au如何把多段音频调成同一个音色

粉丝1.2万获赞35.4万
相关视频
 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿ai 慢距变线绊脚石之一就是音色同步难,角色音色不统一,不用反复调试。今天就拆解 cadence 二点零的音频参考功能,教你轻松搞定适配合规变现实操。关于 ai 短片中音色共鸣的痛点, cadence 二点零早已给出了完美解决方, 操作简单且易落地。很多创作者都忽略了,二点零不仅支持图片、视频两种参考形式,更暗藏音频参考功能,这正是实现角色音色统一,提升内容质感,进而增强变现竞争力的核心关键。话不多说,先听一段刚录制好的音频演示,死胖子, 你天天就跟 ai 过去吧,眼里还有我这个老婆吗?接下来,我们就把这段音频的音色精准赋予画面中的美女角色,步骤简单,跟着操作就能学会。 我们以还原音频中的场景为例,完整实操流程拆解留下建议,重点记好每一步。第一步,将提前准备好的人物、角色素材、场景图片以及这段参考音频一并上传至 cds 二点零后台。第二步,剧情设置,参考此前回复的相关资料。第三步,在美女角色的参数设置中添加一句关键指令,语气及音色参考对应上传音频 有个易踩坑细节需要提醒,画面中的男性角色此时处于沉默状态,无需发声,因此无需设置任何参考音色,直接标注无即可,避免出现音色干扰。所有设置全部完成,接下来我们直接看最终呈现效果。死胖子, 你天天就跟 ai 过去吧,眼里还有我这个老婆!操作就是这么高效!后续创作 ai 短片时,只需 a t t 同一段参考音频就能实现同一角色音色全程统一,大幅提升内容专业度,为变现转化加分。 现在全是 ai, ai 更实用的是,我们还能利用这段固定音色,让角色演唱粤语伤感情歌,丰富内容呈现形式,吸引更多流量。 这套音频参考实操技巧相信大家已经掌握了,今天的实操分享就到这里了,更高级的漫剧的轻创业实战库我都整理好了。老规矩点关注评论区扣装备,看主页置顶详情。
105大圣AI轻创业 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿如何解决 ai 短片中角色音色不一致问题?其实这个问题 cds 二点零已经彻底帮我们解决了。二点零除了支持图片视频参考外,其实它还支持音频参考。先听听这条刚录的声音,死胖子 天天, ai, ai 眼里还有我这个老婆吗?你干脆就和 ai 过一辈子去吧! 现在将这条音色赋予这个美女,要做什么呢?我要还原刚刚音频中发生的事情。整个过程如下,将他丢给 cds 二点零,人物角色场景图以及参考音频也一同传上去。在剧情前面艾特对应的参考素材, 在对应的人物后面加上这句话,语气和音色参考对应音频,男人此时已丧失发言权,不配说话,也不敢说话,所以参考音色无现在发送出去,我们来看看怎么肥四吧! 死胖子天天, ai, ai 眼里还有我这个老婆吗?你干脆就和 ai 过一辈子去吧! 声音参考就是这么简单,当我们在创作下个视频时,爱的相同音频就能完美保持角色音色一致。我真是怎么会看上这个死胖子,当初,当初还说要陪我一辈子, 现在现在全是 ai, ai 甚至还能让他使用这个音色用粤语唱着伤心情歌, 现在你学会了吗?那问题来了,现在这种情况我该怎么办?请支个招,在线等急!
