果。执行一下,我们得出来结果,这个就是每秒钟有多少个请求请求这个接口。 那么我现在的服务是分布到两个 pos 上,这个接口分布到两个 pos 上,我如果想去查询整个服务,整个接口,它的请求率该怎么样查看呢?会通过 zuma 把这两个服务的相加起来 执行一下,我们得到的这个结果就是所有服务上这个接口的请求率。下一个如果我想看内存的使用率,我该怎么样看呢?我可以通过这个来查看, 这个指标表示是内存的总使用情况,这表示内存的可用情况,他们两个相减,再除以总情况就是内存使用的情况,也就是说内存的使用率。我们来执行一下, 这个表示内存的使用率,它是百分之十八。同样的我们想看一下啊,此盘的使用率,我们也可以直接用这个计算公式,我们得到这个就是此盘的使用率。我们看 我们在 prometheus 当中看这些指标的时候不是太直观,那我们有没有更直观的方式呢?我们可以通过 graph 呢去来直观的查看。什么是 graph 呢?一句话说它就可以将数据变成可识图表, 那么 graph 呢?怎么安装呢?它也可以通过 kbs 当中可以通过 ym 的 方式安装。 我们可以从 kata 来下载一下 graph 呢的 ym, 你 看这个就是 graph 呢的 ym。 然后在这里我有配置,它要绑定的 power 是 它的地址和端口,就是配置它的数据源。 我们看一下在这里配置了它的数据源之后,我们在 command 那 的界面,在 connections data sources 这里能看到后面 shows, 我 们配置的数据源端口是九零九零, 这里端口也是九零九零。好,我们进去以后我们可以 test 测试一下这个 success 表示连接成功,我们可以用我们本地的 progress 作为它的数据源, 然后这个关法呢,我们别看它的界面很多,它其实它我们最常用到的,我们百分之九十都是用只用这个 dashbox 这个界面,这个界面就是 我们用来去查看这些我们的数据图标的情况。在这个界面我需要配置一下,我需要查看什么指标的数据图标, 然后在这里也可以用 dashboard, 然后在这里添加配置。我们看这里的 bit source 是 permission 这个界面,我们别看它也会觉得它很复杂,其实我们能用到的也是只用那几块来讲一下。 首先我们需要写我们刚才在 permission 这里写的一些语句,比如说我要计算一下请求的总数, 可以把这个语句复制过来,然后在 code 这里,我们看这里是可以切换的,我们选择 code 在 这里去输入,去把刚才的语句粘贴进去。这个表示请求的 总次数,我们看这里 or base unit 密码,它表示所有的格式化的图标, 我们这个请求的次数,它表示只是一个只增不减的一个次数,所以我们需要用的是 state, 我 们看这个图标,它的这个上方它是有一个数字,它就适合来展示一个当前的数字。我们用这个 state, 我 们 在这个页面查出来他也是有四个数据的,然后在这里也是有四个数据。还有一个我们需要改的地方,就是我们可以改一下他的单位,就是这里他显示的单位, 我们在 santa 的 这里去修改它的单位, unit 就是 它的单位。我们请求总数一般是用 shift 去做单位的,这里修改好它单位以后,我们要把这个图标给保存起来,在这里去写下这个图标的名称, 保存就是请求总数的图标,我们继续增加图标,我们在这里先看,我们在刚才有序计算一个指标,就是某个接口它的 qps, 我 们当时是用的这个语句 改一下它的标签,改成请求次数比较多的一个标签,我们再加一个条件, 让它只计算一个接口,再加一个条件 master, 好, 我们把这个计算的语句 放到算法那里面,我们同样的也是在 code 这里,我们优化一下,可以看到这个是它这个接口每秒的 qps, 这里同样要选择一下这个图标的类型,我们这个指标它是 qps, 它是要查看 流量怎么随时间变化,所以它应该是一个坐标的形式。现在默认选择的这个 time series, 它是符合我们想要的情况的。我们看一下下面还有一个 time series, 里面还有一个另一个图标,它和这个图标数据是一样的,但是只是样式不一样。 同样的我们在这里选一下它的单位,我们 qps 的 单位需要用这个 i e qps, 选了以后,我们看我们的重坐标发生了改变,就是它的单位变成了 i e q i e q 杠 s, 这表示 qps 的 单位。同样的我们来保存一下这个图标,保存为接口 qps。 接下来我们再建一个内存使用率的一个函数化图标, 我们同样的在这里去执行一下我们刚才写的获取内存使用率的指标,刚才指标是这个,我们执行一下,我们 这个表示内存使用率是百分之十九,同样的我们去这个官方的里面去写下这个语句,然后让一下我们看内存使用的情况, 他是想看当前使用了多少内存,有没有超标,所以这个图标不太适合我们想要的情况,我们来选择帧这个图标,这也就表示他内存使用了百分之十八点六,然后我们再选下他的单位, 在这里我们需要的单位是百分号,我们需要查看内存的使用率是百分之多少,所以他的单位是百分号,来查询一下 是零到一百百分号,我选这个好,我们现在就看出来了,内存使用的情况是百分之十八点六,同样的我们保存一下看看它的名字, 这就是在官方那里面添加的三个,我们想要其他更多的指标,也可以在官方那里面添加。
75小北爱编程 04:41查看AI文稿AI文稿
