如何利用线性预测公式计算预测值

粉丝9.3万获赞43.6万
相关视频
 04:35查看AI文稿AI文稿
04:35查看AI文稿AI文稿大家好,我是研发教育的山西老师,今天我们继续讲解一个 sir 数据预测, 上节课讲到了趋势线预测法,那么这一节课我们继续来深入的理解趋势线预测法的应用。 趋势线预测它是根据历史数据进行回归分析。礼盒出来一条回归方程,它主要有三种场景, 第一个是线性的,线性的用一元线性回归方程,第二个是非线性的,用二字多项式。 第三种是曲线指数回归方程,不管哪一种,先要通过三面图来观察图形,然后来决定用哪种方法。前面也讲到了,我们如 何来判别数据的趋势呢?首先可以制作一个折线图来观察他是线性的还是非线性的,还是曲线,甚至是是否具有季节性。好,我们来先看一元线性回归方程。 一元线线回合方程,他是 y 等于 a 加 ex, x 是自变量, b 是系数, a 是他的长量, y 就是他的音变量。我们可以通过一元线下回合方程求出 ab 的值,然后 通过未来的知名量 s 来预测我们的最终的预测值。歪,它的整个的 思路是什么呢?首先第一个我们要插入散点图来进行观察。第二,然后添加趋势线得出回归方程,同时要观察监测指标,就是二方值入二方值 小于零点六,说明这个合格方程是不显著的,也就是说不可靠,那么就要换方法了,这种方法就是不行,最后计算预设值。 好,我们来看一下这个案例,人均 gdp 从零四年到幺四年,现在要预测 二零一五年的人均 gdp, 我们先看一下他的一个图表,选中 a 二到 b 十二,插入图表闪电图, 然后选中图表,在图表工具设计下面有添加图表元素。趋势线,线性, 其实我们做散点图也好,折线图也好,他这个就是一个线性的,就一条线,他是线性的, 他不是曲线,曲线他是弯的。然后点右键设置虚实线格式, 在下面勾选显示公式,显示二方值。我们首先来看这个公式可不可靠,就看二方值,他是等于零点九九,接近于一,说明 是相当可靠的啊,非常可靠,都接近一了,如果低于零点六就是不可靠了, 那么 y 等于四百五十二点六二, x 减九零三零零三,这个就是它的离合方程, x 就是二零一五。带入这个公式就得出二零一五年的人均 gdp, 好等于四五二点六二乘以 二零一五减九零三零零三,回车 好,九零二六点三,就是二零一五年人均 evp 的预测,这个预测的可靠性 是非常高的,为什么呢?二方指它接近于一 好,这个就是通过一元线性回合方程来求得的预测值,相对 可靠性比较高。还有一种方法是通过数据分析工具来求走的。好,我们下节课再来讲,谢谢大家。
760跟尚西学PowerBI 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿大家好,今天我们来聊了线性回归算法。线性回归是一种机器学习算法,它可以帮助我们预测一个变量与另一个变量之间的关系,它可以帮助我们更准确地预测未来的趋势,从而更好的决策。 线性回归算法的基本原理是,他会根据给定的输入数据拟合一条最佳拟合直线,以此来预测未来的趋势。线性回归算法的优点是,他可以快速有效的处理大量数据, 并且可以很好的拟合复杂的数据。但是他也有一些缺点,比如他不能处理非线性数据,也不能处理多元关系。因此,我们需要更多的研究来改进线性回归散发,以获得 更准确的预测结果。让我们一起来探索线性回归算法如何获得更准确的预测结果。假设我们想要预测一个人的体重,根据他们的身高,我们可以使用线性回归算法来计算出一个公式 来预测一个人的体重,公式为,体重等于身高乘以零点七五加五十。假设一个人的身高为一百八十厘米,那么他的体重就是 一百八十乘零点七五加五十等于一百七十五公斤。线性回归算法可以用于赖预测,因为它可以根据给定的输入数据 你和一条最佳拟合直线,以此来预测未来的趋势。例如,假设我们想要预测一个公司的股票价格, 我们可以使用现行回归散法来预测未来的股票价格走势,从而更好地决策我们是否要购入。那么你心动了吗?赶紧学起来!
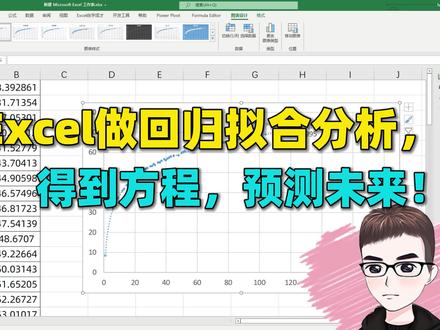 02:02查看AI文稿AI文稿
02:02查看AI文稿AI文稿大家好,今天分享的技巧是用 excel 制作回归分析,或者说是你和分析。 举个例子,左边我们现在有一个数据员,然后有 x 和 y 轴的数据,我们现在要得到他的一个分析,他的一个规律,那么用 excel 得出他的一个你和的一个曲线方程,比如这里是一个对数方程,这应该怎么做 好?我们先把做好的进行删除,首先我们选中所有的数据,然后点击插入选择闪点图,好,我们选择这个闪点图,那么我们可以把图表标题进行删除,然后我们选中这个数据区域进行双击,然后在 右边的话就可以有他的一个标记,然后在标记选项里面可以改成类似,然后把标记点给他调小,然后我们可以在添加图标元素这里面选择添加趋势线 好,然后趋势线的话可以添加不同的种类,有线性的指数的或者等等的,比如我们现在随便添加一个线性的 好,添加完了之后,我们在右边可以选择我们的趋势线,我们点击趋势线选项,然后这里会有几种趋势线的一个选项,那我们看一下,我们这个是对数的,所以我们选择对数, 然后在底下的话可以显示公式以及显示啊平方值。如果说我们这个线条呈现一个线性的话,我们可以选择线性的,那么线性方程也会给 你列出来是多少,当然如果是指数的话,他也会列出来这个是最符合指数的一个方程是多少, 然后我们可以根据这个方程输入一个我们想要的 x 值,就可以得出一个预测的 y 值。好,关于这个小技巧,你学会了吗?喜欢我视频就点个赞,有什么不懂的欢迎在视频下方留言,我们下节再见。
9512Excel技巧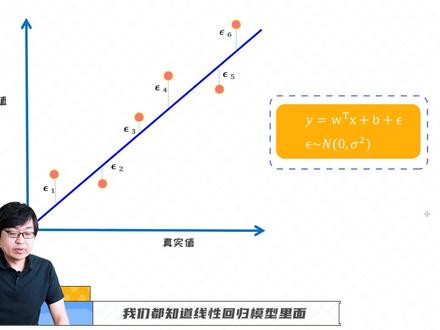 05:12查看AI文稿AI文稿