2391AIGC自修室 06:20查看AI文稿AI文稿
06:20查看AI文稿AI文稿哈喽,大家好,感谢订阅观看我的频道啊,今天这个视频和大家分享的是有生疏萌新朋友特别关注的一个话题, 也是特别基础的特别重要的一个话题,就是在试音的时候啊,他这个试音要求里面会有什么啊,四四一零零,四八零零零啊等等这样的一些参数,我们应该如何去 选择?他在哪里?他都究竟是些什么鬼啊?首先我们打开哎呦,然后呢?新建一个, 新建之后在这里更改名字,这里没有更改,稍后也可以继续更改,不用着急。大家说的这个四四一零零和四八零零,四八零零零在这里叫采样率, 在这里更改啊,比如这条试音要求的是四八零零零更改完毕。立体声,这个啊,大家一定要记住了,最好我们录音的时候建立的是单声道,而不是立体声, 为什么呢?因为我们只有一支麦克风,一支麦克风呢?只能输入一个信号,你就这么理解简单点啊,太复杂的可能,第一我解释不太清楚,第二您听也听不明白, 您就记住录音的时候选单声道,我们保存的时候选择立体声就 ok 了。然后大家看底下这个什么二十四位啊,三十二位辅点在这里叫位深度, 这里选择,比如这一个要求的是二十四位,然后我们按确定 建立之后呢,按这个红色的录音键开始吧啦吧啦吧啊,录音录完之后我们是要保存啊, ok, 看啊,这里更改名字命名 这里无所谓,不更改了之后您可以从音频文件上面也可以更改,这里选择地址,这是最近用的几个保存地,地址,也可以从浏览这个地方选择自己想要保存的位置。 这里就是 m p 三格式的选择。看啊,我们一般用的就是 m p 三或者是 v 五,一般就这两种啊,比如此处要求是 m p 三选这个, 然后呢?采样类型四八零零零。刚才更改过了,这个我们不说这里保存的时候改成立体声,如果甲方要求就改成立体声,也就是说单声到立体声 从这个地方更改。其实呢,他也不是真正的立体声啊,只是把我们这个地方一个信号复制了一遍,变成了两个双声道啊。我们平时听音乐的时候会发现左耳和右耳听到戴耳机啊,左耳和右耳听到的可能有不同的乐器,不同的音效,不同的。呃, 人生那个才叫真正的立体声,也就是说所谓的是左右两边有一些不一样的地方啊,那左右两边都一样的, 我觉得应该只能叫做双声道吧。啊,我们这也不去纠结他了啊,反正你就记住从这里更改,就是把这一个复制了一遍,变成两个。 ok, 这 这里接着可以更改。刚才这样,比如二十四,好的,按确定。有的朋友说那个什么二五六啊,什么三二 零啊,怎么更改在这里啊?有一个比特律看到没有,这里 二五六三二零,从这里更改啊,比如此处要求的是二五六,选择他按确定,最后再按确定, 然后这个音频就保存好了。那有的朋友说我有没有就是录音的时候直接就录成双声道,然保存的时候不就省事吗?省的时候我到时候忘了。其实也可以也有怎么去处理呢?我们 点这个 au 上方啊,这里有一个首选项,然后一个音频声道映射选这里。我们一般输入都是声卡嘛,你看我这里就是呃自己的这 这个看一下啊,这里我们选它,看这样的把这个位置啊,我这里没有选成声卡,我把它重新选一下,音频音 硬件啊,输出啊,没有办法,我现在录屏,所以他只能这个样子了估计。那 ok, 那我就先不去更改这个啊,大家知 这个明白就 ok 了。选音频声道映射,把这两个都选成一样的,一般我们上面这个是单声道,是声卡,比如说声卡的一到二,或者说声卡的一,我们把底下这个,你看现在他是不是都是这一样的,我们 可能你的默认的是底下,我们选成上面,就是说这两个选成一样的,然后按确定我们建立的时候, 从这里直接建立一个立体声,看上下两个我们按录音啊,那就巴拉巴拉巴拉就录下来了,就是这个样子。如果我的分享对你有帮助的话,希望可以订阅、点赞、评论、转发、投币, 欢迎有生疏的萌新主播,想提升普通话的朋友加入到我们的 qq 交流群当中,如果想加入我们一起学习普通话的打卡活动呢,切记在添加我微信的时候要备注三个字,普 通话,否则不通过。想加入打卡的朋友呢,希望您可以查看往期发布过的视频,寻找视频名 称,前方带有一起学习普通话零零一零零二零零三零零四啊零零几这样的视频。回看一下前期发布的关于普通话的一些打卡需要的知道的事项啊,以前分享过的专业知识,还有理论的内容。 ok, 今天这条视频就到这里,希望可以帮助到你,我们下期视频再见。