04:41查看AI文稿AI文稿面试官问你,在 kys 里刚发布了一个业务 port, 如果要让外部用户访问这个服务,你会怎么做?有哪几种方法可以实现?如果直接回答给这个 port 分 配个外网 ip, 或者直接在数主机上做个端口映射,这个回答是不及格的。 kys 里的 port 是 短命的, 随时可能因为节点故障或者更新被销毁重建。如果只盯着 port 的 ip 搞静态映射,等下次业务重启,外网直接断联, 连 service 这个核心概念都没提。面试官会认为你没摸透 k 八 s 的 网络架构。在 k 八 s 中把内网业务暴露给外部,核心是利用 service 这个对象来实现解偶。根据业务场景的复杂度,我会提供三个梯度的方案。这三个方案通常不是相互独立的, 它们在底层是一层一层往上嵌套的。第一种是最直接的 load port, 它的原理是在集权的每一个物理节点上强制开启一个三万以上的端口。 不管用户的请求打在哪个节点,底层的 google prox 都会把流量拦截并转发给后端的破等。它的优点是简单粗暴,适合开发测试阶段快速验证。缺点是端口不好记,业务多了之后,端口管理非常混乱。第二种是生产环境最主流的 ingris, 当微服务多起来之后,开一堆物理端口就不现实了。 ingris 相当于集权的总入口,它本质上是一个七层反向代理, 通常这个入口本身也需要通过 load port 暴露给外网。有了这个底座,只需要统一对外开放八零或四十三端口,外部流量先进来, ingress 会根据 http 里的域名或者 url 路径智能分发给内部对应的业务, 这样不仅附用了端口,还顺手把 http 证书和辉度发布的问题给解决了。第三种是云原生标准形态的 load balancer, 如果集权跑在阿里云或 aws 这类公有云上,直接把 servers 申名为 load balancer, 类型 k 八 s, 就 会自动呼叫云厂商的 api 给分配一个真实的公网 ip, 这是公有云环境里最常见用为成本最低的方案之一。下面实际演示一下通过 ingris 做流量分发的过程。先确认一下集群里的 ingris 控制器底座有没有正常工作。 看一下这一行 ingris nix controller, 它的类型是 load port, 这说明流量大门已经配好。后续外部的 http 请求统一通过数主机的三幺零六二端口进入集群底座,确认后,开始在集群里手动部署两个简单的业务,看一下准备好的业务配套件, 这份文件定义了 a 和 b 两个业务的 deployment 和 service。 可以 看到这两个 service 的 类型都是默认的 class ip, 所以 业务运行起来后只会分配到内部虚拟 ip, 外部网络是无法访问的。先把业务部署起来, 提示自然创建成功。来确认一下它们在集群内部的运行状态,看一下输出结果。 a 和 b 两个业务的破的已经处于软底状态,对应的 service a 和 service b 也拿到了各自的 cluster ip。 到这一步,内部的业务资源池就已经就绪了。在配置外部的入口之前,可以先在集权内部测试一下服务 a 直接使用查到的 service a 的 cluster ip 进行访问, 可以看到 a 业务是正常的,然后给这两个业务配置对外的入口看一下路由规则文件。 在这份配置文件里面,我定义了路由转发的分流逻辑访问路径前缀是 a 的 请求交给 service a 处理,前缀是 b 的 请求交给 service b 处理。这里只通过 service 的 名称作绑定,没有写死任何破的 ip。 业务层和入口层是完全结偶的,让这条规则生效 执行完之后,后台的英格瑞斯控制器会监听到变动,自动重载 n g x 配置,这个过程对业务本身没有影响,最后进行一下外网的访问。当前测试环境里面,英格瑞斯控制器暴露在数主机的三幺零六二端口, 外网访问的测试就用这一台八十八号机器做测试,它不是集群内的机器,所以相对于集群来说,它是一个外网环境。先测试 a 业务 正常返回了 a 业务的内容,再测试 b 业务同样返回了 b 业务的内容。整个过程只访问了同一个数主机的 ip 和同一个端口, 因为 u i l 路径的不同,流量就被分发到了对应的后端业务 port。 后续就算底层的 port 发生重启或者 ip 变动,只要 servers 的 规则还在,这套对外的路由就不需要做任何改变,这就是 ingress 带来的便利。当然这只是测试环境里的演示,所以直接访问了三幺零六二端口。 真实生长环境里面对外肯定要走标准的八零和四四三端口。如果是自建的物理机集群,常规做法是在数主机最外层加一个 n x 做反向代理,外层的 n x 监控八零和四四三,把流量转发给里面的三幺零六二,这样做不仅能隐藏高位端口,还能在外层统一管理 http 证书 集群内部的业务全走 http, 免去了逐个微服务配置证书的麻烦。如果用的是工友云,直接把 service 升名为 loadblender 云,厂商会自动分配公网 ip 并绑定好标准端口,配置上会更简单。
354爱睡懒觉 04:54查看AI文稿AI文稿
04:54查看AI文稿AI文稿说一下 loki, loki 是 什么?它其实就是用来收集、存储以及查询日制的地方。那么我们有个疑问,为什么要用 loki 呢?我们把日制存在本地,去本地的文件里面去查询不就好了吗?在 kbs 部署里面, 多个 pod 可能分布在不同的机器上,日制在不同的机器上,我们查日制的时候,不可能一个机器一个机器的去查。还有一个问题是,如果一个 pod 被销毁重建, pod 一 死, 里面的日制也就没了,所以需要我们通过 loki 去存储。 ok? 它是怎么收集日制的?它和 prom 数值是一样去拉取日制的吗?不是的, 是在每台机器上部署 prometail, prometail 会去日制文件抓取数据,然后推给 loki。 那 prometail 又是什么呢?我们看一下它的英文,它是由 prom 加 tail 两个单词组成的, prom 是 来自于 promise shoes, promise shoes 它的前几个单词是 p l m, 所以 用 prom 就是 为了说明它和 promise shoes 是 一个生态, tail 就是 跟踪读取日历的末尾。我们的 loki, broly shoes 和 plato 其实都是一家公司的, 那么如何安装 loki 和 plato 呢?可以直接通过 help 我 们的方式去安装,这个是安装的步骤,第一步是添加仓库, 第二步是用 upgrade 的 命令直接安装。安装了以后,我们怎么配置 prompter 要抓取的日制的目录呢?默认情况是不需要配置的,因为 kbs 所有的 pos 默认日制路径都在 v r logpos 目录里面, prompter 会自动地读取这个路径,因为我们没有把程序设置打到 standout 里面才需要配置,那么我们如何配置呢?我们需要通过 prompter 的 configmap 来配置, 我们看一下这个是 configmap 的 配置。 yam 下面有个 pass 字段,这里就可以配置 pomtool, 抓取日制的路径。