05:12查看AI文稿AI文稿我们都知道线型回归模型里面,其实他的目标函数呢,是平方误差,所以核心是这里的一个误差的概念。所以假如呢,我们给定了几个数,几个样本,然后呢,我们学出了一条线,那这条线的方程呢?其实我们知道可以用 w x 加 b 的方式来表示的,那这里的假设呢?就是啊,假设 x 它是一个多一个多维项链,也就是特征个数为更多的时候,我们可以用项链化的方式来表示。 但是呢,我学完一个一条线之后,其实每个样本他可能会有一些误差的, 那误差呢,我们分别用 f 三六一到 f 三六六来表示,然后这里面我们仔细来想一想,假设我把每个误差呢,把它想象想作为一个 变量,然后我假设这里面我只有六个六个样本,因为为了方便,期间我只只花了六个样本,但是假如呢,我们手里面有大概有一万个样本,或者是更多,所以我手里可能有啊,可能大概有一万个,或者甚至更多的一个误差的一个变量。 所以当我把这些误差变量把它合在一起的时候,我们是不是可以联想到一个非常重要的一个性质,就是叫做中心极限定理, 英文叫 central limiter, 什么意思呢?所以假,假如我手里面有非常多的样本,假设有一万个或者上,甚至呃,几十万个,那我手里面其实有这么多的误差变量,然后呢,英文我的个数已经很多了,所以 根据中心极限定理的哈,我们可以得到这些误差的变量呢,他可以服从一个正态分布,那这个就是一个非常非常著名的一个极限定理,然后根据这个极限定理呢,我们可以模拟出就是这么多的误差, 在这里叫做 fcelong, 那 fcelong 的误差呢?当他很多的时候,样本个数比较多的时候,他会服从一个正态分布,也就是这里的 f solo, 他会服从一个这种正态分布的形式,那这一点非常的重要。然后我们从这个点出发, 接着从一个概率统计的方式来去引导引引出我们最终的目标函数,所以这是另外一种方式。我们之前的方法呢,是直接通过 f 三网来去引出咱们最终的目标函数的,就是平方误差的 啊那块。但现在呢,我们从另外一个角度想去引出我们同样的目标函数,但这个方法论呢,更偏向于使用这种概率统计,包括一些把一些分布,把它用起来。所以在现阶段我们要记住的一点是,当我们学了一个 一条线,然后呢即便我学出一个很准确的一条线,我们每个点其实他会有一个误差的,就是对于每个样本来讲,他有一个误差, 但是呢这个误差比较比说很大的时候,也就说我的样本个数很大的时候,那这些所有的误差, 根据中心极限定理,他会服从一个正态分布,所以啊,这点很重要。 那下面我们具体来写一下刚才我们所说的误差模型。 所以呢,我们现在学了一个方程,叫 w 和 b 两个参数,然后这是我的预测值,左边是我的预测值, 然后我加了一个误差,叫 f 送一,那对于 y 二也是一样的,那我在他的基础上,我加了一个 f, 送了二,我就得到他的一个真实的,这叫 y 二吗?所以每个样本 x 一到 x n, 我们都可以把它写成这种形式。 但是这里呢,当我把这些误差全部单独拿出来去观察的时候,而且我的 n 可能是比较大的,那我们会 通过中心极限定理,我们可以认为这些误差他其实可以服从一个正态分布,对吧?那这个正态分布呢?可能是以可能是类似于这样的一个正态分布,比如说 c 码的平方。然后我们在 这里假定的是它它的均值为零,因为有些误差呢,它是正向的,有些误差呢,它是负向的。所以当我的数据量很多的时候,我们可以认为 他的误差他的均值可能会服从零。但是我有一个类似于方叉,叫四个码的一个这样的一个方叉,然后呢,具体的模型的话,我们可以通过这个方式来表示。所以在这里呢,我们假定我的 apson 他是个随机变量, 然后这里的 f 送一到 f, 送了 n 呢,是这个随机变量的一个具体的一个展示的形态而已。 然后呢,这里的 fcelong 就服从一个零到 c 吗?平方的一个正态分布。所以现在开始,我们有一个很重要的一个思维的转变,就是把 fcelong 把它看作是一个随机变量,我们之前没有从这个角度考虑,但现现在开始呢,我们把 apsolon 就把它看作是个随机变量,然后这里的每个 f, x, l, e 到 x, l, n, 实际上就是随机变量的具体的某一个值,然后这个随机变量呢?它服从一个正态分布,那我们先记住到这里。
542文哲聊AI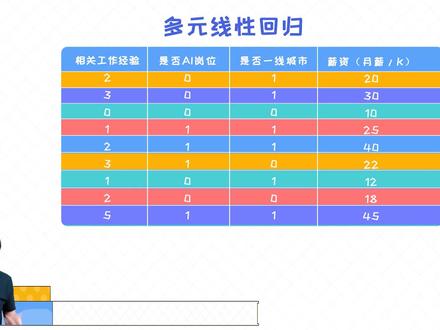 06:25查看AI文稿AI文稿
06:25查看AI文稿AI文稿下面我们来看一下。呃,咱们啊一个样本数据,那这个数据里呢,我们有一个预测的 一个词,叫做薪薪资,那这个呢是我们需要去预测的,也就是啊,我们把它叫做歪, 然后剩下的咱们每个变量来讲,他有三个特征,那相关工作经验是一个特征,然后是否有 a, 是否是 ai 岗位是一个特征,然后是否是一线城市,他是一个特征,所以我们总共有三个特征, 然后对于这个数据来讲,我们总共有一二三四五六七八九九个样本,然后我们分别把每个样本标记为,比如说这个样本呢叫 x 一,这个样本叫 x 二, 那这个样本是 x 九,然后每个预测值呢,我们把它叫做 y 一, 歪二一直到歪九,这是我们要预测的一个值,然后呢每个样本我们也知道他是有三个变量来构成的,也就是三个特征。 好,那接下来我们想通过一个线性的模型来去,你和他那线性模型,我们也知道他有两个参数,一个叫 w, 一个叫 b, 然后在一元线性回归模型里呢啊,因为我们只有一个特征,所以 w 本身他是一个标量, 他是个具体的值。但是现在我们考虑的是一个多元线性回归,也就是也就是说每个变量就是每个, 咱们这个,每个每个样本他有多个特征,所以这个时候我们的 w 应该是一个项链。 那在这里呢,我们总共有三个特征,所以我的 w 他的一个大小应该也是三位, 所以这是多元线性回归跟一元线性回归之间的一个主要的区别。所以针对每一个变量呢,我们其实需要有一个参数叫 w 一,比如说 w 二和 w 三, 就是针对每个参数,我们需要有一个啊,就是针对每个特征,我们需要制定一个参数,然后呢我们这个预测值呢? 怎么得到的?