1098DUBBER TE 02:22查看AI文稿AI文稿
02:22查看AI文稿AI文稿人生太刺耳怎么办?教你简单一步改善听感,眼前这个音频就是非常刺耳的,我们来听一下,若你能活着回到长安,你去问问张涛,我说的是不是真的。 我们还是先讲 au 自带的效果器滤波与均衡参数均衡器,把这边的这个 lp 也就是高切点亮,然后频率点规定在八千赫兹,这边这个斜率一定要改, 改成六 db 的 谐律啊,比较缓,并不会真的高切。另外呢,把第四个点改成五千,第五个点改成八千,然后分别衰减两到五 db。 再来听一下,若你能活着回到长安,你去问问张涛,我说的是不是真的。 我们把效果器旁通掉,来听一下他原声的一个听感,我说的是不是真的,开起来,我说的是不是真的, 听上去柔和很多了。当然更好的一个操作就是把这个五千和八千的衰减换成去齿音的一个 操作,我们之前的视频详细讲过怎么去齿音,可以去我的主页查找,调整完以后你可以保存为一个预设,然后就可以在这个预设里面找到,或者说点击这个五角星来去保存为一个收藏,那么就可以在收藏夹里面找到,下次就可以一键处理了。 我们再来讲一下通过肥波的叉线怎么去实现,之前讲过这个 prods 恢复到默认,然后规定一个频率段,这个音频的频率段比较的宽,所以说我们给它规定在五千到十四千 range 呢,调在六 db 这个预值也不用动。然后点击应用,你会明显看到这个频谱上面的那个能量暗了很多,波形也有明显变化,再用肥波的 q 三也是跟刚才那个均衡器一个道理,去创建一个点,然后选择高切,也就是第五个, 这个频率点呢,规定在八千,斜率,规定在六 db, 这边有一个相位模式,改成第三个限行相位应用,他的八千以上还是有频率的,并不是说一刀切了, 这是一个非常柔和的平滑高频的这么一个操作。刚才那个八千赫兹也可以根据具体音频来去做调整,一般来说调在八千到一万之间。好了,这期视频你学会了吗?
125萧声帮_帮主 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿做声音后期不知道 au 和 pr 的 重新混合,那你就 out 到天涯海角了。百分之九十的情况你都可以利用重新混合随意的剪辑你的配乐到任意长度,百分之九十的大众根本就听不出来剪辑痕迹。废话不多说,我这边新建了一个多轨工程,拖入了一个人声和一条音乐, 现在音乐比人生短,我想让这首音乐完美的去匹配这个人生的长度,那么我就可以右键这条音乐,在这上面找到重新混合起,用重新混合 a u 就 会自动的分析节拍和声过渡点,分析完后右上角就会出现这个波浪线, 你可以拖动这个波浪线来去让他适配你人生的长度,他就会做无缝的剪切和交叉淡化音频。上面出现了两条波浪线,这个波浪线就是他剪切的点, 他把三十六秒给剪到了一分钟的后面,这边呢是把七秒钟的地方剪到了一分三十一秒的地方,我们来听一下他剪的怎么样。 完美, 非常完美,拉长和缩短都是可以的,比如说要到这边结束,不过有时候你会发现他并没有给你精确到某个时间点,而你恰恰想要卡在这个人生结束以后的这个空白处,让这个音乐结束, 就可以在窗口里面点开属性的面板,然后选中这个剪辑,这个属性就会显示此剪辑的属性。点开重新混合,然后点开高级,这里面有一个拉伸为确切的持续时间,把这个勾上, 那么我想要在这个人生结束以后的这个一分五十二秒的位置结束,也是随心所欲了。他的逻辑是先通过重新混合分析剪接,再通过伸缩这条音频,也就是加速减速来去适应你需要的长度,只要这个伸缩没有超过百分之五都是 ok 的, 你看现在是百分之一百零三,也就是说这个音乐变慢了,我们可以再听一下这边有没有剪接好, 又是 ok 的 好,这招你学会了吗?