我们在配置完成以后,通过 hero upgrade 来让配置生效一下。 那我们是需要在每个节点都安装 pomtool 吗?在 kbs 里面,它会自动地在每个节点都安装上 pomtool, 它是通过 demo set 的 方式,让每一个节点上都跑一个 parameter。 安装了 parameter 以后,你看我们 lucky 它收集的日期格式是什么样的呢? 这个 lucky 它不做解析日期内容,它只存储日期,也就是说我们在程序里面输出的日期格式是是什么样的, lucky 它就存成是什么样的。 看一下这个是我们存储的在程序里面存储的日制格式, lock 就 直接把这个日制存储下来。这个界面是我在官方那里面 加了 locky 的 数据源,然后显示 locky 的 日制。那官方呢?如何添加 locky 数据源呢? 可以在官方那的 em 文件里面配置,我们看一下这个是官方那的 config map, 我 们在这个 data resource em 里面,你看之前我配置参数,所以现在这里再增加一个配置,把 lock 也加进去。 lock 它端口是三幺零零, 然后我们重新部署一下,在这里就可以找到 lockkey 的 数据源。添加 lockkey 的 数据源以后,我们也是可以在面板里面加 lockkey 的 面板你看在这里有 dashboard, 然后我们在 deletereshot 这里设置数据源是 lockkey, 同样的,我们在 code 这里去写 lockkey 的 表达式, ok, 它的语句是比较简单的,在括号里面去写筛选条件,在这里我想筛选已知内容, app 等于 backend, 它可以从设置里面儿筛选到这些内容,然后返回一下,筛选到以后,我们想要再去过滤某些内容,我们可以通过这个符号,等于让以后里面要写我们想要过滤的内容。比如说我写上, 如果我们想把数据改成,让它显示成 javascript 形式,我们可以在后面继续加 javascript 一下,它就显示为 javascript 的 形式。 loki 的 查询日制的语法还是比较简单的,一般用到的只有筛选和过滤,以及后面是格式内容。 我在这里需要查询音符日制里面的音符日制,然后我在这里刷新一下我的页面,它会把音符日制写到容器里面的目录里面,然后我们在这里就可以查到我们的日制,这就是 loki 以及它结合关阀的使用。
48小北爱编程 08:0837小刘运维
08:0837小刘运维 05:00查看AI文稿AI文稿
05:00查看AI文稿AI文稿kasp 付费如何将请求转发至 kasp 集团外部呢?可能大家会觉得很奇怪, kasp 付费主要服务的对象就是 kasp 集团,那为什么又会存在将请求转发至 kasp 集团外部这样一个场景呢?如果真有这样的场景,为什么不在 kasp 集团外部搭建 index 来处理这件事情? 要了解这个设计的话,需要了解一下我们公司的价格背景,大家可以翻翻我之前的价格是怎么样,然后价格背景是什么?在这里呢,给大家回顾一下。我们公司的 架构是裸机数 k 八十,也就是所有的物理机是没有虚拟化,整成了一个 k 八十机群,在这种场景下, n 个是没有必要存在的,所以我们的链路非常短,从方浩强然而在服务器群到 k 八十机群, k 八十机群的 get 位,再转发请求到我们的 service, 我 们的 service 在 k 八十机群到我们的后台服务啊,这是大概的一个过程, 当然呃, kplus 极具外部也有一个赋能,但是这个赋能是防火墙在做。当然很多公司其实也会使用硬件的赋能,比如说 f, 我 们公司体量不大,所以没有用到这个硬件,直接使用防火墙的赋能来完成的。那既然如此,裸金属 kplus 理论上是不需要转发到外部, 那为什么我们还会存在这样的场景呢?其实就是因为我们没有做到百分之百的逻辑做 k 八十,这个是因为在我们切换的时候才发现的,在最初设计的时候,预演的时候都没有啊,考虑到这个东西,什么东西呢?就是我们采购的一个系统,它是一个边缘的系统, 我们采购的这个系统呢,它的商业授权是单机版的,它要求绑定 mac 地址,并且不能部署到 k 八十机群里面, 哪怕你部署到 kps 群里面,它也会限制你没法运行,所以,嗯,设置于这个的话,我们就必须把这个系统部署到 kps 群外部。 但是我们采购的这个服务器生产服务器又没有考虑这种场景,当时给我愁坏了,那怎么办呢?最后还是把测试环境的服务器腾出来作为它的服务器。为什么会这样干呢?是因为这个系统它就是一个边缘系统,你说它有用吗? 很多时候又没人用,你说他没用吧,偶尔又会有人用,是非常边缘的一个系统,所边缘到我都会忽略他,所以在设计之初就忽略了,忽略掉了这个系统,导致了这个问题,所以最后使用测试环境的这个服务器来作为他的服务。 但是呢,我依然觉得比较浪费,因为测试服务器它的 cpu 和内存也挺多的,这样一个边缘的系统,它独享其实也有点浪费,有点浪费好,不然我觉得后面可能还会用这个服务器来做一些其他的事情,比如说做一些呃,数据备份什么之类的,也可以,也没什么问题,反正我不会浪费它,一定要充分利用它。 所以这个服务部署到机群外部的一个服务器里面啊,部署到之后,我们如何将这个服务暴露到外面呢?这个时候问题就来了,因为我们的八零和四十三这两个端口已经分配给 k 八十 getv 了, 分配给他之后,那我这个边缘的系统就用不上八零四十三了,除非你经过啊 get 位转发过去,那就能用到,否则的话你只能改端口,而且我们的 h t t b s 的 证书也在 get 位里面,也就是说如果不改端口,且要用到 h d b s 证书保持原封不动的情况下,那只能经过开发的 get 位, 这是我们最优选的一个方案,其次才是备选方案,就是改端口,然后降到 h t p, 把 h t p s 废掉,但是这个是我们不用看到的,所以,嗯,我们想方设法看一下能不能从 get 位转发到 我们的这个边缘系统里面。最后啊,还是从 kios 的 service 切入来处理这件事情。大家知道 kios 的 service 有 三个,就是普通的 service, 还有无的 service, 还有这个外部 service, 我 们主要用的就是这个普通的 service, 当然这个普通的 service 是 没有这个 slato 的, 也就是没有匹配器, 直接就是一个普通的 service 来给它配置端口。