比如说我们这个预测值叫薪资,那我们可以这么表示,比如说薪资,他 他的预测值,他等于我的工作经验, w 一呈上一个工作经验, 加上 w 二乘上第二个特征叫 a i 岗位,我们简写一下,然后呢 w 三呈上咱们的一线城市这个特征,最后加一个偏音量叫做 b, 所以我们是通过这个方式来得出新的啊这个薪资的。所以在这个情况下,我们可以看到我的参数有 wb, wb 是我们的参数, 但是这个时候呢,我的 w 他是三位的项链,因为我有三个特征,所以每个特征啊,这个下面我都有一个 w 的一个参数,然后呢我的 b 呢?跟之前一样,他也是一个,他就是一个标量, 所以这是跟意愿限行回归之间最大的区别,所以我这边 w 就变成了一个项链的形式。那下面我们来具体看一下这个样本,那针对于第一个样本,我们知道他的预测值呢是二十,所以啊不是预测值,是他的一个真实的 只是二十,所以 y 一等于二十, y 二等于三十,所以这列代表的是咱们每个样本的一个真实的值。那这个预测值我怎么去算呢?比如说针对第一个样本,我的预测值呢?我们根据这个方程可以得出他的预测值,我们这么表示歪的预测值, 那这里的五加一的预测值等于二乘以 w 一二 w 一,零乘以 w 零 w 二,然后呢加上一乘以 w 三, 然后呢再加上咱们的这个偏音量叫 b, 那类似的,那剩下的,比如说 y 二的预测值等于三乘以 w 一,三 w 一加上零乘以 w 二是零,然后呢一乘以 w 三, w 三加上 b, 然后呢,针对于 x 九也是一样的,那 y 九他的一个估计就是预测值等于五乘以 w 一,加上一乘以 w 二,然后加上一乘以 w 三,再加一个骗一辆叫 b, 所以这是预测值,这是真实的值。然后呢,对于多元线性回归模型来讲,那我们仍然需要学出来的是 wb, 而且我们在这里也可以表示出他俩的一个误差误差,也就是 y 减去这个 y 的平方,我们可以算出来的,我们列一下,那这个误差呢? l 等于每个样本那个误差值,那第一个样本的误差呢?其实就是这个二 w 一加上零,加上 w 三加上 b, 减去什么呢?减去咱们这个预测值叫二十二十的平方加上第二样本的误差误差, 那这个是这是预测值零,这是三三 w 一,然后呢 w 三 减加上 d 减去我们预测值交三十,然后一直加到咱们第九个样本,那这是五 w 一加上 w 二加上 w 三加上 b, 减去咱们他的一个真实的值得平方,所以这个就是我们的 l, 也就是我们的目标函数,那通过最小化咱们这个函数呢,可以得出 w 和 b 的这个值,就是每个 w 一, w 二, w 三我都可以求出来, 那这是我们接下来要做的一个优化的过程,其实跟一元现行回归模型其实没有本质的区别,唯一的区别就是我原来的参数 w 原来是标量,现在是变成了什么呢?项链的形式,他是多维的项链。
689文哲聊AI 00:21查看AI文稿AI文稿
00:21查看AI文稿AI文稿怎么用 excel 做预测分析呢?选中数据,插入一个普通的折线图,右键添加趋势线, 选择符合要求的趋势线,可以显示公式和二平方值。如果需要预测未来四个月的数据,可以在后推周期中输入四,这样就做了一个线性预测分析图了。
3528米小蕉-数据分析 08:29查看AI文稿AI文稿
08:29查看AI文稿AI文稿给我足量数据,我将挖掘未来。大家好,我是江哥,那我们前面的视频已经借助一个工具,简单的写出了线性回归的模型, 很多小伙伴会问,线性模型能够怎么用?我们可以这样说,线性模型是整个基于学习算法当中最简单的,也是最基础的一个模型, 那么他可以解决掉一些比较简单的一些问题。那么我们今天就用线性模型,借助在线性模型当中最经典的数据集,波士顿房价数据集, 来预测一下波士顿房价, ok, 也是很简单哦,学完它,你可能对 线性模型会有一个更深的认识。话不多说,我们开始吧。 ok, 那么我们今天啊就使用在 sk 认当中, 嗯,比较经典的一个数据集,嗯,博士顿房价的数据集,来练习一下,先行回归,其实懂了原理以后,只是,嗯,把你的理解给实现了,很简单哦,我们来看一下第一步,导入工具, 呃,那我们导入工具, ok, 然后前面那个导入不说了,上一个视频我们说过了,那么这个导入呢?就是导入我们的波士顿的这个数据集,因为他是内置到我们的 sk 论当中的。 ok, 啊, 那么导入数据底以后,那我们要去把它给实力化一下啊,把这个导入进来的数据给他,实力化博士顿,然后的话,当然了,还是和刚才一样,我们有一个要有一个线性模型,对吧?嗯,蓝猫等 来 modow, 呃,波斯顿,然后也是给他一个线性回归器, ok, 没问题,在这个当中我们需要干什么?我们需要看一下这个数据机,对吗?因为我们只是把数据机拿下来了以后我们需要再看一下,是吧? 我们怎么样用这个数据仪?这个数据集当中都有什么数据? ok, 我们把数据仪看一下,可以看到茫茫多的数据,对吧?前面是一个 rrry, 这里面是带着,这说明这是里面是数据,对吧? 里面是艾瑞,艾瑞里面有各种各样的数据,那么往下面走,哎,这里面有个标签,这也是一个艾瑞,这应该就是他的这个价格,对吧?这里面也是一个艾瑞,然后再往下面走, 好,这里面给了我们一些什么数据了,这就说他的标签都是什么,对吗?然后我们可以看到有城镇这个人均犯罪率, 这个等等等等等等,然后还有二 m 是这个平均房间数,呃, d i s 到波士顿到五个中心甲醛的距离,我们就直接想象一下,那么一般情况下房价和面积啊,房价和面积是正相关的,所以我们要取 出这个数据,那就取出这个,呃,房间数,对吧?看看是什么?那他在第几个呢?一个、两个、三个、四个、五个、六个,但是在第六个,那我们把这个第六个给取出来,怎么取呢?哎,那就是 ok, 就是他啊,把他把第六个数据全部取出来, ok, 没问题,取出来了以后这是不能用的,你们知道为什么不能用吗?因为 这个数据他是一维的,对吧?是个列表型的,是个,他是个一维数据,那我们需要导 导入的数据是什么?