95萧声帮_帮主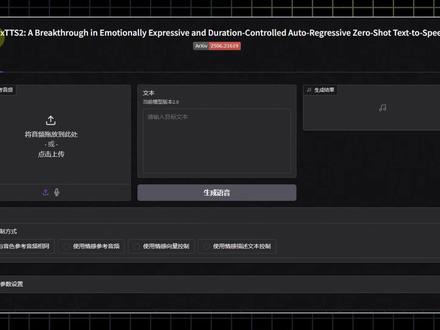 01:45查看AI文稿AI文稿
01:45查看AI文稿AI文稿这是一个天花板级别并且开源免费的 ai 声音克隆工具翻译翻译,什么叫惊喜? 告诉黄四郎,放学别走!他就是来自 b 站团队的 index t t s。 二,最大的特点就是情感控制和原声翻译。我们看一下翻译效果,更贵森严几个人不得信口雌黄, the palace is strict no false rumors lady qi 除了可以在本地安装部署外,目前还可以免费在线体验。我们在摩达社区搜索关键字 t t s r 就 能在创空间分类找到, 用法也非常简单。在这里上传想要模仿的梦贵森严几个人,然后输入配音内容,点击下面的按钮,稍等片刻,就能得到处理好的声音。点击这里放局。今天我和甄嬛你必须二选一,可以进行试听和下载。 情绪控制方面,我们还可以上传参考音频,比如用这样的音色,当然我是你前男友,配合这样的情感,能死而复生的人一个也没有来生成语音, 今天你必须把话说明白。除此之外,用这个情感向量控制模式,我们可以手动调整情绪参数来生成一段声音。 最后还有一种自由度最高的方式,这种模式下,我们可以随意输入一种情绪的文字描述当年征服祸罪,所有奴仆全部充公便卖,让他根据我们的要求来生成配音。 这个 index t t s。 二真的是太好用了!关注阿莫,了解更多 ai 玩法。
812阿莫同学 01:43查看AI文稿AI文稿
01:43查看AI文稿AI文稿以前我们要想让 ai 视频里的角色说出指定的音色,需要跨越三个软件才有可能实现,但现在可灵二点六只需要一步就能全部搞定。其实刚刚这段话不是我本人说的,而是我的 ai 音色在说话。这就是可灵刚刚上线的音色控制功能。简单来说就是你给他一段声音,他能让视频里的人用这个声音说话, 也是全球首个音色一致模型。这回真的是把声情合一玩明白了。现在看实测,我直接上传了一段杨幂采访的音频,然后上传照片,接着就是写文案,记得打开这个音画同步。写提示词的时候选择好刚刚设置的音色,一定要放在人物后面,点击生成后,画面里的人就能直接用你的音色开口说话, 你永远不知道下一块会是什么味道。你还可以选择情感标签,比如认真的说,温柔的说,轻声的说都可以,可以看到人物的情绪表情跟台词结合的都非常到位。今天的奶茶真好喝, 快分享一下谁家的?最离谱的是这个中英双语切换,哪怕你不会英文输入一段英文台词,他也能用你指定的声音说一口地道的英文, i love you from now until forever。 这意味着你可以用一个声音打造不同风格的内容啊,是不是很酷,并且还可以唱歌? 视频中的环境音也可以灵活控制, 你再也不用担心换个视频声音就变了。音色一致性意味着你可以规模化地生产内容,同时还能保持极高的人设辨识度。大家好,我是宅急送你们好吗? 整体来说,可令这个音色控制功能让 ai 视频制作更完整了。如果你是内容创作者、品牌方,或者单纯对 ai 视频感兴趣,我都建议你去试试看,毕竟在这个 ai 时代,早一步掌握工具,就多一份创作优势。
109宅急颂AI 02:12查看AI文稿AI文稿