关键点来了,大家知道这个普通的 service, 只要你有这个 slack, 也就是有这个匹配器,有选择器,你就可以自动匹配到 keypass 内部的 pod, 也就是服务。匹配到这个服务之后啊,它就可以做转发,做这个覆盖均衡。 但是没有这个匹配器,该怎么去做服务的转发呢?这个时候就不得不讲到呃 class 的 endpoints, 其实普通的设备是在匹配到 pos 的 时候,它会自动生成 endpoints, 这也是 class 的 呃服务发现的能力, 所以这个是因为我们的这个边缘系统,它不在 class 机里面,它没有服务发现的能力,也就没法自动生成 endpoints, 也没法自动匹配这个服务,所以我们得自己创建 endpoints, 这个时候只要 endpoints 和 service 的 名字是一样的,它就会关联起来。 endpoints 是 可以自己定义 ip 地址以及端口的。好,通过这种方式我们就可以啊,在 kasperget 位里面调用这个 service, 然后再转发到我们的这个边缘系统里面去,这是一个解决方案啊, 理论上纯裸技术 kasper 是 不需要这样干的,这也是没办法,如果说大家后续也遇到这种情况,也可以考虑使用这种方式来处理啊,这也是后续 得到了一个提升,因为我一开始从来没有想过,就是说我需要将请求转发到批发市场外物去啊,这个是确实没想到过,这个给大家补充一下。好,本期的分享先到这,大家如果觉得还满意的话,可以点点关注点点赞,咱们下期再会。
139朗无月 13:29查看AI文稿AI文稿
13:29查看AI文稿AI文稿这节我们继续使用 istencil 安装 graphing 插件,插件中带有一个预配置的 graph, 可以 用来对付网格的流量进行监控。 开始之前要设置 graphing enable 等于处。我们先设一下 graphing enable 等于处, 然后呢,确认集群中普米修斯服务正在运行, 这个应该没问题吧?没问题,验证 graph 呢?是否在集群中运行我们还没有去做是吧? 做之前我们先看看 graphina 的 镜像,看看是不是要改一下镜像地址。 charts graphina values。 我 们看到 repository 确实是,改一下吧。 rescue 点,西安杭州一些 s 点 come come i moke istto。 看看下边还有吗? 好的,下边没有什么需要改的了,然后还有一个 ingress, 我 们也一块给它开启吧,肯定是要访问的。 instance graph 点默克点 com, 然后还有什么需要改的吗? contest pass, 这个我们改成 com 呗, 其他的不需要。然后继续去生成一下 instance 点 java 生成模板文件 apply est 点 y。 好 嘞,下一步就可以去检查 graph node 是 否运行没问题,运行着,然后通过 graph node 打开 est 仪表盘就可以访问了,是吧? 然后访问之前我要配置一个 host e t c, 然后搜 estu 点 graph, 然后访问一下 estu 杠 graph 点目客点 com, 确实是可以访问了。 galley dashboard easy to mess dashboard, mixer, performance, pilot, service, workload 啊,有一些主键相关的 dashboard, 还有性能的 service 的 pilot 的 默认,就给我们配置好了好多的 dashboard。 它这个给的例子是 mess dashboard, 刷新几次页面产生一些流量,我们先看一下有没有流量。 mess dashboard 确实是没什么流量,是吧,我们先刷新一下 哦,稍等一会再看一看,我看到已经有流量过来了。 global request 是 一点一 o p s 全部是成功的, 下边有对应的服务的详细信息, workloads, 然后是请求的请求率, p 五零, p 九零和 p 九九主要是用来看我们请求的延迟情况。 ok, 这是这样的仪表盘,其他的仪表盘呢,大家也可以自己去看,其实呢无非就是这个 graph 呢,去查询普米修斯的一些数据,然后把它展示出来而已,没有什么特别需要说的。 下面是分别给你看了几个 graphing 的 视例,大家可以自己去详细的去看一下,你就不挨个去给大家看了 graphing 我 们就到这很简单, 然后回到这个里边呢,其实我们主要的这个主干功能都给大家演示完了,那下边呢,一些都是属于分支类的功能嘛,大家如果感兴趣可以自己去找自己感兴趣的内容去学习。 然后除了这些呢,还有一个地方我们没有讲到,是一个比较重要的地方,任务里边的遥测下边有一个网格格式化,我们把这块呢也学习一下。 刚刚这个任务呢是对 use to 服务网格进行多角度的可适化,首先要安装家里插件,然后使用 web 界面查询网格内的服务以及 use to 配置对象。 ok, 任务中也是使用了 bug infoseal 策略作为测试案例。 然后下边告诉我们了 kylie 安装的方法。首先在命名空间中创建一个 secret, 作为 kylie 的 一个登录凭证,我们就设置一下它的用户名,设置的是 oedmi, 我 们也设置为 oedmi 吧。一样的 password 等于 my secret, name space 等于 instillation, 然后 name space 我 们肯定创建完了,然后再创建一下 kali 的 这个需要的一个 secret 创建完了,创建之后,根据 hell 我 们来安装 kali, 然后必须设置成 kali enable 等于 true, 是 吧。我们去设一下 kali enable, 我 们改成 true, 然后就可以去使用了。最好是还要看一下具体卡列里边有没有什么需要改的地方。 首先一个 docker 的 镜像,我们就需要改吧,改一下镜像地址 which is to 点心 看杭州啊,里面 cs 点 com i'm ok 是, 然后下边 contest pass, 我 们先改掉 访问它的 ui 的 时候的 contest pass, 然后是不还应该有一个 ingress 啊,既然有 ui 的 话, 把一并给它都改掉。 