我们需要导入的数据是二维的,所以我们要把它变成二维的,怎么变呢?执行这一段你可以看到他就变成一个二维的了, 没问题吧?我们直接使用切片就把它变,就把它切下来就变成二维的了, ok, 然后每一个数分成二位,这时候我们准备数据的阶段结束了,在这个时候我们就要干什么呢?废训练对吗?导入废这个方法开始训练,训练导入的数据是第一个 我们导入这个面积数据,最后给他这个波士顿的这个房价的这个数据,好吗?然后这两个其实我们可以看一下啊,可以看一下这个 是他是九点一啊,这个就是前面那个系数是九点一,后面这个结局像是多少,大概是负三十四 点六七这个样子啊,这个就是有现成的数值了。好吧,那我们看一下预测值啊,我们看一下预测值,预测值的话执行完以后我们看一下预测值, 大概是二十五、二十三、三,三十二十九这样子,那我们前面是不是前面我们有这个他给对不对? 二十四、二十一,哎,似乎还差不多啊,二十四、二十一、三十四啊,似乎还可以,不像我们想象的那么差劲,对吧?那么是不是我们在看这个,我们在看这个的过程当中是不太直观的 啊?不太直观呢?一般我们做项目以后,他最后要一个这个数据考试画嘛?那我们要把这个数据画出来,应该怎么画呢?啊?这个时候啊,到这里线性模型就已经完全结束了, 线性的执行的这个预测就已经结束了,后面是我们为了让这个东西更加直观一点,所以我们要把这个图形画出来呢, 没问题,我们导入这个画图的这个工具,对吧?导入工具以后,我们首先先画一个散点图,散点图是什么?散点图是把整个数据集当中的 x 轴是他的房间数, 外轴是他的这个房价, xo 和外轴房间数和房价形成的这个点状的一个图,这个散点。 ok, 我们把它画出来执行一下。画出来。画出来以后我们先执行一下数,看到吗?这就是每一个房价啊,相对来说比较密集的在这个区域,对吧?大概期我们想象的话会有这样一条线 过去,是不是我们预测的呢?啊?我们预测的这条线是不是正确的呢?然后我们把我们的预测值 倒进来,对吗?那预测值倒进来以后我们再执行售。哦。 前面这个直行在直行,他在直行受可以看到啊,可以看到似乎是我们刚才画的那条线,对吧?这样我们整个就已经完成了。 ok, 似乎是这个蓝色的线,是, 这不是,嗯,这个看不太清楚,不太美观,那我们可以这个把它换一个颜色,对吧?嗯,颜色卡拉,嗯,卡拉 red。 我们执行他,把他画出来。哦,执行他,执行他,再把他画出来,然后这样就可以看到了,这就是我们预测的这条线,应该是是我们预期的这条线,对吧?这样 过来这条线,那么我们看到房间数啊,六个房间,你大概有六个房间的话,你的这个房价大概就是在这个位置,大概是在二十这个位置, 好吗?好了。嗯,是不是很简单呢?关注我,你会有不一样的收获呦。这期视频就到这里,我们下期见,拜拜。
53江哥伴你学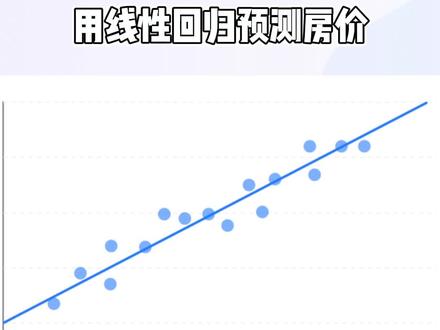 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿用线性回归预测房价,这是案例数据,打开 spospro, 找到线性回归,将房价作为烟边量 y 平方楼层房龄作为自变量 x, 配套电梯作为自变量 x。 二。结果出来了, 这是你和效果图,我们来预测下,一百平方七楼五年无电梯的房子多少钱呢?哇,一百八十三万,你们猜下这是哪个城市的房价呢?
 03:12查看AI文稿AI文稿
03:12查看AI文稿AI文稿大家好,这里是大表哥,今天呢继续给大家分享 s 开头的函数叫做 steyx, 嗯,他是可以计算我们的一个标准误差的一个函数, 看一下他的一个题本的内容。我们的韩式名称 styx 是可以计算通过线性回归法预测呃每一个 x 的一个 y 值时所产生的这个标准误差的。 哦,这个标准误差呢,是在针对单独 x 预测 y 时的一个错误量的一个量值 啊,你就是实现这样的一个场景的我们这样的一个函数,然后他的语法构成了就是由两部分的这个 x 值跟 y 值构成的参数,一是 y 值,参数二呢是一个 x 值,然后他也会是有一些呃,备注说明项,就是需要注意的一些点,然后其实 都是重要的一个,就是说我们的这个预测直歪的一个标准误差,他的一个计算公式明细就是长这样子的,就说我们的这个函数 styx, 他就是直接解决这样的一个计算公式这样的一个过程的,可以给到我们能直接的一个结果, 我们只需要输入并的 x 值跟 y 值就 ok 了。然后他也有一些呃,说明 公司当中的一个 x 和 y 是一个样本的一个平均值,然后呢?这个样本平均值,然后呢? n 是一个样本的一个数量吗?样本的一个大小啊,我们直接看一下怎么通过我们的这个 styx 来做一个具体的一个计算。 嗯,在我们的这个案例当中,呃,数值 y 跟数值 x 是分别分布于 a 列跟 b 列当中的,如果说我们要 计算这两组数字,他的一个限行回归计算的一个呃,标准误差的话,我们只需要通过我们在 a 十单元格当中写入等号,然后呃选中我们的一个 styx 函数,第一个是选我们的首优,优先选我们的一个, 嗯,歪直,歪直是分布到 a 二好 a 八单元格当中的,我们改一下,定制一下。 然而一开始值,此时呢是分布在 b 二到 b 八单元格当中的, 好直接回车,此时就可以得到我们的一个计算公式,它的值呢就是我们此时此刻这样一组数据,它的一个预测值是所产生的一个标准误差值,是三点三零五七的一个 啊,不出结果。嗯,这样的一个阿迪的计算结果呢,也是一个相对标准,如果说我们在某一个使用场景 下面,大于三和小于三分别是通过跟不通过的一个结果结果,所以说我们此时他的一个只要根据具体的一个使用场景和具体的一个业务来做一个判断。 嗯,但是我们这个函数最主要的目的就是可以快速的实现这样的一个公式的一个输结果,这就是他最大的一个意义。然后今天的任务就到这里,我是大表哥, 关注我主页还有更多数据小知识哦,有任何不懂的地方我们留言板见。呃,我们下期见!