02:12查看AI文稿AI文稿你想批量给你的音频降噪、压缩、限幅、标准化等操作吗?甚至批量应用任意效果器的组合,都可以利用 au 的 批处理和收藏夹联动的这一功能。大家好,我是肖帮主,在 au 里每一个效果器的界面上都有一个五角星的图标, 点击这个图标就可以把当前这个参数设置成一个收藏给他存放在收藏夹里面, 而这个收藏夹里面的内容是可以和批处理联动的。点击编辑批处理,就可以打开批处理的面板,然后这边有一个收藏,可以去选择收藏夹里面的操作。批量处理,我们先拖入几个音频,拖到批处理的面板, 比如说现在他们的采样率和声道不统一,我可以批量的给他们转换成四八零零零,然后全部转换成立体声。这边显示不全的话,需要把左下角的导出取消勾选, 然后就能够显示全了啊,批量变换为四八零零零,点击运行,批量变换为立体声,这里面甚至可以放几千条音频去批量处理,比如说批量的给它们标准化为负一 d b, 批量的去应用去口水音的插件, 甚至批量应用组合效果,我这边有一个一键处理干音,它是由多个步骤组成的, 那么这个组合效果怎么去保存到收藏夹呢?你需要在收藏夹里面去点击开始记录收藏,不再显示此警告确定,这时候比如说我去给他应用一个混响,调一个参数, 然后再去应用一个延迟,点击停止录制收藏,然后取个名字梦境回忆 确定,那么就可以在这个 p 出里的面板里面看到这个操作,梦境回忆,是吧?然后点击运行的话,他就会批量的对这些音频去应用这个效果。你比如说我去切换一个音频来去播放一下这个音频有没有混响延迟了,我听施主说过这件事。 好,这期视频你学会了吗?我主页还有更多的声音,后期干货,下期见。拜拜。
100萧声帮_帮主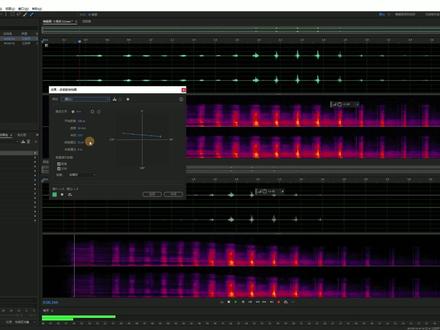 03:19查看AI文稿AI文稿
03:19查看AI文稿AI文稿哈哈哈哈,今天我们来看一个特别有趣的效果多普勒换挡器,多普勒是什么意思呢?就是你站在原地,然后有个声音呢,快速的从你身边经过,在经过的过程中会有一些音量声像音调频率的变化, 比如这个小鬼笑,我们来听一下原声,哈哈哈哈,没有任何的多普勒的变化,来看一下。如果说我们运用这个特殊效果多普勒换挡器里面的这个默认的预设,这个默认的参数正好可以适配这个素材, 哈哈哈哈,这个效果器只能够在波形编辑器里面使用,不能在多轨里面使用,然后每次打开呢都会自动的打开这个预览编辑器, 能够让你看到就是应用完以后的波形和频谱的变化。这边有两个运动轨迹可以选择,第一个是直线,第二个是绕圈, 然后开始距离,就是说刚开始的那个声音离你多远?速度五十米每秒,相当于这个声音到你身边需要两秒, 从距离你一百米的地方开始,然后到你这边的时候花了两秒,再花两秒非远。所以如果这个音频的时长是六秒,速度保持不变的话,这个开始距离需要设成多少米? 也就是六除以二三秒,然后三秒乘以五十一百五十米。这里面的逻辑应该很简单啊,然后度数呢?就说你来自哪个角度,从哪个角度到哪个角度,前端通过就是在你的前方多少米经过,也可以在后方经过, 右侧通过,也可以是左侧通过。音量调节的依据呢,这个距离和方向肯定是要打勾的啊,然后这个质量可以选择的更好一些,接近完美或者说完美 不差这点处理的时间了。然后我们可以选择预设里面的圆中旋转,这里可以看到声音将每多少秒绕圈一次, 其实他就是一个左右声像的来回摆动,半径四十米,相当于就是这个声音离你四十米,下面这些参数跟刚才都是一样的,我们来试听一下,哈哈哈哈。 如果你把手机横过来,应该是能够听到这个声像变化的,或者戴耳机听就很明显,那比如说这个素材, 他基本上一直在靠左边的地方扑腾,我们打开这个特殊效果多普勒换挡器, 现在我们需要怎么去设置一下,让这个声音最大的地方在这个音频的中间呢?这个音频的长度大概是六秒,那么如果说开始距离保持不变的话,这个速度就是在三十三米每秒左右,如果速度保持不变的话,那么开始距离就是在一百五十米来听一下。 然后有一点需要注意,如果是正常的人声,你就不要用这个多普乐来去实现这个运动关系了, 直接调音量声像混响频率会相对精准一些。好,想要系统学习有声后期的欢迎私信留言,拜拜!