host username 点目客点 com, 其他的就不需要改了。 然后再生成一下 username 点幺,再去生成一下带有 kali 的 配置, 回过来,我们都完成了,就可以部署,不运行早就部署完了是吧?然后验证一下,这肯定没问题吧。 get service, 设网格,发送流量,然后干什么呀?然后访问家里的 u i l ok, 行了,然后就可以去访问了。哦,还不行,我们还要配置一下 host, 然后访问一下 is to 杠,加了一点默克点 com 五零三是吧?说明我们的服务是不是还没起来啊。 get pause 杠 n is to system 果然 made pool。 我 们看一看是 describe 一下呗。 six 层又多了一层 kali。 好 吧,我们又弄错了那一块儿 s kali values 上边多了一层去掉, ok, 重来一遍, play 一下,然后再看看 port, 哦,很快马上就起来了, 然后再访问一下服务,可以访问了,用户名是什么呢?刚才我们定的那个默认,然后密码是看一看,这块儿密码设置的是 my secret, my secret 登录看着会比我们之前用的那几个会强大一些,是吧?功能至少是比较多,我们再去刷新一下这个服务, 刷新刷新刷新。好的,然后等一会儿去看看。 before 命名空间下有四个应用都是健康状态,是一个 overview, 然后呢? graph 呢? empty 等一会儿被 application 状态是正常的 workloads 状态,正常的 service, 还有 is to configure, 可以管理我们 estu 的 相关的一些配置,是吧?这里边有很多配置, getaway 是 我们 book info, 那 个 getaway, what's your service 都可以在这里边去查看,看一下 跟我们定义的那个配置文件是一样的,是吧?然后呢,在这个 getaway 里边,在这个 getaway 我 们还可以点进去看到它具体的详细的信息,甚至可以在这儿去修改和保存,相当于给了我们一个 istio 的 一个后台维护的这样的一个功能, 包括具体的 virtual service 也都可以看到, 这块儿还是挺方便的。然后我们再回过去看看,这个 graph 现在已经生成了,我们刚才访问了几次, 可以看到当前的这个版本的关系。 product page v 一 版本调用了 detail page 的 v 一 版本,然后调用了 reviews 的 v 三版本。目前我们只是访问了 v 三版本,是吧?只有这个红色的,只是访问了一个, 这样的话他就看到了这一个版本,然后再用了 rating 的 唯一版本,总体来说这个功能呢,相对确实是比较强大一些,但是它其实并没有对那个每一个请求的这个链路追踪的信息,是吧?可以说跟我们之前的那个 jagger 还有 graphnote 是 一个互补的一个关系吧, 它定位呢,其实主要就是 estu 的 一个后台管理这样的一个功能,从这个 overview 里边就可以大致看出来了它的一个功能定位了。 好,关于更多的细节呢,当然还是留给大家去自己的一点一点的去研究。到这呢,我们这个 estu 的 实践就结束了, 从刚开始呢,我们体验了流量控制,路由策略,数据收集,统计,以及建立在此基础之上的分布式的链路追踪。 但不管上层是多么炫酷的功能,都离不开底层的这个基本逻辑。在 car, in vivo, 陌陌的结果,流量 palette 控制 invoice 实现了流量的控制。然后在上程呢,就支持了我们配置各种的 crd, getaway 啊, watch, service, destination, rule 等等。然后 mixer 呢,负责收集 invoice 上报上来的数据,并且呢把数据输送给存储的后端, 从而得以给我们在上城提供更多的仕途,同时也支持了多种分步式追踪的主见。这些大致的原理大家首先要搞清楚,然后在后边进行细节的学习呢,就会非常容易 ok, estu 呢,我们就讲到这。
14架构运维 18:55查看AI文稿AI文稿
18:55查看AI文稿AI文稿上节呢,我们准备好了我们实践的环境,这一节呢,我们就开始部署高可用的集群。 首先我们要部署一个 keepalive, 它适用于 a p s server 的 高可用的。由于 keepalive 一 般是一组一倍,它们共享一个虚拟 ip, 所以呢,我们就任选两个 master 节点去安装 keepalive, 我们就选择前两个节点吧,幺八和幺九,安装一下 keep live。 好 的,在我这个环境中, keep live 应该是已经存在了。 安装完 keep live 之后呢,我们就要配置一下 keep live 的 配置文件。首先我们先创建好这个配置文件的目录, 然后我们去到那个中转节点,分发一下 keep live 的 配置文件。 到中转节点, 首先是 master ip, 我 们的 master 就 放到第一个幺七二点幺八点四幺点幺八。然后是 back up 节点, back up 的 配置文件 root, 幺七二点幺八点四幺点幺九。除了这个 keyboard live 的 配置文件之外,我们还需要一个检查 aki server 是 否正常的,这样的脚本 用户是 root 马斯 ip, 幺七二点幺八点四幺点幺八。检查 ip server 的 脚本呢,是同一个文件,在两个节点上都是一样的,我们直接修改一下 ip 地址。 上传完之后呢,我们可以简单来看一下这个配置文件,一个是 etc keeplife keeplife 点 com, 首先是定义了一个 root id, 然后定义了一个检查 ip server 的 脚本,每隔三秒执行一次,如果发现 script 返回的是非零的话,就会给它的权重减二,当前节点的状态是 master, 网络接口是 bond 一, 然后是 root id, root id 主背是一样的。六十八是我们自己定义的一个值, priority 啊,它的优先级在主节点上的优先级要比背节点上的高,我们可以一起来看一下 back up 节点 state back up 优先级是九十九,主节点是一百,其他的都是一样的。 