153Excel数据处理大表哥 02:57查看AI文稿AI文稿
02:57查看AI文稿AI文稿如果我说只需要一根 k 线就可以知道第二天股价市场是跌,你敢相信吗?就像这张图上的 k 线知道了 a, 然后可以通过公式计算得到 b 的高点和低点。 这就是我今日要分享给你的一套实木大佬专用的计算公式。计算公式直接带入数据,就可以轻松判断明日的高低点。先点个赞,干货正式开始! 你看他,当你的股票涨停突破前期平台时,很多投者都会选择继续持有,结果你发现只要你不卖,立马就会跌,随着股价破位,终于熬不住了,开始割肉,结果一卖就大涨。 如果我们能够提前测算出涨停板,第二天的糕点的价格是不是可以就卖到糕点了呢?那么如何去测算呢?请看下图。首先我们 要计算出来一个基值,对于不同形态的 k 线,基值计算公式也不同,我们将 k 线分为阳线、阴线和十字星三种形态,所对应的基值计算公式如下,阳线基值 r 等于高点价格乘以二,加上低点价格,加上售房价除以二 一线就是 r 等于低点价格乘以二,加上高点价格,加上收盘价除以二。 实质性机值二等于收盘价乘以二,加上高点价格,加上低点价格除以二,计算出来的机值,我们就可以预测明日的高低点了。 明日预测高点等于 r 值,减去低点价格。明日预测低点等于 r 值,减去高点价格。讲到这里你可能有点懵,不用着急,我们一起来实战一下。看这个音线,我们 用一线的 r 值公式去进行测算,找到当天的高低收三个价格带入公式,得出的 r 值是二八九九点,随即利用明日预测里的明高点公式, 即二八九九减去幺四三四,得出的点是幺四六五点,结果第二天你发现他的实际高点是一四六六,跟实际仅仅相差一个点,是不是很神奇?你可能觉得一个案例是巧合,我们再来看这根线,线是个十字星, 我们用十字心的计算公式,计算出的 r 值是二六零四点,第二天预测的高点就等于 r 值减低点,价格 算出来的结果是幺三幺幺点,实际上是幺三幺三点,仅仅误差两个点。如果测算低点呢,也就是 r 值减去一三零七点,得出的结果是 幺二九七点,最终吃的低点是幺二九九点,也仅仅相差两个点。有没有觉得这个公式很神奇?通过这个公式就可以预测明日的高低点了,做到短线高低点找。知道这个方法你学会了吗?给您出一个思考题, 此方法的 r 值计算公式分为几种情况呢?一种还是三种?欢迎大家踊跃留言,看看谁会答错,别忘了点个关注,下期学习干货不迷路!
445弘历投资-股票小达人 13:47查看AI文稿AI文稿
13:47查看AI文稿AI文稿大家好,我是研发教育的伤心老师,今天我们一起学习 excel 数据建模与预测分析案例实战。对于预测分析 我们并不陌生,在我们的工作职场当中,都是需要做预测分析的,比如说我们要对销售进行分析,这是最常见的,还有我们的财务预算要分析, 电商、物流、 hr 等等,都是需要做预测分析的。对于我们的工作生活,比如说 股票、基金投资,也是需要进行预测分析,所以所以说预测分析不仅仅对我们的工作有帮助,还能帮我们赚钱。 向投资分析,他就是为我们创造价值的,所以说预测分析需要我们每个人好好的去掌握。对于预测分析,大部分人都有一个误解,就是 拿到一个数据就马上用一个函数,或者是说用一个移动拼接法就把预测求出来了,那么这样的做法是不对的。预测分析相对是一个比较专业的工具模型, 它需要根据你的业务场景来匹配相应的预测工具,不同的数据的特性,不同的业务场景用到的预测分析的工具是不一样的。 概括来说,我把预测分析模型分为两大类,两大业务场景,一类业务场景是没有季节性的数据的分析预测,第二类场景是带有季节性的预测模型, 这两个场景一定要把它分开,如果不区分,那么做出来的预测的结果是不准确的,那么我的整个的课程就是围绕这两大义务场景来分解 讲解的。像非季节性的预测工具,主要有移动平均法、指数平滑法、预测工作表法,还有函数预测、趋势线回归预测、季节性的预测模型 相对来说要复杂一点,主要是三三种方法,第一个是居中移动平原法,第二个是规划求解,第三个是线性回归系数调整法。这两大业务场景都是以案例分析的形式来给大家讲解的,所以 基础一个社会基础比较差的学员不影响预测分析的学习,这个请大家放心。 下面是我的一个介绍,这个图片就是我本人,帅的一塌糊涂。一个 ceo 的培训,我已经 有十二年的经验,包括线上和线下,除此之外,我对 bi 的培训学习也是有一定经验的。预测 分析本质上就是时间序列的预测,我们的预测都是基于时间来的,脱离的时间预测就是没有意义了, 因为我们的预测一定是随着时间的推移来观测我们数据的变化,这个时间可以是连阅日记等等,包括你自定义的其他的时间都是可以的。 时间序列我们做预测的时候一定要清楚它的四种成分,这个是一个我们分析的一个前提和基础, 哪四种成分呢?第一个就是趋势成分,我的一个数据摆在面前,我们要观察 我的这个整个的趋势,随着时间的变化,他的变化趋势是上升还是下降,还是说震荡 平稳,震荡的,还是说是线性的还是非线性的,这就是它的一个趋势成分。它的趋势成分如何去识别呢?很简单, 画一个折线图就可以看出来,这个后面会有讲解。第二个是季节成分,季节成分 它是反映时间系列在一年中有规律的变化,它是由什么引起的?是特殊的季节或者是节假日引起的,每年会重复出现。比如说服装销售,它每年的都有它的一个淡旺季,你像夏装,那么在夏天七八 酒卖的比较好,冬装在冬天卖的比较好。