33萧声帮_帮主 08:35查看AI文稿AI文稿
08:35查看AI文稿AI文稿今天给大家分享一个干音处理的案例,拿到手的音频是这样的,我们首先第一步给他拉高一些音量,直接拖拽这个小旋钮,拖到大部分的音频都超过负九 db。 这时候我们来试听一下雪纷纷扬扬的下起来了,可以听得出来他底噪是很大的,我们可以单独播放 它的空白处,底噪达到了负三十多,然后我们会发现这个波形状态是一个异常状态,像这样的波形一般都是因为它的基频有干扰, 特别是一百赫兹以下的基频,我们可以切换成完全对数,然后来去看一下基频的能量怎么样。使用快捷键,或者说右键平铺的这个空白区完全对数, 然后把频谱的分辨率调整到最清晰的状态,可以在这边右键,然后点击增加频率分辨率或者降低频率分辨率,我这边就用快捷键了。 现在我们可以看到他的人生的主要音色都在一百五以上,但如果说你的频谱分辨率没调好的话,这个频段的 分布就显得有点迷,下面一片黄色,有时候你低切了,下面还是这样子,你感觉好像你低切了个寂寞,但其实你已经低切成功了,只不过是你的频谱分辨率没调好。 现在我们可以看到他一百以下的贫苦能量还是比较重的,这就导致了刚才的那个情况出现。那我们现在要做的一步就是低切,低切多少呢?要根据人生的音色来决定。我们来听一下雪地上滚来了一个小雪球, 这是一个不太依赖低频的音色,我们看他的频谱的能量分布也能够知道啊,他一百五以下的那个能量微乎其微,但是我们也不能随意的低切一百五,针对这个音色,我们可以低切到一百。收藏家低切一百赫兹, 这个收藏家里面的内容怎么来的?可以去翻看我其他视频机切完了以后,刚才那个现象就正常了。我们再来看一下他现在底噪是多少。 机切完了以后直接到了负四十八。所以说为什么要在降噪之前先低切,就是不想要降噪程序,再去多余的参考一百赫兹以下的底噪了,对吧? 那有可能对人生造成没有必要的影响。 d c 完了以后,我们就是要考虑呃,怎么去降噪。现在这个例子底噪还是比较均匀的,比较适合用 r x 的 voice to noise 来去降噪。我们调出降噪插件, 切换到默认,把这个自适应模式给取消,勾选 filter type, 改成剪头,然后去找一段比较均匀的底噪。 他这边的底照基本上没有超过两秒钟的啊,都是比较短的一个空白, 这段还算是比较均匀的,你在看均匀底照的时候,你必须要切换到完全对数,这样的话才有参考性。选定了以后,我们点击这个学习,然后播放, 大概播放个两秒以上就够了。采集了样本以后呢,我们可以把这个域值和处理的力度推高个一两格, 然后取消框选,点击应用,再去播放这一段,看一下底噪多少了。 负六十以下了,这个底噪已经是完全合格了,基本上听不到了。如果说你降完一次以后,这个底噪还在负五十五以上,那你还可以再降一次,或者说用 ns 一 五点零过一遍, 我们再来试听一下现在这个音频的状态是什么样的。雪纷纷扬扬的下起来了,树木穿上了厚厚的雪大衣,大地披上了厚厚的雪被子, 雪地上滚来了一个小雪球。雪球站了起来,抖抖长耳,哎,有没有听到一声口水音? 雪球站了起来,听到了吗?也是用 r x 的 插件再还原 r x。 最后第四个 mouse click 点开以后,你选择默认,然后把那个灵敏度调在五点零就 ok 了,直接应用。 我们再来听一下,现在这个口水音还有吗?雪球站了起来,还是有,但是我相信他已经消灭了不少经典的口水音了。那么这时候就牵扯到另外一个小技巧了,就是怎么在人生中找到杂音,然后去除掉呢? 我们可以听着这个杂音,然后去观察频谱哪一个地方比较的异常。雪球站了起来,这一声大,我猜就是这个小点,来看一下是不是这个小点给它抹除掉。 雪球站了起来,哎,还真没有了,那么现在这个音频还有什么问题吗?