vip 就是 呃,我们定义的那个 a p s server vip 是 由 keep alive 来保证的,然后定义了 track script 检查的脚本, ok, 然后我们就去看一下这个检查的脚本。 首先他去检查了本地的六四四三端口,如果这个端口不可用的话,这个命令会直接异常退出,否则的话他会去检查当前的节点是否拥有了这个虚拟 ip, 如果已经拥有了这个虚拟 ip 的 话,他就会去检查这个虚拟 ip, 看看他是不是正常的。如果这个虚拟 ip 不 正常了,就说明自己已经不具备持有这个 ip 的 能力了,他就会异常的退出。很简单的一个脚本回到我们的文档, 接下来我们就是启动 keep live 的, 分别在主节点和备节点上启动 keep live, 然后检查一下它的状态, running running, 然后再看一下它的日制, 嗯,脚本的退出状态是不正常的,这个是预期之内,因为我们并没有 a p s server 在 上面运行。 然后我们看一下这个 ip 是 否是已经有了呢?在这个主节点上发现这个虚拟 ip 已经绑定到了这个 master 节点上, 在被节点肯定是没有的。然后我们可以拼一下,这个虚拟 ip 是 可以拼通的,相当拼到了本机。 keep live 安装完之后,我们就可以开始部署第一个主节点了,我们需要给它上传一个我们生成的这个配置文件, google home 点 com 到中转节点,给它上传一个配置文件, 上传到主节点上, 对应那个 node ip 主节点上,然后我们去主节点去执行 init, 库比特 mean init。 我 们先看一下这个配置文件吧,库比特 m 点 com 可以 改变的呢,主要就这一些,一个是版本啊,一个是 a p s server 的 虚拟 ip, 这个是 ip server 来通过虚拟 ip 和端口访问的方式,然后定义了这个 etcd 的 各种的监听地址,三七九二三八零,还有它的 hostname, 还有一个就是 port 的 cid 二, 然后库比特密呢,是会根据这个配置会去出手划这个节点。 ok, 所有的工作都是他自动完成的,我们只需要等一会就好了。在这块呢,如果大家没有这个预先下载镜像的话,这个地方等待的时间会比较长。 好,如果大家看到最后这一行啊, you can now join any number of mercenaries by running the following on its know, 就是 这个 could be the mean join 打印出来这样的一个命令。这个命令呢,我先去给它记录一下, 给它保存一下,然后一会再加入 work 节点的时候会用到这个命令,这就说明当前这个节点已经部署化完成了。好,我们再去回到文档里边配置一下,会 be ctrl 这个命令, 我们新建一个目录,然后把 cookie control 用到的这个管理啊,默认的这个配置文件给它移到这个默认的位置,这个时候我们就可以去使用 cookie control 这个命令了。我们试一下, 大家看到我们这个 getpos 已经是可以工作了,然后我们这个 dns 是 盆景状态,其他都是正常状态,为什么呢?因为我们的 dns 它是要运行在工作节点的,也就是 worker 上,我们现在还没有一个 worker, 对 吧? 然后第一个主节点我们就配置完成了,然后在配置另外的两个主节点之前,我们需要拷贝一些配置, 就是说三个节点有一些配置是需要是一模一样的,不能都是自己来生成,因为他们几个毕竟要组成一个基群,对不对?比如说他们的企业证书必须是一样的,才能互相的信任,互相的通讯。 我们这里给出的方式呢,是先在中转节点上把第一个 master 节点上的配置文件拷贝到中转节点,然后再由中转节点去拷贝到其他的两个节点。 当然如果你的中转节点就是主节点的话,你可以直接拷贝到另外两个主节点。我这呢是先把主节点的拷贝到中转节点, 主节点的用户名,主节点的 ip, 主节点的目录。 pki 啊,这个证书目录拷贝到本地, 然后再拷贝一个配置文件, 单独的拷贝一下这个 administrator, 这个配置文件 用户是 root, 然后幺七二点幺八四二点幺八拷贝到当前目录, 然后我们要删除它多余的文件,对不对?因为我们上面列了一个这个文件的列表,除了这些文件之外,我们并不需要那些多余的。我们把 api server 的 东西删掉, 然后把 proxy 的 删掉,然后把 etcd 的 没有用的给它删掉。 删完之后我们就分别把下载下来的这些文件分发到另外两个 master 节点里面。 第二个是幺七二幺八点四幺点幺九 啊,没有输入这个用户名, root, ok, 然后另外一台是二零。 好,然后同样呢把这个 admin com 也拷贝到对应的目录下边, 幺九 二零。好。拷贝完这些证书相关的文件之后,我们还有一个文件需要拷贝, 就是对应节点的这个快捷键键 com, 这个文件要拷贝到另外两个节点去。这个文件呢,是每一个主节点都是有一点区别的,所以我们要写上对应的 ip 幺九, 幺九,对应的就是幺九, 然后是二零,不要忘了把前面的目录名也要改成二零,因为它每一个节点都是不一样的。好, 拷贝完之后,文件准备好了,我们就开始部署第二个 master 节点,我们上传一个 master 节点的部署的脚本, 第二台幺七二幺九。好,下面我们就去运行这个脚本了,可以我们到这个第二台第二个节点上, 我们先看一下这个脚本,嗯,第一部分是 quilite 的 一些引导的配置啊,这些脚本都是在官方文档上有的,我这呢主要是做了一个整合,并没有任何的修改。 第二部分是加入 etcd 的 集群,因为我们之前的 etcd 只有一个节点,现在呢,我们要再加入一个节点进去,所以啊,通过一些命令去组合成两个 etcd 的 集群。 第三部分是部署主节点相关的,组建,好,我们执行一下。 好的,有类似于我这种输出,就说明这个安装过程应该是正常的。然后我们可以稍等一会去查看一下这个节点的端口监听情况, 大家可以看到这个六四四三端口 a p s 二的,然后二三八零,二三七九, 还有这个幺零开头的, proce 的, kublite 的, scatter 的, 说明我们这些服务都已经正常的启动了。