不同的业务场景,它的数据可能会呈现出它的季节成分,这个要结合你的业务场景,也可以通过趋势成分来把它显示出来。 季节成分的预测分析相对来说要懒一些,它主要是要计算它的季节指数,这个在后面的课程也会讲到。 第三个成分是周期成分,周期成分它是反映的时间系列,在超过一年的时间内有规律的变化,大家注意这个周期一定是超过一年的。 如果是说在几个月或者几周里面,你想反映他的周期,这个基本上是很难的周期 他的成分主要是由他的经济状态的变动引起的,有波风和波股。所以这个周期的预测分析啊,往往需要 数据跨度要相对大一些,至少要一年,你不超过一年,你就不用考虑这个周期了。所以周期性分析,预测分析难度相对来说要大一些,复杂一点,因为他需要的数据样本要多一些。第四是不规则成分, 不规的成分它是不归因于上面的三种,并不是所有的数据都是可以预测的,有些数据他是预测不了的,他没有趋势, 也没有周期的成分,也没有季节性的成分,他就是杂乱无章的一个随机的。你如果非有预测,那只有 一个办法,很简单,就是求他的平均值。所以第三个洲际成分和第四个不规则成分, 在我们的商业数据分析当中啊,其实基本上可以把它去忽略,重点要考虑什么呢?重点要考虑它的趋势成分和季节成分,这也是我的整个课程主要要考虑的这两个成分。季节, 季节性因素我们应该怎么去预测?带有非季节性,也就是说趋势性怎么去预测?我们做时间系列的预测 有几步,首先第一步确定时间序列的类型,这个类型是由它的成分决定的,也就是趋势性和季节性。 首先呢,我们看趋势成分,它是根据时间序列的观测词的数据汇一张折线图,下面三张图可以看得出来,第一个就是没有趋势的时间序列, 如果要对他进行预测,那么他的工具方法和后面的是不一样的。第二个是线性趋势的时间系列,那么他的预测方法也是不一样的。第三个是非线性趋势, 它就是一个指数性,一个增长,这三张图表它的预测工具和方法是不一样的。所以我们在拿到数据的时候,第一步就要画这三张图,这个非常重要,包括我后面的课程,有的课程里面可能就 要画这个图,就不代表这个图不考虑,不是的,一定要自己先要把数据把它的趋势来观测出来。第二个季节成分,季节成分 一般需要的数据往往是两年或者两年以上的数据,而且要有一定的间隔,要间隔一年。我们在拿到一个数据的时候,要分析它的季节成分,就是画一张折线图 来观测他的多风多股是否存在季节成分,那如何判断呢?这个时候你不能就数据而论,数据一定要结合你的业务场景,比如说我这个是服装店的一个销售趋势,可以看出六七八,他就有 有一个季节性的因素,它有一个波风,这就说明我拿到这个数据就存在明显的季节成分。那我们在做预测分析的时候,一定要采用非季节性预测模型的三种三种工具。 第二步就要选择合适的方法建立预测模型。我这里做了一个小节, 对于一些数据,他们既没有趋势成分,也没有季节成分,这时呢我们可以用什么方法来移动平均或者指数平滑我的数,我们的数据如果有趋势成分的 上升或者下降,有趋势成分的,根据数据的特性,我们就要用到趋势预算法当中的三种方法其中的 一种,比如说一一元回归,二项式回归,还有指数回归, 这个后面会有讲到。第三个是我们数据如果是有季节成分的,就要用三种方法求出它的季节指数, 要用到季节指数法,我的整个的预测分析的课程都是围绕这些来的,季节性和非季节性的数据场景。 第三步是平价模型的准确性,确定最优的模型参数。我们有的时候用了一些工具方法,一定要评估模型的准确性,比如说我用移动平均或者是植入平滑,中间要求他的阻力系 数或者是间隔数,那么这个时候你就要进行试算,来确定最优的一个参数是什么,这个在后面的课程会详细的讲到。第四步是按要求进行预测,确定的模型参数之后,最后可以通过我们的 公式把它预测值求出来。这个就比较简单,比如说回归方程系数和常数都已经预测好了,那么我们就需要把它直接带入公式,算出来就得到一个预测值。 好,这个就是时间系列的四步。前面讲的四步我把它概括一下,第一就是要识别数据背后的业务 场景,它是季节性还是非季节性,我们通过一张图表能观察,同时你要结合你的业务场景。第二个对于你的数据,你在做图的时候,以及在正式分析之后,你一定要把你不必要的数据进行整理清洗, 来确保数据的准确性。第三步就是要做图发现规律,然后再选择合适的预测方法或模型,这个是关键。最后一步需要注意的是,如果是用回归 礼盒出来的预测,一定要观测他的监控值,他的监控值值就是阿方,这个阿方代表你这个方程的可信度,关于阿方他是如何 合计识别和判断,后面的课程会讲到一个 ceo 的基础,对于学好预算分析, 其实关联性不是很大,你只要学几个函数就可以了,上半数三拍大了,以及预测函数这几个也是非常简单,所以即使是零基础,你把这几个函数在我的课程当中把它消化一下,其实 也是没有没有多大关系的。第二个是规划求解的原理和技能,那么这一个呢?在整个预测分析的课程当中,会专门去讲解他的原理,数据分析工具库,尤其是回归分析, 他的原理在我的课程当中会穿插的给大家去讲解,所以说如果你是一 这个 cl 零,记住对于学习预测分析其实是没有任何障碍的,这个大家也放心 好了,关于预测分析模型,今天就介绍到这里,希望通过整个课程的学习,大家成为预测分析的高手。最后祝大家学习愉快,身体健康,万事如意,谢谢大家!