首先它的高频是有点多的,矢音是有点重的,另外我们还需要达到目标响度,比如说我们需要达到负十四的响度, 那我们就可以在这一步先去查看一下响度,政府统计扫描,现在这个响度是负十七还不够,如果不压缩,那这个音频需要加三 db 才能够达到负十四的响度,对吧?那加完三 db 以后,有一些音频是已经超过了零 db, 这时候怎么办呢?可以限幅负一啊, au 限幅负一,那如果说我们需要限制在负三以下呢?那么观察这个波形,如果强制限幅负三,就会看着有点像平头哥,虽然说在我看来轻微的平头哥根本是无所谓的, 因为它并不是削波,只不过是把超出预值的部分音量给降下去而已,只要你不是特别平的那种,也不会影响到情绪发挥什么的。那如果说非要限制在负三以下,应该怎么做呢?就是需要压缩,我们退回到刚才的那个状态, 这时候的响度是负十七,我们需要控制在负三以下,而且响度要达到负十四。我们来调出我最喜欢的压缩插件肥波的 pro c two, 根据我的经验,像现在这个状态,直接用他的默认参数就能够达到负十四的响度。我们压缩完以后直接查看一下响度,现在是负十六点四三,要达到负十四的话,只需要加两点四三, 那么现在这个强度就是负十四了。如果说你非得把这些毛刺也给限制在负三的话,那么这时候强制限负负三完全是一点毛病都没有。再来听一下现在这个状态,雪纷纷扬扬的下起来了, 高频确实有点多了,我们调出肥波的 q 三,然后在默认情况下规定一个点三千以上,然后减个三 d b, 换成高频歌架,在这个固定频率衰减的基础上,再去创建一个动态的衰减,给他衰减个八 db 吧,然后再来试听一下,雪纷纷扬扬的下起来了。 把这个效果器关掉的话,雪纷纷扬扬的下起来了。开上的话,雪纷纷扬扬的下起来了。然后如果说你要做比较大的改动,那么就把这个零延迟改成限行相位,不然的话这个相位就会偏移 点击应用。由于刚才我们的 q 三是做了部分频率的衰减,所以这个音频的波形也矮了一截,那刚才我们不是白处理了吗?这时候我们还是需要测下强度,然后呢加零点八三 给他补上去再扫描,现在就是复式四。所以在处理干音的流程当中,有一句话是这样的, 动态问题大,先压缩,频率问题大,先 eq 好。 今天的视频有没有帮到你呢?下期再见喽!拜拜。
67萧声帮_帮主 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿用这个可灵视频二点六模型提示词,就能够让你的 ip 形象在任何场景中说话都保持音色一致和没班上,别再说自己消费降级了,说的好像以前消费的很高级一样。用这个提示词就能让你的 ai 模特在所有的营销视频中都呈现出一样的音色。干纹细纹, 改善熬夜垮脸,即使是中英文交替也毫无破绽! strength and skin barrier 超级靠谱!当我们用 ai 指出音画同步的视频时,经常会遇到一个问题,同一个人物,昨天生成的是萝莉音,好用又省钱。今天可能生成的就是御姐风,好用又省钱,差别很大, 但是现在可怜!视频二点六模型新推出了音色控制的功能,能够为你的虚拟形象创建专属音色,实现了形象与音色的一一对应。详细操作方法 是秒分享给你。在视频二点六模型下上传你的模特图,点下方选择音色,新建音色,上传一段五到三十秒无噪音的音频给 ai 学习,然后命名保存在音色列表中,就有了专属音色。接着将音色添加到提示词中人物台词的前面, 在深沉视频就好了。这款面霜质地丝滑易吸收,能修复干纹细纹,改善熬夜垮脸。如果你想让人物说话带情感,只要在提示词里加上语气情感描述, ai 会让专属音色准确响应,表达出情感。所以以后再也不用担心角色的音色不匹配的问题了。好的,学会了吗?那还愣着干什么?快去试试吧!