我们还可以用 drps 去看一下相关的容器, 看它是不是起了很多个容器啊,然后可以看一下日制,去打开看一下现在的系统有没有问题。 大家可以看到有一个问题是没有这个 c i c i config 还没有输出化,我们还没有部署这个 c i 插件,对吧?正常的,下面这一小块呢是可选的,如果你想在这个节点上使用 quick control, 就 可以去做一下这个操作, 然后把这个文件放到这个 quick control 默认的那个配置文件里边,我们可以试一下 正常的。接下来我们就可以部署第三个节点了,也是一样,我们先要上传一个这个第三个节点的抽象脚本, 二零 啊,可以看到这个脚本跟第二个节点的脚本呢是一样的,除了它们的这个 ip 地址,还有就是这个 etcd 这个配置会有区别以外,其他的都是一样的。 这块的 etcd 呢,就相当于是在现有的两个 etcd 集群基础上再增加了一个 etcd, 就 变成三个 etcd 集群了,我们执行一下。 好,同样的,我们用 united state 看一下端口啊,应该没什么问题,看一下日制也是一样心爱的问题, 这样我们三个主节点就已经部署完了,下面我们开始部署网络插件 c n i catalog, 我 们在这个拥有这个酷比 control 的 节点上随便找一个都可以创建一个目录, 然后我们在中转节点把这个 catalog 的 配置文件给它上传上去。 当然这个 cadillac 的 配置文件呢,大家也可以在官方去下载,跟我这个是一模一样的,在我这呢只是帮助大家给里边的那个 pad 新 id 给它改掉了,别的是没有区别的。 幺八好上传了两个文件,然后我就可以部署 cadillac 了,在幺八上执行, ok, 创建 calico。 然后我们可以看一下这个 calico 的 port 的 状态, 这个得稍等一会儿,我们再看一下,大家看到并没有完全运行起来对不对?因为它还缺了一个 worker 节点, calico 呢,它也是有需要运行在这个 worker 节点上的。 然后接下来我们就去加入 work 节点了,加入 work 节点非常简单,我们把刚才保存的那个 n 档拿出来复制一下, 然后去 work 节点上去执行四幺,还有四二去执行一下这个命令。 好,大家看到了这个 run 可以 ctrl get node on the master node, 看一看这个节点是不是被加进去了,出现那个就说明应该是正常了。 好,我们两个节点都加完,然后 google ctrl get node, 大家可以看到四幺这个节点已经处于 ready 状态了,嗯,四二也处于 ready 状态了, 节点都正常了,我们就去看一下这个 calico 是 不是正常了呢?看一看这个所有的 pod, 大家看到这回这个 pod 都处于 running 并且 ready 状态了,说明我们这个集群应该是没有什么问题了。在下一节中,我们去验证这个集群是不是完全正常, 通过 kubito 的 方式去搭建这个集群还是非常方便的,速度也是很快的, 需要我们人工去处理的地方不多。下一节呢,我们就去验证一下我们的一个集群,看看他有没有什么问题。
14架构运维 01:57查看AI文稿AI文稿
01:57查看AI文稿AI文稿开始突然之间不能发布应用了,但是纯量的服务却是可用的啊。这个问题是我上个礼拜收到一个粉丝的求助的一个内容,他跟我说他的服务啊在之前是没有做任何的改动,但是 就是突然之间啊不能发布了,原因是什么?让我去帮他们看一下。那这个问题当然是解决了,就其实很简单,这个问题理论上只要你用过了,开发时这个问题就很简单啊。屏幕前的各位网友也可以思考一下这个问题是什么问题?有可能是什么问题?其实这个问题非常非常简单,这个问题其实就是啊证书过期,说白了就是证书过期, 因为,呃,很多没有上过生产的,呃。这个 k 八十选手呢?呃,最容易忽略这个问题,为什么呢?因为你在自己做实验的时候或自己玩的时候是不可能会说一个鸡群,我玩一年对吧?他可能就是你搭好的,这过几天对吧, 就不玩了,就给他消毁了。所以真正运行超过一年以上的只有在生产环境。所以说这个问题其实理论上也可以用来啊,顾虑掉很多啊。这个实验型的 运维出来,他没有任何生产经验,他可以假装说他有生产经验,他有一些 k 八十的这个知识,但是你只要通过这个知识点去问他一嘴,他绝对啊很可能就露馅,就能把这个 k 八十的新手给它过滤掉。这个是一个非常简单的一个问题啊。 但这个问题其实修复的话就非常简单,因为开始它本身有这个命令,可以一键更换证书,那替换完之后要做的一些事情就这里就不再复述了,无非就是说你做完之后,你需要把这个证书分发到所有提现里面,当然这个动作其实可以通过流水线定时去啊做维护, 如果说啊,你还需要人工去维护,我觉得是真的是没有必要的,为什么?因为这个东西一个命令就可以解决的事情,分发这个证书其实也很简单啊,所以,嗯,这个问题,呃,大家可以提前去 看一下这个证书是怎么回事,就是什么时候过期,然后在接听流水线里面定时的去更新,这样的话你基本上不用担心这个证书过期的问题了。好,本期咱们下期再会。
124朗无月 03:08查看AI文稿AI文稿
03:08查看AI文稿AI文稿上一期视频我们讲到裸金属 k s 内存扩容,我更推荐使用的方案是先使用扩展这个命令进入维护模式,然后通过调整 deployment 的 pad 数量来进一步清空这个节点上的所有的 pad, 然后再停机,然后再加内存, 以这种方式来扩容。那这种方式呢?嗯,网友是有一些争议的,主要争议点在于就是,嗯,可能觉得这个方案其实整个过程是比较啊冷藏的,而且比较耗时的,所以有些网友觉得为什么不直接使用转这个命令来排空所有的呃, pod 主要原因是什么呢?在这里给大家解释一下。那使用 gel 这个命令呢?它是简单粗暴,虽然是啊,时间快了,但是它会面临一个问题,那就是驱逐后的这个炮的 他会在别的 note 再重新启动。这里面我们需要考虑一个点,那就是在内存扩容这个场景下,很有可能是资源不够的,那资源不够的情况下,你在直接暴力去除所有的 pad, 在 没有任何准备的前提下,暴力去除所有 pad。 你 需要面临的一个问题是 逻辑素开发师有很多基础的组建,是部署到开发师里面的基础组建他的优先级理论上都要比应用的 pod 要更高。