210跟尚西学PowerBI 03:431185价投有道
03:431185价投有道 05:03查看AI文稿AI文稿
05:03查看AI文稿AI文稿百分之九十九的股民都不知道股价明日的正常波动范围,其实通过 k 线就可以知道明天的价格运行区间,你 想知道吗?今天就来分享一套由斯专用的明日预测的高低点测算公式,只要你会加减法,你也可以轻松的测算明天的高点和低点了。买在低点,卖在高点。 当确定要买入一支股票时,就该分析买入的价位了。合理的买入价位有助于将来准确的判断,迈出时机。很多人面对盘中的涨涨跌跌时,心中没底,其实很简单, 你首先要知道国家的正常走势,也就是正常的波动范围,如果不在正常的波波动范围之内,就是异常的波动了。那么如何才能够知道什么是正常的波动呢?如何去对高低点进行明日预测呢? 首先,我们可以通过今天收了阳线,阴线还是十字星来进行去判断。不同的 k 线方式计算公式是不一样的。进行明日预测时,如果 当天收了阳线,我们就用阳线的 x 值进行去计算。如果当天收的是阴线,我们就用阴线的 x 值去计算。 我当天收的是十字星,那么十字星意味着开版价和收盘价相差很小。用十字星的 x 值去计算。明日预测大多数所用到的是今天的最高价,加上今天的最低价,加上今天的收盘价,这三个数值是一 样的。如果 x 线是阳线,那就加上当天的最高价如果是阴线,那就加上当天的最低价如果是收了十字星,那就加上当天的收盘 价。用四个数值的和除以二,最终得出了 x 的值,那么明天的最高价该如何去进行明日预测呢?用得出的 x 值减去当天的最低价,就可以预测出明天的高点在哪里了。同样的,明日预测的最低价呢?用 算出来的 f 值减去当今的最高价就可以了。我们来看一下明日预测的实战案例。在这个图中,六月二十二日这个位置收出的是一根阳线,我们就用阳线的 f 值来进行计算。 今天的最高价加上今天的最低价,加上今天的收款价,再加上今天的最高价。那么找到今天的各个数据形成的和相加除以二,最终得出的数值呢?是七千一百零六点。那么明日预测的高价要如何去计算呢? 明日的最高价用 x 值减去当天的最低价,也就是用七幺零六点减去当天的最低价是三千五百三十六点。 又得出了明天的最高价,预测的位置呢,在三千五百七十点。那么等到六月二十三号的时候,他的最高点呢?在三千五百七十七。和我们明日预测的位置呢,相差只有几个点。 同样的方法,我们来给大家看一下。音线要如何进行明日预测。这是六月二日的一根音线,用音线的 x 值我们去进行测算, 找到当天的高低,收相加之后数以二,得出 x 值是七千一百九十七。那么要如何进行高低点的明日预测呢?明日预测里的最高价等于 x 值减去当天的最低。 要是用七千一百九十七减去三千五百八十一,得出的点呢?是三千六百一十三。那么第二天你发现他的最高价是三千六百一十八,相差只有五个点。 同样呢,我们通过在当天收出来的这根 k 线形态,就可以进行高点和低点的每个人预测了。首先,咱们要先判断当天是收了一个什么样的状态,这是个十特星。然后呢,把公式 找出来进行测算。测算之后呢,第二天我们就可以用它去测明日的高低价了。我们测算出 f 的值等于七千零四十四,那么减去当天的最高价或者是最 最低价。我们来判断一下明日的最高价,就是减去当天的最低价,最终得出的是三千五百四十一。那么你发现第二天的最高价 是三千五百四十,相差仅有一个点。那么明日的最低价减去的是当天的最高价,也就是用 x 的值减去三千五百三十五,最终得出的是三千五百零九。那么你发现次日的最低价所得出的点位呢?是三 三千五百零四,和他呢,仅差了五个点。通过明日预测的这种方法,咱们就可以预知明日股价的正常波动范围会在哪个区间了。明日预测的高低点就能够作为买卖交易时的重要的参考点了。但 反式没有绝对,也没有百分之百。大胆假设,小心求证,综合分析效果更佳。如果能够结合整体的趋势,效果会更加好。您的股票今天是收了阳线还是阴线呢?快套用上面的公式来算一算他明天会在哪个区间运行吧!关注猎装小课堂,与主力同行,与机构同步!
411猎庄小课堂 07:47查看AI文稿AI文稿
07:47查看AI文稿AI文稿大家好,我是云发教育的上期老师,今天我们继续学习一个 cel 数据建模与预测分析, 今天要进入的是第二大部分季节性预测模型。季节性预测模型比前面的非季节性预测难度要大,他主要是三种方法, 居中移动规划求解和线性回归系数调整法。这三种方法难度都是比较大的,所以我通过一个 季节性销售预测模型,一个案例讲这三种方法是如何实现的,从他的 每一个步骤以及最后的试用场景,会给大家做一个非常详细的讲解。 季节性销售预测模型,我们很多行业在不同的时段,它存在淡旺季,比如说旅游、食品、 服装等等,他都存在相对的旺季和淡季。对于销售比较稳定的行业,可以采用 非季节性的预测模型。比如说在前面讲到了回归分析、趋势分析、移动平均和指数平滑法, 但是对于销售波动比较大的企业,存在季节性变化的,那就需要 计算他的季节性指数,这个是我们做季节性预测模型最关键的一步。 这里有个案例,就是某店铺有三年每个月份的饮饮料的销售记录,他是三年。对于季节性预测,在前面的第一课就讲到了至少要有一年的数据,这是三年的数据, 公司目前准备预测该种饮料下一年度的销量,我们现在需要根据三年的历史销售数据来预测下一年每个月份的销售数量。 这个案例非常具有代表性,有时间销售量啊,这个就是历史,历史数据也并不复杂, 我们看一个数据,他到底是非季节性还是季节性的?在前面课程也讲 到了,首先第一我们要结合业务场景,比如说饮料、服装,他肯定是有季节性的。第二个我们要看他的数据表现是否有季节性和趋势性。这个成分 怎么实现呢?就是需要画一个鹅线图,就可以 通过折叠图我们看出。可以看得出来这三年期间,每年的五月到十月是销售旺季,其中七月和八月他是夏天的销售高峰,这个是每个月, 每年他是每年都会出现的, 这就是季节性。如果不是每年都出现, 说幺八年七八月份是旺季,幺九年没出现,幺零年也没出现,那这七八月是不是旺季了?可以理解为不是旺季。所谓的季节性,他是 一年以上的数据都是重复出现的,你看这个就比较有规律性,然后结合我们的业务场景就可以判断它是具有季节性的,所以要用到季节性预测模型三种方法, 这三种方法在后面会陆续的展开。首先是第一种方法,居中移动平均法,他是什么意思呢?他就是要计算每个月的居中移动平均销售量。