111白石AI实战笔记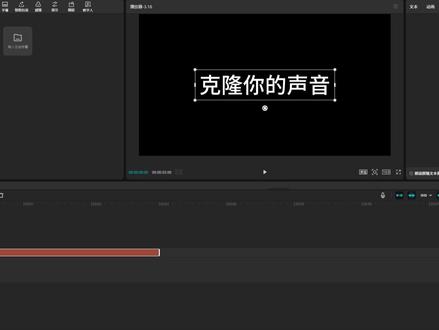 00:40查看AI文稿AI文稿
00:40查看AI文稿AI文稿用剪映专业版如何克隆你自己的声音?找到朗读克隆音色,点击克隆,这里可以选择导入你的声音,也可以选择录制音频,比如说选择录制音频, 点击开始录制。植物就像是地球上的绿色工厂,他们通过光和作用,把阳光、 水和空气中的二氧化碳转化成糖分,同时释放出氧气。稍等一会,你可以在这里选择保留口音或者是标准发音,你还能选语言音色命名,保存音色在这里就是了。
40小神-短视频 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿我曾触摸过星辰,曾见证过数千个太阳的光芒,而如今 这个视频我们讲如何制作怪兽巨龙类的声音效果。这样的特殊角色其实需要根据体型的大小来去设计声线,比人类体型大两倍以上的角色,声线都可以是较为粗犷的,那么我们就可以先给声音降个调, 降多少呢?可以根据角色的体型大小来做决定。开头演示的效果是把这个降调比例改成零点七,这个效果器是在时间与变调里面,我们先把这些效果器全部旁通来听一下原声。我曾触摸过星辰,然后只开这个变调来听一下。 我曾触摸过星辰,其实已经挺像那么回事了是吧?但其实像这类的角色,说话的分贝都会比人类说话要大的多,所以传的也会比较远,反弹的也会比较多,就算是在室外也会带出一些混响和回声,这回我们还是选用这个室内混响, 然后预设,直接选择人声混响小就行了,再去挂载一个回声,也是 au 自带的延迟与回声啊。这个 然后可以抄一下我这个参数,在他默认预设的基础上,分别把这个左右声道的反馈给他,调在百分之四十左右,回声电瓶调到百分之五十, 然后把右边的这个回声的一个均衡器调到这么一个曲线,你可以直接抄我这个数值,那么这个回声的听感呢?就会更加接近真实场景中的回声。如果你这个角色是邪恶的,可以把这个默认设置给他,取消勾选, 然后把拼接频率调在一百到两百之间,比如说调一个一百八,我曾触摸过星辰,曾见证过数千个太阳的光芒,而如今, 我被这优雅蒙蔽了双眼。
81萧声帮_帮主 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿大家好,今天给大家讲一下 cds 二点零怎么固定角色的音色。 选好 sd 二点零之后,我们选参考图,还可以选择一个音频文件,然后我们点击从设定中选选择一个角色。 选了之后呢,还可以选它的音色,唉,这啥玩意儿,怎么又输了? 那接下来输入提示词,那指定音色用音频一,这样就好了,点击提交。 过了一段时间,这个结果出来了,我们看一下效果。你好,欢迎光临。可以看到角色外貌和音色都保持了一致。今天的教程就到这里啦,欢迎来 f d studio 体验。