为什么要更高呢?因为基础组建肯定不可能被干掉,对吧?而 pod 不 一样了, pod 可能 应用的 pod, 应用的 pod 就 不一样了,因为应用的 pod 可能有很多个,所以他干掉了一个倒无所谓,所以这里面有一个天然的优先级的啊, 不同在这里面。所以如果当你需要扩容的这个节点有这个,呃,技术组件的时候,你直接暴力驱逐,会面临一个问题,就是在资源不够的前提下,他优先会驱逐其他节点上的正常的 pod, 然后来 重启这个啊被驱逐的中间键。那这种情况下就有可能会导致啊驱逐的啊,应用炮的有可能是,嗯,某一个服务的,所有的炮的都被驱逐了,这种情况下可能会导致某一个服务不可用,那这个服务不可用,有可能就会导致某一条业务线直接挂掉。 好,所以这个就是一个风险,所以我不推荐使用这种方式的原因就在于此,就是,呃,像资源不够的情况下,我们一定要采用更温和的方式去处理这个问题。好,这个的话啊是一个 最大的区别。当然不管是 call 等还是转,他其实都是在利用啊,五点底层都是在利用这个五点去做啊做这个操作的, 所以,嗯,领导你不用这个 call 腾不用撞,你也可以通过五点来达到相同的效果。好,这个是,这个是。嗯,关于啊在开发时维护的时候的 维护命令,或者说维护的方案选择上的一个思路啊,这个思路仅供参考,大家如果有其他想法的话可以在评论区讨论一下。 这期主要就是简单的介绍一下进入维护模式,或者说在维护啊裸金属开关式的时候常用的一些命令都有哪些,并且给大家介绍一下使用的场景。为什么啊?要使用这几个命令,什么情况下使用这个命令 啊?这个都是我觉得应该是,嗯,比较实战性的一个啊。这个视频大家如果感兴趣的话可以点点关注点点赞,咱们下期再会。
111朗无月 04:24查看AI文稿AI文稿
04:24查看AI文稿AI文稿面试官问生长环境, k 八 s 刚发布了一个新的业务,但是这个破的状态一直处于攀顶,死活起不来,这种现象是怎么回事儿?你怎么排查?如果直接回答,遇到起不来的情况, 先用酷猫 c t l 洛克斯看看有没有业务报错信息,那在懂行的面试官眼里是不及格的。破的处于攀顶状态,大概率它正卡在 k 八 s 调度阶段,这个时候 k 八 s 都还没决定把它分配到哪台具体的节点上, 连个容身之处都没有,容器自然也没有被创建,业务代码更是一行都没跑。这时候去看日制,除了一个容器未创建的报错之外,什么都看不到。这个问题可以这么回答, 排查攀顶核心思路,去看看调度器为什么不放行。直接用库八 c t l disco pad 命令去查看,这个 pad 的 英文指事件流。 k 八 s 的 调度器会把详细的调度失败原因记录在最下面,拿到具体的报错信息就可以对症下药了。通常来说,导致攀顶的高频原因无非就集中在这么几个方向,最常见的一种 就是资源不足报错。你一般会看到 insufficient cpu 或者 memory 的 字眼,这通常说明整个集群或者符合调度条件的节点已经没有足够的可分配资源了。而且这里调度器看的并不是机器实时的 cpu 使用率,而是 pod 在 request 时, 你声明的调度资源,调度器发现已经没有合适的资源能分给这个 pod, 一 时找不到合适的位置,它只能先攀登在那。 如果资源没问题,那大概率就是调度规则没匹配上。这里面通常有两种情况,一种是污点冲突,也就是节点被打上了特定的探头污点,比如控制节点默认不允许普通业务调度,或者某些专用节点只允许特定业务运行。但是我们破的的亚某文件里并没有配置相应的容忍度,那调度器肯定会把它拦在门外。 另一种情况正好相反,是 pad 自己比较挑剔,也就是选择器不匹配。比如 pad 通过 load select 或者节点亲和性明确要求自己必须跑在带有 gpu 或者 ssd 硬盘标签的节点上。但是调度器在集团内部转了一圈,发现暂时匹配不到带有这种标签的机器,它也只能在原地待命。除了算力和节点,还有一个地方非常容易踩坑, 就是存储券未绑定。如果你的 pad 声明呢,需要挂载一台持久化存储,但是对应的 pvc 一 直处于攀顶状态,也就是底层的 pvc 还没准备就绪,那为了保证数据的正常读写,在存储准备好之前, pad 也是不会被调度起来的。 下面演示一下最常见的资源不足。这是一个一主四从的 pbs 集群。这里的 seven 八十四原本是管理节点,通常控制组件和 etc 混装的话,管理节点要做高可用。为了避免误导,我移除了它的 low schedule 污点和角色标签, 让它作为普通的 word 节点参与业务调度。后面再演示控制平面与 etcd 的 高可用机制的时候,再恢复它的管理身份。当然,这里只是测试环境的演示,配置生产环境不要这么搞。现在发布一个准备好的业务破的发布之前,先看一下这个亚某文件, 前面都是常规的 nxt 镜像配置,关键看 resource。 这里故意把 cpu 的 请求量写成了一百,狮子大开口要求集权必须给它存出一百个独立的 cpu 核心才肯干活。现在把它发布出去, 查看一下状态,不出意外,状态卡在了攀比,跳过那些没用的排查步骤,直接查事件详情, 看最底下的一文字, pbs 调度器的报错都会写在这里,报错信息非常直白。集群里一共有五台机器全军覆没,其中一台是管理节点,有五点不让跑业务,剩下的四台工作节点全部提示 cpu 资源不足。继续看这个 pod 到底申请了多少资源。 这里也可以发现,它张口要一百个 cpu 核心,把这四台工作节点全绑在一起也凑不出来这么多调度器,自然没法给它分配位置。排查到这里,问题就明确了,先把它删了, 然后把请求改成零点五个核心,再看一眼这个亚马文件,已经改过来了,重新发布。再查一次状态,自然分配正常。之后, pos 很 快就开始创建容器了,再看一下,这个时候要稍等一下, ok, 后面状态也就正常 running 了。到这里,一整套流程就走完了。前面说处于攀点敲库包, ctl、 logx 看不到日制特指卡在调度阶段,如果 pod 已经调度成功,只是因为粗始化容器报错或者拉取镜像失败导致的攀点, 这种特定情况下是能查到日制的。所以 pod 起不来的时候,第一步通常可以先看英文字,大部分关键问题,调度器已经把原因写得很清楚了。
397爱睡懒觉





猜你喜欢
最新视频
- 6712尔尔r