然后第二步就是每个月的实际销量,除以他的居中移动平均销量,得到 销售指数,然后再平均就得到了季节性销售指数,知道了季节性销售指数,到最后根据我们的预算, 已知预算总销售量在乘以每个月的季节性销售指数,就可以得到预测,预测年度每个月的预计销售量。这三步其实最关键也是最难的一步,就是第一步如何计算每个月的居中移动平均销售量? 他的计算方法我们首先通一个底层的原理来解释,比如说我们要统计这个周 周的,那个周四的,他的一个居中移动平均法,一周有七天,比如说 平均周一到周日的销售量,我们可以找到周四,那么周四的居中移动平均法,周四的居中移动, 他是怎么求呢?是周一到周六,周一到周六中间,周四他刚好处于终点位置,你看前面三个,后面三个。 如果要招周五来,那往后推一下,周五就是周二到周一啊,这个叫移动平均。什么叫移动平均呢?就是这个意思, 给大家科普一下统计学啊。周四就是周一到周日,周五就是周二到周一啊,这是以周为一个周期的他的移动平均, 那周六那就是周三到周二了,以此类推,这个叫移动平。 这个是移动平均的一个底层原理。但是对于年度来说,因为一年的总月份是偶数,比如说我要计算一到十二月的十二个月的居中移动平均值,比如说我要计算 比如说一月到十二月他的平均值,他既不是六月,也不是七月啊,他是七月头,他是七月头,那怎么办呢?那要算两次,第一个是七,一月到十二月算的是七月头,然后二月到一月, 二月到一月算的是七月底,那么七月头加七月底,再除以二,就是他的七月的移动居中移动平均,这个在后面的案例会掩饰到,所以这个原理是非常重要的。 所以说解决这个问题还需要再找到二月到明年一月的平均值,然后再平均这两个平均值,也就是说 一月到十二月他的平均值是什么呢?是七月头,二月到一月 他的平均值是七月底,七月头叫七月底,在平均印象就是七月份的,那么以此类推啊,八月就是也是往后啊推移,以此类推。 那么八月就是二月到明年一月和三月到明年二月的平均值,这两个平均值再平均,那么就是 按照月份月份的居中移动平均。好,我们理解的这个原理啊,那我们后面再求 每个月的居中移动平均法就比较简单了。那么居中移动平均法这个案例呢?他分为六个步骤,我们先暂停一下,那么下节课我们详细来讲解每一个步骤是如何去实操的。
529跟尚西学PowerBI 00:59查看AI文稿AI文稿
00:59查看AI文稿AI文稿说如果以 yt 表示 dt 七的实际观测值, ft 表示 dt 七的指数平滑预测值二发表示平滑系数,则指数平滑预测值应该是什么样的计算公式啊?这个是 t 七表示 yt 啊,表示 dt 七的实际观测值, t 七的预测值。让我们计算一下,实际上就是预测期的预测值。那就是考你这个公式吗?你要知道我们要用指数平衡法去确定预测值,用的都是替用的都是预测期前一期的数据。 那现在预测期前一期指的就是提期,你看你预测的是哎,提加一期,所以用的都是提期的数据。有提期的实际纸,提期的预测纸 只是实际值用平花系数作为全数,预测值用一减,平花系数作为全数,所以都要用梯起的。没有梯加一起的啊,都用梯七的,所以这个一算应该就是币啊。
58刘艳霞中级经济师 02:28查看AI文稿AI文稿
02:28查看AI文稿AI文稿哈喽,小伙伴们,我们今天继续使用卡西欧 f x 杠九九幺间计算器来为大家讲解第八个教程啦。今天是有很多小伙伴疑问到的一个问题,如何使用这款计算器进行一个回归计算?就是我们现在右侧的这一道题, 那我们首先机器要先进入到一个统计模式,选择六之后我们是要进行一个线性回归计算,它的公式是 y 等于 a 叉加 b 哦,要进入第二个模式, 那我们向这边右边的话,他是有解有说到,就是如果您本身里面有程序的,就是有数据的话,要把它给删掉的哦,好,那现在我们看一下下一道例题给大家看一下,你看一下右侧的 制造立体哦,我们先看一下这些数据,然后他这里有一个小提醒点,就是说如果您这组数据里面有重重复的,您就直接把平速打开,是什么意思呢?就是例如我这一列的话,他有五个一,我就把 平数打开,然后只要输入一个一,然后在平数这里写五,他就可以了,他这个计算器会自动就是 呃记忆在里面的,但是呃如果你没有操作这个评数的话,就会比较麻烦,浪费一点点时间。那像我们这局数据的话,他这一列的话都没有重复的,所以就不需要打开,那我现在依次输入了哦,一 二三,接下来是四,然后按右关标键一次把它调成为 这一列,然后依次输入一四九十六。 好啦,我们依次说好了,你就是点 optm, 然后选择回归计算,四就算出来了啊, b 等于五, a 等于五, b 等于负, r 等于零点九八四三可以看到吧?然后如果要你和其他的统计模模型,例如, 嗯,二次回归,那你就按 optm 把它进行一个调化,或者是双变量计算,选择三,他就会把这些统计量全部都算出来了,可以看到吧,非常方便的。 好啦,这期的教程就到这里啦,各位小伙伴们可以看一下,不清楚的可以直接留言哦!
333信隆发办公 01:34查看AI文稿AI文稿
01:34查看AI文稿AI文稿机器学习中的线性回归就能预测股市。这个真实数据集包含了二零零五年到二零二零年间美国几个巨头公司的股市数据,包括每天的开盘价、收盘价、最高价、最低价、成交量、换手率等信息。今天我们就用它来练练手,看看我们会亏还是会赚。 下载数据集,我们先来看一看这些年表现一直非常稳健的苹果公司。这里一共有三千七百三十二天的股市数据,每一行数据有六十三列。 这里有一列数据很特别,叫做 close forecast, 它是股票的次日收盘价。在爬取的原始数据中,这一列并不存在,是 k 狗为了将其改为更适合积极学习练习数据级而加入的。 我们选取 close forecast 这一列作为机器学习模型的预测目标 target, 也就是标签 label。 其余的六十二列作为特征 feature。 然后用百分之七十五的数据作为训练机,百分之二十五的数据作为测试机。然后到用 s k learn 的 linear regression face。 方法。还是简单的两行代码,我们就把渐进回归的模型预测出来了。 有了这个模型,就该我们的测试级上场了。我们将模型在测试级上进行预测,做个测测试来看一看 啊。这结果乍一看呢,可能会吓你一跳,预测出来的骨架波动的也太厉害了。不过我们可以先给大家吃一颗定心丸。我们的先进回归魔性没有问题,而且事实上它的效果很好, 上面的代码大家只管放心的去用。至于为什么会有这么杂乱啊?变动的一个预测结果,我们将在下期内容中再详细分析。跟我一起一天一点继续学习,大家再见。
26机器学习了吗



猜你喜欢
- 20.5万喜乐安怡
最新视频
- 11.7万体育狠人录